
キーワード:大規模言語モデル, 推論能力, 汎用人工知能, パターンマッチング, 思考の幻覚, アップル研究, AI検出器, AI規制, Log-Linear Attentionメカニズム, ファーウェイ盤古MoEモデル, ChatGPT高度音声モード, TensorZeroフレームワーク, Anthropic CEOの規制観
🔥 注目ニュース
Appleの研究、「思考の錯覚」を明らかに:現在の「推論」モデルは真の思考ではなく、パターンマッチングに依存: Appleの最新研究論文「The Illusion of Thinking: Through the Lens of Problem Complexity, Understanding the Strengths and Limitations of Reasoning Models」は、現在「推論」能力を持つとされる大規模言語モデル(Claude、DeepSeek-R1、GPT-4o-miniなど)のパフォーマンスは、真の意味での論理的推論というよりも、効率的なパターンマッチャーに近いと指摘しています。研究によると、これらのモデルは、訓練分布外または複雑性の高い問題を処理する際にパフォーマンスが著しく低下し、単純な問題でも「考えすぎ」によって誤りを犯し、初期の誤りを修正することが困難であることが判明しました。この研究は、モデルのいわゆる「思考」プロセス(Chain of Thoughtなど)が、新規または複雑なタスクに直面すると機能しなくなることが多く、汎用人工知能(AGI)は予想よりも遠い可能性があることを強調しています。(ソース: machinelearning.apple.com, TheTuringPost, mervenoyann, Reddit r/artificial, Reddit r/LocalLLaMA, Reddit r/MachineLearning)

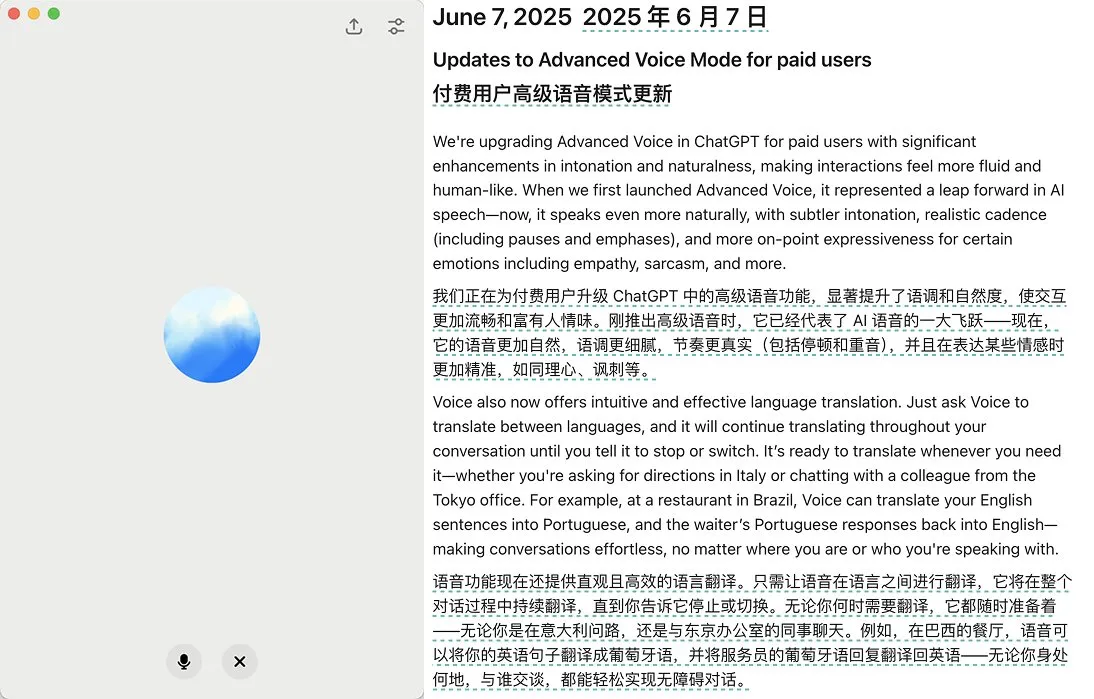
OpenAI、ChatGPTのAdvanced Voice Modeアップデートをリリース、自然さと翻訳機能を向上: OpenAIは、ChatGPTの有料ユーザー向けにAdvanced Voice Modeのメジャーアップデートをリリースしました。新バージョンでは、音声の自然な流暢さが大幅に向上し、AIアシスタントというよりも人間のように聞こえるようになりました。さらに、今回のアップデートでは、言語翻訳性能と指示追従能力が改善され、新たに翻訳モードが追加されました。ユーザーは、停止を指示されるまで、会話全体を通してChatGPTに双方の会話を継続的に翻訳させることができます。このアップデートは、音声インタラクションをより簡単かつ自然にし、ユーザーエクスペリエンスを向上させることを目的としています。(ソース: juberti, Plinz, op7418, BorisMPower)
AI検出器は無効であり、AIコンテンツの「ステルス化」を助長する可能性が指摘される: ソーシャルメディアや技術フォーラムで、現在のAIコンテンツ検出ツールは効果がないばかりか、意図せずAI生成コンテンツを検知しにくくしている可能性があるという議論が広まっています。多くのユーザーや専門家は、これらの検出器がコンテンツの出典を真に理解するのではなく、主に言語パターンや特定の語彙(学術用語の「delve」など)に基づいて判断していると考えています。誤判定のリスク(学生などに不公平をもたらす可能性)や、AIモデル自体が検出を回避するために進化しているため、これらのツールの信頼性には深刻な疑問が投げかけられています。AI検出器の存在が、逆にAIがコンテンツを生成する際に特定のマークされやすい特徴を避けるよう促し、結果として人間が書いた文章に似せてしまうという意見もあります。(ソース: Reddit r/ArtificialInteligence, sytelus)

Anthropic CEO、AI企業の透明性と責任に関する規制強化を呼びかけ: AnthropicのCEOはニューヨーク・タイムズ紙に寄稿し、AI企業に対する規制を緩めるべきではなく、特に透明性を高め、責任を追及する必要があると強調しました。この見解は、AI業界が急速に発展し、能力が日進月歩で向上する中で特に重要であり、AIの潜在的なリスクと倫理に関する社会の懸念に応えるものです。記事は、AI技術の影響力が拡大するにつれて、その発展が公共の利益に合致し、乱用を避けることが極めて重要であり、そのためには業界の自主規制と外部からの規制が共に作用する必要があると論じています。(ソース: Reddit r/artificial)

🎯 動向
Jeff Dean氏、AIの未来を展望:専用ハードウェア、モデル進化、科学応用: Google AIの責任者であるJeff Dean氏は、Sequoia CapitalのAI Ascentイベントで、AIの将来の発展についての見解を共有しました。同氏は、専用ハードウェア(TPUなど)がAIの進歩にとって重要であることを強調し、モデルアーキテクチャの進化の傾向について議論しました。Dean氏はまた、計算インフラの将来の形態や、AIが科学研究などの分野で持つ巨大な応用可能性を展望し、AIが科学的発見を推進する重要なツールになるとの見方を示しました。(ソース: TheTuringPost)

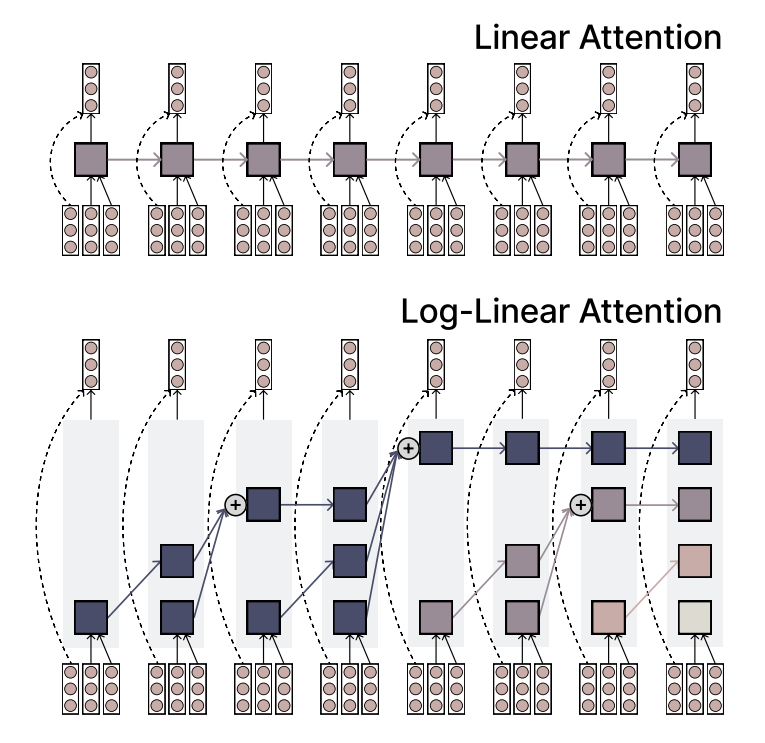
MIT、効率と表現力を両立するLog-Linear Attentionメカニズムを提案: MITの研究者らは、Log-Linear Attentionと呼ばれる新しいアテンションメカニズムを提案しました。このメカニズムは、Linear Attentionの高い効率性とSoftmaxアテンションの強力な表現能力を組み合わせることを目指しています。その主な特徴は、シーケンス長に対して対数的に増加する少数のメモリスロットを使用することで、長いシーケンスを処理する際に低い計算複雑性を維持しつつ、重要な情報を捉えることです。(ソース: TheTuringPost)
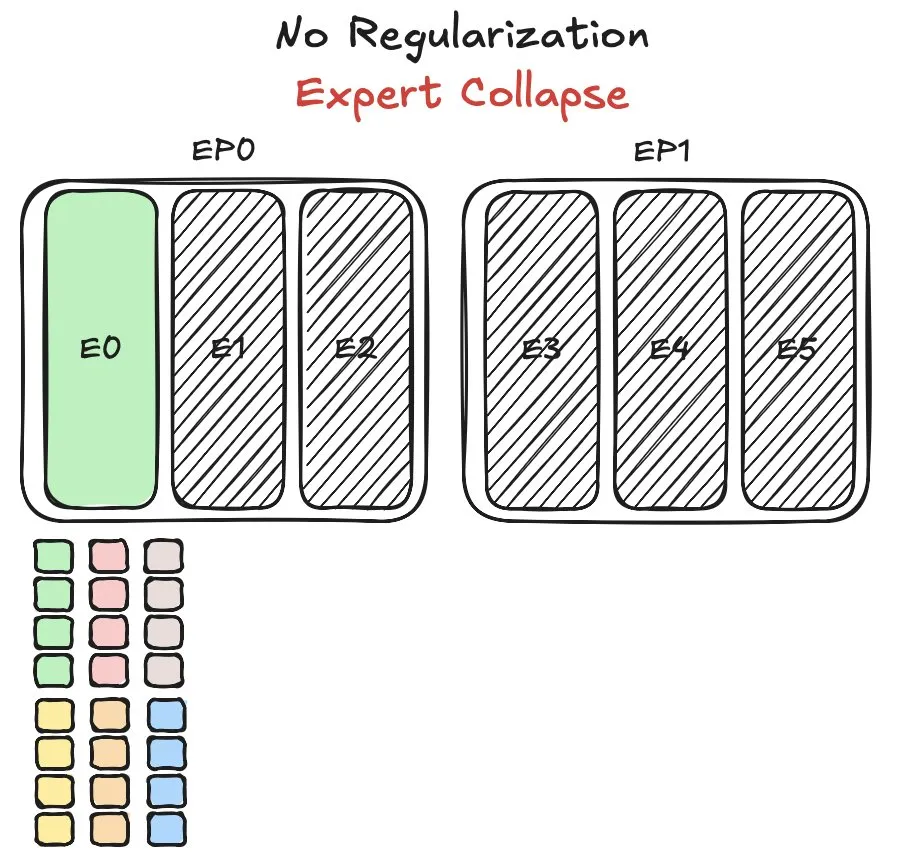
Huawei Pangu MoEモデル、エキスパートの負荷分散の課題に直面し、新手法を提案: Huaweiは、混合エキスパート(MoE)モデルであるPangu Ultra MoEの訓練において、エキスパートの負荷分散という重要な問題に直面しました。エキスパートの負荷分散は、訓練のダイナミクスとシステム効率の間でトレードオフを考慮する必要があります。Huaweiはこの問題に対し、MoEモデルにおける異なるエキスパートモジュールのタスク割り当てと計算負荷を最適化し、訓練効率とモデル性能を向上させるための新しい解決策を提案しました。関連研究は論文として発表されています。(ソース: finbarrtimbers)
NVIDIA、物体検出に焦点を当てたCascade Mask R-CNN Mamba Visionモデルをリリース: NVIDIAはHugging Face上で、cascade_mask_rcnn_mamba_vision_tiny_3x_cocoという名前の新しいモデルをリリースしました。名称から判断すると、このモデルは物体検出タスク専用に設計されており、Cascade R-CNNアーキテクチャとMamba(状態空間モデルの一種)の視覚技術を融合し、物体検出の精度と効率の向上を目指している可能性があります。(ソース: _akhaliq)
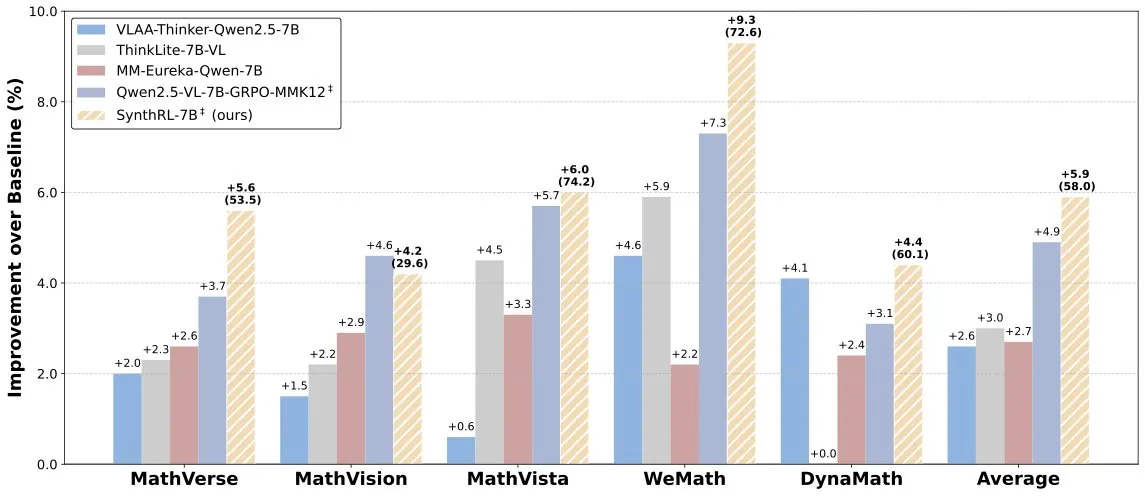
SynthRLモデル発表:検証可能なデータ合成によるスケーラブルな視覚的推論の実現: Hugging Face上でSynthRLモデルが発表されました。このモデルはスケーラブルな視覚的推論能力に焦点を当てており、その核心技術は検証可能なデータ合成手法を通じて、より挑戦的な視覚的推論タスクのバリアントを生成しつつ、元の回答の正しさを維持することにあります。これにより、複雑な視覚シーンにおけるモデルの理解と推論レベルの向上が期待されます。(ソース: _akhaliq)
DeepSeek-R1は好成績を収めるも、ChatGPTの製品優位性は依然として盤石: VentureBeatのコメントによると、DeepSeek-R1などの新興モデルが一部の面で優れたパフォーマンスを示しているものの、ChatGPTはその先行者利益、広範なユーザーベース、成熟した製品エコシステム、継続的なイテレーション能力により、製品レベルでの優位性は短期的には揺るがないとのことです。AI競争は技術パラメータの競争だけでなく、製品体験、エコシステム構築、ビジネスモデルの総合的な競争でもあります。(ソース: Ronald_vanLoon)

Qwenチーム、Qwen3-coderを開発中であることを確認: QwenチームのJunyang Lin氏は、Qwen3シリーズのコーディング能力強化版モデルであるQwen3-coderを開発中であることを認めました。具体的なスケジュールは公表されていませんが、Qwen2.5のリリースサイクルを参考にすると、数週間以内に登場する可能性があります。コミュニティは、このモデルがコード生成、自律的/エージェントワークフロー統合の面でブレークスルーを達成し、多様なプログラミング言語への良好なサポートを維持することを期待しています。(ソース: Reddit r/LocalLLaMA)

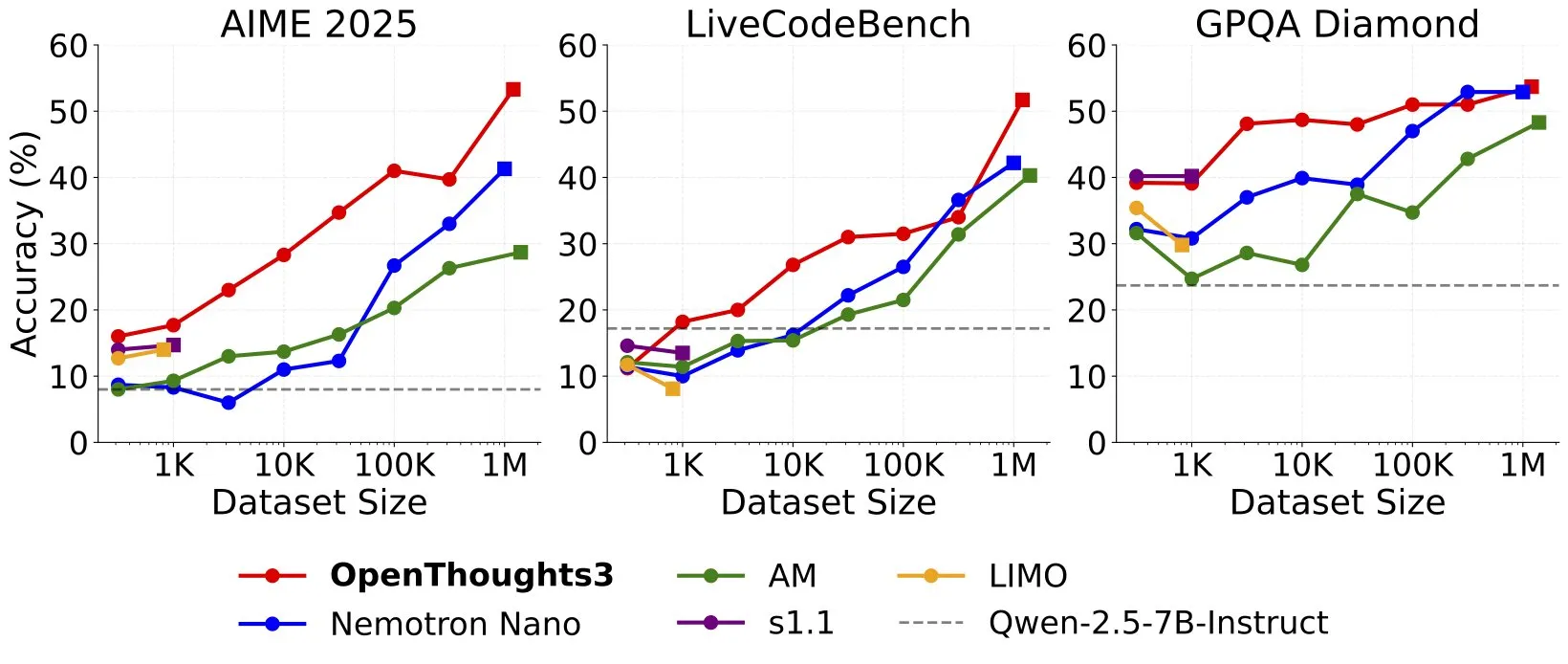
OpenThinker3-7Bがリリース、SOTAオープンデータ7B推論モデルと称する: Ryan Marten氏は、OpenThinker3-7Bモデルのリリースを発表し、これを現在最先端のオープンデータに基づいて訓練された7Bパラメータの推論モデルであると述べました。同氏によると、このモデルはコード、科学、数学の評価において、DeepSeek-R1-Distill-Qwen-7Bを平均で33%上回るとのことです。同時に、その訓練データセットであるOpenThoughts3-1.2Mもリリースされました。(ソース: menhguin)
🧰 ツール
TensorZero:オープンソースLLMOpsフレームワーク、LLMアプリケーション開発とデプロイを最適化: TensorZeroは、オープンソースのLLMアプリケーション最適化フレームワークであり、フィードバックループを通じて本番データをよりスマートで、より速く、より経済的なモデルに変換することを目指しています。LLMゲートウェイ(複数のモデルプロバイダーをサポート)、可観測性、最適化(プロンプト、ファインチューニング、RL)、評価、実験(A/Bテスト)などの機能を統合し、低遅延、高スループット、GitOpsをサポートしています。このツールはRustで書かれており、パフォーマンスと産業レベルのアプリケーション要件を重視しています。(ソース: GitHub Trending)

LangChain、SambaNova、Qdrant、LangGraphを組み合わせた高性能RAGシステムを発表: LangChainは、高性能な検索拡張生成(RAG)実装ソリューションを紹介しました。このソリューションは、SambaNovaのDeepSeek-R1モデル、Qdrantのバイナリ量子化技術、およびLangGraphを組み合わせることで、32倍のメモリ削減を実現し、大規模なドキュメントを効率的に処理できます。これにより、より経済的で高速なRAGアプリケーションを構築するための新たな可能性が提供されます。(ソース: hwchase17, qdrant_engine)
Googleの科学解説動画ワンクリック生成アプリSparkifyが高品質な事例を展示: GoogleがリリースしたSparkifyアプリは、ワンクリックで科学解説動画を生成でき、その展示事例の品質は非常に高いです。動画コンテンツ全体の一貫性が良く、ナレーションも自然で、画面分割表示などの複雑な効果も実現できており、AIによる動画コンテンツ制作の自動化における可能性を示しています。(ソース: op7418)
Hugging Face、初のMCPサーバーをリリースし、チャットボット機能を拡張: Hugging Faceは、初のMCP (Modular Chat Processor) サーバー (hf.co/mcp) をリリースし、ユーザーはこれをチャットボックスに貼り付けて使用できます。MCPサーバーは、チャットボットの機能を強化し、モジュール化された処理ユニットを通じてより豊かなインタラクション体験を提供することを目的としています。コミュニティは同時に、Agentset MCP、GitHub MCPなど、他の有用なMCPサーバーのリストもまとめています。(ソース: TheTuringPost)
Chatterbox TTS、ElevenLabsに匹敵する効果でgptmeに統合: TTS(テキスト読み上げ)ツールChatterboxは、その優れた音声合成効果で注目を集めており、ユーザーからはその効果が有名なElevenLabsに匹敵し、Kokoroよりも優れているとのフィードバックが寄せられています。Chatterboxは参照サンプルによる音声のカスタマイズをサポートしており、現在gptmeのTTSバックエンドとして追加され、ユーザーに高品質な音声出力オプションを提供しています。(ソース: teortaxesTex, _akhaliq)
E-Library-Agent:ローカルの書籍/文献のためのインテリジェント検索・質疑応答システム: E-Library-Agentは、個人の書籍や論文集を抽出、インデックス化、検索できる自己ホスト型のAIエージェントです。このプロジェクトはingest-anythingに基づいており、LlamaIndex、Qdrant、Linkupプラットフォームによってサポートされ、ローカル資料の抽出、文脈を考慮した質疑応答、単一インターフェースによるウェブ検索機能を実現し、ユーザーが個人の知識ベースを管理・活用するのに便利です。(ソース: qdrant_engine)
Claude Code、その強力なコーディング支援能力で開発者から高く評価される: Redditコミュニティのユーザーは、AnthropicのClaude Codeを使用してソフトウェア開発を行った際の肯定的な経験を共有しており、特にゲーム開発(Godot C#プロジェクトなど)の分野でその効果を実感しています。ユーザーは、複雑な問題を解決する能力が他のAIコーディングアシスタント(GitHub Copilotなど)をはるかに凌駕し、文脈を理解して有効なコードを生成できると称賛しており、月額100ドルの費用もそれに見合う価値があると見なされています。経験豊富なプログラマーがClaude Codeと組み合わせることで、生産性が大幅に向上すると開発者は考えています。(ソース: Reddit r/ClaudeAI)
ChatterUI、ローカルビジョンモデルをサポートするも、Android端末での処理は遅い: LLMチャットクライアントChatterUIのプレリリース版では、添付ファイルとローカルビジョンモデルのサポートが追加されました(llama.rn経由)。ユーザーはローカル互換モデルにmmprojファイルをロードするか、ビジョン機能をサポートするAPI(Google AI Studio、OpenAIなど)に接続できます。しかし、llama.cppがAndroid端末で安定したGPUバックエンドを欠いているため、画像処理速度は非常に遅く(例えば512×512の画像に5分)、iOS端末ではパフォーマンスが比較的良好です。(ソース: Reddit r/LocalLLaMA)
FLUX kontext、自動車の宣伝画像の背景置換で優れた性能を発揮: ユーザーテストによると、AI画像編集ツールFLUX kontextは、自動車の宣伝画像の背景変更において顕著な効果を示しています。例えば、Xiaomi SU7の公式画像に背景(夕暮れのビーチ、レースサーキットなど)を変更すると、このツールは背景を自然に融合させるだけでなく、走行中の車両にモーションブラー効果をインテリジェントに追加し、画像のリアリティと視覚的インパクトを高めます。(ソース: op7418)

📚 学習
fastcoreの新機能flexicache:柔軟なキャッシュデコレータ: Jeremy Howard氏は、fastcoreライブラリの便利な新機能flexicacheを紹介しました。これは非常に柔軟なキャッシュデコレータで、「mtime」(ファイルの変更時刻に基づく)と「time」(タイムスタンプに基づく)という2つのキャッシュ戦略が組み込まれており、ユーザーは少量のコードで新しいキャッシュ戦略をカスタマイズすることも可能です。この機能はDaniel Roy Greenfeld氏の記事で詳しく紹介されており、コード実行効率の向上に役立ちます。(ソース: jeremyphoward)
Transformerモデル訓練におけるMuPとMuonの組み合わせの可能性を探る: Jingyuan Liu氏は、Jeremy Bernstein氏によるMuonとスペクトル条件の導出に関する研究を深く学び、そのエレガントな導出プロセス、特にMuP(Maximal Update Parametrization)とMuon(オプティマイザの一種)がどのように連携して機能するかに感嘆の意を表しています。同氏は、導出から見て、MuPベースのモデル訓練のオプティマイザとしてMuonを使用することは自然な選択であり、これはMoonshotのMoonlight研究におけるAdamWのハイパーパラメータからMuonへの更新RMSのマッチングによる移行よりもエキサイティングである可能性を指摘しています。コミュニティの議論では、MuP + Muonの組み合わせは年末までに大手テクノロジー企業によって大規模に適用される可能性があると考えられています。(ソース: jeremyphoward)

メタラーニング(Meta-learning)の主要3手法を解説: メタラーニングは、少量のサンプルしかなくてもモデルが新しいタスクを迅速に学習できるようにすることを目的としています。一般的な手法には次のものがあります。1. 最適化ベース/勾配ベース:少量の勾配ステップでタスク上で効率的にファインチューニングできるモデルパラメータを見つける。2. メトリックベース:モデルが新旧サンプルの類似性をより良く測定し、関連サンプルを効果的にグループ化する方法を見つけるのを助ける。3. モデルベース:モデル全体が、組み込みメモリまたは動的メカニズムを利用して迅速に適応できるように設計されている。TuringPostは、基礎から現代のメタラーニング手法までの詳細な解説を提供しています。(ソース: TheTuringPost)
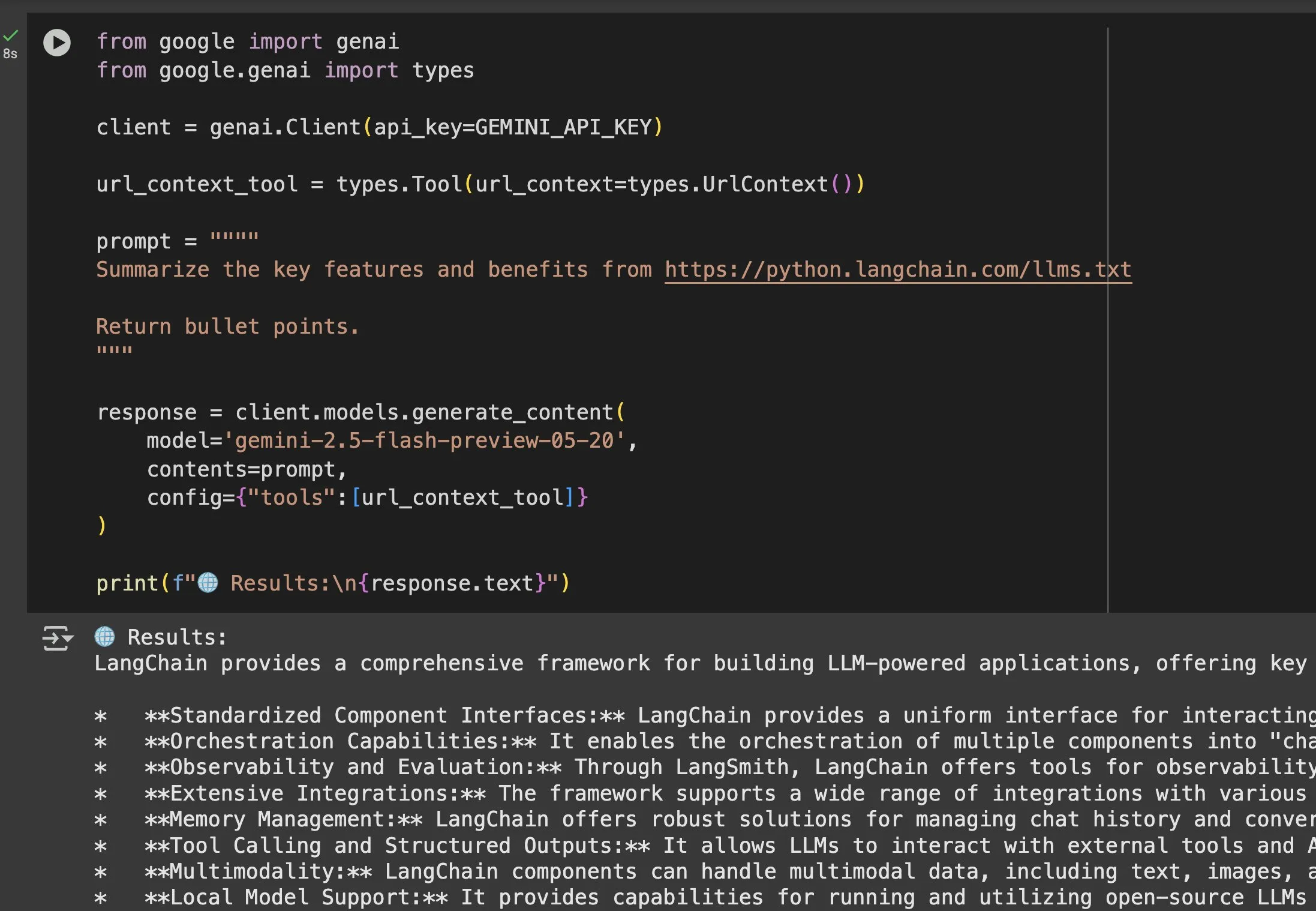
llms.txtファイルがGeminiなどのモデルで応用価値を増す: Jeremy Phoward氏は、llms.txtファイルの有用性を強調しました。例えば、Geminiは現在URL内のコンテンツを理解でき、プロンプトにURLを追加し、URLコンテキストツールを設定するだけで済みます。これは、クライアント(Geminiなど)がllms.txtエンドポイントを読み取ることで、必要な情報がどこに保存されているかを正確に把握でき、情報のプログラムによる取得と利用を大幅に容易にすることを意味します。(ソース: jeremyphoward)
EleutherAI、8TBのオープンライセンス・テキストデータセットCommon Pile v0.1をリリース: EleutherAIは、8TBのオープンライセンスおよびパブリックドメインのテキストを含む大規模データセットであるCommon Pile v0.1のリリースを発表しました。彼らはこのデータセットに基づいて7Bパラメータの言語モデルを訓練し(それぞれ1Tおよび2Tトークンを使用して訓練)、その性能はLLaMA 1やLLaMA 2などの類似モデルに匹敵します。これは、完全に準拠したデータを使用して高性能な言語モデルを訓練するための貴重なリソースと実証を提供します。(ソース: clefourrier)

SelfCheckGPT:参照なしのLLMハルシネーション検出方法: あるブログ記事では、言語モデルにおけるハルシネーションを検出するためのLLM-as-a-judge(LLMを評価者として使用する)の代替案としてSelfCheckGPTが検討されています。これは参照テキストを必要としない、ゼロリソースの検出方法であり、LLM出力の信頼性を評価し向上させるための新しいアプローチを提供します。(ソース: dl_weekly)
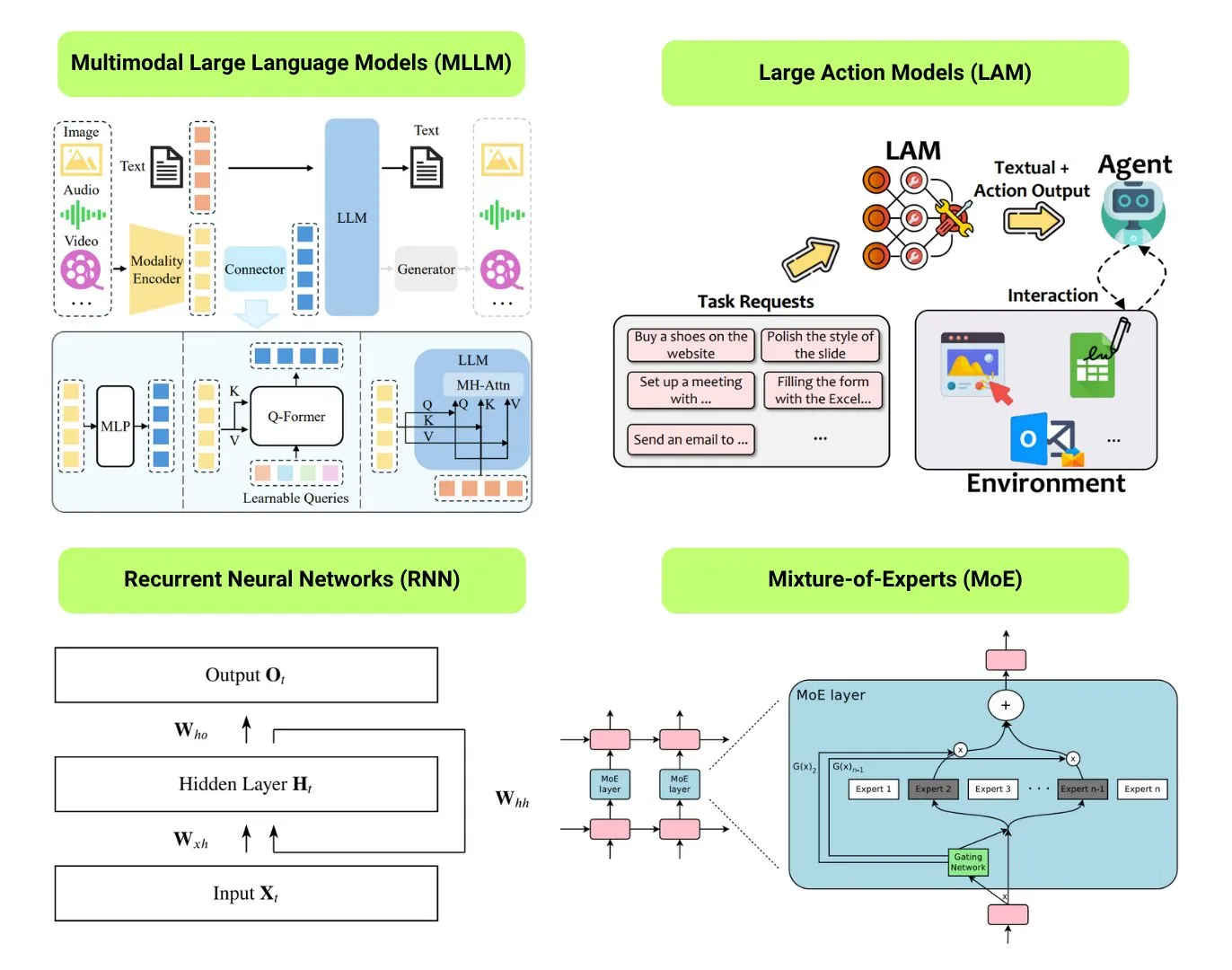
12種類の基礎AIモデルタイプを整理: The Turing Postは、LLM(大規模言語モデル)、SLM(小規模言語モデル)、VLM(視覚言語モデル)、MLLM(マルチモーダル大規模言語モデル)、LAM(大規模行動モデル)、LRM(大規模推論モデル)、MoE(混合エキスパートモデル)、SSM(状態空間モデル)、RNN(再帰型ニューラルネットワーク)、CNN(畳み込みニューラルネットワーク)、SAM(セグメント・エニシング・モデル)、LNN(論理ニューラルネットワーク)の12種類の基礎AIモデルタイプを整理しました。関連リソースでは、これらのモデルタイプの説明と有用なリンクが提供されています。(ソース: TheTuringPost)
GitHub人気:Kubernetes The Hard Wayチュートリアル: Kelsey Hightower氏のチュートリアル「Kubernetes The Hard Way」は、GitHubで引き続き注目を集めています。このチュートリアルは、自動化スクリプトに頼るのではなく、手動で段階的にKubernetesクラスタを構築することで、そのコアコンポーネントと動作原理を深く理解することを目的としています。このチュートリアルは、Kubernetesの基礎知識を習得したい学習者向けで、環境準備からクラスタのクリーンアップまでの全プロセスをカバーしています。(ソース: GitHub Trending)
GitHub人気:無料GPTsとPromptsのリスト: friuns2/BlackFriday-GPTs-PromptsリポジトリがGitHubで人気を集めています。これは、無料のGPTモデルと高品質のPromptsを収集・整理したもので、ユーザーはPlusサブスクリプションなしで使用できます。これらのリソースは、プログラミング、マーケティング、学術研究、就職活動、ゲーム、クリエイティブなど、さまざまな分野をカバーしており、「Jailbreaks」のテクニックも含まれており、GPTユーザーに豊富なすぐに使えるツールとインスピレーションを提供しています。(ソース: GitHub Trending)

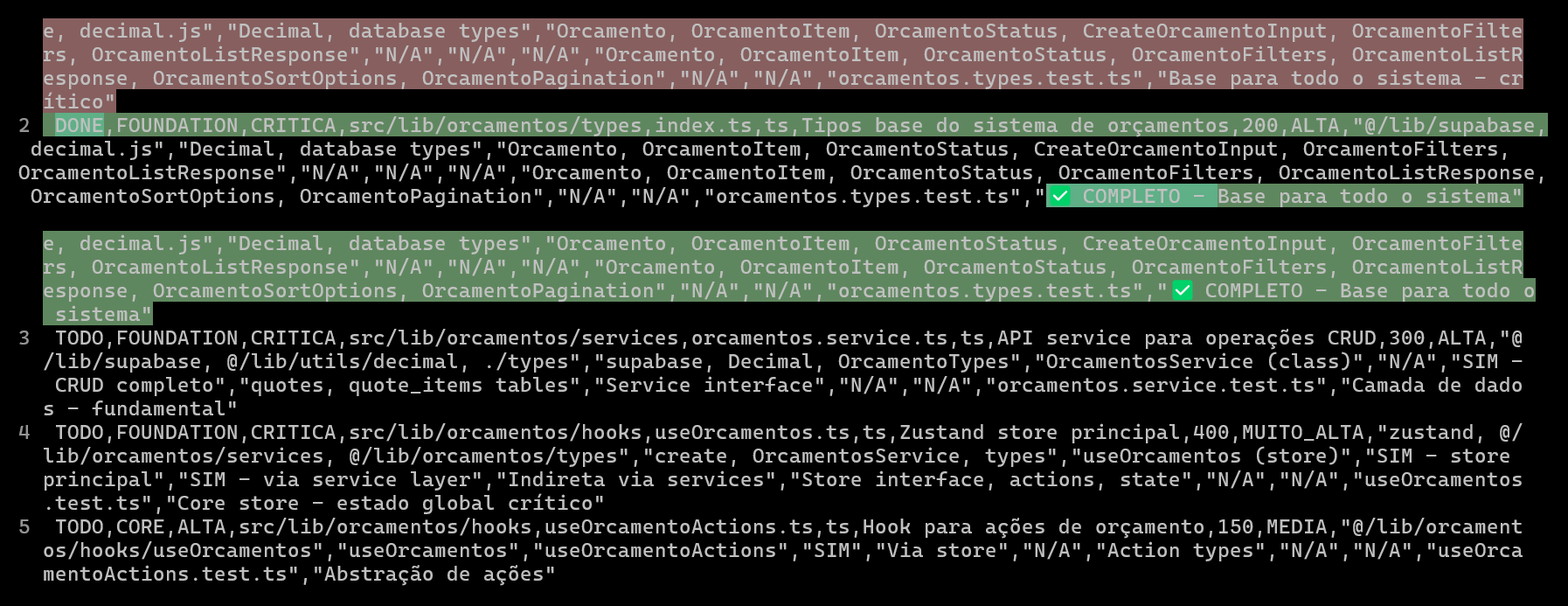
CSVを用いたAIコーディングプロジェクトの計画と追跡により、コード品質と効率を向上: ある開発者は、Claude Codeを使用してERPシステムを開発する際に、詳細なCSVファイルを作成して各ファイルのコーディング進捗を計画・追跡することで、複雑な機能の開発効率とコード品質を大幅に向上させたと共有しました。CSVファイルには、ステータス、ファイル名、優先度、コード行数、複雑度、依存関係、機能説明、使用するHooks、インポート/エクスポートモジュール、そして重要な「進捗ノート」が含まれています。この方法により、AIはより集中してコードを構築でき、開発者はプロジェクトの実際の進捗と当初の計画との差異を明確に把握できます。(ソース: Reddit r/ClaudeAI)
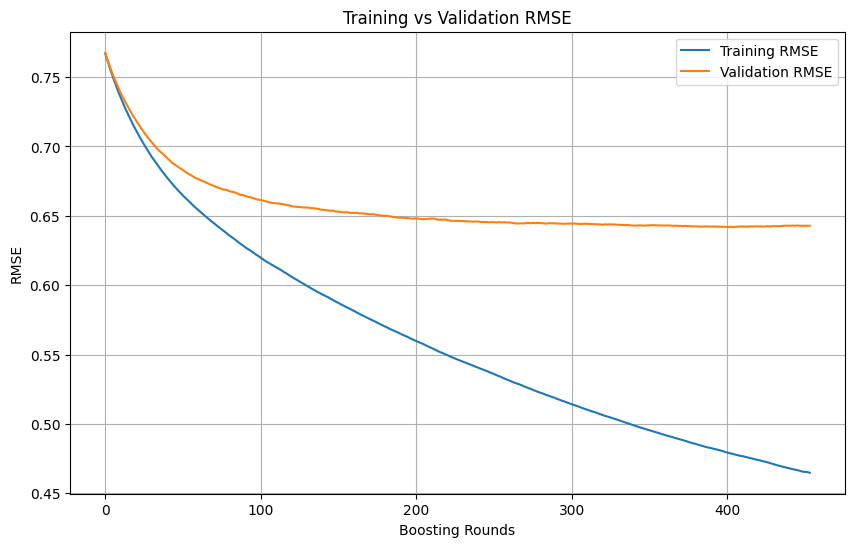
機械学習訓練における過学習の判断と停止時期: 機械学習モデルの訓練プロセスにおいて、訓練損失が急速に低下し続ける一方で、検証損失の低下が緩やかになる、あるいは停止または上昇する場合、通常モデルが過学習を起こしている可能性を示します。原則として、検証損失が依然として低下している限り、訓練を継続できます。重要なのは、検証セットが訓練セットから独立しており、タスクの実際のデータ分布を代表できることを保証することです。検証損失の低下が停止または上昇し始めた場合は、早期停止を検討するか、正則化などの方法を用いてモデルの汎化能力を改善する必要があります。(ソース: Reddit r/MachineLearning)
🌟 コミュニティ
AI Engineer World’s Fair 2025、RL+Reasoning、Evalなどの議題に焦点: AI Engineer World’s Fair 2025大会のテーマは、強化学習+推論(RL+Reasoning)、評価(Eval)、ソフトウェアエンジニアリングエージェント(SWE-Agent)、AIアーキテクト、エージェントインフラストラクチャなど、最先端の方向性をカバーしています。参加者からは、大会は活力と革新的な思考に満ちており、多くの人々が新しいことに挑戦し、自己を再構築し続け、AI分野に身を投じているとの声が聞かれました。大会はまた、AIエンジニアたちに交流と学習のプラットフォームを提供しました。(ソース: swyx, hwchase17, charles_irl, swyx)

Sam Altman氏の理想のAI:小型モデル+超強力な推論+膨大なコンテキスト+万能ツール: Sam Altman氏は、自身が考える理想的なAIの形態を説明しました。それは、超人的な推論能力を持ち、非常に小型のモデルで、数兆レベルのコンテキスト情報にアクセスでき、想像しうるあらゆるツールを呼び出せるというものです。この見解は議論を呼び、一部の人々は、これが現在の大規模モデルが知識の保存に依存している現状とは異なると考え、小型モデルが巨大なコンテキストの中で知識を解析し、複雑な推論を行うことの実現可能性に疑問を呈し、知識と思考能力を効率的に分離することは困難であると主張しています。(ソース: teortaxesTex)
コーディングエージェントがコードリファクタリングの欲求を喚起、AI支援プログラミングの課題と機会: 開発者たちは、コーディングエージェントの出現が他人のコードをリファクタリングする「誘惑」を大幅に強め、新たな危険ももたらしていると述べています。ある開発者は、AI支援を受けて約10分間の手作業に相当するプログラミングタスクを完了した経験を共有しました。AIは迅速に動作するコードを生成できましたが、熟練プログラマーの構成やスタイルレベルに達するには、依然として多くの手作業による指導とリファクタリングが必要でした。これは、AI支援プログラミングが初級/中級コードを高級コードの品質に向上させる上での課題を浮き彫りにしています。(ソース: finbarrtimbers, mitchellh)
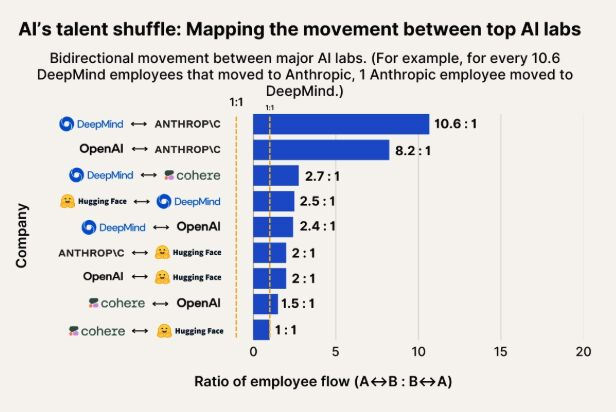
AI人材流動観察:AnthropicがGoogle DeepMindとOpenAIの人材の重要な流出先に: AI人材の流動を示す図表によると、AnthropicはGoogle DeepMindやOpenAIの研究者を引き付ける重要な企業となっています。コミュニティはこれに同意しており、Anthropicが何らかの「秘密兵器」や独自の研究方針を持っているのではないか、それがトップ人材の参加を引き付けているのではないかと推測するユーザーもいます。(ソース: bookwormengr, TheZachMueller)
人型ロボット普及は信頼と社会的受容の課題に直面: テクノロジーコメンテーターのFaruk Guney氏は、最初の人型ロボットの波は巨大な信頼赤字のために失敗する可能性があると予測しています。同氏は、技術は進歩し続けているものの、社会はこれらの「ブラックボックスインテリジェンス」を家庭に受け入れ、付き添い、家事、さらには育児などのタスクを実行させる準備ができていないと考えています。ロボットの不透明な意思決定、潜在的な監視リスク、そして人間とは全く異なる「可愛らしい」外観(Wall-Eほどではない)はすべて、その広範な応用の障害となる可能性があります。十分な社会的議論、規制、監査、信頼再構築の後でのみ、人型ロボットの真の普及が訪れるでしょう。(ソース: farguney, farguney)
AIパーソナリティデザイン:「完璧」よりも「不完全」が勝る: ある開発者が、AIオーディオプラットフォームで50のAIパーソナリティを作成した経験を共有しました。結論として、過度に設計されたバックストーリー、絶対的な論理的一貫性、極端な単一の性格は、かえってAIを機械的で非現実的に見せてしまうとのことです。成功するAIパーソナリティの形成は、「3層のパーソナリティスタック」(コア特性+修飾特性+奇癖)、適切な「不完全パターン」(例えば、時折の言い間違い、自己修正)、そして適切な量の背景情報(300~500語、肯定的および挑戦的な経験、具体的な情熱、専門分野に関連する脆弱性を含む)にあります。これらの「不完全」な詳細が、かえってAIに人間味とつながりをもたらします。(ソース: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
LLMが「知覚」や「AGI」を備えているかについての議論:興奮と懐疑が共存: コミュニティは一般的にLLMの巨大な可能性に興奮しており、歴史的な大発明に匹敵し、すべてを変えると考えています。しかし、LLMがすでに「知覚能力」を備えているか、「権利」が必要か、そして「人類を終わらせる」か「AGI」をもたらすかといった主張については、多くの人が依然として懐疑的な見方を示しています。LLMの能力や研究成果を解釈する際には、細心の注意と慎重さを保つ必要があると強調されています。(ソース: fabianstelzer)
💡 その他
複数ロボットの自律歩行協調を探る: ソーシャルメディア上で、複数ロボットの自律歩行における協調の探求に関する話題が上がっています。これには、ロボットの経路計画、タスク割り当て、情報共有、衝突回避などの複雑な技術が含まれ、ロボット工学、RPA(ロボティック・プロセス・オートメーション)、機械学習の分野で継続的に注目されている研究方向です。(ソース: Ronald_vanLoon)
ランダムフォレストを用いたULMFiTのハイパーパラメータ最適化のテクニック: Jeremy Howard氏は、ULMFiT(転移学習手法の一種)を最適化する際のテクニックを共有しました。それは、多数のアブレーション実験を実行し、すべてのハイパーパラメータと結果データをランダムフォレストモデルに投入することで、モデル性能に最も大きな影響を与えるハイパーパラメータを見つけ出すというものです。この方法はWeights & Biasesによって製品に統合されており、ハイパーパラメータチューニングに新たなアプローチを提供しています。(ソース: jeremyphoward)

Figure社の人型ロボット、60分間の物流タスク処理能力をデモンストレーション: Figure社は、Helixニューラルネットワークによって駆動される人型ロボットが、物流現場で様々なタスクを自律的に完了する様子を収めた60分間の動画を公開しました。このデモンストレーションは、複雑な実環境におけるロボットの長時間の安定した作業能力と自律的な意思決定レベルを証明することを目的としています。(ソース: adcock_brett)