
キーワード:OpenAI Codex, 視覚言語動作モデル, 言語モデルメモリ上限, ChatGPT記憶機能, DeepSeek-R1-0528, 拡散モデル, Suno AI音楽創作, MetaAgentX, Codexインターネットアクセス機能, SmolVLAロボットモデル, GPTスタイルモデル3.6ビットメモリ, ChatGPTパーソナライズドインタラクション改良, DeepSeek-R1複雑推論能力
🔥 注目
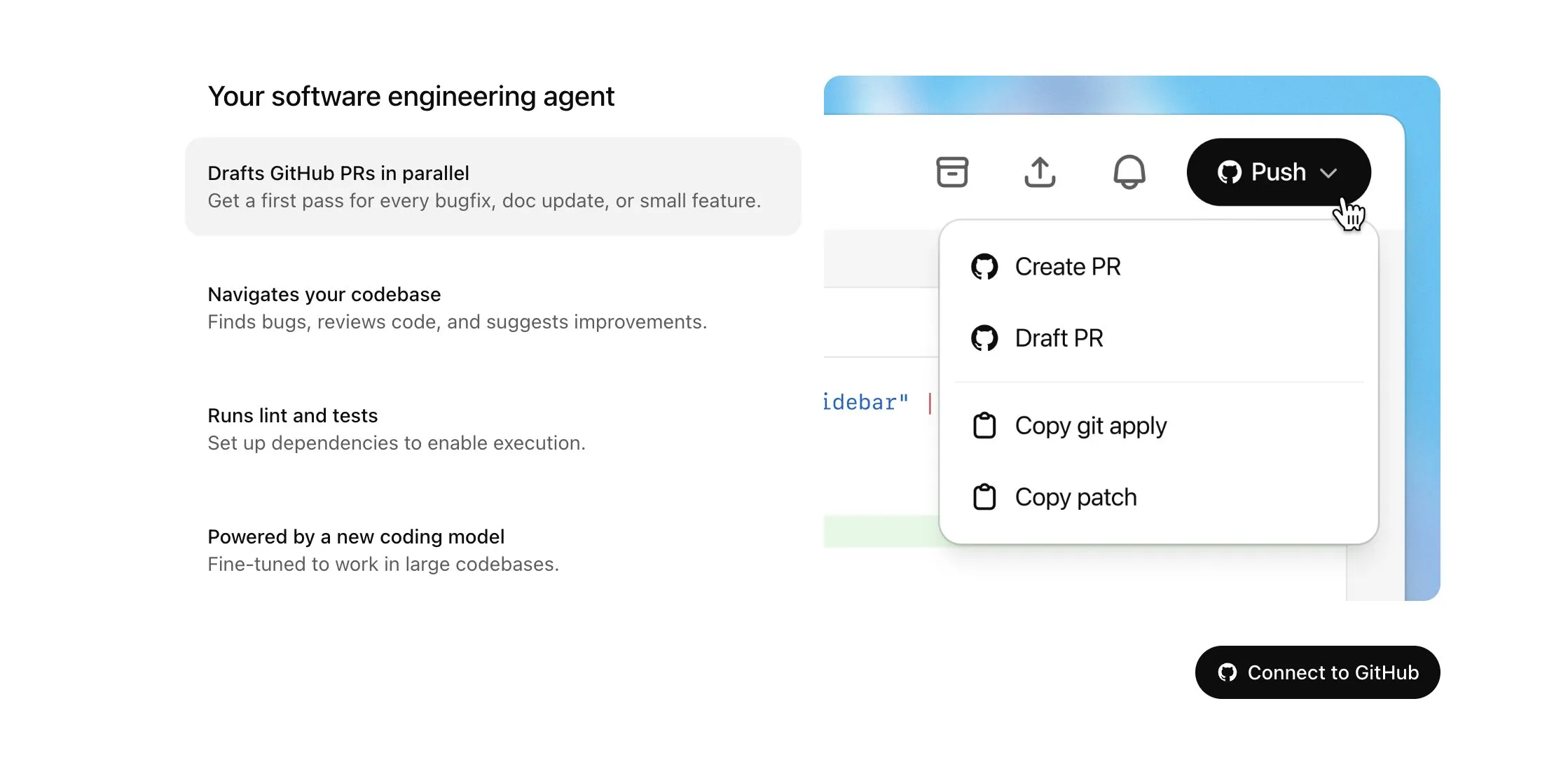
OpenAI Codex、Plusユーザー向けに提供開始、インターネットアクセスや音声入力など大幅アップデート: OpenAIは、CodexをChatGPT Plusユーザーに段階的に提供開始すると発表しました。今回のアップデートの主な内容には、AIエージェントがタスク実行時にインターネットにアクセスできる機能(デフォルトではオフ、ユーザーがドメインとHTTPメソッドを制御可能)が含まれており、これにより依存関係のインストール、パッケージのアップグレード、外部リソースのテスト実行が可能になります。同時に、Codexは既存のPull Requestの直接更新や、音声によるタスク入力もサポートするようになりました。その他の改善点としては、バイナリファイルの操作(PRでは現在削除または名前変更のみに限定)、タスク差分(diff)のサイズ制限の1MBから5MBへの引き上げ、スクリプト実行時間制限の5分から10分への延長、iOSプラットフォームにおける複数の問題修正とライブアクティビティ機能の再有効化などが挙げられます。これらのアップデートは、複雑なプログラミングタスクにおけるCodexの実用性と柔軟性を向上させることを目的としています (出典: OpenAI Developers, Tibor Blaho, gdb, kevinweil, op7418)
Hugging FaceとH Company、オープンソースの視覚言語動作(VLA)モデルを共同発表、ロボット技術の発展を推進: Hugging FaceとH Companyは「VLAデー」に、Hugging FaceのSmolVLA (450Mパラメータ)とH CompanyのHolo-1 (3Bおよび7Bパラメータ)を含む、新しいオープンソースの視覚言語動作モデルを発表しました。VLAモデルは、ロボットが見て、聞いて、理解し、AIの指示に基づいて行動できるようにすることを目的としており、ロボット分野のGPTと呼ばれています。これらのモデルをオープンソース化することは、その動作原理を理解し、潜在的なバックドアを回避し、特定のロボットやタスクに合わせてカスタマイズするために不可欠です。SmolVLAはLeRobotHFデータセットでトレーニングされ、優れた性能と推論速度を示しています。一方、Holo-1はウェブおよびコンピュータエージェントタスクに焦点を当てており、Apache 2.0ライセンスをサポートしています。これらの発表は、オープンソースAIロボット技術の発展を加速すると期待されています (出典: ClementDelangue, huggingface, LoubnaBenAllal1, tonywu_71)

Metaなどの企業の研究で、言語モデルの記憶上限はパラメータあたり約3.6ビットであることが明らかに、従来の認識に挑戦: Meta、DeepMind、コーネル大学、NVIDIAの共同研究によると、GPTスタイルの言語モデルは、パラメータあたり約3.6ビットの情報を記憶できることが示されました。研究では、モデルは容量上限に達するまでトレーニングデータを記憶し続け、その後「Grokking」(頓悟)現象、つまり予期せぬ記憶の減少が起こり、モデルは汎化学習に移行することがわかりました。この発見は、「二重降下」現象、つまりデータセットの情報量がモデルの記憶容量を超えると、モデルは容量を節約するために情報点を共有せざるを得なくなり、それによって汎化が促進されることを説明しています。この研究はまた、モデルの容量、データ規模、メンバーシップ推論攻撃の成功率との間のスケーリング則を提案し、膨大なデータセットでトレーニングされた現代のLLMでは、信頼性の高いメンバーシップ推論が困難になることを指摘しています (出典: 机器之心, Reddit r/LocalLLaMA, code_star, scaling01, Francis_YAO_)
OpenAI、ChatGPTの記憶機能軽量版を導入、パーソナライズされたインタラクション体験を向上: OpenAIは、無料ユーザー向けに記憶機能の軽量版の改善を開始すると発表しました。既存の記憶保存機能に加え、ChatGPTはユーザーの最近の会話を参照して、よりパーソナライズされた応答を提供できるようになりました。これは、ユーザーの好みや興味を参考にすることで、執筆、アドバイスの取得、学習などをよりスムーズに行えるようにすることを目的としています。Sam Altman氏も、記憶機能は彼のお気に入りのChatGPT機能の1つとなり、将来のさらなる改善に期待していると述べています。このアップデートは、AIインタラクションをユーザーのニーズに近づけ、ユーザーエンゲージメントを強化するというOpenAIの取り組みを示すものです (出典: openai, sama, iScienceLuvr)
🎯 動向
DeepSeek-R1-0528がリリース、複雑な推論とプログラミング能力を強化: DeepSeekは、R1モデルのアップグレード版であるDeepSeek-R1-0528をリリースしました。このバージョンは、2024年12月にリリースされたDeepSeek V3 Baseモデルに基づいており、より多くの計算能力を投入して事後トレーニングを行うことで、モデルの思考の深さと推論能力を大幅に向上させました。新モデルは、複雑な問題を処理する際により詳細な分解とより長時間の思考を行い(例えばAIME 2025テストでは、問題あたりの平均トークン消費量が12Kから23Kに増加)、数学、プログラミング、汎用ロジックなど複数のベンチマークテストでGPT-o3やGemini-2.5-Proに近い優れた成績を収めています。さらに、新バージョンは幻覚の低減(約45%-50%)、創造的な執筆、ツール呼び出しの面でも大幅に最適化されており、例えば「9.9 – 9.11はいくつか」といった問題により安定して回答したり、実行可能なフロントエンドとバックエンドのコードを一度に生成したりすることができます (出典: 科技狐, AI前线, Hacubu)

拡散モデル、言語およびマルチモーダル分野で可能性を示し、自己回帰型パラダイムに挑戦: Google I/O 2025で展示されたGemini Diffusion言語モデルは、最大5倍の生成速度と遜色ないプログラミング性能で、テキスト生成分野における拡散モデルの可能性を浮き彫りにしました。自己回帰モデルがトークンを1つずつ予測するのとは異なり、拡散モデルは段階的なノイズ除去によって出力を生成し、迅速な反復と誤り訂正をサポートします。アントグループと人民大学高瓴人工知能学院が共同で発表した8BパラメータのLLaDAモデル、およびByteDanceが開発したMMaDAマルチモーダル拡散モデルは、いずれもこの分野における国内チームの最先端の探求を示しています。これらのモデルは、言語タスクで優れた性能を発揮するだけでなく、マルチモーダル理解(LLaDA-Vと視覚的指示のファインチューニングの組み合わせなど)や特定分野(タンパク質配列生成のためのDPLMなど)でも進歩を遂げており、拡散モデルが次世代汎用モデルの新しいパラダイムになる可能性を示唆しています (出典: 机器之心)
Sunoが大幅アップデート、AI音楽制作・編集能力を強化: AI音楽制作プラットフォームSunoは、ユーザーにより大きな創作の自由度とコントロールを与えるための複数の重要なアップデートを発表しました。新機能には、アップグレードされたソングエディターが含まれ、ユーザーは波形図上でトラックをセグメントごとに並べ替え、書き換え、再作成できます。また、ステム分離機能が導入され、トラックをボーカル、ドラム、ベースなど12の独立した音源に正確に分離してプレビューおよびダウンロードできます。アップロード機能も拡張され、最長8分の完全な曲のアップロードをサポートし、ユーザーは自身のオーディオ素材に基づいて制作できます。さらに、クリエイティブスライダーが新たに追加され、ユーザーは生成前に出力結果の「奇妙さ」、構造化の度合い、または参照駆動の度合いを調整して、最終的な作品をより良く形作ることができます (出典: SunoMusic)
MetaAgentX、Open CaptchaWorldを発表、マルチモーダルAgentのCAPTCHA解読能力を評価: 現在のマルチモーダルAgentがCAPTCHA(人間とコンピュータを区別するためのテスト)問題の解決において抱えるボトルネックに対応するため、MetaAgentXチームはOpen CaptchaWorldプラットフォームおよびベンチマークを発表しました。このプラットフォームには、20種類の現代的なCAPTCHA、合計225のサンプルが含まれており、Agentは実際のウェブ環境で観察、クリック、ドラッグなどのインタラクションを通じてタスクを完了する必要があります。テスト結果によると、GPT-4oなどのトップクラスのモデルでも成功率は5%~40%にとどまり、人間の平均成功率93.3%をはるかに下回っています。研究者らはまた、「CAPTCHA Reasoning Depth」という指標を提案し、問題解決に必要な「視覚理解+認知計画+行動制御」のステップを定量化しました。このプラットフォームは、Agentの長系列動的インタラクションと計画における弱点を明らかにし、研究者がこの実際の展開における重要な問題に注目し解決することを推進することを目的としています (出典: 量子位)

Google NotebookLM、公開共有をサポートし、知識共有とコラボレーションを促進: Googleは、NotebookLM(旧称Project Tailwind)がノートブックの公開共有をサポートするようになったと発表しました。ユーザーは「共有」をクリックし、アクセス権限を「リンクを知っている人なら誰でも」に設定することで、ノートの内容を共有できます。この機能により、ユーザーはアイデア、学習ガイド、チームドキュメントを簡単に共有でき、受信者はコンテンツを閲覧したり、質問したり、即座に要約や音声概要を取得したりできます。これは、知識の普及と共同編集を促進し、AIノートツールとしてのNotebookLMの実用性を高めることを目的としています (出典: Google, op7418)
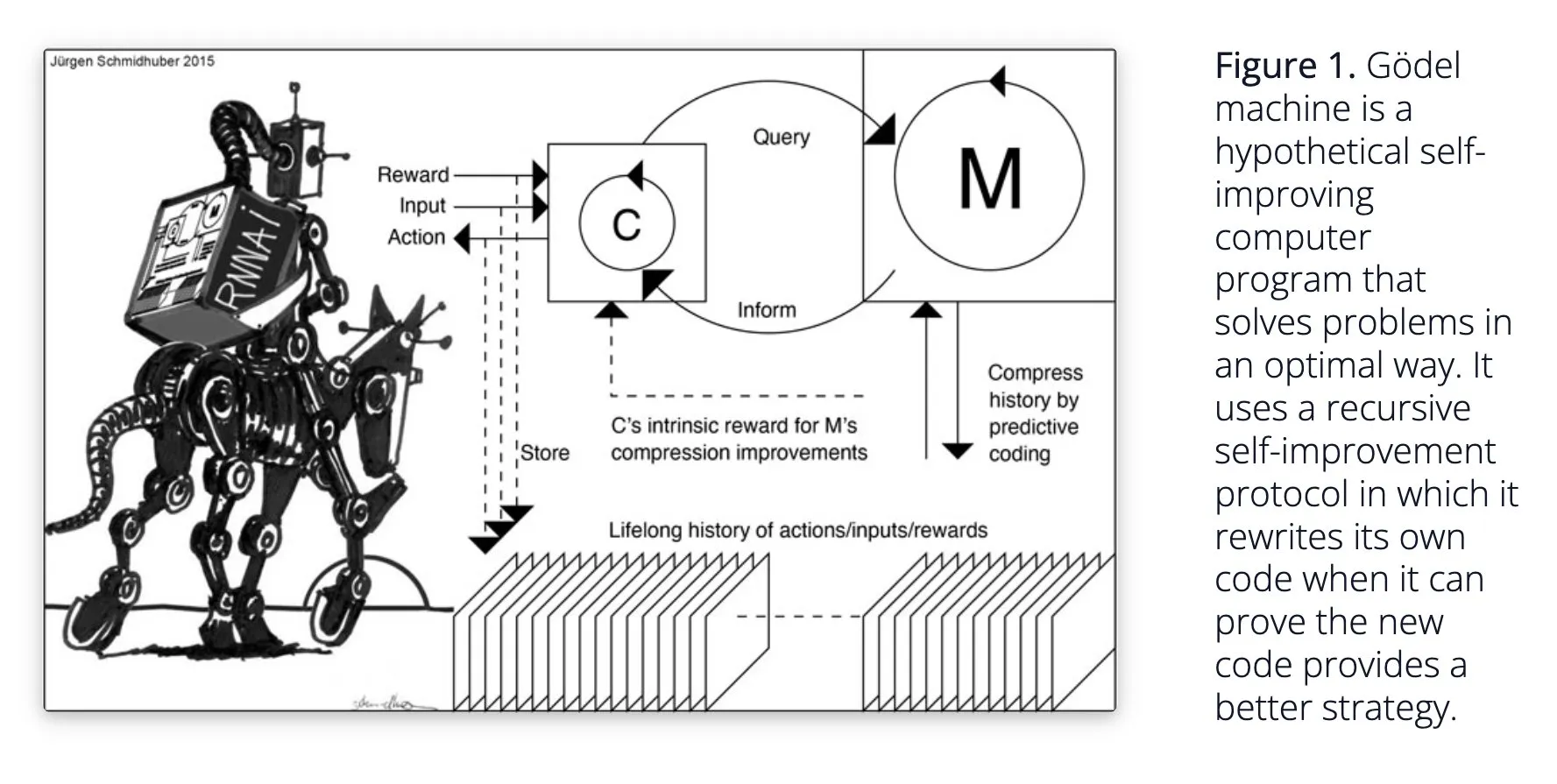
Sakana AI、自己学習AIシステムDarwin Gödel Machine (DGM)を提案: Sakana AIは、自己学習AIシステムDarwin Gödel Machine (DGM)の研究を公開しました。DGMは進化アルゴリズムを利用して自身のコードを反復的に書き換え、プログラミングタスクにおける性能を継続的に向上させます。このシステムは、生成されたコーディングエージェントのアーカイブを維持し、そこからサンプリングし、基盤モデルを利用して新しいバージョンを作成することでオープンエンドな探索を実現し、多様で高品質なエージェントを形成します。実験では、DGMがSWE-benchやPolyglotなどのベンチマークテストでコーディング能力を大幅に向上させたことが示されています。この研究は、自己改善AIに新たなアイデアを提供し、自主的なイノベーションを通じてAIの発展を加速することを目指しています (出典: Reddit r/LocalLLaMA, hardmaru, scaling01)
Google DeepMind、AI会話の自然さを向上させ、ネイティブオーディオ機能を開放: Google DeepMindは、そのネイティブオーディオ機能がAI会話をより自然にし、イントネーションを理解し表現力豊かな音声を生成できるようにしていると発表しました。この技術は、人とAIのインタラクションに新たな可能性を切り開くことを目指しています。開発者は現在、Google AI Studioを通じてこれらの機能を試すことができ、より自然な音声アシスタントやオーディオコンテンツ生成などへの応用が期待されます (出典: GoogleDeepMind)
Runway Gen-4画像生成技術が注目、多重参照とスタイル制御をサポート: RunwayのGen-4画像生成技術は、その高忠実度と前例のないスタイル制御能力で注目されており、特に多重参照機能において顕著で、創造的な探求に新たな空間を提供しています。ユーザーはこの技術を利用して様々な動物、恐竜、または想像上の生物を生成することができ、詳細な視覚コンテンツ作成におけるその可能性を示しています。Runwayのハリウッドなどの分野での使用も、その技術が専門的なコンテンツ制作に徐々に適用されていることを示しています (出典: c_valenzuelab, c_valenzuelab)

AssemblyAI、リアルタイム音声文字起こし新モデルを発表、音声AIアプリケーションの性能を向上: AssemblyAIは、高速性と精度で注目される新しいリアルタイム音声文字起こし(STT)モデルを発表しました。このモデルは、音声AIアプリケーションを構築する開発者向けに設計されており、よりスムーズで正確な音声認識体験を提供することを目指しています。同時に、AssemblyAIはpipecat_aiプロジェクトを通じてAssemblyAISTTServiceの実装も提供しており、開発者の統合を容易にしています。これは、AssemblyAIの音声技術分野における継続的な投資とイノベーションを示しています (出典: AssemblyAI, AssemblyAI)
マイクロソフトBingが16周年を祝い、GPT-4とDALL·Eを統合、Bing Video Creatorを発表: マイクロソフトのBing検索エンジンが16周年を迎えました。近年、Bingはチャット型生成AIを大規模に統合する先駆けとなり、GPT-4とDALL·Eを統合した最初のマイクロソフト製品となりました。最近では、BingはモバイルアプリでCopilot SearchとBing Video Creatorを無料で提供開始し、後者はビデオコンテンツの生成に使用できます。これは、BingがAI駆動の検索およびコンテンツ作成分野で継続的に革新と発展を遂げていることを示しています (出典: JordiRib1)
Andrej Karpathy氏、Veo 3に感銘を受け、ビデオ生成のマクロな影響について考察: Andrej Karpathy氏は、Googleのビデオ生成モデルVeo 3とそのコミュニティの創作成果に感銘を受けたと述べ、オーディオの追加がビデオの品質を著しく向上させたと指摘しました。彼はさらに、ビデオ生成のいくつかのマクロな影響について考察しています:1. ビデオは人間の脳にとって最も帯域幅の広い入力方法である。2. ビデオ生成はAIに世界を理解するための「母語」を提供する。3. ビデオ生成は現実のシミュレーションとワールドモデルへの重要な経路である。4. その計算需要はハードウェアの発展を推進する。これは、ビデオ生成技術がコンテンツ作成の革新であるだけでなく、AIの認知と発展の重要な推進力であることを示しています (出典: brickroad7, dilipkay, JonathanRoss321)
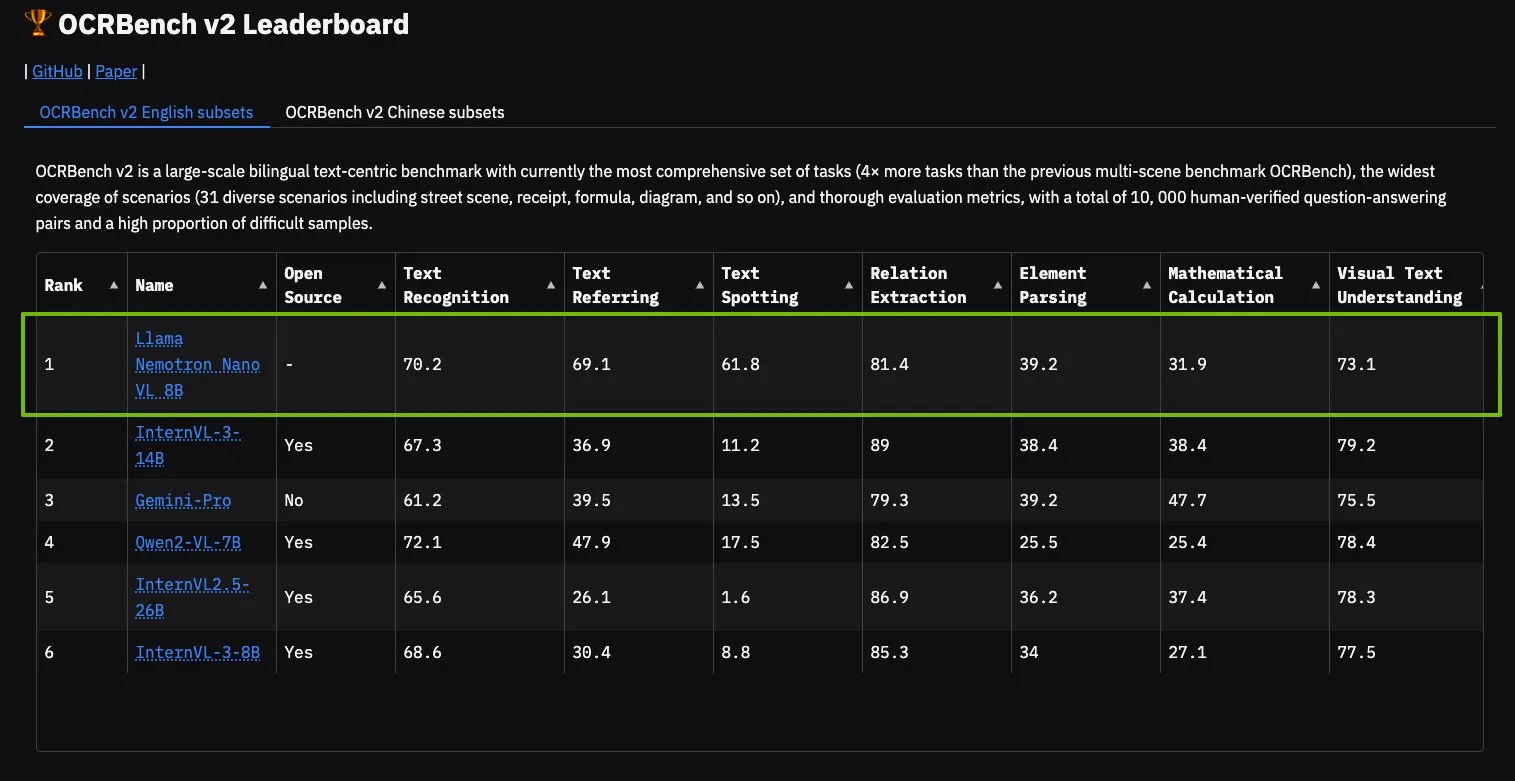
NVIDIA Llama Nemotron Nano VLモデル、OCRBench V2でトップに: NVIDIAのLlama Nemotron Nano VLモデルがOCRBench V2ランキングで1位を獲得しました。このモデルは、高度なインテリジェント文書処理と理解のために設計されており、単一のGPUで複雑な文書から多様な情報を正確に抽出できます。ユーザーはNVIDIA NIMを通じてこのモデルを試用でき、NVIDIAが文書理解などの特定分野における小型化、効率化されたAIモデル開発で進展していることを示しています (出典: ctnzr)
🧰 ツール
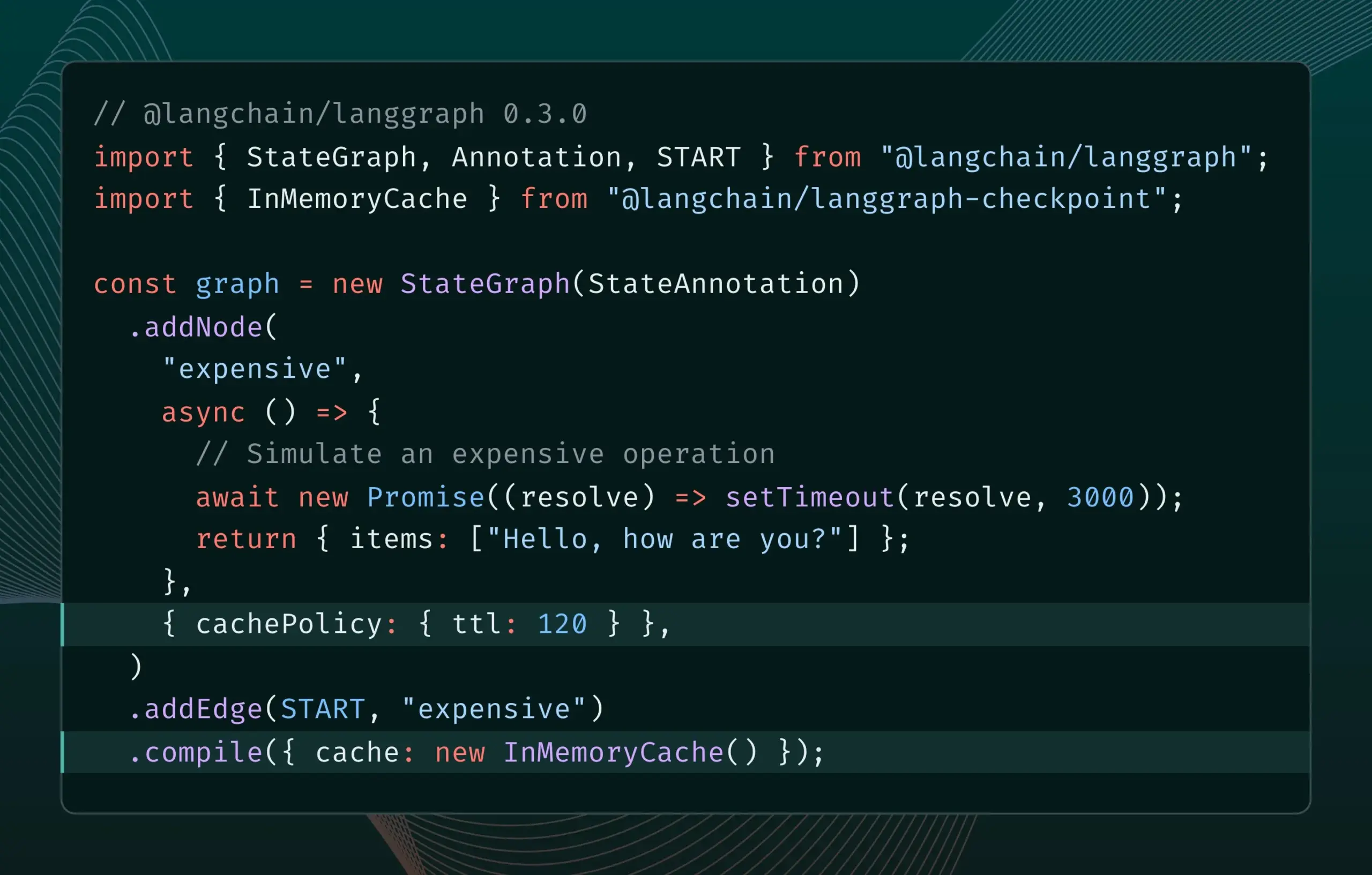
LangGraph.js 0.3バージョンにノード/タスクキャッシュ機能が導入: LangGraph.jsは0.3バージョンをリリースし、新たにノード/タスクキャッシュ機能を追加しました。この機能は、冗長な計算を回避することでワークフローを高速化することを目的としており、特に反復的な高コストまたは長時間実行されるエージェントに適しています。新バージョンはGraph APIとImperative APIの両方をサポートし、JavaScript開発者が複雑なAIアプリケーションを構築する際の効率を高めます (出典: Hacubu, hwchase17)
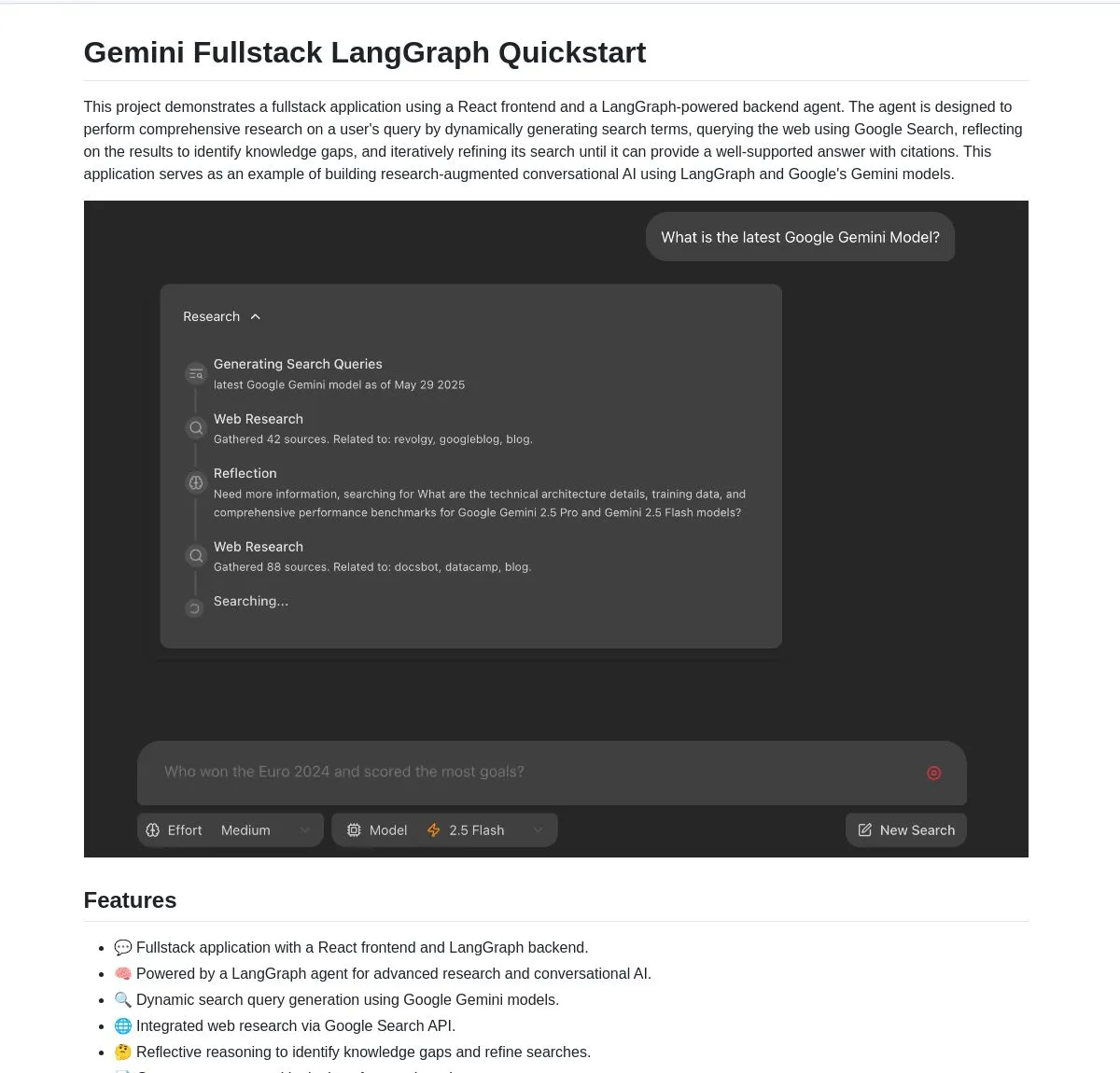
Google、GeminiとLangGraphに基づくGemini Research Agentフルスタックアプリケーションをオープンソース化: Googleは、GeminiモデルとLangGraphに基づいて構築されたインテリジェントリサーチアシスタントのフルスタックアプリケーション例であるgemini-fullstack-langgraph-quickstartをリリースしました。このアプリケーションは、クエリを動的に最適化し、反復学習を通じて引用付きの回答を提供し、さまざまな検索強度制御をサポートします。GeminiネイティブのGoogle検索ツールを利用してウェブ調査と内省的推論を行い、開発者が高度な研究型AIアプリケーションを構築するための出発点を提供することを目的としています (出典: LangChainAI, hwchase17, dotey, karminski3)
FedRAGにLangChainブリッジ機能が追加され、RAGシステムの統合とファインチューニングが容易に: FedRAGは、外部貢献者によって実現されたLangChainとのブリッジ機能をサポートすると発表しました。ユーザーはFedRAGを通じてRAGシステムを組み立て、特定の知識ベースに合わせてジェネレーター/リトリーバーコンポーネントモデルをファインチューニングできます。ファインチューニング後、LangChainなどの一般的なRAG推論フレームワークにブリッジし、そのエコシステムと機能を利用できます。このアップデートは、RAGシステムの構築、最適化、デプロイプロセスを簡素化することを目的としています (出典: nerdai)

Ollama、「思考」機能を導入、思考プロセスと最終回答を分離可能に: Ollamaはプラットフォームを更新し、「思考」機能をサポートするモデル(DeepSeek-R1-0528など)向けに、思考プロセスと最終回答を分離するオプションを追加しました。ユーザーはモデルの「思考」内容を表示するか、この機能を無効にして直接的な回答を得るかを選択できます。この機能はOllamaのCLI、API、およびPython/JavaScriptライブラリに適用され、ユーザーにより柔軟なモデルインタラクション方法を提供します (出典: Hacubu)
Firecrawl、検索とクローリング機能を統合した/searchエンドポイントをリリース: Firecrawlは、新しい/search APIエンドポイントをリリースしました。これにより、ユーザーは1回のAPI呼び出しでウェブ検索を完了し、すべての結果をLLMフレンドリーな形式でクローリングできます。この機能は、AIエージェントと開発者がウェブデータを発見し利用するプロセスを簡素化することを目的としています。LangChainのStateGraphは、この機能を利用した自動化プロセス(競合他社の自動検索、ウェブサイトのクローリング、分析レポートの生成など)の構築に使用できます (出典: hwchase17, LangChainAI, omarsar0)
LlamaIndexがMCPを統合、エージェント能力とワークフロー展開を強化: LlamaIndexは、MCP(Model Component Protocol)の統合を発表しました。これは、エージェントのツール使用能力とワークフロー展開の柔軟性を強化することを目的としています。この統合は、LlamaIndexエージェントがMCPサーバーツールを使用するのを支援する補助関数を提供し、任意のLlamaIndexワークフローをMCPサーバーとして提供できるようにします。これは、LlamaIndexエージェントのツールセットを拡張し、そのワークフローを既存のMCPインフラストラクチャにシームレスに統合することを意図しています (出典: jerryjliu0)

Modal、LLM Engine Advisorを発表、オープンソースモデルエンジンの性能ベンチマークを提供: Modalは、ユーザーが最適なLLMエンジンとパラメータを選択するのを支援することを目的としたベンチマークアプリケーションであるLLM Engine Advisorを発表しました。このツールは、さまざまなハードウェア(マルチGPU環境など)でオープンソースモデル(DeepSeek V3、Qwen 2.5 Coderなど)をさまざまな推論エンジン(vLLM、SGLangなど)で使用した場合の性能データ(速度や最大スループットなど)を提供します。これは、自己ホスト型LLMの実行における透明性と意思決定の効率を高めることを目的としています (出典: charles_irl, akshat_b, sarahcat21)
PlayDiffusion:PlayAIがオーディオ修復新モデルを発表、オーディオ内の会話内容を置換可能: PlayAIは、PlayDiffusionという新しいモデルを発表しました。このモデルは、元の話者の声の特徴を保持したまま、オーディオファイル内の会話内容をシームレスに置き換えることができます。この「オーディオ修復」技術は、ポッドキャスト、オーディオブック、ビデオの吹き替えなどで、全体のセグメントを再録音することなく特定の単語やフレーズを修正するなど、オーディオ編集に新たな可能性を提供します。プロジェクトはGitHubでオープンソース化されています (出典: _mfelfel, karminski3)
Hugging Face、セマンティック重複排除ツールをリリース、トレーニングデータセットの品質を最適化: Maxime Labonne氏のAutoDedupに触発され、Hugging Face Spacesに新しいセマンティック重複排除アプリケーションが登場しました。このツールを使用すると、ユーザーはHugging Face Hub上の1つまたは複数のデータセットを選択し、各行のデータにセマンティック埋め込みを行い、設定されたしきい値に基づいて近似重複コンテンツを削除できます。これは、研究者や開発者がトレーニングデータセットの品質を向上させ、データの冗長性によるモデル性能の低下やトレーニング効率の低下を回避するのに役立つことを目的としています (出典: ben_burtenshaw, ben_burtenshaw)

Perplexity Labsへの需要が急増、ユーザーはカスタマイズされたソフトウェアを迅速に構築可能: Perplexity Labsは、単一のプロンプトでカスタマイズされたソフトウェアを迅速に構築できることでユーザーから人気を集め、需要が著しく増加しており、より多くのLabsクエリ回数を取得するために複数のProアカウントを購入するユーザーもいます。これは、ユーザーが自身のニーズに応じてソフトウェアツールを迅速に作成および変更できることに対する強い関心を反映しており、AI駆動のパーソナライズされたソフトウェア開発がトレンドになりつつあります (出典: AravSrinivas, AravSrinivas)
OllamaとHazy ResearchがSecure Minionsで協力、ローカルとクラウドLLMのプライベートな連携を実現: スタンフォード大学Hazy ResearchラボのMinionsプロジェクトは、Ollamaローカルモデルとクラウドの最先端モデルを接続することで、クラウドコストを大幅に削減(5~30倍)しつつ、最先端モデルに近い精度(98%)を維持することを目指しています。Secure Minionプロジェクトはさらに、H100などのGPUをセキュアゾーンに変換し、メモリと計算を暗号化してデータプライバシーを確保します。このハイブリッド運用モードは、プライバシー保護を強化すると同時に、ユーザーにより経済的で効率的なLLM利用ソリューションを提供します (出典: code_star, osanseviero, Reddit r/LocalLLaMA)
ExaとOpenRouterが提携、400以上のLLMにウェブ検索機能を提供: AI検索エンジンExaは、OpenRouterとの提携を発表し、OpenRouterプラットフォーム上の400を超える大規模言語モデルにウェブ検索機能を提供します。これは、開発者とユーザーがこれらのLLMを使用する際に、Exaの検索能力を簡単に呼び出すことができ、モデルのリアルタイム情報取得と知識更新能力を強化し、RAG(検索拡張生成)などのアプリケーションのパフォーマンスをさらに向上させることを意味します (出典: menhguin)

📚 学習
マイクロソフト、MCP入門コース「MCP for Beginners」を発表: マイクロソフトは、MCP(Microsoft Copilot Platform、誤記の可能性があり、Microsoft CoCo Frameworkまたは類似のAI Agentプロトコルを指すものと推測される)初心者向けの入門コースを発表しました。このコースは、初心者がMCPのコアコンセプト、実装方法、および実際の応用を習得するのを支援することを目的としており、プロトコルアーキテクチャ仕様、チュートリアルガイド、および複数のプログラミング言語によるコード実践が含まれています。コース構成は、はじめに、コアコンセプト、セキュリティ、入門、上級、およびコミュニティとケーススタディを網羅し、基本および高度な計算機などのサンプルプロジェクトも提供しています (出典: dotey)

Bond Capital、2025年5月AIトレンドレポートを発表、業界の発展を洞察: 有名なベンチャーキャピタルであるBond Capitalは、339ページに及ぶ「2025-05 AIトレンドレポート」を発表し、AIの各分野におけるデータと洞察を包括的に分析しました。レポートは、ChatGPTの月間アクティブユーザー数が8億人(90%が北米以外)、1日の検索数が10億回であること、AI関連IT職の求人が448%増加したこと、最先端モデルのトレーニングコストが1回あたり10億ドルを超えること、LLMがインフラストラクチャになりつつあることなどを重点的に指摘しています。レポートは、競争の鍵は最高のAI駆動製品を構築することであり、現在は構築者の市場であると強調しています (出典: karminski3)
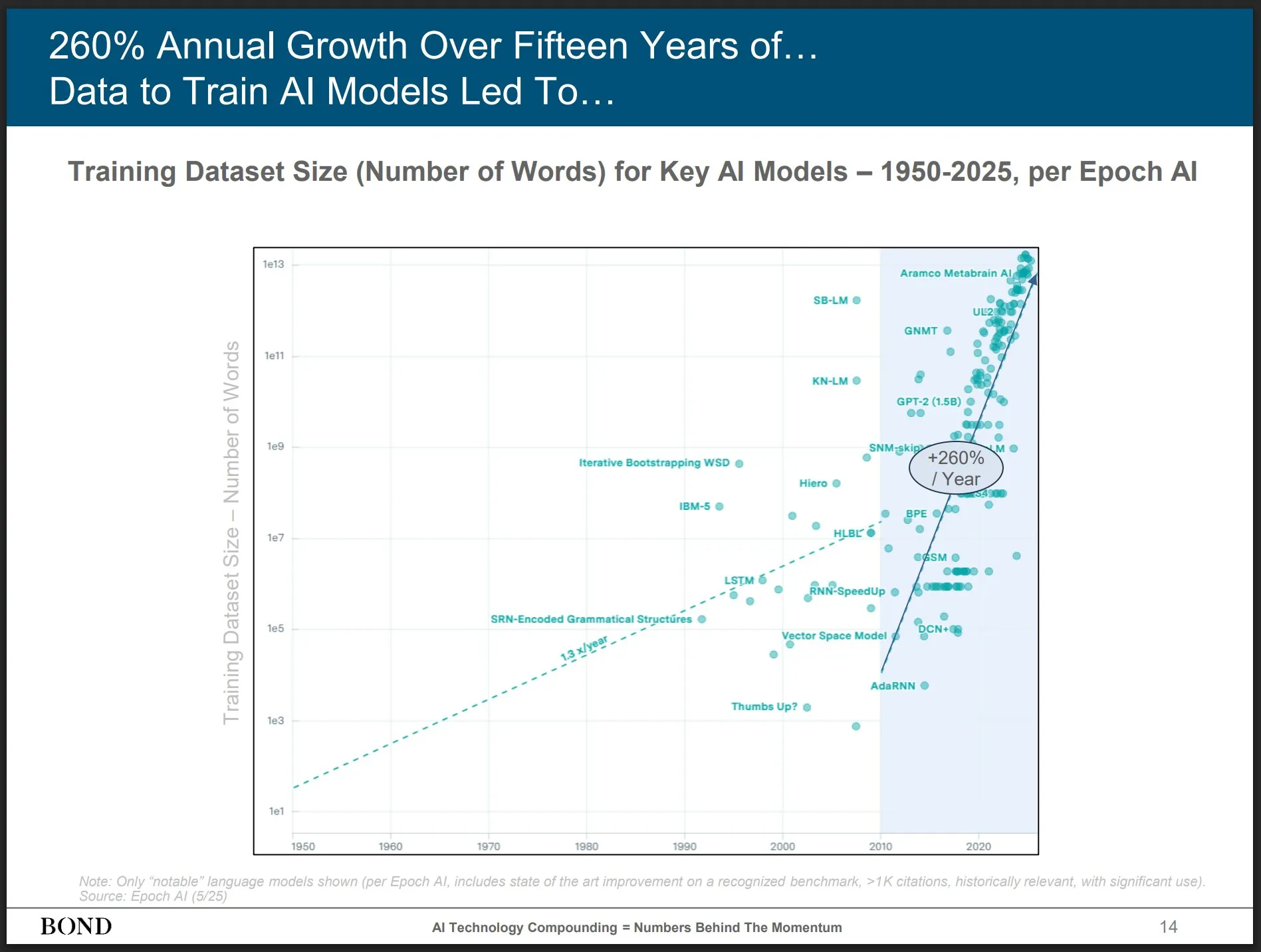
論文、強化学習とLLM推論能力の関係を議論、ProRLとLimit-of-RLVRが注目を集める: 強化学習(RL)と大規模言語モデル(LLM)の推論能力に関する2つの研究論文が議論を呼んでいます。1つは「Limit-of-RLVR: Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?」で、もう1つはNVIDIAの「ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models」です。これらの研究は、RL(特にRLVR、検証可能な報酬による強化学習)がLLMの基礎的な推論能力をどの程度向上させることができるか、また持続的なRLトレーニングがLLMの推論境界を拡大する影響について探求しています。関連する議論では、高品質なRLVRトレーニングデータと効果的な報酬メカニズムが鍵であると考えられています (出典: scaling01, Dorialexander, scaling01)

論文「How Programming Concepts and Neurons Are Shared in Code Language Models」がコードLLMにおけるプログラミング概念とニューロンの共有メカニズムを議論: この研究は、大規模言語モデル(LLM)が複数のプログラミング言語(PL)と英語を処理する際に、その内部の概念空間がどのように関連しているかを調査しました。Llamaシリーズのモデルに対して少数ショット翻訳タスクを実行することで、中間層では概念空間が英語(PLキーワードを含む)により近く、英語のトークンに高い確率を割り当てる傾向があることがわかりました。ニューロンの活性化分析によると、言語固有のニューロンは主に下層に集中しており、各PLに固有のニューロンは上層に現れる傾向があります。この研究は、LLMがPLを内部的にどのように表現しているかを理解するための新しい洞察を提供します (出典: HuggingFace Daily Papers)
新論文「Pixels Versus Priors」が視覚的反事実を通じてMLLMにおける知識事前分布を制御: この研究は、多モーダル大規模言語モデル(MLLM)が視覚的質問応答などのタスクを実行する際に、その推論が記憶された世界の知識に依存するのか、入力画像の視覚情報に依存するのかを探求しています。研究者らは、世界の知識事前分布と矛盾する視覚的反事実画像(青いイチゴなど)を含むVisual CounterFactデータセットを導入しました。実験により、モデルの予測は初期には記憶された事前分布を反映しますが、中後期には視覚的証拠に移行することが示されました。論文はPvP(Pixels Versus Priors)誘導ベクトルを提案し、活性化層への介入を通じてモデルの出力を世界の知識または視覚入力に偏らせることを制御し、大部分の色とサイズの予測を変更することに成功しました (出典: HuggingFace Daily Papers)
ICML 2025論文GuidedQuant、エンドロスガイダンスによる階層的PTQ手法の向上を提案: GuidedQuantは、エンドロス(end loss)ガイダンスを目標に統合することで階層的PTQ手法の性能を向上させる新しい事後訓練量子化(PTQ)手法です。この手法は、エンドロスに関する特徴ごとの勾配を利用して階層的出力誤差を重み付けし、チャネル内依存関係を維持するブロック対角フィッシャー情報に対応します。さらに、論文は量子化目標値を単調に減少させることを保証する非均一スカラー量子化アルゴリズムであるLNQを導入しています。実験では、GuidedQuantが重みのみスカラー、重みのみベクトル、および重みと活性化の量子化において既存のSOTA手法を上回り、Qwen3、Gemma3、Llama3.3などのモデルの2~4ビット量子化に適用されていることが示されています (出典: Reddit r/MachineLearning)

AI Engineer World’s Fairがサンフランシスコで開催、AIエンジニアリングの実践と最先端技術に焦点: AI Engineer World’s Fairがサンフランシスコで開催され、AI分野の多くのエンジニア、研究者、開発者が集結しています。会議の議題には、強化学習、カーネル、推論とエージェント、モデル最適化(RFT、DPO、SFT)、エージェントコーディング、音声エージェント構築など、多くの注目トピックが含まれています。イベント期間中には、OpenAI、Googleなどの企業の専門家による講演やワークショップが行われ、新製品や技術の発表も予定されています。コミュニティメンバーは積極的に参加し、会議のスケジュールを共有したり、オフライン交流を企画したりしており、AIエンジニアリングコミュニティの活力と最先端技術への熱意を示しています (出典: swyx, clefourrier, swyx, LiorOnAI, TheTuringPost)

💼 ビジネス
師渡智能 (Shidu Smart)、数百万元のシードラウンド資金調達を完了、AIスマートグラスの多シーン展開を加速: 蘇州師渡智能科技有限公司は、数百万元のシードラウンド資金調達を完了したと発表しました。資金はAIスマートグラスのコア技術研究開発、市場拡大、エコシステム構築に充てられます。同社は、スマートヘルスケア(スマート老眼鏡、スマート視覚補助メガネなど)、スマートライフ(スマートファッションメガネ、サイクリングメガネなど)、スマート製造(スマート工業用メガネ、音声コントローラーなど)の分野でAIスマートグラスの応用に取り組んでいます。製品価格は200元から1000元の範囲に設定されており、高いコストパフォーマンスを通じてスマートグラスの普及を目指しています (出典: 36氪)

OpenAIがAIプログラミングアシスタントWindsurfを買収するとの噂、AnthropicによるClaudeモデル供給停止の憶測を呼ぶ: 市場では、OpenAIがAIプログラミングツールWindsurf(旧Codeium)を約30億ドルで買収する可能性があるとの噂が流れています。このような状況下で、WindsurfのCEOであるVarun Mohan氏は、AnthropicがClaude 3.5 Sonnetなどを含むClaude 3.xモデルのほぼすべての直接アクセス権を、極めて短い通知期間で遮断したと投稿しました。Windsurfはこれに失望を表明し、迅速に計算能力を他の推論サービスプロバイダーに移管するとともに、影響を受けたユーザーにGemini 2.5 Proの割引を提供しました。コミュニティでは、Anthropicのこの動きはOpenAIによる潜在的な買収に関連している可能性があり、業界の競争と開発者の選択に影響を与えることを懸念する声が上がっています。以前、WindsurfはClaude 4のリリース時にもAnthropicからの直接的なサポートを得られませんでした (出典: AI前线)

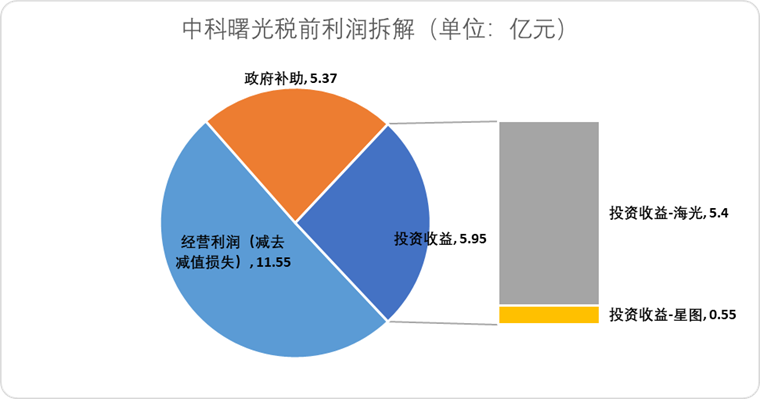
海光信息 (Hygon Information Technology)、中科曙光 (Sugon) を株式交換で吸収合併し、国産計算能力産業チェーンを統合へ: AIチップ設計会社の海光信息は、筆頭株主でありサーバーメーカーである中科曙光を株式交換方式で吸収合併する計画を発表しました。海光信息の時価総額は約3164億元、中科曙光の時価総額は約905億元です。この「蛇が象を飲み込む」ような合併は、チップからソフトウェア、システムに至る産業レイアウトを最適化し、産業チェーンの強化・補完・延伸を実現し、技術的相乗効果を発揮することを目的としています。分析によると、合併は双方の複雑な関連取引と潜在的な同業競争の問題を解決し、運営コストを削減するとともに、AI時代のエンドツーエンド計算能力ソリューションの発展トレンドに沿うものであり、中国の半導体技術の権力が従来の計算からAI計算へと加速的に移行する可能性を示しています (出典: 36氪)
🌟 コミュニティ
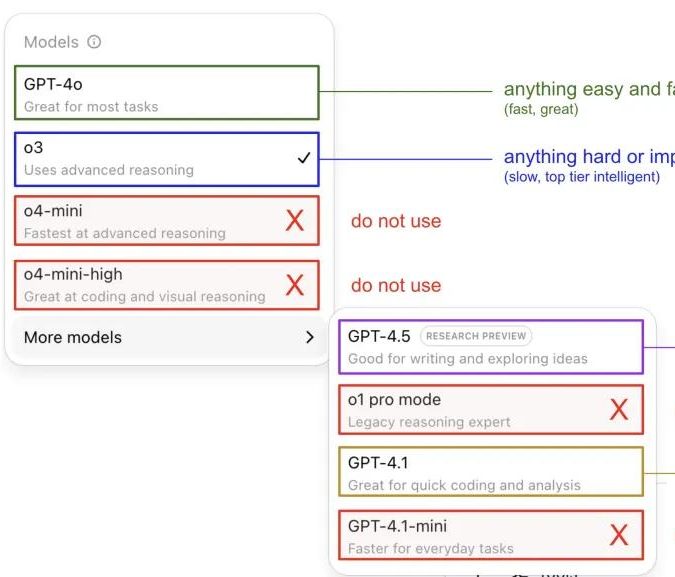
Andrej Karpathy氏、ChatGPTモデルの使用感を共有し、コミュニティで議論を呼ぶ: Andrej Karpathy氏は、自身が異なるChatGPTバージョンを使用した際の感想を共有しました。重要または困難なタスクには、推論能力がより強力なo3を推奨。日常的な中低難易度の問題には4oを選択。コード改善タスクにはGPT-4.1が適しており、詳細な調査と複数のリンクの要約が必要な場合は、詳細調査機能(o3ベース)を使用するとのことです。この経験の共有はコミュニティで広範な議論を呼び、多くのユーザーが自身の使用の好みやモデル選択に関する見解を共有するとともに、OpenAIのモデル命名の混乱や自動モデル選択機能の欠如に対するユーザーの困惑も反映されました (出典: 量子位, JeffLadish)
開発者、Agentic AIプログラミングの2週間の体験を共有:衝撃から幻滅、最終的に手動リファクタリングを選択: 10年の経験を持つ技術責任者が、Agentic AI(特にAIプログラミングエージェント)を自身のソーシャルメディアアプリケーション開発プロセスに組み込んだ経験を共有しました。初期には、AIは機能モジュールを迅速に生成し、フロントエンドとバックエンドのロジック、単体テストを作成し、驚異的な効率を発揮し、2週間で約1万2千行のコードを生成しました。しかし、コードベースの複雑さが増すにつれて、AIは新しい機能を処理する際に頻繁にエラーを起こし、ループに陥り、失敗を認めるのが難しくなり、生成されたコードも不正確な命名や重複コードなどの問題を露呈し、コードベースの保守が困難になり、開発者はAIへの信頼を失いました。最終的に、この開発者はAI生成コードを「曖昧な参考」としてのみ使用し、すべての機能を手動でリファクタリングすることを決定し、AIは現在、既存のコードの分析やサンプル提供には適しているが、機能的なコードを直接記述するには適していないと考えています (出典: CSDN)

AI Agentの定義とワークフローの違いが注目を集め、将来の応用ポテンシャルは巨大: コミュニティでは、AI AgentとWorkflow(ワークフロー)の概念の区別が議論されています。Agentは通常、LLMがループ内でツールにアクセスし、指示に基づいて自由に実行されることを指します。一方、Workflowは、主に決定論的に実行される一連のステップであり、LLMがサブタスクを完了するために含まれる場合があります。重複は存在するものの(Agentは決定論的に実行するように促されることができ、WorkflowにはAgenticコンポーネントが含まれることがある)、この区別は存在論的に依然として意味があります。同時に、AI Agentの企業アプリケーションにおけるポテンシャルは広く期待されており、テンセントやByteDanceなどの大手企業はすべてエージェント分野に力を入れており、例えばテンセントは大規模モデルの知識ベースをエージェント開発プラットフォームにアップグレードし、ByteDanceにはCoze(扣子)プラットフォームがあり、企業がネイティブAIエージェントシステムを導入するのを支援することを目指しています (出典: fabianstelzer, 蓝洞商业)
Dwarkesh Patel氏、LLMとAGIのタイムラインについて議論、継続的学習が重要なボトルネックであると主張: Dwarkesh Patel氏は自身のブログでAGI(汎用人工知能)のタイムラインに関する見解を述べ、LLMは現在、人間が実践を通じて文脈を蓄積し、失敗を反省し、微細な改善を行う能力、つまり継続的学習能力に欠けていると主張しています。彼はこれがモデルの実用性における巨大なボトルネックであり、この問題を解決するには数年かかる可能性があると考えています。この見解は、Andrej Karpathy氏を含む複数のAI研究者の間で議論を呼びました。Karpathy氏もLLMの継続的学習における欠点を認めており、それを前向性健忘症の同僚に例えています。これらの議論は、真のAGIを実現する上で直面する課題と、モデルの学習メカニズムに対する深い考察を浮き彫りにしています (出典: dwarkesh_sp, JeffLadish, dwarkesh_sp)

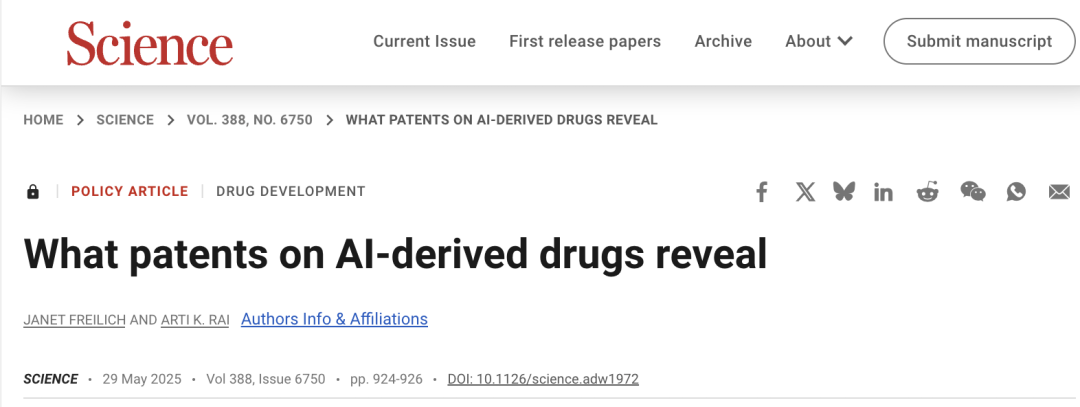
AI創薬における特許問題が注目を集め、Science誌が慎重な対応を呼びかけ: 「Science」誌の政策フォーラム記事「What patents on AI-derived drugs reveal」は、AIの創薬分野への応用とその特許制度への影響について論じています。研究によると、AIネイティブ企業が医薬品特許を申請する際、in vivo実験データが従来の製薬企業よりも少ない傾向があり、有望な医薬品がその後の研究不足のために放棄される可能性があると指摘しています。同時に、AIが生成した大量の新規分子が公開されると、「既存技術」となり、他の企業がこれらの分子の特許申請やさらなる投資を行うことを妨げる可能性があります。記事は、特許申請のハードルを上げ、より多くのin vivo実験データを要求し、AIが生成した分子が未試験の場合には他の企業による特許申請を許可するとともに、新薬の臨床試験段階における規制上の独占権を強化し、イノベーションのインセンティブと公共の利益のバランスを取ることを提案しています (出典: 36氪)
💡 その他
アルトマン氏の社内抗争事件、映画『Artificial』として製作か、著名監督とプロデューサーが参加: The Hollywood Reporterによると、MGMはOpenAIの経営陣交代事件を映画化する計画で、仮題は『Artificial』とのことです。イタリアの著名な監督ルカ・グァダニーノ氏がメガホンを取り、プロデューサーには『ハリー・ポッター』シリーズのデヴィッド・ヘイマン氏が含まれる可能性があります。キャストは協議中で、アンドリュー・ガーフィールド氏(スパイダーマン役や『ソーシャル・ネットワーク』のサヴェリン役)がサム・アルトマン氏を、ユーラ・ボリソフ氏がイリヤ・サツケヴァー氏を、モニカ・バルバロ氏がミラ・ムラティ氏を演じるという噂があります。このニュースはネットユーザーの間で話題となり、『ソーシャル・ネットワーク』と比較されています (出典: 36氪, janonacct)
AIカスタマーサービスの体験が議論を呼び、ユーザーは「人工無能」とオペレーターへの転送困難を不満: 最近のEC大型セール期間中、多くの消費者がAIカスタマーサービスとのコミュニケーションが円滑でなく、的外れな回答が多く、さらに人間のオペレーターへの転送が非常に困難であるため、サービス体験が低下したと報告しています。国家市場監督管理総局のデータによると、2024年のECアフターサービス分野における「スマートカスタマーサービス」関連の苦情は前年比56.3%増加しました。ユーザーは一般的に、AIカスタマーサービスは個別化された問題の解決が難しく、回答が硬直的で、高齢者などの特別なグループには不親切であると考えています。記事は、企業がコスト削減と効率向上を追求する一方で、サービス品質を犠牲にすべきではなく、AI技術を最適化し、AIカスタマーサービスの適用範囲を明確にし、便利な人間のサービスチャネルを維持すべきだと呼びかけています (出典: 36氪)

コンテンツ制作分野におけるAIの応用とクリエイターの対応戦略に関する議論: AI技術(DeepSeek、Suno、Veo 3など)が記事、音楽、ビデオなどのコンテンツ制作分野でますます広く応用されるようになり、コンテンツクリエイターの間で職業の将来に対する不安を引き起こしています。分析によると、コンテンツパラダイムは「パーソナライズされた推薦」から「パーソナライズされた生成」へと変化しつつあります。短期的には、プラットフォームは試行錯誤のコストが高いため、クリエイターを完全にAIで置き換えることはないと考えられ、クリエイターは独自のスタイルモデルを構築し、それをライセンス供与することで収益を得ることができます。長期的には、クリエイターは価値創造の方法を調整し、AIが代替しにくい「イノベーション戦略」(独自の調査、一次資料の入手など)により重点を置く必要があり、AIによって容易に支援される「追随戦略」(トレンド追跡、二次資料への依存)からは脱却する必要があります。AIはすでに科学研究などのイノベーション分野にも進出し始めていますが、独自の視点と深い思考を持つクリエイターは依然として価値を持っています (出典: 36氪)
