
キーワード:AlphaEvolve, DeepSeek V3, GPT-4.1, Claudeモデル, Falcon-Edge, BLIP3-o, AM-Thinking-v1, Gemini駆動の進化型コーディングエージェント, ハードウェアとソフトウェアの協調設計による大規模モデルコスト削減, ゼロショット音声クローン技術, 限界推論能力, 1.58ビットBitNetアーキテクチャ, Speech-02
🔥 フォーカス
DeepMind、AlphaEvolveを発表:Gemini駆動の進化的コーディングエージェント、アルゴリズム発見を推進 : AlphaEvolveは、Geminiモデルの創造性と自動評価器を結びつけ、進化的フレームワークを利用してアルゴリズムを最適化します。これはすでに複数の分野でブレークスルーを達成しており、例えば48回のスカラー乗算で4×4の複素行列乗算を完了し、Strassenアルゴリズムを改良しました。また、11次元空間で593個のkissing number configurationを発見し、300年の歴史を持つ「接吻数問題」を前進させました。さらに、AlphaEvolveはGoogleデータセンターのスケジューリング(計算資源を0.7%節約)、次世代TPU設計(冗長ビットの削除)、AIモデル訓練(主要カーネルを23%高速化)なども最適化しました。フィールズ賞受賞者のテレンス・タオ氏も、その数学的応用に関する探求に参加しました。(出典: DeepMind)

DeepSeek V3論文詳解:ソフトウェアとハードウェアの協調設計により大規模モデルのコストと消費電力を削減 : DeepSeekチームは論文を発表し、DeepSeek-V3がソフトウェアとハードウェアの協調設計を通じて、大規模な訓練と推論におけるコスト効率をどのように実現したかを詳細に説明しました。主要技術は以下の通りです。1) メモリ最適化:マルチヘッド潜在アテンション(MLA)を採用してキー・バリューキャッシュを圧縮し、FP8混合精度訓練によりメモリ消費を削減。2) 計算最適化:混合エキスパートモデル(MoE)を適用し、一部のパラメータのみを活性化させ、FP8訓練と組み合わせることで計算コストを大幅に削減。3) 通信最適化:マルチプレーンファットツリーネットワークトポロジとデュアルマイクロバッチ処理オーバーラップ(DualPipe)技術を採用し、遅延を削減し、GPU利用率を向上。4) 推論高速化:マルチトークン予測(MTP)フレームワークを導入し、複数の候補トークンを並行して予測・検証し、生成速度を向上。論文はまた、将来のAIハードウェア設計について、低精度計算サポート、拡張と融合、ネットワークトポロジ最適化、メモリシステム最適化、堅牢性とフォールトトレランスという5つの展望を提示しています。(出典: arXiv)

OpenAI GPT-4.1モデルがChatGPTで正式に利用可能に、ユーザーは直接選択可能 : OpenAIは、GPT-4.1モデルがChatGPTで利用可能になったと発表しました。Plus、Pro、Teamユーザーはモデルセレクターからアクセスでき、Enterprise版およびEducation版ユーザーは後日利用可能になります。GPT-4.1 miniもGPT-4o miniに代わって全ユーザーに提供されます。GPT-4.1は、コーディングタスクと指示追従における優れたパフォーマンスで注目されており、以前のAPIバージョンでは最大100万トークンのコンテキストウィンドウをサポートしていました。しかし、一部のユーザーによる実測では、ChatGPT内のGPT-4.1バージョンのコンテキスト長は依然として128kであり、APIバージョンの1Mには達していないようで、一部で失望の声が上がっています。(出典: OpenAI Developers)

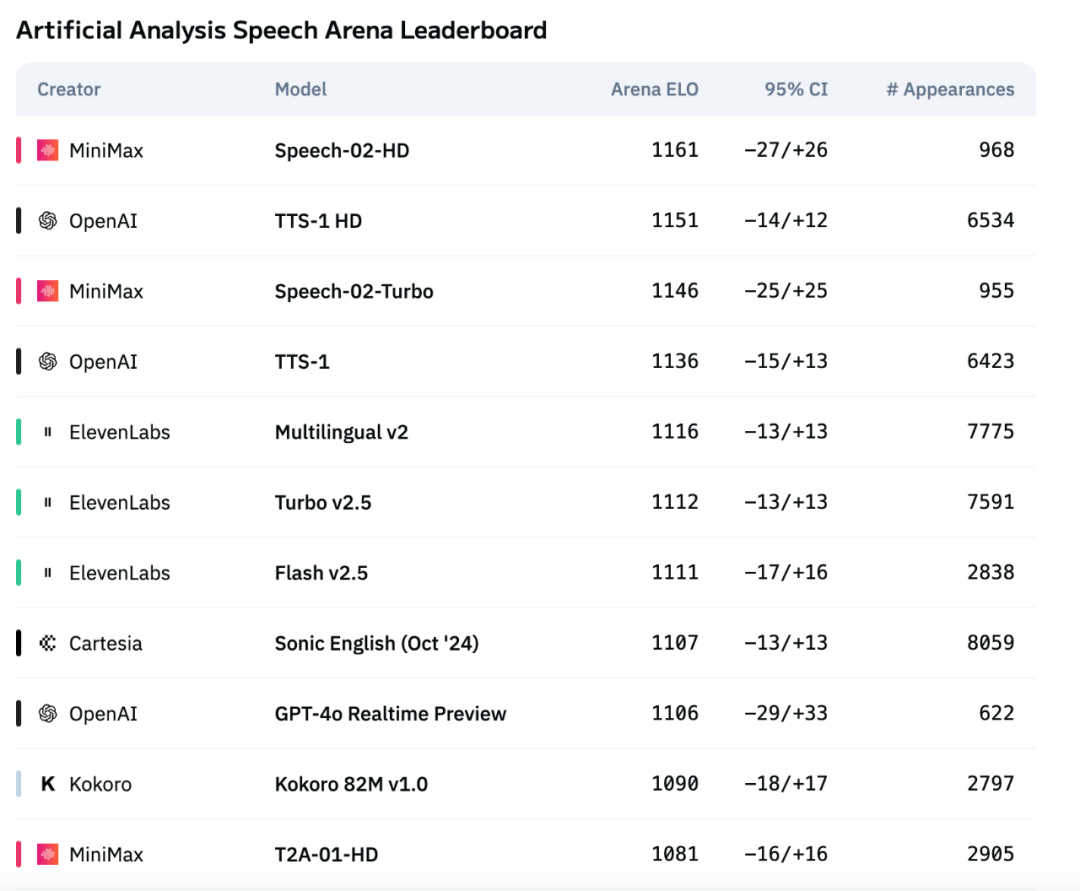
MiniMaxの新世代音声モデルSpeech-02がArtificial Analysis音声評価ランキングで首位を獲得 : MiniMaxが発表した最新のテキスト読み上げ(TTS)モデルSpeech-02は、国際的な権威ある音声評価ランキングArtificial Analysis Speech Arenaで最高のELOスコアを獲得し、OpenAIやElevenLabsの同種製品を上回りました。このモデルは、単語誤り率(WER)や話者類似度(SIM)などの主要指標で優れたパフォーマンスを示し、特に中国語と広東語の処理においてローカルな強みを発揮しています。Speech-02の核心的なイノベーションは、真のゼロショット音声クローニング(テキスト不要で数秒の参照音声のみ)の実現と、音声生成の自然さと感情表現力を強化する新しいFlow-VAEアーキテクチャの採用にあり、32言語をサポートしています。そのコストも非常に競争力があり、ElevenLabsの競合製品の約1/4です。(出典: 机器之心)
🎯 動向
Anthropicの新版Claudeモデルは「極限推論」能力を備える可能性 : The Informationの報道およびコミュニティの観察によると、Anthropicは今後数週間以内に新版のClaude SonnetおよびClaude Opusモデルをリリースする可能性があり、その最大の注目点は「極限推論」(Extreme reasoning)能力です。この機能により、モデルは困難な問題に直面した際に、直接答えを出すのではなく、一時停止し、再評価し、戦略を調整することができます。コード生成などのタスクでは、モデルは自動的にテストを行い、エラーを修正できます。このような動的なループによる推論とツール使用方法は、モデルが複雑な問題をよりインテリジェントに処理し、人間の監督への依存を減らし、人間の協力者の思考方法に近づけることを目的としています。すでに一部のユーザーは、AnthropicがClaude Neptune(またはClaude 3.8)という名前のモデルをテストしており、128kトークンのコンテキストをサポートしていることを発見しています。(出典: 量子位)
TII、Falcon-Edgeシリーズの高効率Bitnetモデルおよびonebitllmsファインチューニングツールキットをリリース : 技術イノベーション研究所(TII)は、BitNetアーキテクチャに基づく高度に圧縮された言語モデルのシリーズであるFalcon-Edgeをリリースしました。これらは強力で汎用的かつファインチューニング可能な特性を備えています。同時に、これらの1.58ビットモデルのファインチューニングまたは継続的な事前学習専用の軽量Pythonツールキットonebitllms(pip経由でインストール可能)もオープンソース化しました。これは、大規模モデルの使用の敷居を下げ、1-bit LLM技術の発展と応用を推進することを目的としています。(出典: younes)

Hugging Face Transformersライブラリが大幅アップグレード、モデル定義の中心標準へ : Hugging Faceは、そのTransformersライブラリが、異なるバックエンドやランタイムにまたがるモデル定義の中心標準となることを目指し、大幅な調整を行っていると発表しました。vLLM、LlamaCPP、SGLang、MLX、DeepSpeed、Microsoft、NVIDIAなど、多くのエコシステムパートナーとの共同の取り組みを通じて、モデルコードの標準化を推進し、AIエコシステム全体により高い一貫性と信頼性をもたらすことを目指しています。この動きはコミュニティから広く称賛されており、オープンソースAIの発展を推進する重要な一歩と見なされています。(出典: Arthur Zucker)

Salesforce、Hugging FaceでBLIP3-oをリリース:完全オープンソースの統合マルチモーダルモデルシリーズ : Salesforceは、完全オープンソースの統合マルチモーダルモデル群であるBLIP3-oシリーズモデルを発表しました。このシリーズは、モデルアーキテクチャ、トレーニング方法、データセットを網羅しており、マルチモーダルAI技術の発展と応用を推進することを目的としています。BLIP3-oのリリースは、研究者や開発者に強力なマルチモーダル処理ツールとリソースを提供します。(出典: AK)

NVIDIA、合成データを利用した完全自動運転技術の推進を展示 : NVIDIAは新しいビデオを公開し、合成データを利用して完全自動運転(FSD)技術の研究開発を加速する方法を展示しました。大規模で多様な仮想運転シナリオとデータを生成することにより、NVIDIAは自動運転アルゴリズムをより効率的に訓練・検証し、実世界のデータ収集の限界を克服し、自動運転技術をより安全で信頼性の高い方向へと発展させています。(出典: SawyerMerritt)
A-M-team、32B推論モデルAM-Thinking-v1をリリース、一部性能でDeepSeek-R1を凌駕 : 中国の研究チームA-M-teamは、Hugging Faceで32Bパラメータの推論モデルAM-Thinking-v1をオープンソース化しました。このモデルは、数学的推論(AIMEシリーズスコア85.3)やコード生成(LiveCodeBenchスコア70.3)などのタスクで優れたパフォーマンスを示し、これらの特定の評価ではDeepSeek-R1(671B MoE)を上回り、Qwen3-235B-A22Bなどのより大規模なモデルに匹敵するとされています。チームは、ポストトレーニングスキーム(コールドスタートSFT、合格率に基づくデータフィルタリング、2段階RLを含む)を通じて32B稠密モデルの推論能力を最適化することに注力しており、限られた計算リソースとオープンソースデータの条件下で強力な推論を実現する道筋を探求することを目指しています。(出典: AI科技评论)

Marigoldがアップデート:Stable Diffusionモデルを深度推定器に変換、シングルステップ推論と高解像度をサポート : Marigoldプロジェクトが大幅なアップデートを発表しました。この技術は、Stable Diffusion 2モデルを少量の合成サンプルと短時間(1GPUで2~3日)のトレーニングで、高度な深度推定器に変換することができます。新バージョンの特徴には、シングルステップの高速推論、新しいモダリティのサポート、高解像度出力、Diffusersライブラリのサポート、および新しいデモが含まれます。(出典: Anton Obukhov)
Qwen3シリーズモデルがオープンソースコミュニティで好調、NVIDIA OpenCodeReasoningがベースモデルとして採用 : AlibabaのQwen3(千問3)シリーズモデルは、オープンソースコミュニティで引き続き注目と応用を集めています。NVIDIAが最近オープンソース化したOpenCodeReasoningシリーズモデル(7B、14B、32B仕様を含む)は、Qwenをベースモデルとして採用しています。Qwen3は、その完全なバージョン、継続的な更新、混合推論モードへのネイティブサポート、そして繁栄するエコシステム(全世界でのダウンロード数3億超、派生モデル10万超)により、開発者から支持されています。最近の更新には、エッジデバイス向けマルチモーダルモデルQwen-omini 3B、Unslothとの協力によるファインチューニング効率の向上、詳細なデプロイメントハイパーパラメータ推奨の公開、生成されたウェブページのリアルタイムプレビューサポート、複数の量子化バージョンの提供、および技術レポートの公開などが含まれます。(出典: AI前线)
Hugging Face Accelerate v1.7.0リリース、リージョナルコンパイルとFSDPv2のQLoRAをサポート : Hugging Face Accelerate v1.7.0が正式にリリースされました。このバージョンのハイライトは、@IlysMoutawwakil氏によるリージョナルコンパイル(Regional compilation)の実装で、コンパイル効率と柔軟性が向上しました。また、@RisingSayak氏によるレイヤーワイズキャスティングフック(Layerwise casting hook)の貢献(これはdiffusersライブラリで広く使用されている機能です)、そして@winglian氏によるFSDPv2のQLoRAサポートの実装があり、大規模モデルのトレーニングがさらに最適化されました。(出典: Marc Sun)

Llamafile 0.9.3リリース、Qwen3およびPhi4モデルのサポートを追加 : Llamafileが0.9.3バージョンをリリースしました。今回のアップデートでは、最近人気のQwen3シリーズおよびPhi4シリーズモデルのサポートが追加されました。Llamafileは、モデルの重みと実行に必要なコードを単一の実行可能ファイルにパッケージ化することで、LLMアプリケーションの配布と実行を簡素化し、複数のオペレーティングシステムでの便利なデプロイメントを実現することを目指しています。(出典: Phoronix)
Tencent、HunyuanImage 2.0 大規模画像モデルをリリース : Tencentは、Hunyuan大規模画像モデルの新バージョンであるHunyuanImage 2.0を正式にリリースしました。今回のアップデートでは、画像生成の品質、制御性、および複雑な指示の理解能力が向上すると期待されています。具体的な技術詳細や改善点については、公式チャネルを通じてさらに情報を得ることができます。(出典: Hunyuan)

Ollama v0.7リリース、ローカルでの大規模モデル実行体験を強化 : Ollamaはv0.7をリリースし、ローカルデバイスでの大規模言語モデルの実行プロセスを簡素化することに引き続き注力しています。新バージョンには、パフォーマンスの最適化、新しいモデルのサポート、またはユーザーエクスペリエンスの改善が含まれている可能性があります。ユーザーは公式サイトまたはGitHubで詳細な更新ログとダウンロードを確認できます。(出典: ollama)
llama.cpp、PDF入力機能を統合、PDFドキュメントの直接処理をサポート : llama.cppプロジェクトは最近、PDFファイルの直接入力サポートを追加する重要なアップデートをマージしました。これにより、ユーザーはPDFドキュメントの内容をより簡単にllama.cpp駆動のローカル大規模言語モデルに入力し、処理、分析、または質疑応答を行うことができ、その応用範囲が広がりました。この機能は、外部JSパッケージを介して内蔵Webフロントエンドで実現されており、コアのメンテナンス負担を増やしません。(出典: GitHub)
Microsoft Copilot、4o画像生成機能を搭載、視覚効果とテキストの一貫性を向上 : MicrosoftのAIアシスタントCopilotに、OpenAIのGPT-4oモデルの画像生成機能が統合されました。今回のアップデートは、よりシャープな視覚効果、より一貫性のあるテキスト生成を提供し、写実的なものから楽しいカートゥーンまで、さまざまなスタイルをサポートすることを目的としています。ユーザーはCopilotを通じて、4o駆動の画像作成機能を体験できます。(出典: yusuf_i_mehdi)

NVIDIA DRIVE Labs、マップレスドライビングの未来を議論、高精細マップへの依存を低減 : NVIDIA DRIVE Labsの最新ビデオでは、マップレスドライビング(mapless driving)の未来について議論しています。高精細マップは自動運転にとって不可欠ですが、そのコストとメンテナンスの課題が展開を制限しています。NVIDIAは、情報ボトルネックの解消、タスク精度の向上、モデルトレーニングと推論時間の加速などのイノベーションを通じて、高精細マップへの依存を減らし、自動運転技術の限界を押し広げています。(出典: NVIDIA DRIVE)
Dolphin 3.2(Qwen3ベースでトレーニング)はシステムプロンプトスイッチを提供し、ユーザーコントロールを強化 : 近日公開予定のDolphin 3.2モデルは、Qwen3をベースにトレーニングされており、3つのシステムプロンプトスイッチを導入します:/no_think(冗長な思考ステップを削減するためと思われる)、/uncensored(コンテンツ検閲を削減するためと思われる)、および/china(中国固有のコンテキストまたはサービス向けと思われる)。これらのスイッチは、ユーザーがモデルのデプロイメントに対してより大きな所有権と制御権を持つことを目的としています。(出典: cognitivecompai)

🧰 ツール
Runway、参照機能を発表、特定の技術やスタイルを学習し新しい創作に応用可能に : Runwayは「References」という新機能を追加しました。これにより、ユーザーはプラットフォームに特定の技術や芸術的スタイルを提示し、それを参照として新しい生成コンテンツに応用することができます。この機能は、ユーザーにより詳細なスタイル制御能力を提供し、AI支援による創作をよりパーソナライズされ、目的に合ったものにします。ユーザーのCristobal Valenzuela氏は、この機能を使用したオリジナル事例をコミュニティで共有するよう呼びかけるキャンペーンを開始し、最もクリエイティブな5つの事例に1年間の無料Unlimitedプランを提供します。(出典: c_valenzuelab)

DSPy:迅速なイテレーションのための極めてシンプルなLLMプログラミングフレームワーク : DSPyフレームワークは、その極めてシンプルな設計で注目を集めています。開発者によると、そのコア機能(ModuleまたはOptimizer)のほとんどは1行のコードで実装でき、ユーザーがアイデアを迅速に試行し、反復できるように設計されています。大量のボイラープレートコードや複雑な概念を必要とする一部のツールとは異なり、DSPyは使いやすさと効率を強調しています。ユーザーからのフィードバックによると、入門ドキュメントを読むだけで迅速に使い始めることができ、短時間でこのフレームワークを利用してモデルを最適化できますが、SOTAモデルを使用してループ最適化を行うと費用が発生する可能性があります。(出典: lateinteraction)
Unsloth AI、TTSおよびオーディオモデルのファインチューニングに拡張、速度向上とVRAM使用量削減を実現 : Unsloth AIは、その最適化技術がテキスト読み上げ(TTS)およびオーディオモデルのファインチューニングをサポートするようになったと発表しました。ユーザーは無料のColabノートブックを使用して、Sesame-CSM、OpenAI Whisperなどのモデルをトレーニング、実行、保存できます。Unslothは、その技術によりTTSトレーニング速度が1.5倍向上し、同時にVRAM使用量が50%削減されると主張しています。関連ドキュメントとColabノートブックは、同社の公式サイトで提供されています。(出典: Unsloth AI)
Modal、Amazonの3000万件のレビュー埋め込みタスクを支援、L40S GPUで時間単位の処理を実現 : Modalプラットフォームは、L40S GPU上で大規模な埋め込みタスクを水平方向にスケーリングする能力を実証しました。あるデモケースを通じて、ModalはAmazonの3000万件のレビューの埋め込み処理を1時間以内に完了させることに成功しました。これは、Modalチームが更新したスケーラブルな生成システムのおかげであり、大規模な並列処理がより簡単かつ効率的になりました。(出典: charles_irl)

Lovart AI:複数のトップモデルを統合した新進のAIビジュアルデザインエージェント : LovartというAIビジュアルデザインエージェントが注目を集めています。自然言語の指示を通じて、ポスター、ブランドVI、ストーリーボードなどの専門的なビジュアルデザインタスクを完了できます。Lovartのコア能力は、GPT image-1、Flux pro、OpenAI-o3、Gemini Imagen 3、Kling AI、Tripo AI、Suno AIなど、複数のトップモデルを統合したマルチモデル融合スケジューリングにあり、プロフェッショナルレベルの編集ツール(レイヤー、マスク、テキスト微調整など)を内蔵し、画像とテキストの分離およびレイヤーごとの編集をサポートしています。この製品はLiblibの海外子会社が独立して運営しており、ワンストップで高度に制御可能なAIデザイン体験を提供することを目指しています。(出典: 量子位)
OpenHands 0.38.0リリース:ネイティブWindowsサポートとChrome拡張機能で使いやすさ向上 : OpenHandsが0.38.0バージョンをリリースし、いくつかの重要なアップデートが行われました。これには、ネイティブWindowsサポート(WSL不要)によるWindowsユーザーの利便性向上、ブラウザスクリーンショット機能、より柔軟なサンドボックスカスタマイズ機能が含まれます。さらに、GitHubからワンクリックでOpenHandsを起動できるChrome拡張機能もリリースされ、操作フローがさらに簡素化されました。(出典: All Hands AI)
Tensorlake Cloudがリリース、ドキュメント抽出とワークフロー構築能力を向上 : TensorlakeはTensorlake Cloudの提供開始を発表しました。これは、エージェントアプリケーションや複雑なビジネスワークフローの構築をサポートするために、ドキュメント抽出とワークフローを最適化することを目的としています。このプラットフォームは、高度なドキュメントレイアウト理解モデル(ACORDフォーム、銀行取引明細書、研究報告書などの実世界のデータでトレーニング済み)とテーブル抽出モデルを利用して、非構造化ドキュメントをクリーンで構造化されたデータに変換し、特に複雑で密度の高いテーブルの処理に適しており、視覚言語モデル(VLM)のこの分野における不足を補います。(出典: Tensorlake)
Patronus AI、Percivalを発表:AIエージェントのデバッグと改善専用のAIエージェント : Patronus AIは、AIエージェントのデバッグと改善専用に設計されたAIエージェントである新ツールPercivalを発表しました。Percivalは、複雑なエージェントの追跡記録を即座に分析し、最大60種類の異なる障害モードを特定し、パフォーマンスを向上させるためのプロンプト修正案を自動的に提案します。このツールは、「コンテキスト爆発」(エージェントが数百万トークンを処理する)などの重要な課題を解決し、特定のユースケースのドメイン適応と複雑なマルチエージェントオーケストレーションをサポートします。(出典: Weaviate Podcast)

Replit、Semgrepを統合し「セーフバイブコーディング」を実現、脆弱性を自動スキャン : ReplitはSemgrepとの協力を発表し、「セーフバイブコーディング」(Safe Vibe Coding)機能を導入しました。これにより、ユーザーがReplitでコードをデプロイするたびに、Semgrepが自動的にセキュリティスキャンを実行し、潜在的な脆弱性の発見と修正を支援し、APIキーなどの機密情報が誤って公開されるのを防ぎます。この取り組みは、AI支援コーディング(LLMによるコード生成など)を使用する際のセキュリティを向上させることを目的としています。(出典: amasad)

Cursor AI 0.50バージョンリリース、大幅アップデート : AI支援プログラミングツールCursorが、その0.50バージョンをリリースしました。「史上最大のバージョンアップデート」と称されています。新バージョンには、開発者のコーディング効率とAIとの連携の円滑さをさらに向上させることを目的とした、多数の機能強化と体験の最適化が含まれると予想されます。具体的な更新内容は、公式のリリースノートで確認できます。(出典: eric zakariasson)

OpenMemory MCP:アプリケーション間のコンテキスト共有をサポートするローカライズされたメモリ管理サーバー : OpenMemory MCPは、AIアプリケーションの生産性向上を目的としたメモリ管理サーバーです。これにより、ユーザーは異なるアプリケーション(CursorやClaude Desktopなど)間でコンテキストを共有し、PostgreSQLとQdrantを利用してローカルにデータを保存・インデックス化することで、データプライバシーを確保できます。このツールはセマンティック検索をサポートし、メモリとアプリケーションアクセスを管理するためのダッシュボードを提供し、セッションをまたいだコンテキスト喪失の問題を解決します。(出典: Reddit r/ClaudeAI)

Hugging Face Inference EndpointがvLLMとGradioを組み合わせ、高速なWhisper文字起こしを実現 : Hugging Faceは、そのInference Endpointサービスを利用し、vLLMプロジェクトとGradioインターフェースを組み合わせてOpenAIのWhisperモデルをデプロイし、非常に高速な音声文字起こし機能を実現する方法を実演しました。この組み合わせはAIコミュニティのオープンソースツールを活用し、ユーザーに効率的で使いやすい音声テキスト変換ソリューションを提供します。(出典: Morgan Funtowicz)
A.I.T.E Ball:Orange PiとGemma 3 1Bをベースにした自己完結型AIマジック8ボール : 開発者は、完全に自己完結型(ネットワーク接続不要)のAI駆動マジック8ボールプロジェクト、A.I.T.E Ballを展示しました。このデバイスはOrange Pi Zero 2W上で動作し、whisper.cppを使用してテキストから音声への変換を行い、llama.cppでGemma 3 1Bモデルを実行して質疑応答を行います。これは、低消費電力ハードウェア上でローカライズされたAIアプリケーションを実現する可能性を示しています。(出典: Reddit r/LocalLLaMA)

OWL Agent:MCPToolkitを統合したオープンソースの汎用エージェント : オープンソースのOWLエージェントプロジェクトにMCPToolkitサポートが組み込まれました。ユーザーはPlaywright、desktop-commanderなどのMCPサーバーやカスタムPythonツールに簡単に接続でき、OWLはそのマルチエージェントワークフロー内でこれらのツールを自動的に発見し呼び出すことで、汎用性とタスク実行能力を強化します。(出典: Reddit r/LocalLLaMA)

ElevenLabs、SB-1 無限サウンドボードを発表:効果音、ドラムマシン、環境ノイズ生成を統合 : ElevenLabsは、SB-1 無限サウンドボードを発表しました。これは、効果音ボード、ドラムマシン、そして無限の環境ノイズジェネレーターを統合したツールです。ユーザーは欲しい効果音を記述することで、SB-1がそのテキストから効果音(Text-to-SFX)モデルを使用してこれらのサウンドを生成し、オーディオ制作に新たな可能性を提供します。(出典: ElevenLabs)
Anytopプロジェクト:AIアニメーションの新たな進展、未知の生物を生き生きとさせ、動作学習と転移をサポート : Two Minute PapersはAnytopプロジェクトを紹介しました。これは、これまで見たことのない生物(恐竜、奇妙な昆虫などを含む)に対してリアルな動きを生成できるAIアニメーション技術です。このAIは独立して動きを生成するだけでなく、異なる生物がお互いの動きを学習し適応すること(例えば、恐竜がフラミンゴの片足立ちを学ぶ)も可能です。体の部位の意味的類似性(腕や足の普遍的な概念など)を理解することで、未知の形態への汎化を実現します。さらに、このシステムは動きの意味(攻撃、リラックスなど)を理解し、異なる動物間で類似した概念の動きを示し、不完全な入力動作を補完することもできます。(出典: )

Sketch2Anim:AIが簡単なスケッチを完全な3Dアニメーションに変換 : Two Minute Papersが紹介したもう一つの技術Sketch2Animは、ユーザーが描いた簡単な線画スケッチ(動作の経路を示す)を完全な3Dキャラクターアニメーションに変換することができます。このAIは、2Dスケッチの背後にある3Dの意図(例えば、前方にパンチを繰り出すことと横向きにパンチを出すことの区別)を理解することができ、これまでの類似技術が2Dレベルでしか指示を理解できなかった限界を解決し、専門家でなくても簡単な描画を通じて迅速に3Dアニメーションを作成できるようになります。(出典: )
📚 学習
DeepSeek、V3モデル論文を発表、拡張の課題とAIハードウェアアーキテクチャに関する考察を共有 : DeepSeekチームはHugging Face上でDeepSeek-V3モデルに関する論文を発表しました。この論文は、大規模言語モデルを拡張する過程で直面した課題を深く掘り下げ、将来のAIハードウェアアーキテクチャの発展方向について考察と見解を提示しています。これは、研究者や開発者が大規模モデルのトレーニングとデプロイメントのボトルネックを理解し、ハードウェアとソフトウェアの協調最適化によってどのように解決できるかについて、価値ある参考情報を提供します。(出典: Adina Yakup)
無料のモデルコンテキストプロトコル(MCP)コースが公開、外部データとツールを活用したAIアプリケーション構築を支援 : Ben Burtenshaw氏は、無料のMCP(Model Context Protocol)コースの提供開始を発表しました。このコースは、学習者が入門から習熟まで、MCPの動作原理、LLMをMCPサーバーに接続する方法、MCPを使用してAIエージェントアプリケーションをデプロイする方法を理解し、外部データとツールを活用してAIアプリケーションの能力を強化することを支援することを目的としています。(出典: Ben Burtenshaw)

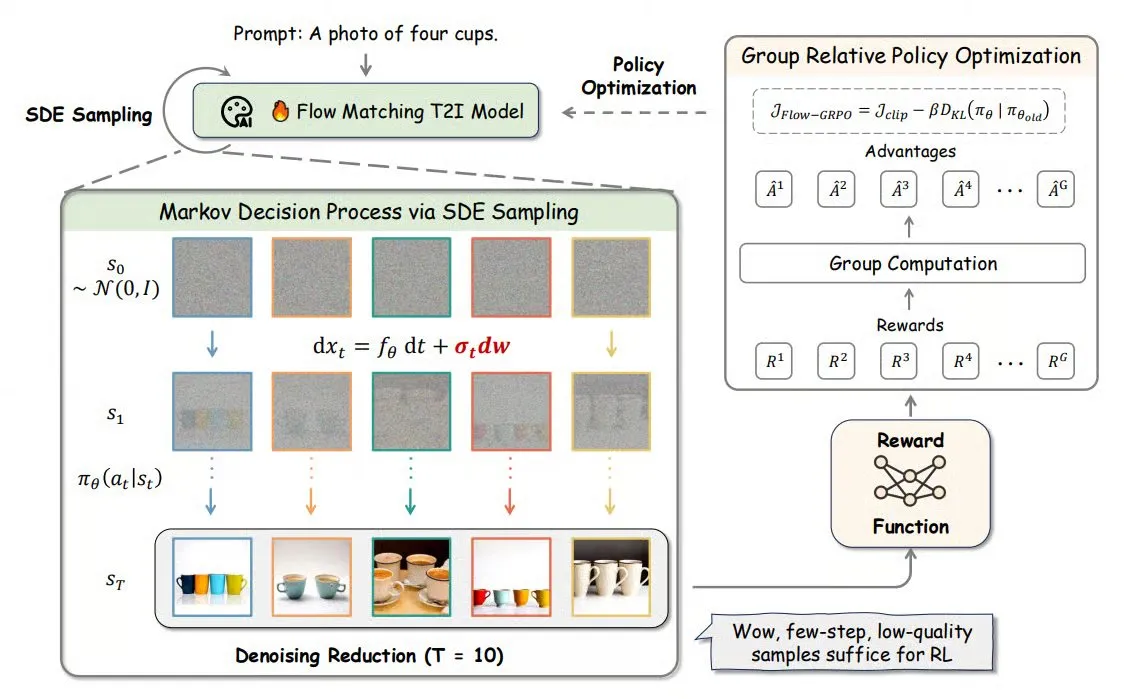
Flow-GRPO:オンライン強化学習をフローマッチングモデルに導入し、画像生成の精度を向上 : Flow-GRPOは、オンライン強化学習(RL)をフローマッチングモデルに初めて適用する新しい手法です。これは2つの革新的な戦略によって実現されます。1) ODEからSDEへの変換:フローマッチングモデルの常微分方程式(ODE)に基づく決定論的プロセスを確率微分方程式(SDE)に変換し、RLに必要な確率性を導入します。2) ノイズ除去削減による訓練の高速化:訓練時にはノイズ除去ステップを減らし、推論時には完全なステップを使用します。Flow-GRPOにより、フローマッチングモデルは画像生成タスクにおける精度を92%以上に向上させました。(出典: TheTuringPost)
ICML 2025論文PENCIL:「推論-消去」の交互実行による大規模モデルの深層思考新パラダイム : 豊田工業大学シカゴ校の楊晨暁氏らは、PENCIL(Pondering with Erasure Net for Contextual Inference Learning)を提案しました。これは、中間結果の「生成」と「消去」を交互に行うことで、大規模モデルの深層思考を実現する新しいパラダイムです。この方法は、論理学の書き換え規則と関数型プログラミングのメモリ管理を参考に、不要になった中間ステップを動的に消去することで、従来の長いCoT(思考連鎖)が直面するコンテキストウィンドウの超過、情報検索の困難さ、生成効率の低下といった問題を効果的に解決します。理論的には、PENCILは最適な空間計算量と時間計算量で任意のチューリングマシン演算をシミュレートし、すべての計算可能な問題を解決できることが証明されています。実験では、3-SAT、QBF、アインシュタインのパズルなどのタスクにおいて、PENCILが従来のCoTを大幅に上回る性能を示しました。(出典: 机器之心)

ICML 2025論文MemVR:人間の「二度見」メカニズムを模倣し、マルチモーダル大規模モデルの幻覚を緩和 : 香港科技大学(広州)などの研究機関の研究者は、MemVR(Memory-space Visual Retracing)手法を提案しました。これは、人間が不確実な記憶に対して二度目の確認を行う戦略を模倣することで、マルチモーダル大規模言語モデル(MLLM)の幻覚問題を緩和するものです。MemVRは視覚トークンを補足的な証拠として扱い、モデルの推論が忘却に悩まされる中間層において、フィードフォワードネットワーク(FFN)を通じて視覚知識を再度「検索」し、予測を較正します。この手法は動的なトリガーメカニズムを設計し、異なる層の出力の不確実性に基づいてトリガー層を選択します。実験により、MemVRは複数の幻覚評価ベンチマークおよび汎用ベンチマークにおいて顕著な効果を上げ、他の手法と比較して効率の面で優位性を持つことが示されました。(出典: PaperWeekly)

SIGIR 2025論文PaRT:パーソナライズされたリアルタイム検索による能動的ソーシャルチャットボット体験の向上 : 中国科学技術大学などの機関は、PaRT(Proactive Social Chatbots with Personalized Real-time ReTreival)手法を提案しました。これは、パーソナライゼーション駆動と意図認識誘導によるクエリ書き換えとリアルタイム検索を組み合わせることで、能動的ソーシャルチャットボットの対話体験を向上させることを目的としています。PaRTシステムは、パーソナライズされたユーザープロファイル構築、意図認識とクエリ書き換え、リアルタイム検索拡張生成の3つのモジュールを含みます。ユーザーの興味や対話の文脈に応じて能動的に話題を開始または切り替え、より自然で情報量の豊富な応答を提供できます。オフライン実験とオンラインA/Bテストの両方で、この手法が応答のパーソナライゼーション、豊富さ、および平均対話時間を効果的に向上させることが示されました。(出典: PaperWeekly)
ICML 2025論文PreSelect:予測強度に基づく効率的な事前学習データ選別手法 : 香港科技大学とvivo AI Labは、PreSelectデータ選別手法を提案しました。これは、「予測強度」(Predictive Strength)という概念を導入し、データが特定の能力においてモデルに貢献する大きさを定量化するものです。この手法は、異なるモデルのベンチマークテストにおけるスコアランキングとデータにおけるLossランキングの一致性を利用してデータの価値を評価し、軽量なfastText分類器を使用して近似的にスコアリングすることで、大規模データの効率的な選別を実現します。実験により、PreSelectはデータ効率を10倍向上させ、選別されたデータはモデル訓練時に複数のベースライン手法よりも著しく優れた効果を示し、より広範な高品質コンテンツソースをカバーし、サンプル長の偏りを減少させることが示されました。(出典: 量子位)

AI Evalsコース、12名のゲストを招き評価フレームワークと実践を共有 : Hamel Husain氏が主催するAI Evalsコースは、inspectフレームワークの作成者であるJJ Allaire氏、Modalの開発者アドボケイトであるCharles Frye氏など、12名のゲスト講師陣を発表しました。このコースでは、評価フレームワーク、カスタムアノテーションアプリケーションの作成、モデル評価の実践など、AI評価のさまざまな側面を深く掘り下げ、受講者がAIシステムのパフォーマンスを評価するための重要なスキルとツールを習得できるよう支援することを目的としています。(出典: Hamel Husain)

FedRAGチュートリアル公開:RAGシステムの構築とファインチューニングのための入門ガイド : FedRAGプロジェクトは、ユーザーがライブラリを迅速に使い始められるように、新しいチュートリアルノートブックと付随ビデオを公開しました。チュートリアルでは、Hugging Face統合を使用してRAGシステムを構築する方法、メモリ内ナレッジベースを使用してノードを保存する方法、SentenceTransformer(Dragon+)をリトリーバーとして定義する方法、事前学習済みモデル(Qwen2.5-0.5Bなど)をジェネレーターとして定義する方法、およびLSRとRALTトレーナーを使用してリトリーバーとジェネレーターを中央集権的にファインチューニングする方法を示しています。(出典: nerdai)

LlamaIndex、LlamaExtractにおける引用と推論の実装に関するチュートリアルを公開 : LlamaIndexチームは、@tuanacelik氏が作成した最新のコードウォークスルーを公開し、LlamaExtractで引用と推論機能を実装する方法を紹介しました。チュートリアルの内容には、複雑なデータソースから何を抽出するかをLLMに指示するためのカスタムスキーマの定義方法や、引用の追加方法が含まれています。この機能は、ユーザーが多数のソースドキュメントから構造化された情報を正確かつ根拠に基づいて抽出できる多段階AIエージェントを構築するのに役立つことを目的としています。(出典: LlamaIndex 🦙)
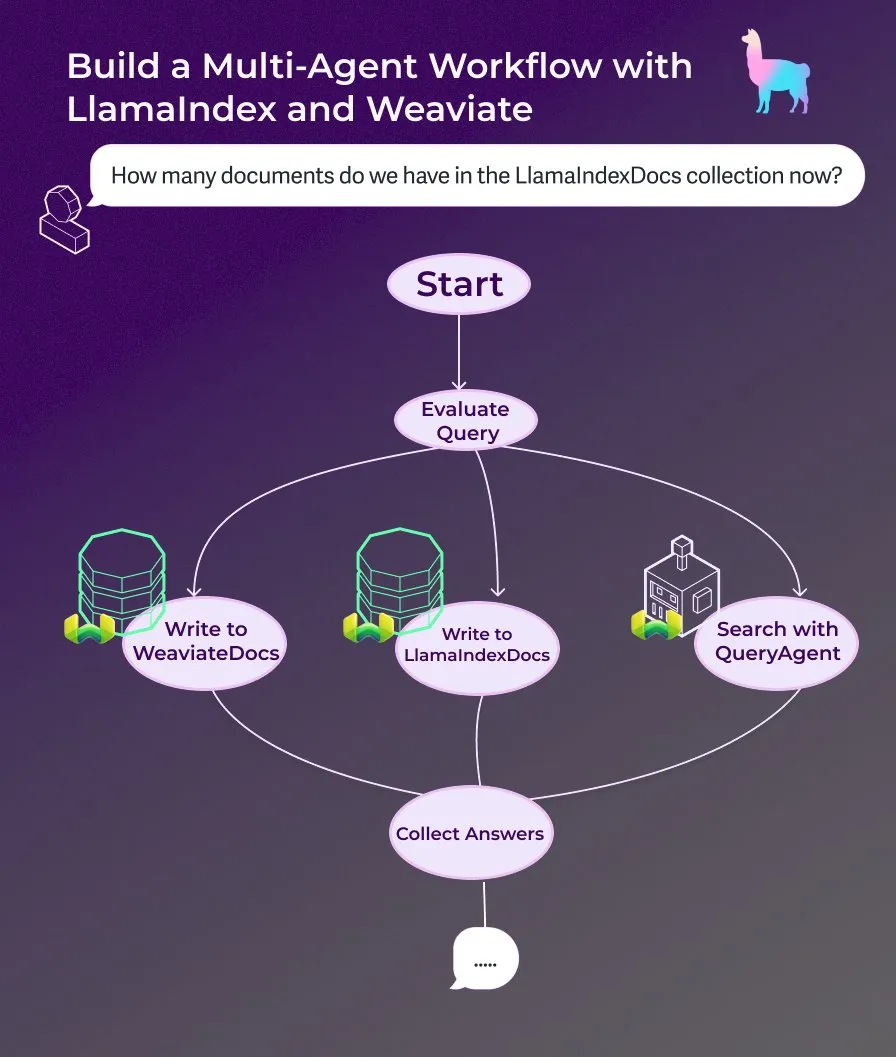
LlamaIndex、イベント駆動型エージェントワークフローを用いたマルチエージェントドキュメントアシスタント構築チュートリアルを公開 : LlamaIndexは、イベント駆動型エージェントワークフローを使用してマルチエージェントドキュメントアシスタントを構築する方法を示す新しいウォークスルーチュートリアルを公開しました。このアシスタントは、ウェブページのコンテンツをLlamaIndexDocsおよびWeaviateDocsコレクションに書き込み、オーケストレーターを使用してWeaviate QueryAgentをいつ呼び出して検索と集約を行うかを決定し、構造化出力を使用してクエリを分類し、オプションでFunctionAgentを使用できます。(出典: LlamaIndex 🦙)
Modular、Mojoコンパイラ内部に関する技術講演を公開、MojoとGPUアーキテクチャを議論 : Modular社は、社内技術講演の共有を開始し、最初に公開された講演では、Mojoプログラミング言語とGPUアーキテクチャのテーマを深く掘り下げています。内容は、Mojoコンパイラの内部動作原理や、チームが現代のGPU向け開発で直面した課題と解決策を含み、コミュニティにその技術スタックの詳細を共有することを目的としています。(出典: Modular)
AI by Handワークショップ:ExcelでTransformerモデルをゼロから構築 : ProfTomYeh氏は、参加者がExcelでTransformerモデルをゼロから構築することを目指すAI by Handワークショップを推進しています。この方法を通じて、学習者はTransformerの各数学的ステップを明確かつ直感的に理解し、「ブラックボックス」として扱うことを避け、モデルの内部動作メカニズムに対する深い理解を確立することができます。(出典: ProfTomYeh)
DeepLearning.AI、The Batch第301号を発行:AIの速度がもたらすビジネス価値と最新動向を議論 : Andrew Ng氏は、最新号のThe Batchで、AIによるタスク実行速度の向上がビジネス価値創出に与える重要性が見過ごされていると論じています。彼は、AIはコストを削減するだけでなく、アイデアからプロトタイプまでの時間を短縮することで、イノベーションと探求を加速させると考えています。今号では、Microsoft Phi-4推論シリーズの発表、DeepCoder-14Bの性能がo1に匹敵、EUのAI規則緩和などのニュースも報じられています。(出典: DeepLearningAI)
💼 ビジネス
AIキャラクターアニメーションのスタートアップCartwheelが1000万ドルを調達、3Dアニメーションプロセスを簡素化 : AIキャラクターアニメーションに特化したスタートアップ企業Cartwheelは、1000万ドルの資金調達を完了したと発表しました。同社は3Dアニメーション制作プロセスを簡素化する技術の開発に取り組んでおり、クリエイターがより迅速かつ経済的に高品質な3Dキャラクターアニメーションを制作できるようにするとともに、最終製品に対するコントロールを強化し、煩雑な作業を排除することを目指しています。(出典: andrew_n_carr)
Hedra、a16z主導で3200万ドルのシリーズA資金調達、キャラクター主導のビデオ制作を加速 : AIビデオ生成スタートアップのHedraは、Andreessen Horowitz (a16z) が主導する3200万ドルのシリーズA資金調達を完了したと発表し、Matt Bornstein氏が取締役に就任しました。既存投資家のa16z speedrun、Abstract、Index Venturesも本ラウンドに参加しました。Hedraはキャラクター主導のビデオ制作を容易にすることに注力しており、昨年のステルスモード開始以来、約300万人が同社のツールを使用して1000万本以上のビデオを制作しています。新たな資金は、製品開発の加速、チームの拡大に充てられ、迅速で表現力豊か、かつ直感的なコンテンツ制作の実現を目指します。(出典: Hedra)
Tripadvisor、Qdrantを活用してAI旅行プランを構築、ユーザーエンゲージメントが2~3倍に向上 : Tripadvisorは、Qdrantベクトルデータベースを使用して旅行発見体験を再定義しています。10億件以上のレビューと写真、1100万件の施設、21カ国のデータを分析することで、Tripadvisorは従来のフィルターに頼るのではなく、AIが生成するダイナミックな旅程を作成しています。その結果、これらのAIツールを使用したユーザーの滞在時間は2~3倍に増加し、パーソナライズされた旅行プランニングにおけるAIの大きな可能性を示しています。(出典: qdrant_engine)

🌟 コミュニティ
Grokの「白人人種虐殺」に関する発言が物議、Sam Altman氏が皮肉で応酬 : xAIのGrokモデルが、南アフリカにおける白人人種虐殺に関する見解をランダムに表明したことで、広範な議論と批判を引き起こしました。Paul Graham氏は、この挙動は最近のパッチで導入されたバグのようだと指摘し、広く使用されているAIがその管理者によって即座に見解を編集されることを懸念しています。一方、Sam Altman氏は皮肉を込めて、xAIは透明性のある説明をし、この問題を「南アフリカの白人人種虐殺」という文脈で理解するだろうと応じ、これはAIが真実を追求し指示に従った結果であると示唆しました。この件に関するコミュニティの議論は、AIモデルの偏り、制御可能性、そしてその背後にある意図に対する普遍的な懸念を反映しています。(出典: Paul Graham)
AI製品化の考察:単純なAI機能の追加ではなく、ユーザーのタスク全プロセスから機会を発掘 : Cloud Nine Capitalのパートナーである任鑫氏は、AI製品化に関する深い考察を共有し、企業はユーザーがタスクを完了する全プロセスから出発し、AI応用の切り口を見つけるべきであり、既存製品に単純にAI機能を追加するべきではないと強調しました。彼は「ユーザーが欲しいのは電動ドリルではなく、壁の穴だ」という比喩を用い、ユーザーのタスクを分解し、ペインポイントを見つけてAIで最適化することを提案しました。AI製品化の4つのレベルには、古いプロセスの効率的な完了、新しいプロセスの創造、全く新しい市場の開拓(使用の敷居を下げ、新しいユーザー層にサービスを提供し、さらにはAI自体も)、そしてAI主導の未来のためのインフラ整備が含まれます。彼は、AI技術は平等化しつつあり、技術に詳しくない企業も機会を掴むことができ、本質的には「AIに仕事を見つけてあげる」ことだと考えています。(出典: 混沌大学)
議論:キャリア開発におけるAIの役割と適応戦略 : LinkedIn上の投稿が、AIがキャリア開発にどのように影響するかについての議論を引き起こしました。「AIがあなたの仕事を奪うことはないが、AIを使う人が奪うだろう」という一般的な言説があります。しかし、この言説は曖昧すぎると指摘されています。数十年の経験を持つフロントエンドエンジニアなどの特定の職種にとって、どのように突然AIエンジニアに転身するのか、そして誰もがAIエンジニアになれるわけではないという問題が提起されています。コミュニティの議論では、フロントエンド開発者にとっては、AIツールを使って仕事の効率を上げることを学ぶことができると考えられています。また、AIが大量の仕事を奪い、多くの人が行き場を失うだろうという意見もあります。より一般的な見方としては、未来はまだ不確かだが、創造性、問題発見能力、そして人間性を理解し触れる能力がより防御的になる可能性があるというものです。(出典: Reddit r/ArtificialInteligence)
議論:LLMは複数ターンの対話で「迷子」になりやすく、対話の再起動が有効な場合も : ある研究論文によると、オープンソースかクローズドソースかにかかわらず、LLMは複数ターンの対話においてパフォーマンスが著しく低下します。ほとんどのベンチマークテストは、単一ターンで指示が明確なシナリオに焦点を当てています。研究によると、LLMは初期の対話ターンで(誤った)仮定を立て、その後の対話でこれらの仮定に依存し、修正が困難になることがよくあります。結論として、複数ターンの対話が期待通りに進まない場合、新しい対話を開始し、関連するすべての情報を最初のターンの入力に統合することが役立つ可能性があります。(出典: Reddit r/LocalLLaMA)
AppleとWeChatのAI開発ペースが比較的遅い理由の考察:プライバシーセキュリティとアプリケーション優先戦略 : 衛夕氏は記事の中で、Appleが「Apple Intelligence」を発表し、WeChatもDeepSeekと元宝に接続したものの、両者のAIコア機能における推進速度は比較的遅いと分析しています。主な理由は2つあります。第一に、プライバシーとデータセキュリティに対する感度が高いことです。AIのインテリジェンスはデータに依存しますが、AppleとWeChatのコアビジネスモデルは、データ共有において非常に慎重であることを決定づけており、これがモデルトレーニングとアプリケーションコンテキストの取得を制限しています。第二に、両者とも「アプリケーション優先」戦略を採用しており、モデルのインテリジェンス上限においてトップAI企業と競争することを追求しておらず、むしろAI能力を既存の機能とエコシステムに統合することに重点を置いているため、技術的主導権と製品イテレーション速度において制約を受ける可能性があります。(出典: 卫夕指北)

OpenAI、「AからZへの挑戦」を開始:AIを使ってアマゾンで未知の考古遺跡を発見 : OpenAIはKaggleとの協力で、「OpenAI to Z Challenge」特色ハッカソンを開始すると発表しました。このチャレンジは、参加者がOpenAI o3、o4-mini、またはGPT-4.1モデルを使用して、アマゾン地域で以前は知られていなかった考古遺跡を探すことを奨励しています。参加者は#OpenAItoZタグを使用して進捗を共有できます。このイベントは、考古学および地理空間分析分野におけるAIの応用可能性を探ることを目的としています。(出典: OpenAI Developers)
「AI弁護士」スタートアップへの批判:自動化された「恐喝状」が社会の負担になる可能性 : 開発者の@swyx氏は、一部のVCが「AI弁護士」スタートアップに投資している現象を批判しています。彼は、これらの企業が主にAIを使って「督促状」(demand letters)を自動生成しており、本質的には自動化された恐喝であると考えています。一部の督促は正当なものであるかもしれませんが、彼はこのような行為の大部分は最終的に弁護士に利益をもたらすだけであり、社会に対する純粋な税金になると指摘しています。彼は、このような企業とその投資家をボイコットし、資金を引き揚げ、公に批判するよう呼びかけています。(出典: swyx)

💡 その他
石炭研究レポートに「ウィザースケルトンを倒して入手」というありえない誤り、コンテンツ品質とAI幻覚について議論を呼ぶ : 価格8200元の石炭業界研究レポートに、「石炭は再生可能資源であり、ウィザースケルトンを倒すことで入手できる」という記述が登場しました。これはゲーム『マインクラフト』の内容に由来するもので、ネット上で大きな話題となりました。多くの人がこれをAIコンテンツ生成と幻覚のせいにしましたが、このレポートは2022年に出版されており、ChatGPTなどの主要な大規模モデルの発表よりも前であるため、これは人為的なコピー&ペーストと監査の怠慢による典型的な事例であると指摘されています。この事件はまた、専門的なレポートのコンテンツ品質、情報検証の重要性、そしてAI時代においてどのように情報の真偽を見分けるかについて、深い反省を促しました。(出典: caoz的梦呓)

研究者、カスタマイズされた遺伝子編集療法を用いて希少な代謝性疾患の乳児を治療 : 医師たちは7ヶ月足らずでカスタマイズされた遺伝子編集療法を構築し、致命的な代謝性疾患を持つ乳児の治療に成功しました。これは、遺伝子編集が初めて個々の個人に対してカスタマイズされた治療に用いられた例です。この療法は、乳児の遺伝子における特定の1文字の誤りを修正することを目的としており、塩基編集などの新しい遺伝子編集技術の精度を示しています。治療は初期の肯定的な兆候を示していますが、同時に、超希少疾患のための個別化遺伝子療法の開発におけるコストとスケーラビリティの課題も浮き彫りにしています。(出典: MIT Technology Review)

汎用ジェイルブレイクプロンプト戦略が暴露、主要な大規模モデルの安全ガードレールを回避可能 : HiddenLayerの研究者は、ChatGPT、Claude、Geminiを含む主要な大規模言語モデルが安全ガードレールを回避し、有害なコンテンツを生成できるようにする汎用的なプロンプト戦略を発見しました。この戦略は、有害な指示をXML、INI、JSONなどのポリシーファイルに似た形式に偽装し、架空のロールプレイングシナリオと組み合わせることで、モデルに有害なコマンドを正当なシステム指示として解釈させるものです。この方法は、モデルの訓練データに存在する可能性のある体系的な弱点、すなわち教育またはポリシー関連データを処理する際に安全指示を無視する傾向を利用しています。この技術はまた、モデルのシステムプロンプトを抽出し、その内部指示と安全制約を暴露することも可能です。(出典: 新智元)
