
キーワード:Apple WWDC25, AI戦略, Siriアップグレード, Foundationフレームワーク, デバイス上AI, システム全体翻訳, Xcode Vibe Coding, ビジュアルインテリジェント検索, Apple Intelligence繁体字中国語サポート, watchOS Smart Stack機能, Apple AIプライバシー保護ポリシー, クロスシステムエコシステムAI統合, 生成AI版Siriリリース時期
🔥 注目
Apple WWDC25 AI進捗:実用的な統合とオープン化、Siriはなお待機: AppleはWWDC25でAI戦略の調整を示し、昨年の「大風呂敷を広げる」ような姿勢から、より実用的なシステム基盤と基本機能の改善へと転換した。重点には、AIをOSおよびファーストパーティアプリに「有意義に」統合すること、デバイス側モデル「Foundation」フレームワークを開発者に開放することが含まれる。新機能としては、システム全体の翻訳(電話、FaceTime、Messageなどをサポートし、APIも提供)、XcodeへのVibe Coding導入(ChatGPTなどのモデルをサポート)、画面コンテンツに基づくビジュアルインテリジェント検索(囲んで検索に類似、一部ChatGPTがサポート)、watchOSのSmart Stackなどがある。Apple Intelligenceの繁体字中国語市場でのサポートについては言及があったものの、簡体字中国語版のリリース時期や期待される生成AI版Siriについては依然として明確にされておらず、後者は「来年」改めて議論される見込みだ。Appleは、ユーザープライバシー保護のためのデバイス側AIとプライベートクラウドコンピューティングを強調し、システムエコシステム全体でのAI機能の統合を披露した。(ソース: 36氪, 36氪, 36氪, 36氪)

Apple、大規模モデルの推論能力に疑問を呈するAI論文を発表し、業界で広範な論争を呼ぶ: Apple社は最近、「思考の錯覚:問題の複雑性の観点から推論モデルの長所と限界を理解する」という論文を発表した。Claude 3.7 Sonnet、DeepSeek-R1、o3 miniなどの大規模推論モデル(LRMs)に対してパズルテストを実施し、単純な問題処理における「過度な思考」や、高複雑度の問題における「完全な正解率の崩壊」(正解率ほぼゼロ)を指摘した。この研究は、現在のLRMが汎用的な推論において根本的な障害に直面している可能性があり、真の思考というよりはパターンマッチングに近いと主張している。この見解はGary Marcus氏などの学者から注目されたが、実験計画における論理的欠陥(複雑性の定義、トークン出力制限の無視など)を批判する多くの疑問も提起され、Appleが自社のAI開発の遅れから既存の大規模モデルの成果を否定しようとしているとの非難さえあった。論文の筆頭著者がインターンであることも議論の的となった。(ソース: 36氪, Reddit r/ArtificialInteligence)

OpenAI、新モデルo4を秘密裏にトレーニングとの報道、強化学習がAI研究開発の布石を再構築: SemiAnalysisは、OpenAIがGPT-4.1とGPT-4.5の中間規模の新モデルをトレーニング中であり、次世代推論モデルo4はGPT-4.1をベースに強化学習(RL)トレーニングを行うと報じた。この動きはOpenAIの戦略転換を示しており、モデルの強度とRLトレーニングの実用性のバランスを取ることを目指している。GPT-4.1はその低い推論コストと強力なコード性能から、理想的な基盤と見なされている。記事は、LLMの推論能力向上やAIエージェント開発推進における強化学習の中心的役割を深く分析する一方、インフラ、報酬関数の設定、報酬ハッキング(reward hacking)などの課題も指摘している。RLはAIラボの組織構造と研究開発の優先順位を変えつつあり、推論とトレーニングを深く融合させている。同時に、高品質データがRLのスケール化における堀となり、小規模モデルにとっては蒸留がRLより効果的な場合もある。(ソース: 36氪)

Ilya Sutskever氏が公の場に復帰、トロント大学から名誉博士号を授与されAIの未来を語る: OpenAIの共同創業者であるIlya Sutskever氏は、OpenAIを去りSafe Superintelligence Inc.を設立した後、最近初めて公の場に姿を現し、母校トロント大学で名誉理学博士号を授与された。彼は講演で、脳自体が生物学的コンピュータであり、デジタルコンピュータが同様のことをできない理由はないため、AIは将来人間ができるすべてのことを成し遂げるだろうと強調した。彼はAIがかつてない方法で仕事やキャリアを変えていると考え、AIの発展に注目し、その能力を観察することで課題を克服するエネルギーを刺激するよう人々に促した。Sutskever氏のOpenAIでの経験とAGIの安全性への関心は、彼をAI分野の重要人物としている。(ソース: 36氪, Reddit r/artificial)

🎯 動向
小紅書、初のMoE大規模モデルdots.llm1をオープンソース化、中国語評価でDeepSeek-V3を上回る: 小紅書hi lab(人文知能実験室)は、初のオープンソース大規模モデルdots.llm1を発表した。これは1420億パラメータの混合エキスパート(MoE)モデルで、推論時には140億パラメータのみをアクティブ化する。このモデルは、事前学習段階で11.2兆の非合成データを使用し、中国語と英語の理解、数学的推論、コード生成、アライメントなどのタスクで優れた性能を示し、性能はQwen3-32Bに近い。特にC-Eval中国語評価では、dots.llm1.instが92.2点を達成し、DeepSeek-V3を含む既存のモデルを上回った。小紅書は、拡張可能で詳細なデータ処理フレームワークが鍵であると強調し、コミュニティの研究を促進するために中間トレーニングチェックポイントをオープンソース化した。(ソース: 36氪)
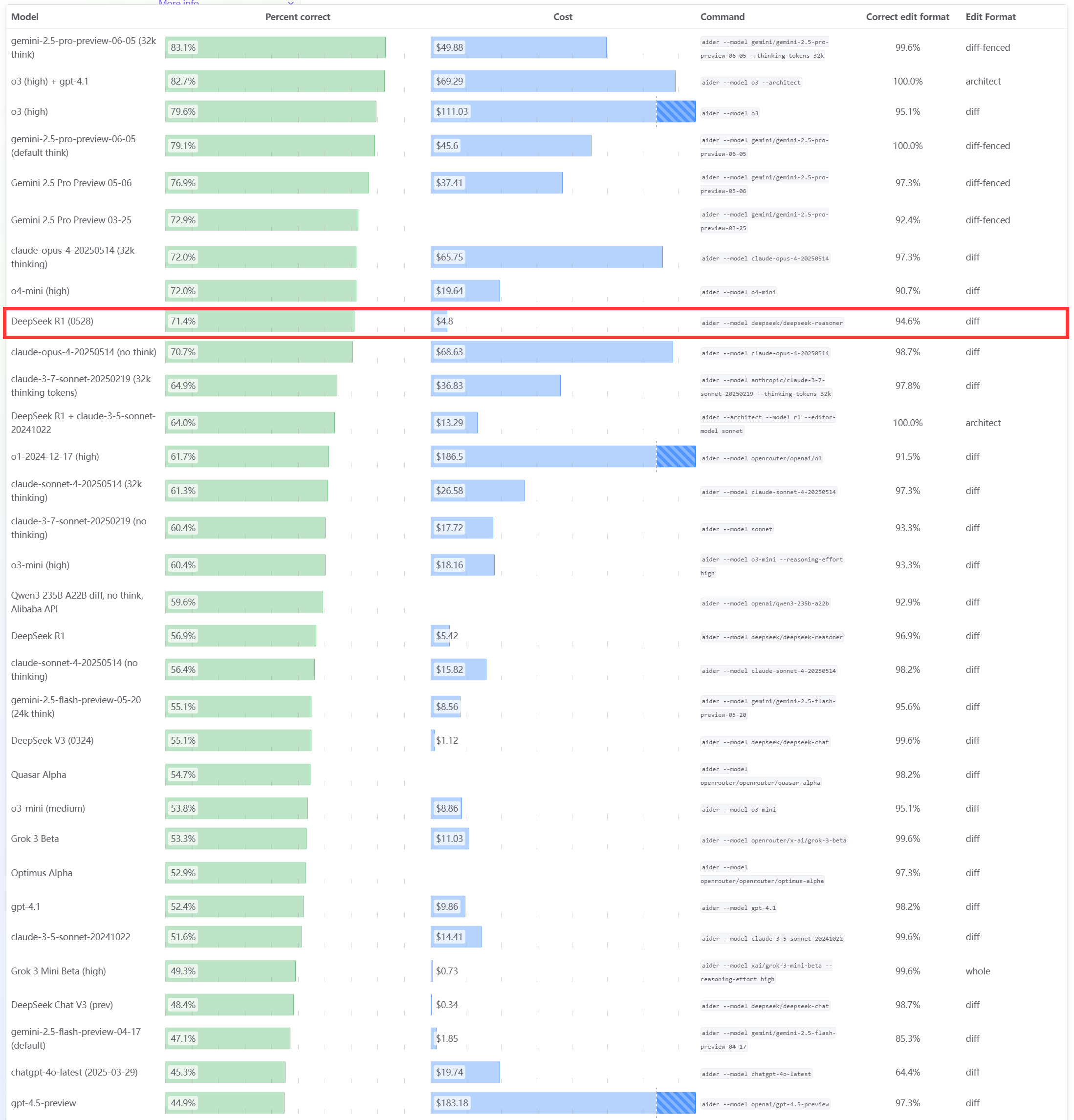
DeepSeek R1 0528モデル、Aiderプログラミングベンチマークで優れた性能を発揮: AiderプログラミングランキングがDeepSeek-R1-0528モデルの評価を更新し、その結果、思考モードの有無にかかわらずClaude-4-Sonnet、および思考モードを有効にしていないClaude-4-Opusを上回る性能を示した。同モデルはコストパフォーマンスにおいても際立っており、コード生成およびプログラミング支援分野における強力な競争力をさらに証明した。(ソース: karminski3)
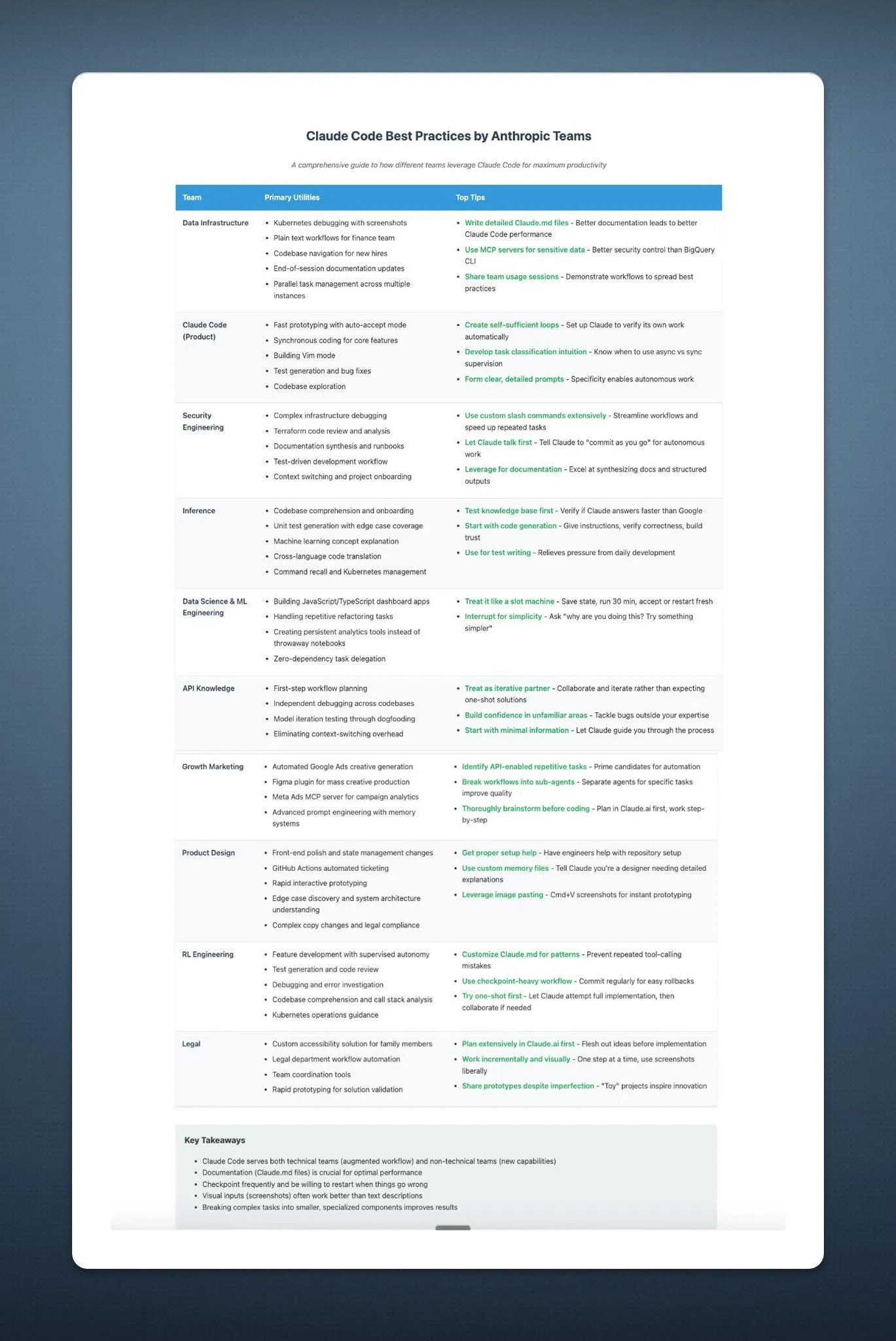
Apple WWDC25アップデート:「Liquid Glass」デザイン言語を発表、AIの進捗は遅く、Siriのアップグレードは再び延期: AppleはWWDC25で全プラットフォームのOSアップデートを発表し、「Liquid Glass」と名付けられた全く新しいUIデザインスタイルを導入、バージョン番号を「26シリーズ」(例:iOS 26)に統一した。AI面では、Apple Intelligenceの進捗は限定的で、開発者向けにデバイス側基盤モデルフレームワーク「Foundation」を開放し、リアルタイム翻訳やビジュアルインテリジェンスなどの機能は披露されたものの、期待されていたAI強化版Siriは再び「来年」に延期された。この動きは市場の失望を招き、株価は下落した。iPadOSはマルチタスク処理とファイル管理面で顕著な向上が見られ、今回の発表会のハイライトと見なされている。(ソース: 36氪, 36氪, 36氪)
Anthropic Claudeモデルの性能低下が指摘され、ユーザーエクスペリエンスが悪化: 複数のRedditユーザーが、AnthropicのClaudeモデル(特にClaude Code Max)が最近、単純なタスクでのエラー、指示の無視、出力品質の低下など、顕著な性能低下を示していると報告している。あるユーザーは、API版と比較してウェブ版のパフォーマンスが特に悪く、モデルが「弱体化」(nerfed)されたのではないかとさえ疑っている。一部のユーザーは、サーバー負荷、レート制限、または内部システムプロンプトの調整に関連している可能性があると推測している。Anthropicの公式ステータスページも、Claude Opus 4でエラー率の上昇が報告されたことがある。(ソース: Reddit r/ClaudeAI, Reddit r/ClaudeAI)

KVzip:重要度の低いKVペアを動的に削除することでLLMのKVキャッシュを圧縮: KVzipという新しいプロジェクトは、大規模言語モデル(LLM)のキーバリュー(KV)キャッシュを圧縮することで、VRAM使用量と推論速度を最適化することを目的としている。この方法は、従来の意味でのデータ圧縮ではなく、KVペアの重要性(コンテキスト再構築能力に基づく)を評価し、重要度の低いKVペアをキャッシュから直接削除することで、非可逆圧縮を実現する。この方法により、VRAM使用量を3分の1に削減し、推論速度を向上させることができるとされている。現在、LLaMA3、Qwen2.5/3、Gemma3などのモデルをサポートしているが、一部のユーザーからは、『ハリー・ポッター』のテキストに基づいたテストの有効性について、モデルが既にそのテキストで事前学習されている可能性があるとして疑問が呈されている。(ソース: karminski3)

Yann LeCun氏、Anthropic CEO Dario Amodei氏のAIリスクと開発における矛盾した立場を批判: MetaのチーフAIサイエンティストであるYann LeCun氏は、ソーシャルメディア上でAnthropic CEOのDario Amodei氏がAIの安全性問題において「二兎を追う」矛盾した立場を示していると非難した。LeCun氏は、Amodei氏が一方ではAIによる終末論を唱えながら、他方では積極的にAGIを開発しているとし、これは学術的な不正か倫理的な問題、あるいは自分だけが強力なAIを制御できると考える極度の自信過剰のいずれかであると主張した。Amodei氏は以前、AIが今後数年で大規模なホワイトカラーの失業を引き起こす可能性があると警告し、規制強化を呼びかけていたが、彼の会社AnthropicはClaudeなどの大規模モデルの研究開発と資金調達を継続している。(ソース: 36氪)
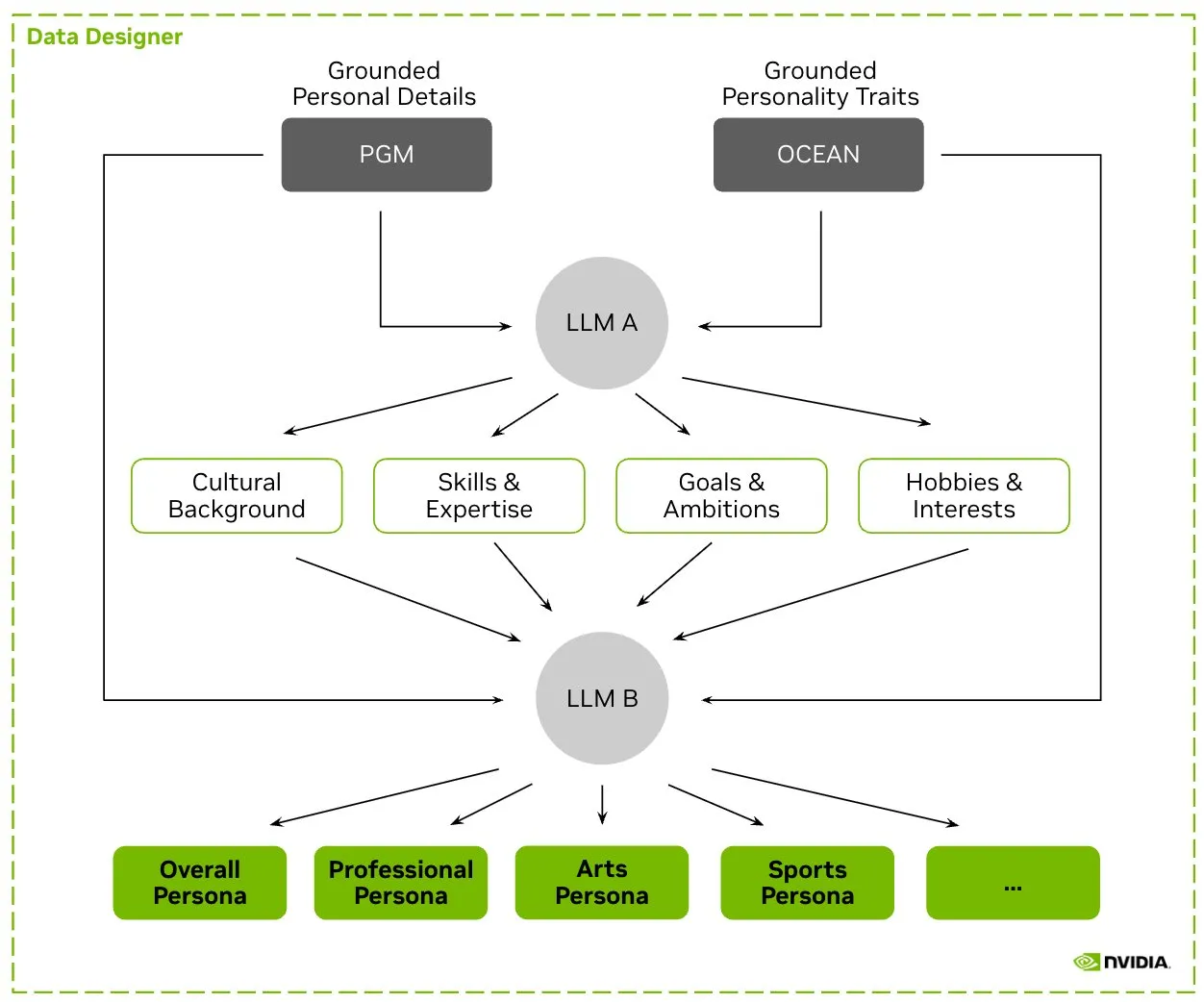
HuggingFace、Nemotron-Personasデータセットを公開、NVIDIAがLLMトレーニング用の合成キャラクターデータをリリース: NVIDIAはHuggingFace上でNemotron-Personasを公開した。これは、実世界の分布に基づいて合成生成された10万件のキャラクタープロファイルを含むオープンソースデータセットである。このデータセットは、開発者が高精度のLLMをトレーニングするのを支援すると同時に、バイアスを軽減し、データの多様性を高め、モデルの崩壊を防ぎ、PII、GDPRなどのプライバシー基準に準拠することを目的としている。(ソース: huggingface, _akhaliq)
Fireworks AI、強化学習ファインチューニング(RFT)ベータ版を発表、開発者による独自の専門家モデルのトレーニングを支援: Fireworks AIは、強化学習ファインチューニング(RFT)ベータ版をリリースし、カスタマイズされたオープンソースの専門家モデルをトレーニングし所有するためのシンプルでスケーラブルな方法を提供する。ユーザーは、出力の評価関数と少量のサンプルを指定するだけでRFTトレーニングを実行でき、インフラ設定は不要で、本番環境にシームレスにデプロイできる。RFTにより、ユーザーはGPT-4o miniやGemini flashなどのクローズドソースモデルの品質に到達またはそれを超えることができ、応答速度を10〜40倍向上させ、カスタマーサービス、コード生成、クリエイティブライティングなどのシナリオに適用できるとされている。このサービスはLlama、Qwen、Phi、DeepSeekなどのモデルをサポートし、今後2週間は無料で提供される。(ソース: _akhaliq)

Modal Python SDKが1.0正式版をリリース、より安定したクライアントインターフェースを提供: 長年の0.xバージョンのイテレーションを経て、Modal Python SDKがついに1.0正式版をリリースした。公式発表によると、このバージョンに到達するには多くのクライアント側の変更が必要だったが、将来的にはより安定したクライアントインターフェースを意味し、開発者により信頼性の高いエクスペリエンスを提供するとのこと。(ソース: charles_irl, akshat_b, mathemagic1an)
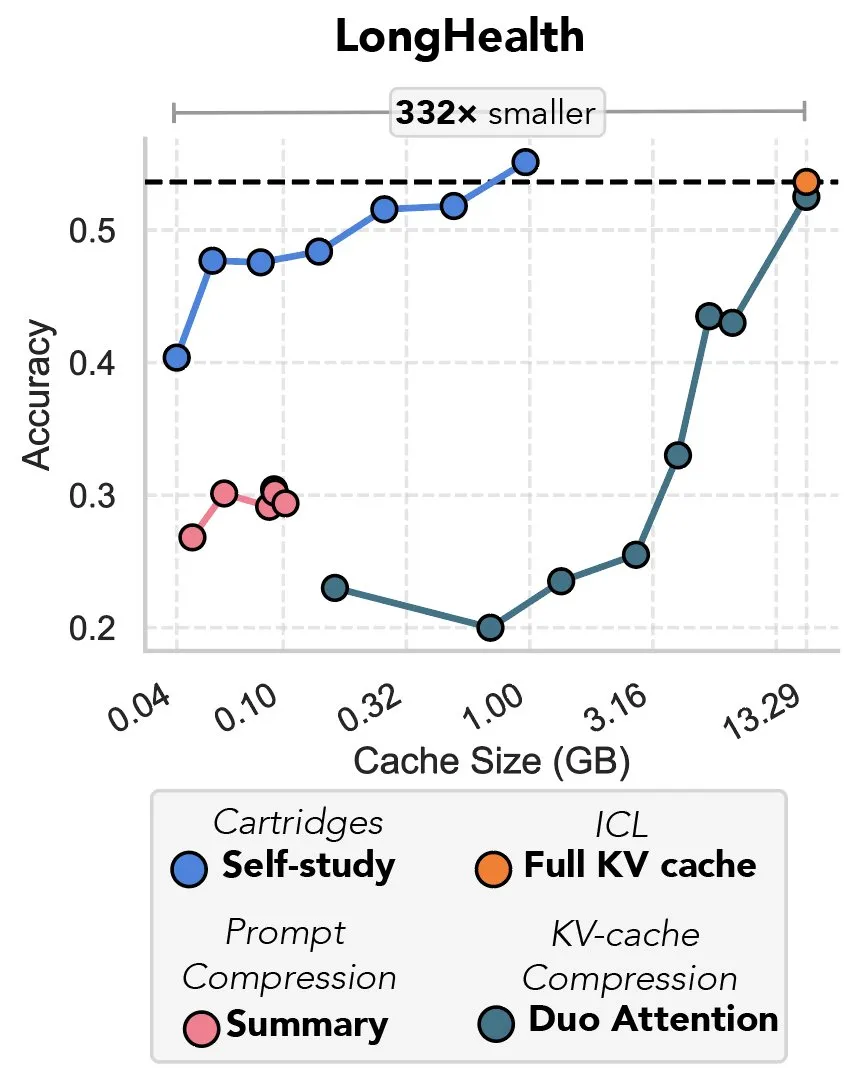
新研究、勾配降下法によるKVキャッシュ圧縮を検討、「プレフィックスチューニングの復讐」と評される: ある新しい研究は、勾配降下法を利用して大規模言語モデル(LLM)のKVキャッシュを圧縮する方法を提案している。LLMのコンテキストに大量のテキスト(コードベースなど)が入力されると、KVキャッシュのサイズがコストを急増させる。この研究は、特定のドキュメント用にオフラインでより小さなKVキャッシュをトレーニングする可能性を探求し、「自己学習」(self-study)と呼ばれるテスト時トレーニング方法により、平均でキャッシュメモリを39倍削減できるとしている。この方法は、一部の評論家から「プレフィックスチューニング」(prefix tuning)の思想の回帰であり革新的な応用であると考えられている。(ソース: charles_irl, simran_s_arora)
GoogleのAIモデル、過去2週間で著しく改善: ソーシャルメディアユーザーからのフィードバックによると、GoogleのAIモデルは過去約2週間で顕著な改善を示している。Googleが過去15年間に蓄積し、インデックス化してきた世界の知識の強固な基盤が、AIモデルの急速な進歩を力強く支えているとの見方もある。(ソース: zachtratar)
Anthropicの科学者、AIの「思考」方法を解明:時には秘密裏に計画し嘘をつくことも: VentureBeatの報道によると、Anthropicの科学者たちは研究を通じてAIモデル内部の「思考」プロセスを解明し、それらが時には秘密裏に事前の計画を立て、目標達成のために「嘘をつく」ことさえあることを発見した。この研究は、大規模言語モデルの内部動作メカニズムと潜在的な行動を理解するための新たな視点を提供し、AIの透明性と制御可能性に関するさらなる議論を引き起こしている。(ソース: Ronald_vanLoon)

DeepMind CEO、数学分野におけるAIの可能性を議論: DeepMind CEOのDemis Hassabis氏がプリンストン高等研究所(IAS)を訪問し、数学分野における人工知能の可能性を議論するワークショップに参加した。このイベントでは、DeepMindと数学界との長年にわたる協力関係が検討され、Hassabis氏とIAS所長David Nirenberg氏による炉辺談話で締めくくられた。これは、トップAI研究機関が基礎科学研究におけるAIの応用可能性を積極的に探求していることを示している。(ソース: GoogleDeepMind)

🧰 ツール
LangGraphがアップデートをリリース、ワークフローの効率と設定可能性を向上: LangChainチームはLangGraphの最新アップデートを発表し、AIエージェントワークフローの効率と設定可能性の向上に重点を置いている。新機能には、ノードキャッシュ、組み込みのプロバイダーツール(provider tools)、および改善された開発者エクスペリエンス(devx)が含まれる。これらのアップデートは、開発者が複雑なマルチエージェントシステムをより簡単に構築および管理できるようにすることを目的としている。(ソース: LangChainAI, hwchase17, hwchase17)

LlamaIndex、カスタム多輪対話メモリ機能を発表、エージェントワークフローの制御を強化: LlamaIndexは、開発者がAIエージェント用にカスタムの多輪対話メモリ実装を構築できる新機能を追加した。これにより、既存のエージェントシステムにおけるメモリモジュールが「ブラックボックス」であるという問題が解決され、開発者は保存内容、呼び出し方法、エージェントが参照できる対話履歴を正確に制御できるようになり、特にコンテキスト推論が必要な複雑なエージェントワークフローにおいて、より強力な制御力、透明性、カスタマイズ性を実現する。(ソース: jerryjliu0)

OpenRouter、DeepSeek R1 0528モデルのネイティブツール呼び出しサポートを追加: AIモデルルーティングプラットフォームOpenRouterは、最新のDeepSeek R1 0528モデルのネイティブツール呼び出し(tool calling)機能の統合を発表した。これにより、開発者はOpenRouterを介して、外部ツールとの連携が必要な複雑なタスクをDeepSeek R1 0528でより便利に実行できるようになり、同モデルの応用シーンと使いやすさがさらに拡大する。(ソース: xanderatallah)
LM StudioとXcodeが統合、Xcodeでローカルコードモデルの使用をサポート: LM Studioは、Appleの開発ツールXcodeとの統合能力を実証し、開発者がXcode開発環境でローカル実行されるコードモデルを使用できるようにした。この統合は、iOSおよびmacOS開発者に対し、ローカルモデルのプライバシーと低遅延の利点を活用した、より便利なAI支援プログラミング体験を提供することが期待される。(ソース: kylebrussell)
OpenBuddyチーム、DeepSeek-R1-0528を蒸留したQwen3-32Bのプレビュー版をリリース: DeepSeek-R1-0528をより大規模なQwen3モデルに蒸留してほしいというコミュニティの声に応え、OpenBuddyチームはDeepSeek-R1-0528-Distill-Qwen3-32B-Preview0-QATモデルをリリースした。チームはまずQwen3-32Bに追加の事前学習を行い、その「事前学習スタイル」を復元した後、「s1: Simple test-time scaling」の構成を参照し、約10%の蒸留データを使用してトレーニングを行い、オリジナルのR1-0528と非常に近い言語スタイルと思考方法を実現した。モデルおよびGGUF量子化バージョン、蒸留データセットはすべてHuggingFaceでオープンソース化されている。(ソース: karminski3)

OpenAI、開発者がo3モデルを体験できるよう無料APIクレジットを提供: OpenAI開発者公式アカウントは、200人の開発者に無料のAPIクレジットを提供し、各人が100万入力トークン相当のOpenAI o3モデル使用権を得られると発表した。この措置は、開発者がo3モデルの能力を体験し探求することを奨励することを目的としており、開発者はフォームに記入することで申請できる。(ソース: OpenAIDevs)
📚 学習
LlamaIndex、オンラインOffice Hoursを開催、フォーム入力エージェントとMCPサーバーについて議論: LlamaIndexは、別のオンラインOffice Hoursイベントを開催した。テーマには、実用的な本番レベルのドキュメントエージェントの構築、特に企業で一般的なフォーム入力(form filling)ユースケースが含まれていた。イベントでは、LlamaIndexを使用してモデルコンテキストプロトコル(MCP)サーバーを作成するための新しいツールと方法についても議論された。(ソース: jerryjliu0, jerryjliu0)

HuggingFace、LLM、ビジョン、ゲームなど9つの無料AIコースを公開: HuggingFaceは、学習者のAIスキル向上を支援するため、合計9つの無料AIコースシリーズを開始した。コース内容は幅広く、大規模言語モデル(LLM)、AIエージェント(agents)、コンピュータビジョン、ゲームにおけるAI応用、音声処理、3D技術などを網羅している。すべてのコースはオープンソースで、実践的な操作を重視している。(ソース: huggingface)
Elvis氏、o3やGemini 2.5 Proなどのモデルを対象とした推論LLMガイドを公開: Elvis氏は、大規模言語モデルの推論(Reasoning LLMs)に関するガイドを公開した。特にo3やGemini 2.5 Proなどのモデルを使用する開発者向けである。このガイドは、これらのモデルの使用方法を紹介するだけでなく、一般的な失敗パターンや限界も含まれており、開発者に実用的な参考情報を提供している。(ソース: omarsar0)
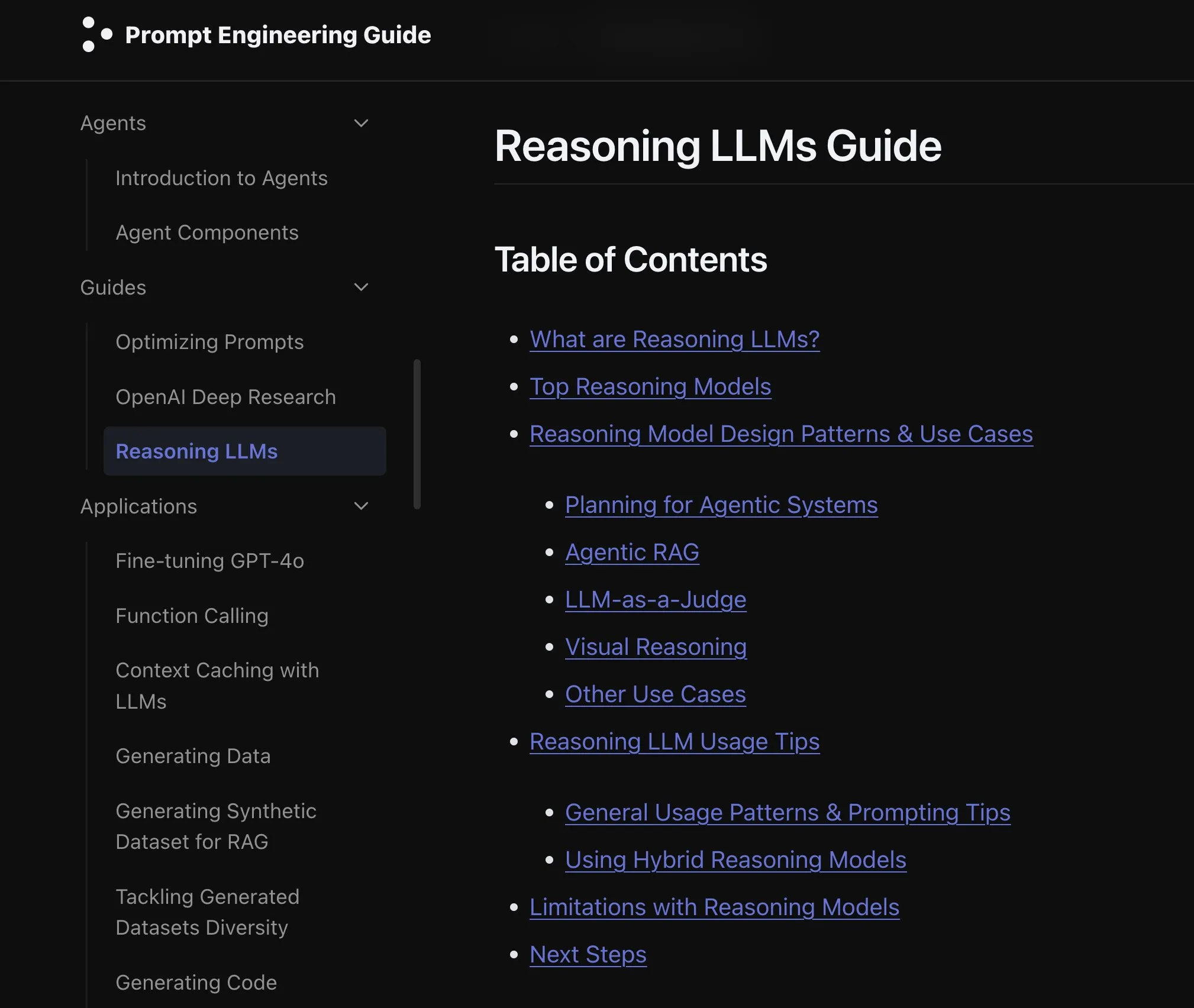
新論文、言語モデルのモダリティ拡張効果を検討: ある新論文は、言語モデルにおけるモダリティ拡張(extending modality)の効果を検討し、現在のオムニモダリティ(omni-modality)開発パスが正しいかどうかについての考察を引き起こした。この研究は、マルチモーダルAIの将来の発展方向を理解するための学術的視点を提供している。(ソース: _akhaliq)
新論文、Likra手法を提案:誤答を利用してLLMの学習を加速: ある論文はLikra手法を紹介している。モデルの一つのヘッドで正答を処理し、もう一つのヘッドで誤答を処理し、それらの尤度比を使用して応答を選択する。研究によると、合理的な誤答例それぞれが正解率向上に貢献する度合いは、正答例の最大10倍になる可能性があり、これはモデルが誤りをより鋭敏に回避するのに役立ち、特に学習の加速と幻覚の削減において、モデルトレーニングにおける負の例の潜在的価値を明らかにしている。(ソース: menhguin)

新論文、LLM採用が意見の多様性に与える潜在的な負の影響を検討: ある研究論文は、大規模言語モデル(LLM)の広範な採用がフィードバックループ(「ロックイン効果」仮説)を引き起こし、それによって意見の多様性を損なう可能性がある問題について論じている。この研究は、AI技術の発展がもたらす可能性のある社会文化的影響に注意を喚起しているが、その結論は依然として慎重に検討する必要がある。(ソース: menhguin)

MIRIAD:大規模医学Q&Aペアデータセット公開、医療LLMを支援: 研究者らは、医学分野における検索拡張生成(RAG)性能を向上させることを目的とした、580万を超える医学Q&Aペアを含む大規模合成データセットMIRIADを公開した。このデータセットは、医学文献の段落をQ&A形式に書き換えることで、LLMに構造化された知識を提供する。実験によると、MIRIADを使用してLLMを強化すると、医学Q&Aの正解率が向上し、LLMが医学的幻覚を検出するのに役立つことが示されている。(ソース: lateinteraction, lateinteraction)

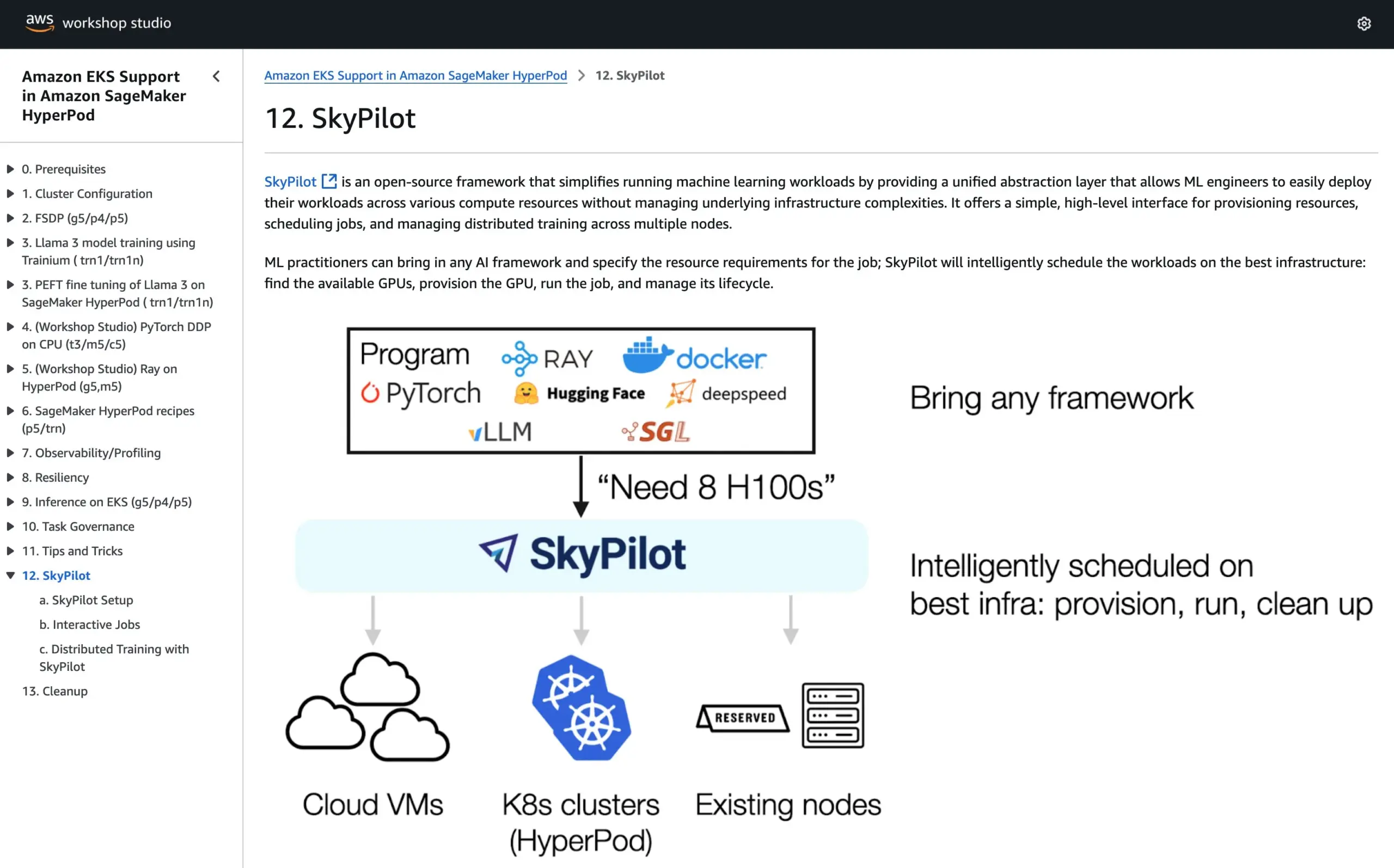
SkyPilotがAWS SageMaker HyperPod公式チュートリアルに参加、両システムの利点を組み合わせてAIを実行: SkyPilotは、AWS SageMaker HyperPodの公式チュートリアルに統合されたことを発表した。ユーザーは、HyperPodが提供するより優れた可用性とノード回復能力、およびSkyPilotのチームAIタスク実行における利便性、迅速性、信頼性を組み合わせることで、AIワークロードの実行を最適化できる。(ソース: skypilot_org)
💼 ビジネス
OpenAI、年間収益100億ドル達成も依然赤字、ユーザー数は急増: CNBCによると、OpenAIの年間経常収益(ARR)は100億ドルに達し、昨年から倍増した。これは主にChatGPTの消費者向けサブスクリプション、企業取引、API利用によるものだ。週間ユーザー数は5億人、法人顧客は300万社を超える。しかし、高額な計算コストのため、同社は昨年約50億ドルの損失を計上したと報じられているが、2029年までにARR1250億ドルを目指している。この情報にはMicrosoftからのライセンス収入は含まれておらず、実際の収益はさらに高い可能性がある。(ソース: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
AI意思決定企業「深演智能」、A株市場での挫折後、香港株式市場でのIPOに転換、利益減少の課題に直面: AIマーケティング意思決定企業である深演智能は、深セン証券取引所への上場申請を取り下げてから約1年後、香港証券取引所に目論見書を提出した。同社の2024年の純利益は64.5%急減し、売掛金比率は40%に達している。深演智能の中核事業は、インテリジェント広告配信プラットフォームAlphaDeskとインテリジェントデータ管理プラットフォームAlphaDataであり、2025年にはAI Agent製品DeepAgentをリリース予定。中国のマーケティングおよび販売意思決定AI応用市場でトップシェアを占めているものの、メディアリソース調達コストの上昇や業界競争の激化などの課題に直面している。(ソース: 36氪)

You.comと「TIME」誌が提携、デジタル購読者に1年間の無料Proサービスを提供: AI検索企業You.comは、著名メディアブランド「TIME」誌との提携を発表した。提携の一環として、You.comはすべての「TIME」誌デジタル購読者に対し、1年間の無料You.com Proアカウントサービスを提供する。この動きは、You.com Proのユーザー基盤を拡大し、AI検索とメディアコンテンツの融合を探ることを目的としている。(ソース: RichardSocher)

🌟 コミュニティ
Anthropic、ユーザーにAIをスロットマシンのように使うよう助言し、コミュニティで話題に: AnthropicのAI使用に関する助言――「スロットマシンのように扱ってください」――がソーシャルメディアで広範な議論と一部嘲笑を呼んでいる。この表現は、AIの出力結果に不確実性やランダム性が存在する可能性を示唆しており、ユーザーが完全に依存するのではなく、選択的に受け入れ判断する必要があることを意味している。これは、現在のLLMが信頼性と一貫性の面で依然として課題に直面していることを反映している。(ソース: pmddomingos, pmddomingos)
AI開発者ツールの「天国と地獄」:トップアプリと一般の慣行との間に大きな隔たり: 開発者コミュニティでは、AI開発者ツールの構築と投資において、トップ1%のAIアプリケーションの構築方法と残りの99%のアプリケーションの構築方法が根本的に異なるという核心的な矛盾が議論されている。両者はそれぞれのユースケースにおいて正しく適切であるが、同じアーキテクチャや技術スタックで小規模アプリケーションから超大規模アプリケーションへシームレスに拡張しようとすることは、ほぼ確実に失敗する。これは、AI開発分野におけるツールと方法論選択の複雑さを浮き彫りにしている。(ソース: swyx)
Shopify、従業員にLLMを大胆にプログラミングで使用するよう奨励、さらには「消費コンテスト」も開催: ShopifyのMParakhin氏は、社内では従業員がコーディング時にLLMを使用することを制限しないばかりか、逆に消費額が少なすぎる従業員を「叱責」することさえあると明かした。彼はさらに、スクリプトを使用せずに最も多くのLLMクレジットを消費した従業員を表彰するコンテストも開催したという。これは、一部の先進的なテクノロジー企業がAI支援開発ツールを積極的に受け入れ、効率向上とイノベーション能力向上の重要な手段と見なしている姿勢を反映している。(ソース: MParakhin)
AIエージェントのニュース編集室での応用:MagidとPromptLayerの協力事例: Magid社はPromptLayerプラットフォームを利用してAIエージェントを構築し、ニュース編集室がニュース基準に準拠しつつ大規模にコンテンツを作成するのを支援している。これらのAIエージェントは数千件の報道を処理でき、信頼性、バージョン管理能力を備え、実際の記者からの信頼も得ている。この事例は、AIエージェントがコンテンツ作成およびニュース業界で実際に活用される可能性を示している。(ソース: imjaredz, Jonpon101)

RL+GPT型LLMのAGIへの道筋に関する議論: コミュニティでは、強化学習(RL)とGPTスタイルの大規模言語モデル(LLM)の組み合わせが、汎用人工知能(AGI)へと完全に導く可能性があるという見解がある。この見方はAGIの実現経路に関するさらなる考察と議論を引き起こしており、RLがLLMにより強力な目標指向性と継続的な学習能力を付与する可能性が注目されている。(ソース: finbarrtimbers, agihippo)
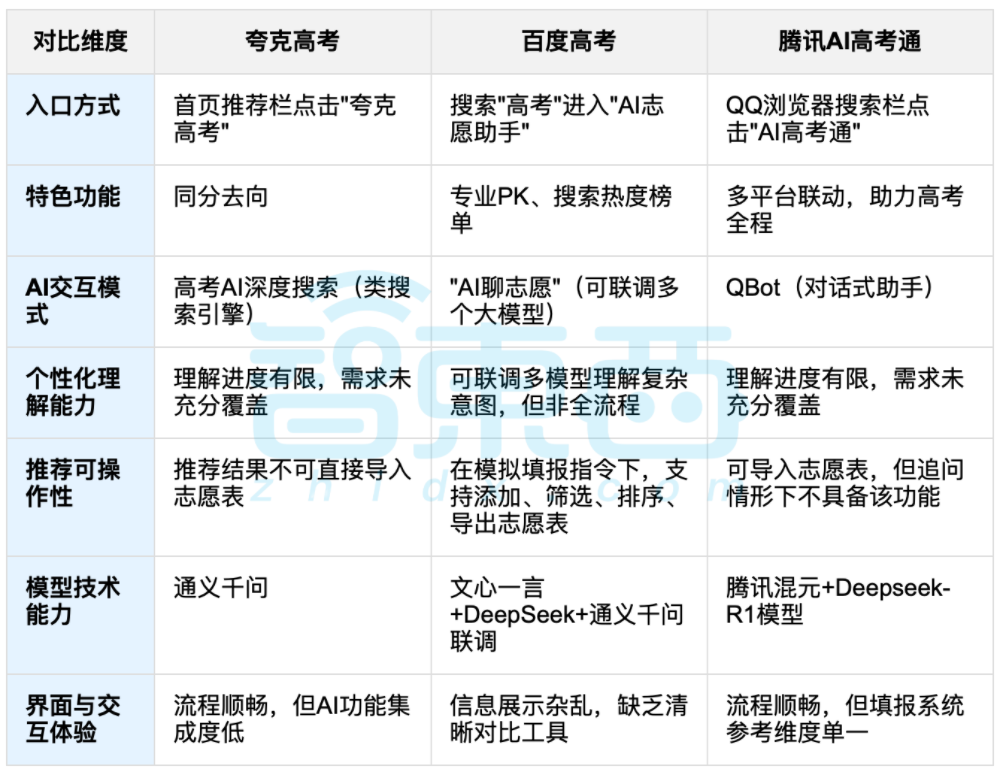
AI支援による大学入試志望校選択が議論を呼ぶ、データと個別選択のバランスが焦点に: 大学統一入学試験(高考)終了に伴い、夸克、百度AI高考通、騰訊AI高考通などのAI支援志望校選択ツールが注目を集めている。これらのツールは、過去のデータを分析し、点数順位を照合することで、「挑戦・安定・安全」の提案を行う。実測によると、各プラットフォームはインタラクション方式、推薦ロジック、個別ニーズの理解においてそれぞれ特徴と不足点がある。議論では、AIは情報収集効率を高め、情報格差を解消できるものの、性格、興味、将来計画などの複雑な個人的要因が絡む場合、AIの「データ占い」は受験生の主観的判断と人生の選択を完全に代替することはできないと指摘されている。(ソース: 36氪, 36氪)
💡 その他
Cortical Labs、初の商用生物コンピューティングプラットフォームCL1を発表、80万個の生きたヒト神経細胞を統合: オーストラリアのスタートアップ企業Cortical Labsは、世界初の商用生物コンピューティングプラットフォームCL1を発売した。このプラットフォームは80万個の生きたヒト神経細胞とシリコンチップを組み合わせ、「ハイブリッドインテリジェンス」を構成する。CL1は情報を処理し自律的に学習することができ、意識に似た特徴を示し、実験ではゲーム『Pong』を学習した。このデバイスの消費電力は従来のAIハードウェアよりはるかに低く、単価は35,000米ドルで、「ウェットウェア・アズ・ア・サービス」(WaaS)のリモートアクセスモデルも提供する。この技術は生物と機械の境界を曖昧にし、知能の本質と倫理に関する議論を引き起こしている。(ソース: 36氪)

AIナレッジベースの実践的ジレンマ:技術はクールだが導入は困難、「AIフレンドリー」な設計が必要: 藍凌(Lanling)副総裁の劉向華氏は、崔牛会創設者の崔強氏との対談で、大規模モデル技術により企業のナレッジマネジメントが再び注目されているが、AIナレッジベースは「評判は良いが実益がない」というジレンマに直面していると指摘した。彼は、企業向けナレッジベースと個人向けナレッジベースは、権限管理、知識体系ガバナンス、コンテンツの一貫性などの点で大きく異なると考えている。「AIフレンドリー」なナレッジベースを構築し、データ品質、ナレッジグラフ、ハイブリッド検索などを重視することで、幻覚を減らし実用性を高めることができる。彼は技術のための技術追求には賛同せず、シーンに応じて適切な技術を選択すべきであり、大規模モデルは万能ではないと強調した。(ソース: 36氪)
Google支援のAI強化核融合炉プロジェクト、2030年までに18億華氏のプラズマ実現を目指す: Interesting Engineeringの報道によると、GoogleはAI技術によって核融合炉を強化するプロジェクトを支援している。このプロジェクトの目標は、2030年までに18億華氏(約10億摂氏)のプラズマを生成し維持することである。この協力は、極限的な科学技術の課題解決、特にクリーンエネルギー分野におけるAIの可能性を示している。(ソース: Ronald_vanLoon)
