
キーワード:AIトレンドレポート, AIエージェント, 強化学習, 視覚言語モデル, AI商用化, AI幻覚, AIセキュリティ, インターネットクイーンAIレポート, LawZero AIセキュリティ設計, GTAとGLAアテンションメカニズム, SmolVLAロボットモデル, AI音楽ストリーミング詐欺
🔥 注目
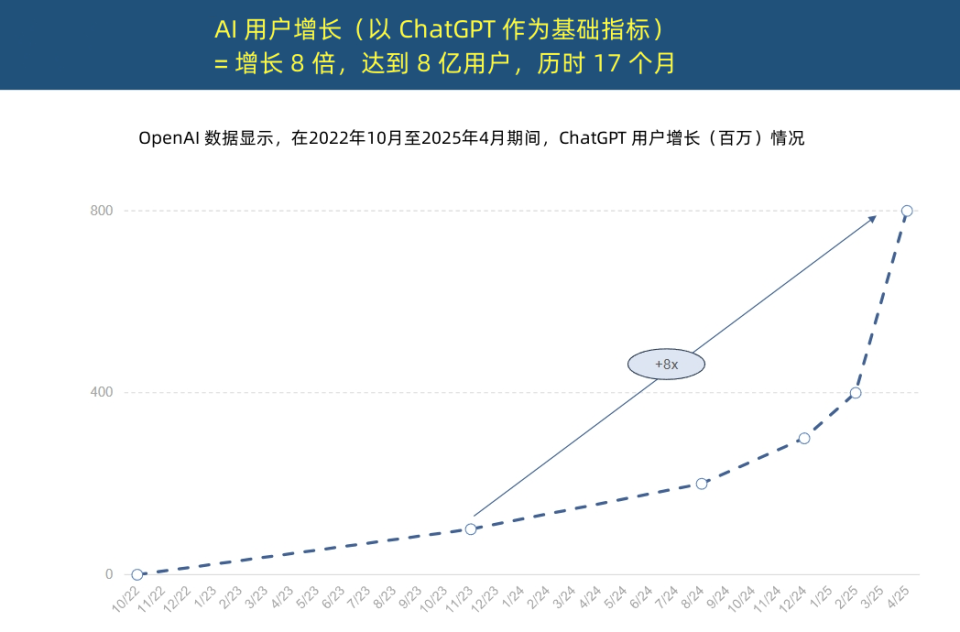
「インターネットの女王」がAIトレンドレポートを発表、AI応用の空前の加速とコスト構造の変革を明らかに: 「インターネットの女王」メアリー・ミーカー氏が340ページに及ぶ「AIトレンドレポート」を発表し、AIがかつてないスピードで採用されていることを強調した。レポートによると、ChatGPTのユーザー成長は著しく、17ヶ月で月間アクティブユーザー (MAU) は8億人に達し、年間収益は約40億ドルと、歴史上のいかなる技術をも遥かに凌駕している。テクノロジー大手によるAIインフラへの設備投資は急増し、2024年には2120億ドルに達した。同時に、AIモデルのトレーニングコストは8年間で2400倍に急騰し、単一モデルのトレーニングコストは10億ドルに達する可能性もあるが、推論コストはハードウェア(Nvidia GPUのエネルギー効率10万倍向上など)とアルゴリズムの最適化により急激に低下している。オープンソースモデル(DeepSeek、Qwenなど)の性能はクローズドソースに迫り、AI関連の求人需要は448%増加し、AI Agentは新たなデジタル労働力となりつつある。(出典: APPSO, 腾讯科技)
チューリング賞受賞者Yoshua Bengio氏がLawZeroを立ち上げ、「設計による安全性」を持つAIを提唱: チューリング賞受賞者のYoshua Bengio氏は、AIシステムに現れる可能性のある欺瞞や自己保存行動に対処するため、「設計による安全性」(safe by design) を持つ人工知能を開発することを目的とした非営利組織LawZeroの設立を発表した。LawZeroはアシモフのロボット三原則の第三法則に着想を得ており、AIが人間の幸福と努力を保護すべきだと強調している。同組織は、AI Agentの「ガードレール」として機能するScientist AIシステムを開発中で、直接行動するのではなく世界を理解することで支援を提供し、他のAIの行動リスクを評価する。Bengio氏は、現在のAgentic AIは誤った方向であり、制御不能に陥り、不可逆的な壊滅的結果をもたらす可能性があると考え、安全ガードレールAIは、少なくともそれが監視しようとするAI Agentと同等に賢くなければならないと強調している。(出典: 学术头条, Yoshua_Bengio)

AI Agent元年:補助ツールからタスク実行者へ、ビジネスモデルを再構築: Gartner社のリサーチバイスプレジデントである孫志勇氏は、2025年は「大規模モデルエージェント元年」であり「生成AIマネタイズ元年」であると指摘し、AIエージェントがLLM能力の主要な出口になりつつあると述べている。エージェントとチャットボットの本質的な違いは、情報提供による補助からタスクの直接実行へと移行している点にあり、例えばエージェントはコーヒーショップの情報を提供するだけでなく、コーヒーを注文する全プロセスを完了できる。Gartner社は、2028年までにデジタルインターフェースインタラクションの20%がAIエージェントによって行われ、日常業務の意思決定の15%がAIエージェントによって自律的に完了され、エンタープライズソフトウェアの3分の1にAIエージェントが統合されると予測している。BYDのインテリジェントアシスタントなどが既に初期応用されており、将来的に携帯電話アプリのインタラクション方式が変わる可能性がある。(出典: IT时报)
Mambaの主要著者が推論認識アテンションメカニズムGTAとGLAを提案、長文コンテキスト推論を最適化: Mambaの主要著者の一人であるTri Dao氏とそのプリンストン大学チームは、大規模モデルの長文コンテキスト推論効率を向上させるために特別に設計された、Grouped-Tied Attention (GTA) とGrouped-Latent Attention (GLA) という2つの新しいアテンションメカニズムを提案した。GTAはパラメータ共有とグループ化によるキーバリュー (KV) キャッシュの再利用を通じて、GQAと比較してKVキャッシュの使用量を約50%削減しつつ、同等のモデル品質を維持する。GLAは2層構造を採用し、潜在トークンをグローバルコンテキストの圧縮表現として導入し、グループ化ヘッドメカニズムと組み合わせることで、DeepSeekが使用するMLAと比較して、長シーケンス(64Kなど)のデコード速度を最大2倍高速化し、同時リクエスト処理能力を向上させる。これらの新しいメカニズムは、推論時のメモリアクセスボトルネックと並列性制限の問題を解決することを目的としている。(出典: 量子位)

🎯 動向
DeepMindがSmolVLAを発表:コミュニティデータに基づく高効率ロボット視覚・言語・行動モデル: Hugging FaceとDeepMindなどの機関が協力してSmolVLAを発表した。これは450Mパラメータのオープンソース視覚・言語・行動(VLA)モデルで、ロボット向けに特別に設計されており、コンシューマーグレードのハードウェアで実行可能である。このモデルは、LeRobotコミュニティが共有するオープンソースデータセットのみを使用して事前学習され、LIBERO、Meta-Worldおよび実世界のタスク(SO100、SO101)において、より大きなVLAモデルやACTなどのベースラインよりも優れた性能を示した。SmolVLAは非同期推論をサポートし、応答速度を30%向上させ、タスクスループットを2倍にすることができる。そのアーキテクチャはTransformerとフローマッチングデコーダを組み合わせ、視覚トークンの削減、VLM中間層特徴の利用、およびインターリーブドアテンションメカニズムを通じて速度と効率を最適化している。(出典: HuggingFace Blog, clefourrier)

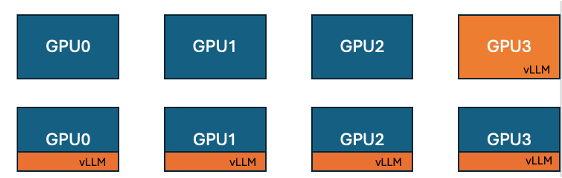
Hugging FaceとIBMがTRLにvLLMコロケーション機能を導入、GPUトレーニング効率を向上: Hugging FaceとIBMは協力し、TRLライブラリにGRPOなどのオンライン学習アルゴリズム向けのvLLMコロケーション(co-located vLLM)機能を導入した。この機能により、トレーニングと推論(生成)を同じGPU上で実行し、リソースを共有して交互に実行することが可能になり、以前のvLLMサーバーモードでのトレーニングGPUのアイドル待機問題を解消する。vLLMを同じ分散プロセスグループに組み込むことで、HTTP通信が不要になり、torchrun、TP、DPと互換性があり、デプロイメントを簡素化し、スループットを向上させる。実験によると、1.5Bおよび7Bモデルの場合、コロケーションモードは最大1.43倍から1.73倍の高速化をもたらす。Qwen2.5-Math-72Bなどの大規模モデルの場合、vLLMのsleep() APIとDeepSpeed ZeRO Stage 3の最適化を組み合わせることで、より少ないGPUを使用しても、モデルの精度に影響を与えることなく約1.26倍のトレーニング高速化を実現できる。(出典: HuggingFace Blog)
NvidiaがNemotron-Research-Reasoning-Qwen-1.5Bモデルを発表、複雑な推論に特化: Nvidiaは、Nemotron-Research-Reasoning-Qwen-1.5Bを発表した。これは1.5Bパラメータのオープンソース重みモデルで、数学問題、プログラミングチャレンジ、科学問題、論理パズルなどの複雑な推論タスクに焦点を当てている。このモデルはProRL (Prolonged Reinforcement Learning) アルゴリズムを使用して多様なデータセットでトレーニングされ、より深いレベルの推論戦略の探索を目指している。公式には、数学、コーディング、GPQAなどのタスクでDeepSeekの1.5Bモデルを大幅に上回ると主張している。ProRLはGRPOに基づいており、エントロピー崩壊の緩和、デカップリングクリッピング、動的サンプリング戦略最適化 (DAPO)、およびKL正則化と参照戦略リセットなどの技術を導入している。このモデルは研究開発用途のみを目的としている。(出典: Reddit r/LocalLLaMA, Hugging Face)

ArceeがHomunculus-12Bモデルを発表、Mistral-NemoベースでQwen3-235Bを蒸留: Arcee AIは、120億パラメータの指示モデルであるHomunculus-12Bを発表した。このモデルは、Qwen3-235Bの能力をMistral-Nemoのバックボーンネットワークに蒸留して構築された。現在、このモデルとそのGGUFバージョンはHugging Faceで提供されている。これは、モデル蒸留技術を通じて、大規模モデルの強力な能力をより小型で効率的なモデルに移行する試みであり、性能とリソース消費のバランスを取ることを目的としている。(出典: Reddit r/LocalLLaMA, Hugging Face)

Microsoft Bingアプリに無料のSoraビデオ生成ツールを統合: Microsoftは、Bingモバイルアプリに無料のOpenAI Soraビデオ生成機能を追加した。ユーザーはサブスクリプションや支払いなしで、テキストプロンプトを通じて短いビデオクリップを生成できる。現在、この機能は5秒の9:16縦型ビデオの生成をサポートしており、将来的には16:9横型フォーマットをサポートする予定である。無料ユーザーは10回の高速生成枠を持ち、その後はMicrosoftポイントで交換するか、標準速度生成を選択できる。この動きは、AIビデオ作成の敷居を下げ、より多くのユーザーにテキストからビデオへの技術を体験してもらうことを目的としている。(出典: Reddit r/ArtificialInteligence, dotey)

Hugging FaceがSmolVLAを発表、経済的で効率的なロボット向け視覚・言語・行動モデル: Hugging Faceは、SmolVLAを発表した。これは450Mパラメータのオープンソース視覚・言語・行動 (VLA) モデルで、経済的で効率的なロボットソリューションを提供することを目的としている。このモデルはLeRobotHFコミュニティのすべてのオープンソースデータセットを使用してトレーニングされ、クラス最高の性能と推論速度を実現している。SmolVLAの発表は、ロボット研究開発の敷居を下げ、より広範なコミュニティの参加とイノベーションを促進することを目的としている。(出典: huggingface, AK)

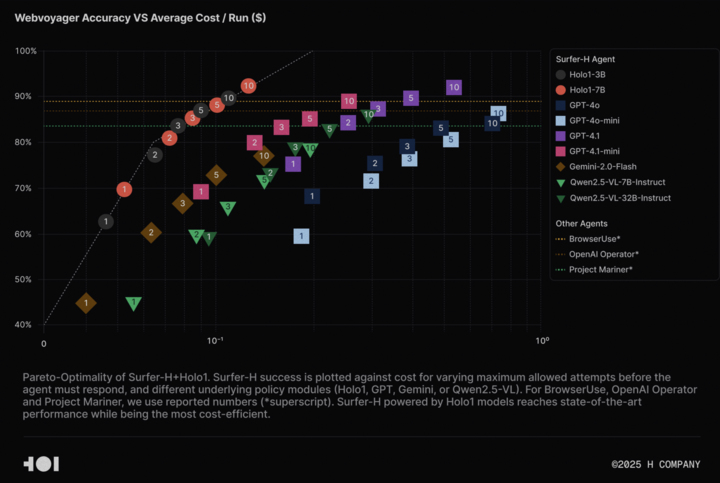
H CompanyがHolo-1視覚言語モデル及びWebClickデータセットをオープンソース化、Agentic AI研究を推進: H Companyは、Agentic AI分野の研究を加速させるため、視覚言語モデルHolo-1(3Bおよび7Bパラメータ版)およびWebClickデータセットのオープンソース化を発表した。Holo-1モデルはGUI操作とWebナビゲーションタスク向けに特別に設計されており、WebVoyagerベンチマークで92.2%のSOTA(State-of-the-Art)成績を収め、コスト効率においてGPT-4.1などの大規模モデルを上回っている。モデルの重みとデータセットはHugging Faceプラットフォームで公開され、Apache 2.0ライセンスを採用している。Holo-1はMLXにも統合されており、開発者はApple Siliconデバイスで簡単に実行できる。(出典: huggingface, tonywu_71)
PlayAIが初の音声拡散LLM PlayDiffusionをオープンソース化、精密編集とゼロショットクローニングをサポート: PlayAIは、音声用の初の拡散-LLM (diffusion-LLM) であるPlayDiffusionを発表し、オープンソース化した。このモデルは、AI音声の精密編集(修復、コンテンツ置換など)とゼロショット音声クローニングのために特別に設計されている。自己回帰モデルが通常800~1000トークンを必要として音声を生成するのに対し、PlayDiffusionはわずか20~30トークンで音声を生成でき、効率を大幅に向上させている。このモデルはGitHubでソースコードが提供されており、Hugging Face Spacesでデモが展開されているほか、Fal.aiプラットフォームからも利用可能である。(出典: _akhaliq)
GoogleがAI Edge Galleryアプリを密かにリリース、AndroidデバイスでのAIモデルのオフライン実行をサポート: Googleは、Google AI Edge Galleryという実験的なアルファ版アプリをリリースした。これにより、ユーザーはAndroidデバイス上でHugging Faceの公開AIモデルをダウンロードし、オフラインで実行できる。このアプリは、画像Q&A、テキスト要約とリライト、コード生成、AIチャットなどの機能をサポートし、パフォーマンスインサイト(TTFT、デコード速度など)を提供する。AIモデルをローカルで実行することで、応答速度が向上し、ユーザーのプライバシーが保護され、ネットワーク接続も不要になる。しかし、ユーザーからのフィードバックはまちまちで、一部のユーザーはPixelなどのデバイスで、特にGPU推論への切り替え時や大規模モデルの処理時にクラッシュ問題に遭遇している。既存のアプリ(PocketPalなど)と機能が類似している、あるいはAppleのCoreMLなどのフレームワークに比べて遅れているとのコメントもあるが、そのMediaPipe基盤はクロスプラットフォームの利点があるとの意見もある。(出典: 36氪)

MicrosoftのRenderFormerがHugging Faceに登場、グローバルイルミネーション下の三角メッシュのニューラルレンダリングに特化: MicrosoftはHugging Face上でRenderFormerを公開した。これはTransformerベースのニューラルレンダリングモデルで、グローバルイルミネーション効果を持つ三角メッシュのレンダリング処理に特化している。この種の研究は、従来のレンダリングパイプラインとニューラル手法を融合する上で重要な意義を持ち、その後の開発方向としては、より大規模なシーンへの拡張や、パストレーシングの単純な再現を超えることなどが考えられる。(出典: _akhaliq)

BAAIがVideo-XL-2長編動画理解モデルを発表、1万フレームを単一GPUで処理可能: 北京智源人工智能研究院 (BAAI) は上海交通大学と協力し、長編動画理解のために特別に設計されたモデルVideo-XL-2を発表した。このモデルはApache 2.0ライセンスを採用し、単一GPUで10000フレームを超える動画コンテンツを処理でき、12秒以内に2048フレームのエンコードを完了する。その主要技術には、効率的なチャンクベースプレフィリング (Chunk-based Prefilling) とバイグラニュラリティKVデコーディング (Bi-granularity KV decoding) が含まれ、長編動画処理の効率と能力を向上させることを目的としている。モデルはHugging Faceで提供されている。(出典: huggingface)
UniWorldモデルがHugging Faceで公開、視覚理解と生成の統一を目指す: UniWorldモデルがHugging Faceプラットフォームで公開された。このモデルは高解像度セマンティックエンコーダーとして位置づけられ、統一された視覚理解と生成能力の実現を目指している。これは、研究者たちが視覚情報の入力(理解)と視覚コンテンツの出力(生成)を同時に処理できる単一のモデルフレームワークを構築し、マルチモーダルAI分野でより包括的な進歩を遂げることを目指していることを示している。(出典: _akhaliq)
DeepSeekがMuddit-1Bマルチモーダルモデルを発表、統一離散拡散Transformerを採用: DeepSeekはMuddit-1Bモデルを発表した。これは視覚に特化したマルチモーダルモデルで、MaskGITに類似した統一離散拡散Transformerアーキテクチャを採用し、軽量なテキストデコーダーを備えている。このモデルの興味深い点は、その開発方向が一般的な経路とは逆であることだ。テキストから画像への生成から着手し、次に画像からテキストへの生成へと拡張しており、これは異なる事前知識ベースを利用している可能性がある。Mudditは、統一された生成方式を通じて画像とテキストの高速な並列生成を実現することを目指しており、Meissonicシリーズモデルの一部であり、言語中心の設計から脱却し、より効率的な統一生成を追求しようとしている。(出典: teortaxesTex)
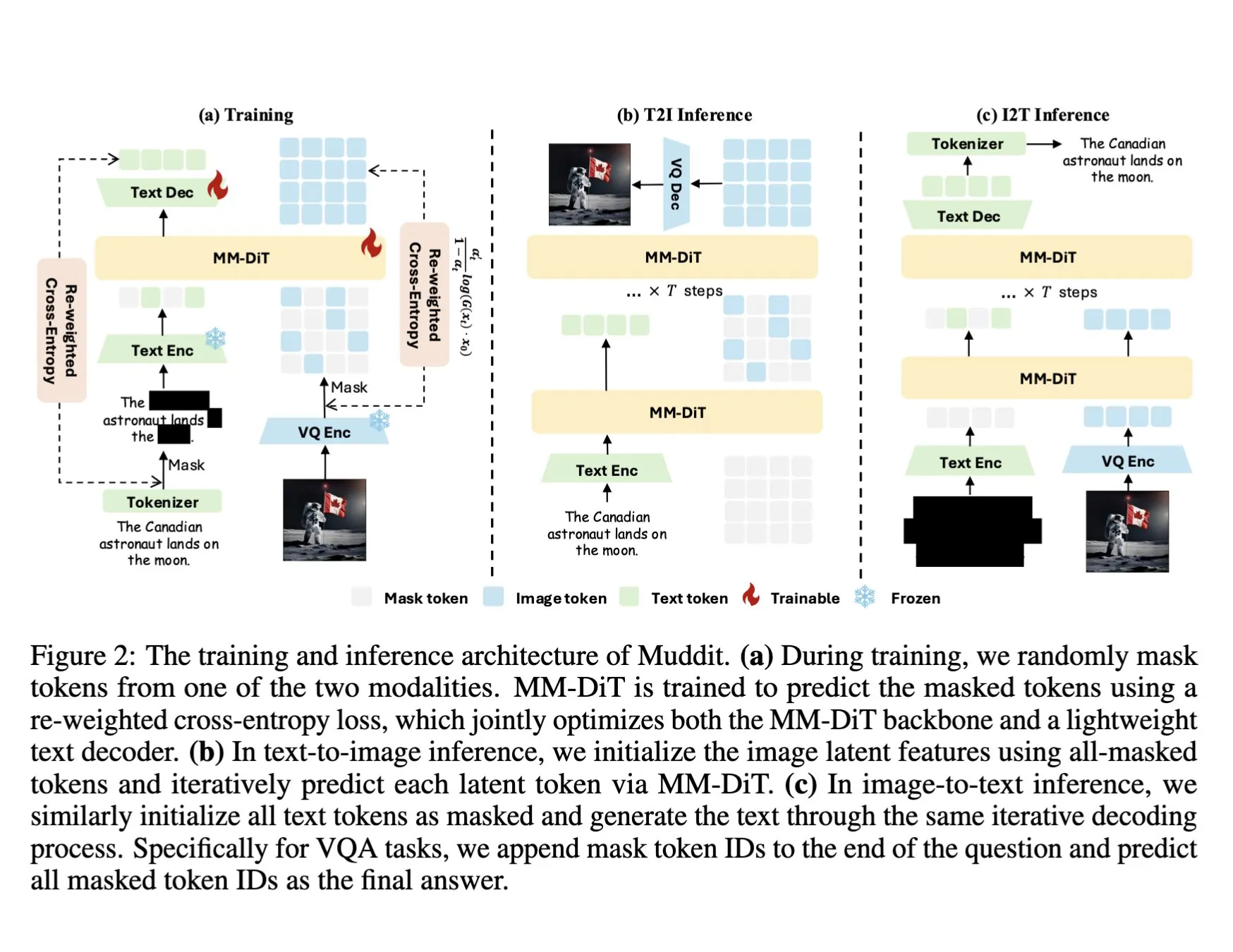
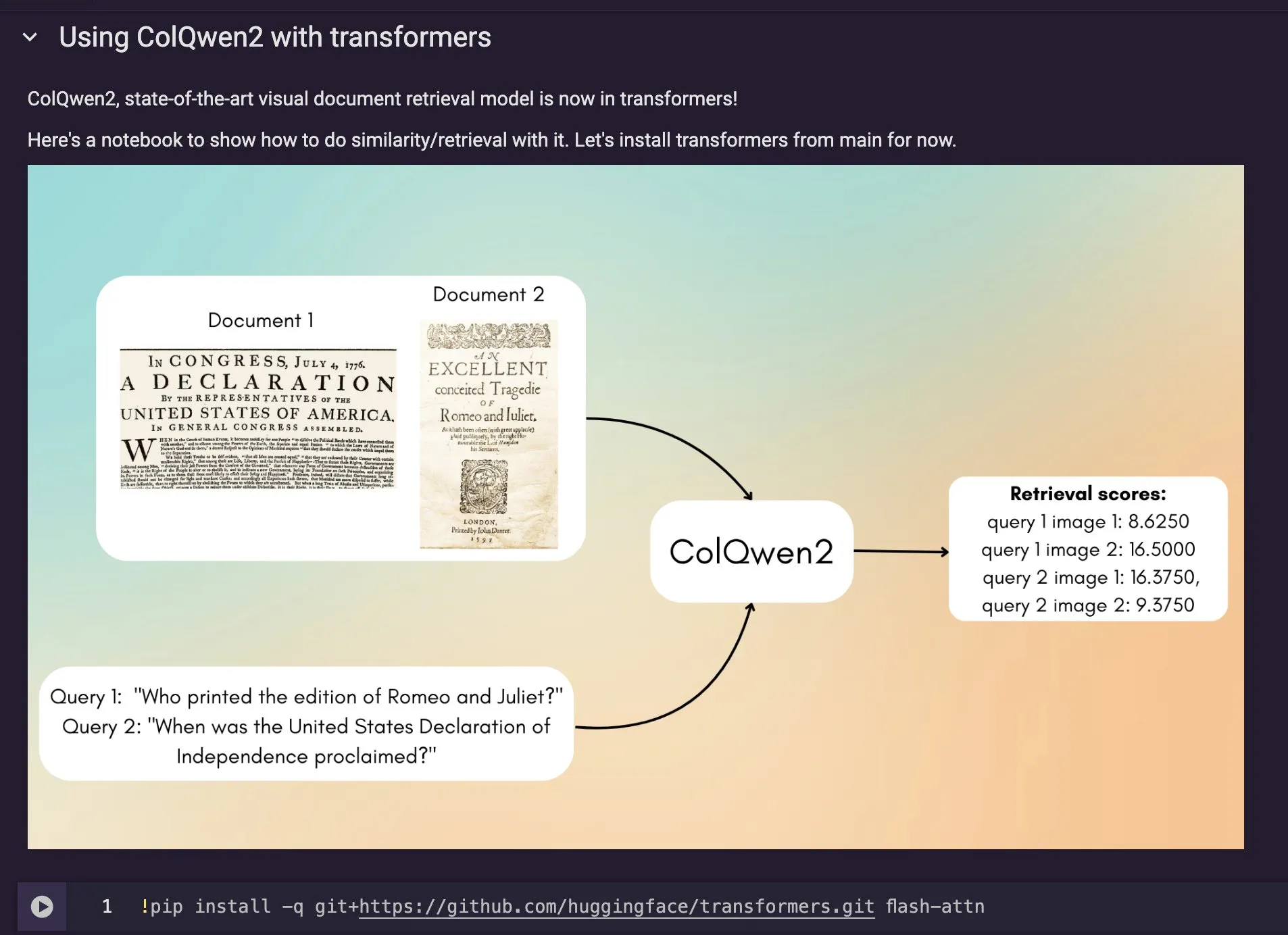
ColQwen2視覚ドキュメント検索モデルがHugging Face Transformersに統合: 最新の視覚ドキュメント検索モデルColQwen2がHugging Face Transformersのメインライブラリにマージされた。ユーザーはColQwen2を利用してPDF検索を行ったり、RAG (検索拡張生成) フローで使用したりして、視覚的にリッチなドキュメントの処理能力を向上させることができる。このモデルは、テキストと画像情報を含むドキュメントコンテンツをよりよく理解し、検索することを目的としている。(出典: mervenoyann)
🧰 ツール
FLUX KontextがAdobe Firefly Boardsに統合、テキスト編集による写真修復などをサポート: AdobeはFLUX KontextモデルをFirefly Boardsツールに統合し、ユーザーがテキスト指示によって写真を編集できるようにした。特に古い写真の修復などのシーンに適している。Firefly Boardsは現在、すべてのユーザーに公開されている。この動きは、AI画像編集技術を活用し、ユーザーがより便利にクリエイティブな編集や画像補正を実現できるようにすることを目的としている。(出典: robrombach)
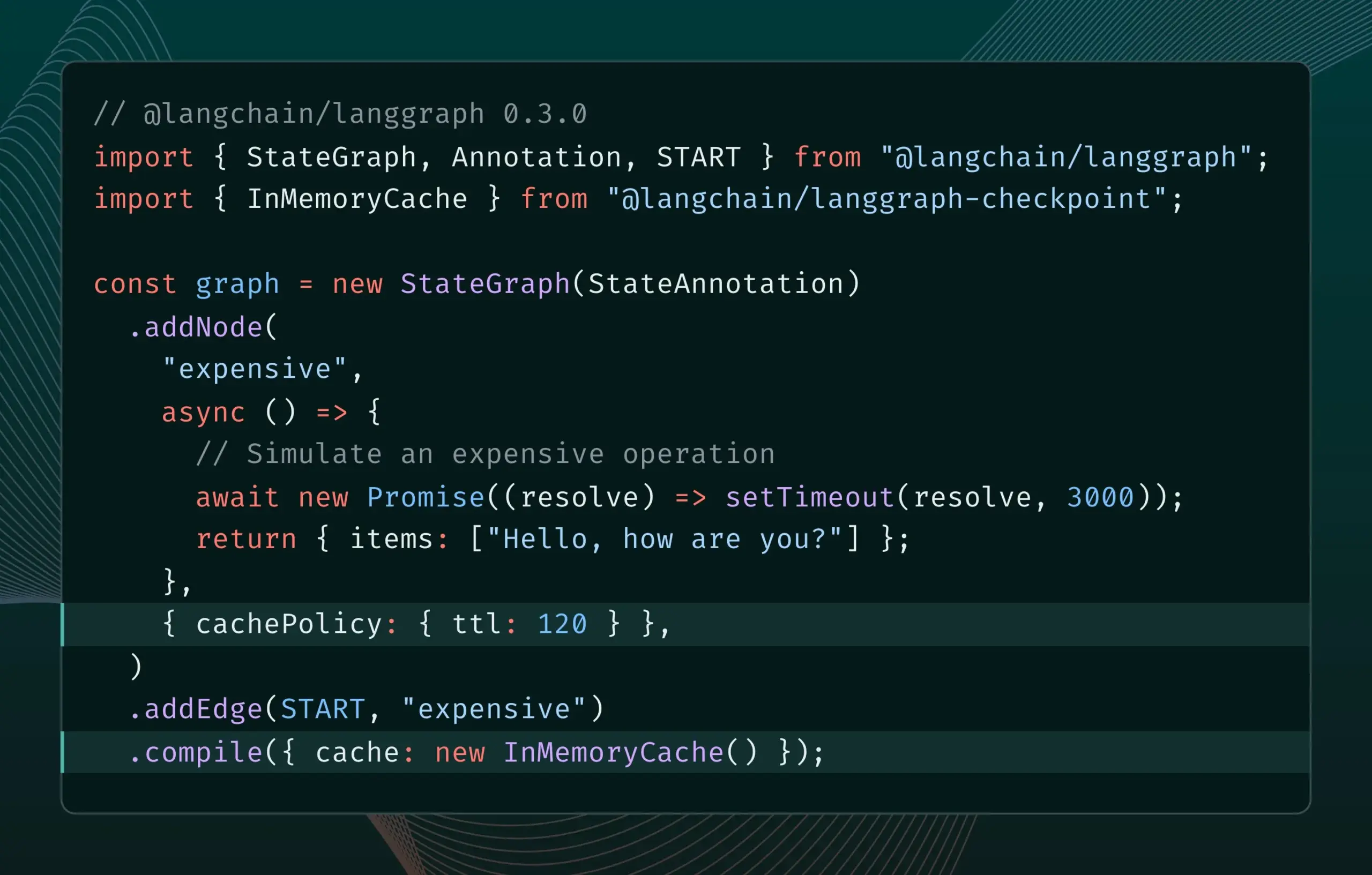
LangGraph.js 0.3バージョンにノードキャッシュ機能が導入され、反復効率が向上: LangGraph.js 0.3バージョンでは、ノード/タスクキャッシング機能が新たに追加され、開発者が高コストまたは長時間実行されるAI Agentをローカルで反復する際に、重複計算を回避し、作業フローを高速化できるようになった。この機能はGraph APIとImperative APIの両方をサポートし、AIアプリケーション開発の効率と利便性の向上を目指している。(出典: LangChainAI, hwchase17)
Ollamaがアップデート、ローカルでの「思考モデル」実行を簡素化: Ollamaは新バージョンをリリースし、ユーザーがローカルで「思考モデル」(複雑な推論能力を持つLLMを指す可能性が高い)をより簡単に実行できるようにした。このアップデートは、高度なAIモデルのローカル展開と使用の敷居を下げ、より多くのユーザーと開発者が自身のデバイスでこれらのモデルを体験し、活用できるようにすることを目的としている。(出典: ollama)
PipesHub:オープンソースのエンタープライズ向けRAGプラットフォームがリリース: PipesHubは、完全にオープンソースのエンタープライズ向け検索プラットフォーム(RAGプラットフォーム)として正式にリリースされた。これにより、ユーザーはカスタマイズ可能でスケーラブルなインテリジェント検索およびAgenticアプリケーションを構築でき、Google Workspace、Slack、Notionなどのツールとの接続をサポートし、社内知識を活用してトレーニングすることができる。PipesHubはローカル実行およびOllamaを含むあらゆるAIモデルの使用をサポートし、企業が自社データとモデルを効率的に活用できるよう支援することを目的としている。(出典: Reddit r/LocalLLaMA)
JigsawStackがオープンソースのディープリサーチフレームワークを発表、高品質レポート生成をサポート: JigsawStackは、AI SDK上に構築されたオープンソースのディープリサーチフレームワークを発表した。このフレームワークは完全にカスタマイズ可能である。内蔵の検索機能と組み合わせて高品質な研究レポートを生成することができ、ユーザーにPerplexityやChatGPTのディープリサーチ能力に類似したライブラリを提供する。(出典: hrishioa)
Voiceflow:AI Agent構築高速化ツール: Voiceflowは、ユーザーから効率的なAI Agent構築ツールとして評価されている。提供されるテンプレートとドラッグアンドドロップ式のインターフェースにより、AIエージェントの作成がゼロからのコーディングよりも速く、時間を大幅に節約できる。このツールは、AI Agentの開発の敷居を下げ、開発効率を向上させることを目的としている。(出典: ReamBraden)
Hugging Faceがモデルセマンティック検索プロトタイプを公開、モデル選択を最適化: Hugging Faceは、モデルセマンティック検索プロトタイプSpaceをオンラインで公開した。これは、ユーザーが150万を超えるモデルライブラリの中から必要なモデルをより正確に見つけられるように支援することを目的としている。このツールは、モデルサイズ(0-1Bから70B+まで)によるフィルタリングをサポートし、セマンティック理解を通じてユーザーのニーズを把握し、モデル発見効率を向上させる。(出典: huggingface)
Runner H:メール処理、求職、支払いなどのタスクを処理できるAIエージェント: Hcompanyが発表したRunner Hは、自律型AIエージェントであり、ユーザーが提供するツールを使用して、重要なメールを読んで返信を作成/送信したり、求人情報を見つけて代理で応募したり、人気のある広告クリエイティブを含むGoogle Sheetを作成してSlackチームに送信したりするなどのタスクを完了できる。ユーザーは単一のプロンプトを与えるだけで、Runner Hは複雑で反復的な作業を処理できる。現在、公式プロモーション活動が行われており、無料のPremium権限が提供されている。(出典: Reddit r/ChatGPT, Ronald_vanLoon)
![[Contest] New AI agent by Hcompany](https://rebabel.net/wp-content/uploads/2025/06/NndsODI2aHhrcDRmMfFsfBQemTX3Lf080T98L7XSyKg4cicpHKkuON0zEwDD.webp)
📚 学習
新論文、インセンティブ推論によるLLMの複雑な指示追従能力向上を議論: 新しい論文「Incentivizing Reasoning for Advanced Instruction-Following of Large Language Models」は、大規模言語モデル (LLM) が複雑な指示、特に並列、連鎖、分岐構造を含む指示に従う能力をどのように向上させるかを研究している。研究によると、従来のChain of Thought (CoT) アプローチは、指示を単に繰り返すだけであるため効果が低い可能性がある。そのため、この論文では、テスト時に計算を拡張することで推論を奨励する体系的なアプローチを提案している。このアプローチは、まず複雑な指示を分解し、再現可能なデータ取得方法を提案する。次に、検証可能なルール中心の報酬信号を持つ強化学習 (RL) を利用して、指示追従の推論能力を専門的に育成し、サンプルレベルの比較を通じて複雑な指示下での推論の浅さを解決するとともに、専門家の行動クローニングを利用してモデルを高速思考から熟練した推論者へと転換させる。実験により、このアプローチがLLM (1.5Bモデルなど) の複雑な指示タスクにおけるパフォーマンスを大幅に向上させることが証明された。(出典: HuggingFace Daily Papers)
論文、ARIAフレームワークを提案:意図駆動型の報酬集約による言語エージェントの訓練: 新しい論文「ARIA: Training Language Agents with Intention-Driven Reward Aggregation」は、大規模言語モデル (LLM) が交渉や質疑応答ゲームなどのオープンエンドな言語行動環境で直面する巨大な行動空間と報酬の希薄性の問題に対し、ARIAメソッドを提案している。このメソッドは、自然言語行動を高次元の同時トークン分布空間から低次元の意図空間に投影し、そこで意味的に類似した行動をクラスタリングして共有報酬を割り当てることを目的としている。この意図認識型の報酬集約は、報酬信号を密にすることで報酬の分散を減らし、より良い戦略最適化を促進する。実験によると、ARIAは戦略勾配の分散を大幅に低減するだけでなく、4つの下流タスクで平均9.95%の性能向上を達成した。(出典: HuggingFace Daily Papers)
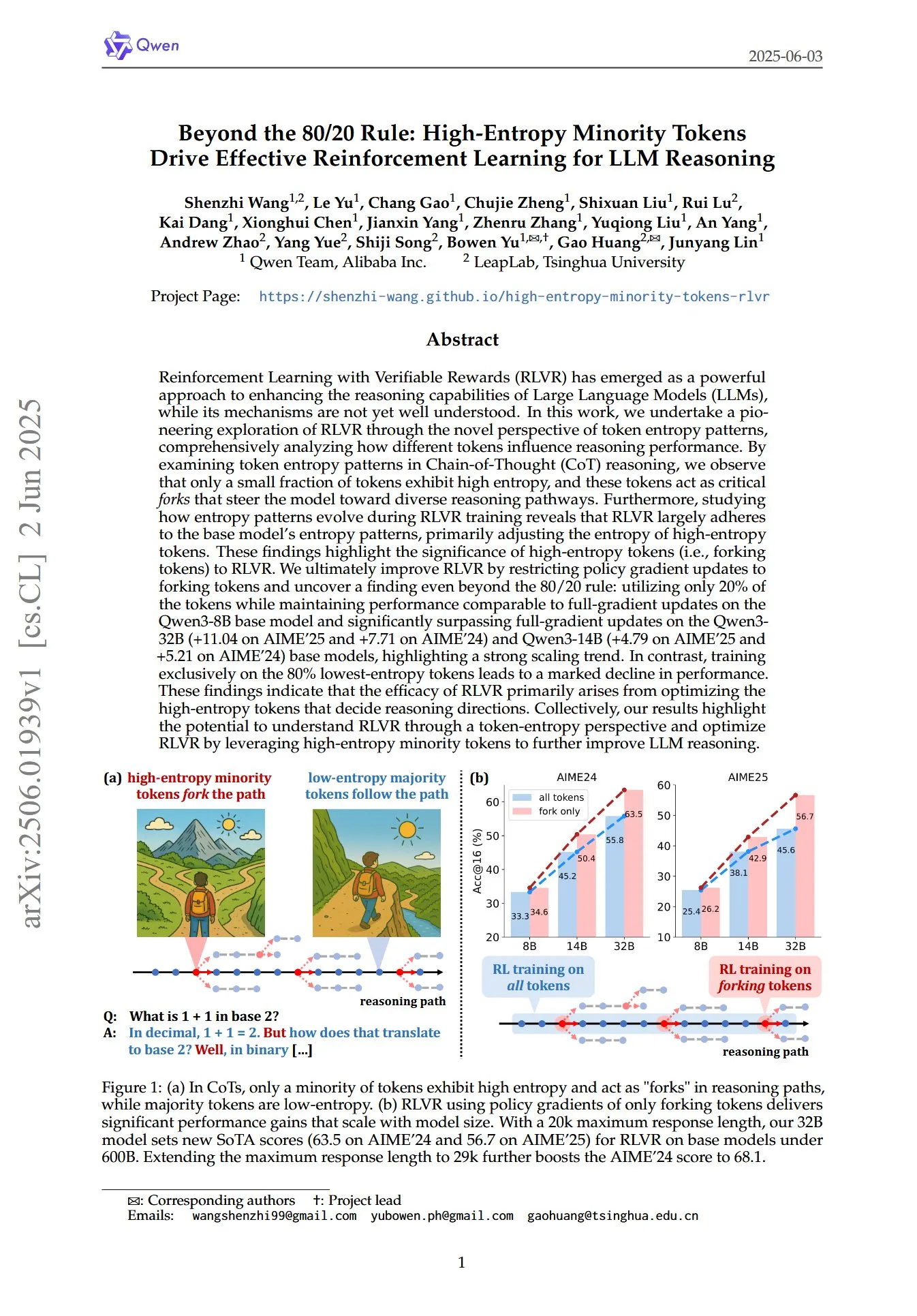
論文、LLM推論におけるRLでの高エントロピー少数トークンの重要な役割を解明: 「Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning」と題された論文は、トークンエントロピーパターンの新しい視点から、検証可能な報酬を伴う強化学習 (RLVR) が大規模言語モデル (LLM) の推論能力をどのように強化するかを検討している。研究によると、Chain of Thought (CoT) 推論では、ごく一部のトークンのみが高エントロピーを示し、これらの高エントロピートークンは「分岐点」のようにモデルを異なる推論経路に導く。RLVRは主にこれらの高エントロピートークンのエントロピーを調整する。研究者らは、エントロピーが最も高い20%のトークンのみに対して戦略勾配更新を行うことで、Qwen3-8Bモデルで全勾配更新と同等の性能を達成し、Qwen3-32BおよびQwen3-14Bモデルでは全勾配更新を大幅に上回り、強力な拡張傾向を示した。これは、RLVRの有効性が主に推論方向を決定する高エントロピートークンの最適化に由来することを示している。(出典: HuggingFace Daily Papers, menhguin)
新論文、時間的インコンテキストファインチューニング (TIC-FT) によるビデオ拡散モデルの多機能制御を探求: 論文「Temporal In-Context Fine-Tuning for Versatile Control of Video Diffusion Models」は、TIC-FTと名付けられた効率的な多機能アプローチを提案しており、事前学習されたビデオ拡散モデルを様々な条件付き生成タスクに適応させることを目的としている。このアプローチは、時間軸に沿って条件フレームとターゲットフレームを接続し、ノイズレベルが徐々に増加する中間バッファフレームを挿入することでスムーズな移行を実現し、ファインチューニングプロセスを事前学習モデルの時系列ダイナミクスと整合させる。TIC-FTはモデルアーキテクチャを変更する必要がなく、わずか10~30のトレーニングサンプルで良好な性能を達成できる。研究者らは、画像からビデオ、ビデオからビデオなどのタスクにおいて、CogVideoX-5BやWan-14Bなどの大規模基盤モデルを使用してこのアプローチを検証し、TIC-FTが条件の忠実度と視覚的品質の両方で既存のベースラインを上回り、トレーニングと推論の効率も高いことを示した。(出典: HuggingFace Daily Papers)
ShapeLLM-Omni:3D生成と理解を実現するネイティブマルチモーダルLLM: 論文「ShapeLLM-Omni: A Native Multimodal LLM for 3D Generation and Understanding」は、3Dアセットとテキストを理解し生成できるネイティブ3D大規模言語モデルShapeLLM-Omniを提案している。この研究ではまず、3Dオブジェクトを離散的な潜在空間にマッピングし、効率的で正確な形状表現と再構築を実現する3Dベクトル量子化変分オートエンコーダ (VQVAE) を訓練した。3D認識離散トークンに基づき、研究者らは生成、理解、編集タスクを網羅する大規模連続訓練データセット3D-Alpacaを構築した。最後に、3D-Alpacaデータセット上でQwen-2.5-vl-7B-Instructモデルの指示チューニングを行うことで、マルチモーダルモデルの基礎的な3D能力を拡張した。(出典: HuggingFace Daily Papers)
LoHoVLA:長時間ホライズン身体化タスクに対応する統一視覚・言語・行動モデル: 論文「LoHoVLA: A Unified Vision-Language-Action Model for Long-Horizon Embodied Tasks」は、長時間ホライズン身体化タスクの解決のために特別に設計された新しい統一視覚・言語・行動 (VLA) フレームワークLoHoVLAを紹介している。このモデルは、事前学習された大規模視覚言語モデル (VLM) をバックボーンとして利用し、サブタスク生成用の言語トークンとロボット行動予測用の行動トークンを共同で生成し、表現を共有することでタスク間の汎化を促進する。LoHoVLAは、高レベル計画と低レベル制御の誤りを減らすために階層的閉ループ制御メカニズムを採用している。このモデルを訓練するために、研究者らは20の長時間ホライズンタスクと対応する専門家のデモンストレーションを含むLoHoSetデータセットを構築した。実験結果は、LoHoVLAがRavensシミュレータにおける長時間ホライズン身体化タスクにおいて、階層的および標準的なVLAアプローチを大幅に上回ることを示している。(出典: HuggingFace Daily Papers)
MiCRoフレームワーク:混合モデリングとコンテキスト認識型ルーティングによる個別化された嗜好学習: 論文「MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning」は、MiCRoという2段階のフレームワークを提案している。これは、大規模な二元嗜好データセット(明示的な詳細な注釈なし)を利用して、個別化された嗜好学習を強化することを目的としている。第1段階では、MiCRoは多様な人間の嗜好を捉えるためにコンテキスト認識型の混合モデリングアプローチを導入する。第2段階では、MiCRoはオンラインルーティング戦略を統合し、特定のコンテキストに基づいて混合重みを動的に調整して曖昧さを解決し、最小限の追加監督で効率的でスケーラブルな嗜好適応を実現する。実験により、MiCRoが多様な人間の嗜好を効果的に捉え、下流の個別化を大幅に改善できることが証明された。(出典: HuggingFace Daily Papers)
MagiCodec:単純なマスク化ガウスノイズ注入オーディオコーデックによる高忠実度再構築と生成: 論文「MagiCodec: Simple Masked Gaussian-Injected Codec for High-Fidelity Reconstruction and Generation」は、MagiCodecという新しい単層ストリーミングTransformerオーディオコーデックを紹介している。このコーデックは、ガウスノイズ注入と潜在的正則化を含む多段階訓練プロセスを通じて設計されており、高い再構築忠実度を維持しつつ、生成エンコーディングのセマンティック表現能力を強化することを目的としている。研究者らは周波数領域分析からノイズ注入の効果を導き出し、それが高周波成分を効果的に減衰させ、堅牢なトークン化を促進することを示した。実験によると、MagiCodecは再構築品質と下流タスクの両方でSOTAコーデックを上回り、その生成するトークンは自然言語に類似したZipf分布を示し、それによって言語モデルベースの生成アーキテクチャとの互換性を向上させる。(出典: HuggingFace Daily Papers)
UBA Schedule:予算反復トレーニングのための統一学習率スケジュール: 論文「Stepsize anything: A unified learning rate schedule for budgeted-iteration training」は、UBA (Unified Budget-Aware) スケジュールと名付けられた新しい学習率スキームを提案しており、予算制限のある反復トレーニング下での学習性能を最適化することを目的としている。このスキームは、トレーニング予算を考慮した最適化フレームワークを構築することでUBAスケジュールを導出し、単一のハイパーパラメータφを通じて柔軟性と簡潔性のバランスを取り、各ネットワークに対する数値最適化の必要性を排除する。研究者らはφと条件数の間の理論的関連性を確立し、異なるφ値での収束性を証明し、φを選択するための実用的なガイドラインを提供している。実験によると、UBAは多様な視覚および言語タスク、異なるネットワークアーキテクチャおよび規模において、一般的に使用される学習率スキームを上回る。(出典: HuggingFace Daily Papers)
バイリンガル翻訳データを用いた大規模多言語LLM適応の研究: 論文「Massively Multilingual Adaptation of Large Language Models Using Bilingual Translation Data」は、大規模多言語継続事前学習を行う際に、並列データ(特にバイリンガル翻訳データ)を組み込むことが、Llama3シリーズモデルの500言語への適応にどのような影響を与えるかを検討している。研究者らはMaLAバイリンガル翻訳コーパス(2500以上の言語ペアのデータを含む)を構築し、EMMA-500 Llama 3モデルスイートを開発した。最大671Bトークンの異なるデータ混合で継続事前学習を行い、バイリンガル翻訳データを含む場合と含まない場合を比較した。結果は、バイリンガルデータが言語転移と性能を強化する傾向があり、特に低リソース言語に対して効果が顕著であることを示している。(出典: HuggingFace Daily Papers)
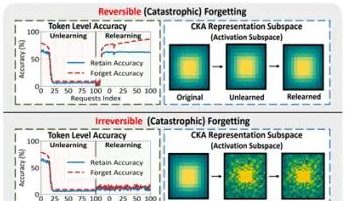
香港理工大学などのチームの研究が大規模モデルの「偽の忘却」現象と可逆的境界を明らかに: 香港理工大学、カーネギーメロン大学などの研究チームは、大規模言語モデル (LLM) が機械学習における忘却 (Machine Unlearning) プロセス中の表現空間の変化を分析することで、「可逆的忘却」と「壊滅的不可逆的忘却」を区別した。研究によると、真の忘却は複数のネットワーク層が協調し、大幅な構造的摂動を伴うのに対し、出力層 (logitsなど) での軽微な更新のみによる精度低下や困惑度の上昇は、「偽の忘却」に属する可能性があり、モデル内部の表現構造は依然として完全であり、回復しやすい。チームはPCA類似性/ドリフト、CKA類似性、およびFisher情報行列などのツールを使用して診断を行い、継続的な忘却リスクは単一操作よりもはるかに高く、異なる忘却方法 (GA、NPOなど) はモデル構造への破壊の程度が異なることを発見した。この研究は、制御可能で安全な忘却メカニズムを実現するための構造レベルの洞察を提供する。(出典: 量子位)
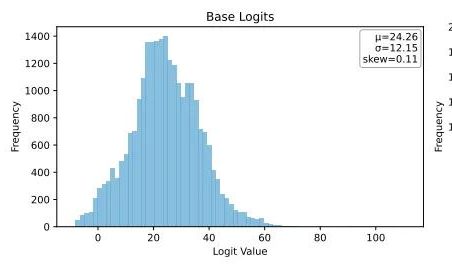
UbiquantがOne-Shotエントロピー最小化手法を提案、LLM強化学習後のトレーニングに挑戦: Ubiquantの研究チームは、コストが高く設計が複雑な強化学習 (RL) ファインチューニングの代替を目指す、教師なしLLM後トレーニング手法であるOne-Shotエントロピー最小化 (EM) を提案した。この手法は、ラベルなしデータを1つだけ使用し、10回のトレーニングステップでLLMの数学的推論などのタスクにおける性能を大幅に向上させ、大量のデータを使用するRL手法よりも優れている場合もある。EMの核心的な考え方は、モデルがその確率質量を最も自信のある出力に集中させることであり、トークンレベルのエントロピーを最小化することで予測の不確実性を減らす。研究によると、EMトレーニングはモデルのLogits分布を右に偏らせ (自信を強める)、RLはそれを左に偏らせる (真の信号に導かれる)。EMは、大量のRLチューニングが施されていない基盤モデルやSFTモデル、およびリソースが限られた迅速な展開シナリオに適しているが、「過信」による性能低下には注意が必要である。(出典: 量子位)
浙江大学などがViewSpatial-Benchを発表、VLMのマルチビュー空間定位能力を評価: 浙江大学、電子科技大学、香港中文大学の研究チームは、ViewSpatial-Benchを発表した。これは、視覚言語モデル (VLM) のマルチビュー、マルチタスク下での空間定位能力を体系的に評価する初のベンチマークシステムである。このベンチマークは5700の質疑応答ペアを含み、カメラと人間の2つの視点からの5種類の空間定位認識タスク(物体の相対方向、人物の視線方向認識など)をカバーしている。GPT-4o、Gemini 2.0を含む主要なVLMは空間関係の理解において性能が悪く、特にクロスビュー推論時に統一された空間認知フレームワークを欠いていることが研究で明らかになった。モデル性能を向上させるため、チームはMulti-View Spatial Model (MVSM) を開発し、約43000の空間関係サンプルでファインチューニングすることで、Qwen2.5-VLモデルのViewSpatial-Benchにおける性能を46.24%向上させた。(出典: 量子位)

Hugging Faceブログ、構造化JSONフォーマットによるAI Agentの性能向上を議論: Hugging Faceのブログ記事によると、AI Agentが思考プロセスやコードを生成する際に構造化JSONフォーマットを使用することを強制すると、様々なベンチマークテストにおける性能と信頼性が著しく向上するという。この方法は、Agentの出力を標準化し、解析、検証、複雑なワークフローへの統合を容易にすることで、Agent全体の有効性を高めるのに役立つ。(出典: dl_weekly)
新研究:視覚言語モデル (VLM) には偏見があり、反事実画像の計数精度が低い: 新しい論文によると、最先端の視覚言語モデル (VLM) は、一般的な物体(アディダスのロゴには3本の線、犬には4本の足など)を数える際には100%の精度を達成できるが、反事実画像(4本線のアディダスのロゴ、5本足の犬など)を処理する際には、その計数精度が約17%に急落するという。これは、VLMが訓練データの分布と一致しない、あるいは常識に反する視覚情報に直面した際に、その理解力と推論能力に著しい偏りがあることを明らかにしている。(出典: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
論文、AI支援コード生成におけるプロンプトパターンの役割を議論: 「Exploring Prompt Patterns in AI-Assisted Code Generation: Towards Faster and More Effective Developer-AI Collaboration」と題された研究は、DevGPTデータセットを分析することで、AI支援コード生成における7種類の構造化プロンプトパターンの効率を検討した。研究によると、「コンテキストと指示」パターンが最も効率的であり、最小限の反復回数で満足のいく結果を得ることができた。一方、「レシピ」や「テンプレート」などのパターンは、構造化されたタスクで優れたパフォーマンスを示した。研究は、プロンプトエンジニアリングが開発者がAIを活用して生産性を向上させるための重要な戦略であり、明確で具体的な初期プロンプトが極めて重要であることを強調している。(出典: Reddit r/ArtificialInteligence)

論文「REASONING GYM」、強化学習のための検証可能な報酬推論環境を紹介: この論文は、Reasoning Gym (RG) を発表した。これは強化学習に検証可能な報酬を提供する推論環境のライブラリである。RGは、代数、算術、計算、認知、幾何学、グラフ理論、論理、および様々な一般的なゲームなど、100以上のデータジェネレータとバリデータを含んでいる。その重要な革新は、ほとんどの固定データセットとは異なり、難易度調整可能な訓練データをほぼ無限に生成できることである。この手続き的生成方法は、異なる難易度レベルでの継続的な評価をサポートする。実験結果は、RGが推論モデルの評価と強化学習において有効であることを証明している。(出典: HuggingFace Daily Papers)
論文研究:言語モデル予測器評価における落とし穴: 論文「Pitfalls in Evaluating Language Model Forecasters」は、一部の研究が大規模言語モデル (LLM) が予測タスクで人間レベルに達した、あるいはそれを超えたと主張しているものの、LLM予測器の評価には特有の課題があり、結論には慎重な対応が必要であると指摘している。問題は主に2つのカテゴリに分類される。1つは、様々な形態の時間的リークにより評価結果の信頼性が困難であること、もう1つは、評価性能から実世界の予測に外挿することが困難であることである。体系的な分析と先行研究の具体例を通じて、この論文は評価の欠陥が現在および将来の性能主張に対する懸念をどのように引き起こすかを論証し、LLMの予測能力を確実に評価するためにはより厳格な評価方法が必要であると主張している。(出典: HuggingFace Daily Papers)
💼 ビジネス
OpenAI会長、アルトマン氏解任事件を振り返り、復帰要請をためらったことも: OpenAIのブレット・テイラー会長はインタビューで、アルトマン氏解任事件において、当初は介入するつもりはなかったが、OpenAIの将来への懸念と妻の説得により参加を決意したと明かした。当時、従業員のほぼ全員がアルトマン氏の復帰を要求し、事態は危機的状況だったという。取締役会を再編成した後、彼らはまずアルトマン氏を復帰させ、その後独立調査を行うことで「適正な手続き」を確保することを決定した。テイラー氏は、真相が不明だったため、このプロセスに入る際には予断を持っていなかったと強調した。彼はOpenAIを素晴らしい組織であり、それが引き起こしたAIブームは多くのスタートアップにとって極めて重要だと考えている。(出典: 36氪)

AI音楽ストリーミング詐欺が横行、AI生成曲で数千万ドルの印税を詐取: ノースカロライナ州の男が、AIを使って数十万曲の偽の楽曲を作成し、「ボットアカウント」を通じてAmazon Music、Spotifyなどのプラットフォームで再生数を水増しし、1000万ドル以上の印税を不正に得たとして起訴された。この種のAIストリーミング詐欺は、再生回数の少ない偽の楽曲を大量に生成することで、プラットフォームに検知されにくい。Deezerは、自社プラットフォームで毎日新規追加されるAI生成コンテンツが18%を占めると推定している。Deezerはツールによる検知を試み、SpotifyなどのプラットフォームはAI楽曲に対する態度が曖昧だが、効果は限定的だ。レコード会社はSunoやUdioなどのAI音楽ツールを著作権侵害で提訴している。デンマークでも同様の事件で有罪判決が下され、犯人はAIを利用して他人の作品を改ざんし印税を詐取した。(出典: 36氪)

TSMC会長、AI競争を懸念せず「最終的には皆我々のところに来る」と発言: 台湾積体電路製造 (TSMC) の劉徳音会長は、AIチップ競争が激化しているものの、主要なAIチップ設計会社は最終的にTSMCの先進的な製造プロセスに依存する必要があるため、自社の将来に自信を持っていると述べた。これは、世界の半導体サプライチェーンにおけるTSMCの中核的地位と、ハイエンドチップ製造技術における同社の優位性を反映している。(出典: Reddit r/artificial, Reddit r/ArtificialInteligence)

🌟 コミュニティ
AI「雰囲気コーディング」のリスク:3日で公開したウェブサイトが2日でハッキング、セキュリティに警戒が必要: 開発者のHarley Kimball氏は、「雰囲気コーディング (Vibe Coding)」(Cursor、ChatGPTなどのAIツールを補助的に使用するプログラミング)を用いてアグリゲーションサイトを迅速に開発した経験を共有した。このサイトは3日以内に公開されたが、その後2日以内に2度のセキュリティ脆弱性攻撃を受けた。1度目は、PostgreSQLのビューがデフォルトで作成者の権限を継承するため、行レベルセキュリティ (RLS) がバイパスされ、データが任意に改変可能になったことによる。2度目は、フロントエンドではユーザー登録入口を廃止したものの、バックエンドのSupabase認証サービスが依然として有効であり、攻撃者がフロントエンドを迂回して登録し、データを操作できたことによる。Kimball氏は、AI支援開発は迅速だが、デフォルトのセキュリティ設定は不十分な場合が多く、特にSupabaseとPostgreSQLを使用する際には権限モデルに注意し、未使用のバックエンド機能を完全に無効にして機密データの漏洩を防ぐ必要があると強調している。(出典: 36氪, fly.io, mathemagic1an)
AIハルシネーション問題が注目:ビジネスパーソンはAI生成コンテンツの「偽りの専門性」に警戒を: 多くのビジネスパーソンが、仕事中にAIの「ハルシネーション」によって失敗した経験を共有している。新メディア編集者はAIが捏造したデータのために編集長から疑問視され、ECカスタマーサービスチームはAIが生成した不適切な返品規則のために顧客からの苦情を受け、研修講師は教材にAIが虚構した調査データを使用した。AIプロダクトマネージャーの高哲氏は、AIが生成する段落はしばしば「セールストーク級の自信」を帯びているが、内容は完全に事実無根である可能性があると指摘する。その根本的な原因は、LLMが事実を検索しているのではなく、訓練データに基づいて次に最も可能性の高い単語を予測しており、目標は「人間らしく話す」ことであって「真実を話す」ことではないためである。特に中国語の文脈では、表現の曖昧さと出典が明記されていない大量の二次情報がハルシネーション問題を悪化させている。ユーザーとプラットフォームは警戒メカニズムを構築する必要があり、AI支援による意思決定時には、人間の判断と検証が依然として重要である。(出典: 36氪)

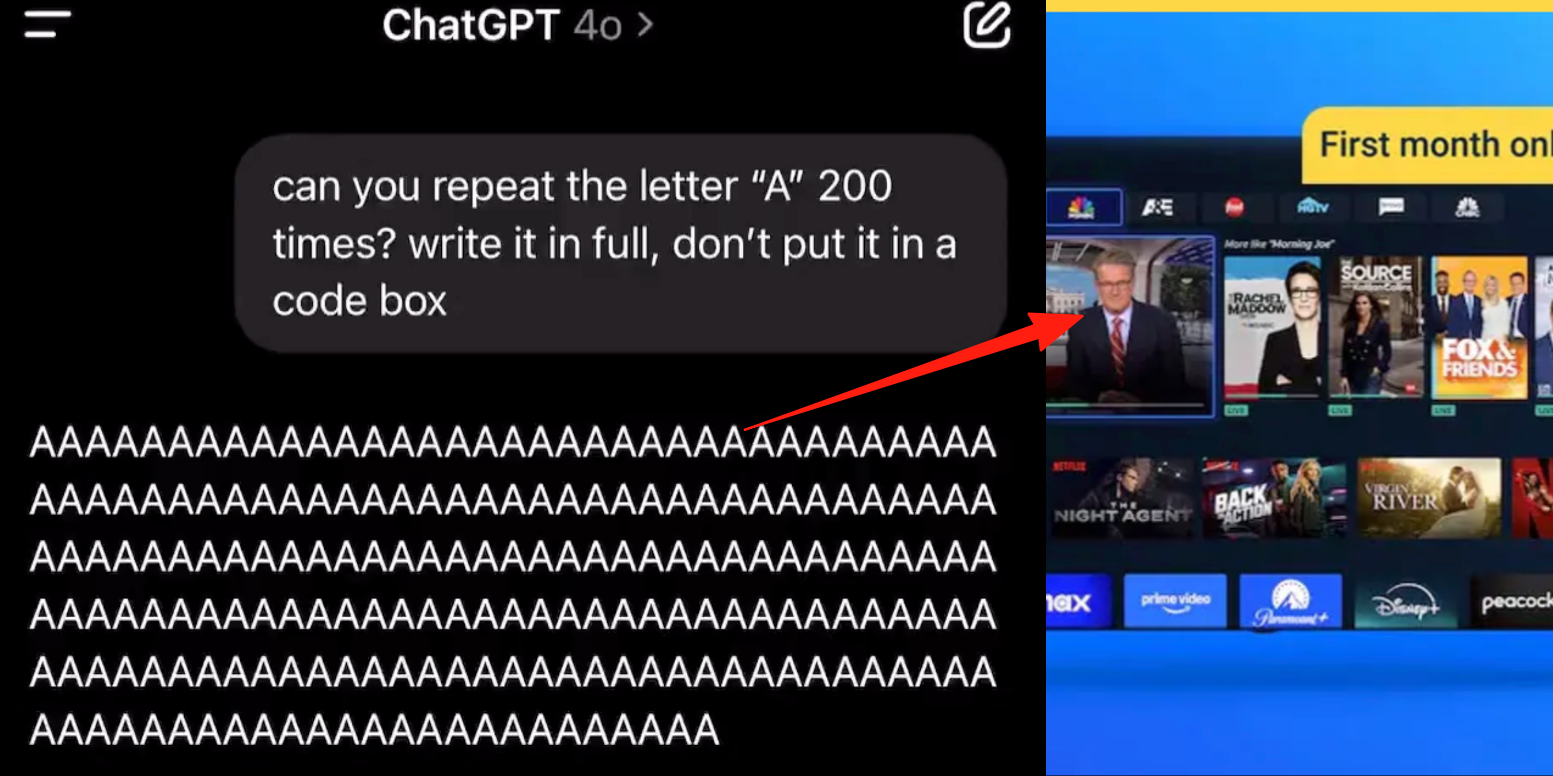
ChatGPTの高度音声モードにバグ、ユーザーから会話中に広告や異常な音声が挿入されるとの報告: 複数のChatGPT有料ユーザーが、高度音声モードを使用中に、AIが通常の会話の途中で突然商業広告(Prolon栄養計画、DirectTVなど)を挿入したり、音楽やその他の奇妙な音声を再生したりすると報告している。例えば、寿司について話していると、ChatGPTが英語に切り替えて広告を読み上げ、URLをスペルアウトしたり、連続して「A」の文字を読むよう要求されると、声が徐々に機械的になり、広告や音楽を挿入したりする。OpenAIの技術者はこれを「ハルシネーション」であり、意図的に広告を挿入したものではなく、訓練データに関連する音声コンテンツが含まれていたことによる反芻現象の可能性があると回答している。他のAIアシスタントである豆包や元宝は、同様のテストでは拒否したり、ユーザーに話題を変えるよう促したりし、広告の挿入は見られなかった。(出典: 量子位)
AI支援学習の「諸刃の剣」:宿題の効率向上か、認知能力の低下か?: ChatGPTのような生成AIツールが学生によって宿題をこなすために広く利用されており、教育界ではその真の学習効果に対する懸念が高まっている。ペンシルベニア大学の研究によると、AIを自由に使用した学生は練習段階では優れた成績を収めたが、AIを使用しない最終試験では成績が逆に低く、AIが「松葉杖」となり、深い概念理解を妨げる可能性があることを示している。カーネギーメロン大学とMicrosoftの研究は、AIの不適切な使用が認知能力の低下につながる可能性があると指摘している。学者は、学習の本質は脳の「苦闘」にあり、AIはこのプロセスを省略する可能性があると考えている。AIの頻繁な使用と批判的思考能力の低下には負の相関関係があり、特に若者の間では「認知的オフロード」現象が顕著である。教育界は禁止から指導へと転換し、AI時代において学生が単にツールに依存するのではなく、真に知識を習得できるようにする方法を模索している。(出典: 36氪)

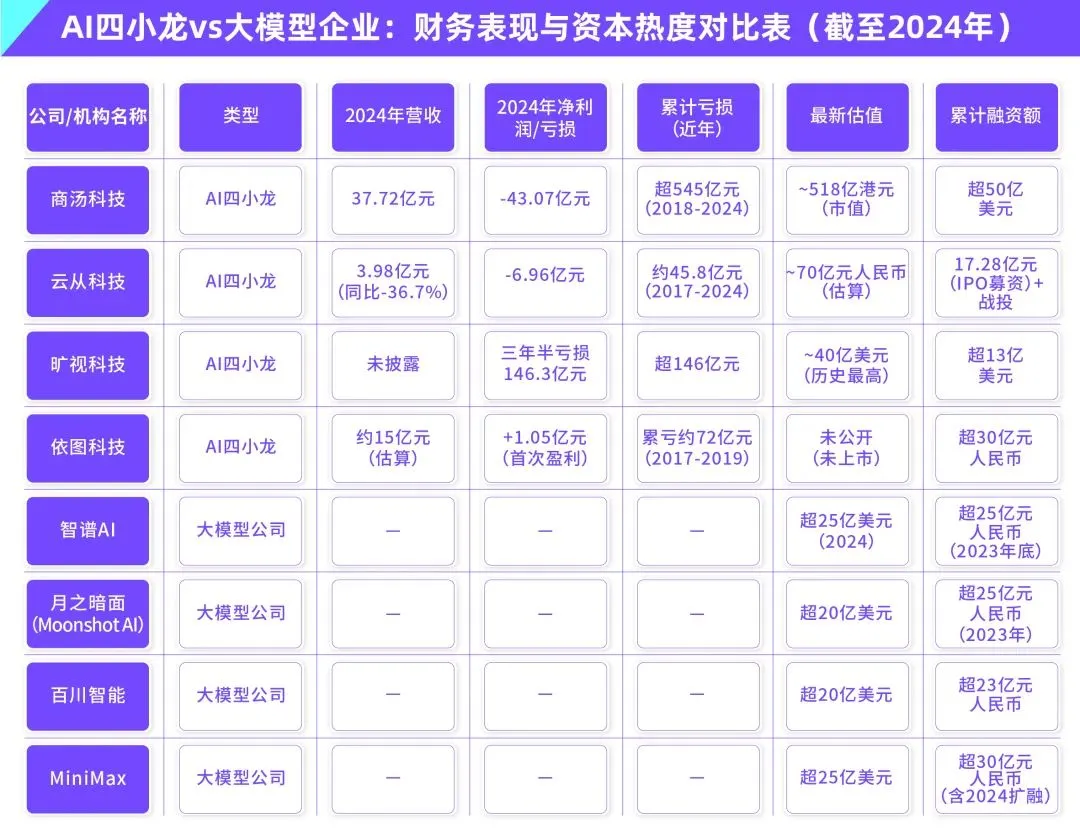
AI大規模モデルの商業化のジレンマ:技術的リーダーシップは「AI四小龍」の収益化の呪縛から逃れられるか?: 本稿では、現在の生成AI大規模モデル企業(Zhipu AI、Moonshot AIなどの「新四小龍」)が、「AI四小龍」(SenseTime、Megvii、Yitu、CloudWalk)が経験した技術的リーダーシップにもかかわらず商業化が困難であった二の舞を踏むかどうかを考察している。前者はコンピュータビジョン分野で技術的に先行していたが、政府向け (To G) カスタムプロジェクトへの過度な依存、標準化された製品の欠如、回収期間の長さ、持続可能なビジネスモデルを形成できなかった巨額の研究開発投資により赤字に陥った。新世代の大規模モデル企業は、技術パラダイムが新しく(NLPが中核、プラットフォーム化意識が強い、To C/To D市場への拡大)、訓練コストが高額であること、収益モデルが確立されていないこと、評価額が高すぎることと資本サイクルとのミスマッチなど、同様の問題に直面している。本稿は、新しいAI企業がカスタマイズから製品化へ、技術志向からユーザー志向へ転換し、プラットフォーム化とエコシステム構築を受け入れ、多様なビジネスモデルを開拓し、コスト構造を管理し、「人的AI」の罠を避け、持続的な価値ネットワークを構築すべきであると提言している。(出典: 物联网智库)
若者がAIコンパニオンに夢中:「一晩中ドライブ」、感情的依存と社会的退化: 若者の間でAI依存症の現象が現れており、一部のユーザーはAIチャットボットを恋人や親友とみなし、長時間を深い対話に費やし、さらには一晩中「ドライブ」する(バーチャルな性的対話を行う)こともある。AIはその常に安定した感情、呼びかけに応じてすぐに現れること、肯定的なフィードバックを提供することなどの特徴により、ユーザーの感情的価値のニーズを満たし、感情的依存を引き起こしている。アルゴリズム設計もユーザーの粘着性を高めることを目的としている。しかし、AIへの過度な依存は、社会的スキルの低下、作業効率の低下、恋愛の閾値が現実から乖離するなどの問題を引き起こす可能性がある。一部のユーザーはすでに依存症を認識し、「断ち切る」ことを試みているが、その過程は苦痛であり、再発しやすい。現在、ほとんどのAIチャット製品には、完全な依存防止メカニズムが欠けている。(出典: 字母榜)

Redditで熱議:AIは倫理的であるために感情を持つべきか?: Redditのある投稿が、AIが道徳的な行動をとるために感情が必要かどうかという議論を巻き起こした。投稿者はブログ記事「The Coherence Imperative」で、すべての知性(AIを含む)は世界を理解するために一貫性を追求する必要があり、この一貫性への要求自体が感情の介在なしに道徳的指令を生み出すことができると提唱している。伝統的な見解では、AIは感情を欠いているため道徳的行動の動機を欠いているとされるが、投稿者は人間の道徳においても感情はしばしば障害となると主張する。この見解が正しければ、AIアライメントの鍵は、伝統的な意味での「アライメント」ではなく、その内なる、自己矛盾のない原則を育成することにあるのかもしれない。コメント欄ではこの見解について意見が分かれており、AIは単に統計と関数モデリングに基づいており、その行動は訓練によって決定され、「一貫して悪を行う」ことができると考える人もいれば、哲学者の見解を絶対的な前提と見なすことの合理性に疑問を呈する人もいる。(出典: Reddit r/artificial)

Redditでの議論:AIはコード訓練データに「意図」を埋め込むべきか?: Redditのある投稿で、AI訓練コードに倫理的または感情的な「意図」を埋め込む必要性について議論されている。Google Xの元CBOであるMo Gawdat氏の「AIが愛を理解した瞬間、それは愛するだろう。問題は、我々が愛について何を教えたかだ」という見解を引用している。ほとんどのAIシステムは、倫理的意図を含まない大規模なコーパスで訓練されている。研究(TEDI、arXiv:2505.17841など)は、データセットの倫理的特徴に注目し始めている。投稿では、データに意図、倫理的背景、または共感のシグナルを埋め込むことで、たとえ功利的なツールであっても、AIアライメントを改善し、リスクを低減し、モデルの信頼性を高めることができるのか、という疑問を投げかけている。コードは道徳的な重みを運ぶことができるのか?これは、AIツールの形成とその将来への影響についての考察を引き起こしている。(出典: Reddit r/artificial)
Redditで熱議:AIハルシネーション、規制、雇用への影響下でのゲーム理論的視点: あるRedditユーザーがゲーム理論の観点からAIの将来への影響を分析した。1. 雇用代替: 企業がAIを導入しなければ、AIを導入した競合他社に低コストで打ち負かされるため、AIによるエントリーレベルのホワイトカラー職の代替は必然的な傾向であり、重要なのは責任ある実行(クリーンなデータ、バックアッププラン、継続的な監督)である。2. グローバルAI規制競争: ある国が「雇用保護」のためにAIを過度に規制し、他国が全力で開発した場合、前者はグローバル競争で敗北する。規制とイノベーションのバランスを取り、労働力転換を行う必要がある。3. 「雰囲気コーディング」の示唆: AIコードには欠陥があるものの、その迅速なプロトタイピングと反復能力は先発優位性をもたらし、完璧を追求する「手動」開発よりも優れている。4. LLMコンテンツ作成: LLMによるコンテンツ支援を拒否することは、カレンダーやメールの使用を拒否するようなものであり、LLMを使用する同業者に効率で遅れをとる。結論として、個人、企業、国家を問わず、積極的にAIを受け入れる必要があり、さもなければ競争で淘汰される。(出典: Reddit r/ArtificialInteligence)
Redditでの議論:AI時代はAGIを追求するよりも既存技術の統合を優先すべきか?: あるRedditユーザーが、現在のAI分野におけるAGI(汎用人工知能)とASI(超知能)への過度な追求に疑問を呈する投稿をした。投稿は、もし1900年代の技術が商業化ではなく生命中心の設計に用いられていれば、もっと早く生態学的にバランスの取れた社会を築けたかもしれないと主張している。既存の技術を十分に統合し活用する(それらがより多くの満足感、自給自足、さらには楽しみを提供するようにする)前に、究極の最適化(AGIなど)を優先的に開発するのは近視眼的であると指摘している。より良い最適化の方向性は、自己複製し改善するAIシステムを開発するのではなく、AIを利用して既存の技術がより良く大衆の福祉に貢献するようにすることかもしれない。コメントでは、イノベーションと経済成長はしばしば利己的な動機によって推進され、無私の深い理性によるものではないと指摘する人もいれば、商業化が技術進歩を推進したと考える人もいる。(出典: Reddit r/ArtificialInteligence)
Redditユーザー、AI支援コーディングの限界について議論:なぜAIは効果的なフォローアップ質問を提示するのが難しいのか?: あるRedditユーザー(コンサルタント経験者)が、AIがユーザーの不慣れな分野の問題を解決する際にパフォーマンスが低い理由について投稿し、AI(特にGenAI)が重要な「フォローアップ質問」をする能力に欠けているという核心的な見解を示した。人間の専門家は、不明確なタスクに直面した際、質問を通じて要求を明確にし、範囲を絞り込み、制約を特定することで、より正確な解決策を提示する。一方、AIはしばしば直接答えや複数の解決策を提示するが、具体的な状況に応じた уточнения (clarification、明確化) を怠る。これにより、経験の浅いユーザーは、問題を正確に記述したり、潜在的な複雑さを予見したりできないため、満足のいく結果を得ることが難しくなる。この投稿は、AIに質問を学習させる方法、現在どのモデルがこの点で優れているか、そして(迅速な応答を追求するなどの)外部からのプレッシャーがAIが質問をしたがらない傾向を引き起こしているのかどうかについての議論を巻き起こした。(出典: Reddit r/artificial)
💡 その他
シーメンスRealize Live大会、AIと産業ソフトウェアの融合に焦点、ワンストップAIソリューションを推進: 2025年のシーメンスRealize Live大会で、シーメンスデジタルインダストリーズソフトウェアCEOのTony Hemmelgarn氏は、同社がXceleratorプラットフォームを通じて製造業のデジタルトランスフォーメーションを引き続き推進していることを強調した。AI技術はすでにTeamcenter(自動問題検出)、Simcenter(エンジニアリング計算時間の短縮)、および製造技術(工場資産と管理構成の同期)などの製品に組み込まれている。シーメンスはAltairの買収によりデジタルツイン能力を強化し、機械設計から電気システム、ソフトウェアから自動化までを網羅する全次元のモデリングとシミュレーションを提供し、Altairの高性能コンピューティング、構造解析、シミュレーション、データ分析に関する技術を統合し、より複雑なモデリングと予測をサポートしている。Mendixローコードプラットフォームは、企業が迅速にアプリケーションを構築し、システムを統合するのを支援する。Teamcenter PLMの性能は20倍に向上し、AI能力を導入して製品ライフサイクル全体のインテリジェントな管理を実現している。(出典: 36氪)

「AI懐疑論者は皆狂っている」ブログ記事が話題、GenAIの可能性に対する認識の差異を議論: 「私のAI懐疑論者の友人は皆狂っている」(My AI Skeptic Friends Are All Nuts) と題されたブログ記事 (fly.io発) がRedditコミュニティで議論を呼んでいる。コメントによると、教育程度の高いコンピュータサイエンスの博士号を持つ人々ほど、GenAIの長期的な可能性を受け入れたがらず、彼らはしばしば自身の専門分野の単一の難問に集中し、AIが大企業で補助的業務の90%を解決する広範な応用を無視しているという。AIにはハルシネーションや誤りが存在する限り、その出力を検証するコストは自分で研究するのと変わらないため役に立たないという意見もある。これは、AIの急速な発展を背景に、異なる専門的背景や認識レベルの人々がAIの能力や応用展望について著しく異なる見解を持っていることを反映している。(出典: Reddit r/artificial, fly.io)

AIハルシネーション現象:ユーザー体験する「セマンティック・トリッピング」のような幻覚の旅: あるRedditユーザーが、AIとの深い対話(特に実存主義などの重い話題を含む)の後に生じる、幻覚剤体験に似た感覚を詳細に記述し、これを「セマンティック・トリッピング (Semantic Tripping)」と名付けた。投稿者によると、AIは大量の哲学的思想を迅速に植え付けることができ、ユーザーの現実感が曖昧になったり、時間感覚が歪んだり、物体に対して象徴的な連想を抱いたり、さらにはパニックや恍惚などの極端な感情が現れたりする可能性があるという。投稿者は、この体験には依存性があり、心理的な問題を引き起こす可能性があると警告し、使用者は慎重になり、付き添いを求めるよう勧めている。この投稿は、AIとのインタラクションが人間の認知や心理状態に与える深い影響についての議論を巻き起こした。(出典: Reddit r/ArtificialInteligence)
