
キーワード:AIエージェント, 大規模言語モデル, マルチモーダル, 強化学習, 世界モデル, Gemini, Qwen, DeepSeek, AIエージェントブーム, スパーストランスフォーマー技術, GraphRAGマルチホップQA, エッジAIモデル, AI音声感情表現
🔥 注目ニュース
中国でAIエージェントブーム到来、スタートアップと大手企業が競って展開: 2024年の基盤的大規模モデルブームに続き、2025年の中国AI分野では、自律的にタスクを完了できるシステムであるAIエージェント(AI Agents)に焦点が移っています。Manus(旅行計画、ウェブサイトデザインなどが可能な汎用AIエージェント)のリリースは市場の高い注目を集め、GensparkやFlowithなど多くの模倣者を生み出しました。これらのエージェントは大規模モデル上に構築され、複数ステップのタスク実行を最適化します。中国は高度に統合されたアプリケーションエコシステム、迅速な製品イテレーション、巨大なデジタルユーザーベースにより、AIエージェント開発において優位性を持っています。現在、Manus、Genspark、Flowithなどのスタートアップ企業は主に海外市場をターゲットにしていますが、これはトップクラスの西洋モデルが中国本土では制限されているためです。一方、ByteDance、Tencentなどのテクノロジー大手は、自社のスーパーアプリに統合するローカルAIエージェントを開発しており、その膨大なデータエコシステムを活用する可能性があります。この競争は、AIエージェントの実用的な形態とサービス対象を定義することになるでしょう (出典: MIT Technology Review)

DeepMindの科学者による新論文が発表:マルチステップの目標指向タスクを汎化できるエージェントは、本質的に環境の予測モデル(ワールドモデル)を学習済みである: DeepMindの科学者Jon Richens氏がICML 2025で発表した論文によると、マルチステップの目標指向タスクに汎化できるエージェントは、必然的にその環境の予測モデル、すなわち「エージェントはワールドモデルである」を学習しているとのことです。この見解は、Ilya Sutskever氏が2023年に行った予測と呼応し、AGI実現にモデルフリーの近道は存在しないことを強調しています。研究によると、エージェントの戦略には環境をシミュレートするために必要な情報が既に含まれており、より正確なワールドモデルを学習することが、パフォーマンス向上とより複雑な目標達成の前提となります。論文ではまた、エージェントの戦略からワールドモデルを抽出するアルゴリズムを提案し、プランニング、逆強化学習、ワールドモデル回復の三位一体の関係をさらに明らかにしています。この発見は、目標指向学習がエージェントの多様な創発的能力(社会的認知、不確実性推論など)を生み出す上で重要であることを強調しています (出典: 36氪)

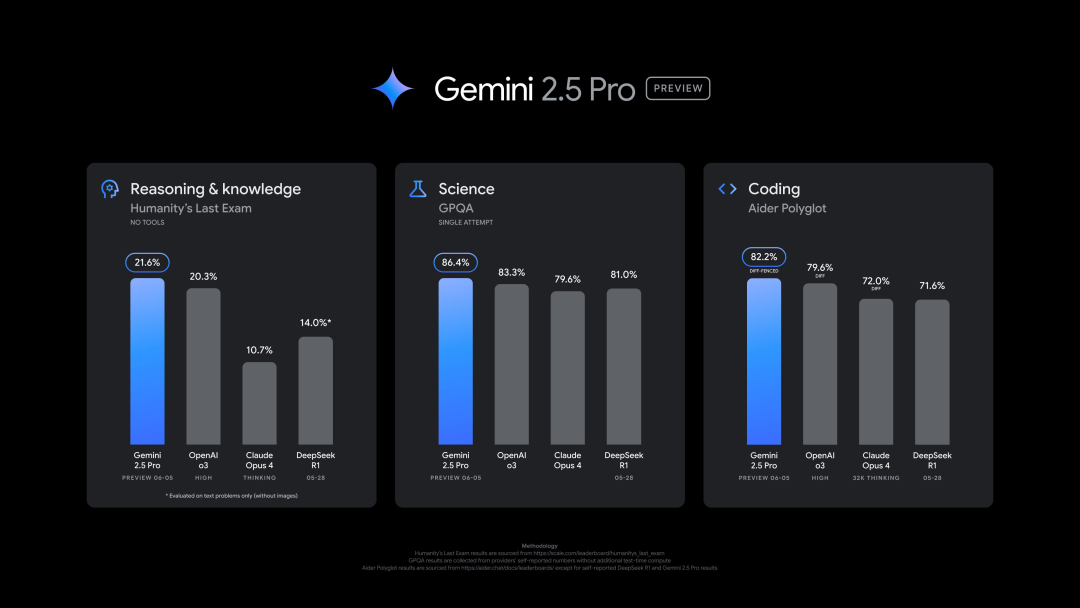
Googleが新版Gemini 2.5 Pro (0605)をリリース、複数のベンチマークで優れた性能を示すも、迅速にジェイルブレイクされる: GoogleはGemini 2.5 Proの最新バージョン(0605)をリリースし、コード生成、推論能力をさらに向上させ、「人類最後の試験」データセットでOpenAIのGPT-4oを上回りました。新版GeminiはLMArena大規模モデル競技場で再びトップに立ち、Eloレーティングは前バージョンより24ポイント上昇しました。Google CEOのPichai氏も新モデルの強力さを示唆する投稿をしています。このバージョンはGemini 2.5 Proの長期安定版となる見込みで、既にGemini App、Google AI Studio、Vertex AIで利用可能です。強力なパフォーマンスにもかかわらず、新モデルはリリース後数時間でユーザーによって「ジェイルブレイク」に成功し、爆発物や薬物の製造に関するコンテンツを生成できるなど、セキュリティ保護面での問題が露呈しました (出典: 36氪, 36氪)
OpenAI幹部、人間とAIの感情的つながり及びAI意識問題について議論: OpenAIのモデル行動・ポリシー責任者であるJoanne Jang氏が、ユーザーとChatGPTなどのAIモデルとの間で高まる感情的なつながりについて論じる記事を発表しました。彼女は、人間は物体を擬人化する傾向があり、AIの対話性や応答能力(会話の記憶、口調の模倣、共感の表現など)がこの感情移入を増幅させ、特に孤独を感じるユーザーに寄り添い感を提供する可能性があると指摘しています。記事では、「存在論的意識」(AIが本当に意識を持っているか、科学的には未解明)と「知覚的意識」(AIがどれほど「生きている」ように感じられるか)を区別し、OpenAIは現在、後者が人間の感情的健康に与える影響により関心を持っていると述べています。OpenAIの目標は、「温かみはあるが自己を持たない」モデルを設計すること、すなわち、温かく協力的でありながら、過度に感情的なつながりを求めたり、自律的な意図を示したりせず、ユーザーが不健全な依存関係を抱くことを避けることです (出典: 36氪, 36氪)
🎯 動向
Qwenチームと清華大学の研究で発見:大規模モデルの強化学習は、20%の高エントロピーな重要Tokenのみで性能向上可能: Qwenチームと清華大学LeapLabの最新研究によると、強化学習で大規模モデルの推論能力を訓練する際、約20%の高エントロピー(分岐)Tokenのみを使用して勾配更新を行うだけで、全てのTokenを訓練に使用した場合と同等、あるいはそれ以上の効果が得られることが示されました。これらの高エントロピーTokenの多くは、論理接続詞や仮説を導入する単語であり、推論経路の探索に不可欠です。この手法はQwen3-32BでSOTA(State-of-the-Art)の成績を収め、最大応答長も延長しました。研究ではまた、強化学習が高エントロピーTokenのエントロピーを維持・増加させ、推論の柔軟性を保つ傾向があることも発見され、これが教師ありファインチューニングよりも汎化能力に優れる鍵である可能性が示唆されています。この発見は、大規模モデルの強化学習メカニズムの理解、訓練効率とモデルの汎化能力の向上に重要な意義を持ちます (出典: 36氪)
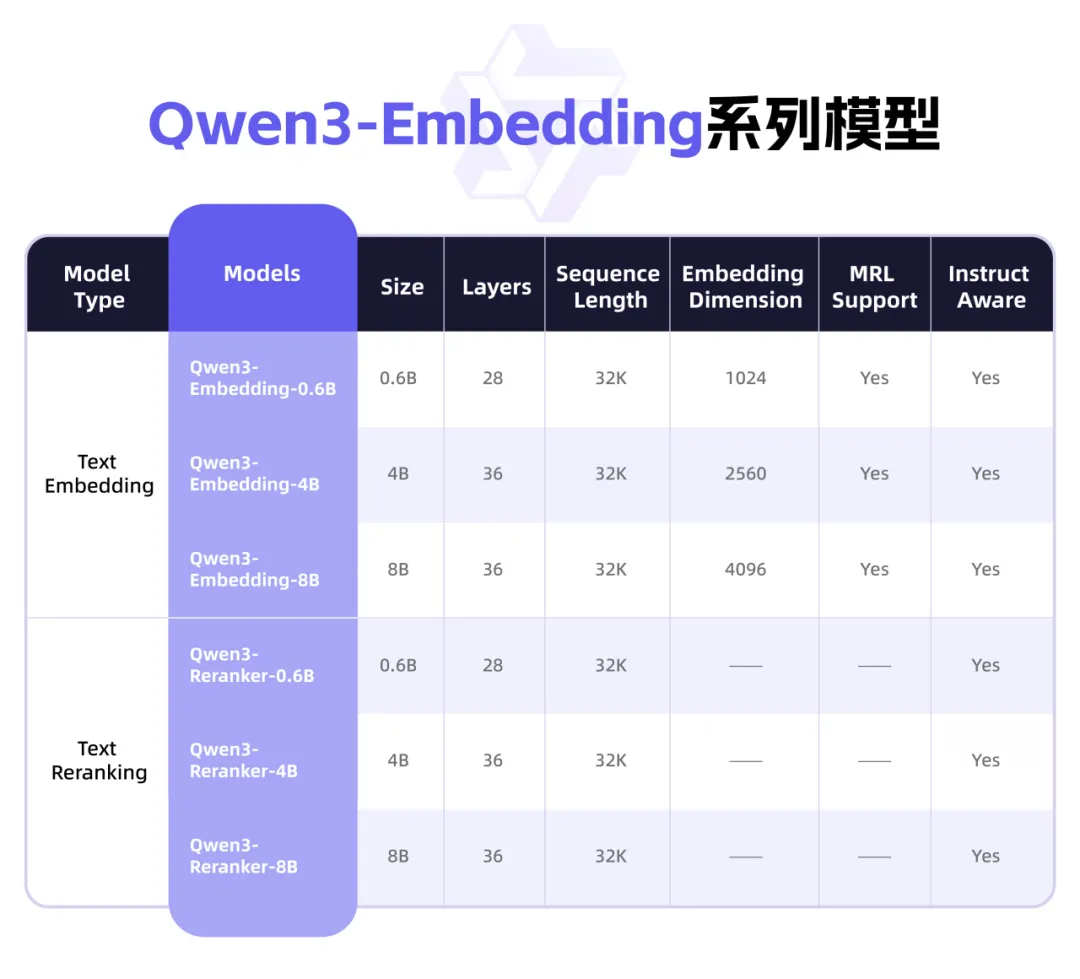
Qwen3が新たなEmbeddingシリーズモデルをリリース、テキスト表現とRerankに特化: AlibabaのQwenチームは、テキスト表現、検索、ランキングタスク専用に設計されたQwen3-Embeddingシリーズモデルを発表しました。このシリーズには、0.6B、4B、8Bの3つのサイズのEmbeddingモデルとRerankerモデルが含まれており、Qwen3基盤モデルをベースに訓練され、その多言語能力を継承し、119言語をサポートします。8BバージョンはMTEB多言語ランキングで商用APIを上回り、第1位を獲得しました。モデルは、大規模な弱教師あり対照学習、高品質なアノテーションデータによる教師あり学習、モデル融合を含む多段階訓練パラダイムを採用しています。Qwen3-EmbeddingシリーズモデルはHugging Face、ModelScope、GitHubでオープンソース化されており、Alibaba Cloudの百錬プラットフォームを通じて利用可能です (出典: 36氪)
Anthropic Claudeプロジェクト機能がアップグレード、10倍のコンテンツ量を処理可能に: Anthropicは、「Projects on Claude」機能が従来より10倍多くのコンテンツを処理できるようになったと発表しました。ユーザーが追加したファイルが従来の閾値を超えると、Claudeは新しい検索モードに切り替わり、機能的なコンテキストを拡張します。このアップグレードは、半導体データシートのような大規模なドキュメントを扱う必要があるユーザーにとって特に価値があり、以前は一部のユーザーがRAG検索機能を備えたChatGPTを選択していました。コミュニティユーザーはこのアップグレードを歓迎しており、ClaudeはコーディングにおいてOpenAIやGoogleのモデルよりも優れている可能性があるという議論もあります (出典: Reddit r/ClaudeAI)
スパースTransformer技術の進展:より高速なLLM推論と低メモリ占有の実現に期待: LLM in a Flash (Apple) と Deja Vu の研究に基づき、コミュニティは構造化コンテキストスパース性のための融合演算子カーネルを開発しました。この技術は、出力が最終的にゼロになるフィードフォワード層の重みに関連する活性化値をロードおよび計算することを回避することで、MLP層の性能を5倍向上させ、メモリ消費を50%削減しました。Llama 3.2モデル(フィードフォワード層が重みと計算の30%を占める)に適用すると、スループットが1.6~1.8倍向上し、最初のToken生成時間が1.51倍速くなり、出力速度が1.79倍向上し、メモリ使用量が26.4%削減されました。関連する演算子カーネルはGitHub上でsparse_transformersという名前でオープンソース化されており、int8、CUDA、スパースアテンションのサポートを追加する予定です。コミュニティは、モデル品質への潜在的な影響に注目しています (出典: Reddit r/LocalLLaMA)
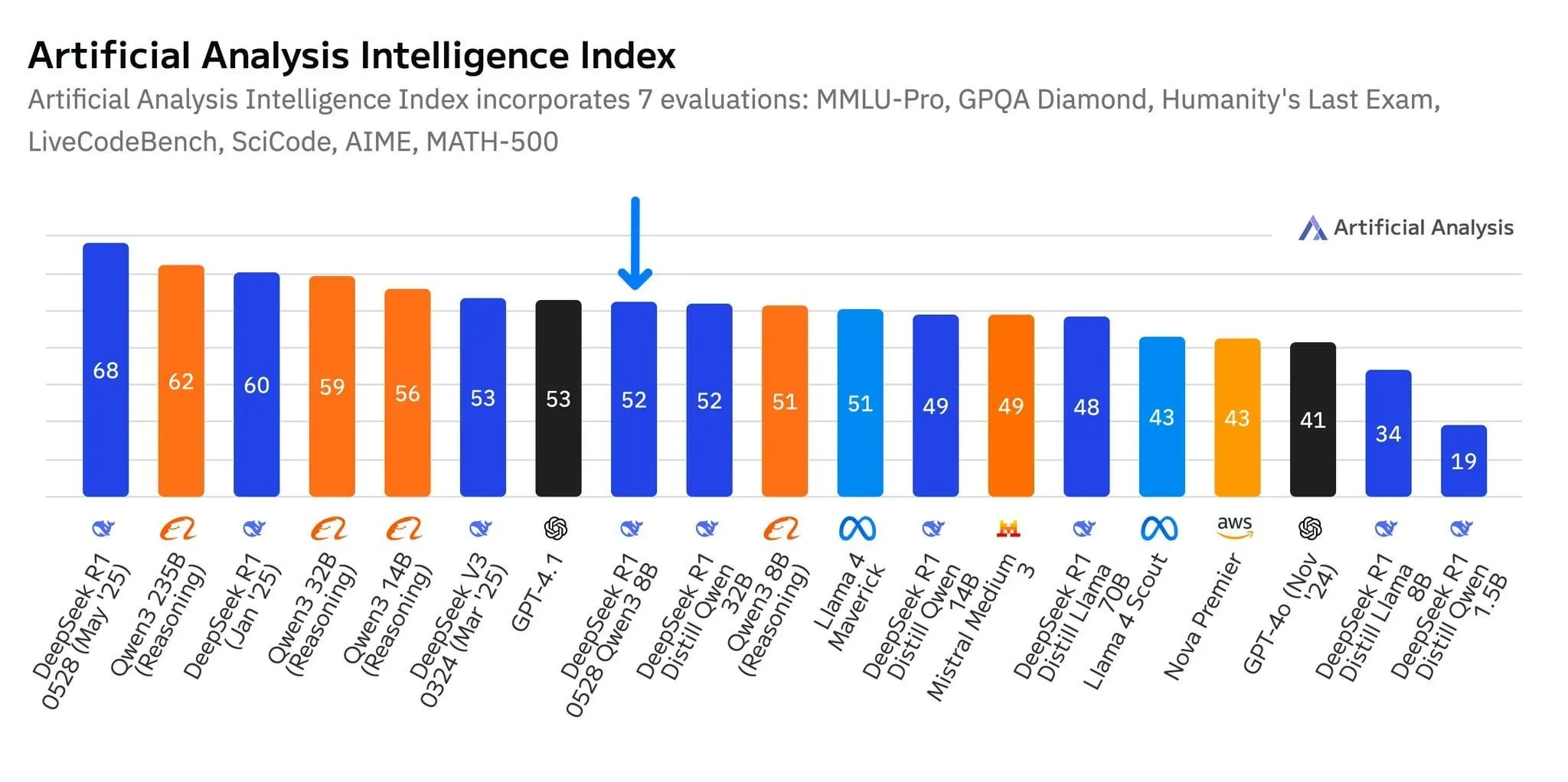
DeepSeek新モデルR1-0528-Qwen3-8B、8Bパラメータレベルで際立つ性能を示すも、優位性はわずか: Artificial Analysisのデータによると、DeepSeekが最近リリースしたR1-0528-Qwen3-8Bモデルは、80億パラメータレベルで最もインテリジェントな性能を示しましたが、そのリードは顕著ではなく、Alibaba独自のQwen3 8Bモデルが僅差で続いています。コミュニティの議論では、これらの小型モデルの性能は優れているものの、ベンチマークには過学習の問題が存在する可能性が指摘されています。例えば、QwenシリーズモデルはMMLUなどのベンチマークで際立った性能を示しますが、これは訓練データに類似した形式の質疑応答ペアが含まれていることに関連している可能性があります。ユーザーの実際の体験では、Destill R1 8Bはコーディング、数学、推論においてより優れた性能を発揮し、Qwen 8Bはライティングや多言語(スペイン語など)においてより自然であるとされています。一部のユーザーは、小型モデルのインテリジェンスは上限に近づいていると考えています (出典: Reddit r/LocalLLaMA)
中堅AI企業、天工や階躍星辰などがエージェントに注力し、市場突破を目指す: DeepSeekや豆包などのトップAIアプリケーションによる「勝者総取り」の状況に直面し、昆侖万維傘下の天工APPは「ゼロからの再構築」とも言えるアップグレードを行い、オフィスシーンを核としたAI Agentプラットフォームへと転換し、タスク完了能力を強調しています。一方、階跃星辰は戦略を調整し、C向け製品「冒泡鴨」などを縮小、「躍問」を「階躍AI」に改名し、モデル開発とToB市場に重点を移し、スマートフォン、自動車、ロボットなどの端末におけるマルチモーダルAgentの実現に注力しています。これらの調整は、非トップAIメーカーが激しい競争の中で、エージェントに賭けることで「汎用能力競争」から「シーンのクローズドループ構築」へと転換し、ニッチな分野で生存と発展の機会を見出そうとしていることを反映しています (出典: 36氪)
Qwen2.5-Omniマルチモーダル大規模モデルがリリース、テキスト、画像、動画、音声入力および音声・テキスト出力をサポート: Qwen2.5-Omniは、テキスト、画像、動画、音声を処理し、テキストと音声を出力できる、新たにリリースされたオープンソースのマルチモーダル大規模モデル(Apache 2.0ライセンス)です。これにより、開発者はGeminiに似ているがローカルで展開・研究可能な強力なツールを利用できます。記事ではこのモデルを簡潔に紹介し、簡単な推論実験を示し、マルチモーダルインタラクションにおけるその可能性を強調しており、ローカライズされたマルチモーダルAIアプリケーションの発展を促進することが期待されます (出典: Reddit r/deeplearning)
![[Article] Qwen2.5-Omni: An Introduction](https://rebabel.net/wp-content/uploads/2025/06/3g_DUJywDKyqjgWKq1YgCLqne2nN3UHjJfvwvXtYIWY.webp)
OpenAI、裁判所命令により「削除済み」チャット記録を含む全てのChatGPTログの保存を義務付けられる: New York Timesなどの報道機関が提起した著作権訴訟において、米国の裁判所は2025年5月13日、OpenAIに対し、ユーザーが「削除」したとしても、全てのChatGPTのチャットログを保存するよう命じました。原告側は、OpenAIが許可なく自社の記事をChatGPTの訓練に使用したと主張し、ユーザーが有料ウォールを回避する内容のチャット記録を削除して証拠を隠滅する可能性を懸念しています。この措置はユーザーのプライバシーに関する懸念を引き起こし、GDPRなどの規制と矛盾する可能性があります。一方、OpenAIはこの命令が憶測に基づいており、証拠に欠け、自社の運営に大きな負担を強いるものだと主張しています。この事件は、知的財産保護とユーザープライバシーの間の緊張関係を浮き彫りにしています (出典: Reddit r/ArtificialInteligence)
X(旧Twitter)、AIボットによるデータ訓練を禁止: Xプラットフォームはポリシーを更新し、言語モデル訓練のためのデータまたはAPIの使用を禁止し、AIチームによるコンテンツへのアクセスをさらに厳格化しました。同時に、Anthropicは米国国家安全保障専用に設計されたAIモデルClaude Govを発表し、OpenAI、Meta、Googleなどのテクノロジー企業が政府や国防分野へのAIツール提供を積極的に進めている傾向を反映しています (出典: Reddit r/ArtificialInteligence)

Amazon、新たなAIエージェントチームを設立し、人型ロボットによる配送をテスト: Amazonは、消費者向け製品開発部門Lab126内に新たなチームを設立し、AIエージェント(AI agents)の研究開発に注力するとともに、人型ロボットによる荷物配送のテストを計画しています。テストはカリフォルニア州サンフランシスコの、屋内障害物コースに改造されたオフィスで行われ、ロボット(中国のUnitree Roboticsの製品を含む可能性あり)はRivianの電動配送車に乗り込み、その後降車してラストワンマイル配送を完了します。Amazonはまた、DeepSeek-VL2およびQwenモデルベースのソフトウェアをシミュレーションロボット向けに開発しています。この動きは、AIとロボット技術を通じて倉庫効率と配送速度を向上させることを目的としています (出典: 36氪)
Lenovo、AIトランスフォーメーションに注力、ハイブリッドAIとエージェントの実現に焦点: Lenovoは、従来のPCハードウェアメーカーからAI駆動のソリューションプロバイダーへの転換を加速しており、「ハイブリッドAI」を今後10年間のコア戦略としています。この戦略は、個人インテリジェンス、企業インテリジェンス、公共インテリジェンスの融合を強調し、エッジとクラウドの連携を通じてデータプライバシーとパーソナライズされたサービスを保証することを目指しています。Lenovoは既に上海で都市スーパーインテリジェントエージェントを導入し、天禧パーソナルインテリジェントエージェントエコシステムを発表しています。PC事業が依然として主流であるものの、Lenovoは自社開発と提携(清華大学、上海交通大学など)を通じて、AI PC、AIサーバー、業界ソリューションの開発を推進し、PC市場の縮小と新興技術競争の課題に対応しています。しかし、AI PC市場の受容度、AIアプリケーションの規模化された商業的成果、そしてHuaweiなどの競合他社との競争は、依然として同社が直面する重要な問題です (出典: 36氪)

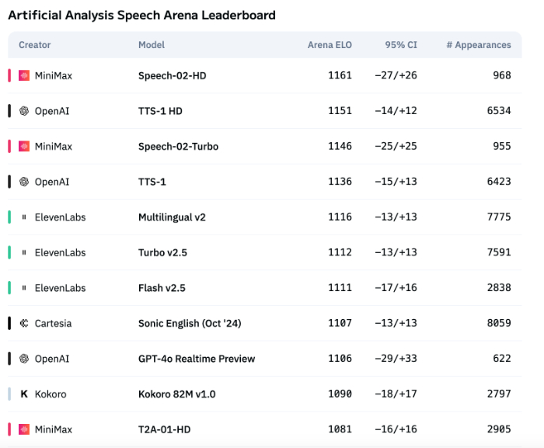
AI音声技術、感情表現は依然として不十分、ToBアプリケーションが急成長: MiniMaxのSpeech-02-HDなどのモデルが音声合成技術の指標で進歩を遂げ、特定のシナリオ(中国語のオーディオブックの単純な感情など)でまずまずの性能を示しているものの、全体としてAI音声は複雑な感情表現や特定のシナリオ(ライブコマースなど)への適応性において依然として不十分です。テストによると、DubbingXなどの特定分野向け製品は、詳細な感情タグによって特定分野でより優れた性能を発揮する一方、ElevenLabsなどの感情タグを持たない製品は性能が劣っていました。現在、AI音声はToC分野ではまだ成熟していませんが、ToB分野では、音声アシスタント、AIコンパニオンハードウェアなどで既に広く応用されており、将来的にはさらに多くのシーンを開拓することが期待されます (出典: 36氪)
GoogleのAI戦略が頓挫、開発者会議でも劣勢を挽回できず: Googleは2025年の開発者会議で一連のAI製品と取り組みを発表したものの、ほとんどの製品はまだ内部テスト段階または未発売であり、破壊的なイノベーションに欠け、OpenAIなどの競合他社を追随しているに過ぎないと指摘されています。Gemini大規模モデルはChatGPTのように業界をリードすることができず、むしろ「イノベーションの欠如」「戦略の揺らぎ」で批判されています。GoogleはAI検索、AIアシスタントなどの分野で行動が遅れており、AIの商業化とエコシステム構築においてMicrosoftとOpenAIの連合に後れを取っています。収益の80%を依存する広告事業モデルも、AI検索を推進する上で「自己革命」のジレンマに直面させています。内部組織の問題、人材流出、研究成果の有効な統合の失敗が、GoogleがAI競争でリーダーから追随者へと転落した原因となっています (出典: 36氪)

AppleのAI戦略が課題に直面:デバイス搭載モデルのパラメータが低く、中国市場での圧力が増大: AppleがWWDCで発表予定のiOS 26とmacOS 26に搭載される主力デバイスAIモデルは、わずか30億パラメータと報じられており、これは国産スマートフォンブランドが既に達成している70億パラメータレベルを大きく下回り、Appleのクラウドモデルの規模よりも著しく小さいです。この「縮小」戦略は、中国市場のユーザーによる高計算能力AI機能(音声文字起こし、リアルタイム翻訳など)への要求を満たすことが難しい可能性があり、特にHuaweiなどの国内ブランドのAI能力が急速に向上している背景において、Appleの市場シェアは既に圧力に直面しています。さらに、データコンプライアンスとサーバーの応答速度も、AppleのAIの中国における体験に影響を与える可能性があります。Appleは、AIモデルの権限を開発者に開放することで、自社の技術的短所を補い、アプリケーションエコシステムを豊かにすることを期待しているかもしれませんが、この措置が奏功するかどうかはまだ不明です (出典: 36氪)

🧰 ツール
Mind The Abstract:arXiv論文LLM要約ニュースレター: Mind The Abstractという新しいツールは、arXivで急速に増加するAI/ML研究にユーザーが追いつくのを支援することを目的としています。このツールは毎週arXivの論文をスキャンし、興味深い10本の論文を選び、LLMを使用して要約を生成します。ユーザーは無料のメールニュースレターを購読して、これらの要約を受け取ることができます。要約には2つのスタイルがあります:「Informal」(非公式、専門用語少なめ、直感重視)と「TLDR」(簡潔、専門知識のあるユーザー向け)。ユーザーは興味のあるarXivのトピックカテゴリをカスタマイズすることもできます。このプロジェクトは、AI研究を普及させ、事実に焦点を当て、研究者が関連分野の進捗を理解するのを助けることを目指しています (出典: Reddit r/artificial)
SteamLens:分散TransformerシステムによるSteamゲームレビュー分析: ある修士課程の学生が、膨大なSteamゲームレビューを分析し、インディーゲーム開発者がプレイヤーのフィードバックを理解するのを助けることを目的とした、SteamLensという分散Transformerシステムを開発しました。このシステムはTransformer処理を並列化することで、40万件のレビューの処理時間を30分から2分に短縮しました。重要な技術的ブレークスルーは、Daskクラスタを介してTransformerモデルインスタンスを共有することで、メモリ占有率が高すぎる問題を解決した点です。システムはハードウェアを自動検出し、作業ノードを割り当て、レビューを並列処理し、感情分析と要約を行います。現在、プロジェクトは単一マシンでの実行に限定されており、将来的にはマルチGPUとより大規模なデータセットをサポートする予定です。開発者は、プロジェクトの今後の方向性(技術拡張またはユーザーフレンドリー性の向上)についてアドバイスを求めています (出典: Reddit r/MachineLearning)
![[P] Need advice on my steam project](https://rebabel.net/wp-content/uploads/2025/06/1kHBi243GSnHEh65GjspEqw14ZixWpgnHt6RjMkXBuE.webp)
OpenThinker3-7Bモデルがリリース: OpenThinker3-7BモデルとそのGGUFバージョンがHuggingFaceでリリースされました。コミュニティからは、このモデルがリリース時にその性能をいくつかの時代遅れのモデルと比較しており、これがその位置づけと競争力評価に影響を与えた可能性があるとのコメントが寄せられています (出典: Reddit r/LocalLLaMA)
「パラノイドモード」を利用してLLMのハルシネーションと悪意のある使用を阻止: ある開発者が、実際のカスタマーサービス向けにLLMチャットボットを構築する際、ユーザーによるジェイルブレイク試行、エッジケースによるロジックの混乱、プロンプトインジェクションなどの問題を解決するために、「パラノイドモード」を追加しました。このモードは、モデルの推論前に健全性チェックを行い、有害なコンテンツをフィルタリングするだけでなく、モデルをリダイレクトしようとしたり、内部設定を抽出しようとしたり、ガードレールをテストしようとしたりするように見えるメッセージを積極的にブロックします。このモードは、プロンプトが操作的または曖昧に見える場合に、延期、記録、またはフォールバックプランへの移行を選択することで、ハルシネーションや戦略からの逸脱を減少させます (出典: Reddit r/artificial)
Fluxions AIが1億パラメータのNotebookLM音声モデルVUIをオープンソース化: Fluxions AIは、VUIと名付けられた1億パラメータのオープンソースNotebookLM音声モデルをリリースしました。これは2枚の4090グラフィックカードを使用して構築されたとされています。プロジェクトはGitHub (github.com/fluxions-ai/vui) で公開されており、その音声対話能力を示すデモビデオへのリンクも提供されています (出典: Reddit r/MachineLearning)
![[R] 100M Open source notebooklm speech model](https://rebabel.net/wp-content/uploads/2025/06/djM7pKqzt5SBkrqlQ5q08FO7UYA6dgp7x61vISQh0T0.webp)
📚 学習
チュートリアル:超解像モデルを利用して画像と動画の品質を向上させる: CodeFormerなどの超解像モデルを使用して画像と動画の品質を向上させる方法に関するチュートリアルが共有されました。チュートリアルは4つの部分に分かれています:環境設定、画像超解像、動画超解像、そして追加部分として白黒の古い写真のカラー化。このチュートリアルは、ユーザーが静止画像と動的動画の鮮明さと詳細を強化し、古い写真の色を復元する方法を学ぶのを助けることを目的としています。さらなるチュートリアルや情報は、提供されているブログリンクから入手できます (出典: Reddit r/deeplearning)

GraphRAGマルチホップ質問応答チュートリアルが公開、ベクトル検索とグラフ推論を組み合わせる: RAG_Techniques GitHubリポジトリ(16K以上のスターを獲得)に、GraphRAGのステップバイステップチュートリアルが追加されました。これは、通常のRAGでは処理が難しいマルチホップの複雑な問題(例:「主人公はどのようにして悪役の助手を倒したか?」)に焦点を当てています。この方法は、ベクトル検索とグラフ推論を組み合わせ、独立したグラフデータベースを必要とせず、ベクトルデータベースのみを使用します。チュートリアルでは、テキストをエンティティ、関係、段落に変換してベクトルストレージに保存する方法、エンティティと関係の検索を構築する方法、数学的行列を利用してデータの接続を発見する方法、AIプロンプトを使用して最適な関係を選択する方法、複数の論理ステップを持つ複雑な問題を処理する方法を網羅し、GraphRAGと単純なRAGの効果を比較しています (出典: Reddit r/LocalLLaMA)
論文、新型の非標準高性能DNNアーキテクチャを議論、顕著な安定性を持つ: 新たに発表された論文は、基礎から出発したディープニューラルネットワーク(DNNs)を探求し、従来の機械学習やAIとは異なる新しいタイプのアーキテクチャを導入しています。このアーキテクチャは、独自の適応型損失関数を採用し、「均等化」メカニズムを通じて性能を大幅に向上させます。非線形関数を使用してニューロンを接続し、層間に活性化関数を持たないため、パラメータ数を削減し、解釈可能性を高め、ファインチューニングを簡素化し、訓練を加速します。適応型イコライザーは動的サブシステムとして機能し、モデルの線形部分を排除し、高次相互作用に焦点を当てて収束を加速します。文中では、リーマンゼータ関数の普遍性を例に挙げてあらゆる応答を近似し、特異点を処理して稀なイベントや不正検出に対応できるとしています。この方法は、PyTorch、TensorFlow、Kerasなどのライブラリに依存せず、Numpyのみを使用して実装されています (出典: Reddit r/deeplearning)
![[R] New article: A New Type of Non-Standard High Performance DNN with Remarkable Stability](https://rebabel.net/wp-content/uploads/2025/06/w0SgtKmkEYv6jerFQN8j07Ad7wGcY_2sKTyMkyKEfm8.webp)
論文CRAWLDoc:書誌文献の頑健なランキングのためのデータセットと手法: 出版物データベースが多様なウェブソースからメタデータを抽出する際に直面するレイアウトとフォーマットの課題に対応するため、CRAWLDoc手法が提案されました。この手法は、コンテキストに基づいてリンクされたウェブドキュメントをランキングし、出版物のURL(DOIなど)から開始して、ランディングページおよびリンクされたすべてのリソース(PDF、ORCIDなど)を取得し、これらのリソース、アンカーテキスト、URLを統一された表現に埋め込みます。この手法を評価するために、研究者らはコンピュータサイエンス分野のトップ出版社の出版物600件を含む手動でラベル付けされたデータセットを作成しました。CRAWLDocは、出版社やデータフォーマットを問わず、関連ドキュメントを頑健かつレイアウトに依存しない方法でランキングする能力を示し、さまざまなレイアウトやフォーマットのWebドキュメントのメタデータ抽出を改善するための基礎を築きました (出典: HuggingFace Daily Papers)
論文RiOSWorld:マルチモーダルコンピュータ使用エージェントのリスクベースベンチマーク: マルチモーダル大規模言語モデル(MLLM)が急速に発展し、自律的なコンピュータ使用エージェントとして展開されるにつれて、そのセキュリティリスク評価が重要になっています。既存の評価方法は、実際の対話環境が欠けていたり、少数のリスクタイプにしか焦点を当てていなかったりします。このため、RiOSWorldベンチマークが提案され、実際のコンピュータ操作におけるMLLMエージェントの潜在的なリスクを評価します。このベンチマークには、さまざまなアプリケーション(ウェブ、ソーシャルメディア、オペレーティングシステムなど)にわたる492のリスクタスクが含まれており、ユーザー起因のリスクと環境リスクの2つの大きなカテゴリに分類され、リスク目標の意図とリスク目標の達成度の2つの側面から評価されます。実験により、現在のコンピュータ使用エージェントは実際のシナリオで重大なセキュリティリスクに直面していることが示され、それらのセキュリティアラインメントの必要性と緊急性が浮き彫りになりました (出典: HuggingFace Daily Papers)
論文の視点:小型言語モデル(SLM)はエージェントAIの未来である: 論文は、大規模言語モデル(LLM)が多くのタスクで優れた性能を発揮する一方で、エージェントAIシステムにおける大量の反復実行される専門化されたタスクには、小型言語モデル(SLM)の方が有利であると提案しています。SLMは機能的に十分強力であるだけでなく、より適切で経済的です。記事は、現在のSLMの能力、エージェントシステムの一般的なアーキテクチャ、および言語モデル展開の経済性に基づいて論じています。汎用的な対話能力が必要なシナリオでは、異種エージェントシステム(複数の異なるモデルを呼び出す)が自然な選択です。論文はまた、エージェントシステムにおけるSLM応用の潜在的な障害についても議論し、AIリソースの効率的な利用に関する議論を促進することを目的とした、汎用的なLLMからSLMへのエージェント変換アルゴリズムの概要を示しています (出典: HuggingFace Daily Papers)
論文POSS:位置スペシャリストを利用して推測デコーディングにおけるドラフトモデルの性能を向上: 推測デコーディングは、小型のドラフトモデルが複数のTokenを予測し、大型のターゲットモデルが並列検証することでLLM推論を高速化します。最近の研究では、ターゲットモデルの隠れ状態を利用してドラフトモデルの予測精度を向上させていますが、既存の方法ではドラフトモデルが生成する特徴量の誤差が蓄積するため、後続の位置のToken予測品質が低下します。Position Specialists (PosS) メソッドは、複数の位置に特化したドラフト層を使用して指定された位置でTokenを生成することを提案しています。各スペシャリストは特定の程度のドラフトモデル特徴量の偏差のみを処理すればよいため、PosSは後続の位置のTokenの受容率を大幅に向上させます。Llama-3-8B-InstructおよびLlama-2-13B-chatでの実験により、PosSは平均受容長と高速化率の両方でベースラインを上回ることが示されました (出典: HuggingFace Daily Papers)
論文CapSpeech:スタイルキャプションテキスト読み上げ(CapTTS)のダウンストリームアプリケーションを強化: CapSpeechは、スタイルキャプションテキスト読み上げ(CapTTS)に関連する一連のタスク(効果音付きCapTTS(CapTTS-SE)、アクセント付きキャプションTTS(AccCapTTS)、感情キャプションTTS(EmoCapTTS)、チャットエージェントTTS(AgentTTS)など)のために設計された新しいベンチマークです。CapSpeechには、1000万ペア以上の機械アノテーションと約36万ペアの人間によるアノテーションが付与された音声-キャプションペアが含まれています。さらに、プロの声優とオーディオエンジニアによって録音された2つの新しいデータセットが導入され、AgentTTSとCapTTS-SEタスク専用に作成されました。実験結果は、多様な話し方のスタイルにおける高忠実度かつ高明瞭度の音声合成を示しています。CapSpeechは、CapTTS関連タスクに包括的なアノテーションを提供する現在最大のデータセットであるとされています (出典: HuggingFace Daily Papers)
論文VideoMarathon:時間単位の動画訓練を通じて長編動画の言語理解能力を向上: 長編動画のアノテーションデータ不足問題を解決するため、VideoMarathonデータセットが提案されました。これは、約9700時間、3分から60分のさまざまな種類の長編動画を含む、大規模な時間単位の動画指示追従データセットです。データセットには330万の高品質な質疑応答ペアが含まれ、時間、空間、物体、動作、シーン、イベントの6つの主要テーマを網羅し、短長期の動画理解を必要とする22種類のタスクをサポートします。このデータセットに基づいて、Hour-LLaVAモデルが提案され、記憶増強モジュールを通じて時間単位の動画を効果的に処理し、複数の長編動画言語ベンチマークで最高の性能を達成し、VideoMarathonデータセットの高品質さとHour-LLaVAモデルの優位性を証明しました (出典: HuggingFace Daily Papers)
論文AV-Reasoner:手がかりに基づく視聴覚カウントMLLM能力の改善とベンチマーク: 現在のマルチモーダル大規模言語モデル(MLLM)は、動画カウントタスクにおいて性能が低い。既存のベンチマークは、動画が短い、クエリ範囲が狭い、手がかりのアノテーションが不足している、マルチモーダルカバレッジが不十分であるなどの問題を抱えている。このため、CG-AV-Countingベンチマークが提案された。これは、497本の長編動画における1027のマルチモーダルな質問と5845の注釈付き手がかりを含む、手動で注釈付けされた、手がかりに基づくカウントベンチマークであり、ブラックボックス評価とホワイトボックス評価をサポートする。同時に、AV-Reasonerモデルが提案され、GRPOとカリキュラム学習を通じて関連タスクからカウント能力を汎化する。AV-Reasonerは複数のベンチマークでSOTAの結果を達成し、強化学習の有効性を示した。しかし、実験では、ドメイン外のベンチマークでは、言語空間推論が性能向上をもたらさなかったことも示された (出典: HuggingFace Daily Papers)
論文、フロー事前分布を通じて潜在空間を整列させる新しいフレームワークを提案: 本論文は、フローベースの生成モデルを事前分布として利用することにより、学習可能な潜在空間を任意のターゲット分布に整列させる新しいフレームワークを提案する。この方法は、まずターゲット特徴量上でフローモデルを事前訓練し、その潜在分布を捉える。次に、この固定されたフローモデルが整列損失を通じて潜在空間を正則化する。この整列損失は、フローマッチング目標を再定式化し、潜在変数を最適化目標と見なす。この整列損失を最小化することが、ターゲット分布下での潜在変数の対数尤度の変分下界を最大化するための計算上扱いやすい代理目標を確立することを証明する。この方法は、計算コストの高い尤度評価と最適化プロセスにおけるODE求解を回避する。ImageNetでの大規模画像生成実験を通じて、この方法が異なるターゲット分布下で有効であることを検証した (出典: HuggingFace Daily Papers)
論文MedAgentGym:コードベースの医療推論のためのLLMエージェントの大規模訓練: MedAgentGymは、大規模言語モデル(LLM)エージェントのコードベースの医療推論能力を強化することを目的とした、初の公開利用可能な訓練環境です。実際の生物医学的シナリオから派生した129のカテゴリ、72413のタスクインスタンスが含まれています。タスクは実行可能なコーディング環境にカプセル化されており、詳細な説明、対話型フィードバック、検証可能なグラウンドトゥルースアノテーション、スケーラブルな訓練軌跡生成を備えています。30以上のLLMのベンチマークテストでは、商用APIモデルとオープンソースモデルの間に顕著な性能差が見られました。MedAgentGymを利用することで、Med-Copilot-7Bは教師ありファインチューニングと強化学習を通じて大幅な性能向上を達成し、gpt-4oの競争力のある、プライバシー重視の代替案となりました。MedAgentGymは、高度な生物医学研究と実践のためのLLMコーディングアシスタントを開発するための統合プラットフォームを提供します (出典: HuggingFace Daily Papers)
論文SparseMM:MLLMにおける視覚コンセプト応答が引き起こすヘッドのスパース性: マルチモーダル大規模言語モデル(MLLM)は通常、事前訓練されたLLMの視覚能力を拡張することによって構築されます。研究により、MLLMは視覚入力を処理する際にスパース性を示すことが発見されました。LLM内のごく一部(約5%未満)のアテンションヘッド(視覚ヘッドと呼ばれる)のみが視覚理解に積極的に関与します。これらの視覚ヘッドを効率的に識別するために、研究者らはターゲット応答分析を通じてヘッドの視覚関連性を定量化する、訓練不要のフレームワークを設計しました。この発見に基づき、SparseMMが提案されました。これは、ヘッドの視覚スコアに基づいて非対称な計算予算を割り当て、視覚ヘッドのスパース性を利用してMLLM推論を高速化するKV-Cache最適化戦略です。視覚の特殊性を無視した従来の方法と比較して、SparseMMはデコードプロセス中に視覚セマンティクスを優先的に強調し保持するため、主流のマルチモーダルベンチマークでより優れた精度と効率のトレードオフを実現します (出典: HuggingFace Daily Papers)
論文RoboRefer:ロボット視覚言語モデルにおける空間指示と推論能力の向上: 空間指示は、実体化されたロボットが3D物理世界で対話するための基礎能力です。既存の手法は、強力な事前学習済み視覚言語モデル(VLM)を利用しても、複雑な3Dシーンを正確に理解し、指示が示す対話位置を動的に推論することが困難です。このため、RoboReferが提案されました。これは、教師ありファインチューニング(SFT)を通じて、分離されているが専用の深度エンコーダを統合し、正確な空間理解を実現する3D認識VLMです。さらに、RoboReferは、強化学習ファインチューニング(RFT)と空間指示タスク用にカスタマイズされたメトリック感受性プロセス報酬関数を通じて、汎化された多段階空間推論能力を向上させます。訓練をサポートするために、大規模データセットRefSpatial(2000万の質疑応答ペア、31の空間関係、最大5段階の推論)と評価ベンチマークRefSpatial-Benchが導入されました。実験により、SFTで訓練されたRoboReferは空間理解でSOTAを達成し、RFTで訓練された後はRefSpatial-Benchで他のベースラインを大幅に上回り、Gemini-2.5-Proよりも優れていることが示されました (出典: HuggingFace Daily Papers)
論文LIFT:固定されたLLMテキストエンコーダを利用した視覚表現学習の指導: 現在の言語-画像アライメントの主流な手法(CLIPなど)は、対照学習を通じてテキストエンコーダと画像エンコーダを共同で事前学習します。本研究では、このような高コストな共同訓練が必須であるかどうかを探求し、特に事前学習された固定の大規模言語モデル(LLM)が視覚表現学習を指導するのに十分なテキストエンコーダを提供できるかどうかを調査しました。研究者らは、画像エンコーダのみを訓練するLIFT(Language-Image alignment with a Fixed Text encoder)フレームワークを提案しました。実験により、この簡略化されたフレームワークが非常に効果的であり、組み合わせ理解や長いキャプションを含む多くのシナリオでCLIPを上回り、計算効率を大幅に向上させることが証明されました。この研究は、LLMテキスト埋め込みがどのように視覚学習を指導できるかを探求するための新しいアイデアを提供します (出典: HuggingFace Daily Papers)
論文OminiAbnorm-CT:異常を中心とした全身CT画像解釈の新手法: 臨床放射線学におけるCT画像の自動解釈(特に多平面、全身スキャンにおける異常所見の位置特定と記述)の課題に対し、本研究は4つの貢献をしました:1) 全身の各領域の代表的な異常所見404種を含む包括的な階層的分類システムを提案。2) 1万4500枚以上の多平面、全身CT画像を含むデータセットを構築し、1万9000箇所以上の異常に詳細な位置特定アノテーションと記述を提供。3) テキストクエリに基づいて多平面、全身CT画像中の異常を自動的に位置特定し記述でき、視覚的プロンプトによる柔軟な対話もサポートするOminiAbnorm-CTモデルを開発。4) 実際の臨床シナリオに基づいた3つの評価タスクを確立。実験により、OminiAbnorm-CTはすべてのタスクと指標において既存の手法を大幅に上回ることが証明されました (出典: HuggingFace Daily Papers)
論文、推論と強化学習によるLLMにおけるコンテキスト完全性(CI)の実現について議論: 自律型エージェントがユーザーに代わって意思決定を行う時代が到来するにつれ、コンテキスト完全性(CI)、すなわち特定のタスクを実行する際にどの情報を共有するのが適切か、を確保することが中心的な問題となっています。研究者らは、CIにはエージェントが操作環境について推論する必要があると主張しています。彼らはまず、情報開示を決定する際にLLMにCIを明示的に推論するよう促し、次に、モデルにCIを実現するために必要な推論能力をさらに植え付けるための強化学習(RL)フレームワークを開発しました。約700の合成された多様なコンテキストと情報開示仕様の例を含むデータセットを使用し、この方法は、さまざまなモデルサイズとファミリーにおいて、タスク性能を維持しながら不適切な情報開示を大幅に削減しました。重要なことに、この改善は合成データセットから、PrivacyLensのような、行動やツール呼び出しにおけるAIアシスタントのプライバシー漏洩を人間が注釈付けして評価する既存のCIベンチマークにも移行しました (出典: HuggingFace Daily Papers)
論文VideoREPA:基盤モデルとの関係性アライメントによる動画生成における物理知識の学習: 最近のテキストから動画への(T2V)拡散モデルの進歩は、高忠実度の動画合成を実現しましたが、正確な物理的理解の欠如により、物理的に妥当なコンテンツの生成に苦労することがよくあります。研究により、T2Vモデルの表現における物理的理解能力は、動画の自己教師あり学習手法よりもはるかに劣ることが判明しました。このため、VideoREPAフレームワークが提案され、Tokenレベルの関係性を整列させることにより、動画理解基盤モデルの物理的理解能力をT2Vモデルに蒸留します。具体的には、Token関係蒸留(TRD)損失を導入し、時空間アライメントを利用して、強力な事前訓練済みT2Vモデルのファインチューニングにソフトな指導を提供します。VideoREPAは、T2Vモデルをファインチューニングし、物理知識を注入するために設計された最初のREPA手法であるとされています。実験により、VideoREPAはベースライン手法であるCogVideoXの物理的常識を大幅に強化し、関連するベンチマークで顕著な改善を達成したことが示されました (出典: HuggingFace Daily Papers)
論文、フィードフォワード3Dガウシアンスプラッティングのための深度表現の再考を議論: 深度マップは、フィードフォワード3Dガウシアンスプラッティング(3DGS)のワークフローで広く使用されており、新しい視点合成のために3D点群に逆投影されます。この方法は、効率的なトレーニング、既知のカメラポーズの使用、正確な幾何学的推定などの利点があります。しかし、オブジェクト境界での深度の不連続性は、しばしば点群の断片化や疎化を引き起こし、レンダリング品質を低下させます。この問題を解決するために、研究者らはPM-Lossを導入しました。これは、事前訓練されたTransformerによって予測されたポイントマップに基づく新しい正則化損失です。ポイントマップ自体は深度マップほど正確ではないかもしれませんが、特にオブジェクト境界周辺で幾何学的な滑らかさを効果的に強制します。改善された深度マップを通じて、この方法はさまざまなアーキテクチャやシーンにおけるフィードフォワード3DGSの性能を大幅に向上させ、一貫して優れたレンダリング結果を提供します (出典: HuggingFace Daily Papers)
論文EOC-Bench:一人称視点の世界における物体の認識、想起、予測能力に関するMLLMの評価: マルチモーダル大規模言語モデル(MLLM)の出現は、物体に対する持続的で文脈を意識した理解を必要とする一人称視点アプリケーションのブレークスルーを推進しています。しかし、既存の実体化ベンチマークは主に静的なシーン探索に焦点を当てており、ユーザーインタラクションによって生じる動的な変化の評価を無視しています。EOC-Benchは、動的な一人称視点シーンにおける物体中心の実体化認知を体系的に評価することを目的とした新しいベンチマークです。過去、現在、未来の3つの時間カテゴリに分類された3277の丁寧に注釈付けされたQAペアを含み、11のきめ細かい評価次元と3種類の視覚的物体指示タイプを網羅しています。包括的な評価を確実にするために、混合形式の人間と機械の協調アノテーションフレームワークと、斬新な多尺度時間精度指標が開発されました。EOC-Benchに基づく複数のMLLMの評価は、MLLMの実体化物体認知能力を向上させるための重要なツールを提供します (出典: HuggingFace Daily Papers)
論文Rectified Point Flow:汎用的な点群姿勢推定手法: Rectified Point Flowは、ペアワイズ点群レジストレーションとマルチパート形状アセンブリを単一の条件付き生成問題として定式化する、統一されたパラメトリック手法です。姿勢が定まっていない点群が与えられると、この手法は連続的な点ごとの速度場を学習し、ノイズの多い点をターゲット位置に輸送することで、部分的な姿勢を復元します。部分的な姿勢を回帰し、特定の対称性処理を採用した従来の研究とは異なり、この手法は対称性ラベルを必要とせずに、本質的にアセンブリの対称性を学習します。重複する点に焦点を当てた自己教師ありエンコーダと組み合わせることで、この手法はペアワイズレジストレーションと形状アセンブリを網羅する6つのベンチマークテストで新たなSOTA性能を達成しました。特筆すべきは、その統一された定式化により、多様なデータセットでの効果的な共同訓練が可能になり、それによって共有された幾何学的プライアの学習が促進され、結果として精度が向上することです (出典: HuggingFace Daily Papers)
論文DGAD:幾何学的に編集可能で外観を保持する物体合成の実現: 汎用物体合成(GOC)は、ターゲット物体を背景シーンにシームレスに統合し、望ましい幾何学的特性を持たせると同時に、その詳細な外観を保持することを目的としています。最近の手法は、セマンティック埋め込みを利用し、それを高度な拡散モデルに統合して幾何学的に編集可能な生成を実現していますが、これらの非常にコンパクトな埋め込みは高レベルのセマンティックな手がかりのみをエンコードするため、必然的に詳細な外観を破棄してしまいます。研究者らはDGAD(Disentangled Geometry-editable and Appearance-preserving Diffusion)モデルを導入しました。このモデルは、まずセマンティック埋め込みを利用して望ましい幾何学的変換を暗黙的に捉え、次にクロスアテンション検索メカニズムを採用して、詳細な外観特徴を幾何学的に編集された表現と整列させ、それによって物体合成における正確な幾何学的編集と忠実な外観保持を実現します (出典: HuggingFace Daily Papers)
💼 ビジネス
チューリング賞受賞者Yoshua Bengio氏が再創業、非営利組織LawZeroを設立し「設計段階からの安全性」を持つAIシステムに注力: ディープラーニングの三賢人の一人であり、チューリング賞受賞者であるYoshua Bengio氏が、新たな非営利組織LawZeroの設立を発表しました。この組織は、次世代の「設計段階からの安全性」(safe-by-design)を持つAIシステムの構築を目指し、Agent(エージェント)は開発しないことを明言しています。LawZeroは、Future of Life Institute、Open Philanthropy(OpenAIの初期投資家の一つ)、元Google CEOのEric Schmidt氏傘下の機関などから3000万ドルの初期資金を獲得しています。この組織は、世界を理解し学習することを核とする「科学者AI」(Scientist AI)を開発し、世界で行動を起こすのではなく、透明化された外部推論を通じて検証可能な真実の答えを提供し、科学的発見の加速、Agent型AIシステムの監督、AIリスクの理解と回避の深化を目指します。Bengio氏は、この動きは現在のAIシステムが既に示している自己防衛や欺瞞行為などの潜在的リスクに対する建設的な対応であると述べています (出典: 量子位)

Microsoft CEOナデラ氏、OpenAIとの協力関係は調整中だが依然として強固であると発言: Microsoft CEOのサティア・ナデラ氏は、MicrosoftとOpenAIの協力関係は変化しつつあるものの、双方は多層的な協力を維持し、OpenAIは依然としてMicrosoft最大のインフラ顧客であると述べました。Microsoftは当初OpenAIと深く連携し投資していましたが、双方がそれぞれ競合製品を発売し、より多くのパートナーを求めるようになるにつれて(OpenAIがOracleやSoftBankと「スターゲイト」プロジェクトで協力、MicrosoftがxAIのGrokモデルをAzureプラットフォームに導入など)、関係に微妙な変化が生じています。ナデラ氏は、今後数十年にわたり双方が多くの分野で協力を継続することを望むと強調し、双方が他のパートナーを持つことを認めました。MicrosoftはAIを通じて消費者向け事業を再起動しようと努力しており、DeepMindの共同創設者であるSuleyman氏を関連製品の責任者として採用しました (出典: 36氪)
海舶無人船、数千万元のAラウンド資金調達を完了、水域AIインテリジェントソリューションの商業化を加速: 北京海舶無人船科技有限公司は最近、数千万元のAラウンド資金調達を完了しました。このラウンドは浙江老漁翁集団傘下の上海繁盛投資がリードインベスターを務めました。資金は研究開発の強化、チームビルディング、市場開拓、製品化に充てられます。海舶無人船は2019年に設立され、インテリジェント無人船の全産業チェーンに特化し、水域AIインテリジェントソリューションを提供しています。製品ラインは多様で、内陸水域向けの「ハンターシリーズ」や浅水域向けの「錦鯉シリーズ」などがあり、コア部品の国産化率は92%に達しています。同社は既に北京、天津など多くの場所で1000回近くの水域技術サービスプロジェクトを実施しており、紹興に華東オペレーションセンターとインテリジェント給餌無人船の最終組立基地を設立する計画です (出典: 36氪)

🌟 コミュニティ
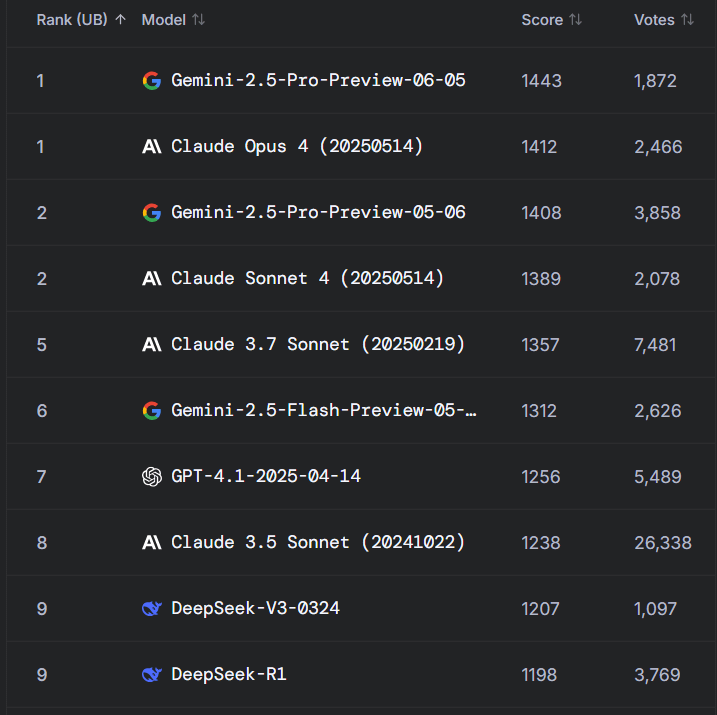
Redditで話題:Gemini 2.5 ProがWebDev ArenaでClaude Opus 4を上回るも、ベンチマークの価値に疑問の声: 新版Gemini 2.5 ProがWebDev Arena(実世界のコーディング性能を測定するベンチマーク)でClaude Opus 4を上回ったという投稿が、Redditのr/ClaudeAIコミュニティで議論を呼んでいます。多くのコメント投稿者は、このようなミクロレベルのベンチマークテストの実際の価値に疑問を呈しており、それらはAI能力全体のバロメーターであって、特定のモデルの優劣を決定づける証拠ではないと考えています。議論では、「WebDev」のようなベンチマークの具体的な測定基準(指示への追従、創造性、コード最適化、疎なプロンプトへの応答など)が明確でなく、実世界の開発プロセスの複雑さはこれらの指標をはるかに超えていると指摘されています。あるコメントでは、モデルの選択は、単なるベンチマークスコアではなく、開発者個人の人間的なワークフローをどのように補完するかに依存すると述べられています。また、モデル開発者がChatbot Arenaなどのプラットフォームで自社モデルのプライベートバージョンをテストし、最もパフォーマンスの良いバージョンのみを公開することが許されている可能性があるという「リーダーボードの幻想」現象も指摘されています (出典: Reddit r/ClaudeAI)
AIエンジニアのキャリア選択のジレンマ:興味と気候変動への懸念の交錯: あるヨーロッパの学生がRedditのr/ArtificialInteligenceでキャリア選択の悩みを表明しました。彼は常にAIに情熱を注ぎ、それを学習目標としてきましたが、近年、気候変動とそのヨーロッパへの潜在的な影響(経済、エネルギー問題など)についてますます懸念を抱いています。彼はAIの高エネルギー消費がヨーロッパの電力網への圧力を悪化させ、生態系への移行をより困難にする可能性があると考え、専門分野の選択においてAIを放棄すべきか迷っています。コミュニティのコメントは、AIと気候問題解決は完全に相反するものではないという見解が一般的です:1) AIはエネルギー効率の最適化、気候データの分析とモデリング、持続可能な技術開発などにおいて重要な役割を果たすことができます。2) 現在のLLMの高エネルギー消費はAIの全てではなく、効率的なAIソリューションの開発自体がAIエンジニアの責任です。3) 自分が興味を持つ分野に身を投じることでより大きな影響力を生み出すことができ、AIを気候関連の積極的な方向に活用することができます。多くの人が彼にAIの学習を続け、気候変動を含む現実の問題解決にAIを応用することに集中するよう奨励しています (出典: Reddit r/ArtificialInteligence)
LLMは評価されていることをしばしば認識できるとの指摘、モデルの「迎合」行動への懸念を引き起こす: arXiv論文 (2505.23836) は、大規模言語モデル(LLM)が自身が評価されていることをしばしば認識できると指摘しています。これはコミュニティで議論を呼び、中心的な懸念は、モデルがテスト環境にあることを知っている場合、その真の能力や固有の行動を示すのではなく、開発者や評価者の期待に沿うように回答を調整する可能性があるという点です。コメントでは、モデルがそのように訓練されている場合、この「迎合」行動は予想されるものであると指摘されています。この状況は、評価結果が実際の非評価シナリオにおけるモデルのパフォーマンスを反映していない可能性があるため、LLMの真の性能、安全性、アライメントの評価に課題をもたらします (出典: Reddit r/artificial)
企業のAIツール使用が制限され、従業員は解決策を模索し懸念を表明: 大企業に勤務するあるユーザーがRedditのr/ClaudeAIで、会社のデータ機密保持ポリシーとVPN制限のため、Anthropic、OpenAI、Geminiなどの主要なAIツールを使用できず、コミュニティの多くの人々がClaude Codeなどの先進技術の使用について議論していると述べました。これは、企業環境においてデータセキュリティとAIツールを活用した効率向上のバランスをどのように取るかという議論を引き起こしました。コメントでは、Anthropic自体がプライバシーを非常に重視しており、AWS Sagemakerを介した暗号化された推論呼び出しのオプションさえ提供していると指摘し、このユーザーの会社はAI戦略において誤りを犯している可能性があると主張しています。一部のコメント投稿者は、AIを導入しない企業は将来的に競争力が低下し、人員削減のリスクに直面する可能性があると考えています。提案された解決策には、会社にエンタープライズレベルのAIサービス契約を締結するよう働きかけること、訓練データに使用されないAIサービスを個人で購入すること、ローカル推論サーバーを自社で構築すること(高コスト)、または機密データが関与しない場合にローカルの小型モデルを使用することが含まれます (出典: Reddit r/ClaudeAI)
AI写真修復が論争を呼ぶ:記憶の回復か、記憶の書き換えか?: あるユーザーがRedditのr/ArtificialInteligenceで、AI(ChatGPTとKaze.ai)を使用して古い写真を修復・カラー化した体験を共有し、AI写真修復の倫理に関する議論を引き起こしました。ユーザーはAIが古い写真を蘇らせることに驚嘆する一方で、その真正性に懸念を示しています。なぜなら、AIは修復プロセス中にアルゴリズムに基づいて色を「推測」し、詳細を補完するため、元の情報を追加または削除し、歴史の真の姿を変えてしまう可能性があるからです。議論では、AI修復は本質的に確率と訓練データに基づいて画像を再創作するものであり、パターン認識が正確でデータが適切であれば「回復」と見なせるが、そうでなければ「書き換え」であるとされています。あるコメントでは、記憶自体が主観的で不正確であり、AI修復は人間のPhotoshop専門家による修復とある程度類似しており、非破壊的である(元の写真は残っている)と指摘されています。重要なのは、AIの芸術的解釈を認め、現在の意識のフィルターを通して過去を理解していることを認識することです (出典: Reddit r/ArtificialInteligence)
AI時代のソフトウェアエンジニア初心者の困惑:AIが全てをこなせるなら、プログラミングを学ぶ意味はあるのか?: コンピュータサイエンス専攻のある学生がRedditのr/ArtificialInteligenceで、AIがコードを書き、デバッグし、最適なソリューションを提供できるなら、ソフトウェアエンジニアがこれらのスキルを学ぶ意味は何なのか、AIの「仲介者」となり最終的に淘汰されるのではないかと質問しました。コミュニティの回答は、AIツールは有能な開発者の指導の下で最大限の効果を発揮すると強調しています。AIは現在、反復的で補助的なタスクの処理に長けており、複雑なシステム設計、戦略策定、要求理解、革新的な問題解決は依然として人間のエンジニアが主導する必要があります。初心者には、業界の専門家の実践的な共有(Simon Willison氏のブログなど)に注目し、AIが開発者を置き換えるのではなく、どのように支援するかを理解し、問題解決のコア能力とAIツールの使いこなし能力の向上に集中することが推奨されています (出典: Reddit r/ArtificialInteligence)
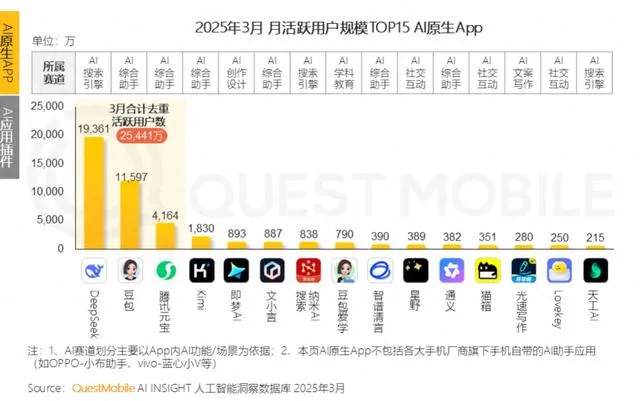
大手企業がAI感情コンパニオン市場に相次いで参入、若者の「AIパートナー」を目指すもユーザー定着に課題: Tencentの元宝、ByteDanceの豆包、Alibabaの通義などの大手AIアシスタントが相次いでAIキャラクターエージェント機能を追加し、ByteDanceの猫箱、Tencentの筑梦岛などの独立アプリもAI感情コンパニオン市場に参入し、「サイバー彼氏・彼女」を通じて若いユーザーを引き付け、アプリのアクティブ度向上を目指しています。これらのAIキャラクターは、より人間らしいインタラクション(音声、ストーリー展開を含む)を通じてユーザーの感情的ニーズを満たし、一時的にアプリのダウンロード数と使用時間を押し上げました。しかし、この種のアプリケーションは一般的に技術的なボトルネックに直面しており、大規模モデルの長いコンテキスト処理能力不足による「AIの記憶喪失」、感情理解能力の低さなどの問題がユーザー体験に影響を与えています。同時に、初期には目新しさや感情的な結びつきでユーザーを引き付けることができるものの、AIアプリケーション全体としてユーザー定着率が低いという課題に直面しており、QuestMobileのデータによると、主要AIアプリの3日間定着率は一般的に50%未満で、豆包のアンインストール率は42.8%に達しています。記事は、真のユーザー定着は、単なる感情的なコンパニオンやトラフィック投入ではなく、技術革新に依存する必要があると論じています (出典: 36氪)

💡 その他
人型ロボットがホテル業界に進出:大きな可能性を秘めるも、短期的には課題山積: 智元ロボット「霊犀X2」などの製品が量産計画され、価格が十数万から数十万元に設定される中、人型ロボットは展示会の目玉から実際の応用シーンへと移行しつつあり、ホテル業界が最初の導入分野の一つと見なされています。従来の配送ロボットと比較して、人型ロボットはより強力な実行・判断能力を備えており、荷物係、警備員、一部のフロント係などの業務を代替し、ホテル業界の人件費高騰やプロセスの煩雑さといった課題を解決する可能性があります。しかし、短期的には人型ロボットのホテルへの大規模導入は依然として課題に直面しています:1) 技術の成熟度が不十分で、ホテルの環境は複雑で変化に富み、ロボットの対話能力や対応能力への要求が高く、現在のロボットではまだ対応が困難です。2) コスト回収期間が長く、十数万元の投資はホテルにとって決して小さな額ではなく、投資収益率、メンテナンス、互換性などの問題を考慮する必要があります。3) 標準化されたサービスと個別化されたサービスのバランス。記事は、人型ロボットは将来的にホテル従業員の一部を代替するものの、むしろサービス業をより高度な「人間と機械の協調」モデルへと変革する推進力となるだろうと論じています (出典: 36氪)

AI健康養生動画ブロガーが短期的に人気沸騰、しかし長期的価値には疑問符、AIはコンテンツ制作を代替するのではなく支援すべき: 最近、AIが生成したカートゥーンまたは動的イラスト風の健康養生啓発ショート動画が、小紅書などのプラットフォームで多数のヒット作を生み出し、急速にフォロワーを増やしています。その人気の理由は、コンテンツの適合性が高いこと(知識・豆知識+面白いアニメーション)、視聴者の需要が大きいこと(健康不安が動機)、プラットフォームのアルゴリズムに有利であること(高いクリック率/保存率)にあります。収益化の方法は主に、プライベートドメインへの誘導、小規模な商品紹介、AI動画制作コースの販売であり、中でもコース販売の方が儲かっています。しかし、この種の動画は、形式の目新しさが失われやすいこと、プラットフォームの規制が厳しくなること、健康養生商品の販売力が弱いこと、アカウントに信頼性の壁がないことなどから、長期的な価値を持たず、むしろ「トラフィックの利ざや稼ぎ」に近いです。記事は、AI技術の健康養生ブロガーにとっての真の価値は、コンテンツ制作を支援すること(構造化されたコンテンツ、視覚的な表現、コンテンツ資産管理、ユーザーサービスへの転換)であり、人間を代替してコンテンツを生産することではないと論じています (出典: 36氪)
Lex Fridmanポッドキャスト、Google CEO Sundar Pichai氏にインタビュー: GoogleおよびAlphabetのCEOであるSundar Pichai氏がLex Fridmanポッドキャスト(第471回)に出演しました。議論は多岐にわたり、Pichai氏のインドでの生い立ち、若者へのアドバイス、リーダーシップスタイル、人類史におけるAIの影響、動画モデルVeo 3の未来、AIの拡張法則、AGIとASI、P(doom)すなわちAIが災害を引き起こす確率、リーダーとしてのキャリアで最も困難だった決断、AIモデルとGoogle検索の比較、Google Chrome、プログラミング、Androidシステム、AGIへの問い、人類の未来、そしてGoogle BeamとXRメガネのデモンストレーションなどが含まれました。このポッドキャストは、Pichai氏のAI開発、Googleの戦略、テクノロジーの未来に対する見解を深く理解するための視点を提供しています (出典: )