
キーワード:AIエージェント, 大規模言語モデル, Gemini 2.5 Pro, NVIDIA AIスーパーコンピュータ, Microsoft Buildカンファレンス, 研究用AIエージェント, 推論能力評価, AIプログラミング, コーディングエージェントによるバグ自主修復, Microsoft Discovery研究プラットフォーム, NVLink Fusion技術, CloudMatrix 384スーパーノード, EdgeInfiniteアルゴリズム
🔥 焦点
AIエージェントが開発と科学研究のパラダイムを再定義: Microsoft Buildカンファレンスで、バグの自動修正やコードメンテナンスを行うCoding Agent、アイデア生成・結果シミュレーション・自律学習が可能な科学研究エージェントプラットフォームMicrosoft Discoveryなど、一連のAIエージェントツールが発表された。同時に、OpenAIのCPOであるKevin Weil氏およびAnthropicのCEOであるDario Amodei氏は、AIが既に高度なプログラミング能力を備えていると表明し、初級プログラマーの職が代替される可能性を示唆しており、開発者の役割は「AI指導者」へと変化するだろう。これらの進展は、AIエージェントが補助ツールから、複雑なプロジェクトで独立して機能する中核的な力へと進化していることを示しており、ソフトウェア開発と科学研究のプロセスと効率に深刻な変革をもたらすだろう (出典: GitHub Trending, X)
大規模言語モデルの推論能力は新たな課題と評価に直面: 最近の複数の研究と議論により、大規模言語モデルが複雑な推論タスクにおいて限界があることが明らかになった。ハーバード大学などの研究機関は、思考の連鎖 (Chain-of-Thought, CoT) が、モデルの指示遵守における精度を低下させる可能性があると指摘している。これは、内容の計画に過度に注力するあまり、単純な制約を無視するためである。同時に、現実世界の物理タスク(部品加工など)や複雑な視空間推論(立方体の積み重ね問題など)も、o3やGemini 2.5 Proを含むトップレベルのAIモデルの不備を露呈している。モデルの能力をより正確に評価するため、EMMAやSPOTなどの新しいベンチマークが提案されており、AIのマルチモーダル融合や科学的検証などにおける真のレベルを検出し、モデルをより堅牢で信頼性の高い推論へと進化させることを目指している (出典: HuggingFace Daily Papers, 量子位)
Google AIがあらゆる方面で力を発揮、Gemini 2.5 Proが強力なパフォーマンスを示す: GoogleはAI分野で全面的な攻勢を見せており、そのGemini 2.5 Proモデルは複数のベンチマークテスト(LMSYS Chatbot Arenaなど)で優れたパフォーマンスを示し、特に長文コンテキストと動画理解においてトップレベルに達し、WebDev Arenaでは前世代バージョンを上回った。Google Cloud Next ‘25カンファレンスでは、GoogleはGemini 2.5 Flash、Imagen 3、Veo 2、Vertex AI Agent Development Kit (ADK) およびAgent2Agent (A2A) プロトコルを含む200以上のアップデートを発表し、AIをクラウドプラットフォームの各層に統合し、企業の規模拡大展開を推進する決意を示した。Google LabsもNotebookLMなど、AIネイティブの革新的な製品を継続的に育成しており、強力な製品革新と反復能力を示している (出典: Google, GoogleDeepMind)
NVIDIAがデスクトップレベルのAIスーパーコンピューター及びエンタープライズレベルのAIファクトリーソリューションを発表: NVIDIAはComputexカンファレンスで多数の注目製品を発表した。これには、GB300スーパーチップを搭載し、最大784GBのユニファイドメモリを備え、1Tパラメータの大規模モデルの実行をサポートするパーソナルAIコンピュータDGX Stationや、AIエージェント、物理AI、科学計算など多様なアプリケーションを加速する企業向けRTX PRO Serverが含まれる。同時に、NVIDIAはセミカスタム化されたNVLink Fusion技術とNVIDIA AIデータプラットフォームを発表し、Disneyなどと協力して物理AIエンジンNewtonを開発すると発表した。これらの動きは、NVIDIAがチップ企業からAIインフラ企業へと転換し、デスクトップからデータセンターまでの完全なAIエコシステムの構築を目指していることを示している (出典: nvidia, 量子位)

🎯 動向
Kimi.aiが長文思考モデルkimi-thinking-previewをリリース: Kimi.aiは、最新の長文思考モデルkimi-thinking-previewを発表し、現在platform.moonshot.aiで公開されている。このモデルは優れたマルチモーダル能力と推論能力を持つとされ、新規ユーザー登録で5ドルのバウチャーが試用できる。コミュニティのコメントでは、第三者による同モデルの評価が提案されており、Kimiが以前に専用の思考モデルでlivecodebenchでリードしていたことにも言及されている (出典: X)
Red HatがKubernetesベースの分散型推論フレームワークllm-dを発表: LLM推論の速度低下、高コスト、拡張困難の問題を解決するため、Red HatはKubernetesネイティブの分散型推論フレームワークllm-dを発表した。このフレームワークはvLLM、インテリジェントスケジューリング、および計算の分離を利用してLLM推論を最適化する。llm-dは、vLLM(高性能LLM推論エンジン)、Kubernetes(コンテナオーケストレーション標準)、およびInference Gateway (IGW)(Gateway API拡張によるインテリジェントルーティング実現)という3つのオープンソース基盤上に構築されており、LLM推論の効率とスケーラビリティの向上を目指している (出典: X, X)
Meta AIが1億を超える分子構造体を含むOMol25データセットを公開: Meta AIはHuggingFace上で、1億を超える分子構造体を含むOMol25データセットを公開した。これには83種類の元素と多様な化学環境が含まれる。このデータセットは、DFT(密度汎関数理論)レベルの精度を達成しつつ、計算コストを大幅に削減できる機械学習モデルの訓練を目的としている。これにより、創薬、先端材料設計、クリーンエネルギーソリューションなどの分野における研究と応用が加速されることが期待される (出典: X)
Gemini 2.5 ProがNotebookLMドイツ地区iOSアプリストアに登場: GoogleのNotebookLMアプリ(Gemini 2.5 Pro統合)がドイツ地区のiOS App Storeで公開された。以前はEU地区のiOS版はTestFlight経由でのみ提供されていた。同時に、Android版はより広範囲で利用可能になっているようだ。NotebookLMは、ユーザーが長文ドキュメントやメモなどを理解し処理するのを支援することを目的としている (出典: X)
ByteDanceのAI研究が活発化、最近多数の論文を発表: ByteDance傘下のSEEDチームは過去2ヶ月間に少なくとも13本のAI関連研究論文を発表しており、その分野はモデル統合、強化学習による適応的思考連鎖(AdaCoT)、潜在表現による推論最適化(LatentSeek)など多岐にわたる。これらの研究は、ByteDanceが大規模言語モデルの効率、推論能力、訓練方法の向上に継続的に投資し、探求していることを示している (出典: X, X)
AI駆動の次世代亜鉛電池が99.8%の効率と4300時間の稼働時間を達成: 人工知能による最適化を通じて、新世代の亜鉛電池が99.8%のクーロン効率と最大4300時間の稼働時間を達成した。この技術的ブレークスルーは、材料科学とエネルギー貯蔵分野におけるAIの応用可能性を示しており、より効率的で長持ちする電池技術の発展を推進し、再生可能エネルギー貯蔵や携帯型電子機器にとって重要な意味を持つことが期待される (出典: X)

PerplexityがAIスマートブラウザCometの早期テストを開始: Perplexityは、エージェント機能を備えたウェブブラウザCometの早期テスターへの提供を開始した。このブラウザは、全く新しい「雰囲気ブラウジング」(vibe browsing)体験を提供すると予想されており、Perplexityの強力なAI検索と情報統合能力を組み合わせ、ユーザーによりスマートでパーソナライズされたウェブブラウジング方法をもたらす可能性がある (出典: X)
Intelが高コストパフォーマンスのArc Pro Bシリーズグラフィックカードを発表、大容量VRAMを特徴とする: IntelはArc Pro B50(16GB VRAM、299ドル)とAIワークステーション向けに設計されたArc Pro B60(24GB VRAM、単体500ドル)グラフィックカードを発表した。B60はAI推論テストでNVIDIA RTX A1000を上回る性能を示し、より大きなVRAMにより大規模モデル実行時に優位性を持つ。Project BattlematrixワークステーションはXeonプロセッサを採用し、最大8基のB60 GPU(合計192GB VRAM)を搭載可能で、700億以上のパラメータを持つモデルをサポートする。この動きは、IntelがAIハードウェア市場でコストパフォーマンスによる突破口を模索する戦略と見なされている (出典: 量子位)

Huawei CloudがCloudMatrix 384スーパーノードを発表、AI計算能力を向上: Huawei CloudはCloudMatrix 384スーパーノードを発表した。これは完全なピアツーピア相互接続アーキテクチャを採用し、384枚のAIアクセラレータカードを相互接続してスーパーサーバーを形成し、最大300Pflopsの計算能力を提供する。AI訓練と推論における通信効率、メモリウォール、信頼性の課題解決を目指す。このアーキテクチャは特にMoEモデルへの親和性、ネットワークによる計算強化、ストレージによる計算強化などの特徴を強調しており、DeepSeek-R1などの大規模モデルの推論サービスをサポートするために既に適用されている (出典: 量子位)

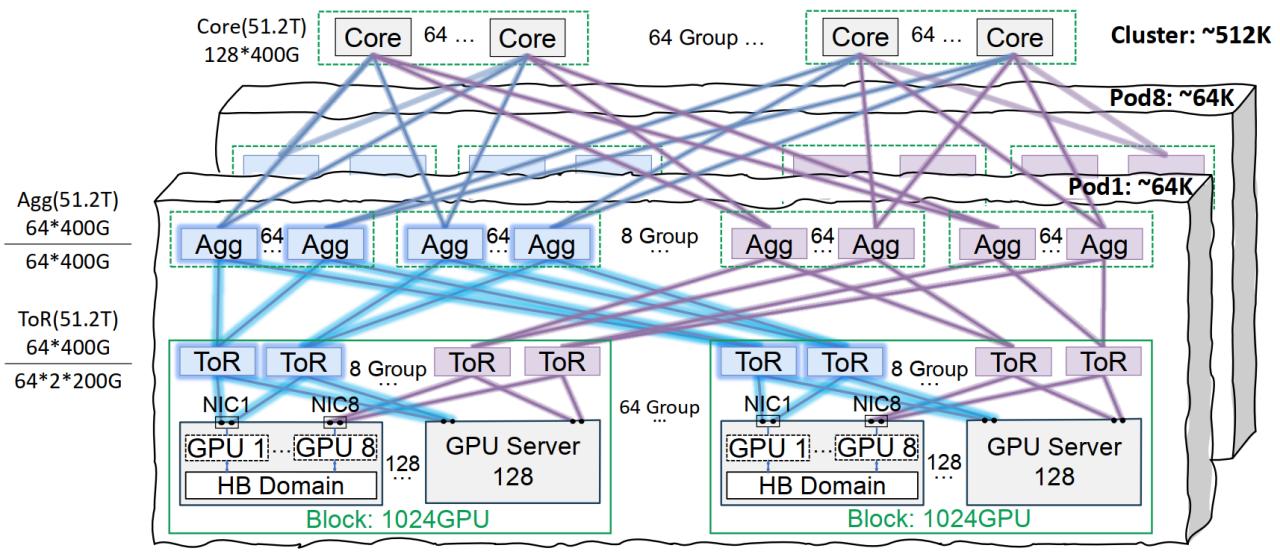
Tencent Cloudの星脈ネットワークインフラストラクチャが大規模モデル訓練を最適化: Tencent Cloudは、大規模AIモデルの訓練と推論のために設計された星脈高性能ネットワークインフラストラクチャソリューションを発表した。このソリューションは、同一軌道相互接続アーキテクチャ(単一Podで6.4万GPU、全クラスターで51.2万GPUのネットワーク構成をサポート)、最適化された電源管理と冷却ソリューション、およびインテリジェント監視システムを通じて、従来のデータセンターにおけるネットワーク、展開密度、故障特定に関するボトルネックを解決する。星脈は既にTencent混元などの自社開発業務をサポートしており、DeepSeekのDeepEP通信フレームワークに性能最適化を提供している (出典: 量子位)
Stability AIがSV4D2.0モデルをリリース、動画生成分野への回帰を示唆か: Stability AIはHugging Face上でsv4d2.0という名前のモデルをリリースし、コミュニティの注目を集めている。詳細は不明だが、この動きはStability AIが動画生成または関連する3D/4D分野で新たな技術的進展や製品の反復を行っている可能性を意味し、調整期間を経てAI生成分野の最前線に復帰する可能性を示唆している (出典: X)
Meta AIがAdjoint Sampling学習アルゴリズムを発表: Meta AIは、スカラー報酬に基づく生成モデルを訓練するための新しい学習アルゴリズムAdjoint Samplingを提案した。このアルゴリズムはFAIRが開発した理論的基礎に基づいており、高いスケーラビリティを備え、将来のスケーラブルなサンプリング手法研究の基礎となることが期待される。関連する研究論文、モデル、コード、ベンチマークが公開されている (出典: X)
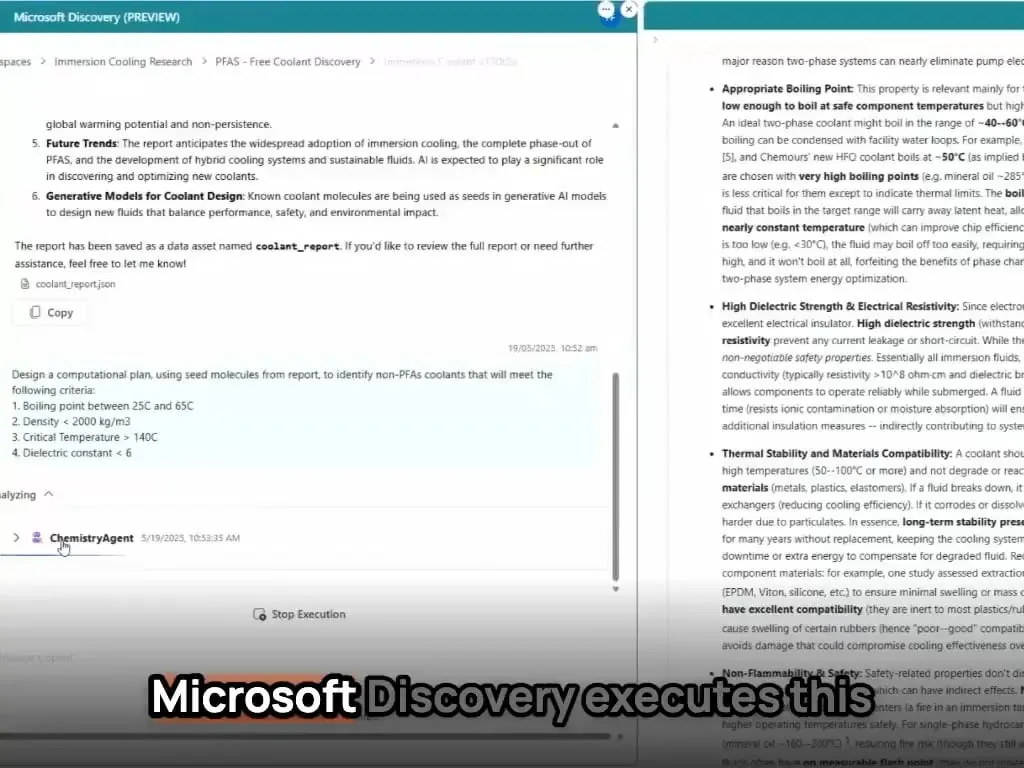
MicrosoftのAIエージェントが数時間で新材料の発見と合成を完了: Microsoftは、科学研究開発におけるAIエージェントの強力な能力を実証した。これらのエージェントは、科学文献のスキャン、計画立案、コード作成、シミュレーション実行を行い、通常数年の研究開発を要する新型データセンター冷却材の発見を数時間で完了した。さらに、チームはAIが設計した新型冷却材の合成に成功し、実際のメインボードでデモンストレーションを行い、AIが材料科学などの分野で自律的な発見と創造を加速する巨大な可能性を示した (出典: Reddit r/artificial)
智源研究院がBGEシリーズのベクトルモデル3種を発表、コードとマルチモーダル検索に特化: 智源研究院は大学と共同で、BGE-Code-v1(コードベクトルモデル)、BGE-VL-v1.5(汎用マルチモーダルベクトルモデル)、およびBGE-VL-Screenshot(視覚化ドキュメントベクトルモデル)を発表した。これらのモデルはCoIR、Code-RAG、MMEB、MVRBなどのベンチマークテストで優れた性能を示し、BGE-Code-v1はQwen2.5-Coder-1.5B、BGE-VL-v1.5はLLaVA-1.6、BGE-VL-ScreenshotはQwen2.5-VL-3B-Instructに基づいており、コード検索、画像・テキスト理解、複雑な視覚ドキュメント検索の性能向上を目指し、全面的にオープンソース化されている (出典: WeChat)
HuaweiのOmniPlacement技術がMoEモデルの推論を最適化、DeepSeek-V3の遅延を理論上10%削減: 混合エキスパート(MoE)モデルにおけるエキスパートネットワークの負荷不均衡(「ホットエキスパート」と「コールドエキスパート」)による推論性能の制約問題に対し、HuaweiチームはOmniPlacement技術を提案した。この技術は、エキスパートの再配置、層間冗長配置、および近リアルタイム動的スケジューリングを通じて、DeepSeek-V3などのモデルで理論上約10%の推論遅延削減と約10%のスループット向上を実現できる。このソリューションは近々全面的にオープンソース化される予定 (出典: WeChat)

vivoがEdgeInfiniteアルゴリズムを発表、スマートフォン端末での128K長文テキストの効率的な処理を実現: vivo AI研究院はACL 2025で研究を発表し、端末側デバイス向けに設計されたEdgeInfiniteアルゴリズムを発表した。訓練可能なゲート付きメモリモジュールとメモリ圧縮/解凍技術を通じて、Transformerアーキテクチャで超長文テキストを効率的に処理する。このアルゴリズムはBlueLM-3Bモデルでテストされ、10GB GPUメモリデバイスで128Kトークンを処理でき、LongBenchの多数のタスクで優れた性能を示し、最初の単語の出力時間とメモリ使用量を大幅に削減した (出典: WeChat)

🧰 工具
LlamaParseがアップデート、ドキュメント解析能力を強化: LlamaParseは、AIエージェント駆動のドキュメント解析ツールとしての性能を向上させる複数のアップデートを発表した。新機能には、Gemini 2.5 Pro、GPT-4.1のサポート、傾き検出と信頼度スコアの追加が含まれる。さらに、解析設定を直接コードベースにコピーできるコードスニペットボタンが導入され、ユースケースプリセットとレンダリング/生Markdown間のエクスポート切り替え機能が追加された (出典: X)
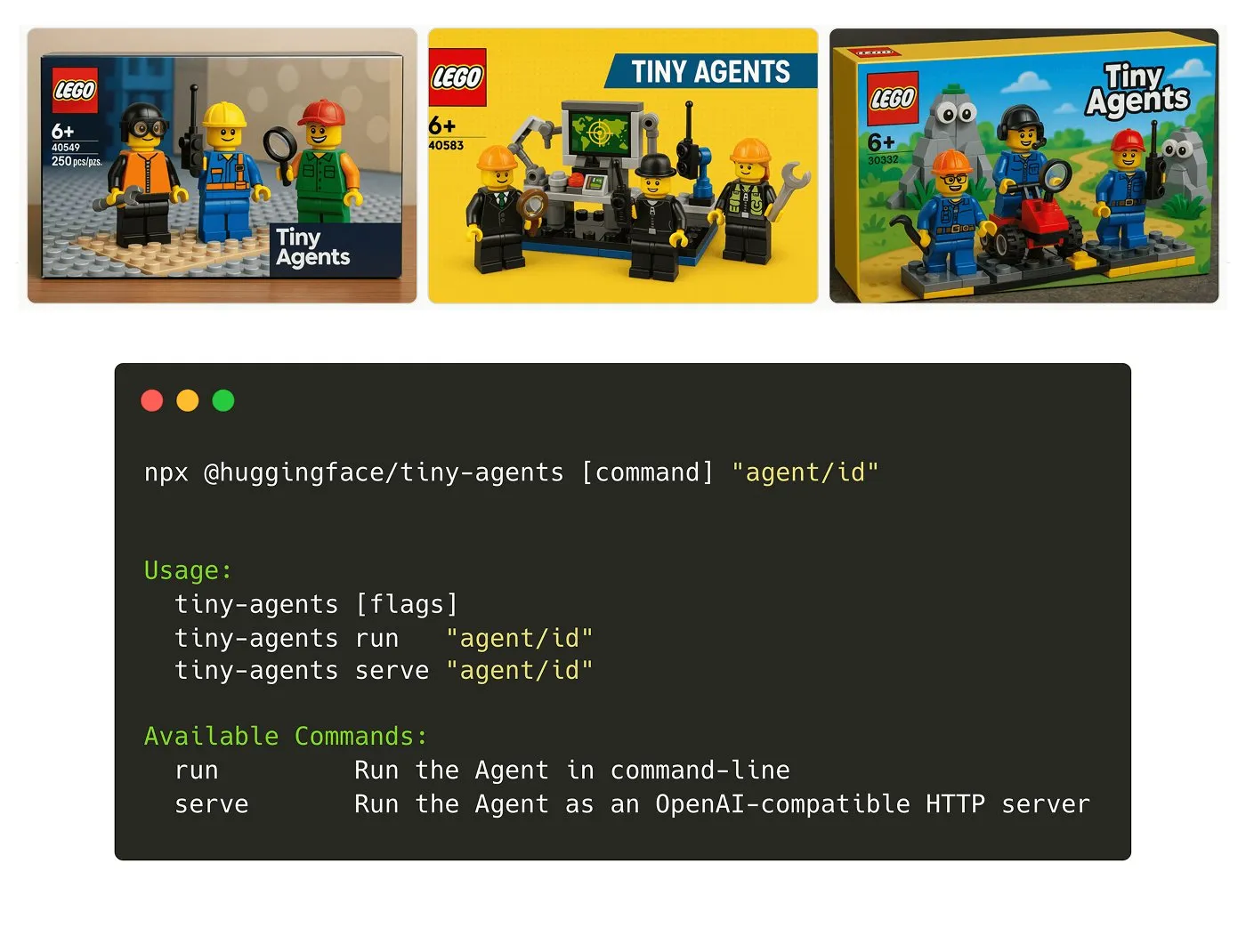
Hugging FaceがTiny Agents NPMパッケージをリリース: Julien Chaumond氏は、軽量で構成可能なエージェントNPMパッケージであるTiny Agentsをリリースした。これはHugging FaceのInference ClientとMCP (Model Component Protocol) スタックに基づいて構築されており、開発者が迅速に小型エージェントアプリケーションを開発・構築できるようにすることを目的としている。公式の入門チュートリアルが提供されている (出典: X)
LangGraphプラットフォームにMCPサポートが追加され、エージェント統合を簡素化: LangGraphプラットフォームは現在MCP (Model Component Protocol) をサポートしており、プラットフォームにデプロイされた各エージェントは自動的にMCPエンドポイントを公開する。これは、ユーザーがこれらのエージェントをツールとして利用し、MCPのストリーミング可能なHTTPをサポートする任意のクライアントで使用できることを意味し、カスタムコードの作成や追加インフラストラクチャの設定が不要になり、エージェント間の統合と相互運用性が簡素化される (出典: X)

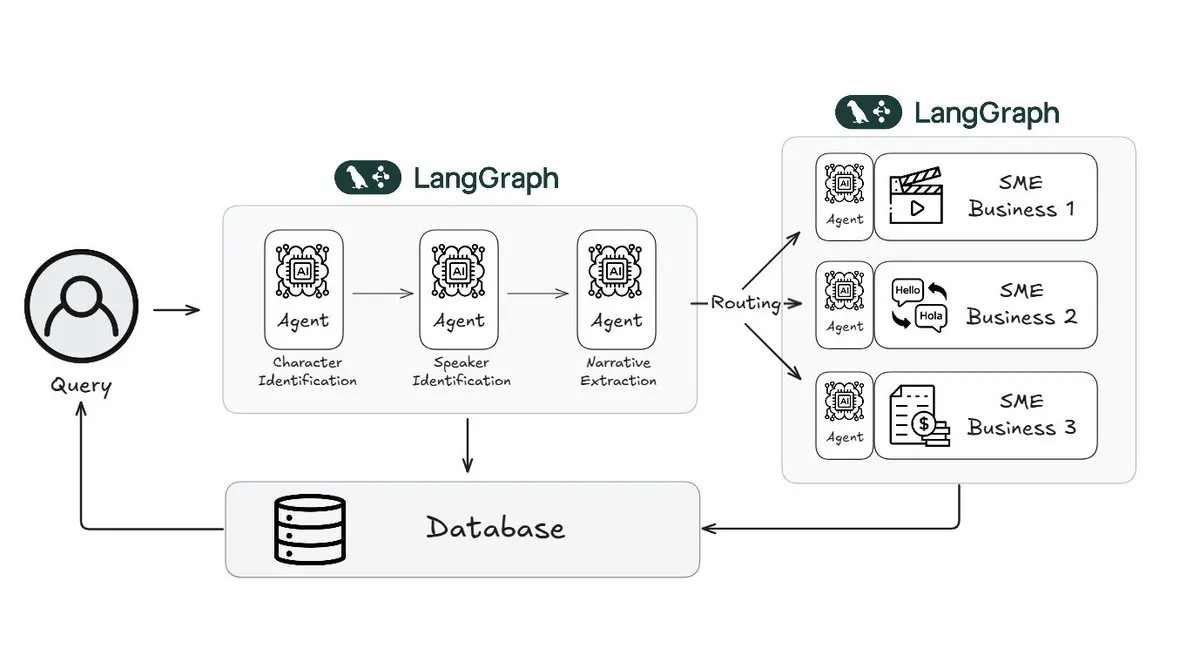
WebtoonがLangGraphを利用してストーリー審査の作業量を70%削減: デジタルコミックのリーダーであるWebtoonは、Webtoon Comprehension AI (WCAI) を構築し、LangGraphを使用して膨大なコンテンツライブラリの物語理解を自動化した。WCAIは、インテリジェントなマルチモーダルエージェントによって手作業による閲覧を置き換え、キャラクターと発言者の識別、プロットとトーンの抽出、自然言語による洞察クエリを実行でき、マーケティング、翻訳、推薦チームの作業量を70%削減し、創造性を向上させた (出典: X)
OpenMemory MCPがAIツール間の永続的なプライベートメモリ共有を実現: Mem0プロジェクトはOpenMemory MCPサーバーを発表した。これはAIアプリケーションにクロスプラットフォーム、クロスセッションの永続的なプライベートメモリを提供することを目的としている。ユーザーはローカルにデプロイし、MCPプロトコルを通じてOpenMemoryをCursorなどのクライアントツールに接続し、メモリの追加、検索、一覧表示、削除を実現できる。このツールはダッシュボードを通じてメモリ管理機能を提供し、AIエージェントのパーソナライズとコンテキスト理解能力を強化することが期待される (出典: WeChat)

妙多AI 2.0がリリース、インターフェースデザインAIアシスタントとして位置づけ: 妙多AI 2.0はインターフェースデザイン分野のAIアシスタントとしてリリースされ、ユーザーと協力してデザインタスクを完了することを目的としている。新バージョンはAIマジックボックスを通じてインタラクションを強化し、対話型編集と反復的なデザイン案作成をサポートし、プリセットスタイルやユーザー入力(長文テキスト、スケッチ、参考画像)に基づいて複数のインターフェース案を生成し、主流のデザインシステムと互換性がある。さらに、画像・テキスト処理、デザインコンサルティング、ショートカットコマンド(自然言語からAPI呼び出しへ)などの機能も提供する。妙多AIはMCPプロトコルをサポートし、デザインデータを大規模モデルが読み取れるように最適化し、高再現度のフロントエンドコードを生成する (出典: 量子位)

llmbasedos:MCPベースのオープンソース起動可能AIオペレーティングシステム概念実証: 開発者iluxu氏は、Microsoftが「AIアプリ向けUSB-C」コンセプト(MCPベース)を発表する3日前に、llmbasedosプロジェクトをオープンソース化した。このプロジェクトは、USBまたは仮想マシンから迅速に起動できるAIオペレーティングシステムであり、FastAPIゲートウェイを介してJSON-RPCで小型Pythonデーモンと通信し、ユーザーのスクリプトが簡単なcap.json設定を通じてChatGPT/Claude/VS Codeなどから呼び出されることを可能にする。デフォルトではオフラインのllama.cppを使用するが、GPT-4oやClaude 3に切り替えることも可能で、オープンなAIアプリケーション接続標準の推進を目指している (出典: Reddit r/LocalLLaMA)
📚 学習
知識蒸留 (KD) はなぜ有効なのか? 新たな研究が簡潔な説明を提供: Kyunghyun Cho氏らは、知識蒸留 (KD) の有効性について簡潔な説明を提案した。彼らは、教師モデルからの低エントロピー近似サンプリングを使用すると、生徒モデルはより高い精度を持つが再現率が低下すると仮定している。自己回帰言語モデルは本質的に無限に連鎖する混合分布であるため、彼らはSmolLMを通じてこの仮説を検証した。この研究は、現在の評価方法が精度に偏りすぎており、再現率の損失を無視している可能性があり、これは大規模な汎用モデルが見落とす可能性のある内容やユーザー層に関係すると主張している (出典: X)

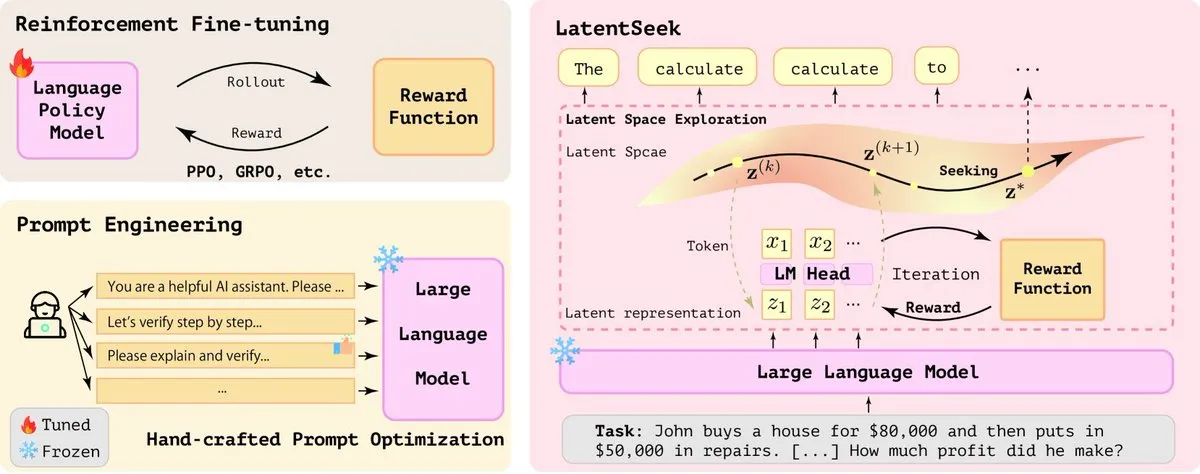
LatentSeek:潜在空間における戦略勾配最適化によるLLM推論能力の向上: 「Seek in the Dark」という論文では、テスト時に潜在空間におけるインスタンスレベルの戦略勾配を通じて大規模言語モデル (LLM) の推論能力を強化する新しいパラダイムLatentSeekが提案されている。この方法は、訓練、データ、報酬モデルを必要とせず、潜在表現を最適化することでモデルの推論プロセスを改善することを目的としている。この訓練不要な方法は、LLMの複雑な推論タスクの性能向上において可能性を示している (出典: X)
MicrosoftがCoML:言語モデルの連鎖モデル学習を提案: Microsoft Researchは、「連鎖モデル学習」(Chain-of-Model Learning, CoML) という新しい学習パラダイムを提案した。この方法は、隠れ状態の因果関係を連鎖構造として各層のネットワークに組み込み、モデル訓練のスケーリング効率とデプロイ時の推論の柔軟性を向上させることを目的としている。その中核概念である「連鎖表現」(CoR) は、各層の隠れ状態を複数のサブレプリゼンテーションチェーンに分解し、後続のチェーンは先行するすべてのチェーンの入力表現にアクセスできるため、モデルはチェーンを追加することで漸進的に拡張でき、異なる数のチェーンを選択することで様々な規模のサブモデルを提供し、弾力的な推論を可能にする。この原理に基づいて設計されたCoLM (連鎖言語モデル) とその変種であるCoLM-Air (KV共有メカニズムを導入) は、標準的なTransformerと同等の性能を示し、漸進的な拡張と弾力的な推論の利点をもたらした (出典: X, HuggingFace Daily Papers)

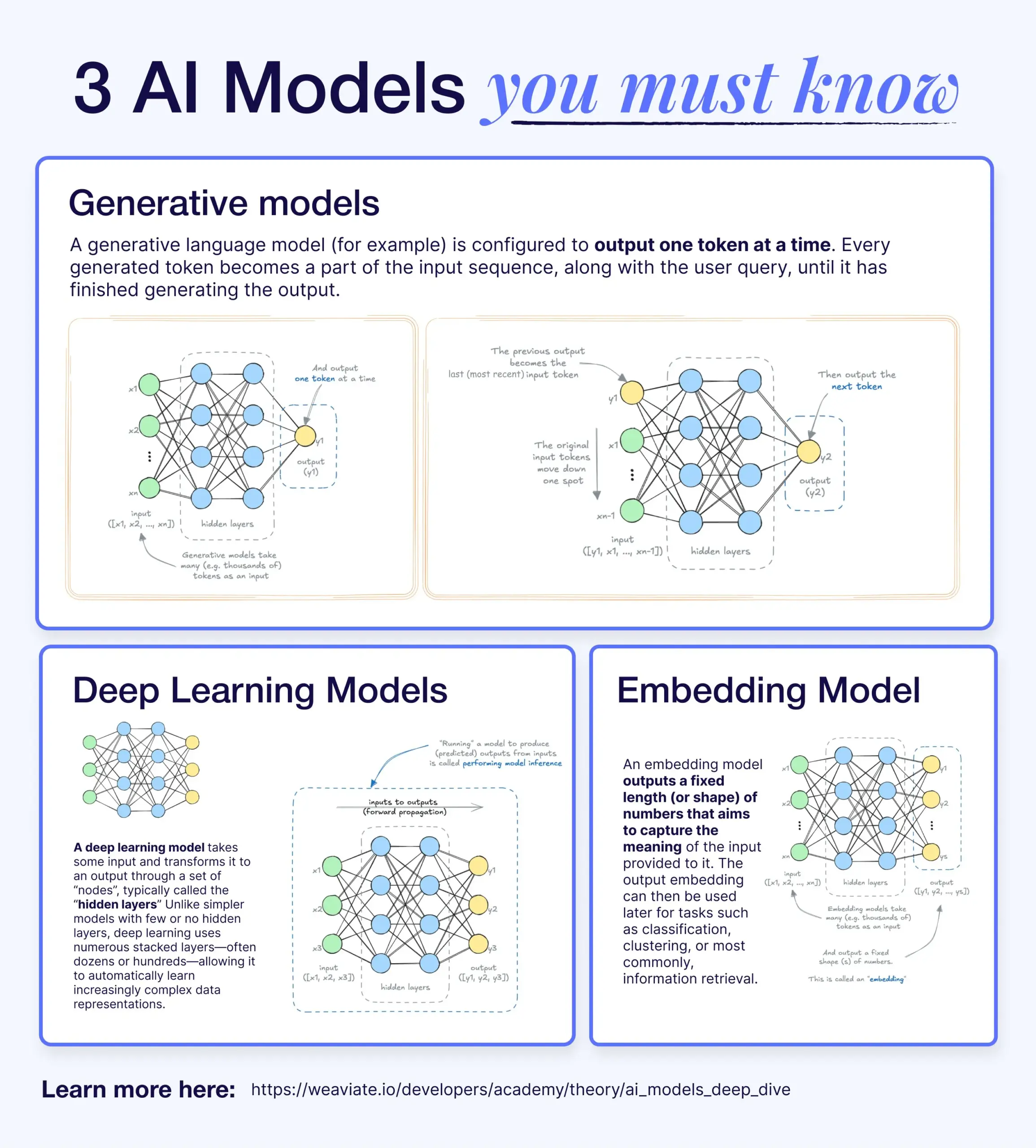
深層学習、生成モデル、埋め込みモデルの違いと関連性: ある解説記事が、深層学習モデル、生成モデル、埋め込みモデルの関係を説明している。深層学習モデルは基礎的なアーキテクチャであり、多層ニューラルネットワークを通じて数値の入出力を処理する。生成モデルは深層学習モデルの一種で、訓練データに類似した新しいコンテンツ(GPT、DALL-Eなど)を作成するために特化している。埋め込みモデルも深層学習モデルの一種で、データ(テキスト、画像など)を意味情報を捉えた数値ベクトル表現に変換するために使用され、類似性検索やRAGシステムでよく用いられる。多くのAIシステムでは、これらのモデルが協調して動作し、例えばRAGシステムは埋め込みモデルを検索に利用し、その後生成モデルが応答を生成する (出典: X)
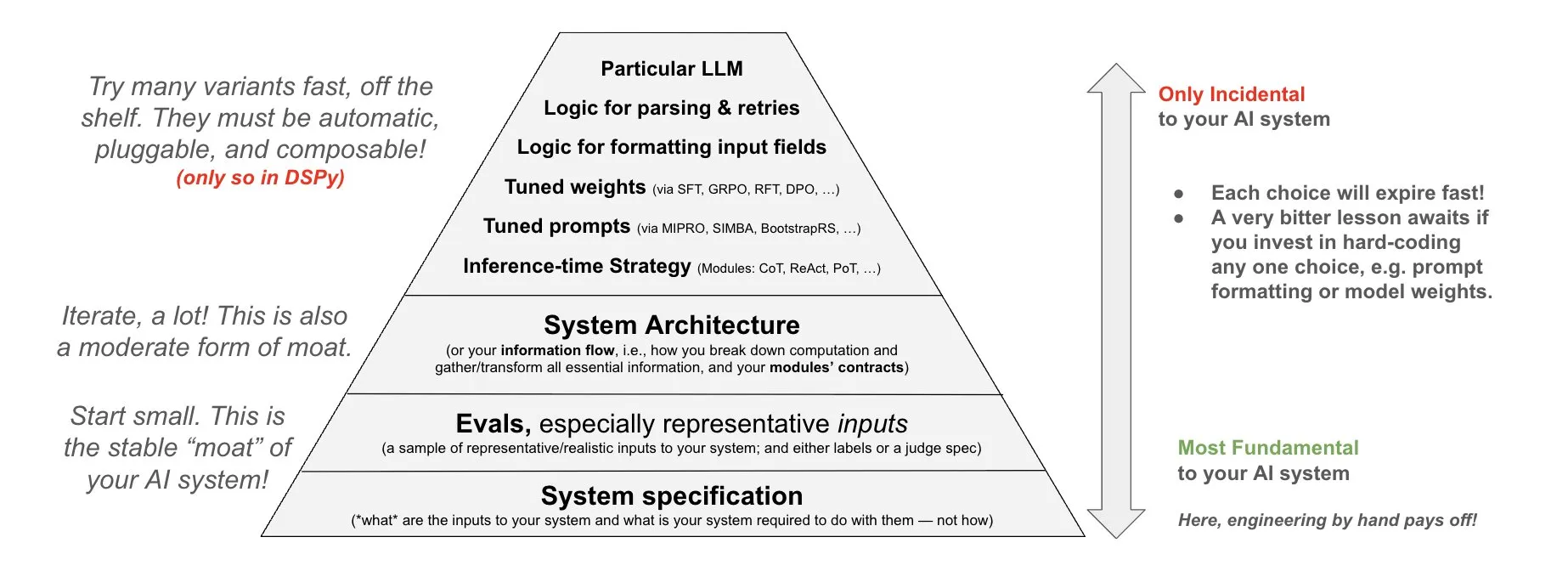
DSPyがAIシステムへの投資哲学を提案: DSPyは、AIシステムへの投資に関する哲学を共有し、AIシステムの3つの基礎層であるデータ、モデル、アルゴリズムにエネルギーを投入すべきだと強調している。彼らは、構成可能なトップレベルモジュール (Prompts, Demonstrations, Optimizers, Metrics, Tools, Agents, Reasoning Modules) を提供することで、開発者はこれら3つの基礎層を迅速に反復し、より強力なAIシステムを構築できると考えている (出典: X)
Transformersライブラリが更新、最適化カーネルへの自動切り替えで性能向上: 最新版のHugging Face Transformersライブラリは、ハードウェアが許容する場合に最適化カーネルへ自動的に切り替える機能を実現した。この更新はkernelsライブラリを統合し、Llamaなどの人気モデルを対象に、Hugging Face Hubで最も人気のあるコミュニティカーネルを利用し、互換性のあるハードウェア上でのモデルの実行効率と性能向上を目指している (出典: X)
ARC-AGI-2ベンチマークが公開、最先端AI推論システムに挑戦: François Chollet氏らは、ARC-AGI-2ベンチマークに関する論文を発表し、その設計原則、挑戦性、人間のパフォーマンス分析、および現在のモデルの性能について詳述した。このベンチマークはAIの抽象的推論能力を評価することを目的としており、人間はタスクの100%を解決できるのに対し、現在の最先端AIモデルのスコアは5%未満であり、高度な抽象的推論においてAIと人間の間に依然として大きな隔たりがあることを示している (出典: X)

テレンス・タオ氏がGitHub Copilotを用いた関数極限証明のチュートリアルを公開: 数学者のテレンス・タオ氏が、GitHub Copilotを用いて関数の極限問題(和、差、積の定理を含む)を証明する補助を行うビデオチュートリアルを公開した。彼は、Copilotがコードの骨子や既存のライブラリ関数のヒントを迅速に生成できるものの、複雑な数学的詳細、特殊なケースの処理、創造的な解決策においては依然として多くの人手による介入と調整が必要であり、時には紙とペンによる推論と形式的検証を組み合わせる方が効率的である可能性を強調している (出典: 36氪)
PhyT2VフレームワークがLLMを利用してテキストから動画への物理的一貫性を向上: ピッツバーグ大学の研究チームはPhyT2Vフレームワークを提案し、大規模言語モデルによる思考の連鎖 (CoT) と反復的な自己修正メカニズムを通じてテキストプロンプトを最適化し、既存のテキストから動画へ (T2V) モデルが生成するコンテンツの物理的リアリズムを強化する。この方法はモデルの再訓練を必要とせず、生成された動画とプロンプトの間の意味的な不一致を分析し、物理法則と組み合わせてプロンプトを修正することで、T2Vモデルが分布外 (OOD) シナリオを処理する際の物理的一貫性を向上させることを目指す。実験では、PhyT2VがCogVideoX、OpenSoraなどのモデルのVideoPhy、PhyGenBenchなどのベンチマークにおけるパフォーマンスを大幅に向上させることが示された (出典: WeChat)

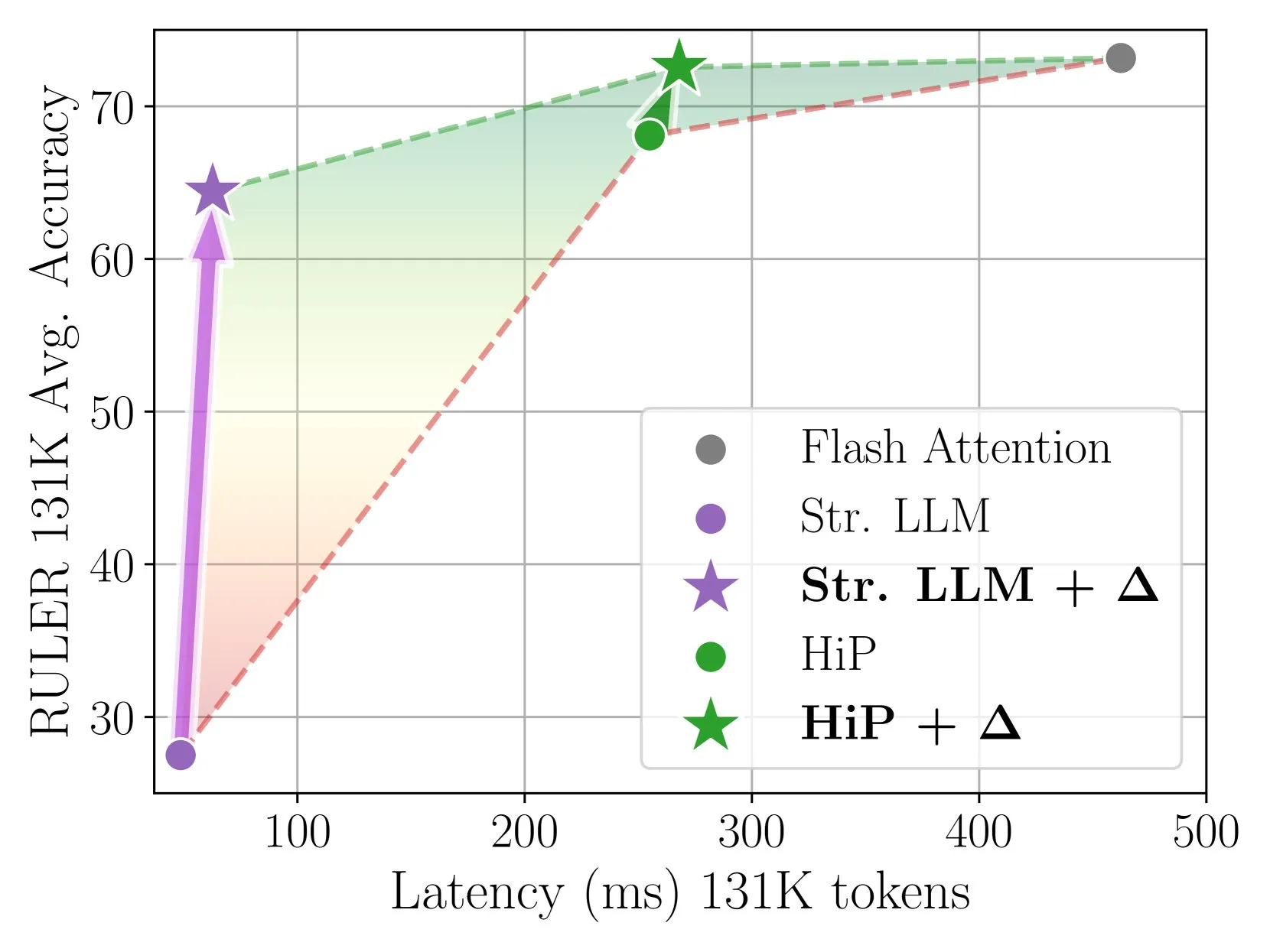
Delta Attentionがインクリメンタル補正により高速かつ正確なスパースアテンション推論を実現: この研究では、スパースアテンション計算がアテンション出力の分布シフトを引き起こし、モデルの性能を低下させることが発見された。Delta Attentionは、この分布シフトを補正することで、スパースアテンションの出力分布をフルアテンションに近づけ、高いスパース度(約98.5%)を維持しつつ、性能を大幅に向上させ、RULERベンチマークにおいてスライディングウィンドウアテンション(シンクトークン付き)のフルアテンション精度の88%を回復し、計算コストも小さい。1Mトークンのプレフィル処理において、Flash Attention 2より32倍高速である (出典: HuggingFace Daily Papers)
ThinklessフレームワークがLLMにCoT推論を行うべき時を学習させる: 大規模言語モデル (LLM) が全てのクエリで複雑な思考の連鎖 (CoT) 推論を使用することによる計算効率の低下問題を解決するため、研究者らはThinklessフレームワークを提案した。このフレームワークは強化学習を通じてLLMを訓練し、タスクの複雑さと自身の能力に応じて短形式または長形式の推論を適応的に選択できるようにする。中核アルゴリズムDeGRPOは、学習目標を制御トークン損失(推論モードを決定)と応答損失(回答の精度を向上)に分解し、訓練プロセスを安定させる。実験では、ThinklessがMinerva Algebraなどのベンチマークで長鎖思考の使用を50%-90%削減し、推論効率を大幅に向上させることが示された (出典: HuggingFace Daily Papers)
CPGDアルゴリズムがルールベース言語モデルの強化学習の安定性を向上: 既存のルールベース強化学習手法(GRPO, REINFORCE++, RLOOなど)が言語モデルの訓練時に訓練の不安定性を引き起こす可能性がある問題に対し、研究者らはCPGD(戦略ドリフトを伴うクリッピング戦略勾配最適化)アルゴリズムを提案した。CPGDは、KLダイバージェンスに基づく戦略ドリフト制約を導入して戦略更新を動的に正則化し、対数比率クリッピングメカニズムを利用して過度な戦略更新を防ぐ。理論的および実証的分析により、CPGDが不安定性を緩和し、訓練の安定性を維持しつつ性能を大幅に向上させることが示された (出典: HuggingFace Daily Papers)
ニューラルシンボリッククエリコンパイラQCompilerがRAGシステムの複雑なクエリ処理能力を向上: 検索拡張生成 (RAG) システムが、ネスト構造や依存関係を持つ複雑なクエリを処理する際、特にリソースが限られた状況で検索意図を正確に特定することが困難であるという問題を解決するため、QCompilerフレームワークが提案された。このフレームワークは、言語学の文法規則とコンパイラ設計に着想を得て、まず最小かつ十分なBNF文法G[q]を設計して複雑なクエリを形式化し、次にクエリ式変換器、字句文法解析器、再帰下降プロセッサを通じてクエリを抽象構文木 (AST) にコンパイルして実行する。葉ノードのサブクエリの原子性が、より正確なドキュメント検索と応答生成を保証する (出典: HuggingFace Daily Papers)
JediデータセットとOSWorld-Gベンチマークがコンピュータ使用シーンにおけるGUI要素特定研究を推進: グラフィカルユーザーインターフェース (GUI) 特定(自然言語指示をGUI操作にマッピングする)のボトルネックを解決するため、研究者らはOSWorld-Gベンチマーク(テキストマッチング、要素認識、レイアウト理解、精密操作をカバーする564の細粒度アノテーション付きサンプル)と大規模合成データセットJedi(400万サンプル)を公開した。Jediで訓練されたマルチスケールモデルは、ScreenSpot-v2、ScreenSpot-Pro、OSWorld-Gのいずれにおいても既存の手法を上回り、汎用基盤モデルの複雑なコンピュータタスク(OSWorld)におけるエージェント能力を5%から27%に向上させることができた (出典: HuggingFace Daily Papers)
分割思考連鎖推論 (Fractured CoT) がLLMの推論効率と性能を向上: CoT推論がもたらす高いトークンコストの問題を解決するため、研究者らは、CoTを途中で打ち切る(推論を完了する前に停止し、直接回答を生成する)ことで、通常、完全なCoTと同等の性能を達成しつつ、トークン消費を大幅に削減できることを発見した。これに基づき、Fractured Samplingという統一的な推論戦略を提案し、推論軌跡の数、各軌跡の最終解の数、および推論トレースの打ち切り深度という3つの次元を調整することで、複数の推論ベンチマークとモデル規模において、より優れた精度とコストのトレードオフを実現し、より効率的でスケーラブルなLLM推論への道を開いた (出典: HuggingFace Daily Papers)
LLMコンテキスト条件付けとPWPプロンプティングによる化学式のマルチモーダル検証: 研究者らは、構造化LLMコンテキスト条件付けを探求し、永続的ワークフロープロンプティング (PWP) 原則と組み合わせることで、LLMの推論時の振る舞いを調整し、特に画像を含む複雑な科学文書を扱う際の、化学式などの精密な検証タスクにおける信頼性を向上させることを目指した。この方法は、APIやモデルの変更を必要とせず、標準的なチャットインターフェース (Gemini 2.5 Pro, ChatGPT Plus o3) のみを使用する。予備実験では、この方法がテキストエラーの認識を改善し、Gemini 2.5 Proが人手によるレビューで見落とされた画像内の数式エラーを特定するのに役立ったことが示された (出典: HuggingFace Daily Papers)
PWP、メタプロンプティング、メタ推論を用いたAI駆動の学術的査読の実現: 研究者らは、永続的ワークフロープロンプティング (PWP) 手法を提案し、標準的なLLMチャットインターフェースを通じて科学論文の批判的な査読を実現する。PWPは階層的モジュラーアーキテクチャ (Markdown構造化) を採用して詳細な分析ワークフローを定義し、メタプロンプティングとメタ推論を通じて専門家の査読プロセス (暗黙知を含む) を体系的にエンコードする。PWPはLLMを誘導して、主張と証拠の区別、テキスト/画像/図表分析の統合、定量的実現可能性チェックの実行など、体系的なマルチモーダル評価を行わせ、テストケースでは方法論的欠陥の特定に成功した (出典: HuggingFace Daily Papers)
SPOTベンチマークがAIによる科学研究の自動検証能力を評価: 大規模言語モデル (LLM) を「AI共同科学者」として、学術論文の自動検証能力を評価するため、研究者らはSPOTベンチマークを発表した。このベンチマークには、83本の既発表論文と、訂正または撤回につながるほどの91箇所の誤りが含まれており、原著者と人手によるアノテーターによってクロス検証されている。実験結果によると、最先端のLLM (o3など) でさえ、SPOTにおける再現率は21.1%を超えず、適合率は6.1%未満であり、モデルの信頼度も低く、複数回の実行結果に一貫性がないことが示され、現在のLLMが信頼性の高い学術検証において実際のニーズと大きな隔たりがあることを示している (出典: HuggingFace Daily Papers)
ExTransがサンプル拡張強化学習により多言語深層推論翻訳を実現: 機械翻訳における大規模推論モデル (LRM) の能力向上、特に多言語シナリオにおいて、研究者らはExTransを提案した。この方法は、戦略翻訳モデルと強力なLRM (DeepSeek-R1-671Bなど) の翻訳結果を比較することで報酬を定量化する新しい報酬モデリング手法を設計した。実験では、Qwen2.5-7B-Instructをバックボーンとして訓練されたモデルが文学翻訳でSOTAを達成し、OpenAI-o1およびDeepSeeK-R1を上回った。軽量な報酬モデリングにより、この方法は単一方向の翻訳能力を11言語90翻訳方向に効果的に移行できる (出典: HuggingFace Daily Papers)
訓練可能なスパースアテンションVSAがビデオ拡散モデルを高速化: ビデオ拡散Transformer (DiT) における3Dフルアテンションメカニズムの二次的な複雑さの問題を解決するため、研究者らはVSA (訓練可能なスパースアテンション) を提案した。VSAは、軽量な粗い段階でトークンをブロックに集約し、重要なトークンを識別した後、これらのブロック内で詳細なトークンレベルのアテンション計算を行う。VSAはエンドツーエンドで訓練可能な単一の微分可能カーネルであり、後処理分析を必要とせず、FlashAttention3 MFUの85%を維持する。実験では、VSAが拡散損失を低下させることなく、訓練FLOPSを2.53倍削減し、オープンソースのWan-2.1モデルのアテンション時間を6倍高速化し、エンドツーエンドの生成時間を31秒から18秒に短縮したことが示された (出典: HuggingFace Daily Papers)
SoftCoT++:ソフトな思考連鎖推論によるテスト時拡張の実現: 連続潜在空間で推論を行うSoftCoT手法の探索能力を強化するため、研究者らはSoftCoT++を提案した。この方法は、複数の専用初期トークンを用いて潜在的な思考を摂動させ、対照学習を適用してソフトな思考表現の多様性を促進することで、SoftCoTをテスト時拡張 (TTS) パラダイムに拡張する。実験では、SoftCoT++がSoftCoTの性能を大幅に向上させ、自己整合性拡張を伴うSoftCoTを上回り、自己整合性などの従来の拡張技術との互換性も高いことが示された (出典: HuggingFace Daily Papers)
MTVCrafter:オープンワールド人体画像アニメーションのための4D運動トークン化: 既存の手法が2Dポーズ画像に依存し、汎化能力が限定的であるという問題を解決するため、MTVCrafterは生の3D運動シーケンス(4D運動)を直接モデル化することを提案する。その中核は4DMoT(4D運動トーカーナイザー)であり、3D運動シーケンスを4D運動トークンに量子化し、より堅牢な時空間手がかりを提供する。その後、独自の運動アテンションと4D位置エンコーディングで設計されたMV-DiT(運動認識ビデオDiT)がこれらのトークンをコンテキストとして効果的に利用し、複雑な3D世界で人体画像アニメーションを実現する。実験では、MTVCrafterがFID-VIDで6.98を達成し、SOTAを大幅に上回り、異なるスタイルやシーンの多様なキャラクターにうまく汎化できることが示された (出典: HuggingFace Daily Papers)
QVGen:量子化ビデオ生成モデルの限界を押し広げる: ビデオ拡散モデル (DM) の計算およびメモリ需要が大きいという問題を解決するため、QVGenは極低ビット量子化 (4ビット以下など) 向けに特別に設計された新しい量子化対応訓練 (QAT) フレームワークを提案した。理論分析を通じて、研究者らは勾配ノルムの低減がQATの収束に不可欠であることを発見し、大きな量子化誤差を軽減するための補助モジュール (Phi) を導入した。Phiの推論オーバーヘッドを排除するため、SVDとランクベースの正則化を通じてPhiを段階的に排除するランク減衰戦略を提案した。実験では、QVGenが4ビット設定で初めて全精度と同等の品質を達成し、既存の手法を大幅に上回ることが示された (出典: HuggingFace Daily Papers)
ViPlan:視覚的プランニングのための記号的述語と視覚言語モデルのベンチマーク: VLM駆動の記号的プランニングと直接的なVLMプランニング手法の比較におけるギャップを埋めるため、ViPlanが初のオープンソース視覚的プランニングベンチマークとして提案された。ViPlanは、視覚版Blocksworldとシミュレートされた家庭用ロボット環境という2つの主要領域における、難易度が段階的に上昇する一連のタスクを含む。9つのオープンソースVLMファミリーおよび一部のクローズドソースモデルのベンチマークテストの結果、記号的プランニングはBlocksworld(正確な画像位置特定が重要)でより優れた性能を示し、直接的なVLMプランニングは家庭用ロボットタスク(常識的知識とエラー回復能力が重要)でより優れていた。研究はまた、CoTプロンプトがほとんどのモデルと手法に顕著な利益をもたらさなかったことを示しており、現在のVLMの視覚的推論能力にはまだ改善の余地があることを示唆している (出典: HuggingFace Daily Papers)
原始的な叫びから文法へ:協調的採餌環境における言語進化の研究: 言語の起源と進化を探求するため、研究者らはマルチエージェント採餌ゲームで初期人類の協調シナリオをシミュレートした。エンドツーエンドの深層強化学習を通じて、エージェントはゼロから行動とコミュニケーション戦略を学習する。研究の結果、エージェントが開発したコミュニケーションプロトコルは、自然言語の象徴的な特徴である任意性、相互交換可能性、変位性、文化的伝達、組み合わせ性を示した。このフレームワークは、部分的に観測可能で、時間的推論と協調目標によって駆動される具現化されたマルチエージェント環境で言語がどのように進化するかを研究するためのプラットフォームを提供する (出典: HuggingFace Daily Papers)
Tiny QA Benchmark++:超軽量多言語合成データセット生成とLLM継続的評価のためのスモークテスト: Tiny QA Benchmark++ (TQB++) は、LLMパイプラインにユニットテストのようなセーフティネットを提供することを目的とした、超軽量の多言語スモークテストスイートであり、数秒で極めて低コストで実行できる。TQB++には52項目の英語ゴールデンセットが含まれ、LiteLLMベースの小型合成データジェネレータ (pypiパッケージ) が提供されており、ユーザーはカスタム言語、ドメイン、または難易度の小さなテストパッケージを生成できる。プロジェクトは既に10言語の既製パッケージを提供しており、OpenAI-Evals、LangChainなどのツールをサポートし、CI/CDプロセスへの統合を容易にし、プロンプトテンプレートエラー、トークナイザードリフト、ファインチューニングの副作用の迅速な検出に使用される (出典: HuggingFace Daily Papers)
HelpSteer3-Preference:マルチタスク・多言語にわたるオープンな人間による注釈付き選好データセット: 高品質で多様なオープン選好データのニーズに応えるため、NVIDIAはHelpSteer3-Preferenceデータセットを公開した。このデータセットには、CC-BY-4.0ライセンスに従い、STEM、コーディング、多言語シナリオなど、LLMの実際の応用をカバーする40,000を超える人間による注釈付き選好サンプルが含まれている。このデータセットを使用して訓練された報酬モデル (RM) は、RM-Bench (82.4%) とJudgeBench (73.7%) の両方でSOTA性能を達成し、以前の最良結果を約10%向上させた。このデータセットは、生成型RMの訓練や、RLHFによる戦略モデルの調整にも使用できる (出典: HuggingFace Daily Papers)
SEED-GRPO:不確実性を考慮した戦略最適化のためのセマンティックエントロピー強化GRPO: GRPOが戦略更新時にLLMの入力プロンプトに対する不確実性を考慮していない問題を解決するため、研究者らはSEED-GRPOを提案した。この方法は、セマンティックエントロピーを通じてLLMの入力プロンプトに対する不確実性(すなわち、複数の生成された回答のセマンティックな多様性)を明示的に測定し、これに基づいて戦略更新の大きさを調整する。この不確実性を考慮した訓練メカニズムにより、高不確実性の問題に対してより保守的な更新が可能になると同時に、信頼性の高い問題に対する元の学習信号を維持する。実験では、SEED-GRPOが5つの数学的推論ベンチマーク全てでSOTA性能を達成したことが示された (出典: HuggingFace Daily Papers)
コンピュータ利用からの汎用ユーザーモデル (GUM) の作成: 研究者らは、ユーザーとコンピュータのあらゆるインタラクション(デバイスのスクリーンショットなど)を観察することでユーザーの知識と嗜好を学習し、信頼度で重み付けされた命題を構築する汎用ユーザーモデル (GUM) アーキテクチャを提案した。GUMは、非構造化マルチモーダル観測から新しい命題を推論し、関連する命題をコンテキストとして検索し、既存の命題を継続的に修正することができる。このアーキテクチャは、チャットアシスタントを強化し、オペレーティングシステムの通知を管理し、インタラクティブエージェントがアプリケーション間でユーザーの嗜好に適応できるようにすることを目的としている。実験では、GUMが較正され正確なユーザー推論を行うことができ、GUMベースのアシスタントがユーザーが明示的に要求していない有用な操作を積極的に特定し実行できることが示された (出典: HuggingFace Daily Papers)
DataExpert-io/data-engineer-handbook: GitHub上の人気プロジェクトで、2024年の入門ロードマップ、6週間の無料YouTubeトレーニングキャンプ資料、プロジェクト事例、面接テクニック、推薦書籍、コミュニティとニュースレターのリストを含む、包括的なデータエンジニアリング学習リソース庫を提供している。推薦書籍には、『Fundamentals of Data Engineering』、『Designing Data-Intensive Applications』、『Designing Machine Learning Systems』が含まれる。このハンドブックはまた、Mage(オーケストレーション)、Databricks(データレイク)、Snowflake(データウェアハウス)、dbt(データ品質)、LangChain(LLMアプリケーションライブラリ)など、データエンジニアリングの各分野の企業をリストアップし、著名企業のデータエンジニアリングブログや重要なホワイトペーパーへのリンクも提供している (出典: GitHub Trending)
💼 ビジネス
CohereとSAPが提携、エンタープライズレベルのAIエージェントをグローバルビジネスに導入: CohereはSAPとの提携を発表し、そのエンタープライズレベルのAIエージェント技術をSAP Business Suiteに組み込み、グローバル企業に安全でスケーラブルなAI能力を提供する。Cohereの最先端モデルもSAP AI Coreに登場し、企業が金融、医療などの分野で多言語、特定分野のAIモデル(Command, Embed, Rerank)を活用できるようにし、企業AIアプリケーションを加速し、実際のビジネス価値を解放することを目指す (出典: X, X)
xAIが政府データの活用を模索、企業および政府向けビジネスを拡大: The Informationの報道によると、Elon Musk氏のxAI社は、政府機関のデータを利用してモデルやアプリケーションを開発し、それらを政府顧客に販売する計画である。この動きはxAIの商業化戦略の重要な部分となる可能性があるが、データの使用と潜在的な偏見に関する議論も引き起こしている (出典: X)
WeaviateとAWSがグローバルな協力を深化、生成AIイニシアチブを加速: ベクトルデータベース企業のWeaviateは、AWSとのグローバルな協力を強化し、共同で生成AIプロジェクトを加速することを目指すと発表した。この協力は、グローバルな開発者により速いスピード、より大きな規模、より優れた開発者体験を提供することに焦点を当て、生成AI技術の応用と発展を推進する (出典: X)

🌟 コミュニティ
AIプログラミングエージェントの台頭がプログラマーのキャリア展望に関する議論を呼ぶ: Microsoft、OpenAIなどの企業が相次いでAIプログラミングエージェント (Coding Agents) を発表または強化している。GitHub Copilot Coding AgentやOpenAI Codexなどがその例で、これらはコーディング、バグ修正、コードメンテナンスなどのタスクを自律的に完了できる。AnthropicのCEOであるDario Amodei氏は、AIが短期間でコードの大部分または全てを作成する可能性があると予測しており、OpenAIのCPOであるKevin Weil氏もAIが初級エンジニアからアーキテクトへと成長すると考えている。これはコミュニティでプログラマーのキャリアの将来に関する広範な議論を引き起こしている。一部の人々は初級の職が代替され、AIが大量のプログラミング作業を自動化することを懸念している。他の人々は、AIがプログラマーの効率を向上させ、より高度なアーキテクチャ設計やイノベーションに集中できるようになり、役割が「AI指導者」に変わると考えている。全体的な傾向として、AIとの効率的な協調学習がプログラマーの中核スキルになることを示している (出典: X, X, 36氪, 36氪)
AI Agentの概念と標準に関する議論が活発化、MCPプロトコルが注目を集める: AI Agentアプリケーションの台頭(Manus、Genspark Super Agent、Fellou.aiなど)に伴い、コミュニティではAgentの定義、能力レベル、開発パラダイムに関する議論が活発化している。著名なベンチャーキャピタルBVPは、AgentのL0からL6までの7つのレベル分けを提案した。同時に、モデルコンテキストプロトコル (MCP) がAIアプリケーション間の相互運用性を実現する重要な技術として注目されており、Anthropic、OpenAI、Googleなどの海外大手企業はMCPをサポートまたはサポート予定であり、国内ではAlibaba Cloud、Tencent CloudなどもMCPを中心にローカライズされたAgent開発プラットフォームの構築を開始している。開発者iluxu氏は、Microsoftが「AIアプリ向けUSB-C」コンセプトを提案する前に、同様のllmbasedosプロジェクトをオープンソース化し、オープンなAgent接続標準の推進を目指している (出典: X, X, WeChat, Reddit r/LocalLLaMA)
LLMが特定の推論タスクで振るわず、その能力の限界についての議論を引き起こす: コミュニティでは、LLMが一部の単純に見える物理的または視空間的推論タスクで軒並み「失敗」する現象が話題になっている。例えば、積み重ねた立方体でより大きな立方体を形成するという問題では、o3やGemini 2.5 Proなどのトップモデルでさえ誤った答えを出した。同時に、ある評価記事では、部品製造などの基本的な物理タスクにおいて、LLM(o3を含む)は経験豊富な作業員に劣ると指摘されており、主な原因は視覚能力の不足と物理的推論の誤り、そして現実世界の暗黙知の欠如である。これらの事例は、LLMの真の理解能力、幻覚問題(o3が推論時に幻覚率が上昇するなど)、および現在のBenchmarkの有効性に関する議論を引き起こし、AIが特定の分野の知識と複雑な推論において依然として大きな改善の余地があることを強調している (出典: 量子位, 36氪)

米中テクノロジー競争とAI開発戦略が注目を集める: NVIDIAのCEOであるジェンスン・フアン氏はインタビューで、チップ規制、AIファクトリー、企業のプラグマティズムについて語り、その見解は現在の米中テクノロジー競争の構図に対する深い洞察として解釈されている。一部のコメントでは、米国が中国の高度なAIリソースへのアクセスを制限することで主導的地位を維持しようとしているが、これは双方にとって損失となり、世界のAI発展を遅らせる可能性があるとされている。一方、フアン氏は、真の競争は長期的であり、米国は短期的な相対的優位性を求めるだけでなく、包括的にリードすべき(チップ、工場、インフラ、モデル、アプリケーション)であり、さもなければAI時代の発展機会を逃し、最終的に総合的な国力競争で遅れをとる可能性があると考えているようだ (出典: X)
ChatGPTなどAIツールのメンタルヘルス支援における応用と議論: Redditコミュニティのユーザーが、ChatGPTなどのAIツールをメンタルヘルスサポートに利用した経験を共有し、専門的な治療の合間に役立ち、特に複雑な感情を整理し表現する上で有効であると述べている。ユーザーはAIに質問したり、AIに自身の感情について質問させたりすることで、感情の原因をよりよく理解し、改善計画を立てている。コメントの中には、(自称セラピストを含む)一部のユーザーが、AIが特定の状況下では一部の人間のセラピストよりも優れているとさえ考えており、特に専門的な助けを得にくい、または人間のセラピストに信頼上の障害がある個人にとってはそうであると述べている。しかし、AIが専門的な治療を完全に代替することはできず、個人データのプライバシー問題にも注意すべきであると警告するユーザーもいる (出典: Reddit r/ChatGPT)
💡 その他
「啓智杯」アルゴリズムコンテストが開始、AIの3つの最先端分野に焦点: 啓元実験室が「啓智杯」アルゴリズムコンテストを開始し、総賞金は75万元。コンテストは「衛星リモートセンシング画像のロバストインスタンスセグメンテーション」、「組み込みプラットフォーム向けドローン対地目標検出」、「マルチモーダル大規模モデル向け敵対的攻撃」の3つのトラックを設定し、ロバストな知覚、軽量化展開、敵対的防御などのAIコア技術の革新と応用展開を推進することを目的としている。このイベントは国内の研究機関、企業、事業部門に開かれている (出典: WeChat)

シカゴ・サンタイムズ紙、AI生成コンテンツに誤り、存在しない書籍や専門家を推薦: 「シカゴ・サンタイムズ」紙は、ある夏のイベント推薦記事の一部で、AIによって生成されたと疑われる内容を掲載し、その中には実在する作家が創作した架空の書籍の推薦や、存在しないと思われる「専門家」の意見の引用が含まれていた。例えば、Min Jin Lee氏の『Nightshade Market』やRebecca Makkai氏の『Boiling Point』を推薦図書として挙げていたが、これらの書籍は存在しない。この事件は、報道機関がAI生成コンテンツを使用する際の正確性と審査メカニズムに関する懸念を引き起こした (出典: Reddit r/artificial)
AIの使用が「不正行為」にあたるかどうかの議論: コミュニティでは、仕事や学習でAIツール(ChatGPT、Claudeなど)を使用する境界線について議論されている。一般的な見解としては、明確な禁止規則がない場合(大学の課題など)、AIツールを使用して効率を上げたり、反復的なタスクを完了したり、思考を補助したりすることは「不正行為」ではなく、電卓や検索エンジンを使用するのと同様であるとされている。重要なのは、使用者がAIの出力を理解し、それを効果的に調整・検証できるか、そしてAIの補助的な役割を正直に申告するか(特に学術的な場面で)どうかである。しかし、AIが生成したコンテンツに完全に依存し、それを吟味せずにオリジナルであると主張する場合は、学術的不正行為に関与したり、個人のスキル開発に影響を与えたりする可能性がある (出典: Reddit r/ArtificialInteligence)