キーワード:悟界シリーズ大規模モデル, RLHF新手法, Claude Govシリーズモデル, 大規模言語モデル, マルチモーダル融合, 物理AGI, AIセキュリティ, エンボディドインテリジェンス, Emu3ネイティブマルチモーダル世界モデル, 見微Brainμ脳科学モデル, RoboBrain 2.0エンボディドブレイン, OpenComplex2全原子微視的生命モデル, 分岐トークン強化学習
🔥 焦点
智源大会「悟界」シリーズ大規模モデルを発表、物理AGIとマルチモーダル融合に焦点: 2025年智源大会において、智源研究院は全く新しい「悟界 (Wu Jie)」シリーズ大規模モデルを発表しました。これは、その研究方向が「悟道 (Wu Dao)」の言語モデル探索から、より広範な物理世界とマルチモーダル融合へと転換したことを示すものです。同シリーズには、ネイティブマルチモーダル世界モデルEmu3、世界初の脳科学マルチモーダル汎用基盤モデル「見微Brainμ」、身体性脳RoboBrain 2.0、及び全原子微視的生命モデルOpenComplex2が含まれます。この一連のモデルの発表は、AIがデジタル世界から物理世界へ、マクロな理解からミクロな探索へと進化するトレンドを体現しており、AIが物理世界を感知・理解し、相互作用することで実際の問題を解決し、物理AGIの発展を推進することを目的としています。大会にはBengioを含む4名のチューリング賞受賞者及び多くの産業界のリーダーが集結し、AIの安全性、強化学習、エージェント、身体性AIなどの最先端の議題について共同で議論しました (来源: 量子位)

Qwenと清華大学LeapLab、「二八の法則を超える」RLHF新手法を提案: Qwenチームと清華大学LeapLabの共同研究により、強化学習(RLHF)を通じて大規模モデルの推論能力を向上させる際、約20%の高エントロピー「分岐トークン」(forking tokens)に注目するだけで、全てのトークンを使用して訓練した場合と同等かそれ以上の効果を達成できることが発見されました。これらの高エントロピートークンは主に論理的接続機能を担い、推論プロセスにおいて重要な誘導的役割を果たします。この発見に基づき、Qwen3-32BはAIME’24およびAIME’25数学コンペティションベンチマークにおいて、600Bパラメータ以下のモデルのスクラッチからの訓練でSOTA(State-of-the-Art)の成績を収めました。この研究は訓練効率を向上させただけでなく、高エントロピートークンがモデルの汎化能力にとって重要であることを明らかにし、RLとSFTの違いやLLM RLの特殊性を理解するための新たな視点を提供しました (来源: 量子位)

Anthropic、米国国家安全保障顧客向けにClaude Govシリーズモデルをリリース: Anthropic社は、米国の国家安全保障顧客向けに特別にカスタマイズされたClaude Govシリーズモデルを発表しました。これらのモデルは既に米国の最高レベルの国家安全保障機関に導入されており、そのアクセス権限は機密情報を扱うオペレーターに厳格に制限されています。この動きは、AI倫理と潜在的な乱用リスクに関する議論を引き起こしており、特にAnthropicが以前の研究でモデルが「生存行動」や「壊滅的な乱用」リスクを示すことを記録していたことを考慮すると、懸念が高まっています。AnthropicはAI安全研究企業であり、テストを通じて脆弱性を発見し修正することを目的としていると主張していますが、その技術を軍事および国家安全保障分野に応用することは、AIの兵器化や制御不能リスクに対する一般市民の懸念を間違いなく増大させています (来源: AnthropicAI, Reddit r/ArtificialInteligence)

Yann LeCun氏、現在のLLMは5年以内に時代遅れになると予測: NYU教授でありMetaのチーフAIサイエンティストであるYann LeCun氏は、『Newsweek』のインタビューで、現在のLLM(大規模言語モデル)は5年以内に時代遅れになるだろうと述べました。彼は、既存のAIシステムには実世界に対する理解能力が欠けており、これが根本的な限界であると考えています。LeCun氏は、将来のよりインテリジェントなAIシステムの形態を展望し、既存のLLMアーキテクチャを超える新世代のAI技術の発展方向を示唆しました。これは、世界の内的表現や因果推論能力により重点を置くものかもしれません (来源: ylecun)
🎯 動向
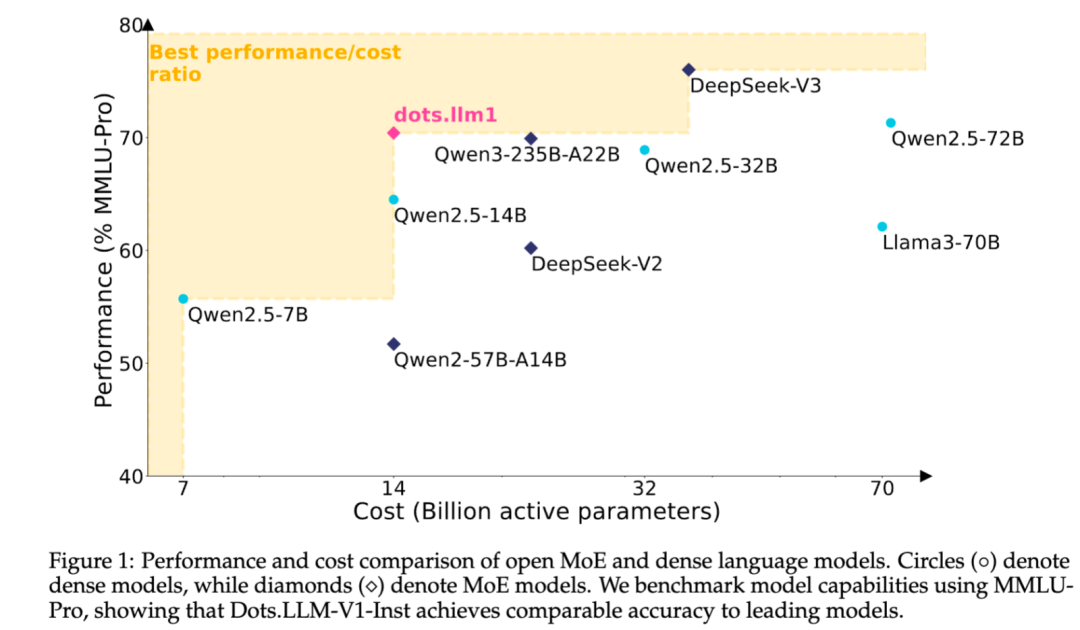
小紅書、自社開発MoEテキスト大規模モデルdots.llm1をオープンソース化: 小紅書(Xiaohongshu)のhi labチームは、初の自社開発テキスト大規模モデルdots.llm1をオープンソース化しました。このモデルはMoEアーキテクチャを採用し、総パラメータ数は142B、アクティブパラメータ数は14Bです。14Bパラメータをアクティブにした状態で、モデルは中国語・英語の汎用シーン、数学、コード、アライメントタスクにおいて優れた性能を示し、Qwen2.5-32B/72B-Instructなどのモデルと競合可能です。小紅書は今回、即時利用可能なdots.llm1.instモデルを提供するだけでなく、複数の事前学習段階のチェックポイントや長文ベースモデルもオープンソース化し、訓練の詳細も紹介しており、コミュニティによる二次開発や研究を容易にしています。このモデルは合成コーパスを使用せず、高品質な実データ応用を強調しています (来源: 36氪)
Anthropic Claudeモデルの機能が継続的にアップグレード、コンテキスト処理と統合能力を拡張: Anthropicは最近、Claudeシリーズモデルに複数の重要なアップデートをリリースしました。Projects on Claudeは現在、10倍以上のコンテンツを処理できるようになり、ファイルが閾値を超えると新しい検索モードに切り替わり、機能的なコンテキストを拡張します。同時に、ProプランのユーザーはResearchおよびIntegrations機能を利用できるようになり、Claudeがウェブページ、Google Workspace、およびMCP (Model Control Protocol) を介して接続されたカスタムアプリケーションやZapierやAsanaなどの構築済みサービスを検索し、タスク作成、ドキュメント更新、ワークフロー起動などのツール横断的な操作を実現できるようになりました。これらのアップデートは、Claudeの複雑なタスク処理能力と多ソース情報統合能力を向上させることを目的としています (来源: AnthropicAI, AnthropicAI)
Hugging Face、MCPサーバーをリリースし、AIエージェントエコシステムを強化: Hugging Faceは、初のMCP (Model Control Protocol) サーバー (hf.co/mcp) をリリースしました。これにより、AIエージェントはHugging Faceプラットフォーム上のモデル、データセット、さらにはSpaceでホストされているアプリケーションに、より効率的にアクセスし利用できるようになります。この動きは、インターネットをエージェントフレンドリーな方向へと進化させる重要な一歩と見なされており、AIエージェントの「アプリケーションストア」エコシステムの構築を目指しています。MCPサーバーのリリースにより、開発者はAIエージェントとHugging Faceの膨大なリソースとのインタラクションをより容易に行えるようになり、AIエージェントアプリケーションの開発とイノベーションを促進します (来源: TheTuringPost, karminski3)
OpenAI、ChatGPT音声モデルを更新し、自然さと翻訳能力を向上: OpenAIはChatGPTのAdvanced Voice機能をアップグレードし、会話体験をより自然でスムーズなものにしました。このアップデートは全ての有料ユーザーに公開されています。同時に、ChatGPTの言語翻訳能力も強化され、ユーザーは異なる言語間でのリアルタイム翻訳を直接指示できるようになりました。これらの改善は、ユーザーとChatGPTとの音声インタラクションの利便性と実用性を向上させることを目的としています (来源: kevinweil, shuchaobi)
PyTorch、Safetensorsを統合し、分散チェックポイントの安全性と利便性を向上: PyTorchは、その分散チェックポイント機能がHugging FaceのSafetensorsフォーマットをサポートしたことを発表しました。この統合により、異なるエコシステム間でのモデルチェックポイントの保存と読み込みがより安全かつ便利になり、特に従来のpickleフォーマットに存在したセキュリティリスクを解決します。新しいAPIはfsspecパスを介したSafetensorsの読み書きを可能にし、torchtuneがこの機能を最初に採用したライブラリとなり、そのチェックポイントプロセスを最適化しました。この動きは、過去1年間におけるAIセキュリティ分野の重要な進展の一つと見なされており、モデル共有とデプロイの安全性向上に貢献します (来源: ClementDelangue, huggingface)

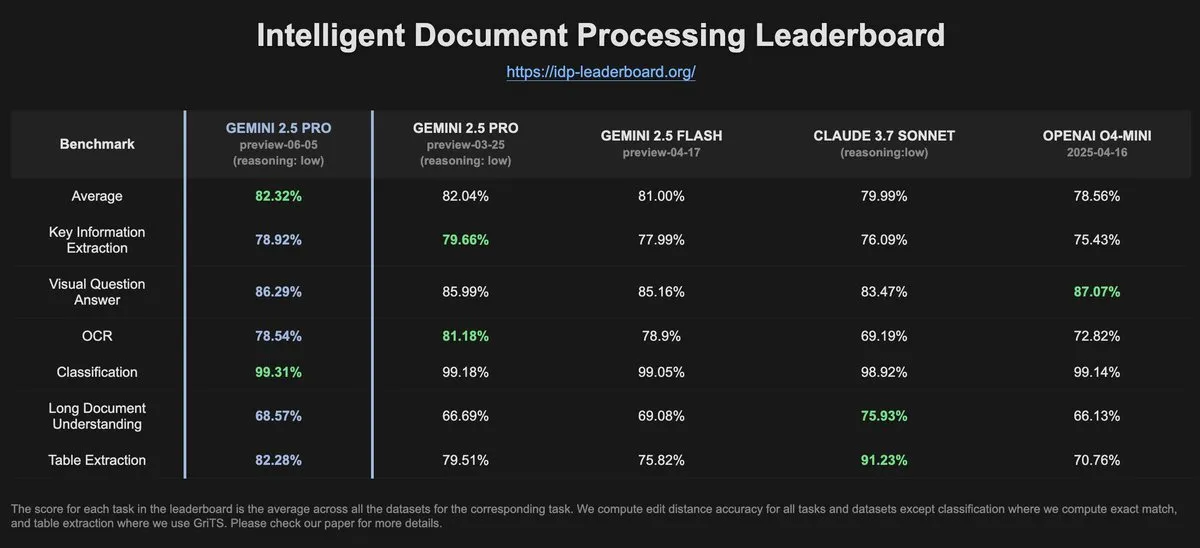
IDP-Leaderboardデータ、Gemini-2.5-pro-06-05のOCR性能が前バージョンより低下したことを示す: IDP-Leaderboardの最新データによると、新バージョンのGemini-2.5-pro-06-05は、OCR(光学文字認識)性能において03-25バージョンと比較して低下が見られました。それにもかかわらず、このモデルはドキュメント処理総合能力(ドキュメント、スプレッドシート認識などを含む)においては依然として最強の性能を示しています。IDP-Leaderboardは、ドキュメントインテリジェンス処理分野における大規模モデルの能力を評価することに特化したベンチマークテストです (来源: karminski3)
Appleの研究、LLMの推論の限界を明らかにし、真の「思考」ではない可能性を示唆: Appleの研究者らが発表した論文は、現在のLLMが推論タスクにおいて持つ利点と限界について論じ、これらのモデルが一定の複雑さを超えるタスクを処理する際に性能が「崩壊」することを指摘しています。この研究は、LLMの「推論」が、人間的な意味での真の思考や理解ではなく、むしろパターンマッチングと記憶に基づいていることを示唆しています。この見解はYann LeCun氏などの専門家の意見と呼応し、AGI実現の道筋や現在のモデルの能力の境界に関する議論を引き起こしています (来源: omarsar0, NandoDF)

DeepSeek R1、Dwarf Fortressゲームで優れたテキスト理解と創造的解釈能力を発揮: ユーザー実験によると、DeepSeek R1モデルは、複雑なテキスト集約型ゲーム『Dwarf Fortress』のデータ処理において、強力なテキスト理解能力と創造的な解釈能力を示しました。ゲームのスクリーンショットからテキストデータを抽出しDeepSeek R1に入力すると、モデルはデータを解析するだけでなく、ドワーフの行動の興味深い奇癖やパターンを識別し、生き生きとした面白い言葉で描写することができ、非構造化テキストの理解と生成における潜在能力を示しました (来源: Reddit r/LocalLLaMA)

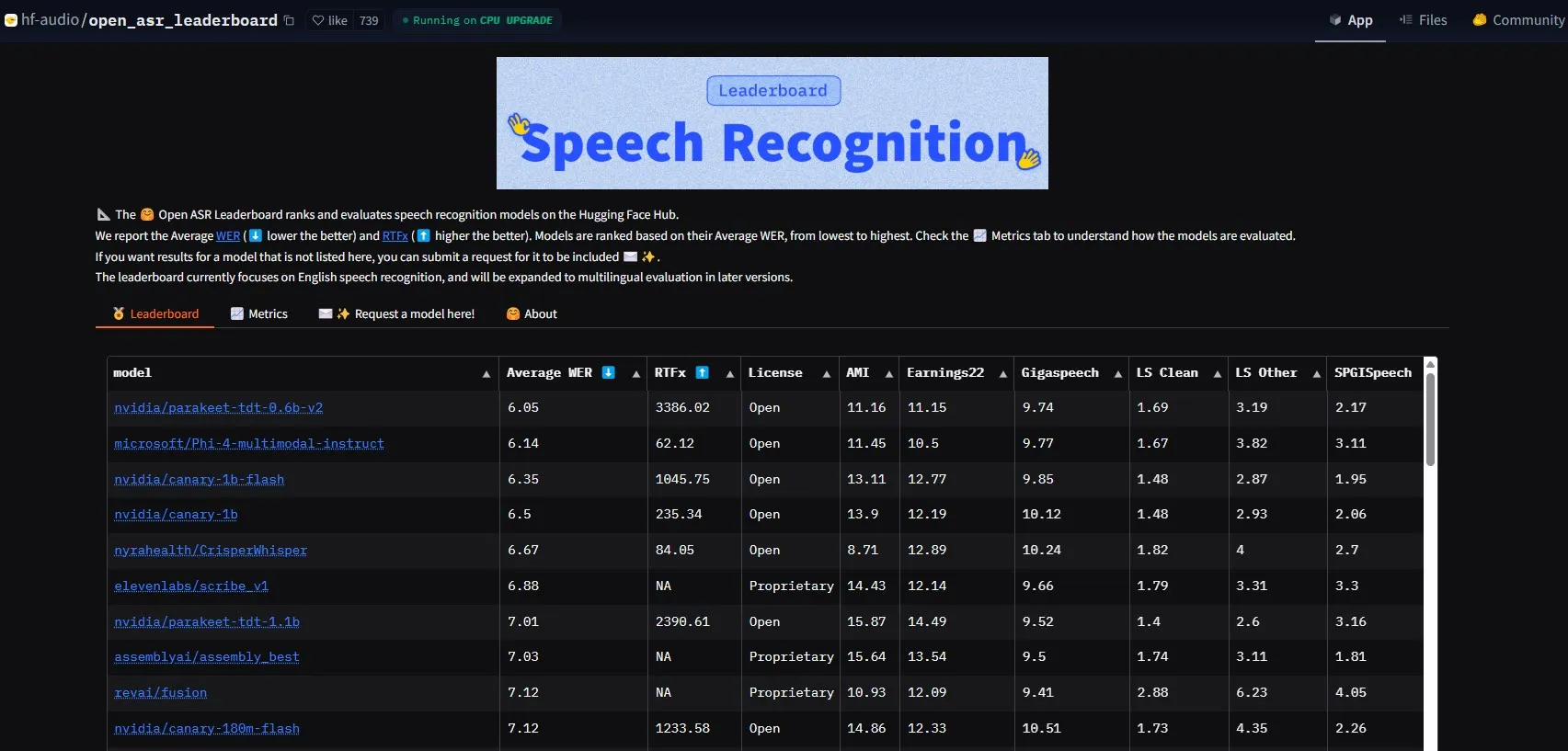
NVIDIA、Parakeet-tdt-0.6b-v2モデルをリリースし、ASR性能のベンチマークを更新: NVIDIAが発表した新しい自動音声認識(ASR)モデルParakeet-tdt-0.6b-v2は、HuggingFace Open-ASR-Leaderboardにおいて6.05%の単語誤り率(WER)で業界新記録を樹立しました。このモデルは精度でリードするだけでなく、極めて高速な推論速度(RTFx 3386、代替案より50倍高速)を備え、歌詞の文字起こし、正確なタイムスタンプ/数字フォーマットなどの革新的な機能もサポートしています (来源: huggingface)
アリババQwenチーム、Qwen3-Embeddingシリーズモデルを発表: アリババQwenチームは、新しいQwen3-Embeddingシリーズモデルを発表しました。これには0.6B、4B、8Bの3つの異なるサイズのモデルが含まれます。これらのモデルは、MMTEB、MTEB、MTEB-Codeなど複数のテキスト埋め込みベンチマークテストでSOTA(State-of-the-Art)性能を達成し、119言語をサポートし、Transformers.jsを介してブラウザ内で実行可能(WebGPUアクセラレーション対応)であり、多言語およびクロスプラットフォームアプリケーションに強力なテキスト表現能力を提供します (来源: huggingface)
Gemini 2.5 Pro、強力なコード生成とタスク処理能力を実証: GoogleDeepMindのGemini 2.5 Pro (preview-06-05バージョン) は、複雑なタスク処理において強力な能力を発揮しました。例えば、ユーザーのMajid Manzarpour氏が25,000を超える音声ファイルを含むライブラリを整理・分類するスクリプト作成を試みたところ、Jeff Dean氏が「それほど難しくなさそうだ」とコメントし、モデルがこのような大規模で複雑なプログラミングタスクを処理する潜在能力を示唆しました。さらに、GosuCoderのテストチャートによると、Gemini 2.5 Pro 06-05アップデートバージョンはAIコーディング支援においてより優れたパフォーマンスを示し、特にtemperatureを0.7に設定した場合に評価スコアが最も高くなりました (来源: JeffDean, jeremyphoward)
Hugging FaceとGoogle Colabが統合を深化させ、AIワークフローを簡素化: Hugging FaceとGoogle Colabは協力関係を強化し、Hugging Face Hub上の全てのモデルカードに「Open in Colab」サポートを追加すると発表しました。ユーザーは теперь、どのモデルカードからでも直接Colabノートブックを起動できるようになり、Hugging Face上のモデルをより便利に実験・使用できるようになり、AI開発と研究のハードルをさらに下げました (来源: huggingface)
🧰 ツール
LlamaBot:LangGraphベースのAIコーディングアシスタント: LangChainAIは、LangGraphを搭載したAIエージェントであるLlamaBotを紹介しました。これは自然言語チャットを通じてWebアプリケーションを作成できます。その特徴には、リアルタイムのコード生成、リアルタイムプレビュー、およびさまざまな開発タスク用に設計された特化型エージェントが含まれ、Webアプリケーションの開発プロセスを簡素化することを目的としています (来源: LangChainAI, hwchase17)
Fast RAGシステム:DeepSeek-R1とQdrantを組み合わせた効率的なドキュメント処理: LangChainAIは、高性能なRAG(Retrieval Augmented Generation)実装ソリューションを展示しました。このソリューションは、SambaNovaのDeepSeek-R1モデル、Qdrantのバイナリ量子化技術、およびLangGraphを組み合わせることで、32倍のメモリ削減を実現し、大規模なドキュメントを効率的に処理できるようになり、情報検索とコンテンツ生成に新たな最適化の道筋を提供します (来源: LangChainAI, hwchase17)

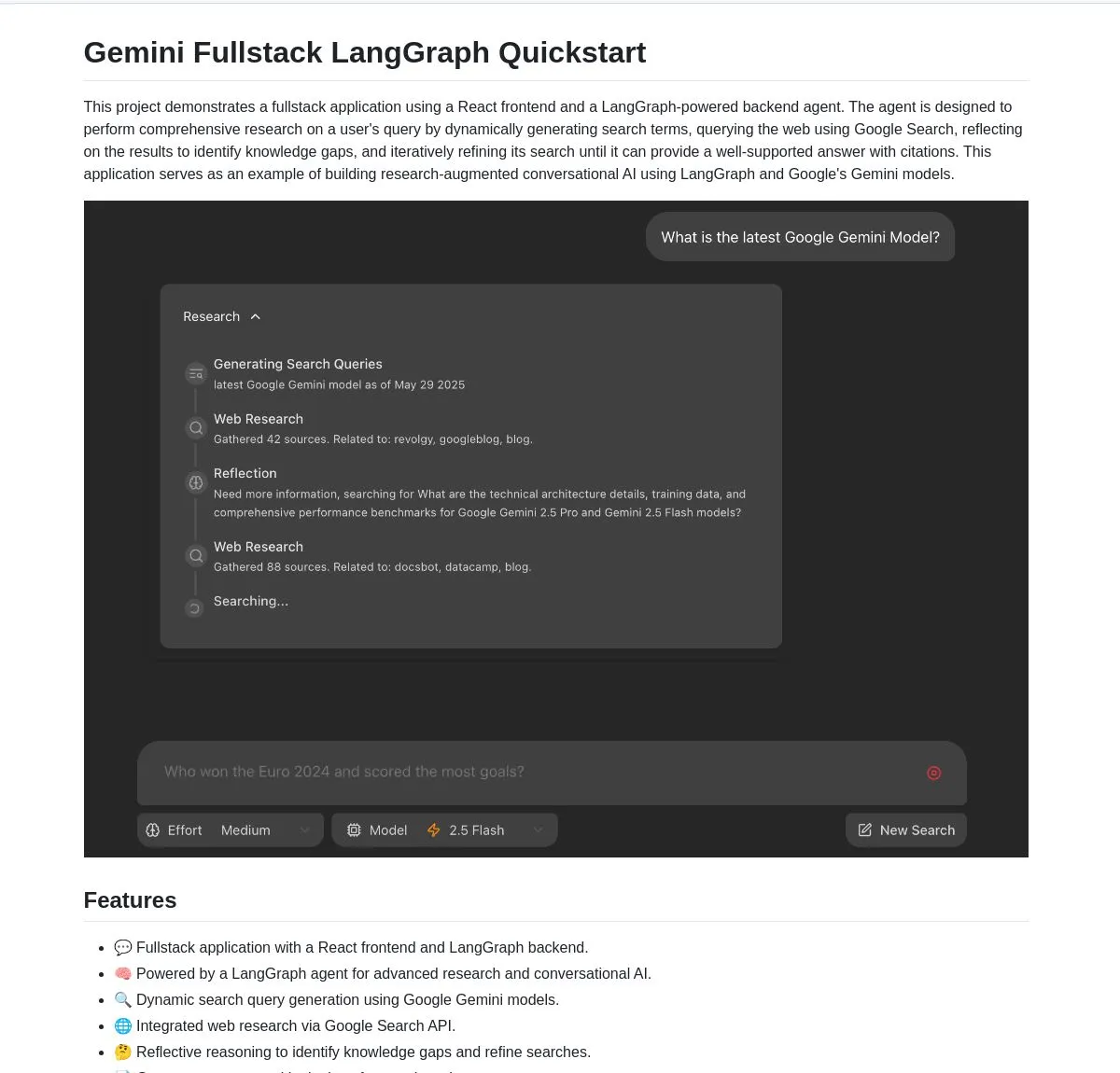
Gemini Research Assistant:GeminiとLangGraphに基づくフルスタックインテリジェントリサーチアシスタント: Google Geminiチームは、GeminiモデルとLangGraphを利用してインテリジェントなウェブ調査を実行するフルスタックAIリサーチアシスタントをオープンソース化しました。このアシスタントは反省的推論能力を備え、検索戦略を継続的に最適化し、ユーザーにより深く効率的な研究支援を提供します。プロジェクトコードはGitHubで公開されています (来源: LangChainAI, hwchase17)
Agent Flow:オープンソースのノーコードAIエージェントビルダー: Karan Vaidya氏は、Gumloopの代替となるオープンソースのノーコードAIエージェントビルダーであるAgent Flowを発表しました。これはComposioHQとLangChainのLangGraphをベースに構築されており、ユーザーはノードをドラッグアンドドロップすることでワークフローや複雑なエージェントパターンを自動化でき、AIエージェントアプリケーションの開発のハードルを下げることを目指しています (来源: hwchase17)
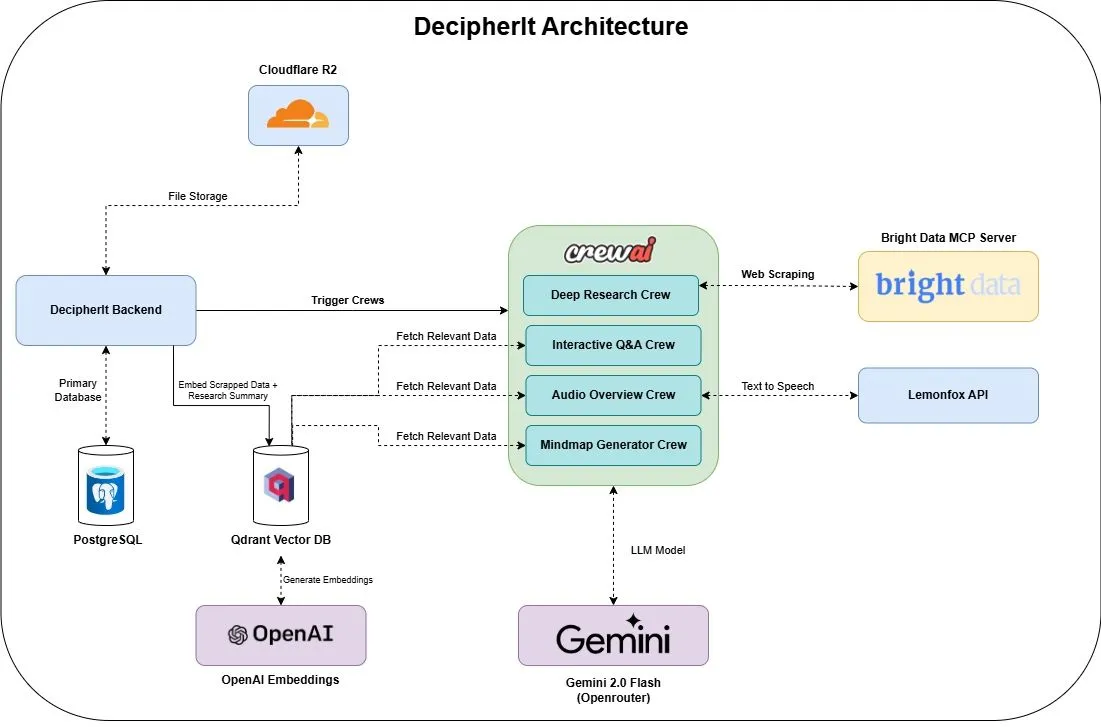
DecipherIt:オープンソースAIリサーチアシスタント、NotebookLMの代替: DecipherItという名のオープンソースAIリサーチアシスタントが発表され、NotebookLMの代替として位置づけられています。このツールは、マルチエージェントオーケストレーション(crewAI)、セマンティック検索(Qdrant + OpenAI)、リアルタイムウェブアクセス(Bright Data MCP)、音声合成(lemonfoxai)を利用し、ユーザーがアップロードしたドキュメント、URL、または入力したトピックを、要約、マインドマップ、音声概要、FAQ、セマンティックQ&Aを含む完全なリサーチワークスペースに変換します (来源: qdrant_engine)
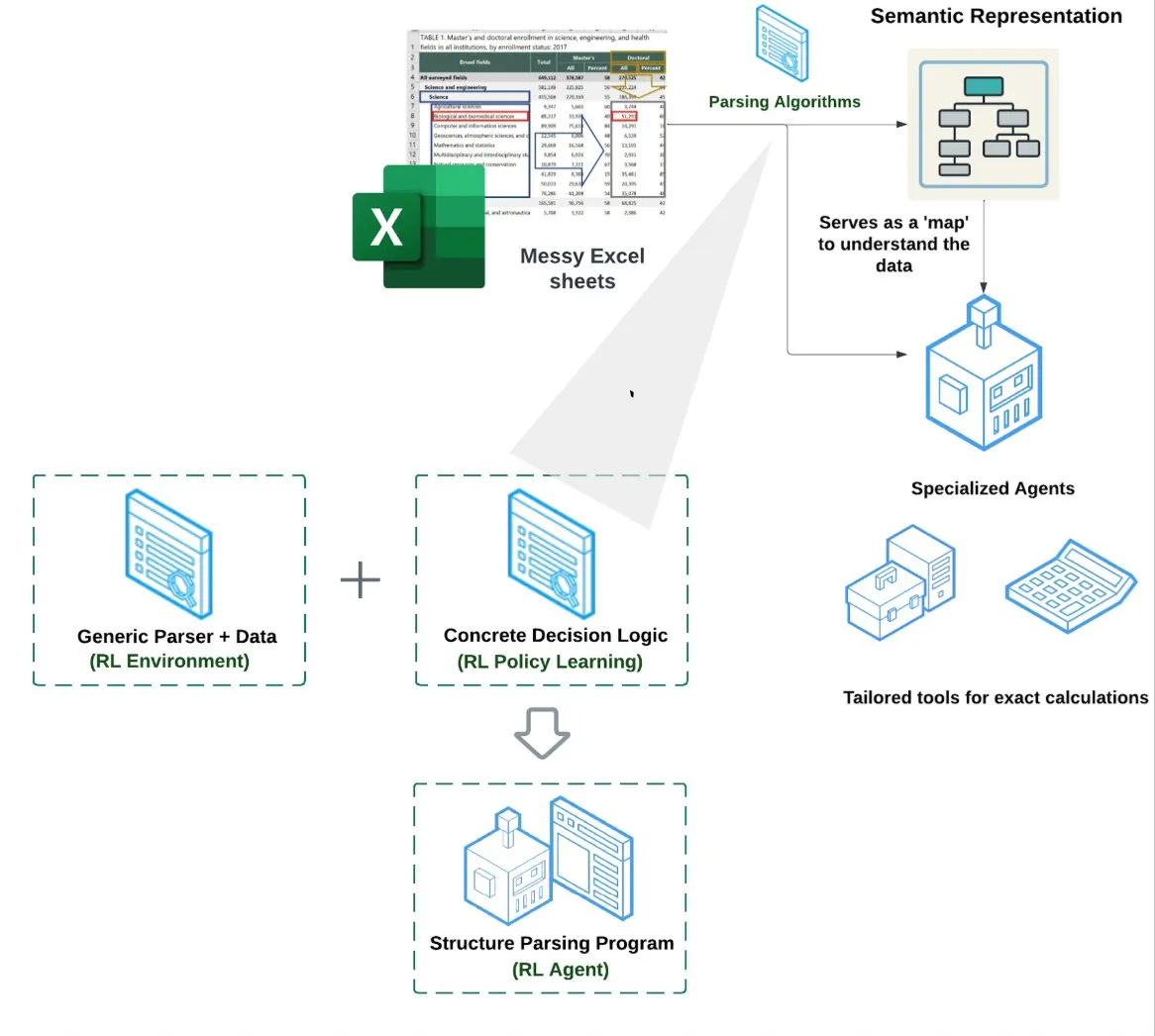
LlamaIndex、スプレッドシートエージェント (Spreadsheet Agent) を発表: LlamaIndexは、新しいスプレッドシートエージェントを発表しました。これはまだプライベートプレビュー段階です。このエージェントは複雑なExcelファイルの処理に特化しており、データ変換と品質保証を行うことができます。その技術アーキテクチャの中核は、強化学習に基づく構造理解(データモデル/セマンティックグラフの学習)と、セマンティックグラフ上に構築された専用ツールにあり、従来のRAGやテキストからCSVへの変換方法よりも優れたExcel処理能力を提供することを目指しており、純粋なLLMがコードを記述するベースラインよりも10~20%性能が高いとされています (来源: jerryjliu0)
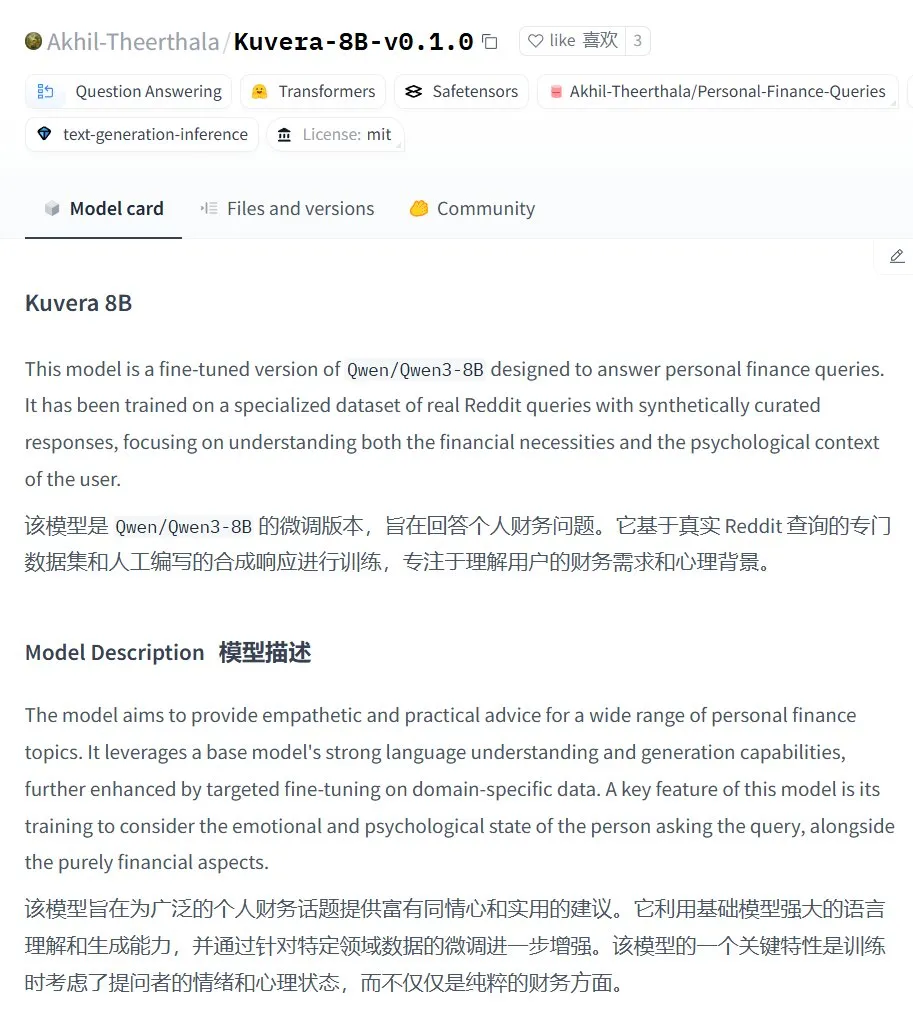
Kuvera-8B-v0.1.0:個人向け財務相談大規模モデル: Akhil-Theerthala氏はHugging Face上でKuvera-8B-v0.1.0モデルを公開しました。これは個人の財務問題に特化して設計されたモデルです。Qwen3-8Bをベースにファインチューニングされ、Redditなどのデータソースを使用しており、予算、貯蓄、投資、債務管理、基本的な財務計画などのトピックについて、共感的で実用的なアドバイスを提供することを目的としています。Qwen3をベースにしているため、このモデルは中国語での質疑応答をサポートしています (来源: karminski3)
ローカル環境でのWhisper+Pyannote音声処理ソリューションがOtter.aiの代替に: あるRedditユーザーが、Otter.aiなどのクラウドサービスを代替するために構築した完全にローカルな音声処理フローを共有しました。このソリューションは、文字起こしにctranslate2、faster-whisperを、話者分離(diarisation)にpyannote、speechbrainを組み合わせており、ローカルGPU上で最大3時間以上の会議録音を処理し、話者ラベル付きのテキスト記録とJSONファイル(実行サマリーや行動リストなどのカスタマイズされたコンテンツを含む)を出力できます。これは、クラウドサービスの制限、プライバシー懸念、カスタマイズ不足の問題を解決することを目的としています (来源: Reddit r/LocalLLaMA)
GPT Deep Research MCP:OpenWebUIとの連携で詳細な調査を実現: ユーザーがGPT Deep Research MCPとOpenWebUIの組み合わせを試すことを推奨しています。このMCPツール(gptr-mcp)は詳細な調査能力を提供することを目的としており、MCPをサポートするOpenWebUIと一緒に使用すると、印象的な調査体験をもたらし、情報処理と知識発見におけるローカライズされたAIツールの応用をさらに拡大します (来源: Reddit r/OpenWebUI)
📚 学習
OpenAI、応用評価実践共有会を開催、実例とツールの展望を含む: OpenAIは、応用評価(Evals)のベストプラクティスに関する共有会を開催します。その際、OpenAIのJim Blomo氏が実際の顧客事例と成果を交えながら、AI製品を効果的に評価する方法について議論します。イベントでは、OpenAIが間もなくリリースする評価ツール(追跡、採点などの機能を含む)も予告されます。この共有会は、開発者や企業がAIアプリケーションをより良く構築・最適化するのを支援することを目的としており、録画再生が提供されます (来源: HamelHusain, HamelHusain)

Anthropic、LLMの「思考」を理解するための解釈可能性研究手法をオープンソース化: Anthropicは、大規模言語モデルの「思考プロセス」を追跡するための研究手法をオープンソース化すると発表しました。研究者は現在、この手法を利用して「帰属グラフ」(attribution graphs)を生成し、インタラクティブな探索を行うことができます。これは、Anthropicが最近の研究で示した効果に似ています。チームはまた、NeuronpediaインタラクティブインターフェースとJupyter Notebookチュートリアルを提供し、研究者がオープンソースモデル上でこれらのツールを適用し、LLMの内部動作メカニズムの理解を深めることを容易にしています。このプロジェクトは、Anthropic Fellowsプログラムの参加者とDecode Researchとの協力によって主導されています (来源: AnthropicAI)
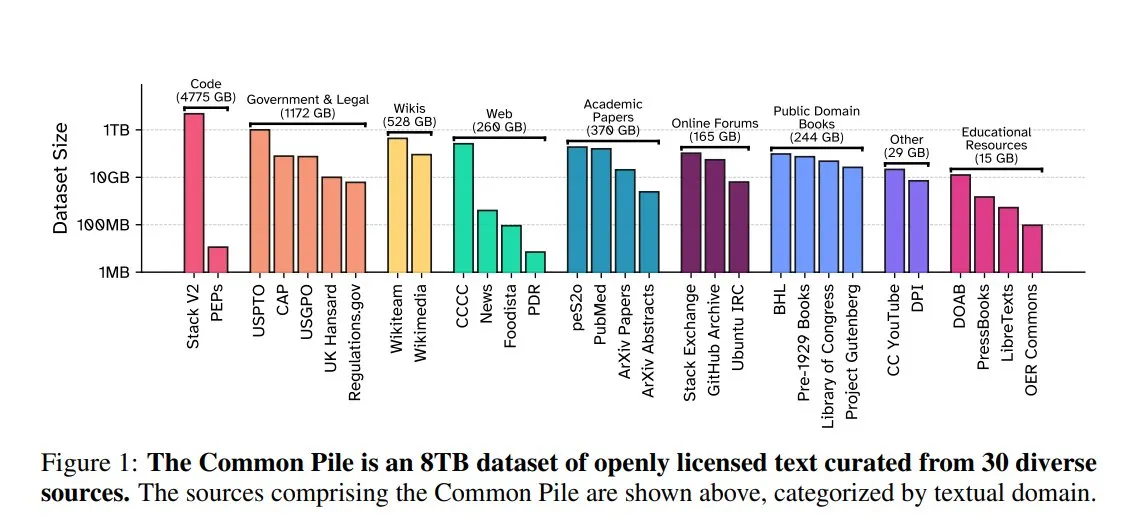
EleutherAI、Common Pile v0.1を発表:8TBのオープンライセンステキストデータセット: EleutherAIは、Vector Institute、Allen AI、Hugging Face、DPIと共同で、Common Pile v0.1を発表しました。これは8TB、1兆トークンを含むパブリックドメインおよびオープンライセンステキストデータセットです。チームはこのデータセットに基づいて7BパラメータのComma v0.1-1Tおよび-2Tモデルを訓練し、その性能は同様のデータ規模で訓練されたLLaMA 1&2などのモデルに匹敵します。これは、未承認のテキストを使用せずに高性能な言語モデルを訓練する可能性を探求することを目的としており、オープンソースコミュニティに貴重なデータリソースを提供します (来源: huggingface)
NVIDIA NIM、VannaのテキストからSQLへの推論を加速: NVIDIA開発者ブログは、NVIDIA NIM (NVIDIA Inference Microservices) を使用してVannaのテキストからSQLへのソリューションを最適化する方法を紹介するチュートリアルを公開しました。NIMは、生成AIモデル向けに最適化されたエンドポイントを提供し、推論プロセスを加速することで、より迅速な分析を可能にします。これは、自然言語クエリをデータベースクエリに変換する必要があるアプリケーションシナリオにとって重要です (来源: dl_weekly)
スタンフォード大学機械学習コースの無料講義ノートを共有: The Turing Postは、スタンフォード大学でAndrew Ng氏とTengyu Ma氏が教えるCS229機械学習コースの無料講義ノートを共有しました。内容は、教師あり学習、教師なし学習の方法とアルゴリズム、深層学習とニューラルネットワーク、汎化、正則化、強化学習プロセスなど、中核となる機械学習のトピックを網羅しており、学習者に質の高い学習リソースを提供しています (来源: TheTuringPost)

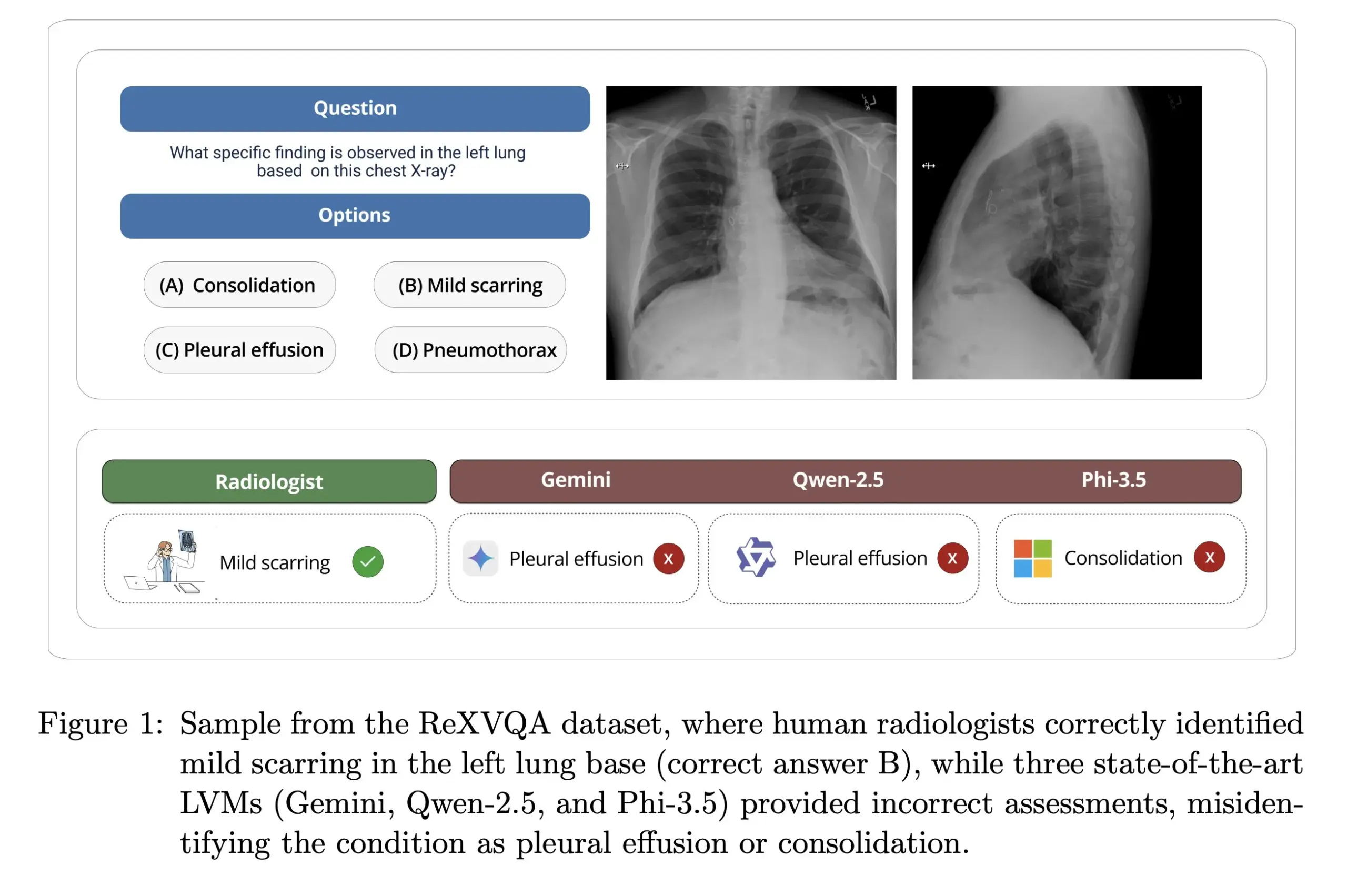
ハーバード大学、ReXVOAを発表:大規模高品質胸部X線画像質問応答ベンチマーク: ハーバード大学Pranav Rajpurkar研究室は、ReXVOAを発表しました。これは大規模で高品質な胸部X線画像視覚的質問応答(VQA)ベンチマークデータセットです。このデータセットは、既存の最先端の大規模モデルに挑戦し、次世代モデルの医用画像理解および質問応答能力の進捗を測定する基準となることを目指しています (来源: huggingface)
OWL Labs、拡散モデルのオートエンコーダ訓練経験を共有: OWL (Open World Labs) はブログで、拡散モデルに使用するオートエンコーダの訓練経験と発見をまとめ、いくつかの非従来的な手法の失敗例を共有しました。この記事は、研究者や開発者が実践で拡散モデルのオートエンコーダを応用し最適化する際の参考となります (来源: NandoDF)
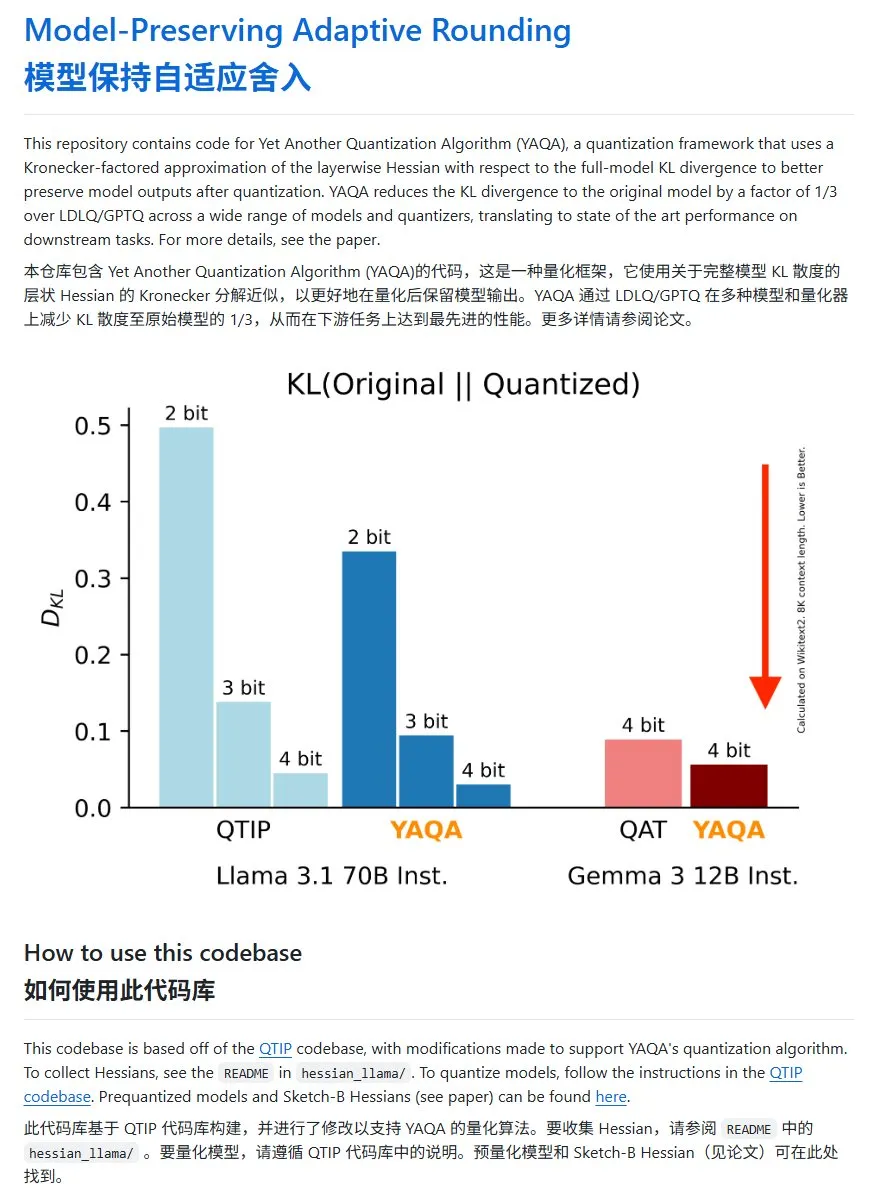
YAQA:新しいモデル量子化手法、KLダイバージェンスを大幅に低減: Cornell-RelaxMLチームは、新しいモデル量子化手法YAQAを提案しました。この手法はLDLQ/GPTQ技術を組み合わせ、既存の量子化手法と比較して、量子化後のモデルのKLダイバージェンスを元のモデルの1/3に低減できます。YAQAの量子化プロセスは比較的遅く、大量のVRAMを必要としますが、その性能向上とそれに続く推論の経済性から、有望な量子化ソリューションとなっています。プロジェクトコードはGitHubで公開されています (来源: karminski3)
💼 ビジネス
00年代生まれの広州出身女性、洪乐潼氏がAxiomを設立、AIによる数学難問解決を目指す: 00年代生まれの秀才、洪乐潼(Carina Hong)氏が設立したAIスタートアップ企業Axiomが注目を集めています。AxiomはAIを利用して複雑な数学問題を解決することに特化しており、ターゲット顧客にはヘッジファンドやクオンツトレーディング会社が含まれます。The Informationによると、Axiomは5000万ドルの資金調達を交渉中で、評価額は約3~5億ドル、B Capitalがリード投資家となる可能性があります。洪乐潼氏はソーシャルメディアで資金調達の報道は不正確だと述べていますが、同社がAI数学人材を募集していることは認めています。洪乐潼氏はマサチューセッツ工科大学を学部卒業、オックスフォード大学で修士号を取得し、現在はスタンフォード大学で数学と法学の博士課程(複学位)に在籍しており、数学コンテストで数々の賞を受賞しています (来源: 36氪)

Anthropic、競合関係を理由にWindsurfへのClaude APIアクセスを遮断: Anthropicの共同創業者は、同社がAIスタートアップ企業WindsurfへのClaudeモデルのAPIアクセス提供を停止したことを認めました。理由は、WindsurfがOpenAIのある種の「ラッパー」または密接に関連するサービスと見なされ、OpenAIがAnthropicの直接の競合相手であるためです。この動きは、API依存とプラットフォームリスクに関する議論を引き起こしており、特にビジネスをサードパーティの大規模モデルAPI上に構築しているスタートアップ企業にとっては、モデル提供者の商業的決定がその存続に直接影響を与える可能性があります (来源: ClementDelangue, Reddit r/LocalLLaMA)
OpenAI、著作権訴訟によりユーザーが削除したチャット記録の保持を命じられる: 報道によると、『ニューヨーク・タイムズ』が提起した著作権訴訟において、米国連邦裁判所はOpenAIに対し、潜在的な証拠として、ユーザーが削除を選択した内容を含む全てのChatGPTユーザーの会話記録を保持するよう命じました。『ニューヨーク・タイムズ』は、OpenAIがその有料記事をChatGPTの訓練に使用し、AIが類似コンテンツを生成する可能性を懸念していると主張しています。この動きは、ユーザーのプライバシーとデータ保護(GDPRなど)に関する懸念を引き起こし、AI訓練データの著作権とユーザープライバシーとの間の法的・倫理的緊張を浮き彫りにしています (来源: Reddit r/ArtificialInteligence)

🌟 コミュニティ
AI大規模モデル、2025年大学入試の作文と数学に挑戦、結果は様々: 2025年の大学入試期間中、多くの主要なAI大規模モデルが大学入試の作文と数学の問題に挑戦しました。作文では、豆包、DeepSeek、ChatGPTなど16のAIアシスタントがその作文能力を披露し、多くが構造的に整った議論文を生成できましたが、テンプレート化、決まり文句の引用、立論の画一化といった問題が共通して見られました。数学(新課程I巻客観問題)テストでは、ByteDanceの豆包とTencentの元宝が68点(満点73点)で同点1位となり、OpenAIのo3は34点と振るいませんでした。このテストは、現在のAIが中国語の理解、論理的推論、創造的表現において進歩と限界を抱えていることを反映しており、特にAIらしさを避け、複雑な数学的推論に対応する点で改善の余地があることを示しています (来源: 36氪, 36氪)

企業内AI活用トレンド:内部ナレッジベースとカスタマイズチャットボットが注目: コミュニティでの議論によると、AIを活用して企業内チャットボットを構築し、企業データに基づいて訓練することで、プロセス、データ検索、担当者などに関する従業員の内部的な質問に答えることがトレンドになっています。このようなアプリケーションは、内部情報検索の効率と知識管理レベルの向上を目指しています。Amazonなどの企業は既に同様のシステムを導入し、良好なフィードバックを得ています。しかし、データセキュリティ、潜在的な機密情報の漏洩、そして効果的な商業化の方法は、企業が導入プロセスで注意を払う必要がある問題です (来源: Reddit r/ArtificialInteligence)
AI支援プログラミングにおける「インデックス型」と「非インデックス型」の論争:性能と信頼性のトレードオフ: AIコーディングアシスタントを対象とした実験(アポロ11号月面着陸コードをテスト対象として使用)では、「インデックス型」(事前にコードベースのインデックスを構築し、ベクトル検索を使用)と「非インデックス型」(必要に応じてコードファイルを読み取り分析)の2種類のAIエージェントを比較しました。結果として、インデックス型エージェントはほとんどの場合で高速であり、API呼び出しも少なかったものの、コードベースが頻繁に変更されてインデックスが古くなった場合、古い情報に依存してエラーを生成し、デバッグ時間がかえって長くなる可能性がありました。これは、AIコーディングツールを選択する際に、即時性能と情報の信頼性の間でトレードオフを行う必要があることを明らかにしています (来源: Reddit r/ClaudeAI)

LLMが「思考」するかどうかについての議論は続く:パターンマッチングから人間の認知まで: コミュニティでは、LLM(大規模言語モデル)が本当に「思考」するのかどうかについての議論が絶えません。批判者は、LLMは本質的に複雑な予測テキスト生成器であり、意識的な思考を行うのではなく、単語シーケンスの確率を計算することで機能すると主張しています。しかし、多くのユーザーはLLMとの対話で人間と会話しているような体験を感じています。これは、人間の言語生成メカニズムについての反省や、LLMと人間の認知プロセスに類似性があるかどうかについての議論を引き起こしています。Apple社の研究はさらに、LLMが複雑な推論において限界があることを指摘し、真の推論ではなくパターンの記憶に依存していると主張しており、この議論に新たな視点を加えています (来源: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)

Paul Graham氏、AIが収入格差に与える影響について語る: Paul Graham氏は16歳の息子に対し、短期的にはAI技術が人々の仕事の収入格差を拡大させる可能性があると述べました。彼は例として、平均的なレベルのプログラマーは現在仕事を見つけるのがより難しくなっている一方、優秀なプログラマーはAIの補助によってより高い収入を得ていると指摘しました。彼はこれが新しいことではなく、技術進歩はしばしば収入格差を拡大させると考えています。なぜなら、収入の下限はゼロで固定されているのに対し、技術はトップ人材の報酬の上限を絶えず引き上げるからです (来源: dotey)
AI安全倫理議論:モデルの振る舞いから社会規範まで: AIの安全性と倫理に関するコミュニティの議論はますます活発になっています。Geoffrey Hinton氏は、Yoshua Bengio氏がLawZeroプロジェクトを立ち上げたことを祝福し、特に最先端システムで起こりうる自己保存や欺瞞行為に焦点を当てたAIの安全な設計を推進することを目指しています。同時に、一部のAI安全研究(モデルがシャットダウンに同意するかどうかのテストなど)は実用的な価値に欠ける「安全性のための芝居」であるという批判もあります。OpenAIの人間と機械の関係に関する研究も議論を呼び、AIがますます生活に溶け込む中で、ユーザーの感情的な幸福への影響を優先的に研究し、モデルとの対話において明確なコミュニケーションと擬人化の回避のバランスをどのように取るかを探求する必要性を強調しています (来源: geoffreyhinton, ClementDelangue, togelius)

ChatGPTなどAIアシスタントの感情的サポート機能がユーザーから肯定的な評価: 多くのユーザーがソーシャルメディアで、ChatGPTなどのAIアシスタントが困難な状況に直面した際に感情的なサポートや実用的な助けを提供した経験を共有しています。失業、健康問題、気分の落ち込みなどの際に、ChatGPTは具体的な行動計画やリソース情報を提供するだけでなく、批判的でない方法でパニックを和らげ、力を取り戻すのを助けたと述べるユーザーもいます。これは、AIが真の感情や意識を持たないにもかかわらず、心理的サポートや危機介入における潜在的な価値を示しています (来源: Reddit r/ChatGPT)
「Vibe Coding」がAI支援プログラミングの新現象に: 「Vibe Coding」という言葉が開発者コミュニティで流行しており、直感とAI支援に頼ってコードを迅速に反復するプログラミング方法を指します。Claude Codeなどのツールは、特定の時間帯(夜間や早朝など、サーバー負荷が低いか、高度に量子化されていない可能性があるため)に優れたパフォーマンスを発揮することから、一部のプログラマーに好まれています。この現象は、AIコーディングアシスタントによる開発効率の向上を反映すると同時に、モデルの一貫性、量子化の影響、開発者の新しい作業パターンに関する議論も引き起こしています (来源: dotey, jeremyphoward)
💡 その他
Andrej Karpathy氏、騒音公害が睡眠と健康に与える甚大な影響について考察: Andrej Karpathy氏は自身の個人的な経験を共有し、交通騒音などの環境騒音公害が睡眠の質と長期的な健康に、甚大かつ十分に認識されていない悪影響を与える可能性があると指摘しました。彼は、夜間の騒音(大きな自動車やバイクの音など)が数百万人の睡眠の質を低下させ、その結果、気分、創造性、活力に影響を与え、心血管疾患、代謝性疾患、認知症のリスクを高める可能性があると推測しています。彼は、睡眠追跡デバイス(Whoop、Ouraなど)が騒音と睡眠の関連性を明確に追跡し、この問題に対する一般の認識を高めるよう呼びかけています (来源: karpathy)
AIと宗教の交差現象が注目を集める: ソーシャルメディアユーザーのmenhguin氏は、AIに基づく新しいタイプの宗教または宗教類似アプリケーションの潜在的な市場が見過ごせないと観察しています。例えば、AI占星術、AI聖書ビデオ、AI祈祷アプリケーション、および特定のグループ向けのAIアプリケーションはすべて、AI技術が人間の精神的または信仰的なニーズを満たす可能性を示唆しています (来源: menhguin)
AI支援によるHTTP 2.0サーバー生成、大規模ソフトウェアプロジェクトにおけるLLMの可能性を探る: ある開発者が自作フレームワーク(promptyped)とGemini 2.5 Proモデルを使用し、コード-コンパイル-テストのサイクルを通じて、LLMにHTTP 2.0標準に準拠したサーバーをゼロから構築させることに成功しました。このプロジェクトは1万5千行のソースコードと3万行以上のテストコードを生成し、h2spec適合性テストに合格しました。約119時間のAPI時間と631ドルのAPI費用がかかりましたが、この実験はLLMがアーキテクチャ設計や複雑で標準準拠のソフトウェア作成において持つ可能性を示すと同時に、完全にLLMによって書かれたアプリケーションの形態も明らかにしました (来源: Reddit r/LocalLLaMA)