
キーワード:Gemini 2.5 Pro, VeBrain, Segment Anything Model 2, Qwen3-Embedding, AI Agent, Gemini 2.5 Pro Deep Thinkモード, VeBrain汎用エンボディメントAIフレームワーク, SAM 2画像・動画セグメンテーション, Qwen3-Embedding 32kコンテキスト, AI Agentマルチモーダル理解
🔥 注目ニュース
Google、AIに関する複数の新進展を発表、Gemini 2.5 Pro Deep Thinkモードが複雑な推論能力を向上: Google I/Oカンファレンスにおいて、GoogleはGemini 2.5 ProのDeep Thinkモードを発表しました。これは、(USAMOレベルの数学の難問など)複雑な問題を処理する際のAIの推論能力を大幅に強化することを目的としています。同時に、GoogleはAlphaEvolveも発表しました。これはGeminiによって駆動されるコーディングエージェントで、アルゴリズム発見に用いられ、すでに行列乗算アルゴリズムの設計やオープンな数学問題の解決で成果を上げており、Google内部のデータセンター、チップ設計、AIトレーニング効率の最適化に応用されています。さらに、動画モデルVeo 3、画像モデルImagen 4、AI編集ツールFLOWも同時に発表され、マルチモーダルAI分野におけるGoogleの包括的な展開と急速な進展を示しています。(出典: OriolVinyalsML, demishassabis, demishassabis, op7418)
上海AIラボ、汎用身体性AI脳フレームワークVeBrainを共同発表: 上海人工智能実験室は複数の機関と共同でVeBrain(Visual Embodied Brain)を発表しました。これは視覚認識、空間推論、ロボット制御能力の統一を目指す汎用身体性AI脳フレームワークです。このフレームワークは、ロボット制御タスクをMLLMにおける2D空間テキストタスク(キーポイント検出や身体的スキル認識など)に変換し、「ロボットアダプター」を導入することで、テキスト決定から実際の動作への正確なマッピングと閉ループ制御を実現します。モデル訓練をサポートするため、チームはVeBrain-600kデータセットを構築しました。これには60万件の指示データが含まれ、マルチモーダル理解、視空間推論、ロボット操作の3種類のタスクをカバーしています。テストの結果、VeBrainはマルチモーダル理解、空間推論、および実ロボット制御(ロボットアームとロボット犬)においてSOTAレベルを達成したことが示されています。(出典: 量子位)

Anthropic、LLM可視化ツール「circuit tracing」をオープンソース化、モデルの解釈可能性を向上: Anthropicは、大規模言語モデル(LLM)の内部動作メカニズムの研究者による理解を助けることを目的としたオープンソースツール「circuit tracing」を発表しました。このツールは、「attribution graphs」(帰属グラフ)を生成することで、モデルが情報を処理する際の内部スーパーノードとその接続関係を可視化します。これはニューラルネットワークの模式図に似ています。研究者はノードの活性値を操作し、モデルの行動変化を観察することで、各ノードの機能を検証し、LLMの意思決定ロジックを解読できます。このツールは、主要なオープンソースモデル上で帰属グラフを生成することをサポートし、可視化、注釈付け、共有のためのインタラクティブなフロントエンドインターフェースNeuronpediaを提供します。この取り組みは、AIの解釈可能性研究を推進し、より広範なコミュニティがモデルの行動を探求し理解できるようにすることを目的としています。(出典: 量子位, swyx)
Meta、Segment Anything Model 2 (SAM 2)を発表、画像・動画セグメンテーション能力を向上: Meta AI研究所(FAIR)は、広く利用されているSegment Anything Modelのアップグレード版であるSAM 2を発表しました。SAM 2は、画像や動画内のプロンプト可能な視覚セグメンテーションタスクに特化した基盤モデルであり、プロンプト(点、ボックス、テキストなど)に基づいて画像や動画内の特定のオブジェクトや領域を正確に識別し、セグメント化することができます。このモデルは現在オープンソース化されており、Apacheライセンスに従って、研究者や開発者が無料で利用し、アプリケーションを構築できるようになっており、コンピュータビジョン分野のさらなる発展を推進します。(出典: AIatMeta)
🎯 動向
智源研究院、Video-XL-2をオープンソース化、シングルカードで1万フレームの動画理解を実現: 智源研究院は上海交通大学などの機関と共同で、新世代の超長尺動画理解モデルVideo-XL-2を発表しました。このモデルは効果、処理長、速度のいずれにおいても大幅な向上を遂げており、シングルカードで1万フレームの動画入力を処理でき、2048フレームの動画エンコードはわずか12秒で完了します。Video-XL-2はSigLIP-SO400M視覚エンコーダー、動的トークン合成モジュール(DTS)、およびQwen2.5-Instruct大規模言語モデルを採用し、4段階の漸進的トレーニングと効率最適化戦略(セグメント化事前充填やデュアルグラニュラリティKVデコーディングなど)を通じて高性能を実現しています。モデルはMLVU、Video-MMEなどのベンチマークテストで優れた性能を示し、重みはオープンソース化されています。(出典: 量子位)

Character.ai、AvatarFX動画生成機能をリリース、画像の人物が動き、対話可能に: 主要なAIコンパニオンアプリであるCharacter.ai(c.ai)は、AvatarFX機能を発表しました。これにより、ユーザーは静止画像内の人物(ペットなどの非人間キャラクターを含む)をアニメーション化し、話したり歌ったり、ユーザーと対話したりできるようになります。この機能はDiTアーキテクチャに基づいており、高忠実度と時間的一貫性を重視し、マルチキャラクターや長編シーケンス対話などの複雑なシーンでも安定性を維持します。現在、AvatarFXはウェブ版ですべてのユーザーに公開されており、アプリ版も間もなくリリース予定です。同時に、c.aiはScenes(インタラクティブなストーリーシーン)、Imagine Animated Chat(アニメーション化されたチャット履歴)、Stream(キャラクター間のストーリー生成)などの新機能も発表し、AI創作体験をさらに豊かにしています。(出典: 量子位)

Nvidia、Llama-3.1 Nemotron-Nano-VL-8B-V1視覚言語モデルを発表: Nvidiaは、新しい視覚からテキストへのモデルLlama-3.1-Nemotron-Nano-VL-8B-V1を発表しました。このモデルは、画像、動画、テキスト入力を処理し、テキスト出力を生成することができ、ある程度の画像推論および認識能力を備えています。このモデルの発表は、NvidiaのマルチモーダルAI分野への継続的な投資の現れです。同時に、コミュニティの議論では、Llama-4が70B以下のモデルを放棄したことが、Gemma3やQwen3などのモデルにとってファインチューニング市場での機会をもたらす可能性があると指摘されています。(出典: karminski3)
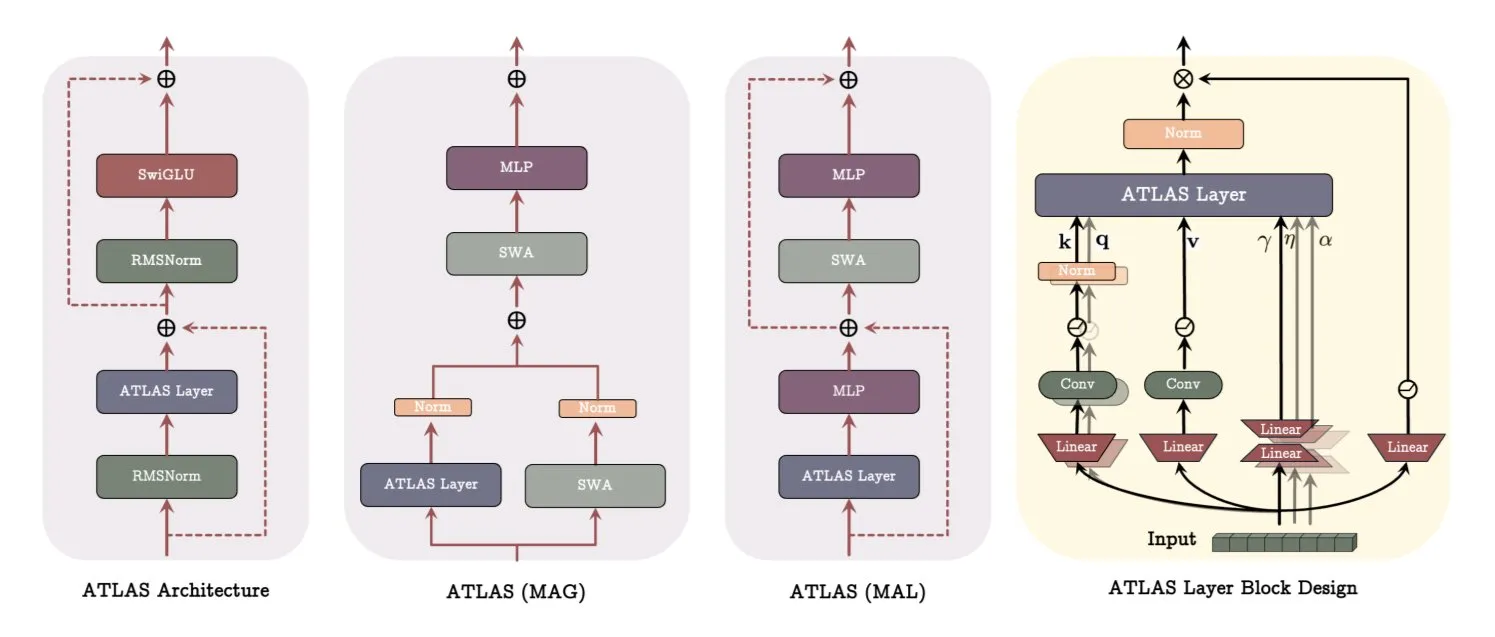
Google、ATLASアーキテクチャ論文を発表、モデルの学習と記憶方式を革新: Googleの最新論文では、ATLASと名付けられた新しいモデルアーキテクチャが紹介されています。これは、アクティブメモリ(Omegaルールが最近のc個のトークンを処理)とよりスマートなメモリ容量管理(多項式および指数特徴マッピング)を通じて、モデルの学習および記憶能力を最適化することを目的としています。ATLASは、より効果的なメモリ更新のためにMuonオプティマイザを採用し、DeepTransformersやDot(Deep Omega Transformers)などの設計を導入して、従来の固定アテンションを学習可能でメモリ駆動のメカニズムに置き換えます。この研究は、AIがよりスマートでコンテキスト認識型のシステムへと進む画期的なものであり、AIが大規模データセットを処理し活用する能力を向上させることが期待されます。(出典: TheTuringPost)
Qwen、Qwen3-Embeddingシリーズモデルを発表、埋め込み性能を大幅に向上: Qwenチームは、新しいQwen3-Embeddingモデルシリーズを発表しました。これには0.6B、4B、8Bの3つのバージョンが含まれます。これらのモデルは最大32kのコンテキスト長と100言語をサポートし、MTEB(Massive Text Embedding Benchmark)でSOTAの成績を収め、一部の指標では2位に10ポイントの差をつけています。この進展は、テキスト埋め込み技術におけるもう一つの重要なブレークスルーであり、セマンティック検索やRAGなどのアプリケーションに、より強力な基盤を提供します。(出典: AymericRoucher, ClementDelangue)

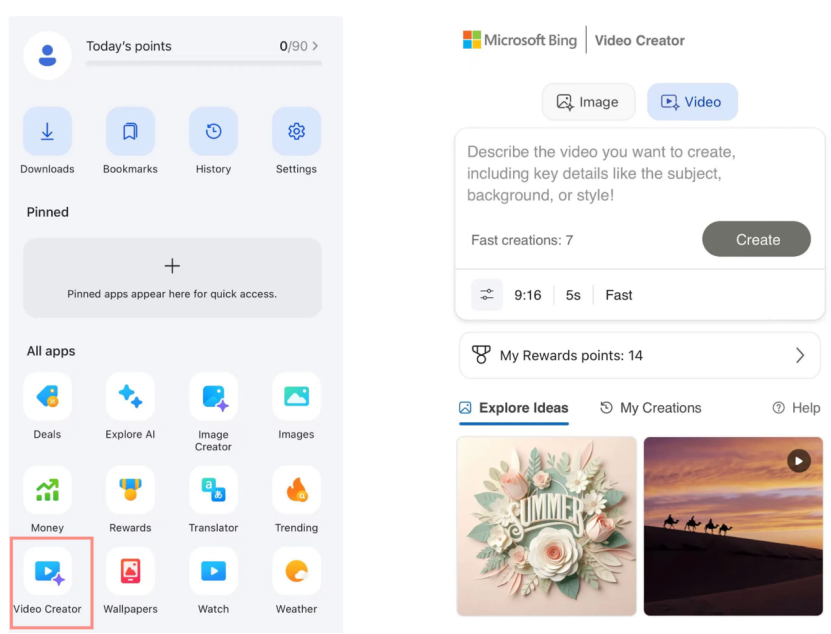
Microsoft Bing動画クリエーターがリリース、OpenAI Soraモデルベースで無料開放: Microsoftは、BingアプリケーションにBing Video Creatorを導入しました。この機能はOpenAIのSoraモデルに基づいており、ユーザーはテキストプロンプトを通じて無料で動画を生成できます。これはSoraモデルが初めて一般向けに大規模に無料開放された事例です。無料ではありますが、現在機能には制限があり、動画の長さはわずか5秒、9:16の比率、生成速度が遅いなどがあります。ユーザーのフィードバックによると、その効果は現在のSOTA動画モデル(Kling、Veo3など)と比較して差があり、Soraの技術イテレーション速度とMicrosoftの製品戦略に関する議論を引き起こしています。(出典: 36氪)
OpenAI、複数のエンタープライズ向け機能を発表、職場への統合を強化: OpenAIは、エンタープライズユーザー向けの一連の新機能を発表しました。これには、Google Driveなどのアプリケーション向けの専用コネクタの提供、ChatGPTでの会議記録、文字起こし、要約機能の実装、SSO(シングルサインオン)およびポイントベースのエンタープライズ版価格設定のサポートが含まれます。これらのアップデートは、ChatGPTを企業のワークフローにより深く統合し、オフィス効率を向上させることを目的としています。(出典: TheRundownAI, EdwardSun0909)
Hugging Face、高効率ロボットモデルSmolVLAを発表、MacBook上で実行可能: Hugging Faceは、SmolVLAと名付けられたロボットモデルを発表しました。その特徴は非常に高い効率で、MacBook上でも実行可能です。このモデルは、少量(例えば31個)のデモンストレーションデータでファインチューニングした後、特定のタスク(Koch Arm操作など)でシングルタスクのベースラインと同等以上の性能を達成し、リソースが制限された環境でのロボットAIの展開の可能性を示しています。(出典: mervenoyann, sytelus)
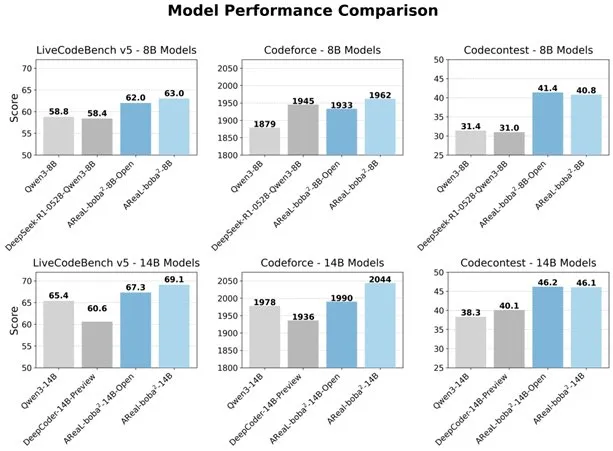
アリババ、完全非同期RLシステムAReaL-boba²をオープンソース化、LLMのコード能力を向上: アリババのQwenチームは、大規模言語モデル(LLM)向けに設計された完全非同期強化学習システムAReaL-boba²をオープンソース化し、Qwen3-14BでSOTAのコード強化学習効果を達成しました。このシステムは、システムとアルゴリズムの協調設計により、2.77倍のトレーニング加速を実現し、LiveCodeBenchで69.1点を達成し、複数ラウンドの強化学習をサポートします。(出典: _akhaliq)
DuckDB、DuckLake拡張機能を発表、データレイクとカタログフォーマットを統合: DuckDBは、DuckLake拡張機能を発表しました。これはSQLとParquetに基づいたオープンなレイクハウスフォーマットです。DuckLakeはメタデータをカタログデータベースに保存し、データをParquetファイルに保存します。この拡張機能により、DuckDBはDuckLake内のデータを直接読み書きでき、テーブルの作成、変更、クエリ、タイムトラベル、スキーマ進化などの機能をサポートし、データレイクの構築と管理の簡素化を目指しています。(出典: GitHub Trending)
Model Context Protocol (MCP) Ruby SDKがリリース: Model Context Protocol (MCP) は公式Ruby SDKをリリースしました。このSDKはShopifyと共同でメンテナンスされ、MCPサーバーの実装に使用されます。MCPは、AIモデル(特にエージェント)がツールを発見して呼び出し、リソースにアクセスし、事前定義されたプロンプトを実行するための標準化された方法を提供することを目的としています。このSDKはJSON-RPC 2.0をサポートし、ツール登録、プロンプト管理、リソースアクセスなどのコア機能を提供し、開発者がMCP仕様に準拠したAIアプリケーションを構築するのを容易にします。(出典: GitHub Trending)
AI技術が亜鉛電池の99.8%の効率と4300時間の稼働を実現: 人工知能による最適化を通じて、新世代の亜鉛電池は99.8%のクーロン効率と最大4300時間の稼働時間を達成しました。材料科学分野におけるAIの応用、特に電池設計と性能予測における応用は、エネルギー貯蔵技術のブレークスルーを推進しており、電気自動車や携帯電子機器などの分野により効率的で長持ちするエネルギーソリューションをもたらすことが期待されています。(出典: Ronald_vanLoon)

🧰 ツール
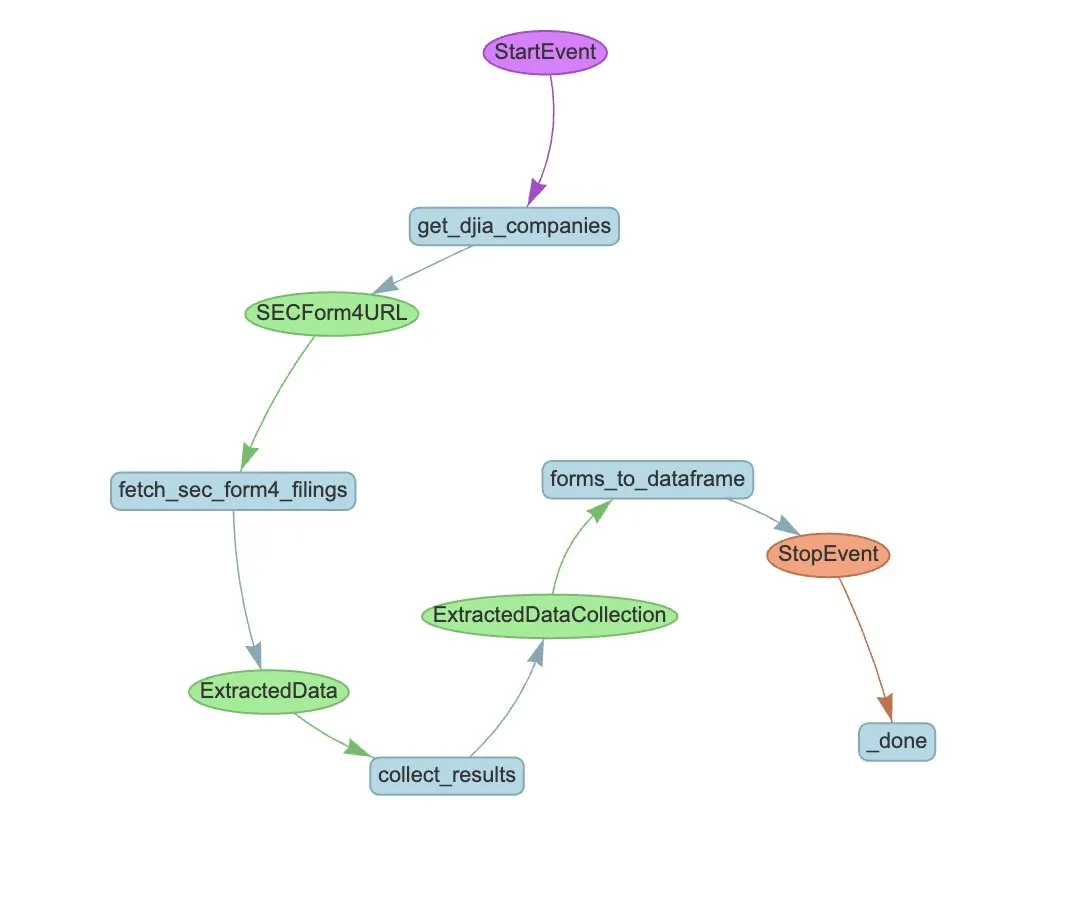
LlamaIndex、LlamaExtractとAgentワークフローでSEC Form 4の抽出を自動化: LlamaIndexは、LlamaExtractとAgentワークフローを使用して、SEC Form 4ファイルから構造化情報を自動的に抽出する方法を実演しました。SEC Form 4は、上場企業の役員、取締役、主要株主が株式取引を開示するための重要な文書です。抽出エージェントとスケーラブルなワークフローを構築することで、ダウ工業株30種平均の全企業のForm 4申告ファイルを効率的に処理し、市場の透明性とデータ分析効率を向上させることができます。(出典: jerryjliu0)
Cognee:AI Agentに動的メモリを提供するオープンソースツール: Cogneeは、AI Agentに動的メモリ能力を提供することを目的としたオープンソースプロジェクトで、わずか5行のコードで統合できると謳っています。拡張可能でモジュール式のECL(Extract, Cognify, Load)パイプラインを構築することで、Agentが過去の会話、ドキュメント、画像、音声文字起こしを相互接続し、検索するのを助け、従来のRAGシステムを置き換え、開発の難易度とコストを削減し、30以上のデータソースからのデータ処理とロードをサポートします。(出典: GitHub Trending)
Claude CodeがProユーザーに開放、コミュニティ版GitHub Actionも登場: AnthropicのAIプログラミングアシスタントClaude CodeがProサブスクリプションユーザーに開放され、ユーザーはJetBrains IDEプラグインなどを通じて利用できるようになりました。コミュニティ開発者はまた、Claude Code GitHub Actionのフォーク版をリリースし、有料ユーザーがGitHub IssuesやPRで直接Claude Codeを呼び出し、追加のAPI費用を支払うことなく、サブスクリプションの割り当てを利用してコードレビューや問題解決などのタスクを完了できるようにしました。(出典: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
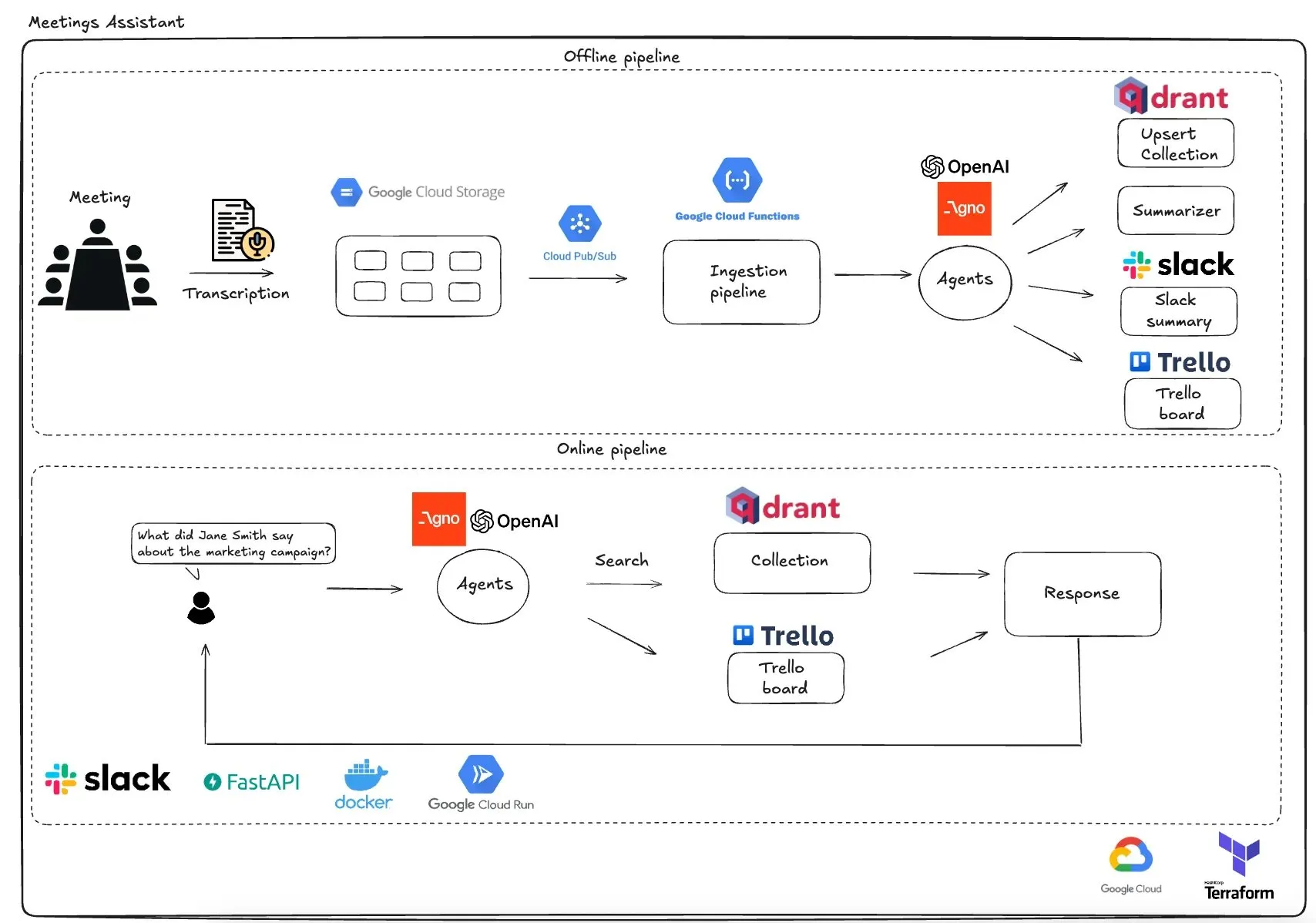
Qdrant、GCPベースのマルチエージェント会議アシスタントを発表: Qdrantは、完全にサーバーレスなマルチエージェント会議アシスタントシステムを実演しました。このシステムは、会議内容を文字起こしし、LLMエージェントを使用して要約し、コンテキスト情報をQdrantベクトルデータベースに保存し、タスクをTrelloに同期し、最終結果をSlackで直接配信します。このシステムは、エージェントオーケストレーションにAgnoAgiを利用し、Cloud Run上でFastAPIを実行し、埋め込みと推論にOpenAIを使用します。(出典: qdrant_engine)
Microsoft、GUI-Actorを発表、座標なしのGUI要素特定を実現: MicrosoftはHugging Face上でGUI-Actorを発表しました。これは座標を必要としないGUI(グラフィカルユーザーインターフェース)要素の特定方法です。この方法により、AIエージェントは特別な<actor>トークンを介して、テキストベースの座標予測に依存するのではなく、ネイティブな視覚ブロック(visual patches)を直接指し示すことができ、GUIエージェント操作の精度と堅牢性を向上させることを目指しています。(出典: _akhaliq)

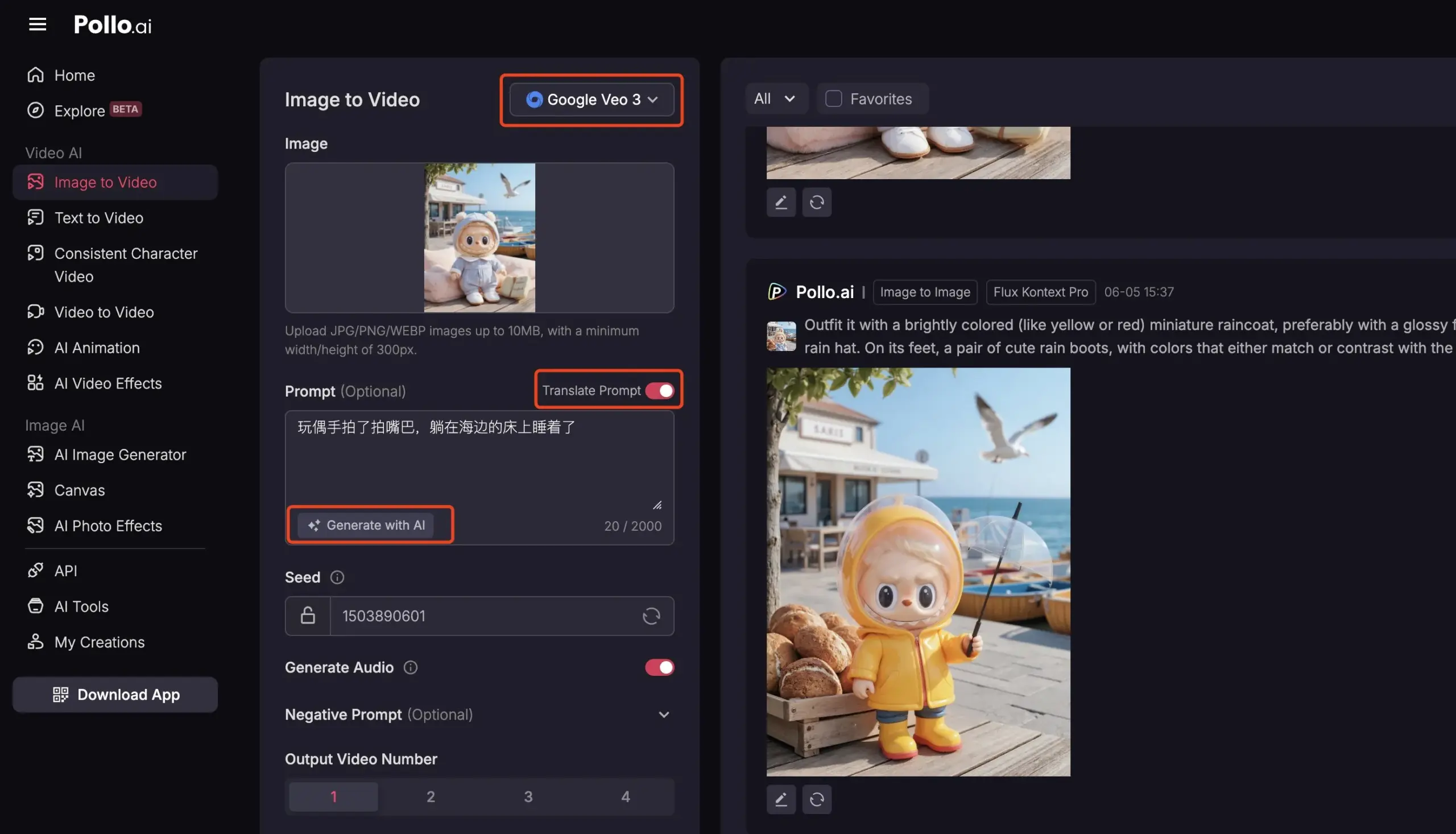
Pollo AI、Veo3とFLUX Kontextを統合し、包括的なAI動画サービスを提供: AIツールプラットフォームPollo AIは最近頻繁に更新され、Google Veo3動画生成モデルとFLUX Kontext画像編集機能を統合しました。ユーザーはこのプラットフォームでFLUX Kontextを使用して画像を修正した後、直接Veo3に送信して動画を生成できます。プラットフォームはまた、APIインターフェースを提供し、市場の複数の主要な動画大規模モデルへのワンストップアクセスをサポートし、AIプロンプト生成、多言語翻訳などの補助機能を内蔵しており、AI動画制作の利便性と効率を向上させることを目指しています。(出典: op7418)
📚 学習
Meta-Learning詳細解説:AIに学習方法を学習させる: Meta-Learning(メタラーニング)、別名「学習方法の学習」は、モデルが少量のサンプルしかなくても新しいタスクに迅速に適応できるように訓練するというのが中心的な考え方です。このプロセスは通常、2つのモデルが関与します。ベースラーナー(base-learner)は内部学習ループで特定のタスク(少数サンプル画像分類など)に迅速に適応し、メタラーナー(meta-learner)は外部学習ループでベースラーナーのパラメータや戦略を管理・更新し、新しいタスクを解決する能力を向上させます。訓練完了後、ベースラーナーはメタラーナーが学習した知識を利用して初期化されます。(出典: TheTuringPost, TheTuringPost)

論文解説『A Controllable Examination for Long-Context Language Models』: 本論文は、既存の長文脈言語モデル(LCLM)評価フレームワークの限界(実世界のタスクは複雑で解決が難しく、データ汚染の影響を受けやすい。NIAHのような合成タスクは文脈的一貫性に欠ける)に対し、理想的な評価フレームワークが備えるべき3つの特徴(シームレスな文脈、制御可能な設定、健全な評価)を提案しています。そして、人工的に生成された伝記を制御された環境として利用し、理解、推論、信頼性の次元からLCLMを評価する新しいベンチマークLongBioBenchを発表しました。実験により、多くのモデルが意味理解、初歩的な推論、および長文脈における信頼性の面で依然として不十分であることが示されました。(出典: HuggingFace Daily Papers)
論文解説『Advancing Multimodal Reasoning: From Optimized Cold Start to Staged Reinforcement Learning』: Deepseek-R1の複雑なテキストタスクにおける卓越した推論能力に触発され、本研究は最適化されたコールドスタートと段階的強化学習(RL)を通じて、マルチモーダル大規模言語モデル(MLLM)の複雑な推論能力をどのように向上させるかを探求しています。研究により、効果的なコールドスタート初期化がMLLMの推論を強化するために不可欠であり、厳選されたテキストデータのみで初期化するだけで多くの既存モデルを上回ることが明らかになりました。標準的なGRPOをマルチモーダルRLに適用すると勾配停滞の問題が発生しますが、その後の純粋なテキストRLトレーニングはマルチモーダル推論をさらに強化できます。これらの発見に基づき、研究者らはReVisual-R1を発表し、複数の挑戦的なベンチマークでSOTAの成績を収めました。(出典: HuggingFace Daily Papers)
論文解説『Unleashing the Reasoning Potential of Pre-trained LLMs by Critique Fine-Tuning on One Problem』: 本研究は、事前学習済みLLMの推論潜在能力を効率的に引き出す方法として、単一問題批判的ファインチューニング(Critique Fine-Tuning, CFT)を提案しています。モデルが単一の問題に対して生成した複数の解決策を収集し、教師LLMを利用して詳細な批判を提供し、批判データを構築してファインチューニングを行います。実験により、QwenおよびLlamaシリーズのモデルに単一問題CFTを実施した後、複数の推論タスクで顕著な性能向上が見られ、例えばQwen-Math-7B-CFTは数学および論理推論ベンチマークで平均15-16%向上し、計算コストは強化学習よりもはるかに低いことが示されました。(出典: HuggingFace Daily Papers)
論文解説『SVGenius: Benchmarking LLMs in SVG Understanding, Editing and Generation』: 既存のSVG(スケーラブル・ベクター・グラフィックス)処理ベンチマークのカバレッジが限定的で、複雑度の階層化が欠如し、評価パラダイムが断片化している問題を解決するために、SVGeniusが開発されました。これは2377個のクエリを含む包括的なベンチマークであり、理解、編集、生成の3つの次元をカバーし、24の応用分野の実データに基づいて構築され、体系的な複雑度の階層化が行われています。8つのタスクカテゴリと18の指標を通じて22の主要モデルを評価し、現在のモデルが複雑なSVGを処理する際の限界を明らかにし、純粋な規模拡大よりも推論強化トレーニングの方が効果的であることを指摘しています。(出典: HuggingFace Daily Papers)
Hugging Face Hub更新ログが公開: Hugging Face Hubは最新の更新ログを公開しました。ユーザーはこれを参照することで、プラットフォームの新機能、モデルライブラリの更新、データセットの拡充、ツールチェーンの改善などの最新動向を把握できます。これにより、コミュニティユーザーはHugging Faceエコシステムの最新リソースと能力をタイムリーに理解し、活用することができます。(出典: huggingface, _akhaliq)
Maxime Labonne氏らが多数のLLM Notebooksをオープンソース化: LLMエンジニアマニュアルの著者であるMaxime Labonne氏とIustin Paul氏は、LLM関連の一連のJupyter Notebooksをオープンソース化しました。これらのNotebooksは内容が豊富で、基本的なファインチューニング技術だけでなく、自動評価、レイジーマージ(lazy merges)、混合エキスパートモデル(frankenMoEs)の構築、検閲解除テクニックなどの高度なトピックもカバーしており、LLM開発者や研究者にとって貴重な実践リソースを提供しています。(出典: maximelabonne)
DeepLearningAI、The Batch週報を発行、AI FundがいかにAIビルダーを育成するかを議論: Andrew Ng氏は最新号のThe Batch週報で、AI FundがAI人材とビルダーを育成する上での経験と戦略を共有しました。今週号では、DeepSeekの新オープンソースモデルがトップLLMに匹敵する性能を持つこと、DuolingoがAIを利用して言語コースを拡大していること、AIのエネルギー消費のトレードオフ、悪意のあるリンクがAI Agentを誤誘導する可能性などのホットな話題も取り上げています。(出典: DeepLearningAI)

💼 ビジネス
Reddit、Anthropicを提訴、AI訓練のためのユーザーデータの無断使用を主張: RedditはAI企業Anthropicに対し、同社が自動化ボットを使用してRedditのコンテンツを無許可で収集し、AIモデル(Claudeなど)の訓練に使用したとして、契約違反および不正競争にあたるとして訴訟を起こしました。この訴訟は、現在のAI開発におけるデータ収集とモデル訓練の合法性に関する論争を浮き彫りにするとともに、コンテンツプラットフォームが自社のデータ価値保護をますます重視していることを反映しています。(出典: Reddit r/artificial, Reddit r/ArtificialInteligence, TheRundownAI)

Amazon、ノースカロライナ州にAIデータセンター建設のため100億ドルを投資計画: Amazonは、増大するAIビジネスの需要をサポートするため、ノースカロライナ州に新たなデータセンター建設のため100億ドルを投資すると発表しました。この動きは、大手テクノロジー企業がAIインフラに継続的に投資していることを反映しており、AIモデルの訓練と推論に必要な大規模な計算およびストレージリソースを満たすことを目指しています。(出典: Reddit r/artificial)

Anthropic、Windsurf.aiへのClaudeモデルAPIアクセス権を削減、プラットフォームリスクへの懸念高まる: AIアプリケーション開発プラットフォームWindsurf.aiは、Anthropicがわずか5日前の通知で、Claude 3.xおよびClaude 4モデルへのAPIアクセス容量を大幅に削減したことを明らかにしました。この措置により、Windsurf.aiは有料ユーザーサービスを保証するために緊急にサードパーティベンダーを探すことを余儀なくされ、無料およびProユーザーにはBYOK(Bring Your Own Key)オプションを提供することになりました。この出来事は、AIモデルプロバイダーがいつでもサービス戦略を調整し、さらには下流のアプリケーションと競合する可能性があるという、開発者のAIモデルプロバイダーのプラットフォームリスクに対する懸念を強めています。(出典: swyx, scaling01, mervenoyann)
🌟 コミュニティ
AIエンジニアカンファレンス(@aiDotEngineer)が話題、Agent設計とAIスタートアップに焦点: サンフランシスコで開催されたAIエンジニアカンファレンス(@aiDotEngineer)がコミュニティで話題の中心となっています。LlamaIndexは本番環境で効果的なAgent設計パターンを共有しました。Anthropicは会議でスタートアップ向けの「要求リスト」を発表し、新分野でのMCPサーバーの応用、サーバー構築の簡素化、AIアプリケーションのセキュリティ(ツールポイズニングなど)に注目しました。GraphiteはAI駆動のコードレビューツールを展示しました。カンファレンスでは、次世代GPTモデルの拡張が直面する基礎研究の課題なども議論されました。(出典: swyx, swyx, swyx, iScienceLuvr)

研究者Rohan Anil氏のAnthropic参加が注目を集める: 研究者のRohan Anil氏がAnthropicチームに参加すると発表し、このニュースはAIコミュニティで広範な注目と議論を呼びました。多くの業界関係者やフォロワーがこれに祝意を表し、Anthropicの研究活動への新たな貢献に期待を寄せています。これはまた、トップAI人材の流動が業界の構図に与える潜在的な影響を反映しています。(出典: arohan, gallabytes, andersonbcdefg, scaling01, zacharynado)
裁判所、OpenAIに全ChatGPTログの保存を要求、データ保持戦略に関する議論を呼ぶ: OpenAIが裁判所から、すべてのChatGPTログ(「一時的なチャット」や削除されるべきAPIリクエストを含む)を保持するよう要求されたと報じられています。このニュースは、特にOpenAI APIを使用するアプリケーションにとって、データ保持戦略に関するコミュニティの議論を引き起こしました。これは、それら自身のデータ保持ポリシーが完全に遵守されない可能性を意味し、ユーザーのプライバシーとデータ管理に新たな課題をもたらす可能性があります。可能な場合はデータを保護するためにローカルモデルを優先的に使用することが推奨されます。(出典: code_star, TomLikesRobots)

AI生成コンテンツの氾濫と「AI Slop」現象が懸念を呼ぶ: ソーシャルメディア上で低品質で注目を集めるためのAI生成コンテンツ(「AI Slop」と呼ばれる)が増加しており、Reddit上のAI生成投稿からFacebook上の「エビのイエス」などのAI画像まで、ユーザーは情報品質とネットワーク環境の悪化を懸念しています。これらのコンテンツは通常、ボットやトラフィックを求める人々によって安価に生成され、「エンゲージメントベイト」を通じて「いいね!」や共有を得ることを目的としています。研究によると、インターネットトラフィックの大部分はすでに「悪質なボット」によって構成されており、それらは偽情報を拡散し、データを盗んでいます。この現象はユーザーエクスペリエンスに影響を与えるだけでなく、民主主義や政治的コミュニケーションにも脅威を与え、将来のAIモデルの訓練データを汚染する可能性もあります。(出典: aihub.org)

LLMコスト議論:Geminiのコストパフォーマンス高く、Claude 4のコーディングコストが注目される: コミュニティの議論によると、現在のLLMの使用コストには大きな差があります。例えば、Geminiを使用して保険書類全体を処理し、多数の質問をするコストは約0.01ドルに過ぎず、高いコストパフォーマンスを示しています。対照的に、Claude 4モデルはコーディングなどのタスクで優れた性能を発揮しますが、Cursor.aiなどのプラットフォームでの最大モード(max mode)の使用コストが高く、ユーザーはGoogle Gemini 2.5 Proなどのよりコスト効率の高い選択肢に移行するよう促しています。(出典: finbarrtimbers, Teknium1)
AI Agent、実際のウェブページシナリオでのCAPTCHA(人間認証)解決に課題: MetaAgentXチームは、マルチモーダルインタラクティブエージェントのCAPTCHA解決能力評価に特化したOpen CaptchaWorldプラットフォームを発表しました。テストによると、GPT-4oなどのSOTAモデルでさえ、20種類の実際のウェブページ環境におけるインタラクティブな認証コードの処理において、成功率はわずか5%~40%であり、人間の平均成功率93.3%をはるかに下回っています。これは、現在のAI Agentが視覚理解、多段階計画、状態追跡、および正確なインタラクションにおいて依然としてボトルネックを抱えており、認証コードがその実際の展開における大きな障害となっていることを示しています。(出典: 量子位)

AIエージェント研修市場が活況、コースの質と就職の見通しに注目: AI Agentの概念の台頭に伴い、関連する研修コースも多数出現しています。一部の研修機関は、入門から就職までの包括的な指導を提供すると主張し、さらには「就職保証」を約束しており、授業料は数百元から数万元に及びます。しかし、市場のコースの質はまちまちで、一部のコースは内容が浅薄で過剰なマーケティングが行われ、知識の乏しい者から搾取するAI速習コースに類似していると指摘されています。受講者や観察者は、この種の研修の実際の効果、講師の資格、および「就職保証」の約束の信憑性について慎重な態度をとっており、AI開発の過渡期における新たな「偽りの需要」になるのではないかと懸念しています。(出典: 36氪)

💡 その他
ロボット分野におけるAIの応用進展:触覚感知ハンド、水陸両用ロボット、消防ロボット犬: AI技術はロボット能力の限界を押し広げています。研究者たちは触覚感知能力を持つロボットハンドを開発し、環境とのより良いインタラクションを可能にしました。Copperstone HELIX Neptuneは、AI駆動の水陸両用ロボットを展示し、さまざまな地形で作業できることを示しました。中国では、60メートルの水を噴射し、階段を登り、救助活動をライブ配信できる消防ロボット犬が発表されました。これらの進展は、ロボットの知覚、意思決定、複雑なタスク実行能力を向上させるAIの可能性を示しています。(出典: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

AI Agentと生成AIの比較議論: コミュニティでは、AI Agent(インテリジェントAI)と生成AI(Generative AI)の違いと関連性についての議論が起こっています。生成AIは主にコンテンツの創造に焦点を当てていますが、AI Agentは知覚、計画、行動に基づく自律的な意思決定とタスク実行により重点を置いています。両者の違いを理解することは、AI技術の発展方向と応用シーンをより良く把握するのに役立ちます。(出典: Ronald_vanLoon, Ronald_vanLoon)
複雑な組織プロセスの自動化におけるAIの課題についての議論: AIは特定のタスクの自動化や支援において進歩を遂げていますが、より広範な経済変革を実現するために人間やチームを置き換えるには、大きな複雑さに直面しています。多くの組織には、明確に記録されていないものの非常に重要なプロセスが存在し、これらのプロセスはリスクが高いものの偶発的であり、慣例化してその理由が忘れられている可能性があります。AIエージェントは、コストが高く学習機会が限られているため、このような暗黙知を試行錯誤によって学習することが困難です。これには単純な機械学習ではなく、新しい技術パラダイムが必要です。(出典: random_walker)