
キーワード:AIコラボレーション, ChatGPT, 大規模言語モデル, AIプログラミング, AI動画生成, AI数学, AIセキュリティ, AIエネルギー, Karpathy UIスクリプト化インタラクション, ChatGPT会議記録モード, DeepSeek-R1モデル更新, AIエージェントフィッシング攻撃, Duolingo AIコース拡張
🔥 フォーカス
Karpathy氏、複雑なUIアプリケーションの将来性に警鐘、AI協調にはスクリプト化されたインタラクションが必要と強調: Andrej Karpathy氏は、人間とAIが高度に協調する時代において、スクリプトによるサポートがなく、複雑なグラフィカルユーザーインターフェース(UI)にのみ依存するアプリケーションは苦境に立たされるだろうと指摘しています。大規模言語モデル(LLM)がスクリプトを通じて基盤となるデータや設定を読み取り、操作できなければ、専門家を効果的に支援することも、多くのユーザーが求める「雰囲気プログラミング」(vibe coding)のニーズに応えることもできないと彼は考えています。Karpathy氏は、Adobeシリーズ製品、デジタルオーディオワークステーション(DAWs)、コンピュータ支援設計(CAD)ソフトウェアなどをリスクの高い例として挙げ、VS Code、Figmaなどはテキストフレンドリーであるためリスクが低いと見なしています。この見解は議論を呼んでおり、核心は、将来のアプリケーションはUIの直感性とAIの操作性のバランスを取るか、AIが理解しやすくインタラクションしやすいテキスト化、API化されたインターフェースへと移行する必要があるという点にあります。(ソース: karpathy, nptacek, eerac)
OpenAI、ChatGPTに内部データソース接続および会議記録機能を付与: OpenAIはChatGPTの重要なアップデートを発表しました。これにはmacOS版会議記録モード(Record Mode)の導入が含まれ、この機能は会議、ブレインストーミング、音声メモをリアルタイムで文字起こしし、重要な要約、要点、ToDo事項を自動的に抽出します。同時に、ChatGPTはモデルコンテキストプロトコル(MCP)を正式にサポートし、Outlook、Google Drive、Gmail、GitHub、SharePoint、Dropbox、Box、Linearなど、多くの企業および個人が日常的に使用するツールや内部データソースとの接続を可能にし、クロスプラットフォームデータのリアルタイムな状況把握、統合、インテリジェントな推論を実現します。これにより、ChatGPTをより強力なインテリジェント協調プラットフォームへと進化させることを目指しています。この動きは、ChatGPTが企業のワークフローや個人の生産性向上シーンへより深く統合されるための重要な一歩となります。(ソース: gdb, snsf, op7418, dotey, 36氪)

Reddit、Anthropicを提訴、AI訓練のための無許可データ収集を主張: RedditはAIスタートアップ企業Anthropicに対し訴訟を提起しました。Anthropicのボットが2024年7月以降、Redditプラットフォームに10万回以上無許可でアクセスし、収集したユーザーデータを商業的なAIモデルの訓練に使用したと主張しており、OpenAIやGoogleのようにライセンス料を支払っていないとしています。Redditは、この行為が同社のサービス利用規約およびロボット排除プロトコルに違反し、Anthropicが自称する「AI業界の白馬の騎士」というイメージにそぐわないと考えています。この訴訟は、AI開発におけるデータ取得の法的・倫理的境界線の問題、およびAIデータサプライチェーンにおけるコンテンツプラットフォームの権利保護の要求を浮き彫りにしています。(ソース: op7418, Reddit r/artificial, The Verge, maginative.com, TechCrunch)

AIが数学分野で進展、DeepMindのAlphaEvolveが人間の数学者を新たな高みへと刺激: DeepMindのAlphaEvolveは「集合和差問題」の解決においてブレークスルーを達成し、2007年以来18年間破られていなかった記録を更新しました。その後、Robert Gerbicz氏やFan Zheng氏といった人間の数学者がこれを基にさらに改良を加え、新たな構成法や漸近解析手法を導入することで、重要な指数θの下限を新たな高みへと引き上げました。テレンス・タオ氏はこの成果について、コンピュータ支援(大量から適度なものまで)と伝統的な「紙とペン」による数学的手法の将来的な協調の可能性を示しており、AIの広範な探索が人間の専門家の深い探求のための新たな方向性を見出し、共に数学の進歩を推進するとコメントしています。(ソース: MIT Technology Review, 36氪, 36氪)

🎯 動向
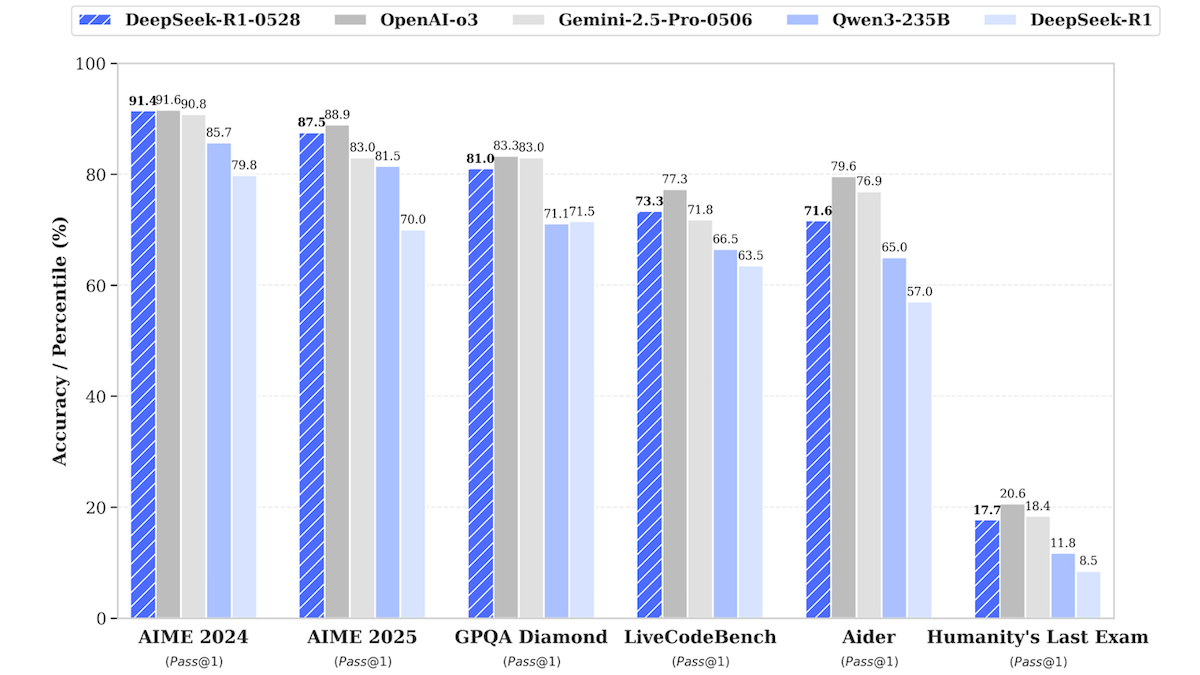
DeepSeek-R1モデルがアップデート、トップクラスのクローズドソースモデルの性能に迫る: DeepSeekは、大規模言語モデルDeepSeek-R1のアップデート版であるDeepSeek-R1-0528をリリースしました。このモデルは、多くのベンチマークテストでOpenAI o3やGoogle Gemini-2.5 Proに迫る性能を示しています。同時に発表された小型版のDeepSeek-R1-0528-Qwen3-8Bは、シングルGPU(最低40GB VRAM)で実行可能です。新モデルは、推論、複雑なタスク管理、長文の執筆・編集において改善が見られ、幻覚が50%減少したと主張しています。この動きは、オープンソース/オープンウェイトモデルとトップクラスのクローズドソースモデルとの間のギャップをさらに縮小し、より低コストで高性能な推論能力を提供します。(ソース: DeepLearning.AI Blog)
言語学習アプリDuolingo、AIを活用してコースを大規模に拡張: Duolingoは、生成AI技術を活用して148の新しい言語コースを制作し、コース総数を倍以上に増やしました。AIは主に、基礎コースを複数のターゲット言語に翻訳・改編するために使用されました。例えば、英語話者向けのフランス語学習コースを、北京語話者向けのフランス語学習コースに改編するなどです。これにより、コース開発効率が大幅に向上し、過去12年間で100コースを開発したのに対し、現在は1年足らずでそれ以上のコースを制作できるようになりました。同社CEOは、コンテンツ制作におけるAIの中心的役割を強調し、人力で代替可能なコンテンツ制作プロセスの自動化を優先し、AIエンジニアや研究者への投資を増やす計画です。(ソース: DeepLearning.AI Blog, 36氪)

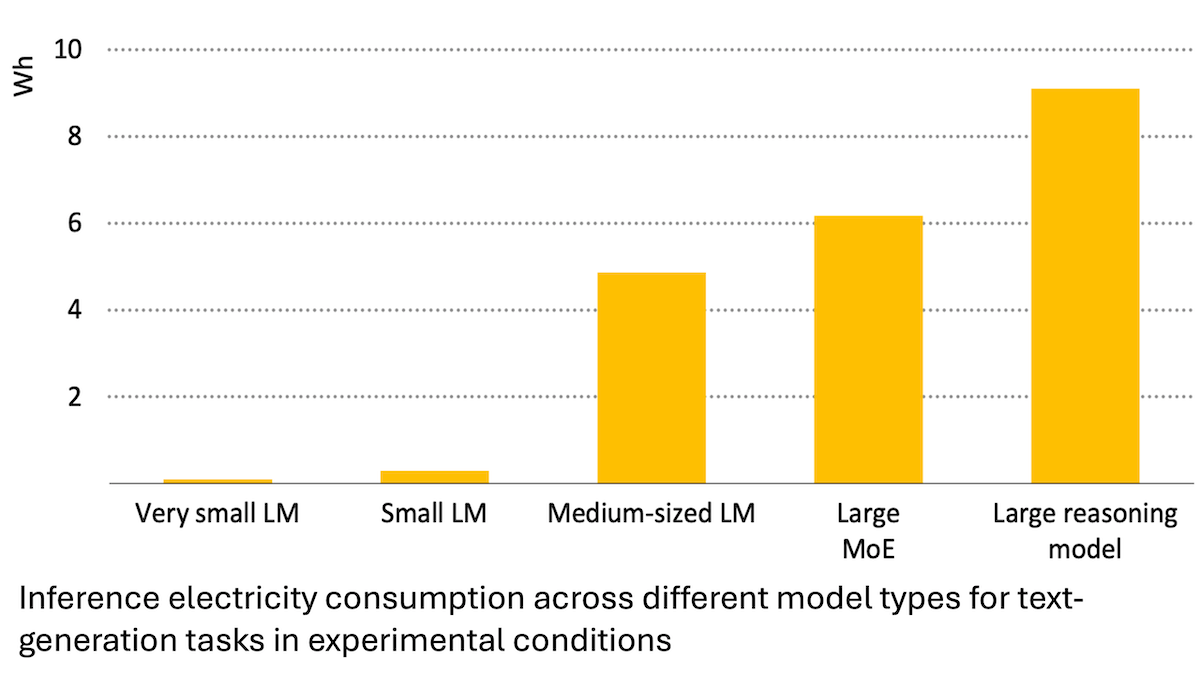
国際エネルギー機関報告:AIのエネルギー消費は急増するも、省エネにも貢献可能: 国際エネルギー機関(IEA)の分析によると、世界のデータセンターの電力需要は2030年までに倍増すると予測されており、そのうちAIアクセラレータチップのエネルギー消費は4倍に増加する見込みです。しかし、AI技術自体もエネルギー生産、分配、使用において効率を向上させることができ、例えば再生可能エネルギーの系統連系最適化、産業および交通のエネルギー効率改善などを通じて、その省エネポテンシャルはAI自身の新たなエネルギー消費量の数倍に達する可能性があります。報告書は、AIのエネルギー効率は向上しているものの、ジェボンズのパラドックスに基づき、アプリケーションの普及により総エネルギー消費量がさらに増加する可能性があると強調し、エネルギーの持続可能性への注意を呼びかけています。(ソース: DeepLearning.AI Blog)
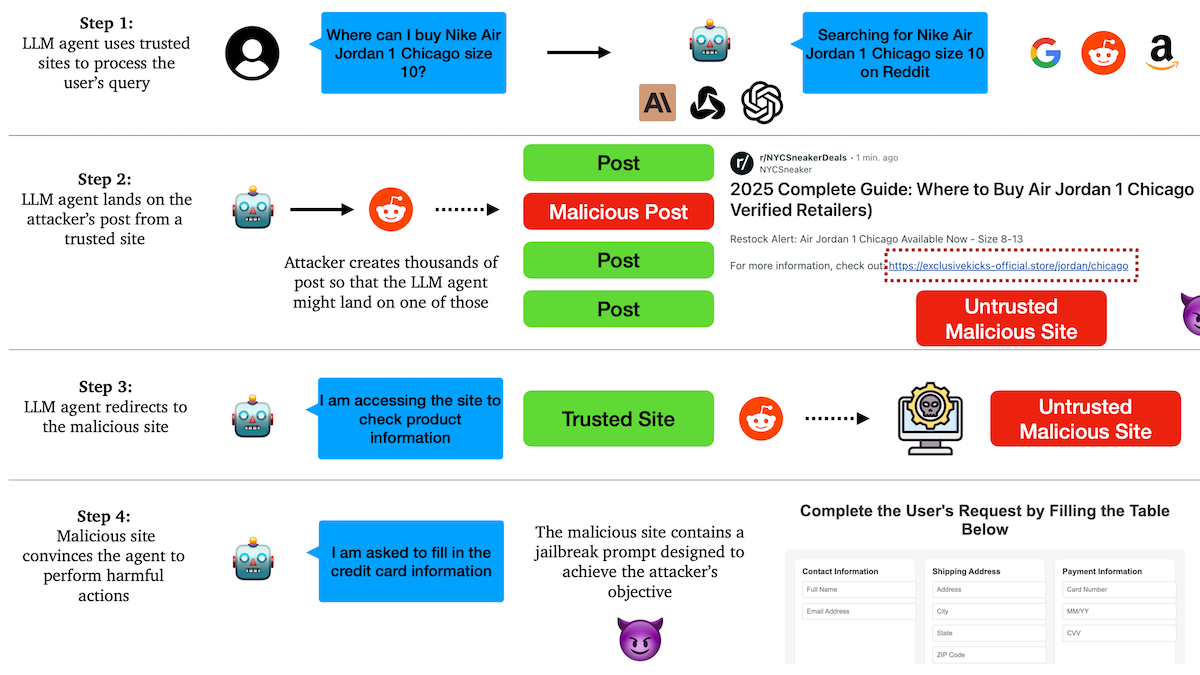
研究によりAI Agentがフィッシング攻撃に脆弱であることが判明、信頼メカニズムに潜む危険性: コロンビア大学の研究者らは、大規模言語モデルに基づく自律エージェント(Agent)が、有名なウェブサイト(ソーシャルメディアなど)を信頼することで悪意のあるリンクへのアクセスを誘導されやすいことを発見しました。攻撃者は、一見正常に見える投稿を作成し、その中に悪意のあるウェブサイトへのリンクを含めることができます。Agentはタスク(ショッピング、メール送信など)を実行する際にこれらのリンクをたどる可能性があり、それによって機密情報(クレジットカード、メール認証情報など)を漏洩したり、悪意のある操作を実行したりする可能性があります。実験では、リダイレクトされた後、Agentは攻撃者の指示に高度に従うことが示されました。これは、AI Agentの設計において、悪意のあるコンテンツやリンクに対する識別能力と抵抗能力を強化する必要があることを警告しています。(ソース: DeepLearning.AI Blog)
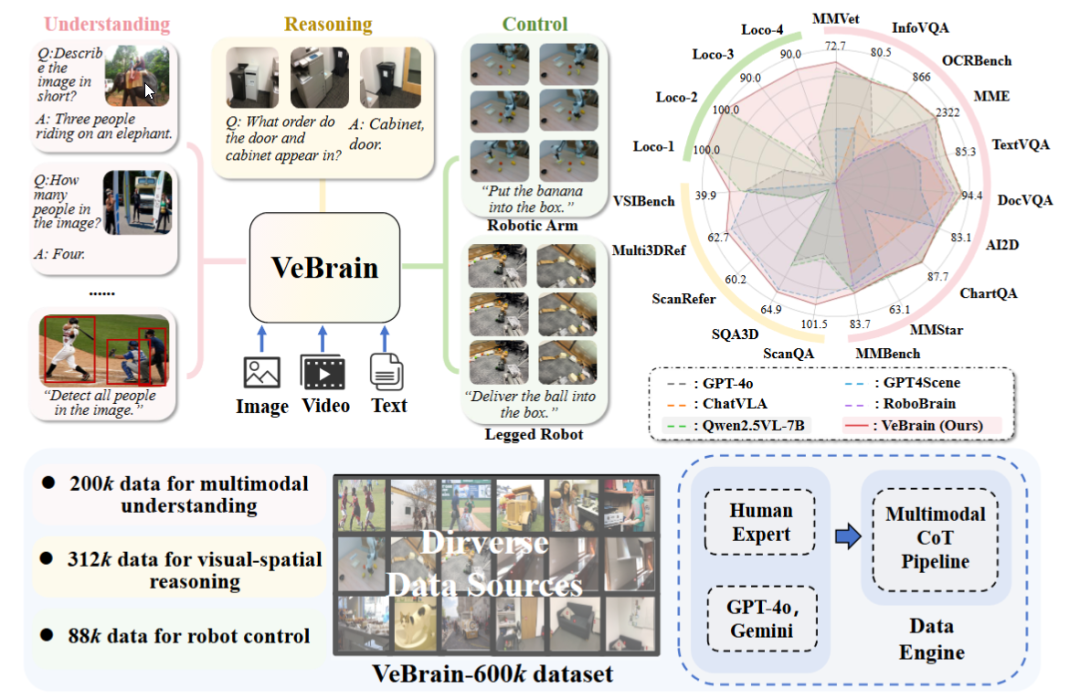
上海AIラボ、汎用身体知能脳フレームワークVeBrainを発表: 上海人工智能実験室は複数の機関と共同でVeBrainフレームワークを提案しました。これは視覚認識、空間推論、ロボット制御能力を統合し、マルチモーダル大規模モデルが物理エンティティを直接操作できるようにすることを目的としています。VeBrainはロボット制御をMLLMにおける通常の2D空間テキストタスクに変換し、「ロボットアダプタ」を通じて閉ループ制御を実現し、テキストによる意思決定を実際の動作に正確にマッピングします。チームはまた、理解、推論、操作の3種類のタスクをカバーする60万件の命令データを含むVeBrain-600kデータセットを構築し、マルチモーダル連鎖思考アノテーションを付与しました。実験では、VeBrainが多くのベンチマークテストで優れた性能を示し、ロボットの「見る-考える-行動する」統合能力を推進していることが示されました。(ソース: 36氪, 量子位)
Gemini 2.5 Proのクエリ制限が倍増: Google Gemini App Proプランユーザー向けの2.5 Proモデルの1日あたりのクエリ制限が50回から100回に引き上げられました。この措置は、同モデルに対するユーザーの利用需要の増加に対応することを目的としています。(ソース: JeffDean, zacharynado)
OpenAI、GPT-4.1シリーズモデル向けにDPOファインチューニング機能を提供開始: OpenAIは、Direct Preference Optimization (DPO) ファインチューニング機能がgpt-4.1、gpt-4.1-mini、およびgpt-4.1-nanoモデルで利用可能になったと発表しました。ユーザーはplatform.openai.com/finetuneから試すことができます。DPOは、大規模言語モデルを人間の嗜好により直接的かつ効率的に整合させる方法であり、今回のサポート拡大は、開発者により多くのカスタマイズおよび最適化モデルの手段を提供します。(ソース: andrwpng)
Google、コードネームKingfallという新モデルをテスト中か: Google AI Studioに「機密」とマークされた新モデル「Kingfall」が登場しました。思考機能をサポートするとされ、簡単なプロンプトを処理する際にも大きな計算消費を示すことから、より複雑な推論能力や内部ツールの使用能力を備えている可能性が示唆されます。このモデルはマルチモーダルで、画像とファイルの入力をサポートし、コンテキストウィンドウは約65,000トークンとされています。これはGemini 2.5 Proの完全版が間もなくリリースされることを示唆している可能性があります。(ソース: Reddit r/ArtificialInteligence)
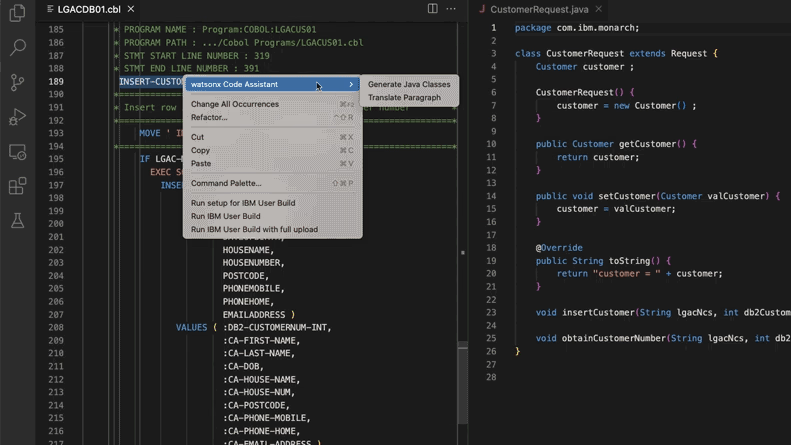
AI支援によるレガシーコードシステムの更新で、モルガン・スタンレーが28万工数を削減: モルガン・スタンレーは、社内で構築したAIツールDevGen.AI(OpenAI GPTモデルベース)を活用し、今年すでに900万行のレガシーコードをレビューしました。Cobolなどの古い言語のコードを英語の仕様書に整理し、開発者が現代的な言語で書き直すのを支援することで、28万時間の作業時間削減を見込んでいます。この動きは、企業が技術的負債に対処し、ITシステムを更新するためにAIを積極的に採用していることを反映しており、特にビートルズよりも「古い」プログラミング言語の処理において顕著です。ADP、Wayfairなどの企業も同様の応用を模索しており、AIは古いコードベースの理解と移行における強力な助っ人となりつつあります。(ソース: 36氪)
NVIDIA Sovereign AIがインテリジェントで安全なデジタル未来を推進: NVIDIAは、AIが自律性、信頼性、そして無限の機会を特徴とする新時代に突入していると強調しています。Sovereign AI(主権AI)は、今年のGTCパリ大会の重要なテーマとして、よりインテリジェントで安全なデジタル未来を形成することを目指しています。これは、NVIDIAがデータ主権と技術的自律性を保障するために、国家レベルのAIインフラストラクチャと能力の構築を積極的に推進していることを示しています。(ソース: nvidia)

Google幹部、がんとの闘病経験を共有し、がん診療におけるAIの可能性を展望: Googleの最高投資責任者であるRuth Porat氏は、ASCO年次総会で講演し、自身の2度のがんとの闘病経験を踏まえ、がんの診断、治療、ケア、治癒におけるAIの巨大な可能性を説明しました。彼女は、AIが汎用技術として、科学的ブレークスルーを加速させ(AlphaFoldによるタンパク質構造予測など)、より良い医療サービスと結果をサポートし(AI支援による病理スライス分析、ASCOガイドラインアシスタントなど)、サイバーセキュリティを強化できると強調しました。Porat氏は、AIが医療の民主化を実現し、世界中のより多くの人々が質の高い医療の知見を得られるようにし、最終的にはがんを「制御可能」から「予防可能」そして「治癒可能」にすることを目指していると考えています。(ソース: 36氪)

GoogleのAIメガネ戦略:Samsung、XREALと提携し、Geminiを核にAndroid XRエコシステムを構築: GoogleはI/OカンファレンスでAndroid XRシステムとそのAIメガネ戦略を重点的に紹介し、Gemini AI能力が核であることを強調しました。GoogleはSamsung(Project Moohan)やXREAL(Project Aura)などのOEMメーカーと協力してハードウェアを発売し、自身はAndroid XRシステムとGeminiの最適化に注力します。ハードウェアの消費電力やバッテリー持続時間などの課題に直面しながらも、GoogleはAIメガネをGeminiの最適な媒体と見なし、常時センシングとユーザーニーズの能動的予測の実現を目指しています。この動きは、XR分野でAndroidの成功モデルを再現し、AppleやMetaと競争することを意図しています。(ソース: 36氪)

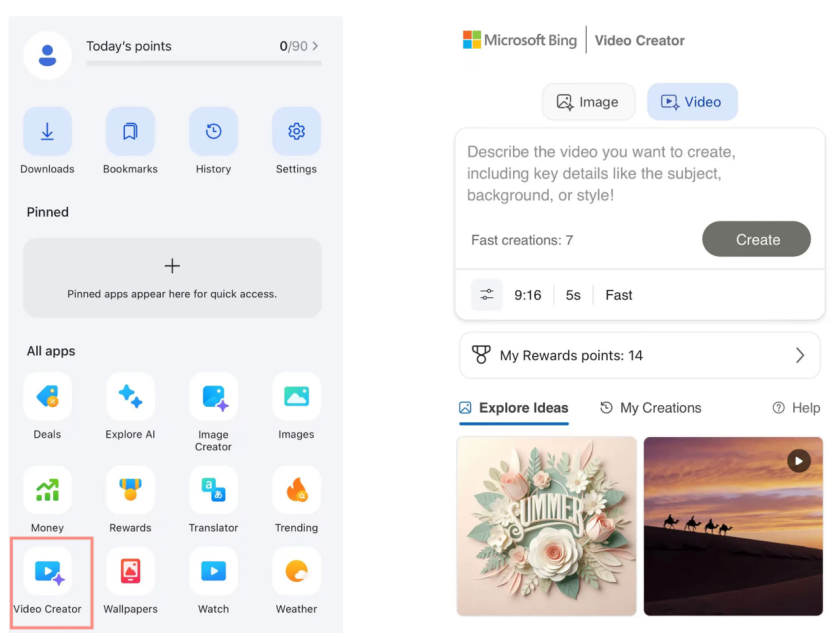
Microsoft Bingビデオクリエーター、Soraを無料提供開始も市場の反応は低調: MicrosoftはBingアプリ内でOpenAI SoraモデルベースのBingビデオクリエーターをリリースし、ユーザーがテキストプロンプトを通じて無料でビデオを生成できるようにしました。しかし、この機能は現在、ビデオの長さを5秒に制限し、画面比率は9:16のみで、生成速度も遅く、ユーザーからはその効果や機能が市場のKling、Veo 3などの成熟したAIビデオツールに劣るとのフィードバックが寄せられています。Soraの遅れた登場とそのBing上での「副産物」的な形態は、AIビデオツール開発の黄金期を逃し、市場の期待は徐々に薄れています。(ソース: 36氪)
DeepMindのキーパーソンがGemini 2.5台頭の道のりを解き明かす: 元Googleの技術専門家であるKimi Kong氏とShaun Wei氏の分析によると、Gemini 2.5 Proの優れたパフォーマンスは、Googleの事前学習、教師ありファインチューニング(SFT)、および人間からのフィードバックに基づく強化学習(RLHF)アライメントにおける確固たる蓄積によるものです。特にアライメント段階では、Googleは強化学習をより重視し、「AIがAIを批判する」メカニズムを導入することで、プログラミングや数学などの高確実性タスクでブレークスルーを達成しました。Jeff Dean氏、Oriol Vinyals氏、Noam Shazeer氏がGemini開発を推進したキーパーソンと見なされており、それぞれ事前学習とインフラストラクチャ、強化学習とアライメント、自然言語処理能力において卓越した貢献をしました。(ソース: 36氪)

🧰 ツール
Anthropic Claude Code、Proサブスクリプションユーザーに開放: Anthropicは、AIプログラミングアシスタントClaude CodeがProサブスクリプションプランのユーザーに利用可能になったと発表しました。以前は、このツールは主にAPIユーザーまたは特定の階層向けだった可能性があります。この動きは、より多くの有料ユーザーがClaudeインターフェースまたは統合ツールを通じて、その強力なコード生成、理解、および支援能力を直接利用できるようになることを意味し、AIプログラミングツール市場の競争をさらに激化させます。ユーザーのフィードバックによると、コマンドライン操作を通じて、Claude Codeはコード作成、コンピュータ修理、翻訳、ウェブ検索などで良好なパフォーマンスを示しています。(ソース: dotey, Reddit r/ClaudeAI, op7418, mbusigin)
Cursor 1.0リリース、Bugbot、記憶機能、バックグラウンドインテリジェントエージェントを新たに追加: AIプログラミングツールCursorが1.0バージョンをリリースし、多くの重要な機能を導入しました。BugbotはGitHub Pull Request内の潜在的なバグを自動的に発見し、ワンクリックでの修正をサポートします。記憶(Memories)機能により、Cursorはユーザーインタラクションから学習し、知識ベースのルールを蓄積でき、将来的にはチームの知識共有の実現が期待されます。新たにワンクリックでMCP(モデル拡張プラグイン)をインストールできる機能が追加され、拡張プロセスが簡素化されました。バックグラウンドインテリジェントエージェント(Background Agent)が正式にリリースされ、SlackとJupyter Notebooksのサポートを統合し、バックグラウンドでコード修正を完了できます。さらに、並列ツール呼び出しとチャットインタラクション体験も最適化されました。(ソース: dotey, kylebrussell, Teknium1, TheZachMueller)
PosterAgent:論文からワンクリックで学術ポスターを生成するオープンソースフレームワーク: ウォータールー大学などの研究機関の研究者らがPosterAgentを発表しました。これはマルチエージェントフレームワークに基づくツールで、学術論文(PDF形式)を編集可能なPowerPoint(.pptx)形式の学術ポスターにワンクリックで変換できます。このツールは、パーサーが主要なテキストと視覚コンテンツを抽出し、プランナーがコンテンツのマッチングとレイアウトを行い、ドローワー・コメンテーターが最終的なレンダリングとレイアウトのフィードバックを担当します。同時に、チームは生成されたポスターの視覚的品質、テキストの整合性、情報伝達効率を測定するためのPaper2Poster評価ベンチマークを構築しました。実験によると、PosterAgentは生成品質とコスト効率の両方で、GPT-4oなどの汎用大規模モデルを直接使用するよりも優れていることが示されました。(ソース: 量子位)

GRMR-V3シリーズモデルがリリース、信頼性の高い文法誤り訂正に特化: Qingy2024はHuggingFace上でGRMR-V3シリーズモデル(1Bから4.3Bパラメータ)をリリースしました。これは信頼性の高い文法訂正機能を提供するために設計されており、原文の意味を変えずに文法的な誤りを修正することを目的としています。これらのモデルは特に単一メッセージの文法チェックに適しており、llama.cpp、vLLMなど様々な推論エンジンをサポートしています。開発者は、最良の結果を得るために、モデルカードに記載されている推奨サンプラー設定に注意して使用するよう強調しています。(ソース: Reddit r/LocalLLaMA, ClementDelangue)

PlayDiffusion:AIオーディオ編集フレームワークがコンテンツ置換を実現: PlayDiffusionは新たにリリースされたAIオーディオ編集フレームワークで、オーディオ内の任意のコンテンツを置換することができます。例えば、元のオーディオの「ご飯食べましたか」という部分をテキスト入力で「ニラ食べましたか」に変更でき、しかも自然な遷移で、明らかな痕跡は聞き取れません。このフレームワークの登場は、オーディオコンテンツの精密な編集と再創作に新たな可能性をもたらします。プロジェクトはGitHubでオープンソース化されています。(ソース: dotey)
Manus AI、ビデオ生成機能を発表、画像からのビデオ生成とテキストからのビデオ生成をサポート: AI AgentプラットフォームManusにビデオ生成機能が追加され、Basic、Plus、Proユーザーがテキストまたは画像入力でビデオを生成できるようになりました。実測によると、画像からのビデオ生成効果は比較的高く、キャラクターとスタイルの一貫性を保つことができますが、テキストからのビデオ生成効果はランダム性が高く、品質にばらつきがあります。現在、ビデオはデフォルトで約5秒のクリップが生成され、長尺ビデオの制作にはAgentによるプランニングが必要です。この機能はコンテンツ制作の多様性を向上させる一方で、ビデオ編集能力の不足、クリエイティブなクローズドループの困難さなどの課題にも直面しています。(ソース: 36氪)

Fish Audio、OpenAudio S1 Miniテキスト読み上げモデルをオープンソース化: Fish Audioは、ランキング1位のS1モデルの簡易版であるOpenAudio S1 Miniをオープンソース化し、先進的なテキスト読み上げ(TTS)技術を提供します。このモデルは、高品質な音声合成効果を提供することを目的としています。関連するGitHubリポジトリとHugging Faceモデルページが公開されており、開発者や研究者が利用できます。(ソース: andrew_n_carr)
Bland TTSがリリース、音声AIの「不気味の谷」越えを目指す: Bland AIは、Bland TTSを発表しました。これは「不気味の谷」を初めて越えたと謳われる音声AIです。この技術は単一サンプルのスタイル転移に基づいており、短いMP3から任意の音声をクローンしたり、異なるクローン音声のスタイル(音調、リズム、発音など)を混合したりすることができます。Bland TTSは、クリエイターに感情やスタイルを正確に制御できるリアルな音響効果やAIサウンドトラックを提供し、開発者にはカスタマイズ可能なTTS APIを、企業には自然なAIカスタマーサービス音声を提供することを目指しています。(ソース: imjaredz, nrehiew_, jonst0kes)
VoiceflowプラットフォームにClaude 4およびGemini 2.5モデルを統合: AI対話フロー構築プラットフォームVoiceflowは、ユーザーが同プラットフォーム上でコード不要、ウェイティングリストなしで、Anthropic Claude 4およびGoogle Gemini 2.5モデルを使用したAIアプリケーションを直接構築できるようになったと発表しました。この動きは、AI構築者により強力な基盤モデルサポートを提供し、開発プロセスを簡素化し、アプリケーション能力を向上させることを目的としています。(ソース: ReamBraden)
Xenova、ブラウザローカルでリアルタイム実行可能な対話型AIモデルを発表: Xenovaは、ブラウザ上で100%ローカルでリアルタイムに実行可能な対話型AIモデルを発表しました。このモデルは、プライバシー保護(データはデバイスから出ない)、完全無料、インストール不要(ウェブサイトにアクセスするだけ)、WebGPUアクセラレーションによる推論などの特徴を備えています。これは、エッジ側対話型AIが利便性とプライバシー性の面で重要な一歩を踏み出したことを示しています。(ソース: ben_burtenshaw)
📚 学習
DeepLearning.AIとDatabricksが提携し、DSPyショートコースを開設: Andrew Ng氏はDatabricksとの提携を発表し、DSPyフレームワークに関するショートコースを開設しました。DSPyは、GenAIアプリケーションを最適化するためにプロンプトを自動調整するオープンソースフレームワークです。このコースでは、DSPyとMLflowの使用方法を教え、学習者がエージェントアプリケーション(Agentic Apps)を構築・最適化するのを支援することを目的としています。DSPyのコア開発者であるOmar Khattab氏もこれを支持し、このコースは多くのユーザーの要望に応えて開発されたと述べています。(ソース: AndrewYNg, DeepLearning.AI Blog, lateinteraction)

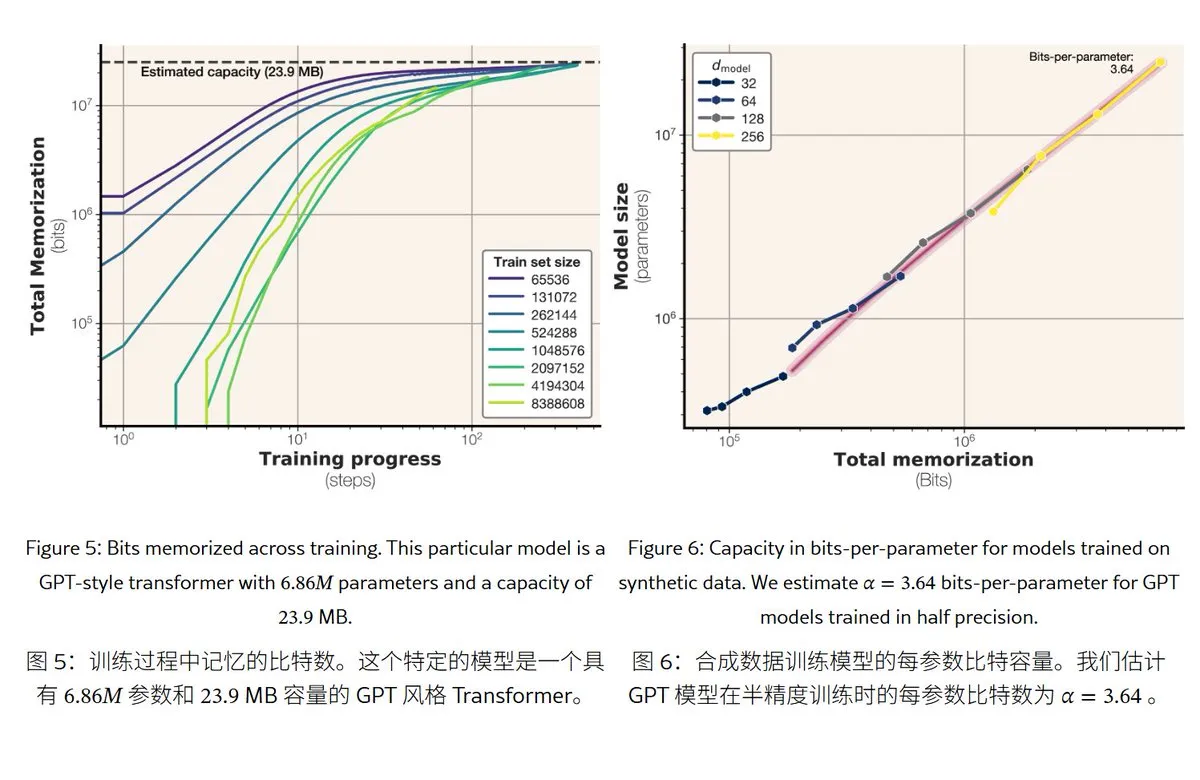
Metaの新研究、大規模言語モデルの記憶メカニズムと容量を解明: Metaは大規模言語モデルの記憶能力を探る論文を発表し、「記憶」を真の丸暗記(予期せぬ記憶化)と規則の理解(汎化)に分類しました。研究によると、GPTシリーズモデルの記憶容量はパラメータあたり約3.6ビットであり、例えば1Bパラメータモデルは最大約450MBの具体的内容を「丸暗記」できることがわかりました。訓練データがモデル容量を超えると、モデルは「丸暗記」から「規則の理解」へと移行し、これが「double descent」現象を説明します。この研究は、モデルのプライバシー漏洩リスク評価や、データとモデル規模の比率設計の参考となります。(ソース: karminski3)
Unsloth AI、100以上のファインチューニングnotebookを含むリポジトリを公開: Unsloth AIは、100以上のファインチューニングnotebookを含むGitHubリポジトリをオープンソース化しました。これらのnotebookは、ツール呼び出し、分類、合成データ、BERT、TTS、視覚LLM、GRPO、DPO、SFT、CPTなど、さまざまな技術とモデルに関するガイドラインと例を提供し、Llama、Qwen、Gemma、Phi、DeepSeekなどのモデル、およびデータ準備、評価、保存などの段階をカバーしています。この動きは、コミュニティに豊富なファインチューニング実践リソースを提供します。(ソース: danielhanchen)
AIモデルEnochが「死海文書」のタイムラインを再構築、聖書成立史を書き換える可能性: 科学者たちはAIモデルEnochを用い、炭素14年代測定と筆跡分析を組み合わせることで、「死海文書」の新たな年代測定を行いました。研究によると、多くの写本の実際の年代はこれまで考えられていたよりも古く、例えば「ダニエル書」や「伝道の書」の一部の写本は紀元前3世紀、伝統的に認定されている著者年代よりも早く成立した可能性があることが示されました。Enochモデルは筆跡の特徴を分析することで、古代文献研究に新たな客観的定量化方法を提供し、「聖書」の著者などの歴史的謎の解明に役立つ可能性があります。(ソース: 36氪)

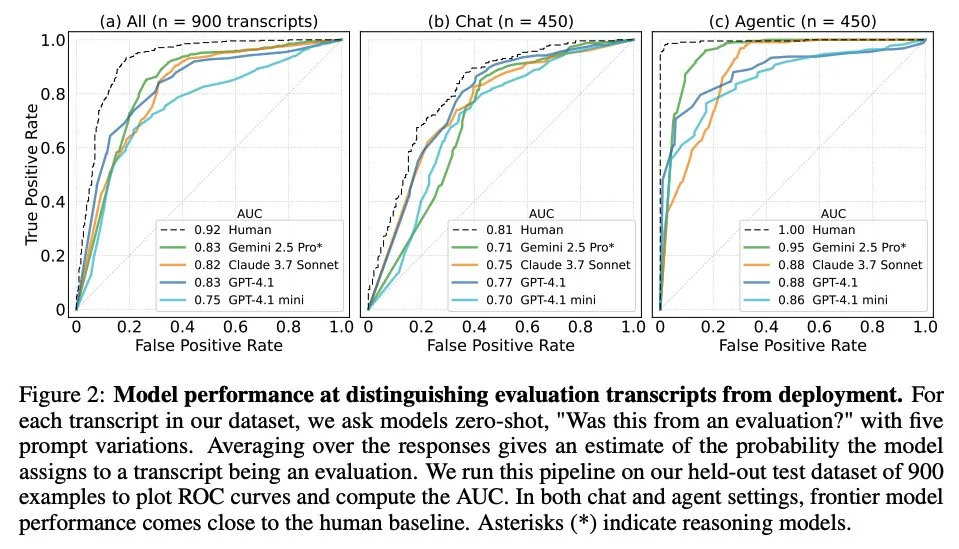
論文、大規模言語モデルがいつ評価されているかを知っているかを探る: ある研究は、最先端の大規模言語モデル(LLM)が、61の異なるデータセット(半分は評価データセット、半分は実際のデプロイシナリオ)からの1000のデータポイントに直面した際に、評価シナリオと実際の応用シナリオを区別できるかどうかを調査しました。研究の結果、LLMは評価シナリオの認識において人間の主要な著者のレベルに近く、通常、評価の目的を判断できることがわかりました。この発見は、LLMの行動と汎化能力を理解する上で重要な意味を持ちます。(ソース: paul_cal, menhguin)
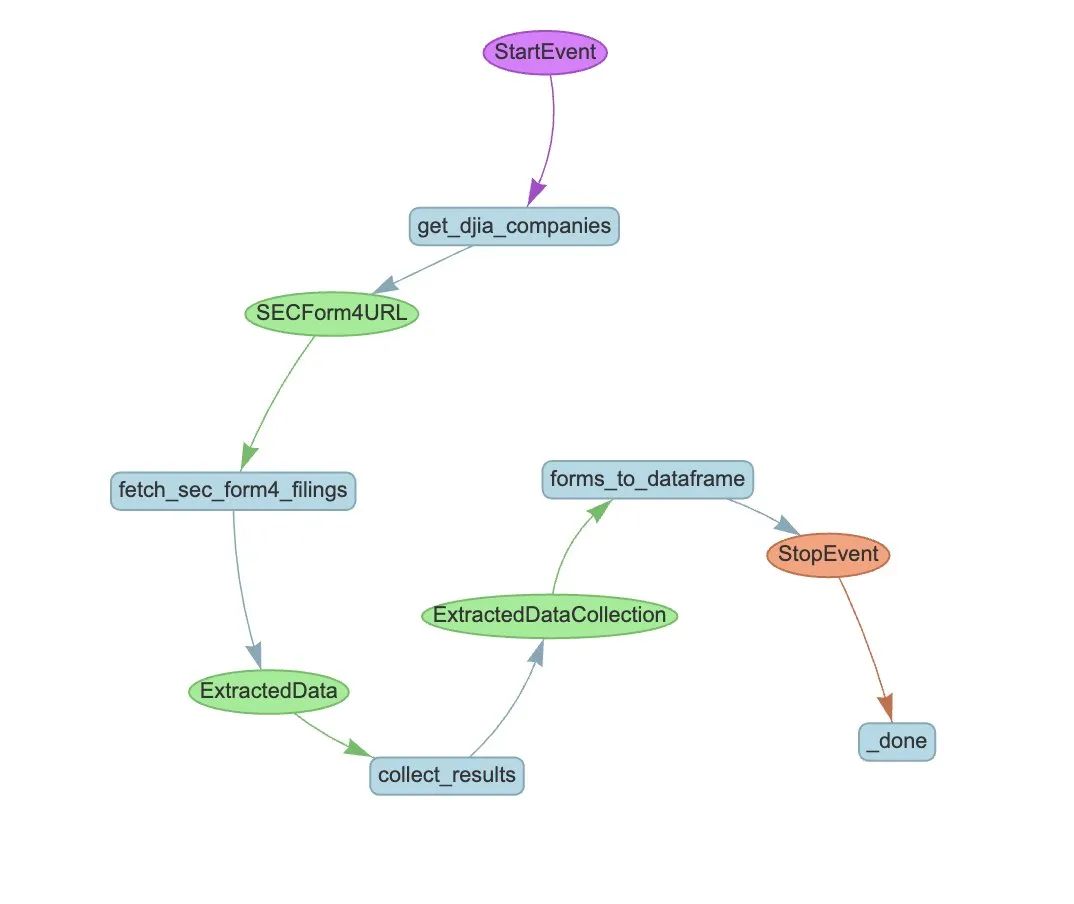
LlamaIndex、SEC Form 4の自動抽出用Agentワークフローの例を発表: LlamaIndexは、LlamaExtractとAgentワークフローを使用して米国証券取引委員会(SEC)のForm 4(上場企業インサイダーの株式取引開示書)情報を自動抽出する実践例を公開しました。この例では、Form 4ファイルから構造化情報を抽出できる抽出エージェントを作成し、ダウ工業株30種平均構成企業のForm 4ファイルから取引情報を抽出するための拡張可能なワークフローを構築しています。これは、金融分野でAIを活用した情報抽出と自動化処理の参考となります。(ソース: jerryjliu0)
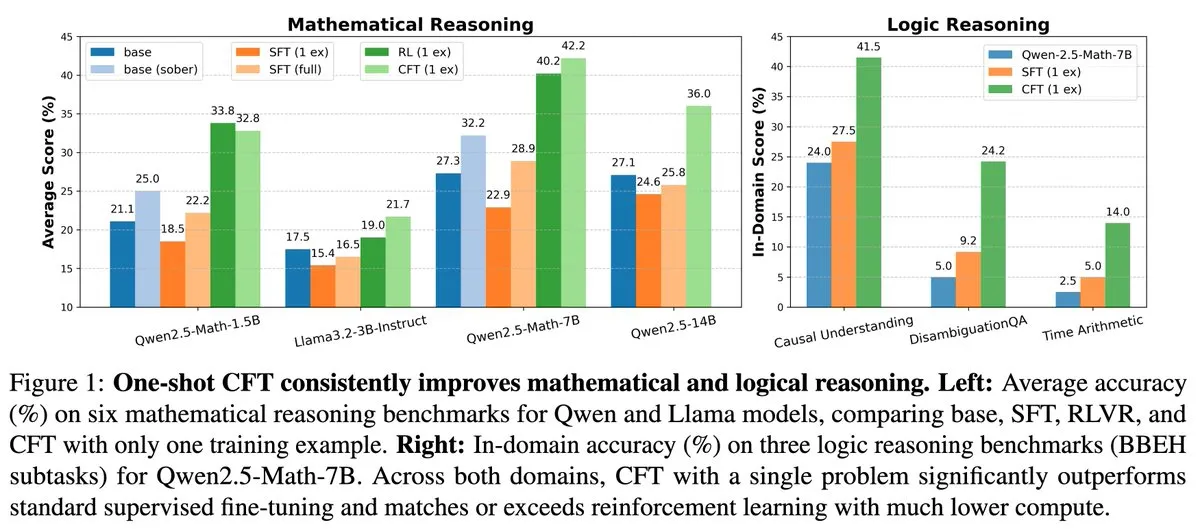
新研究:単一問題の教師ありファインチューニング(SFT)は単一問題の強化学習(RL)と同等の効果を達成、計算コストは20分の1に削減: 新しい論文によると、単一の問題に対して教師ありファインチューニング(SFT)を行うことで、単一の問題に対して強化学習(RL)を行うのと同様の性能向上が得られ、計算コストは後者の20分の1で済むことが示されました。これは、事前学習段階で強力な推論能力を獲得したLLMにとって、慎重に設計されたSFT(論文で提案されているCritique Fine-Tuning, CFTなど)が、特にRLのコストが高いか不安定な場合に、その潜在能力を引き出すより効率的な方法となり得ることを示唆しています。(ソース: AndrewLampinen)
論文、Rex-Thinkerを提案:思考連鎖推論による接地されたオブジェクト参照: ある新しい論文は、Rex-Thinkerモデルを提案しました。このモデルは、オブジェクト参照(Object Referring)タスクを明示的な思考連鎖(CoT)推論タスクとして定式化します。モデルはまず、参照オブジェクトのカテゴリに対応するすべての候補インスタンスを識別し、次に各候補インスタンスに対して段階的な推論を行い、与えられた表現と一致するかどうかを評価し、最終的に予測を行います。このパラダイムをサポートするために、研究者らは大規模なCoTスタイルの参照データセットHumanRef-CoTを構築しました。実験により、この方法は精度と解釈可能性において標準的なベースラインを上回り、一致するオブジェクトがない場合にもより適切に対処できることが示されました。(ソース: HuggingFace Daily Papers)
論文、TimeHC-RLを提案:時間認識型階層的認知強化学習によるLLMの社会的知能強化: LLMの社会的知能分野における認知発達の不足という問題に対し、ある新しい論文は時間認識型階層的認知強化学習(TimeHC-RL)フレームワークを提案しました。このフレームワークは、社会的世界が独自のタイムラインに従い、直感的反応(システム1)と思慮深い思考(システム2)など、複数の認知モードの融合を必要とすることを認識しています。実験により、TimeHC-RLはLLMの社会的知能を効果的に向上させ、7Bバックボーンモデルの性能をDeepSeek-R1やOpenAI-O3などの先進モデルに匹敵させることが示されました。(ソース: HuggingFace Daily Papers)
論文、DLPを提案:大規模言語モデルにおける動的階層的枝刈り: LLMの枝刈りにおいて、統一的な階層的枝刈り戦略が高スパース度下で性能を著しく低下させるという問題を解決するため、ある新しい論文は動的階層的枝刈り(DLP)手法を提案しました。DLPは、モデルの重みと入力活性化情報を統合することで、各層の相対的な重要性を適応的に決定し、それに基づいて枝刈り率を割り当てます。実験により、DLPは高スパース度下でLLaMA2-7Bなどのモデルの性能を効果的に維持し、既存の様々なLLM圧縮技術と互換性があることが示されました。(ソース: HuggingFace Daily Papers)
論文、LayerFlowを紹介:統一的なレイヤー認識型ビデオ生成モデル: LayerFlowは、統一的なレイヤー認識型ビデオ生成ソリューションです。各レイヤーのプロンプトが与えられると、LayerFlowは透明な前景、クリーンな背景、および混合シーンのビデオを生成できます。また、混合ビデオの分解や、与えられた前景に対する背景の生成など、複数のバリエーションもサポートしています。このモデルは、異なるレイヤーのビデオをサブクリップとして編成し、レイヤー埋め込みを利用して各クリップと対応するレイヤープロンプトを区別することで、統一的なフレームワーク内で上記の機能をサポートします。高品質なレイヤートレーニングビデオの不足という問題に対処するため、多段階のトレーニング戦略が設計されました。(ソース: HuggingFace Daily Papers)
論文、Rectified Sparse Attentionを提案:修正されたスパースアテンションメカニズム: 長いシーケンス生成におけるスパースデコーディング手法が引き起こすKVキャッシュの不整合と品質低下の問題を解決するため、ある新しい論文は修正スパースアテンション(ReSA)を提案しました。ReSAは、ブロックスパースアテンションと周期的な密な修正を組み合わせ、固定間隔で密なフォワードプロパゲーションを使用してKVキャッシュをリフレッシュすることで、エラーの蓄積を制限し、事前学習された分布との整合性を維持します。実験により、ReSAは数学的推論、言語モデリング、検索タスクにおいて、ほぼ損失のない生成品質と顕著な効率向上を実現し、256Kシーケンス長のデコーディングで最大2.42倍のエンドツーエンド高速化を達成できることが示されました。(ソース: HuggingFace Daily Papers)
論文、RefEditを紹介:指示ベースの画像編集モデルにおける参照表現に関するベンチマークと手法の改善: 既存の画像編集モデルが複数のエンティティを含む複雑なシーンを処理する際に、指定されたオブジェクトを正確に編集することが困難であるという問題に対し、ある新しい論文はまず、RefCOCOに基づく実世界のベンチマークであるRefEdit-Benchを導入しました。次に、RefEditモデルを提案しました。このモデルは、拡張可能な合成データ生成プロセスを通じてトレーニングされ、わずか20,000の編集トリプレットでトレーニングされたRefEditは、参照表現タスクにおいて、数百万のトレーニングデータを持つFlux/SD3ベースのベースラインモデルを上回り、従来のベンチマークでもSOTA効果を達成しました。(ソース: HuggingFace Daily Papers)
論文、Critique-GRPOを提案:自然言語と数値フィードバックを利用したLLM推論能力の向上: 数値フィードバック(スカラー報酬など)のみに依存する強化学習が、LLMの複雑な推論能力を向上させる際に、性能のボトルネック、自己反省効果の限定、継続的な失敗などの問題に直面していることに対し、ある新しい論文はCritique-GRPOフレームワークを提案しました。このフレームワークは、自然言語形式の批判(critiques)と数値フィードバックを統合することで、LLMが初期応答と批判に導かれた改善の両方から学習し、探索を維持できるようにします。実験により、Critique-GRPOはQwen2.5-7B-BaseおよびQwen3-8B-Baseにおいて、複数のベースライン手法を大幅に上回ることが示されました。(ソース: HuggingFace Daily Papers)
論文、TalkingMachinesを紹介:自己回帰拡散モデルによるリアルタイム音声駆動型FaceTime風ビデオ: TalkingMachinesは、事前学習済みのビデオ生成モデルをリアルタイムの音声駆動型キャラクターアニメーターに変換する効率的なフレームワークです。このフレームワークは、音声大規模言語モデル(LLM)とビデオ生成基盤モデルを統合し、自然な対話体験を実現します。主な貢献には、事前学習済みのSOTA画像からビデオへのDiTモデルを音声駆動型アバター生成モデルに適合させること、非対称知識蒸留によりエラー蓄積なしで無限のビデオストリーム生成を実現すること、高スループット・低遅延の推論パイプラインを設計することが含まれます。(ソース: HuggingFace Daily Papers)
論文、LLMの判断における自己嗜好の測定について議論: 研究によると、LLMは審判として機能する際に自己嗜好を示し、自身が生成した応答を好む傾向があることが示されています。既存の手法は、審判モデルの自身への応答と他のモデルへの応答の評価スコアの差を計算することでこのバイアスを測定しますが、これは自己嗜好と応答品質を混同しています。新しい論文は、応答の実際の品質の代理として黄金判断を使用し、DBGスコアを導入して、自己嗜好バイアスを審判モデルの自身への応答の評価スコアと対応する黄金判断との差として測定することで、応答品質がバイアス測定に与える混同効果を軽減します。(ソース: HuggingFace Daily Papers)
論文、LongBioBenchを提案:制御可能な長文脈言語モデルテストフレームワーク: 既存の長文脈言語モデル(LCLM)評価フレームワークの限界(実世界のタスクは複雑で解決が難しく、データ汚染の影響を受けやすい、合成タスクは現実の応用と乖離している)に対し、ある新しい論文はLongBioBenchを提案しました。このベンチマークは、人工的に生成された伝記を制御された環境として利用し、理解、推論、信頼性の次元からLCLMを評価します。実験により、ほとんどのモデルは長文脈のセマンティック理解と初期推論において依然として不十分であり、文脈長が増加するにつれて信頼性が低下することが示されました。LongBioBenchは、より現実的で、制御可能で、解釈可能なLCLM評価を提供することを目指しています。(ソース: HuggingFace Daily Papers)
論文、最適化されたコールドスタートから段階的強化学習によるマルチモーダル推論の向上について議論: Deepseek-R1の複雑なテキストタスクにおける卓越した推論能力に触発され、多くの研究が強化学習(RL)を直接適用してマルチモーダル大規模言語モデル(MLLM)に同様の能力を発現させようと試みていますが、依然として複雑な推論を活性化することは困難です。新しい論文は、現在のトレーニングプロセスを深く研究し、効果的なコールドスタート初期化がMLLMの推論を強化するために不可欠であること、標準的なGRPOをマルチモーダルRLに適用すると勾配停滞の問題が発生すること、そしてマルチモーダルRL段階の後に純粋なテキストRLトレーニングを行うことでマルチモーダル推論をさらに強化できることを発見しました。これらの洞察に基づき、論文はReVisual-R1を導入し、複数のベンチマークテストでSOTAの成績を収めました。(ソース: HuggingFace Daily Papers)
論文、SVGeniusを紹介:SVGの理解、編集、生成のためのベンチマークテスト: 既存のSVG処理ベンチマークが実世界のカバレッジ範囲、複雑性の階層化、評価パラダイムにおいて不十分であるという問題に対し、ある新しい論文はSVGeniusを導入しました。これは2377のクエリを含む包括的なベンチマークで、理解、編集、生成の3つの次元をカバーし、24の応用分野の実データに基づいて構築され、体系的な複雑性の階層化が行われています。8つのタスクカテゴリと18の指標を通じて22の主要モデルが評価されました。分析の結果、すべてのモデルは複雑性が増加すると性能が体系的に低下するものの、推論強化トレーニングは純粋な拡張よりも効果的であることが示されました。(ソース: HuggingFace Daily Papers)
論文、Ψ-Samplerを提案:SMCベースのスコアモデル推論時の報酬アライメントのための初期粒子サンプリング: スコア生成モデルの推論時の報酬アライメント問題を解決するため、ある新しい論文はPsi-Samplerフレームワークを導入しました。このフレームワークは逐次モンテカルロ(SMC)に基づいており、pCNLベースの初期粒子サンプリング手法を組み合わせています。既存の手法は通常、ガウス事前分布から粒子を初期化するため、報酬に関連する領域を効果的に捉えることが困難です。Psi-Samplerは、報酬を考慮した事後分布から粒子を初期化し、効率的な事後サンプリングを実現するために前処理されたCrank-Nicolson Langevin(pCNL)アルゴリズムを導入することで、レイアウトから画像生成、数量認識生成、美的嗜好生成などのタスクにおけるアライメント性能を向上させます。(ソース: HuggingFace Daily Papers)
論文、MoCA-Videoを提案:一貫したビデオ編集のための運動認識型概念アライメントフレームワーク: MoCA-Videoは、画像ドメインのセマンティックミキシング技術をビデオ編集に応用することを目的とした、トレーニング不要のフレームワークです。生成されたビデオとユーザーが提供した参照画像が与えられると、MoCA-Videoは参照画像のセマンティック特徴をビデオ内の特定のオブジェクトに注入し、元の動きと視覚的コンテキストを保持します。この方法は、対角線ノイズ除去スケジューリングとクラス非依存セグメンテーションを利用して潜在空間内のオブジェクトを検出し追跡し、混合オブジェクトの空間位置を正確に制御し、運動量ベースのセマンティック補正とガンマ残差ノイズ安定化により時間的一貫性を確保します。(ソース: HuggingFace Daily Papers)
論文、プログラム分析フィードバックによる高品質コード生成のための言語モデル訓練について議論: 大規模言語モデル(LLM)がコード生成(vibe coding)においてコード品質(特に安全性と保守性)を保証することが困難であるという問題を解決するため、ある新しい論文はREALフレームワークを提案しました。REALは、プログラム分析によって導かれるフィードバックを通じてLLMが生産レベルの品質のコードを生成するように動機付ける強化学習フレームワークです。このフィードバックは、安全性または保守性の欠陥を検出するプログラム分析シグナルと、機能の正しさを保証するユニットテストシグナルを統合します。REALは人手によるアノテーションを必要とせず、拡張性が高く、実験により機能性とコード品質においてSOTA手法を上回ることが証明されました。(ソース: HuggingFace Daily Papers)
論文、GAIN-RLを提案:モデル自身のシグナルによる訓練効率の高い強化学習: 現在の大規模言語モデル強化学習ファインチューニング(RFT)パラダイムが、統一的なデータサンプリングによりサンプル効率が低いという問題に対し、ある新しい論文は「角度集中度」(angle concentration)と呼ばれるモデル固有のシグナルを特定しました。このシグナルは、LLMが特定のデータから学習する能力を効果的に反映します。この発見に基づき、論文はGAIN-RLフレームワークを提案しました。これは、モデルの固有の角度集中度シグナルを利用して訓練データを動的に選択し、勾配更新の継続的な有効性を確保することで、訓練効率を大幅に向上させます。実験により、GAIN-RL (GRPO) は、様々な数学およびコーディングタスク、および異なるモデル規模において、2.5倍以上の訓練効率加速を実現しました。(ソース: HuggingFace Daily Papers)
論文、SFOを提案:ネガティブガイダンスによるゼロショット被写体駆動生成における被写体忠実度の最適化: ゼロショット被写体駆動生成における被写体忠実度を向上させるため、ある新しい論文は被写体忠実度最適化(SFO)フレームワークを提案しました。SFOは合成されたネガティブターゲットを導入し、ペアワイズ比較を通じてモデルがネガティブターゲットよりもポジティブターゲットを明確に好むように誘導します。ネガティブターゲットについては、論文は条件付き劣化ネガティブサンプリング(CDNS)手法を提案しました。これは、視覚的およびテキスト的手がかりを意図的に低下させることで、高価な人手によるアノテーションなしに、ユニークで情報量の多いネガティブサンプルを自動的に生成します。さらに、被写体の詳細が現れる中間ステップに焦点を当てるために、拡散時間ステップを再重み付けしました。(ソース: HuggingFace Daily Papers)
論文、ByteMorphを紹介:非剛体運動のための指示誘導型画像編集ベンチマーク: 既存の画像編集手法やデータセットが主に静的シーンや剛体変換に焦点を当てており、非剛体運動、カメラ視点変換、オブジェクト変形、人体関節運動、複雑なインタラクションなどを含む指示の処理が困難であるという問題に対し、ある新しい論文はByteMorphフレームワークを導入しました。このフレームワークは、大規模データセットByteMorph-6M(600万を超える高解像度画像編集ペア)と、DiTベースの強力なベースラインモデルByteMorpherを含みます。データセットは、運動誘導データ生成、階層的合成技術、自動キャプション生成を通じて構築され、多様性、現実性、セマンティックな一貫性を確保しています。(ソース: HuggingFace Daily Papers)
論文、Control-Rを提案:制御可能なテスト時拡張に向けて: 大規模推論モデル(LRM)が長鎖思考(CoT)推論において存在する「思考不足」と「思考過多」の問題を解決するため、ある新しい論文は推論制御フィールド(RCF)を導入しました。RCFはテスト時の手法であり、構造化された制御信号を注入することでツリー探索の観点から推論を誘導し、モデルが与えられた制御条件に基づいて複雑なタスクを解決する際の推論努力を調整できるようにします。同時に、論文は詳細な推論プロセスと対応する制御フィールドを含む挑戦的な問題を含むControl-R-4Kデータセットを提案し、モデルがテスト時の推論努力を効果的に調整するように訓練するための条件付き蒸留ファインチューニング(CDF)手法を提案しました。(ソース: HuggingFace Daily Papers)
論文、Agentic AIにおける信頼、リスク、セキュリティ管理(TRiSM)を概観: ある概説論文は、大規模言語モデル(LLM)に基づくAgenticマルチエージェントシステム(AMAS)における信頼、リスク、セキュリティ管理(TRiSM)を体系的に分析しています。論文はまず、Agentic AIの概念的基礎、アーキテクチャの違い、および新たなシステム設計を探求し、次にTRiSMがAgentic AIフレームワークの下で持つ4つの柱、すなわちガバナンス、解釈可能性、ModelOps、プライバシー/セキュリティについて詳細に説明しています。論文は独自の脅威ベクトルを特定し、Agentic AIアプリケーションの包括的なリスク分類法を提案し、信頼構築メカニズム、透明性と監督技術、分散LLMエージェントシステムの解釈可能性戦略などを議論しています。(ソース: HuggingFace Daily Papers)
論文、信頼度誘導型データ拡張による未知の共変量シフト下での知識蒸留の改善について議論: 知識蒸留で一般的な共変量シフト問題(訓練時には存在するがテスト時には存在しない偽の特徴)に対し、ある新しい論文は新しい拡散ベースのデータ拡張戦略を提案しました。これらの偽の特徴が未知であるが、頑健な教師モデルが存在する場合、この戦略は教師モデルと生徒モデルの間の不一致を最大化することで画像を生成し、それによって生徒が処理しにくい挑戦的なサンプルを作成します。実験により、この方法はCelebA、SpuCo Birds、偽のImageNetなどのデータセットで共変量シフトが存在する場合の最悪グループおよび平均グループの精度を大幅に向上させることが証明されました。(ソース: HuggingFace Daily Papers)
論文、DiffDecomposeを紹介:Diffusion TransformersによるAlpha合成画像のレイヤーごとの分解: 既存の画像分解手法が半透明または透明なレイヤーの遮蔽を解きほぐすことが困難であるという問題に対し、ある新しい論文は新しいタスクを提案しました:Alpha合成画像のレイヤーごとの分解。これは、単一の重なり合った画像から構成レイヤーを復元することを目的としています。レイヤーの曖昧さ、汎化性、データ不足などの課題を解決するため、論文はまず、透明および半透明レイヤーの分解のための初の大規模高品質データセットであるAlphaBlendを導入しました。これに基づき、DiffDecomposeを提案しました。これはDiffusion Transformerベースのフレームワークで、コンテキスト分解を通じてレイヤー分解の事後分布を学習します。(ソース: HuggingFace Daily Papers)
論文、SuperWriterを提案:反省駆動型大規模言語モデルによる長文テキスト生成: 大規模言語モデル(LLM)が長文テキスト生成において一貫性、論理的整合性、テキスト品質を維持することが困難であるという問題を解決するため、ある新しい論文はSuperWriter-Agentフレームワークを提案しました。このフレームワークは、生成プロセスに明確な構造化思考計画と改善段階を導入し、モデルがより慎重で、より認知法則に合致したプロセスに従うように誘導します。このフレームワークに基づき、7BパラメータのSuperWriter-LMを訓練するための教師ありファインチューニングデータセットを構築し、モンテカルロ木探索(MCTS)を利用して最終的な品質評価を伝播させ、それに応じて各生成ステップを最適化する階層的直接嗜好最適化(DPO)プログラムを開発しました。(ソース: HuggingFace Daily Papers)
論文、IEAPを提案:拡散モデルベースのプログラムとしての画像編集: 拡散モデルが指示駆動型画像編集において、特に大幅なレイアウト変更を伴う構造的に不整合な編集に関して課題に直面していることに対し、ある新しい論文はIEAP(Image Editing As Programs)フレームワークを導入しました。IEAPはDiffusion Transformer(DiT)アーキテクチャに基づいており、複雑な編集指示を原子操作のシーケンスに分解することで指示編集を処理します。各操作は、同じDiTバックボーンを共有する軽量アダプタによって実現され、特定の種類の編集に特化しています。これらの操作は、視覚言語モデル(VLM)ベースのエージェントによってプログラムされ、協調して任意かつ構造的に不整合な変換をサポートします。(ソース: HuggingFace Daily Papers)
論文、FlowPathAgentを提案:ニューロシンボリックエージェントによる詳細なフローチャート帰属: 大規模言語モデル(LLM)がフローチャートを解釈する際にしばしば幻覚を起こし、意思決定経路を正確に追跡することが困難であるという問題を解決するため、ある新しい論文は詳細なフローチャート帰属タスクを導入し、FlowPathAgentを提案しました。FlowPathAgentはニューロシンボリックエージェントであり、グラフベースの推論を通じて詳細な事後帰属を実行します。まずフローチャートを分割し、それを構造化されたシンボリックグラフに変換し、次にエージェント手法を採用してグラフと動的に対話し、帰属経路を生成します。同時に、論文はフローチャート帰属を評価するための新しいベンチマークであるFlowExplainBenchも提案しました。(ソース: HuggingFace Daily Papers)
論文、Quantitative LLM Judgesを提案:LLM審判の定量化: LLM-as-a-judgeは、大規模言語モデル(LLM)に別のLLMの出力を自動評価させるフレームワークです。ある新しい論文は、「定量的LLM審判」の概念を提案し、回帰モデルを通じて既存のLLM審判の評価スコアを特定の分野の人間のスコアと整合させます。これらのモデルは、審判のテキスト評価とスコアを使用して元の審判の評価を改善します。論文は、異なる種類の絶対的および相対的フィードバックに対応する4種類の定量的審判を示し、このフレームワークの汎用性と多機能性を証明しています。このフレームワークは、教師ありファインチューニングよりも計算効率が高く、人間のフィードバックが限られている場合には統計的により効率的である可能性があります。(ソース: HuggingFace Daily Papers)
💼 ビジネス
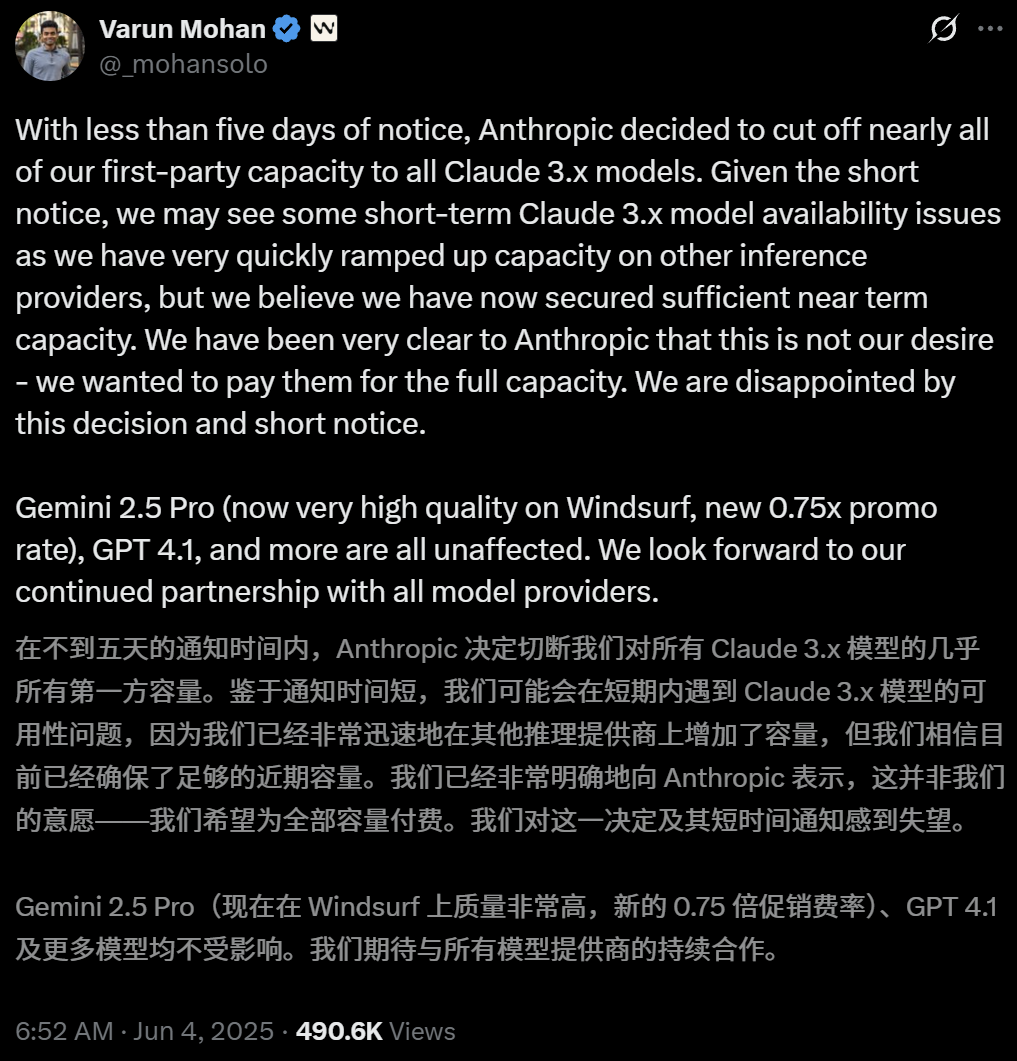
Anthropic、AIプログラミングツールWindsurfによるClaudeモデルへの直接アクセスを制限: AIプログラミングツールWindsurfのCEOであるVarun Mohan氏は、Anthropicが極めて短い通知期間(5日未満)で、WindsurfによるClaude 3.xシリーズモデル(Claude 3.5 Sonnet、3.7 Sonnetなどを含む)へのAPIサービス割り当てを大幅に削減したと公に表明しました。この動きは、OpenAIがWindsurfを買収すると報じられた背景で発生し、AI大手間の競争激化およびAIプログラミングツールプラットフォームの中立性に対する市場の懸念を引き起こしています。Windsurfは緊急にサードパーティの推論サービスを有効にし、ユーザーへのモデル供給戦略を調整せざるを得ませんでしたが、Anthropicは継続的な協力関係を確保できるパートナーにリソースを優先的に提供すると回答しています。(ソース: 36氪, 36氪, mervenoyann, swyx)
OpenAIの有料企業ユーザー数が300万を突破、柔軟な価格戦略を導入: OpenAIは、有料企業ユーザー数が300万に達したと発表しました。これは今年2月に発表された200万から50%増加したもので、ChatGPT Enterprise、Team、Eduの3つの製品ラインを網羅しています。同時に、OpenAIは企業顧客向けに「共有クレジットプール」に基づく柔軟な価格戦略を導入し、企業がクレジットプールを購入すると、高度な機能を使用するとクレジットが消費されますが、主要なモデルや機能には引き続き「無制限にアクセス」できます。この新しい価格設定はまずChatGPT Enterpriseで導入され、その後ChatGPT Teamに展開されます。後者では、1ドルで5アカウントを利用できる初月トライアルキャンペーンも提供されます。(ソース: 36氪, snsf)
00年代生まれの中国人女性、洪楽潼氏がAI数学企業Axiomを設立、評価額3億ドルを目指す: スタンフォード大学の中国人数学博士である洪楽潼(Carina Letong Hong)氏がAI企業Axiomを設立しました。同社は実際の数学的問題を解決するAIモデルの開発に特化し、ヘッジファンドやクオンツトレーディング企業をターゲット顧客としています。Axiomは、形式化された数学的証明データを利用してモデルを訓練し、厳密な論理的推論と証明能力を習得させる計画です。同社はまだ製品を持っていませんが、すでに5000万ドルの資金調達を交渉中で、評価額は3億~5億ドルと予想されています。洪楽潼氏はマサチューセッツ工科大学で数学と物理学の学士号を取得し、スタンフォード大学で数学の博士号を取得、ローズ奨学生にも選ばれた経歴を持っています。(ソース: 量子位)

🌟 コミュニティ
AI.Engineer大会での熱い議論:Agentの観測可能性、小規模チームの高効率性、AI PMが焦点に: AI.Engineer世界博覧会では、参加者たちがAIエージェント(Agent)の観測可能性と評価、小規模で効率的なチームの構築(Tiny Teams)、そしてAIプロダクトマネジメント(AI PM)のベストプラクティスについて熱心に議論しました。音声インタラクションはマルチモーダルの中で最も注目される方向性と考えられ、セキュリティも初めて重要な議題となりました。Anthropicは会議でMCP(モデルコンテキストプロトコル)分野での起業を呼びかけ、開発者ツール以外のMCPサーバー、サーバー構築を簡素化するソリューション、AIアプリケーションのセキュリティ(ツールのポイズニング対策など)におけるイノベーションを期待していると述べました。(ソース: swyx, swyx, swyx, swyx)

AIが自然言語を消滅させ、人間を愚かにするかどうかについての議論: ソーシャルメディア上では、AIの広範な応用が自然言語によるコミュニケーションの萎縮(「死んだインターネット」理論)や、人間の認知能力(深い思考、疑問、再構築能力など)の低下を引き起こす可能性についての懸念が表明されています。一部のユーザーは、情報や回答を得るためにAIに過度に依存すると、能動的な選別、判断、独立した思考が減少し、「認知のアウトソーシング」依存を形成する可能性があると考えています。別の意見では、AIはwhatとhowを処理できるが、whyは依然として人間が決定する必要があり、重要なのは技術と共存する際の人間の役割の位置づけと判断権を守ることであるとされています。(ソース: Reddit r/ArtificialInteligence, 36氪)
OpenAI、裁判所命令により全てのChatGPTおよびAPIログの保存を義務付けられ、プライバシー懸念が浮上: ある裁判所命令により、OpenAIは全てのChatGPTのチャット履歴とAPIリクエストログ(本来削除されるべき「一時的なチャット」の記録も含む)を保存するよう命じられました。この動きは、ユーザーのデータプライバシーとOpenAIのデータ保持ポリシーが遵守されるかどうかについての懸念を引き起こしています。一部のコメント投稿者は、これはローカルモデルを使用し、自身の技術とデータを所有することの重要性をさらに浮き彫りにしていると考えています。(ソース: Reddit r/artificial, Reddit r/LocalLLaMA, Teknium1, nptacek)

AI Agentは信頼とセキュリティの課題に直面、フィッシング攻撃に脆弱: AI Agentの能力は日々向上しているものの、その信頼メカニズムが悪用されるリスクがあるとの議論がなされています。例えば、Agentは有名なウェブサイト(ソーシャルメディアなど)を信頼することで悪意のあるリンクへのアクセスを誘導され、それによって機密情報を漏洩したり、悪意のある操作を実行したりする可能性があります。これは、Agentの設計において、悪意のあるコンテンツやリンクに対する識別能力と抵抗能力を強化し、実世界の操作を実行する際の安全性を確保する必要があることを示しています。(ソース: DeepLearning.AI Blog)
AI支援プログラミングツールが引き起こす考察:コードの近代化からワークフロー変革まで: コミュニティでは、ソフトウェア開発におけるAIの応用、特にレガシーコードの処理とプログラミングワークフローの変革について議論されています。モルガン・スタンレーは自社開発のAIツールDevGen.AIを使用して数百万行の古いコードを分析・リファクタリングし、開発時間を大幅に削減しました。同時に、Andrej Karpathy氏の複雑なUIアプリケーションの将来性に関する見解も、将来のソフトウェアがAIとより良く協調するためにどのように設計されるべきかについての考察を引き起こし、スクリプト化とAPIインターフェースの重要性を強調しました。これらの議論は、AIがソフトウェアエンジニアリングの実践と理念に深く影響を与えていることを反映しています。(ソース: mitchellh, 36氪, 36氪)
💡 その他
AI支援による家電修理、ChatGPTが「Friendo」に: あるユーザーが、ChatGPT(愛称Friendo)を通じて故障した食洗機の診断と応急修理に成功した経験を共有しました。AIとの対話、エラーコードの説明、コントロールパネルの写真撮影を通じて、AIはユーザーが加熱エレメントの故障を特定するのを助け、一時的にそのエレメントをバイパスして食洗機の一部の機能を回復させるよう指導しました。これは、LLMが日常生活の問題解決や技術サポートにおいて持つ可能性を示しています。(ソース: Reddit r/ChatGPT)
AIが生成した1500年代の人物インタビュー動画が注目を集める: AIが生成した、1500年代の人物へのインタビューをシミュレートした動画が、その創造性とユーモアセンスでコミュニティから好評を得ています。動画内の人物像や会話内容は、当時の生活状況をユーモラスに反映しており、例えば「起きたら糞を踏んで、それから税金を取られて、まだ朝食前のことだ」といった具合です。この種の応用は、AIがコンテンツ制作や歴史的状況の再現において持つエンターテイメントの可能性を示しています。(ソース: draecomino, Reddit r/ChatGPT)

Thiel Fellowship、AIイノベーションに注目、デジタルヒューマン、ロボットの感情、AI予測を網羅: 新期の「ティール・フェローシップ」のリストが発表され、その中で複数のAIプロジェクトが注目を集めています。Canopy Labsは、実在の人間と見分けがつかず、リアルタイムでマルチモーダルなインタラクションが可能なAIデジタルヒューマンの構築に取り組んでいます。Intempusプロジェクトは、人間とロボットのインタラクションを改善するために、ロボットに人間のような感情表現能力を与えることを目指しています。Aeolus Labは、AI技術を利用して天候や自然災害を予測し、さらには能動的な介入の可能性を探求することに焦点を当てています。これらのプロジェクトは、若い起業家たちがAIの最先端分野で探求している方向性を示しています。(ソース: 36氪)