
キーワード:AIプログラミングエージェント, Codex, AlphaEvolve, AI推論パラダイム, MoEモデル, AIチップ, AI教育, AIショートドラマ, OpenAI Codex-1モデル, Google DeepMind AlphaEvolve, ByteDance Seed1.5-VL, Qwen ParScale技術, NVIDIA GB300システム
🔥 注目
OpenAI、クラウドAIプログラミングエージェントCodexを発表、新モデルcodex-1を搭載: OpenAIは、ソフトウェアエンジニアリング向けに最適化されたo3特別調整版codex-1をベースにしたクラウドAIプログラミングエージェントCodexを発表しました。Codexは、クラウドサンドボックス内で安全に複数のタスクを並列処理でき、GitHubとの統合によりコードリポジトリを直接呼び出し、モジュールの迅速な構築、コードリポジトリに関する問題解決、脆弱性修正、PRの提出、自動テスト検証を実現します。従来数日または数時間かかっていたタスクを、Codexは30分以内に完了できます。このツールはChatGPT Pro、Enterprise、Teamのユーザーに公開されており、開発者の「10xエンジニア」となり、ソフトウェア開発プロセスを再構築することを目指しています。(出所: 36Kr)
Google DeepMind、AlphaEvolveを発表、AIの自律的進化により数学とアルゴリズムでブレークスルー: Google DeepMindのAIシステムAlphaEvolveは、自己進化と大規模言語モデルのトレーニングを通じて、複数の数学および科学分野でブレークスルーを達成しました。4×4行列乗算アルゴリズムを改善し(56年ぶり)、六角形充填問題を最適化し(16年ぶり)、「接吻数問題」を進展させました。AlphaEvolveはアルゴリズムを自律的に最適化でき、Geminiモデルのトレーニングを加速する方法も見出し、Google内部の計算インフラストラクチャの最適化に応用され、計算リソースを0.7%節約しました。これはAIが問題を解決するだけでなく、新たな知識を発見できることを示しており、科学研究のパラダイムを覆し、AIによる科学創造を実現する可能性があります。(出所: 36Kr)
サム・アルトマン氏、Sequoia AI Summitで講演:AIは3年以内に現実世界に進出し、生活と仕事を再構築する: OpenAIのCEOサム・アルトマン氏は、Sequoia AI Summitで、2025年にはAIエージェントが実用化され(特にコーディング分野)、2026年にはAIが重要な科学的発見を推進し、2027年にはロボットが物理世界に進出して価値を創造すると予測しました。彼はOpenAIの初期の探求からChatGPTの誕生までの道のりを振り返り、将来のAI製品は個人の全人生経験を収容できる「コアAIサブスクリプション」サービスとなり、インテリジェントなデフォルトインターフェースになると提唱しました。OpenAIはコアモデルと応用シーンに注力し、「小規模チーム、大きな責任」という組織効率を維持します。(出所: 36Kr)
NVIDIA、Computexで講演:パーソナルAIコンピュータ生産開始、次世代GB300システム発表、台湾にAIスパコン建設予定: NVIDIAのCEOジェンスン・フアン氏はComputex 2025で、パーソナルAIコンピュータDGX Sparkが全面的に生産開始され、数週間以内に発売されること、次世代AIシステムGB300(72基のBlackwell Ultra GPUと36基のGrace CPUを搭載)が第3四半期に発表されることを発表しました。NVIDIAはTSMC、Foxconnと共同で台湾にAIスーパーコンピューティングセンターを設立します。同時にBlackwell RTX Pro 6000ワークステーションシリーズとGrace Blackwell Ultra Superchipを発表し、7月にはロボットトレーニング用のNewton物理エンジンをオープンソース化する計画です。フアン氏はAIがあらゆる場所に存在し、その革命的な影響を改めて強調しました。(出所: 36Kr)

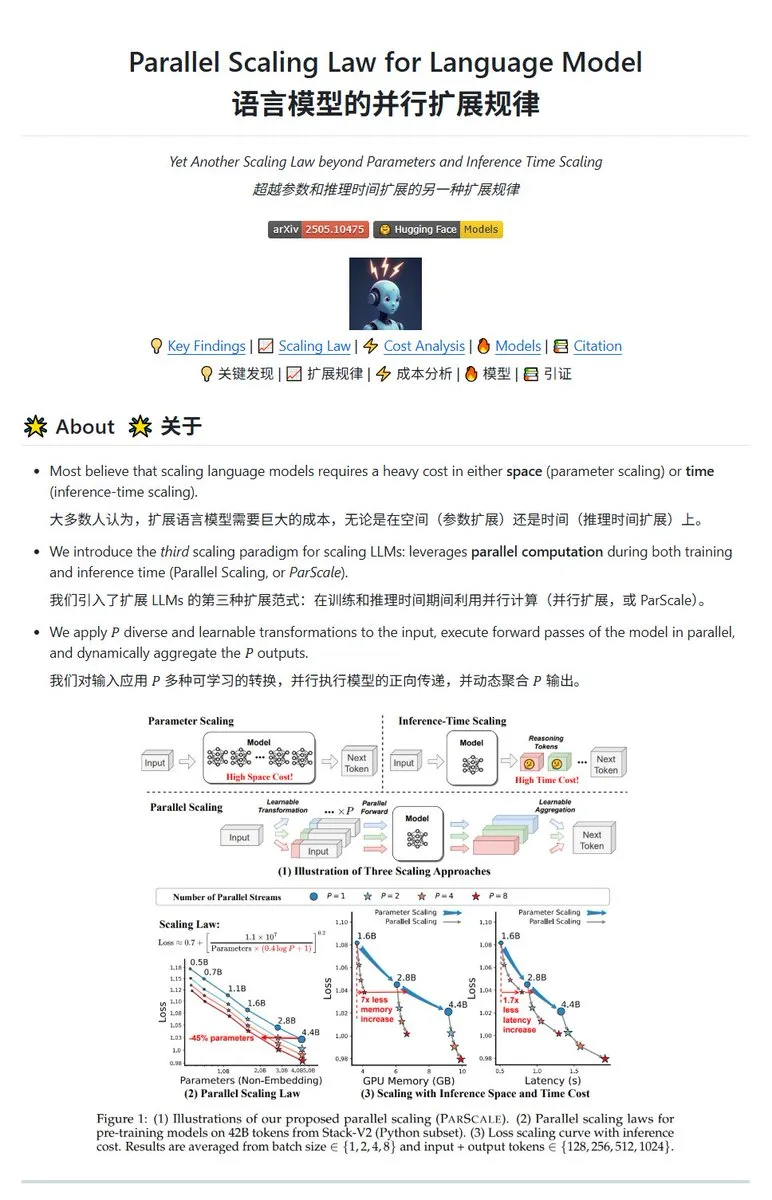
Qwen、ParScale並列スケーリング技術を発表、小規模モデルで大規模モデルの効果を実現可能: Qwenチームは、並列推論によってモデル能力を向上させるParScale技術を発表しました。この方法は、n個の並列ストリームを使用して推論を行い、各ストリームは学習可能な差分変換を用いて入力を処理し、最後に動的集約メカニズムによって結果を統合します。研究によると、P個の並列ストリームの効果は、モデルのパラメータ数をO(log P)倍に増やすことに近似し、例えば30Bモデルは8つの並列ストリームによって42.5Bモデルの効果を達成できます。この技術は、GPUメモリ占有量を大幅に増加させることなくモデル性能を向上させるか、並列度を上げることで既存モデルの規模を縮小する可能性がある一方で、計算需要の増加と推論速度の低下を代償とする可能性があります。(出所: karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
🎯 動向
Poeレポート:OpenAIとGoogleがAI競争をリード、Anthropicは失速: Poeの最新利用レポート(2025年1月~5月)によると、AI市場の構図は激変しています。テキスト生成分野ではGPT-4o(35.8%)がリードし、Gemini 2.5 Proが推論能力(31.5%)でトップに立ちました。画像生成はImagen3、GPT-Image-1、Fluxシリーズが主導しています。動画生成分野ではKling-2.0-Masterが急成長し、Runwayのシェアは大幅に減少しました。エージェントに関しては、o3が最高のパフォーマンスを示しました。レポートは、推論能力が重要な戦場となっており、AnthropicのClaudeの市場シェアが低下し、DeepSeek R1のユーザー比率もピーク時から減少していると指摘しています。企業は複雑なタスクにおけるモデルの正確性と信頼性に注目し、柔軟にAIモデルを選択する必要があります。(出所: 36Kr)

MetaのフラッグシップAIモデルBehemoth(Llama 4)のリリース延期、AI戦略調整の可能性: 報道によると、Metaが4月にリリース予定だった2兆パラメータの大規模モデルBehemoth(Llama 4)は、性能が期待に達しなかったため、秋以降に延期されました。同モデルは30Tのマルチモーダルトークンを使用し、32K GPUで事前学習され、OpenAIやGoogleなどに対抗することを目指していました。開発の難航は、Llama 4チームのパフォーマンスに対する内部的な失望を引き起こし、AI製品チームの調整につながる可能性があります。同時に、Llama 1の初期チーム14人のうち11人がすでに退職しています。Metaの幹部は「チームの80%が辞職した」という噂を否定し、退職者は主にLlama 1論文チームのメンバーであると強調しました。この出来事は、MetaがAI競争でボトルネックに陥っているのではないかという外部の懸念を強めています。(出所: 36Kr)

ByteDanceとGoogle DeepMind、新たなMoEモデル研究を発表、効率と生産システム応用に着目: ByteDanceの論文「MegaScale-MoE: Large-Scale Communication-Efficient Training of Mixture-of-Experts Models in Production」は、大規模MoEモデルの効率的なトレーニング専用に設計された生産システムを紹介しており、演算子レベルで通信と計算をオーバーラップさせることにより、Megatron-LMの1.88倍の効率向上を実現し、すでにデータセンターで製品モデル(Internal-352B、32エキスパート、top-3など)のトレーニングに展開されています。Google DeepMindはAlphaEvolveを発表し、AIの自己進化とLLMのトレーニングを通じて、4×4行列乗算や六角形充填問題の改善など、数学およびアルゴリズム分野でブレークスルーを達成し、科学的発見におけるAIの可能性を示しました。(出所: teortaxesTex, 36Kr)

OpenAI、AI推論パラダイムを議論、性能向上への重要な役割を強調: OpenAIの研究者Noam Brown氏は、AIの発展は事前学習パラダイム(大量データによる次の単語予測)から推論パラダイムへと移行したと指摘しました。事前学習コストは高額ですが、推論パラダイムはモデルの「思考」時間(推論計算量)を増やすことで回答の質を向上させ、トレーニングコストが変わらなくても可能です。例えば、oシリーズモデルは数学コンテスト(AIME)や博士レベルの科学問題(GPQA)において、より長い推論時間によってGPT-4oをはるかに超える精度を達成しました。OpenAIのチーフエコノミストRonnie Chatterji氏は、AIによる企業構造の再編について議論し、重要なのは企業がAIをどのように統合して人間の役割を強化または代替するか、そしてAI技術がどのようにバリューチェーンに組み込まれるかであると述べました。(出所: 36Kr)

Google CEOピチャイ氏、「Googleは死んだ」論に反論、AI駆動の検索進化とインフラ優位性を強調: Google CEOのサンダー・ピチャイ氏はインタビューで、「Google検索がAIに取って代わられる」という懸念に対し、Googleは「AI概観」や「AIモード」などの機能を通じて、検索を応答型クエリから予測的でパーソナライズされたインテリジェントアシスタントへと転換していると述べました。彼は、AIインフラ(自社開発TPU、大規模データセンター)とモデル効率への長期的な投資が中核的な優位性であり、高いコストパフォーマンスで先進的なモデルを提供できると強調しました。ピチャイ氏は、AIは「全シーン対応技術プラットフォーム」であり、検索、YouTube、Cloudなどのコアビジネスを再構築し、新たな形態を生み出すと考えています。また、中国のAI(DeepSeekなど)の競争力も無視できないとし、電力がAI発展の重要なボトルネックになると指摘しました。(出所: 36Kr)

AI教育分野におけるスタートアップ企業リスト: 記事では、2025年に注目すべきAI教育スタートアップ13社をリストアップしており、これらの企業はパーソナライズされた学習パス、インテリジェントな個別指導システム、自動採点、没入型コンテンツ作成などを通じて教育を変革しています。例えば、Merlynは音声操作AIアシスタントで、教師の事務負担を軽減します。Brisk TeachingはChrome拡張機能で、教育タスクを簡素化します。EdexiaはAI採点プラットフォームで、教師のスタイルを学習します。StorytailorはビブリオセラピーとAIを組み合わせてパーソナライズされた物語を作成します。BrainlyはAI強化された宿題支援を提供します。これらの企業は、効率向上からパーソナライズされた学習や教育の公平性の実現まで、教育分野におけるAIの幅広い応用可能性を示しています。(出所: 36Kr)
AIショートドラマ、技術的・商業的課題に直面、制作効果と期待にギャップ: AIツールはショートドラマの制作コスト削減や制作期間短縮に期待されていますが、制作者たちはAIショートドラマが主体の一貫性、口パクの同期、カメラワークの自然さなどの点で顕著な技術的課題を抱えており、多くの作品が「PPT風ショートドラマ」のようになっていることを発見しました。AIは超現実的なアイデアを理解することが難しく、ファンタジーやSFといったジャンルの表現を制限しています。現在、AI技術は完全なショートドラマよりも短編動画の制作に適しており、商業化の見通しは不透明です。博納影業や華策集団のような大手映画会社はリソースの優位性により突破する可能性が高い一方、多くの中小クリエイターは試行錯誤のコストが高く、技術の反復が速いために作品がすぐに時代遅れになるという問題に直面しています。(出所: 36Kr)
MSI、NVIDIA GB10スーパーチップ搭載AI PCを発表、6144 CUDAコアと128GB LPDDR5Xメモリを搭載: MSIは、NVIDIA GB10スーパーチップを搭載したAI PC、EdgeExpert MS-C931 Sを展示しました。このチップは6144個のCUDAコアと128GBのLPDDR5Xメモリを搭載していることが確認されています。これはASUS、Dell、Lenovoに続き、NVIDIA DGX Sparkアーキテクチャに基づくパーソナルAIコンピュータを発表した新たなメーカーとなります。このような製品の登場は、高性能AIコンピューティング能力が個人およびエッジデバイスに徐々に普及していることを示していますが、その価格設定がMac Miniなどの製品との競争を困難にする可能性があるというコメントもあります。(出所: Reddit r/LocalLLaMA)
Qwen3-30B、VLLM上で高スループットを実現、データセット管理に適用: Qwen3-30B-A3Bモデルは、VLLMフレームワークとRTX 3090sグラフィックカード上で優れた推論速度(5K t/sプレフィル、1K t/s生成)を示し、データセットのフィルタリングや管理などのタスクに非常に適しています。QwQと比較すると若干の回帰があるかもしれませんが、その速度の利点により、データ処理においてより実用的です。現在の主な問題はトレーニング速度が非常に遅いことですが、Hugging Face Transformersライブラリにはこの問題を解決しようとするPRがあり、将来的にはQwen3-30Bに基づいて改善されたデータセットのRpRモデルが登場することが期待されます。(出所: Reddit r/LocalLLaMA)
Bilibili、アニメ動画生成モデルIndex-AniSoraをオープンソース化、多様な二次元スタイルをサポート: Bilibiliは、二次元動画生成専用のオープンソースモデルIndex-AniSoraを発表しました。これは同社のAniSora技術フレームワーク(IJCAI25に採択済み)に基づいています。このモデルは漫画をワンクリックでアニメに生成でき、アニメシリーズ、国産アニメ、漫画原作、VTuberなど多様なスタイルをサポートします。AniSoraシステムは、数千万規模の高品質なテキスト-動画ペアデータセットを構築し、統一された拡散生成フレームワークを開発し、時空間マスキングメカニズムを導入することで、キャラクターの口の動きや動作の精密な制御を実現します。同時に、Bilibiliはアニメ動画向けの評価ベンチマークとVLM最適化に基づく自動評価システムを設計しました。オープンソースコンテンツには、AniSoraV1.0(CogVideoX-5Bベース)、AniSoraV2.0(Wan2.1-14Bベース、Huawei 910Bトレーニングをサポート)および関連するデータセット構築・評価ツールが含まれます。(出所: WeChat)

ByteDance、視覚言語モデルSeed1.5-VLを発表、マルチモーダルタスクで優れた性能: ByteDanceは、532Mパラメータの視覚エンコーダと20Bアクティブパラメータの混合エキスパート(MoE)LLMから構成される視覚言語モデルSeed1.5-VLを発表しました。このモデルは、60の公開ベンチマークテストのうち38でSOTA性能を達成し、GUI制御やゲームプレイなどのエージェント中心のタスクにおいてOpenAI CUAやClaude 3.7などの主要システムを上回り、強力なマルチモーダル理解と推論能力を示しました。(出所: WeChat)
Nous Research、Psyche Networkを発表、40BパラメータLLMの分散型事前学習を実現: Nous Researchは、DeepSeek V3 MLAアーキテクチャに基づく分散型トレーニングネットワークPsyche Networkを発表し、最初のテストで400億パラメータの大規模言語モデルの事前学習を行いました。このネットワークはDisTrOオプティマイザとカスタムピアツーピアネットワークスタックを利用し、世界中の分散GPU計算能力を統合し、個人や小規模グループが単一のH/DGX上でトレーニングし、3090 GPU上で実行することを可能にします。これは、テクノロジー大手の計算能力独占を打破し、大規模モデルのトレーニングをより利用しやすくすることを目的としています。(出所: 量子位)

🧰 ツール
Sim Studio:オープンソースAIエージェントワークフロービルダー: Sim Studioは、オープンソースの軽量なAIエージェントワークフロー構築プラットフォームであり、直感的なインターフェースを提供し、ユーザーは様々なツールに接続されたLLMアプリケーションを迅速に構築・展開できます。クラウドホスト版とセルフホスト版(Docker環境推奨、Ollamaなどのローカルモデルをサポート)をサポートしています。技術スタックには、Next.js、Bun、PostgreSQL、Drizzle ORM、Better Auth、Shadcn UI、Tailwind CSS、Zustand、ReactFlow、Turborepoが含まれます。(出所: GitHub Trending)

Cherry Studio:多機能なオープンソースLLMフロントエンドデスクトップアプリが注目: Cherry Studioは、RAG、ウェブ検索、ローカルモデル(Ollama、LM Studio経由で接続)およびクラウドモデル(Gemini、ChatGPTなど)へのアクセスなど、多くの機能を統合したオープンソースのLLMフロントエンドデスクトップアプリケーションです。ユーザーからは、そのMCP(マルチコントロールプロトコル)のサポートと管理がOpen WebUIやLibreChatよりも優れており、インストールと設定が容易であるとのフィードバックがあります。このアプリケーションは、Obsidianナレッジベースへの直接接続もサポートしています。一部のユーザーはその出所について懸念を示していますが、その包括的な機能セットにより、魅力的な選択肢となっています。(出所: Reddit r/LocalLLaMA)

MLX-LM-LoRA:MLXモデルにLoRAを追加し、複数のトレーニング方法をサポート: オープンソースプロジェクトmlx-lm-loraは、ユーザーがApple MLXフレームワーク下のモデルにLoRA(Low-Rank Adaptation)モジュールを統合できるようにします。このプロジェクトはLoRAの追加をサポートするだけでなく、ORPO、DPO、CPO、GRPOなど複数のアライメントトレーニング方法を内蔵しており、ユーザーが自身のニーズに合わせてモデルを微調整し、カスタマイズされたLoRAモジュールを生成し、それを好みのMLXモデルに適用するのに便利です。(出所: karminski3)
DeepDrone:QwenベースのAI制御ドローンプロジェクトがオープンソース化: ある開発者がQwen大規模モデルをベースにDeepDroneという名のAI制御ドローンプロジェクトを作成し、HuggingFaceとGitHubでオープンソース化しました。このプロジェクトは、大規模言語モデルをドローンの自律制御に応用する可能性を示し、AIの自動化と潜在的な軍事応用に関する議論を引き起こしました。(出所: karminski3)
Qwen Web Dev:ワンクリックプロンプトでウェブサイトを生成・展開: Alibaba Qwenチームは、Qwen Web Devツールが強化され、ユーザーはプロンプト1つでウェブサイトを生成し、ワンクリックで展開できるようになったと発表しました。このツールは、ウェブ開発のハードルを下げ、ユーザーがアイデアをより簡単に実際にアクセス可能なウェブサイトに変換し、世界と共有できるようにすることを目的としています。(出所: Alibaba_Qwen, huybery)
SuperGo.AI:8種類のLLMモデルを単一インターフェースに統合したツール: AI愛好家がSuperGo.AIというツールを開発しました。これは、8つの異なる役割を持つLLM(AIスーパーブレイン、AIイマジネーション、AI倫理、AIユニバースなど)を1つのインターフェースに統合したものです。これらのAIキャラクターは互いに感知し合い、対話することができ、ユーザーは「クリエイティブ」「サイエンス」「ミックス」モードを選択して混合応答を得ることができます。このツールは、斬新なマルチAI協調体験を提供することを目的としており、現在ペイウォールはありません。(出所: Reddit r/artificial)
Kokoro-JS:無制限のローカルテキスト読み上げ(TTS)を実現: Kokoro-JSは、100%ローカルで実行され、100%オープンソースのテキスト読み上げツールで、ブラウザ側で約300MBのAIモデルをダウンロードすることで実現します。ユーザーが入力したテキストはどのサーバーにも送信されず、プライバシーとオフラインでの可用性を保証します。このツールは、無制限のTTS機能を提供することを目的としています。(出所: Reddit r/LocalLLaMA)
📚 学習
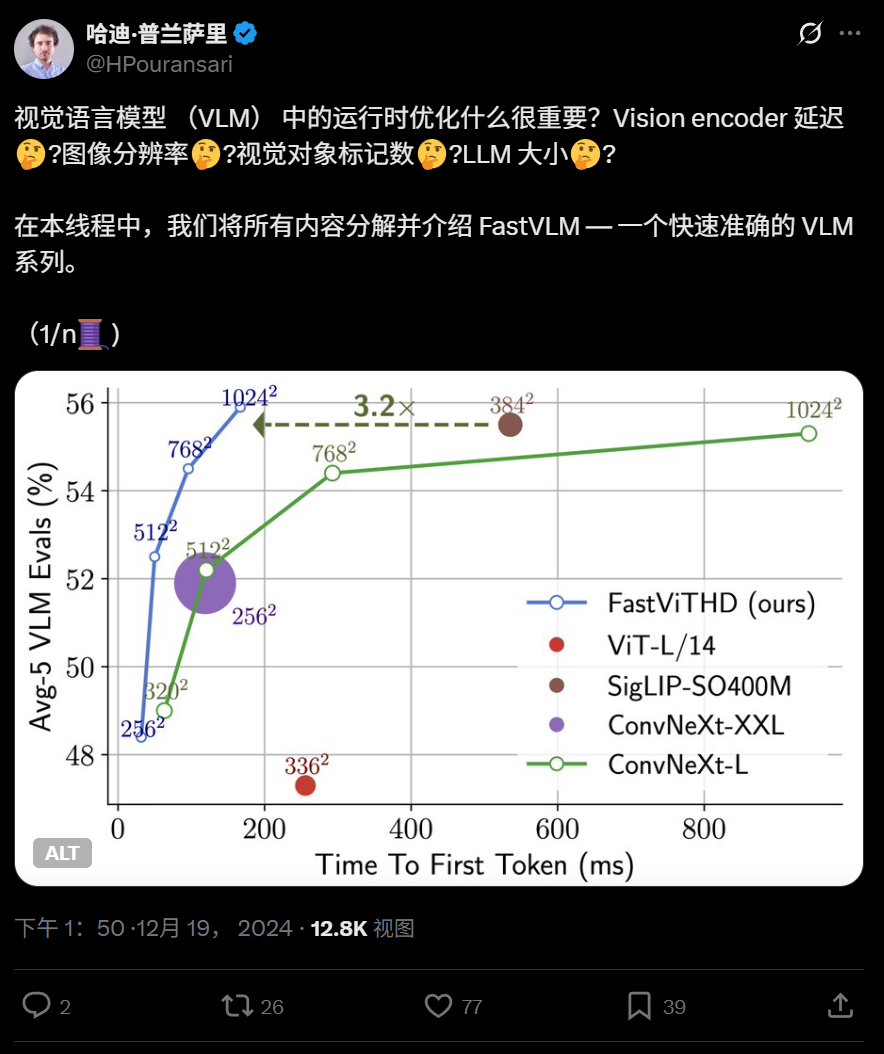
Apple、高効率視覚言語モデルFastVLMをオープンソース化、エッジデバイスでの実行を最適化: Apple社は、iPhoneなどのデバイス上で効率的に実行するために特別に設計された視覚言語モデルFastVLMをオープンソース化しました。FastVLMは、畳み込み層とTransformerモジュールを組み合わせた新しいハイブリッド視覚エンコーダFastViTHDを導入し、マルチスケールプーリングとダウンサンプリング技術を採用することで、画像の処理に必要な視覚トークンの数を大幅に削減し(従来のViTより16倍少ない)、最初のトークン出力速度を85倍向上させました。このモデルは主要なLLMと互換性があり、MLXフレームワークに基づくiOS/macOSデモアプリケーションがすでに提供されており、エッジデバイスやリアルタイムの画像・テキストタスクに適しています。(出所: WeChat)
ハルビン工業大学とペンシルベニア大学、KANベースで3D点群分析を改善するPointKANを提案: ハルビン工業大学(深圳)とペンシルベニア大学の研究チームは、Kolmogorov-Arnold Networks (KANs) に基づく新しい3D認識アーキテクチャPointKANを発表しました。PointKANは、従来のMLPにおける固定活性化関数を学習可能な活性化関数に置き換えることで、複雑な幾何学的特徴の学習能力を強化します。これには、幾何学的アフィンモジュールと並列局所特徴抽出モジュールが含まれます。チームはまた、Efficient-KANs構造を採用したPointKAN-eliteバージョンも提案しました。これは、基底関数として有理関数を使用し、パラメータをグループ化して共有することで、パラメータ数と計算複雑性を大幅に削減し、同時に分類、部分セグメンテーション、および少数サンプル学習タスクでSOTA性能を示しました。(出所: 量子位)

ピッツバーグ大学、PhyT2Vフレームワークを提案、AI生成動画の物理的リアリティを向上: ピッツバーグ大学インテリジェントシステム研究所は、テキストから動画(T2V)モデルが生成するコンテンツの物理的一貫性を向上させることを目的としたPhyT2Vフレームワークを開発しました。この方法は、モデルの再トレーニングや大規模な外部データを必要とせず、大規模言語モデル(LLM)による連鎖的推論(CoT)と反復的自己修正メカニズムを通じて、テキストプロンプトに対して複数回の物理法則分析と最適化を行います。PhyT2Vは物理法則や意味的な不一致を識別し、修正プロンプトを生成することで、主要なT2Vモデル(CogVideoX、OpenSoraなど)の現実の物理シーン(固体、流体、重力など)における汎化能力を強化し、特に分布外のシーンで効果が顕著であり、物理常識(PC)と意味遵守度(SA)の指標が最大2.3倍向上しました。(出所: WeChat)
LLM最新研究速報:マルチモーダル、テスト時アライメント、エージェント、RAG最適化など: 1週間のLLM研究進展には以下が含まれます:1. ワシントン大学がQALIGNを提案。モデル変更やlogitsへのアクセスなしに、MCMCを用いてテキスト生成でより良いアライメントを実現するテスト時アライメント手法。2. UCLAがClinical ModernBERTを事前学習。生物医学分野エンコーダのコンテキスト長を8192トークンに拡張。3. Skoltechが外部情報(エンティティの流行度、問題タイプ)に基づく軽量LLM独立自己適応型RAG検索手法を提案。4. PSUがLLMマルチエージェントシステムの自動故障帰属問題を定義し、評価データセットと手法を開発。5. 復旦大学が多次元制約フレームワークと自動化命令生成プロセスを提案し、LLMの命令遵守能力を向上。6. a-m-teamがAM-Thinking-v1 (32B)をオープンソース化。数学的コーディング能力はDeepSeek-R1-671Bに匹敵。7. XiaomiがMiMo-7Bを発表。事前学習と事後学習の最適化により、推論タスクで優れた性能を発揮。8. MiniMaxがMiniMax-Speech自己回帰TTSモデルを提案。32言語のゼロショット声質クローニングをサポート。9. ByteDanceがSeed1.5-VL視覚言語モデルを構築。マルチモーダルタスクとエージェント中心タスクで優れた性能を発揮。10. 世界初の32Bパラメータ言語モデルINTELLECT-2が分散強化学習トレーニングを実現し、PRIME-RLフレームワークを提案。(出所: WeChat)
AAAI 2025ワークショップ、ニューラル推論、数学的発見、AIによる科学工学の加速に注目: AAAI 2025のワークショップでは、AIの科学分野への応用が重点的に議論されました。その中で、「ニューラル推論と数学的発見」ワークショップは、ブラックボックスニューラルネットワークが数学的予想の提示や新しい幾何学的図形の生成に利用できることを強調しましたが、記号レベルの論理推論には達しないと指摘し、学際的アプローチを提唱しました。もう一つの「AIによる科学と工学の加速」ワークショップ(第4回、テーマはAI生物科学)は、治療設計の基礎モデル、創薬の生成モデル、実験室での閉ループ抗体設計、ゲノミクスにおける深層学習、生物学的応用における因果推論などの議題に焦点を当て、生成モデルの生物科学における課題と機会について議論しました。(出所: aihub.org)

GoogleとAnthropic、AI解釈可能性研究で意見の相違、メカニズム解釈可能性は課題に直面: AIの「ブラックボックス」特性は、多くの重要な分野での応用を制限しています。Google DeepMindは最近、「メカニズム解釈可能性」(mechanistic interpretability)研究の優先度を引き下げると発表し、スパースオートエンコーダ(SAE)などの手法によるAI内部メカニズムの逆行エンジニアリングは、客観的参照の欠如、概念の網羅性の不備、特徴の歪みなど多くの問題に直面しており、既存のSAE技術は重要なタスクで必要な「概念」を特定できていないと主張しました。一方、Anthropic CEOのDario Amodei氏は、この分野の研究を強化すべきだと主張し、今後5~10年で「AIの核磁気共鳴画像法」を実現することに楽観的な見方を示しました。この論争は、AIの行動を理解し制御するという深層的な課題を浮き彫りにしています。(出所: 36Kr)

北京大学/StepStar/Lightelligence、InfiniteHBDを提案:新世代GPU広帯域ドメインアーキテクチャでコスト削減と効率向上: 既存の広帯域ドメイン(HBD)アーキテクチャのスケーラビリティ、コスト、フォールトトレランスの制限に対し、北京大学、StepStar、LightelligenceのチームはInfiniteHBDアーキテクチャを提案しました。このアーキテクチャは光スイッチモジュール(OCSTrx)を中心とし、光電変換モジュールに低コスト光スイッチ(OCS)機能を組み込むことで、データセンター規模の動的再構成可能なK-Hop Ringトポロジとノードレベルの故障分離を実現します。InfiniteHBDの単位コストはNVL-72のわずか31%であり、GPUの浪費率はほぼゼロ、MFU(モデルFLOPs利用率)はNVIDIA DGXと比較して最大3.37倍向上し、大規模な大規模モデルトレーニングに優れたソリューションを提供します。論文はSIGCOMM 2025に採択されました。(出所: WeChat)

OceanBase、PowerRAGを発表、AIを全面的に採用し、Data×AI一体化データ基盤を構築: OceanBaseは開発者会議で、AI向けアプリケーション製品PowerRAGを発表しました。これは、すぐに使えるRAG開発能力を提供し、データ、プラットフォーム、インターフェース、アプリケーション層を連携させることを目的としています。CTOの楊傳輝氏はOceanBaseのAI戦略を詳述しました:Data×AI能力を構築し、一体化データベースから一体化データ基盤へと進化します。OceanBaseはベクトル能力を強化し、融合検索を向上させ、企業知識ストレージの動的更新を実現し、モデルの事後トレーニングと微調整を深く統合し、すでにDify、FastGPTなどの主要なAgentプラットフォームおよびMCPプロトコルに対応しています。そのベクトル性能はVectorDBBenchテストで優れた結果を示し、BQ量子化アルゴリズムによってメモリ需要を大幅に削減しました。(出所: WeChat)

💼 ビジネス
上海国投系ファンド、芯耀輝、燧原科技、壁仞科技などのAIチップ企業に投資: 上海国有資本投資有限公司(上海国投)は最近、半導体企業3社、芯耀輝(XINYAOHUI)、燧原科技(Enflame Technology)、壁仞科技(Biren Technology)と投資契約を締結しました。これに先立ち、同社の先導AIマザーファンドは壁仞科技のIPO前資金調達をリードしていました。上海国投は、基礎モデル、計算能力チップ、具身知能などの分野に積極的に展開すると表明しています。芯耀輝は半導体IP、特にChiplet技術に特化しており、創業者の曾克強氏はかつてSynopsys中国の副総経理を務めていました。燧原科技と壁仞科技はいずれもGPUチップ設計会社です。この動きは、上海国投がAI産業チェーンの上流、特に計算能力チップ分野に重点的に布石を打っていることを示しています。(出所: 36Kr)
Sakana AI、三菱UFJ銀行と包括的パートナーシップを締結、銀行専用AIを開発: 日本のAIスタートアップSakana AIは、三菱UFJ銀行(MUFG)と複数年にわたるパートナーシップ契約を締結したと発表しました。Sakana AIはMUFG向けに銀行業務に特化したAIエージェントを開発し、銀行業務の変革とAIの実用化を推進することを目指します。同時に、Sakana AIの共同創業者兼COOである伊藤錬氏がMUFGの顧問に就任し、同行のAI戦略実施を支援します。この協力は、Sakana AIが先進的なAI技術を日本の金融業界の具体的な課題解決に応用する重要な一歩となります。(出所: SakanaAILabs, SakanaAILabs, SakanaAILabs, SakanaAILabs, SakanaAILabs)

01.AI共同創業者 谷雪梅氏が退職し起業、同社事業はBtoBに重心移動: 01.AIの共同創業者で、モデル事前学習とC向け製品を担当していた谷雪梅氏が数ヶ月前に退職し、最近起業準備を進めています。01.AIはこの事実を認め、彼女の貢献に感謝の意を示しました。2025年以降、01.AIの事業重心はAI ToCアプリケーションとモデルAPIから、デジタルヒューマン、モデルカスタマイズ、デプロイメントなどのBtoBシーンへと移行しています。国内版オフィスツール「万知」などのC向け製品は、ユーザー数が期待に届かず運営を停止しており、海外のロールプレイング製品Monaの商業化も芳しくありません。以前には、共同創業者の戴宗宏氏も退職し起業しています。(出所: 36Kr)

🌟 コミュニティ
AI論文AIGC検出が論争を呼ぶ、正確性に疑問、学生の卒業に影響: 今年、多くの大学が卒業論文審査の一環としてAIGC検出を導入し、学生によるAIライティングの乱用防止を目指しました。しかし、この措置は広範な論争を引き起こしています。学生からは、自身が執筆した内容がAI生成と誤判定されることが多く、AIによる修正後はむしろAIらしさが上昇するとの声が上がっています。さらには、「滕王閣序」のAI生成らしさが99.2%に達するというテスト結果も示されました。AIGC検出ツール自体もAIによって駆動されており、その原理はテキストの言語的特徴をAIのライティングパターンと比較分析するものですが、正確性は疑わしいです。OpenAIの初期ツールは正解率わずか26%でした。このような不確実性は、学生に混乱と追加費用(検出サイトによって結果が異なり、リライトサービスは有料)をもたらすだけでなく、AIツールの本質についての反省も促しています。AIが人間の文章を模倣し、さらにAIを使って人間の文章がAIらしいかどうかを検出すること自体、論理的矛盾をはらんでいます。(出所: 36Kr)

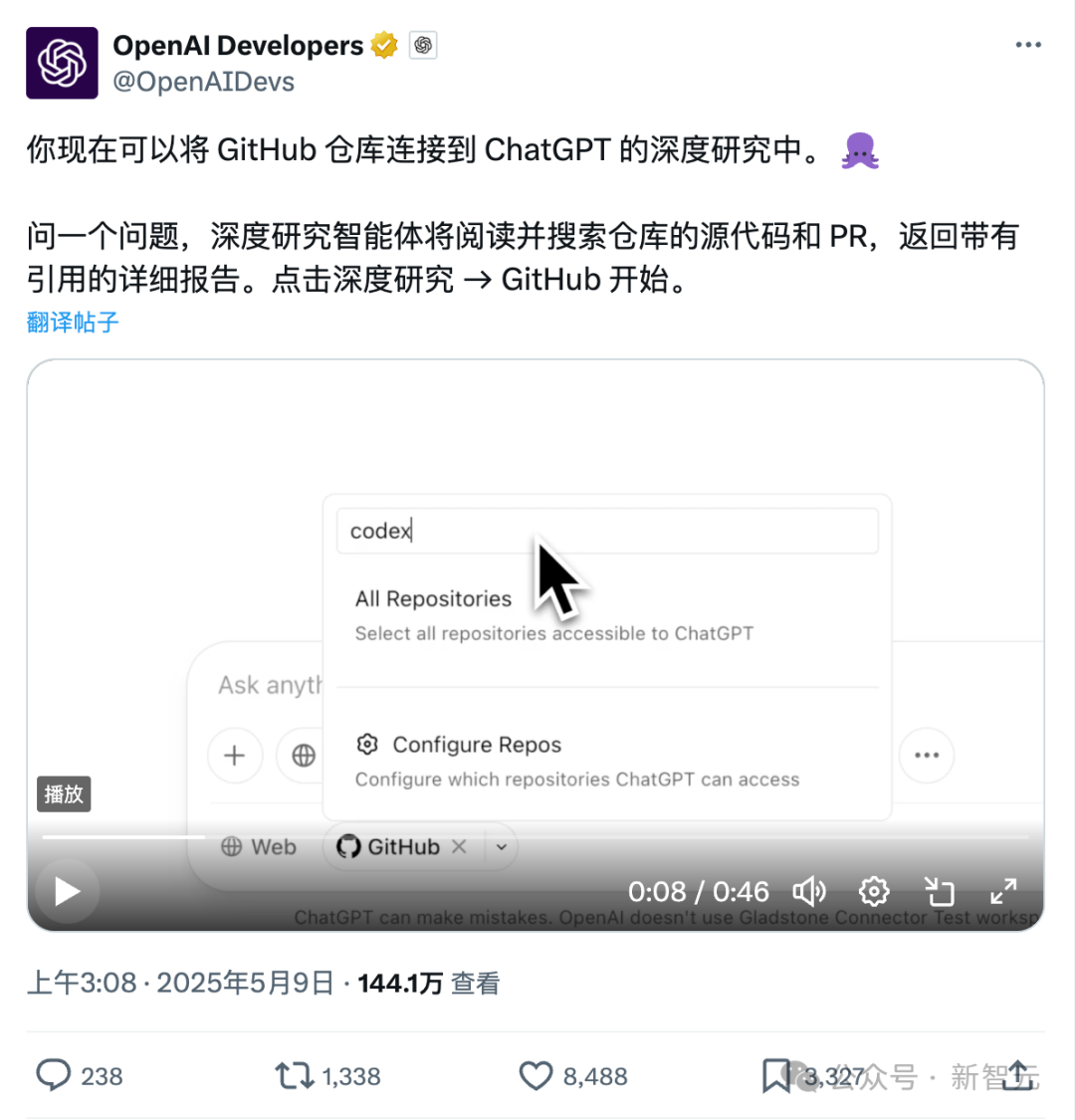
ChatGPT、Githubへの直接接続新機能:コードリポジトリと専門文書の詳細研究: ChatGPTが最近リリースしたDeep Research機能に、Githubリポジトリへの直接接続機能が追加されました。ユーザーはChatGPTに公開またはプライベートリポジトリへのアクセスを許可し、詳細なコード分析、機能アーキテクチャの要約、技術スタックの特定、コード品質評価、プロジェクト適合性分析などを行うことができます。この機能はコードに限定されず、ユーザーはPDFやWordなど様々な種類の文書をGithubリポジトリにアップロードし、ChatGPTを利用して特定分野の資料を詳細に研究することができ、限定範囲のRAG+MCPの組み合わせを実現したことになります。この機能は現在Plusユーザーに公開されており、研究範囲を限定することで、研究レポートの専門性と正確性を向上させ、ハルシネーションを減少させることが期待されます。(出所: 36Kr)
AI Agent市場競争激化、Manusが全面登録開放、ByteDanceやBaiduなど大手も参入: 「万能Agent」と呼ばれるManusが5月12日に全面登録開放を発表し、ユーザーは待つことなく利用枠を獲得できるようになりました。同時に、市場ではManusが15億ドルの評価額で新たな資金調達ラウンドを進めているとの噂が流れています。3月の発表以来、ManusはAgent系プロジェクトのブームを引き起こしましたが、トラフィックの減少や競合製品の出現という課題にも直面しています。ByteDanceはCoze Spaceを、Baiduは「秒哒」と「心响」をリリースし、デザインAgentのLovartもテストを開始しました。Agent市場は、初期の概念実証から製品機能、ビジネスモデル、ユーザー獲得の全面的な競争へと移行しつつあります。(出所: 36Kr)
AI支援コーディングが開発者のワークフローを変革、生産性向上も過度な依存に注意: Redditユーザーが、AIコードアシスタントが特に大規模なレガシープロジェクトの扱いや複雑なコードの理解において、自身のコーディング体験をいかに大きく変えたかを共有しました。AIツールはコードを一行ずつ説明し、提案を提供し、潜在的な問題をハイライトし、ファイルを要約し、スニペットを検索し、コメントを生成するなど、まるで24時間体制の専門家指導を受けているかのようです。コメントでは、AIが反復的なコーディングをこなし、効率を向上させ、新しいアプローチを導き、コメントを追加し、さらには開発者が能力を超えるタスクを完了するのを助け、数日の作業を数時間に短縮できると指摘されています。しかし、これは開発者のスキル進化とAIツールへの依存性についての考察も引き起こしています。(出所: Reddit r/artificial)
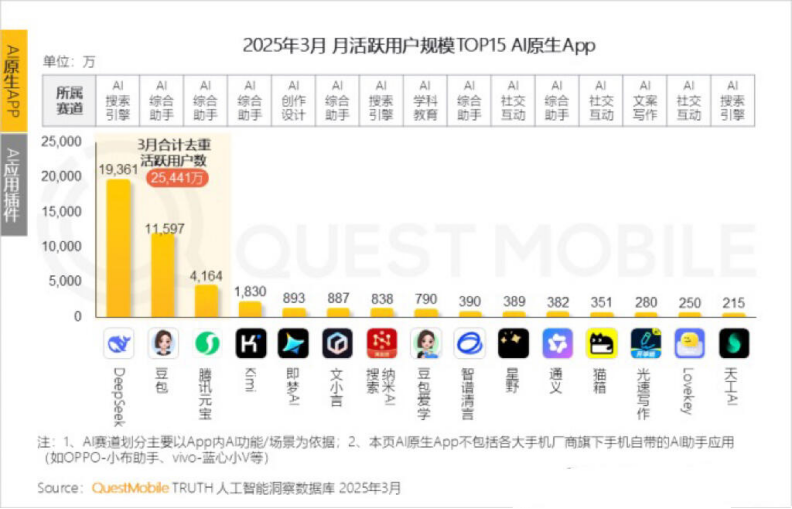
Kimiの月間アクティブユーザーが減少、Moonshot AIは特定分野での突破とソーシャル化への転換を模索: Moonshot AI傘下のKimi Chatは、QuestMobileのデータによると、月間アクティブユーザー数が昨年10月の3600万人から今年3月には1820万人に減少し、ランキングも4位に後退しました。ユーザー維持率向上のため、Kimiは汎用大規模モデルから特定分野への展開を進めており、例えば財新伝媒(Caixin Media)と協力して金融コンテンツの検索品質を向上させ、AI医療検索分野に布石を打ち、Bilibiliの動画コンテンツを導入しています。同時に、Kimiは小紅書(Xiaohongshu)でチェックインチャレンジを開始し、ソーシャルプラットフォームを通じてより多くのCtoCユーザーにリーチしようとしています。ユーザーインターフェースもマルチモーダル化、豆包(Doubao)風、コミュニティ化の方向に調整されています。DeepSeekなどの競合他社や大手企業がAIアプリケーションに続々と参入する中、Kimiの技術的優位性は揺らぎ、商業化への圧力が増大しており、新たな成長ポイントを積極的に模索しています。(出所: 36Kr)
AIが一人称で自称すべきかについての議論: Redditユーザーが、ChatGPTなどのLLMが「私」や「あなた」と自称したりユーザーを呼んだりするのは不適切かもしれないという議論を提起しました。その本質は「物」であり「人」ではないため、第三人称(例:「ChatGPTがお手伝いします…」)を使用することで、ユーザーにそれが人格化された存在であるという印象を与えるのを避け、潜在的な危険や倫理的問題を引き起こすのを防ぐべきだと提案しています。コメントでは、第三人称の方がむしろ自己意識を示唆するという意見や、第三人称は馬鹿げて聞こえ、不快に感じるという意見もありました。この議論は、AIのアイデンティティの位置づけや人間と機械のインタラクション方法に対するユーザーの考察を反映しています。(出所: Reddit r/ArtificialInteligence)
💡 その他
MIT、注目を集めたAI論文を緊急撤回、データと研究の信憑性に疑義: マサチューセッツ工科大学(MIT)は、同大学経済学部の博士課程学生エイダン・トナー=ロジャース氏が執筆した論文「人工知能、科学的発見と製品イノベーション」を撤回しました。この論文は、AIツールがトップ科学者のイノベーション効率を大幅に向上させる一方で、科学研究における「貧富の差」を拡大させ、一般の研究者の幸福度を低下させる可能性があると提唱したことで注目を集め、ノーベル賞受賞者など著名な教授からも称賛されていました。MITは声明で、研究倫理に関する告発を受け内部調査を行った結果、論文のデータソース、信頼性、有効性、および研究の信憑性に対する信頼を失ったとし、arXivと「The Quarterly Journal of Economics」に同論文の取り下げを要請したと発表しました。著者はMITを去り、関連教授も関係を否定する声明を発表しています。報道によると、著者は調査期間中に偽のドメイン名を購入して大企業のメールを装い、見破られて起訴されたとのことです。(出所: 36Kr)

AI生成画像がネット詐欺に利用され、ユーザーに警戒を促す: Redditユーザーが、Facebookなどのソーシャルメディアで、AI生成の人物画像を利用した商品プロモーションの事例を共有しました。これらの画像中の人物や場面には、しばしば非論理的な点(モデルが奇妙な方法で箱に出入りする、背景に無関係な人物が現れるなど)が存在しますが、キャラクターのイメージの一貫性は高いです。コメント投稿者は、この種のAI生成コンテンツがすでに詐欺に利用されていると指摘し、ユーザーに警戒を呼びかけています。Pleasant Greenなどのブロガーも、この種の詐欺を暴露する動画を制作しています。(出所: Reddit r/ChatGPT)
AI生成画像のスタイル模倣とプロンプト抽出の議論: ユーザーは、AIモデル(DALL-E 3など)に特定の芸術スタイル(ピクサー風とデザイナー・トイ風を組み合わせたサルバドール・ダリなど)を模倣させて人物画像を作成させる方法について議論し、詳細なプロンプトを共有しました。人物の特徴、背景、光と影、そして核となる概念(精神的投影としての影など)を強調しています。さらに、画像からスタイルパラメータを抽出し、JSON形式で出力するためのプロンプトテンプレートを提供したユーザーもおり、画像のスタイルをリバースエンジニアリングするのに役立つことを目指していますが、正確な再現には依然として困難が伴います。(出所: dotey, dotey)
