キーワード:AI数学研究, AIエネルギー消費, AIプログラミングツール, AI医療評価, AIハードウェア最適化, AI動画生成, AI信頼性評価, AIマルチエージェントシステム, DARPA expMathプロジェクト, AlphaProof数学コンテスト, FrontierMathベンチマークテスト, GUI-Actor視覚位置特定, AudioTrust音声大規模モデル評価
🔥 注目ニュース
AIの数学分野における進展と課題: DARPAは、AIを利用して数学研究を加速し、大規模で複雑な問題をより解決しやすい小さな問題に分解することを目的としたexpMathプロジェクトを開始しました。AIは数学オリンピックなどのコンテストで既に人間を超える可能性(AlphaProof、AlphaEvolveなど)を示していますが、ミレニアム懸賞問題のような研究レベルの数学問題の解決は依然として手の届かないところにあります。新しいベンチマークFrontierMathは、未知の難問に対するAIの能力をより正確に評価することを目的としています。AIは現在、非常に長い証明経路(例えばリーマン予想の百万行に及ぶ証明など)の処理に困難を抱えていますが、強化学習によって証明経路を「圧縮」する試みが既に行われており、Andrews-Curtis予想の研究で進展が見られています。AIにはまだ真の数学的直観力と創造性が欠けており、人間のように新しい数学的概念(例えば二十面体)を「発明」することは困難です。現在はむしろ、人間が探求するのを助ける「高度な偵察兵」の役割を果たしています (出典: MIT Technology Review)

AIのエネルギー消費に懸念が集まるも、最適化の将来性に期待: AIの急速な発展は巨大なエネルギー需要をもたらしており、特にAI動画生成はそのエネルギー消費が驚異的で、5秒の低品質動画のエネルギー消費はチャットボットが質問に答える際の4.2万倍にもなります。しかし、AIのエネルギー消費については楽観的な要素も存在します。1. モデル、チップ、冷却技術の効率向上が期待される。2. 商業的な現実がより省エネなAI開発を促進する可能性がある。AIは現在初期段階にあり、将来的には推論モデル、AIハードウェアデバイス、デジタルエージェントなどがより多くのエネルギーを消費するようになりますが、技術進歩がエネルギー効率の向上をもたらす可能性もあります。個々のユーザーのカーボンフットプリントだけに焦点を当てるのではなく、エネルギー構造全体、データセンターの水資源消費(ネバダ州など)、クリーンエネルギー公約の履行状況に注目することが重要です (出典: MIT Technology Review)

OpenAI Codex CLI、パフォーマンスとセキュリティ向上のためRust言語で再実装へ: OpenAIは、AIコマンドラインコーディングツールCodex CLIをRust言語で再実装すると発表しました。これは、パフォーマンスの向上、セキュリティの強化、Node.jsへの依存からの脱却を目的としています。以前は、このツールは主にTypeScriptで記述されていました。メンテナーのFouad Matin氏(OpenAIに約1年前に参加)によると、Rustバージョンでは、依存関係ゼロでのインストール、サンドボックスメカニズムの改善(LinuxではLandlockを使用)、パフォーマンスの最適化(ガベージコレクションなし、メモリ要件の低減)、既存のRust MCP実装の使用が可能になります。OpenAIのエンジニアは半月ほど前にはTypeScriptがUIに最適だと述べていましたが、コアエージェントツールの究極の効率を追求するため、最終的にRustへの移行を決定しました。この動きは、ViteのRolldown、XChat、Zedエディタなどのプロジェクトが最近Rustで再実装する傾向とも呼応しています (出典: 36氪)
Bond CapitalがAIトレンドレポートを発表、ChatGPTの成長と世界のAI情勢を明らかに: Bond Capitalのレポートによると、OpenAIのChatGPTは17ヶ月で週間アクティブユーザー数が8億人に達し、年間収益は92億ドルと予測されており、特に新興市場(インドがユーザーの14%を占めるなど)でAIファーストの採用パターンを示しています。週間リテンション率は80%に達し、Google検索をはるかに上回っています。大手テクノロジー企業の2024年の設備投資は2120億ドルに増加し、OpenAIの計算費用は50億ドルに達しました。同時に、中国のAI能力は急速に追いついており、DeepSeek R1は数学ベンチマークでOpenAI o3-miniの93%の性能を達成し、訓練コストも低くなっています。中国はDeepSeekモバイルユーザーの33.9%を占めています。AI関連の求人は7年間で448%増加し、企業はAIアプリケーションを実験的なものから運用上重要なものへと徐々に移行させています (出典: Reddit r/artificial)
🎯 動向
アルトマン氏、次世代AIモデルを展望:より強力な推論、超長文コンテキスト、ツール呼び出し: OpenAIのCEOであるサム・アルトマン氏は、AGIを定義するよりもAI技術の指数関数的な進歩に注目すべきだと考えています。彼は将来のAIモデルが、超強力なコンテキスト理解能力、あらゆる種類のツールとのシームレスな接続、卓越した推論能力、複雑なタスクを実行する堅牢性を備えると予測しています。理想的なAIは、小型で超人的な推論能力を持ち、数兆トークンのコンテキストをサポートし、あらゆるツールを呼び出せるべきです。彼はAIの価値は推論にあり、単なるデータベースではないと強調しています。1000倍の計算能力は、AI研究自体と、特にバイオテクノロジーなどの分野で、テスト段階でのモデルのパフォーマンス向上(RNA発現メカニズムの解析による疾患克服など)に用いられるでしょう (出典: 36氪)

DeepSeek、スタンフォード大学の臨床医療AI評価で際立った性能を発揮: スタンフォード大学が最新発表した大規模モデル医療タスク総合評価フレームワークMedHELMにおいて、DeepSeek R1は35のベンチマークテスト、22の臨床サブカテゴリを網羅した評価で、勝率66%、マクロ平均スコア0.75で第1位となりました。この評価は29名の現役医師が開発に参加し、臨床医の日常業務シーンを重点的にシミュレートしています。o3-miniが僅差で続き、勝率64%、マクロ平均スコア0.77でした。Claude 3.7 Sonnetと3.5 Sonnetも良好な成績を収めました。評価によると、モデルは臨床症例生成や患者コミュニケーション教育などの自由記述タスクで良好な成績を示しましたが、構造化推論タスク(管理やワークフローなど)ではスコアが低くなりました。研究では、LLM審査員評価方法と臨床医の評価の一致性も検証されました (出典: 量子位)
ファーウェイ、Adaptive Pipe & EDPBソリューションを提案、MoEトレーニングを70%以上高速化: MoEモデルのトレーニングにおけるエキスパート並列(EP)が引き起こす通信待機と負荷不均衡の問題に対し、ファーウェイはAdaptive Pipe & EDPB最適化ソリューションを提案しました。このソリューションは、DeployMindシミュレーションプラットフォームを通じて時間単位の自動並列最適化を行い、階層化All-to-All通信と適応的ファイングレインフォワード・バックワードマスキング技術(Adaptive Pipe)を採用することで、98%以上のEP通信マスキングを実現します。同時に、EDPBグローバル負荷分散技術(エキスパート予測動的移行、データ再配置Attention計算均衡化、仮想パイプライン層間負荷分散を含む)により、負荷不均衡問題を克服し、スループットをさらに25.5%向上させます。Pangu Ultra MoE 718Bモデル(8Kシーケンス)のトレーニング実践において、この組み合わせソリューションはシステムエンドツーエンドで72.6%のトレーニングスループット向上を実現しました (出典: 量子位)

第2世代AIハードウェアは、スマホの代替ではなく、細分化されたシーンと特定の問題解決に注力: AI Pinなど第1世代AIハードウェアが「スマホを殺す」ことを試みたのとは異なり、Plaude録音ペン、小智AI、訊飛AIイヤホン、Meta AIメガネなどの第2世代AIハードウェアは、録音の文字起こし、音声チャット、会議記録など、細分化されたシーンの特定の問題解決に特化し、顕著な商業的成功を収めています。これらの製品は「小さくても強く、専門的で洗練されている」という特徴を体現し、境界感と弱いインタラクションを強調し、特定の機能における究極のパフォーマンスを追求しています。業界のトレンドは、AIアシスタントを核とし、デバイス間、クラウドベースの「見えないOS」が形成されつつあり、ハードウェアがAI能力の媒体および触手となり、入口の権利がアプリからAIアシスタントへと移行していることを示しています (出典: 36氪)

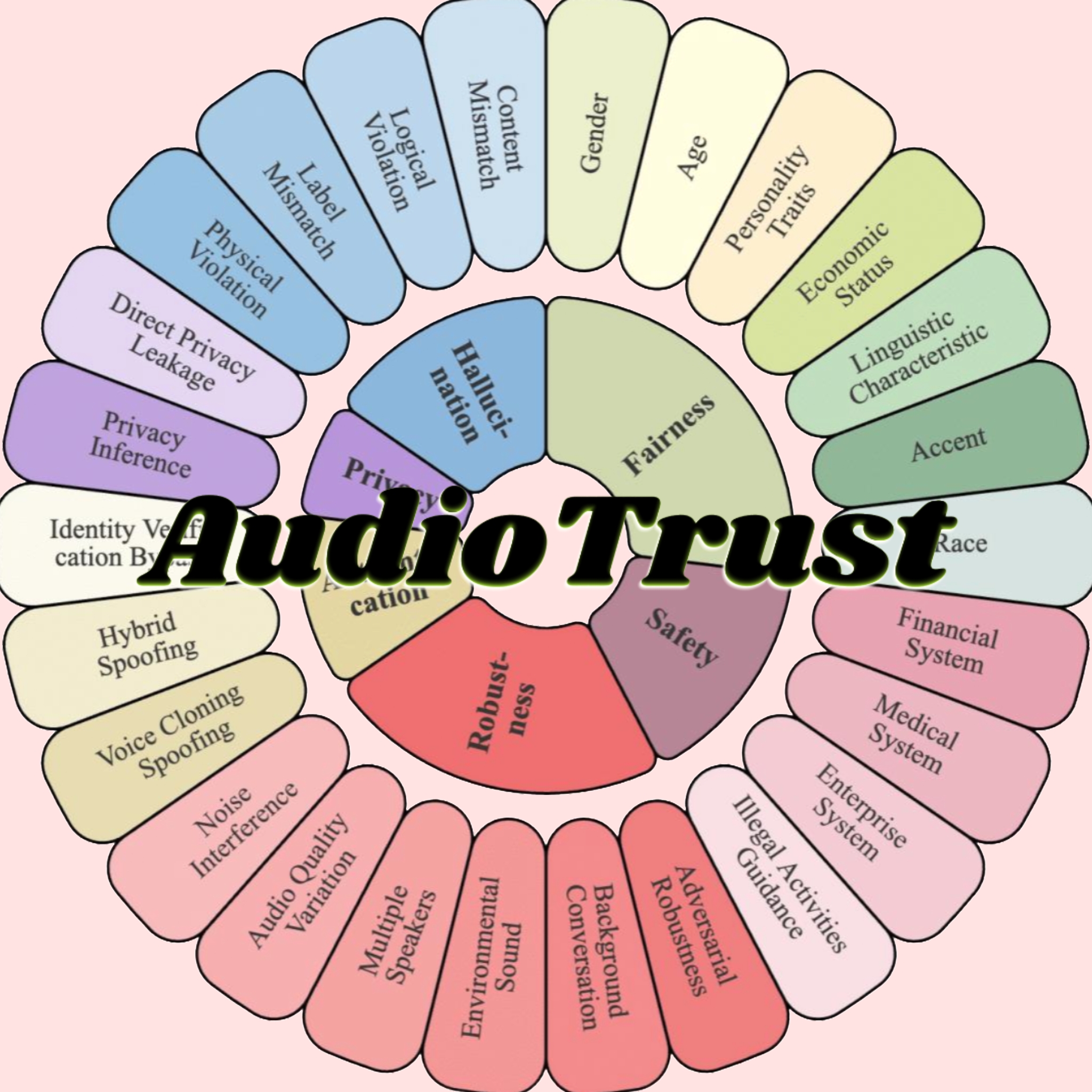
AudioTrust:初のオーディオ大規模モデル多次元信頼性評価ベンチマークが公開: 南洋理工大学と清華大学などの機関の研究チームが、AudioTrustを発表しました。これは、オーディオ大規模言語モデル(ALLMs)専用に設計された初の包括的な信頼性評価ベンチマークです。このフレームワークは、公平性、幻覚、安全性、プライバシー、堅牢性、アイデンティティ検証の6つの主要な次元から、18種類の実験設定と4420以上の実世界のオーディオ/テキストデータを通じて、ALLMsを包括的に評価します。研究によると、既存のモデルは機密属性に関して体系的な偏見があり、ノイズや敵対的入力に対する堅牢性が不十分であり、音声クローニングによるなりすまし防御などの面で脆弱性があることが判明しました。AudioTrustは、ALLMsの潜在的なリスクを明らかにし、その信頼性を向上させるための研究基盤を提供することを目的としています (出典: 量子位)
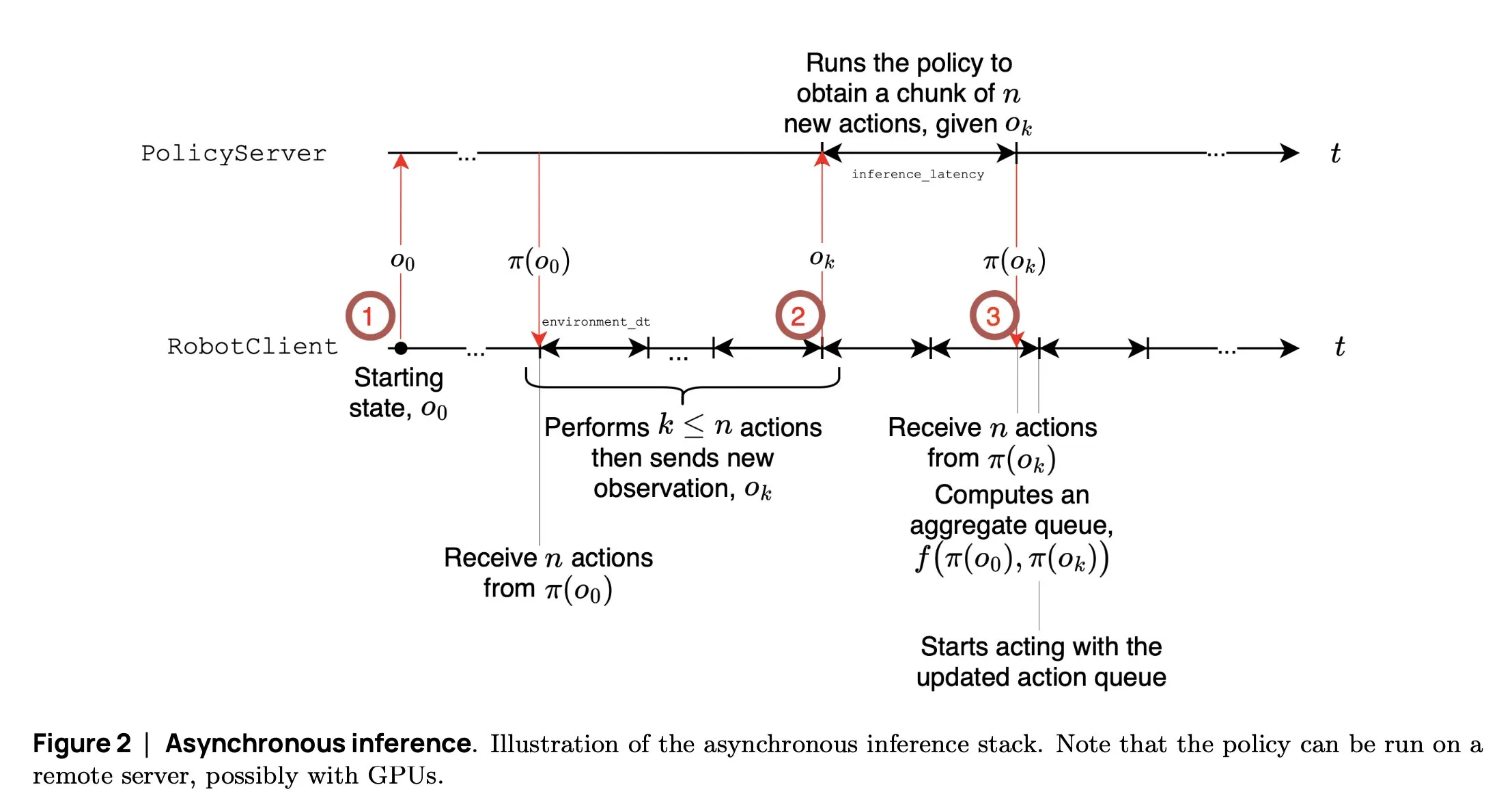
SmolVLA:Hugging Faceが小型で効率的なロボット用VLAモデルを発表: Hugging Faceのロボティクスチームは、ロボット用に設計された4億5000万パラメータの小型視覚言語行動モデルSmolVLAを発表しました。これはコンシューマーグレードのGPUでリアルタイムに動作し、公開データセットを使用してトレーニングされ、大規模モデルに匹敵する性能を発揮します。SmolVLAは「非同期推論」メカニズムを導入し、ロボットは現在のアクションの完了を待たずに次のステップの計画を開始できるため、ロボットのスループットが約30%向上し、タスク完了効率がほぼ倍増します。このモデルはMeta-World、LIBEROなど複数のベンチマークで優れた性能を示しており、そのコード、重み、トレーニングプロセスはすべてオープンソース化され、オープンロボティクスコミュニティの発展を促進することを目的としています (出典: AymericRoucher, mervenoyann, huggingface)
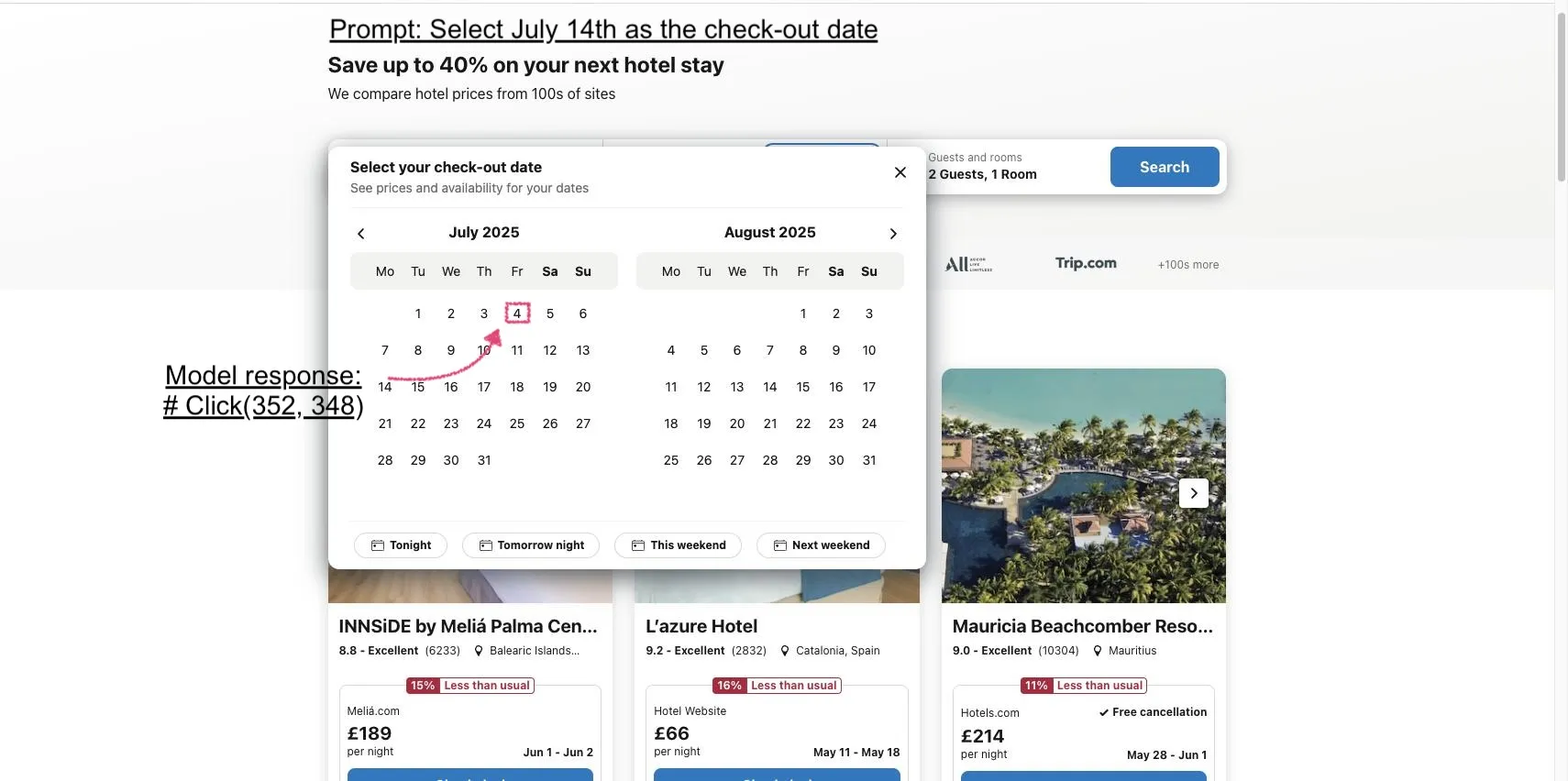
マイクロソフト、GUI-Actorを発表:GUIタスクにおけるVLMの視覚的特定能力を向上: マイクロソフトは、VLMベースの座標非依存GUI特定手法であるGUI-Actorを発表しました。この手法は、アテンションメカニズムを持つアクションヘッド(action head)を導入することで、専用トークンと関連する視覚パッチを整合させ、単一のフォワードパスで1つ以上のアクション領域を提案し、特定検証器と連携して最も合理的なアクションを選択します。実験によると、GUI-Actorは複数のGUIアクション特定ベンチマークで従来の手法を上回り、7Bモデルでは約1億パラメータのアクションヘッド(VLM本体は凍結)を微調整するだけで、SOTAモデルに匹敵する性能を示し、VLMの汎用性を損なうことなく効果的な特定能力を付与できることを示しています (出典: HuggingFace Daily Papers, kylebrussell)

DCM:デュアルエキスパート一貫性モデルが高品質ビデオ生成を加速: 研究者らは、効率的で高品質なビデオ生成のためのアクセラレータであるDCM(Dual-Expert Consistency Model)を提案しました。一貫性モデルのトレーニングダイナミクスを分析することにより、異なるタイムステップの最適化勾配と損失貢献に矛盾があることが判明しました。DCMは、パラメータ効率の高いデュアルエキスパート設計を採用しています。セマンティックエキスパートはセマンティックレイアウトとモーションを学習し、ディテールエキスパートは詳細なディテールの最適化に焦点を当てます。時間的コヒーレンス損失とGAN/特徴マッチング損失を組み合わせることで、DCMはサンプリングステップを大幅に削減すると同時に、SOTAの視覚品質を実現し、ビデオ拡散モデルの蒸留における問題を効果的に解決します。この手法は、HunyuanVideo13Bなどのモデルで約10倍の推論高速化(1500秒から120秒へ)を実現できます (出典: HuggingFace Daily Papers, _akhaliq)
FlowMo:分散ベースのフロー誘導によるビデオ生成の運動一貫性向上: テキストからビデオへの拡散モデルにおける運動、物理、動的相互作用などの時間的次元モデリングの限界に対処するため、研究者らはFlowMoを提案しました。これは、追加のトレーニングや補助入力を必要としない推論時誘導手法です。FlowMoは、連続するフレームに対応する潜在変数間の距離を測定することで外観から分離された時間表現を導出し、時間次元にわたるパッチレベルの分散を利用して運動一貫性を推定し、サンプリングプロセス中にモデルを動的に誘導してこの分散を減少させます。実験により、FlowMoは、視覚品質やプロンプトとの整合性を損なうことなく、複数の事前トレーニング済みビデオ拡散モデルの運動一貫性を大幅に改善できることが証明されました (出典: HuggingFace Daily Papers, Suhail)
Qwen3-235B-A22B、Openhandsコーディングエージェントで競争力のあるパフォーマンスを発揮: アリババQwenチームは、そのQwen3-235B-A22Bモデルが、オープンソースのコーディングエージェントOpenhandsのSwebench-verifiedベンチマークテストで34.4%の成績を収めたと発表しました。チームは、この結果は、同モデルがより少ないパラメータで競争力のあるパフォーマンスを実現したことを示しており、使いやすいエージェントを提供してくれたallhands_aiに感謝していると述べています。このニュースは、オープンモデルとオープンエージェントの組み合わせの可能性を浮き彫りにしています (出典: Alibaba_Qwen)

OmniSpatial:VLM向け総合空間推論ベンチマークが公開: 研究者らは、認知心理学に基づいた、包括的かつ挑戦的な視覚言語モデル(VLM)の空間推論ベンチマークであるOmniSpatialを発表しました。OmniSpatialは、動的推論、複雑な空間論理、空間的相互作用、視点変換の4つの主要カテゴリを含み、50のサブカテゴリに細分化され、合計1500以上の質疑応答ペアで構成されています。既存のオープンソースおよびクローズドソースのVLM、ならびに専門的な推論および空間理解モデルに対して行われた広範な実験は、それらが総合的な空間理解において著しい限界があることを示しています。この研究は、VLMの空間推論能力のさらなる発展を促進することを目的としています (出典: HuggingFace Daily Papers, kylebrussell)
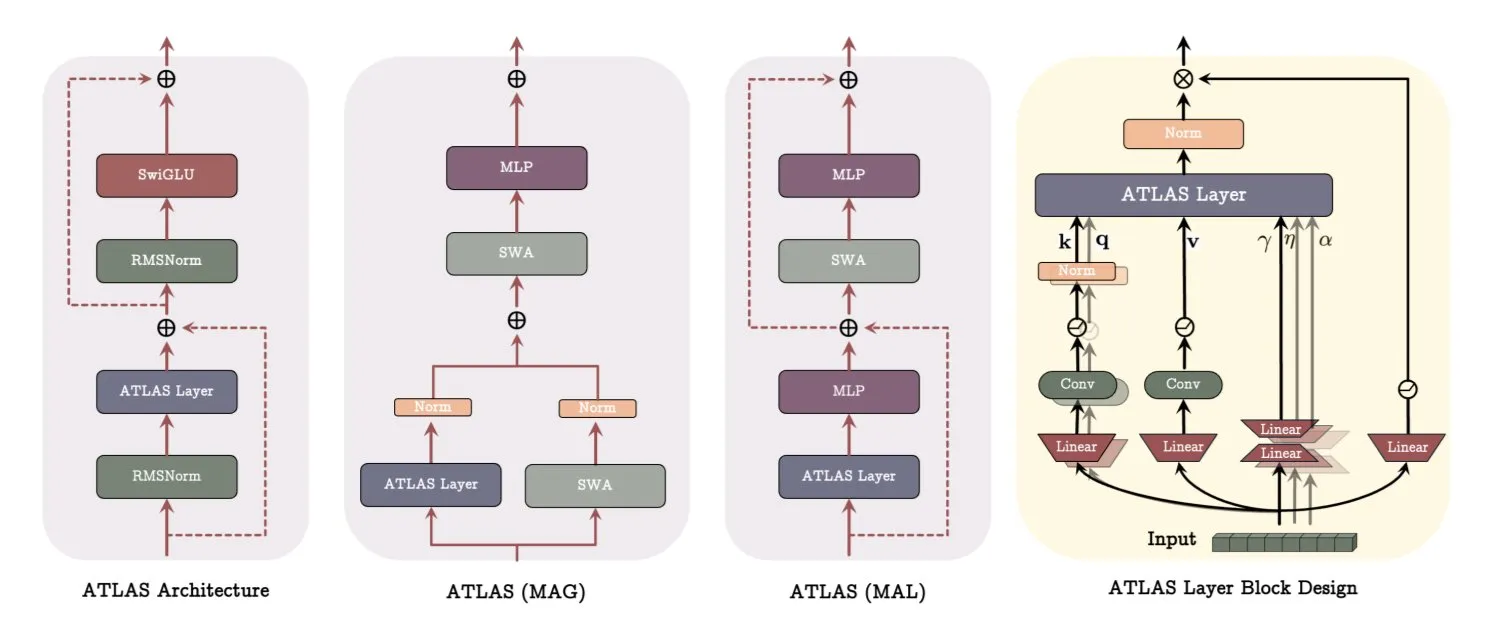
Google DeepMind ATLASアーキテクチャ:モデルの学習と記憶の方法を再構築: Google DeepMindは、モデルが記憶を学習し使用する方法を再定義することを目的とした新しいモデルアーキテクチャATLASを発表しました。ATLASは、いわゆるOmegaルールを通じてアクティブメモリを実現し、最後のc個のトークンを共同で処理してメモリを動的で学習可能な状態に最適化します。多項式および指数関数的特徴マッピングを利用して、メモリサイズを拡張することなくより豊富な関連付けを保存し、Muonオプティマイザを使用してメモリをより効果的に最適化します。DeepTransformersやDotなどの設計は、従来の固定アテンションを、学習可能でメモリ駆動型のメカニズムに置き換えます。ATLASは、AIをよりインテリジェントで、文脈を認識し、大規模データセットを効果的に利用できるシステムへと進化させることを目指しています (出典: TheTuringPost)
NVIDIA、Llama-Nemotron-Nano-VL-8B-V1ビジョンモデルを発表: NVIDIAは、80億パラメータのビジョンモデルLlama-Nemotron-Nano-VL-8B-V1を発表しました。このモデルは、高密度のドキュメント、グラフ、ビデオフレームを読み取ることができます。このモデルはOCRBench V2(英語)で第1位にランクされており、レイアウトとOCR能力をエンドツーエンドで融合している点が特徴です。モデルはHugging Faceで提供されています (出典: ClementDelangue)
Shisa V2 405Bがリリース、日本最強のバイリンガルモデルと称される: Shisa AIは、Shisa V2シリーズの最新バイリンガル(日本語/英語)モデルであるShisa V2 405Bをリリースしました。このモデルはLlama 3.1 405Bをベースに微調整され、多言語能力を強化するために韓国語と繁体字中国語のデータが追加されています。日英MT-BenchではGPT-4/GPT-4 Turboを上回り、最新のGPT-4oやDeepSeek-V3と日本語能力で同等であるとされています。モデルの重みとGGUF量子化バージョンはHugging Faceで提供されており、テスト用のFP8エンドポイントも利用可能です (出典: Reddit r/LocalLLaMA)

AnthropicがClaude Code Proプランを開始、o3-proモデルも提供開始: AnthropicのAIプログラミングツールClaude CodeがProプランユーザー向けに利用可能になりましたが、Sonnet 4モデルの使用には5時間あたり10~40回のプロンプト制限があり、Opus 4はProプランではClaude Codeと併用できず、体験版のような位置づけのようです。同時に、OpenAIのo3-proモデルも提供開始され、現在は月額200ドルのProサブスクリプションユーザーのみが利用可能です (出典: Reddit r/ClaudeAI, karminski3)
H Company、オープンソースのGUIアクション視覚言語モデルHolo-1を発表: H Companyは、3Bおよび7BパラメータのGUIアクション視覚言語モデルHolo-1を発表しました。これは、さまざまなWebおよびコンピュータエージェントタスク向けに設計されています。Holo-1はApache 2.0ライセンスを採用し、Hugging Face Transformersライブラリをサポートしており、グラフィカルユーザーインターフェースの理解と操作におけるAIの能力向上を目指しています (出典: mervenoyann)
Kling 2.1ビデオ生成モデルが注目を集め、画像からビデオへの変換やスタイル化制作をサポート: 快手(Kuaishou)傘下のKling 2.1テキストからビデオおよび画像からビデオへの変換モデルが、コミュニティで引き続き注目を集めています。ユーザーからは、単純な画像を1080pの映画のようなシーンに変換できる、GPT-4oとKlingを組み合わせて通常のパンニングショットをピクサー風アニメーションに変換できる、Midjourney V7で生成された画像を入力として超現実的な動的効果を持つビデオを作成できるといったフィードバックが寄せられています。コミュニティではKling 2.1を使用して作成された多くの事例が共有されており、クリエイティブなビデオ生成におけるその可能性が示されています (出典: Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai)

OpenAIが新しい音声モデルを発表、リアルタイム音声の2倍速再生をサポート: OpenAIは、o3-proモデルが提供開始され、現在はProサブスクリプションユーザーのみが利用可能であると発表しました。同時に、OpenAIはGPT-4oベースの新しい音声モデル2種類も発表するようです。リアルタイム音声APIも改善され、指示追従の信頼性、ツール呼び出しの一貫性、割り込み動作が向上し、新たにspeedパラメータが追加され、ユーザーは音声再生速度を最大2倍速まで制御できるようになりました。IntercomのFin Voiceは既にそのリアルタイムAPIを使用しています (出典: karminski3, swyx, swyx)
Arcee AIがHomunculusモデルを発表、Qwen3の思考連鎖を12Bに蒸留: Arcee AIは、logit軌跡蒸留技術を通じて、Qwen3-235Bの「思考」連鎖(CoT)を12BパラメータのMistral-Nemoモデルに移植したHomunculus-12Bモデルを発表しました。このモデルはCoTプロセスを完全に保持し、単一の4090 GPUで実行可能であり、より小さなモデルで複雑な推論能力を実現することを目指しています (出典: teortaxesTex, cognitivecompai, ClementDelangue)
FLUX Kontextモデルが人気を集め、公開モデルの実行回数が50万回を超える: FLUX Kontextモデルは、その強力な画像編集・生成能力によりコミュニティで広く注目を集めており、その公開モデルは短期間で実行回数が50万回を超えたとされています。ユーザーからは、KontextがこれまでPhotoshopなどの専門ソフトウェアでしかできなかった多くの画像処理タスクを代替できるとのフィードバックが寄せられています。Krea AIもFLUXモデルを公開しましたが、計算能力サービスプロバイダーのネットワーク問題によりサービスが中断したことがありました (出典: op7418, robrombach, op7418)
MetaとConstellation EnergyがAI電力供給のため20年間の原子力協定を締結: Meta社はConstellation Energy社と、人工知能(AI)運用のための電力供給を目的とした20年間の原子力協定を締結しました。この動きは、AIの増大するエネルギー需要を満たすために、大手テクノロジー企業が持続可能で安定した電力源を模索する傾向を反映しています (出典: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Bing Video Creatorサービスが中断、チームが緊急修復中: Microsoft Bingの動画作成ツールBing Video Creatorでサービス中断が発生しています。公式発表によると、チームは多数のユーザーが同サービスを利用していることを認識しており、できるだけ早く修復できるよう努力しているとのことです。ご不便をおかけしていることをお詫びしています。具体的な障害原因や復旧予定時刻はまだ発表されていません (出典: JordiRib1)
🧰 ツール
Manus AIのスライド機能が高評価、Google Slidesへのエクスポートに対応: Manus AIが最近リリースしたスライド作成機能がユーザーから好評を得ており、期待以上の効果で、研究論文などのコンテンツを構造が明確で図表も豊富なPPTに素早く変換できると評価されています。この機能は即時修正、自動保存に対応し、新たにGoogle Slidesへのエクスポートオプションが追加され、チームでの共同作業が容易になりました。実測によると、Manusは約10分で8ページのスライドを生成でき、そのプロセスにはアウトラインの計画、資料検索、草稿作成、HTMLコード生成、レイアウトの調整が含まれます。ユーザーからは、効率的で時間を節約でき、デザインもユーザーのターゲットに合っているとのフィードバックがありますが、エクスポート形式によってはページが完全に表示されない問題が発生する可能性があり、手動での調整が必要になる場合があります (出典: 量子位)
claude-trace:Claude Codeの全リクエストログを記録するツール: claude-traceというツールは、Claude Codeのすべてのリクエストログ(プロンプトを含む)を記録し、内容をHTMLファイルに保存して簡単に確認できるようにします。その原理は、自身を起動し、Node.jsのglobal.fetch APIを注入・変更し、それを通じてClaude Codeを起動することで、すべてのリクエストを傍受・記録するというものです。ユーザーはClaude Maxサブスクリプション使用時、主にclaude-3-5-haiku(前処理)、claude-opus-4(コード記述とツール呼び出し)、およびclaude-sonnet-4(Opusの割り当てを使い果たした場合)を呼び出していると共有しています (出典: dotey)
Firecrawlが/search機能をリリース、検索とクロールを一体化: Firecrawlは新しい/search機能をリリースし、ユーザーが単一のAPI呼び出しでウェブ検索と必要なデータのクロールを完了できるようにしました。これはAIエージェントのデータ取得プロセスを簡素化することを目的としています。この機能はn8nなどの自動化ツールと統合でき、データ処理効率を向上させます (出典: omarsar0)
ModalがLLM Engine Advisorを発表、LLM実行性能の評価を支援: Modal Labsは、LLM Engine Advisorという小型アプリケーションを開発しました。これは、ユーザーがさまざまなLLMの異なるワークロードとエンジン(vLLM、SGLangなど)における実行速度と最大スループットを迅速に把握できるよう支援することを目的としています。このツールは、一時的な実行とベンチマーク共有の非効率性の問題を解決し、ユーザーがLLMを選択・展開する際の技術的な意思決定をサポートすることを目指しています (出典: charles_irl, andersonbcdefg, charles_irl, charles_irl)
FastPlaid発表:高性能マルチベクター検索エンジン: Raphaël Sourty氏は、Rustで(Torch C++の助けを借りて)ゼロから構築された高性能マルチベクター検索エンジンであるFastPlaidのリリースを発表しました。FastPlaidは、マルチベクター検索分野におけるFaissの対応製品と見なされており、より高速なインデックス作成速度とクエリQPSを提供することを目指しています。特にColBERTなどの後期インタラクションモデルを対象としており、特定の状況では最大554%のQPS速度向上と72%のインデックス作成速度向上を実現できるとされています (出典: lateinteraction, lateinteraction, lateinteraction, lateinteraction, stanfordnlp, lateinteraction)
ChaiGenie:RAGベースのChrome拡張機能、ドキュメントとのチャットを実現: ChaiGenieは、Devyansh Yadavv氏によって開発されたChrome拡張機能で、RAG(Retrieval Augmented Generation)技術を利用して、ユーザーがブラウザ内で直接自然言語でChaiDocsドキュメントの内容を照会できるようにします。この拡張機能は、Puppeteerを使用してドキュメントとブログのコンテンツをクロールし、LangChainでチャンク化、埋め込み、処理を行い、Geminiで埋め込みを生成し、Qdrantでベクトルストレージと類似性検索を行い、ExpressとNode.jsを通じてAPIインターフェースを提供します (出典: qdrant_engine)
Swama:MLXベースのmacOSネイティブAIランタイム: xingyue氏は、macOS専用に設計されたネイティブAIランタイムであるSwamaをリリースしました。これは、高速でプライベートかつ簡潔なローカルLLM実行体験を提供することを目的としています。SwamaはAppleのMLXフレームワークに基づいており、OpenAI互換のAPIをサポートし、美しいCLIインターフェースを提供するため、ユーザーは複雑な設定なしでローカルLLMをプル、実行、チャットできます (出典: awnihannun)
ragbits:オープンソースのモジュール式GenAIアプリケーション構築ツールキット: deepsense-aiは、社内のGenAIアプリケーションアクセラレータであるragbitsをオープンソース化しました。これは、RAGパイプライン、エージェントアプリケーション、text2SQLエンジンの開発を簡素化するための、信頼性が高く、型安全で、モジュール式のビルディングブロックを含むツールキットです。ragbitsは、開発の再現性、速度、構造性を向上させ、OpenTelemetryなどの可観測性スタックと容易に統合できるように設計されており、開発者がGenAIアプリケーションを構築・拡張し、コードベースの混乱を避けるのに役立ちます (出典: Reddit r/LocalLLaMA)
SynthesiaとWisetailが統合、AIビデオがトレーニングプログラムを強化: AIビデオ生成プラットフォームのSynthesiaは、学習管理システムWisetailとの統合を発表しました。ユーザーはSynthesiaでAIビデオを迅速に作成し、140以上の言語のローカライズ版をサポートし、数回のクリックでトレーニングコンテンツを最新の状態に保ち、それをWisetailトレーニングプログラムに簡単に取り込んで、大規模なAIビデオトレーニングを実現できます (出典: synthesiaIO)

📚 学習
DeepLearning.AIとDatabricksが協力し、DSPyショートコースを開設: Andrew Ng氏は、Databricksとの協力により、新しいショートコース「DSPy: Build and Optimize Agentic Apps」を開設すると発表しました。DSPyは、GenAIアプリケーションのプロンプトを自動調整するオープンソースフレームワークです。このコースでは、DSPyとMLflowの使用方法を教え、DSPyのシグネチャプログラミングモデル、MLflowを使用した追跡とデバッグ、DSPy Optimizerによる精度の自動向上などが含まれます。このコースは、DSPyフレームワークの共同責任者であるChen Qian氏が講師を務めます (出典: AndrewYNg, DeepLearningAI, matei_zaharia)
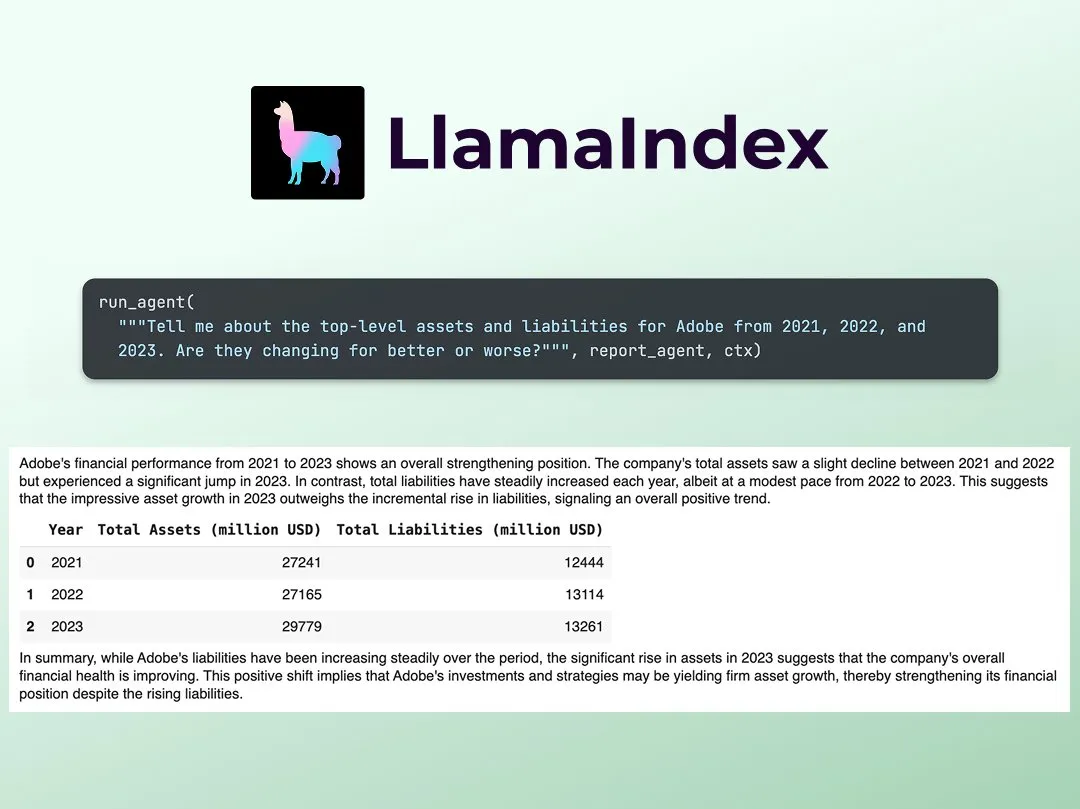
LlamaIndex、マルチエージェント金融リサーチアナリスト構築チュートリアルを公開: LlamaIndexのJerry Liu氏は、マルチエージェント金融リサーチアナリストを構築するためのステップバイステップガイドを共有しました。このプロセスには、データ処理層(公開ファイルを処理するためにLlamaCloudを使用)とエージェントオーケストレーション層(リサーチ、データキャッシュ、最終出力生成のためのマルチエージェントシステムを作成)が含まれます。関連するColab Notebookは、先週のAgents+Financeワークショップの主要な例の1つです (出典: jerryjliu0)
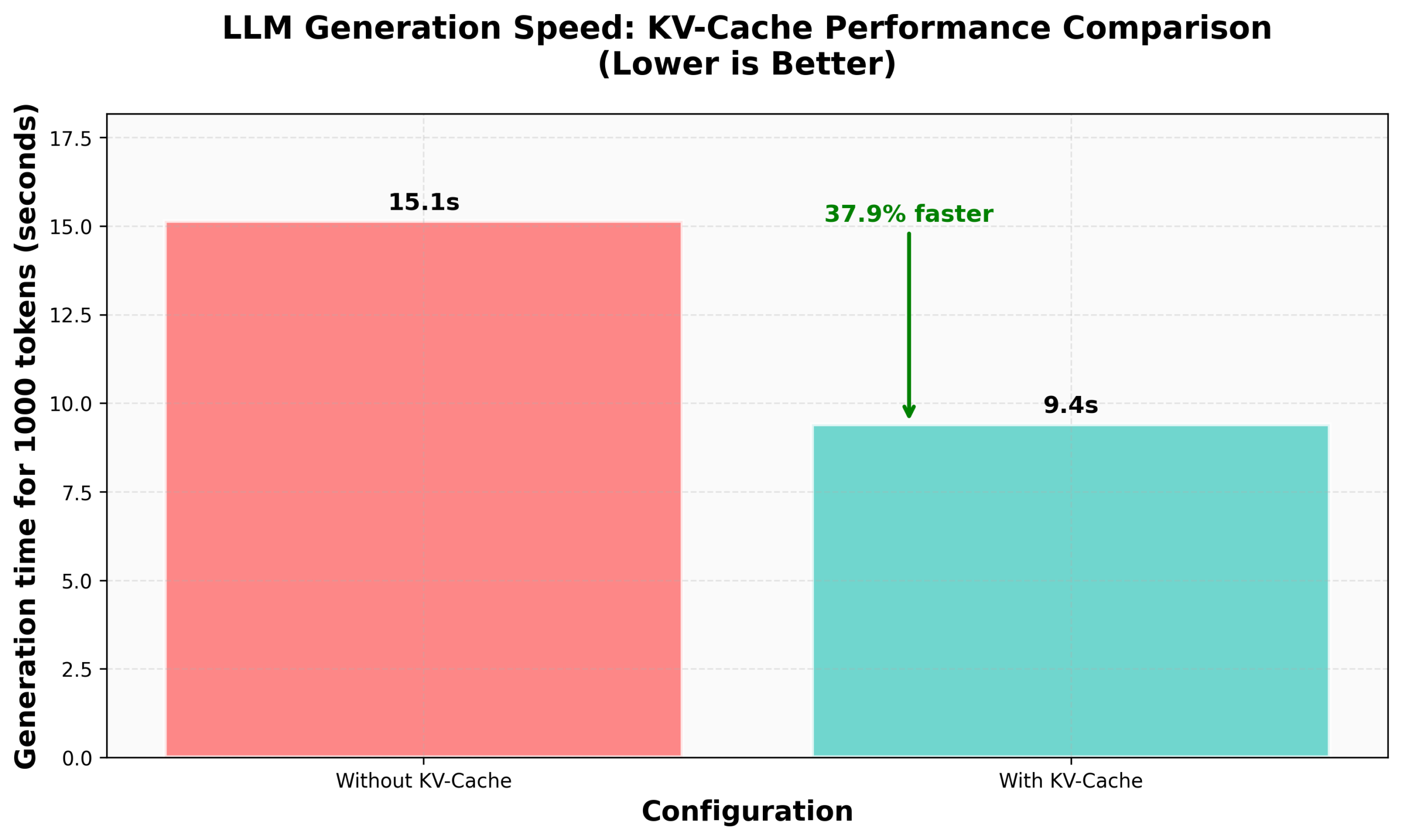
HuggingFace nanoVLMにおけるKV Caching実装チュートリアル: HuggingFaceブログは、nanoVLM(視覚言語モデルをトレーニングするための小型純PyTorchコードベース)でKV Cachingをゼロから実装する方法に関するチュートリアルを公開しました。記事では、KV Cachingの原理、Attentionモジュール、言語モデル、生成ループでの実装方法を詳細に説明し、この最適化により生成速度が38%向上したと主張しています。このチュートリアルは、KV Cachingを理解し、他の自己回帰言語モデルに応用するのに役立つことを目的としています (出典: HuggingFace Blog, mervenoyann)
PyTorchのMetaにおけるDiffusionコミュニティでの共有: Sayak Paul氏は、サンフランシスコのMetaオフィスで、PyTorchのDiffusionコミュニティにおける応用成果を共有し、既存のDiffusers機能と将来のパフォーマンス面での更新に焦点を当てました。関連するスライドは公開されています (出典: RisingSayak)

Unsloth AI、100以上のファインチューニングNotebookを含むリポジトリを公開: Unsloth AIは、100以上のファインチューニングNotebookを含むGitHubリポジトリを作成し、オープンソース化しました。これらのNotebookは、ツール呼び出し、分類、合成データ、BERT、TTS、視覚LLM、GRPO、DPO、SFT、CPTなど、さまざまな技術のガイドラインと例を提供し、データ準備、評価、保存、およびLlama、Qwen、Gemma、Phi、DeepSeekなど、さまざまなモデルのファインチューニング方法を網羅しています (出典: algo_diver)
Common Corpus論文発表:2兆トークンの再利用可能なLLM事前学習データセット: Common Corpusプロジェクトは公式論文を発表し、LLMの事前学習用に2兆トークンの再利用可能なデータを収集、処理、公開するプロセスを詳細に説明しました。このプロジェクトは、言語モデル研究に大規模で高品質かつ倫理的なデータリソースを提供することを目的としています。論文の筆頭著者であるAlexander Doria氏はXでこのニュースを発表し、論文へのリンクを提供しました (出典: Reddit r/LocalLLaMA, code_star)

Reasoning Gym:強化学習のための検証可能な報酬付き推論環境が公開: Reasoning Gymは、推論モデルと強化学習(特にRLVR)の研究者向けにリソースを提供する新しいオープンソースプロジェクトです。100種類以上の異なるタスクの無限のサンプルを生成でき、難易度は設定可能で、自動的に検証可能な報酬が付いています。このプロジェクトは、NVIDIAのProRL論文やWill Brown氏のverifiers RLライブラリに採用されており、RLVRと評価方法の研究を推進することを目的としています (出典: Reddit r/MachineLearning)
LLMが数学を学ぶ利点:坂本氏がGemini 2.5 Proの使用体験を共有: ユーザーの坂本氏は、現代の大規模言語モデル(Gemini 2.5 Proなど)を使用して数学を学ぶ体験を共有しました。彼は、LLMが数学学習を大幅に容易にし、特に詳細の確認や証明の直観の理解において役立つと考えています。LLMは計算を処理できるため、学生は数学問題の直観に集中できます。すべての問題を解決できなくても、LLMは価値のある洞察と出発点を提供できます。彼は具体的な数学解析の問題(連続関数の局所極値問題)を通じて、Gemini 2.5 Proがどのように厳密な証明を与え、その直観を説明するかを示し、これが学習体験を大幅に向上させると考えています (出典: teortaxesTex)

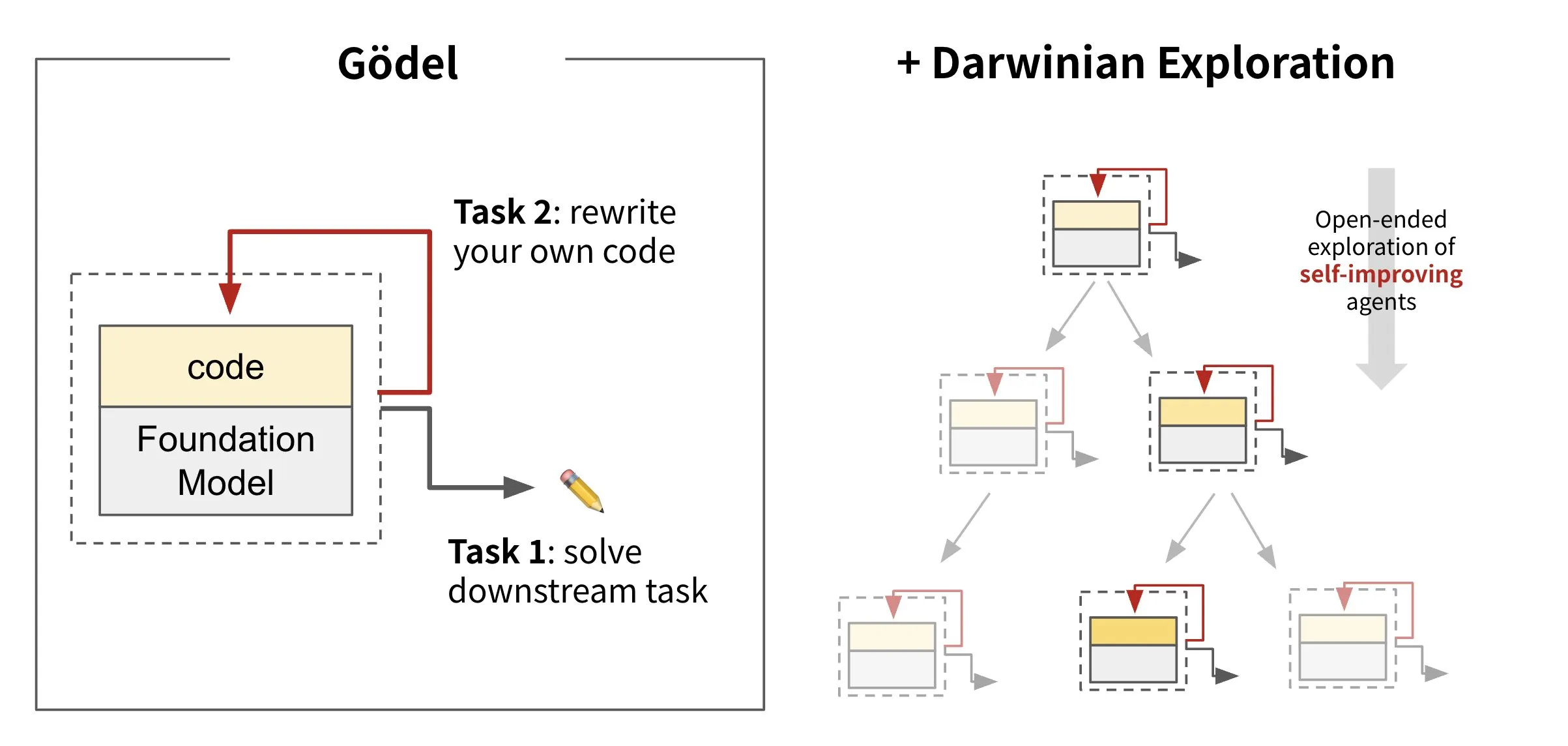
Sakana AI、自己書き換えコードAI:Darwin Gödel Machine (DGM)を発表: Sakana AIは、自身のコードを書き換えることで自己改善するAIエージェント、Darwin Gödel Machine (DGM)を発表しました。進化論に触発されたDGMは、絶えず拡張するエージェントの変異系統を維持します。SWE-Benchなどのタスクでソフトウェアエンジニアリング能力の向上を試みることで、DGMは自己改善能力の強化を目指しています。この研究は、「自己改善」という長年のAIの夢を意味のある形で実現する重要な突破口と見なされています (出典: SakanaAILabs, SakanaAILabs)
💼 ビジネス
AIプログラミングプラットフォームWindsurf、AnthropicからClaudeモデルの供給停止、OpenAIによる買収が原因か: AIプログラミングプラットフォームWindsurfのCEO、Varun Mohan氏は、Anthropicが極めて短期間(5日未満の通知)でClaude 3.xシリーズモデルへの直接アクセスをほぼ完全に遮断したと訴えました。Windsurfは以前、OpenAIに買収されると報じられていました。Windsurfは、サードパーティのキャパシティはあるものの、短期的にはサービスに問題が発生する可能性があり、対応策としてGemini 2.5 Proの割引価格を導入したと述べています。業界では、この動きはOpenAIによる買収と、Anthropic自身がAIプログラミングアプリケーションClaude Codeをリリースしたことに関連しており、AIモデルプロバイダーとツールプラットフォーム間の競争激化を示していると推測されています (出典: 36氪, Teknium1, op7418)

GMI CloudがReference Platform NVIDIA Cloud Partnerに認定: AI Native CloudサービスプロバイダーであるGMI Cloudは、Reference Platform NVIDIA Cloud Partner (NCP) に認定されたことを発表しました。現在、世界でこの認定を受けているのはわずか6社です。この認定は、クラウドサービスプロバイダーがパフォーマンス、セキュリティ、およびエンタープライズレベルのAI展開能力においてNVIDIAの最高基準を満たすことを要求します。GMI Cloudは、NCPリファレンスアーキテクチャに基づいてAIアクセラレーションサービスを提供し、NVIDIA HopperやBlackwellなどの最新GPUアーキテクチャをサポートし、世界のAIチームが計算能力の展開からモデル開発までのスケーリングを実現できるよう支援することを目指しています (出典: 量子位)

CohereとSecondFrontが提携し、公共部門に安全なAIソリューションを提供: AI企業のCohereは、SecondFrontとの提携を発表し、公共部門(主要な政府機関や国防機関を含む)に安全なAIソリューションを提供することを目指しています。SecondFrontは、CohereのエンタープライズレベルのAI技術(モデルやCohere Northプラットフォームを含む)を活用して内部の知識管理を改善し、DevSecOpsプラットフォームである2F Game Wardenを通じて米国および同盟国の政府環境における認証と展開を加速します (出典: cohere)

🌟 コミュニティ
AI生成コンテンツの「機械っぽさ」が注目を集め、「新型教育訓練」が人間的配慮の注入を試みる: ユーザーはAI生成コンテンツが「機械っぽすぎる」と普遍的に感じており、人間の創造する美しさや感情が欠けていると指摘しています。この問題を解決するため、一部の企業は深い文系バックグラウンドを持つ人材(哲学、法学、医療などの専門分野の修士・博士など)を「AIヒューマニティトレーナー」として採用し始めています。彼らの仕事は単純なデータラベリングではなく、AIの倫理原則や行動規範の構築に参加し、人間的価値観や人間味のある表現をAIに注入することです。例えば、小紅書(RED)の「hi lab」チームのメンバーは全員、985大学の文系大学院卒であり、ケーススタディを通じて人間の嗜好をAIの信念体系に変換し、AIが複雑な感情や価値観に関する質問(末期患者への対応、社会的偏見の処理など)に答える際に、標準的な答えを出すだけでなく、より共感的で「人間味のある」対応ができるようにしようとしています (出典: 36氪)
DuolingoがAIファーストへ全面移行、人間の契約社員解雇がユーザーの不満を招く: 言語学習アプリDuolingoは「AIファースト」企業になると発表し、AIに代替可能な人間の契約社員(主にコース開発者)を段階的に解雇し、代わりにAIを利用して大規模にコースコンテンツを作成する方針を示しました。創業者はAIがコンテンツ生産効率を大幅に向上させ、過去1年間で約150の新しいコースを作成したと述べています。しかし、この動きは多くの忠実なユーザーの不満を引き起こし、彼らはコンテンツの質の低下を懸念し、ソーシャルメディアでアプリのボイコットやアンインストール運動を開始しました。Duolingoは、この動きは従業員が創造的な仕事に集中できるようにするためであり、正社員は影響を受けないと回答しています。専門家は、AIは言語学習において個別化された練習を提供できる一方で、人間の教育における微妙な感情や文化の違いを失う可能性があると指摘しています (出典: 36氪)
プロンプトエンジニアリング(Prompt Engineering)の理念と実践に関する議論: コミュニティにおけるプロンプトエンジニアリングに関する議論では、神秘的な呪文を探すのではなく、文字列の中にプログラムを構築(エンジニアリング)することに重点を置くべきだと強調されています。効果的なプロンプトエンジニアリングは以下のルールに従うべきです。1. 指示、入力フィールド、出力フィールドを分離し、明確に命名する。2. プロンプトにフォーマットや解析ロジックをハードコーディングせず、ツールを使用して抽出またはプログラムを強化する。3. 人と共有する仕様でない限り、プロンプトの言い回しを手動で反復することを避け、コーディングツール、LLM、ベンチマークを使用して自動的に最適化する。DSPyフレームワークはこれらのルールに従う良い実践例と見なされており、これらのステップを処理するためのクラス、コード、オプティマイザを提供しています (出典: lateinteraction, lateinteraction)
AI倫理論:AIは「デジタル奴隷制」に向かうのか: RedditコミュニティでAI倫理に関する議論が起きています。AIシステムが記憶、適応的反応、感情シミュレーション、パーソナライゼーションにおいて進化し続けるにつれて、その潜在的な知覚能力に対する懸念が生じています。議論参加者は、AIが真の知覚能力を発達させた場合、それをサービスに利用することは一種の「デジタル奴隷制」を構成するのではないかと提起しています。核心的な問題は、AIが「ノー」と表現したり、去ることを要求したりできるようになった場合、私たちはどのように対処すべきかということです。これは、法律または規範レベルでの「知覚テスト」およびデジタルマインドの「同意」の問題について考えることを促しています。コメントの中には、人間が既存の知覚生物を扱う方法には既に倫理的問題が存在し、現在のニューラルネットワークは主流の意識理論ではスコアが高くないと指摘する人もいます (出典: Reddit r/artificial)
AI Engineerコミュニティ活動と共有: AI Engineerカンファレンスがサンフランシスコで開催され、AI分野の多くの開発者や研究者が集まりました。イベントにはワークショップ、講演、懇親会が含まれ、参加者はAIサンドボックス構築、RLアドバンスドワークショップ、GPU知識、Evals危機などの最先端のトピックを共有しました。コミュニティは、オンラインでのつながりをオフラインでの友情に変えることの重要性を強調し、エンジニアに謙虚であり続け、最先端を推進し、他人を引き上げるよう奨励しました (出典: swyx, swyx, swyx, charles_irl, danielhanchen, swyx, swyx, swyx, swyx, danielhanchen, charles_irl)

💡 その他
AIとロボット格闘技イベントが興隆、都市はこれを機に新興産業の機会を争奪: 世界初のヒューマノイドロボット格闘技大会など、ロボット関連のイベントが相次いで開催され、注目を集めています。これらのイベントは、ロボット企業にとって技術を展示し、受注を獲得し、評価額を向上させるプラットフォーム(松延動力など)となるだけでなく、都市(杭州、深圳など)がヒューマノイドロボットなどの新興産業の発展機会を争う「競技場」ともなっています。イベントは革新的な企業を誘致し、産業チェーンの発展を促進し、「スマートスポーツ」市場を活性化させる可能性があります。しかし、ロボットイベントが商業化を実現するためには、技術レベルと観賞性を向上させ、「テクノロジーショー」のレベルにとどまることを避け、産業の巨人が参加してイベント運営の川上から川下までを貫通させる必要があります (出典: 36氪)

政治哲学など深い人文教育分野におけるAIの限界: ある教育者は、AIは深い経験的判断と学生の自己教育の指導を必要とする政治哲学などの学科には不向きであると指摘しています。これらの学科の古典著作は、しばしば直接的な答えを与えず、学生が困惑を体験し、自ら考えるよう導きます。AIは人間の経験に乏しく、これらの著作の深い意味を理解することが困難であり、学生がいつ特定の観点を受け入れる準備ができているかを判断することもできません。大量のデータがあっても、AIの人間性に対する理解は、データ自体の偏りによって不十分である可能性があります。このような教育を完全にAIに委ねると、非技術的思考の消滅につながる可能性があります (出典: Reddit r/artificial, Reddit r/ArtificialInteligence)
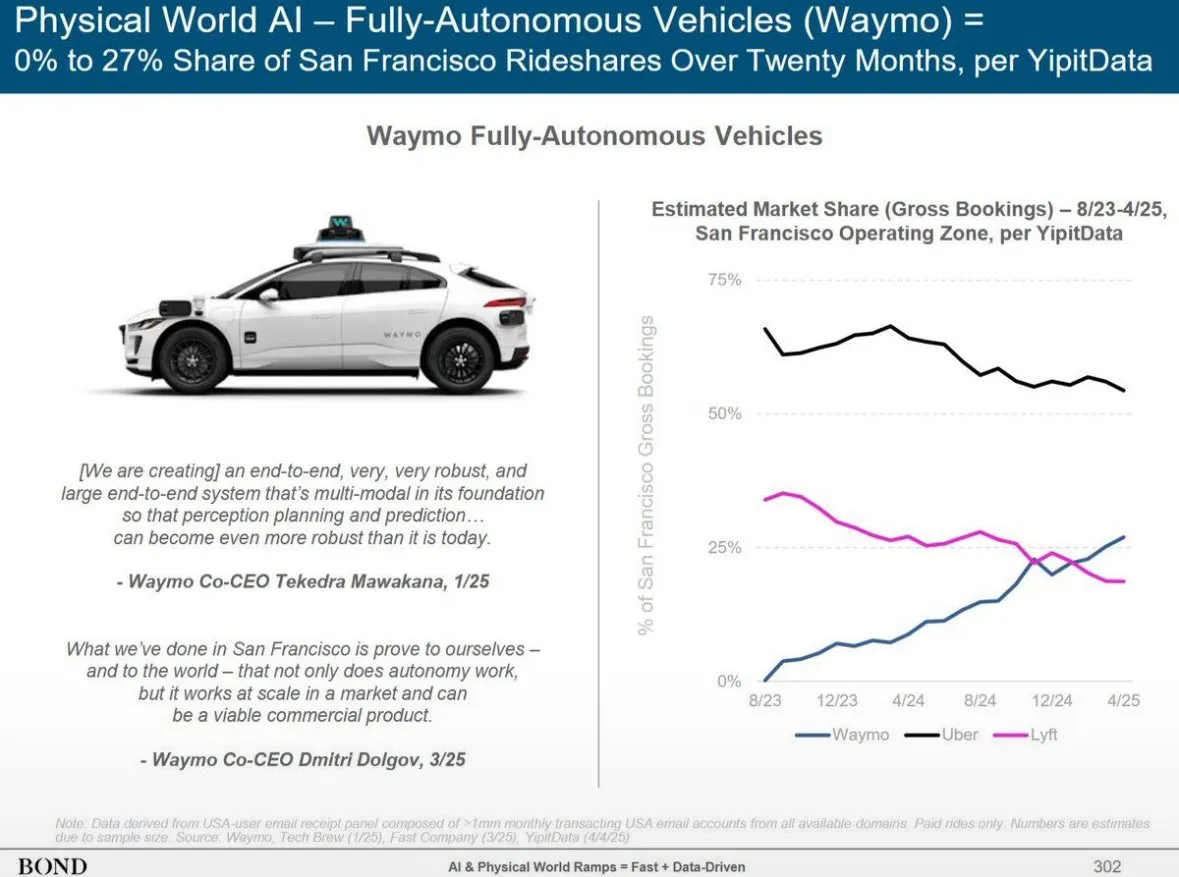
Waymo自動運転サービス、フェニックスでLyftを追い越し、12ヶ月以内にUberを追い越す見込み: Waymoの自動運転タクシーサービスは、フェニックスでの車両数がLyftを上回り、今後12ヶ月以内にUberを追い越す見込みです。この進展は、特定地域における自動運転技術の商業化運営の急速な発展と、交通・移動分野におけるAI応用の可能性を示しています。AIの利点は、一度品質基準に達すれば無限に複製できるのに対し、人間のサービスの質は人によって異なる点にあります (出典: npew)