
キーワード:AlphaEvolve, Claude Sonnet, GPT-4.1, Meta FAIR, Qwen3, Phi-4-reasoning, AI規制, Gemini駆動のコーディングエージェント, 行列乗算アルゴリズムの最適化, データセンター効率化, 多言語マルチモーダルモデル, 分散型AIトレーニングネットワーク, Seed1.5-VL
🔥 注目ニュース
Google DeepMind、AlphaEvolveを発表:Gemini駆動のコーディングエージェント、アルゴリズム発見に革命: Google DeepMindは、Gemini駆動のAIコーディングエージェントであるAlphaEvolveを発表しました。これは、大規模言語モデルの創造性と自動評価器を組み合わせることで、複雑なアルゴリズムを発見・最適化することを目的としています。AlphaEvolveは、より高速な行列乗算アルゴリズムの設計に成功し、Erdősの最小重複問題や接吻数問題などの未解決の数学的問題を解決しました。また、Google内部ではデータセンターの効率最適化(平均0.7%の計算資源を回収)、チップ設計、Gemini自体のトレーニング加速に使用され、AIが科学的発見と工学的最適化において大きな可能性を秘めていることを示しています。(ソース: GoogleDeepMind, DeepLearning.AI Blog)
Anthropic、Claude SonnetとOpusの新モデルを間もなく発表、推論とツール呼び出し能力を強化: The Informationの報道によると、Anthropicは今後数週間以内にClaude SonnetとClaude Opusの新バージョンをリリースする計画です。新モデルの主な特徴は、「思考モード」と「ツール使用モード」を柔軟に切り替えられる点です。外部ツール(アプリケーション、データベースなど)を使用して問題解決に行き詰まった場合、モデルは能動的に「推論モード」に戻り、反省して自己修正できます。コード生成に関しては、新モデルは生成されたコードを自動的にテストし、エラーが発見された場合は一時停止し、思考して修正します。この「思考―行動―反省」の閉ループは、モデルが複雑な問題を解決する能力と信頼性を大幅に向上させることが期待されます。(ソース: steph_palazzolo, dotey)

米国共和党議員、10年間の連邦および州レベルでのAI規制禁止を提案、激しい議論を呼ぶ: 米国共和党議員は、予算調整法案に条項を追加し、今後10年間、連邦および州政府による人工知能モデル、システム、または自動意思決定システムの規制を禁止することを提案し、AIの商業化および連邦政府のITシステムへの応用を支援するために5億ドルの予算を計画しています。この動きは、一部のテクノロジー業界関係者からはAIイノベーションを保護し、規制による扼殺を防ぐ積極的なシグナルと見なされていますが、DeepFakeの蔓延、データプライバシーの制御不能、AI倫理および環境への影響などの潜在的なリスクに対する懸念も引き起こしています。この提案が可決されれば、既存および将来のAI立法に重大な影響を与えるでしょう。(ソース: Reddit r/ArtificialInteligence, Yoshua_Bengio)

OpenAI、GPT-4.1モデルをリリースし安全性評価センターを開設、コーディングと指示追従能力を強調: OpenAIは、ユーザーの要望に応え、GPT-4.1モデルを本日よりChatGPTで利用可能にすると発表しました(Plus、Pro、Teamユーザー向け、Enterprise版とEducation版は後日提供)。GPT-4.1はコーディングタスクと指示追従に特化して最適化されており、より高速で、o3およびo4-miniの日常的なコーディング代替品として使用できます。同時に、GPT-4.1 miniは、現在すべてのユーザーが使用しているGPT-4o miniに取って代わります。さらに、OpenAIは安全性評価センター(Safety Evaluations Hub)を立ち上げ、モデルの安全性テスト結果と指標を公開し、定期的に更新することで、安全性に関するコミュニケーションの透明性を高めます。(ソース: openai, michpokrass)
Meta FAIR、分子発見と原子モデリングに焦点を当てた複数のAI研究成果を発表: Meta AI (FAIR) は、分子特性予測、言語処理、神経科学の分野における最新のオープンソースバージョンを発表しました。これには、大規模原子システムのシミュレーションのための分子発見データセットであるOpen Molecules 2025 (OMol25)、材料および分子の原子間相互作用モデリングに幅広く応用可能な機械学習原子間ポテンシャルモデルであるUniversal Model for Atoms (UMA)、スカラー報酬に基づいて生成モデルをトレーニングするためのスケーラブルなアルゴリズムであるAdjoint Samplingが含まれます。さらに、FAIRはロスチャイルド財団病院との共同研究により、人間とLLMの言語発達における著しい類似性を明らかにしました。(ソース: AIatMeta)
🎯 動向
ByteDance、Seed1.5-VL視覚言語大規模モデルを発表、20Bアクティブパラメータで卓越した性能: ByteDanceは、視覚-言語マルチモーダル大規模モデルSeed1.5-VLを発表しました。このモデルは、わずか20Bのアクティブパラメータで、Gemini 2.5 Proに匹敵する性能を示し、60の公開評価ベンチマークのうち38でSOTAを達成しました。Seed1.5-VLは、汎用的なマルチモーダル理解と推論能力を強化し、特に視覚的定位、推論、ビデオ理解、マルチモーダルエージェントにおいて優れた性能を発揮します。モデルはVolcengineでAPIが公開されており、推論入力価格は0.003元/千トークン、出力は0.009元/千トークンです。(ソース: 机器之心)

Qwen3技術レポートが明らかに:思考モードと非思考モードを融合、大規模モデルが小規模モデルを蒸留: AlibabaはQwen3シリーズモデルの技術レポートを発表し、0.6Bから235Bパラメータまでの8つのモデルが含まれています。中核となるイノベーションはデュアルワークモードであり、モデルはタスクの複雑さに応じて「思考モード」(複雑な推論)と「非思考モード」(迅速な応答)を自動的に切り替え、「思考バジェット」パラメータを通じて計算リソースを動的に割り当てます。トレーニングは3段階の事前学習(一般知識、推論強化、長文テキスト)と4段階の事後学習(長思考連鎖コールドスタート、推論強化学習、思考モード融合、一般強化学習)を採用しています。同時に、「大が小を導く」データ蒸留戦略を採用し、教師モデル(例:235B)の出力を使用して学生モデル(例:30B)をトレーニングし、知識移転を実現します。(ソース: 36氪)

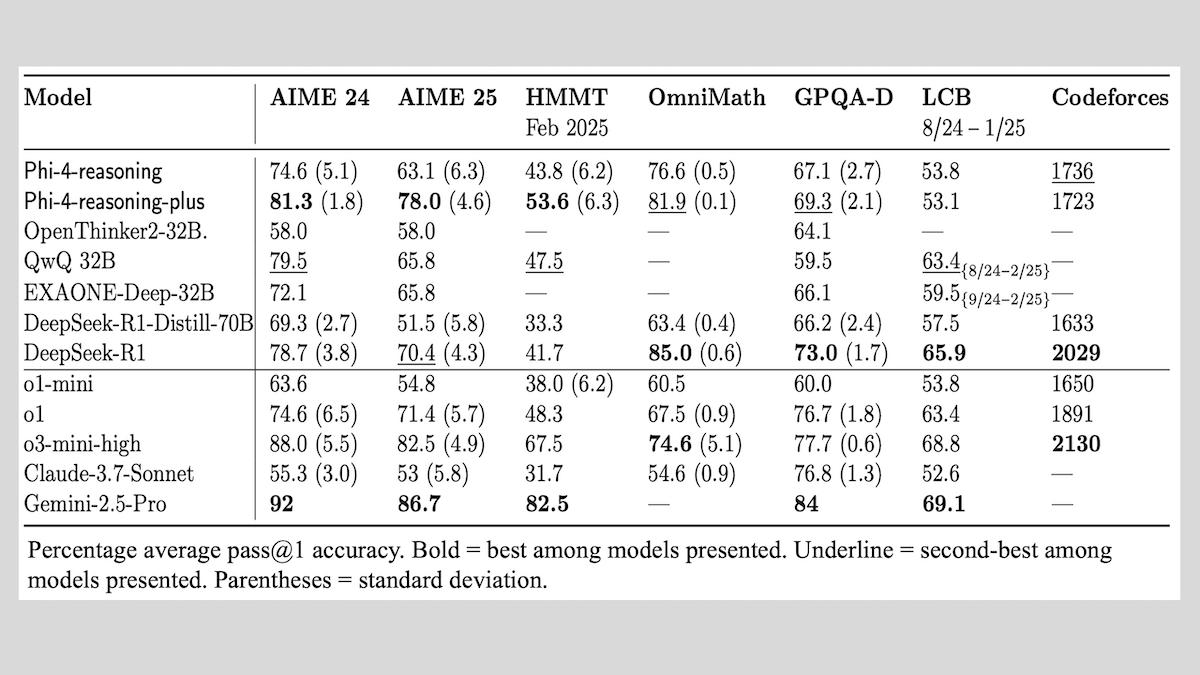
Microsoft、Phi-4-reasoningシリーズモデルを発表、推論モデルのトレーニング経験を共有: Microsoftは、Phi-4-reasoning、Phi-4-reasoning-plus(いずれも14Bパラメータ)、およびPhi-4-mini-reasoning(3.8Bパラメータ)の3つのモデルを発表し、そのトレーニング方法と経験を公開しました。これらのモデルは、事前トレーニング済みモデルのファインチューニングを通じて、数学的推論などの能力向上に焦点を当てています。例えば、Phi-4-reasoning-plusは強化学習により数学的問題で優れた性能を発揮し、Phi-4-mini-reasoningは段階的にSFTとRLファインチューニングを行います。レポートでは、小規模モデルのトレーニングで発生しうる不安定性とその対処法、および大規模モデルのRLトレーニングにおけるデータ選択と報酬関数設計に関する考察が共有されています。モデルの重みはHugging FaceでMITライセンスの下で公開されています。(ソース: DeepLearning.AI Blog)
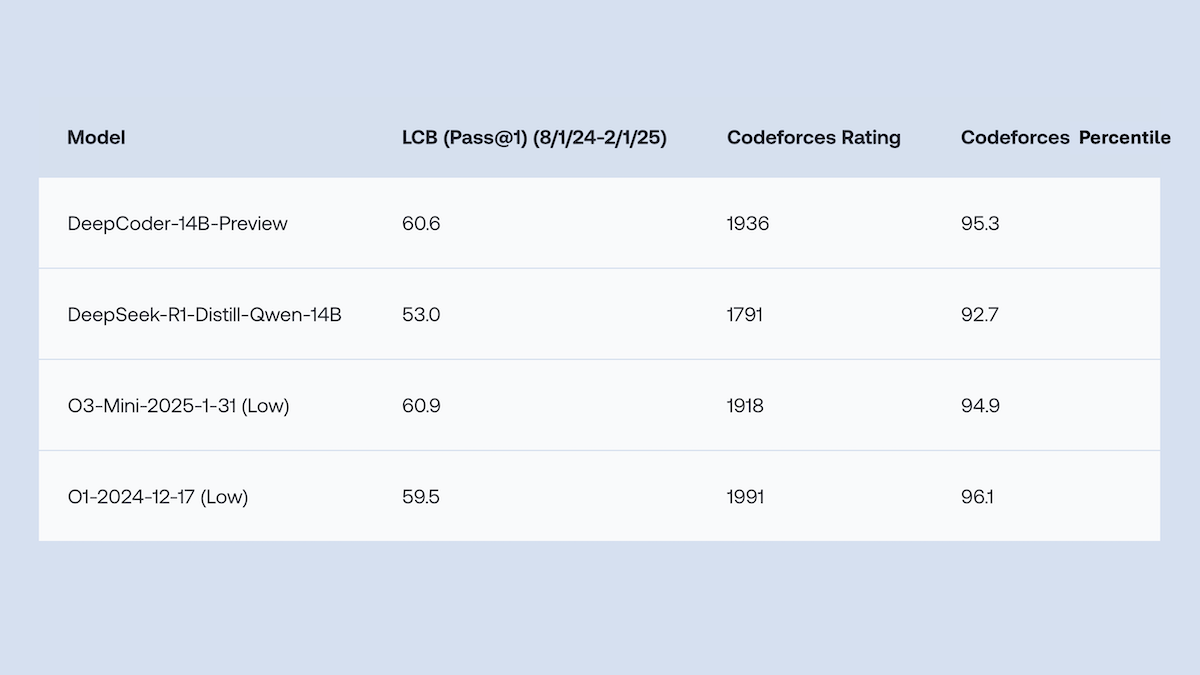
Together.AIとAgentica、DeepCoder-14B-Previewをオープンソース化、コード生成性能はo1に匹敵: Together.AIとAgenticaチームは、14Bパラメータのコード生成モデルであるDeepCoder-14B-Previewをリリースしました。その性能は、複数のコーディングベンチマークにおいて、DeepSeek-R1やOpenAI o1などのより大きなモデルに匹敵します。このモデルは、DeepSeek-R1-Distilled-Qwen-14Bをファインチューニングすることで開発され、簡略化された強化学習手法(GRPOとDAPOの最適化を組み合わせたもの)を採用し、RLライブラリVerlの並列処理能力を改善することで、トレーニング時間を大幅に短縮しました。モデルの重み、コード、データセット、トレーニングログはすべてMITライセンスでオープンソース化されています。(ソース: DeepLearning.AI Blog)
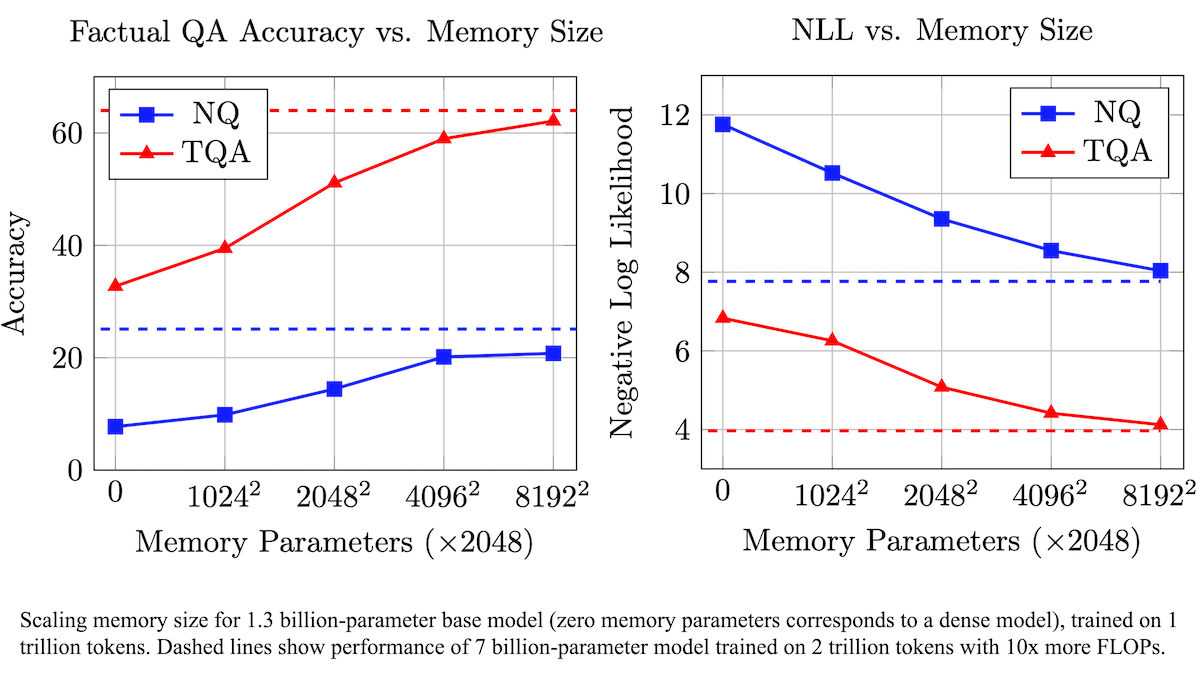
Meta、訓練可能なメモリ層によりLLMの事実正確性を向上させ、計算需要を削減する手法を提案: Metaの研究者は、Transformerアーキテクチャに訓練可能なメモリ層を追加することで、大規模言語モデルの事実想起における正確性を向上させると同時に、計算量を大幅に増加させることなく実現しました。この方法は、キーと対応する値を学習して情報を保存し、キーを2つのハーフキーに分解する戦略を採用することで、大規模なキー検索時の計算ボトルネックを効果的に解決します。実験では、メモリ層を備えた8Bパラメータモデルが、複数の質問応答データセットにおいてメモリ層のない同クラスのモデルを上回り、事前学習データと計算量の需要において優位性を示しました。(ソース: DeepLearning.AI Blog)
Alibaba、Wan2.1シリーズビデオ基盤モデルをオープンソース化、テキスト/画像からのビデオ生成および編集をサポート: Alibabaは、包括的なオープンソースビデオ基盤モデルスイートであるWan2.1を発表しました。これには1.3Bおよび14Bパラメータバージョンが含まれ、Apache 2.0ライセンスを採用しています。Wan2.1は、テキストからビデオ、画像からビデオ、ビデオ編集、テキストから画像、ビデオからオーディオなど、さまざまなタスクで優れたパフォーマンスを発揮し、特に中国語と英語のテキストによる視覚生成をサポートしています。そのT2V-1.3Bモデルは、わずか8.19GBのVRAMしか必要とせず、コンシューマグレードのGPUで実行可能で、4分以内に5秒の480Pビデオを生成できます。付属のWan-VAEは、1080Pビデオを効率的にエンコードおよびデコードし、時間情報を保持します。(ソース: _akhaliq, Reddit r/LocalLLaMA)

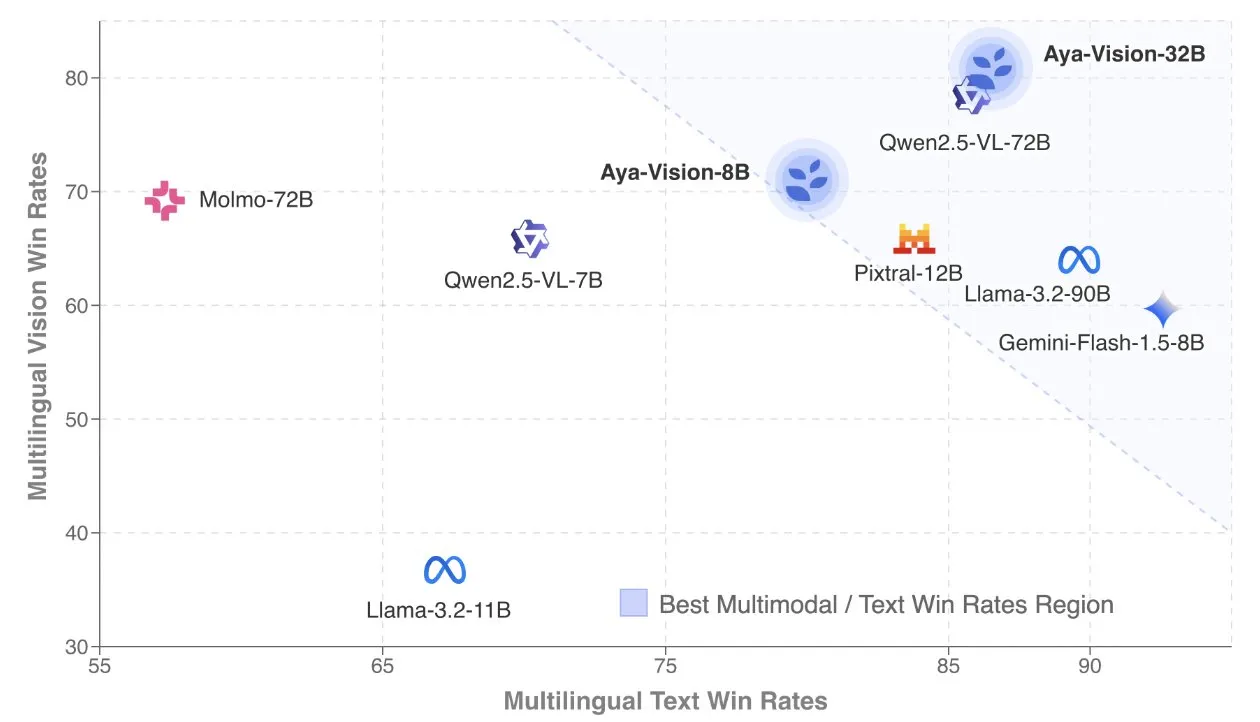
Cohere、Aya Vision技術レポートを発表、多言語マルチモーダルモデルに焦点: Cohere LabsはAya Vision技術レポートを公開し、SOTAの多言語マルチモーダルモデルを構築するためのレシピを詳細に説明しました。Aya Visionモデルは、23言語のマルチモーダルおよびテキストタスクにおける能力を統一することを目的としています。レポートでは、合成多言語データフレームワーク、アーキテクチャ設計、トレーニング方法、クロスモーダルモデルのマージ、およびオープンエンドの多言語生成タスクにおける包括的な評価について論じています。その8Bモデルは、Pixtral-12Bなどのより大きなモデルよりも性能が優れており、32Bモデルはより効率的で、Llama3.2-90Bなどの2倍以上のサイズのモデルを上回っています。(ソース: sarahookr, Cohere Labs)
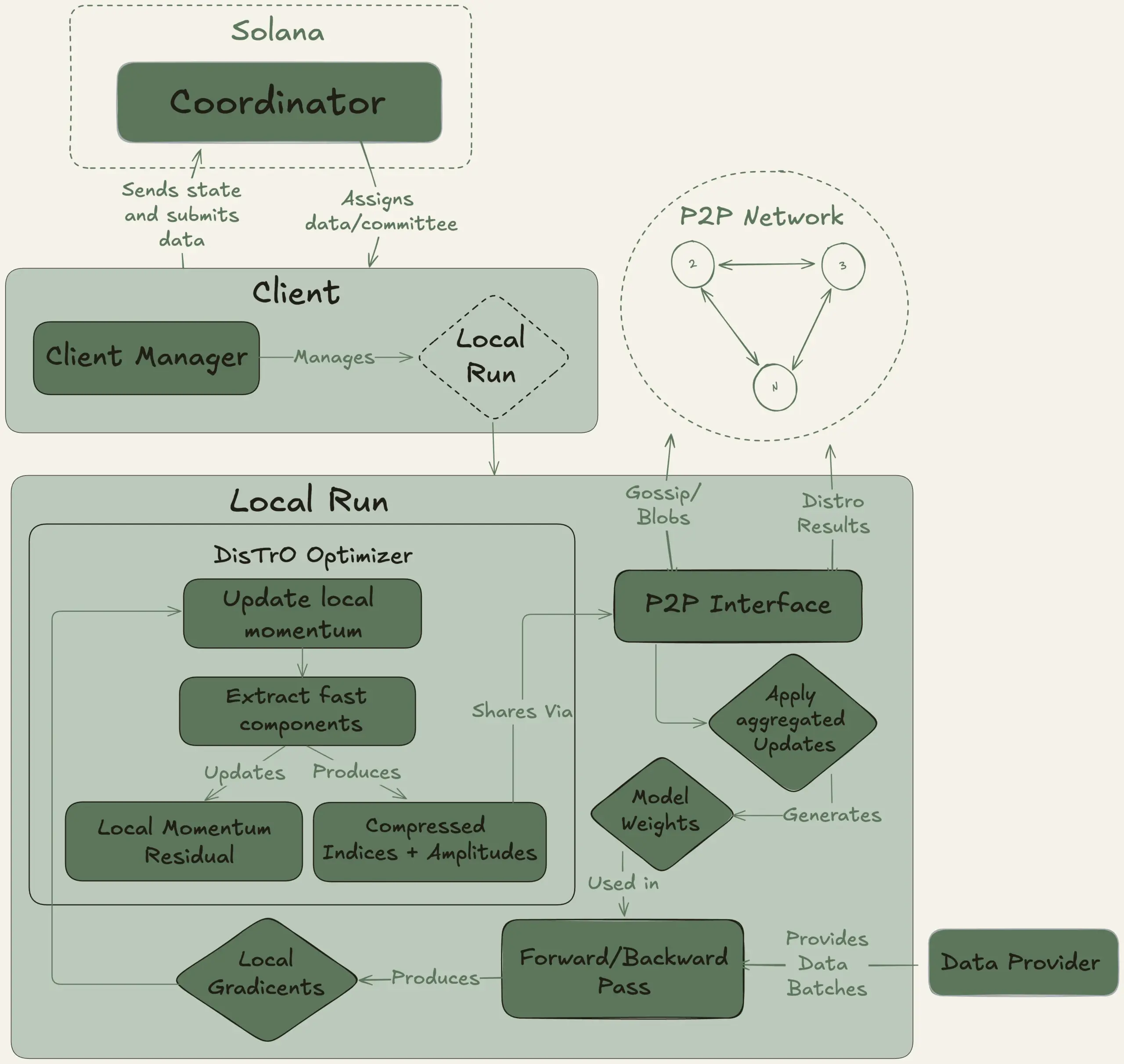
Nous Research、Psycheプロジェクトを開始、40Bパラメータの大規模モデルの分散型トレーニングを目指す: Nous Researchは、Psycheネットワークの開始を発表しました。これは、世界中の計算能力を結集して強力なAIモデルを共同でトレーニングし、個人や小規模コミュニティも大規模モデル開発に参加できるようにすることを目的とした分散型AIトレーニングネットワークです。そのテストネットは、MLAアーキテクチャを採用した40BパラメータのLLMの事前トレーニングを開始しており、データセットにはFineWeb (14T)、FineWeb-2の一部 (4T)、およびThe Stack v2 (1T) が含まれ、合計約20Tトークンです。このモデルのトレーニング完了後、すべてのチェックポイント(未アニール版およびアニール版を含む)およびデータセットがオープンソース化される予定です。(ソース: eliebakouch, Teknium1)
Stability AI、オープンソースのStable Audio Open Smallモデルをリリース、高速なテキストからオーディオ生成に特化: Stability AIはHugging Face上でStable Audio Open Smallモデルをリリースしました。これは高速なテキストからオーディオ生成のために特別に設計されたモデルであり、敵対的ポストトレーニング技術を採用しています。このモデルは、効率的でオープンソースのオーディオ生成ソリューションを提供することを目的としています。(ソース: _akhaliq)
Google Gemini Advanced、GitHubと統合、コーディング支援能力を強化: Googleは、Gemini AdvancedがGitHubと接続され、コーディングアシスタントとしての能力がさらに向上したと発表しました。ユーザーはパブリックまたはプライベートのGitHubリポジトリに直接接続し、Geminiを利用して関数の生成や変更、複雑なコードの説明、コードベースに関する質問、デバッグなどを行うことができます。プロンプト欄の「+」ボタンをクリックし、「コードをインポート」を選択してGitHub URLを貼り付けるだけで使用を開始できます。(ソース: algo_diver)
mlx-omni-server v0.4.0リリース、embeddingsサービスとより多くのTTSモデルを追加: mlx-omni-serverがv0.4.0にアップデートされ、新しい/v1/embeddingsサービスが導入されました。これにより、mlx-embeddingsを介した埋め込み生成が簡素化されます。同時に、より多くのTTSモデル(kokoro、barkなど)が統合され、mlx-lmがqwen3などの新しいモデルをサポートするようにアップグレードされました。(ソース: awnihannun)
Together Chat、PDFファイル処理機能を追加: Together Chatは、PDFファイルのアップロードと処理をサポートすると発表しました。現在のバージョンは主にPDF内のテキストコンテンツを解析し、モデルに渡して処理しますが、将来的にはv2バージョンをリリースし、PDF内の画像コンテンツを読み取るためのOCR機能を追加する予定です。(ソース: togethercompute)
テレンス・タオ氏、再びAIで数学の形式化証明に挑戦、Claudeがo4-miniを上回る性能: 数学者のテレンス・タオ氏は、自身のYouTubeシリーズ動画で、Lean証明アシスタントにおける代数的含意の形式化証明能力をAIでテストしました。実験では、Claudeは約20分でタスクを完了できましたが、コンパイル過程でLeanにおける自然数が0から始まるという規則の理解のずれや対称性の処理の問題が露呈したものの、人為的な介入により修正されました。対照的に、o4-miniはより慎重で、べき関数の定義の問題を認識できましたが、重要な証明ステップで断念し、タスクを完了できませんでした。タオ氏は、自動化への過度な依存は証明全体の構造把握を弱める可能性があり、最適な自動化レベルは0%から100%の間にあり、理解を深めるために人為的な介入を残すべきだと結論付けました。(ソース: 36氪)
アルトマン氏インタビュー:OpenAIの最終目標はコアAIサブスクリプションサービスの構築: OpenAI CEOのサム・アルトマン氏は、Sequoia CapitalのAI Ascent 2025イベントで、OpenAIの「プラトニックな理想」はAIオペレーティングシステムを開発し、ユーザーのコアAIサブスクリプションサービスになることだと述べました。彼は、将来のAIモデルがユーザーの一生のデータ(数兆規模のコンテキストトークン)を処理し、深いパーソナライズされた推論を実現すると構想しています。アルトマン氏はこれがまだ「PPT段階」であることを認めつつも、同社が柔軟性と適応性を誇りとしていることを強調しました。彼はまた、AI音声インタラクションの可能性、2025年がAIエージェントが活躍する年になること、そしてコーディングがモデルの運用とAPI呼び出しを駆動する核心になるとの見解を示しました。(ソース: 36氪, 量子位)

Karminski3、Qwen3-30Bコミュニティ修正版を共有、アクティブエキスパート数が倍増: 開発者コミュニティがQwen3モデルを修正し、Qwen3-30B-A6B-16-Extremeバージョンをリリースしました。モデルパラメータを変更することで、アクティブエキスパート数をA3BからA6Bに増加させ、これにより品質がわずかに向上するとされていますが、生成速度は相応に遅くなります。ユーザーは、llama.cppの実行パラメータ --override-kv http://qwen3moe.expert_used_count=int:24 を変更することでも同様の効果を得るか、逆にQwen3-235B-A22Bのアクティブ量を減らして速度を向上させることも可能です。(ソース: karminski3)

🧰 ツール
OpenMemory MCP発表:ローカル実行の共有メモリシステム、複数のAIツールを連携: mem0aiチームは、オープンモデルコンテキストプロトコル(MCP)に基づいて構築されたプライベートメモリサーバーであるOpenMemory MCPを発表しました。これは100%ローカルで実行され、現在のAIツール(Cursor、Claude Desktop、Windsurf、Clineなど)間でコンテキスト情報が共有されず、セッション終了とともに記憶が失われる問題を解決することを目的としています。ユーザーデータはローカルに保存され、プライバシーの安全性が確保されます。OpenMemory MCPは、標準化されたメモリオペレーションAPI(追加、削除、検索、変更)を提供し、ユーザーがメモリとクライアントアクセス権限を管理するための一元化されたダッシュボードを備え、Dockerを通じて展開を簡素化します。(ソース: 36氪, AI进修生)

LangChain、LangGraphプラットフォーム正式版および多数のアップデートを発表、AIエージェント開発と可観測性を強化: LangChainはInterruptカンファレンスで、LangGraphプラットフォームの正式な一般提供(GA)を発表しました。このプラットフォームは、長時間実行され、ステートフルなAIエージェントワークフローの構築と管理に特化して設計されており、ワンクリックデプロイ、水平スケーリング、メモリ、人間参加型(HIL)、会話履歴などのAPIをサポートしています。同時にリリースされたLangGraph Studio V2は、エージェントIDEとして、ローカル実行、設定の直接編集、Playgroundの統合をサポートし、本番環境の追跡データを取得してローカルでデバッグすることができます。さらに、LangChainはオープンソースのノーコードエージェント構築プラットフォームOpen Agent Platform (OAP) を発表し、LangSmithにおけるツール呼び出しと軌跡に関するエージェントの可観測性を強化しました。(ソース: LangChainAI, hwchase17)
PatronusAI、Percivalを発表:他のAIエージェントを評価・修復できるAIエージェント: PatronusAIは、他のAIエージェントのエラーを評価し自動的に修復できる初のAIエージェントと称するPercivalを発表しました。Percivalは、エージェントの追跡記録における障害を検出するだけでなく、修復提案も行います。GAIAおよびSWE-Benchの人為的にラベル付けされたエラーを含むTRAILデータセットにおいて、Percivalの性能はSOTA LLMよりも2.9倍高いとされています。その機能には、エージェントのプロンプト修復案の自動提案、20種類以上のエージェント障害タイプ(ツール使用、計画調整、ドメイン固有エラーなどを含む)の捕捉、手動デバッグ時間を数時間から1分以内に短縮することが含まれます。(ソース: rebeccatqian, basetenco)
PyWxDump:WeChat情報取得・エクスポートツール、AIトレーニングをサポート: PyWxDumpは、WeChatアカウント情報(ニックネーム、アカウント、携帯電話、メールアドレス、データベースキー)を取得し、データベースを復号化し、ローカルでチャット履歴を表示し、チャット履歴をCSV、HTMLなどの形式でエクスポートできるPythonツールで、AIトレーニング、自動返信などのシーンで使用できます。このツールは、複数アカウントの情報取得とすべてのWeChatバージョンをサポートし、チャット履歴を表示するためのウェブ版UIも提供しています。(ソース: GitHub Trending)

Airweave:AIエージェントがあらゆるアプリケーションを検索できるツール、MCPプロトコルと互換: Airweaveは、AIエージェントがあらゆるアプリケーションのコンテンツを意味的に検索できるようにすることを目的としたツールです。モデルコンテキストプロトコル(MCP)と互換性があり、さまざまなアプリケーション、データベース、またはAPIにシームレスに接続し、そのコンテンツをエージェントが利用可能な知識に変換します。主な機能には、データ同期、エンティティ抽出と変換、マルチテナントアーキテクチャ、増分更新、セマンティック検索、バージョン管理などが含まれます。(ソース: GitHub Trending)

iFLYTEK、viaim AIブレイン搭載の新世代AIイヤホンiFLYBUDS Pro3とAir2を発表: 未来智能は、iFLYTEK AI会議イヤホンiFLYBUDS Pro3とiFLYBUDS Air2を発表しました。両イヤホンとも、新しいviaim AIブレインを搭載しています。viaimは、個人向けビジネスオフィス用のAIエージェントであり、エンドツーエンドのインテリジェントセンシング処理、インテリジェントエージェント協調推論、リアルタイムマルチモーダル機能、データセキュリティプライバシー保護の4つのコアモジュールを統合しています。イヤホンは、便利な記録(通話、現場、オーディオ/ビデオ録音)、AIアシスタント(タイトル要約の自動生成、的を絞った質問)、多言語翻訳(32言語、同時通訳、対面翻訳、通話翻訳)などの機能をサポートし、音質と装着感も向上させています。(ソース: WeChat)

KoboldCpp Smart Launcher発表:LLM性能を最適化するTensor Offload自動調整ツール: KoboldCpp Smart LauncherというGUIおよびCLIツールがリリースされました。これは、ユーザーがローカルでLLMを実行する際にKoboldCppの最適なTensor Offload戦略を自動的に見つけるのを支援することを目的としています。テンソルをCPUとGPU間でより細かく(層全体ではなく)割り当てることにより、このツールはVRAMの需要を増やすことなく生成速度を2倍以上に向上させるとされています。例えば、QwQ Mergeは12GB VRAM GPUで速度が3.95 t/sから10.61 t/sに向上しました。(ソース: Reddit r/LocalLLaMA)
OpenBMB、AgentCPM-GUIをオープンソース化:中国語に最適化された初のデバイス側GUIエージェント: OpenBMBチームは、中国語アプリケーションに特化して最適化された初のデバイス側GUI(グラフィカルユーザーインターフェース)エージェントであるAgentCPM-GUIをオープンソース化しました。このエージェントは、強化学習ファインチューニング(RFT)により推論能力を強化し、コンパクトなアクションスペース設計を採用し、高品質なGUI位置特定(grounding)能力を備えており、中国語環境でのさまざまなアプリケーション操作におけるユーザーエクスペリエンスの向上を目指しています。(ソース: Reddit r/LocalLLaMA)
MAESTRO:ローカルファーストのAI研究アプリケーション、マルチエージェント連携とカスタムLLMをサポート: MAESTRO (Multi-Agent Execution System & Tool-driven Research Orchestrator) は、ローカル制御と能力を重視した新しくリリースされたAI駆動の研究アプリケーションです。ドキュメント抽出、強力なRAGプロセス、マルチエージェントシステム(計画、研究、反省、執筆)を含むモジュラーフレームワークを提供し、複雑な研究問題に対応できます。ユーザーはStreamlit Web UIまたはCLIを介して対話し、独自のドキュメントセットと選択したローカルまたはAPI LLMを使用できます。(ソース: Reddit r/LocalLLaMA)
Contextual AI、RAGに最適化されたドキュメントパーサーを発表: Contextual AIは、検索拡張生成(RAG)システム向けに特別に設計された新しいドキュメントパーサーを発表しました。このツールは、視覚、OCR、視覚言語モデルを組み合わせることで、複雑な非構造化ドキュメントの高精度な解析を提供し、ドキュメントの階層構造を保持し、表、グラフ、図などの複雑なモダリティを処理し、ユーザーが監査できるようにバウンディングボックスと信頼スコアを提供することで、RAGシステムにおける解析失敗によるコンテキスト欠落と幻覚を削減することを目的としています。(ソース: douwekiela)
Gradio、ImageEditorにアンドゥ/リドゥ機能を追加: GradioのImageEditorコンポーネントに、アンドゥ(元に戻す)とリドゥ(やり直し)ボタンが追加されました。これにより、ユーザーはプロフェッショナルな有料アプリケーションと同様のPython画像編集機能を利用でき、インタラクティブ性と使いやすさが向上します。(ソース: _akhaliq)
RunwayML、References新機能を発表、ゼロショットでのマテリアル、衣装、場所、ポーズのテストをサポート: RunwayMLのReferences機能が更新され、ユーザーは従来の3Dマテリアルボールのプレビュー画像を入力として使用し、そのマテリアルを任意のオブジェクトに適用することで、ゼロショットでのマテリアル移行と視覚化を実現できます。さらに、新機能は衣装、場所、キャラクターのポーズのゼロショットテストもサポートし、クリエイティブな生成と迅速なプロトタイピングの可能性を広げます。(ソース: c_valenzuelab, c_valenzuelab)

秘塔AI、「今日学点啥」(今日何を学ぶか)機能をリリース、AIによる構造化学習を支援: 秘塔AIは「今日学点啥」という新機能をリリースしました。これは、AIを情報検索や文書処理のアシスタント役から、能動的に指導・教育できる「AI先生」へと転換させることを目的としています。ユーザーが資料をアップロードまたは検索すると、この機能は体系的かつ構造化されたビデオコースとPPT解説を自動生成し、ユーザーが知識ポイントを整理するのを助けます。また、ユーザーのレベルに応じて異なる解説深度(初心者/専門家)とスタイル(物語風/短気な兄貴風など)を選択できます。さらに、途中での質問や授業後のテストもサポートしています。(ソース: WeChat)

📚 学習
アンドリュー・ン氏とAnthropicが提携し新コースを開設:MCPを用いたリッチコンテキストAIアプリケーションの構築: アンドリュー・ン氏のDeepLearning.AIはAnthropicと提携し、新コース「MCP: Build Rich-Context AI Apps with Anthropic」を開設しました。講師はAnthropicのテクニカルエデュケーション責任者であるElie Schoppik氏が務めます。このコースは、LLMが外部ツール、データ、プロンプトにアクセスする方法を標準化することを目的としたオープンプロトコルであるモデルコンテキストプロトコル(MCP)に焦点を当てています。受講者はMCPのコアアーキテクチャを学び、MCP互換のチャットボットを作成し、MCPサーバーを構築・展開し、それをClaude駆動のアプリケーションや他のサードパーティサーバーに接続することで、リッチコンテキストAIアプリケーションの開発を簡素化する方法を学びます。(ソース: AndrewYNg, DeepLearningAI)
FlashInfer:MLSys 2025最優秀論文、効率的でカスタマイズ可能なLLM推論アテンションエンジン: ワシントン大学の葉子豪(Zihao Ye)氏、NVIDIA、OctoAIの陳天奇氏らが協力したFlashInferプロジェクトがMLSys 2025最優秀論文賞を受賞しました。FlashInferは、LLM推論サービス向けに最適化設計された効率的でカスタマイズ可能なアテンションエンジンであり、メモリアクセスの最適化(ブロックスパース形式とコンポーザブル形式を採用してKVキャッシュを処理)、JITコンパイルに基づく柔軟なアテンション計算テンプレートの提供、および負荷分散タスクスケジューリングメカニズムの導入により、LLM推論性能を大幅に向上させ、vLLM、SGLangなどのプロジェクトに統合されています。(ソース: 机器之心)
ICML 2025論文:データ操作の観点からグラフプロンプティング(Graph Prompting)の理論的分析を提供: 香港中文大学の王群中氏、孫相国博士、程鴻教授はICML 2025で論文を発表し、初めて「データ操作」の観点からグラフプロンプティングの有効性に関する体系的な理論的フレームワークを提供しました。研究では「ブリッジンググラフ」の概念を導入し、グラフプロンプティングメカニズムが理論上、入力グラフデータに対してある種の操作を行うことと等価であり、それによって事前学習済みモデルが新しいタスクに適応するために正しく処理できるようになることを証明しました。論文は誤差の上限を導出し、誤差の源と制御可能性を分析し、誤差分布をモデル化することで、グラフプロンプティングの設計と応用に理論的基礎を提供しました。(ソース: WeChat)
ICML 2025論文:トークンレベル編集による合成テキストデータでモデル崩壊を回避: 上海交通大学などの研究チームはICML 2025で論文を発表し、合成データが引き起こす「モデル崩壊」の問題を探求し、「Token-Level Editing」というデータ生成戦略を提案しました。この方法は、完全に新しいテキストを生成するのではなく、実データ上でモデルが「過度に自信を持っている」トークンを微編集して置き換えることで、より構造が安定し、汎化性の高い半合成データを構築することを目指しています。理論分析によると、この方法はテスト誤差を効果的に制約し、反復ラウンドの増加に伴うモデル性能の崩壊を回避できることが示されています。実験では、事前学習、継続的事前学習、教師ありファインチューニングの各段階でこの方法の有効性が検証されました。(ソース: WeChat)

ICML 2025論文:OmniAudio、360°全景ビデオから3D空間オーディオを生成: OmniAudioチームはICML 2025で、360°全景ビデオから直接一次アンビソニックス(FOA)空間オーディオを生成する技術を発表しました。データ不足の問題を解決するため、チームは大規模な360V2SAデータセットSphere360(10万以上の断片、288時間)を構築しました。OmniAudioは2段階のトレーニングを採用しています。自己教師ありのcoarse-to-fineフローマッチング事前トレーニングで、まず通常のステレオオーディオを疑似FOAに変換してトレーニングし、次に実際のFOAでファインチューニングします。その後、デュアルブランチビデオエンコーダーと組み合わせて教師ありファインチューニングを行い、グローバルおよびローカル視点の特徴を抽出し、高忠実度で方向性の正確な空間オーディオを生成します。(ソース: 量子位)

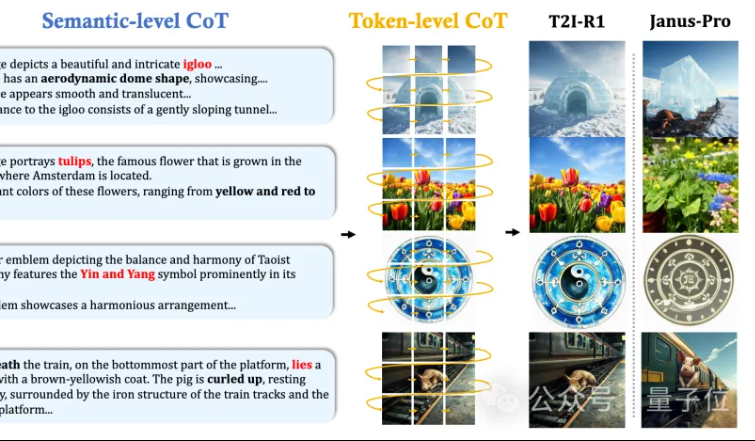
香港中文大学MMLab、T2I-R1を提案:テキストからの画像生成に二層CoT推論と強化学習を導入: 香港中文大学MMLabチームは、強化学習に基づく初の推論強化型テキストからの画像生成モデルであるT2I-R1を発表しました。このモデルは、革新的に二層の思考連鎖(CoT)推論フレームワークを提案しています。Semantic-CoT(テキスト推論、画像のグローバル構造を計画)とToken-CoT(画像のトークンをブロックごとに生成、低レベルの詳細に集中)です。BiCoT-GRPO強化学習手法を通じて、統一されたLMM(Janus-Pro)内でこれら2つのCoT階層を協調的に最適化し、追加のモデルは不要です。報酬モデルは複数の視覚専門家モデルを統合して採用し、評価の信頼性を確保し、過学習を防ぎます。実験により、T2I-R1はユーザーの意図をよりよく理解し、期待に沿った画像を生成でき、T2I-CompBenchおよびWISEベンチマークでベースラインモデルを大幅に上回ることが示されました。(ソース: 量子位, WeChat)
OpenAI、軽量言語モデル評価ライブラリsimple-evalsをリリース: OpenAIは、言語モデルを評価するための軽量ライブラリであるsimple-evalsをオープンソース化しました。これは、最新モデルリリースの精度データを透明化することを目的としています。このライブラリは、ゼロショット、思考連鎖(chain-of-thought)の評価設定を強調し、MMLU、MATH、GPQAなど複数のベンチマークにおける詳細なモデルパフォーマンス比較を提供しています。これには、OpenAI独自のモデル(o3、o4-mini、GPT-4.1、GPT-4oなど)や他の主要モデル(Claude 3.5、Llama 3.1、Grok 2、Gemini 1.5など)が含まれます。(ソース: GitHub Trending)
LLM Engineer’s Handbook韓国語版リリース: Maxime Labonne氏の「LLMエンジニアハンドブック」の韓国語版が、Woocheol Cho氏の翻訳によりリリースされました。このハンドブックのロシア語版、中国語版、ポーランド語版など、さらに多くの言語版も間もなくリリースされる予定で、世界中のLLM開発者に学習リソースを提供します。(ソース: maximelabonne)

ICML 2025オーディオ機械学習ワークショップML4Audio開催決定: 人気のオーディオ機械学習ワークショップ(ML for Audio)が、バンクーバーで開催されるICML 2025期間中の7月19日(土曜日)に再び開催されます。ワークショップには、Dan Ellis氏、Albert Gu氏、Jesse Engel氏、Laura Laurenti氏、Pratyusha Rakshit氏などの著名な学者が講演者として招かれます。論文提出期限は5月23日です。(ソース: sedielem)
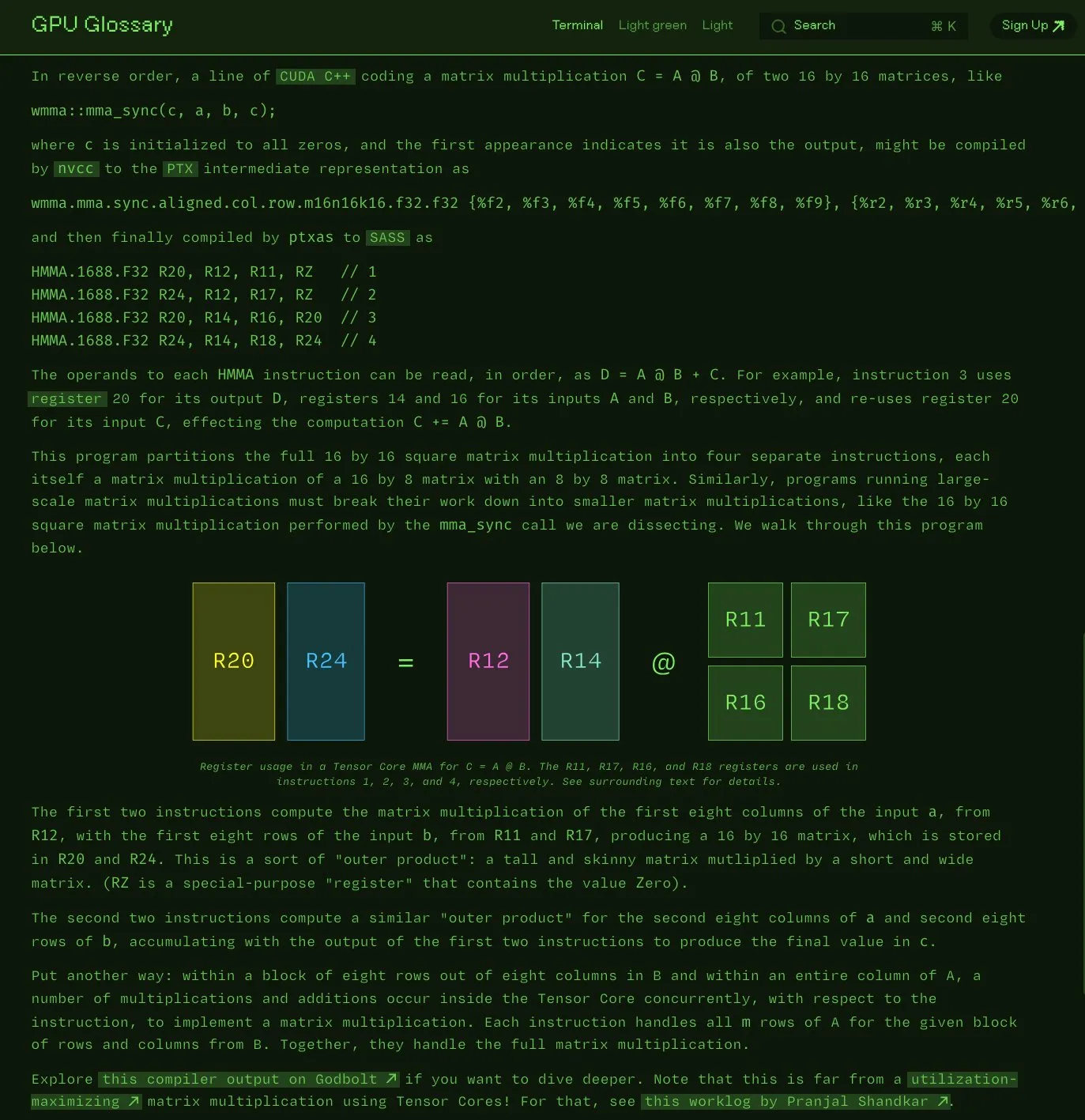
Charles Frye氏、GPU用語集をオープンソース化: Charles Frye氏は、自身が作成したGPU用語集(GPU Glossary)をオープンソース化したことを発表しました。この用語集は、GPUハードウェアとプログラミング関連の概念を理解するのに役立つことを目的としており、最近、Tensor Coreが単純な行列積和(mma)演算を実行する際のSASS命令の分解について更新されました。プロジェクトはGitHubでホストされており、いくつかの未完了タスクがリストされています。(ソース: charles_irl)
OpenAI、GPT-4.1プロンプトエンジニアリングガイドを公開、構造化と明確な指示を強調: OpenAIは、GPT-4.1向けのプロンプトエンジニアリングガイドを公開しました。これは、ユーザーがより効果的にプロンプトを構築するのを支援することを目的としており、特に構造化された出力、推論、ツール使用、エージェントベースのアプリケーションに適しています。ガイドは、役割と目標の明確化、明確な指示(トーン、フォーマット、境界を含む)の提供、オプションのサブ指示、段階的な推論/計画、出力フォーマットの正確な定義、および例の使用の重要性を強調し、重要な指示を強調表示する、MarkdownまたはXMLを使用して入力を構造化するなどの実用的なヒントも提供しています。(ソース: Reddit r/MachineLearning)

KaggleとHugging Faceが連携を深化、モデル呼び出しと発見を簡素化: KaggleはHugging Faceとの連携強化を発表し、ユーザーはKaggle Notebooks内で直接Hugging Faceモデルを起動し、関連する公開コード例を発見し、両プラットフォーム間でシームレスに探索できるようになりました。この統合は、モデルのアクセシビリティを拡大し、KaggleユーザーがHugging Faceエコシステム内のモデルリソースをより便利に活用できるようにすることを目的としています。(ソース: huggingface)
FedRAG:RAGシステムのファインチューニング用オープンソースフレームワーク、連合学習をサポート: Vector Instituteの研究者がFedRAGを発表しました。これは、検索拡張生成(RAG)システムのファインチューニングを簡素化することを目的としたオープンソースフレームワークです。このフレームワークは、典型的な集中型トレーニングをサポートするだけでなく、分散データセットでのトレーニングのニーズに対応するために、特に連合学習アーキテクチャを導入しています。FedRAGはPyTorchおよびHugging Faceエコシステムと互換性があり、Qdrantを知識ベースストレージとして使用することをサポートし、LlamaIndexにブリッジ接続できます。(ソース: nerdai)

💼 ビジネス
Cursorの親会社Anysphere、2年でARR2億ドル、評価額90億ドルに急騰: わずか25歳のMIT中退者Michael Truell氏が率いるAnysphere社は、AIコードエディタCursorにより、マーケティングを行わずに2年間で2億ドルの年間経常収益(ARR)を達成し、企業評価額は急速に90億ドルに達しました。Cursorは、AIを開発プロセスに深く組み込むことでソフトウェア開発のパラダイムを再構築し、個人開発者へのサービス提供に注力することで、世界中の開発者から幅広い認知と口コミを得ています。Thrive Capitalが最新の資金調達ラウンドをリードしました。(ソース: 36氪)

Databricks、Serverless Postgres企業Neonの買収を発表: Databricksは、開発者中心のServerless Postgres企業であるNeonを買収することに合意しました。Neonは、速度、弾力的なスケーリング、およびブランチングとフォーキング機能を提供する斬新なデータベースアーキテクチャで知られており、これらの特性は開発者とAIエージェントの両方にとって魅力的です。今回の買収は、開発者とAIエージェントのために、オープンでServerlessなデータベース基盤を共同で構築することを目的としています。(ソース: jefrankle, matei_zaharia)
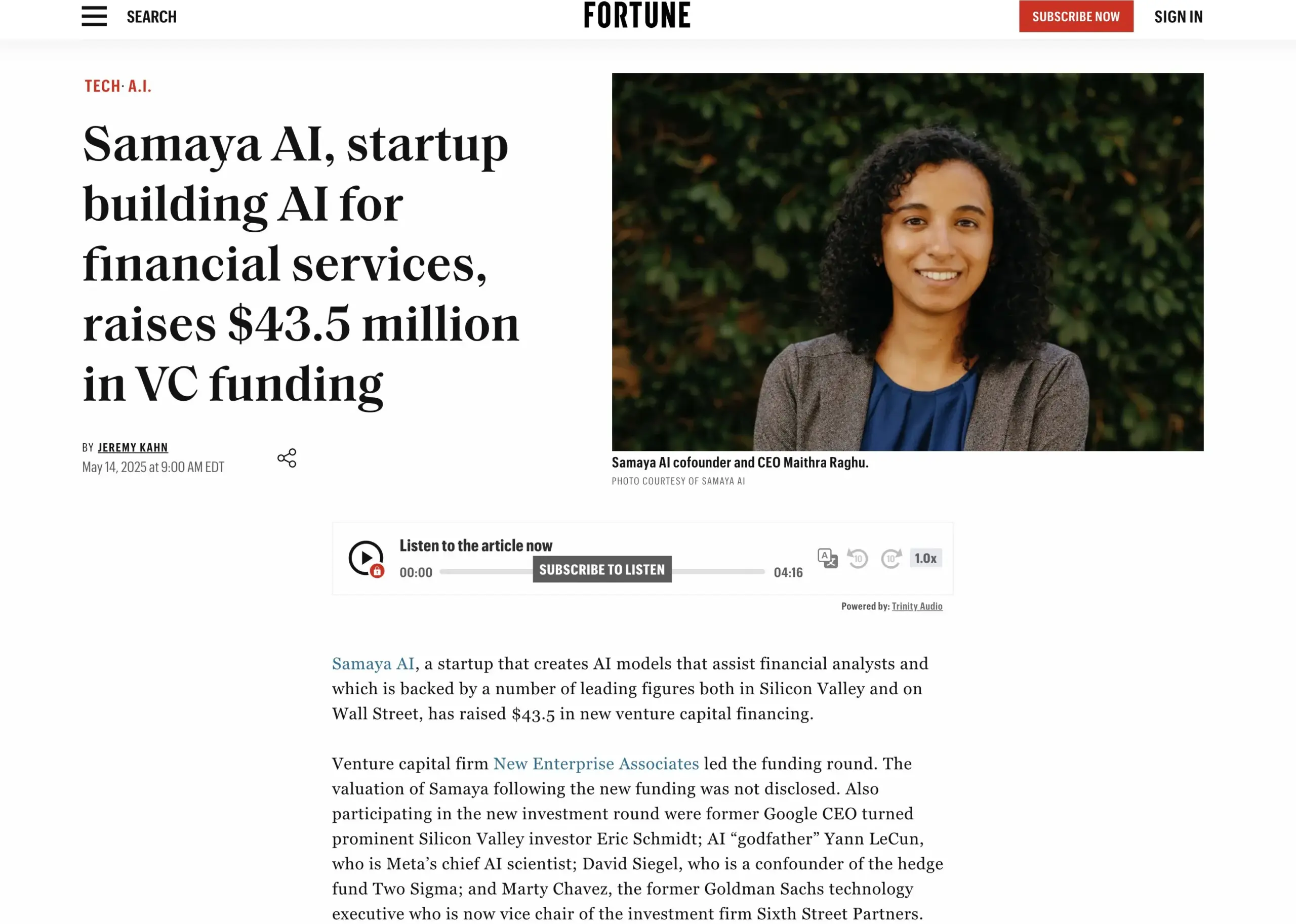
AI金融サービススタートアップSamaya AI、4350万ドルの資金調達を完了: Samaya AIは、NEAが主導する4350万ドルの資金調達を発表しました。これは、金融サービス向けの専門家AIエージェントを構築し、知識労働を大規模に変革することを目的としています。同社は2022年に設立され、複雑な金融ワークフロー向けの専用AIソリューションの開発に注力しています。自社開発のLLMに基づく専門家AIエージェントは、モルガン・スタンレーなどのトップ機関の数千人のユーザーに使用されており、デューデリジェンス、経済モデリング、意思決定支援などのシナリオに応用され、正確性、透明性、幻覚のないことを強調しています。(ソース: maithra_raghu)
🌟 コミュニティ
AIはソフトウェアエンジニアに取って代わるのか?スキルアップの必要性についてコミュニティで議論白熱: ソーシャルメディア上で、AIがソフトウェアエンジニアに取って代わるかどうかという議論が再び起こっています。一般的な見解としては、ソフトウェア開発はコーディング自体よりもはるかに広範であるため、AIがソフトウェアエンジニアに完全に取って代わることはないというものです。しかし、主に反復的なコーディング作業に従事し、システム全体の理解に欠ける「コードモンキー」にとっては、スキルを向上させ、システムアーキテクチャや複雑な問題解決への理解を深めなければ、AI支援ツールに取って代わられるリスクが高いとされています。(ソース: cto_junior, cto_junior)
AI Agentの未来:機会と課題が共存、業界リーダーはその可能性に期待: OpenAIのCEOであるアルトマン氏は、2025年はAI Agentが活躍する年になると予測しており、それらはより多くの実務に関与するようになるでしょう。劉志毅氏もインタビューで、Agentは受動的なツールから能動的な実行システムへと変化しており、その発展は基盤モデルの進歩と物理世界とのインタラクション能力に依存すると強調しています。現在、Agentは応答速度や幻覚制御などの点でまだ不十分な点がありますが、タスクを自律的に実行し、大規模モデルの学習を支援する能力は広く期待されており、すでにスマートカスタマーサービスや金融投資顧問などの分野で応用が始まっています。(ソース: 36氪, 量子位)

Perplexity AI、PayPalおよびVenmoと提携、eコマースと旅行決済を統合: Perplexity AIは、PayPalおよびVenmoと提携し、同社プラットフォームのeコマースショッピング、旅行予約、さらに音声アシスタントおよび近日公開予定のブラウザCometに決済機能を統合すると発表しました。この動きは、閲覧、検索、選択から安全な決済までの商取引プロセス全体を簡素化し、ユーザーエクスペリエンスを向上させることを目的としています。(ソース: AravSrinivas, perplexity_ai)
AIモデル評価に関する議論:IFEvalとChartQAが注目されるも、訓練データ汚染に注意が必要: コミュニティの議論では、IFEvalはそのシンプルかつ巧妙な設計により、優れた指示追従評価ベンチマークの一つと見なされています。一方で、ChartQAのテストデータにはノイズ、曖昧な回答、不整合などの問題があり、廃止される必要があるかもしれないと指摘するユーザーもいます。Vikhyatk氏は、ベンチマークで高い精度を達成したと主張するモデルの多くが、訓練データの汚染問題に気づかれずにいる可能性があると警告しています。(ソース: clefourrier, vikhyatk)

AI生成コンテンツの著作権と倫理が注目:AudibleがAIナレーション使用計画、AI生成人物のネット交際利用に懸念: Audibleは、オーディオブック制作にAI生成ナレーションを使用する計画を発表し、「より多くの物語を生活にもたらす」ことを目指しており、クリエイティブ産業におけるAIの応用に関する議論を呼んでいます。一方、Redditでは、母親がデートサイトでAI生成されたと思われる「実在の男性」のイメージとやり取りしており、騙されるのではないかと心配するユーザーの投稿がありました。これは、AI生成コンテンツの信憑性、感情操作、詐欺における潜在的なリスクを浮き彫りにしています。(ソース: Reddit r/artificial, Reddit r/ArtificialInteligence)

💡 その他
中国企業「星算」、初の宇宙計算衛星12基の打ち上げに成功、宇宙ベースの計算能力の新時代を開く: 国星宇航が主導する「星算」計画は、初の計算衛星12基を宇宙に送り込み、世界初の宇宙計算コンステレーションを形成することに成功しました。各衛星は宇宙計算と相互接続能力を備え、単一衛星の計算能力はT級からP級に向上し、最初のコンステレーションの軌道上計算能力は5POPSに達し、衛星間のレーザー通信速度は最大100Gbpsです。この動きは、宇宙ベースのインテリジェント計算インフラを構築し、地上の計算能力の大きなエネルギー消費と放熱の難しさの問題を解決し、深宇宙探査データの軌道上リアルタイム処理をサポートし、「天数天算」(宇宙のデータは宇宙で計算)を実現することを目的としています。将来的には2800基の衛星を打ち上げて宇宙計算の大規模ネットワークを構築する計画です。(ソース: 量子位)

NVIDIA、年次レビューを発表、AIは新産業革命の中核であり、インテリジェンスこそが製品であると強調: NVIDIAは年次レビューで、世界は新たな産業革命に突入しており、その中核製品は「インテリジェンス」であると指摘しました。NVIDIAはインテリジェンスインフラの構築に取り組み、コンピューティングを各産業の発展を推進する生成的な力へと転換しています。(ソース: nvidia)

NBA、快手Kling AIと提携しAIショートフィルム『カリーの子供時代のダンク』を公開: NBAは、快手傘下のSora風テキストからの動画生成大規模モデルKling AIと提携し、AI TALKが制作した『Childhood Curry’s Dunk』というAIショートフィルムを公開しました。この作品は、Kling AIを使用してカリーの「時空を超えた」ダンクシーンを再現することを試み、NBAプレーオフを盛り上げます。作品中にはバークレー、オニール、ヨキッチも特別出演しています。(ソース: TomLikesRobots)