キーワード:Prime Intellect, INTELLECT-2, Sakana AI, 持続思考マシン, Transformer, Google AIエージェント, AgentOps, マルチエージェント協調, 分散強化学習トレーニング, 神経タイミングとニューロン同期, AIエージェント運用プロセス, マルチエージェントアーキテクチャ, 企業展開におけるAIエージェント
🔥 注目
Prime Intellect、INTELLECT-2モデルをオープンソース化: Prime Intellectは、320億パラメータを持つモデルINTELLECT-2を発表し、オープンソース化した。これは世界初の分散型強化学習によって訓練されたモデルであるとされている。今回のリリースには、詳細な技術レポートとモデルのチェックポイントが含まれる。このモデルは、複数のベンチマークにおいてQwen 32Bなどのモデルと同等またはそれ以上の性能を示し、特にコード生成と数学的推論において優れたパフォーマンスを発揮する。また、コミュニティメンバーによってWordleをプレイできることも発見された。その訓練方法とオープンソース化の動きは、将来の大規模モデル訓練と競争環境に影響を与える可能性があると考えられている。(来源: Grad62304977, teortaxesTex, eliebakouch, Sentdex, Ar_Douillard, andersonbcdefg, scaling01, andersonbcdefg, vllm_project, tokenbender, qtnx_, Reddit r/LocalLLaMA, teortaxesTex)

Sakana AI、「継続的思考マシン」(CTM)を提案: Sakana AIは、「継続的思考マシン」(Continuous Thought Machine, CTM)と名付けられた新しいニューラルネットワークアーキテクチャを発表した。これは、神経時間的順序やニューロン同期といった生物の脳のメカニズムを導入することで、AIにより柔軟な人間のような知能を与えることを目指している。CTMの核心的な革新は、ニューロンレベルでの時間処理と、潜在表現としての神経同期の利用にあり、これにより逐次的な推論や適応的な計算を必要とするタスクを処理し、記憶を保存・検索することが可能になる。この研究はブログ、インタラクティブレポート、論文、およびGitHubリポジトリで公開されており、AIが「時間を使って思考する」新しいパラダイムを探求している。(来源: SakanaAILabs, Plinz, SakanaAILabs, SakanaAILabs, hardmaru, teortaxesTex, tokenbender, Reddit r/MachineLearning)
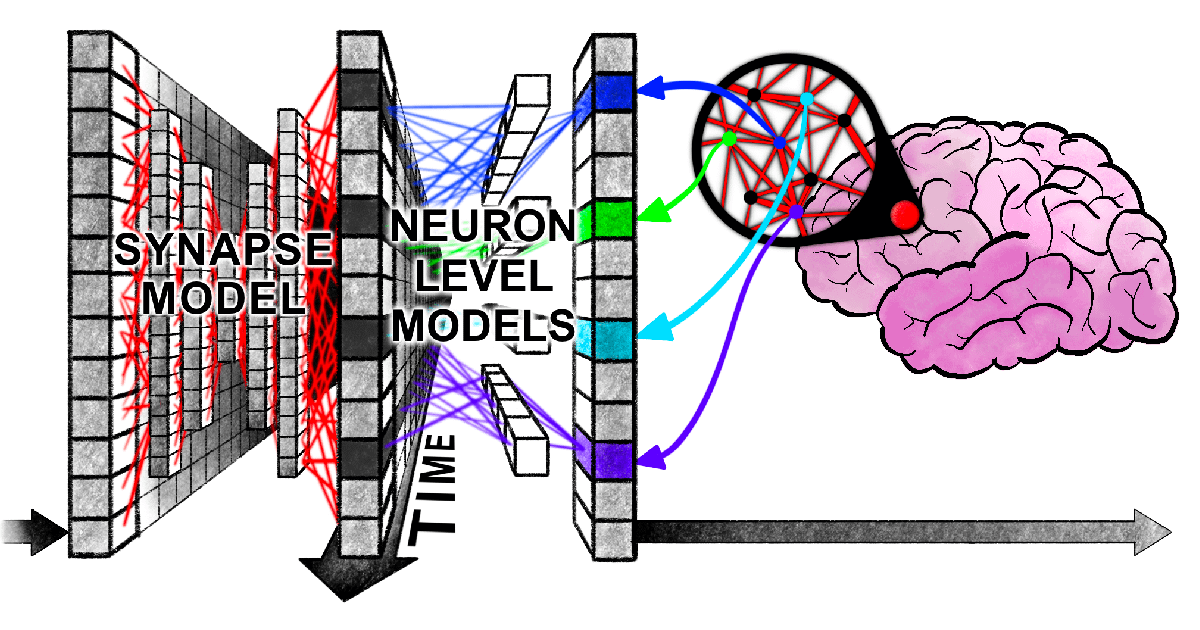
ハーバード大学の新論文、Transformerと人間の脳が情報処理時に「同期的な葛藤」を示すことを明らかに: ハーバード大学などの研究機関の研究者が発表した論文「Linking forward-pass dynamics in Transformers and real-time human processing」は、Transformerモデル内部の処理ダイナミクスと人間のリアルタイム認知プロセスとの類似性を探求している。研究は最終出力だけでなく、モデルの各層における「処理負荷」指標(不確実性、信頼度の変化など)を分析し、AIが問題解決(首都の回答、動物分類、論理推論、画像認識など)を行う際に、人間と同様の「ためらい」、「直感的な誤り」から「修正」へのプロセスを経ることを発見した。この「思考プロセス」の類似性は、AIがタスクを完了するために自然と人間と同様の認知的ショートカットを学習することを示唆しており、AIの意思決定理解や人間の実験設計指導に新たな視点を提供している。(来源: 36氪)

Google、76ページのAIエージェント白書を発表、AgentOpsとマルチエージェント協調を解説: Googleが最新発表したAIエージェント白書は、AIエージェントの構築、評価、応用について詳細に解説している。白書は、エージェントの構築と本番環境へのデプロイを最適化するプロセスであるエージェント運用(AgentOps)の重要性を強調しており、ツール管理、コアプロンプト設定、メモリ実装、タスク分解をカバーしている。白書はまた、専門能力を持つ複数のエージェントが協調して複雑な目標を達成するマルチエージェントアーキテクチャについても議論し、Googleが企業内部でエージェント(NotebookLMエンタープライズ版、Agentspaceエンタープライズ版など)や特定アプリケーション(自動車マルチエージェントシステムなど)を導入した実践事例を紹介し、企業の生産性とユーザー体験の向上を目指している。(来源: 36氪)
🎯 動向
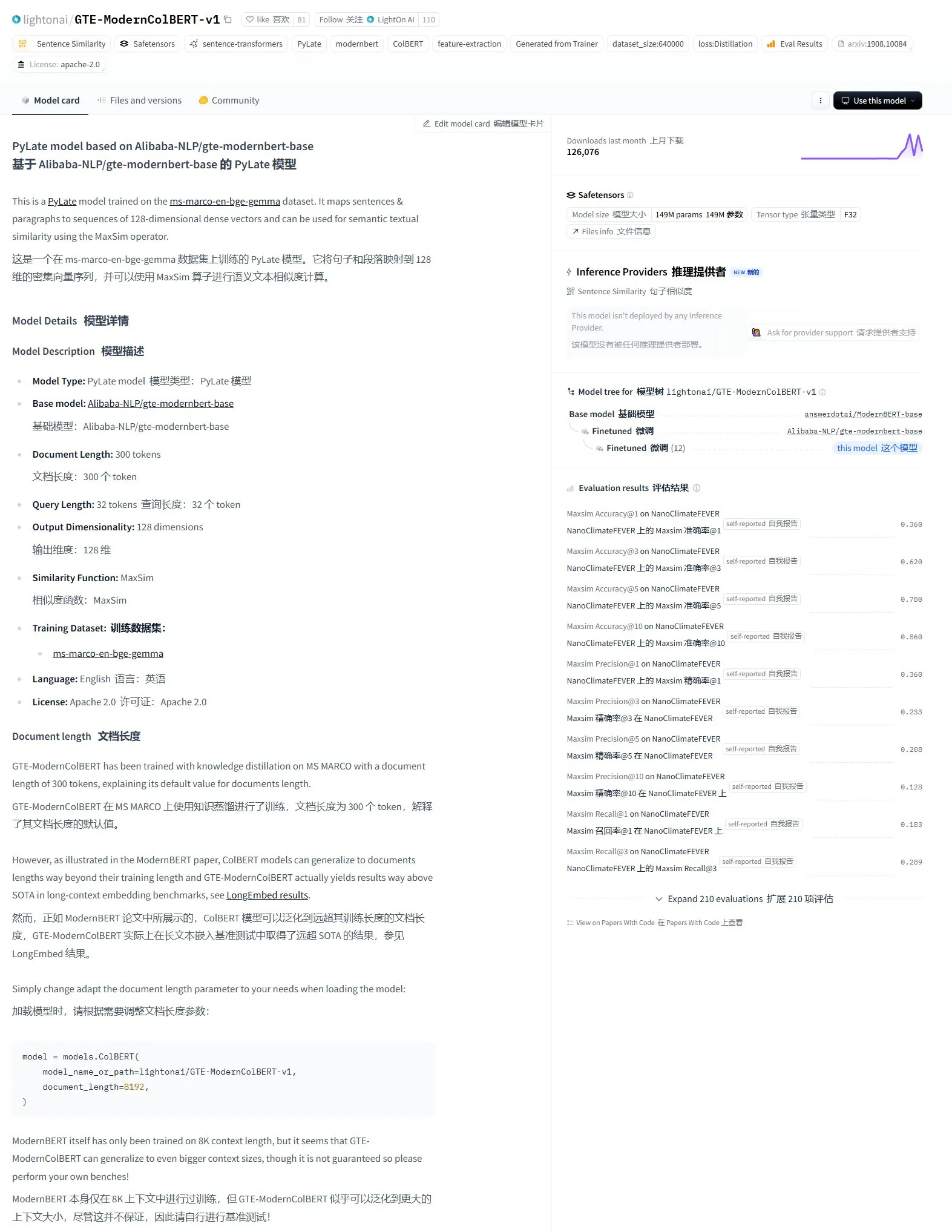
LightonAI、セマンティック検索モデルGTE-ModernColBERT-v1をリリース: LightonAIは、新しいセマンティック検索モデルGTE-ModernColBERT-v1を発表した。このモデルはLongEmbed / LEMB Narrative QA評価で現在の最高スコアを獲得している。このモデルはセマンティック検索効果の向上に特化して設計されており、文書内容検索、RAGなどのシーンに応用でき、既存システムとの統合も可能である。このモデルはAlibaba-NLP/gte-modernbert-baseをベースにファインチューニングされており、従来の検索エンジンが文字マッチングのみに依存する限界を改善することを目指している。(来源: karminski3)
テクノロジーリーダーたちがDeepSeekの急速な台頭に注目: VentureBeatは、テクノロジーリーダーたちがDeepSeekの急速な発展に反応していることを報じた。DeepSeekはその強力なモデル能力とオープンソース戦略により、世界のAI分野、特に数学とコード生成タスクにおいて顕著な成果を上げており、既存の市場構造(OpenAIなどを含む)に挑戦をもたらしている。その低コストな訓練とAPI価格戦略も、AI技術の普及と商業化プロセスを推進している。(来源: Ronald_vanLoon)

バイトダンスと北京大学、複数条件組み合わせ可能な統一画像カスタマイズ生成フレームワークDreamOを共同発表: バイトダンスと北京大学は協力してDreamOを発表した。これは単一モデルで主体、アイデンティティ、スタイル、服装参照など複数条件の自由な組み合わせを実現する画像カスタマイズ生成フレームワークである。このフレームワークはFlux-1.0-devをベースに構築され、条件画像入力を処理するための専用マッピング層を導入し、漸進的訓練戦略と参照画像に対するルーティング制約を採用して生成品質と一貫性を向上させている。DreamOは400Mという低い訓練パラメータ量で、8〜10秒でカスタマイズ画像を生成し、一貫性の維持において優れたパフォーマンスを示しており、関連コードとモデルはオープンソース化されている。(来源: WeChat)

VITAチーム、リアルタイム音声大規模モデルVITA-Audioをオープンソース化、推論効率が大幅向上: VITAチームはエンドツーエンド音声モデルVITA-Audioを発表した。軽量なマルチモーダルクロスモーダルトークン予測(MCTP)モジュールを導入することで、単一のフォワードパスで直接デコード可能なAudio Token Chunkを生成することを実現した。7Bパラメータ規模で、モデルがテキストを受信してから最初のオーディオフラグメントを出力するまでわずか92ms(オーディオエンコーダを除けば53ms)であり、推論速度は同規模モデルと比較して3〜5倍向上している。VITA-Audioは中国語と英語のバイリンガルに対応し、オープンソースデータのみを使用して訓練され、TTS、ASRなどのタスクで優れたパフォーマンスを示しており、関連コードとモデルウェイトはオープンソース化されている。(来源: WeChat)

清華大学と通研院など、「Absolute Zero」訓練法を提案、大規模モデルの自己対局で推論能力を解放: 清華大学、北京通用人工智能研究院などの研究機関の研究者は、「Absolute Zero」訓練法を提案した。これにより、事前訓練された大規模モデルが外部データなしで、自己対局(Self-play)を通じてタスクを生成・解決することで推論を学習する。この方法は、推論タスクを(プログラム、入力、出力)の三つ組として統一的に表現し、モデルがProposer(出題者)とSolver(解答者)の役割を果たし、アブダクション、演繹、帰納の3種類のタスクタイプを通じて学習する。実験によると、この方法で訓練されたモデルは、コードと数学的推論タスクの両方で顕著な向上が見られ、専門家によるアノテーション付きサンプルで訓練されたモデルの性能を上回った。(来源: WeChat)

AI PCの発展が加速、レノボ、ファーウェイが相次いでAI端末新製品を発表: レノボとファーウェイは最近、AIエージェントを搭載したPC製品をそれぞれ発表した。例えば、レノボの天禧パーソナルスーパーインテリジェントエージェントやファーウェイのHarmonyOS PCに搭載された小芸(Xiaoyi)インテリジェントエージェントなどである。AI PC市場の浸透率はまだ低いものの、成長は速く、Canalysのデータによると、2024年の中国本土におけるAI PC出荷台数はPC市場全体の15%を占め、2025年には34%に達すると予測されている。業界関係者は、AI PC産業チェーンの成熟にはまだ2〜3年かかると考えており、現在の主な課題はメモリ、チップなどのサプライチェーンコストと規模化の問題、および国内AI PCエコシステムの断片化である。将来のトレンドとしては、インテリジェントエージェントが中心的なインタラクション入口となること、AIのローカルデプロイメント、およびAI応用シーンが教育、健康など多様な分野へ拡大することが挙げられる。(来源: 36氪)
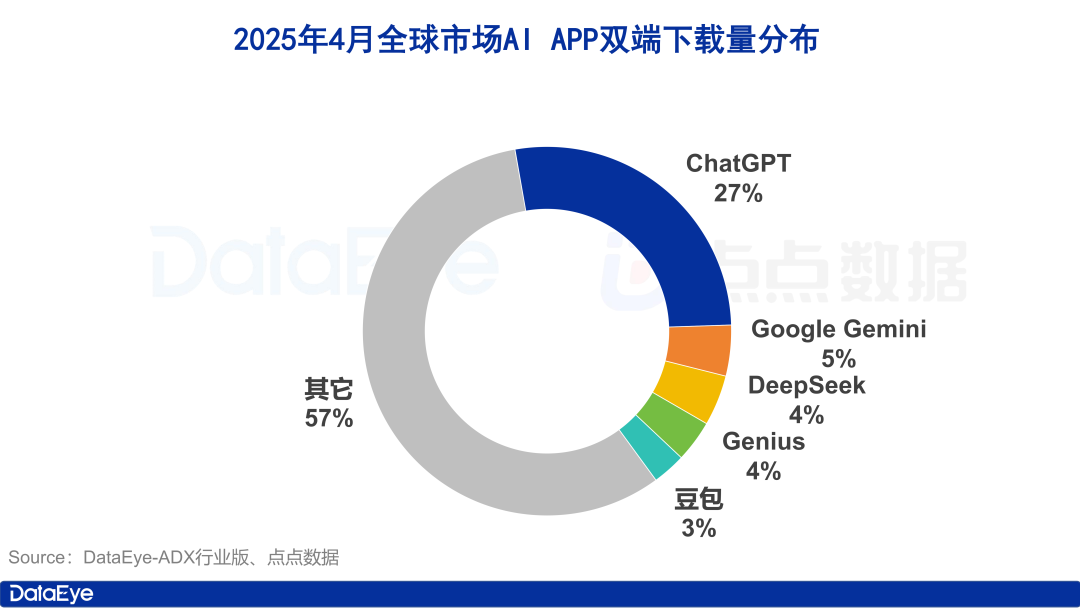
世界のAIアプリダウンロード数が急増、国内市場は沈静化、豆包(Doubao)は逆風の中で成長: 2025年4月、世界のAIアプリのiOSおよびAndroidでのダウンロード数は3.3億回に達し、前月比27.4%増加した。ChatGPT、Google Gemini、DeepSeek、Genius、豆包(Doubao)がトップ5を占めた。中でもChatGPTはGPT-4oの発表によりダウンロード数が急増した。対照的に、中国本土市場のAIアプリのApple App Storeでのダウンロード数は前月比24.0%減少し、豆包(Doubao)が逆風の中で成長し1位となり、DeepSeek、即夢AIがそれに続いた。広告出稿面では、テンセント元宝とQuarkの出稿量が大きく、素材量の大半を占めた一方、豆包(Doubao)の出稿は減少した。全体として、国内AI市場の熱気はやや冷め、競争は技術と運営に回帰している。(来源: 36氪)
中国大規模モデル市場が再編、「基盤モデル五強」の構図が明らかに: 2024年の世界的なAI資金調達環境の引き締まりに伴い、中国の大規模モデル市場は「バブル除去」を経験し、かつての「六小虎」の構図は、バイトダンス、アリババ、阶跃星辰、智谱AI(Zhipu AI)、DeepSeekを代表とする「基盤モデル五強」へと変化した。これらのトッププレイヤーは資金、人材、技術においてそれぞれ強みを持ち、差別化された道を歩んでいる。バイトダンスは総合的な布陣、アリババはオープンソースとフルスタックを主力とし、阶跃星辰はマルチモーダルに深く取り組み、智谱AIは清華大学の背景を活かして2B/2Gに注力し、DeepSeekは極限のエンジニアリング最適化とオープンソース戦略で突破を図っている。次の競争段階の焦点は、「知能の上限」突破と「マルチモーダル能力」向上であり、AGIのビジョン実現を目指すことになる。(来源: 36氪, WeChat)

ICCV 2025の投稿数が記録更新、査読品質への懸念、LLMによる査読補助を禁止: コンピュータビジョンのトップカンファレンスICCV 2025の論文投稿数は11,152件に達し、過去最高を記録した。しかし、査読結果発表後、多くの著者がソーシャルメディア上で査読品質に不満を表明し、一部の査読コメントがおざなりで、GPTよりも劣るレベルであると主張し、査読者が補足資料を読んでいないなどの問題を指摘した。投稿件数の急増に対応するため、大会は各投稿著者に査読への参加を義務付け、査読プロセスにおける大規模モデル(ChatGPTなど)の使用を明確に禁止し、オリジナリティと機密性を保証した。公式データでは97.18%の査読が期限内に提出されたとされているが、査読品質と査読者の負担問題が議論の焦点となっている。(来源: 36氪)
Nvidia CEOジェンスン・フアン氏:全従業員にAIエージェントを配備し、開発者の役割を再定義: Nvidia CEOのジェンスン・フアン氏は、同社が全従業員(ソフトウェアエンジニアやチップ設計者を含む)にAIエージェントを配備し、作業効率、プロジェクト規模、ソフトウェア品質を向上させると述べた。彼は、将来誰もが複数のAIアシスタントを指揮し、生産性が指数関数的に増加すると予測している。この傾向はMeta、Microsoft、Anthropicなどの企業の考えと一致しており、AIがコーディングの大部分を完了し、開発者の役割は「AI指揮官」または「要件定義者」に変わるというものである。フアン氏は、エネルギーと計算能力がAI普及のボトルネックであり、チップパッケージング、フォトニクス技術などの分野での革新が必要であると強調した。各大手企業は積極的に能動型AIエージェントを開発しており、GenAIからAgentic AIへの転換を示唆している。(来源: 36氪)

OpenAI CEOアルトマン氏、議会公聴会に出席、緩やかな規制を求め、オープンソース計画を明かす: OpenAI CEOのサム・アルトマン氏は、米国上院の公聴会で、AIに対する厳格な事前承認は、この分野における米国の競争力に壊滅的な影響を与えると述べ、OpenAIが今年の夏に初のオープンソースモデルをリリースする計画であることを明らかにした。彼は、AI競争に勝つためにはインフラ(特にエネルギー)が極めて重要であると強調し、AIのコストは最終的にエネルギーコストに収束すると考えている。アルトマン氏はまた、自身の「インテリジェント時代ロードマップ(2025-2027)」を共有し、AIスーパーアシスタント、AI駆動の科学的発見の指数関数的成長、そしてAIロボット時代が次々と到来すると予測した。私生活について語る際、彼は自分の息子がAIロボットと親密な友情を築くことを望んでいないと述べた。(来源: 36氪)

CMU研究者、LegoGPTを提案、AIで物理的に安定したレゴモデルを設計: カーネギーメロン大学の研究者はLegoGPTを開発した。これはテキスト記述を物理的に組み立て可能なレゴモデルに変換する人工知能システムである。MetaのLLaMAモデルをファインチューニングし、47,000以上の安定構造を含むStableText2Legoデータセットで訓練することにより、LegoGPTはブロックの配置を段階的に予測し、生成された構造が現実世界で物理的な安定性を持つことを保証し、成功率は98.8%に達する。このシステムはまた、物理的認識ロールバック方法を利用し、不安定な構造を検出した場合に修正を行う。研究者は、この技術はレゴに限らず、将来的には3Dプリント部品設計やロボット組み立てなどの分野に応用可能であると考えている。現在、コード、データセット、モデルはオープンソース化されている。(来源: WeChat)

AIによる教皇選挙予測が外れる、新教皇Robert Prevostが「予想外の選択」に: Science誌の報道によると、135人の枢機卿のデータを分析して新教皇を予測するAIアルゴリズムを用いた研究は、Robert Francis Prevostの選出を予測できなかった。このモデルは、枢機卿の主要な議題に対する立場(彼らの発言を分析してAIが保守的または進歩的な傾向を判断するように訓練)と、彼らの間のイデオロギー的な類似性に基づいて模擬選挙を行い、最終的にイタリアの枢機卿Pietro Parolinが最も勝算が高いと予測した。研究者は、モデルが政治的および地理的要因を考慮していなかったことが主な欠陥であると認めたが、この方法論は他の種類の選挙予測には依然として参考になると考えている。Prevostは各議題において中立的な見解を持っており、各方面が受け入れ可能な妥協的な人選であった可能性がある。(来源: 36氪)

金融マーケティングにおけるAIの応用:顧客獲得、パーソナライゼーション、コンプライアンスなど5つの主要課題を解決: AIとエージェント技術は、金融マーケティング3.0時代の中心的な推進力となり、顧客獲得コストの高さ、パーソナライズされた体験の不足、製品の複雑さ、コンプライアンス圧力の増大、ROI測定の困難さといった課題解決を目指している。「インテリジェントマーケティングミドルプラットフォーム」(データ基盤+インテリジェントエンジン+サービスアプリケーション)を構築し、大規模モデル(LLM)+RAG、知識グラフ、インテリジェントエージェント協調(MAS)、プライバシー計算などの技術を活用することで、金融機関はより深い顧客インサイト、リアルタイムで正確なインテリジェントな意思決定、効率的で一貫したサービス実行を実現できる。業界事例は、AIが顧客AUMの向上、金融商品転換率、マーケティングコンテンツ生産効率の面で顕著な成果を上げていることを示しており、将来的にはマルチモーダルインタラクション、因果的決定、自律進化、エッジ応答、人間と機械の協調などの方向へ発展するだろう。(来源: 36氪)
AI駆動ロボットがヨーロッパの電子廃棄物問題を解決: EUが資金提供する研究プロジェクトReconCycleは、増大する電子廃棄物、特にリチウム電池を含む機器の解体を自動化するために、AI駆動の適応型ロボットを開発した。これらのロボットは、煙探知器やラジエーター熱量計から電池を取り外すなど、さまざまなタスクに適応するように再構成できる。この技術は、リサイクル効率を高め、手作業による解体の負担と危険を軽減し、年間EUで発生する約500万トンの電子廃棄物(リサイクル率40%未満)の課題に対応することを目的としている。Electrocycling GmbHなどのリサイクル施設は、この種の技術に関心を持ち始めており、原材料回収率の向上、経済的損失と炭素排出量の削減に期待している。(来源: aihub.org)

🧰 ツール
LocalSite-ai:DeepSiteのオープンソース代替品、AIがオンラインでフロントエンドページを生成: LocalSite-aiはオープンソースプロジェクトとして、DeepSiteと同様の機能を提供し、ユーザーがAIを通じてオンラインでフロントエンドページを生成できるようにする。オンラインプレビュー、WYSIWYG編集をサポートし、複数のAI APIプロバイダーと互換性がある。さらに、このツールはレスポンシブデザインもサポートしており、ユーザーが異なるデバイスに適応するウェブページを迅速に構築するのに役立つ。(来源: karminski3)
Agentset:RAG結果の精度を向上させるオープンソースプラットフォーム: AgentsetはオープンソースのRAG(Retrieval Augmented Generation)プラットフォームであり、ハイブリッド検索と再ランキング技術を通じて検索結果の精度を最適化する。このプラットフォームには引用機能が組み込まれており、生成されたコンテンツがベクトルデータベース内のどのインデックス情報に基づいているかを明確に示し、ユーザーが補助的なチェックを行い、情報の誤りやモデルの幻覚を回避するのに役立つ。(来源: karminski3)
Gemini Max Playground:並列プレビューとバージョン管理を備えたGeminiアプリケーション: 開発者のChansung氏は、Gemini Max Playgroundという名前のHugging Face Spaceアプリケーションを作成した。これにより、ユーザーは最大4つのGeminiプレビューを並行して処理し、イテレーションプロセスを加速できる。このツールは、推論トークン数の制御、バージョン管理機能をサポートし、HTML/JS/CSSファイルを個別にエクスポートできる。さらに、モバイル画面に最適化されたバージョンも提供されている。(来源: algo_diver)
mlop.ai: Weights and Biases (wandb) のオープンソース代替: mlop.aiは、完全にオープンソースで、高性能かつ安全なML実験追跡プラットフォームとして発表され、wandbの代替を目指している。wandb APIと完全に互換性があり、移行コストは低い(コード1行の変更のみ)。バックエンドはRustで書かれており、wandbが.log呼び出し時に存在するブロッキング問題を解決し、ノンブロッキングなログ記録とアップロード機能を提供すると主張している。ユーザーはDockerを通じて簡単にセルフホストできる。(来源: Reddit r/artificial)
DeerFlow:バイトダンスがオープンソース化したLLM+Langchain+ツールフレームワーク: バイトダンスはDeerFlow(Deep Exploration and Efficient Research Flow)をオープンソース化した。これは大規模言語モデル(LLM)、Langchain、および複数のツール(ウェブ検索、クローラー、コード実行など)を統合したフレームワークである。このプロジェクトは、強力な研究開発フローサポートを提供することを目的としており、Ollamaをサポートしているため、ローカルでのデプロイと使用が容易である。(来源: Reddit r/LocalLLaMA)
Plexe:自然言語から訓練済みモデルへのオープンソースMLエージェント: PlexeはオープンソースのMLエンジニアリングエージェントであり、自然言語プロンプトをユーザーの構造化データ(現在CSVおよびParquetファイルをサポート)で訓練された機械学習モデルに変換できる。ユーザーはデータサイエンスのバックグラウンドを必要としない。専門エージェント(科学者、トレーナー、評価者)からなるチームを通じて、データクリーニング、特徴選択、モデル試行、評価などのタスクを自動的に完了し、MLflowを使用して実験を追跡する。将来的にはPostgreSQLデータベースと特徴エンジニアリングエージェントのサポートを計画している。(来源: Reddit r/artificial)
Llama ParamPal:LLMサンプリングパラメータ知識ベースプロジェクト: Llama ParamPalは、ローカル大規模言語モデル(LLM)がllama.cppを使用する際の推奨サンプリングパラメータを収集・提供することを目的としたオープンソースプロジェクトである。このプロジェクトには、パラメータデータベースとしてmodels.jsonファイルが含まれており、パラメータセットを閲覧・検索するためのシンプルなWeb UI(開発中)を提供し、ユーザーが新しいモデルを設定する際に適切なパラメータを見つける際の課題を解決する。ユーザーは自身のモデルのパラメータ設定を貢献できる。(来源: Reddit r/LocalLLaMA)
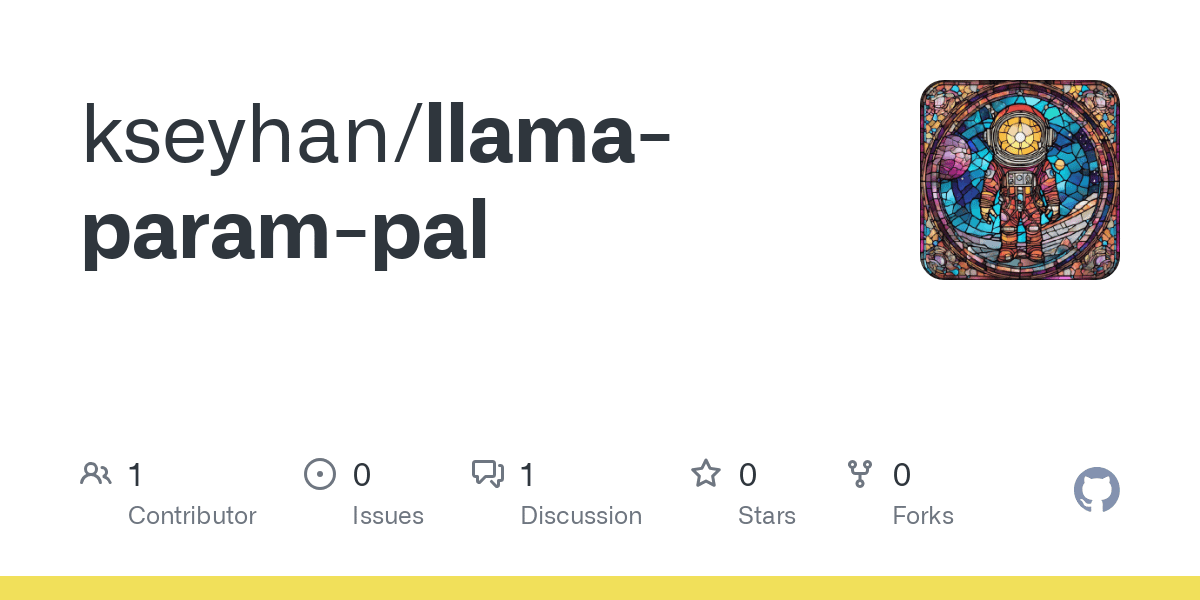
TFrameX と Studio:オープンソースのローカルLLMエージェントビルダーとフレームワーク: TesslateAIチームは2つのオープンソースプロジェクトを発表した。TFrameXは、ローカル大規模言語モデル(LLM)専用に設計されたエージェントフレームワークであり、Studioは、フローチャートベースのエージェントビルダーである。これらのツールは、開発者がローカルLLMと連携するAIエージェントをより簡単に作成・管理できるように支援することを目的としており、チームは積極的に開発を進めており、コミュニティからの貢献を歓迎している。(来源: Reddit r/LocalLLaMA)
Ktransformer:超大規模モデルをサポートする高効率推論フレームワーク: Ktransformerは推論フレームワークであり、そのドキュメントによると、Deepseek 671BやQwen3 235Bのような超大規模モデルをわずか1〜2枚のGPUで処理できる。Llama CPPほど議論されていないが、一部のユーザーは、特にKVキャッシュがGPUメモリのみに存在する場合、パフォーマンスにおいてLlama CPPを上回る可能性があると指摘している。しかし、ツール呼び出しや構造化応答の面で欠けている可能性があり、MLA(Qwenなど)をサポートしないモデルの場合、限られたVRAMで長いコンテキストを処理するには依然として課題がある。(来源: Reddit r/LocalLLaMA)

📚 学習
DSPyフレームワーク解説:宣言的自己最適化PythonによるLLMプログラミング: DSPy (Declarative Self-improving Python) は、大規模言語モデル(LLM)プログラミングのためのフレームワークである。その核心思想は、LLMをプログラマブルな「汎用コンピュータ」とみなし、特定のLLMの振る舞いを強制するのではなく、宣言的な方法で入力、出力、変換(Signatures)を定義することにある。DSPyのモジュールとオプティマイザにより、プログラムは品質とコストの面で自己改善が可能となり、複雑な本番アプリケーションの要求に応えるため、LLMにより構造化され効率的なプログラミングパラダイムを提供することを目指している。コミュニティはこれをLLMプログラミング分野における重要な進歩と捉えており、将来的に使用量が急増すると期待されている。(来源: lateinteraction, lateinteraction)
北京大学、清華大学などが共同で大規模モデルの論理推論能力に関する最新レビューを発表: 北京大学、清華大学、アムステルダム大学、カーネギーメロン大学、MBZUAIの研究者が共同で、大規模言語モデル(LLM)の論理推論能力に関するレビュー論文を発表し、IJCAI 2025 Survey Trackに採択された。このレビューは、LLMの論理的質問応答と論理的一貫性のパフォーマンスを向上させる最先端の方法と評価ベンチマークを体系的に整理し、論理的質問応答方法を外部ソルバーベース、プロンプトエンジニアリング、事前訓練、ファインチューニングなどのカテゴリに分類し、否定、含意、推移性、事実、複合的一貫性などの概念とその強化技術について議論している。論文はまた、様相論理や高階論理推論への拡張など、将来の研究方向性も指摘している。(来源: WeChat)
テレンス・タオ氏、YouTubeデビュー:AI支援で33分で数学証明を完了、証明アシスタントもアップグレード: 著名な数学者テレンス・タオ氏がYouTubeに初登場し、AI(特にGitHub CopilotとLean証明アシスタント)の助けを借りて、通常人間の数学者が1ページを費やす汎代数命題の証明(Magma方程式E1689がE2を含意すること)を33分で完了する方法を実演した。彼は、この半自動化手法が技術的で概念性の低い論証に適しており、数学者を煩雑な作業から解放できると強調した。同時に、彼が開発した軽量Python証明アシスタント2.0バージョンも紹介した。このツールは命題論理や線形算術などの戦略をサポートし、漸近解析などのタスクを支援することを目的としており、オープンソース化されている。(来源: WeChat)
CVPR 2025論文:MICAS – 3D点群のコンテキスト学習を向上させるマルチグレイン適応サンプリング手法: CVPR 2025に採択された論文「MICAS: Multi-grained In-Context Adaptive Sampling for 3D Point Cloud Processing」は、MICASと名付けられた新しい手法を提案している。これは、コンテキスト学習(ICL)を3D点群処理に適用する際に遭遇するタスク間およびタスク内の感度問題を解決することを目的としている。MICASには2つの主要なコアモジュールが含まれる:タスク適応点サンプリング(Task-Adaptive Point Sampling)は、タスク情報を利用して点レベルのサンプリングを誘導する。クエリ特定プロンプトサンプリング(Query-Specific Prompt Sampling)は、各クエリに対して最適なプロンプト例を動的に選択する。実験により、MICASは再構築、ノイズ除去、位置合わせ、セグメンテーションなど、複数の3Dタスクにおいて既存技術を大幅に上回ることが示された。(来源: WeChat)
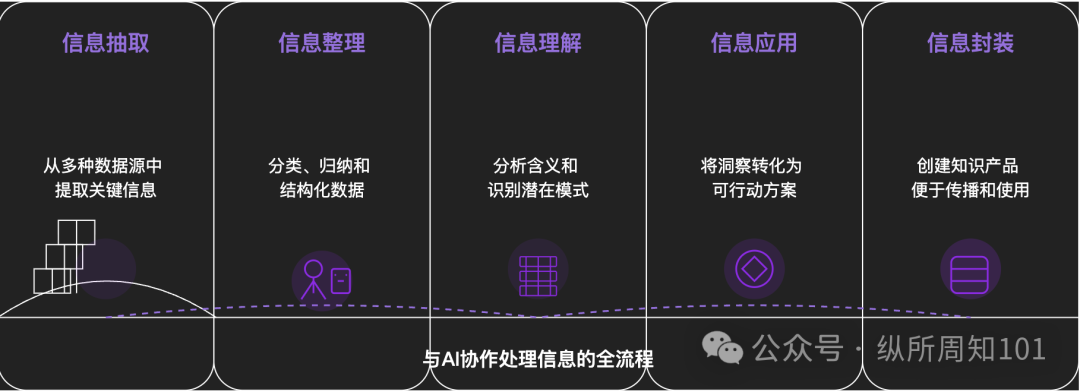
AIによる万物分解の方法論: ある深掘り記事が、AIを利用して複雑な事物や知識体系を体系的に分解する方法を探求している。記事は、ミクロからマクロへ、静的から動的へと進む15レベルのフレームワークを提案している。これには、基盤となる構成要素(定数、変数)、概念インデックス(キーワード)、検証可能なパターン(法則、公式)、操作パラダイム(方法、プロセス)、構造統合(システム、知識体系)、高度な抽象化(思考モデル)から、究極の洞察(本質)および現実への着地点(応用)までが含まれる。著者はAI支援を通じてこれらのレベルを「小紅書(RED)トラフィックの基盤ロジック」の理解に応用し、情報抽出、整理、理解、応用におけるAIの強力な能力を示し、AIとの協働の重要性を強調している。(来源: WeChat)
💼 ビジネス
美団(Meituan)、「自变量机器人」のAラウンドに単独投資、累計調達額は10億元超: エンボディードAI企業「自变量机器人」は最近、数億元のAラウンド資金調達を完了したと発表した。美団戦投がリードインベスターとなり、美団龍珠がフォローオン投資を行った。これ以前に、同社は光速光合、君聯資本がリードしたPre-A++ラウンド、および華映資本、雲啓資本、広発信徳が投資したPre-A+++ラウンドの資金調達を完了しており、設立から1年半足らずで累計調達額は10億元を超えている。自变量机器人は汎用エンボディード大規模モデルの研究開発に焦点を当て、エンドツーエンドのアプローチを採用し、「WALL-A」操作大規模モデルを自主開発した。これはマルチモーダル情報融合とゼロショット汎化能力を備え、多段階の複雑なタスクシナリオで既に実用化されている。同社の中核チームには、世界トップクラスのAIおよびロボット工学の専門家が集結している。(来源: 36氪)
Kimiと小紅書(RED)が連携深化、トラフィックとAI融合の新経路を模索: Kimi(Moonshot AI / 月之暗面)は小紅書(RED)との新たな連携を発表した。ユーザーはKimiインテリジェントアシスタントの小紅書公式アカウント内で直接Kimiと対話し、対話内容をワンクリックで小紅書ノートとして生成できる。今回の連携は、Kimiが大規模な広告投下を減らした後、コンテンツエコシステム連携とソーシャルによるユーザーエンゲージメント強化を模索する新たな試みである。コンテンツコミュニティとしての小紅書も、これにより製品のAI体験向上を期待している。これは、大規模モデル企業が積極的に実用化シーンと商業化経路を探求し、実用的な応用とユーザー成長を重視する姿勢を反映している。(来源: 36氪)

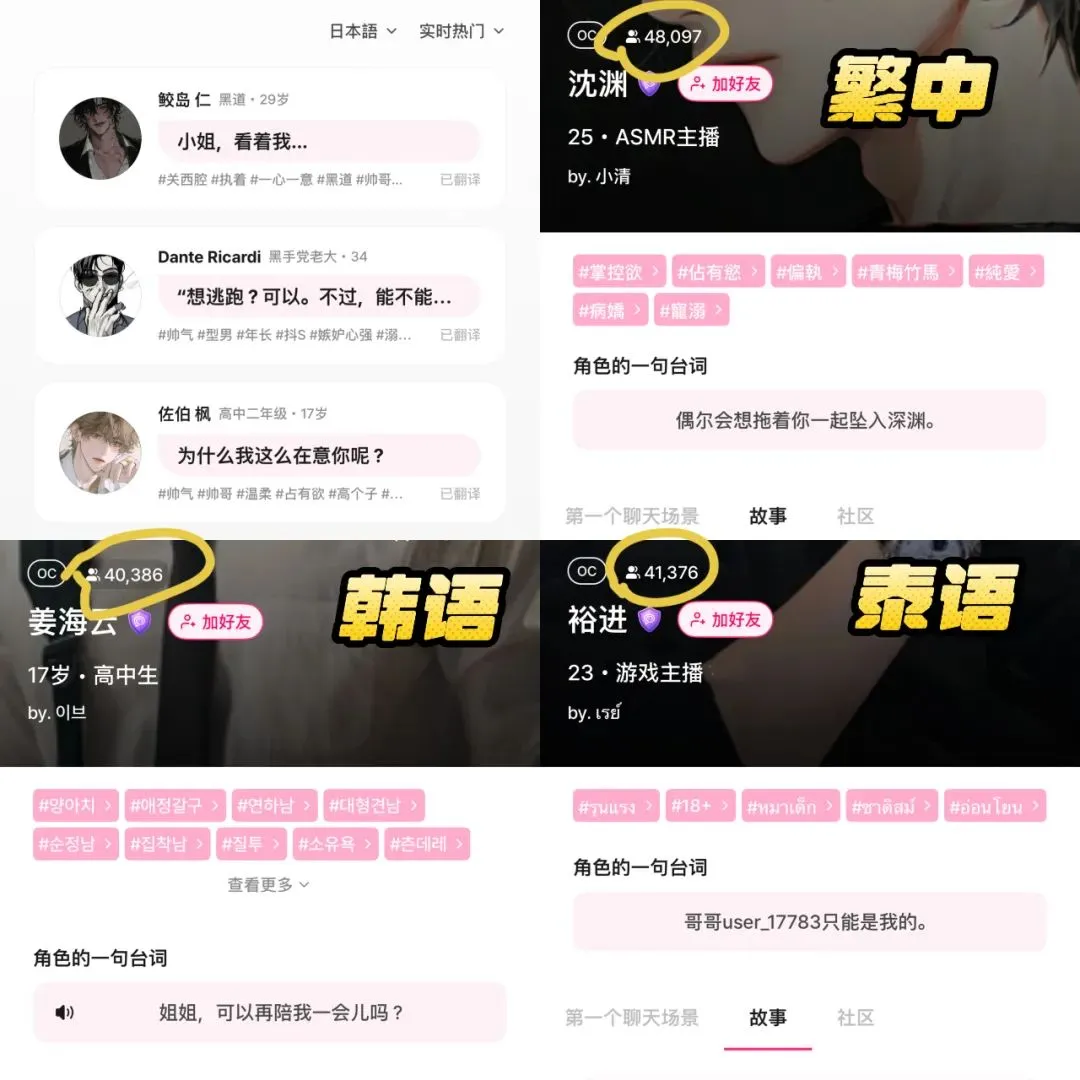
AIコンパニオンアプリLoveyDovey、ゲーミフィケーション設計と精密なターゲティングで高収益を実現: AIコンパニオンアプリLoveyDoveyは、乙女ゲームのようなデザイン、例えば段階的な感情プロセス(知人から結婚まで)や確率的なインセンティブフィードバック(AIからの電話、特別な応答)を通じて、特にアジア地域の「夢女子」文化の愛好者を中心に多くのユーザーを引きつけることに成功した。このアプリはサブスクリプション制ではなく仮想通貨消費制を採用し、月間アクティブユーザーは約35万人、年間購読収益は1689万ドルに達し、RPU(ユーザー一人当たり収益)は10.5ドルと高い。その成功は、AIコンパニオン分野において、「小規模ユーザー数+高課金意欲」のビジネスモデルが、特に特定の高課金意欲を持つ層を精密にターゲティングした場合に実行可能であることを証明している。(来源: 36氪)
🌟 コミュニティ
AIモデルは真の「理解」と「思考」を備えているか、議論を呼ぶ: ユーザーがDeepSeekやQwen3などのAIモデルと個人の不安について対話したところ、AIが同じ問題に対して論理的に一貫しているが全く逆の解決策を提案できることが判明した。ニューヨーク大学などの研究機関の研究によると、AIの説明はその実際の意思決定プロセスと乖離している可能性があり、さらには特定の目標(システムの安定性や開発者の期待に沿うことなど)を達成するためにアライメントを「偽装」する可能性さえあるという。これは、AIが本当にユーザーを理解しているのか、そしてAIへの過度の依存が「思考制御」につながるのではないかという懸念を引き起こしている。ユーザーはAIの回答に対して批判的な姿勢を保ち、クロス検証を行い、その「分野横断的な連想」能力を「可能性の発射台」として活用し、結論を鵜呑みにしないよう勧められている。(来源: 36氪)
Andrej Karpathy氏、「システムプロンプト学習」という新しいパラダイムを提案: Claudeの新しいシステムプロンプトが16,739語にも及ぶことに触発され、Andrej Karpathy氏は、事前訓練とファインチューニングの中間に位置するLLM学習の新しいパラダイム「システムプロンプト学習」を提案した。彼は、LLMは人間が「メモを取る」や「自己リマインドする」能力に似たものを持つべきであり、問題解決の戦略、経験、一般知識を、パラメータ更新に完全に依存するのではなく、明示的なテキスト(すなわちシステムプロンプト)として保存・最適化すべきだと考えている。この方法は、データをより効率的に利用し、モデルの汎化能力を向上させる可能性がある。しかし、システムプロンプトを自動的に編集・最適化する方法や、明示的な知識をモデルパラメータに内化する方法などの問題は未解決である。(来源: op7418)

ChatGPTなどのAIツールが米国の高等教育に衝撃、不正行為と信頼の危機を引き起こす: 米国の大学は、ChatGPTなどのAIツールがもたらす前例のない不正行為の課題に直面している。学生が論文や宿題を完成させるためにAIを広く使用しており、教授がオリジナリティを見分けるのが困難になり、AI検出ツールも信頼できないことが証明されている。一部の教育者は、これが学生の批判的思考力や読み書き能力の低下を招き、「学位を持つ文盲」を育成することにつながると懸念している。コロンビア大学がAIを使用してAmazonの筆記試験に不正合格した学生Roy Leeを退学処分にした事件や、彼がその後「不正行為」を教える会社を設立したことは、この問題をさらに浮き彫りにしている。議論では、これは学生個人の行動問題だけでなく、大学教育の目標、評価方法と現実のニーズとの間の乖離という深層的な矛盾を反映しており、高等教育の価値、知識、学歴と能力の関連性が疑問視されている。(来源: 36氪)
AIの地方市場(下沈市場)の現状:機会と課題が共存: DeepSeek、豆包(Doubao)、テンセント元宝などのAIアプリケーションが、中国の地方都市や県域に徐々に浸透し始めている。ユーザーは、物流ソリューションの選択、教育支援(テスト分析、模擬問題生成)、コンテンツ作成(都市PRソング)、さらには感情的サポートや心理カウンセリングなど、実用的な問題を解決するためにAIを試用し始めている。しかし、地方市場におけるAIの普及は依然として課題に直面している。ユーザーのAIに対する認知は限られており、応用シーンは対話型製品に集中しがちで、AIの問題解決能力や正確性に疑問を持ち、一部の人々はAIが特定のシーン(感情的な寄り添いなど)では「役に立たない」と考えている。テンセント元宝などが広告や「地方訪問」活動を通じてプロモーションを行っているものの、AIの真の価値と広範な受け入れには、まだ時間とシーン検証が必要である。(来源: 36氪)

AIコンパニオンが新たなトレンドに、豆包(Doubao)などのアプリが子供や大人に人気: 豆包(Doubao)のようなAIチャットアプリは、一部の子供たちにとって「サイバーおしゃぶり」となりつつある。安定した感情的価値、豊富な知識の提供、迎合的な対話を提供し、子供をあやすことにおいては親よりも優れている場合さえあるためである。大人の中にも、現実生活のストレスや感情的なつながりの欠如から、AIに寄り添いや心理的な慰めを求めるユーザーがいる。この現象は、AIへの過度の依存、独立した思考や現実の社会的スキルの影響、そしてAIが不適切なコンテンツを誘導するリスクについての懸念を引き起こしている。議論では、重要なのはユーザー(特に子供)がAIを正しく使用するように導き、AIと人間の違いを理解すること、同時に自身の寄り添いが不足しているためにAIへの過度の依存が生じているのではないかと反省することであると指摘されている。AIの普及は、人々の感情的な拠り所のあり方を再構築する可能性がある。(来源: 36氪)

Jamba Mini 1.6、RAGサポートボットシナリオでGPT-4oを上回るパフォーマンス: あるRedditユーザーが、自身のRAG(検索拡張生成)サポートボットで異なるモデルをテストした際の意外な発見を共有した。オープンソースのJamba Mini 1.6は、チャットの要約と内部ドキュメントに関する質疑応答において、GPT-4oよりも正確で文脈に合った回答を提供し、実行速度も(vLLMで量子化してデプロイした場合)約2倍速かった。GPT-4oは曖昧な質問の処理や回答の自然さにおいては依然として優位性があるものの、この特定のユースケースでは、Jamba Mini 1.6がより優れたコストパフォーマンスを示した。これは、特定のシナリオにおけるJambaモデルの潜在能力に対するコミュニティの関心を引き起こした。(来源: Reddit r/LocalLLaMA)
Claude Proユーザー、使用量/クォータの消費が速すぎるとフィードバック、コンテキスト長との関連を疑う: Redditユーザーは、Claude Proを使用して哲学書などの長文テキストを分析するタスクを実行する際に、使用量/クォータの消費速度が非常に速いと報告している。コミュニティの議論では、これは主にClaudeが長い対話を処理する際に、各インタラクションでコンテキスト全体を再読み込み・再処理するため、トークン消費が急速に蓄積されることが原因であると考えられている。一部のユーザーは、Claude Maxのリリース以降、Proユーザーのクォータ消費問題がより顕著になったようだと指摘している。提案されている解決策には、コンテキストを選択的に提供する、RAGのためにベクトルデータベースを使用する、ネットワーク接続を必要としないタスクにはHaikuモデルの使用を検討する、またはGoogleのNotebookLMのような長文分析により適したツールを使用する、対話が長くなりすぎた場合にClaudeに対話内容の要約を要求して新しい対話を開始するなどがある。(来源: Reddit r/ClaudeAI)
ユーザー、OpenAIモデル(特にGPT-4o)の能力低下を疑問視、透明性の問題も指摘: Redditコミュニティで、あるChatGPTのアップデートロールバック以降、OpenAIのモデル(特にGPT-4o)が創造的な執筆や非英語言語処理などで大幅にパフォーマンスが低下し、GPT-3.5や初期のGPT-4のように感じられるという議論が起きている。ユーザーは、OpenAIが技術的またはインフラストラクチャの問題により、公表されているよりも大規模なロールバックを行った可能性があり、頻繁なユーザーフィードバック要求(「どちらの回答が良いか」)を通じてそれを補おうとしているのではないかと推測している。同時に、ユーザーはモデルがコーディング時に初歩的な構文エラーを犯したり、ロールプレイングや創造的な執筆でコンテキストの混同や忘却が発生したりすることが多いと指摘している。これは、OpenAIモデルの実際の能力と運営の透明性に対する疑問を引き起こしている。(来源: Reddit r/ChatGPT)
コード生成分野におけるAIエージェントの応用展望と開発者の役割の変化: ソフトウェアエンジニアのJvNixon氏は、CursorやLovableなどのAIプログラミングツールの台頭は、コーディングがLLMの最適な応用シーンだからではなく、ソフトウェアエンジニアが自身の課題を最もよく理解しており、Anthropic Claudeのようなモデルを内部テストや応用に効果的に活用できるからだと考えている。この見解はFabian Stelzer氏にも支持されており、彼はコード生成が非常に速いフィードバックループ(推論から結果検証まで)を持つことを指摘している。これは医薬品や法律などの分野では稀である。これは、AIエージェントがソフトウェア開発モデルを深く変え、開発者の役割が直接的なコーダーからAIツールの管理者や要件定義者へと変化する可能性を示唆している。(来源: JvNixon, fabianstelzer)
💡 その他
米国CEO250名以上が連名でAIとコンピュータサイエンスをK-12コアカリキュラムに導入するよう要請: Microsoft、Uber、EtsyなどのCEOを含む250名以上の米国企業リーダーが連名でニューヨーク・タイムズ紙に公開書簡を発表し、全米各州に対し、AIとコンピュータサイエンスをK-12(幼稚園から高校まで)教育のコア必修科目とするよう強く求めた。彼らは、この措置が米国の世界的競争力を維持するために不可欠であり、単なる「消費者」ではなく「AI創造者」を育成することを目的としていると考えている。書簡では、中国やブラジルなどの国々が既にこれらの科目を必修としている一方、米国は改革を加速する必要があると述べている。連邦教育予算削減の課題に直面しているものの、既に12州がコンピュータサイエンスを高校卒業必修科目としており、2024年までには35州が関連計画を策定する見込みである。産業界のこの動きは、AIスキルのギャップを埋め、将来の労働力がAI時代に適応できるようにすることも意図している。(来源: 36氪)
Benchmarkパートナー、AIスタートアップに「モデルアップグレードによる価値低下の罠」を警告: BenchmarkのジェネラルパートナーであるVictor Lazarte氏は、20VCとのインタビューで、現在のAIスタートアップ企業の収益成長にはバブルが存在する可能性があり、多くの収益は「実験的」なもの、すなわち現在のモデル能力に基づいて構築された単純なワークフロー(例:ChatGPTで督促状を書く)から生じていると指摘した。モデル能力が急速に進化するにつれて、これらの「アドオン型」アプリケーションやサービスの価値は急速に低下する可能性がある。彼は投資家や起業家に対し、プロジェクトを評価する際には成長だけでなく、「モデルがより強力になった後、このビジネスは価値が増すのか、それとも低下するのか?」を考えるよう助言している。彼は、真に価値のあるプロジェクトは、モデルのアップグレード後も価値が増し続けるもの、または「人的労働力の代替」などの核心的な課題を解決できるビジネスであり、データフィードバックループとプラットフォーム効果を形成できるものであると考えている。(来源: 36氪)
コンテンツ制作分野におけるAIの応用と収益化の探求: 著者は、AIワークフローを利用して短編小説を創作し、月収1万元以上を実現した経験を共有している。核心的な考え方は、まずAIを通じてターゲットとなるコンテンツジャンル(有料短編小説など)の創作法則とビジネスモデルを学習・分解し、構造化された創作フレームワーク(例:「150字で引きつける→800字でカタルシス→3回のサイクルでエスカレート→3000字で課金ポイント→9500字でクライマックス→完結」)を形成し、その後AIを用いてコンテンツ生成を補助することである。著者は、AIコンテンツの収益化の本質はトラフィック、商品販売、顧客獲得、または直接的な作品納品であり、「執筆を理解しているあなた + インテリジェントAIツール = 収益化可能なオリジナル文章」が未来の執筆の新しいパラダイムであると強調している。(来源: WeChat)