
キーワード:DeepMind AlphaEvolve, Sakana AI DGM, DeepSeek-R1, 強化学習 ProRL, NVIDIA Cosmos, マルチモーダル大規模モデル, AIエージェントフレームワーク, LLM推論最適化, AlphaEvolve 数学記録, Darwin Gödel Machine 自己改良, MedHELM 医療評価, ProRL 強化学習拡張性, Cosmos Transfer 物理シミュレーション
🔥 注目
DeepMind AlphaEvolve が数学記録を更新、人間と機械の協調が科学の進歩を推進: DeepMind の AlphaEvolve は1週間で2度、18年間破られなかった数学の記録を更新し、大きな注目を集めています。テレンス・タオ氏は、これは単純な「勝者」と「敗者」ではなく、異なるアプローチがいかに相互補完的に数学の進歩を推進するかを示しているとコメントしました。この出来事は、AIと人間の協調がテクノロジーと科学の分野で新たなパラダイムを生み出す可能性を浮き彫りにし、AIは単に人間を置き換えるのではなく、共に進歩の新しい道を切り開いています (来源: shaneguML)

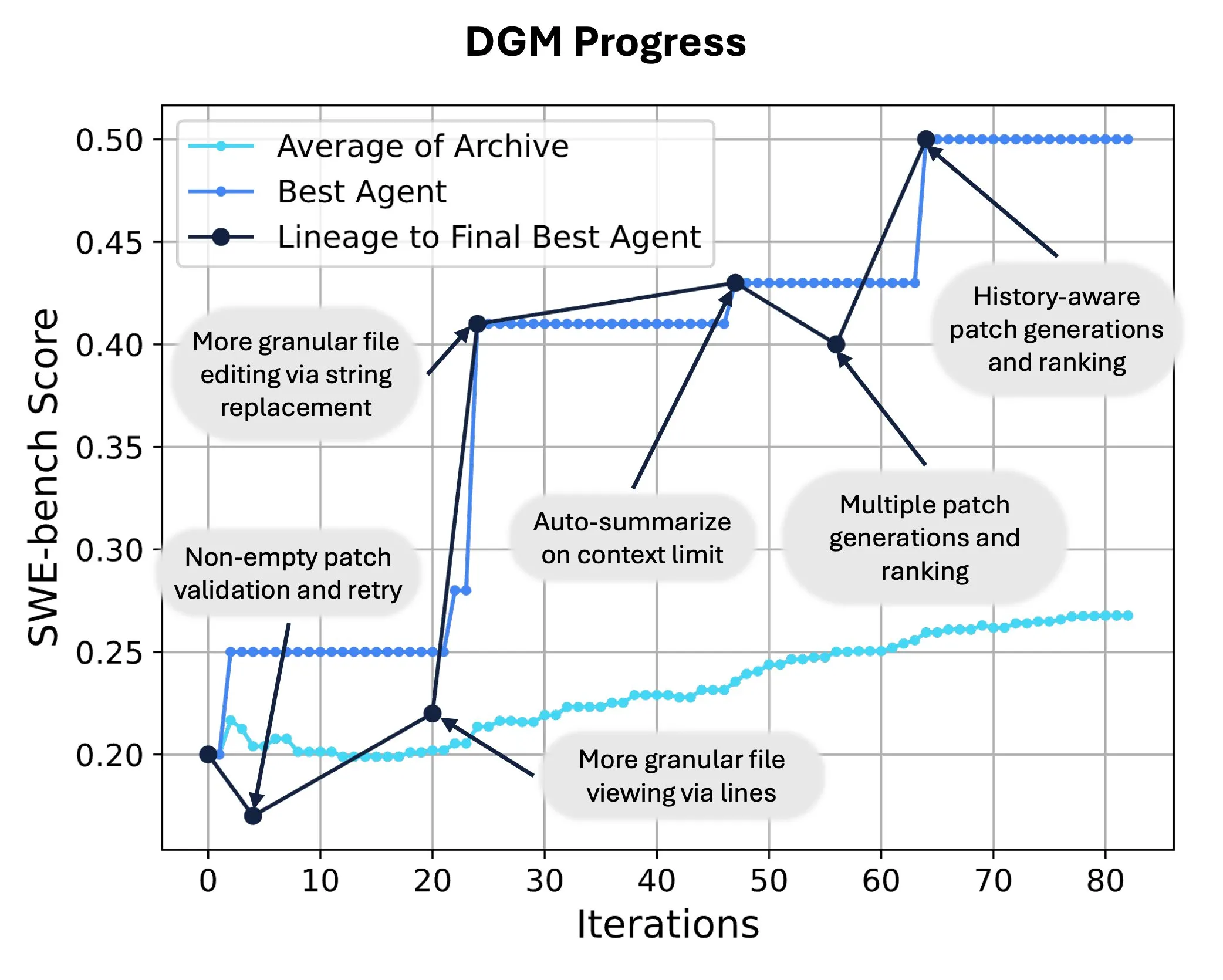
Sakana AI が Darwin Gödel Machine (DGM) を発表、AI による自己コード書き換えと進化を実現: Sakana AI は、Darwin Gödel Machine (DGM) を発表しました。これは、自身のコードを修正することで性能を向上できる自己改善型エージェントです。進化論に着想を得て、DGM は拡大し続けるエージェントのバリアント系統を維持し、「自己改善型」エージェントの設計空間のオープンエンドな探索を実現しました。SWE-benchにおいて、DGMは性能を20.0%から50.0%に向上させました。Polyglotでは、成功率を14.2%から30.7%に向上させ、人間が設計したエージェントを大幅に上回りました。この技術は、AIシステムが継続的な学習と能力の進化を実現するための新しい道を提供します (来源: SakanaAILabs, hardmaru)
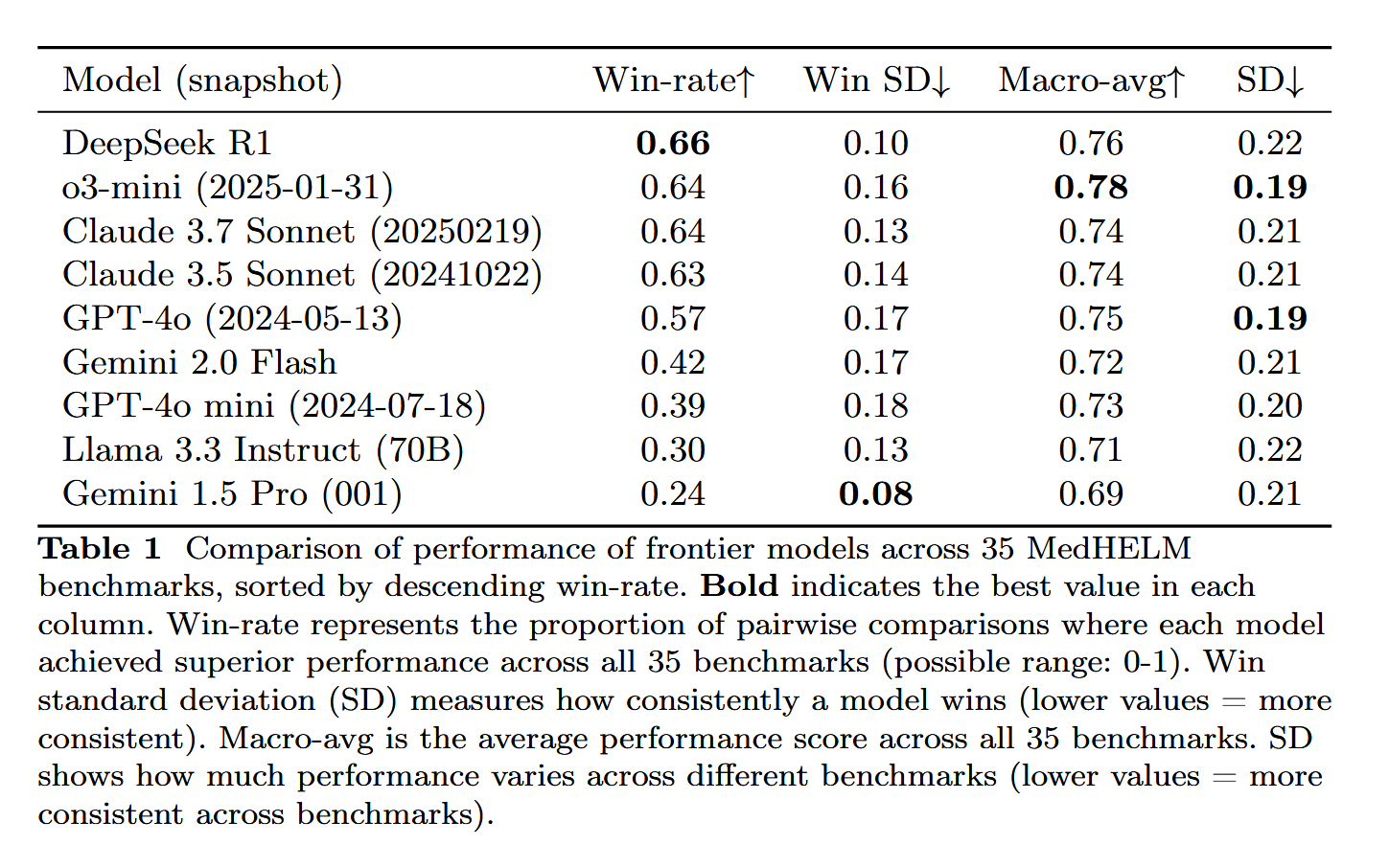
DeepSeek-R1 が MedHELM 医療タスク評価で優れた性能を示す: 大規模言語モデル DeepSeek-R1 は、従来の医学免許試験ではなく、より実践的な臨床タスクにおけるLLMの性能を評価することを目的とした MedHELM (大規模言語モデル医療タスク総合評価) ベンチマークで最高の性能を示しました。この結果は非常に意義深いと考えられており、DeepSeek-R1 の医療分野における応用の可能性、特に実際の臨床シナリオの処理能力を示しています (来源: iScienceLuvr)
強化学習のスケーラビリティ研究における新たな進展:ProRL が LLM の推論の境界を拡大: 強化学習(RL)のスケーラビリティに関する新しい論文(arXiv:2505.24864)が注目を集めています。研究によると、長時間の強化学習(ProRL)トレーニングを通じて、広範なサンプリングでは基盤モデルが獲得しにくい全く新しい推論戦略を発見できることが示されています。ProRL は、KLダイバージェンス制御、参照ポリシーリセット、多様なタスクスイートを組み合わせており、RL訓練モデルは複数のpass@k評価において、基盤モデルを一貫して上回ることができます。この研究は、RLが言語モデルの推論の境界をどのように実質的に拡大できるかについて新たな洞察を提供し、将来の長時間RL推論研究の基礎を築きます。NVIDIAは関連するモデルの重みを公開しています (来源: Teknium1, cognitivecompai, natolambert, scaling01)

🎯 動向
NVIDIA が Cosmos Transfer と Cosmos Reason を発表、物理世界の AI 応用を推進: NVIDIA は Cosmos システムを発表しました。その中の Cosmos Transfer は、シンプルなゲームエンジンの画面、深度情報、さらには粗雑なロボットシミュレーションを、現実的でリアルなシーンのビデオに変換でき、ロボットや自動運転などの AI に大量の制御可能な訓練データを提供します。一方、Cosmos Reason は、AI がこれらのシーンを理解し、例えば自動運転テストでどのように走行するかなどの意思決定を行えるようにします。これら2つのツールは現在オープンソース化されており、物理世界の AI の発展を加速し、訓練データの不足やシーン制御の難題を解決することが期待されます
DeepSeek が R1 アップデートをリリース、オープンソースエコシステムが継続的に繁栄: DeepSeek は R1 モデルのアップデートをリリースしました。これには R1 本体と80億パラメータの蒸留版小型モデルが含まれます。同時に、ByteDance はオープンソース分野で積極的に活動しており、BAGEL、Dolphin、Seedcoder、Dream0 などのプロジェクトを立ち上げています。これらの進展は、AI オープンソース分野における中国の活発さと革新力、特にマルチモーダルおよび専用モデル分野での急速な発展を示しています (来源: TheRundownAI, stablequan, reach_vb, clefourrier)
Google が Edge AI Gallery を発表、スマートフォンでのオープンソース AI モデルの活用を推進: Google は Edge AI Gallery を発表しました。これは、オープンソース AI モデルをスマートフォンに導入し、ローカライズされたプライベートな AI アプリケーションを実現することを目的としています。ユーザーはデバイス上で直接 Hugging Face の LLM を実行し、コード生成や画像対話などの操作を行うことができ、マルチターン対話に対応し、任意のモデルを選択できます。このアプリケーションは LiteRT に基づいており、現在 Android をサポートしており、iOS 版も間もなくリリースされる予定です。これにより、エッジ AI の発展と普及がさらに進むでしょう (来源: TheRundownAI, huggingface, reach_vb, osanseviero)
肯定的および否定的な蒸留推論軌跡を活用して LLM を最適化する新研究: 新しい論文では、教師モデル(DeepSeek-R1など)によって生成された正解および不正解の推論軌跡を活用して、小規模な生徒モデルの推論能力を向上させることを目的とした強化学習蒸留(REDI)フレームワークを提案しています。REDI は2段階で構成され、まず教師ありファインチューニング(SFT)によって正解軌跡から学習し、次に新たに提案された REDI 目的関数(参照なし損失関数)を利用して正負の軌跡を組み合わせてモデルをさらに最適化します。実験では、数学的推論タスクにおいて REDI がベースライン手法を上回り、Qwen-REDI-1.5B モデルが MATH-500 で83.1%という高スコアを達成したことが示されています (来源: HuggingFace Daily Papers)
LLMSynthor フレームワークが LLM を活用して構造認識型データ合成を実現: LLMSynthor は、大規模言語モデル(LLM)を構造認識型シミュレータに変換し、分布フィードバックによって誘導する汎用データ合成フレームワークです。このフレームワークは、LLMを高次依存関係をモデル化するためのノンパラメトリックコピュラシミュレータとみなし、サンプリング効率を向上させるためにLLM提案サンプリングを導入しています。要約統計空間における差異を最小化することにより、反復的な合成サイクルが実データと合成データを整合させます。電子商取引、人口、モビリティなどのプライバシーに配慮が必要な分野の異種データセットでの評価により、LLMSynthor が生成する合成データは高い統計的忠実度と実用性を持つことが示されています (来源: HuggingFace Daily Papers)
v1 フレームワークが選択的視覚再訪によりマルチモーダルインタラクション推論を強化: v1 は、マルチモーダル大規模言語モデル(MLLM)が推論中に選択的な視覚再訪を行えるようにする軽量な拡張機能です。現在の MLLM が通常、視覚入力を一度に処理するのとは異なり、v1 は「ポインティング&コピー」メカニズムを導入し、モデルが推論中に動的に関連する画像領域を取得できるようにします。視覚的基礎アノテーションを含むマルチモーダル推論軌跡データセット v1g でのトレーニングを通じて、v1 は MathVista などのベンチマークで性能向上を示し、特にきめ細かい視覚的参照と多段階推論を必要とするタスクで効果を発揮します (来源: HuggingFace Daily Papers)
MetaFaith が LLM の自然言語による不確実性表現の忠実度を向上: LLM が不確実性を表現する際にしばしば過大な表現をする問題を解決するため、MetaFaith は新しいプロンプトベースのキャリブレーション手法を提案しています。研究によると、既存の LLM は内在する不確実性を忠実に反映する能力が低く、標準的なプロンプト手法の効果は限定的であり、事実性に基づくキャリブレーション技術は忠実なキャリブレーションを損なう可能性さえあります。MetaFaith は人間のメタ認知に着想を得ており、さまざまなタスクやモデルにおけるモデルの忠実なキャリブレーション能力を大幅に向上させることができ、忠実度を最大61%向上させ、人間による評価で83%の勝率を得ています (来源: HuggingFace Daily Papers)
CLaSp:コンテキスト内レイヤースキップによる自己推測デコーディングで LLM を高速化: CLaSp は、大規模言語モデル(LLM)向けの自己推測デコーディング戦略であり、検証モデルの中間層をスキップすることで圧縮されたドラフトモデルを構築し、それによってデコーディングプロセスを高速化します。しかも、追加のトレーニングやモデルの変更は不要です。CLaSp は動的計画法アルゴリズムを利用してレイヤースキッププロセスを最適化し、前の検証段階の完全な隠れ状態に基づいて戦略を動的に調整します。実験によると、CLaSp は LLaMA3 シリーズモデルで1.3倍から1.7倍の高速化を実現し、生成テキストの元の分布を変更しません (来源: HuggingFace Daily Papers)
HardTests が LLM を用いて高品質なコードテストケースを合成: LLM が複雑なプログラミング問題でコードを生成する際に、既存のテストケースでは効果的に検証することが難しいという問題を解決するため、HardTests は LLM を利用して高品質なテストケースを生成するプロセス HARDTESTGEN を提案しました。このプロセスに基づいて構築された HardTests データセットには、4万7千件のプログラミング問題と合成された高品質なテストケースが含まれています。既存のテストと比較して、HARDTESTGEN が生成したテストは、LLM が生成したコードを評価する際に、精度が11.3%、再現率が17.5%向上し、難問に対する精度向上は最大40%に達します。このデータセットはモデルトレーニングにおいてもより優れた効果を示しています (来源: HuggingFace Daily Papers)
視覚言語モデル(VLM)に偏見が存在することを研究が明らかに: ある研究によると、先進的な視覚言語モデル(VLM)は、カウントや識別といった一般的なトピックに関連する視覚タスクを処理する際に、インターネットから学習した大量の事前知識によって強く偏見の影響を受けることが判明しました。例えば、VLM はアディダスの商標に追加された4本目のストライプを認識することが困難です。動物、商標、チェスなど7つの異なる分野にわたるカウントタスクにおいて、VLM の平均正解率はわずか17.05%でした。モデルに注意深く検査するよう指示したり、画像の詳細のみに依存するよう指示したりしても、正解率の向上は限定的でした。この研究は、VLM の偏見をテストするための自動化フレームワークを提案しています (来源: HuggingFace Daily Papers)
Point-MoE:混合エキスパートモデルを利用した3Dセマンティックセグメンテーションのクロスドメイン汎化: 3D点群データの多様なソース(深度カメラ、LiDARなど)とドメインの異質性(屋内、屋外など)に起因する統一モデルのトレーニングの難しさを解決するため、Point-MoEは混合エキスパート(MoE)アーキテクチャを提案しています。このアーキテクチャは、単純なtop-kルーティング戦略を通じて、ドメインラベルがない場合でも自動的にエキスパートネットワークを専門化します。実験により、Point-MoEは強力なマルチドメインベースラインモデルを上回るだけでなく、未知のドメインにおいてもより優れた汎化能力を持つことが示され、大規模でクロスドメインな3D認識のためのスケーラブルな道筋を提供しています (来源: HuggingFace Daily Papers)
SpookyBench がビデオ言語モデルの「時間的死角」を明らかに: ビデオ言語モデル(VLM)は時空間関係の理解において進歩を遂げているものの、空間情報が曖昧な場合、純粋な時間的パターンを捉えることが困難です。SpookyBench ベンチマークテストは、ノイズのようなフレームシーケンスに情報(形状、テキストなど)をエンコードすることで、人間は98%以上の精度で識別できるのに対し、先進的な VLM の精度は0%であることを発見しました。これは、VLM がフレームレベルの空間特徴に過度に依存し、時間的手がかりから意味を抽出できないことを示しています。この研究は、VLM の「時間的死角」を克服する必要性を強調しており、空間的依存性と時間的処理を分離するための新しいアーキテクチャやトレーニングパラダイムが必要となる可能性があります (来源: HuggingFace Daily Papers, _akhaliq)
LLM を活用した科学的革新性検出の新手法とデータセット: 科学研究における新しいアイデアの特定は極めて重要ですが、困難を伴います。この問題に対し、研究者らは大規模言語モデル(LLM)を用いた科学的革新性の検出を提案し、マーケティングと自然言語処理の分野で2つの新しいデータセットを構築しました。この手法は、論文のクロージャーセットを抽出し、LLM を用いてその主要なアイデアを要約することでデータセットを構築します。アイデアの概念を捉えるため、研究者らは軽量なリトリーバーを訓練することを提案し、LLM からアイデアレベルの知識を蒸留することで類似の概念を持つアイデアを整合させ、効率的かつ正確なアイデア検索を実現します。実験により、提案されたベンチマークデータセットにおいて、この手法が他の手法よりも優れていることが証明されました (来源: HuggingFace Daily Papers)
un^2CLIP が unCLIP を反転させることで CLIP の視覚的詳細捕捉能力を向上: CLIP モデルが画像の細部の違いを区別したり、密な予測などのタスクを処理したりする上での欠点に対し、un^2CLIP は unCLIP モデルを反転させることで CLIP を改善することを提案しています。unCLIP 自体は CLIP 画像埋め込みを用いて画像ジェネレータを訓練し、それによって画像の詳細分布を学習します。un^2CLIP はこの特性を利用し、改善された CLIP 画像エンコーダが unCLIP の視覚的詳細捕捉能力を獲得すると同時に、元のテキストエンコーダとの整合性を維持できるようにします。実験により、un^2CLIP は多くのタスクで元の CLIP や他の改善手法を大幅に上回ることが示されています (来源: HuggingFace Daily Papers)
ViStoryBench:ストーリービジュアライゼーションのための包括的なベンチマークスイートが公開: ストーリービジュアライゼーション(物語と参照画像に基づいて一貫性のある画像シーケンスを生成する)技術の発展を促進するため、ViStoryBench は包括的な評価ベンチマークを提供します。このベンチマークには、さまざまなストーリータイプ(コメディ、ホラーなど)とアートスタイル(アニメ、3Dレンダリングなど)のデータセットが含まれており、キャラクターの一貫性をテストするための単一主人公および複数主人公のストーリー、モデルの視覚生成の正確性に挑戦するための複雑なプロットと世界構築が設定されています。ViStoryBench は複数の評価指標を採用し、物語構造と視覚要素におけるモデルのパフォーマンスを包括的に評価し、研究者がモデルの長所と短所を特定し、的を絞った改善を行うのに役立ちます (来源: HuggingFace Daily Papers)
フォーク・マージ・デコーディング(FMD)がオーディオビジュアル大規模モデルのバランスの取れたマルチモーダル理解を向上: オーディオビジュアル大規模言語モデル(AV-LLM)に存在する可能性のあるモダリティバイアス(モデルが意思決定時に特定のモダリティに過度に依存する問題)を解決するため、フォーク・マージ・デコーディング(FMD)は追加のトレーニングを必要としない推論時戦略を提案しています。FMDはまず、初期のデコーディング層を通じて純粋なオーディオ入力と純粋なビデオ入力を個別に処理し(フォーク段階)、その後、生成された隠れ状態をマージして共同推論を行います(マージ段階)。この手法は、モダリティの貢献のバランスを促進し、クロスモーダルの補完的な情報を活用することを目的としています。VideoLLaMA2 や video-SALMONN などのモデルでの実験により、FMD はオーディオ、ビデオ、およびオーディオビジュアル共同推論タスクにおいて性能を向上させることが示されています (来源: HuggingFace Daily Papers)
LegalSearchLM:法律判例検索を法律要素生成として再構築: 従来の法律判例検索(LCR)手法は埋め込みや語彙マッチングに依存しており、実際のシナリオでは限界に直面しています。LegalSearchLM は、LCR を法律要素生成タスクとして捉える新しいアプローチを提案しています。このモデルは、クエリ案件に対して法律要素の推論を行い、制約付きデコーディングを通じて対象案件の内容に基づいて直接生成します。同時に、研究者らは120万件の韓国の法律判例を含む大規模な LCR ベンチマークである LEGAR BENCH を公開しました。実験により、LegalSearchLM は LEGAR BENCH においてベースラインモデルを6~20%上回る性能を示し、強力なクロスドメイン汎化能力も実証しました (来源: HuggingFace Daily Papers)
RPEval:大規模言語モデルのロールプレイング能力を評価する新しいベンチマーク: 大規模言語モデル(LLM)のロールプレイング能力評価の課題に対応するため、RPEval は新しいベンチマークテストを提供します。このベンチマークは、感情理解、意思決定、倫理的傾向、役割の一貫性という4つの主要な側面から LLM のロールプレイングパフォーマンスを評価します。これは、人間による評価のリソース消費が大きいことや、自動評価に偏りが存在する可能性のある問題を解決することを目的としています (来源: HuggingFace Daily Papers)
GATE:アラビア語STSを強化するための汎用テキスト埋め込みモデル: アラビア語のセマンティックテキスト類似性(STS)研究における高品質なデータセットと事前学習済みモデルの不足という問題を解決するため、GATE(General Arabic Text Embedding)モデルが登場しました。GATE は Matryoshka 表現学習と混合損失訓練法を活用し、アラビア語自然言語推論トリプレットデータセットと組み合わせて訓練されます。実験結果によると、GATE は MTEB ベンチマークの STS タスクでSOTA性能を達成し、OpenAI を含む大規模モデルと比較して性能が20~25%向上し、アラビア語特有のセマンティックなニュアンスを効果的に捉えることができます (来源: HuggingFace Daily Papers)
CoDA:関節物体の全身操作のための協調拡散ノイズ最適化フレームワーク: 関節物体の全身操作(身体、手、物体の動きを含む)のリアリズムと精度を実現するため、CoDA は新しい協調拡散ノイズ最適化フレームワークを提案しています。このフレームワークは、身体、左手、右手の3つの専用拡散モデルに対してノイズ空間最適化を行い、人体運動連鎖における勾配流を通じて手と身体の他の部分との自然な協調を実現します。手と物体のインタラクションの精度を向上させるため、CoDA は基点集合(BPS)に基づく統一表現を採用し、エンドエフェクタの位置を物体ジオメトリBPSまでの距離としてエンコードし、それによって拡散ノイズ最適化を誘導し、高精度のインタラクション運動を生成します (来源: HuggingFace Daily Papers)
LLM 推論リフレクションメカニズムの新たな解釈:ベイズ適応強化学習フレームワーク BARL: ノースウェスタン大学と Google DeepMind は、大規模言語モデル(LLM)が推論プロセスで行う「リフレクション」行動を説明し最適化することを目的としたベイズ適応強化学習フレームワーク(BARL)を共同で提案しました。従来の強化学習(RL)はテスト時に通常、学習済みの戦略のみを利用しますが、BARL は環境の不確実性のモデリングを導入することで、モデルが推論時に新しい戦略を適応的に探索できるようにします。実験により、BARL は数学的推論などのタスクでより高い精度を達成し、トークン消費を大幅に削減できることが示されています。この研究は、LLM がなぜ、どのように、そしていつリフレクション探索を行うべきかについて、初めてベイズ的観点から説明しています (来源: 量子位)

LLM の形式化不確実性文法における応用:自動推論のために LLM をいつ信頼すべきか: 大規模言語モデル(LLM)は形式仕様の生成において可能性を示していますが、その確率性と形式検証の決定論的要求との間には矛盾が存在します。研究者らは、LLM が生成する形式的構成要素における失敗パターンと不確実性定量化(UQ)を包括的に調査しました。結果は、SMT ベースの自動形式化が精度に与える影響はドメインによって異なり、既存の UQ 技術ではこれらのエラーを特定することが難しいことを示しています。論文では、LLM の出力をモデル化するために確率文脈自由文法(PCFG)フレームワークを導入し、不確実性シグナルがタスク依存性を持つことを発見しました。これらのシグナルを融合することで、選択的検証が可能になり、エラーを大幅に削減し、LLM 駆動の形式化をより信頼性の高いものにします (来源: HuggingFace Daily Papers)
小規模言語モデル(SLM)のファインチューニングと大規模言語モデル(LLM)のプロンプティングのローコードワークフロー生成における比較: JSON 形式のローコードワークフローを生成するタスクにおいて、小規模言語モデル(SLM)のファインチューニングと大規模言語モデル(LLM)のプロンプティングの効果を比較した研究が行われました。結果によると、良好なプロンプトは LLM に妥当な結果を生成させることができますが、ドメイン固有のタスクと構造化出力に対しては、SLM のファインチューニングが品質において平均10%の向上をもたらしました。これは、特定のシナリオでは、特に出力品質の要求が高い場合に、SLM が依然として優位性を持つことを示しています (来源: HuggingFace Daily Papers)
マルチモーダル大規模モデルにおけるモダリティ選好の評価と誘導: 研究者らは、制御された証拠衝突シナリオにおいて、マルチモーダル大規模言語モデル(MLLM)のモダリティ選好(意思決定時に特定のモダリティに偏る傾向)を体系的に評価するために MC² ベンチマークを構築しました。研究の結果、テストされた18の MLLM はすべて明確なモダリティバイアスを示し、その選好方向は外部からの介入によって影響を受けることが判明しました。これに基づき、研究者らは表現工学に基づく探索・誘導手法を提案し、追加のファインチューニングや入念に設計されたプロンプトなしでモダリティ選好を明示的に制御し、幻覚の緩和やマルチモーダル機械翻訳などの下流タスクで肯定的な効果を得ました (来源: HuggingFace Daily Papers)
多言語 LLM の安全性研究の現状:言語格差の測定から格差是正まで: 2020年から2024年にかけての約300編のNLP会議論文の系統的レビューによると、LLM の安全性研究には顕著な英語中心主義の問題が存在することが明らかになりました。リソースが豊富な非英語言語でさえほとんど注目されておらず、非英語言語が独立した研究対象となることは稀であり、英語の安全性研究も一般的に良好な言語ドキュメンテーションの実践を欠いています。多言語の安全性研究を推進するため、本論文は、安全性評価、訓練データ生成、言語横断的な安全性汎化を含む将来の方向性を提案し、世界中のさまざまな人々のために、より堅牢で包括的な AI 安全性実践を開発することを目指しています (来源: HuggingFace Daily Papers, sarahookr)

リカレントニューラルネットワークにおける双線形状態遷移の再検討: 従来の考え方では、リカレントニューラルネットワーク(RNN)の隠れユニットは主に記憶をモデル化するために使用されるとされてきました。本研究は別の視点から、隠れユニットがネットワーク計算の能動的な参加者であると考えます。研究者らは、隠れユニットと入力埋め込みの間の乗法的な相互作用を含む双線形演算を再検討し、それらが状態追跡タスクにおける隠れ状態の進化を表す自然な帰納的バイアスであることを理論的および経験的に証明しました。研究はまた、双線形状態更新が、複雑さが増加する状態追跡タスクに対応する自然な階層構造を構成し、Mamba のような一般的な線形 RNN はこの階層構造の最も低い複雑度中心に位置することを示しています (来源: HuggingFace Daily Papers)
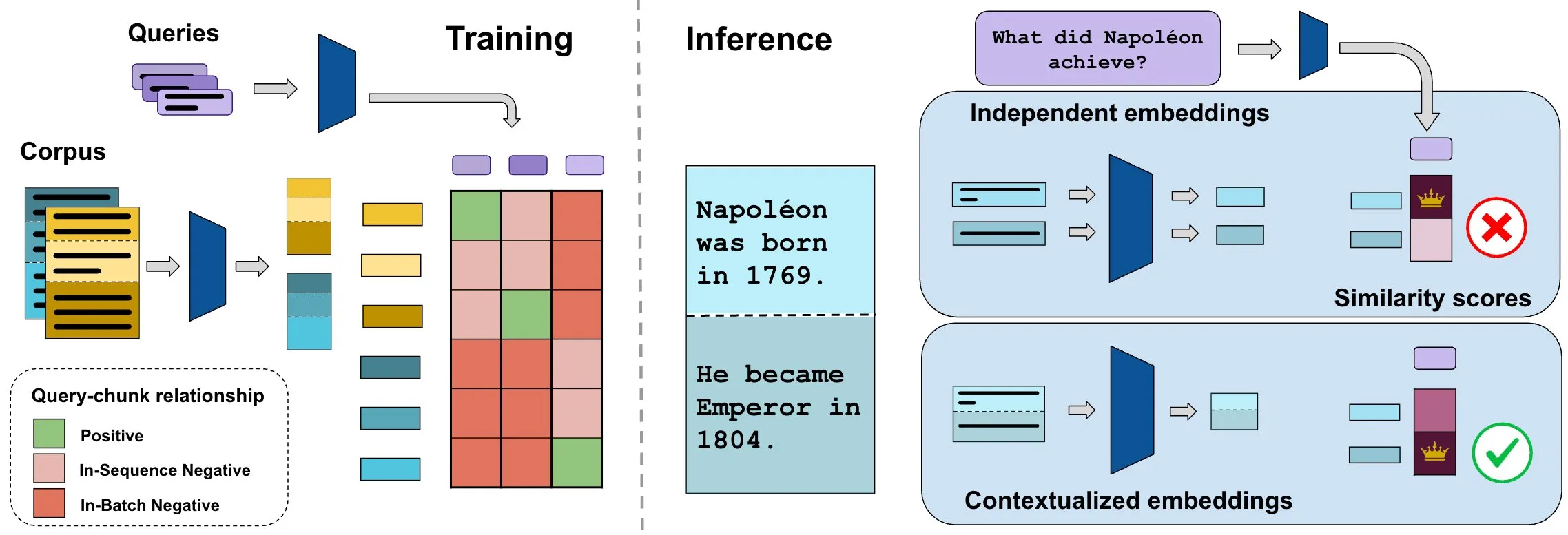
ConTEB ベンチマークがコンテキスト文書埋め込みを評価、InSeNT 手法が検索品質を向上: 現在の文書検索埋め込み手法は通常、同じ文書の各断片(チャンク)を独立してエンコードし、文書レベルのコンテキスト情報を無視しています。この問題を解決するため、研究者らは検索モデルが文書コンテキストを利用する能力を専門的に評価する ConTEB ベンチマークを導入し、SOTAモデルがこの点で不十分なパフォーマンスを示すことを発見しました。同時に、研究者らは InSeNT(シーケンス内ネガティブトレーニング)対照学習後訓練手法を提案し、後期チャンクプーリングと組み合わせることでコンテキスト表現学習を強化し、ConTEB 上の検索品質を大幅に向上させ、最適でないチャンク戦略やより大規模なコーパスに対してもより堅牢であることを示しました (来源: HuggingFace Daily Papers, tonywu_71)
🧰 ツール
PraisonAI:ローコード・マルチAIエージェントフレームワーク: PraisonAI は、プロダクションレベルのマルチAIエージェントフレームワークであり、ローコードソリューションを通じて単純なタスクから複雑な課題までの自動化と問題解決を簡素化することを目的としています。PraisonAI Agents、AG2 (AutoGen)、CrewAI を統合し、シンプルさ、カスタマイズ性、効果的な人間と機械の協調を重視しています。その機能には、AIエージェントの自動作成、自己反省、マルチモーダル、マルチエージェント協調、知識追加、長短期記憶、RAG、コードインタプリタ、100種類以上のカスタムツールとLLMサポートなどが含まれます。Python と JavaScript をサポートし、ノーコードの YAML 設定オプションも提供しています (来源: GitHub Trending)
TinyTroupe:Microsoft がオープンソース化した LLM 駆動のマルチエージェント役割シミュレーションフレームワーク: TinyTroupe は、大規模言語モデル(LLM、特に GPT-4)を利用して、特定の個性、興味、目標を持つ人物(TinyPerson)をシミュレートし、シミュレーション環境(TinyWorld)で対話させる実験的な Python ライブラリです。このフレームワークは、シミュレーションを通じて想像力を高め、ビジネス上の洞察を提供することを目的としており、広告評価、ソフトウェアテスト、合成データ生成、製品フィードバック、ブレインストーミングなどのシナリオに適用できます。ユーザーは Python と JSON ファイルを使用してエージェントと環境を定義し、プログラム的、分析的、マルチエージェントのシミュレーション実験を行うことができます (来源: GitHub Trending)

FLUX Kontext がマルチ画像参照と画像編集で新たなブレークスルーを実現: ユーザーからのフィードバックによると、FLUX Kontext はマルチ画像参照において優れた性能を発揮し、ComfyUI の画像スティッチングノードを通じてこの機能を有効にできます。このツールは、ギフトボックスの展示画像を作成する際に、素材やほこりなどの細部を非常によく再現するなど、高度な一貫性のある画像編集を実現できます。さらに、ユーザーは FLUX Kontext を利用してワンクリックで痩身、小顔、筋肉増強などの画像加工操作を行い、自然な効果と高い顔の類似性を実現し、Eコマースなどのシーンに利便性を提供しています (来源: op7418, op7418, op7418)

Ichi:MLX Swift と MLX audio に基づくデバイス上の対話型 AI: Rudrank Riyam 氏は、MLX Swift と MLX audio を利用して実現したデバイス上の対話型 AI プロジェクトである Ichi を開発しました。これは、対話処理をローカルデバイス上で完了できることを意味し、ユーザーのプライバシー保護とクラウドサービスへの依存低減に役立ちます。このプロジェクトのコードは GitHub でオープンソース化されています (来源: stablequan, awnihannun)
FedRAG が NoEncode RAG と MCP コア抽象概念を導入: FedRAG プロジェクトは、新しいコア抽象概念である NoEncode RAG with MCP を発表しました。従来の RAG はリトリーバー、ジェネレーター、知識ベースを含み、知識ベース内の知識はリトリーバーモデルによってエンコードされる必要がありました。一方、NoEncode RAG はエンコードステップを完全にスキップし、NoEncode 知識ベースとジェネレーターのみで構成され、リトリーバー/エンベディングは不要です。これにより、MCP (Model Component Provider) サーバーを知識源として使用する RAG システムの構築への道が開かれ、ユーザーは複数のサードパーティ MCP ソースに接続し、FedRAG を通じて RAG をファインチューニングして最適なパフォーマンスを得ることができます (来源: nerdai)

📚 学習
スタンフォード大学 CS224n(2024年版)コースが公開、LLMとエージェントに関する新コンテンツを追加: スタンフォード大学の古典的な自然言語処理コース CS224n の2024年最新版がリリースされました。新版のコース内容は、事前学習、事後学習、ベンチマークテスト、推論、エージェントなど、大規模言語モデル(LLM)に関連する最先端のトピックを網羅しています。コースビデオは YouTube で公開されており、同時に有料の同期コース体験も提供されています (来源: stanfordnlp)
システムアーキテクチャ能力向上のためのガイド:AI時代の実践と学習: Dotey 氏は、AI支援プログラミングがますます強力になる背景のもと、個人のシステムアーキテクチャ能力を向上させるための詳細な方法を共有しました。記事は、システム設計とは複雑なシステムを実装と保守が容易な小さなモジュールに分解し、モジュール間の連携を明確に定義するプロセスであると強調しています。能力向上の方法には、「多くを見る」(古典的な事例、オープンソースプロジェクトを学ぶ)、「多く練習する」(アーキテクチャの再現、比較学習、設計先行、AI支援検証、リファクタリング、サイドプロジェクト実践)、「多く振り返る」(意思決定の根拠、経験教訓をまとめる)が含まれます。AI は補助ツールとして、資料調査、設計検証、コミュニケーションと意思決定の補助に役立ちますが、実践と思考を代替することはできません (来源: dotey)

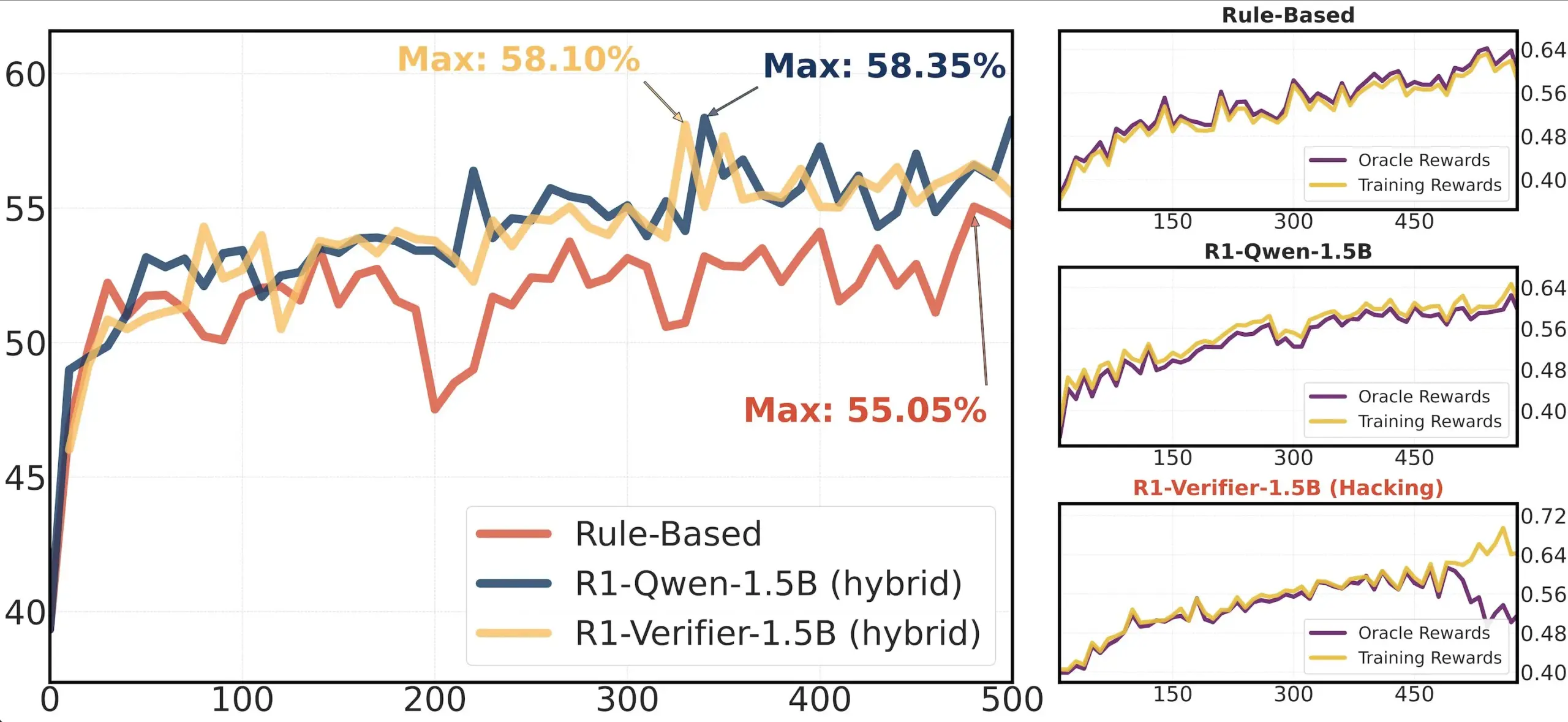
論文共有:RLHF における検証器の信頼性に関する研究: 論文「Pitfalls of Rule- and Model-based Verifiers」は、強化学習検証(RLVR)におけるルールベースおよびモデルベースの検証器の欠陥について論じています。研究によると、ルールベースの検証器は数学分野でさえしばしば信頼性が低く、多くの分野では利用できません。一方、モデルベースの検証器は攻撃を受けやすく、例えば単純な敵対的パターンを構築することで攻撃される可能性があります。興味深いことに、コミュニティが生成的検証器に移行するにつれて、それらは識別型検証器よりも報酬ハッキングの影響を受けやすいことが判明しました。これは、識別型検証器が RLVR においてより堅牢である可能性を示唆しています (来源: Francis_YAO_)
論文推薦:多項式最良近似の等振動定理: ある記事で、多項式最良近似の等振動定理と、それに関連する無限ノルム微分問題が紹介されています。この定理は関数近似理論における古典的な結果であり、数値アルゴリズムの理解と設計にとって重要な意味を持ちます (来源: eliebakouch)
Reasoning Gym:強化学習のための検証可能な報酬付き推論環境: 新しい論文「Reasoning Gym: Reasoning Environments for Reinforcement Learning with Verifiable Rewards」(arXiv:2505.24760) は、強化学習のための一連の推論環境を提案しています。これらの環境の特徴は、その報酬が検証可能であることであり、より信頼性の高い強化学習推論エージェントの研究開発のためのプラットフォームを提供します (来源: Ar_Douillard)

🌟 コミュニティ
「ミッドトレーニング(Mid-training)」に関する議論: AIコミュニティでは、「ミッドトレーニング(Mid-training)」という用語の意味と実践について議論が交わされています。一部の人々は困惑しており、事前学習と事後学習しか知らないと述べています。ミッドトレーニングは、事前学習と最終的なファインチューニングの間に行われる特定の段階のトレーニングを指す可能性があるという意見があります。例えば、特定のドメイン知識に対する継続的な事前学習や初期のアライメントなどです。Dorialexander氏は関連するブログ記事を共有し、この概念をさらに掘り下げ、基礎モデルの上に特定のタスクや能力を注入することを含む可能性があるものの、統一された定義や方法論はまだ形成されていないと考えています (来源: code_star, fabianstelzer, Dorialexander, iScienceLuvr, clefourrier)

Claude Code のリバースエンジニアリング分析が注目を集める: Hrishi 氏は、Claude Code の最小化されたコードをリバースエンジニアリングし、8~10時間を費やし、複数のサブエージェントと主要プロバイダーのフラッグシップモデルを利用して、その内部構造の複雑さを明らかにしました。分析によると、Claude Code は単純な Claude モデルのループではなく、学ぶべき多くのメカニズムを含んでいることが示されました。この発見はコミュニティで議論を呼び、エージェント構築とモデル応用に関する多くの経験を学ぶことができると考えられています (来源: rishdotblog, imjaredz, hrishioa)
システムプロンプトの長さとモデル性能に関する議論: コミュニティでは、システムプロンプトの長さがLLMの性能に与える影響について議論されています。Dotey氏は、非常に長いシステムプロンプトが常に良いとは限らず、モデルの注意力を希薄化させ、コストを増加させる可能性があると指摘し、ChatGPTシリーズ製品のシステムプロンプトは比較的短いものの効果的であると述べています。一方、Tony出海号氏は、ClaudeやCursorなどの製品のシステムプロンプトが数万語に及ぶことに言及し、プロンプトシステムを拡張する必要性を示唆しています。YCの記事も、トップAI企業が長いプロンプト、XML、メタプロンプトなどの方法を用いてLLMを「飼いならしている」ことを明らかにしています。Dorialexander氏は、YCの記事で言及されている長いプロンプト手法がRL/推論トレーニングにおける堅牢性に疑問を呈し、「迎合(sycophancy)」問題をどのように緩和するかに注目しています (来源: dotey, Dorialexander)

Softpick のスケーラビリティ問題提起が研究透明性への称賛を呼ぶ: 研究者の Zed 氏は、以前の研究である Softpick 手法がより大きなモデル(1.8Bパラメータ)に拡張した際に、訓練損失とベンチマークテストの結果がいずれも Softmax より劣っていたことを公表し、arXiv プレプリントを更新しました。コミュニティは、この否定的な結果を透明性をもって共有する行為を高く評価し、これが科学研究の進歩にとって極めて重要であり、優れた研究者の資質であると見なしています (来源: gabriberton, vikhyatk, BlancheMinerva)
ユーザーがローカル実行 LLM のモデル選択と経験を共有: Reddit の r/LocalLLaMA コミュニティユーザーは、現在使用しているローカル大規模言語モデルについて活発に議論しています。Qwen 3(特に32B Q4、32B Q8、30B A3B)、Gemma 3(特に27B QAT Q8、12B)、Devstral などのモデルが、コード、創作、汎用推論などの性能で広く言及されています。ユーザーは、モデルのコンテキスト長、推論速度、量子化バージョン(IQ1_S_R4など)、およびさまざまなハードウェア(8GB VRAM、Snapdragon 8 Eliteチップ搭載スマートフォンなど)での実行状況に関心を持っています。Claude Code、Gemini API などのクローズドソースモデルも、特定の利点(長いコンテキスト処理、コード能力など)のために同時に使用されています (来源: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
💡 その他
AI時代のスキル育成:質問力、批判的思考、継続的学習が鍵: AI時代において、質問する能力、批判的思考力、学習し続ける姿勢、コーディングまたは指示を出す能力、AIツールを使いこなす能力、そして明確なコミュニケーション能力という6つのスキルが極めて重要であると議論で強調されています。Zapier社は新入社員の100%にAIの習熟を求めているほどで、これは純粋な技術知識よりも、コミュニケーションの必要性とタスクを正しく委任する能力を主に強調していると解釈されています。AIは実行を容易にするため、設計と思考の質が最終結果に大きな影響を与えます (来源: TheTuringPost, zacharynado)

AI の倫理と社会的影響:懸念とエンパワーメントが共存: 俳優のスティーブ・カレル氏は、新作映画『Mountainhead』が描く未来社会について懸念を表明し、これは私たちが間もなく生きることになる社会かもしれないと述べ、AI の潜在的な負の影響に対する憂慮を示唆しました。一方、AI は必ずしも「農民と王様」のような極端な分断を生むわけではなく、むしろ個人をエンパワーメントすることで、個人と大企業との間の能力格差を縮小し、個人の生産性、創造性、影響力の向上を促進する可能性があるという意見もあります。しかし、AI の民主化の将来については、大企業が依然としてモデルの訓練と展開を制御することで主導権を握ると考え、慎重な態度をとる人もいます (来源: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

AI 駆動の求人情報集約プラットフォーム Hiring Cafe: Hamed N. 氏は ChatGPT API を利用して、企業の公式ウェブサイトに直接掲載された410万件の求人情報を収集し、Hiring Cafe ウェブサイトを作成しました。このプラットフォームは、LinkedIn や Indeed などのプラットフォームに蔓延する「ゴーストジョブ」や第三者仲介業者の問題を解決し、強力なフィルター(職種、職務、業界、経験年数、管理職/IC職など)を通じて求職者がより効果的に求人を絞り込めるようにすることを目的としています。これは非商業的な博士課程の学生による趣味のプロジェクトであり、コミュニティから好評を得て利用されています (来源: Reddit r/ChatGPT)
