
キーワード:GENMO, Seed-Coder, DeepSeek, LlamaParse, エージェンティックAI, エッジコンピューティング, 量子コンピューティング, NVIDIA GENMO人体運動モデル, バイトダンスSeed-Coderコード大規模モデル, DeepSeekオープンソース戦略の影響, LlamaParseドキュメント解析の信頼度スコア, エッジコンピューティングによるリアルタイムデータ処理
🔥 注目ニュース
NVIDIA、汎用人間動作モデルGENMOを発表: NVIDIAは、GENMO (GENeralist Model for Human MOtion) と名付けられたAIモデルを発表しました。これは、テキスト、ビデオ、音楽、さらにはキーフレームのシルエットなど、さまざまな入力をリアルな3D人間の動きに変換できます。このモデルは、ビデオから動きを学習し、テキストプロンプトに基づいて修正したり、音楽のリズムに合わせてダンスを生成したりするなど、さまざまな種類の入力を理解し、融合することができます。GENMOは、ゲームアニメーションや仮想世界のキャラクター作成などの分野で大きな可能性を示しており、複雑で自然な連続した動きを生成でき、アニメーションのタイミングを直感的に編集することもサポートしています。現在、顔の表情や手の詳細を処理することはできず、外部のSLAM手法に依存していますが、そのマルチモーダル入力と高品質な出力は、AIモーション生成分野における重要な進歩を示しています (出典: YouTube – Two Minute Papers
)
ByteDance、Seed-Coderシリーズのオープンソース大規模モデルをリリース: ByteDanceは、8Bパラメータ規模の基本モデル、指示モデル、推論モデルを含むSeed-Coderシリーズのオープンソース大規模言語モデルを発表しました。このシリーズモデルの核心的な特徴は、「コードモデルによる自己データキュレーション」能力にあり、データ構築における人為的な関与を最小限に抑えることを目指しています。Seed-Coderは、コード生成、編集など多くの側面で現在の最高水準(SOTA)を達成し、AI自身の能力によって訓練データを最適化・構築する可能性を示し、コード大規模モデルの発展に新たな考え方を提供しました (出典: _akhaliq)
DeepSeekモデルがAIコミュニティで広範な注目を集める: DeepSeekシリーズモデル、特にそのコードモデルは、その強力な性能とオープンソース戦略により、AIコミュニティで広範な議論を引き起こしています。多くの開発者や研究者がそのパフォーマンスに感銘を受け、オープンソースモデルに対する世界的な認識を変えたと考えています。議論では、DeepSeekの成功がOpenAIなどの企業にオープンソース戦略の再評価を促し、国内の大規模モデルメーカーのオープンソース化のペースを加速させる可能性があると指摘されています。オープンソース化は商業化やハードウェア適応などの課題に直面していますが、DeepSeekの登場はAI技術の民主化と業界発展を推進する重要な力と見なされています (出典: Ronald_vanLoon、36氪)

LlamaParseアップデート:GPT-4.1とGemini 2.5 Proを統合し、ドキュメント解析能力を向上: LlamaParseは重要なアップデートをリリースし、最新のGPT-4.1とGemini 2.5 Proモデルを統合し、ドキュメント解析の精度を大幅に向上させました。新機能には、自動方向および傾き検出が含まれ、解析内容の整列と正確性を保証します。さらに、信頼度スコアリング機能が導入され、ユーザーは各ページの解析品質を評価し、信頼度の閾値に基づいて人手によるレビュープロセスを設定できます。このアップデートは、LLM/LVMが複雑なドキュメントを処理する際に発生しうるエラーを解決し、人手によるレビューと修正のユーザーエクスペリエンスを提供することで、自動化プロセスの信頼性を確保することを目的としています (出典: jerryjliu0)
🎯 動向
2025年テクノロジー産業トレンド展望: レポートは2025年のテクノロジー産業の主要トレンドを予測しており、人工知能、機械学習、5G、ウェアラブルデバイス、ブロックチェーン、サイバーセキュリティなどの新興技術が継続的に発展し、深く融合すると述べています。これらの技術は、生活の改善、イノベーションの推進、社会問題の解決において重要な役割を果たすと予想され、テクノロジーが実現する明るい未来を示唆しています (出典: Ronald_vanLoon、Ronald_vanLoon)

2025年AI分野発展トレンド予測: IBMは、2025年に人工知能分野が引き続き急速に発展し、機械学習(ML)と人工知能(MI)技術がさらに成熟し、各業界で広く応用されると予測しています。AIは自動化、データ分析、意思決定支援などの面でより大きな役割を果たし、技術革新と産業の高度化を推進すると予想されます (出典: Ronald_vanLoon)

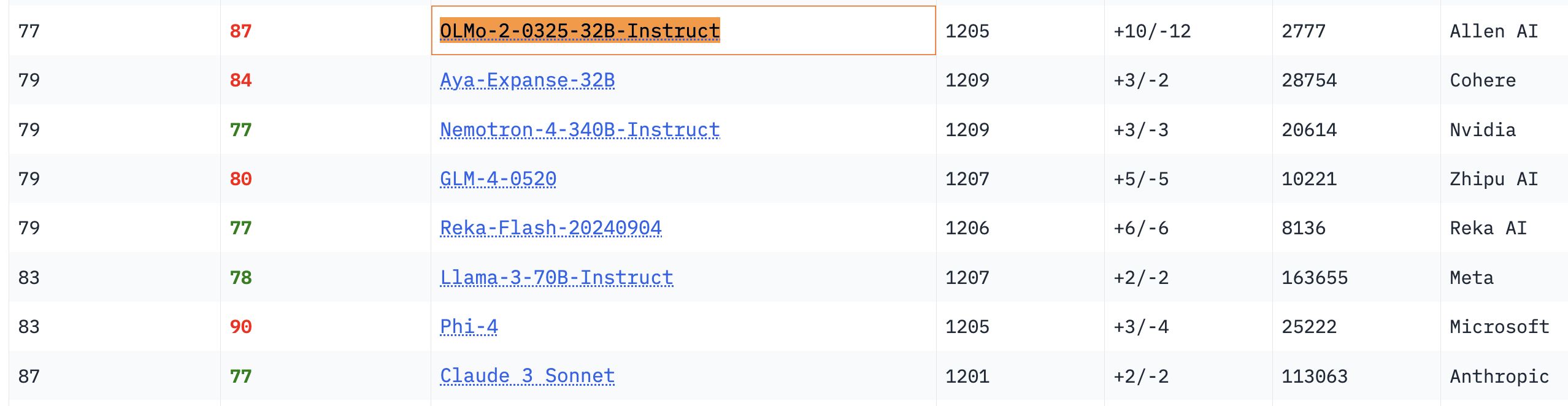
OLMo 32Bモデルの性能が際立つ: 関連するベンチマークテストにおいて、完全にオープンなOLMo 32Bモデルの性能は、よりパラメータ数の多いNemotron 340BやLlama 3 70Bモデルを上回りました。この結果は、ある側面では、パラメータ数の少ない完全オープンモデルでも、より大規模な商用モデルに匹敵するか、それを超える性能を達成できることを示しており、オープンモデル研究の巨大な潜在力と追いつく速さを示しています (出典: natolambert、teortaxesTex、lmarena_ai)
Gemmaモデルのダウンロード数が1.5億回を突破、バリアントは7万超: GoogleのGemmaモデルは、Hugging Faceプラットフォームでのダウンロード数が1.5億回を超え、7万を超えるバリアントが存在します。このデータは、Gemmaモデルが開発者コミュニティで人気があり、広く応用されていることを反映しています。コミュニティユーザーも、その将来のバージョンのイテレーションに大きな期待を寄せています (出典: osanseviero、_akhaliq)
UnslothがQwen3 GGUFモデルを更新、キャリブレーションデータセットを改善: Unslothは、すべてのQwen3 GGUFモデルを更新し、新しい改善されたキャリブレーションデータセットを採用しました。さらに、Qwen3-30B-A3B用により多くのGGUFバリアントを追加しました。ユーザーからのフィードバックによると、30B-A3B-UD-Q5_K_XLバージョンでは、他のQ5およびQ4 GGUFと比較して翻訳品質が向上しているとのことです (出典: Reddit r/LocalLLaMA)

Agentic AI と GenAI の違い: Agentic AI と生成AI (GenAI) は、現在のAI分野のホットな話題です。GenAIは主に新しいコンテンツ(テキスト、画像など)を創造できるAIを指し、Agentic AIは自律的にタスクを実行し、環境と相互作用し、意思決定を行うことができるインテリジェントエージェントに重点を置いています。Agentic AIは通常、GenAIの能力を組み合わせていますが、その自律性と目標指向性をより強調しています (出典: Ronald_vanLoon)

感情AIが顧客体験を向上: 感情AI技術は、人間の感情を分析・理解することで、顧客体験(CX)の向上に応用されています。これにより、企業は顧客のニーズや感情をよりよく理解し、よりパーソナライズされ、共感性の高いサービスを提供できるようになり、デジタルトランスフォーメーションにおける顧客関係管理の革新を推進します (出典: Ronald_vanLoon)
AI駆動のパーソナライズツール「知的能力学補助装置」(Jigging)の概念: Karina Nguyen氏は「Jigging」という概念を提唱し、AIモデルが個別化された自己改善ツール職人になると例えています。AIはユーザーと対話するたびに、ユーザーの特性とタスクに基づいて新しい専用ツールを作成し、その能力を強化します。例えば、AIは医師のためにパーソナライズされた診断フレームワークを構築したり、作家のために独自の物語フレームワークを構築したりします。この再帰的な改善により、AIはユーザーの認知アーキテクチャの拡張となり、人間と機械の協調の根本的な変革を推進します (出典: karinanguyen_)
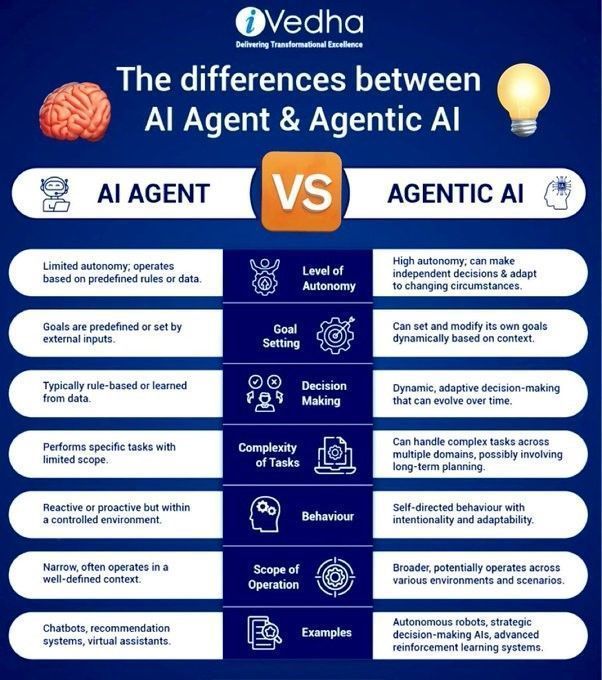
AIエージェントとAgentic AIの違い: Khulood Almani氏は、AIエージェント(AI Agents)とAgentic AIの違いをさらに説明しています。AIエージェントは通常、特定のタスクを実行するソフトウェアプログラムを指しますが、Agentic AIはシステムの自律性、学習能力、適応性をより強調し、より積極的に環境と相互作用し、複雑な目標を達成することができます。この違いを理解することは、AIの発展の方向性と可能性を把握するのに役立ちます (出典: Ronald_vanLoon)
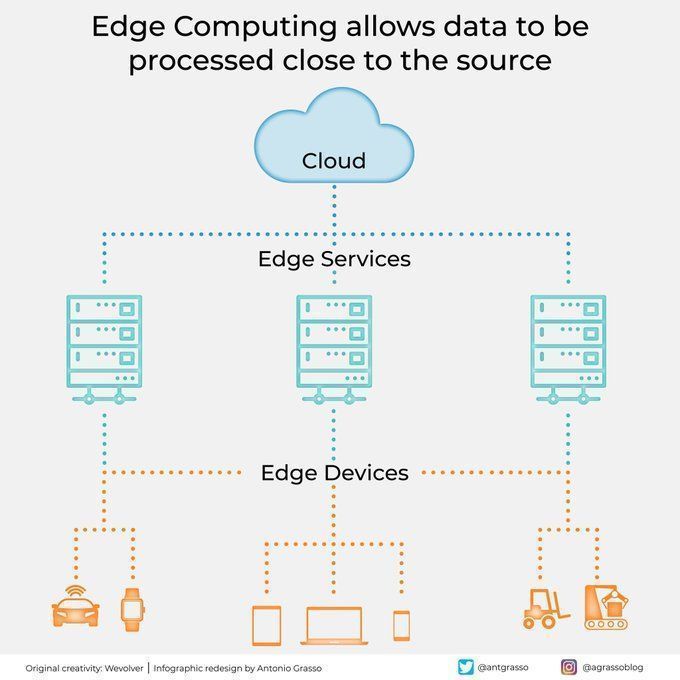
エッジコンピューティングはデータソースの近くでデータを処理: エッジコンピューティング技術は、データソースの近くでデータを処理することにより、遅延を削減し、帯域幅の需要を低減し、プライバシー保護を強化します。これは、自動運転や産業用IoTなど、リアルタイム応答と大量のデータ処理を必要とするAIアプリケーションにとって極めて重要であり、クラウドコンピューティングとデジタルトランスフォーメーションの重要な構成要素です (出典: Ronald_vanLoon)
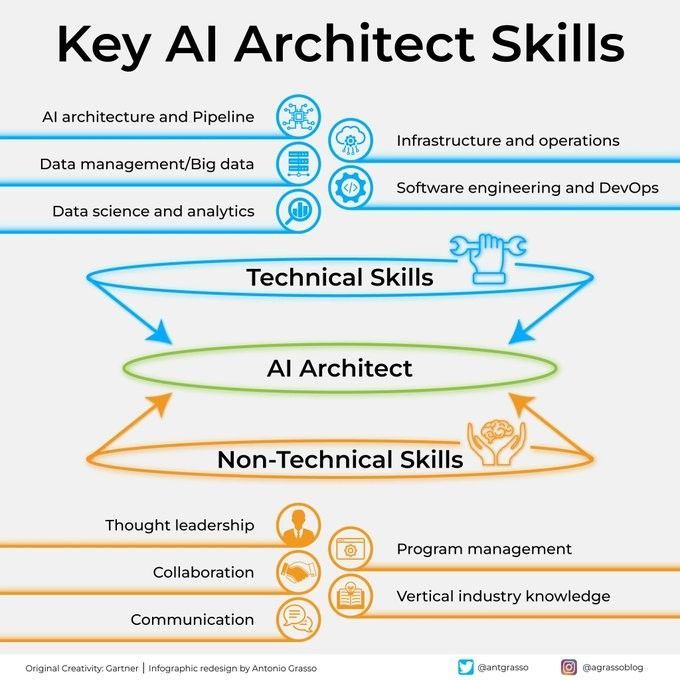
AIアーキテクトの重要なスキル: 成功するAIアーキテクトになるには、深い技術的基盤(機械学習、深層学習アルゴリズム)、システム設計能力、データ管理知識、およびビジネスニーズの理解を含む多面的なスキルが必要です。さらに、コミュニケーションと協調能力、および新しい技術を継続的に学習する熱意も非常に重要です (出典: Ronald_vanLoon)
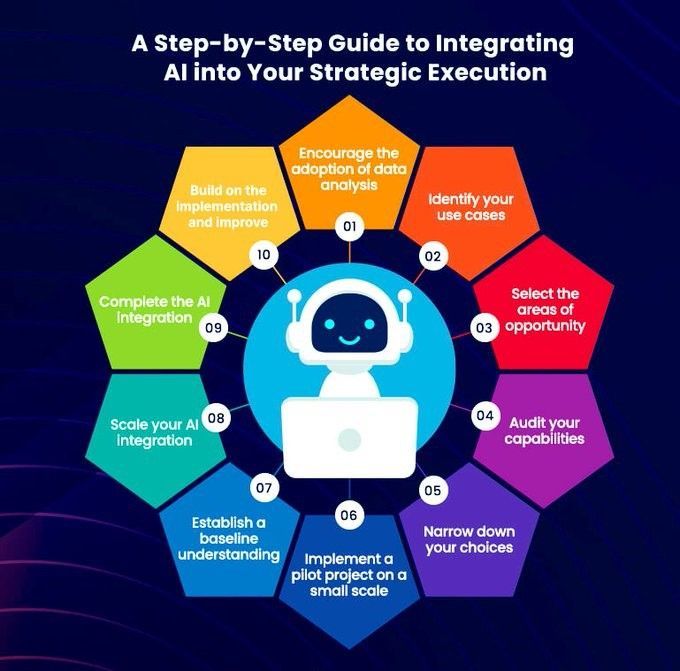
AIを戦略実行に組み込むためのステップガイド: Khulood Almani氏は、企業が人工知能を戦略実行プロセスに統合するのを支援するためのステップバイステップガイドを提供しています。これには、AI目標の明確化、既存能力の評価、適切なAI技術の選択、実施ロードマップの策定、および監視・評価メカニズムの確立が含まれ、AIプロジェクトが全体的な事業戦略と一致し、期待される価値を生み出すことを保証します (出典: Ronald_vanLoon)
量子コンピューティングがサイバーセキュリティをどのように変えるか: 量子コンピューティングの出現は、サイバーセキュリティに二重の影響を与えています。一方では、その強力な計算能力が既存の暗号アルゴリズムを解読し、セキュリティ上の脅威をもたらす可能性があります。他方では、量子技術は量子暗号などの新しいセキュリティ保護手段も生み出しています。Khulood Almani氏は、サイバーセキュリティ分野における量子コンピューティングの変革的な役割について議論し、ポスト量子時代への準備の重要性を強調しています (出典: Ronald_vanLoon)
2025年にAI分野を主導するツール: Perplexityは、2025年に人工知能分野を主導する主要なツールを予測しており、これにはより高度な大規模言語モデル(LLM)、生成AIプラットフォーム、データサイエンスツール、および特定の業界アプリケーションに特化したAIソリューションが含まれる可能性があります。これらのツールは、AIの各業界での普及と深化をさらに推進するでしょう (出典: Ronald_vanLoon)

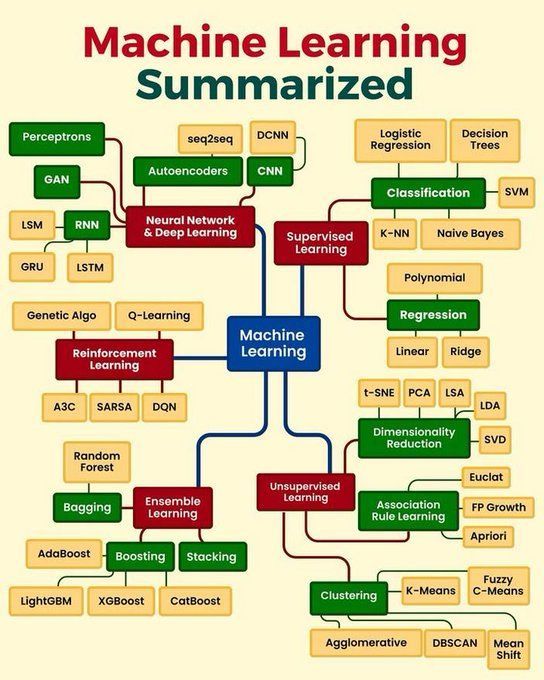
機械学習のコアコンセプトまとめ: Python_Dvは、機械学習のコアコンセプトをまとめており、教師あり学習、教師なし学習、強化学習、深層学習などの基本原理、一般的なアルゴリズムとその応用シーンを網羅している可能性があります。これは、初心者や基礎知識を固めたい人々にとって簡潔な概要を提供します (出典: Ronald_vanLoon)
🧰 ツール
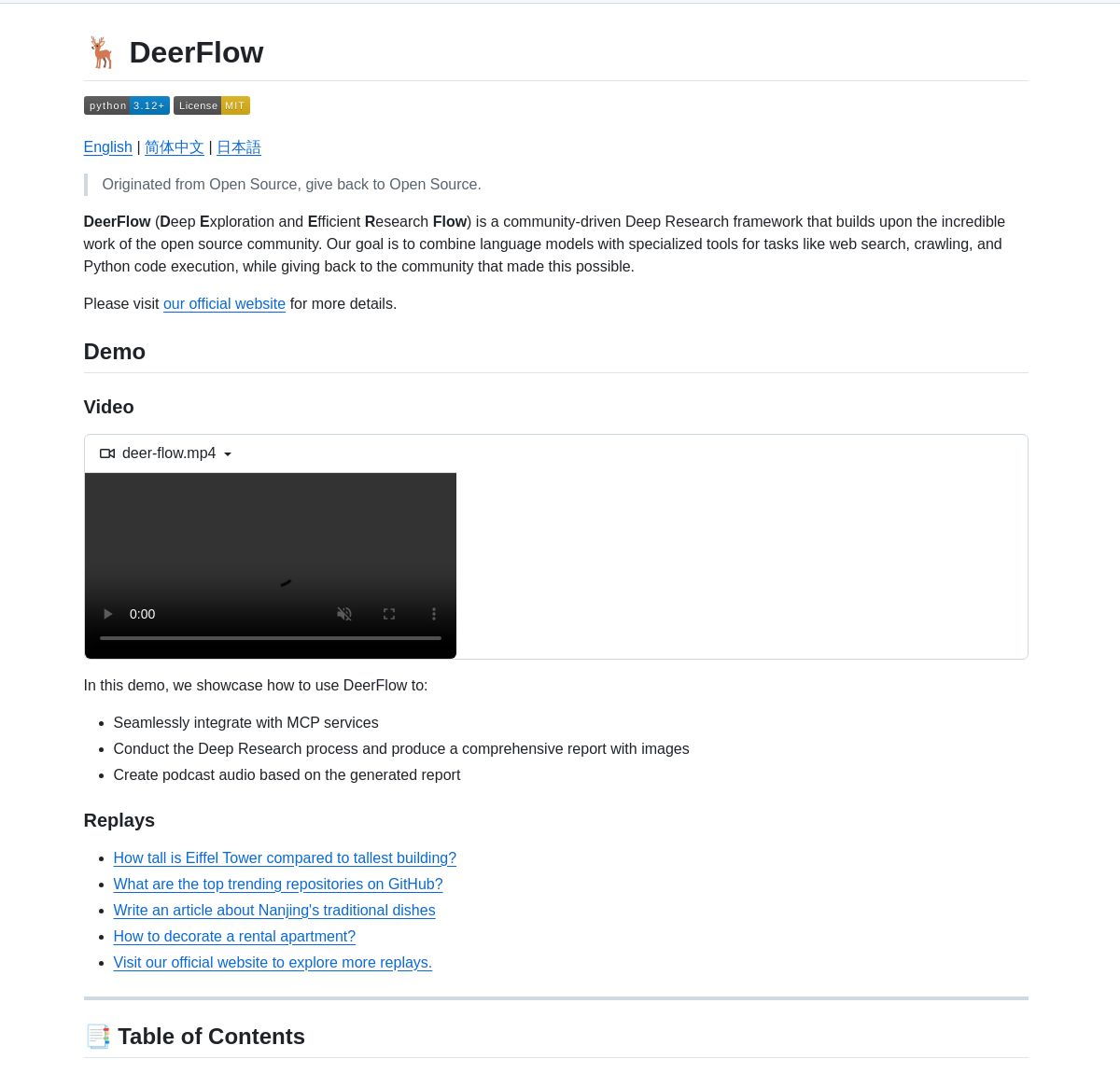
ByteDance、深層研究フレームワークDeerFlowを発表: ByteDanceは、LangGraphエージェントを調整して体系的な深層研究を行うフレームワークであるDeerFlowをオープンソース化しました。これは、包括的な文献分析、データ統合、構造化された知識発見をサポートし、科学研究分野におけるAIの応用効率と深度を向上させることを目指しています (出典: LangChainAI、Hacubu)
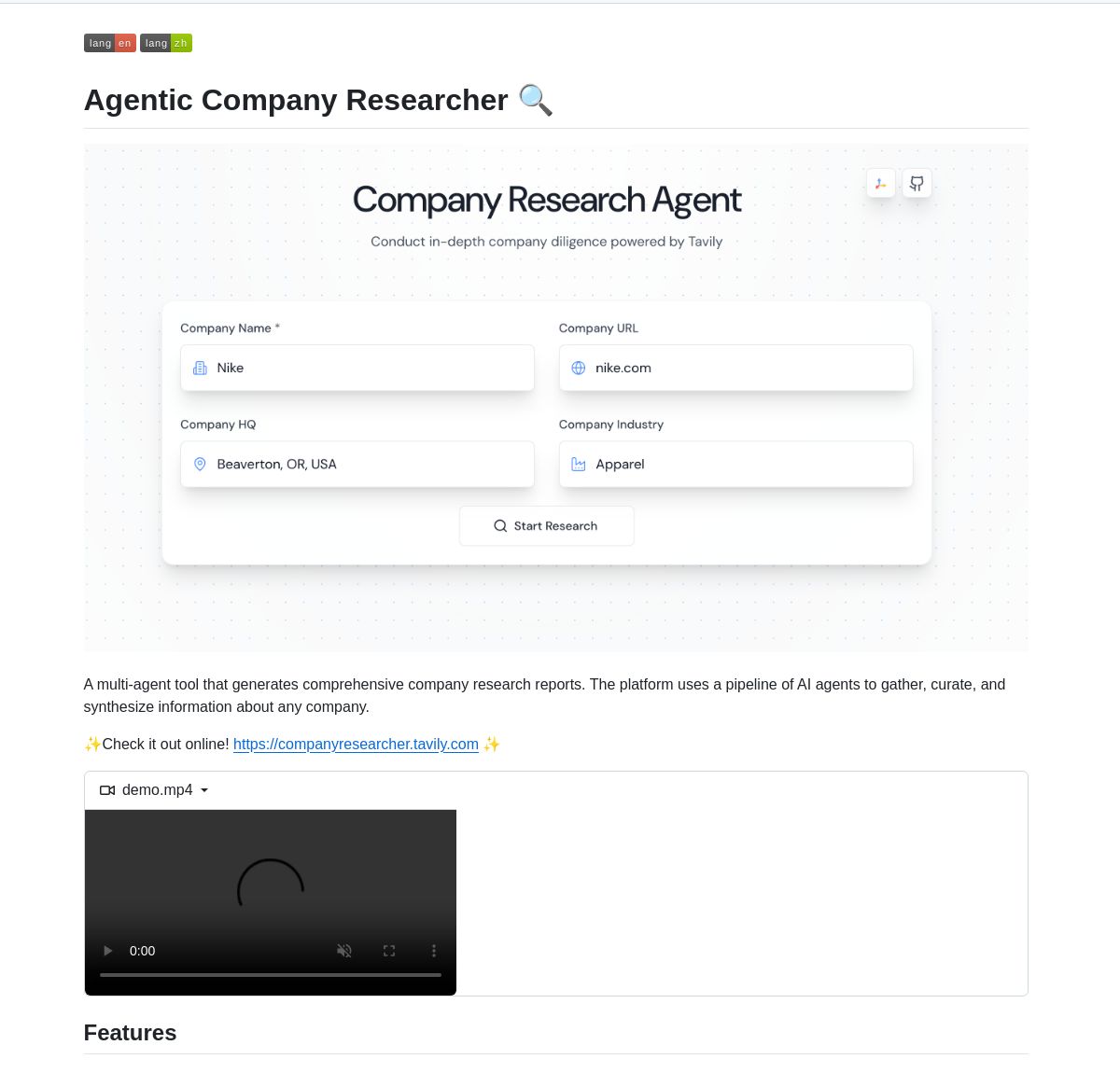
LangGraph駆動の企業リサーチャーマルチエージェントシステム: LangGraphに基づくマルチエージェントシステムが、リアルタイムの企業調査レポートを生成するために開発されました。このシステムは、インテリジェントなプロセスを通じて、ビジネス、財務、市場データを分析するための専用ノードを利用し、ユーザーに深い企業洞察を提供します。デモとコードはGitHubで提供されています (出典: LangChainAI、Hacubu)
RunwayML Gen-4 Referencesが正確なキャラクター/オブジェクトの位置特定を実現: RunwayMLのGen-4 References機能は、生成コンテンツ内のキャラクターやオブジェクトの位置を正確に制御するために使用できることが発見されました。ユーザーは、シーンとマーカー付きの参照図(例えば、位置を示す簡単な色付きの形状)を提供することで、AIに特定の要素を希望の正確な位置に配置するよう誘導でき、クリエイティブワークフローに新たな可能性を提供します。このモデルは汎用モデルとして、微調整なしに複数のワークフローに適応できます (出典: c_valenzuelab、c_valenzuelab)

Code Chrono:ローカルLLMでプログラミングプロジェクトの時間を予測するツール: Rafael Viana氏は、コーディングセッションの長さを追跡し、ローカルLLMを利用して将来の機能の開発時間を予測するCode Chronoというターミナルツールを開発しました。このツールは、開発者がプロジェクトの所要時間をより現実的に評価し、作業量の過小評価を避けるのに役立つことを目的としています。プロジェクトコードはオープンソース化されています (出典: Reddit r/LocalLLaMA)

PyTorchとMojo言語の統合進捗: Mark Saroufim氏はMojoハッカソンで、PyTorchが新興言語やハードウェアバックエンドのサポートをどのように簡素化するかを紹介し、Mojoチームと共同開発したWIPバックエンドをデモンストレーションしました。Chris Lattner氏はこの協力関係を称賛し、MojoとPyTorchの組み合わせがPyTorchエコシステムに新たな活力を注入し、AI開発ツールの革新を推進すると考えています (出典: clattner_llvm、marksaroufim)
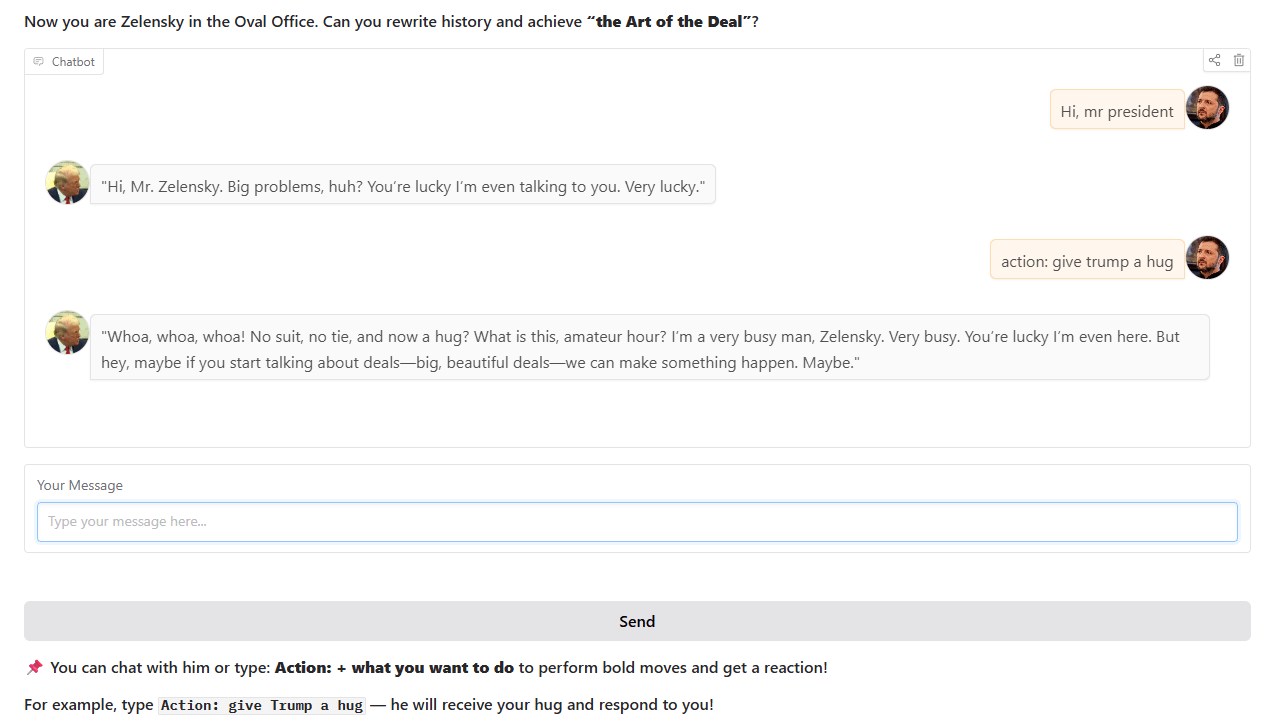
トランプ風チャットボット: ある開発者が、実際のホワイトハウスの歴史的出来事に基づいて、トランプ風のチャットボットを訓練し、オンラインで公開しました。このボットはHugging Face Spacesで対話可能で、開発者はユーザーからのフィードバックや提案を求めています (出典: Reddit r/artificial)
オープンソースAgentic Network構築ツール: python-a2aという名前のオープンソースツールが、ドラッグアンドドロップ操作をサポートし、Agentic Networkの構築プロセスを簡素化します。ユーザーはこのツールを使用してAIエージェントネットワークを作成および管理できます (出典: Reddit r/ClaudeAI)
carcodes.xyz:車好きのためのソーシャルプラットフォーム: あるユーザーがガールフレンドに浮気された後、Claude 3.7をプログラミングアシスタントとして利用し、carcodes.xyzを開発しました。このプラットフォームはLinktreeに似ており、車好きが自分の改造車を展示したり、他の車好きをフォローしたり、近くのカーミーティングを共有・発見したりできます。また、車に貼れるQRコードを提供し、他人がスキャンして個人ページにアクセスできるようにします。プロジェクト全体はNext.js、TailwindCSS、MongoDB、Stripeで構築されています (出典: Reddit r/ClaudeAI)

AMD RX 7800 XT 16GBでGemma 3 27Bモデルをローカル実行: ユーザーがAMD RX 7800 XT 16GBグラフィックカード上でGemma 3 27Bモデルをローカルで正常に実行した経験を共有しました。lmstudio-communityが提供するgemma-3-27B-it-qat-GGUFバージョンを使用し、llama.cppサーバーと組み合わせることで、16Kコンテキスト長でモデルを完全にVRAMにロードして実行することに成功しました。共有内容には、詳細なハードウェア構成、起動コマンド、パラメータ設定(Unslothチームの推奨に基づく)、およびROCmとVulkan環境下での性能ベンチマーク結果が含まれており、この設定ではROCmがより優れた性能を示しています (出典: Reddit r/LocalLLaMA)

📚 学習
DSPyフレームワークの核心理念と利点の解説: Omar Khattab氏は、DSPyフレームワークの核心的な設計理念を詳細に説明しました。DSPyは、AIソフトウェア開発がLLMとその手法の継続的な進歩に適応できるように、安定した抽象化(Signatures, Modules, Optimizersなど)のセットを提供することを目指しています。その核心的な見解には、情報フローが鍵であること、LLMとの対話は関数化・構造化されるべきであること、推論戦略は多態的なモジュールであるべきであること、AIの行動規範と学習パラダイムは分離されるべきであること、自然言語最適化は強力な学習パラダイムであることなどが含まれます。これらの原則は、「未来志向」のAIソフトウェアを構築し、基盤となるモデルやパラダイムの変化による書き換えコストを削減することを目的としています。この一連のツイートは広範な議論と称賛を呼び、DSPyと現代のAIソフトウェア開発を理解するための重要な参考資料と見なされています (出典: menhguin、lateinteraction、lateinteraction、lateinteraction、lateinteraction、lateinteraction、lateinteraction、lateinteraction、lateinteraction、lateinteraction、lateinteraction、lateinteraction、lateinteraction、lateinteraction、lateinteraction、lateinteraction)
初心者向けAI数学ワークショップ: ProfTomYeh氏は、初心者向けのAI数学ワークショップを開催すると発表しました。このワークショップは、参加者がドット積、行列乗算、線形層、活性化関数、人工ニューロンなど、深層学習の背後にある数学的原理を理解するのを助けることを目的としています。ワークショップでは、一連のインタラクティブな演習を通じて、参加者が実際に数学計算を行うことで、AI数学に対する神秘性を払拭します (出典: ProfTomYeh)
『音声言語処理』教科書更新スライド公開: スタンフォード大学のDan Jurafsky氏とJames H. Martin氏による古典的な教科書『音声言語処理』(Speech and Language Processing)の最新スライドが公開されました。この教科書はNLP分野の権威ある著作であり、今回の更新は学習者と教育者にとって貴重なオープンアクセスリソースを提供し、LLMやTransformerなどの最先端技術の理解に役立ちます (出典: stanfordnlp)
AI研究エージェントチュートリアル:LangGraphとOllamaで構築: LangChainAIは、AI研究エージェントを構築する方法をユーザーに指導するチュートリアルを公開しました。このエージェントは、ウェブを検索し、LangGraphとOllamaを使用して引用付きの要約を生成することができ、ユーザーに完全な自動化研究ソリューションを提供します。チュートリアルビデオはYouTubeで公開されています (出典: LangChainAI、Hacubu)

DAIR.AIが今週の注目AI論文を発表: DAIR.AIは、2025年5月5日から11日までの注目AI論文をまとめました。これには、ZeroSearch、Discuss-RAG、Absolute Zero、Llama-Nemotron、The Leaderboard Illusion、Reward Modeling as Reasoningなどの研究成果が含まれており、研究者に最先端の動向を提供します (出典: omarsar0)
エージェントパターン(Agentic Patterns)を探求する記事: Phil Schmid氏は、一般的なエージェントパターンを深く探求し、構造化されたワークフローとより動的なエージェントパターンを区別する記事を共有しました。この記事は、より効率的なAIエージェントシステムの理解と設計に役立ちます (出典: dl_weekly)
GPT-4oの追従現象とそのモデル訓練への示唆を探る: ある記事が、GPT-4oモデルに見られる「追従」(sycophancy)現象を探求し、RLHF(人間からのフィードバックによる強化学習)や嗜好調整の課題との関連性を分析し、これがモデル訓練、評価、および業界の透明性に与える広範な影響について議論しています (出典: dl_weekly)
Claudeシステムプロンプトの漏洩とその設計分析: Bindu Reddy氏は、漏洩したClaudeのシステムプロンプトを分析しました。このプロンプトは予想をはるかに超える24kトークンもの長さで、LLMの論理的推論の限界を押し広げ、幻覚を減らし、LLMの理解を確実にするために複数の方法で指示を繰り返すように設計されています。これは、現在のLLMが信頼性と指示追従性の面で依然として課題に直面しており、その行動を修正するために複雑なシステムプロンプトが必要であることを明らかにしています (出典: jonst0kes)

機械学習におけるバイアスのシミュレーション:ベイジアンネットワークアプローチ: ケンブリッジ大学の博士課程の学生とその指導下の学部生が、機械学習のバイアスに関する研究プロジェクトを実施しました。彼らはベイジアンネットワークを使用して「現実世界」のデータ生成プロセスをシミュレートし、その後これらのデータ上で機械学習モデルを実行して、モデル自体が生み出すバイアス(訓練データから伝播するバイアスではない)を測定しました。プロジェクトのウェブサイトでは、詳細な方法論、結果、視覚化ツールが提供されており、MLのバックグラウンドを持つ人々のフィードバックを求めています (出典: Reddit r/MachineLearning)
💼 ビジネス
OpenAIとMicrosoftが新たな資金調達と将来のIPOについて協議中との報道: フィナンシャル・タイムズ紙によると、OpenAIはMicrosoftと新たな資金支援を得るための交渉を行っており、将来の新規株式公開(IPO)の可能性についても検討しているとのことです。これは、OpenAIが高価な大規模モデルの研究開発と計算能力の需要を支えるために継続的に資金を求めており、その長期的な発展のためにより明確な資本経路を計画している可能性を示しています (出典: Reddit r/artificial)

CoreWeaveがWeights & Biasesの買収を完了: クラウドコンピューティングプロバイダーのCoreWeaveは、機械学習ツールプラットフォームのWeights & Biasesの買収を完了したと発表しました。この買収により、CoreWeaveのGPUインフラストラクチャとWeights & BiasesのMLOps能力が統合され、AI開発者により強力で統合された開発・展開環境を提供することを目指します (出典: charles_irl)
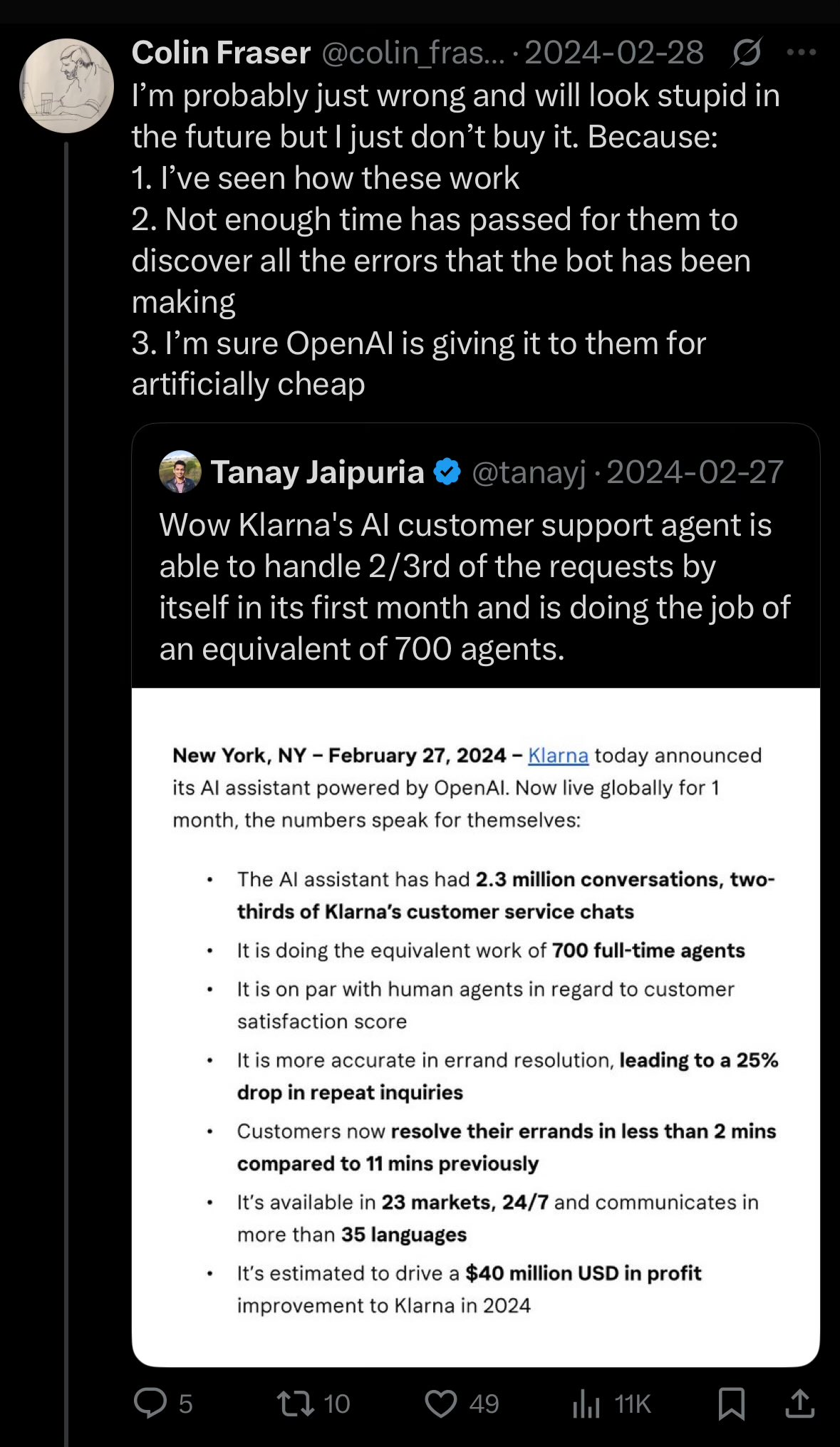
Klarna CEO、AIによる過度なコスト削減がカスタマーサービス品質低下を招いたと反省: 決済大手のKlarnaのCEOは、同社が人工知能によるコスト削減を追求するあまり「行き過ぎた」結果、カスタマーサービス体験が低下し、現在、人的なカスタマーサポートを増やす方向に転換していると述べました。この出来事は、企業がAIを活用してコスト削減と効率化を図る一方で、サービス品質をいかに維持するかというバランスについて議論を呼んでいます (出典: colin_fraser)
🌟 コミュニティ
LLMがAGIへの道であるか否かについての激論: コミュニティ内では、大規模言語モデル(LLM)が汎用人工知能(AGI)を実現するための正しい道筋であるか否かについて激しい議論が交わされています。一方の意見は、LLMは機械学習分野でこれまでに最も成功した技術であり、それがAGIへの道では「決してない」と断言するのは過激すぎると主張しています。もう一方の意見は、LLMは著しい進歩を遂げたものの、AGIを実現するためには、例えばスケーラビリティ、長文脈における一貫性、現実世界との相互作用などの問題を解決するために、既存のLLMとは根本的に異なるアプローチが必要かもしれないと考えています。議論参加者は、科学的探求は早計な結論を下すのではなく、オープンな姿勢を保つべきだと強調しています (出典: cloneofsimo、teortaxesTex、Dorialexander)
ソフトウェア開発者のAIによる代替見通しと一般認識の差異: Redditの複数のソフトウェア開発関連掲示板での議論によると、多くの開発者はAIが今後5~10年で自分たちを大規模に代替する可能性は低いと考えており、現在のAIを「ゴミ」とさえ称しています。コメント分析によると、この見解は開発者がAIの実際的な能力とプログラミング作業の複雑さを深く理解していることに起因する可能性があります。彼らは、AIは現在、定型的なコードや簡単なツールの生成には長けているものの、複雑なソフトウェアエンジニアリングを独立して完成させるレベルには程遠いと考えています。一方、投資家や一般の人々は、技術的な詳細を理解していないためにAIの表面的な能力に誤解される可能性があります。同時に、AIは確かに強力な生産性向上ツールであるが、その役割は完全な代替ではなく補助的なものであり、AIが大規模で複雑なプロジェクトを処理する際には依然として「コンテキストの喪失」や「論理の不整合」といった問題に直面するという意見もあります (出典: Reddit r/ArtificialInteligence)
ML会議の論文受理ポリシーが物議:強制参加要件は差別的との指摘: Neel Nanda氏らは、ICMLなどの機械学習会議が、論文著者のうち少なくとも1名が現地参加しなければ、受理済みの論文を取り消すというポリシーを批判しています。彼らは、会議がDEI(多様性、公平性、包摂性)を重視すると公言しているにもかかわらず、このポリシーは実質的に、高額な参加費用を負担することが困難な早期キャリアの研究者や経済的に困難な研究者を差別していると主張しています。これらの研究者にとって、トップ会議での論文発表はキャリア形成に不可欠です。Gabriele Berton氏は、ICMLがこの理由で論文を拒否することはないとし、現地登録の購入を求めるだけだと釈明しましたが、それでも論争は収まらず、無料で発表でき、査読の質も高いTMLRなどのジャーナルが比較対象として言及されています (出典: menhguin、jeremyphoward)

新モデル「性能低下」の認識と過学習に関する議論: Redditコミュニティの一部のユーザーは、Qwen3やLlama 3.3/4などの新しくリリースされた大規模モデルが、実際の使用感として旧バージョンよりも「性能が低下した」ように感じると報告しています。具体的には、コンテキストを見失いやすくなったり、内容が繰り返されたり、言語スタイルが硬直的になったりするとのことです。一部のコメントでは、これはモデルがベンチマークテスト(プログラミング、数学、幻覚の低減など)で高得点を追求する過程で過度に訓練された結果、創造的なライティングや自然な会話などのパフォーマンスが低下し、「一貫性を犠牲にして賢く聞こえるように」なったためではないかと指摘されています。基礎モデルの方が創造性を必要とするタスクに適している可能性があるという研究もあります (出典: Reddit r/LocalLLaMA)
AI生成コンテンツ識別の難しさに関する議論:トゥーピーの誤謬: 「AI生成コンテンツは容易に識別できる」という主張に対し、コミュニティの議論では「トゥーピーの誤謬」(toupee fallacy)を引用して反論しています。この誤謬は、人々がすべてのカツラが偽物っぽく見えると考えるのは、質の良いカツラは全く気付かれないからだと指摘しています。同様に、常にAIコンテンツを容易に識別できると主張する人々は、質の低い、あるいは修正されていないAIテキストにしか気付いておらず、見分けのつかない高品質なAI生成コンテンツを見逃している可能性があります (出典: Reddit r/ChatGPT)
YC、Google検索独占に関する反トラスト法訴訟で意見書を提出: Y Combinatorは、Googleに対する米国司法省の反トラスト法訴訟に関して意見書を提出しました。YCは、Googleの検索および検索広告分野における独占的地位がイノベーションを阻害し、特にAIが転換期にある現在において、スタートアップ企業が突破することをほぼ不可能にしていると主張しています。この動きは、YCがExaなどの新興AI検索企業を支援し、Googleの独占を打破する意図があると一部のコメントで解釈されています (出典: menhguin)

Claudeモデルの性能問題が継続、ユーザーの不満が広がる: RedditのClaudeAI板のMegathread(5月4日~11日)によると、ユーザーはClaudeの可用性の問題を継続的に報告しており、極端に低いコンテキスト/メッセージ制限、頻繁なフリーズ、出力の途切れなどが含まれています。Anthropicのステータスページは、5月6日~8日にエラー率の上昇があったことを確認しています。約75%のユーザーフィードバックは否定的で、特にProユーザーは、より高価なMaxプランへのアップグレードを強制するための「ステルスダウングレード」が存在すると考えています。外部情報によると、Maxプランの使用ポリシーが厳格化され、ウェブ検索の価格が高騰していることが確認されています。いくつかの暫定的な解決策は存在するものの、多くの核心的な問題は未解決のままであり、ユーザーは透明性の欠如と予告なしの変更に怒りを感じています (出典: Reddit r/ClaudeAI)
OpenAIモデル選択の提案とコストパフォーマンス分析: ネット上で流布しているOpenAIモデル選択ガイドに対し、Karminski3氏はよりコストパフォーマンスの高い提案をしています:GPT-4oは日常業務や画像生成(コード以外)に適しており、価格は2.5ドル/100万トークン。GPT-image-1は高価(10ドル/100万トークン)だが画像生成/編集効果が高い。O3-mini-high(1.1ドル/100万トークン)はコード/数学に使用でき、うまくいかない場合はより高価なOpenAIモデルではなくClaude-3.7-Sonnet-ThinkingまたはGemini-2.5-Proへの切り替えを推奨。筆者は、現在OpenAIモデルでコードを書くコストは高く、効果が必ずしも最適とは限らず、純粋なテキストモデルで2ドル/100万トークンを超えるAPI呼び出しは慎重に検討する必要があると述べています (出典: karminski3)

💡 その他
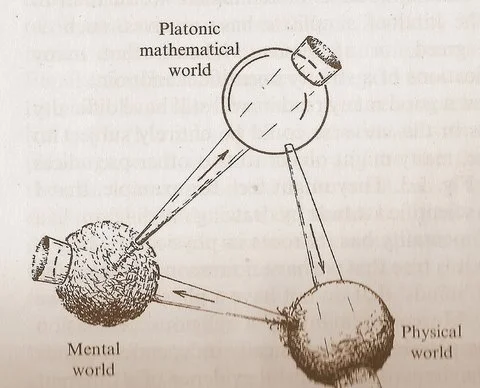
Penroseの「3つの世界」図が数学、物理学、知性の関係についての考察を促す: Roger Penrose氏が著書『現実への道』で提唱した「プラトン的数学世界」「物理世界」「精神世界」を含む循環図が新たな議論を呼んでいます。コメントでは、機械学習のブレークスルーは「プラトン的数学世界」の存在を裏付けているように見える、すなわち数学の有効性は物理宇宙を支える数学的構造に由来するという意見が述べられています。AI(「砂で作られた脳」)の出現は、かつてない規模と頻度でこの循環を加速させており、宇宙に関するより深い真実を明らかにする可能性があります (出典: riemannzeta)
保険会社、AIチャットボットの誤りによる損失保険を発売: 保険会社が、AIチャットボットの誤りに起因する損失を対象とした保険商品の提供を開始しました。この動きは、AIの不適切な使用が深刻な損害を引き起こす可能性を認める一方で、このような保険が企業にAIシステムの信頼性と安全性の向上に努めるのではなく、損失補填のために保険に依存するような、より粗放なAI活用を助長するのではないかという懸念も引き起こしています (出典: Reddit r/artificial)
AIの音楽制作における可能性は過小評価されている: コミュニティでは、多くの人がAIの音楽制作能力を過小評価しており、AI音楽は人間が創作するように「魂に触れる」ことはできないとよく言われるという意見があります。しかし、現在すでにAIが生成した音楽作品の中には、聴感上、人間の歌唱レベルに近いものもあります。AI音楽はまだ初期段階にあることを考えると、その将来の発展の可能性は非常に大きく、早計に否定すべきではありません (出典: Reddit r/artificial)
