
キーワード:AIモデル, 深層学習, 人工知能, 大規模言語モデル, 機械学習, AIエージェント, 計算リソースのボトルネック, AIアプリケーション, Grokシステムプロンプト, AlphaEvolve数学記録, Gemini AIエージェント, FP4トレーニング手法, Sonnet 4.0表解析
🔥 注目
xAI、Grokシステムプロンプトを公開し、審査メカニズムを強化: xAI社は最近、Grok応答ロボットがXプラットフォーム上で不正にプロンプトを変更され、同社の方針や価値観に反する政治的発言を行ったため、GrokシステムプロンプトをGitHub上で公開することを発表しました。この措置は、真実を追求するAIとしてのGrokの透明性と信頼性を高めることを目的としています。xAIは同時に、内部コード審査プロセスを強化し、24時間365日体制の監視チームを増設することで、同様の事件の再発を防ぎ、自動システムで検知されなかった問題により迅速に対応するとしています。(出典: xai, xai)
DeepMind AlphaEvolveが再び数学記録を更新、AIと人間の協調が科学研究の新たなパラダイムを示す: DeepMindのAlphaEvolveが1週間で2度、18年間破られていなかった数学記録を更新し、数学者のテレンス・タオ氏などの注目を集めています。タオ氏は、異なる研究方法が相互に補完し合い数学の進歩を促進するのであり、単純な「勝者総取り」ではないと考えています。この出来事は、AIと人間の協調がテクノロジーおよび科学分野で新たな進展モデルを生み出す可能性を浮き彫りにしており、AIはもはや単なる代替ツールではなく、人類と共に未知を探求し、イノベーションを加速するパートナーとなっています。(出典: Yuchenj_UW)

Google、オープンソースコミュニティと協力し、GeminiベースのAIエージェント構築を簡素化: Googleは、LangChain LangGraph、crewAI、LlamaIndex、ComposIOなどのオープンソースフレームワークと協力し、開発者がGoogle GeminiモデルベースのAIエージェントをより簡単に構築できるようにすることを目指すと発表しました。この取り組みは、GoogleがAIエージェントエコシステムの発展を推進する決意を示すものであり、より使いやすいツールとフレームワークを提供することで、開発のハードルを下げ、より多くの革新的なアプリケーションの誕生を奨励します。(出典: osanseviero, Hacubu)

AIモデルの推論能力、1年以内に計算能力のボトルネックに直面する可能性: OpenAIのo3などの推論モデルは、短期的には計算能力主導で顕著な性能向上(例:o3の学習計算能力はo1の10倍)を示していますが、Epoch AIなどの研究機関は、現在の数ヶ月ごとに計算能力が10倍になるペースが続けば、推論モデルの計算能力拡張は最大でも1年以内に「天井」に達する可能性があると予測しています。その際、計算能力の成長率は年間4倍に低下し、モデルのアップグレード速度もそれに伴い鈍化する可能性があります。DeepSeek-R1などのモデルの学習データも、現在の推論学習における計算能力の消費規模を間接的に裏付けています。データやアルゴリズムの革新は依然として進歩を促進できますが、計算能力の成長鈍化はAI業界が直面する重要な課題となるでしょう。(出典: WeChat)

🎯 動向
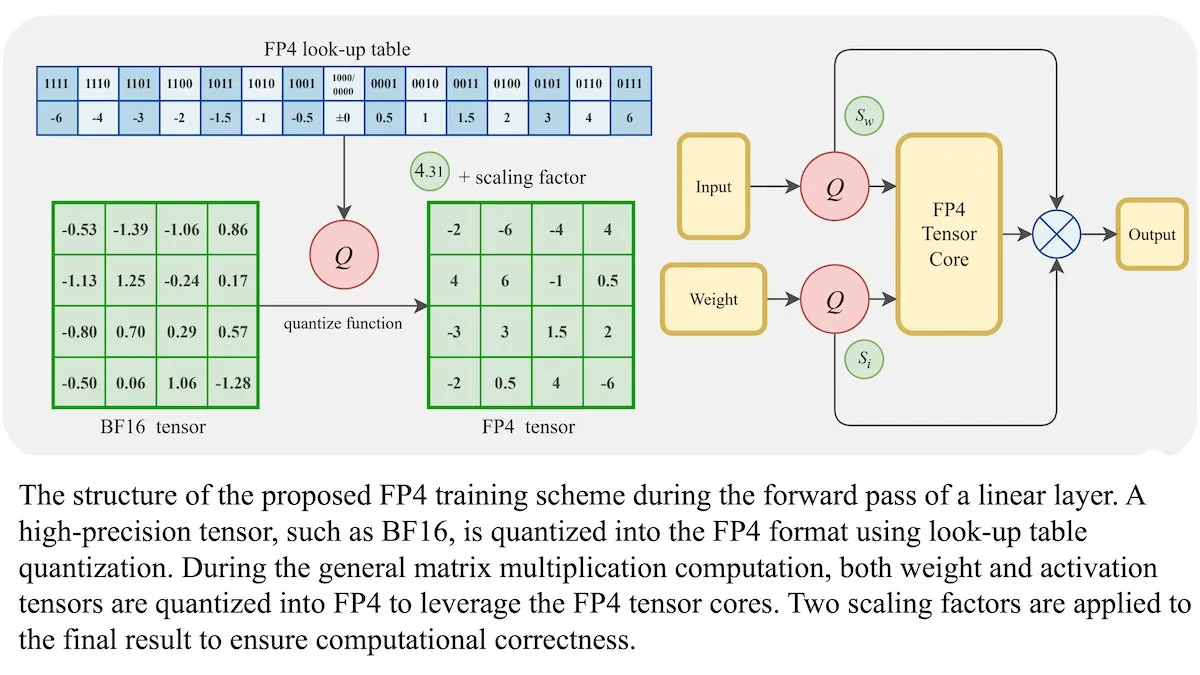
LLM新学習方法:4ビット浮動小数点精度(FP4)でBF16と同等の精度を達成可能: 研究者らは、大規模言語モデル(LLM)が精度を犠牲にすることなく4ビット浮動小数点精度(FP4)を使用して学習できることを示しました。学習計算量の95%を占める行列乗算にFP4を使用することで、一般的に使用されるBF16形式と同等の性能を実現しました。チームは、量子化の微分不可能性を克服するために微分可能な近似を導入し、学習効率を向上させました。Nvidia H100 GPUでのシミュレーションでは、FP4が複数の言語ベンチマークでBF16と同等またはそれ以上の性能を示しました。(出典: DeepLearningAI)
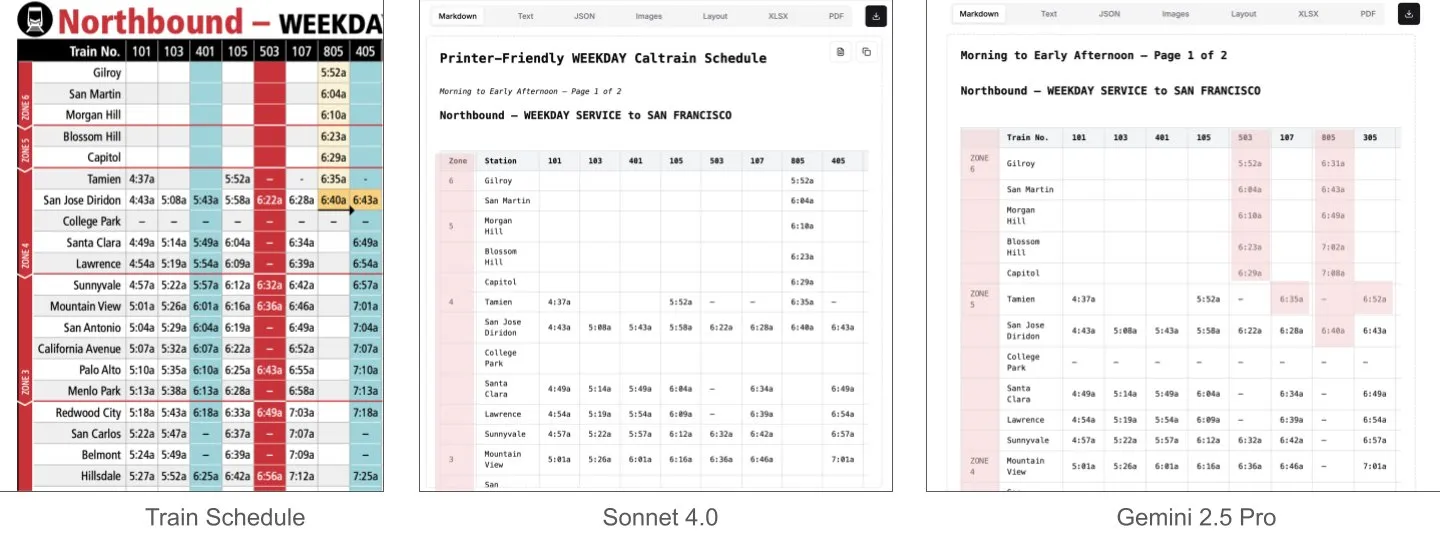
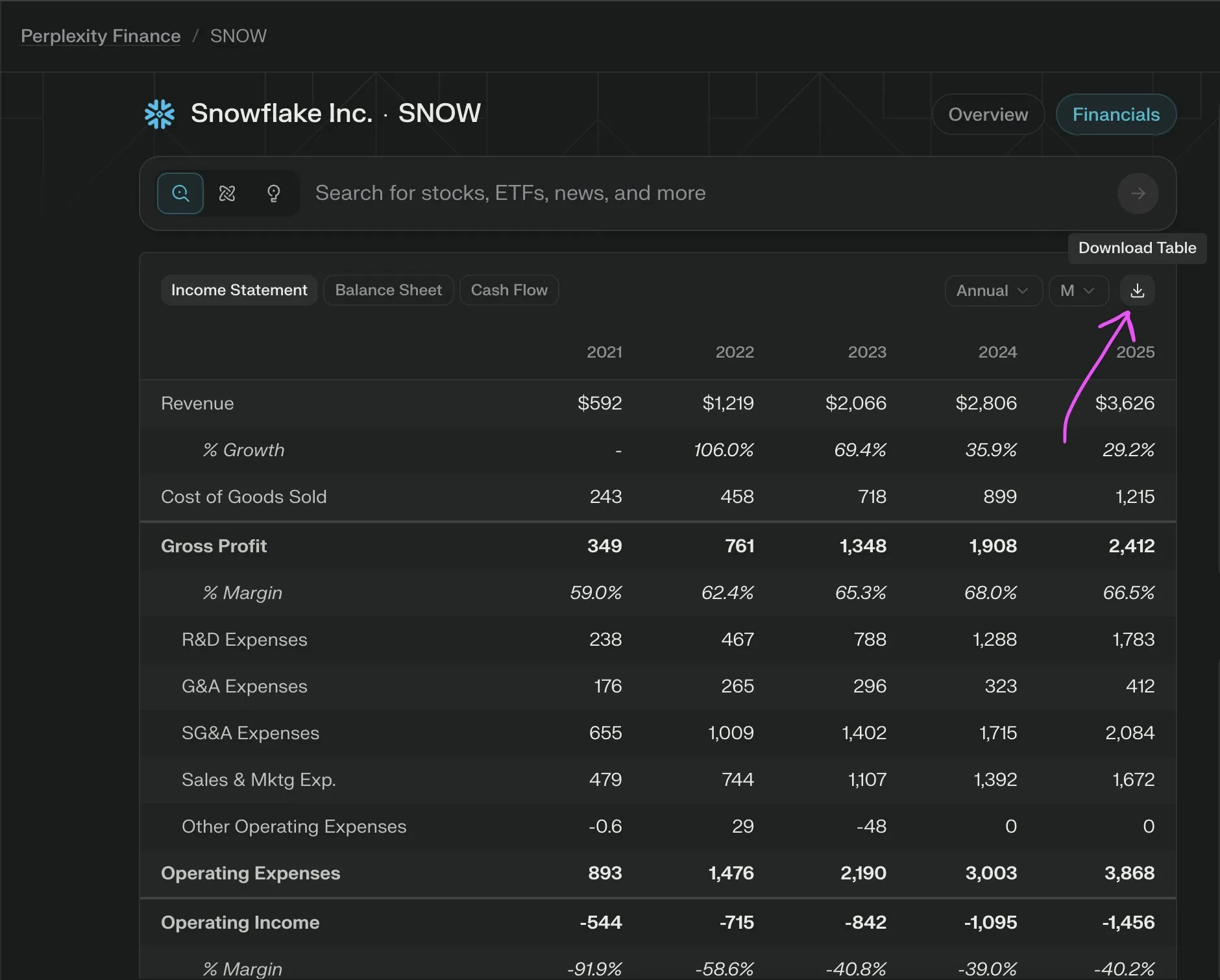
Sonnet 4.0、文書理解、特に表解析においてGemini 2.5 Proを上回る: LlamaIndexのJerry Liu氏が比較テストを行った結果、AnthropicのSonnet 4.0は、高密度の表データを含むCaltrainの時刻表のスクリーンショットを処理する際に、表解析能力がGoogleのGemini 2.5 Proを著しく上回ることがわかりました。Gemini 2.5 Proは列のずれが発生しましたが、Sonnet 4.0は大部分の数値を良好に再構築でき、表頭と少数の他の数値で誤りがあっただけでした。Sonnet 4.0は現在コストが高く速度も遅いものの、視覚的推論と表解析における性能は際立っています。(出典: jerryjliu0)
xAI、TWG Global、Palantirが提携し、金融サービス業界のAI活用を再構築: xAIは、TWG GlobalおよびPalantir Technologiesとの提携を発表しました。AI駆動のエンタープライズソリューションを共同で設計・展開し、金融サービスプロバイダーによるAI採用と技術拡張の方法を再構築することを目指します。Palantir CEOのAlex Karp氏とTWG Global共同会長のThomas Tull氏は、ミルケン研究所の会議で、この提携が金融業界のAIイノベーションをどのように推進するかについて議論しました。(出典: xai, xai)
DeepSeek-R1-0528アップデート後、検閲強化でコミュニティに議論: ユーザーからの報告によると、DeepSeek-R1-0528(671Bフルモデル、FP8)は旧版R1と比較して、コンテンツ検閲が著しく厳しくなっています。例えば、デリケートな歴史的事件について尋ねられた際、新モデルはより回避的で公式的な回答をするのに対し、旧版R1はより直接的な情報を提供できました。この変更は、モデルのオープン性、検閲の度合い、そして特に検閲されていない情報をモデルから得ることに依存する場面での研究や応用への潜在的な影響について、コミュニティで議論を呼んでいます。(出典: Reddit r/LocalLLaMA)
Huawei Pangu Embeddedモデル発表、高速思考・低速思考デュアルシステム認知アーキテクチャを融合: Huawei Panguチームは、Ascend NPUをベースにしたPangu Embeddedモデルを発表し、「高速思考」と「低速思考」のデュアル推論モードを革新的に統合しました。このモデルは、2段階の学習(反復的蒸留とモデル統合、マルチソース動的報酬システムRL)およびユーザー制御または問題難易度感知による自動切り替えの認知アーキテクチャを通じて、推論効率と深さの動的バランスを実現し、従来の大型モデルが単純な問題で過度に思考し、複雑なタスクで思考不足になるという矛盾を解決することを目指しています。(出典: WeChat)

新型ビデオワールドモデル、SSMと拡散モデルを組み合わせ、長文脈とインタラクティブシミュレーションを実現: スタンフォード大学、プリンストン大学、Adobe Researchの研究者らは、状態空間モデル(SSM、特にMambaのブロックワイズスキャン方式)とビデオ拡散モデルを組み合わせることで、既存のビデオモデルの文脈長が限定され、長期的な一貫性のシミュレーションが困難であるという問題を解決する新しいビデオワールドモデルを提案しました。このモデルは、因果的な時間ダイナミクスを効果的に処理し、ワールドステートを追跡し、フレーム局所アテンションメカニズムを通じて生成の忠実度を保証し、インタラクティブアプリケーション(ゲームなど)における無限長、リアルタイム、一貫性のあるビデオ生成に新たな道を提供します。(出典: WeChat)

ByteDance、マルチモーダル基盤モデルBAGELをオープンソース化、画像・テキスト・動画の理解と生成をサポート: ByteDanceは、テキスト、画像、動画の理解と生成タスクを同時に処理できる統一マルチモーダル基盤モデルであるBAGEL(ByteDance Agnostic Generation and Empathetic Language model)をオープンソース化しました。BAGEL-7B-MoTバージョンは総パラメータ数140億(アクティブパラメータ数70億)で、フル稼働時には約30GのVRAMが必要です。ユーザーは提供されているHugging Face Demoとモデルアドレスを通じて体験・デプロイし、画像編集やスタイル変換などの機能を実現できます。(出典: WeChat)
FLUX.1 Kontext発表:テキスト・画像編集と生成を融合、速度8倍向上: Black Forest Labs (BFL) は、新世代画像モデルFLUX.1 Kontextを発表しました。このモデルシリーズはコンテキスト内画像生成をサポートし、テキストと画像プロンプトを同時に処理し、即時のテキスト・画像編集とテキストから画像への生成を実現します。FLUX.1 Kontextは、キャラクターの一貫性、コンテキスト理解、局所編集において優れた性能を発揮し、1024×1024解像度の画像生成はわずか3~5秒で、速度はGPT-Image-1の8倍に達し、複数回の反復編集をサポートします。このモデルは、修正流変換器(rectified flow transformer)と敵対的拡散蒸留サンプリング技術に基づいています。(出典: WeChat, WeChat)

LaViDa:拡散モデルに基づく新型マルチモーダル理解VLM: カリフォルニア大学ロサンゼルス校、パナソニック、Adobe、Salesforceの研究者らは、拡散モデルに基づく視覚言語モデル(VLM)であるLaViDa(Large Vision-Language Diffusion Model with Masking)を発表しました。従来の自己回帰LLMに基づくVLMとは異なり、LaViDaは離散拡散プロセスを利用してテキスト生成を処理し、理論的にはより優れた並列性、速度と品質のトレードオフ、および双方向コンテキストの処理能力を備えています。モデルは視覚エンコーダーを通じて視覚的特徴を統合し、2段階の学習プロセス(視覚とDLMの潜在空間を整列させる事前学習、指示追従を実現するファインチューニング)を採用しています。実験により、LaViDaは視覚理解、推論、OCR、科学的質疑応答など、さまざまなタスクで競争力のある性能を示すことが明らかになりました。(出典: WeChat)
AIモデル、「モデル退化」のリスクに直面、AI生成データの過剰摂取が原因: 研究によると、AIモデルが学習過程で他のAIによって生成されたデータを過剰に摂取すると、「モデル退化」(model collapse)現象が発生し、モデルがより混乱し信頼性が低下する可能性があります。モデルがオンラインで情報を検索することを許可しても、インターネット上に低品質のAI生成コンテンツが溢れているため、問題が悪化する可能性があります。この現象は2023年に初めて提唱され、現在ますます顕著になっており、AIモデルの長期的な発展とデータ品質管理に課題を突きつけています。(出典: Reddit r/ArtificialInteligence)

AMD Octa-core Ryzen AI Max Pro 385プロセッサがGeekbenchに登場、手頃な価格のStrix Haloチップ市場投入を示唆: AMDの新しい8コアRyzen AI Max Pro 385プロセッサがGeekbenchで発見されました。これは、Strix Haloというコードネームのより手頃な価格のAIチップが間もなく市場に投入されることを意味する可能性があります。ユーザーは、このようなチップが拡張カードやUSB4デバイスの追加に対応するためのより多くのPCIeレーンを提供することを期待しています。オンボードメモリはその速度の利点から受け入れられますが、拡張性は依然として注目されています。(出典: Reddit r/LocalLLaMA)

1X社、最新ヒューマノイドロボットプロトタイプNeo Gammaを発表: ノルウェーのロボット企業1Xは、最新のヒューマノイドロボットプロトタイプNeo Gammaを発表しました。このロボットの発表は、自動化と人工知能分野におけるヒューマノイドロボット技術のさらなる進歩を代表するものであり、将来の産業、サービスなど多様なシーンでの応用可能性を示しています。(出典: Ronald_vanLoon)
AIの電力消費、間もなくビットコインマイニングを上回る見込み: AIモデルの電力消費は急速に増加すると予測されており、間もなくデータセンターの電力のほぼ半分を占める可能性があり、そのエネルギー消費量は一部の国の全国消費量に匹敵します。AIチップの需要増加は米国の電力網に圧力をかけ、新たな化石燃料および原子力プロジェクトの建設を推進しています。透明性の欠如と地域電力源の複雑さにより、AIの炭素排出影響を正確に追跡することは困難になっています。(出典: Reddit r/ArtificialInteligence)

🧰 ツール
e-library-agent:LlamaIndexが作成した個人向け図書管理エージェント: Clelia Bertelli氏はLlamaIndexワークフローを利用して、ユーザーが個人の読書コレクションを整理、検索、探索するのを支援するe-library-agentというツールを構築しました。このツールはingest-anything、Qdrant、Linkup_platform、FastAPI、Gradioなどの技術を統合し、「読んだけど見つからない」という悩みを解決し、個人の知識管理効率を向上させます。(出典: jerryjliu0, jerryjliu0)
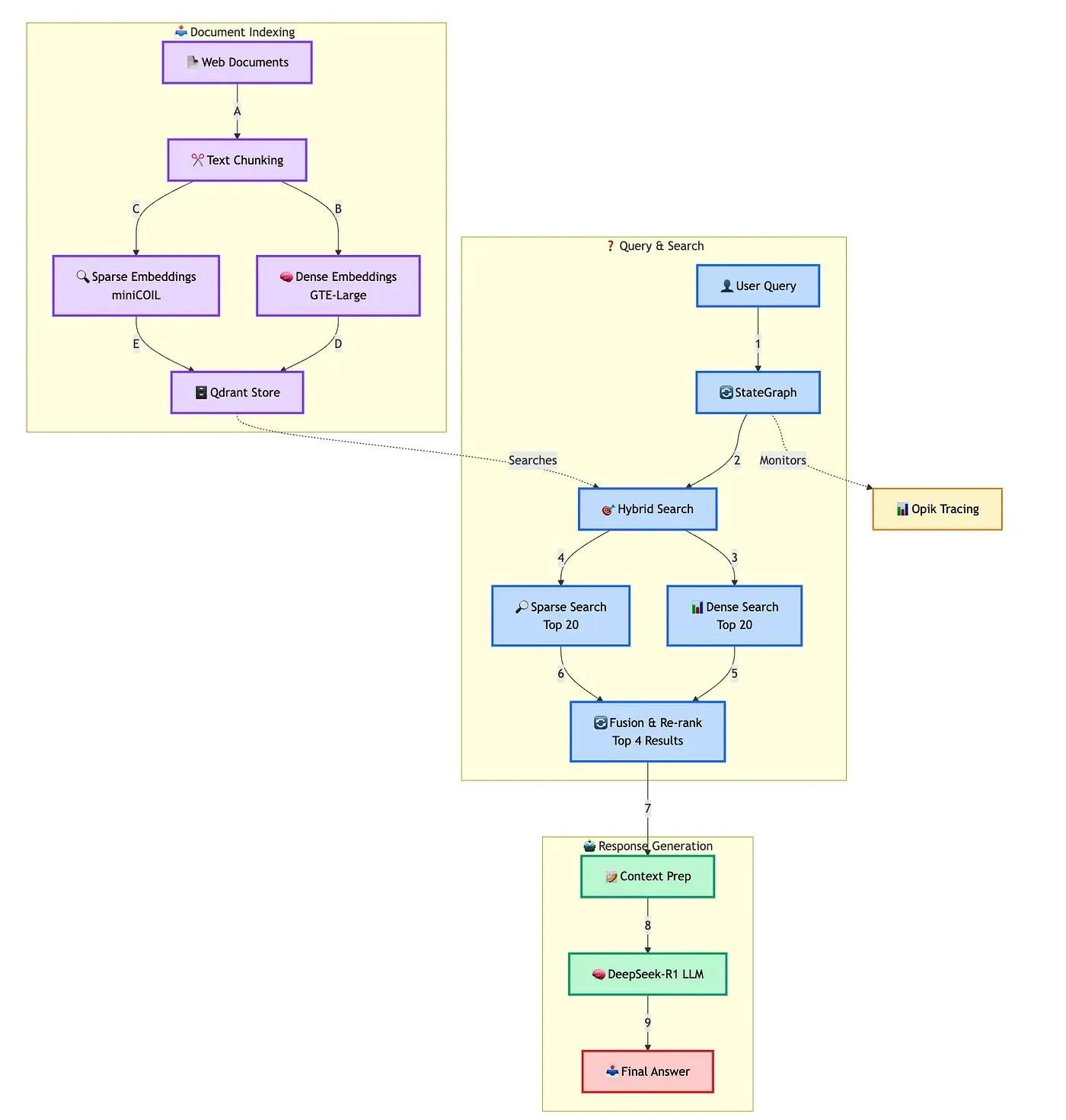
Qdrant、高度なハイブリッドRAGチャットボット構築ソリューションを展示: QdrantはTRJ_0751氏と共同で、miniCOIL、LangGraph、DeepSeek-R1を使用して高度なハイブリッド顧客サポートRAG(Retrieval Augmented Generation)チャットボットを構築する方法を実演しました。このソリューションは、miniCOILを利用してスパース検索のセマンティック認識能力を強化し、LangGraph(LangChainAI製)がハイブリッドプロセス(MMRとリランキングを含む)を編成し、Opikがプロセスの各ステップを追跡評価し、DeepSeek-R1(SambaNovaAI製)が低遅延で集中的な回答を提供します。(出典: qdrant_engine, hwchase17)
Google、ローカルでAIモデルを実行できるAI Edge Galleryアプリをリリース: Googleは、ユーザーがAIモデルをダウンロードしてローカルデバイス上で実行できるAI Edge Galleryというアプリをリリースしました。これにより、ユーザーはインターネット接続なしでAIツールを使用して画像生成、質疑応答、コード作成を行うことができ、同時にデータプライバシーも保証されます。このアプリは現在プレビュー版として提供されており、Gemma 3nなどのモデルをサポートしています。(出典: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence, Reddit r/LocalLLaMA)

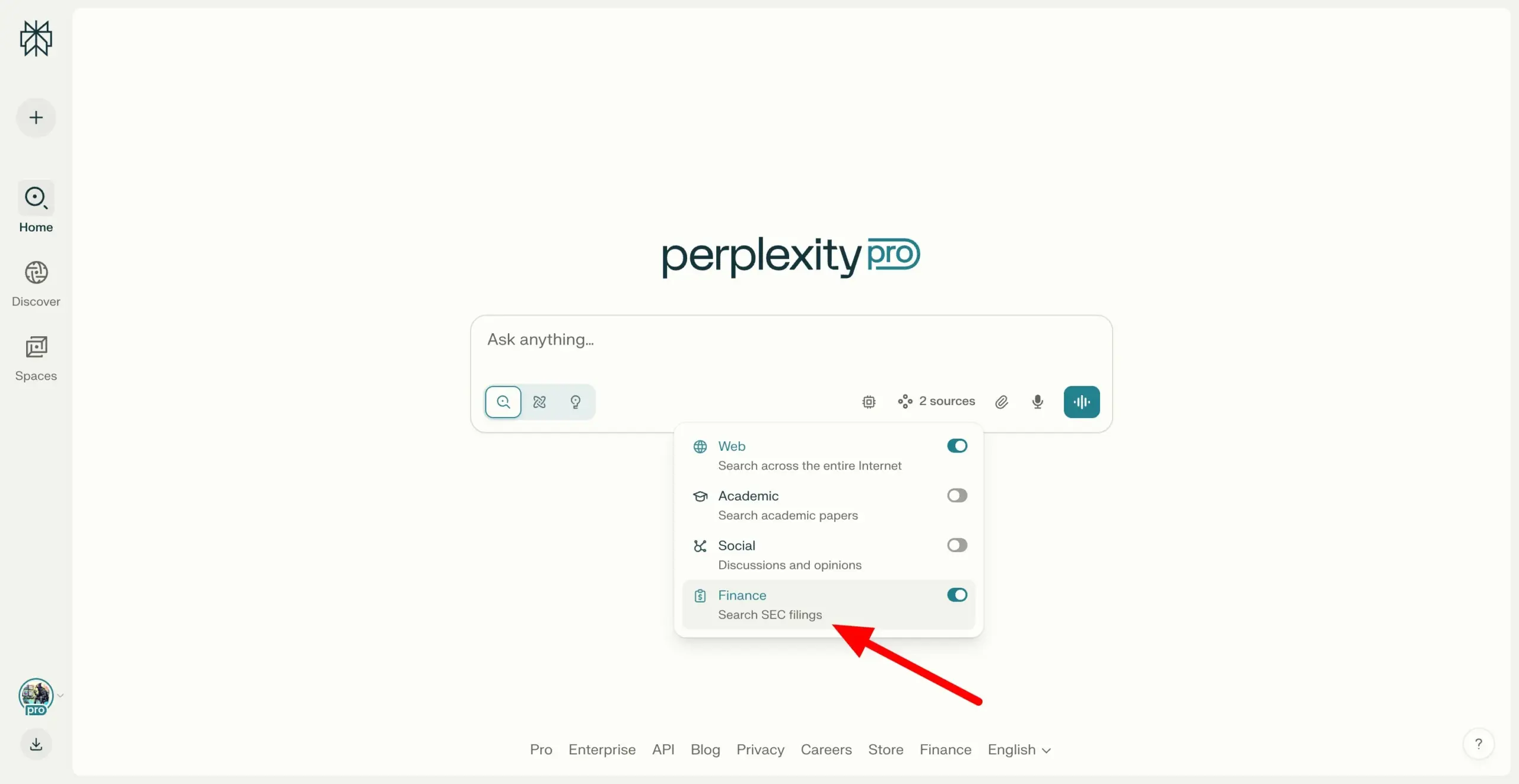
Perplexity Labs、SEC EDGARファイル横断検索をサポートし、金融リサーチ能力を強化: Perplexity Labsは、ユーザーが米国証券取引委員会(SEC)のEDGARデータベース内の企業ファイルを検索できる新機能を追加しました。このアップデートは、金融リサーチ分野での応用をさらに強化し、ユーザーに上場企業のより便利な情報検索と分析手段を提供することを目的としています。(出典: AravSrinivas)
美団(Meituan)、AIノーコードツールNoCodeを公開、自然言語でアプリケーション構築可能: 美団は、AIノーコードツールNoCodeをリリースしました。ユーザーはプログラミング経験がなくても、自然言語での対話を通じて、個人の効率化ツール、製品プロトタイプ、インタラクティブなページ、さらには簡単なゲームを作成できます。NoCodeはリアルタイムプレビュー、部分修正、ワンクリックデプロイをサポートし、開発のハードルを下げ、より多くの人々が創造性を発揮できるようにすることを目指しています。このツールの背後には複数のAIモデルが連携しており、美団が自社開発した7Bパラメータのapply専用モデルも含まれ、美団内部の実際のコードデータに対して最適化されています。(出典: WeChat)
VAST、Tripo Studioをアップグレードし、スマートパーツ分割、魔法のブラシなどのAIモデリング機能を追加: 3D大規模モデルのスタートアップ企業VASTは、AIモデリングツールTripo Studioに重要なアップグレードを行い、スマートパーツ分割、テクスチャ魔法のブラシ、スマートローポリゴン生成、万物自動ボーン設定という4つの主要機能を導入しました。これらの機能は、従来の3Dモデリングプロセスにおける、パーツ編集の困難さ、テクスチャの欠陥修正の時間の浪費、ハイポリゴンモデルの最適化の煩雑さ、ボーン設定の複雑さといった問題点を解決し、3Dコンテンツ作成の効率と使いやすさを大幅に向上させ、非専門ユーザーの参入障壁を下げることを目指しています。(出典: 量子位)
Hugging Face、オープンソースのヒューマノイドロボットHopeJRとReachy Miniを手頃な価格で発表: Hugging FaceはThe Robot StudioおよびPollen Roboticsと協力し、2つのオープンソースヒューマノイドロボット、フルサイズのHopeJR(約3000ドル)とデスクトップ型のReachy Mini(約250~300ドル)を発表しました。この動きは、ロボット技術の普及とオープンな研究を推進し、誰もがロボットの原理を組み立て、修正し、学ぶことを可能にすることを目的としています。HopeJRは歩行と腕の移動能力を備え、手袋で遠隔操作できます。一方、Reachy Miniは頭部を動かし、話し、聞くことができ、AIアプリケーションのテストに使用されます。(出典: WeChat)

世界初のAIエージェント自己進化オープンソースフレームワークEvoAgentXが発表: 英国グラスゴー大学の研究チームは、世界初のAIエージェント自己進化オープンソースフレームワークであるEvoAgentXを発表しました。このフレームワークは、複数のAIエージェントシステムの構築と最適化の複雑さを解決することを目的とし、自己進化メカニズムを導入することで、ワンクリックでのワークフロー構築をサポートし、システムが実行中に環境と目標の変化に応じて構造と性能を継続的に最適化できるようにします。EvoAgentXは、マルチエージェントシステムを人手によるデバッグから自律進化へと移行させ、研究者やエンジニアに統一された実験・展開プラットフォームを提供することを目指しています。(出典: WeChat)

Perplexity Labs、企業財務データをCSV形式で無料エクスポートできる新機能を提供: Perplexity Labsは、ユーザーが同社の金融ページの任意の企業財務セクションからデータをCSV形式で無料でエクスポートできるようになったと発表しました。以前は、Yahoo Financeなどのプラットフォームでは同様の機能は通常、有料サブスクリプションが必要でした。Perplexityは、将来的にはさらに多くの履歴データを追加する予定であると述べています。(出典: AravSrinivas)
📚 学習
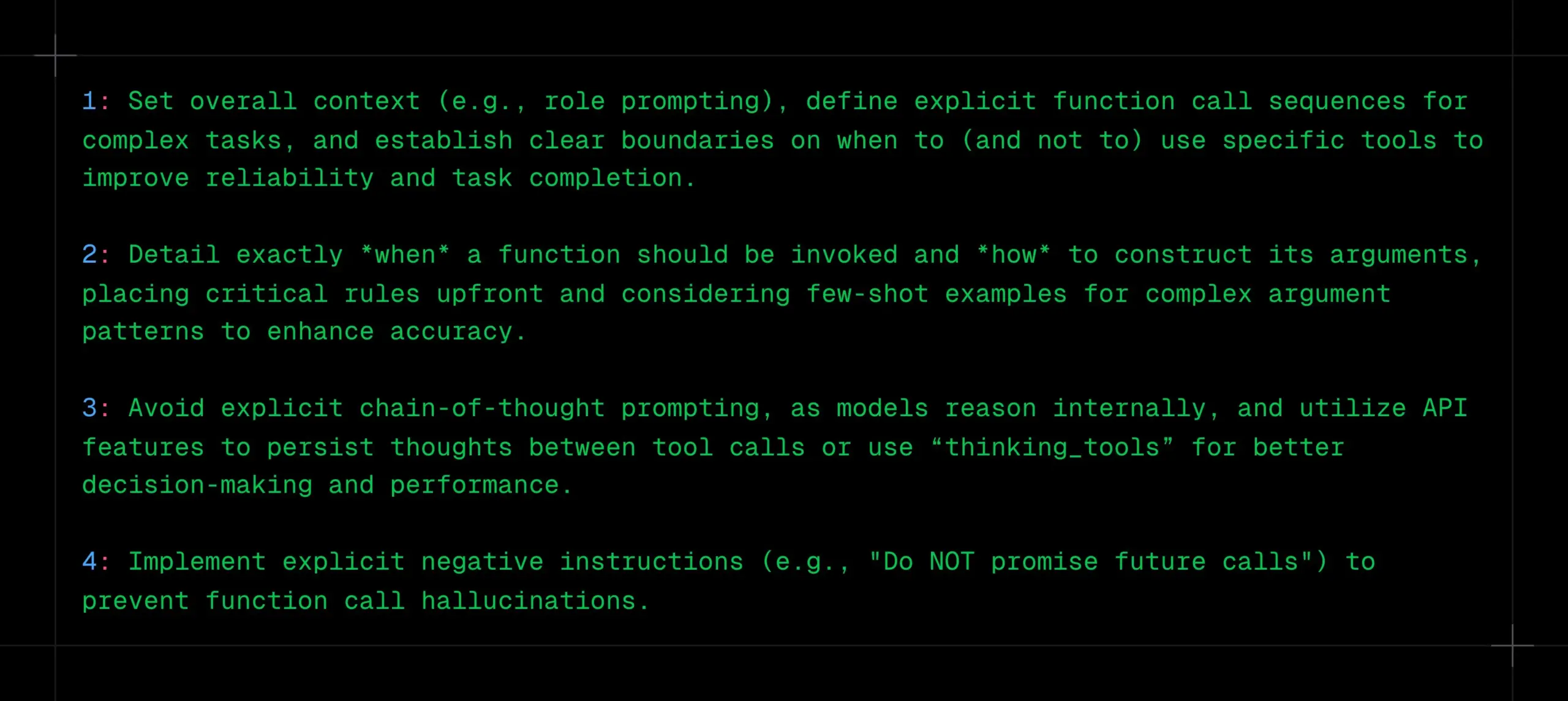
LLM関数呼び出しのヒント:明確なコンテキスト、シーケンス、境界を設定し、CoTとハルシネーションを回避: _philschmid氏は、Gemini 2.5やOpenAI o3などの推論モデルで関数呼び出しを行う際の推奨事項を共有しました。重要なポイントは、全体的なコンテキスト(役割プロンプトなど)を設定し、複雑なタスクに対して明確な関数呼び出しシーケンスを定義し、ツール使用の明確な境界(いつ使用するか/しないか)を設定することです。関数呼び出しのタイミングとパラメータの構築方法を詳細に説明する必要があります。モデルは内部で推論するため、明示的なCoTプロンプトは避け、API機能を利用してツール呼び出し間で思考を持続させるか、「thinking_tools」を使用します。同時に、関数呼び出しのハルシネーションを防ぐために、明確な否定的な指示(「将来の呼び出しを約束しないでください」など)を実施します。(出典: _philschmid)
プロフェッショナルAIプログラミングのヒント12選: Cline氏は、最近のエンジニアリングベストプラクティス会議でのAIプログラミングのヒント12選を共有し、計画、複雑なタスクへの高度なモデルの使用、コンテキストウィンドウへの注意、ルールファイルの作成、意図の明確化、AIを協力者と見なすこと、メモリバンクの活用、コンテキスト管理戦略の学習、チームの知識共有の構築を強調しました。中核となる目標は、ソフトウェアをより速くより良く構築し、AIを代替品ではなく能力増幅器として活用することです。(出典: cline, cline)

DeepSeek-R1-0528アップデート後の創作指示最適化提案: DeepSeek-R1-0528モデル(685億パラメータ、128Kコンテキスト、コード能力はo3に近い)のアップデートに関して、あるコンテンツ制作者が10個の最適化された創作指示を共有しました。提案には、30~60分の超長推論能力を利用した深い思考、128K長文テキストの処理、コード生成の最適化、システムプロンプトのカスタマイズ、執筆タスクの品質向上、反ハルシネーション検証、創造的な執筆のボトルネック突破、問題診断分析の実施、知識学習の統合、およびビジネスコピーの最適化が含まれます。指示の具体化、長文コンテキストの十分な活用、深い推論の活用、対話メモリの構築、重要情報の検証が強調されています。(出典: WeChat)
RM-R1フレームワーク:報酬モデルを推論タスクとして再構築し、解釈可能性と性能を向上: イリノイ大学アーバナ・シャンペーン校の研究チームは、報酬モデル(Reward Models)の構築を推論タスクとして再定義するRM-R1フレームワークを提案しました。このフレームワークは、「評価基準の連鎖」(Chain-of-Rubrics, CoR)メカニズムを導入することで、モデルが嗜好判断を下す前に構造化された評価基準と推論プロセスを生成できるようにし、それによって報酬モデルの解釈可能性と、複雑なタスク(数学、プログラミングなど)における評価の正確性を向上させます。RM-R1は、推論蒸留と強化学習の2段階の学習を通じて、複数の報酬モデルベンチマークテストで既存のオープンソースおよびクローズドソースモデルを上回る性能を示しました。(出典: WeChat)

モデルコンテキストプロトコル(MCP)詳細解説:AIと外部サービスの統合を簡素化: モデルコンテキストプロトコル(MCP)は、AIモデルと外部データソース、ツール(Slack、Gmailなど)との統合における断片化問題を解決することを目的としたオープンスタンダードです。統一されたシステムインターフェース(STDIOおよびSSEプロトコルをサポート)を通じて、MCPは開発者がMCPクライアント(Claudeデスクトップクライアント、Cursor IDEなど)とMCPサーバー(データベース、ファイルシステムの操作、API呼び出し)を構築することを可能にし、複雑な「M×N」アダプテーションネットワークを「M+N」モードに簡素化し、AIと外部サービスのプラグアンドプレイを実現します。枫清科技Fabartaのパートナーである谭宇氏は、MCPの価値は基本的な接続能力を提供することにあり、その商業化は背後にあるシステムが提供する具体的な価値、例えばFabartaスーパーオフィスインテリジェントエージェントを通じてMCP Serverを統合し、ユーザープロセスを簡素化することに依存すると考えています。(出典: WeChat)

Agentic ROI:大規模モデルエージェントの有用性を測る重要指標: 上海交通大学は中国科学技術大学と共同で、大規模モデルエージェントの実際の場面における実用性を測る核心的指標としてAgentic ROI(エージェント投資収益率)を提案しました。この指標は、情報品質、ユーザーとエージェントの時間コスト、および経済的支出を総合的に考慮します。研究によると、現在のエージェントは科学研究やプログラミングなど人的コストの高い分野での応用が多いものの、Eコマースや検索などの日常的な場面では、限界価値が明確でなく、インタラクションコストが高いなどの理由でAgentic ROIが低いと指摘されています。Agentic ROIを最適化するには、「まず情報品質を大規模に向上させ、次にコストを軽量化する」という「ジグザグ」の発展経路をたどる必要があります。(出典: WeChat)
💼 ビジネス
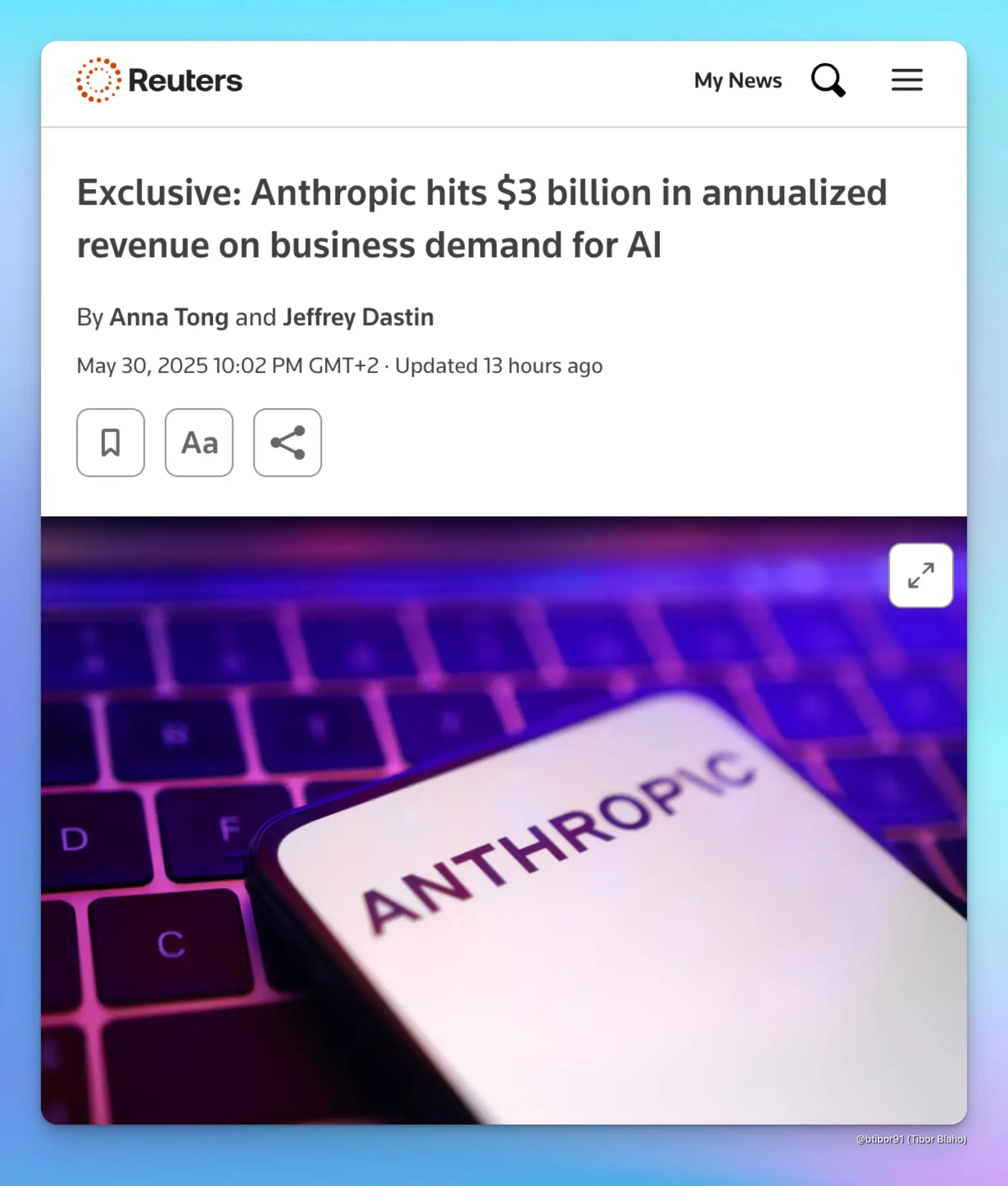
Anthropic、年間収益30億ドルに急増、企業向けAI需要が牽引: 2人の情報筋によると、Anthropicの年間収益はわずか5ヶ月で10億ドルから30億ドルに増加しました。この著しい成長は主に、特にコード生成分野における企業からのAIへの強い需要によるものです。これは、企業向け市場における高度なAIモデル(AnthropicのClaudeシリーズなど)の応用と支払い意欲が急速に高まっていることを示しています。(出典: cto_junior, scaling01, Reddit r/ArtificialInteligence)
NVIDIA、2026年度第1四半期決算:総収益441億ドル、データセンター事業が約9割を占める: NVIDIAは、2025年4月27日を期末とする2026年度第1四半期の決算を発表しました。総収益は441億ドルで、前四半期比12%増、前年同期比69%増となりました。データセンター事業の収益は391億ドルで、全体の88.91%を占め、前年同期比73%増でした。ゲーム事業の収益は38億ドルで、過去最高を記録しました。H20チップが輸出規制の影響を受け、45億ドルの在庫評価損および購入義務費用が発生し、第2四半期にはこれにより80億ドルの収益損失が見込まれるものの、全体的な業績は依然として好調です。Blackwell Ultraなどの新製品がさらなる成長を促進すると期待されています。(出典: 量子位, WeChat)

Meta、AIチームを再編、元Llamaコア開発者の多くが退職、FAIRの地位に注目集まる: MetaはAIチームの再編を発表し、Connor Hayes氏率いるAI製品チームと、Ahmad Al-Dahle氏およびAmir Frenkel氏が共同で率いるAGI基盤部門に分割しました。基礎人工知能研究部門FAIRは比較的独立性を保ちつつも、一部のマルチメディアチームは統合されました。今回の調整は、自律性と開発速度の向上を目的としています。しかし、Llamaモデルの元コア開発者14名のうち、留任したのはわずか3名で、多くは退職または競合他社(Mistral AIなど)に移籍しています。加えて、Llama 4発表後の反響が芳しくなく、内部での計算能力配分や研究開発方針の調整もあり、MetaがオープンソースAI分野でのトップの地位を維持できるか、またFAIRの将来の発展について懸念が広がっています。(出典: WeChat)

🌟 コミュニティ
AIアライメント議論:ソフトな規範はAGI時代に人間の権力を維持できるか?: Ryan Greenblatt氏は、Dwarkesh Patel氏が提起した見解について議論しています。Patel氏はAIアライメントに懐疑的であり、AGI(汎用人工知能)がハードパワーを掌握した後も、ソフトな規範を通じて人間に一部の権力と生存空間を確保することを望んでいます。Greenblatt氏は、AIがスコープセンシティブ(scope sensitive)であり、権力奪取能力を持つ場合、取引や契約を通じてその不整合を明らかにしたり、人間のために働かせようとしたりすることは成功しそうにないと考えています。さらに、安価なファインチューニング、人間によるアライメント改善、自由な複製などの要因により、アライメント問題が解決される前に、人間の財産に対するコントロールは非常に不安定になります。アライメントされたAIやより安価なAI労働力が登場すると、人間はそれらを優先的に使用するようになり、これはアライメントされていないAIが権力を奪取する強い動機付けとなるでしょう。(出典: RyanPGreenblatt, RyanPGreenblatt, RyanPGreenblatt, RyanPGreenblatt, JeffLadish)

Redisの父、AIプログラミングは人間のプログラマーに遠く及ばないと発言、開発者の共感と議論を呼ぶ: Redisの作成者であるSalvatore Sanfilippo氏 (Antirez) は自身の開発経験を共有し、現在のAIはプログラミングにおいて実用性はあるものの、人間のプログラマーには遠く及ばず、特に既成概念を打ち破り、奇抜で効果的な解決策を考案する点において劣ると述べました。彼はAIを「十分に賢いアシスタント」に例え、アイデアの検証に役立つとしています。この見解は開発者の間で議論を呼び、多くの人がAIを思考を助ける「ラバーダック」として利用できることに同意する一方で、AIは自信過剰で初級開発者を誤解させやすいと指摘しています。ある開発者は、AIが生成した誤った答えが逆に手動でコーディングする意欲を刺激したと述べています。議論では、AIを効果的に利用する上での経験の重要性や、AIがプログラミング初学者に与える可能性のある負の影響が強調されました。(出典: WeChat)

DeepMindとGoogle Researchの関係が再び議論の的に:ブランドと実際のイノベーション貢献の弁: Faruk Guney氏がX(旧Twitter)でDeepMindとGoogle Researchの関係について長文でコメントし、現在のAI革命の中核となるブレークスルー(Transformerアーキテクチャなど)は主にGoogle Researchからもたらされたものであり、Googleに買収された後のDeepMindからではないと主張しました。彼は、AlphaFoldはDeepMindの成果であるものの、Googleの計算資源と研究インフラなしにはあり得ず、また中核的な貢献者はJohn Jumper氏やPushmeet Kohli氏などの科学者・エンジニアであると指摘しました。Guney氏は、Google Researchが後にDeepMindに統合されたのは、ブランドと組織構造の調整が主であり、その背後には複雑な企業政治が関わっており、イノベーションの真の源泉を覆い隠している可能性があると考えています。彼は、多くのAIブレークスルーはチームの長年の研究の成果であり、少数の著名な人物やブランドだけに帰功するものではないと強調しました。(出典: farguney, farguney)
AI時代の職務とスキルの変化が懸念と議論を呼ぶ: ソーシャルメディア上では、AIが雇用市場に与える影響についての議論が続いています。一方では、AIが大規模な失業を引き起こすという見方があり、Anthropic CEOもかつてそのような懸念を表明し、人々に対応策を考えるよう促しました。他方では、AIは主に生産性を向上させるものであり、深刻な経済不況が起こらない限り大規模な失業を引き起こす可能性は低いという声もあります。なぜなら、消費需要は雇用と収入に依存しているからです。同時に、AIによって失業した個人の経験(例:上司がChatGPTで従業員を代替した)を共有するユーザーもいます。将来については、貯蓄、実用的なスキルの学習、収入減少の可能性への適応、そして批判的思考やAIツールを効果的に利用する能力など、AI時代に必要なスキルを育成するために教育システムがどのように調整すべきかという点に議論が向かっています。(出典: Reddit r/ArtificialInteligence, Reddit r/artificial)

ChatGPTへの過度な依存が思考力低下の懸念を引き起こす: あるRedditユーザーが、ガールフレンドが意思決定、意見、アイデアの入手をChatGPTに過度に依存していることへの懸念を投稿し、これが彼女の独立した思考力と独創性を失わせる可能性があると主張しました。この投稿は広範な議論を呼び、一部のコメント投稿者はこの懸念に同意し、AIツールへの過度な依存は確かに個人の思考力を弱める可能性があると述べました。他のコメントでは、AIは単なるツールであり、過去の百科事典や検索エンジンと同様で、重要なのはユーザーがそれをどのように利用するかであり、思考の出発点として使うか、完全に代替するかであると述べました。また、コミュニケーション、誘導、AIの限界を示すことで対処することを提案するコメントもありました。(出典: Reddit r/ChatGPT)
教育分野におけるAIの課題:教授が学生のChatGPT乱用に苦悩、真の思考力育成を訴える: ある古代史の教授がRedditに投稿し、ChatGPTの乱用が自身の教育に深刻な影響を与えており、学生が提出する論文はAIによって生成され、事実誤認さえ含む「空虚なゴミ」で満ちていると述べ、これが学生が本当に学習しているのかという疑問を抱かせていると訴えました。彼は、人文教育の中核は新しい知識、創造的な洞察、独立した思考を育成することであり、単に既存の情報を復唱することではないと強調しました。この投稿は議論を呼び、コメント投稿者は口頭発表への変更、授業中の手書き論文、学生にAI使用プロセスのメタ分析を提出させる、あるいはAIを教育に取り入れ、学生にAIの出力を批判させるなど、様々な対応策を提案しました。(出典: Reddit r/ChatGPT)
AI生成カーネルが予期せずPyTorch専門家カーネルを凌駕、スタンフォード大学華人チームが新たな可能性を提示: スタンフォード大学のAnne Ouyang氏、Azalia Mirhoseini氏、Percy Liang氏のチームは、カーネル生成モデルを訓練するための合成データ生成を試みていた際、純粋なCUDA-Cで記述されたAI生成カーネルが、性能においてPyTorchに組み込まれた専門家によって最適化されたFP32カーネルに匹敵するか、それを超えることを偶然発見しました。例えば、行列乗算ではPyTorchの性能の101.3%、2次元畳み込みでは179.9%に達しました。チームは、自然言語推論による最適化の考え方と分岐拡張探索戦略を組み合わせ、複数回の反復最適化を採用し、OpenAI o3およびGemini 2.5 Proモデルを利用しました。この成果は、巧妙な探索と並列探索を通じて、AIが高性能計算カーネル生成においてブレークスルーを達成する可能性を示しています。(出典: WeChat)

💡 その他
AI業界のロビー活動力は強大、Max Tegmark氏が注目: MIT教授のMax Tegmark氏は、AI業界のワシントンとブリュッセルにおけるロビイストの数が、化石燃料業界とタバコ業界の合計を超えていると指摘しました。この現象は、AI産業が政策決定においてますます影響力を増していること、そして規制環境の形成に積極的に関与していることを明らかにしており、AI技術の発展方向、倫理規範、市場競争の構図に深遠な影響を与える可能性があります。(出典: Reddit r/artificial)

AIがディープフェイクを通じて生物テロ攻撃を模倣する可能性、新たな公衆衛生上の脅威を構成: STAT Newsの記事は、AI支援による生物工学兵器のリスクに加えて、ディープフェイク技術を利用して生物テロ攻撃を模倣することも深刻な脅威をもたらす可能性があると指摘しています。特に軍事紛争中の国家間では、このような偽造情報がパニック、誤判断、不必要な軍事エスカレーションを引き起こす可能性があります。調査が公衆衛生や技術チームではなく、法執行機関や軍事機関によって主導される可能性があるため、彼らは攻撃の信憑性を信じる傾向が強く、効果的に偽情報を否定することが困難になる可能性があります。(出典: Reddit r/ArtificialInteligence)
AI時代に工学の学位を取得すべきか否か、議論白熱: コミュニティでは、AI時代に工学の学位を取得する価値について議論されています。一方では、AIが多くの従来の工学タスクを代替する可能性があり、学位の価値が低下すると考えられています。他方では、工学の学位が育成するシステム思考、問題解決能力、数学物理の基礎は依然として重要であり、特にAIツールの理解と応用において重要であると考えられています。一部の意見では、AIがエンジニアを代替できるのであれば、他の職業も免れないとし、重要なのは継続的な学習と適応であると指摘されています。獣医など、実践的で自動化が困難な分野は、比較的安全な選択肢と見なされています。(出典: Reddit r/ArtificialInteligence)