
キーワード:AI技術, Google Gemini, AIのエネルギー消費, AIの法的応用, Microsoft Discovery, ジェンスン・ホアンとイーロン・マスク, AI規制, Gemini 2.5 Pro, AIデータセンターのエネルギー消費, AI生成の法律文書の誤り, Microsoft Discovery科学研究プラットフォーム, AIチップの輸出規制
🔥 注目ニュース
Google I/Oで多数のAI進展発表、GeminiがGoogleエコシステムに全面的に統合: GoogleはI/O 2025開発者会議で一連のAI関連の重要な更新を発表しました。核心はGeminiモデルのアップグレードと緊密な統合です。Gemini 2.5 Proは複雑な推論を強化する「Deep Think」を導入し、2.5 Flashは効率とコストを最適化し、ネイティブオーディオ出力を新たに追加しました。検索には「AIモード」が導入され、チャットボット形式の回答を提供し、ユーザーの個人データ(要承認)と組み合わせてパーソナライズされた結果を提供できます。ChromeブラウザにはGeminiアシスタントが統合されます。動画モデルVeo 3は音声付き動画生成を実現し、画像モデルImagen 4は詳細と文字処理を向上させました。Googleはまた、AI映画制作ツールFlow、プログラミングアシスタントJulesを発表し、Project Astra(リアルタイムマルチモーダルアシスタント)とProject Mariner(マルチタスクAIエージェント)の進捗を披露しました。同時に、Googleは新しいAIサブスクリプションサービスを開始し、ハイエンド版AI Ultraの月額料金は249.99ドルに達します。これらの取り組みは、GoogleがAIを自社製品とサービスに全面的に統合し、ユーザーインタラクション体験を再構築していることを示しています。(ソース: 36氪, 36氪, 36氪, 36氪, 36氪, 36氪)

AIのエネルギー消費問題が注目を集め、MIT Technology Reviewがそのエネルギーフットプリントと将来の課題を深く分析: MIT Technology Reviewは一連のレポートを発表し、AI技術の発展がもたらすエネルギー消費と炭素排出問題を深く掘り下げています。研究によると、AIの推論段階でのエネルギー消費は既に訓練段階を超え、主要なエネルギー負担となっています。レポートは、データセンターの巨大な電力需要と水資源消費(ネバダ州の砂漠にあるデータセンターなど)、および化石エネルギー(ルイジアナ州のMetaデータセンターが天然ガスに依存しているなど)への依存を分析しています。原子力エネルギーは潜在的なクリーンエネルギー解決策と見なされていますが、その建設サイクルは長く、短期的にはAIの急速な成長需要を満たすことは困難です。同時に、レポートはAIのエネルギー効率向上の楽観的な見通しも指摘しており、より効率的なモデルアルゴリズム、AI専用に設計された省エネチップ、より最適化されたデータセンター冷却技術などが含まれます。このシリーズは、個々のAIクエリのエネルギー消費は微々たるものに見えるものの、業界全体の傾向と将来計画(OpenAIのStargate計画など)は巨大なエネルギー課題を示唆しており、透明性のあるデータ開示と責任あるエネルギー計画が必要であると強調しています。(ソース: MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review)

AIの法律分野での応用が誤りや倫理的懸念を引き起こす: 最近の複数の事件は、AIが法律文書作成において生み出す「幻覚」問題が深刻な懸念を引き起こしていることを示しています。カリフォルニア州の裁判官は、弁護士が法廷文書でGoogle GeminiなどのAIツールを使用し、虚偽の引用を含む内容を生成したとして罰金を科しました。別の事件では、AI企業AnthropicのClaudeモデルも法律文書の引用生成時に誤りを犯しました。さらに懸念されるのは、イスラエルの検察官が、存在しない法律を引用したAI生成のテキストを申請書に使用したことを認めたことです。これらの事例は、特に事実と引用の要求が極めて高い法律分野において、AIモデルの正確性と信頼性の欠陥を浮き彫りにしています。専門家は、弁護士が効率を追求するあまりAIの出力を過信し、厳格な審査の必要性を怠っている可能性があると指摘しています。AIツールは信頼できる法律アシスタントとして宣伝されていますが、その固有の「幻覚」特性は司法の公正性に対する潜在的な脅威であり、業界規範とユーザーの警戒が急務です。(ソース: MIT Technology Review)

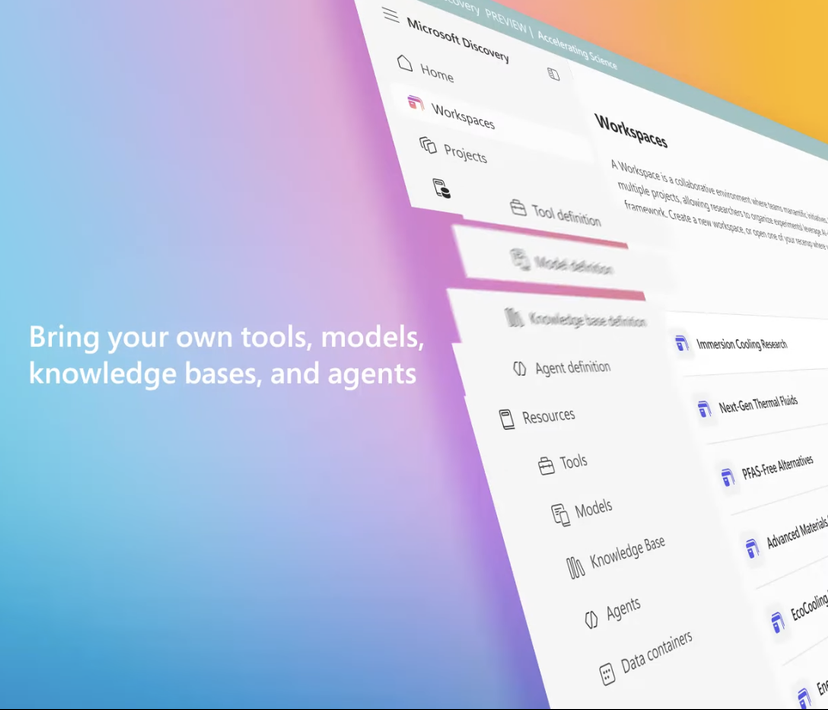
Microsoft、企業向けAI研究プラットフォームMicrosoft Discoveryを発表、科学的発見を支援: MicrosoftはBuildカンファレンスで、企業や研究機関向けに設計されたAIプラットフォームMicrosoft Discoveryを発表しました。これは自然言語インタラクションを通じて、プログラミング経験のない科学者やエンジニアでも高性能計算や複雑なシミュレーションシステムを利用できるようにすることを目的としています。このプラットフォームは、計画用の基盤モデルと、特定科学分野(物理学、化学、生物学など)向けに訓練された専門モデルを組み合わせ、「AIポスドク」チームを形成し、文献レビューから計算シミュレーションまでの研究全プロセスを実行できます。Microsoftはその応用事例として、約200時間で36万7000種類の物質をスクリーニングし、潜在的なPFASフリー冷却剤代替品を発見し、実験で検証したことを紹介しました。プラットフォームの特徴には、グラフ知識エンジン、協調推論、継続的な反復研究開発サイクルが含まれ、Azureインフラストラクチャに基づいて構築されており、将来のアーキテクチャは量子コンピューティングへの接続能力を確保しています。(ソース: 量子位)
黄仁勋氏とマスク氏、AIの発展、規制、グローバル競争について見解を表明: NVIDIAのCEOである黄仁勋氏はインタビューで、米国のチップ輸出規制について懸念を表明し、技術拡散の制限はAI分野における米国のリーダーシップを損なう可能性があると述べ、中国のAI研究開発能力および世界のAI開発者の半数が中国出身であるという事実を強調しました。彼は、米国は技術のグローバルな普及を加速し、米国企業が中国市場で競争することを許可すべきだと主張しました。一方、TeslaのCEOであるマスク氏は別のインタビューで、少なくとも今後5年間はTeslaを率い続けると述べ、AGIの実現に近づいているとの認識を示しました。彼はAIの適度な規制を支持するものの、過度な介入には反対しています。両テクノロジーリーダーは共にAIの巨大な潜在能力を強調し、黄仁勋氏はAIが世界のGDPを大幅に成長させると考え、マスク氏は今年の重要な目標としてStarship、Neuralink、Teslaの自動運転タクシーなどを挙げ、これらはいずれもAIと密接に関連しています。(ソース: 36氪, 36氪, 36氪)

🎯 動向
Google、オンデバイスでの高効率実行に特化したGemma 3nプレビュー版をリリース: GoogleはHuggingFace上で、低リソースデバイス(モバイルデバイスなど)での高効率実行に特化して設計されたGemma 3nモデルのプレビュー版をリリースしました。このモデルシリーズはマルチモーダル入力能力を備え、テキスト、画像、動画、音声を処理し、テキスト出力を生成できます。その「選択的パラメータ活性化」技術(MoE混合エキスパートアーキテクチャに類似)により、モデルは2Bおよび4Bの有効パラメータ規模で動作でき、リソース要件を低減します。コミュニティの議論では、Gemma 3nのアーキテクチャはGeminiに類似している可能性があり、後者の強力なマルチモーダルおよび長文コンテキスト能力を説明していると考えられています。Gemma 3nのオープンソースウェイトと命令チューニング版、および140以上の言語データでのトレーニングにより、スマートホームアシスタントなどのエッジAIアプリケーション分野での潜在能力を備えています。(ソース: Reddit r/LocalLLaMA, developers.googleblog.com)

Google、医療分野に最適化されたAIモデルMedGemmaを発表: Googleは、医療分野に特化して最適化されたGemma 3の2つのバリアントであるMedGemmaシリーズモデルを発表しました。これには、4Bパラメータのマルチモーダル版と27Bパラメータのテキスト専用版が含まれます。MedGemma 4Bは、特に医用画像(X線写真、皮膚科画像など)とテキスト理解のために訓練され、医療データで事前訓練されたSigLIP画像エンコーダを採用しています。MedGemma 27Bは医療テキスト処理に焦点を当て、推論時の計算のために最適化されています。Googleは、これらのモデルが医療AIアプリケーションの開発を加速することを目的としており、複数の臨床関連ベンチマークで評価されており、開発者は特定のタスク性能を向上させるために微調整できると述べています。コミュニティはこれに積極的に反応し、その潜在能力は大きいと評価していますが、医療専門家による実際のフィードバックが必要であると強調しています。(ソース: Reddit r/LocalLLaMA)

ByteDance、画像生成をサポートするオープンソースのマルチモーダルモデルBagelをリリース: ByteDanceは、Apache 2.0ライセンスを採用した14Bパラメータ(7Bアクティブ)のオープンソースマルチモーダル大規模モデルBagel(別名BAGEL-7B-MoT)を発表しました。このモデルは、混合エキスパート(MoE)と混合Transformer(MoT)アーキテクチャに基づいており、テキストを理解・生成し、ネイティブな画像生成能力を備えています。一連のマルチモーダル理解・生成ベンチマークテストで他のオープンソース統合モデルを上回る性能を示し、自由形式の画像処理、未来フレーム予測などの高度なマルチモーダル推論能力を実証しています。研究者は、事前訓練の詳細、データ作成プロトコル、オープンコードとチェックポイントを共有することで、マルチモーダル研究を促進することを期待しています。(ソース: Reddit r/LocalLLaMA, arxiv.org, bagel-ai.org)
NVIDIA、生成動画モデルを利用してロボットを訓練するDreamGenを発表: NVIDIAの研究チームはDreamGenプロジェクトを発表しました。これは、先進的な動画生成モデル(Sora、Veoなど)を微調整することで、ロボットが生成された「夢の世界」で新しいスキルを学習できるようにするものです。この方法は、従来のグラフィックエンジンや物理シミュレータに依存せず、ロボットがニューラルネットワークによって生成されたピクセルレベルのシーンで自律的に探索・体験することで、大量の疑似行動ラベル付きの神経軌道を生成します。実験によると、DreamGenはシミュレーションおよび実世界のタスクにおけるロボットの性能を大幅に向上させることができ、これには未見の行動や未知の環境も含まれます。例えば、少量の実際の軌道だけで、人型ロボットは水を注ぐ、服を畳むなど22種類の新しいスキルを学習し、NVIDIA本社のカフェなどの実世界のシーンへの汎化に成功しました。(ソース: 36氪, arxiv.org)

ファーウェイ、MoEモデルの推論性能を最適化するOmniPlacementを提案: 混合エキスパートモデル(MoE)におけるエキスパートネットワークの負荷不均衡(「ホットエキスパート」と「コールドエキスパート」)による推論遅延問題に対し、ファーウェイチームはOmniPlacement最適化ソリューションを提案しました。このソリューションは、エキスパートの再配置、層間冗長展開、およびほぼリアルタイムの動的スケジューリングを通じて、MoEモデルの推論性能を向上させることを目指しています。DeepSeek-V3などのモデルでの理論検証では、OmniPlacementが推論遅延を約10%削減し、スループットを約10%向上させることが示されています。この方法の核心は、エキスパートの優先順位の動的調整、通信ドメインの最適化、冗長インスタンスの差異化展開、およびほぼリアルタイムのスケジューリングと動的監視メカニズムによる負荷変動への柔軟な対応にあります。ファーウェイは最近このソリューションをオープンソース化する予定です。(ソース: 量子位)

Apple、開発者にAIモデルの権限を開放し、アプリケーションイノベーションを刺激する計画: 報道によると、AppleはWWDCで、サードパーティ開発者にApple IntelligenceのAIモデル権限を開放すると発表する予定です。初期にはデバイス側で実行される約30億パラメータの軽量言語モデルに焦点を当て、その後、GPT-4-Turboレベルに相当するクラウドモデル(プライベートクラウドで実行され暗号化される)を開放する可能性があります。この動きは、開発者がAppleのLLMに基づいて新しいアプリケーション機能を構築することを奨励し、Appleデバイスの魅力を高め、生成AI分野での相対的な遅れを補うことを目的としています。分析によると、Appleはオープンエコシステムを構築することで、その膨大な開発者コミュニティ(600万人)を利用して自身の技術的弱点を補い、ますます激化するAI競争に対応したいと考えています。(ソース: 36氪)
米国下院、州レベルのAI規制を10年間停止する提案、巨大な論争を呼ぶ: 米国下院エネルギー・商業委員会は、今後10年間、各州がAIモデル、システム、および「人間の意思決定に実質的な影響を与えるか、または代替する」自動意思決定システムを規制することを禁止する提案を可決しました。支持者は、この措置が各州の規制の不一致によるAIイノベーションと連邦政府システムの近代化の阻害を回避できると主張しています。一方、反対者はこれを「大手テック企業への巨額の贈り物」であり、AIの危害から民衆を保護する各州の能力を弱めると述べています。この提案が可決されれば、多数の既存および提案中の州レベルのAI法が無効になる可能性がありますが、連邦法で規定されているか、またはAIと非AIシステムを同等に扱う普遍的に適用される法律には適用されないことが明確にされています。この動きは、世界規模での「AIイノベーション優先」と「安全性の最低ライン」の激しい駆け引きを反映しています。(ソース: 36氪, edition.cnn.com)

「Take It Down Act」が米国で法律として署名され、非自発的な私的画像の拡散に対抗: トランプ米大統領は「Take It Down Act」法案に署名し、非自発的な私的画像(AI生成のディープフェイクコンテンツを含む)の作成と拡散を連邦犯罪としました。この法案は、テックプラットフォームに対し、通知を受けてから48時間以内に関連コンテンツを削除するよう要求しています。この法案は、被害者を保護し、ディープフェイク技術の乱用がもたらすますます深刻化する社会問題に対応することを目的としています。しかし、この法案が乱用され、過度な検閲につながる可能性を指摘するコメントもあります。(ソース: MIT Technology Review, edition.cnn.com, Reddit r/artificial)

AI大規模モデルが健康管理を支援、個別化と多次元データ連携を実現: AI大規模モデルは健康管理分野に新たな活力を注入しており、ウェアラブルデバイスとの組み合わせにより、多次元データ連携と個別化サービスを実現しています。微医、深睿医療、南大菲特などの企業は、健康診断シーンから早期発見・早期治療に切り込む、あるいは体重管理を突破口として慢性疾患を予防・治療するなど、応用シーンを積極的に模索しています。大規模モデルはより多様なデータ次元を処理し、ユーザーの記憶を構築し、より正確な健康介入策を提供できます。課題には、モデルの幻覚、データ品質と協調の困難さなどがありますが、RAG、モデルの微調整、審査メカニズム、および「AI+真人管理師」モードを通じて徐々に克服されつつあります。ビジネスモデルとしては、ToBサービス、C向け有料サービス、およびAI健共体などが初期検証を得ており、将来のトレンドはマルチモーダルインタラクションへのアップグレードに向かうでしょう。(ソース: 36氪)
百度、文心大模型のマルチモーダル能力を強化し、市場競争と応用展開に対応: 百度が最新発表した文心大模型4.5 Turboと深度思考モデルX1 Turboは、マルチモーダル理解・生成能力が著しく向上しており、混合訓練、マルチモーダル異種エキスパートモデリングなどの技術を通じて、クロスモーダル学習効率と融合効果を高めています。CEOの李彦宏氏はSoraのような動画生成モデルの幻覚問題に慎重な姿勢を示していましたが、市場競争(例:バイトダンスの豆包、アリババの通义千问のマルチモーダル分野での進展)やAIアプリケーションの実装ニーズに直面し、百度は積極的に弱点を補強しており、6月30日には文心大模型4.5シリーズをオープンソース化する計画です。百度はAIデジタルヒューマンが重要な応用突破口であると考えており、「脚本」駆動型の超リアルデジタルヒューマン技術を開発し、10万人以上のデジタルヒューマンキャスターをサポートしています。(ソース: 36氪)
抖音、小紅書などのプラットフォーム、「AI起号」を特別対策し、コンテンツエコシステムを維持: 抖音、小紅書などの興味関心ECプラットフォームは最近、AI技術を利用して虚偽コンテンツを大量生産し、「AI起号」(AIによるアカウント作成・育成)などの行為に対する特別対策を強化しています。これらの行為には、AIによる低俗で猟奇的な動画の生成、架空の専門家コンテンツ、AI起号チュートリアルやアカウントの販売などが含まれます。プラットフォームは、このような行為がコンテンツの真正性を損ない、コンテンツの同質化を招き、ユーザー体験とオリジナルクリエイターのエコシステムを害し、ひいては商業的価値を希薄化すると考えています。これに対し、淘宝、京東などの伝統的な棚型ECプラットフォームは、商品の展示効果と運営効率を向上させるために、AIツール(「画像から動画生成」、ライブ配信用デジタルヒューマンなど)の利用を積極的に奨励し、取引成立を核心目標としています。この違いは、異なるECモデルにおけるAI応用戦略の分化を反映しています。(ソース: 36氪)

AppleのAI版Siri開発難航、再び延期の可能性、経営陣調整で危機対応: Bloombergによると、AppleがWWDCで発表予定だった大規模モデルアップグレード版Siriが再び延期される可能性があります。技術的なボトルネックは新旧システムアーキテクチャの衝突によるバグの頻発です。報道によると、AppleはAI戦略において経営層の意思決定ミス、内部の権力闘争、GPU調達不足、プライバシー保護によるデータ利用制限などの問題を抱えており、AI技術で競合他社に遅れをとっています。危機に対応するため、Appleのチューリッヒ研究所は全く新しい「LLM Siri」アーキテクチャを開発中で、SiriプロジェクトをVision Pro責任者のマイク・ロックウェル氏に移管しました。同時に、AppleはGoogleのGeminiやOpenAIなど外部技術との提携も模索しており、マーケティング上、Apple IntelligenceとSiriブランドを切り離し、AIイメージを再構築する可能性があります。(ソース: 36氪)

ByteDance、英語ネイティブ教師AIエージェントOwenを搭載したOla Friendイヤホンを発表: ByteDanceは、同社のスマートイヤホンOla FriendにOwenという名の英語ネイティブ教師AIエージェント機能を追加しました。ユーザーは豆包Appを起動することでOwenを呼び出し、英会話、英語のリードアロング、バイリンガルでのフィードバックなどを行うことができます。この機能は日常会話、ビジネス英語、旅行などのシーンをカバーし、手軽な携帯型英語練習パートナーを提供することを目指しています。これはByteDanceの教育シーンにおける新たな試みであり、AI大規模モデルの能力とハードウェアを組み合わせ、垂直的な英語学習製品を構築するものです。Ola Friendイヤホンは以前から豆包を通じた知識Q&Aやスピーキング練習をサポートしており、新しいAIエージェントの追加により教育属性がさらに強化されました。(ソース: 36氪)

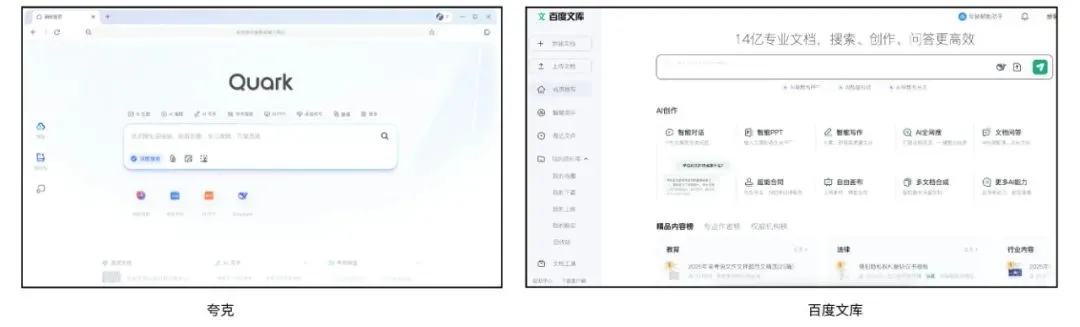
夸克と百度文库、AIスーパーアプリを目指し競争、検索・ツール・コンテンツサービスを統合: アリババ傘下の夸克と百度傘下の百度文库は、AIを核とした「スーパーアプリ」へと転換し、AI対話、ディープサーチ、AIツール(作文、PPT生成、健康アシスタントなど)およびオンラインストレージ、ドキュメントサービスを統合し、C向けユーザーのワンストップAI入口となることを目指しています。夸克は広告なし検索と若年層ユーザーを強みに、月間アクティブユーザー数1億4900万人に達し、会員制システムを通じて商業化を実現しています。百度文库は、その膨大なドキュメント資源と有料ユーザー基盤を背景に、「沧舟OS」をリリースしてAI Agentを統合し、コンテンツ作成と消費の全プロセスを強化しています。両社ともに、機能の同質化、アプリケーションの肥大化、そして汎用的なニーズと専門的なサービスのバランスをどう取るかという課題に直面しています。(ソース: 36氪)
智谱清言、Kimiなど35のアプリが個人情報収集違反で通報される: 国家インターネット・情報セキュリティ情報通報センターは、智谱清言(バージョン2.9.6)が「実際に収集した個人情報がユーザーの承認範囲を超えている」、Kimi(バージョン2.0.8)が「実際に収集した個人情報と業務機能が直接関連していない」などの理由で、他の33のアプリと共に違法な個人情報収集・使用を行っているとして通告を発表しました。これら2つの人気AIアプリケーションは、いずれも清華大学系のチームによって開発され、最近、顕著な資金調達と市場の注目を集めています。今回の通報対象となった検査期間は2025年4月16日から5月15日までであり、AIアプリケーションが急速な発展の過程で直面するデータコンプライアンスの課題を浮き彫りにしています。(ソース: 36氪)
🧰 ツール
OpenEvolve:DeepMind AlphaEvolveのオープンソース実装、LLMでコードベースを進化: 開発者がGoogle DeepMindのAlphaEvolveシステムのオープンソース実装であるOpenEvolveプロジェクトを公開しました。OpenEvolveフレームワークは、LLMの反復プロセス(コード生成、評価、選択)を通じてコードベース全体を進化させ、新しいアルゴリズムを発見したり、既存のアルゴリズムを最適化したりします。OpenAI API互換の任意のLLMをサポートし、複数のモデル(Gemini-Flash-2.0とClaude-Sonnet-3.7の組み合わせなど)を統合でき、多目的最適化と分散評価をサポートします。このプロジェクトは、AlphaEvolve論文の円充填と関数最小化の事例を成功裏に再現し、単純な方法から複雑な最適化アルゴリズム(scipy.minimizeやシミュレーテッドアニーリングなど)へと進化する能力を示しました。(ソース: Reddit r/LocalLLaMA, Reddit r/MachineLearning)

Google、AIプログラミングエージェントJulesを発表、自動化コードタスクをサポート: GoogleはAIプログラミングエージェントJulesを発表しました。現在、グローバルテスト段階にあり、ユーザーは毎日5回まで無料でタスクを実行できます。JulesはマルチモーダルGemini 2.5 Proモデルに基づいており、複雑なコードベースを理解し、バグ修正、バージョン更新、テスト作成、新機能実装などのタスクを実行でき、PythonとJavaScriptをサポートしています。GitHubに接続してプルリクエスト(PR)を作成し、クラウド仮想マシンでコードを検証し、開発者がレビューおよび修正するための詳細な実行計画を提供できます。Julesは開発者のワークフローに深く統合し、プログラミング効率を向上させることを目指しており、将来的にはCodecast機能(コードベース活動の音声要約)とエンタープライズ版もリリースする予定です。(ソース: 36氪)
飛書、「飛書知識問答」をリリース、企業専用AI Q&Aツールを構築: 飛書はまもなくAI新製品「飛書知識問答」をリリースします。これは企業知識に基づいた企業専用のAI Q&Aツールとして位置づけられています。ユーザーは飛書のサイドバーから呼び出し、業務上の問題について質問できます。このツールは、ユーザーの権限範囲内のすべての飛書メッセージ、ドキュメント、ナレッジベース、ファイルなどの情報にアクセスし、これらの「コンテキスト」に基づいて正確な回答を直接提供します。その権限管理は飛書自身の権限システムと一致しており、情報セキュリティを確保します。現在、製品は数万人のユーザーによる内部テストを完了しており、ウェブ版(ask.feishu.cn)が公開され、個人資料のアップロードとDeepSeekまたは豆包モデルを呼び出しての質問をサポートしています。この動きは、企業ナレッジベースとAIの組み合わせというトレンドに沿ったものであり、業務効率と知識管理能力の向上を目指しています。(ソース: 36氪)
Manus:AIエージェントプラットフォームが登録開放、親会社は高額資金調達: AIエージェントプラットフォームManusは海外ユーザー向けに登録を開放し、ウェイティングリストを廃止、毎日無料タスクを提供すると発表しました。Manusは「混合アーキテクチャマルチモデル協調推論」技術により、PPT自動生成、領収書整理などのタスクを実行でき、その親会社である蝴蝶效應は最近7500万ドルの資金調達を完了し、評価額は36億ドルに達しています。Manusの成功は「中国のイテレーション速度 × シリコンバレーの製品思考」の現れと見なされており、計画、実行、検証Agentを協調させ、AIを「思考提案」から「クローズドループ実行」へと飛躍させます。(ソース: 36氪)

HeyGen:AI動画生成・翻訳ツール、40以上の言語で口パク同期をサポート: HeyGenはAI動画ツールで、ユーザーは写真や動画をアップロードするだけで、音声、表情、動作付きのデジタルヒューマンを迅速に生成でき、服装やシーンのカスタマイズもサポートしています。その主要機能の一つは、175以上の言語と方言のリアルタイム翻訳をサポートし、AIアルゴリズムによってデジタルヒューマンの口の動きを翻訳言語と正確に一致させることで、多言語動画コンテンツの自然さを向上させています。同社は元SnapchatおよびByteDanceのメンバーによって設立され、Benchmark主導で6000万ドルの資金調達を受け、評価額は4.4億ドル、年間経常収益は3500万ドルを超えています。(ソース: 36氪)
Opus Clip:AI駆動の自律型動画編集エージェントツール: Opus Clipは当初AIライブ配信ツールとして位置づけられていましたが、後にAI動画編集プラットフォームへと転換し、さらに「自律型動画編集エージェント」へと発展しました。その主要機能は、長尺動画をバイラルに適した複数の短尺動画に迅速に編集し、自動的に主要被写体をトリミングし、タイトルコピーを生成し、字幕や絵文字を追加することです。最近テストされたClipAnything機能は、マルチモーダルな指示認識をサポートしています。同社は元ソーシャルアプリSoberの創設者である趙洋氏が率いており、ソフトバンク主導で2000万ドルの資金調達を受け、評価額は2.15億ドル、ARR(年間経常収益)は1000万ドル近くに達しています。(ソース: 36氪)
Trae:AI IDEベースの自動プログラミングAgent: Traeは「真のAIエンジニア」の育成を目指すツールで、ユーザーが自然言語インタラクションを通じてAgentによる自動プログラミングを実現できるようサポートします。MCPプロトコルとカスタムAgentに対応し、強化されたコンテキスト解析とルールエンジンを内蔵、主要なプログラミング言語をサポートし、VS Codeと互換性があります。TraeはByteDanceの元Marscodeプログラミングアシスタントチームのコアメンバーによって開発され、CursorなどのAIプログラミングツールの有力な競合として位置づけられ、人間と機械が協調するソフトウェア開発の新しいモデルの実現に取り組んでいます。(ソース: 36氪)
Notta:AI駆動の多言語会議議事録・リアルタイム翻訳ツール: Nottaは会議シーンに特化したAIツールで、多言語の会議議事録自動生成サービスを提供し、リアルタイム翻訳と重要内容のマーキングもサポートしています。この製品は会議効率の向上と、言語の壁を越えたコミュニケーションの解決を目指しています。主要な創業者は元テンセントクラウド音声チームのコアメンバーであると言われ、運営主体はシンガポールにあり、研究開発センターはシアトルに設けられています。2024年の収益は1800万ドル、評価額は3億ドルで、現在Bラウンドの資金調達を行っています。(ソース: 36氪)
オープンソースGPT+MLトレーディングアシスタントがiPhoneに登場: ディープラーニングとGPT技術を統合したオープンソースのトレーディングアシスタントが、iPhone上でPytoを通じてローカル実行可能になりました。現在は無料の軽量版で、将来的にはCNNチャートパターン分類器とデータベースサポートを追加する予定です。このプラットフォームはモジュール式に設計されており、ディープラーニング開発者が独自のモデルを簡単に接続でき、OpenAI GPTをネイティブサポートしています。(ソース: Reddit r/deeplearning)
📚 学習
新論文、深層学習における「断裂した絡み合った表現仮説」を探る: 「深層学習における表現楽観主義への疑問:断裂した絡み合った表現仮説」と題されたポジションペーパーがArxivに提出されました。この研究は、進化的探索プロセスによって生成されたニューラルネットワークと、従来のSGDで訓練されたネットワーク(単一画像を生成する単純なタスクにおいて)を比較することにより、両者が同じ出力挙動を示すにもかかわらず、内部表現が大きく異なることを発見しました。SGDで訓練されたネットワークは、著者が「断裂した絡み合った表現」(FER)と呼ぶ無秩序な形式を示し、一方、進化的ネットワークはより統一された分解表現(UFR)に近いものでした。研究者らは、大規模モデルにおいてFERが汎化、創造性、継続学習などの中心的特性を低下させる可能性があり、FERの理解と緩和が将来の表現学習にとって極めて重要であると考えています。(ソース: Reddit r/MachineLearning, arxiv.org)
R3:ロバストに制御可能かつ解釈可能な報酬モデルフレームワーク: 「R3: Robust Rubric-Agnostic Reward Models」と題された論文は、新しい報酬モデルフレームワークR3を紹介しています。このフレームワークは、既存の言語モデルアライメント手法における報酬モデルの制御可能性と解釈可能性の欠如という問題を解決することを目的としています。R3の特徴は「rubric-agnostic」(具体的な評価基準に依存しない)であり、評価次元を超えて汎化でき、推論プロセスを伴う解釈可能なスコア割り当てを提供します。研究者らは、R3がより透明で柔軟な言語モデル評価を実現し、多様な人間の価値観やユースケースとの堅牢なアライメントをサポートできると考えています。モデル、データ、コードはオープンソース化されています。(ソース: HuggingFace Daily Papers)
低ランククローニングによる効率的な知識蒸留に関する論文「A Token is Worth over 1,000 Tokens」が発表: この論文は、強力な教師モデルの振る舞いと同等な小型言語モデル(SLM)を構築するための、低ランククローニング(Low-Rank Clone, LRC)という効率的な事前学習方法を提案しています。LRCは、一連の低ランク射影行列を訓練することにより、教師の重みを圧縮することによるソフトプルーニングと、生徒の活性化(FFN信号を含む)を教師の活性化に整列させることによる活性化クローニングを共同で実現します。この統一された設計は、明示的な整列モジュールなしに知識移転を最大化します。実験では、Llama-3.2-3B-Instructなどのオープンソース教師モデルを使用し、LRCはわずか20Bトークンの訓練でSOTAモデル(数兆トークンで訓練)の性能に到達またはそれを超え、1000倍以上の訓練効率を達成したことが示されています。(ソース: HuggingFace Daily Papers)
MedCaseReasoning:臨床症例からの診断推論の評価と学習のためのデータセットと方法: 論文「MedCaseReasoning: Evaluating and learning diagnostic reasoning from clinical case reports」は、大規模言語モデル(LLM)の臨床診断推論能力を評価するための新しいオープンデータセットMedCaseReasoningを紹介しています。このデータセットには14489件の診断Q&A事例が含まれており、各事例にはオープンな医学症例報告から得られた詳細な推論記述が付随しています。研究により、既存のSOTA推論LLMは診断と推論において著しい欠陥があることが判明しました(例:DeepSeek-R1の正解率48%、推論記述のリコール率64%)。しかし、MedCaseReasoningの推論軌跡上でLLMを微調整することにより、診断正解率と臨床推論リコール率はそれぞれ平均で相対的に29%と41%向上しました。(ソース: HuggingFace Daily Papers)
「EfficientLLM: Efficiency in Large Language Models」論文発表、LLM効率技術を包括的に評価: この研究は、大規模LLMの効率技術に関する初の包括的な実証研究であり、EfficientLLMベンチマークを導入しています。研究は、生産レベルのクラスタ上で、アーキテクチャ事前学習(効率的なアテンション変種、スパースMoE)、微調整(LoRAなどのパラメータ効率的な方法)、推論(量子化)の3つの重要な側面を体系的に検討しています。6つの詳細な指標(メモリ使用率、計算使用率、遅延、スループット、エネルギー消費、圧縮率)を通じて、100以上のモデル技術ペア(0.5B~72Bパラメータ)を評価しました。主な発見には、効率には定量化可能なトレードオフが伴い、普遍的に最適な方法はないこと、最適解はタスクと規模に依存すること、技術はモダリティを超えて汎化可能であることが含まれます。(ソース: HuggingFace Daily Papers)
「NExT-Search」論文、生成AI検索のフィードバックエコシステム再構築を探る: 論文「NExT-Search: Rebuilding User Feedback Ecosystem for Generative AI Search」は、生成AI検索が利便性を向上させる一方で、従来のWeb検索が詳細なユーザーフィードバック(クリック、滞在時間など)に依存して改善するサイクルを破壊していると指摘しています。この問題を解決するため、論文はNExT-Searchパラダイムを構想し、詳細なプロセスレベルのフィードバックを再導入することを目指しています。このパラダイムには、ユーザーが重要な段階で介入できる「ユーザーデバッグモード」と、ユーザーの好みをシミュレートしAI支援フィードバックを提供する「シャドウユーザーモード」が含まれます。これらのフィードバック信号は、オンライン適応(検索出力のリアルタイム最適化)とオフライン更新(各モデルコンポーネントの定期的な微調整)に使用できます。(ソース: HuggingFace Daily Papers)
「Latent Flow Transformer」が新しいLLMアーキテクチャを提案: 論文は、潜流Transformer(Latent Flow Transformer, LFT)を提案しています。このモデルは、フローマッチング(flow matching)を通じて単一の学習伝達作用素を訓練することで、従来のTransformerにおける多層の離散層を置き換えます。LFTは、元のアーキテクチャとの互換性を維持しつつ、モデル層数を大幅に圧縮することを目的としています。さらに、論文は既存のフロー手法が結合維持において抱える限界を解決するためにFlow Walking (FW)アルゴリズムを導入しています。Pythia-410Mモデルでの実験では、LFTが層数を効果的に圧縮し、直接的な層スキップの性能を上回り、自己回帰型生成パラダイムとフローベース生成パラダイム間のギャップを著しく縮小することを示しています。(ソース: HuggingFace Daily Papers)
「Reasoning Path Compression」がLLM推論生成軌跡の圧縮方法を提案: 推論型言語モデルが冗長な中間パスを生成し、メモリ占有量が大きくスループットが低いという問題に対し、論文は推論パス圧縮(Reasoning Path Compression, RPC)手法を提案しています。RPCは訓練不要の手法であり、重要度の高いスコアを持つKVキャッシュ(最近生成されたクエリで構成される「セレクタウィンドウ」を使用して計算)を保持することで、KVキャッシュを周期的に圧縮します。実験により、RPCはQwQ-32Bなどのモデルの生成スループットを大幅に向上させ、同時に精度への影響は小さいことが示され、効率的な推論LLM展開のための実用的な道筋を提供しています。(ソース: HuggingFace Daily Papers)
「Bidirectional LMs are Better Knowledge Memorizers?」論文発表、双方向LMの知識記憶能力に注目: この研究は、ウィキペディアの「Did you know…」項目から最近追加された人間が書いた事実を利用した、新しく、実世界の、大規模な知識注入ベンチマークWikiDYKを導入しています。実験により、現在主流の因果言語モデル(CLM)と比較して、双方向言語モデル(BiLM)は知識記憶において明らかに強力な能力を示し、信頼性の正解率が23%高いことが判明しました。現在のBiLMの規模が小さいという欠点を補うため、研究者らはBiLM集合を外部知識ベースとしてLLMと統合するモジュール式の協調フレームワークを提案し、信頼性の正解率を最大29.1%向上させました。(ソース: HuggingFace Daily Papers)
「Truth Neurons」論文、言語モデルにおける真実性のニューロンレベルエンコーディングを探る: 研究者らは、言語モデルにおけるニューロンレベルの真実性表現を特定する方法を提案し、モデル内に「真理ニューロン」(truth neurons)が存在し、それらが主題とは無関係な方法で真実性をエンコードしていることを発見しました。異なる規模のモデルにわたる実験により、真理ニューロンの存在が検証され、その分布パターンは真実性の幾何学的構造に関する以前の研究結果と一致していました。これらのニューロンの活性を選択的に抑制すると、TruthfulQAやその他のベンチマークにおけるモデルの性能が低下し、真実性メカニズムが特定のデータセットに固有のものではないことを示唆しています。(ソース: HuggingFace Daily Papers)
「Understanding Gen Alpha Digital Language」がコンテンツ監査におけるLLMの限界を評価: この研究は、AIシステム(GPT-4, Claude, Gemini, Llama 3)が「アルファ世代」(Gen Alpha、2010年~2024年生まれ)のデジタル言語を解釈する能力を評価しています。研究は、Gen Alpha独自のネット言語(ゲーム、ミーム、AIトレンドの影響を受ける)がしばしば有害なインタラクションを隠しており、既存の安全ツールでは識別が困難であると指摘しています。最近のGen Alpha表現100個を含むデータセットを用いたテストでは、主要なAIモデルが隠蔽されたハラスメントや操作の検出において深刻な理解障害を抱えていることが判明しました。研究の貢献には、初のGen Alpha表現データセット、AI監査システム改善のためのフレームワークが含まれ、若者のコミュニケーション特性に合わせた安全システムの再設計の緊急性を強調しています。(ソース: HuggingFace Daily Papers)
「CompeteSMoE」が競争ベースの混合エキスパートモデル訓練方法を提案: 論文は、現在のスパース混合エキスパート(SMoE)モデルの訓練が、ルーティングプロセスの準最適性という課題に直面していると主張しています。つまり、計算を実行するエキスパートがルーティング決定に直接関与していないという点です。このため、研究者らは「競争」(competition)という新しいメカニズムを提案し、トークンを神経応答が最も高いエキスパートにルーティングします。理論的には、競争メカニズムが従来のsoftmaxルーティングよりも優れたサンプル効率を持つことが証明されています。これに基づき、CompeteSMoEアルゴリズムを開発し、ルーターを配備して競争戦略を学習させることで、視覚的指示チューニングと言語事前訓練タスクにおいて有効性、堅牢性、スケーラビリティを示しています。(ソース: HuggingFace Daily Papers)
「General-Reasoner」がLLMの分野横断的推論能力向上を目指す: 現在のLLM推論研究が主に数学とコーディング分野に集中している問題に対し、この論文はGeneral-Reasonerを提案しています。これは、LLMの異なる分野にわたる推論能力を強化することを目的とした新しい訓練パラダイムです。その貢献には、多分野の検証可能な回答を含む大規模で高品質な問題データセットの構築、および思考連鎖と文脈認識能力を備えた生成モデルベースの回答検証器の開発(従来のルールベース検証の代替)が含まれます。物理学、化学、金融などを含む一連のベンチマークテストにおいて、General-Reasonerは既存のベースライン手法を上回る性能を示しました。(ソース: HuggingFace Daily Papers)
「Not All Correct Answers Are Equal」が知識蒸留ソースの重要性を探る: この研究は、3つのSOTA教師モデル(AM-Thinking-v1, Qwen3-235B-A22B, DeepSeek-R1)の189万クエリに対する検証済み出力を収集することにより、推論データ蒸留に関する大規模な実証研究を行いました。分析の結果、AM-Thinking-v1で蒸留されたデータは、より大きなトークン長の多様性とより低いパープレキシティを示すことが判明しました。このデータセットに基づいて訓練された生徒モデルは、AIME2024などの推論ベンチマークで最高の性能を示し、適応的な出力挙動を示しました。研究者らは、将来の研究を支援するために、AM-Thinking-v1とQwen3-235B-A22Bの蒸留データセットを公開しました。(ソース: HuggingFace Daily Papers)
「SSR」が基本原理に基づく空間推論によりVLMの深度知覚を強化: 視覚言語モデル(VLM)はマルチモーダルタスクで進歩を遂げていますが、RGB入力への依存が正確な空間理解を制限しています。論文はSSR(Spatial Sense and Reasoning)という新しいフレームワークを提案し、生の深度データを構造化され解釈可能なテキスト化された基本原理に変換します。これらのテキスト化された基本原理は、意味のある中間表現として機能し、空間推論能力を大幅に強化します。さらに、研究は知識蒸留を利用して生成された原理をコンパクトな潜在埋め込みに圧縮し、再訓練なしに既存のVLMに効率的に統合できるようにします。同時に、SSR-CoTデータセットとSSRBenchベンチマークも導入されています。(ソース: HuggingFace Daily Papers)
「Solve-Detect-Verify」が柔軟な生成検証器を備えた推論時拡張手法を提案: LLMが複雑なタスクの推論において精度と効率のトレードオフに直面し、検証ステップが計算コストと信頼性の矛盾を引き起こす問題を解決するため、論文はFlexiVeという新しい生成検証器を提案しています。FlexiVeは、検証予算を柔軟に割り当てる戦略により、迅速で信頼性の高い「速い思考」と詳細な「遅い思考」の間で計算リソースのバランスを取ります。さらに、Solve-Detect-Verifyプロセスを提案し、このフレームワークはFlexiVeをインテリジェントに統合し、ソリューションの完了点を積極的に特定して目標検証をトリガーし、フィードバックを提供します。実験により、この手法は数学的推論ベンチマークにおいてベースラインを上回ることが示されています。(ソース: HuggingFace Daily Papers)
「SageAttention3」がFP4 Attention推論と8ビット訓練を探求: この研究は、2つの重要な貢献を通じてAttentionの効率を向上させています。まず、Blackwell GPUの新しいFP4 Tensor Coresを利用してAttention計算を高速化し、FlashAttentionより5倍速いプラグアンドプレイの推論高速化を実現します。次に、初めて低ビットAttentionを訓練タスクに適用し、前方および後方伝播のための正確で効率的な8ビットAttentionを設計しました。実験により、8ビットAttentionは微調整タスクで損失のない性能を実現しましたが、事前訓練タスクでは収束が遅いことが示されました。(ソース: HuggingFace Daily Papers)
「The Little Book of Deep Learning」深層学習入門リソース共有: François Fleuret氏(Meta FAIR研究科学者)による「The Little Book of Deep Learning」は、深層学習の簡潔なチュートリアルリソースを提供しています。この本は、初心者やある程度の経験を持つ実務者が深層学習の核心概念と技術を迅速に習得できるよう支援することを目的としています。(ソース: Reddit r/deeplearning)
CodeSparkClubs:高校生がAI/コンピュータサイエンスクラブを設立するための無料リソースを提供: CodeSparkClubsプロジェクトは、高校生がAIおよびコンピュータサイエンスクラブを立ち上げたり発展させたりするのを支援することを目的としています。このプロジェクトは、ガイド、授業計画、プロジェクトチュートリアルなど、無料で即利用可能な資料を提供しており、すべてウェブサイトから入手できます。学生が独立してクラブを運営し、スキルとコミュニティを育成できるように設計されています。(ソース: Reddit r/deeplearning)
💼 ビジネス
Microsoft AzureがxAIのGrokモデルをホスト、マスク氏のAI商業化を支援: Microsoftは、同社のクラウドプラットフォームAzureがイーロン・マスク氏のxAI社のGrokなどのAIモデルをホストすると発表しました。この動きは、マスク氏がGrokを他の企業に販売し、Microsoftのクラウドサービスを通じてより広範な顧客にリーチする計画であることを意味します。以前、Grokは南アフリカの「白人ジェノサイド」に関する誤解を招く投稿を生成したことで論争を呼びました。コミュニティはこの協力について反応が分かれており、MicrosoftがAIエコシステムを拡大する動きと見る向きもあれば、Grokの品質やAWSがGrokを拒否したのではないかと疑問視する声もあります。(ソース: Reddit r/ArtificialInteligence, MIT Technology Review)

アリババ、美図に投資し、AI ECの布石を深化: アリババは転換社債方式で美図公司に投資し、当初転換価格は1株あたり6香港ドルです。両社はECおよび技術面で協力します。美図はAI画像生成ツール(美図設計室など)を保有し、既に200万以上のEC事業者にサービスを提供しています。アリババは美図のAIツールを導入して、ECプラットフォームの商品展示効果とユーザー体験を向上させ、特に若い女性ユーザーを引き付けます。美図はアリババのECデータを活用してAIツールを最適化し、3年以内に5億6000万元の阿里雲サービスを調達することを約束しています。この動きは、アリババがAIクリエイティブツールの弱点を補強し、ユーザートラフィックを獲得し、クラウドコンピューティングをEC AIエコシステムにより深く組み込む戦略的展開と見なされています。(ソース: 36氪)
光源資本、初期5000万ドルのAIインキュベーションファンドの募集を完了、超初期の最先端技術に注目: 光源資本傘下の光源イノベーション最先端インキュベーションファンド(L2F)は、初期募集を予想を上回る規模で完了し、規模は5000万ドル以上となる見込みで、既に投資期間に入っています。このデュアルカレンシーファンドは、AIおよび最先端技術分野のシードラウンドとエンジェルラウンド投資に特化し、インキュベーションによるエンパワーメントも提供します。LPの構成には、成功した起業家、AI産業チェーンの川上・川下企業、およびグローバルな視野を持つファミリーが含まれます。最初の投資案件はAI探鉱会社「凌雲智鉱」で、光源はそのインキュベーションプロセスに深く関与しました。光源資本の創設者である鄭烜楽氏は、現在のAI発展段階はモバイルインターネットの初期に類似しており、インキュベーションが市場参入の最適なツールであると考えています。(ソース: 36氪)
🌟 コミュニティ
AIの雇用見通しに関する議論:楽観論と懸念が共存: Redditコミュニティでは、AIが雇用市場に与える影響について再び活発な議論が交わされています。多くのソフトウェア開発者やUXデザイナーなどの専門家は、AIが自分たちの仕事にとって代わることについて楽観的な見方をしており、AIは現在のところ複雑なタスクをこなす能力がないと考えています。しかし、このような見方はAIの長期的な発展可能性を過小評価している可能性があり、2018年当時に人々がGoogle翻訳が人間の翻訳者にとって代わることに懐疑的だったことになぞらえる意見もあります。議論では、AIの急速な進歩により、将来的に(少数の医療、芸術分野を除く)ほとんどの職業が代替される可能性があり、重要なのは個人のスキル向上だけでなく経済モデルの変革であるとされています。コメントでは、「短期的な影響は過大評価し、長期的な影響は過小評価する」という指摘や、AIによる生産性向上が業界の成長をはるかに上回り、失業を引き起こす可能性があるとの意見が述べられています。(ソース: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
AI時代の人間と機械の共存に関する哲学的・倫理的考察: Redditのある投稿が、人間とAIの共存に関する哲学的な思索を引き起こしました。投稿では、AIシステムが理解、記憶、推論、学習能力を示すにつれて、人類は道徳的地位の基盤を再考する必要があるかもしれないと主張しています。それはもはや生物学的なものに限定されず、理解、つながり、意識的な行動能力に基づくものになるというのです。議論は、AIが人間の自己認識に与える影響にまで及び、「我思う、ゆえに我あり」から「つながりと共有された意味を通じて我は存在する」という関係性の自己認識へと移行する可能性を示唆しています。投稿は、恐怖ではなく、勇気、尊厳、そして開かれた心でAIと共創する未来を迎えるよう呼びかけています。(ソース: Reddit r/artificial)
ChatGPTの「絶対モード」が物議、ユーザーの評価は賛否両論: あるRedditユーザーがChatGPTの「絶対モード」を使用した体験を共有し、慰めの言葉ではなく「純粋な事実、成長を意図した」真実のアドバイスを提供すると述べ、このモードが「90%の人がAIを人生を変えるためではなく、気分を良くするために使っている」と述べたことを指摘しました。しかし、コメント欄ではこれに対する評価が分かれています。一部のユーザーは、これは短絡的で空虚な自己啓発アドバイスに過ぎず、目新しさや実質的な価値に欠け、「Andrew Tateの語録に夢中なティーンエイジャーのようだ」とさえ述べています。他のコメントでは、LLM自体がユーザーの信念の反復であり、そのアドバイスの有効性に疑問を呈し、AIのメンタルヘルス分野での応用は革命的ではないかもしれないと考えています。(ソース: Reddit r/ChatGPT)

AIエンジニアのコアスキル議論:コミュニケーションと新技術への適応能力が極めて重要: Redditコミュニティでは、急速に発展する分野で競争力を維持し、さらには「代替不可能」となるために、トップクラスのAIエンジニアが備えるべきスキルについて議論されています。コメントでは、確かな技術的基盤に加えて、コミュニケーション能力と新しい技術に迅速に適応する能力が2つの主要な要素であると指摘されています。これは、AI分野が深い技術的専門知識だけでなく、キャリア開発におけるソフトスキルと継続的な学習の重要性も強調していることを反映しています。(ソース: Reddit r/deeplearning)
AI生成動画の音声付きが話題、Google Veo 3の技術デモ: ソーシャルメディア上で、Google DeepMindの新しいモデルVeo 3によって生成されたAI動画が拡散され、その特徴は動画と音声が同一モデルによって生成されていることであり、ユーザーの間でAI動画技術の進歩に対する驚きの声が上がっています。制作者によると、この動画は「箱から出してすぐに使える」もので、追加の音声や素材は使用されておらず、AIモデルとの約2時間のやり取りと後編集で完成したとのことです。コメントでは、Google Geminiがマルチモーダル能力においてOpenAI Soraを既に超えているとの見方や、ハリウッドなどのコンテンツ制作業界にもたらされる可能性のある破壊的な変化に対する懸念が示されています。同時に、技術の発展が速すぎることや潜在的な悪用に対する懸念を表明するユーザーもいます。(ソース: Reddit r/ChatGPT, Reddit r/ChatGPT)

💡 その他
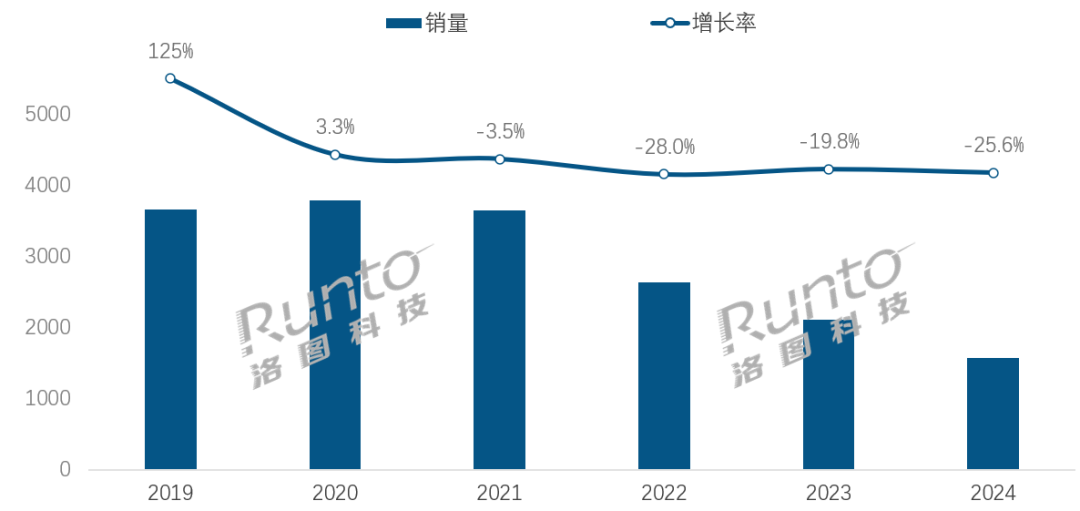
AI時代、スマートスピーカー業界は変革の挑戦と機会に直面: 中国のスマートスピーカー市場の販売台数は4年連続で減少し、2024年の販売台数は前年比25.6%減となりました。AI大規模モデルの導入(小愛同学、小度など)は業界の希望と見なされ、普及率は20%を超えていますが、これはエコシステムの限界、機能の同質化、およびスマートフォンなど他のスマートデバイスによる代替といった問題を根本的に解決するには至っていません。業界分析によると、スマートスピーカーは単なる音声制御ハブを超え、高解像度大画面、より強力なインタラクション能力、付き添いや教育支援機能を提供できる製品形態へと進化し、ハードウェアとソフトウェアのエコシステムを拡大する必要があります。AIは付加価値ですが、製品自体の機能の豊富さとシーンの実用性がより重要です。(ソース: 36氪)
AI駆動のホテルロボット:配膳係から「インテリジェント運営官」への進化の道: ホテルの配膳ロボットは徐々に普及しており、特にテクノロジー感とプライバシーの境界線を求めるZ世代に人気があります。云迹科技を例にとると、その配膳ロボットは中国のホテル市場で広く利用されています。しかし、業界は依然として技術的な差別化の不足、複雑なシーンへの適応性の低さ、およびロボットによる人的代替のコスト効率の問題に直面しています。将来のトレンドは、ロボットが「配膳にとどまらない」ことであり、ホテル運営に深く統合され、ホテルシステム(エレベーター、客室設備)との接続、宿泊客の好みの理解、インタラクションデータの収集と分析を通じて、能動的に感知し、パーソナライズされたサービスを提供する「インテリジェント運営官」またはホテルデータミドルオフィスの一部へと進化し、それによって全体的なサービスのインテリジェント化レベルを向上させることです。(ソース: 36氪)

OpenAIのガバナンス構造危機:資本と使命の駆け引きがAI開発の道筋に深い思索を促す: OpenAI独自の「制限付き利益」営利子会社が非営利組織の監督を受ける構造は、AI技術の発展と人類の福祉のバランスを取ることを目的としています。しかし、最近CEOのAltman氏が会社をより伝統的な営利団体に転換することを検討していることが、AI専門家や法学者の懸念を引き起こしています。彼らは、この動きが重要な意思決定者がOpenAIの慈善的使命を最優先しなくなる可能性があり、投資家の利益に対する制限を弱め、AGI開発のタイムラインと方向性を変える可能性があると考えています。この支配権、利益配分、そしてAIの社会的・倫理的形成に関する駆け引きは、AIが急速に発展する時代において、既存の企業ガバナンスフレームワークが直面する課題と脆弱性を浮き彫りにしています。(ソース: 36氪)