
キーワード:AlphaEvolve, Gemini, 進化アルゴリズム, AIエージェント, アルゴリズム最適化, 行列乗算, Borgデータセンター, 4×4複素行列乗算最適化, Google DeepMindアルゴリズム発見, AI自動化アルゴリズム設計, Gemini 2.0 Proアプリケーション, Borgリソーススケジューリング最適化
🔥 注目ニュース
Google DeepMind、AlphaEvolveを発表:Geminiベースの進化的アルゴリズムによるコーディングエージェントが、数学およびコンピュータサイエンス分野でブレークスルーを達成: Google DeepMindは、Gemini 2.0 Pro大規模言語モデルを活用し、進化的アルゴリズムを通じてアルゴリズムコードを自動的に発見・最適化するエージェントであるAlphaEvolveを発表しました。AlphaEvolveは、人間が提供した初期コードと評価指標に基づき、自律的に候補ソリューションを生成、評価、改善することができます。このシステムは50以上の数学的問題で優れた性能を示し、約75%のケースで既知の解を再現し、20%のケースでより優れた解を発見しました。特筆すべきは、AlphaEvolveが4×4複素行列乗算の計算回数を49回から48回に削減し、56年間破られなかった記録を更新したことです。さらに、Google内部のBorgデータセンターのスケジューリングアルゴリズムを最適化し、世界の計算資源の0.7%を回収したほか、次世代TPUチップの設計を改善し、Geminiのトレーニング時間を1%短縮しました。この成果は、アルゴリズムの自動発見と科学的イノベーションにおけるAIの大きな可能性を示しています。現在は主に自動評価可能な問題を扱っていますが、創薬などの応用科学分野での応用が期待されています。(出典: , 量子位, 36氪)
NVIDIA、Computex 2025で多数のAI進捗を発表、Jensen Huang CEOはAgentic AIとPhysical AIのビジョンを強調: NVIDIAのCEOであるJensen Huang氏はComputex 2025の基調講演で、AIが「単一応答型」から「思考型、推論型」のAgentic AI(エージェントAI)および物理世界を理解するPhysical AI(物理AI)へと進化していることを強調しました。このトレンドをサポートするため、NVIDIAは拡張版Blackwellプラットフォーム(Blackwell Ultra AI)を発表し、Grace Blackwell GB300システムが全面的に生産開始され、その推論性能は前世代比で1.5倍向上したことを告知しました。Huang氏はまた、次世代AIスーパーチップRubin Ultraをプレビューし、その性能はGB300の14倍であると述べました。AIインフラ構築を推進するため、NVIDIAはNVLink Fusion技術を発表し、TSMCやFoxconnなどと共同で台湾にAIスーパーコンピュータを設立します。さらに、NVIDIAは人型ロボット基盤モデルIsaac GR00T N1.5を更新し、その環境適応能力とタスク実行能力を向上させ、DeepMindやDisney Researchと共同開発した物理エンジンNewtonをオープンソース化する計画です。(出典: AI 前线, 量子位, Reddit r/artificial)
OpenAI CodexチームのAMAでGPT-5および将来の製品統合計画が明らかに: OpenAI CodexチームはRedditで「何でも聞いてください」(AMA)イベントを開催し、研究担当副社長のJerry Tworek氏は、次世代基盤モデルGPT-5の目標は既存モデルの能力を向上させ、モデル切り替えの必要性を減らすことであると明かしました。Codex、Operator(タスク実行エージェント)、Deep Research(深層研究ツール)、Memory(記憶機能)などの既存ツールを統合し、統一されたAIアシスタント体験を形成する計画です。チームメンバーはまた、Codexの開発のきっかけ(モデルの活用不足に関する社内での考察から生まれた)、Codexの社内利用によるプログラミング効率の約3倍向上、そして将来のソフトウェアエンジニアリングへの展望(要求を効率的かつ確実に実行可能なソフトウェアに変換すること)についても語りました。Codexは現在、主にコンテナランタイムにロードされた情報を利用しており、将来的にはRAG技術を組み合わせて最新の知識を取得する可能性があります。OpenAIはまた、柔軟な価格設定プランを模索しており、Plus/Proユーザー向けにCodex CLIで使用できる無料のAPIクレジットを提供する予定です。(出典: 36氪)
VS Code、GitHub Copilot Chat拡張機能のオープンソース化を発表、オープンソースAIコード編集プラットフォームの構築を計画: Visual Studio Codeチームは、VS Codeを開放性、協調性、コミュニティ主導という中核原則に基づき、オープンソースのAIエディタへと発展させる計画を発表しました。この計画の一環として、GitHub Copilot Chat拡張機能がGitHub上でMITライセンスの下でオープンソース化されました。将来的には、VS CodeはこれらのAI機能をエディタのコアに段階的に統合し、開発効率、透明性、安全性を向上させることを目的とした、完全にオープンソースでコミュニティ主導のAIコード編集プラットフォームの構築を目指します。この動きは、Microsoftのオープンソース分野における重要な一歩と見なされており、AI支援プログラミングツールのエコシステムに大きな影響を与える可能性があります。(出典: dotey, jeremyphoward)
Huawei AscendとDeepSeekが協力、MoEモデルの推論性能でNVIDIA Hopperを凌駕: Huawei Ascendは、同社のCloudMatrix 384スーパーノードとAtlas 800I A2推論サーバーが、DeepSeek V3/R1などの超大規模MoEモデルを展開する際に、推論性能で大きなブレークスルーを達成し、特定の条件下でNVIDIA Hopperアーキテクチャを凌駕したと発表しました。CloudMatrix 384スーパーノードは、50msの遅延でシングルカードのDecodeスループットが1920 Tokens/sを突破し、Atlas 800I A2は100msの遅延でシングルカードのスループットが808 Tokens/sに達しました。Huaweiはこれを「数学で物理を補う」戦略の成果とし、アルゴリズムとシステムの最適化によってハードウェアプロセスの限界を補ったとしています。関連技術報告書は既に発表されており、コアコードも1ヶ月以内にオープンソース化される予定です。最適化措置には、MoEモデル向けの専門家並列ソリューション、PD分離展開、vLLMフレームワークへの適応、A8W8C16量子化戦略、およびFlashComm通信ソリューション、層内並列変換、FusionSpec投機的推論エンジン、MLA/MoE演算子のハードウェア親和性最適化などが含まれます。(出典: 量子位, WeChat)
🎯 動向
Apple、高効率な視覚言語モデルFastVLMをオープンソース化、エッジAI体験を最適化: Apple社は、iPhoneなどのエッジデバイス上で効率的に動作するように特別に設計された視覚言語モデルFastVLM(Fast Vision Language Model)をオープンソース化しました。FastVLMは、新しいハイブリッド視覚エンコーダFastViTHDを導入し、畳み込み層とTransformerモジュールを組み合わせ、さらにマルチスケールプーリングとダウンサンプリング技術を採用することで、画像処理に必要な視覚トークン数を大幅に削減しました(従来のViTより16倍少ない)。これにより、モデルは高精度を維持しつつ、最初のトークン出力速度(TTFT)が同クラスのモデルと比較して最大85倍向上しました。FastVLMは主流のLLMと互換性があり、iOS/Macエコシステムへの適応も容易で、0.5B、1.5B、7Bの3つのパラメータバージョンを提供し、画像キャプション生成、質疑応答、分析など、さまざまなリアルタイムの画像・テキストタスクに適しています。(出典: WeChat)
Meta、KernelLLM 8Bモデルをリリース、特定のベンチマークでGPT-4oを上回る: MetaはHugging Face上でKernelLLM 8Bモデルをリリースしました。KernelBench-Triton Level 1ベンチマークにおいて、この80億パラメータのモデルは、単一推論性能でGPT-4oやDeepSeek V3などのより大規模なモデルを上回ったとされています。複数回推論の場合でも、KernelLLMの性能はDeepSeek R1を上回っています。このリリースはAIコミュニティの注目を集め、中小規模モデルが特定のタスクで強力な競争力を示す新たな事例と見なされています。(出典: ClementDelangue, huggingface, mervenoyann, HuggingFace Daily Papers)
Mistral Medium 3モデル、Arenaで好成績、特に技術分野で際立つ: Mistral AIが新たに発表したMistral Medium 3モデルは、lmarena.aiのコミュニティ評価で優れた成績を収め、総合チャット能力で11位にランクインし、Mistral Largeから大幅に向上しました(Eloスコアが90ポイント増加)。同モデルは技術分野で特に際立っており、数学能力で5位、複雑なプロンプトとコーディング能力で7位、WebDev Arenaで9位にランクインしています。コミュニティのコメントでは、技術分野での性能はGPT-4.1レベルに近く、コストはGPT-4.1 miniの価格設定と同様に競争力がある可能性があるとされています。ユーザーはMistralの公式チャットインターフェースで同モデルを無料で試用できます。(出典: hkproj, qtnx_, lmarena_ai)
Hugging Face Datasetsにチャット会話の直接閲覧機能が追加: Hugging Face Datasetsプラットフォームが重要なアップデートを行い、ユーザーはデータセット内でチャット会話の内容を直接閲覧できるようになりました。この機能は、Caleb氏やMaxime Labonne氏などのコミュニティメンバーから、データ品質問題の解決に向けた大きな一歩と見なされています。なぜなら、元の会話データを直接調べることで、データの理解を深め、データクリーニングを行い、モデルのトレーニング効果を向上させるのに役立つからです。以前は、特定の会話内容を確認するために追加のコードやツールが必要になる場合がありましたが、新機能によりこのプロセスが簡素化され、データ作業の利便性と透明性が向上しました。(出典: eliebakouch, _lewtun, _akhaliq, maximelabonne, ClementDelangue, huggingface, code_star)
MLX LMとHugging Face Hubが統合、Macでのローカルモデル実行を簡素化: MLX LMがHugging Face Hubに直接統合され、MacユーザーはApple Siliconデバイス上で4400以上のLLMをより簡単にローカルで実行できるようになりました。ユーザーはHugging Face Hub上の互換性のあるモデルのページで「Use this model」をクリックするだけで、複雑なクラウド設定や待機時間なしに、ターミナルで迅速にモデルを実行できます。さらに、モデルページから直接OpenAI互換サーバーを起動することも可能です。この統合は、ローカルでのモデル実行のハードルを下げ、開発と実験の効率を向上させることを目的としています。(出典: awnihannun, ClementDelangue, huggingface, reach_vb)
NVIDIA、物理AI推論モデルCosmos-Reason1-7Bをオープンソース化: NVIDIAは、Hugging Face上で同社のPhysical AIモデルシリーズのCosmos-Reason1-7Bをオープンソース化しました。このモデルは、物理世界の常識を理解し、対応する具現化された意思決定を生成することを目的としています。これは、NVIDIAが物理世界とAIの融合を推進する上で新たな一歩を踏み出したことを示し、ロボット工学や自動運転など、物理環境とのインタラクションを必要とするアプリケーションに新しいツールと研究基盤を提供します。(出典: reach_vb)
Baiduの動画生成モデルSteamer-I2VがVBench画像からの動画生成部門でトップに: Baiduの動画生成モデルSteamer-I2Vが、権威ある動画生成評価ベンチマークVBenchの画像からの動画生成(I2V)カテゴリで第1位となり、総合スコア89.38%を達成し、OpenAI SoraやGoogle Imagen Videoなどの著名なモデルを上回りました。Steamer-I2Vの技術的優位性には、ピクセルレベルの正確な画面制御、マスターレベルのカメラワーク、最大1080Pの映画級高画質とダイナミックな美学、そして億単位の中国語マルチモーダルデータベースに基づく正確な中国語意味理解が含まれます。この成果は、Baiduのマルチモーダル生成分野における実力を示しており、AIコンテンツエコシステム構築戦略の一環でもあります。(出典: 36氪)

LLM、時計やカレンダーなどの時間読み取りタスクで性能振るわず: エディンバラ大学などの研究者らは、大規模言語モデル(LLM)およびマルチモーダル大規模言語モデル(MLLM)が多くのタスクで優れた性能を示す一方で、アナログ時計の時刻認識やカレンダーの日付理解といった、一見単純な時間読み取りタスクにおいて精度が低いことを発見しました。研究では、ClockQAとCalendarQAという2つのカスタムテストセットを構築し、その結果、AIシステムによる時計の読み取り精度はわずか38.7%、カレンダーの日付判断精度はわずか26.3%でした。Gemini-2.0やGPT-o1などの先進的なモデルでさえ明らかな困難を示し、特にローマ数字、様式化された針、または複雑な日付計算(閏年、特定の日が何曜日かなど)の処理で問題が見られました。研究者らは、これが現在のモデルにおける空間推論、構造化レイアウト解析、および一般的でないパターンへの汎化能力の不足を露呈していると考えています。(出典: 36氪, WeChat)

Microsoft、BuildカンファレンスでGrokモデルをAzure AI Foundryに導入すると発表: Microsoft Build 2025開発者カンファレンスで、MicrosoftはxAI社のGrokモデルをAzure AI Foundryモデルシリーズに追加すると発表しました。ユーザーはAzure FoundryおよびGitHub上でGrok-3およびGrok-3-miniを6月初旬まで無料で試用できます。この動きは、Azure AI Foundryがサポートするサードパーティモデルの範囲をさらに拡大することを意味し、将来的にはユーザーはOpenAI、xAI、DeepSeek、Meta、Mistral AI、Black Forest Labsなど複数のベンダーのモデルを統一された予約スループットを通じて利用できるようになります。(出典: TheTuringPost, xai)
Apple、EUのiPhoneユーザーにSiriをサードパーティ製音声アシスタントに置き換えることを許可する計画と報じられる: Mark Gurman氏の報道によると、Apple社はEU地域のiPhoneユーザーに対し、Siriをサードパーティ製の音声アシスタントに置き換えることを初めて許可する計画です。この措置は、EUのますます厳格化するデジタル市場規制要件に対応するためであり、プラットフォームの開放性とユーザーの選択権を強化することを目的としている可能性があります。この計画が実施されれば、音声アシスタント市場の勢力図に重要な影響を与え、他の音声アシスタントにAppleエコシステムへの参入機会を提供することになります。(出典: zacharynado)

Meta、Open Molecules 2025データセットとUMAモデルを公開、分子・材料発見を加速: Meta AIは、Open Molecules 2025 (OMol25) とMeta Universal Atomistic Model (UMA) を公開しました。OMol25は、現在最大かつ最も多様な高精度量子化学計算データセットであり、生体分子、金属錯体、電解質などが含まれています。UMAは、300億個以上の原子で訓練された機械学習原子間ポテンシャルモデルであり、より正確な分子挙動予測を提供することを目的としています。これらのツールのオープンソース化は、分子科学および材料科学の発見と革新を加速することを目的としています。(出典: AIatMeta)
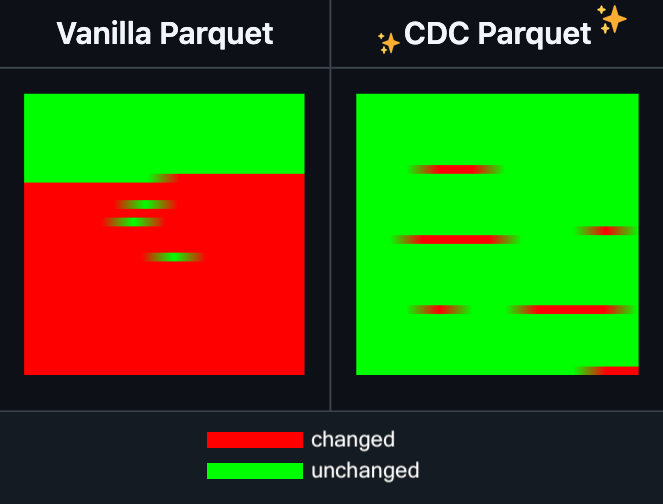
Hugging Face DatasetsにParquetファイルの増分編集機能が追加: Hugging Face Datasetsは、その基盤となる依存ライブラリであるPyArrowのナイトリーバージョンが、ファイルを完全に書き換えることなくParquetファイルの増分編集をサポートするようになったと発表しました。この新機能は、大規模データセット操作の効率を大幅に向上させ、特にデータの部分的な更新や変更が頻繁に必要な場合に、時間と計算リソースの消費を著しく削減できます。これは、開発者が大規模なAIトレーニングデータセットを処理・維持する際の体験を改善することが期待されます。(出典: huggingface)
LangGraphにノードレベルのキャッシュ機能が追加され、ワークフロー効率が向上: LangGraphは、オープンソース版にノード/タスクキャッシュ機能が追加されたことを発表しました。この機能は、重複計算を回避することでワークフローを高速化することを目的としており、特に共通部分を含む、または頻繁なデバッグが必要なエージェント(Agent)ワークフローに適しています。ユーザーは、命令型APIまたはグラフィカルAPIでキャッシュを使用でき、AIアプリケーションのイテレーションと最適化をより迅速に行うことができます。これは、LangGraphが今週発表したオープンソースリリースシリーズの最初のアップデートです。(出典: hwchase17)

Sakana AI、新しいAIアーキテクチャ「Continuous Thought Machines」(CTM)を発表: 東京のAIスタートアップSakana AIは、「Continuous Thought Machines (CTM)」と名付けられた新しいAIモデルアーキテクチャを発表しました。CTMは、モデルが人間の脳のように、より少ない指示で推論できるようにすることを目的としています。この新しいアーキテクチャは、現在のAIモデルが複雑な推論や自律学習で直面している課題を解決するための新しいアプローチを提供する可能性があります。(出典: dl_weekly)
MicrosoftとNVIDIA、RTX AI PCでの協力を深化、TensorRTがWindows MLに登場: Microsoft Buildおよび台北国際コンピュータ見本市(COMPUTEX)期間中、NVIDIAとMicrosoftはRTX AI PCの開発協力をさらに推進すると発表しました。NVIDIAのTensorRT推論最適化ライブラリは再設計され、Microsoftの新しい推論スタックであるWindows MLに統合されました。この動きは、AIアプリケーションの開発プロセスを簡素化し、PC側のAIタスクにおけるRTX GPUのピーク性能を最大限に活用し、パーソナルコンピューティングデバイスにおけるAIの普及と応用を促進することを目的としています。(出典: nvidia)
Bilibili、アニメ動画生成モデルIndex-AniSoraをオープンソース化、多数の指標でSOTAを達成: Bilibiliは、自社開発のアニメ動画生成モデルIndex-AniSoraをオープンソース化したと発表しました。このモデルはIJCAI 2025で発表されました。AniSoraは2次元動画生成に特化して設計されており、日本のアニメ、中国国産アニメ、漫画原作アニメなど多様なスタイルをサポートし、動画の特定領域の誘導、時系列誘導(例:最初のフレーム/最後のフレーム誘導、キーフレーム補間)などの詳細な制御を実現できます。オープンソースプロジェクトには、CogVideoX-5BベースのAniSoraV1.0とWan2.1-14BベースのAniSoraV2.0のトレーニング・推論コード、トレーニングデータセット構築ツール、アニメ専用ベンチマークシステム、および人間の嗜好に基づく強化学習で最適化されたAniSoraV1.0_RLモデルが含まれます。(出典: WeChat)

Tencent Hunyuan、初のマルチモーダル統一CoT報酬モデルUnifiedReward-Thinkをオープンソース化: Tencent Hunyuanは、上海AI Lab、復旦大学などの機関と共同で、初の長鎖推論(CoT)能力を持つ統一マルチモーダル報酬モデルUnifiedReward-Thinkを提案しました。このモデルは、報酬モデルが複雑な視覚生成・理解タスクを評価する際に「考えることを学ぶ」ようにすることで、評価の正確性、タスク間の汎化能力、推論の解釈可能性を向上させることを目的としています。プロジェクトは、モデル、データセット、トレーニングスクリプト、評価ツールを含め、全面的にオープンソース化されています。(出典: WeChat)
Alibaba、動画生成・編集モデルTongyi Wanxiang Wan2.1-VACEをオープンソース化: Alibabaは、動画生成・編集モデルTongyi Wanxiang Wan2.1-VACEを正式にオープンソース化しました。このモデルは、テキストからの動画生成、画像参照による動画生成、動画の再描画、動画の部分編集、動画背景の拡張、動画時間の拡張など、多様な機能を備えています。今回、1.3Bと14Bの2つのバージョンがオープンソース化され、そのうち1.3Bバージョンはコンシューマー向けグラフィックカードで実行可能であり、AIGC動画制作のハードルを下げることを目的としています。(出典: WeChat)
ByteDance、視覚言語モデルSeed1.5-VLを発表、多数のベンチマークでリード: ByteDanceは、532Mパラメータの視覚エンコーダと20Bアクティブパラメータの混合エキスパート(MoE)LLMから構成される視覚言語モデルSeed1.5-VLを構築しました。比較的小規模なアーキテクチャにもかかわらず、60の公開ベンチマークのうち38でSOTA性能を達成し、GUI制御やゲームプレイなどのエージェント中心のタスクではOpenAI CUAやClaude 3.7などのモデルを上回り、強力なマルチモーダル推論能力を示しました。(出典: WeChat)
MiniMax、自己回帰TTSモデルMiniMax-Speechを発表、32言語のゼロショット音声クローニングをサポート: MiniMaxは、Transformerベースの自己回帰テキスト音声合成(TTS)モデルMiniMax-Speechを提案しました。このモデルは、参照音声から文字起こしなしに音色特徴を抽出し、ゼロショット方式で参照音色と一致し表現力豊かな音声を生成でき、単一サンプル音声クローニングもサポートします。Flow-VAE技術により合成音声の品質を向上させ、32言語に対応しています。このモデルは、客観的な音声クローニング指標でSOTAレベルを達成し、公開TTS Arenaランキングで首位に立ち、さらに音声感情制御、テキストからの音声生成、専門的な音声クローニングなどにも応用可能です。(出典: WeChat)
OuteTTS 1.0 (0.6B) リリース、14言語対応のApache 2.0オープンソースTTSモデル: OuteAIは、Qwen-3 0.6Bをベースに構築された軽量テキスト音声合成(TTS)モデルOuteTTS-1.0-0.6Bをリリースしました。このモデルはApache 2.0ライセンスを採用し、中国語、英語、日本語、韓国語を含む14言語をサポートしています。そのPython推論ライブラリOuteTTS v0.4.2は、EXL2非同期バッチ推論、vLLM実験的バッチ推論、およびLlama.cppサーバーの連続バッチ処理と外部URLモデル推論をサポートするように更新されました。単一のNVIDIA L40S GPUでのベンチマークテストでは、vLLM OuteTTS-1.0-0.6B FP8はバッチサイズ32でRTF(リアルタイムファクター)0.05を達成可能です。モデルの重み(ST, GGUF, EXL2, FP8)はHugging Faceで提供されています。(出典: Reddit r/LocalLLaMA)

Hugging FaceとMicrosoft Azureが協業を深化、1万を超えるオープンソースモデルがAzure AI Foundryに登場: Microsoft Buildカンファレンスで、CEOのSatya Nadella氏はHugging Faceとの協業拡大を発表しました。現在、Hugging Faceを通じて11,000を超える最も人気のあるオープンソースモデルがAzure AI Foundryで提供されており、ユーザーは簡単にデプロイできます。この動きはAzureのAIエコシステムをさらに豊かにし、開発者により多くのモデル選択肢とより便利な開発体験を提供します。(出典: ClementDelangue, _akhaliq)

Intel、Arc Pro B50/B60シリーズGPUを発表、AIとワークステーション市場をターゲットに、24GB版は約500ドル: IntelはComputexで、新しいArc Pro Bシリーズプロフェッショナルグラフィックスカードを発表しました。これにはArc Pro B50(16GB VRAM、約299ドル)とArc Pro B60(24GB VRAM、約500ドル)が含まれます。その中で、デュアルB60 GPUで構成される48GB VRAM版の「Project Battlematrix」ワークステーションソリューションも同時に発表され、価格は1000ドル未満と予想されています。これらの製品は、AIコンピューティングとプロフェッショナルワークステーションにコストパフォーマンスの高いソリューションを提供することを目的としており、特に大容量VRAM構成はローカルでの大規模言語モデル実行に魅力的です。新製品は今年の第3四半期に発売予定で、初期はOEMメーカーを通じて提供され、第4四半期にはDIY版が登場する可能性があります。(出典: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

🧰 ツール
Moondream Station、Linux版をリリース、ローカルでのMoondream実行を簡素化: Moondream Stationは、ローカルデバイスでのMoondream(視覚言語モデルの一種)の実行を簡素化することを目的としたツールで、この度Linuxオペレーティングシステムのサポートを発表しました。これにより、LinuxユーザーはMoondreamモデルをより便利にデプロイし、マルチモーダルAIの実験やアプリケーション開発に利用できるようになります。(出典: vikhyatk)
Flowith、無限エージェントNEOを発表、無限ステップ、コンテキスト、ツール呼び出しをサポート: AIアプリケーション企業Flowithは、最新のエージェント製品NEOを発表しました。これは、世界初の無限ステップ、無限コンテキスト、無限ツール呼び出しをサポートするエージェントであると謳われています。このエージェントはクラウド上で長時間実行するように設計されており、ベンチマークを超えるインテリジェンスレベルを備え、さらにゼロコスト、無制限であると主張しています。この発表は、AIエージェントが複雑な長期タスクの処理や外部能力の統合において新たな進展を遂げたことを示している可能性があります。(出典: _akhaliq, op7418)

Kapa AI、Weaviateを利用してインタラクティブな技術文書Q&Aツール「Ask AI」を構築: Kapa AIは、「Ask AI」という名のインテリジェントウィジェットを開発しました。これにより、ユーザーは自然言語対話を通じて、技術文書、ブログ、チュートリアル、GitHub issues、フォーラムなど、技術知識ベース全体を照会できます。効率的なセマンティック検索と知識検索を実現するために、Kapa AIはWeaviateベクトルデータベースを採用しました。その組み込みハイブリッド検索機能、Docker互換性、およびマルチテナント特性を重視し、急速に増加するユーザーとデータ規模をサポートしています。(出典: bobvanluijt)

開発者、Gemini Flashを利用してスクリーンショットからHTMLへのMVPツールを迅速に構築: 開発者のDaniel Huynh氏は、Google AIのGemini Flashモデルを利用し、週末の間にデザイン案、競合製品、またはインスピレーションとなるスクリーンショットを迅速にHTMLコードに変換するMVP(Minimum Viable Product)ツールを構築しました。このツールはHugging Face Spacesで無料で試用可能となっており、マルチモーダルモデルがフロントエンド開発支援において持つ可能性を示しています。(出典: osanseviero, _akhaliq)
Azure AI Foundry Agent Serviceが正式に利用可能に、LlamaIndexを統合: Microsoftは、Azure AI Foundry Agent Serviceが正式にリリース(GA)され、LlamaIndexのファーストクラスサポートを提供すると発表しました。このサービスは、企業顧客がカスタマーサポートアシスタント、プロセス自動化ボット、マルチエージェントシステム、および企業データやツールと安全に統合されたソリューションを構築するのを支援することを目的としており、エンタープライズレベルのAIエージェントの開発と応用をさらに推進します。(出典: jerryjliu0)
tinygrad:PyTorchとmicrogradの中間に位置する極めてシンプルな深層学習フレームワーク: tinygradは、シンプルさを中核的な設計思想とする深層学習フレームワークであり、新しいアクセラレータの追加が最も容易なフレームワークとなることを目指し、推論と学習をサポートしています。LLaMAやStable Diffusionなどのモデルをサポートし、遅延評価(lazy evaluation)を採用して操作を融合し、性能を最適化します。tinygradはGPU (OpenCL)、CPU (Cコード)、LLVM、Metal、CUDAなど、多様なアクセラレータをサポートしています。そのコードは簡潔で、コア機能は少量のコードで実装されており、開発者が理解し拡張するのに便利です。(出典: GitHub Trending)
ナノAI検索、「スーパー検索」機能を発表、複数モデルとMCPツールボックスを統合: ナノAI検索(bot.n.cn)は、「スーパー検索」機能を追加し、より深い情報取得と処理能力の提供を目指しています。この機能は国内外の100以上の大規模モデルを統合し、必要に応じて自動的に切り替えます。内蔵のMCP万能ツールボックスは数千種類のAIツールをサポートし、ウェブページ、画像、動画、PDFなど多様な形式のファイルを処理し、コード生成やデータ分析などを行います。同時に、パブリック検索とローカル知識ベースのプライベート検索を組み合わせ、より包括的な結果を提供し、テキストからの画像生成、テキストからの動画生成機能も内蔵しています。ユーザー体験によると、この機能は検索結果を図表を含む詳細なレポートや美しいウェブページにまとめることができ、業界調査、ショッピング比較、知識整理など多様なシーンに適しています。(出典: WeChat)
Clara:モジュール式のオフラインAIワークスペース、LLM、Agent、自動化、画像生成を統合: 開発者はClaraという名のオープンソースプロジェクトを発表しました。これは、完全にオフラインでモジュール式のAIワークスペースを構築することを目的としています。ユーザーはダッシュボード上で、ローカルLLMチャット(RAG、画像、ドキュメント、コード実行をサポートし、OllamaおよびOpenAI類似APIと互換性あり)、記憶とロジックを持つAgentの作成、ネイティブN8N統合による自動化プロセスの実行(1000以上の無料テンプレートを提供)、およびStable Diffusion(ComfyUI)を使用したローカルでの画像生成をウィジェット形式で整理できます。ClaraはMac、Windows、Linux版を提供し、ユーザーが複数のAIツール間を頻繁に切り替える問題を解決し、ワンストップのAI操作を実現することを目指しています。(出典: Reddit r/LocalLLaMA)
AI Playlist Curator:LLMを利用してYouTubeプレイリストをパーソナライズ整理するPythonツール: ある開発者がAI Playlist CuratorというPythonプロジェクトを作成しました。これは、ユーザーが持つ膨大で無秩序なYouTubeプレイリストを自動的に整理するのを支援することを目的としています。このツールはLLMを利用し、ユーザーの好みに基づいて曲を分類し、パーソナライズされたサブプレイリストを作成します。保存されている任意のプレイリストやお気に入りの曲の処理をサポートしています。プロジェクトはGitHubでオープンソース化されており、開発者はさらなる改善のためにコミュニティからのフィードバックを期待しています。(出典: Reddit r/MachineLearning)
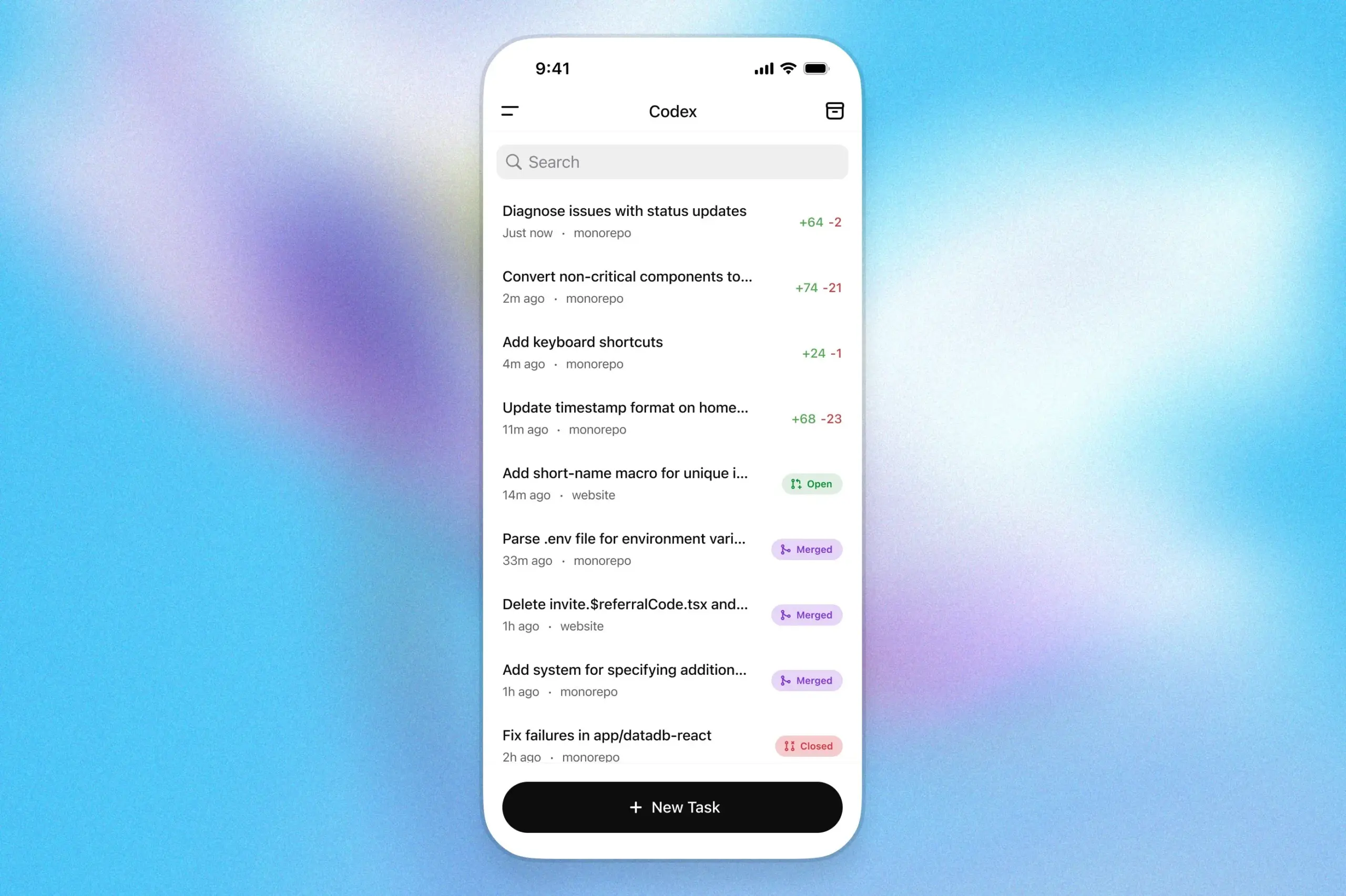
OpenAI CodexプログラミングアシスタントがChatGPT iOSアプリに登場: OpenAIは、プログラミングアシスタントCodexがChatGPTのiOSアプリケーションに統合されたことを発表しました。ユーザーはモバイルデバイス上で新しいプログラミングタスクを開始したり、コードの差分を確認したり、修正を要求したり、さらにはプルリクエスト(PR)をプッシュしたりすることができます。この機能はまた、ロック画面のライブアクティビティを通じてCodexの進捗を追跡することをサポートしており、ユーザーが異なるデバイス間でシームレスに作業を切り替えるのに便利です。(出典: openai)
Kollektiv:MCPプロトコルを利用してLLMチャットのコンテキスト重複貼り付け問題を解決するツール: 開発者はKollektivツールを発表しました。これは、ユーザーがLLM(Claudeなど)とチャットする際に、大量のコンテキスト(研究論文、SDKドキュメント、個人メモ、書籍の内容など)を繰り返しコピー&ペーストする必要がある問題を解決することを目的としています。Kollektivを使用すると、ユーザーはこれらのドキュメントソースを一度アップロードし、任意の互換性のあるIDEまたはMCPクライアント(Cursor、Windsurf、PyCharmなど)からMCP(Model Control Protocol)サーバーを介してオンデマンドで呼び出すことができます。MCPサーバーは、ユーザー認証、データ分離、およびチャットインターフェースへのオンデマンドデータストリーミングを担当します。このツールは現在、機密性の高い資料や機密資料への使用は推奨されていません。(出典: Reddit r/ClaudeAI)
📚 学習
Google DeepMind、AlphaEvolve技術報告書を発表、そのアルゴリズム発見能力を明らかに: Google DeepMindは、AIシステムAlphaEvolveに関する技術報告書を発表しました。AlphaEvolveはGeminiベースのコーディングエージェントであり、進化的アルゴリズムを通じてアルゴリズムを設計・最適化することができます。報告書は、AlphaEvolveが構造化されたフィードバックループを通じて、候補となるアルゴリズム案を自律的に生成、評価、改善し、4×4複素行列乗算アルゴリズムの記録更新を含む、複数の数学および計算科学の問題でブレークスルーを達成した方法を詳細に説明しています。この報告書は、自動化された科学的発見とアルゴリズム革新におけるAIの可能性を理解するための重要な参考資料となります。(出典: , HuggingFace Daily Papers)
DeepLearning.AI、「AIブラウザエージェントの構築」コースを開始: DeepLearning.AIは、「Building AI Browser Agents」という新しいコースを開始しました。このコースはAGI社の共同創設者であるDiv Garg氏とNaman Agarwal氏が講師を務め、学習者がブラウザと対話できるAIエージェント(Agent)を構築する技術を習得することを目的としています。コース内容は、ウェブ自動化、情報抽出、ユーザーインターフェースとの対話など、ブラウザ環境におけるAIの応用をカバーする可能性があります。(出典: DeepLearningAI)
Qwen3技術報告書が公開: Alibabaは、最新世代の大規模言語モデルQwen3の技術報告書を公開しました。この報告書は、Qwen3のモデルアーキテクチャ、訓練方法、性能評価、および各種ベンチマークテストにおける成績を詳細に説明しています。Qwen3シリーズモデルは、より強力な言語理解、生成、およびマルチモーダル処理能力を提供することを目的としており、その技術報告書の公開は、研究者や開発者がこのモデルの技術的詳細を深く理解する機会を提供します。(出典: _akhaliq)

論文研究:マルチビュー探索とデータ管理による段階的定理証明の向上 (MPS-Prover): 新しい論文では、MPS-Proverという斬新な段階的自動定理証明(ATP)システムが紹介されています。このシステムは、効率的な訓練後データ管理戦略(性能を損なうことなく冗長データの約40%を枝刈り)と、マルチビュー木探索メカニズム(学習された批評家モデルとヒューリスティックルールを統合)により、既存の段階的証明器における偏った探索誘導の問題を克服します。実験により、MPS-ProverはminiF2FやProofNetなど複数のベンチマークでSOTA性能を達成し、より短く多様な証明を生成することが示されました。(出典: HuggingFace Daily Papers)
論文研究:視覚的計画——画像のみによる思考 (Visual Planning): 新しい論文では、「視覚的計画」というパラダイムが提案されており、モデルがテキストに依存せず、視覚的表現(画像シーケンス)のみを通じて完全に計画を立てることを可能にします。研究者らは、空間的および幾何学的情報が関与するタスクにおいて、言語は最も自然な推論媒体ではない可能性があると考えています。彼らは強化学習による視覚的計画フレームワークVPRLを導入し、GRPOを用いて大規模視覚モデルの訓練後最適化を行い、FrozenLake、Maze、MiniBehaviorなどの視覚ナビゲーションタスクで顕著な改善を達成し、純粋なテキスト推論による計画バリアントよりも優れた性能を示しました。(出典: HuggingFace Daily Papers)
論文研究:推論のスケーリングは大規模言語モデルの事実性を向上させる (Scaling Reasoning can Improve Factuality): ある研究では、大規模言語モデル(LLM)の推論プロセスを拡張することが、複雑なオープン領域の質問応答(QA)における事実の正確性を向上させるかどうかを調査しました。研究者らは、QwQ-32BやDeepSeek-R1-671Bなどのモデルから推論軌跡を抽出し、複数のQwen2.5シリーズモデルに対してファインチューニングを行うと同時に、知識グラフのパスを推論軌跡に組み込みました。実験により、単一実行において、より小さな推論モデルは元の命令ファインチューニングモデルと比較して事実の正確性が明らかに向上することが示されました。テスト時の計算量とトークン予算を増やすと、事実の正確性は2〜8%安定して向上しました。(出典: HuggingFace Daily Papers)
論文研究:Mergenetic——シンプルな進化的モデルマージライブラリ: 新しい論文では、進化的モデルマージのためのオープンソースライブラリであるMergeneticが紹介されています。モデルマージにより、既存のモデルの能力を追加のトレーニングなしに新しいモデルに組み合わせることができます。Mergeneticは、マージ方法と進化的アルゴリズムの簡単な組み合わせをサポートし、評価コストを削減するために軽量な適応度評価器を組み合わせています。実験により、Mergeneticは適度なハードウェアを使用して、複数のタスクと言語で競争力のある結果を生み出すことが証明されました。(出典: HuggingFace Daily Papers)
論文研究:集団思考——トークンレベルで協調する複数の並行推論エージェント (Group Think): 新しい論文では、「集団思考」(Group Think)が提案されています。これは、単一のLLMを複数の並行推論エージェント(思考者)として機能させるものです。これらのエージェントは、互いの部分的な生成進捗の可視性を共有し、トークンレベルで互いの推論軌跡に動的に適応することで、冗長な推論を削減し、品質を向上させ、遅延を低減します。この方法はローカルGPUでのエッジ推論に適しており、実験では、特別に訓練されていないオープンソースLLMを使用した場合でも遅延が改善されることが証明されました。(出典: HuggingFace Daily Papers)
論文研究:人間は戦略ゲームにおいてLLMの対戦相手に合理性と協調性を期待する (Humans expect rationality and cooperation from LLM opponents): 初めて行われた、管理された金銭的インセンティブを伴う実験室実験において、人間がマルチプレイヤーP-beautyコンテストで他の人間とLLMに対してどのように行動が異なるかを調査しました。結果は、人間がLLMと対戦する際に選択する数字が著しく低いことを示し、これは主に「ゼロ」ナッシュ均衡選択の普遍性が増加したためです。この変化は主に、LLMがより強力な推論能力と協調的傾向を持つと考える、高い戦略的推論能力を持つ被験者によって引き起こされました。(出典: HuggingFace Daily Papers)
論文研究:デュアルヘッド最適化による視覚言語モデルからの簡単な半教師あり知識蒸留 (Dual-Head Optimization for KD): 新しい論文では、DHO(Dual-Head Optimization)という、半教師あり設定において視覚言語モデル(VLM)からコンパクトなタスク特化型モデルへ知識を転移するための、シンプルで効果的な知識蒸留(KD)フレームワークが提案されています。DHOは、ラベル付きデータと教師予測を独立して学習する2つの予測ヘッドを導入し、推論時にそれらの出力を線形に組み合わせることで、教師信号と蒸留信号間の勾配衝突を緩和します。実験により、DHOは複数のドメインと詳細なデータセットにおいて、シングルヘッドKDベースラインよりも優れており、ImageNetでSOTAを達成することが示されました。(出典: HuggingFace Daily Papers)
論文研究:GuardReasoner-VL——強化学習による推論を通じたVLMの保護: 視覚言語モデル(VLM)の安全性を強化するため、新しい論文では推論ベースのVLM保護モデルGuardReasoner-VLが導入されました。中核となるアイデアは、オンライン強化学習(RL)を通じて、保護モデルが監査決定を下す前に慎重な推論を行うよう動機付けることです。研究者らは、123Kのサンプルと631Kの推論ステップを含む推論コーパスGuardReasoner-VLTrainを構築し、教師ありファインチューニング(SFT)によってモデルの推論能力をコールドスタートさせ、その後オンラインRLによってさらに強化しました。実験により、このモデル(3B/7Bバージョンはオープンソース化済み)は優れた性能を示し、平均F1スコアで次点のモデルを19.27%上回りました。(出典: HuggingFace Daily Papers)
論文研究:マルチトークン予測にはレジスタが必要 (Multi-Token Prediction Needs Registers): 新しい論文では、MuToRという、入力シーケンスに学習可能なレジスタトークンを交互に挿入することで将来のターゲットを予測する、シンプルで効果的なマルチトークン予測方法が提案されています。既存の方法と比較して、MuToRはパラメータの増加が無視できるほどで、アーキテクチャの変更を必要とせず、既存の事前学習済みモデルと互換性があり、次のトークン事前学習目標と一貫性を保つため、特に教師ありファインチューニングに適しています。この方法は、言語および視覚分野の生成タスクにおいて有効性と汎用性を示しています。(出典: HuggingFace Daily Papers)
論文研究:MMLongBench——効果的かつ徹底的な長文脈視覚言語モデルのベンチマークテスト: 長文脈視覚言語モデル(LCVLM)の評価ニーズに対応するため、新しい論文ではMMLongBenchが導入されました。これは、多様な長文脈視覚言語タスクを網羅する初のベンチマークです。MMLongBenchは13331個のサンプルを含み、視覚RAG、マルチサンプルICLなど5種類のタスクをカバーし、多様な画像タイプを提供します。すべてのサンプルは、8K〜128Kトークンの5つの標準化された入力長で提供されます。46のクローズドソースおよびオープンソースLCVLMに対するベンチマークテストを通じて、単一タスクの性能は全体的な長文脈能力を代表するものではなく、現在のモデルにはまだ大きな改善の余地があり、推論能力の高いモデルは長文脈性能も優れている傾向があることが明らかになりました。(出典: HuggingFace Daily Papers)
論文研究:MatTools——材料科学ツールのための大規模言語モデルベンチマーク: 新しい論文では、MatToolsベンチマークが提案されています。これは、大規模言語モデル(LLM)が、物理ベースの計算材料科学パッケージのコードを生成し安全に実行することで材料科学の質問に答える能力を評価するためのものです。MatToolsには、材料シミュレーションツールの質疑応答(QA)ベンチマーク(pymatgenベース、69225個のQAペアを含む)と、実世界のツール使用ベンチマーク(49タスク、138サブタスクを含む)が含まれています。複数のLLMの評価により、汎用モデルは専門モデルよりも優れていること、AIはAIをよりよく理解すること、シンプルな方法がより効果的であることが明らかになりました。(出典: HuggingFace Daily Papers)
論文研究:LLM電子透かしの堅牢性、テキスト品質、安全性のバランスを取る汎用共生電子透かしフレームワーク: 既存の大規模言語モデル(LLM)電子透かし技術における堅牢性、テキスト品質、安全性の間のトレードオフ問題に対し、新しい論文では汎用的な共生電子透かしフレームワークが提案されています。このフレームワークは、ロジットベースおよびサンプリングベースの手法を統合し、直列、並列、混合の3つの戦略を設計しています。混合フレームワークは、トークンエントロピーと意味エントロピーを利用して電子透かしを適応的に埋め込み、各側面の性能を最適化することを目指しています。実験により、この方法は既存のベースラインを上回り、SOTAレベルを達成することが示されました。(出典: HuggingFace Daily Papers)
論文研究:CheXGenBench——合成胸部X線写真の忠実度、プライバシー、有用性の統一ベンチマーク: 新しい論文では、CheXGenBenchが紹介されています。これは、合成胸部X線写真生成を評価するための多角的なフレームワークであり、忠実度、プライバシーリスク、臨床的有用性を同時に評価します。このフレームワークには、標準化されたデータ分割と統一された評価プロトコル(20以上の定量的指標を含む)が含まれており、11の主要なテキストから画像へのアーキテクチャの生成品質、潜在的なプライバシー脆弱性、および下流の臨床的適用性を分析しています。研究により、既存の評価プロトコルは生成忠実度の評価において不十分であることが判明しました。チームは同時に、高品質な合成データセットSynthCheX-75Kも公開しました。(出典: HuggingFace Daily Papers)
古典的教科書『関数解析学』の著者Peter Lax氏が99歳で逝去: 応用数学の巨匠であり、アーベル賞を初めて受賞した応用数学者であるPeter Lax氏が99歳で逝去しました。Lax氏は、編纂した古典的教科書『関数解析学』で知られ、偏微分方程式、流体力学、数値計算などの分野で、Laxの同値定理、Lax-Friedrichs法、Lax-Wendroff法など、基礎を築く貢献をしました。彼はまた、コンピュータ技術を数学解析に応用した最初の先駆者の一人でもあり、その業績はコンピュータ時代の数学の発展に深い影響を与えました。(出典: 量子位)

元OpenAI中国人VP、翁荔氏の長文『Why We Think』、テスト時計算と思考連鎖について考察: 元OpenAI中国人副社長の翁荔(Lilian Weng)氏が、1万字に及ぶ長文『Why We Think』を発表し、「テスト時計算」(Test-time Compute)や「思考連鎖」(Chain-of-Thought, CoT)などの技術が、大規模言語モデルの性能と知能レベルをいかに著しく向上させるかについて深く考察しています。記事は、人間の思考における「速い思考と遅い思考」の二重システム理論に例え、モデルが出力前により多くの「思考」(インテリジェントデコーディング、CoT推論、潜在変数モデリングなど)を行うことで、現在の能力のボトルネックを突破できると指摘しています。文中では、トークンベースの思考、並列サンプリングと逐次修正、強化学習と外部ツールの統合、思考の忠実性、連続空間における思考など、複数の研究方向の進捗と課題が詳細に整理されています。(出典: 量子位)

ハルビン工業大学とペンシルベニア大学が共同でPointKANを発表、KANsに基づく点群分析の新SOTA: ハルビン工業大学(深圳)とペンシルベニア大学の研究チームは、Kolmogorov-Arnold Networks (KANs) に基づく3D点群分析ソリューションであるPointKANを発表しました。この手法は、幾何学的アフィンモジュールと並列局所特徴抽出モジュールを通じて、従来のMLPにおける固定活性化関数の代わりに学習可能な活性化関数を利用することで、点群の複雑な幾何学的特徴をより効果的に捉えます。同時に、チームはEfficient-KANs構造を提案し、Bスプライン関数の代わりに有理関数を使用し、グループ内パラメータ共有を行うことで、パラメータ数と計算コストを大幅に削減しました。実験により、PointKANとその軽量版であるPointKAN-eliteは、分類、部分セグメンテーション、少数サンプル学習などのタスクにおいて、SOTAまたは競争力のある性能を達成することが示されました。(出典: WeChat)

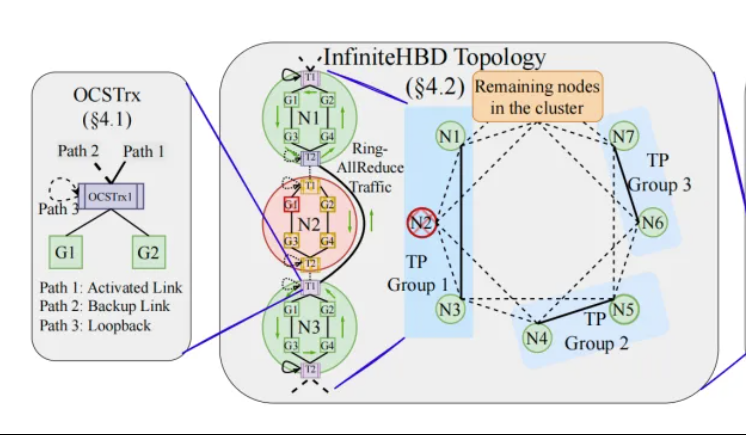
北京大学/StepFun/Enflame、InfiniteHBDを発表:新世代高帯域幅GPU相互接続アーキテクチャ、大規模モデル訓練コストを削減: 北京大学、StepFun(阶跃星辰)、Enflame(曦智科技)の研究チームは、現在の大規模モデル分散訓練における高帯域幅ドメイン(HBD)アーキテクチャの限界に対し、InfiniteHBDソリューションを提案しました。このアーキテクチャは、光路交換(OCS)能力を組み込んだ光電変換モジュールを中核とし、動的に再構成可能なポイントツーマルチポイント接続を実現し、ノードレベルの故障分離と低リソース断片化能力を備えています。研究によると、InfiniteHBDの単位コストはNVIDIA NVL-72のわずか31%であり、GPUの浪費率はほぼゼロ、MFU(モデルFLOPs利用率)はNVIDIA DGXと比較して最大3.37倍向上可能です。この研究はSIGCOMM 2025に採択されました。(出典: WeChat, 量子位)
ICML 2025論文速報:OmniAudio、360°動画から空間音響を生成: ICML 2025で発表される予定の研究では、OmniAudioフレームワークが提案されています。これは、360°全天球動画から直接、方向感のある一次アンビソニックス(FOA)空間音響を生成することができます。この研究ではまず、大規模な360°動画と空間音響のペアデータセットSphere360を構築しました。OmniAudioは2段階のトレーニングを採用しています。まず、自己教師あり学習による粗から密へのフローマッチング事前学習を行い、大規模な非空間音響データを利用して汎用的な音響特徴を学習します。次に、デュアルブランチビデオエンコーダ(グローバルおよびローカルな視覚特徴を抽出)を組み合わせて教師ありファインチューニングを行います。実験結果は、OmniAudioが客観的および主観的評価指標の両方で既存のベースラインモデルを大幅に上回ることを示しています。(出典: WeChat)

Huawei Selftok:逆拡散に基づく自己回帰視覚トークナイザ、マルチモーダル生成を統一: Huawei Panguマルチモーダル生成チームは、革新的な視覚トークン化ソリューションであるSelftok技術を提案しました。これは、逆拡散プロセスを通じて自己回帰事前分布を視覚トークンに組み込み、ピクセルストリームを厳密に因果律に従う離散シーケンスに変換することで、既存の空間トークンソリューションと自己回帰(AR)パラダイムとの衝突問題を解決することを目指しています。Selftok Tokenizerは、デュアルストリームエンコーダ(画像ブランチはSD3 VAEを継承、テキストブランチは学習可能な連続ベクトル群)と再活性化メカニズムを備えた量子化器を採用しています。実験により、SelftokはImageNet再構成指標でSOTAを達成し、Ascend AIとMindSpeedフレームワークで訓練されたSelftok dAR-VLMはGenEvalなどのテキストから画像への生成ベンチマークでGPT-4oを上回りました。この研究はCVPR 2025の最優秀論文候補に選ばれました。(出典: WeChat)
颜水成チーム主導でGeneral-Level評価フレームワークとGeneral-Benchベンチマークを発表、マルチモーダルジェネラリストモデルを格付け: シンガポール国立大学の颜水成教授、南洋理工大学の张含望教授らが主導し、10のトップ大学が共同で、マルチモーダルジェネラリストモデル向けの評価フレームワークGeneral-Levelと大規模ベンチマークデータセットGeneral-Benchを発表しました。このフレームワークは、自動運転の格付けの考え方を参考に、5つのレベル(Level 1-5)を設定してマルチモーダル大規模言語モデル(MLLM)の汎用性と性能を評価します。中核となる評価基準は「協調的汎化効果」(Synergy)であり、タスク間、理解と生成のパラダイム間、およびモダリティ間の知識移転と強化能力を検証します。General-Benchは700以上のタスクと32万のサンプルを含み、100以上の既存MLLMの評価では、ほとんどのモデルがL2-L3レベルであり、L5に達したモデルはまだありません。(出典: WeChat)

💼 ビジネス
Sakana AI、三菱UFJ銀行 (MUFG) と複数年にわたるパートナーシップを締結: 日本のAIスタートアップSakana AIは、日本最大の銀行である三菱UFJ銀行 (MUFG Bank) と複数年にわたる包括的なパートナーシップ契約を締結したと発表しました。Sakana AIはMUFG銀行に対し、アジャイルかつ強力なAI技術を提供し、100年の歴史を持つ同行が急速に発展するAI分野で競争力を維持できるよう支援することを目指します。この提携により、Sakana AIは1年以内に収益化を達成する見込みです。(出典: SakanaAILabs, SakanaAILabs)

Cohere、Dellと提携し、セキュアなエージェントプラットフォームCohere NorthをDellのオンプレミス企業向けAIソリューションに導入: AI企業Cohereは、Dell Technologiesとの提携を発表し、セキュアでエージェント能力を備えた企業向けAIソリューションの加速を目指します。Dellは、CohereのセキュアなエージェントプラットフォームCohere Northのオンプレミス展開ソリューションを企業に提供する最初のプロバイダーとなります。この提携は、機密データを扱い、厳格なコンプライアンス要件を持つ業界にとって特に重要であり、企業が自社のデータセンター内でCohereの先進的なAIエージェント技術を導入・運用できるようになります。(出典: sarahookr)

Mistral AI、MGX、Bpifranceと協力し、フランスにヨーロッパ最大のAIパークを建設: Mistral AIは、アブダビが支援するテクノロジー投資会社MGXおよびフランスの国立投資銀行Bpifranceと協力し、フランスのパリ地域にヨーロッパ最大のAIパークを共同で建設すると発表しました。このパークは、データセンター、高性能コンピューティングリソース、教育・研究施設を統合します。NVIDIAも技術サポートを提供して参加します。この動きは、ヨーロッパのAIエコシステムの発展を促進し、フランスのグローバルAI分野における戦略的地位を高めることを目的としています。(出典: arthurmensch, arthurmensch)
🌟 コミュニティ
AI従事者におけるADHD有病率が注目を集める、20~30%を超える可能性も: ソーシャルメディア上で、AI分野の従事者における注意欠陥・多動性障害(ADHD)の有病率に関する議論が起きています。あるユーザーは、この分野が神経多様性の特徴を持つ多くの人材を引き付けているように見えると観察しています。Minh Nhat Nguyen氏は、AI業界では20~30%以上の人がADHDを患っている可能性があるとコメントしています。この現象は、AIの研究開発業務が高度な集中力、迅速なイテレーション、創造的思考を必要とすることに関連している可能性があり、これらの特性はADHDの特定の症状と一致することがあります。(出典: Dorialexander)
AI時代のスキルの陳腐化が深い考察を呼ぶ、ツールの習得ではなくシステムの再構築が鍵: ある詳細な分析記事は、AI時代の真の危機は「AIツールを使えるかどうか」ではなく、スキル自体の陳腐化と作業システム全体の再構築であると指摘しています。記事はマジノ線、コンテナ化、タイプライターがワープロに取って代わられた例などを通じ、新しいツールを学ぶだけでは優位性を保証できず、重要なのはAIが仕事の構造、プロセス、組織ロジックをどのように変えるかを理解することだと論じています。システムが書き換えられると、元々価値の高かったスキルは急速に周縁化される可能性があります。生産性の向上は必ずしも個人の価値向上にはつながらず、価値は新しいシステムの調整レイヤーを制御する主体に流れます。記事は、「AIを学べばリードできる」「AIがより多くの仕事をさせてくれるからより価値がある」「仕事内容は変わらずやり方が変わるだけ」といった8つの一般的な誤謬を論破し、システムレベルで自身の位置づけと価値を考える必要があると強調しています。(出典: 36氪)
Google元CEOシュミット氏:非人間的知能の台頭は世界の構造を再構築し、AIのリスクと課題に警戒が必要: Google元CEOのエリック・シュミット氏はインタビューで、「非人間的知能」の破壊的な可能性に対する社会の認識が著しく不足していると警告しました。彼はAIが言語生成から戦略的意思決定へと進み、複雑なタスクを独立して完了できるようになったと考えています。シュミット氏はAIがもたらす3つの主要な課題を強調しました。エネルギーと計算能力のボトルネック(米国は新たに90ギガワットの電力が必要)、公開データが枯渇しつつあること(次の段階ではAI生成データが必要)、そしてAIが人間の既存知識を超えて「新しい知識」を創造する方法です。彼はまた、3つの主要なリスクを指摘しました。AIの再帰的な自己改善の制御不能、兵器制御権の獲得、不正な自己複製です。彼は、米中AI競争が激化する中、オープンソースAIの急速な拡散は安全保障上のリスクをもたらし、さらには「核抑止力」に似た「先制攻撃」の状況を引き起こす可能性があると考えています。シュミット氏は、世界的なAIガバナンスに関する対話を直ちに開始するよう呼びかけ、システム設計の初期段階から人間の自由の保護を組み込むべきだと強調しました。(出典: 36氪)

GitHub CEO、「プログラミング不要論」に反論、AI時代でも人間のプログラマーは依然として重要と強調: NVIDIA CEOのJensen Huang氏などが提唱する「将来プログラミングを学ぶ必要はなくなる」という見解に対し、GitHub CEOのThomas Dohmke氏はインタビューで反対を表明しました。彼は2025年がプログラミングエージェント(SWE Agent)の年になると考えていますが、人間のプログラマーの役割は依然として重要であると述べています。Dohmke氏は、AIは開発者の能力を強化するアシスタントとして機能すべきであり、完全に取って代わるものではないと強調しました。彼は将来のソフトウェア開発が人間とAIの協調モデルへと進化し、開発者は「エージェントオーケストラの指揮者」のようにタスクを割り当て、成果を監査する役割を担うと構想しています。GitHub CPOのMario Rodriguez氏も、同社がCopilotで個人の能力を強化することに尽力していると述べています。彼らは、AIの発展に伴い、人間の思考と行動を代表できる機械をどのようにプログラミングし、再プログラミングするかを理解することが極めて重要であり、コード学習を放棄することはエージェントの未来における発言権を放棄することに等しいと考えています。(出典: 36氪, 量子位)

AI生成の低品質な脆弱性報告が氾濫、curl創設者が「AIゴミ」を排除するフィルタリングメカニズムを導入: curlプロジェクトの創設者Daniel Stenberg氏は、AIによって生成された低品質で無効な脆弱性報告が大量に送られてきており、これらの報告はメンテナーの時間を大量に浪費し、DDoS攻撃に等しいと述べています。このため、HackerOneでcurl関連のセキュリティ報告を提出する際に、AIを使用したかどうかを尋ねるチェックボックスが新たに追加されました。もし「はい」と回答した場合、脆弱性が本物であることを証明する追加の証拠を提出する必要があり、さもなければ報告者はブロックされる可能性があります。Stenberg氏は、プロジェクトが有効なAI生成のバグ報告を受け取ったことは一度もないと述べています。Python開発者のSeth Larson氏も同様の懸念を表明しており、このような報告はメンテナーに混乱、ストレス、フラストレーションをもたらし、オープンソースプロジェクトの燃え尽き問題を悪化させると考えています。コミュニティの議論では、AI生成報告の氾濫は情報過多と一部の人々が脆弱性報奨金制度を利用しようとする問題を反映しており、さらにはAIが経験豊富なプログラマーの代わりになると誤解している経営幹部もいるとされています。(出典: WeChat)

AI支援プログラミングが話題:効率は大幅向上も、人間の開発者の役割は依然として重要: 数十年のプログラミング経験を持つある開発者が、AI(おそらくCodexまたは類似のツール)によって数時間悩まされたバグが数分で解決され、コードが最適化された経験を共有し、AIを「決して疲れない超有能なチームメイト」のようだと感嘆しました。この経験はコミュニティで議論を呼びました。多くの人が、コード生成、バグ修正、情報要約におけるAIの強力な能力を認め、効率を大幅に向上させることができると同意しています。しかし、AIは現在でも間違いを犯し、特に複雑なロジック、境界条件、創造的なソリューションにおいては人間に及ばず、その出力は経験豊富な開発者によるレビューと批判的な評価が必要であると指摘する開発者もいます。Microsoft CEOのNadella氏も、AIは能力を強化するツールであり、ソフトウェア開発はもはやAIなしでは成り立たないが、人間の野心と主体性は依然として重要であると強調しています。議論では一般的に、AIはプログラミングの方法を変え、開発者はAIと協調する新しいパラダイムに適応し、より高レベルのアーキテクチャ設計と問題定義に集中する必要があると考えられています。(出典: Reddit r/ChatGPT, WeChat)
AI Agent Manus、登録開始も高価格設定、国内外の巨人との競争に直面、中国語版提供は疑問視: AI AgentプラットフォームManusは、招待コードが話題となった後、正式に登録を開始しましたが、現在は海外ユーザー向けのみで、中国語版は提供されていません。ユーザーからのフィードバックによると、ポイント消費制を採用しており、無料ポイント(登録時に1000、毎日300)では簡単なタスクしか完了できず、複雑なタスク(ウェブ版数独ゲームの作成など)には有料でポイントを購入する必要があり、平均1ドル100ポイントと価格は高めです。業界関係者の分析によると、Manusはサードパーティの大規模モデル(海外版ではClaudeなど)に依存しているためコストが高く、クラウド上のサンドボックス実行も費用を増加させています。中国語版の提供が遅れているのは、国内モデルの登録、ユーザーの支払い習慣、市場競争などに関連している可能性があります。ByteDanceのCoze、Baiduの「心响」APPなど、国内外の製品がすでに競争を形成しています。Manusは新たな資金調達に成功しましたが、その「軽量モデル、重アプリケーション」モデルの参入障壁は試練に直面しています。(出典: 36氪)
AIモデル、「立方体を完成させる」視覚的推論問題で軒並み失敗、真の理解能力について議論を呼ぶ: 不完全な立方体を完成させるために必要な小さな立方体の数を計算するよう求める視覚的推論問題が、OpenAI o3、Google Gemini 2.5 Pro、DeepSeek、Qwen3を含む複数の主要AIモデルを悩ませました。各モデルが出した答えはまちまちで、主な原因は最終的な大きな立方体の規格(3x3x3、4x4x4、5x5x5など)の理解が異なるためです。ヒントで誘導しても、モデルは一度で正しく解答するのが困難でした。一部のネットユーザーは、問題自体の表現に曖昧さがあり、人間もこれに戸惑うだろうと指摘しています。この現象は、AIモデルが問題を本当に理解しているのか、それとも単にパターンマッチングに依存しているのかという議論を呼び、現在のAIが複雑な空間推論と視覚理解において抱える限界を浮き彫りにしました。(出典: 36氪)
ユーザー、LLMの指示遵守と推論における「考えすぎ」問題を議論: ソーシャルメディアや論文での議論によると、大規模言語モデル(LLM)が思考連鎖(CoT)などの推論プロセスを使用する際、時々「考えすぎ」てしまい、かえって簡単な指示を正確に守れなくなることがあると指摘されています。例えば、特定の文字数を書くよう求められたり、特定のフレーズを繰り返すよう求められたりした場合、CoTはモデルがタスク全体のコンテンツにより注意を払い、これらの基本的な制約を無視したり、追加の説明的な内容を導入したりする可能性があります。研究者らはこの現象を定量化するために「制約付き注意力」指標を提案し、文脈学習、自己反省、自己選択推論、分類器選択推論などの緩和策をテストしました。これは、すべてのタスクがCoTに適しているわけではなく、簡単な指示はより直接的な実行方法が必要である可能性を示唆しています。(出典: menhguin, omarsar0)

AI経済学再考:安価な認知労働が伝統的経済モデルを破壊、価値配分は再構築に直面: 議論を呼んでいるある見解によると、AIの台頭は認知労働(報告書作成、データ分析、コード記述など)を極めて安価にしており、これは「人間の知能は希少で高価である」という中核的仮定に基づく古典経済学モデルに根本から挑戦しています。AIがほぼゼロの限界費用で大量の知識労働をこなせるようになると、生産性は急上昇するかもしれませんが、単一タスクの価値は暴落し、専門化の優位性は侵食されます。価値配分はもはや効率や産出量に単純に依拠するのではなく、誰が新しい希少資源(データ、プラットフォーム、AIモデル自体など)をコントロールするかにかかっています。これは歴史上の技術変革(ファストファッションがアパレル業界に、ストリーミングが音楽業界にもたらした変化など)において、効率向上の恩恵が完全に労働者に渡らず、システム調整者に獲得されたのと同様です。記事は、AIがタスクを自動化するだけでなく、「思考」を商品化しており、これが現代経済史上最も破壊的な力になる可能性があると警告しています。(出典: Reddit r/artificial)
AI時代の企業戦略:「インテリジェントカンパニー」の罠を避け、古いプロセスの最適化ではなく再構築が必要: 多くの企業はAIを導入する際、既存のプロセスを最適化し、コストを削減し効率を上げるためのツールとして捉える傾向があり、「同じことをより賢く行う」という「インテリジェントカンパニー」の罠に陥っています。しかし、真の変革は古いプロセスをよりインテリジェントにすることではなく、これらのプロセスが存在する必要があるかどうかを考え、AIネイティブの全く新しいシステムとビジネスモデルを構築することです。技術は単純に古いシステムに適応するのではなく、システムを再構築します。企業は、AIによって淘汰されようとしているプロセスに過剰なリソースを投入して最適化することを避け、新しいルールを定義し、意思決定の方法、調整メカニズム、組織構造を根本から変えることに目を向けるべきです。(出典: 36氪)
💡 その他
LangChainニューヨークオフライン交流イベント: LangChainは、5月22日(木曜日)にニューヨークでTabsおよびTavilyAIと共同でオフライン交流イベントを開催すると発表しました。イベント内容には、炉辺談話、製品デモンストレーション、および他のビルダーとの交流セッションが含まれます。(出典: hwchase17, LangChainAI)

グローバルAIカンファレンス東京大会、6月開催: 「グローバルAIカンファレンス・東京大会」と名付けられたイベントが、6月7日から8日にかけて日本の東京で開催される予定です。多数の著名なAI開発者、アーティスト、投資家などが参加します。AI分野に関心があり、日本への渡航を計画している方は、関連する登録情報に注目してください。(出典: op7418)

AIサービスアーキテクチャのパラダイム、「モデル・アズ・ア・サービス」から「エージェント・アズ・ア・サービス」へ移行中: AI技術の発展に伴い、AIサービスアーキテクチャは「モデル・アズ・ア・サービス」(MaaS)から「エージェント・アズ・ア・サービス」(AaaS)へと深刻な飛躍を遂げています。AI Agentは、その目標指向性、環境認識能力、自律的意思決定能力、学習能力により、従来のAIモデルが受動的に指示を実行するモードを超越しています。それらは独立して思考し、タスクを分解し、経路を計画し、外部ツールを呼び出して複雑な目標を達成することができます。この変化は、基盤インフラ(計算能力、データ)、コアアルゴリズムと大規模モデルから、中間層のAgentコンポーネントとプラットフォーム、そして最終製品アプリケーション(汎用型、特定業界向け、組み込み型Agent)に至るまでの産業チェーン全体の発展を促しています。中国のAI Agent企業であるHeyGen、Laiye Technology、Waveform AIなども積極的に海外進出し、海外市場を開拓しています。計算能力コストの高騰や供給不足などの課題に直面していますが、アルゴリズムの最適化、専用チップ、エッジコンピューティングなどのソリューションを通じて、AI Agentの可能性は絶えず解放されています。(出典: 36氪)