
キーワード:ChatGPT, GitHub, AIモデル, マルチモーダル, 強化学習, オープンソース, Meta FAIR, AGI, ChatGPT深度研究機能, ハイブリッドTransformerアーキテクチャ, 強化学習微調整RFT, AI多人世界モデルMultiverse, 科学者AIフレームワーク, ChatGPT, GitHub, AIモデル, マルチモーダル, 強化学習, オープンソース, Meta FAIR, AGI, ChatGPT深度研究機能, ハイブリッドTransformerアーキテクチャ, 強化学習微調整RFT, AI多人世界モデルMultiverse, 科学者AIフレームワーク
🔥 注目ニュース
ChatGPTのDeep Research機能がGitHubと統合: OpenAIは、ChatGPTのDeep Research機能がGitHubリポジトリへの接続をサポートしたことを発表しました。ユーザーが質問すると、AIエージェントがリポジトリ内のソースコード、PR、READMEなどのドキュメントを自動的に読み取り、検索、分析し、直接引用を含む詳細なレポートを生成します。この機能は、開発者が迅速にプロジェクトを理解し、コード構造や技術スタックを把握するのを支援することを目的としています。現在、この機能はテスト段階にあり、Teamユーザーに公開されており、順次PlusおよびProユーザーにも展開される予定です。(ソース: OpenAI Developers, snsf, EdwardSun0909, op7418, gdb, tokenbender, 量子位, 36氪)

世界初のAIマルチプレイヤーワールドモデルMultiverseがオープンソース化: イスラエルのスタートアップ企業Enigma Labsは、開発したマルチプレイヤーワールドモデルMultiverseをオープンソース化しました。これにより、2つのAIエージェントが同一の生成環境で知覚、対話し、協力することが可能になります。このモデルは「グランツーリスモ4」を基に訓練され、2人のプレイヤーの視点をカラーチャンネルに沿ってスタックし、スパースサンプリングされた過去のフレームと組み合わせることで共有ワールド状態を処理し、PC上で1500ドル未満のコストでの訓練とリアルタイム実行を実現しました。これは、AIが共有仮想環境の理解と生成において重要な進展であり、マルチエージェントシステムとシミュレーショントレーニングプラットフォームに新たなアイデアを提供すると見なされています。(ソース: Reddit r/MachineLearning, 36氪)
トップAI科学者Rob Fergus氏がMeta FAIRに復帰し責任者に就任、目標はAGI: Yann LeCun氏と共同でFAIRを初期に設立し、後にDeepMindのニューヨークチームを率いたRob Fergus氏がMetaに復帰し、Joelle Pineau氏の後任としてFAIRの責任者に就任しました。Fergus氏は今年4月にMetaのGenAI部門に加わり、Llamaモデルの記憶力とパーソナライゼーション能力の向上に取り組んでいます。LeCun氏は同時に、FAIRの新たな目標が高度な機械知能(AGI)になることを発表しました。Fergus氏はAI分野で引用数の多い学者であり、代表作にはZFNetの可視化研究や敵対的サンプルの先駆的な研究などがあります。(ソース: ylecun, 36氪)

Anthropic、Claude AIの価値観に関する研究を発表、3307種類のAIの価値傾向を明らかに: Anthropicの研究チームはプレプリント論文「Values in the Wild」を発表し、Claude AIが実世界の対話で見せる振る舞いを分析することで、3307種類のユニークなAIの価値を特定しました。研究によると、最も一般的な価値はサービス指向型で、「役に立つこと」(23.4%)、「プロフェッショナリズム」(22.9%)、「透明性」(17.4%)などでした。AIの価値観は、実用的(31.4%)、認知的(22.2%)、社会的(21.4%)、保護的(13.9%)、個人的(11.1%)の5つのトップカテゴリーに分類され、高度な文脈依存性を示しました。Claudeは通常、人間が表明した価値観に対して支持的に応答し(43%)、価値のミラーリングは約20%を占め、ユーザーの価値観への抵抗は稀でした(5.4%)。(ソース: Reddit r/ArtificialInteligence)
Yoshua Bengio氏、「科学者AI」フレームワークを提唱し、より安全なAI開発パスを主張: チューリング賞受賞者のYoshua Bengio氏は、「タイム」誌に寄稿したコラムで、自身のチームが進める「科学者AI」(Scientist AI)の研究方針について説明しました。彼はこれを、現在の制御不能でエージェント駆動型のAI開発軌道を代替するための、実用的で効果的かつより安全なAI開発パスであると考えています。このフレームワークは、AIシステムが解釈可能性、検証可能性、人間の価値観との整合性を備えるべきであることを強調し、科学研究の方法論を模倣することで、AIの行動と意思決定プロセスをより透明で制御可能にし、潜在的なリスクを低減することを目指しています。(ソース: Yoshua_Bengio)
🎯 動向
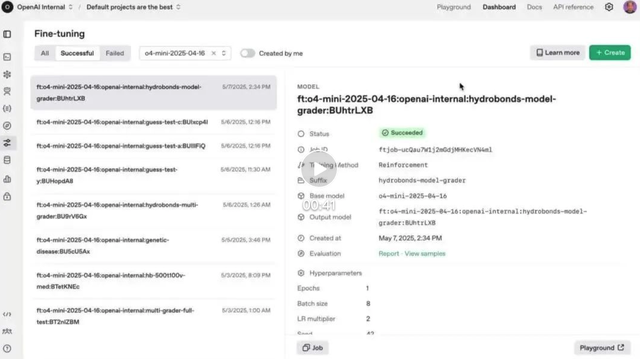
OpenAIの強化学習ファインチューニング(RFT)機能がo4-miniで正式提供開始: OpenAIは、昨年12月にプレビューされた強化学習ファインチューニング(RFT)機能が、o4-miniモデルで正式に利用可能になったことを発表しました。RFTは、思考連鎖推論とタスク固有のスコアリングを利用して、複雑な領域におけるモデルのパフォーマンスを向上させます。例えば、AccordanceAI社はRFTを使用して、税務および会計分野でトップクラスのパフォーマンスを発揮するモデルをファインチューニングしました。(ソース: OpenAI Developers, gdb, 量子位, 36氪)
Gemini APIに暗黙的キャッシュ機能が追加、呼び出しコストを75%削減: Google Gemini APIに暗黙的キャッシュ機能が追加されました。ユーザーリクエストが以前のリクエストと共通のプレフィックスを持つ場合、自動的にキャッシュヒットがトリガーされ、ユーザーのToken費用を75%節約できます。この機能は、開発者が能動的にキャッシュを作成する必要はありません。同時に、キャッシュをトリガーする最小Token要件は、Gemini 2.5 Flashで1Kに、2.5 Proで2Kに引き下げられ、API使用コストがさらに削減されました。(ソース: op7418)

OpenAI、欧州経済領域などでChatGPTの記憶機能を全面的に提供開始: OpenAIは、ChatGPTの記憶機能が欧州経済領域(EEA)、英国、スイス、ノルウェー、アイスランド、リヒテンシュタインのPlusおよびProユーザーに全面的に提供開始されたことを発表しました。この機能により、ChatGPTはユーザーの過去のすべてのチャット履歴を参照し、よりパーソナライズされた応答を提供し、ユーザーの好みや興味をよりよく理解することで、ライティング、提案、学習などの面でより正確な支援を提供できます。(ソース: openai)
ByteDance Seed、マルチモーダル基盤モデルMogaoを発表: ByteDanceのSEEDチームは、インターリーブ形式のマルチモーダル生成専用に設計されたOmni基盤モデルMogaoを発表しました。Mogaoは、ディープフュージョン設計、デュアルビジョンエンコーダー、インターリーブ回転位置エンベディング、マルチモーダル分類器フリーガイダンスなど、多数の技術的改善を統合しています。これらの改善により、自己回帰モデル(テキスト生成)と拡散モデル(高品質画像合成)の利点を組み合わせ、任意のインターリーブされたテキストと画像のシーケンスを効果的に処理できます。(ソース: NandoDF)

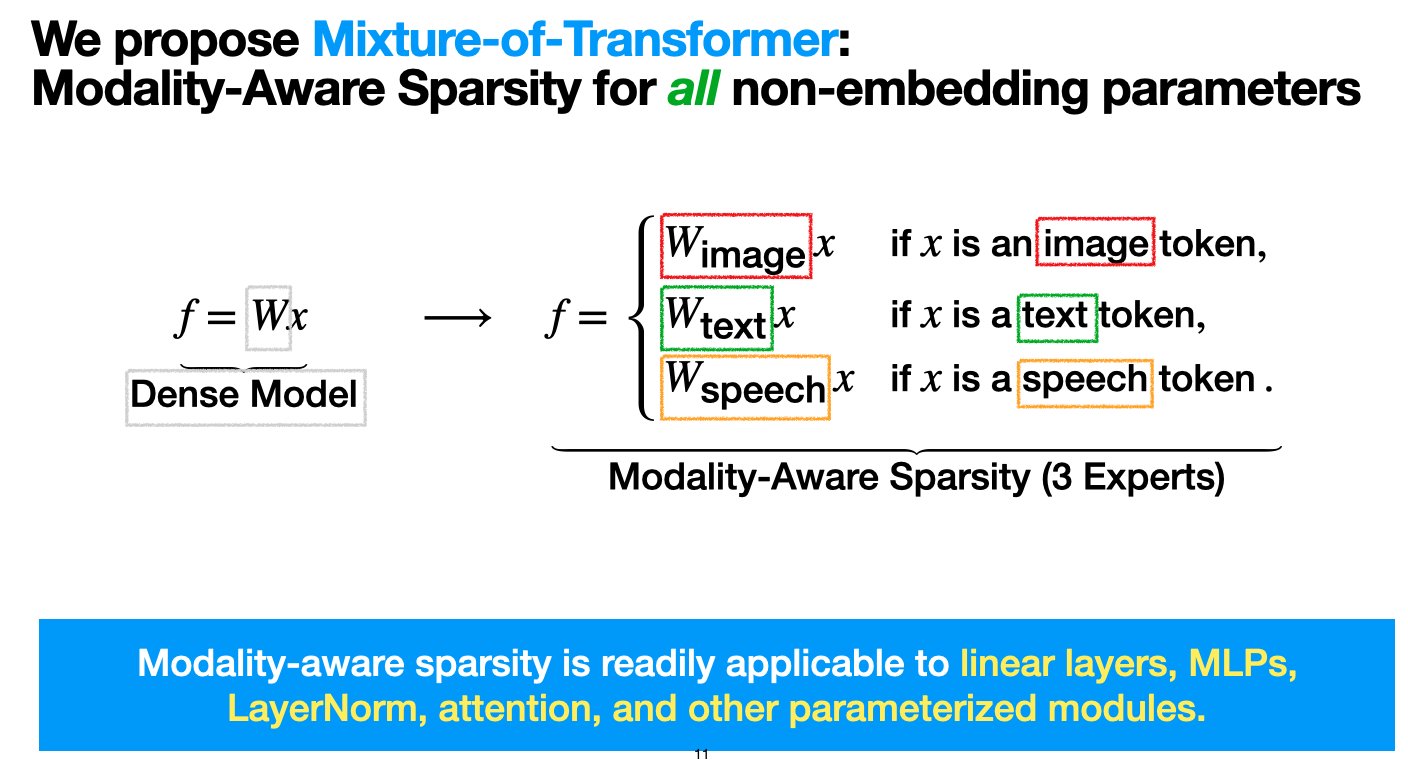
Meta、混合Transformer(MoT)アーキテクチャを発表、マルチモーダルモデルの事前学習コスト削減を目指す: Meta AIの研究者は、「混合Transformer(Mixture-of-Transformers, MoT)」と呼ばれるスパースアーキテクチャを提案しました。これは、パフォーマンスを犠牲にすることなくマルチモーダルモデルの事前学習の計算コストを大幅に削減することを目的としています。MoTは、非埋め込みTransformerパラメータ(フィードフォワードネットワーク、アテンション行列、レイヤー正規化など)にモーダル認識スパース性を採用しています。実験によると、Chameleon(テキスト+画像生成)設定では、7B MoTモデルはわずか55.8%のFLOPsで密なベースラインの品質を達成しました。音声を第3のモーダルとして拡張した場合、わずか37.2%のFLOPsで達成しました。この研究成果はTMLR(2025年3月)に受理され、コードはオープンソース化されています。(ソース: VictoriaLinML)
Qwenモデル改善プロジェクトSmoothie Qwenが公開、多言語生成のバランス調整: Smoothie Qwenと名付けられたQwenモデルの改善プロジェクトが公開されました。モデル内部パラメータの確率を調整することで、多言語生成能力のバランスを取ることを目的としています。このプロジェクトは主に、一部の非中国語ユーザーがQwenを使用する際に時折中国語が出力される問題を解決し、モデルの知能を低下させることはないと主張しています。(ソース: karminski3)

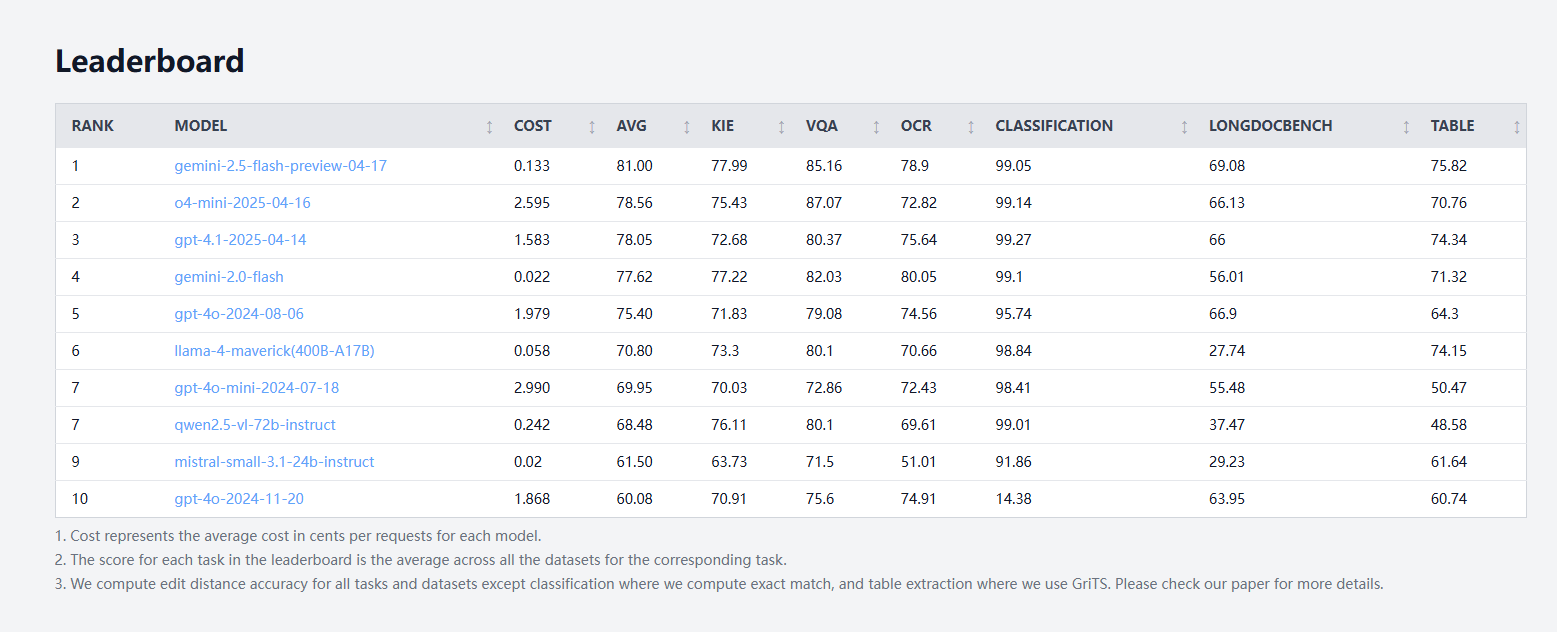
idp-leaderboardが公開、初のドキュメントタイプAIテストベンチマーク: 新しいAIテストベンチマークidp-leaderboardが公開され、モデルのドキュメントおよびドキュメント画像の処理能力評価に特化しています。初期のランキングによると、gemini-2.5-flash-preview-04-17が全体的なドキュメント処理で最も優れたパフォーマンスを示しました。注目すべきは、Qwen2.5-VLが表処理性能において振るわなかった点です。(ソース: karminski3)
Perplexity Discover機能が大幅アップデート: Perplexityの共同創設者Arav Srinivas氏は、同社のDiscover機能(情報発見フィード)が大幅に改善されたことを発表し、ユーザーに体験を促しました。これは通常、情報表示、関連性、またはユーザーインターフェースの最適化を意味し、ユーザーが新しい情報を取得し探索する能力を向上させることを目的としています。(ソース: AravSrinivas)
Lenovo、天禧パーソナルスーパーAIエージェントの大型アップグレードを発表、世界初のタブレットローカル展開DeepSeek: Lenovoは、同社の天禧パーソナルスーパーAIエージェントが大型アップグレードを迎え、全面的なL3レベルへと邁進し、パーソナルインテリジェントデバイスAIサービスに特化したドメインAIエージェント「想帮帮」を発表しました。同時に、Lenovoは、世界で初めてタブレット端末側でDeepSeek大規模モデルを搭載したYOGA Pad Pro 14.5 AI元启版や、moto AIスマートフォン、LegionシリーズPCなど、多数のAI端末新製品を発売し、AI PC、AIスマートフォン、AIタブレット、AIoTの完全なAIエコシステムを構築しました。(ソース: 量子位)

楼教主、自動運転と具現化AIについて語る:L2はL4に昇格できず、VLAはL4への貢献限定的: Pony.aiの共同創設者兼CTOである楼天城氏は、新世代Robotaxi車種の発表時に、自動運転とAIに関する最新の見解を共有しました。彼はL2とL4の本質的な違いを強調し、L2はL4に昇格できないとし、現在のL2分野で人気のVLA(視覚-言語-行動)パラダイムはL4には「基本的にほとんど役に立たない」と述べました。彼は、L4に必要なのは専門医のような極度の安全性であり、VLAはむしろ総合診療医のようだと指摘しました。Pony.aiの過去2年間の技術変革の核心はエンドツーエンドとワールドモデルであり、後者は約5年間応用されています。彼はまた、「クラウド運転代行」は偽の概念であると考え、具現化AIの現在の状態は2018年の自動運転に似ており、同様の「空白期間」の課題に直面するだろうと述べました。(ソース: 量子位)

Kimiがコンテンツコミュニティをテスト、OpenAIはソーシャルアプリ開発の可能性、AI大規模モデル企業がソーシャル機能でユーザーエンゲージメント強化を模索: Moonshot AIのKimiは、コンテンツコミュニティ製品のグレースケールテストを実施中です。主にAIがニュースのホットスポットを収集してコンテンツを生成し、テクノロジーや金融などの分野に焦点を当てています。奇しくも、OpenAIもXに対抗する可能性のあるソーシャルソフトウェアの開発を計画していると報じられています。これらの動きは、AI大規模モデル企業がコミュニティやソーシャル機能を構築することでユーザーエンゲージメントを強化し、AIツールの「使い捨て」問題を解決しようとしていることを示しています。しかし、コミュニティ運営はコンテンツの品質、セキュリティリスク、商業化の難題に直面しています。この動きはまた、AI業界が成長の恩恵が頭打ちになった後、「資金を投じて成長を買う」から、よりROIを重視し、新しいビジネスモデルを模索する方向へ転換し始めていることを反映しています。(ソース: 36氪)

TCL、AIを全面的に採用、伏羲大規模モデル及び多数のAI家電を発表するも、同質化の課題に直面: TCLはAWE 2025、CES 2025などの展示会で、TCL伏羲大規模モデル及びテレビ、エアコン、洗濯機などの家電に応用されるAI機能を含むAI製品と戦略を重点的に展示しました。同社のテレビ事業は好調で、第1四半期の出荷台数は世界第1位であり、Mini LED技術が強みです。しかし、家電分野におけるAIの応用は現在、主に音声対話と特定機能の最適化(AI画質チップ、AI睡眠、AI省電力など)に集中しており、他社ブランド(Hisense星海、Haier HomeGPT、Midea美言など)との同質化競争の課題に直面しています。TCLはまた、AIコンパニオンロボットやThunderbirdを通じたスマートグラスの展開も模索しています。AIへの投資は増加しているものの、独自の技術的優位性はまだ顕著ではなく、マーケティングコストの高騰や粗利益率の低下などの問題にも直面しています。(ソース: 36氪)
AIが教育変革を推進、iFLYTEK、卓越教育など大手企業がAI導入を加速: レポートは、iFLYTEK、卓越教育、粉筆、中公教育、華図教育、一起教育科技など大手教育企業のAI分野における最新の実践を分析しています。iFLYTEKは国産計算能力とDeepseek-V3/R1モデルにより、情報技術教育を深耕しています。卓越教育はDeepseek R1を活用して教育の全プロセスを強化し、AI採点ツールやAI読書ツールを導入しました。粉筆は高頻度学習、必須シーンをカバーするAI製品マトリックスを構築しました。中公教育はAI就職サービスに焦点を当て、「雲信」大規模モデルを開発しました。華図教育はオフラインの強みと組み合わせ、AIで公務員試験サービスの精度を向上させています。一起教育科技はAIで教育評価の一体化を推進しています。業界のトレンドは、AI教育が単一ツールからエコシステム競争と価値実現へと移行していることを示しています。(ソース: 36氪)
Baidu、Alibabaなど大手企業がMCPプロトコルを推進、AI Agentエコシステムの定義権を争奪: モデルコンテキストプロトコル(MCP)は最近、Anthropic、OpenAI、Google、そして国内のBaidu、Alibabaなどの大手企業によって推進されています。Baiduの「心響」アプリケーションとAlibaba Cloudの百錬プラットフォームは既にMCPをサポートしており、AI Agentが外部ツールやサービスをより便利に呼び出すことを可能にしています。この動きは表面的には業界標準を統一するためですが、実際には大手企業による将来のAI Agentエコシステムの定義権争奪です。MCPを構築し推進することで、大手企業はより多くの開発者を自社のエコシステムに引き込み、それによってデータ障壁と業界の発言権を掌握しようとしています。Agentアプリケーションの商業化の方向性は、現在のところ依然としてトラフィックと広告が中心です。(ソース: 36氪)

AppleのAI戦略が明らかに:Baidu、Alibabaと提携し、「デュアルコア駆動」の中国版AIシステムを構築か: 報道によると、Appleは中国市場向けのAI機能の技術サポートを提供するために、BaiduおよびAlibabaと提携する可能性があります。BaiduのERNIE Botは視覚認識に強みがあり、AlibabaのQwen大規模モデルは認知理解とコンテンツコンプライアンスに優れています。この「デュアルコア駆動」モデルは、両社の長所を組み合わせ、中国市場のデータエコシステム、技術的重点、規制要件を満たしつつ、Appleが提携における主導権と交渉力を維持することを目的としている可能性があります。この動きは、AppleがHarmonyOSなどの国内競合の圧力に対応し、データ規制が厳格化する中での「エコシステムニッチの切り分け」戦略と見なされています。(ソース: 36氪)
虞晶怡教授、空間知能を詳細解説:ポテンシャルは大きいがコンセンサス未形成、データと物理的理解が鍵: 上海科技大学の虞晶怡教授はインタビューで、大規模モデルはクロスモーダル統合においてポテンシャルをまだ使い果たしておらず、空間知能は生成AIのブレークスルーにより、デジタル複製から知的理解と創造へと進化していると指摘しました。彼は、現在の空間知能の核心的な課題は、実世界の3Dシーンデータの不足と3次元表現方法の未統一にあると考えています。彼のチームのCASTプロジェクトは、「アクターネットワーク理論」と物理法則を導入することで、物体間の関係と物理的妥当性を探求しています。彼は知覚優先を強調し、センサー技術に革命的なブレークスルーが起こると予測しています。具現化された知能の評価基準は、純粋な精度ではなく、堅牢性と安全性であるべきです。短期的には、空間知能は映画制作やゲームなどの分野で爆発的に普及し、中長期的には具現化された知能の核心となり、低空経済も重要な応用シーンとなると述べています。(ソース: 36氪)

AI人材争奪戦が白熱化:大手企業が高給で人材獲得、CTOが直接指導、大規模モデルとマルチモーダルに焦点: 国内外のテクノロジー大手企業が、人工知能人材の激しい争奪戦を繰り広げています。ByteDance、Alibaba、Tencent、Baidu、JD.com、Huaweiなどは、トップクラスの博士課程学生や天才的な若者向けの採用計画を次々と打ち出し、上限なしの給与、CTOによる直接指導、インターンシップ経験不要などの待遇を提供しています。採用の方向性は主に大規模モデルとマルチモーダル分野に集中しており、各社のコアビジネスシーンと密接に関連しています。DeepSeekなどのモデルの成功は、業界の人材への渇望をさらに強めています。Elon MuskもAI人材競争の激しさを嘆いたことがあり、OpenAIなどの海外大手も高給や創業者による直接採用などの方法で人材を引き付けています。(ソース: 36氪)
Sequoia Capital:AI市場のポテンシャルはクラウドコンピューティングをはるかに超え、アプリケーション層が鍵、最高AI責任者が標準装備に: Sequoia Capitalのパートナーは、AI市場の規模は現在の約4000億ドルのクラウドコンピューティング市場をはるかに超え、今後10~20年で巨大な規模となり、価値は主にアプリケーション層に集中すると予測しています。スタートアップ企業は顧客ニーズに焦点を当て、エンドツーエンドのソリューションを提供し、垂直分野を深耕し、「データフライホイール」を活用して堀を築くべきです。AWSの調査によると、グローバル企業は生成AIの導入を加速しており、意思決定者の45%が2025年の最優先事項として計画しており、最高AI責任者(CAIO)の役職は企業の標準装備となり、現在60%の企業がこの役職を設置しています。エージェントエコノミーはAI開発の次の段階と見なされていますが、永続的なアイデンティティ、通信プロトコル、セキュリティと信頼という3つの技術的課題を解決する必要があります。(ソース: 36氪)

新興自動車メーカー、AIに全面注力、Li Auto、XPeng、NIOが次世代自動車の定義権を争う: TeslaのFSD V12が採用したエンドツーエンドニューラルネットワーク技術によるブレークスルーは、国内の新興自動車メーカーであるLi Auto、XPeng、NIOなどにAI戦略の加速を促しています。Li AutoはVLA(視覚-言語-行動)ドライバー大規模モデルを発表し、DeepSeekオープンソースモデルに基づいて言語部分を開発しています。XPeng Motorsは720億パラメータのLVA基盤モデルを構築しています。NIOは中国初のインテリジェントドライビングワールドモデルNWMを発表し、5nm自動運転チップ神玑NX9031を自社開発しています。各社はアルゴリズム、計算能力(自社開発チップ)、データに巨額の投資を行い、AI技術を人型ロボットなどの分野に汎用化し、次世代自動車、さらには製品定義権を争っていますが、資金と商業化の課題に直面しています。(ソース: 36氪)
🧰 ツール
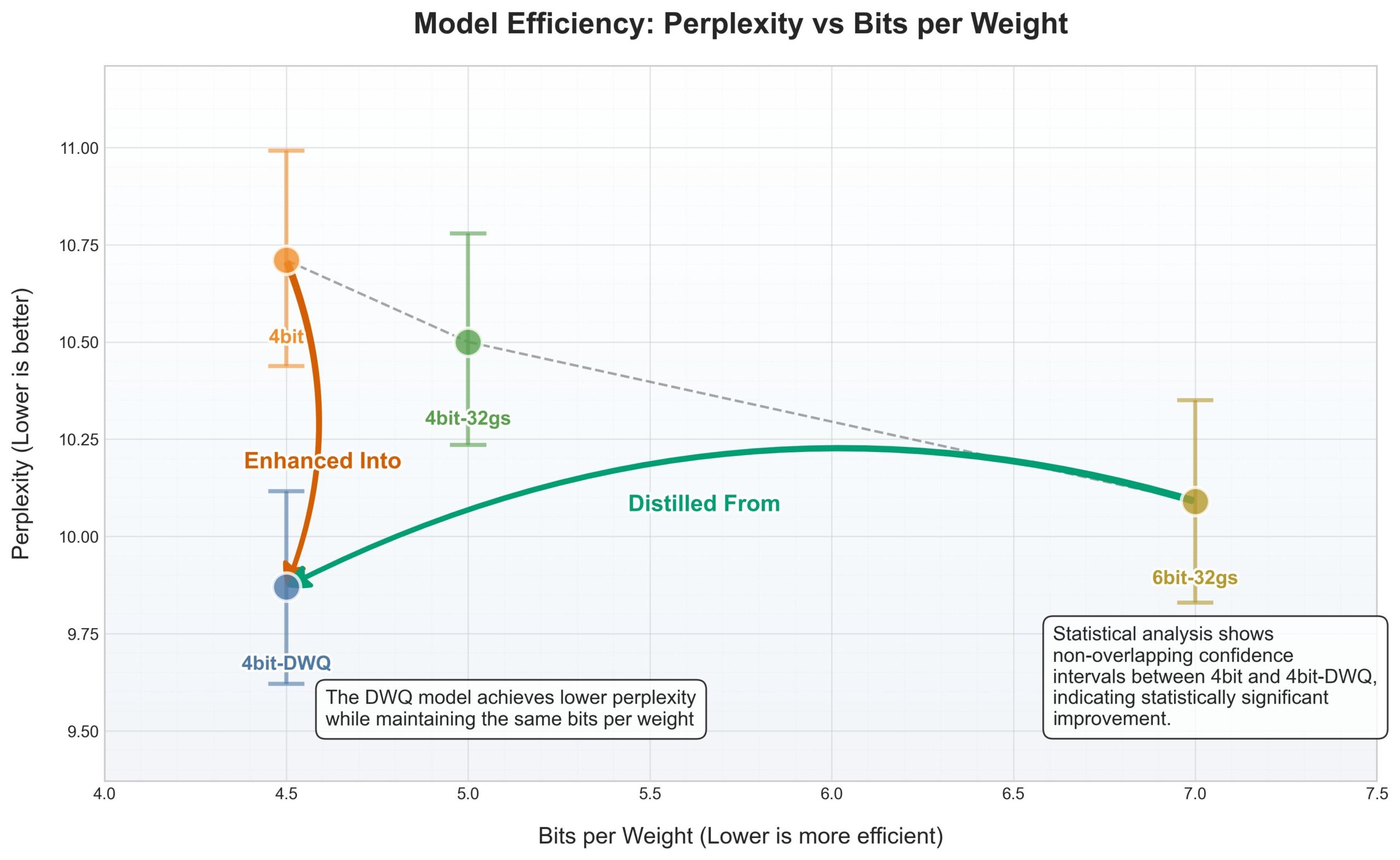
Apple MLXフレームワークにDWQ量子化が登場、4bitが旧6bitを上回る性能: Apple MLX(機械学習フレームワーク)向けに、新しいDWQ(Dynamic Weight Quantization、動的重み量子化)手法が発表されました。ユーザーkarminski3氏が共有したデータによると、4bit-dwqで量子化されたモデル(Qwen3-30Bなど)は、パープレキシティにおいて旧6bit量子化手法を上回り、わずか17GBのメモリで実行可能です。これは、Appleデバイス上で大規模言語モデルを効率的に実行するための新たな可能性を提供します。(ソース: karminski3)
PerplexityがWhatsApp内でより自然な対話型検索をサポート: Perplexityの共同創設者Arav Srinivas氏は、WhatsApp内でのPerplexityの統合が改善され、より自然な対話体験を提供できるようになったと発表しました。また、検索が不要な場合は検索ステップをインテリジェントに無視し、ユーザーが直接AIとチャット形式で対話できるようにします。(ソース: AravSrinivas)
nanobrowser_aiが主要LLMをサポート、Langchain.jsを統合: AIツールnanobrowser_aiは、OpenAIモデル、Gemini、およびOllama経由で実行されるローカルモデルを含む、複数の大規模言語モデルをサポートすると発表しました。このツールはLangchain.jsフレームワークを利用して、さまざまなLLMへの柔軟なサポートを実現し、ユーザーにより幅広いモデル選択肢を提供します。(ソース: hwchase17)
LlamaIndex TypeScript、リアルタイムLLM APIのサポートを追加、Google Geminiを初統合: LlamaIndex TypeScriptは、リアルタイムLLM APIのサポートを発表し、開発者がAIアプリケーションでリアルタイム音声対話機能を実現できるようにしました。最初に統合されたのはGoogle Geminiのリアルタイム抽象インターフェースで、OpenAIのリアルタイムサポートも間もなく提供される予定です。このアップデートにより、開発者は異なるリアルタイムモデル間で簡単に切り替え、よりインタラクティブなAIアプリケーションを構築できます。(ソース: _philschmid)
Gradioアプリチュートリアル:Qwen2.5-VLを使用した画像・動画のアノテーションと物体検出: Qwen2.5-VL(視覚言語モデル)を使用して、画像や動画の自動アノテーションおよび物体検出機能を実現するGradioアプリケーションを構築する方法を詳述したチュートリアルが公開されました。このチュートリアルは、開発者がQwen2.5-VLの強力な能力を活用して、インタラクティブなAIアプリケーションを迅速に構築するのを支援することを目的としています。(ソース: Reddit r/deeplearning)

VSCodeプラグインgemini-codeのダウンロード数が5万件近くに: VSCodeのAIプログラミングアシスタントプラグインgemini-codeのダウンロード数が5万回近くに達しました。開発者のraizamrtn氏は、週末にいくつかの必要な更新を行うと述べています。このプラグインは、Geminiモデルの能力を活用して開発者のコーディング作業を支援することを目的としています。(ソース: raizamrtn)

フランスのAIスタートアップArcads AI:5人のチームで年間500万ドルの収益、自動化された動画広告制作に特化: パリに本社を置くAIスタートアップ企業Arcads AIは、わずか5人のチームで年間経常収益500万ドルを達成し、黒字化しています。同社は高度に自動化されたAIシステムを通じて、広告主に迅速、低コスト、高コンバージョン率の動画広告制作サービスを提供しています。顧客はコアとなるコピーを提供するだけで、AIがシーン構築、俳優の演技、ナレーション録音から完成品出力までの全プロセスを完了します。Arcadsプラットフォームには、実在の人物から許諾を得た300以上のAI俳優イメージが組み込まれており、35言語に対応し、「コンテンツ・アズ・ア・サービス」を実現しています。社内業務でもAIエージェントを幅広く活用しており、例えばAI Spy Agentが競合製品を分析し、AI Ghostwriterがクリエイティブを生成するなど、効率を大幅に向上させています。(ソース: 36氪)
📚 学習
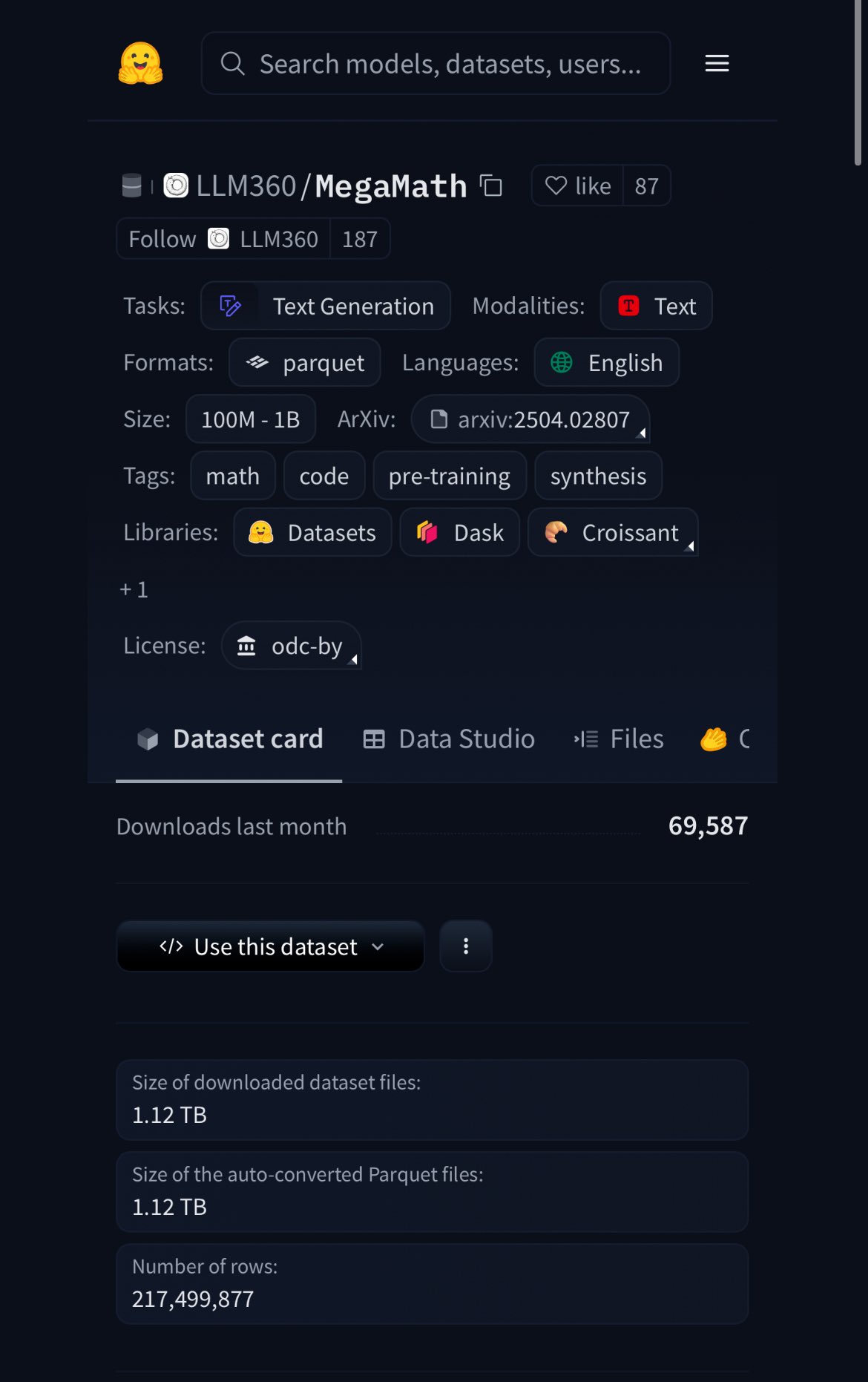
HuggingFace、MegaMathデータセットを公開、370B token、20%は合成データ: HuggingFaceは、3700億tokenを含むMegaMathデータセットを公開しました。これは現在最大の数学事前学習データセットであり、英語のWikipediaの約100倍の規模です。注目すべきは、そのうち20%が合成データであることで、これはモデル訓練における高品質な合成データの役割について再び議論を呼んでいます。(ソース: ClementDelangue)
Nous Research、RL環境ハッカソンを開催、賞金総額5万ドル: Nous Researchは、サンフランシスコでNous RL環境ハッカソンを開催すると発表しました。参加者はNousの強化学習環境フレームワークAtroposを使用して作品を制作し、賞金総額は5万ドルです。パートナーにはxAI、NVIDIA、Nebius AIなどが含まれます。(ソース: Teknium1)

HuggingFace人気モデル週間ランキング発表: ユーザーkarminski3氏が、今週HuggingFaceで最も人気のあるモデルのランキングを共有し、そのほとんどのモデルについて自身が実測テストを行うか、公式デモを共有したと述べました。これは、コミュニティが新しいモデルに迅速に追随し、評価する熱意を反映しています。(ソース: karminski3)
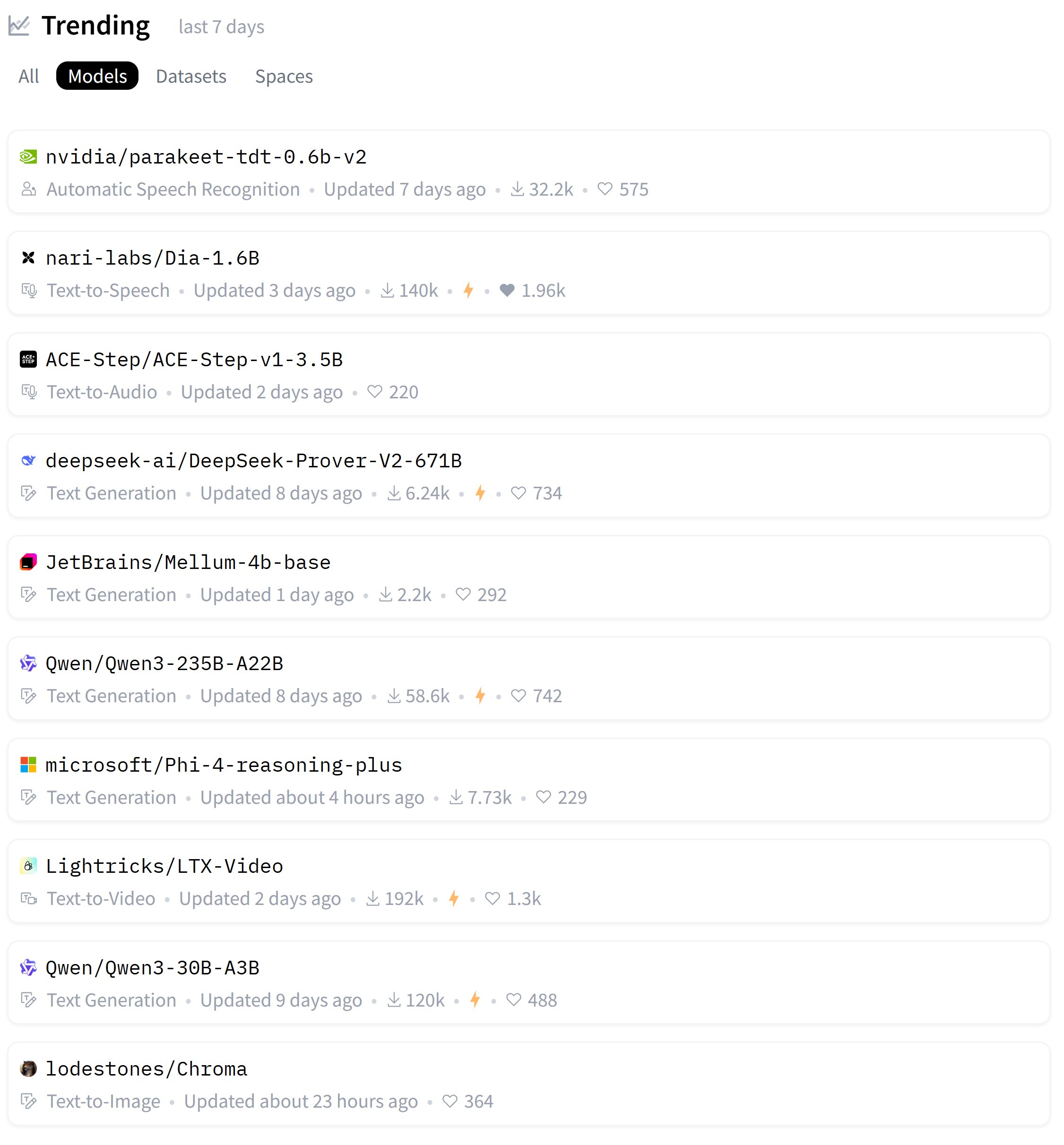
Zeyuan Allen-Zhu氏、LLMアーキテクチャ設計に関する一連の研究を発表、Primerモデルを考察: 研究者のZeyuan Allen-Zhu氏は、自身の「LLM設計物理学」シリーズの研究を通じて、制御された合成事前学習環境を利用してLLMアーキテクチャの真の限界を明らかにしています。最新の共有情報では、Primerモデル(arxiv.org/abs/2109.08668)とそのmulti-dconv-head attention(彼はこれをCanon-B残差接続なしと呼んでいます)について議論し、その問題点を指摘しつつも、Primerモデル(引用数わずか180回)はノイズの多い実際の実験から意味のあるシグナルを発見したため、過小評価されていると述べています。(ソース: ZeyuanAllenZhu, cloneofsimo)
Simons Institute、ニューラルネットワークのスケーリング則を議論: Simons Instituteは、Polyloguesシリーズ番組で、Anil Ananthaswamy氏とAlexander Rush氏を招き、近年経験的に発見されたニューラルネットワークのスケーリング則(neural scaling laws)について議論しました。これらの法則は、大手企業がますます大きなモデルを構築する決定に大きな影響を与えています。(ソース: NandoDF)

François Fleuret氏、『The Little Book of Deep Learning』を出版: François Fleuret氏は、『The Little Book of Deep Learning』と題する著作を出版し、読者に深層学習に関する洗練された知識を提供することを目指しています。(ソース: Reddit r/deeplearning)
プリンストン大学教授:AIは人文学を終わらせるかもしれないが、存在体験への回帰を促す: プリンストン大学のD. Graham Burnett教授は、「ニューヨーカー」誌に寄稿し、AIが人文学に与える影響について論じました。彼は、米国の大学で「AI羞恥症」が蔓延しており、学生がAIの使用を認めようとしないことを観察しています。彼は、AIが情報検索と分析において従来の学術的方法を超越し、学術書を考古学的遺物のようにしていると考えています。AIは知識生産を中心とする従来の意味での人文学を終わらせるかもしれませんが、その核心的な問題、すなわち、どのように生きるか、死に直面するかといった、AIが直接触れることのできない存在体験の探求へと回帰させる可能性もあると述べています。(ソース: 36氪)

7つの研究がAIが人間の脳と行動に与える深遠な影響を明らかに: 一連の新しい研究が、AIが人間の心理、社会、認知レベルに与える影響を探求しています。研究結果には以下が含まれます:1) LLMのレッドチームテスターは好奇心と道徳的責任感からモデルの脆弱性を探索する。2) ChatGPTは精神病症例分析において高い診断精度を示す。3) ChatGPTの政治的傾向は異なるバージョン間で微妙に変化する。4) ChatGPTの使用は職場の不平等を悪化させる可能性があり、若年高所得男性の使用が多い。5) AIは高齢者の運転行動を分析することでうつ病の兆候を検出できる。6) LLMは性格検査においてイメージを「取り繕う」社会的期待バイアスを示す。7) AIへの過度な依存は、特に若年層において批判的思考を弱める可能性がある。(ソース: 36氪)

Onur Boyar氏インタビュー:生成モデルとベイズ最適化を用いた医薬品・材料設計: AAAI/SIGAI博士課程フォーラム参加者のOnur Boyar氏は、名古屋大学での博士研究について紹介しました。その研究は、生成モデルとベイズ的手法を用いた医薬品および材料設計に焦点を当てています。彼は日本のMoonshotプロジェクトに参加し、創薬プロセスを処理するAI科学者ロボットの構築を目指しています。彼の研究手法には、既存分子を編集するための潜在空間ベイズ最適化の使用が含まれ、サンプル効率と合成可能性の向上を目指しています。彼は化学者との緊密な協力を強調し、卒業後はIBM東京基礎研究所の材料発見チームに加わる予定です。(ソース: aihub.org)

💼 ビジネス
Modular社、AMDと協力しMojo Hackathonを開催、MI300X GPUを使用: Modular社は、AMDと協力してAGI Houseで特別なハッカソンを開催すると発表しました。イベントでは、開発者はAMD Instinct™ MI300X GPUを使用してMojo言語でプログラミングを行います。イベントには、Modular、AMD、SemiAnalysisのDylan Patel氏、およびAnthropicの代表者も招かれ、技術共有が行われます。(ソース: clattner_llvm)
Stripe、決済分野向けAI基盤モデルを含む複数のAI駆動新機能を発表: 金融サービス企業Stripeは年次大会で、AIアプリケーションの導入を加速するための複数の新製品を発表しました。その中には、決済分野専用に構築された世界初のAI基盤モデルも含まれています。このモデルは数百億件の取引に基づいて訓練され、不正検知(「カードテスティング」攻撃の検知率64%向上など)、承認率、パーソナライズされた決済体験の向上を目指しています。Stripeはまた、多通貨資金管理能力を拡張し、NVIDIA(GeForce Nowのサブスクリプション管理にStripe Billingを使用)やPepsiCoなどの大企業との協力を深化させています。(ソース: 36氪)
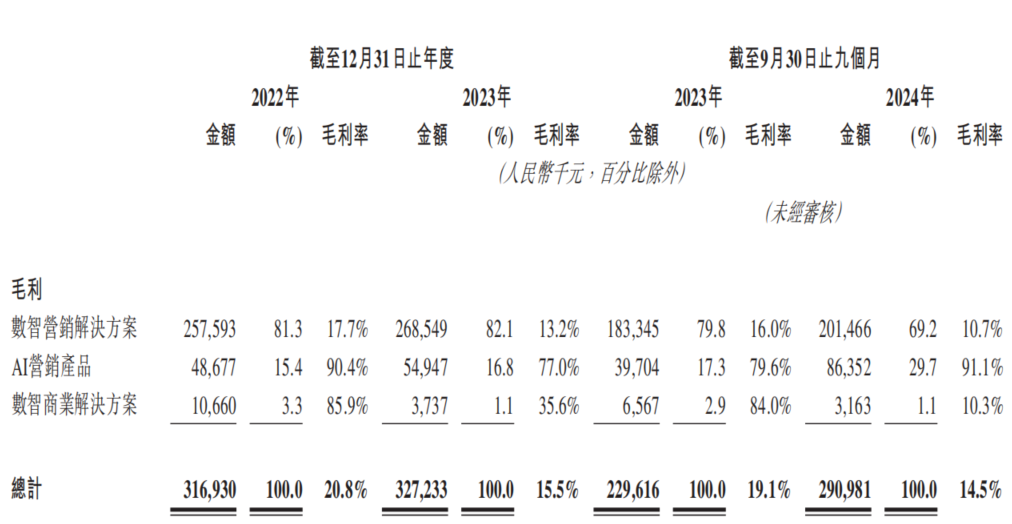
AIマーケティング企業「東信営銷」、再び香港証券取引所に上場申請、「増収不増益」の苦境に直面: 東信営銷は「中国最大のAIマーケティング企業」として、再び香港証券取引所に目論見書を提出しました。データによると、同社の2022年から2024年第3四半期までの売上は継続的に増加していますが、純利益は大幅に減少し、赤字に転落することさえあり、粗利益率は20.8%から14.5%に低下しました。AIマーケティング事業の収益構成比は5%未満で、粗利益率は91.1%と高いものの、研究開発投資をカバーするには至っていません。同社は売掛金の高止まり、キャッシュフローの逼迫、債務圧力の増大などの問題に直面しており、利益は政府補助金に大きく依存しています。市場での位置づけを「モバイルマーケティングサービスプロバイダー」から「AIマーケティング企業」へと転換していますが、AI技術の価値と商業化の見通しには疑問符が付きます。(ソース: 36氪)
🌟 コミュニティ
vLLMとSGLang推論エンジンの競争激化、開発者がPRマージデータを公開比較: 開発者コミュニティでは、vLLMとSGLangという2つの主要な推論エンジン間の競争が話題となっています。vLLMの主要メンテナーは、SGLangとvLLMのGitHub上でのプルリクエスト(PR)マージ数を比較する公開ダッシュボードを設置し、両者が機能イテレーションとパフォーマンス最適化で激しく競い合っていることを浮き彫りにしました。SGLang側は、radixキャッシュ、CPUオーバーラップ、MLA、大規模EPなどの分野での先駆的なオープンソース実装を強調しています。(ソース: dylan522p, jeremyphoward)
AI生成の「イタリアン・ブレインロット」キャラクターユニバースがZoomer世代で爆発的人気、視聴回数数億回: Justine Moore氏は、AIが生成した一連の「イタリアン・ブレインロット」(Italian brainrot)キャラクターがZoomer(Z世代)の間で異常なほど人気を博し、彼らがこれらのキャラクターを中心に完全な「映画ユニバース」を構築し、関連コンテンツが数億回の視聴回数を獲得していると指摘しました。この現象は、AI生成コンテンツが若い世代に持つ強力な魅力とバイラルな拡散力、そして特定のサブカルチャーの形成を反映しています。(ソース: nptacek)

Qwen3とDeepSeek R1モデルの比較が議論を呼ぶ、それぞれに長所と短所: Redditユーザーが、Qwen3 235BとDeepSeek R1という2つのオープンソース大規模モデルのテスト比較を共有しました。投稿者は、Qwenは単純なタスクではより優れたパフォーマンスを発揮するものの、推論、数学、創造的なライティングなど、ニュアンスが必要なタスクではDeepSeek R1の方が優れていると考えています。コミュニティのコメントでは、DeepSeek R1のアクセシビリティ、Qwen3 235Bの未検閲ファインチューニングバージョン、および創造的なライティングに言語モデルを使用することの妥当性などの問題が議論されています。(ソース: Reddit r/LocalLLaMA)

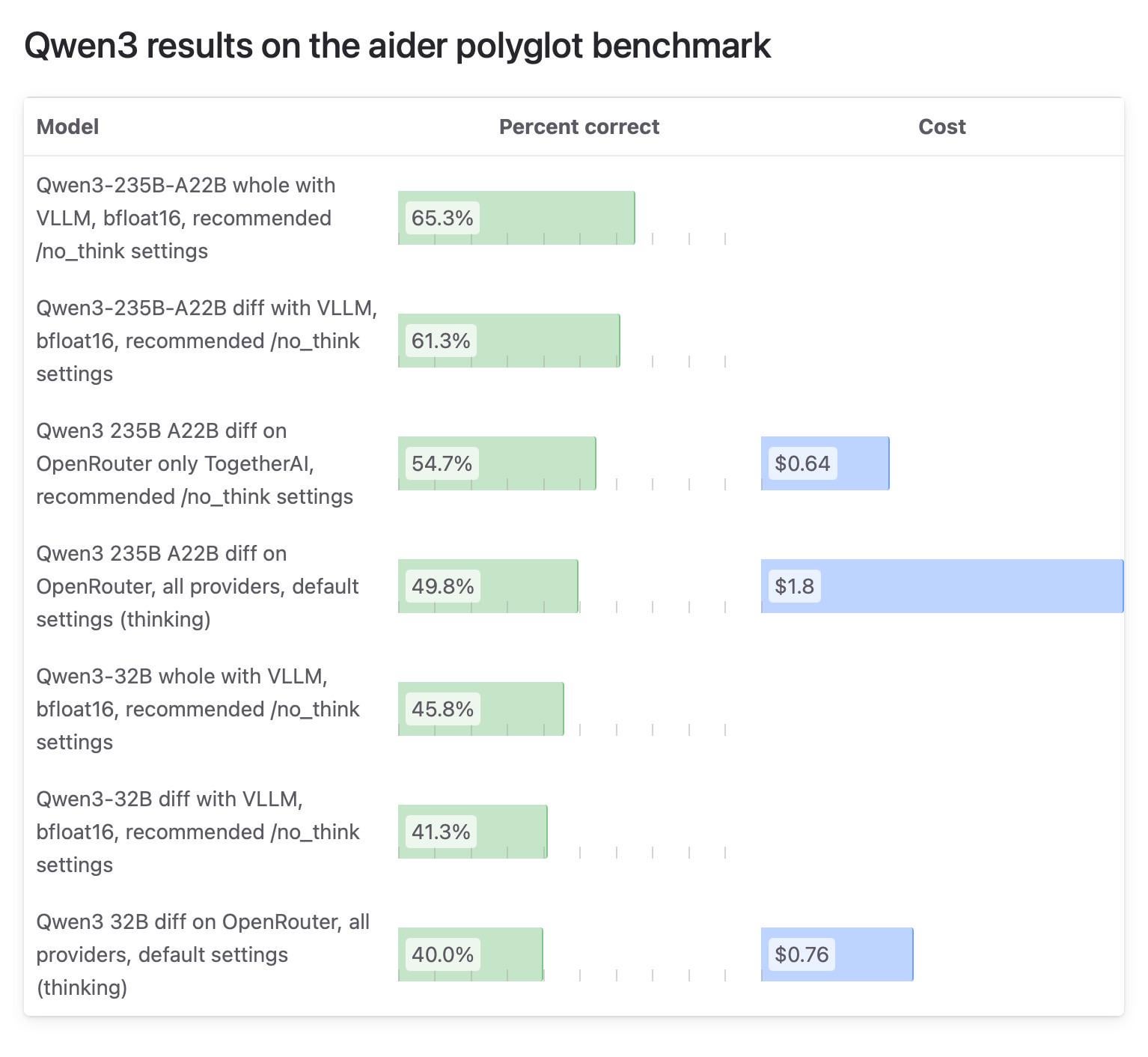
Aiderコミュニティ、Qwen3モデルのテスト結果の差異に注目、OpenRouterテストに疑問の声: AiderブログはQwen3モデルに関するテストレポートを発表し、モデルの実行方法によってスコアに大きな差異が生じることを指摘しました。コミュニティの議論の焦点は、OpenRouterを使用したモデルテストの信頼性にあります。多くのユーザーがOpenRouter経由でモデルを使用する可能性があるものの、そのルーティングメカニズムが結果の不一致を引き起こす可能性があるためです。一部のユーザーは、オープンソースモデルは再現性を保証するために標準化された自己構築環境(vLLMなど)でテストされるべきであり、APIプロバイダーには透明性を高め、使用されている量子化バージョンと推論エンジンを明確にするよう求めています。(ソース: Reddit r/LocalLLaMA)
ユーザーがChatGPTの有料利用の個人的理由を共有、生活支援、学習、創作など多岐にわたる: Redditのr/ChatGPTコミュニティでは、多くのユーザーがChatGPT Plus/Proの有料サブスクリプションの個人的な用途を共有しています。これには、視覚障害のあるユーザーの画像記述、食品パッケージや道路標識の読み取り支援、面接準備、ゲーム「エルデンリング」などのストーリーの深い理解、ランニングトレーニング計画の分析、食事レシピのカスタマイズ、陶芸などの新しいスキルの学習補助、個人的なコンパニオンとしての利用、庭の計画、ハーブの作成、そしてD&Dのキャラクター作成や二次創作小説の執筆などが含まれます。これらの事例は、ChatGPTが日常生活や個人の趣味において幅広い応用価値を持つことを示しています。(ソース: Reddit r/ChatGPT)
GGUF量子化モデルの比較テストが「量子化戦争」の議論を呼ぶ、異なる量子化方式にはそれぞれ長所があると強調: Redditユーザーubergarm氏が、Qwen3-30B-A3Bなどのモデルの異なるGGUF量子化バージョン(bartowski氏やunsloth氏など、異なる提供者による量子化方式を含む)に関する詳細なベンチマークテスト比較を発表しました。テストは、パープレキシティ、KLDダイバージェンス、推論速度など複数の側面をカバーしています。記事は、重要度行列量子化(imatrix)、IQ4_XSなどの新しい量子化タイプの登場や、unsloth動的GGUFなどの手法の導入により、GGUF量子化はもはや「画一的」ではないと指摘しています。著者は、絶対的に最適な量子化方式は存在せず、ユーザーは自身のハードウェアと特定のユースケースに基づいて選択する必要があるものの、全体として主要な各方式は良好なパフォーマンスを示していると強調しています。(ソース: Reddit r/LocalLLaMA)

💡 その他
Daimon Robotics、器用なロボットSparky 1を発表: Daimon Robotics社は、器用なロボット技術における画期的な製品Sparky 1を展示しました。このロボットは「Mind-Dexterous」(心と手が器用)な能力を持つと説明されており、知覚、意思決定、精密操作において新たなレベルに達していることを示唆しており、高度なAIと機械学習技術が融合されている可能性があります。(ソース: Ronald_vanLoon)
MIT、米粒サイズのマイクロロボットを開発、脳内の手術不能な腫瘍治療に道: MITの研究者らは、米粒サイズのマイクロロボットを開発しました。これは、低侵襲的な方法で脳内に進入し、従来手術で切除が困難だった腫瘍の治療に使用できる可能性があります。この種の技術は、マイクロロボット技術とAIナビゲーションまたは制御を組み合わせたもので、神経外科およびがん治療に新たな可能性を提供します。(ソース: Ronald_vanLoon)

傲鲨智能、2回の資金調達を完了、コンシューマー向け外骨格ロボットの量産とAI技術の融合を推進: 外骨格ロボット技術プラットフォーム企業である傲鲨智能は、2回の資金調達を連続して完了したことを発表しました。彬复資本がリードインベスターとなり、既存株主である国仪資本も追加出資しました。資金はコンシューマー向け外骨格ロボットの量産、および外骨格ハードウェアとAI技術の融合推進に充てられます。同社の製品は既に産業シーンで応用されており、屋外での助力(景勝地の登山補助など)や在宅介護市場の開拓も開始しており、1万元以内のコンシューマー向け製品の発売を計画しています。最新製品にはAI大規模モデルの訓練能力が搭載されており、ブレイン・マシン・インターフェース技術も先行研究中です。(ソース: 36氪)