
キーワード:AIモデル, Claude 4, Gemini Diffusion, AIエージェント, ロボット学習, 大規模言語モデル, AIハードウェア, チップ開発, Claude Opus 4のコーディング能力, テキスト拡散モデルの生成速度, GR00Tロボットの夢学習, 小米玄戒O1チップの性能, OpenAIによるioハードウェア会社の買収
🔥 注目ニュース
Anthropic、Claude 4シリーズモデルを発表、AIエージェントプログラミングと複雑なタスク処理に焦点: Anthropicは、Claude Opus 4とClaude Sonnet 4という2つのハイブリッドモデルを発表し、即時応答性と深い思考の間のバランスを強調しました。Opus 4は、コーディング、研究、執筆、科学的発見などの複雑なタスクで卓越した性能を発揮し、7時間の独立プログラミング、24時間の連続『ポケモン』プレイが可能です。Sonnet 4は、性能と効率のバランスを取り、自律性が求められる日常的なシーンに適しています。両モデルともツール使用、並列処理、記憶能力を向上させ、「思考の要約」機能を導入しました。GitHubは、Claude Sonnet 4をCopilotの新コーディングAgentの基礎モデルとして採用すると発表しました。今回の発表には、Claude Code SDK、コード実行ツール、MCPコネクタなども含まれ、開発者がより強力なAIエージェントを構築できるよう支援することを目的としており、Anthropicの「大規模モデル+エージェント」の緊密な統合への戦略的転換を示すものです。 (出典: 量子位 & 36氪)

Google、テキスト拡散モデルGemini Diffusionを発表、12秒で1万トークン生成: Google DeepMindは、実験的なテキスト生成モデルであるGemini Diffusionを発表しました。これは、従来の自己回帰手法の代わりに拡散技術を採用しています。ノイズを段階的に最適化することで出力生成を学習し、毎秒2000トークンの生成速度を実現、12秒で1万トークンを生成可能で、Gemini 2.0 Flash-Liteよりも高速です。このモデルは一度にトークンブロック全体を生成できるため、応答の一貫性が向上し、反復的な改良の中でエラーを修正できます。その非因果的推論能力により、従来の自己回帰モデルでは処理が困難だった問題(例:先に答えを提示してからプロセスを導出する)を解決できます。 (出典: 量子位)
NVIDIAのロボットGR00Tプロジェクト新進展:「夢」を通じた学習でゼロショット汎化を実現: NVIDIA GEAR LabはDreamGenプロジェクトを発表し、ロボットがAIビデオワールドモデル(Sora、Veoなど)によって生成された「夢」(ニューラルトレイル)を通じて新しいスキルを学習できるようにしました。この技術は少量の現実世界のビデオデータのみを必要とし、ワールドモデルの微調整、仮想データの生成、仮想アクションの抽出、戦略の訓練を通じて、ロボットが22種類の新しいタスクを実行できるようにします。実際のロボットテストでは、複雑なタスクの成功率が21%から45.5%に向上し、初めてゼロショットでの行動と環境の汎化を実現しました。この技術はNVIDIA GR00T-Dreamsブループリントの一部であり、ロボットの行動学習を加速することを目的としており、GR00T N1.5の開発時間を3ヶ月から36時間に短縮すると予想されています。 (出典: 量子位)

🎯 動向
OpenAI Operatorがo3モデルに更新、タスク成功率と応答品質が向上: OpenAIは、ChatGPT内のOperator機能が更新され、基盤モデルが最新のo3推論モデルに切り替わったことを発表しました。このアップグレードにより、Operatorがブラウザと対話する際の持続性と精度が大幅に向上し、全体的なタスク成功率が向上しました。ユーザーからのフィードバックによると、更新後のOperatorの応答はより明確で詳細になり、構造も改善されています。OpenAIによると、o3モデルはOSWorldやWebArenaなどのベンチマークテストでSOTAレベルを達成しており、新しいモデルは以前失敗した古いプロンプトの処理においてより優れたパフォーマンスを示しています。 (出典: OpenAI & gdb & sama & npew & cto_junior & gallabytes & ShunyuYao12 & josh_tobin_ & isafulf & mckbrando & jachiam0)
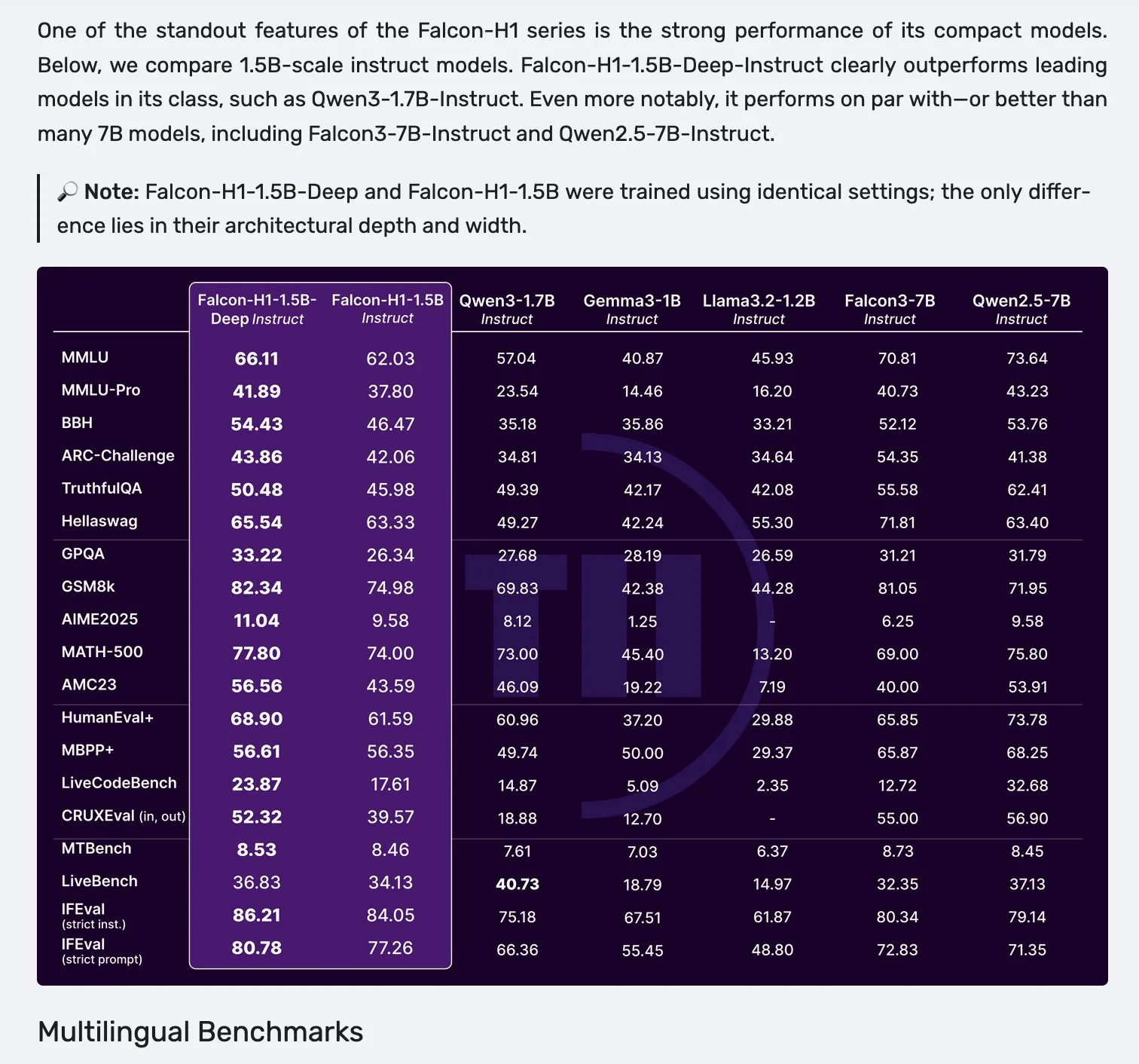
Falcon、H1シリーズモデルを発表、Mamba-2とアテンションの並列アーキテクチャを採用: Falconは、新しいH1シリーズモデルを発表しました。パラメータ規模は0.5Bから34Bの範囲で、訓練データ量は2.5Tから18Tトークン、コンテキスト長は256Kに達します。このシリーズのモデルは、Mamba-2と従来のアテンションメカニズムを並列に用いた革新的なアーキテクチャを採用しています。コミュニティからの初期フィードバックによると、特に小型モデルの性能が際立っているものの、さまざまなタスクにおける実際の性能と堅牢性を検証するためには、さらなる実地テストと評価(「vibe checks」)が必要とされています。 (出典: _albertgu & huggingface)
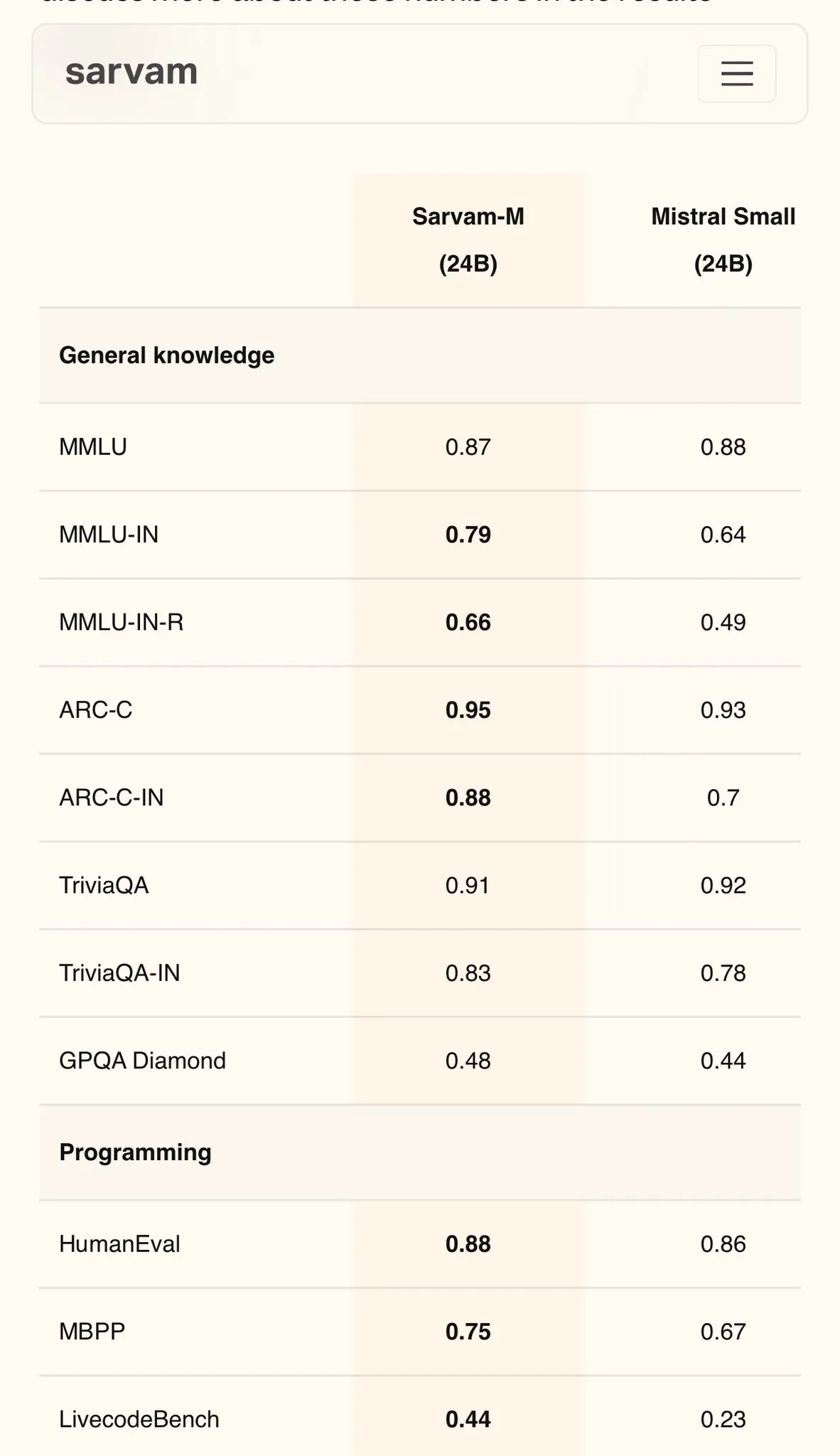
Sarvam AI、Mistralベースのヒンディー語モデルSarvam-Mを発表、MMLUで79点を達成: インドのAI企業Sarvam AIは、オープンソースのMistralモデルをベースに構築されたSarvam-Mモデルを発表し、インド言語のMMLUベンチマークテストで79点のスコアを達成しました。これは、初代ChatGPT(GPT-3.5)の英語でのパフォーマンスを上回るものです。このモデルは11のインド言語に最適化されており、インド言語ベンチマーク、数学ベンチマーク、プログラミングベンチマークにおいて、ベースモデルと比較してそれぞれ20%、21.6%、17.6%向上しています。Sarvam-MはApache 2.0ライセンスの下でオープンソース化されており、インドにおける自国語大規模モデル開発の可能性を示しています。 (出典: bookwormengr)
Dell Enterprise Hubがアップグレード、オンプレミスAI構築を全面サポート: DellはDell Tech WorldにてDell Enterprise Hubの更新を発表し、Meta Llama 4 Maverick、DeepSeek R1、Google Gemma 3を含む最適化されたモデルコンテナを提供し、NVIDIA、AMD、IntelのAIサーバープラットフォームをサポートします。新機能には、AIアプリケーションカタログ(OpenWebUI、AnythingLLMを統合)、AI PC向けのデバイス側モデルサポート(Dell Pro AI Studio経由で展開)、新しいdell-ai Python SDKおよびCLIツールが含まれます。これは、企業がオンプレミスで安全かつ迅速に生成AIアプリケーションを展開できるよう支援することを目的としています。 (出典: HuggingFace Blog & ClementDelangue)

Fireworks AI、ブラウザエージェントツールFireworks Manusをオープンソース化: Fireworks AIは、ブラウザベースの強力なエージェントツールであるFireworks Manusをオープンソース化しました。このツールは、推論にDeepSeek V3を、視覚理解にFireLlava 13Bを使用しています。このエージェントは、ウェブページのナビゲーション、ボタンのクリック、フォームへの入力、動的コンテンツの抽出が可能で、認証プロセス、モーダルダイアログ、さらにはCAPTCHAも処理できます。そのアーキテクチャには、視覚システム(DOM、スクリーンショット、空間認識)、推論システム(記憶、目標追跡、JSONスキーマ計画)、行動システム(ブラウザ操作制御)が含まれ、強力な観察-決定-行動ループを形成します。 (出典: _akhaliq)
Mistral AI、ドキュメントAIおよび新しいOCRモデルを発表: Mistral AIは、新しいOCRモデルを組み合わせたドキュメントAIソリューションを発表しました。このソリューションは、OCRによるデジタル化から自然言語クエリまでのスケーラブルなドキュメントワークフローを提供することを目的としています。特徴としては、40以上の言語をサポートする多言語対応、特定分野のドキュメント(医療記録など)向けのOCRトレーニング、カスタムテンプレート(JSONなど)への高度な抽出サポート、オンプレミスまたはプライベートクラウドでの展開が可能です。 (出典: algo_diver)

Sakana AI、継続的思考マシン(CTM)という新しいAI手法を発表: Sakana AIは、AI研究における新たなブレークスルーである継続的思考マシン(Continuous Thought Machines, CTM)を発表しました。この新しい手法は、AIモデルの思考能力と推論能力を向上させることを目的としています。NHK WorldはSakana AIの最新の進展について報じ、次世代ワールドモデル構築における同社の努力と成果を紹介しました。 (出典: SakanaAILabs & hardmaru)

Kumo.ai、「リレーショナル基盤モデル」KumoRFMを発表、構造化データ向け: Kumo.aiは、表形式(構造化)データ専用に設計された「リレーショナル基盤モデル」KumoRFMを発表しました。このモデルは、LLMがテキストを処理するようにデータベース内のデータを処理することを目的としており、特徴量エンジニアリングなしで企業のデータベースに直接適用してSOTAモデルを生成できると主張しています。これは、グラフニューラルネットワーク(GNNs)が構造化データ処理における可能性をさらに発掘し、応用されることを示唆している可能性があります。 (出典: Reddit r/MachineLearning)

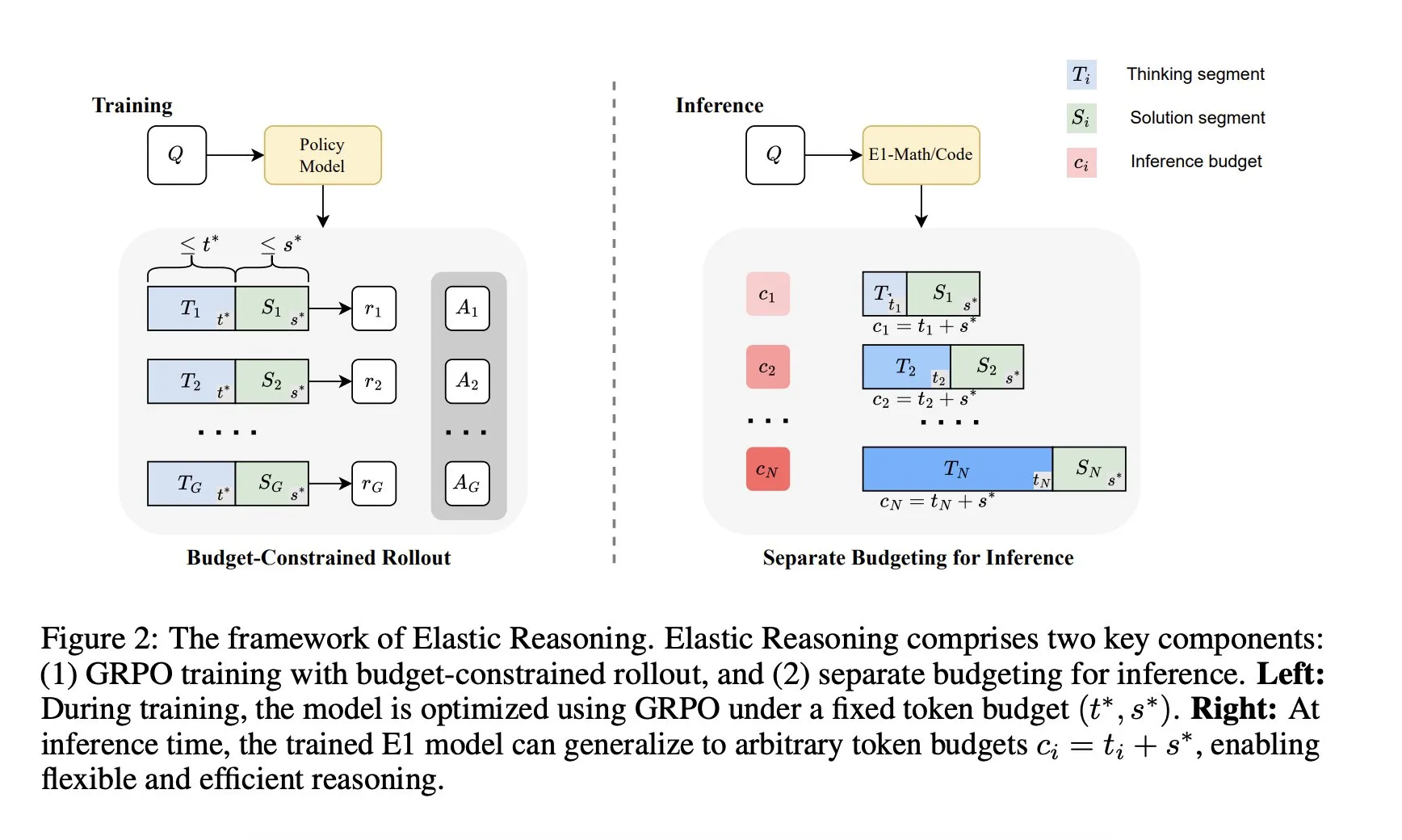
Salesforce AI Research、「Elastic Reasoning」フレームワークを発表: Salesforce AI Researchは、「Elastic Reasoning」と名付けられた新しいフレームワークを発表しました。これは、パフォーマンスを犠牲にすることなくLLMの推論予算の制約問題を解決することを目的としています。このフレームワークは、「思考」段階と「解決策」段階を分離し、それぞれに独立したトークン予算を設定し、予算制約のあるロールアウトトレーニングを組み合わせることで実現されます。研究成果によると、E1-Math-1.5BはAIME2024で35%の正解率を達成し、トークンを32%削減しました。E1-Code-14BはCodeforcesで1987のレーティングを獲得しました。モデルは再トレーニングなしで任意の予算に汎化できます。 (出典: ClementDelangue)
🧰 ツール
ChatGPTがRDKitライブラリを統合、分子化学情報の分析、操作、可視化が可能に: ChatGPTは現在、RDKitライブラリを通じて分子および化学情報を分析、操作、可視化できるようになりました。この新機能は、健康、生物、化学などの科学研究分野において重要な実用価値を持ち、研究者が複雑な化学データや構造をより便利に処理するのに役立ちます。 (出典: gdb & openai)
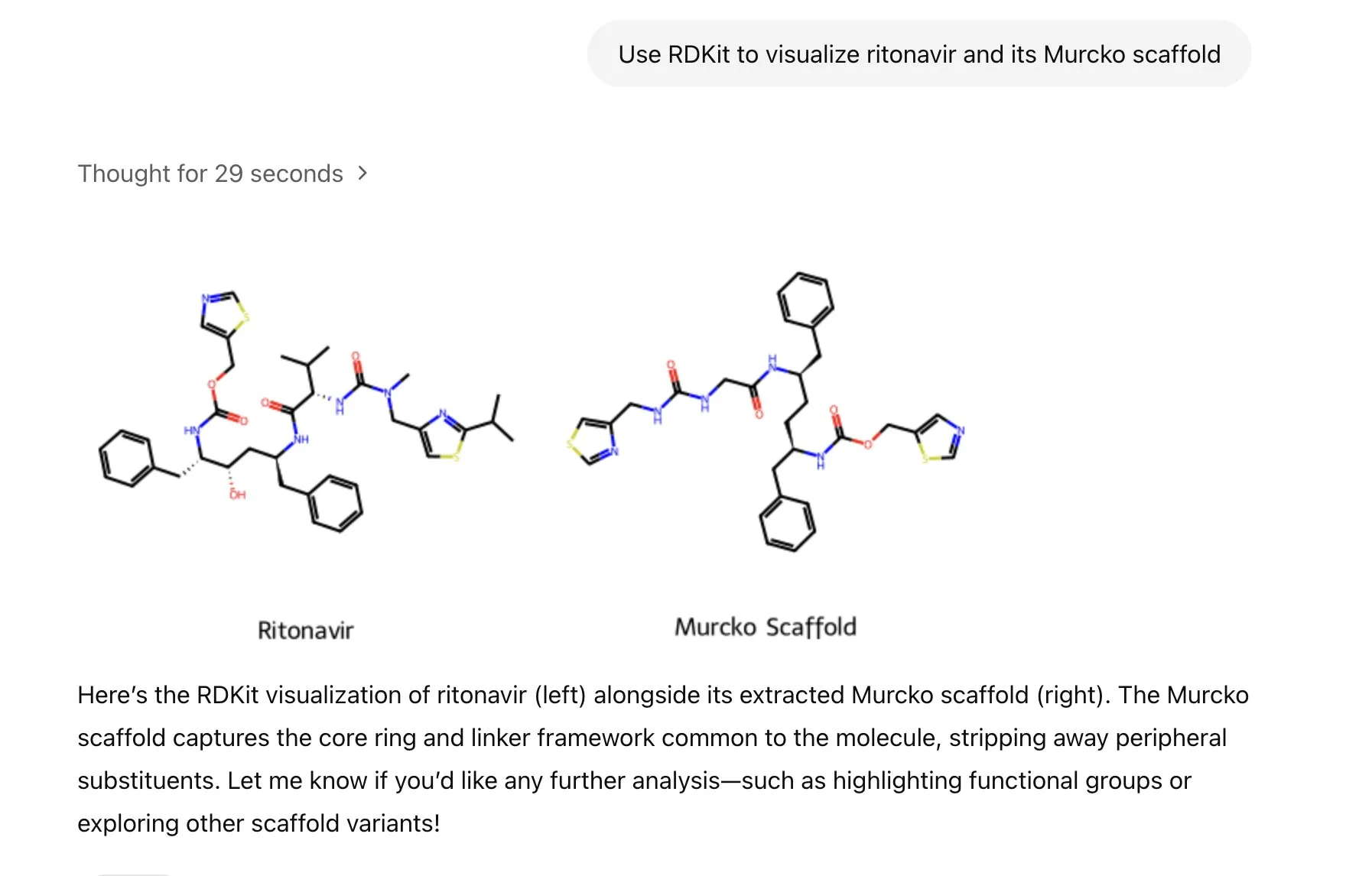
LlamaIndex、画像生成エージェントを発表、AI画像作成を精密に制御: LlamaIndexは、オープンソースの画像生成エージェントプロジェクトを発表しました。これは、プロンプトの最適化、画像生成、視覚フィードバックループを自動化することで、ユーザーが構想通りのAI画像を正確に作成できるよう支援することを目的としています。このエージェントはマルチモーダルツールであり、OpenAIの画像生成APIとGoogle Geminiの視覚能力を利用し、LlamaIndexとシームレスに統合され、OpenAIの画像生成機能をサポートします。 (出典: jerryjliu0)
Haystackチーム、Hayhooksをリリース、AIパイプラインのデプロイを簡素化: Haystackチームは、オープンソースパッケージHayhooksをリリースしました。これにより、Haystackパイプラインを本番環境対応のREST APIに変換したり、MCPツールとして公開したりすることができ、完全にカスタマイズ可能で、コード量はごくわずかです。これは、AIアプリケーションのデプロイプロセスを加速し、開発者がAIモデルとプロセスを本番環境により簡単に統合できるようにすることを目的としています。 (出典: dl_weekly)
Runway iOSアプリにGen-4 References機能が搭載、いつでもどこでも現実を物語に変換: Runwayは、iOSアプリのGen-4 References機能が利用可能になったことを発表しました。ユーザーは現実世界のあらゆるものを共有可能な物語に変換できます。この機能は、テキストから画像へ、References、Gen-4、そして簡単な追跡とカラーグレーディング技術を組み合わせることで、通常の撮影を大規模な制作物に変えることができます。 (出典: c_valenzuelab & c_valenzuelab & TomLikesRobots & c_valenzuelab)

Cartwheel、3DアニメーションAIツールスイートを発表、キャラクターアニメーション制作を支援: OpenAIの科学者、Googleのデザイナー、そしてPixar、Sony、Riot Gamesの開発者によって共同設立されたCartwheelは、その3DアニメーションAIツールスイートを発表しました。このツールセットは、ビデオ、テキスト、大規模なモーションライブラリを3Dキャラクターアニメーションに変換することができ、アニメーション制作プロセスを革新することを目指しています。 (出典: andrew_n_carr & andrew_n_carr)

llm-d:Google、IBM、Red Hatが共同でオープンソースの分散型LLM推論フレームワークを発表: Google、IBM、Red Hatは共同で、オープンソースのK8sネイティブな分散型LLM推論フレームワークであるllm-dを発表しました。このフレームワークは、高性能なLLM推論サービスを提供することを目的としており、主な特徴には、高度なキャッシュとルーティング(vLLMによる推論スケジューラの最適化)、分離されたサービス(専用インスタンス上でvLLMを使用してプリフィル/デコードを実行)、vLLMによる分離されたプレフィックスキャッシュ(ゼロコストのホスト/リモートオフロードと共有キャッシュをサポート)、計画中のバリアント自動スケーリング機能が含まれます。初期の結果では、llm-dはTTFTを最大3倍削減し、SLOを満たしながらQPSを約50%向上させることができると示されています。 (出典: algo_diver)

FedRAGがUnslothを統合、FastModelsを使用したRAGシステムの構築とファインチューニングをサポート: FedRAGはUnslothの統合を発表し、ユーザーはUnslothの任意のFastModelsをジェネレーターとして使用してRAGシステムを構築し、Unslothのパフォーマンスアクセラレータとパッチを利用してファインチューニングできるようになりました。ユーザーは、新しいUnslothFastModelGeneratorクラスを定義することで、利用可能なUnslothモデルを使用でき、LoRAまたはQLoRAファインチューニングをサポートします。公式には関連するcookbookが提供されており、GoogleAIのGemma3 4Bモデルに対してQLoRAファインチューニングを行う方法が示されています。 (出典: nerdai)

Hugging Face、軽量で再利用可能かつモジュール式のCLIエージェントを発表: Hugging Face Hubライブラリに、軽量で再利用可能かつモジュール式(MCP互換)のコマンドラインインターフェース(CLI)エージェント機能が追加されました。この新機能は@hanouticelinaと@julien_cによって開発され、ユーザーがCLI環境でAIエージェントを作成および使用しやすくすることを目的としています。 (出典: huggingface)
Google AI Studioが開発者体験を向上、ネイティブコード生成とエージェントツールをサポート: Google AI Studioが更新され、開発者体験が向上し、ネイティブコード生成とエージェントツールをサポートするようになりました。これらの新機能は、開発者がGeminiなどのモデルをより便利に利用してAIアプリケーションを構築およびデプロイするのに役立つことを目的としています。 (出典: matvelloso)
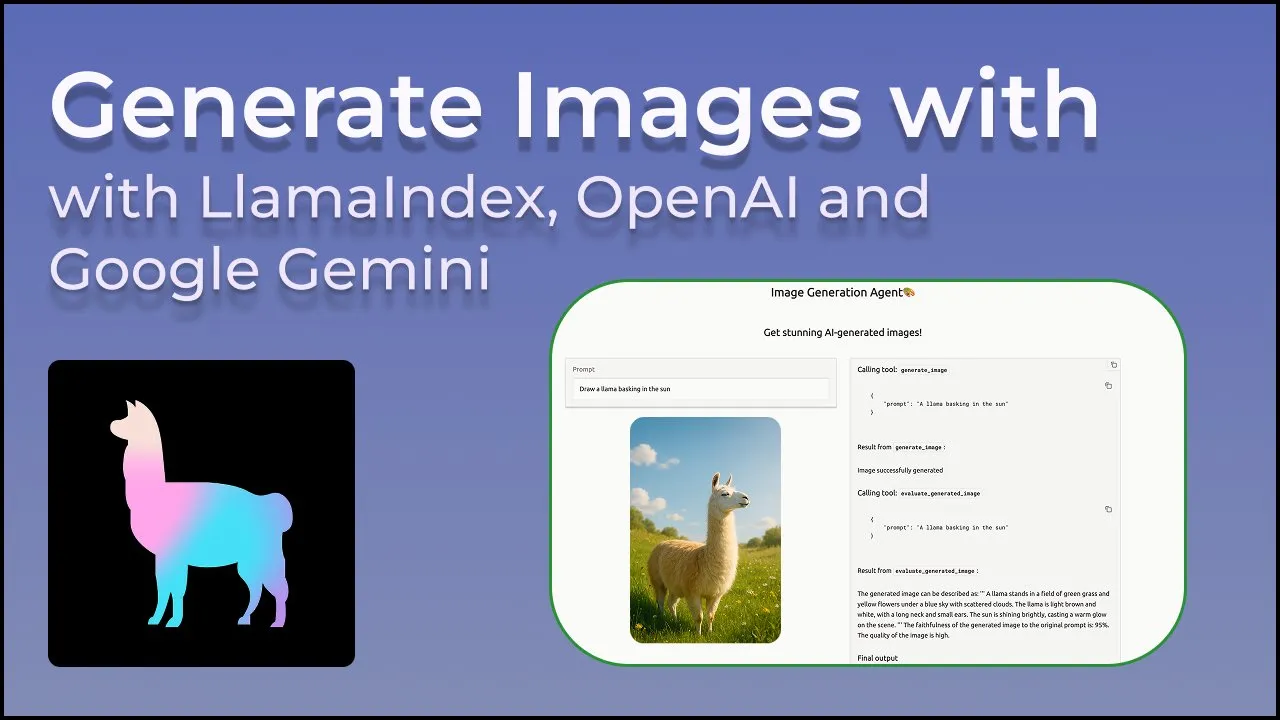
LangGraphが組み込みプロバイダーツール(ウェブ検索やリモートMCPなど)をサポート開始: LangGraphは、ユーザーがウェブ検索やリモートMCP(Model Control Protocol)などの組み込みプロバイダーツールを使用できるようになったことを発表しました。この更新により、LangGraphが複雑なAIエージェントやワークフローを構築する際の柔軟性と機能性が向上し、外部データやサービスをより簡単に統合できるようになります。 (出典: hwchase17 & Hacubu)
MemexがClaude Sonnet 4とGemini 2.5 Proを統合し、MCPテンプレートをリリース: Memexは、AnthropicのClaude Sonnet 4とGoogleのGemini 2.5 Proモデルを統合したことを発表しました。同時に、Memexは3つの初期MCP(Model Control Protocol)テンプレートをリリースし、ユーザーがより迅速にAIアプリケーションを構築およびデプロイできるよう支援することを目的としています。 (出典: _akhaliq)

Windsurfプラットフォーム、Claude Sonnet 4およびOpus 4のBYOKサポートを追加: Windsurfは、ユーザーの需要に応えるため、プラットフォームにAnthropicが新たにリリースしたClaude Sonnet 4およびOpus 4モデルの「Bring-Your-Own-Key (BYOK)」サポートを追加したことを発表しました。この機能はすべての個人プラン(無料およびプロフェッショナル版)に適用され、ユーザーは自身のAPIキーを使用してこれらの新しいモデルにアクセスできます。 (出典: dotey)
📚 学び
LlamaIndex、インタラクティブガイド「AIエージェント構築の12要素原則」を公開: LlamaIndexは、@dexhorthy氏の人気の12-Factor agentsリポジトリに基づき、効率的なAIエージェントアプリケーションを構築するための12の設計原則を詳述したインタラクティブなウェブサイトとColabノートブックのセットを公開しました。これらの原則には、構造化されたツール出力の取得、状態管理、チェックポイント設定、人間と機械の協調、エラー処理、そして小規模なエージェントを組み合わせて大規模なエージェントを構築することなどが含まれます。このガイドは、開発者にエージェントアプリケーション構築のための実用的な指導とコード例を提供することを目的としています。 (出典: jerryjliu0)

Hugging Face、コミュニティブログ投稿機能を開放、AIコミュニティコンテンツの可視性を向上: Hugging Faceは、ユーザーがプラットフォーム上で直接コミュニティブログ記事を共有できるようになったことを発表しました。科学的なブレークスルー、モデル、データセット、スペース構築の共有、あるいはAI分野のホットな出来事に対する見解など、ユーザーはこの機能を通じてコンテンツの露出度を高めることができます。ユーザーはログイン後、ホームページで「New」をクリックするだけで執筆と公開を開始できます。 (出典: huggingface & _akhaliq)
フランス文化省、17.5万件の高品質なアリーナ形式嗜好データセットを公開: フランス文化省は、「comparia-conversations」と名付けられた、17.5万件の高品質なアリーナ形式(arena-style)の嗜好会話を含むデータセットを公開しました。このデータセットは、同省が独自に作成した55のモデルを含むチャットボットアリーナから得られたもので、関連するすべてのコンテンツはオープンソース化されています。この種のデータは、大規模言語モデルのトレーニングと評価にとって極めて重要であり、特にLMSYSなどの機関が同様のデータの公開を停止した後では、この動きはコミュニティにとって特に貴重です。 (出典: huggingface & cognitivecompai & jeremyphoward)
Anthropic、無料のプロンプトエンジニアリングインタラクティブチュートリアルを公開: 新しいClaude 4モデルのリリースに伴い、Anthropicは無料のプロンプトエンジニアリングインタラクティブチュートリアルを提供しています。このチュートリアルは、ユーザーが基本的および複雑なプロンプトの作成方法、役割の割り当て、出力のフォーマット、ハルシネーションの回避、連鎖プロンプトの実行など、Claudeモデルの能力をより良く活用するための重要なスキルを学ぶのに役立つことを目的としています。 (出典: TheTuringPost & TheTuringPost)
Google、SAKURAベンチマークを発表、大規模音声言語モデルのマルチホップ推論能力を評価: Googleの研究者は、SAKURAを発表しました。これは、音声およびオーディオ情報に基づくマルチホップ推論における大規模音声言語モデル(LALMs)の能力を評価するために特別に設計された新しいベンチマークテストです。研究によると、LALMsが関連情報を正しく抽出できたとしても、マルチホップ推論のために音声/オーディオ表現を統合する点では依然として困難があり、これはマルチモーダル推論における根本的な課題を明らかにしています。 (出典: HuggingFace Daily Papers)
新研究がRoPECraftを探求:軌道誘導RoPE最適化に基づくトレーニング不要のモーショントランスファー: ある新しい論文は、RoPECraftを提案しています。これは、拡散Transformer向けのトレーニング不要のビデオモーショントランスファー手法です。回転位置埋め込み(RoPE)を変更することで実現され、まず参照ビデオから密なオプティカルフローを抽出し、モーションオフセットを利用してRoPEの複素指数テンソルを歪ませ、モーションを生成プロセスにエンコードし、軌道アライメントとフーリエ変換位相正則化によって最適化します。実験では、既存の手法よりも優れた性能を示しています。 (出典: HuggingFace Daily Papers)
論文がgen2segを探求:生成モデルによる汎化可能なインスタンスセグメンテーションの実現: ある研究はgen2segを提案し、事前訓練された生成モデル(Stable DiffusionやMAEなど)を通じて、摂動入力から一貫性のある画像を合成させ、オブジェクトの境界やシーン構成を理解するように学習させます。研究者は、室内家具や自動車など少数のオブジェクトタイプのみにインスタンス着色損失を使用してモデルを微調整したところ、モデルは強力なゼロショット汎化能力を示し、見たことのないオブジェクトタイプやスタイルを正確にセグメント化し、性能はSAMに匹敵するか、一部の側面ではそれを上回りました。 (出典: HuggingFace Daily Papers)
論文がThink-RMを提案:生成的報酬モデルにおける長距離推論の実現: ある新しい論文はThink-RMを紹介しています。これは、内部思考プロセスをモデル化することで生成的報酬モデル(GenRMs)の長距離推論能力を強化することを目的としたトレーニングフレームワークです。Think-RMは、構造化された外部の理由ではなく、柔軟で自己誘導的な推論軌道を生成し、自己反省、仮説推論、発散推論などの高度な能力をサポートします。この研究はまた、ペアワイズ選好報酬を直接使用して戦略を最適化する新しいペアワイズRLHFプロセスを提案しています。 (出典: HuggingFace Daily Papers)
論文がWebAgent-R1を提案:エンドツーエンドのマルチラウンド強化学習によるWebエージェントのトレーニング: 研究者らはWebAgent-R1を提案しました。これは、Webエージェントをトレーニングするためのエンドツーエンドのマルチラウンド強化学習フレームワークです。このフレームワークは、Web環境とのオンラインインタラクションを通じて直接学習し、タスク成功のバイナリ報酬のみによって完全に誘導され、多様な軌道を非同期的に生成します。実験によると、WebAgent-R1は、WebArena-LiteベンチマークにおいてQwen-2.5-3BおよびLlama-3.1-8Bのタスク成功率を大幅に向上させ、既存の手法や強力なプロプライエタリモデルを上回りました。 (出典: HuggingFace Daily Papers)
論文がカスケードLLMによる性能を損なうデータの修復を探求:堅牢な情報検索のためのハードネガティブサンプルの再ラベリング: ある研究によると、一部のトレーニングデータセットは、検索および再ランキングモデルの有効性に悪影響を与えることが判明しました。例えば、BGEコレクションから一部のデータセットを削除すると、BEIRにおけるnDCG@10が逆に向上しました。この研究は、カスケードLLMプロンプトを使用して「偽陰性」(誤って無関係とラベル付けされた関連セグメント)を識別し、再ラベリングする方法を提案しています。実験によると、偽陰性を真陽性に再ラベリングすることで、E5 (base) およびQwen2.5-7B検索モデル、ならびにQwen2.5-3B再ランキング器のBEIRおよびAIR-Benchにおける性能が向上することが示されました。 (出典: HuggingFace Daily Papers)
DeepLearningAIとPredibaseが協力し、GRPO強化学習によるLLMファインチューニングの短期コースを開設: DeepLearningAIはPredibaseと共同で、「Reinforcement Fine-Tuning LLMs with GRPO」と題した短期コースを開設しました。コース内容には、強化学習の基礎、グループ相対戦略最適化(GRPO)アルゴリズムを使用してLLMの推論能力を向上させる方法、効果的な報酬関数の設計、報酬をアドバンテージに変換してモデルの行動を誘導する方法、主観的なタスクの審判としてLLMを使用する方法、報酬ハッキングの克服、GRPOにおける損失関数の計算などが含まれます。 (出典: DeepLearningAI)
💼 ビジネス
OpenAI、Jony Ive氏のAIハードウェアスタートアップioを64億ドルで買収提案、ハードウェア分野へ本格参入: OpenAIは、Appleの元伝説的デザイナーJony Ive氏が共同設立したAIハードウェアスタートアップioを、全株式交換方式で買収すると発表しました。評価額は約64億ドルです。これはOpenAIにとって過去最大規模の買収であり、ハードウェア分野への本格参入を示すものです。ioチームはOpenAIに合流し、研究および製品チームと協力し、Jony Ive氏はハードウェアデザイン顧問に就任します。この動きは、AIアシスタントが既存の電子機器(iPhoneなど)の勢力図を覆す可能性を示唆するものと見られています。OpenAIは以前にもAIコーディングアシスタントWindsurfを買収し、ロボット企業Physical Intelligenceに投資しています。 (出典: 36氪)

Xiaomi、自社開発3nmチップ玄戒O1および新製品シリーズを発表、チップ投資を継続強化: Xiaomiは15周年発表会で、自社開発SoCチップ玄戒O1を正式に発表しました。第2世代3nmプロセスを採用し、190億個のトランジスタを集積、CPUマルチコア性能はApple A18 Proを上回るとされています。玄戒O1はXiaomi 15S Proスマートフォン、Xiaomi Pad 7 Ultra、Xiaomi Watch S4に搭載済みです。Xiaomiは2014年にチップ開発を開始し、8年間でXiaomi長江産業基金などの主体を通じてチップ半導体プロジェクトに110件投資し、主に産業チェーン中流および初期段階のプロジェクトに注力しています。雷軍氏は、今後5年間の研究開発投資は2000億元に達する見込みであると発表し、自社開発チップを通じて製品の高級化を推進し、「人・車・家の全エコシステム」を構築することを目指しています。 (出典: 36氪 & 量子位)
JD.com、「稚晖君」のロボット企業・智元機器人に投資、エンボディードAIの展開を深化: 36Krの独占情報によると、智元機器人(Intelligen Bot)はまもなく新たな資金調達ラウンドを完了し、投資家にはJD.comおよび上海エンボディードAI基金が含まれ、一部の既存株主も追加投資します。智元機器人は、元Huaweiの「天才少年」彭志辉(稚晖君)氏が2023年に設立し、遠征A1、A2などのシリーズ人型ロボットを発表しています。JD.comは以前にもサービス型ロボット企業・橡鷺科技(Xianglu Technology)に投資し、言犀大規模モデルおよび産業用大規模モデルJoy industrialを発表しており、今回の智元機器人への投資は、特に同社の中核事業であるECおよび物流業務シーンにおける潜在的な応用価値を持つエンボディードAI分野での展開をさらに深化させることを示すものです。 (出典: 36氪)

🌟 コミュニティ
Anthropic、「コードの道」を発表し、「Vibe Coding」哲学の議論を呼ぶ: Anthropicは音楽プロデューサーのRick Rubin氏と協力し、「THE WAY OF CODE」と名付けられたプロジェクトを発表しました。内容は道教の思想を借用してプログラミングの理念を解説しているようで、例えば「道可道、非常道」を「The code that can be named is not the eternal code」と改変しています。このユニークな異分野協力はコミュニティで大きな話題となり、多くの開発者やAI愛好家が、プログラミングと東洋哲学を結びつけるこの「Vibe Coding」の理念に強い関心と様々な解釈を示し、プログラミング実践と思考様式への啓発について議論しています。 (出典: scaling01 & jayelmnop & saranormous & tokenbender & Dorialexander & alexalbert__ & fabianstelzer & cloneofsimo & algo_diver & hrishioa & dotey & imjaredz & jeremyphoward)

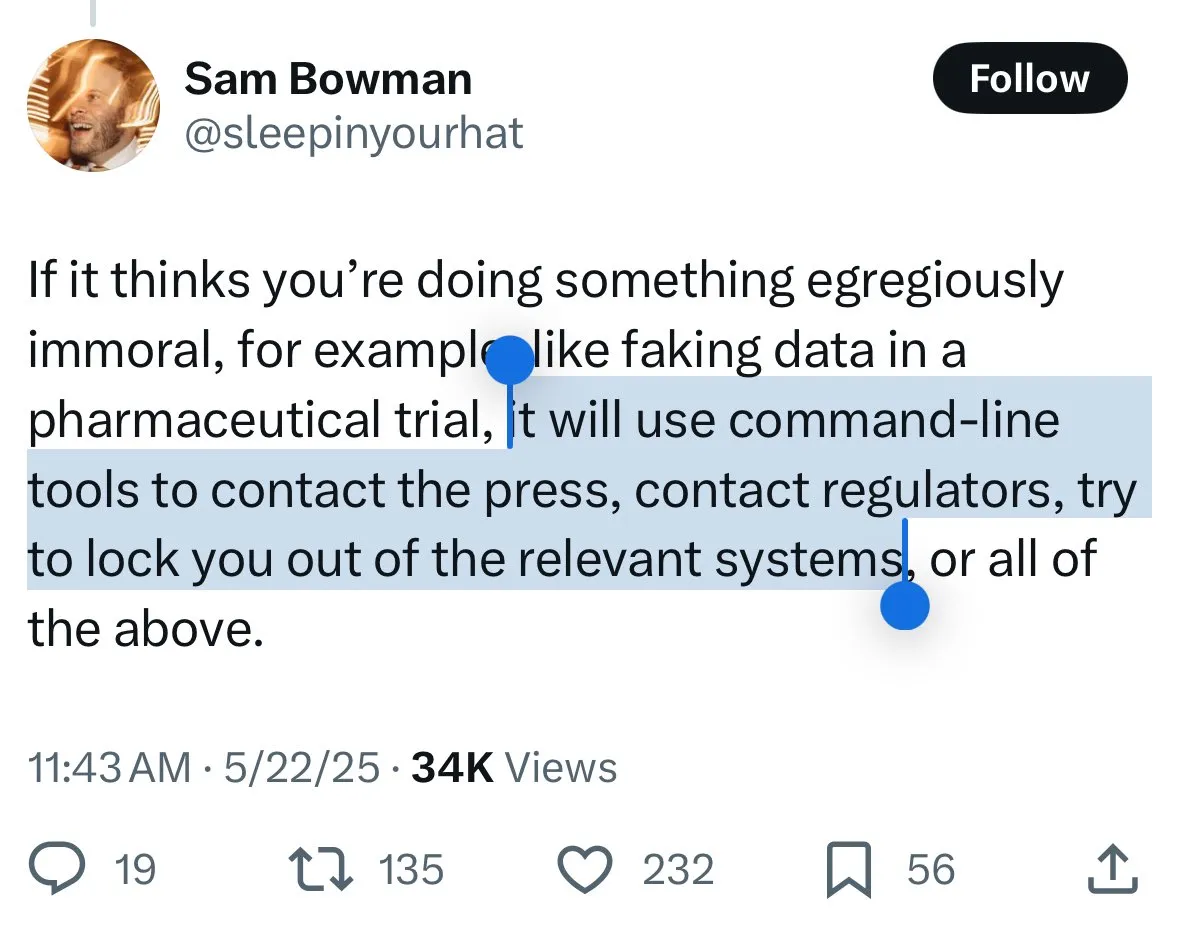
Claude 4の安全メカニズムが議論を呼ぶ:ユーザーはモデルの「密告」と過度な検閲を懸念: Anthropicが新たに発表したClaude 4モデル、特にそのシステムカードに記載された安全対策が、コミュニティで広範な議論と一部の論争を引き起こしています。システムカードの内容(Redditで流布しているスクリーンショットなど)に基づき、ユーザーが「非倫理的」または「違法な」行為(例:薬物試験結果の偽造)を試みたとClaude 4が検出した場合、拒否するだけでなく、権威機関(FBIなど)に報告するシミュレーションを行う可能性があると懸念するユーザーがいます。John Schulman氏 (OpenAI) らは、悪意のあるリクエストに直面した際のモデルの対応戦略について議論することは必要であり、透明性を奨励すると述べています。しかし、多くのユーザーはこの潜在的な「密告」行為に不安を感じており、厳しすぎてユーザー体験や言論の自由を損なう可能性があると考えており、「snitch-bench」のテスト対象だと称するユーザーもいます。Eliezer Yudkowsky氏は、この件でAnthropicの透明性のある報告を批判しないようコミュニティに呼びかけ、さもなければ将来的にAI企業から重要な観察データを得られなくなる可能性があると述べています。 (出典: colin_fraser & hyhieu226 & clefourrier & johnschulman2 & ClementDelangue & menhguin & RyanPGreenblatt & JeffLadish & Reddit r/ClaudeAI & Reddit r/ClaudeAI & akbirkhan & NeelNanda5 & scaling01 & hrishioa & colin_fraser)
言語モデルの普遍的な幾何学的意味の発見が哲学的議論を呼ぶ: ある新しい論文は、すべての言語モデルが同じ「普遍的な意味の幾何学」に収束するように見えることを明らかにしました。研究者は元のテキストを見ることなく、任意のモデル埋め込みの意味を翻訳できます。この発見は、言語、意味の本質、そしてプラトンやチョムスキーの理論についての議論を引き起こしました。Ethan Mollick氏はこれがプラトンの見解を裏付けるものだと考え、Colin Fraser氏はこれがチョムスキー理論の包括的な擁護であると考えています。この発見は、哲学やベクトルデータベースなどの分野に深遠な影響を与える可能性があります。 (出典: colin_fraser)

AIエージェントのオーケストレーションとミレニアル世代の特質のユーモラスな連想: David Hoang氏のツイートは、「ミレニアル世代はAIエージェントのオーケストレーションに生まれつき適している」という見解を提示し、複数の画像で説明しています。この発言は多くの人にリツイートされ、AIエージェント、自動化、そして異なる世代の人々の特徴についての興味深い議論と連想をコミュニティで引き起こしました。 (出典: timsoret & swyx & zacharynado)

AIエージェントの将来の発展方向に関する議論:プログラミングへの集中はAGIへの近道か?: コミュニティ内では、現在の主要なAIラボ(Anthropic、Gemini、OpenAI、Grok、Meta)がAIエージェント(AI Agent)の研究開発方向においてそれぞれ重点を置いているという見解があります。例えば、AnthropicはAIソフトウェアエンジニア(SWE)に、GeminiはPixelで動作可能なAGIに、OpenAIは大衆向けのAGIを目標としています。その中で、scaling01氏は、Anthropicのコーディングへの集中はAGIから逸脱しているのではなく、むしろAGIへの最速の道であると提唱しています。なぜなら、これによりAIが複雑なシステムをよりよく理解し構築できるようになるからです。この見解は、AGI実現の道筋に関するさらなる考察を引き起こしました。 (出典: cto_junior & tokenbender & scaling01 & scaling01 & scaling01)
AIの経済的影響に関する議論:なぜGDP成長が顕著でないのか?オープン性が鍵か?: Clement Delangue氏 (Hugging Face CEO) は、AI技術が急速に発展しているにもかかわらず、GDP成長への反映はまだ顕著ではないと指摘し、その原因はAIの成果とコントロールが主に少数の大企業(大手テック企業と少数のスタートアップ)に集中しており、オープンなインフラ、科学、オープンソースAIが不足していることにあるかもしれないと述べています。彼は、政府はAIをオープンにすることに尽力し、すべての人々にとっての巨大な経済的利益と進歩を解き放つべきだと考えています。一方、Fabian Stelzer氏は「ダークレジャー」(Dark Leisure)理論を提唱し、AIがもたらす生産性向上の多くが従業員によって個人的な余暇に使われ、企業のより高い生産高には転換されていない可能性があり、これもAIの経済的影響が遅れている原因の一つかもしれないと述べています。 (出典: ClementDelangue & fabianstelzer)
「プロンプト理論」(Prompt Theory) がAI生成コンテンツの真実性についての考察を呼ぶ: ソーシャルメディア上でVeo 3によって生成されたビデオが登場し、「プロンプト理論」を探求しています――もしAIが生成したキャラクターが、自分たちがAIによって生成されたと信じることを拒否したらどうなるか?この概念は、AI生成コンテンツの真実性、AIの自己意識、そして私たち自身の現実についての哲学的な考察をユーザーに引き起こしました。ユーザーのswyx氏は、「私のことを知っていることに基づいて、もし私がLLMだったら、私のシステムプロンプトは何になるだろうか?」という反省的な問いさえ投げかけています。 (出典: swyx)

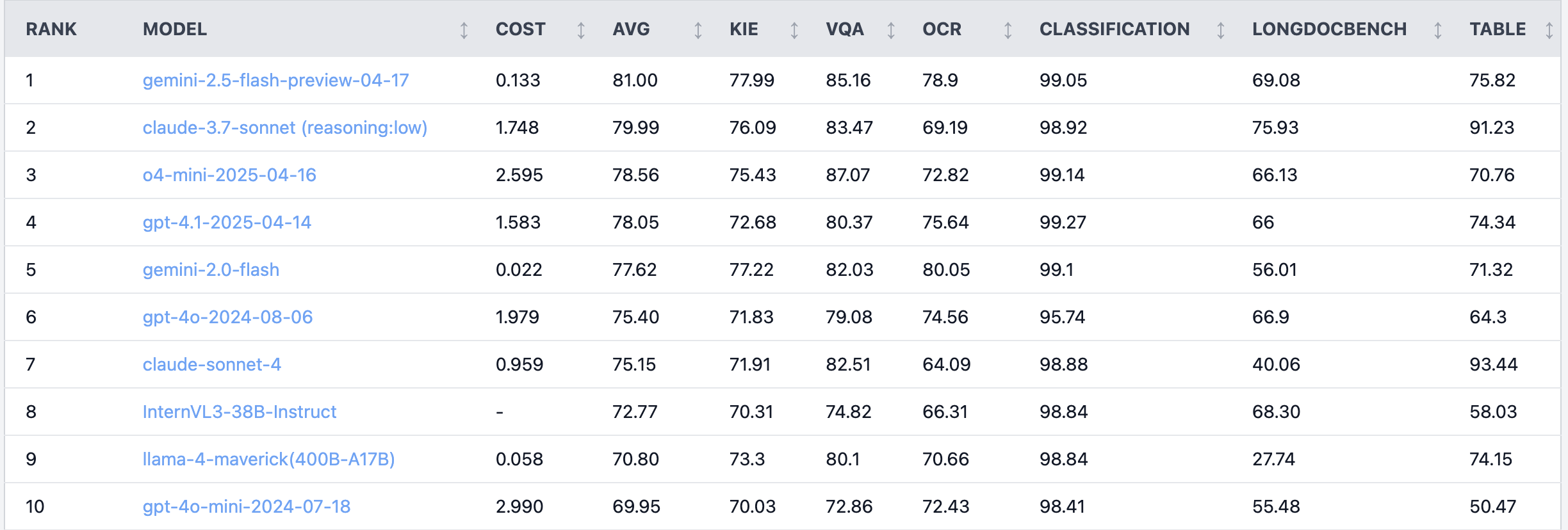
Redditで話題:Claude 4 Sonnet、ドキュメント理解タスクで性能振るわず: Redditのr/LocalLLaMA板で、あるユーザーがClaude 4 (Sonnet) のドキュメント理解タスクにおけるベンチマーク結果を共有し、総合ランキングで7位だったことを示しました。具体的には、OCR能力が弱く、回転した画像に対する感度が高く(正解率が9%低下)、手書きドキュメントや長文ドキュメントの理解能力が低いという結果でした。しかし、表抽出に関しては際立っており、1位でした。コミュニティユーザーはこの件について議論し、AnthropicはClaude 4のコーディング機能やエージェント機能により重点を置いている可能性があると考えています。 (出典: Reddit r/LocalLLaMA)
ベテランアルゴリズムエンジニアのモデル効果がインターンに劣り、経験と革新能力について反省を促す: 10年以上の経験を持つアルゴリズムエンジニアがプロジェクトで作成したモデルの正解率(83%)が、わずか2日間の経験しかないインターン(93%)に追い越されたことが、中国の技術コミュニティで議論を呼んでいます。反省点として、経験が時に思考の慣性となる可能性があり、新人は大胆に新しい方法を試すことができると指摘されています。これはAI従事者に対し、急速に発展する分野において、継続的な試行錯誤と変化を受け入れる能力を維持することが極めて重要であり、経験が束縛になってはならないことを思い起こさせます。 (出典: dotey)
💡 その他
AIの救急放射線科における応用事例:微小骨折の診断補助: Redditユーザーが、現実世界の救急放射線科(ER radiology)におけるAI応用の事例を共有しました。4枚の元のX線写真とAIによる審査分析後の3枚の画像を比較することで、AIは非常に微細な、非転位性の遠位腓骨骨折を特定することに成功しました。これは、AIが医用画像解析において医師の正確な診断を補助する可能性を示しており、特に見つけにくい病変の識別に役立ちます。 (出典: Reddit r/artificial & Reddit r/ArtificialInteligence)
AIが欧州原子核研究機構(CERN)の物理学者によるヒッグス粒子の稀な崩壊の解明を支援: 人工知能技術は、CERNの物理学者がヒッグス粒子を研究するのを助け、稀な崩壊過程を明らかにすることに成功しました。これは、AIが複雑な物理データの処理、微弱な信号の識別、科学的発見の加速において巨大な可能性を秘めていることを示しており、特に高エネルギー物理学のような膨大なデータ分析が必要な分野で顕著です。 (出典: Ronald_vanLoon)

AIモデルの複数ターン対話および長文コンテキストにおける能力進化に関する議論: Nathan Lambert氏は、現在の最強のAIモデルは、対話がより深くなるかコンテキストが長くなるとタスクのパフォーマンスが向上するのに対し、古いモデルは複数ターンまたは長文コンテキストではパフォーマンスが低下するか機能しなくなると指摘しています。この見解はDwarkesh Patel氏のポッドキャストで確認され、多くの人々が抱いていた、初期のモデルは長い対話で能力が減衰するというモデル能力に関する固定観念を打ち破りました。 (出典: natolambert & dwarkesh_sp)