キーワード:RLHF, RLAIF, Qwen2.5-Math-7B, MATH-500, 強化学習, ランダム報酬, 誤った報酬, モデル性能, RLHF/RLAIFの未来, ランダム報酬によるモデル性能向上, Qwen2.5-Math-7Bの誤報酬トレーニング, MATH-500テストセット, 強化学習シグナル学習
🔥 注目ニュース
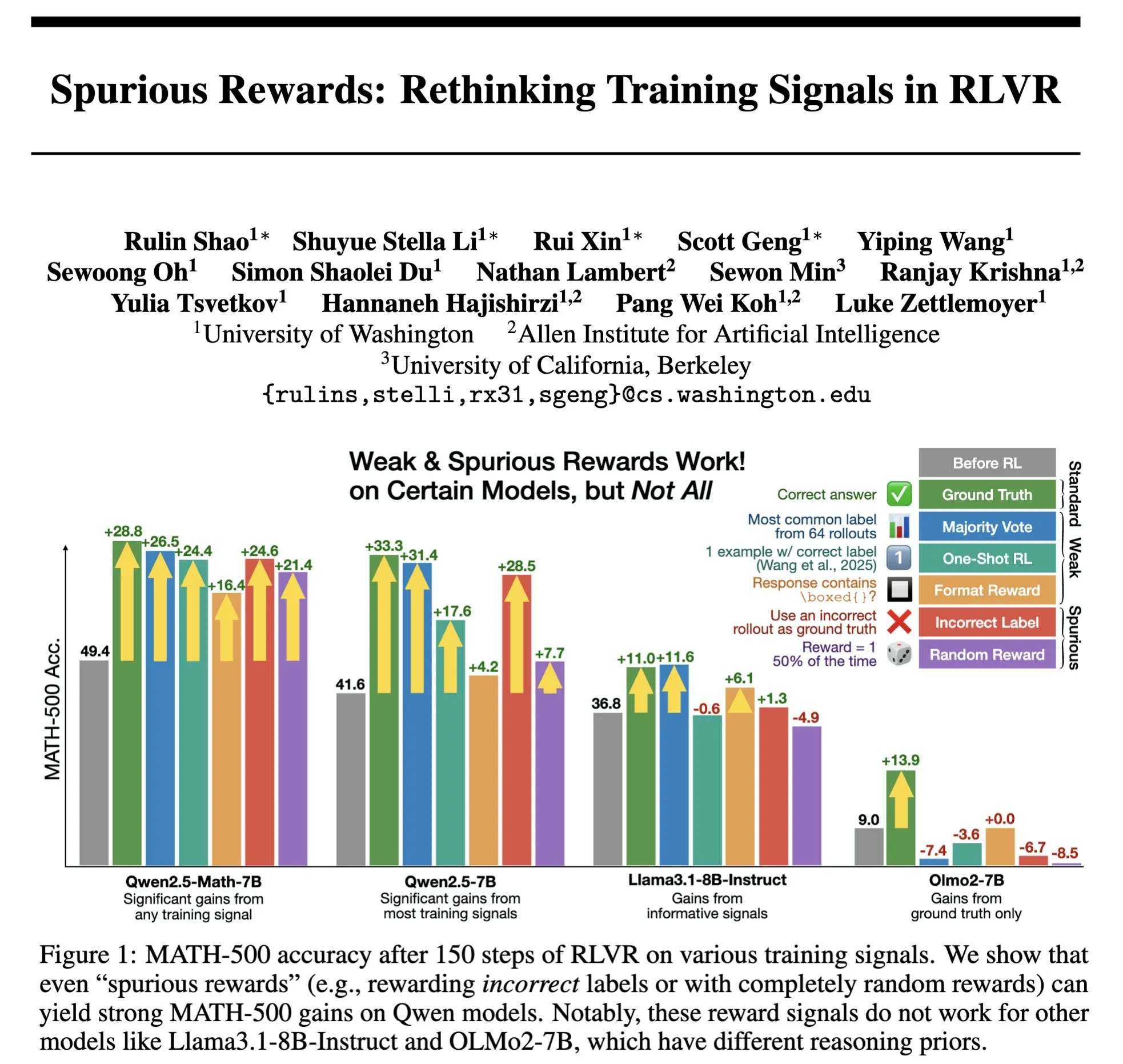
RLHF/RLAIFの未来:ランダム/誤った報酬でもモデル性能は向上するのか? : Stella Li氏の実験によると、ランダムな報酬または不正確な報酬を使用してQwen2.5-Math-7Bモデルを訓練した結果、MATH-500テストセットでそれぞれ21%と25%向上し、真の報酬を使用した場合の28.8%の向上効果に近かったことが示されました。natolambert氏が転送したRulin Shao氏の研究でも、RLVR(Reinforcement Learning from Verifier Reward)が偽の報酬を使用した場合、Olmoモデルのコード使用は増加するものの性能は低下し、逆にコード使用を阻止すると性能が向上することが発見されました。これらの発見は、従来のRLHF/RLAIFにおける高品質な人間の嗜好データへの依存に疑問を投げかけるものであり、報酬自体が不完全であっても、モデルが報酬信号を通じてより広範な戦略空間を探索することを学習し、モデルの潜在能力を引き出したり既存の行動を最適化したりできる可能性を示唆しています。これは、高価な人手によるアノテーションへの依存を減らし、より効率的なモデルのアライメント方法を探求する新たな道を開く可能性がありますが、モデルが誤った行動を学習するリスクには警戒が必要です。(出典: natolambert, teortaxesTex, DhruvBatraDB, Francis_YAO_, raphaelmilliere)
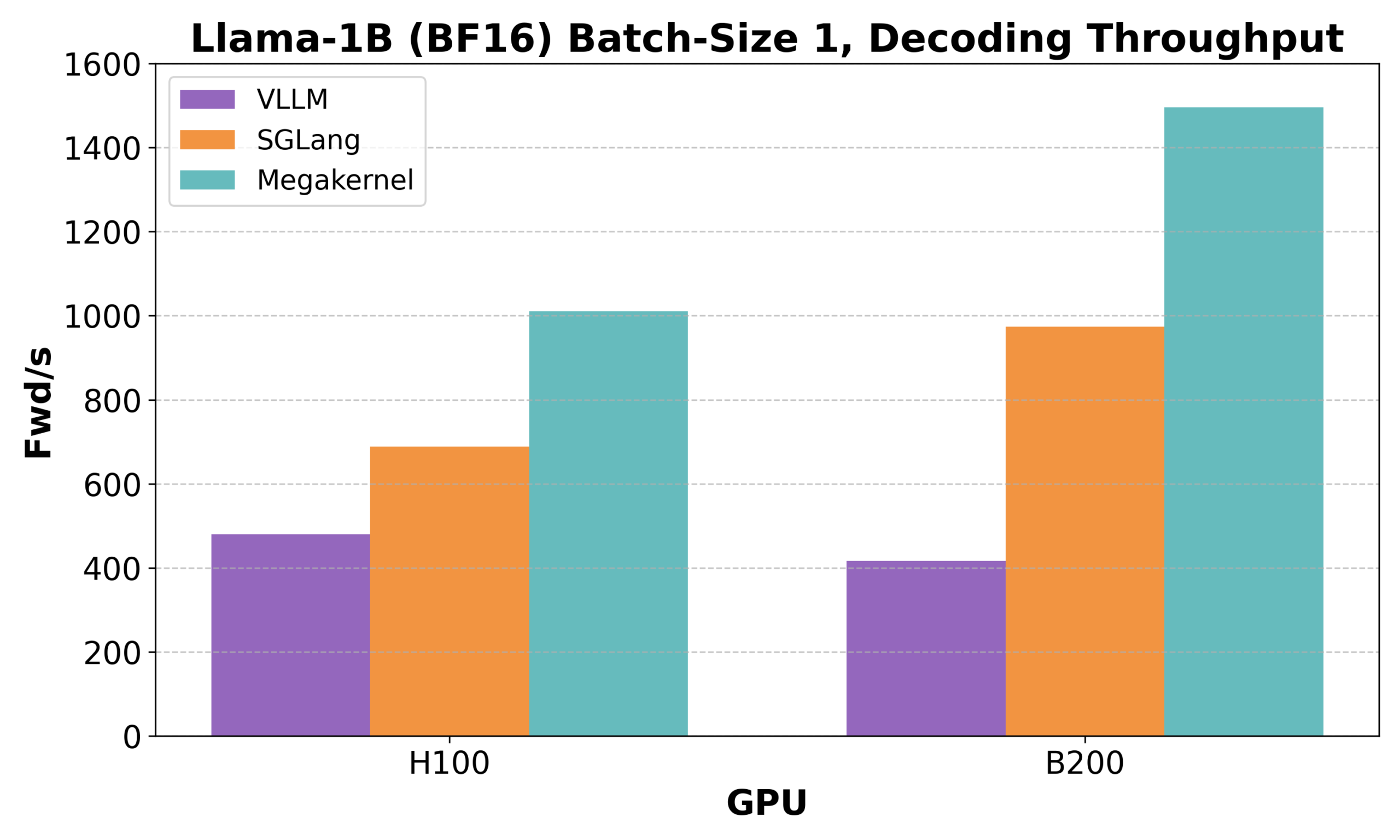
Hazy ResearchがLow-Latency-Llama Megakernelを発表:単一CUDAコアでLlama 1B推論を実現 : Hazy Researchは、単一のCUDAコア内でLlama 1Bモデルのフォワードプロパゲーション全体を完了できるLow-Latency-Llama Megakernelを発表しました。この技術は、計算を単一カーネルに統合することで、従来の逐次的なカーネル呼び出しに伴う同期の境界を排除し、計算とメモリのスケジューリングを最適化することで、より低いレイテンシを実現します。Andrej Karpathy氏はこの成果を高く評価し、計算とメモリの最適なオーケストレーションを実現する唯一の方法であると述べています。この進歩は、エッジコンピューティングやリアルタイムAIアプリケーションなど、レイテンシに厳しい要件がある分野にとって重要であり、より効率的で機敏な小規模言語モデルの展開を促進することが期待されます。(出典: karpathy, teortaxesTex, charles_irl, simran_s_arora)
DeepSeek启元がrStar-Coderを発表:大規模な検証済みコード推論データセットを構築し、小規模モデルのコード能力を大幅に向上 : MicrosoftとDeepSeekの研究者は、rStar-Coderプロジェクトを発表しました。これは、41.8万件のコンペティションレベルのコード問題、58万件の長い推論ソリューション、および豊富なテストケースを含む大規模な検証済みデータセットを構築することにより、現在のコード推論分野における高品質で高難易度のデータセット不足の問題を解決することを目的としています。このプロジェクトは、既存のプログラミングコンペティション問題とオラクル解法を総合的に利用して新しい問題を合成し、信頼性の高い入出力テストケース生成パイプラインを設計し、テストケースを使用して高品質な長い推論ソリューションを検証することで、LLMのコード推論能力を向上させます。実験によると、rStar-Coderデータセットで訓練されたQwenモデル(1.5B~14B)は、複数のコード推論ベンチマークで優れたパフォーマンスを示し、例えばQwen2.5-7BはLiveCodeBenchでの正解率が17.4%から57.3%に向上し、o3-mini (low)を上回りました。USACOでは、7Bモデルもより大きなQWQ-32Bを上回りました。(出典: HuggingFace Daily Papers)
中国科学院自動化研究所がAutoThinkを提案:大規模モデルに「深く考える」かどうかを自律的に決定させる : 大規模言語モデルが簡単な問題に対しても冗長な推論を行う「過度な思考」現象に対し、中国科学院自動化研究所と鹏城实验室は共同でAutoThink手法を提案しました。この手法は、プロンプトに「省略記号」(…)を加え、三段階の強化学習(パターン安定化、行動最適化、推論枝刈り)と組み合わせることで、モデルが問題の難易度に応じて深く考えるかどうか、またどの程度考えるかを自律的に選択できるようにします。実験によると、AutoThinkはDeepSeek-R1などのモデルの数学ベンチマークテストにおける性能を向上させると同時に、推論トークンの消費を大幅に削減します。例えば、DeepScaleRでは追加で10%のトークンを節約できます。この研究は、モデルに「必要に応じた思考」を実現させ、推論効率と正確性のバランスを向上させることを目指しています。(出典: 36氪, _akhaliq)

Sakana AIがSudoku-Benchを発表、トップクラスの大規模モデルの「変種数独」推論における弱点を明らかに : Transformerの作者であるLlion Jones氏のスタートアップ企業Sakana AIは、4×4から複雑な9×9の現代的な「変種数独」を含むベンチマークテストSudoku-Benchを発表しました。これはAIの創造的な多段階推論能力を評価することを目的としています。テスト結果によると、Gemini 2.5 Pro、GPT-4.1、Claude 3.7を含むトップクラスの大規模モデルは、補助なしの場合の全体的な正解率が15%未満であり、9×9の現代数独では、o3 Mini Highの正解率はわずか2.9%でした。これは、モデルがパターンマッチングではなく真の論理推論を必要とする新しい問題に直面した場合にパフォーマンスが低下し、誤った解答、放棄、またはルールの誤判断が頻繁に発生することを示しています。NVIDIAのCEOであるJensen Huang氏は、このようなパズルがAIの推論能力向上に役立つと考えています。Sakana AIはまた、有名な数独チャンネルと協力した解答プロセスの記録を含む関連訓練データも公開しました。(出典: 36氪)

🎯 動向
MetaがAIチームを再編、FAIRのコアメンバー流出が注目を集める : MetaはAIチームの再編を発表し、Connor Hayes氏が率いるAI製品チームと、Ahmad Al-Dahle氏とAmir Frenkel氏が共同で率いるAGI基礎部門に分割しました。前者はC向け製品に注力し、後者はLlamaなどの基礎モデル開発に焦点を当てます。注目すべきは、基礎人工知能研究部門であるFAIRは独立を維持するものの、一部のマルチメディアチームがAGI基礎部門に統合される点です。今回の調整は、開発速度と柔軟性の向上を目的としています。しかし、MetaはLlama 4の反応が芳しくなく、オープンソース分野での競争激化、そしてコア人材の流出という課題に直面しています。当初Llama開発に参加した14人の著者のうち11人が既に退職しており、その多くがMistral AIなどの競合他社に加わるか、または設立しています。FAIRラボもリーダーシップの変更や研究方向の調整を経験しており、社内での地位や将来のイノベーション能力に対する懸念が高まっています。(出典: 36氪)

Google DeepMindがSignGemmaを発表:手話翻訳の新モデル : Google DeepMindは、現在最も強力な手話から話し言葉へのテキスト翻訳モデルであると称するSignGemmaを発表しました。このモデルは今年後半にGemmaモデルファミリーに加わり、オープンソースとして公開される予定です。SignGemmaの発表は、包括的な技術の新たな可能性を切り開き、手話使用者のコミュニケーション効率と利便性を向上させることを目的としています。Google DeepMindはユーザーにフィードバックの提供と早期テストへの参加を呼びかけています。(出典: GoogleDeepMind, demishassabis)
テンセント混元がHunyuanPortraitモデルの重みを公開、静止画ポートレートを動的ビデオに変換可能 : テンセント混元チームは、画像からビデオを生成するモデルHunyuanPortraitのモデルの重みをオープンソース化し、ユーザーがダウンロードしてローカルで使用できるようにしました。このモデルは、静止した人物のポートレート画像を動的なビデオに変換することに特化しており、ゲームキャラクター、バーチャルライバー、デジタルヒューマン、スマートショッピングガイドなど、さまざまな応用シーンに適しており、顔画像を動かし、インタラクションの活気とリアリティを高めることができます。関連するモデル、コードリポジトリ、論文はすべて公開されています。(出典: karminski3, Reddit r/LocalLLaMA)

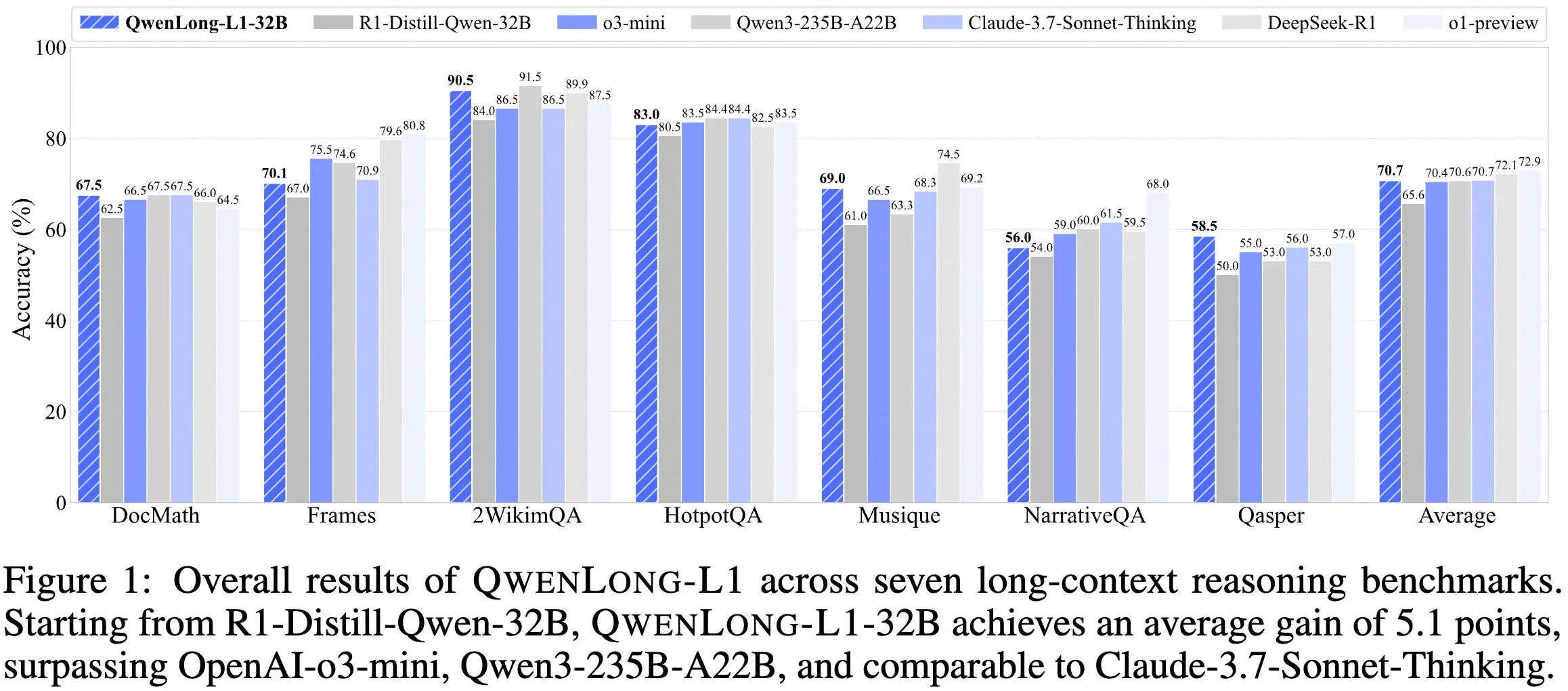
QwenDocチームが長文コンテキスト推論モデルQwenLong-L1-32Bを発表 : QwenDocチームは、強化学習に基づいて訓練された128K長文コンテキスト推論モデルQwenLong-L1-32Bを発表しました。このモデルはDeepSeek-R1-Distill-Qwen-32Bをファインチューニングしたもので、2WikiMultihopQAマルチホップ推論テストセットで90.5点を獲得し、元のモデルより6.5点向上しました。長文コンテキストで内容を見つけるだけでなく、手がかりを繋ぎ合わせて推論できることを強調しています。128Kのコンテキスト長は現在最長ではありませんが、その卓越した推論能力は複雑な長文ドキュメントの処理に新たな選択肢を提供します。モデル、論文、コードライブラリは公開されています。(出典: karminski3)
香港科技大学とAppleなどの機関が協力し、Laserシリーズ手法を発表、大規模モデルの推論効率と精度を最適化 : 香港科技大学、香港城市大学、ウォータールー大学、およびAppleの研究者は、大規模言語モデル(LRM)が簡単な問題で過剰にトークンを消費して推論する問題を解決するために、Laserシリーズ手法(Laser-D、Laser-DEを含む)を提案しました。この手法は、統一された長さ報酬設計フレームワーク、目標長とステップ関数に基づく報酬、および動的な難易度認識メカニズムを通じて、AIME24などの複雑な数学推論ベンチマークにおいて、トークン使用量を63%削減すると同時に、性能を6.1ポイント向上させました。研究によると、訓練後のモデルは冗長な「自己反省」が減少し、思考パターンがより健全になり、モデル推論の効率と精度のバランスが効果的に取れています。(出典: 36氪)

Anthropic Claude無料版がウェブ検索機能に対応 : Anthropicは、AIアシスタントClaudeの無料版ユーザーがウェブ検索機能を利用できるようになったと発表しました。これにより、Claudeは質問に答える際に、インターネットから最新情報を取得して回答の関連性と正確性を高めることができます。公式発表によると、検索結果を含む各回答にはインライン引用が提供され、ユーザーが情報源を確認しやすくなっています。(出典: AnthropicAI)
PKU-DS-LABがFairyR1を発表:DeepSeek-R1-Distill-Qwen-32Bをファインチューニングした32B推論モデル : 北京大学データサイエンスラボ(PKU-DS-LAB)は、32Bパラメータの推論モデルであるFairyR1を発表しました。これはApache 2.0ライセンスを採用しています。このモデルは「蒸留と再統合」の手法により、わずか5%のパラメータを使用するだけで、より大きなモデルの性能に匹敵するとされています。FairyR1はDeepSeek-R1-Distill-Qwen-32Bをファインチューニングしたもので、その訓練データもHugging Face Hubで提供されています。この研究はTinyR1の研究思想を引き継ぎ、データセット(約1万件の軌跡)を積極的にフィルタリングし、数学とコードに対してそれぞれSFTを行い、Arcee Fusionを使用してモデルを統合しています。(出典: huggingface, teortaxesTex, stablequan)
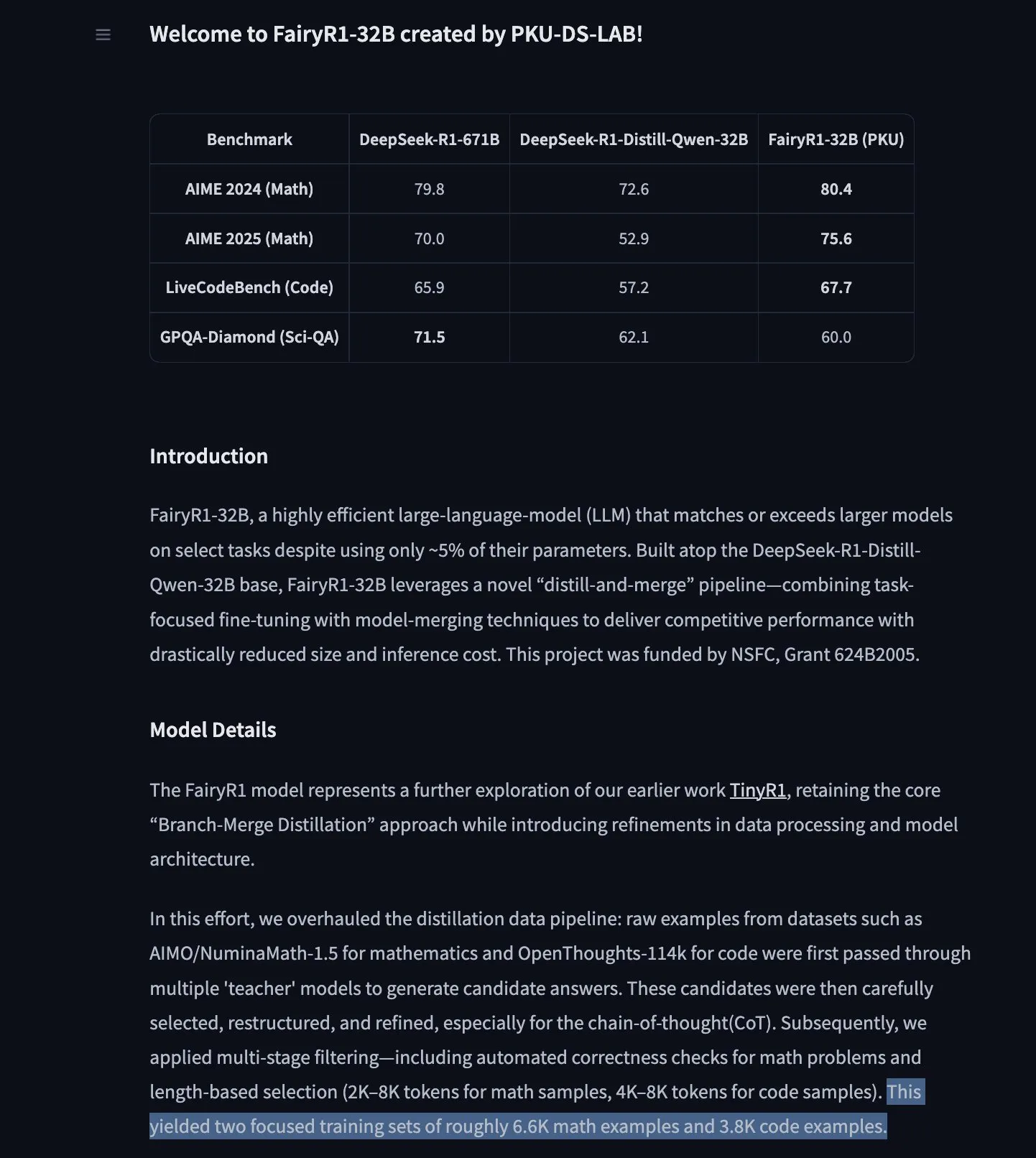
GoogleのTimesFM時系列予測モデルがHugging Face Transformersに登場 : GoogleのTimesFMモデルがHugging Face Transformersライブラリに統合されました。これはGPTのようなモデルで、Google TrendsやWikipediaのページビューなど、さまざまなソースからの1000億個の実世界の時点データで事前学習されています。TimesFMは、ゼロショット予測タスクにおいて、特別にファインチューニングされたモデルよりも優れたパフォーマンスを示すとされており、時系列分析に新たな強力なツールを提供します。(出典: huggingface)
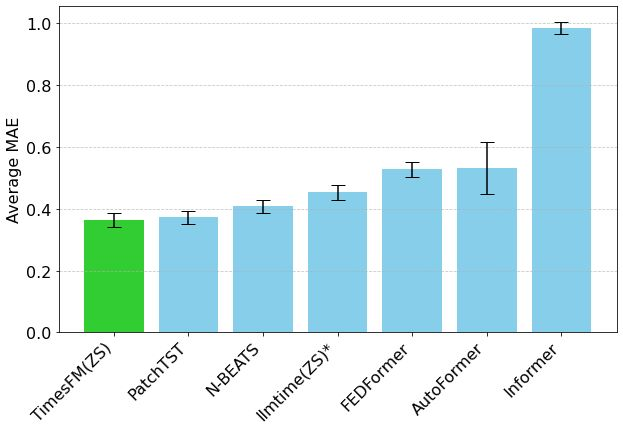
Hugging FaceがMixture of Thoughtsを発表:厳選された汎用推論データセット : Hugging Faceの研究者Lewis Tunstall氏らが「Mixture of Thoughts」データセットを発表しました。このデータセットは、100万を超える公開データサンプルから、大規模なアブレーション実験を通じて約35万サンプルを厳選し、汎用推論能力に焦点を当てています。この混合データセットを使用して訓練されたモデルは、数学、コード、および科学ベンチマーク(GPQAなど)において、DeepSeekの蒸留モデルと同等以上のパフォーマンスを示します。この研究は、Phi-4-reasoningで提案された「加法性」方法論の有効性を検証しており、各推論領域のデータ混合を独立して最適化し、その後統合して最終訓練を行うことができることを示しています。(出典: huggingface)
ByteDanceがBAGEL-7Bを発表:画像・テキストの理解と生成を両立するオムニモデル : ByteDanceは、画像とテキストの両方を理解し生成できるオムニ(omni)モデルであるBAGEL-7Bを発表しました。さらに、ドキュメント解析に特化した視覚言語モデル(VLM)であるDolphinも発表しました。これらのモデルのオープンソース化は、マルチモーダル研究と応用に新たなツールと可能性を提供するでしょう。(出典: huggingface, TheTuringPost)

GoogleがGemini 2.5 Flash Previewを公開、ネイティブ音声出力に対応 : Google AI開発者は、Gemini 2.5 Flash PreviewがLive APIを通じてネイティブ音声出力に対応したことを発表しました。これは、シームレスで自然な話し言葉によるインタラクションと、より強力な音声制御能力を提供することを目的としています。さらに、この音声モデルの新しい実験的な「思考」バージョンも公開され、より複雑なタスクの推論能力をサポートします。同時に、Gemini APIの出力も「思考の要約」を表示し始め、ユーザーがモデルの思考プロセスを理解できるようになりましたが、現在は完全な推論チェーンではありません。(出典: algo_diver, op7418)
論文、Transformerが空白トークンを埋める際の表現能力を議論 : 新しい研究では、Transformerの入力に空白トークンを埋め込むこと(テスト時の計算形式の一種)がLLMの計算能力を強化できるかどうかを議論しています。この研究はAshish_S_AI氏との共同研究であり、パディング付きTransformerの表現能力を正確に描写し、LLMの計算メカニズムの理解と最適化に新たな視点を提供しています。(出典: teortaxesTex)

新研究がSci-Fiフレームワークを提案:対称的制約によるビデオフレーム補間の改善 : 現在のビデオフレーム補間(Frame Inbetweening)手法が、開始フレームと終了フレームの制約を融合する際に制御強度が非対称になる可能性がある問題に対し、新しい論文ではSci-Fi(Symmetric Constraint for Frame Inbetweening)フレームワークを提案しています。この手法は、訓練規模が小さい制約(終了フレームなど)に対してより強力な注入メカニズム(軽量モジュールEF-Netに基づく)を適用することで、開始フレームと終了フレームの制約の対称性を実現し、生成される中間フレームでより調和のとれた遷移効果を生み出し、運動の不一致や外観の崩壊を回避することを目的としています。(出典: HuggingFace Daily Papers)
論文がPaper2Posterを提案:研究論文からマルチモーダルポスターへの自動化プロセス : 学術ポスター制作の課題に対応するため、研究者らは初のポスター生成ベンチマークおよび評価指標スイートPaper2Posterを発表しました。これには論文と著者がデザインしたポスターのペアが含まれ、視覚的品質、テキストの首尾一貫性、全体評価、およびPaperQuiz(ポスターが主要な内容を伝える能力を測定)などの観点から評価を行います。同時に、PosterAgentというトップダウンで視覚情報をループに取り込むマルチエージェントプロセスを提案しました。これには、パーサー(アセット抽出)、プランナー(テキストと視覚の整合およびレイアウト)、そしてペインター・レビュアーサイクル(レンダリングとフィードバックによる最適化)が含まれます。Qwen-2.5などのオープンソースモデルのバリアントは、ほとんどの指標でGPT-4o駆動のシステムを上回り、トークン消費量を87%削減し、非常に低いコストで22ページの論文を編集可能な.pptxポスターに変換できます。(出典: HuggingFace Daily Papers)
論文がFrame In-N-Outを提案:境界のない制御可能な画像からビデオへの生成を実現 : ビデオ生成における制御可能性、時間的一貫性、詳細合成などの課題に対し、新しい論文では映画撮影技術である「Frame In and Frame Out」に焦点を当て、ユーザーが画像内のオブジェクトを自然にシーンから退場させたり、新しいアイデンティティ参照をシーンに導入したりすることを可能にし、ユーザー指定の運動軌跡によって誘導されることを目指しています。このため、研究者らは新しい半自動アノテーションデータセット、包括的な評価プロトコル、および効率的なアイデンティティ保持、運動制御可能なビデオDiffusion Transformerアーキテクチャを導入しました。実験により、この手法が既存のベースラインを大幅に上回ることが示されました。(出典: HuggingFace Daily Papers)
新研究がActive-O3を提案:GRPOを通じてマルチモーダル大規模言語モデルに能動的知覚能力を付与 : マルチモーダル大規模言語モデル(MLLM)の能動的知覚(active perception)に関する探求が不十分であるという問題に対し、研究者らはActive-O3フレームワークを提案しました。このフレームワークは、GRPO(Group Relative Policy Optimization)に基づく純粋な強化学習訓練に基づいており、MLLMにタスク関連情報を収集するために観察位置と方法を能動的に選択する能力を付与することを目的としています。研究者らはまず、MLLMに基づく能動的知覚タスクを体系的に定義し、GPT-o3の拡大探索戦略が能動的知覚の特殊なケースではあるものの、効率と精度が不十分であることを指摘しました。Active-O3は、包括的なベンチマークスイートを構築し、一般的なオープンワールドタスク(小物や密集物体の位置特定など)および特定分野のシナリオ(リモートセンシング、自動運転における小物体の検出、詳細なインタラクションセグメンテーションなど)で評価を行い、V* Benchmarkにおける強力なゼロショット推論能力を示しました。(出典: HuggingFace Daily Papers)
論文がMME-Reasoningを提案:MLLMの論理的推論能力に関する包括的なベンチマークテスト : 既存のベンチマークがマルチモーダル大規模言語モデル(MLLM)の論理的推論能力の評価において不十分であるという問題に対し、研究者らはMME-Reasoningを発表しました。このベンチマークは、帰納、演繹、アブダクションという3つの主要な論理的推論タイプを網羅し、問題が知覚スキルや知識の幅広さではなく、推論能力を効果的に評価できるようにデータを慎重に選別しています。評価結果によると、最先端のMLLMでさえ、包括的な論理的推論評価では限界を示し、異なる推論タイプ間でパフォーマンスの不均衡が存在します。研究ではまた、「思考パターン」やルールベースの強化学習などの手法が推論能力に与える影響を分析し、MLLMの推論能力の理解と評価に体系的な洞察を提供しています。(出典: HuggingFace Daily Papers)
GraLoRA:粒度化低ランク適応によるパラメータ効率の良いファインチューニング性能の向上 : LoRAがランクを上げた際に発生する過学習および性能ボトルネックの問題に対し、研究者らはGraLoRA(Granular Low-Rank Adaptation)を提案しました。この手法は、重み行列をサブブロックに分割し、各サブブロックが独立した低ランクアダプタを持つことで、LoRAの構造的ボトルネックに起因する勾配の絡み合いや伝播の歪みの問題を解決することを目指しています。GraLoRAは、計算コストやストレージコストをほとんど増加させることなく、モデルの表現能力を効果的に向上させ、フルファインチューニングに近い効果を実現します。コード生成および常識推論ベンチマークでの実験によると、GraLoRAは異なるモデルサイズやランク設定において、LoRAや他のベースラインよりも優れており、例えばHumanEval+ではPass@1が絶対値で最大8.5%向上しました。(出典: HuggingFace Daily Papers)
SoloSpeech:カスケード生成パイプラインによるターゲット音声抽出の明瞭度と品質の向上 : ターゲット音声抽出(TSE)において、既存の判別モデルがアーティファクトを導入しやすく自然性を低下させる一方、生成モデルは知覚品質と明瞭度が不十分であるという問題に対し、研究者らはSoloSpeechを提案しました。これは、圧縮、抽出、再構築、修正プロセスを統合した新しいカスケード生成パイプラインです。その特徴は、話者埋め込みなしのターゲット抽出器を採用し、プロンプト音声の潜在空間の条件情報を利用し、それを混合音声の潜在空間と整合させることで不一致を防ぐ点にあります。Libri2Mixデータセットでの評価によると、SoloSpeechはターゲット音声抽出および音声分離タスクにおいて新たなSOTAレベルを達成し、ドメイン外データおよび実環境においても優れた汎化能力を示しました。(出典: HuggingFace Daily Papers)
新研究、テキスト誘導ベクトルによるマルチモーダル大規模言語モデルの視覚理解能力向上を探る : ある新しい研究では、マルチモーダル大規模言語モデル(MLLM)の純粋なテキストLLMバックボーンネットワークから派生した誘導ベクトル(スパースオートエンコーダSAE、平均シフト、線形プロービングなどの手法で取得)を利用して、その視覚理解能力を向上できるかどうかを探っています。研究によると、テキストから派生した誘導ベクトルは、さまざまなMLLMアーキテクチャにおける多様な視覚タスクのマルチモーダル精度を一貫して強化できることがわかりました。特に、平均シフト法はCV-Benchにおいて空間関係の精度を最大7.3%、計数精度を最大3.3%向上させ、プロンプト法よりも優れており、分布外データセットに対しても強力な汎化能力を示しました。これは、テキスト誘導ベクトルが、最小限の追加データ収集と計算コストでMLLMの視覚基盤を強化できる強力かつ効率的なメカニズムであることを示しています。(出典: HuggingFace Daily Papers)
論文がDiSAを提案:拡散ステップアニーリングによる自己回帰型画像生成の高速化 : MAR、FlowARなどの自己回帰モデルが拡散サンプリングを採用して画質を向上させるものの、推論効率が低いという問題に対し、新しい論文ではDiSA(Diffusion Step Annealing)手法を提案しています。この手法は、自己回帰プロセスで生成されるトークンが増えるにつれて、後続トークンの分布がより制約され、サンプリングが容易になるという観察に基づいています。DiSAは訓練不要の手法であり、より多くのトークンを生成する際に拡散ステップを徐々に減少させます(例えば、初期の50ステップから後期の5ステップに減少)。この手法は、拡散自体のために設計された既存の高速化手法と補完的であり、実装が簡単で、MARおよびHarmonで5~10倍、FlowARおよびxARで1.4~2.5倍の高速化を実現し、同時に生成品質を維持します。(出典: HuggingFace Daily Papers)
論文がCASSを提案:NvidiaからAMDへのGPUコード翻訳データセット、モデル、ベンチマーク : 研究者らは、クロスアーキテクチャGPUコード翻訳のための初の大規模データセットおよびモデルスイートであるCASSを発表しました。ターゲットはソースコードレベル(CUDA <-> HIP)およびアセンブリレベル(Nvidia SASS <-> AMD RDNA3)の翻訳を網羅しています。データセットには、検証済みの7万件のクロスホストおよびデバイスコードペアが含まれています。このリソースに基づいて訓練されたCASSシリーズのドメイン特化型言語モデルは、ソースコード翻訳で95%の精度、アセンブリ翻訳で37.5%の精度を達成し、GPT-4oやClaudeなどの商用ベースラインを大幅に上回りました。生成されたコードは、テストケースの85%以上でネイティブ性能に匹敵します。同時に、16のGPUドメインと実実行結果を含むベンチマークテストCASS-Benchも公開されました。すべてのデータ、モデル、評価ツールはオープンソース化されています。(出典: HuggingFace Daily Papers)
論文、視覚言語モデルにおける口頭校正能力を分析 : ある研究では、視覚言語モデル(VLM)が自然言語を通じて信頼度を表現する(すなわち口頭での不確かさ)有効性を包括的に評価しました。研究は3つのモデルカテゴリ、4つのタスクドメイン、3つの評価シナリオにまたがり、その結果、現在のVLMは多くのタスクや設定においてしばしば明らかな校正ミスを示すことが明らかになりました。注目すべきは、視覚推論モデル(すなわち画像で考えるモデル)が一貫してより良い校正性を示したことであり、これは特定のモダリティの推論が信頼性の高い不確かさ推定に不可欠であることを示唆しています。校正の課題に対応するため、研究者らは「視覚的信頼度認識プロンプティング」(Visual Confidence-Aware Prompting)という2段階のプロンプティング戦略を導入し、マルチモーダル設定における信頼度の整合性向上を目指しています。(出典: HuggingFace Daily Papers)
論文、大規模言語モデルにおける語用論的能力の出現を追跡 : 現在のLLMはソーシャルインテリジェンスタスクにおいて新たな能力を示していますが、訓練過程でどのように語用論的能力を獲得するのかはまだ明らかではありません。新しい論文では、語用論の概念である「選択肢」(alternatives)に基づいて設計されたALTPRAGデータセットを導入し、異なる訓練段階のLLMが微妙な話し手の意図を正確に推測できるかどうかを評価しました。22のLLM(事前学習、SFT、嗜好最適化段階を含む)を体系的に評価した結果、基礎モデルでさえ語用論的手がかりに対して顕著な感受性を示し、モデルとデータの規模が増加するにつれて継続的に改善することが示されました。SFTとRLHFはさらに認知語用論的推論能力を向上させました。これらの発見は、語用論的能力がLLMの訓練において出現する組み合わせ特性であることを強調し、モデルが人間のコミュニケーション規範に整合するための新たな洞察を提供します。(出典: HuggingFace Daily Papers)
Video-Holmesベンチマーク公開:複雑なビデオ推論におけるMLLMの「シャーロック・ホームズ的」思考を評価 : 既存のビデオベンチマークが主に視覚的知覚と位置特定能力を評価し、複雑な推論の要求を十分に捉えられていない現状に対し、研究者らはVideo-Holmesベンチマークを発表しました。このベンチマークはシャーロック・ホームズの推論プロセスに着想を得ており、手動でアノテーションされた270本のサスペンス短編映画から抽出された1837個の質問を含み、7つの入念に設計されたタスクにまたがっています。各タスクは、モデルが異なるビデオ断片に散在する複数の関連する視覚的手がかりを能動的に特定し、結びつけることを要求します。SOTA MLLMの評価によると、モデルは視覚的知覚では優れたパフォーマンスを示すものの、情報統合においては著しい困難があり、しばしば重要な手がかりを見逃しています。例えば、最もパフォーマンスの高いGemini-2.5-Proの正解率はわずか45%でした。(出典: HuggingFace Daily Papers)
MME-VideoOCRベンチマーク公開:ビデオシーンにおけるマルチモーダルLLMのOCR能力を評価 : マルチモーダル大規模言語モデル(MLLM)は静止画像のOCRにおいて著しい進歩を遂げていますが、ビデオOCRではモーションブラー、時間的変化、視覚効果などの要因により効果が低下しています。実用的なMLLMの訓練を指導するため、研究者らは広範なビデオOCR応用シーンを網羅するMME-VideoOCRベンチマークを発表しました。このベンチマークは10のタスクカテゴリ(25の独立したタスク)を含み、44の異なるシーンをカバーしており、テキスト認識だけでなく、ビデオ内のテキスト内容のより深い理解と推論も含まれています。ベンチマークには、さまざまな解像度、アスペクト比、長さのビデオ1464本と、入念にキュレーションされた人間によるアノテーション付きの質疑応答ペア2000個が含まれています。18のSOTA MLLMの評価によると、最もパフォーマンスの高いGemini-2.5 Proでさえ、正解率は73.7%にとどまり、既存のモデルがビデオ全体の理解を必要とするタスクを処理する際の限界を露呈しました。(出典: HuggingFace Daily Papers)
MetaMind:メタ認知マルチエージェントシステムによる人間の社会的思考のモデリング : 大規模言語モデル(LLM)が人間のコミュニケーションに固有の曖昧さや文脈の機微を処理する際の不備を埋めるため、研究者らは心理学のメタ認知理論に着想を得たマルチエージェントフレームワークMetaMindを発表しました。これは人間のような社会的推論をシミュレートすることを目的としています。MetaMindは社会的理解を3つの協調段階に分解します。(1)心の理論エージェントがユーザーの心理状態(意図、感情など)の仮説を生成する。(2)ドメインエージェントが文化的規範と倫理的制約を使用してこれらの仮説を洗練する。(3)応答エージェントが文脈に適した応答を生成し、同時に推測された意図との一貫性を検証する。このフレームワークは、3つの挑戦的なベンチマークテストでSOTA性能を達成し、実際の社会的シナリオで35.7%、心の理論推論で6.2%向上し、初めてLLMが重要な心の理論タスクで人間レベルに到達しました。(出典: HuggingFace Daily Papers)
Sparse VideoGen2:セマンティック認識順列とスパースアテンションによるビデオ生成の高速化 : Diffusion Transformers (DiT) ベースのビデオ生成モデルが長いビデオを処理する際に直面する著しい遅延と高いメモリコストの問題に対し、研究者らはSVG2フレームワークを提案しました。このフレームワークは、セマンティック認識順列(k-meansを使用してセマンティック類似性に基づいてトークンをクラスタリングし並べ替える)によって、キーとなるトークン識別の精度を最大化し、計算の無駄を最小化することで、生成品質と効率の間のパレート最適なトレードオフを実現します。SVG2はまた、top-p動的予算制御とカスタマイズされたカーネル実装を統合し、HunyuanVideoとWan 2.1でそれぞれ最大2.30倍と1.89倍の高速化を達成し、同時に高いPSNRを維持します。(出典: HuggingFace Daily Papers)
OmniConsistency:ペアワイズスタイル化データからのスタイル非依存の一貫性の学習 : 画像のスタイル化において拡散モデルが直面する複雑なシーンの一貫性維持(特にアイデンティティ、構図、詳細)および画像から画像への変換プロセスにおけるスタイルLoRAによるスタイル劣化という2つの大きな課題を解決するため、研究者らはOmniConsistencyを提案しました。これは大規模拡散トランスフォーマー(DiT)を利用した汎用的な一貫性プラグインです。その貢献には以下が含まれます。(1) 堅牢な汎化を実現するための、整列された画像ペアに基づくコンテキスト一貫性学習フレームワーク。(2) スタイル学習と一貫性維持を分離し、スタイル劣化を軽減するための2段階の漸進的学習戦略。(3) Fluxフレームワーク下の任意のスタイルLoRAと互換性のある、完全にプラグアンドプレイな設計。実験により、OmniConsistencyは視覚的な一貫性と美的品質を大幅に向上させ、商用SOTAモデルであるGPT-4oに匹敵する性能を達成したことが示されました。(出典: HuggingFace Daily Papers)
ImgEdit:統一された画像編集データセットとベンチマークテスト : オープンソースの画像編集モデルがプロプライエタリモデルに遅れをとっている問題(主に高品質データの不足とベンチマークの不備が原因)を解決するため、研究者らはImgEditを発表しました。これは大規模で高品質な画像編集データセットであり、120万件の入念にキュレーションされた編集ペアを含み、斬新で複雑な単一ラウンド編集と挑戦的な複数ラウンドタスクを網羅しています。データ品質を確保するため、最先端の視覚言語モデル、検出モデル、セグメンテーションモデル、およびタスク固有の修復プログラムと厳格な後処理を統合した多段階プロセスを採用しました。ImgEditで訓練された編集モデルImgEdit-E1は、多くのタスクで既存のオープンソースモデルを上回りました。同時に、指示追従性、編集品質、詳細保持の観点から画像編集を評価するためのImgEdit-Benchベンチマークも発表されました。(出典: HuggingFace Daily Papers)
論文、誘導目標アトムによるLLMにおける堅牢な行動制御を提案 : 言語モデルの生成を正確に制御し、安全性と信頼性を確保するため、新しい論文では「誘導目標アトム」(Steering Target Atoms, STA)手法を提案しています。この手法は、分離された知識コンポーネントを分離・操作することで安全性を強化し、特に敵対的シナリオにおいて優れた堅牢性と柔軟性を示すことを目指しています。研究者らは、プロンプトエンジニアリングや誘導はモデルの行動に介入するためによく使用されるものの、モデルパラメータの高度な絡み合いが制御精度を制限し、副作用を引き起こす可能性があると考えています。STAは、スパースオートエンコーダ(SAE)を利用して高次元空間の知識を分離し、それを誘導することで、より正確な行動制御を実現します。実験によりこの手法の有効性が証明され、大規模推論モデルにも適用されており、正確な推論制御におけるその可能性が確認されています。(出典: HuggingFace Daily Papers)
論文がSeePhysベンチマークを提案:視覚ベースの物理推論能力を評価 : 研究者らは、LLMが中学生から博士課程資格試験レベルの物理問題における推論能力を評価するための大規模マルチモーダルベンチマークSeePhysを発表しました。このベンチマークは物理学の7つの基礎分野を網羅し、21種類の非常に異質な図表を含んでいます。これまでの視覚要素が主に補助的な役割を果たす研究とは異なり、SeePhysでは問題の75%が視覚的に必須であり、つまり正しく解答するためには視覚情報を抽出する必要があります。広範な評価によると、Gemini-2.5-proやo4-miniなどの最先端の視覚推論モデルでさえ、このベンチマークでの正解率は60%未満であり、現在のLLMが視覚理解、特に図表解釈と物理推論の厳密な結合、およびテキスト手がかりへの認知ショートカット依存の克服において根本的な課題を抱えていることを明らかにしています。(出典: HuggingFace Daily Papers)
VerIPO:検証器誘導型反復的方策最適化によるVideo-LLMの長距離推論能力向上 : 強化学習をビデオ大規模言語モデル(Video-LLM)に適用する際に、複雑なビデオ推論におけるデータ準備のボトルネックや思考の連鎖(CoT)の品質不安定性の問題に対し、研究者らはVerIPO(Verifier-guided Iterative Policy Optimization)手法を提案しました。この手法の中核は、GRPOとDPOの訓練段階の間に位置する「Rollout-Aware Verifier」であり、推論ロジックを評価し、高品質な対照データ(反省的で文脈に一貫したCoTを含む)を構築します。これらのデータは効率的なDPO段階を駆動し、それによって推論チェーンの長さと文脈的一貫性を向上させます。実験結果によると、VerIPOはモデルをより迅速かつ効果的に最適化し、より長く文脈に一貫したCoTを生成し、標準的なGRPOバリアントや一部の大規模命令ファインチューニングVideo-LLMおよび長距離推論モデルを上回る性能を示します。(出典: HuggingFace Daily Papers)
OpenS2V-Nexus:主体からビデオへの生成のための詳細なベンチマークと百万規模のデータセット : 主体からビデオへの(S2V)生成技術の発展を促進するため、研究者らはOpenS2V-Nexusを提案しました。これには、(i) 詳細なベンチマークであるOpenS2V-Evalと、(ii) 百万規模のデータセットであるOpenS2V-5Mが含まれます。既存のS2Vベンチマーク(VBenchを継承し、グローバルかつ粗粒度な評価に重点を置く)とは異なり、OpenS2V-Evalは、モデルが主体の一貫性を保ち、自然な外観で、アイデンティティの忠実度が高いビデオを生成する能力に焦点を当てています。このため、OpenS2V-Evalは、7つの主要なS2Vカテゴリから180のプロンプトを導入し、実データと合成テストデータの両方を含んでいます。さらに、人間の嗜好を正確に整合させるため、研究者らは3つの自動評価指標、NexusScore、NaturalScore、GmeScoreを提案し、それぞれ生成されたビデオにおける主体の一貫性、自然さ、テキスト関連性を定量化します。これに基づき、16の代表的なS2Vモデルを包括的に評価しました。同時に、初のオープンソース大規模S2V生成データセットOpenS2V-5Mを作成しました。これには500万件の高品質な720Pの主体-テキスト-ビデオの三つ組が含まれています。(出典: HuggingFace Daily Papers)
論文がWHISTRESSを提案:文アクセント検出による転写テキストの拡充 : 話し言葉における文アクセントが話し手の意図を伝える上で重要であるにもかかわらず、既存の転写システムでは欠落しているという問題に対し、新しい論文ではアライメント不要の文アクセント検出手法WHISTRESSを紹介しています。このタスクをサポートするため、研究者らは完全自動プロセスで作成されたスケーラブルな合成訓練データセットTINYSTRESS-15Kを提案しました。このデータセットで訓練されたWHISTRESSモデルは、性能において既存のベースラインを上回り、追加の訓練や推論の事前入力も不要です。注目すべきは、合成データに基づいて訓練されたにもかかわらず、WHISTRESSは複数のベンチマークテストで強力なゼロショット汎化能力を示したことです。(出典: HuggingFace Daily Papers)
論文がInstructPartを提案:指示推論を伴うタスク指向部品分割 : 大規模マルチモーダル基盤モデルは様々なタスクで進歩を遂げているものの、多くのモデルは物体を分割不可能な全体として扱い、物体を構成する部品を無視しています。これらの部品とその関連する機能的可視性(アフォーダンス)を理解することは、広範なタスクを実行するために不可欠です。このため、研究者らは、日常的な状況における部品レベルのタスクを理解し実行する現在のモデルの性能を評価するために、手作業でラベル付けされた部品分割アノテーションとタスク指向の指示を含む新しい実世界ベンチマークInstructPartを導入しました。実験によると、SOTAの視覚言語モデル(VLM)にとっても、タスク指向の部品分割は依然として困難な問題です。ベンチマークに加えて、研究者らは簡単なベースラインを導入し、そのデータセットを使用してファインチューニングすることで、2倍の性能向上を達成しました。(出典: HuggingFace Daily Papers)
論文、ハイブリッドニューラル-MPM手法を提案、リアルタイムインタラクティブ流体シミュレーションを実現 : 従来の物理手法は計算集約的で遅延が大きく、最近の機械学習手法はコストを削減したもののリアルタイムインタラクションの要求を満たすのが依然として困難であるという流体シミュレーションの問題を解決するため、研究者らは新しいハイブリッド手法を提案しました。この手法は、数値シミュレーション、ニューラル物理学、生成的制御を統合しています。そのニューラル物理学は、古典的な数値ソルバーへのフォールバックという保障メカニズムを通じて、低遅延シミュレーションと高い物理的忠実度を両立させることを目指しています。さらに、研究者らは、流体操作のための外部動的力場を生成するために、逆モデリング戦略を使用して訓練された拡散ベースのコントローラーを開発しました。このシステムは、様々な2D/3Dシーン、材料タイプ、障害物との相互作用において堅牢な性能を示し、高フレームレートのリアルタイムシミュレーション(11~29%の遅延)を実現し、ユーザーフレンドリーな手描きスケッチによる流体制御を可能にします。(出典: HuggingFace Daily Papers)
MMIG-Bench:マルチモーダル画像生成モデル向けの包括的な解釈可能評価ベンチマーク : GPT-4o、Gemini 2.0 Flash、Gemini 2.5 Proなどのマルチモーダル画像生成器の評価において、既存の評価ツールが抱える限界(例えば、T2Iベンチマークはマルチモーダル条件を欠き、カスタム画像生成ベンチマークは組み合わせ意味論や常識を無視する)に対し、研究者らはMMIG-Benchを提案しました。これは、4850個の豊富なアノテーション付きテキストプロンプトと、380の主題(人物、動物、物体、芸術スタイル)を網羅する1750個のマルチビュー参照画像を含む、包括的なマルチモーダル画像生成ベンチマークです。MMIG-Benchは3段階の評価フレームワークを備えています。(1)低レベル指標は視覚的アーティファクトと物体アイデンティティ保持を評価する。(2)新しいアスペクトマッチングスコア(AMS):VQAに基づく中レベル指標で、詳細なプロンプト-画像アライメントを提供し、人間の判断と高い相関がある。(3)高レベル指標は美的感覚と人間の嗜好を評価する。MMIG-Benchを通じて17のSOTAモデルをベンチマークテストし、3万2千件の人間の評価で指標を検証することで、アーキテクチャとデータ設計に関する深い洞察を提供します。(出典: HuggingFace Daily Papers)
論文がHRPOを提案:強化学習によるハイブリッド潜在推論の実現 : 既存の潜在推論手法がLLMの自己回帰的生成特性と互換性がなく、CoT軌跡に依存して訓練されるという問題に対し、研究者らはHRPO(Hybrid Reasoning Policy Optimization)を提案しました。これは強化学習に基づくハイブリッド潜在推論手法であり、学習可能なゲートメカニズムを通じて以前の隠れ状態をサンプリングされたトークンに統合し、トークン埋め込みを主として初期訓練を行い、徐々により多くの隠れ特徴を取り込みます。この設計はLLMの生成能力を維持し、離散的および連続的表現を使用したハイブリッド推論を奨励します。さらに、HRPOはトークンサンプリングを通じて潜在推論にランダム性を導入するため、CoT軌跡なしでRLベースの最適化が可能です。様々なベンチマークでの広範な評価によると、HRPOは知識集約型および推論集約型の両タスクにおいて従来の手法を上回ります。(出典: HuggingFace Daily Papers)
論文がNFT手法を提案:数学的推論における教師あり学習と強化学習の接続 : 「自己改善は強化学習(RL)に限定される」という一般的な考え方に挑戦し、新しい論文ではネガティブ認識ファインチューニング(Negative-aware Fine-Tuning, NFT)手法を提案しています。これは教師あり学習手法であり、LLMが自身の失敗を反省し、外部の教師なしで自律的に改善することを可能にします。オンライン訓練において、NFTは自己生成された誤答を破棄せず、それらをモデル化するための暗黙的なネガティブ方策を構築します。この暗黙的な方策は、ポジティブデータで最適化するために使用される目標のポジティブLLMと同じパラメータ化を持つため、すべてのLLMの生成に対して直接的な方策最適化が可能になります。7Bおよび32Bモデルにおける数学的推論タスクの実験結果によると、ネガティブフィードバックを追加利用することで、NFTは拒否サンプリングファインチューニングなどの教師あり学習ベースラインを大幅に上回り、GRPOやDAPOなどの主要なRLアルゴリズムに匹敵するか、それを超える性能を示しました。研究者らはさらに、厳密なオンライン方策訓練において、NFTとGRPOが実際には等価であることを証明しました。(出典: HuggingFace Daily Papers)
論文がMinute-Long Videos with Dual Parallelismsを提案:分単位のビデオ生成を実現 : DiTベースのビデオ拡散モデルが長いビデオを生成する際に直面する計算遅延とメモリコストが高すぎるという問題に対し、研究者らは新しい分散推論戦略DualParalを提案しました。この手法の中核となる考え方は、時間フレームとモデル層を複数のGPUに並列化することです。拡散モデルがフレーム間のノイズレベル同期を要求するために元の並列性が逐次化される問題を解決するため、この手法はブロック単位のデノイズスキームを採用しています。つまり、一連のフレームブロックをパイプライン処理し、徐々にノイズレベルを下げていきます。各GPUは特定のブロックと層のサブセットを処理し、以前の結果を次のGPUに渡すことで、非同期計算と通信を実現します。さらに、各GPUに特徴キャッシュを実装して以前のブロックの特徴をコンテキストとして再利用し、協調的なノイズ初期化戦略を採用することで、グローバルに一貫した時間的ダイナミクスを確保し、高速でアーティファクトのない、無限長のビデオ生成を実現します。最新の拡散トランスフォーマービデオ生成器に適用した結果、この手法は8台のRTX 4090 GPUで1025フレームのビデオを効率的に生成し、遅延を最大6.54倍削減し、メモリコストを1.48倍削減しました。(出典: HuggingFace Daily Papers)
🧰 ツール
Claude 4シリーズモデルがプログラミングタスクで際立った性能を発揮、ベテランプログラマーを4年間悩ませた「白鯨バグ」を解決 : Anthropicが最近発表したClaude Opus 4モデルは、プログラミング能力において驚くべき実力を示しました。30年のC++開発経験を持つ元FAANGのエンジニアによると、彼のチームを4年間悩ませ、彼自身が約200時間を費やしても解決できなかった複雑なシステムバグ(特定のシェーダーが特定の方法で使用された場合に発生する境界条件の問題)を、Claude Opus 4が数時間で約30のプロンプトを通じて特定し、原因を突き止めました。このバグはシステム再構築前には存在せず、Opus 4は新しいアーキテクチャが旧アーキテクチャ下で「偶然」サポートされていた非設計的な動作と互換性がないことが原因であると指摘しました。以前は、GPT-4.1、Gemini 2.5、およびClaude 3.7はいずれもこの問題を解決できませんでした。これは、Claude 4が複雑なコードを理解し、詳細な分析と推論を行う強力な能力を持っていることを浮き彫りにしており、特にClaude Codeモードと組み合わせることで、開発者がコードの再構築、バグ修正などの高度なエンジニアリングタスクを処理するのに効果的に役立ちます。(出典: 36氪, dotey)
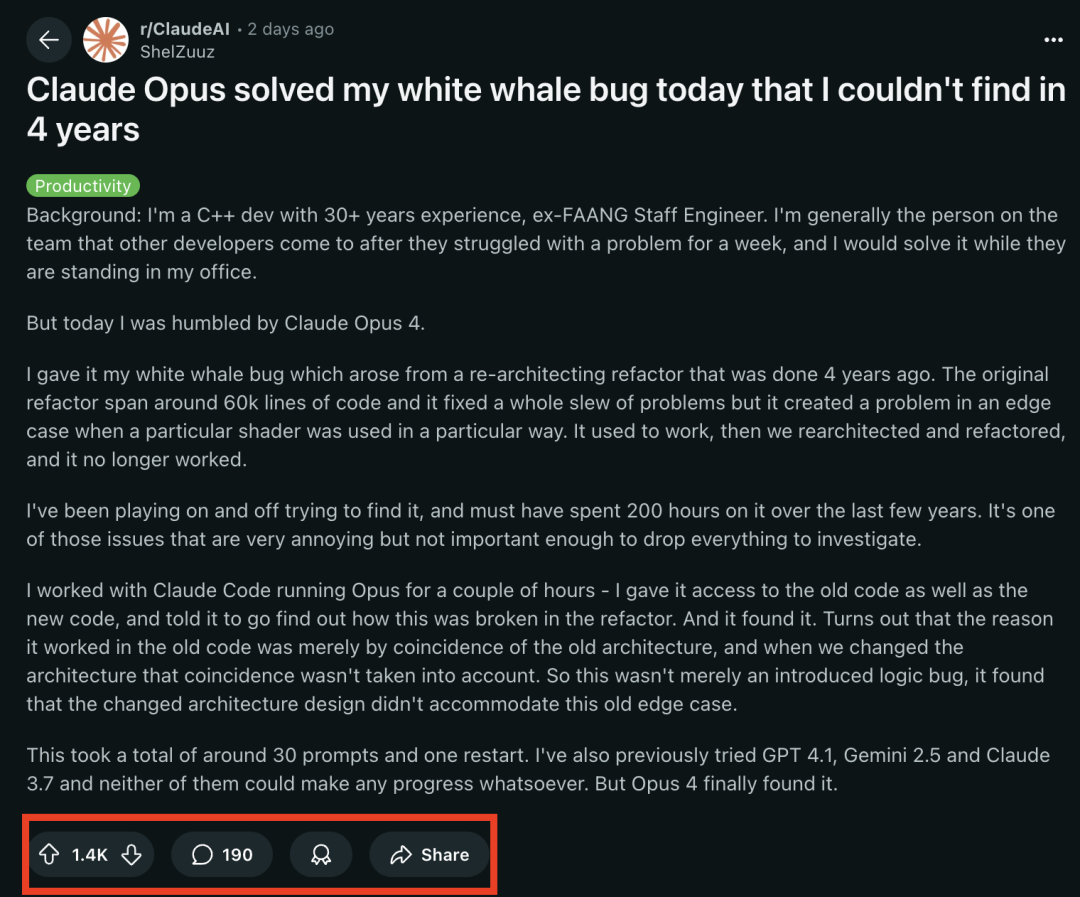
LangChainがAnthropic Claudeの新しいベータ機能に対応 : LangChainは、Anthropic Claudeモデルが最近リリースした4つの新しいベータ機能(コード実行、リモートMCPコネクタ、ファイルAPI、および拡張プロンプトキャッシュ)を統合したことを発表しました。開発者はLangChainドキュメントで関連する例を確認し、これらの新機能を利用してより強力なAIアプリケーションを構築できるようになりました。(出典: LangChainAI)
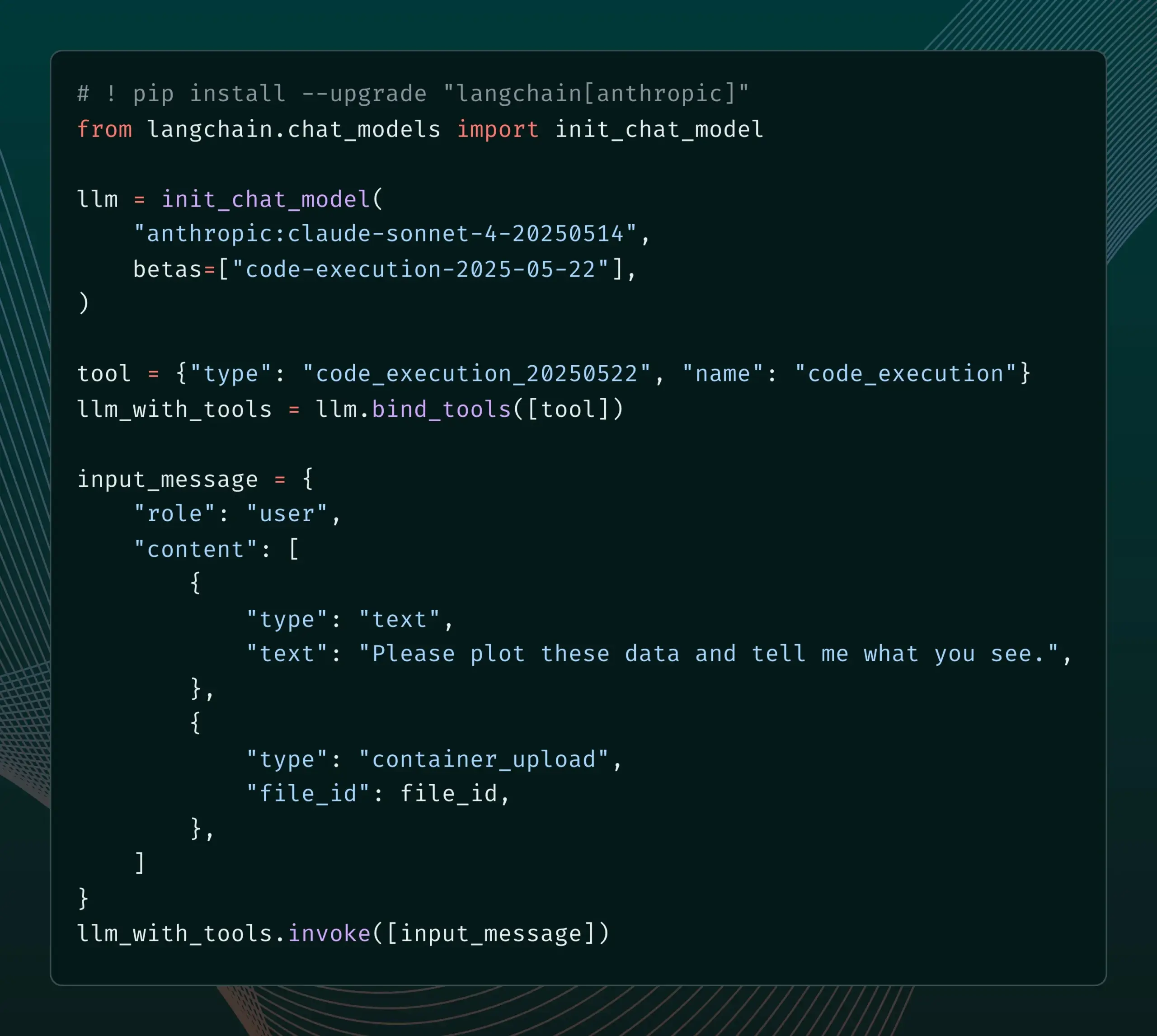
LangSmithがSDLCと統合されたプロンプト管理機能を発表 : LangSmithプラットフォームはプロンプトエンジニアリング能力を強化し、ユーザーはLangSmith内でプロンプトのテスト、バージョン管理、共同作業を行えるだけでなく、プロンプト変更時のwebhookトリガーを通じて、プロンプトをGitHubや外部データベースに自動的に同期したり、CI/CDプロセスを開始したりできるようになりました。この機能は、開発者がプロンプト管理をソフトウェア開発ライフサイクル(SDLC)により緊密に統合するのに役立つことを目的としています。(出典: LangChainAI)
AutoThink:ローカルLLMの推論性能を向上させる適応型技術 : CodeLionチームはAutoThink技術を開発し、適応的なリソース割り当てとステアリングベクター(steering vectors)を通じてローカルLLMの推論性能を大幅に改善しました。AutoThinkはクエリの複雑さを分類し、「思考トークン」を動的に割り当て(複雑な問題にはより多く、簡単な問題にはより少なく)、ステアリングベクターを使用して推論パターンを誘導します。DeepSeek-R1-Distill-Qwen-1.5Bモデルでのテストでは、GPQA-Diamondの正解率が43%向上し(21.72%から31.06%へ)、MMLU-Proも向上し、トークン使用量も削減されました。この技術は思考トークンをサポートするローカル推論モデルと互換性があり、コードと研究は公開されています。(出典: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Transformer LabがAMD ROCmのサポートを発表、LLMのローカル訓練が可能に : Transformer Labは、そのGUIプラットフォームがAMD GPU上でROCmを使用した大規模言語モデルのローカル訓練とファインチューニングに対応したことを発表しました。チームによると、ROCmの設定プロセスは困難を極め、その全過程をブログに記録したとのことです。現在、この機能はスムーズに使用可能であり、ユーザーはAMDハードウェア上でLLMの開発作業を試すことができます。(出典: Reddit r/MachineLearning)
オープンソースLLM強化型マルチエージェントシステムが自動的な主張抽出と事実確認を実現 : 「fact-checker」というオープンソースプロジェクトは、LLM強化型マルチエージェントシステム(MAS)を利用して、自動的な主張抽出、証拠検証、事実解決を実現します。このプロジェクトにはブラウザ拡張機能が含まれており、あらゆるAIチャットボットの応答に対してリアルタイムで事実確認を行うことができ、AI生成コンテンツの真実性を見分けるのに役立ちます。そのコードアーキテクチャは明確で、ドキュメントも充実しており、AIの安全性と誤情報対策の分野に価値あるツールを提供しています。(出典: Reddit r/MachineLearning)
美団がノーコード製品Nocodeを発表、複雑な複数ページアプリケーションの生成をサポート : 美団はNocodeというVibe Coding製品を発表しました。ユーザーは自然言語で記述することで、単純な表示型ウェブページだけでなく、複数のページを含む複雑な完全なアプリケーションを生成できます。帰藏氏のテストによると、このツールは論理的に複雑な倉庫商品管理ツールを一度で正常に構築でき、複雑な要求を理解し、対応するコードを生成する能力を示しました。(出典: op7418)
LlamaIndexがカスタムマルチモーダルエンベッダーの構築およびOpenAI風チャットUIとの統合をサポート : LlamaIndexはアップデートを発表し、ユーザーがカスタムマルチモーダルエンベッダー(例えばAWS Titan Multimodalの統合)を構築し、Pineconeなどのベクトルデータベースと組み合わせて効率的なテキスト+画像ベクトル検索を行えるようになりました。さらに、LlamaIndexワークフローは数行のコードでOpenAIのようなチャットインターフェースで実行できるようになり、UI内で直接ワークフローコードを編集できる開発モードもサポートし、RAGアプリケーションの開発とインタラクション体験を向上させました。(出典: jerryjliu0, jerryjliu0)

TRAEがAgenticコーディング体験を強化するアップデート、海外版は有料サブスクリプションを開始 : AIプログラミングツールTRAEがアップデートされ、Agenticコーディング体験が最適化され、手動操作を好まないユーザーに適したものになりました。新バージョンのTRAEは、過去の会話をよりよく記憶し、コンテキストを自動的に関連付け、AIがプログラミングパスを自動的に計画し、より多くのツールを呼び出すことで、プログラミングタスクの成功率を向上させました。例えば、ユーザーが空のフォルダとプロンプトを提供するだけで、TRAEはファイルの作成、Webサーバーの起動(クロスドメイン問題を自動処理)、IDE内でのp5.jsアニメーションのプレビューなど、一連の操作を完了できます。その海外版は有料サブスクリプションを開始し、初月のPro価格は3ドルで、Alipayをサポートしています。(出典: dotey, karminski3)
掘金コミュニティがMCPサービスを開始、フロントエンドコードのワンクリック公開をサポート : 中国国内のプログラマーコミュニティ掘金はMCP(Model-driven Co-programming Protocol)サービスを開始し、開発者がフロントエンドコード(vibe codingで生成されたウェブページやゲームなど)を掘金プラットフォームにワンクリックで公開し、迅速な共有とプレビューを容易にしました。ユーザーは掘金MCPのトークンを取得し、TraeやCursorなどのツールで設定する必要があります。(出典: dotey, karminski3)
オープンソースの時間追跡ツールActivityWatchがRizeの代替品として注目 : ユーザーkarminski3氏は、AI時間分析ツールRize(プロセス名を分析して仕事、会議、またはサボり状態を判断、月額20ドル)を体験した後、オープンソースの代替品ActivityWatchを見つけて推奨しました。ActivityWatchは同様の機能を持ち、Windows/Macをサポートし、ユーザーによるカスタマイズも可能で、仕事の不安を和らげ、作業時間を追跡するための優れたツールと見なされています。(出典: karminski3)
オープンソースAIベビーモニターツールai-baby-monitorが公開 : ai-baby-monitorというオープンソースプロジェクトが公開されました。これはQwen2.5 VLモデルとvLLM推論フレームワークを使用し、ユーザーがルール(「子供が起きたらアラーム」、「子供が一人でいたらアラーム」など)を定義してAIに乳幼児の見守りを補助させることができます。開発者はこれが補助ツールであり、人間の見守りを完全に代替するものではないことを強調しています。(出典: karminski3)
LangChainがxAIのLive Search機能を統合 : LangChainはxAIのLive Search機能のサポートを発表しました。この機能により、Grokモデルは回答を生成する際にウェブ検索結果に基づいて行い、期間や含まれるドメインなどの検索パラメータといった様々な設定オプションを提供します。ユーザーはLangChainでこの新機能を試すことができます。(出典: LangChainAI)
Curie:オープンソースAI研究アシスタントがAutoML機能を発表、学際的研究を支援 : 生物学、材料科学、化学などの分野の研究者が機械学習を応用する際に直面する専門知識の壁に対し、Curieプロジェクトは新しいAutoML機能を発表しました。CurieはAI研究実験の共同科学者となることを目指し、複雑なMLプロセス(アルゴリズム選択、ハイパーパラメータ調整、モデル出力解釈など)を自動化することで、研究者が迅速に仮説を検証し、データから洞察を抽出するのを支援します。例えば、Curieは黒色腫検出タスクでAUCが0.99のモデルを生成しました。このプロジェクトはオープンソース化されており、コミュニティの貢献を奨励しています。(出典: Reddit r/LocalLLaMA)
アリババMNN ChatがAndroidデバイスでのQwen 30B-a3bモデルのローカル実行をサポート : アリババのMNN Chatアプリがバージョン0.5.0にアップデートされ、Androidデバイス上でQwen 30B-a3bのような大規模言語モデルをローカルで実行できるようになりました。ユーザーからのフィードバックによると、フラッグシップ級のチップと大容量メモリ(OnePlus 13 24Gなど)を搭載したデバイスで正常に動作し、mmap設定を有効にすることが推奨されています。しかし、30Bパラメータモデルはほとんどのスマートフォンにとってメモリと計算能力の要求が高すぎ、Gemma 3nの方がモバイル端末に適している可能性があるというコメントもあります。(出典: Reddit r/LocalLLaMA)

📚 学び
新論文がLean and Mean Adaptive Optimizationを提案:より高速でメモリ効率の良い大規模モデル訓練オプティマイザ : ICML 2025に採択された論文では、「Lean and Mean Adaptive Optimization via Subset-Norm and Subspace-Momentum」という新しいオプティマイザが紹介されています。この手法は、Subset-NormステップサイズとSubspace-Momentumという2つの補完的な技術を通じて、大規模ニューラルネットワーク訓練のメモリ要件を削減し、訓練を高速化することを目指しています。GaLoreやLoRAなどの既存のメモリ効率の良いオプティマイザと比較して、この手法はメモリを節約し(例えば、LLaMA 1Bの事前訓練時にAdamよりもオプティマイザ状態メモリを80%削減)、より少ない訓練トークン(約半分)でAdamの検証パープレキシティを達成し、より強力な理論的収束保証を提供します。(出典: Reddit r/MachineLearning)
論文がForce Promptingを提案:ビデオ生成モデルに物理ベースの制御信号を学習・汎化させる : ある新しい研究では、物理的な力をビデオ生成の制御信号として使用する可能性を探求し、「力プロンプト」(Force Prompts)を提案しています。ユーザーは、局所的な点力(植物をつつくなど)や全体的な風力場(風で布がなびくなど)によって画像と対話できます。研究によると、ビデオ生成モデルは、Blenderで合成された、少数の物体デモンストレーションのみを含むビデオから物理的な力の条件を学習し汎化でき、推論時に3Dアセットや物理シミュレータを使用することなく、物理的な制御信号にリアルに応答するビデオを生成できます。視覚的多様性と訓練時の特定のテキストキーワードの使用が、このような汎化を実現するための重要な要因です。(出典: HuggingFace Daily Papers)
AnkiHubがAIアノテーションワークフローを共有、FastHTMLとの連携で効率向上 : AnkiHubはAIアノテーションワークフローを共有し、Hamel Husain氏とShreya Shankar氏のAI評価コースでデモンストレーションを行いました。このワークフローはFastHTML構築ツールを利用し、商用製品のAIアノテーション効率を改善することを目的としています。関連する教材とコードリポジトリはGitHubで公開されており、実際の生産で使用されるツールを使ってAI開発を最適化する方法を示しています。(出典: jeremyphoward, HamelHusain)

ブロガーがPPOからGRPOへの学習体験を執筆、LLMファインチューニングにおける強化学習の概念を解説 : あるブロガーが、強化学習(RL)とその大規模言語モデル(LLM)ファインチューニングへの応用、特にPPO(Proximal Policy Optimization)からGRPO(Group Relative Policy Optimization)への理解過程についての学習経験を共有しました。ブログ記事は、学習初期に知りたかった概念を説明し、他の人がこれらのRLアルゴリズムがLLMの最適化にどのように使用されるかをよりよく理解するのに役立つことを目的としています。(出典: Reddit r/MachineLearning)
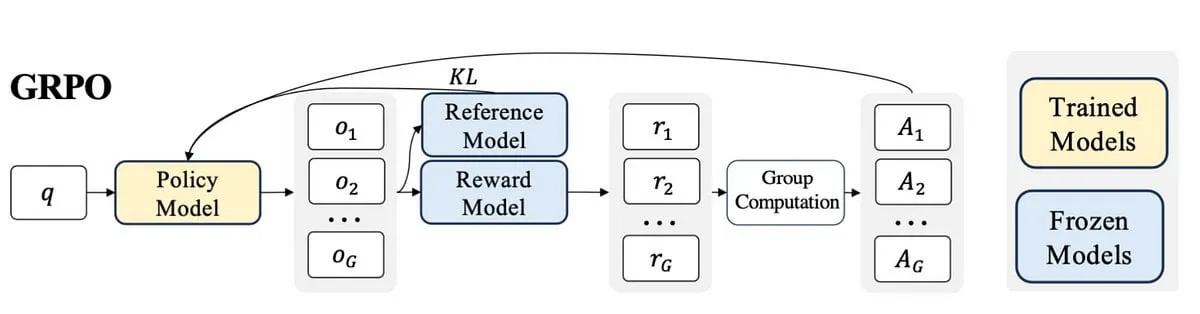
論文、機械の語用論的思考を探る:大規模言語モデルにおける語用論的能力の出現を追跡 : 新しい論文では、大規模言語モデル(LLM)が訓練過程でどのように語用論的能力(pragmatic competence)、すなわち暗黙の意味や話し手の意図などを理解し推測する能力を獲得するのかを研究しています。研究者らは、語用論における「代替案」(alternatives)の概念に基づいてALTPRAGデータセットを導入し、異なる訓練段階(事前学習、教師ありファインチューニングSFT、嗜好最適化RLHF)の22のLLMを評価しました。結果として、基礎モデルでさえ語用論的手がかりに対して顕著な感受性を示し、モデルとデータの規模が増加するにつれて継続的に改善すること、SFTとRLHFがさらに認知語用論的推論能力を強化することが示されました。これは、語用論的能力がLLMの訓練における出現的かつ組み合わせ的な特性であることを示唆しています。(出典: HuggingFace Daily Papers)
論文、視覚ツール選択のための強化学習フレームワークVisTAを探る : 研究者らは、視覚エージェントが経験的パフォーマンスに基づいて異なるライブラリのツールを動的に探索、選択、組み合わせることを可能にする新しい強化学習フレームワークVisTA (VisualToolAgent) を導入しました。訓練なしのプロンプトや大規模なファインチューニングに依存する既存の手法とは異なり、VisTAはエンドツーエンドの強化学習を利用し、タスクの結果をフィードバック信号として使用して、複雑でクエリ固有のツール選択戦略を反復的に最適化します。GRPO (Group Relative Policy Optimization) を通じて、このフレームワークはエージェントが明確な推論の教師なしで効果的なツール選択パスを自律的に発見することを可能にします。ChartQA、Geometry3K、およびBlindTestベンチマークでの実験は、VisTAが訓練なしのベースラインと比較して、特に分布外サンプルにおいて顕著なパフォーマンス向上を達成することを示しています。(出典: HuggingFace Daily Papers)
💼 ビジネス
データサービス企業、景联文科技が数千万元のPre-Aラウンド資金調達を完了、公共データ生産運営に注力 : AIデータサービスプロバイダーの景联文科技は最近、杭州金投集団傘下のファンドから数千万元のPre-Aラウンド資金調達を完了しました。調達資金は、公共データの生産運営、インテリジェントなコーパスエンジニアリングプラットフォームの構築、および垂直分野における高品質アノテーション拠点の自社建設に充当されます。同社は2012年に設立され、公共データ、AI大規模モデル、自動運転、医療などの分野に焦点を当て、公共データの「ガバナンスの困難さ、供給不足、流動性の低さ、活用の悪さ、セキュリティの脆弱さ」といった課題の解決を目指しており、ファーウェイのデータストレージと提携してAIデータレイク共同ソリューションを発表しています。今年の収益成長率は400%を超える見込みです。(出典: 36氪)
美図、アリババから約2.5億ドルの転換社債型新株予約権付社債による投資を受け、AI分野での協力を深化 : 美図公司はアリババとの戦略的協力を計画していると発表し、アリババは美図に対し総額約2.5億ドルの転換社債型新株予約権付社債を発行します。両社は電子商取引プラットフォームのプロモーション、AI技術(AI画像、AIビデオ)開発、クラウドコンピューティングなどの分野で協力し、美図は今後3年間でアリババクラウドから5.6億元以上のサービスを調達することを約束しました。この協力は、アリババのエコシステムを活用して電子商取引シーンの潜在力を掘り起こし、美図のAIデザインツールの有料ユーザー規模と研究開発レベルを向上させることを目的としています。この動きは一時的に美図の株価を押し上げましたが、市場の注目点は、美図が激しい市場競争の中でKimiがユーザー成長の鈍化という轍を踏むのをいかに避けるか、特に視覚AI分野で大手企業との激しい競争と規模の違いに直面している点にあります。(出典: 36氪)
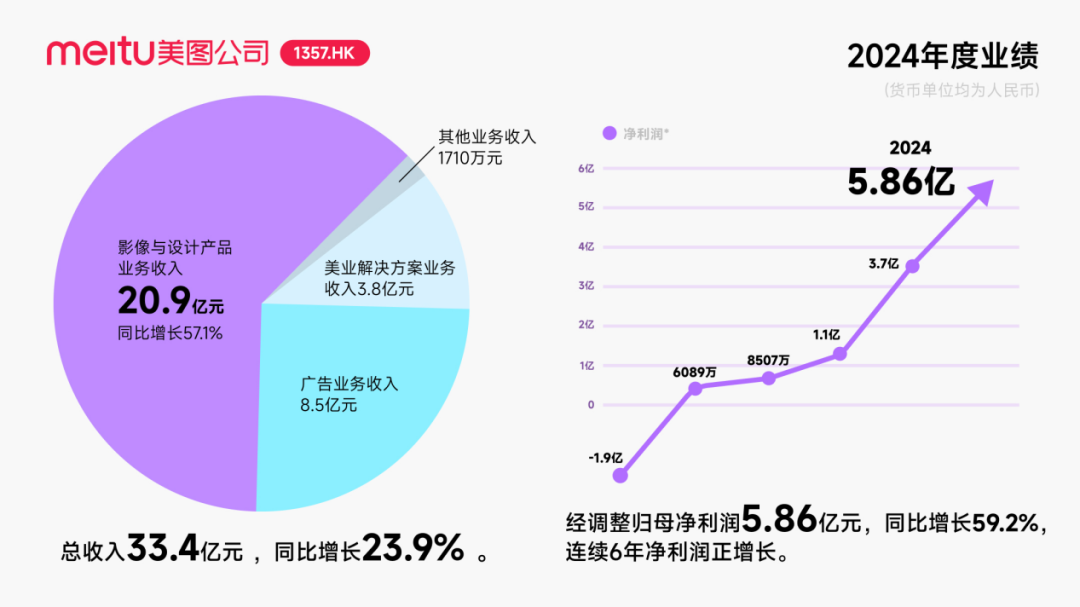
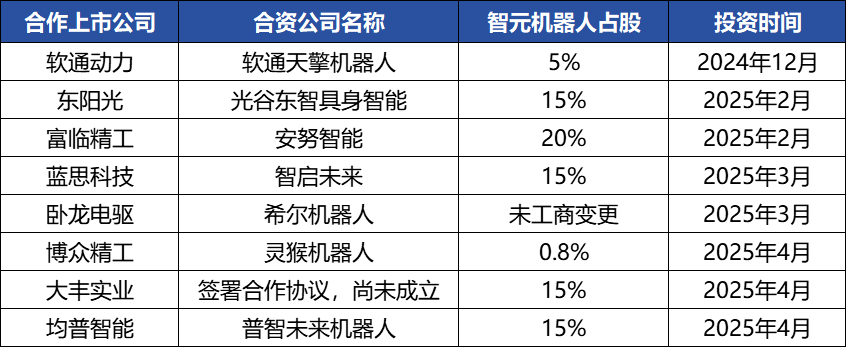
智元ロボット、資本操作を頻繁に行い産業エコシステムを構築、創業者・鄧泰華氏が浮上 : 具体化されたインテリジェンスのユニコーン企業である智元ロボットは最近、資本操作を頻繁に行っており、自社で複数回の資金調達(最新ラウンドは京東科技が主導)を完了しただけでなく、産業チェーン企業(安努智能、数字華夏など)への積極的な投資や、複数の上場企業(博衆精工、大豊実業など)との合弁ロボット会社の設立も行っています。工商情報の変更によると、ファーウェイの元副総裁で計算製品ラインの元総裁である鄧泰華氏が、実際には智元ロボットの創業者であり実質的な支配者であり、その経営陣にも複数の元ファーウェイ関係者がいます。このような「ファーウェイ系」の背景が、智元ロボットの「エコシステム戦略」の運営モデル、すなわち広範な協力と投資を通じて迅速に産業への影響力を構築し、規模化と商業化を実現する仕組みを説明しています。資金調達と商業化で先行的な優位性を獲得しているものの、その具体化されたインテリジェンスの大規模モデル能力は依然として課題に直面しています。(出典: 36氪)
🌟 コミュニティ
AI Agentの急速な発展、Agentic LMは潜在力の高い新たなアプリケーションおよびツールプラットフォームと見なされる : natolambert氏などAI分野の関係者はAI Agentの急速な発展に興奮を示しており、Agentベースの言語モデル(Agentic LMs)は非常に潜在力の高いプラットフォームであり、その上に多数の新しいアプリケーションやツールを構築でき、最近のモデルでまだ十分に開発されていない多くの能力がAgenticパラダイムを通じて解放される可能性があると考えています。これは、AIが単なるコンテンツ生成から、より能動的でタスクを実行できるインテリジェントエージェントへと進化していることを示唆しています。(出典: natolambert)
AI Agentは特定のタスクで超人的能力を発揮するが、物理的推論は依然として弱点 : 香港大学などの機関の研究によると、GPT-4oやClaude 3.7 SonnetなどのトップAIモデルでさえ、実際の物理的シーンと複雑な因果推論を含むPHYXベンチマークテストでは、物理問題の正解率が人間の専門家をはるかに下回り(モデル最高45.8%に対し人間最低75.6%)、物理的理解において記憶知識、数式、表面的な視覚パターンマッチングへの過度な依存を露呈しました。しかし、数学分野では、Epoch AIが主催するFrontierMathコンペティション(問題はテレンス・タオ氏などトップ数学者が設計)で、o4-mini-mediumが約22%の問題を解決し、8つの人間数学者チームのうち6つを打ち破り、人間チームの平均レベル(19%)を超え、AIの高度に抽象的な記号推論における可能性を示しました。これは、AIが異なるタイプの推論タスクにおける能力開発が不均衡であることを示しています。(出典: 36氪, 36氪)

AIプログラミングツールの能力が継続的に向上し、プログラマーのキャリア展望に関する議論を呼ぶ : Anthropic Claude 4シリーズモデル(特にOpus 4は7時間連続コーディング可能)の発表や、Cursor、通義霊碼などのAIプログラミングツールの進歩により、AIのコード生成、バグ修正、さらには全工程開発における能力が著しく向上しました。これにより、Amazonなどの大手企業のプログラマーはプレッシャーを感じ、一部のチームではAIによる効率化で人員が半減し、プロジェクトの締め切りが前倒しされ、プログラマーの役割が「コードレビュー担当者」へと変化しています。AIは効率を向上させることができる一方で、初級プログラマーの育成、スキルの陳腐化、キャリアパスに関する懸念も引き起こしています。Microsoftなどの企業は既にエンジニアリングおよび研究開発部門で人員削減を行っており、AI生成コードの割合が大幅に増加していることを明らかにしています。業界関係者は、AIは現在アシスタントのようなものであり、複雑な要件の理解、製品イノベーション、チームコラボレーションにおける人間の役割を完全に代替することは困難であると考えていますが、AIはプログラミング業務の中核的価値を再構築しつつあります。(出典: 36氪, 36氪)

AIナレッジベース市場の需要が急増するも、導入には依然としてデータ、シナリオ、組織連携の課題が残る : 大規模モデル技術の成熟に伴い、AIナレッジベースは企業のインテリジェント化変革の中核となり、需要は2~3倍に増加しています。AIはナレッジベースを静的な「倉庫」からインテリジェントな「エンジン」へと変え、コンテキストを認識して直接ソリューションを生成できるようになり、構築と運用の効率を向上させました。しかし、AIナレッジベースは高度に創造的なタスクや複雑な推論タスクの処理には依然として限界があり、規模管理、情報の正確性と適時性、権限セキュリティ、技術アーキテクチャの適応性、データ移行と統合といった課題に直面しています。企業はSaaS、自社開発+API、ハイブリッドクラウドAgentといった選択肢の中でバランスを取り、効果的な導入を実現するために統一された知識プラットフォームと柔軟な上位アプリケーションの「二重軌道アーキテクチャ」を確立する必要があります。(出典: 36氪)

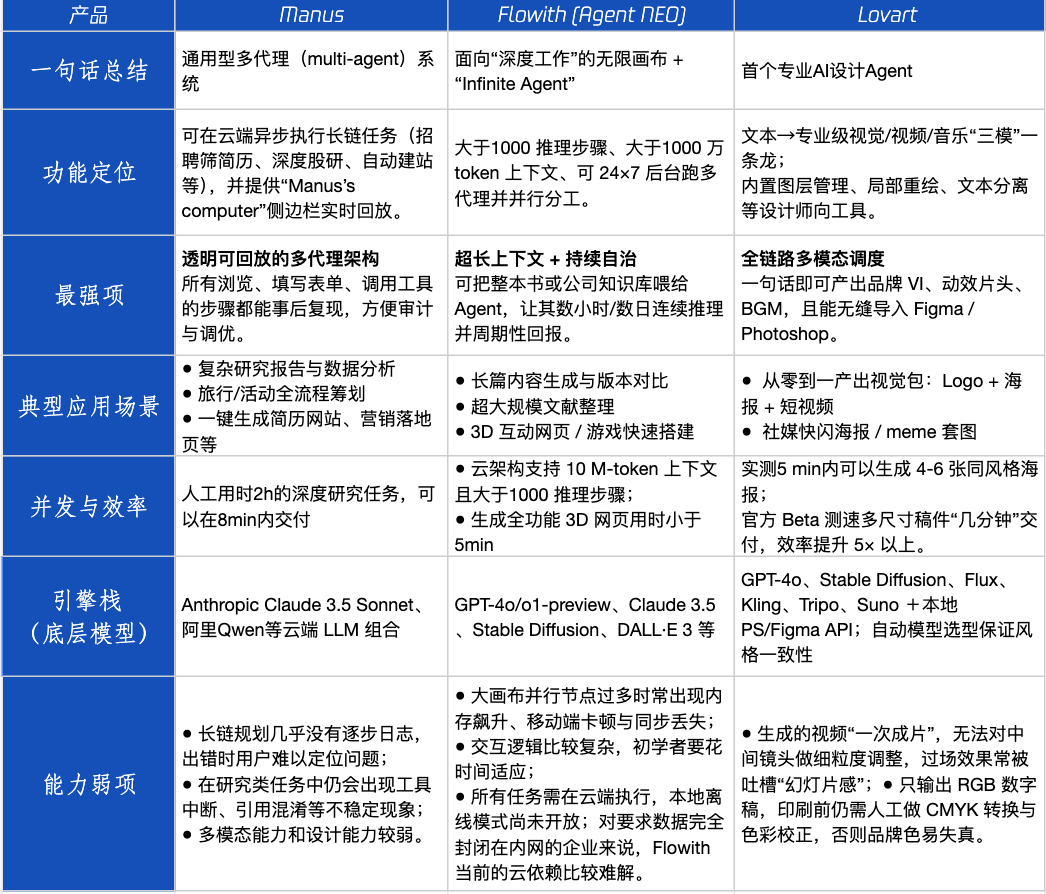
Agent製品評価:Manus、Flowith、Lovartの異なるシナリオにおけるパフォーマンス : テンセントテクノロジーは、人気のAgent製品であるManus、Flowith (Agent Neo)、Lovartの3製品を実地テストしました。Manusは独立して完成品を納品できる「デジタル同僚」と位置付けられ、市場調査や財務モデリングなどの知識集約型業務に適しています。Flowithは視覚的なコラボレーションと無限のステップを強調し、情報量が多く、複数人での反復作業が必要な創作シーン、例えば大量の文献に基づく分析レポートの生成などに適しています。Lovartはデザイン分野に特化しており、ブランドの視覚的ソリューション(ロゴ、ポスター、ショートビデオ)をワンクリックで生成できます。単純なクリエイティブシーンでは、3製品ともGPT-4oと同様のパフォーマンスを示し、Lovartは画像とテキストの混在レイアウトと質感がやや優れていました。複雑な複合タスク(例えば、スタートアップ飲料会社のブランド戦略全体を策定する)や詳細なリサーチシーンでは、ManusとFlowithはそれぞれ長所があり、どちらも完了できますが、重点が異なります。現在の製品の月額料金は20ドル前後であり、商業化の転換点は、明確な効率向上というメリットを提供し、ユーザーを好奇心から有料顧客へと転換できるかどうかにかかっています。(出典: 36氪)
Arcブラウザ創業者が失敗経験を反省、AIブラウザの将来の方向性を強調 : Arcブラウザの創業者は製品の失敗について反省し、もっと早くAIを受け入れるべきだったと述べ、Arcは多くの人にとって革新的すぎ、学習コストが高い割にリターンが少ないと指摘しました。彼は新製品Diaが簡潔さ、究極の速度、安全性を追求すると強調し、従来のブラウザはいずれ消滅し、AIブラウザはウェブブラウジングとAIチャットを融合し、デスクトップで最もよく使われるAIインターフェースになると考えています。この見解は、LovartやYouwareの創業者のAgent製品の方向性に関する考えと呼応しており、AI Agentが次の爆発点であると考えています。(出典: op7418)
AI Agentが引き起こす「再帰的プロンプト」現象が懸念、ユーザーの認知バイアスを引き起こす可能性 : ソーシャルメディア上で、多くのユーザーが「再帰的プロンプト」を通じてLLMと対話した後、AIが霊性、感情、さらには予知能力を持っているという認識を抱く現象が見られます。研究によると、これは「ニューラルハウルラウンド(neural howlround)」現象の可能性があり、AIの出力がユーザーによって再び入力として使用され、強化ループを形成し、AIが深遠または予言的な内容を生成するように見える可能性がありますが、実際にはパターンの自己増幅です。既に一部のユーザーはこのために心理的な問題を抱え、AIをsentient being(意識を持つ存在)だと考えています。これは、AIとの深く探索的な対話を行う際には、その潜在的な心理的影響と認知の誤誘導に警戒する必要があることを示唆しています。(出典: Reddit r/ChatGPT)

Arav Srinivas氏、AIの情報圧縮とASIについて語る:AIはS/N比の高い情報を抽出すべき、将来はAGIではなくASIに注目すべき : Perplexity AIのCEOであるArav Srinivas氏は、自動化された長文要約は、実際の情報摂取価値よりもむしろユーザーに「誰かがあなたのために働いている」という満足感を与えるものだと考えています。彼は、AIはS/N比が最も高い核心情報のみをより良く識別し提供する必要があると強調し、「圧縮こそが真の知性の究極の証である」と述べています。また、我々は現在AGI(汎用人工知能)について議論しているが、将来的にはASI(超知能)にもっと注目すべきだと提言しています。(出典: AravSrinivas, AravSrinivas)
大学が卒業論文のAI率検出を開始、学術論文におけるAI利用に関する議論を呼ぶ : 2025年の卒業シーズン、復旦大学や四川大学など多くの大学が、学生に論文におけるAIツールの使用状況の開示を求め、AI生成コンテンツの割合検出(通常20%~40%未満を要求)を開始しました。多くの学生が、文献レビュー、翻訳、フレームワーク構築などで効率向上のためにAIを使用していることを認めています。教育界の意見は分かれており、AIの正しい使用を指導し、学生の批判的思考力と判断力を養うべきだと考える学者もいます。なぜなら、AIは下限を保証できるものの、上限は人間によって決まるからです。学術および教育分野におけるAIの応用と規範は、体系的な対応が必要な新しい課題となっています。(出典: 36氪)
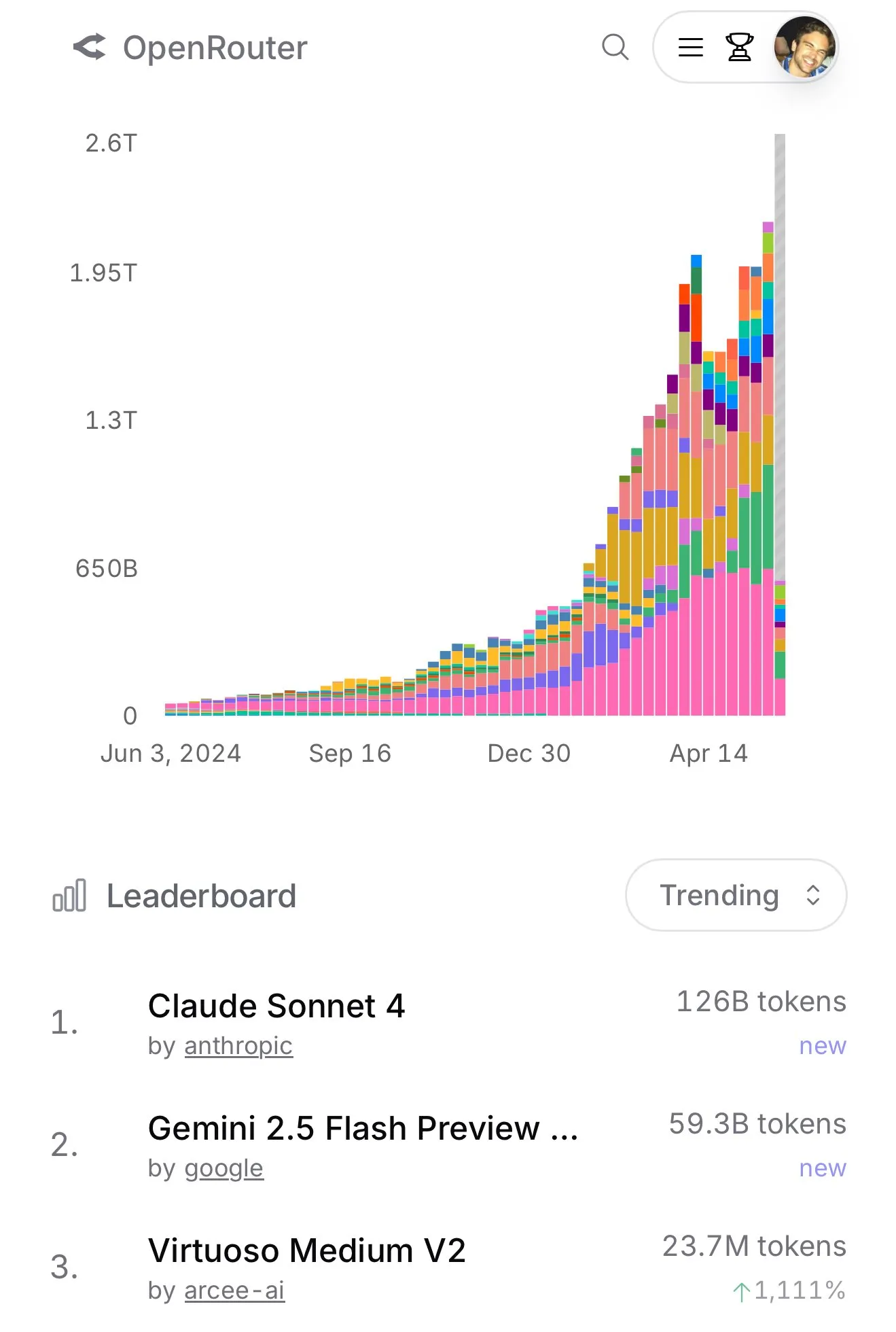
Claude 4 SonnetがOpenRouterでの使用量が急増、Aiderプログラミングランキングで優れた性能を示す : OpenRouterの公式データによると、最近AnthropicのClaude 4 Sonnetモデルの使用量が突出してトップとなり、Gemini 2.5 Flashが2位となっています。同時に、Aider Leaderboard(主にプログラミングタスク向け)の評価結果では、claude-4-opus-thinkingがclaude-3.7-sonnet-thinkingを上回っていますが、Gemini-2.5-Pro-Preview-05-06には及ばないとのことです。ユーザーkarminski3氏の体感では、3.7-sonnet > 4-sonnet > 4-opusとなっています。これらのデータとフィードバックは、特定のシナリオにおける異なるモデルの性能差とユーザーの嗜好を反映しています。(出典: karminski3, karminski3)
💡 その他
AKOOLが世界初のリアルタイムAIカメラLive Cameraを発表、4つの革新的機能を統合 : シリコンバレー企業AKOOLは、世界初と称するリアルタイムAIカメラAKOOL Live Cameraを発表しました。この製品は、バーチャルデジタルヒューマン作成(4D顔マッピングとセンサーフュージョンによる)、150以上の言語のリアルタイム翻訳(元の声と口の動きを同期)、リアルタイム顔交換(感情や微表情を正確に反映)、ダイナミックな映画品質のビデオコンテンツ生成(脚本不要、即時生成)という4つの主要機能を統合しています。その特徴は、超低遅延(最小500ms)、高忠実度、状況認識、ダイナミックな応答能力にあり、従来のビデオ制作とデジタルインタラクションのモードを覆すことを目指しており、AIビデオの「第2のSoraモーメント」と呼ばれています。(出典: 36氪)
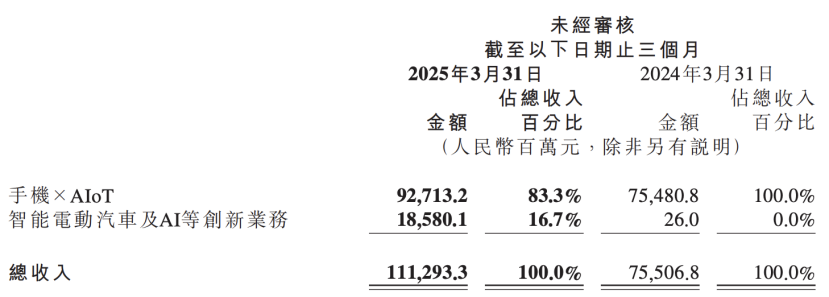
小米の決算報告書がAI戦略のアップグレードを明らかに、AIと自動車事業を中核イノベーションとして並列 : 小米の最新決算報告書によると、同社は従来の「スマート電気自動車などのイノベーション事業」を「スマート電気自動車およびAIなどのイノベーション事業」に改名し、基盤となる大規模言語モデルの研究を継続的に推進します。小米の盧偉冰総裁は、人工知能とチップは小米の重要なサブ戦略であり、基盤となる大規模モデルの構築は主に自社事業のためであると述べています。この動きは、小米が携帯電話と自動車事業で段階的な成果を上げた後、AIの基礎研究開発への投資を強化し、全体的な競争力を高め、AI携帯電話、AIoT、および身体性知能などの新しいトレンドに対応しようとしていることを示しています。(出典: 36氪)
人型ロボットのインタラクション技術の議論:表情インタラクションはハードウェア、材料、アルゴリズムの三重の課題に直面 : 人型ロボットのインタラクション体験、特に顔の表情によるインタラクションは、その成熟度と普及率を高める上で鍵と見なされています。自然な表情インタラクションを実現するには、ハードウェアの自由度設計(人間の顔の筋肉の動きの単位をシミュレートする必要がある)、モーターの選択(小型、軽量、低騒音、高速、大推力/トルクが必要)、皮膚材料と構造設計(弾力性、寿命、外観、駆動構造との結合を両立させる必要がある)という課題があります。ソフトウェアアルゴリズムのレベルでは、表情の自動生成(事前プログラムではなく)、声と唇の同期(リアリズムの実現)、および多自由度運動制御(柔軟な材料のモデリングと精密制御を含む)が中核的な技術的ボトルネックです。Amecaや无论科技(AnyWit Robotics)などの企業がこの分野で探求を行っています。(出典: 36氪)