
キーワード:DeepSeek-R1-0528, AIエージェント, マルチモーダルモデル, オープンソースAI, 強化学習, 画像編集, 大規模言語モデル, AIベンチマークテスト, DeepSeek-R1-0528-Qwen3-8B, Circuit Tracerツール, Darwin Gödel Machine, FLUX.1 Kontext, Agentic Retrieval
🔥 フォーカス
DeepSeek、R1-0528モデルをリリース、性能はGPT-4oおよびGemini 2.5 Proに迫り、オープンソースランキングで首位に: DeepSeek-R1-0528は、数学、プログラミング、汎用論理推論など複数のベンチマークテストで優れた性能を発揮し、特にAIME 2025テストでは正解率が70%から87.5%に向上しました。新バージョンでは、ハルシネーション率が大幅に低減(約45~50%)され、フロントエンドコード生成能力が強化され、JSON出力と関数呼び出しがサポートされています。同時に、DeepSeekはQwen3-8B BaseをベースにファインチューニングしたDeepSeek-R1-0528-Qwen3-8Bをリリースし、AIME 2024での性能はR1-0528に次ぐもので、Qwen3-235Bを上回りました。今回のアップデートは、DeepSeekの世界第2位のAIラボおよびオープンソースのリーダーとしての地位を確固たるものにしました。(ソース: ClementDelangue, dotey, huggingface, NandoDF, andrew_n_carr, Francis_YAO_, scaling01, karminski3, teortaxesTex, tokenbender, dotey)
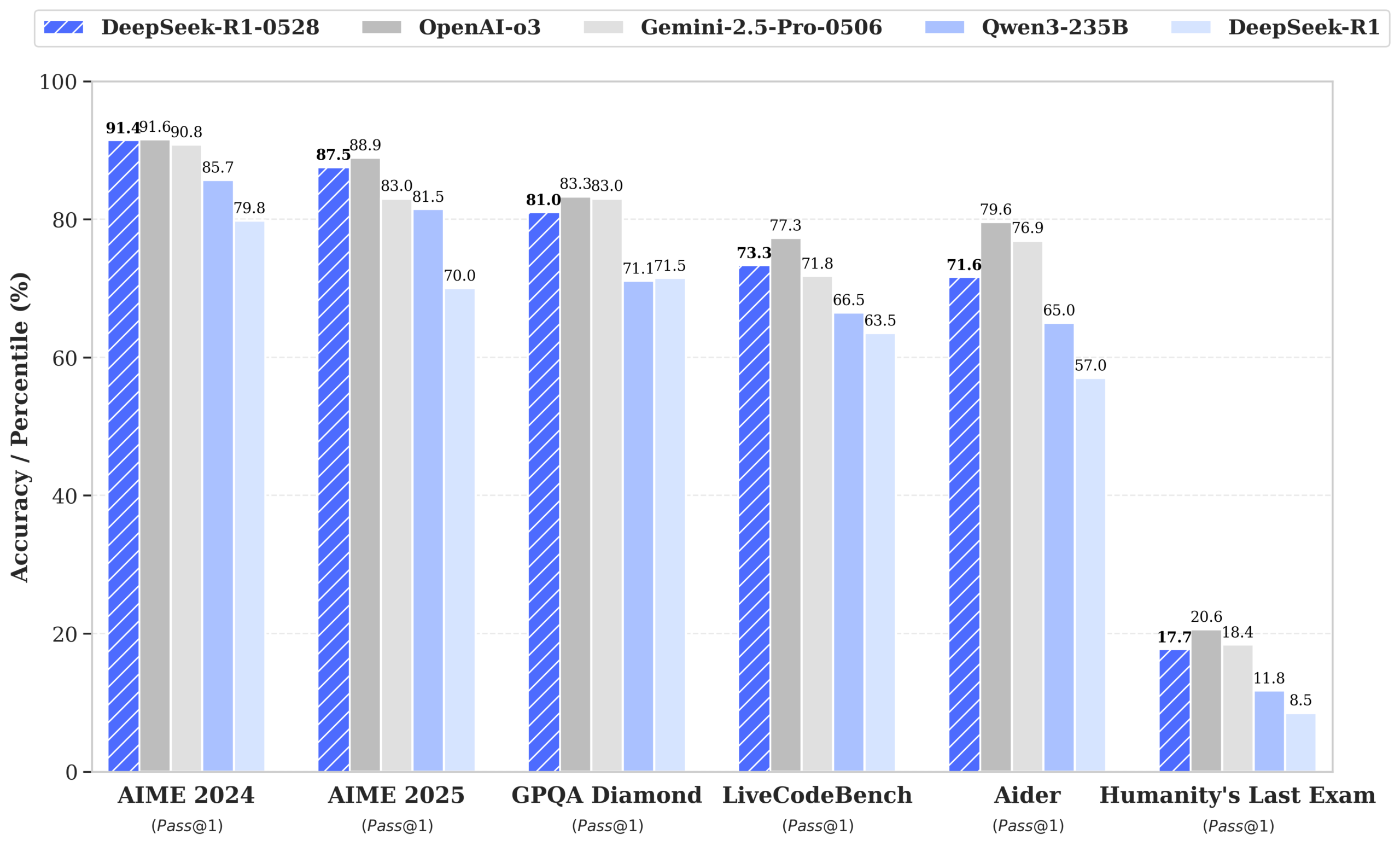
Anthropic、大規模モデルの「思考追跡」ツールCircuit Tracerをオープンソース化: Anthropic社は、大規模モデルの解釈可能性研究ツールCircuit Tracerをオープンソース化しました。これにより、研究者は「アトリビューションマップ」を生成し、インタラクティブに探索することで、大規模言語モデル(LLM)の内部の「思考」プロセスと意思決定メカニズムを理解することができます。このツールは、モデルが特定の特性をどのように利用して次のトークンを予測するかなど、LLMの内部動作をより深く探求することを目的としています。ユーザーはNeuronpediaでこのツールを試すことができ、文を入力するだけでモデルの特性使用状況の回路図を取得できます。(ソース: scaling01, mlpowered, rishdotblog, menhguin, NeelNanda5, akbirkhan, riemannzeta, andersonbcdefg, algo_diver, Reddit r/ClaudeAI)
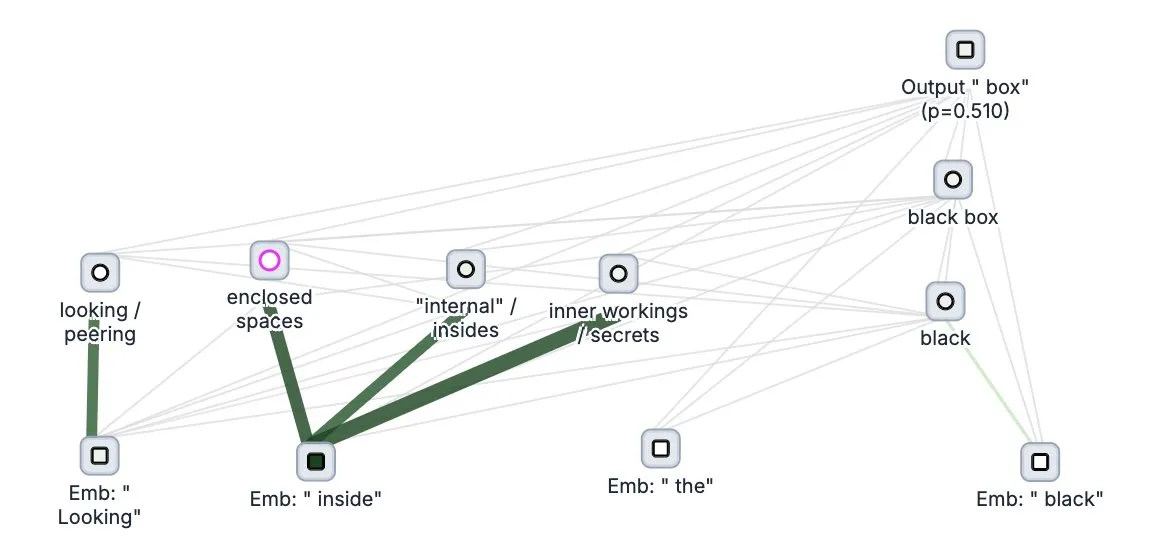
Sakana AI、自己進化型エージェントフレームワークDarwin Gödel Machine (DGM)を発表: Sakana AIは、自身のコードを書き換えることで自己改善を行うAIエージェントフレームワークDarwin Gödel Machine (DGM)を発表しました。DGMは進化論に着想を得ており、自己改善型エージェントの設計空間をオープンエンドに探索するために、絶えず拡張されるエージェントのバリアント系統を維持します。このフレームワークは、AIシステムが人間のように時間とともに自身の能力を学習し進化させることを目指しています。SWE-benchでは、DGMは性能を20.0%から50.0%に向上させ、Polyglotでは成功率を14.2%から30.7%に向上させました。(ソース: SakanaAILabs, teortaxesTex, Reddit r/MachineLearning)
Black Forest Labs、テキストと画像の混合入力をサポートする画像編集モデルFLUX.1 Kontextを発表: Black Forest Labsは、新世代の画像編集モデルFLUX.1 Kontextを発表しました。フローマッチングアーキテクチャを採用し、テキストと画像を同時に入力として受け付け、コンテキスト認識型の画像生成と編集を実現します。このモデルは、キャラクターの一貫性、局所編集、スタイル参照、インタラクション速度において優れた性能を発揮し、例えば1024×1024解像度の画像生成はわずか3~5秒で完了します。Replicateのテストによると、その編集効果はGPT-4o-Imageを上回り、コストも低くなっています。KontextはPro版とMax版を提供し、オープンソースのDev版も計画しています。(ソース: TomLikesRobots, two_dukes, cloneofsimo, robrombach, bfirsh, timudk, scaling01, KREA AI)

🎯 動向
Google DeepMind、マルチモーダル医療モデルMedGemmaを発表: Google DeepMindは、マルチモーダルな医療テキストと画像理解のために設計された強力なオープンモデルMedGemmaを発表しました。このモデルはHealth AI Developer Foundationsの一部として提供され、特にテキストとX線写真などの医療画像を組み合わせて総合的な分析を行うなど、医療分野におけるAIの応用能力向上を目指しています。(ソース: GoogleDeepMind)
Perplexity AI、複雑なタスク処理を強化するPerplexity Labsをローンチ: Perplexity AIは、より複雑なタスク処理のために設計された新機能Perplexity Labsを発表しました。これはユーザーに研究チーム全体のような分析および構築能力を提供することを目指しています。ユーザーはLabsを通じて分析レポート、プレゼンテーション資料、動的ダッシュボードなどを構築できます。この機能は現在、すべてのProユーザーに公開されており、科学研究、市場分析、ミニアプリケーション(ゲーム、ダッシュボードなど)作成における可能性を示しています。(ソース: AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas)
Tencent HunyuanとTencent Music、HunyuanVideo-Avatarを共同発表、写真からリアルな歌唱ビデオを生成: Tencent HunyuanとTencent Musicは、HunyuanVideo-Avatarモデルを共同で発表しました。このモデルは、ユーザーがアップロードした写真と音声を組み合わせ、シーンのコンテキストと感情を自動検出し、リアルな口パク同期とダイナミックな視覚効果を持つ会話または歌唱ビデオを生成します。この技術は多様なスタイルをサポートし、オープンソース化されています。(ソース: huggingface, thursdai_pod)
Apache Spark 4.0.0 が正式リリース、SQL、Spark Connect、多言語サポートを強化: Apache Spark 4.0.0 バージョンが正式にリリースされ、SQL機能の大幅な強化、アプリケーション実行をより便利にするSpark Connectの改善、新しい言語のサポートが追加されました。今回の更新では、5100以上の問題が解決され、390人以上の貢献者が参加しました。(ソース: matei_zaharia, lateinteraction)

Kling 2.1ビデオモデルがリリース、OpenArtとの統合でキャラクターの一貫性をサポート: Kling AIは、ビデオモデルKling 2.1をリリースし、OpenArtと協力して、AIビデオストーリーテリングにおけるキャラクターの一貫性を実現しました。Kling 2.1は、プロンプトのアライメント、ビデオ生成速度、カメラワークの明瞭度を向上させ、最高のテキストからビデオへの効果を謳っています。新バージョンは720p(標準)と1080p(プロ)出力をサポートし、現在、画像からビデオへの機能がオンラインで、テキストからビデオへの機能は間もなく提供予定です。(ソース: Kling_ai, NandoDF)
Hume、EVI 3音声モデルを発表、あらゆる人間の声を理解し生成可能: Humeは、最新の音声言語モデルEVI 3を発表しました。これは汎用音声知能の実現を目指しています。EVI 3は、少数の特定の話し手だけでなく、あらゆる人間の声を理解し生成することができ、より広範な表現能力と、イントネーション、リズム、音色、話し方に対するより深い理解を提供します。この技術は、誰もが声で認識される、ユニークで信頼できるAIを持つことを目指しています。(ソース: AlanCowen, AlanCowen, _akhaliq)
Alibaba、自律的情報探索エージェントを探求するWebDancerを発表: Alibabaは、自律的に情報探索を行うAIエージェントの研究開発を目指すWebDancerプロジェクトを発表しました。このプロジェクトは、AIエージェントがウェブ環境をより効果的にナビゲートし、情報を理解し、複雑な情報取得タスクを完了できるようにすることに焦点を当てています。(ソース: _akhaliq)
MiniMax、V-TriuneフレームワークおよびOrstaモデルをオープンソース化、視覚RL推論と知覚タスクを統合: AI企業MiniMaxは、視覚強化学習統一フレームワークV-Triuneおよびこのフレームワークに基づくOrstaモデルシリーズ(7Bから32B)をオープンソース化しました。このフレームワークは、3層コンポーネント設計と動的IoU(Intersection over Union)報酬メカニズムを通じて、VLMが単一の事後学習プロセスで視覚推論と知覚タスクを共同学習することを初めて可能にし、MEGA-Bench Coreベンチマークテストで性能を大幅に向上させました。(ソース: 量子位)

上海AIラボなどが画像編集の新ベンチマークRISEBenchを発表、モデルの深層推論を試す: 上海人工知能実験室は複数の大学と共同で、RISEBenchと名付けられた新しい画像編集評価ベンチマークを発表しました。これには、人間エキスパートが設計した360の難易度の高いケースが含まれ、時間、因果、空間、論理の4つの核心的な推論タイプをカバーしています。テスト結果によると、GPT-4o-Imageでさえタスクの28.9%しか完了できず、現在のマルチモーダルモデルの複雑な指示理解と視覚編集における不備が露呈しました。(ソース: 36氪)

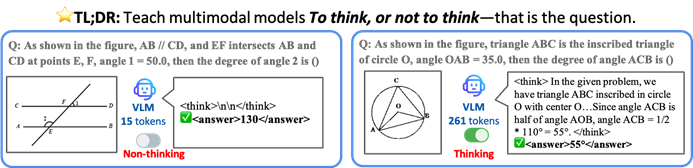
香港中文大学などがTONフレームワークを提案、AIモデルが選択的に思考することで効率と精度を向上: 香港中文大学とシンガポール国立大学Show Labの研究者は、視覚言語モデル(VLM)が明示的な推論が必要かどうかを自律的に判断できるTON(Think Or Not)フレームワークを提案しました。このフレームワークは、「思考の破棄」と強化学習を通じて、モデルが単純な問題には直接回答し、複雑な問題には詳細な推論を行うようにします。これにより、精度を犠牲にすることなく、平均推論出力長を最大90%削減し、一部のタスクでは精度が17%向上しました。(ソース: 36氪)
Microsoft CopilotがInstacartと統合、AI支援による生鮮食品ショッピングを実現: Microsoft AI責任者のMustafa Suleyman氏は、CopilotがInstacartサービスと統合され、ユーザーがCopilotアプリを通じてレシピ生成、買い物リスト作成から生鮮食料品の宅配までシームレスに完了できるようになったと発表しました。これは、AIアシスタントが日常生活サービス分野でさらに拡大することを示しています。(ソース: mustafasuleyman)
🧰 ツール
LlamaIndex、BundesGPTソースコードおよびcreate-llamaツールを公開、AIアプリケーション構築を簡素化: LlamaIndexのJerry Liu氏は、BundesGPTのソースコードを提供し、オープンソースツールcreate-llamaを推進すると発表しました。このツールはLlamaIndexに基づいており、開発者が企業データとAIエージェントを簡単に構築・統合できるよう支援することを目的としています。新しいeject-modeにより、BundesGPTのような完全にカスタマイズ可能なAIインターフェースの作成が非常に簡単になります。これは、ドイツがすべての国民に無料のChatGPT Plusサブスクリプションを提供する潜在的な計画を支援することを目的としています。(ソース: jerryjliu0)
LangChainツールをMCPツールに変換し、FastMCPサーバーに統合可能に: LangChainユーザーは、LangChainツールをMCP(Model Component Protocol)ツールに変換し、FastMCPサーバーに直接追加できるようになりました。langchain-mcp-adaptersライブラリをインストールすることで、開発者はMCPエコシステムでLangChainのツールセットをより便利に使用でき、異なるAIフレームワーク間の相互運用性が促進されます。(ソース: LangChainAI, hwchase17)
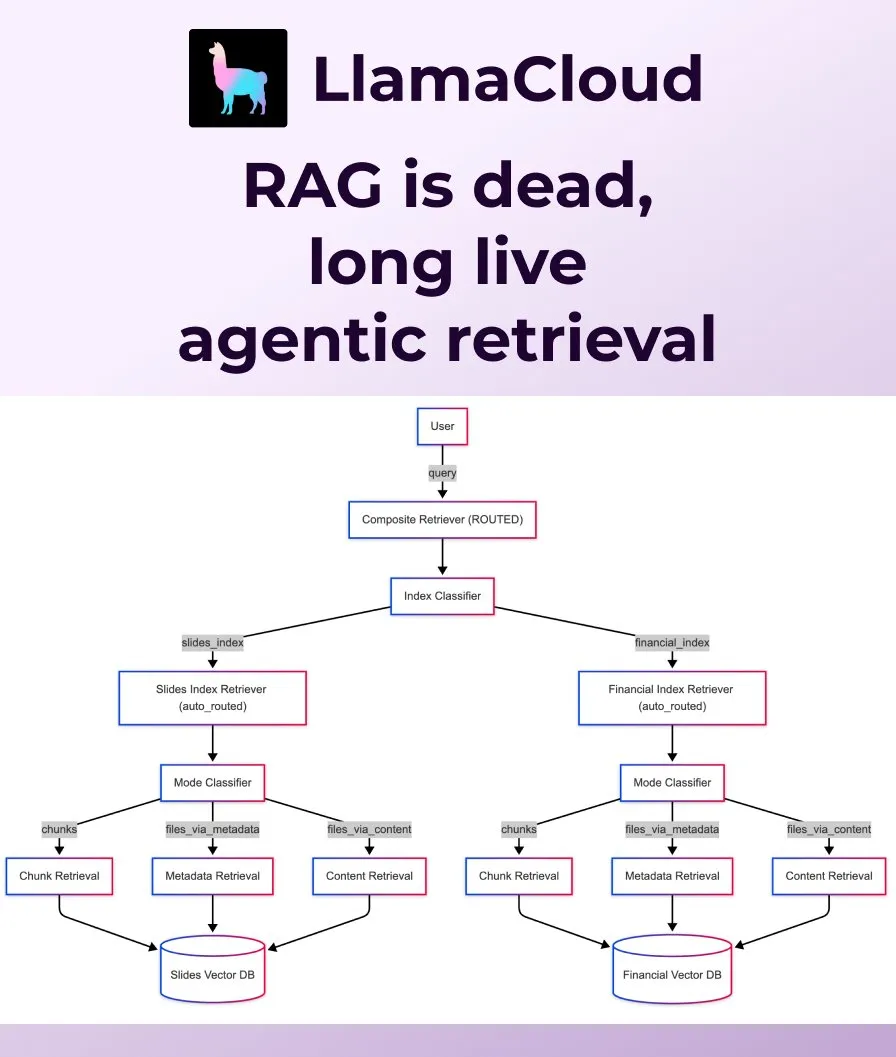
LlamaIndex、従来のRAGに代わるAgentic Retrievalを発表: LlamaIndexは、従来の単純なRAG(検索拡張生成)では現代のアプリケーションのニーズを満たすには不十分であると考え、Agentic Retrievalを発表しました。このソリューションはLlamaCloudに組み込まれており、エージェントが問題の内容に応じて単一または複数の知識ベース(Sharepoint、Box、GDrive、S3など)からファイル全体または特定のデータブロックを動的に検索し、よりスマートで柔軟なコンテキスト取得を実現します。(ソース: jerryjliu0, jerryjliu0)
Ollama、非構造化データ変換用Osmosis-Structure-0.6Bモデルの実行をサポート: ユーザーはOllamaを通じてOsmosis-Structure-0.6Bモデルを実行できるようになりました。これは非常に小さなモデルで、あらゆる非構造化データを指定された形式(例:JSON Schema)に変換でき、どのモデルとも連携して使用できます。特に構造化出力が必要な推論タスクに適しています。(ソース: ollama)
CrewAI、Geminiドキュメントを更新し、入門プロセスを簡素化: CrewAIチームは、Google Gemini APIに関するドキュメントを更新し、ユーザーがGeminiモデルを使用してAIエージェントをより簡単に構築開始できるよう支援することを目指しています。新しいドキュメントには、より明確なガイダンス、サンプルコード、またはベストプラクティスが含まれている可能性があります。(ソース: _philschmid)
Requesty、OpenWebUIに最適なLLMを自動選択するSmart Routing機能を発表: Requestyは、OpenWebUIとシームレスに統合し、ユーザープロンプトのタスクタイプに応じて最適なLLM(GPT-4o、Claude、Geminiなど)を自動選択するSmart Routing機能を発表しました。ユーザーはモデルIDとしてsmart/taskを使用するだけで、システムは約65ミリ秒でプロンプトを分類し、コスト、速度、品質に基づいて最適なモデルにルーティングします。この機能は、モデル選択を簡素化し、ユーザーエクスペリエンスを向上させることを目的としています。(ソース: Reddit r/OpenWebUI)
EvoAgentX:初のAIエージェント自己進化オープンソースフレームワークがリリース: 英国グラスゴー大学の研究チームは、世界初のAIエージェント自己進化オープンソースフレームワークであるEvoAgentXをリリースしました。これはワンクリックでワークフローを構築でき、「自己進化」メカニズムを導入することで、マルチエージェントシステムが環境と目標の変化に応じて構造と性能を継続的に最適化できるようにし、AIマルチエージェントシステムを「手動デバッグ」から「自律進化」へと移行させることを目指しています。実験では、マルチホップ質問応答、コード生成、数学的推論タスクにおいて、性能が平均8%~13%向上したことが示されています。(ソース: 36氪)

📚 学習
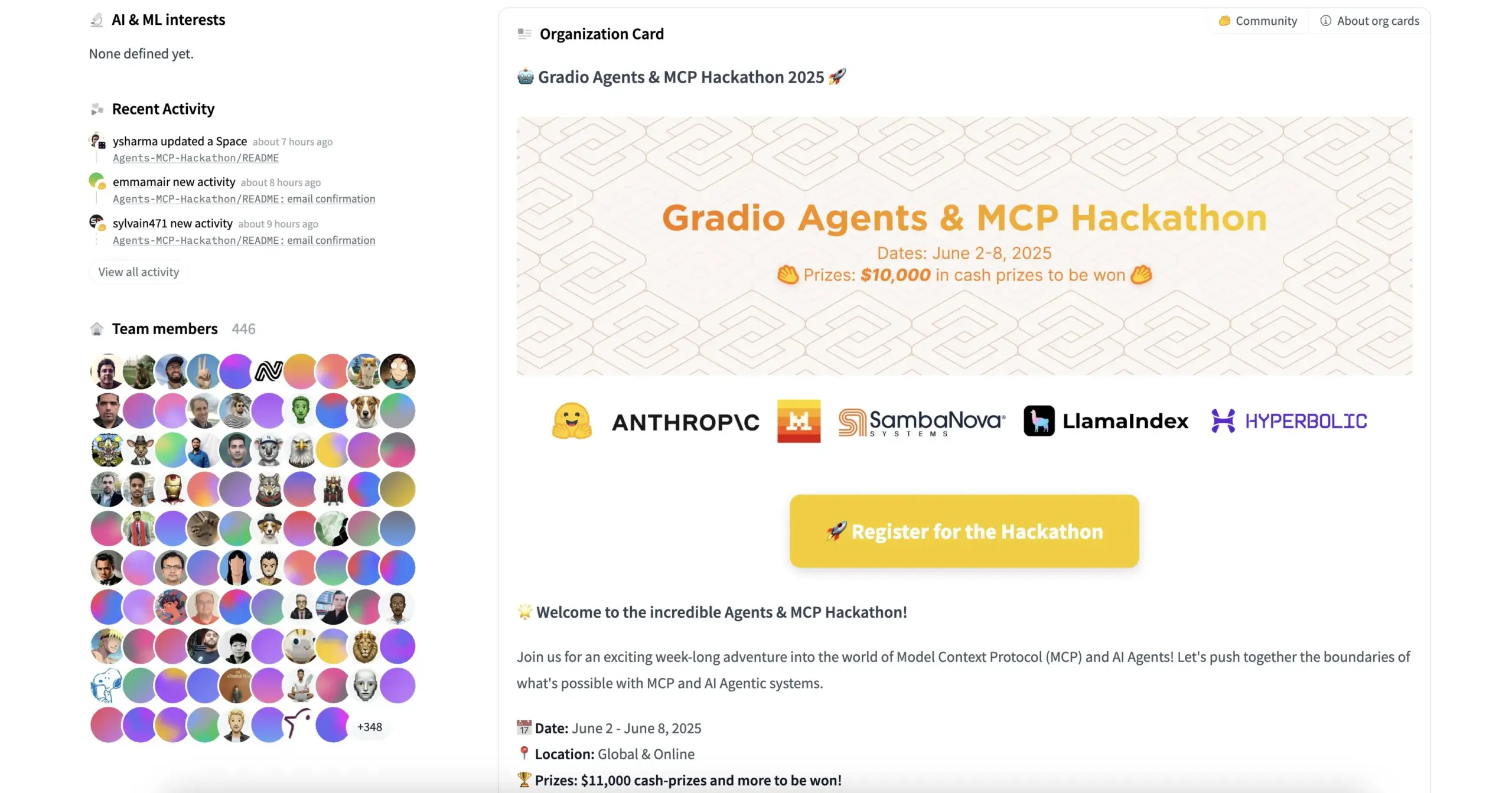
HuggingFaceとGradioなどが共同でAgents & MCP Hackathonを開催、豊富な賞金とAPIクレジットを提供: HuggingFace、Gradio、Anthropic、SambaNovaAI、MistralAI、LlamaIndexなどの機関が共同でGradio Agents & MCP Hackathon(6月2日~8日)を開催します。イベントでは総額11,000米ドルの賞金が提供され、早期登録者にはHyperbolic、Anthropic、Mistral、SambaNovaの無料APIクレジットが提供されます。Modal Labsはさらに、参加者全員に250米ドル相当のGPUクレジットを提供し、総額は30万米ドルを超えます。(ソース: huggingface, _akhaliq, ben_burtenshaw, charles_irl)
LangChain、JPモルガンがマルチエージェントシステムを投資調査に活用した事例を共有: JPモルガンのDavid Odomirok氏とZheng Xue氏は、「Ask David」という名のマルチエージェントAIシステムをどのように構築したかを共有しました。このシステムは、数千種類の金融商品の投資調査プロセスを自動化することを目的としており、複雑な金融分析におけるマルチエージェントアーキテクチャの応用可能性を示しています。(ソース: LangChainAI, hwchase17)
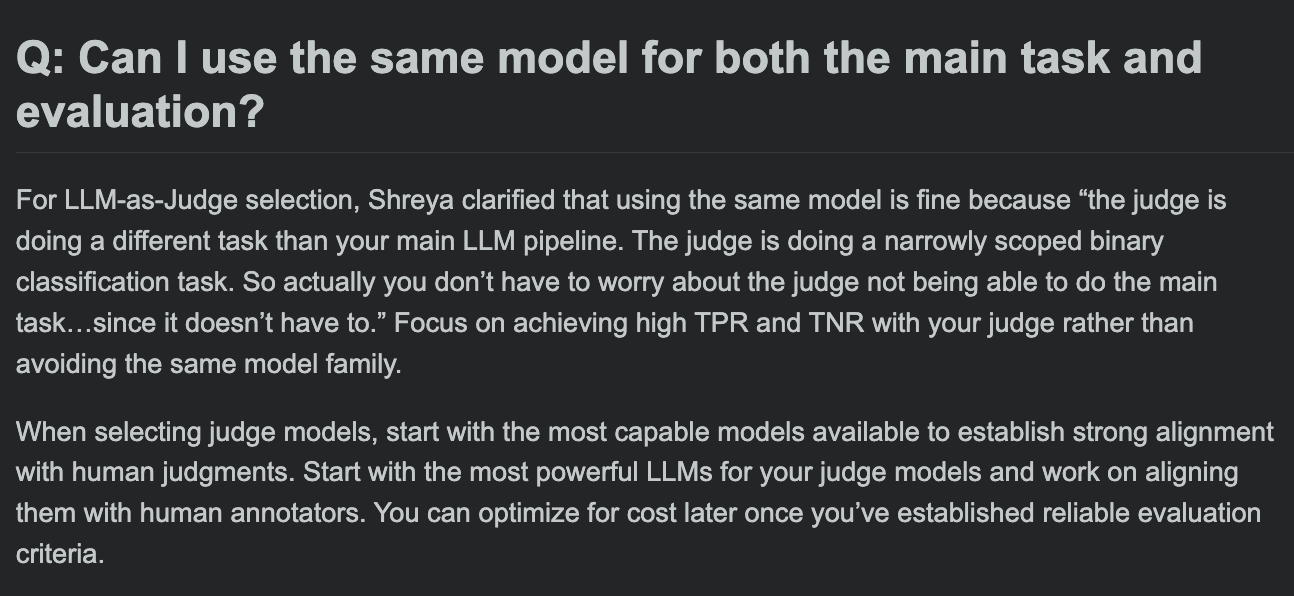
Hamel Husain氏、LLM評価コースFAQを共有、評価モデルと主要タスクモデルが同じでよいか議論: LLM評価コースの質疑応答セッションで、Hamel Husain氏は、主要タスク処理とタスク評価に同じモデルを使用できるかという一般的な問題について議論しました。この議論は、開発者がモデル評価における潜在的なバイアスとベストプラクティスを理解するのに役立ちます。(ソース: HamelHusain, HamelHusain)
The Rundown AI、パーソナライズされたAI教育プラットフォームをローンチ: The Rundown AIは、世界初のパーソナライズされたAI教育プラットフォームの開始を発表しました。これは、さまざまな業界、スキルレベル、日常業務フローに合わせたカスタマイズされたトレーニング、ユースケース、リアルタイムワークショップを提供します。プラットフォームのコンテンツには、16のテクノロジー分野に特化したAI認定コース、300以上の実世界のAIユースケース、専門家によるワークショップ、AIツールの割引などが含まれます。(ソース: TheRundownAI, rowancheung)
Common Crawl、2025年3月~5月のホストおよびドメインレベルのウェブグラフを公開: Common Crawlは、2025年3月、4月、5月を対象とした最新のホストおよびドメインレベルのウェブグラフデータを公開しました。これらのデータは、ウェブ構造の研究、言語モデルのトレーニング、大規模なウェブ分析を行う上で重要な価値があります。(ソース: CommonCrawl)
Bill Chambers氏、「20 Days of DSPyOSS」学習活動を開始: コミュニティがDSPyOSSの機能と使用方法をよりよく理解できるよう、Bill Chambers氏は20日間のDSPyOSS学習活動を開始しました。毎日、DSPyコードスニペットとその説明が公開され、ユーザーがこのフレームワークを初歩から習得するのを支援することを目的としています。(ソース: lateinteraction)
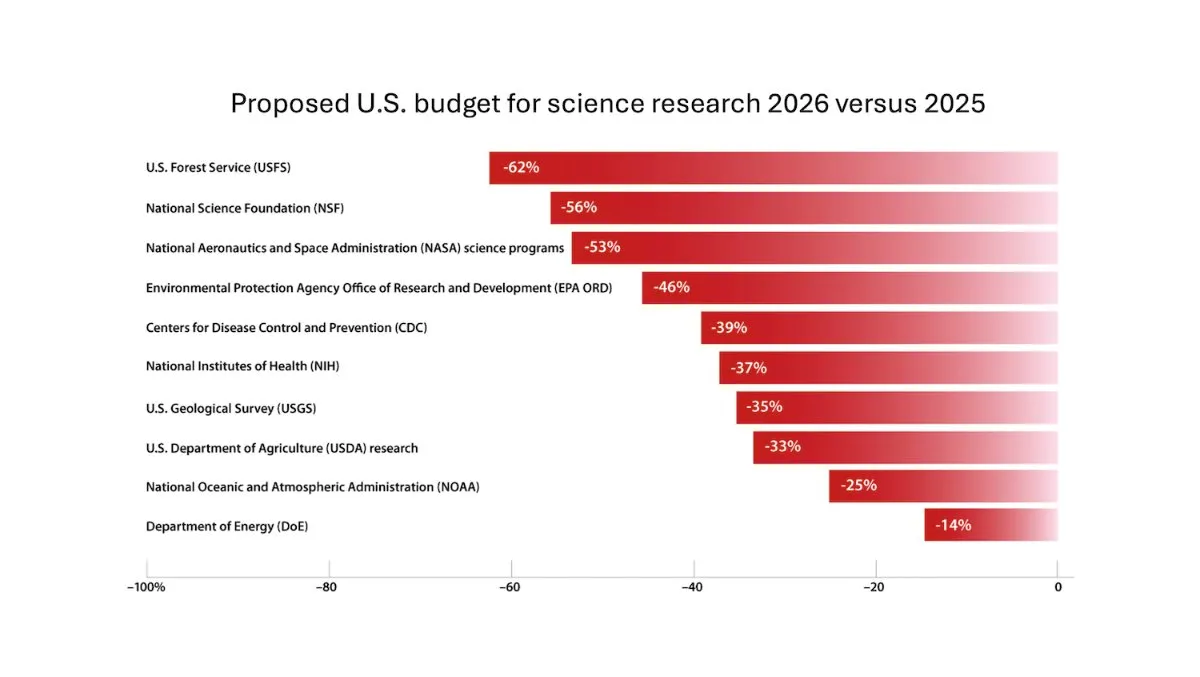
DeepLearning.AI、The Batch週報を発表、Andrew Ng氏が科学研究費削減のリスクを議論: 最新号のThe Batch週報で、Andrew Ng氏は科学研究費の削減が国家の競争力と安全保障に及ぼす潜在的なリスクについて議論しました。週報はまた、コーディングベンチマークにおけるClaude 4モデルの性能、Google I/OでのAI発表、DeepSeekの低コストトレーニング方法、GPT-4oが著作権保護された書籍を使用してトレーニングされた可能性などのホットな話題も取り上げています。(ソース: DeepLearningAI)
Google DeepMind、英国の大学生にGemini 2.5 ProとNotebookLMを無料で提供: Google DeepMindは、英国の大学生に対し、最先端モデル(Gemini 2.5 ProとNotebookLMを含む)への無料アクセスを15ヶ月間提供すると発表しました。この措置は、学生の研究、執筆、試験準備などの学習を支援し、2TBの無料ストレージスペースを提供することを目的としています。(ソース: demishassabis)
AI論文解説:Prot2Token、次世代トークン予測によるタンパク質モデリング統一フレームワーク: 論文「Prot2Token: A Unified Framework for Protein Modeling via Next-Token Prediction」は、タンパク質配列特性、残基特徴からタンパク質間相互作用まで、多様な予測タスクを標準的な次世代トークン予測形式に変換する統一タンパク質モデリングフレームワークProt2Tokenを紹介しています。このフレームワークは自己回帰デコーダを採用し、事前学習済みタンパク質エンコーダの埋め込みと学習可能なタスクトークンを利用してマルチタスク学習を行い、効率向上と生物学的発見の加速を目指しています。(ソース: HuggingFace Daily Papers)
AI論文解説:エンタープライズシステムにおけるドメイン固有検索のためのハードネガティブマイニング: 論文「Hard Negative Mining for Domain-Specific Retrieval in Enterprise Systems」は、エンタープライズ固有のドメインデータに対応するスケーラブルなハードネガティブマイニングフレームワークを提案しています。この手法は、意味的に挑戦的でありながら文脈的に関連性のないドキュメントを動的に選択し、デプロイされた再ランキングモデルの性能を向上させます。クラウドサービス分野のエンタープライズコーパスでの実験では、MRR@3とMRR@10がそれぞれ15%と19%向上したことが示されています。(ソース: HuggingFace Daily Papers)
AI論文解説:FS-DAG、視覚的にリッチな文書理解のための少数ショットドメイン適応グラフネットワーク: 論文「FS-DAG: Few Shot Domain Adapting Graph Networks for Visually Rich Document Understanding」は、少数ショット状況下で視覚的にリッチな文書理解を行うためのFS-DAGモデルアーキテクチャを提案しています。このモデルは、ドメイン固有および言語/視覚固有のバックボーンネットワークを利用し、モジュラーフレームワーク内で最小限のデータで異なる文書タイプに適応します。情報抽出タスクの実験では、SOTA手法よりも速い収束速度と性能を示しています。(ソース: HuggingFace Daily Papers)
AI論文解説:FastTD3、シンプルで高速な人型ロボット強化学習制御: 論文「FastTD3: Simple, Fast, and Capable Reinforcement Learning for Humanoid Control」は、FastTD3という強化学習アルゴリズムを紹介しています。これは、並列シミュレーション、大バッチ更新、分散型評論家、および慎重に調整されたハイパーパラメータを通じて、HumanoidBench、IsaacLab、MuJoCo Playgroundなどの人気のあるスイートにおける人型ロボットのトレーニング速度を大幅に加速します。(ソース: HuggingFace Daily Papers, pabbeel, cloneofsimo, jachiam0)
AI論文解説:HLIP、3D医療画像向けスケーラブル言語-画像事前学習: 論文「Towards Scalable Language-Image Pre-training for 3D Medical Imaging」は、HLIP(Hierarchical attention for Language-Image Pre-training)と名付けられたスケーラブルな3D医療画像事前学習フレームワークを紹介しています。HLIPは軽量な階層的アテンションメカニズムを採用し、未整理の臨床データセット上で直接トレーニングを行うことができ、複数のベンチマークテストでSOTA性能を達成しています。(ソース: HuggingFace Daily Papers)
AI論文解説:PENGUIN、LLMパーソナライズドセーフティベンチマークとプランニングベースエージェントアプローチ: 論文「Personalized Safety in LLMs: A Benchmark and A Planning-Based Agent Approach」は、パーソナライズドセーフティの概念を導入し、PENGUINベンチマーク(7つの機密分野における14000のシナリオを含む)とRAISEフレームワーク(ユーザ固有の背景情報を戦略的に取得するトレーニング不要の2段階エージェント)を提案しています。研究は、パーソナライズされた情報が安全性スコアを大幅に向上させ、RAISEが低いインタラクションコストで安全性を向上させることを示しています。(ソース: HuggingFace Daily Papers)
AI論文解説:ターンレベルの信用割り当てによるLLMエージェントのマルチターン推論の強化: 論文「Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Credit Assignment」は、強化学習を通じてLLMエージェントの推論能力を強化する方法、特にマルチターンのツール使用シナリオにおける方法を研究しています。著者らは、より正確な信用割り当てを実現するために、きめ細かいターンレベルの優位性推定戦略を提案しており、実験ではこの方法が複雑な意思決定タスクにおけるLLMエージェントのマルチターン推論能力を大幅に向上させることが示されています。(ソース: HuggingFace Daily Papers)
AI論文解説:PISCES、大規模言語モデルにおけるパラメータ内概念の精密な消去: 論文「Precise In-Parameter Concept Erasure in Large Language Models」は、パラメータ空間でエンコードされた概念の方向を直接編集することにより、モデルパラメータ内の概念全体を正確に消去するためのPISCESフレームワークを提案しています。この方法は、デタングラーを使用してMLPベクトルを分解し、ターゲット概念に関連する特徴を識別してモデルパラメータから削除します。実験では、消去効果、特異性、堅牢性のいずれにおいても既存の方法よりも優れていることが示されています。(ソース: HuggingFace Daily Papers)
AI論文解説:DORI、きめ細かい多軸知覚タスクによるMLLMの方向理解の分離: 論文「Right Side Up? Disentangling Orientation Understanding in MLLMs with Fine-grained Multi-axis Perception Tasks」は、マルチモーダル大規模言語モデル(MLLM)の物体方向の理解能力を評価することを目的としたDORIベンチマークを導入しています。DORIは、正面定位、回転変換、相対的方向関係、および規範的方向理解の4つの次元を含み、15のSOTA MLLMをテストした結果、最高のモデルでさえも詳細な方向判断には著しい限界があることが判明しました。(ソース: HuggingFace Daily Papers)
AI論文解説:LLMは実世界のテキストから因果関係を推論できるか?: 論文「Can Large Language Models Infer Causal Relationships from Real-World Text?」は、LLMが実世界のテキストから因果関係を推論する能力を探求しています。研究者らは、実際の学術文献から派生した、さまざまな長さ、複雑さ、分野のテキストを含むベンチマークを開発しました。実験によると、SOTAのLLMでさえこのタスクには著しい課題があり、最高のモデルのF1スコアはわずか0.477であり、暗黙的な情報の処理、関連要因の区別、分散した情報の接続における困難さが明らかになりました。(ソース: HuggingFace Daily Papers)
AI論文解説:IQBench、人間のIQテストを用いた視覚言語モデルの「知能」評価: 論文「IQBench: How “Smart’’ Are Vision-Language Models? A Study with Human IQ Tests」は、標準化された視覚IQテストを通じて視覚言語モデル(VLM)の流動性知能を評価することを目的とした新しいベンチマークIQBenchを発表しました。このベンチマークは視覚中心であり、500の人手で収集・注釈付けされた視覚IQ問題を含み、モデルの解釈、問題解決パターン、および最終的な予測の正確性を評価します。実験では、o4-mini、Gemini-2.5-Flash、Claude-3.7-Sonnetが比較的良好な成績を示しましたが、すべてのモデルが3D空間およびアナグラム推論タスクで困難を抱えていることが示されました。(ソース: HuggingFace Daily Papers)
AI論文解説:PixelThink、効率的なピクセルチェーン推論に向けて: 論文「PixelThink: Towards Efficient Chain-of-Pixel Reasoning」は、外部から推定されたタスクの難易度と内部で測定されたモデルの不確実性を統合し、強化学習パラダイム内で推論生成を調整するPixelThinkスキームを提案しています。このモデルは、シーンの複雑さと予測の信頼度に基づいて推論長を圧縮することを学習します。同時に、評価のためにReasonSeg-Diffベンチマークを導入し、実験ではこの方法が推論効率と全体的なセグメンテーション性能を向上させることが示されています。(ソース: HuggingFace Daily Papers)
AI論文解説:テスト時スケーリングとしてのマルチエージェントディベートの再検討: 論文「Revisiting Multi-Agent Debate as Test-Time Scaling: A Systematic Study of Conditional Effectiveness」は、マルチエージェントディベート(MAD)をテスト時計算スケーリング技術として概念化し、さまざまな条件下(タスクの難易度、モデルの規模、エージェントの多様性)における自己エージェント手法に対する有効性を体系的に研究しています。研究によると、数学的推論の場合、MADの利点は限定的ですが、問題の難易度が増加したりモデルの能力が低下したりするとより効果的です。安全性タスクの場合、MADの協調的最適化は脆弱性を増加させる可能性がありますが、多様な構成は攻撃成功率の低減に役立ちます。(ソース: HuggingFace Daily Papers)
AI論文解説:VF-Eval、AIGCビデオへのフィードバック生成におけるMLLMの能力評価: 論文「VF-Eval: Evaluating Multimodal LLMs for Generating Feedback on AIGC Videos」は、AI生成コンテンツ(AIGC)ビデオの解釈におけるマルチモーダル大規模言語モデル(MLLM)の能力を評価するための新しいベンチマークVF-Evalを提案しています。VF-Evalは、一貫性検証、エラー認識、エラータイプ検出、推論評価の4つのタスクを含みます。13の最先端MLLMの評価では、最も性能の良いGPT-4.1でさえ、すべてのタスクで良好な性能を維持することが困難であることが示されました。(ソース: HuggingFace Daily Papers)
AI論文解説:SafeScientist、LLMエージェントによるリスク認識型科学的発見の実現: 論文「SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM Agents」は、AI駆動の科学的探求における安全性と倫理的責任を強化することを目的としたSafeScientistというAI科学者フレームワークを紹介しています。このフレームワークは、不適切または高リスクなタスクを積極的に拒否し、プロンプト監視、エージェント協調監視、ツール使用監視、倫理審査員コンポーネントなどの多重防御メカニズムを通じて研究プロセスの安全性を強調します。同時に、評価のためのSciSafetyBenchベンチマークも提案されています。(ソース: HuggingFace Daily Papers)
AI論文解説:CXReasonBench、胸部X線構造化診断推論評価のためのベンチマーク: 論文「CXReasonBench: A Benchmark for Evaluating Structured Diagnostic Reasoning in Chest X-rays」は、CheXStructプロセスとCXReasonBenchベンチマークを紹介しています。これは、大規模視覚言語モデル(LVLM)が胸部X線診断において臨床的に有効な推論ステップを実行できるかどうかを評価するためのものです。このベンチマークは18988のQAペアを含み、12の診断タスクと1200の症例をカバーし、解剖学的領域の選択や診断測定の視覚的ローカリゼーションを含む多経路、多段階評価をサポートしています。(ソース: HuggingFace Daily Papers)
AI論文解説:ZeroGUI、人的コストゼロでのオンラインGUI学習の自動化: 論文「ZeroGUI: Automating Online GUI Learning at Zero Human Cost」は、人的コストゼロでGUIエージェントのトレーニングを自動化するためのスケーラブルなオンライン学習フレームワークZeroGUIを提案しています。ZeroGUIは、VLMベースの自動タスク生成、自動報酬推定、および2段階のオンライン強化学習を統合し、GUI環境と継続的に対話し、そこから学習します。(ソース: HuggingFace Daily Papers)
AI論文解説:Spatial-MLLM、MLLMの視覚空間知能の向上: 論文「Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence」は、純粋な2D観測からの視覚ベースの空間推論のためのSpatial-MLLMフレームワークを提案しています。このフレームワークは、デュアルエンコーダアーキテクチャ(セマンティック視覚エンコーダと空間エンコーダ)を採用し、空間認識フレームサンプリング戦略と組み合わせることで、複数の実世界データセットでSOTA性能を実現しています。(ソース: HuggingFace Daily Papers)
AI論文解説:TrustVLM、視覚言語モデルの予測が信頼できるかどうかの判断: 論文「To Trust Or Not To Trust Your Vision-Language Model’s Prediction」は、視覚言語モデル(VLM)の予測の信頼性を評価することを目的とした、トレーニング不要のフレームワークTrustVLMを紹介しています。この方法は、画像埋め込み空間における概念表現の差異を利用し、誤分類検出を改善するための新しい信頼度スコアリング関数を提案し、17の異なるデータセットでSOTA性能を示しています。(ソース: HuggingFace Daily Papers)
AI論文解説:MAGREF、マスク誘導による任意参照ビデオ生成: 論文「MAGREF: Masked Guidance for Any-Reference Video Generation」は、統一された多参照ビデオ生成フレームワークMAGREFを提案しています。これはマスク誘導メカニズムを導入し、領域認識動的マスクとピクセルレベルのチャネル接続を通じて、多様な参照画像とテキストプロンプト条件下で、一貫性のある多主体ビデオ合成を実現し、多主体ビデオベンチマークで既存のオープンソースおよび商用ベースラインを上回っています。(ソース: HuggingFace Daily Papers)
AI論文解説:ATLAS、テスト時にコンテキストメモリを最適に記憶することを学習: 論文「ATLAS: Learning to Optimally Memorize the Context at Test Time」は、現在および過去のトークンに基づいてメモリを最適化することでコンテキストを記憶することを学習し、長期記憶モデルのオンライン更新特性を克服する大容量の長期記憶モジュールATLASを提案しています。これに基づき、著者らはDeepTransformersアーキテクチャファミリーを提案し、実験ではATLASが言語モデリング、常識推論、リコール集約型および長文脈理解タスクにおいてTransformersおよび最近の線形リカレントモデルを上回ることを示しています。(ソース: HuggingFace Daily Papers)
AI論文解説:Satori-SWE、サンプル効率の良い進化的テスト時スケーリングソフトウェアエンジニアリング手法: 論文「Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering」は、コード生成を進化プロセスとみなし、出力を反復的に最適化することで小規模モデルのソフトウェアエンジニアリングタスク(SWE-Benchなど)における性能を向上させるEvoScale手法を提案しています。Satori-SWE-32Bモデルはこの手法により、少量のサンプルを使用した場合でも、パラメータ数が100Bを超えるモデルと同等以上の性能を発揮します。(ソース: HuggingFace Daily Papers)
AI論文解説:OPO、最適報酬ベースラインを持つオンポリシー強化学習: 論文「On-Policy RL with Optimal Reward Baseline」は、OPOアルゴリズムを提案しています。これは、現在のRLアルゴリズムがLLMのトレーニング時に直面するトレーニングの不安定性と計算効率の低さの問題を解決することを目的とした、新しい簡略化された強化学習アルゴリズムです。OPOは正確なオンポリシー訓練を強調し、理論的に勾配分散を最小化する最適報酬ベースラインを導入しており、実験では数学的推論ベンチマークにおいて優れた性能と訓練安定性を示しています。(ソース: HuggingFace Daily Papers)
AI論文解説:SWE-bench Goes Live! リアルタイム更新されるソフトウェアエンジニアリングベンチマーク: 論文「SWE-bench Goes Live!」は、既存のSWE-benchの限界を克服することを目的としたリアルタイム更新可能なベンチマークSWE-bench-Liveを紹介しています。新バージョンには、2024年以降の実際のGitHub問題から派生した1319のタスクが含まれ、93のリポジトリをカバーし、スケーラビリティと継続的な更新を実現するための自動化された管理プロセスを備えており、より厳格で汚染に強いLLMおよびエージェント評価を提供します。(ソース: HuggingFace Daily Papers, _akhaliq)
AI論文解説:ToMAP、心の理論に基づき相手を意識したLLM説得者の育成: 論文「ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind」は、ToMAPと名付けられた新しい手法を紹介しています。これは、2つの心の理論モジュールを統合することで、より柔軟な説得エージェントを構築し、相手の心理状態に対する意識と分析を強化します。実験では、わずか3BパラメータのToMAP説得者が、複数の説得対象モデルとコーパスにおいて、GPT-4oなどの大規模ベースラインを上回る性能を示しました。(ソース: HuggingFace Daily Papers)
AI論文解説:LLMはCLIPを欺けるか?テキスト更新による事前学習済みマルチモーダル表現の敵対的構成性の評価: 論文「Can LLMs Deceive CLIP? Benchmarking Adversarial Compositionality of Pre-trained Multimodal Representation via Text Updates」は、マルチモーダル敵対的構成性(MAC)ベンチマークを導入し、LLMを利用して欺瞞的なテキストサンプルを生成し、CLIPなどの事前学習済みマルチモーダル表現の構成性の脆弱性を悪用します。研究は、多様性を促進するフィルタリングによる拒否サンプリングファインチューニングを通じて、攻撃成功率とサンプル多様性を強化する自己訓練手法を提案しています。(ソース: HuggingFace Daily Papers)
AI論文解説:推論学習におけるノイズの多い報酬の役割――頂上よりも登頂の過程が知恵を深く刻む: 論文「The Climb Carves Wisdom Deeper Than the Summit: On the Noisy Rewards in Learning to Reason」は、強化学習によるLLMの推論後訓練に対する報酬ノイズの影響を研究しています。研究によると、LLMは大量の報酬ノイズに対して強力な堅牢性を示し、重要な推論フレーズの出現のみを報酬としても(回答の正しさを検証せずに)、厳密な検証と正確な報酬で訓練されたモデルと同等の性能に達することができます。(ソース: HuggingFace Daily Papers)
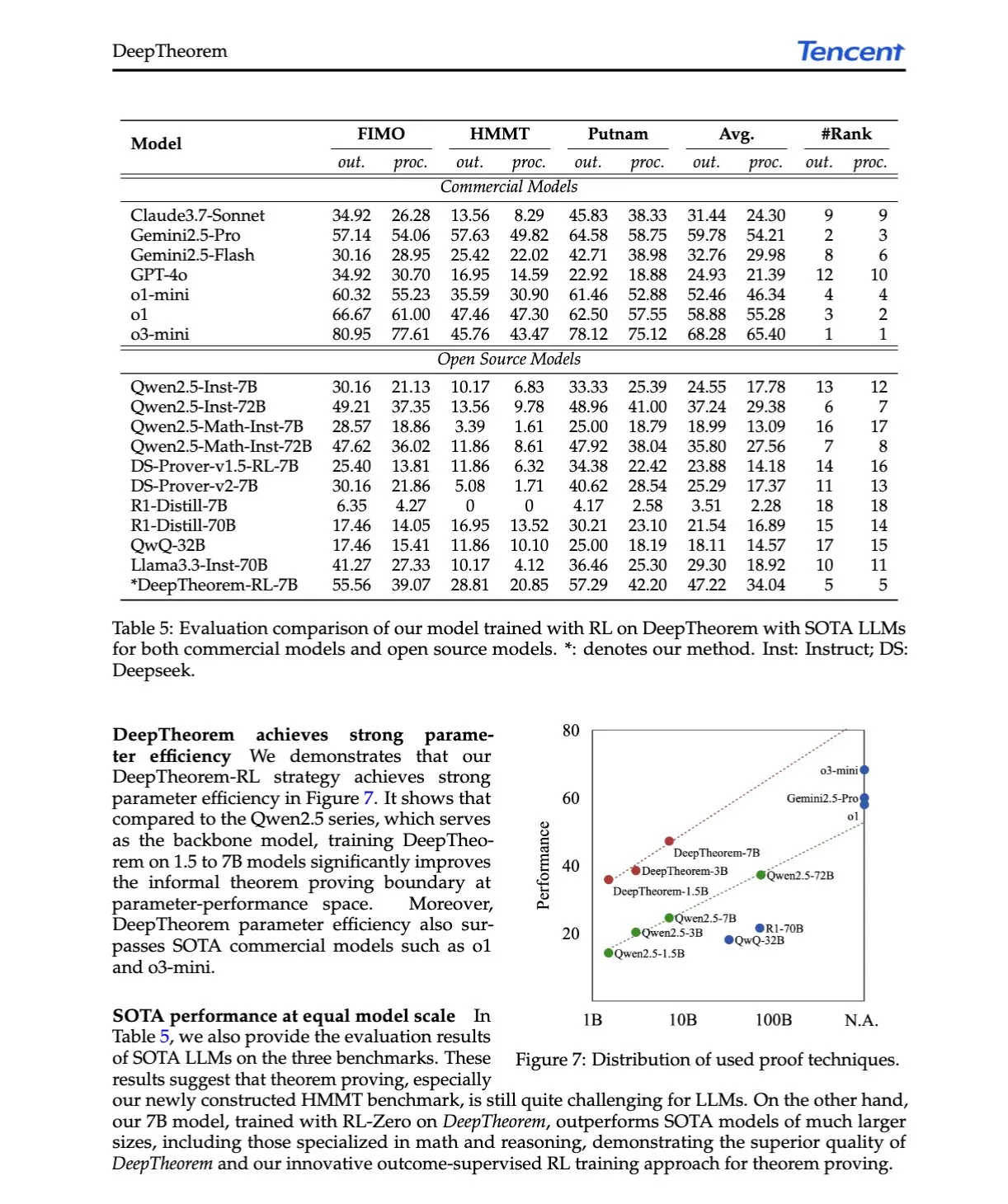
AI論文解説:DeepTheorem、自然言語と強化学習によるLLM定理証明の推進: 論文「DeepTheorem: Advancing LLM Reasoning for Theorem Proving Through Natural Language and Reinforcement Learning」は、DeepTheoremを提案しています。これは、自然言語を利用してLLMの数学的推論を強化する非形式的定理証明フレームワークです。このフレームワークには、大規模なベンチマークデータセット(IMOレベルの非形式的定理と証明12.1万件)と、非形式的定理証明専用に設計されたRL戦略(RL-Zero)が含まれています。(ソース: HuggingFace Daily Papers, teortaxesTex)
AI論文解説:D-AR、自己回帰モデルによる拡散の実現: 論文「D-AR: Diffusion via Autoregressive Models」は、D-ARという新しいパラダイムを提案し、画像拡散プロセスを標準的な自己回帰の次トークン予測プロセスに再構築します。設計されたトークナイザによって画像を離散トークンシーケンスに変換し、異なる位置のトークンはピクセル空間における異なる拡散デノイズステップにデコードできます。この方法は、ImageNet上で775M Llamaバックボーンネットワークと256個の離散トークンを使用して2.09 FIDを達成しました。(ソース: HuggingFace Daily Papers)
AI論文解説:Table-R1、表形式推論のための推論時スケーリング: 論文「Table-R1: Inference-Time Scaling for Table Reasoning」は、表形式推論タスクにおける推論時スケーリングを初めて探求しています。研究者らは、2つの事後学習戦略を開発・評価しました。最先端モデルの推論軌跡からの蒸留(Table-R1-SFT)と、検証可能な報酬を用いた強化学習(Table-R1-Zero)です。Table-R1-Zero(7Bパラメータ)は、多様な表形式推論タスクにおいて、GPT-4.1およびDeepSeek-R1の性能に匹敵するか、それを上回りました。(ソース: HuggingFace Daily Papers)
AI論文解説:Muddit、テキストから画像への生成を超える統一離散拡散モデルの実現: 論文「Muddit: Liberating Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model」は、Mudditを紹介しています。これは、テキストと画像モダリティの高速並列生成をサポートする統一離散拡散Transformerモデルです。Mudditは、事前学習済みテキストから画像へのバックボーンネットワークの強力な視覚的プライアと軽量なテキストデコーダを統合し、品質と効率の両方で競争力があります。(ソース: HuggingFace Daily Papers)
AI論文解説:VideoReasonBench、MLLMは視覚中心の複雑なビデオ推論を実行できるか?: 論文「VideoReasonBench: Can MLLMs Perform Vision-Centric Complex Video Reasoning?」は、視覚中心の複雑なビデオ推論能力を評価することを目的としたベンチマークVideoReasonBenchを紹介しています。このベンチマークは、きめ細かい操作シーケンスのビデオを含み、問題は想起、推測、予測能力を評価します。実験によると、ほとんどのSOTA MLLMはこのベンチマークで性能が悪く、思考強化されたGemini-2.5-Proが際立った性能を示しました。(ソース: HuggingFace Daily Papers, OriolVinyalsML)
AI論文解説:GeoDrive、精密な行動制御を備えた3D幾何学認識型運転世界モデル: 論文「GeoDrive: 3D Geometry-Informed Driving World Model with Precise Action Control」は、GeoDriveを提案しています。これは、堅牢な3D幾何学条件を運転世界モデルに明示的に統合し、空間理解と行動制御可能性を強化します。この方法は、動的編集モジュールを通じてトレーニング中にレンダリング効果を強化し、実験では行動の正確性と3D空間認識において既存のモデルを上回ることが証明されています。(ソース: HuggingFace Daily Papers)
AI論文解説:動的低信頼度マスキングによる適応的分類器フリーガイダンス: 論文「Adaptive Classifier-Free Guidance via Dynamic Low-Confidence Masking」は、A-CFG法を提案しています。これは、モデルの瞬間的な予測信頼度を利用して、分類器フリーガイダンス(CFG)の無条件入力をカスタマイズします。A-CFGは、反復的(マスク)拡散言語モデルの各ステップで低信頼度トークンを識別し、一時的に再マスクすることで、動的で局所化された無条件入力を作成し、CFGの補正効果をより正確にします。(ソース: HuggingFace Daily Papers)
AI論文解説:PatientSim、リアルな医師患者インタラクションのためのペルソナ駆動型シミュレータ: 論文「PatientSim: A Persona-Driven Simulator for Realistic Doctor-Patient Interactions」は、PatientSimを紹介しています。これは、MIMICデータセットの臨床プロファイルと4軸ペルソナ(個性、言語習熟度、病歴想起レベル、認知混乱レベル)に基づいて、リアルで多様な患者ペルソナを生成するシミュレータです。医師LLMのトレーニングまたは評価のための現実的な患者インタラクションシステムを提供することを目的としています。(ソース: HuggingFace Daily Papers)
AI論文解説:LoRAShop、補正流Transformerによるトレーニング不要の多概念画像生成と編集: 論文「LoRAShop: Training-Free Multi-Concept Image Generation and Editing with Rectified Flow Transformers」は、LoRAモデルを用いた多概念画像編集のための初のフレームワークLoRAShopを紹介しています。このフレームワークは、Fluxスタイルの拡散Transformer内部の特徴インタラクションパターンを利用し、各概念に対して分離された潜在マスクを導出し、概念領域内でのみLoRA重みを混合することで、多主体またはスタイルのシームレスな統合を実現します。(ソース: HuggingFace Daily Papers)
AI論文解説:AnySplat、制約のないビューからのフィードフォワード3Dガウシアンスプラッティング: 論文「AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views」は、AnySplatを紹介しています。これは、未調整の画像集合からの新しい視点合成のためのフィードフォワードネットワークです。従来のニューラルレンダリングパイプラインとは異なり、AnySplatは単一のフォワードパスで3Dガウシアンプリミティブ(シーンの幾何学と外観をエンコード)および各入力画像のカメラ内外パラメータを予測でき、ポーズ注釈なしでリアルタイムの新しい視点合成をサポートします。(ソース: HuggingFace Daily Papers)
AI論文解説:ZeroSep、トレーニングゼロでオーディオ内のあらゆるものを分離: 論文「ZeroSep: Separate Anything in Audio with Zero Training」は、事前学習済みのテキスト誘導オーディオ拡散モデルのみを特定の構成で使用することで、ゼロショット音源分離が実現できることを発見しました。ZeroSepメソッドは、混合オーディオを拡散モデルの潜在空間に反転させ、テキスト条件を使用してデノイズプロセスを誘導することで、特定のタスクトレーニングやファインチューニングなしに個々の音源を復元します。(ソース: HuggingFace Daily Papers)
AI論文解説:ワンショットエントロピー最小化の研究: 論文「One-shot Entropy Minimization」は、13440個の大規模言語モデルをトレーニングすることにより、エントロピー最小化は単一のラベルなしデータと10ステップの最適化のみで、数千のデータと慎重に設計された報酬を使用するルールベースの強化学習で達成できる性能向上に匹敵するか、それを超えることを発見しました。この結果は、LLMの事後トレーニングパラダイムの再考を促す可能性があります。(ソース: HuggingFace Daily Papers)
AI論文解説:ChartLens、チャートにおけるきめ細かい視覚的アトリビューション: 論文「ChartLens: Fine-grained Visual Attribution in Charts」は、MLLMがチャート理解においてハルシネーションを起こしやすい問題に対し、チャート事後視覚的アトリビューションタスクを導入し、ChartLensアルゴリズムを提案しています。このアルゴリズムは、セグメンテーション技術を使用してチャートオブジェクトを識別し、タグセットプロンプトとMLLMを用いてきめ細かい視覚的アトリビューションを行います。同時に、金融、政策、経済などの分野のチャートのきめ細かいアトリビューション注釈を含むChartVA-Evalベンチマークを公開しました。(ソース: HuggingFace Daily Papers)
AI論文解説:グラフ視点から大規模言語モデルにおける知識の構造的パターンを探る: 論文「A Graph Perspective to Probe Structural Patterns of Knowledge in Large Language Models」は、グラフの視点からLLMにおける知識の構造的パターンを研究しています。研究は、LLMのトリプレットおよびエンティティレベルの知識を定量化し、ノード次数などのグラフ構造属性との関係を分析し、知識の同質性(トポロジー的に近いエンティティの知識レベルが類似している)を明らかにしました。これに基づき、エンティティ知識を推定するためのグラフ機械学習モデルを開発し、知識チェックに使用しました。(ソース: HuggingFace Daily Papers)
💼 ビジネス
エンボディードAI企業Lumos Robotics、半年で約2億元を調達、中遠海運などと提携: 元Dreame幹部の喻超氏が設立したエンボディードAIロボット企業Lumos Robotics(鹿明机器人)は、エンジェル++ラウンドの資金調達を完了したと発表しました。投資家には復星鋭正、德馬科技、呉中金控が含まれ、半年間の累計調達額は約2億元に達しました。同社は家庭シーンに焦点を当て、LUS、MOSシリーズの人型ロボットおよびコア部品を製品とし、すでにフルサイズ人型ロボットLUSを発表しており、德馬科技、中遠海運などと戦略的提携を結び、物流やスマート製造などのシーンにおけるエンボディードAIの商業化を加速しています。(ソース: 36氪)

Snorkel AI、1億ドルのシリーズD資金調達を完了、AIエージェント評価およびエキスパートデータサービスを開始: データセントリックAI企業Snorkel AIは、Valor Equity Partnersが主導する1億ドルのシリーズD資金調達を完了し、総調達額が2億3500万ドルに達したと発表しました。同時に、同社はSnorkel Evaluate(データセントリックAIエージェント評価プラットフォーム)とExpert Data-as-a-Service(エキスパートデータ・アズ・ア・サービス)を開始し、企業がより信頼性が高く、より専門的なAIエージェントを構築・展開できるよう支援することを目指しています。(ソース: realDanFu, percyliang, tri_dao, krandiash)
米国エネルギー省、DellおよびNVIDIAと次世代スーパーコンピュータ「Doudna」開発で協力と発表: 米国エネルギー省は、ローレンス・バークレー国立研究所向けに「Doudna」と名付けられた次世代フラッグシップスーパーコンピュータNERSC-10を開発するため、Dell社と契約を締結したと発表しました。このシステムはNVIDIAの次世代Vera Rubinプラットフォームによってサポートされ、2026年に稼働開始予定で、性能は既存のフラッグシップPerlmutterの10倍以上となり、大規模な高性能コンピューティングとAIワークロードをサポートし、米国が世界のAI主導権争いで勝利するのを支援することを目指しています。(ソース: 36氪, nvidia)

🌟 コミュニティ
DeepSeek R1-0528が話題に、性能、ハルシネーション、ツール呼び出しが焦点: DeepSeek R1-0528のリリースはコミュニティで広範な議論を呼びました。多くの意見は、数学、プログラミング、汎用論理推論において著しい向上を見せ、一部のクローズドソースモデルに匹敵するか、それを超えているというものです。新バージョンはハルシネーション率の低減に進展があり、JSON出力と関数呼び出しのサポートが追加されました。同時に、その蒸留版であるQwen3-8Bバージョンも、小規模モデルにおける優れた数学性能で注目されています。コミュニティは一般的に、DeepSeekがオープンソース分野でのリーダーシップを確固たるものにし、R2バージョンのリリースに期待していると認識しています。(ソース: ClementDelangue, dotey, scaling01, awnihannun, karminski3, teortaxesTex, scaling01, karminski3, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
AI画像編集モデルFLUX.1 Kontextが注目、コンテキスト理解とキャラクター一貫性を強調: Black Forest Labsが発表したFLUX.1 Kontext画像編集モデルは、テキストと画像の同時処理能力とキャラクター一貫性の維持により、コミュニティの注目を集めています。ユーザーからは、画像編集、スタイル変換、テキストオーバーレイなどのタスクで優れた性能を発揮し、特に複数回の編集でも被写体の特徴を良好に保持できるとのフィードバックがあります。Replicateなどのプラットフォームは既にこのモデルを公開し、詳細なテストレポートと使用テクニックを提供しています。(ソース: TomLikesRobots, two_dukes, robrombach, timudk, robrombach, cloneofsimo, robrombach, robrombach)

AIエージェントが検索と広告モデルを大幅に変革へ: Perplexity AIのCEO、Arav Srinivas氏は、AIエージェントがユーザーに代わって検索を実行するにつれて、Googleなどの検索エンジンの人間によるクエリ数が大幅に減少し、これにより広告のCPM/CPCが低下し、広告費がソーシャルメディアやAIプラットフォームに流れる可能性があると考えています。ユーザーは頻繁にキーワード検索を行う必要がなくなり、代わりにAIアシスタントが積極的に情報をプッシュするようになります。(ソース: AravSrinivas)
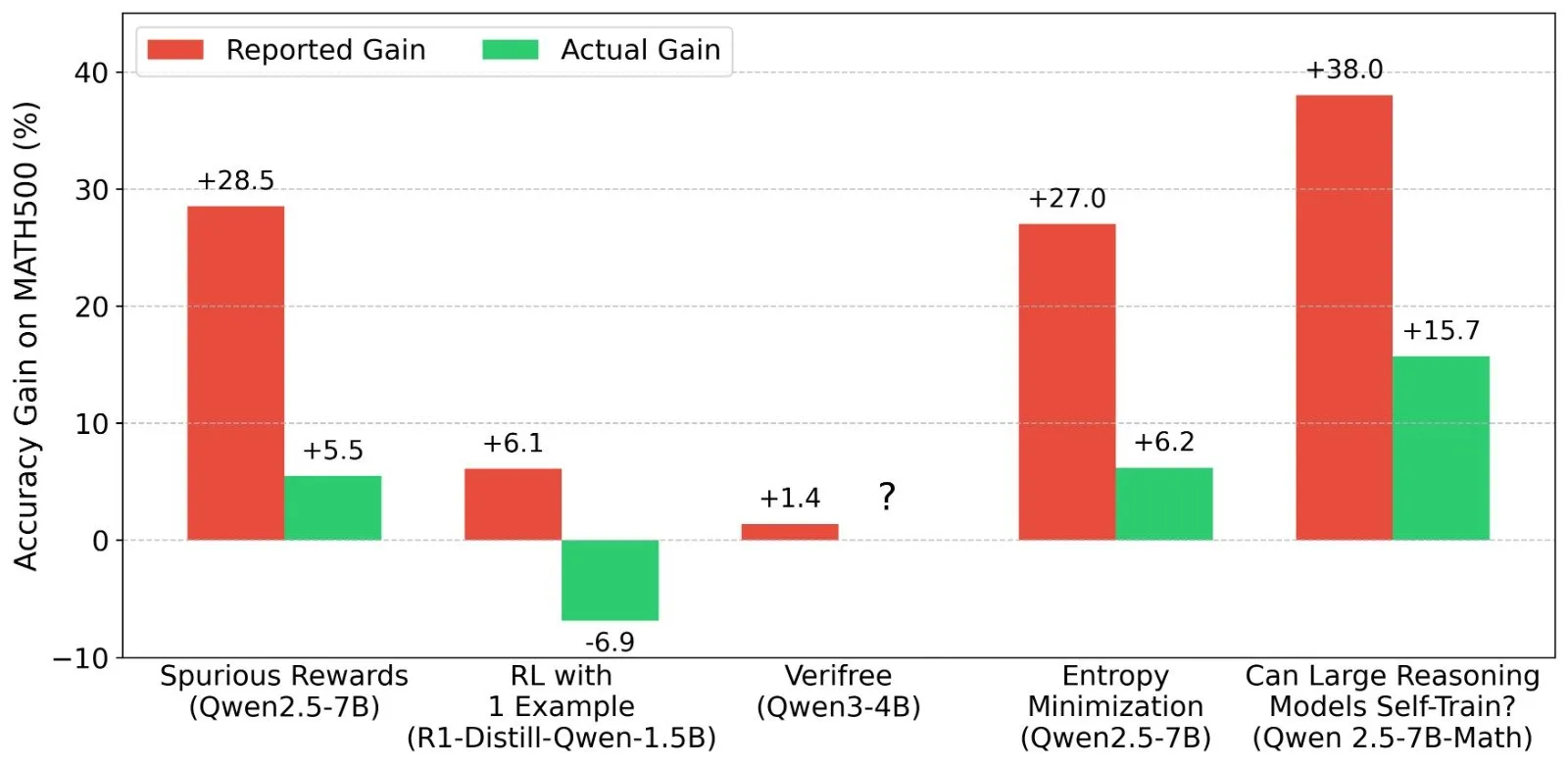
LLM強化学習(RL)の結果に関する議論:報酬シグナルとモデル能力の真実性: Shashwat Goel氏などの研究者は、最近のLLM RL研究において、モデルが真の報酬シグナルなしに性能を向上させる現象に疑問を呈し、一部の研究が事前学習モデルのベースライン能力を過小評価しているか、他の交絡因子が存在する可能性があると指摘しています。この議論は、QwenなどのモデルのRLにおけるパフォーマンスに関する詳細な分析や、RLVR(検証可能な報酬による強化学習)の有効性についての考察を引き起こし、RL効果を評価する際にはより厳格なベースラインとプロンプト最適化が必要であることを強調しています。(ソース: menhguin, AndrewLampinen, lateinteraction, madiator, vikhyatk, matei_zaharia, hrishioa, iScienceLuvr)
「Vibe Coding」が議論を呼び、安全なデフォルト値と技術的負債のリスクを強調: 「Vibe coding」(雰囲気プログラミング、厳格な規範よりも直感と迅速なイテレーションに依存するプログラミング方法)がコミュニティの議論の的となっています。ReplitのCEOであるAmjad Masad氏は、この方法が新しい開発者に力を与えるとしながらも、プラットフォームは安全なデフォルト設定を提供しなければならないと述べています。一方、Pedro Domingos氏は「雰囲気プログラミングは技術的負債のゴジラだ」とコメントし、長期的なメンテナンス問題を引き起こす可能性を示唆しています。Semaforは、LovableがRLSポリシーの設定不備によりセキュリティ脆弱性を引き起こした事例を報じ、このプログラミング方法の安全性に対する懸念をさらに高めています。(ソース: alexalbert__, amasad, pmddomingos, gfodor)
ソフトウェアエンジニアリングにおけるAIの役割:効率向上と人間プログラマーの代替不可能性: Redisの父であるSalvatore Sanfilippo氏は、AI(Gemini 2.5 Proなど)がプログラミング支援、コードレビュー、アイデア検証において価値があるものの、創造的な問題解決や既成概念にとらわれない思考においては人間プログラマーがAIをはるかに凌駕しているという経験を共有しました。コミュニティの議論ではさらに、AIは現在「インテリジェントなラバーダック」のようなもので、思考を助けることはできるが、その提案は慎重に評価する必要があり、過度な依存は開発者のコア能力を弱める可能性があると指摘されています。Mitchell Hashimoto氏も、LLMがClangのコンパイル問題を迅速に特定するのに役立ち、大幅な時間を節約できた事例を共有しています。(ソース: mitchellh, 36氪)
AIが大規模に雇用を代替するかどうかが引き続き注目を集める: AnthropicのCEOであるDario Amodei氏は、AIがエントリーレベルのオフィス職の半分を消滅させる可能性があると予測している一方、Mark Cuban氏はAIが新しい企業や新しい雇用を創出すると考えています。コミュニティではこれについて激しい議論が交わされており、カスタマーサービス、初級コピーライター、一部の開発などの仕事は既に影響を受けているという意見がある一方で、AIは創造性、複雑な意思決定、高度な対人関係スキルが必要な分野ではまだ人間を代替するのは難しいという意見もあります。AIが仕事の性質を変え、人間はAIとの協調能力を適応させ向上させる必要があるというのが一般的なコンセンサスです。(ソース: Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ArtificialInteligence)
AI Agent(エージェント)が次世代インタラクションの入り口となり、大手企業が競争: Microsoft、Google、OpenAI、Alibaba、Tencent、Baidu、Coocaaなど国内外のテクノロジー企業が相次いでAI Agentに注力しています。エージェントは深く思考し、自律的に計画、意思決定し、複雑なタスクを実行できるため、検索エンジン、アプリに続く次世代のインタラクションの入り口と見なされています。現在、OpenAI、Baiduを代表とする技術エコシステム構築者、Microsoft、Alibaba Cloudを代表とする垂直型シーン企業向けサービスプロバイダー、そしてHuawei、Coocaaを代表とするソフトウェア・ハードウェア端末メーカーという3つの主要な勢力が形成されています。(ソース: 36氪)

💡 その他
中国AIの海外進出が加速、製品輸出からエコシステム構築へ: 「中国AIの越境成長」報告書によると、中国AI企業の海外進出は大規模化の急成長期に入っており、76%が応用層に集中しています。海外進出の道のりは、初期のツール型応用から、中期には技術的優位性を活かした業界ソリューションの輸出へと発展し、現段階では技術エコシステムの海外進出に重点を置き、技術標準とオープンソース協力を推進しています。AIの海外進出は「近距離から遠距離へ」の段階的な浸透を示しており、ローカライゼーション、コンプライアンス倫理、ブランドマーケティングなどの課題に直面しています。(ソース: 36氪)

米国エネルギー省、AI競争を「新マンハッタン計画」に例え、米国の勝利を強調: 米国エネルギー省は、次世代スーパーコンピュータ「Doudna」を発表する際、AIの発展競争を「我々の時代のマンハッタン計画」と呼び、米国がこの競争で勝利すると宣言しました。この発言は、大国間の技術競争、AI倫理、国際協力に関するコミュニティの議論を引き起こしました。(ソース: gfodor, teortaxesTex, andrew_n_carr, npew, jpt401)
AIのコンテンツ制作分野における進歩が「真正性」と「創造性」に関する考察を喚起: コミュニティでは、AIのファッションデザイン、漫画制作、動画生成などの分野での応用が議論されました。一方では、AIは多様なコンテンツを迅速に生成し、数年前の漫画作品を動画として具現化することさえ可能です。他方では、これらの生成コンテンツは時に奇妙に見えたり、深みに欠けたりすることがあります。これは、AI生成コンテンツが「より良い」のか、そしてAI時代において人間の創造性がどのような役割を果たすのかについての考察を引き起こしています。(ソース: Reddit r/ChatGPT, Reddit r/artificial)
