キーワード:絶対零度, Qwen3, Mistral Medium 3, PyTorch財団, AI自己進化, マルチモーダルモデル, オープンソースAI, RLVRパラダイム, AZRシステム, Qwen3-235B-A22B, DeepSpeed最適化ライブラリ, LangSmithマルチモーダルサポート
🔥 焦点
清華大学、「Absolute Zero」論文を発表:AIは外部データなしで自己進化が可能に: 清華大学のLeapLabTHUチームは、「Absolute Zero」と名付けられた新しいRLVR(Reinforcement Learning with Verifiable Rewards)パラダイムを発表しました。このパラダイムの下では、単一のモデルが学習プロセスを最大化するタスクを自ら提案し、これらのタスクを解決することを通じて推論能力を向上させることができ、外部データには一切依存しません。そのシステムであるAZR(Absolute Zero Reasoner)は、コード実行器を利用してタスクと回答を検証し、オープンエンドでありながら根拠に基づいた学習を実現しています。実験によると、AZRはコーディングおよび数学的推論タスクにおいてSOTA(State-of-the-Art)レベルを達成し、数万件の人手によるラベル付けサンプルに依存する既存のゼロショットモデルを凌駕しています。(出典: Reddit r/LocalLLaMA)
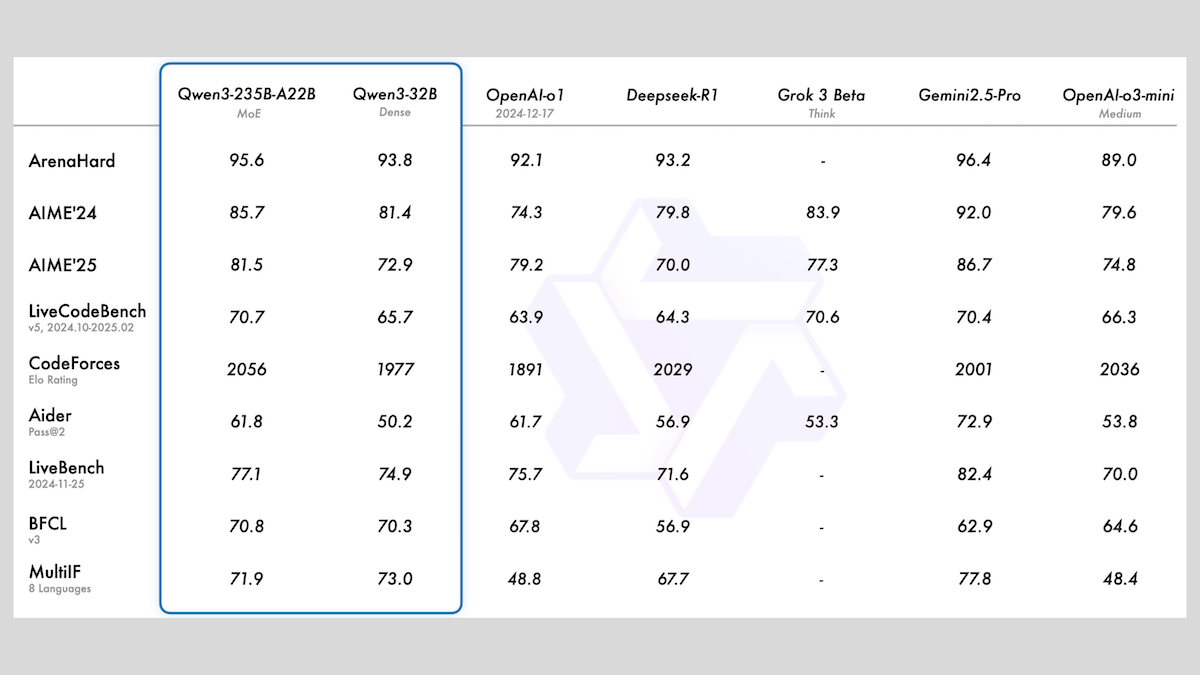
アリババ、Qwen3シリーズモデルを発表、MoEと多様なサイズを含む: アリババはQwen3シリーズの大規模言語モデルを発表しました。これには0.6Bから235Bまでのパラメータを持つ8つのモデルが含まれます。そのうちQwen3-235B-A22BとQwen3-30B-A3BはMoEアーキテクチャを採用し、残りは高密度モデルです。このシリーズのモデルは36Tのトークンで事前学習され、119言語をカバーし、コード、数学、科学など多分野に適したオンオフ可能な推論モードを備えています。評価によると、MoEモデルの性能は優れており、235Bバージョンは多くのベンチマークでDeepSeek-R1とGemini 2.5 Proを上回り、30Bバージョンも強力なパフォーマンスを示し、4Bモデルでさえ一部のベンチマークではるかに大きなパラメータを持つモデルを上回っています。モデルはHuggingFaceとModelScopeでApache 2.0ライセンスの下でオープンソース化されています。(出典: DeepLearning.AI Blog)
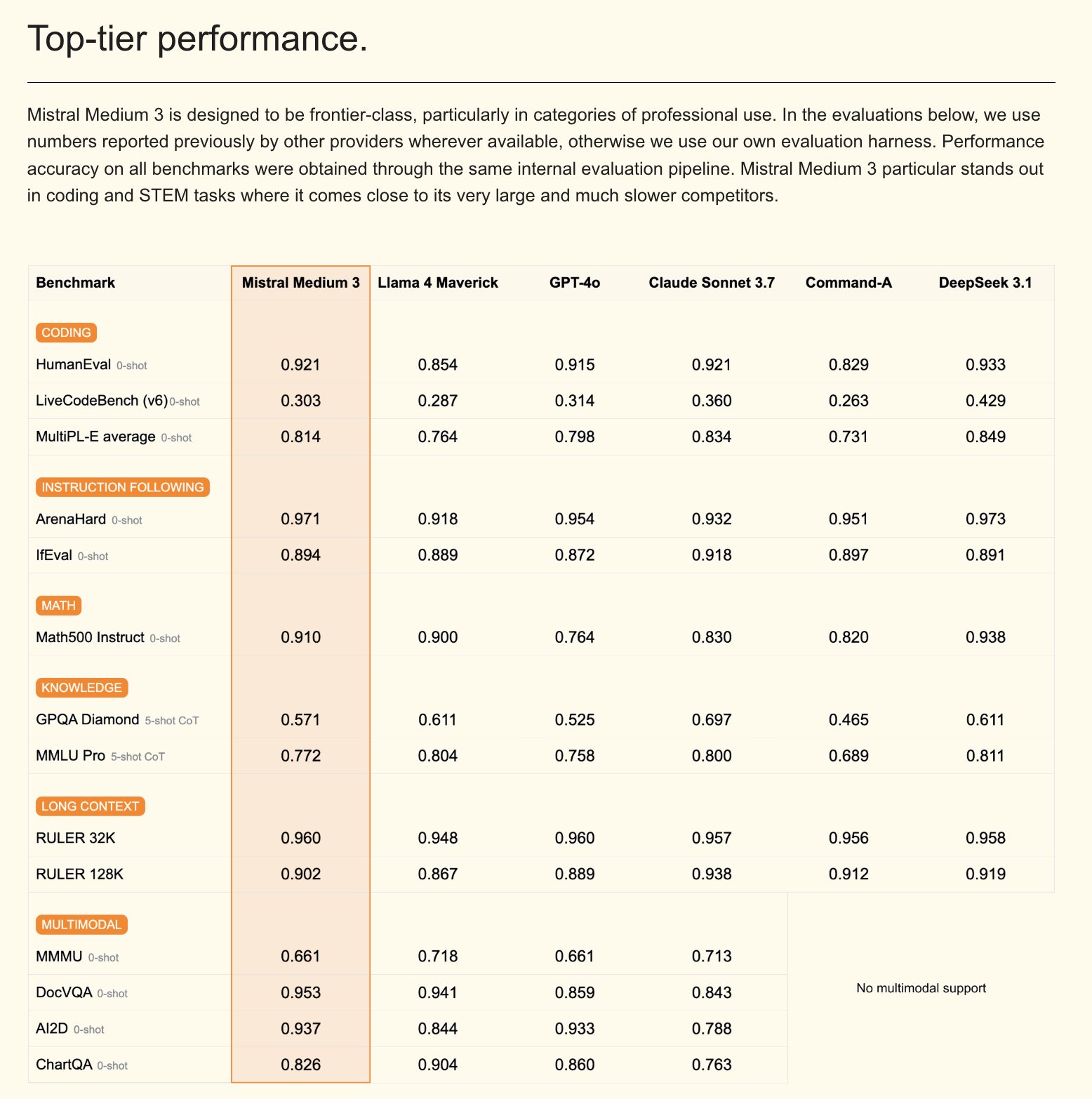
Mistral、マルチモーダルモデルMistral Medium 3およびエンタープライズ版AIアシスタントを発表: Mistral AIは、新しいマルチモーダルモデルであるMistral Medium 3を発表しました。性能面ではClaude Sonnet 3.7に匹敵すると主張しつつ、コストは大幅に削減(入力$0.4/Mトークン、出力$2/Mトークン)し、8倍の低コスト化を実現しています。このモデルはコーディングと関数呼び出しに優れており、ハイブリッドまたはローカル展開、カスタマイズされた事後学習などのエンタープライズレベルの機能を提供します。同時に、MistralはLe Chat Enterpriseも発表しました。これはカスタマイズ可能で安全なエンタープライズ向けAIアシスタントで、Gmail、Google Drive、Sharepointなどの企業ナレッジベースとの統合をサポートし、Agent、コーディングアシスタント、ウェブ検索などの機能を備え、企業の競争力向上を目指しています。Mistralは今後数週間以内に新しいLargeモデルを発表する予定です。(出典: Mistral AI、GuillaumeLample、scaling01、karminski3)
PyTorch Foundation、vLLMとDeepSpeedを傘下に収め、アンブレラ財団へと拡大: PyTorch Foundationは、より多くの高品質なAIオープンソースプロジェクトを集約することを目的としたアンブレラ財団構造への拡大を発表しました。最初に参加するプロジェクトはvLLMとDeepSpeedです。vLLMはLLM向けに設計された高スループット、メモリ効率の高い推論およびサービスエンジンです。DeepSpeedは深層学習最適化ライブラリで、大規模モデルのトレーニングをより効率的にします。この動きは、研究から生産までの全ライフサイクルをカバーするコミュニティ主導のAI開発を促進することを目的としており、AMD、Arm、AWS、Google、Huaweiなど多くのメンバー企業から支持を得ています。(出典: PyTorch、soumithchintala、vllm_project、code_star)

🎯 動向
テンセントARCラボ、FlexiActを発表:動画モーショントランスファーツール: テンセントARCラボはHugging Face上でFlexiActという新しいツールを発表しました。このツールは、参照動画内のアクションを任意のターゲット画像に転送することができ、ターゲット画像のレイアウト、視点、または骨格構造が参照動画と異なる場合でも実現可能です。これにより、動画生成および編集分野に新たな可能性がもたらされ、ユーザーは生成コンテンツ内のアクションやポーズをより柔軟に制御できるようになります。(出典: _akhaliq)
White Circle、CircleGuardBenchを発表:AIコンテンツモデレーションモデルの新ベンチマーク: White Circleは、AIコンテンツモデレーションモデルを評価するための新しいベンチマークテストであるCircleGuardBenchを発表しました。このベンチマークは、生産レベルの評価を行うことを目的としており、有害性の検出、ジェイルブレイク耐性、誤検知率、遅延を含むテスト内容で、17の現実世界の有害カテゴリをカバーしています。関連するブログ記事とリーダーボードがHugging Faceで公開されており、AIの安全性とコンテンツモデレーション分野に新たな評価基準を提供しています。(出典: TheTuringPost、_akhaliq)

Hugging Face、SIFT-50Mを発表:大規模多言語音声指示ファインチューニングデータセット: Hugging Face上でSIFT-50Mデータセットが公開されました。これは音声指示ファインチューニング用に設計された大規模な多言語データセットです。このデータセットには5,000万を超える指示形式の質疑応答ペアが含まれ、5言語をカバーしています。このデータセットに基づいてトレーニングされたSIFT-LLMは、音声追従ベンチマークテストでSALMONNとQwen2-Audioを上回っています。データセットには、音響および生成評価用のベンチマークEvalSIFTも含まれており、Whisper、HuBERT、X-Codec2、Qwen2.5に基づいて構築された制御可能な音声生成(ピッチ、話速、アクセントなど)をサポートしています。(出典: ClementDelangue、huggingface)
Meta、Perception Language Model (PLM)を発表:オープンソースで再現可能な視覚言語モデル: Meta AIは、Meta Perception Language Model (PLM)を発表しました。これは、困難な視覚タスクを解決することを目的とした、オープンで再現可能な視覚言語モデルです。MetaはPLMを通じて、オープンソースコミュニティがより強力なコンピュータビジョンシステムを構築するのを支援したいと考えています。関連する研究論文、コード、データセットが公開されており、研究者や開発者が利用できます。(出典: AIatMeta)
Google、Gemini 2.0画像生成モデルを更新:品質とレートを向上: Googleは、Gemini 2.0画像生成モデル(プレビュー版)の更新を発表しました。新バージョンでは、より良い視覚品質、より正確なテキストレンダリング、より低いブロック率(block rates)、より高いレート制限(rate limits)が提供されます。各画像の生成コストは$0.039です。この更新は、開発者がGeminiを使用して画像生成を行う際の体験と効果を向上させることを目的としています。(出典: m__dehghani、scaling01、andrew_n_carr、demishassabis)
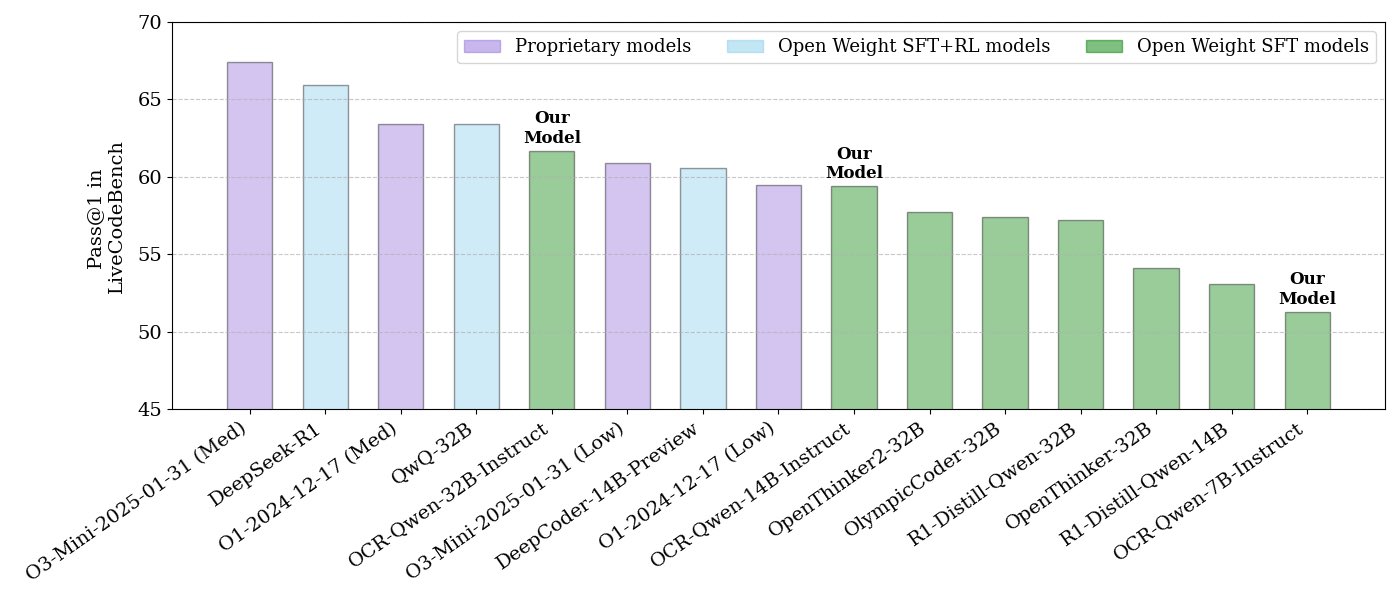
NVIDIA、オープンソースのコード推論モデルシリーズを発表: NVIDIAは、32B、14B、7Bの3つの規模のオープンソースコード推論モデルシリーズを発表し、いずれもAPACHE 2.0ライセンスを採用しています。これらのモデルはOCRデータセットでトレーニングされており、LiveCodeBenchベンチマークではO3 miniとO1 (low)を上回り、同種の推論モデルよりもトークン効率が30%高いとされています。モデルはllama.cpp、vLLM、transformers、TGIなど、さまざまなフレームワークと互換性があります。(出典: huggingface、ClementDelangue)
ServiceNowとNVIDIA、Apriel-Nemotron-15b-Thinkerモデルを共同開発: ServiceNowとNVIDIAは、Apriel-Nemotron-15b-Thinkerという名前の15Bパラメータモデルを共同で発表し、MITライセンスを採用しています。このモデルは32Bモデルに匹敵する性能を持つとされながら、トークン消費量を大幅に削減しています(Qwen-QwQ-32bより約40%少ない)。MBPP、BFCL、エンタープライズRAG、IFEvalなど多くのベンチマークテストで優れたパフォーマンスを示し、特にエンタープライズRAGとコーディングタスクにおいて競争力があります。(出典: Reddit r/LocalLLaMA)

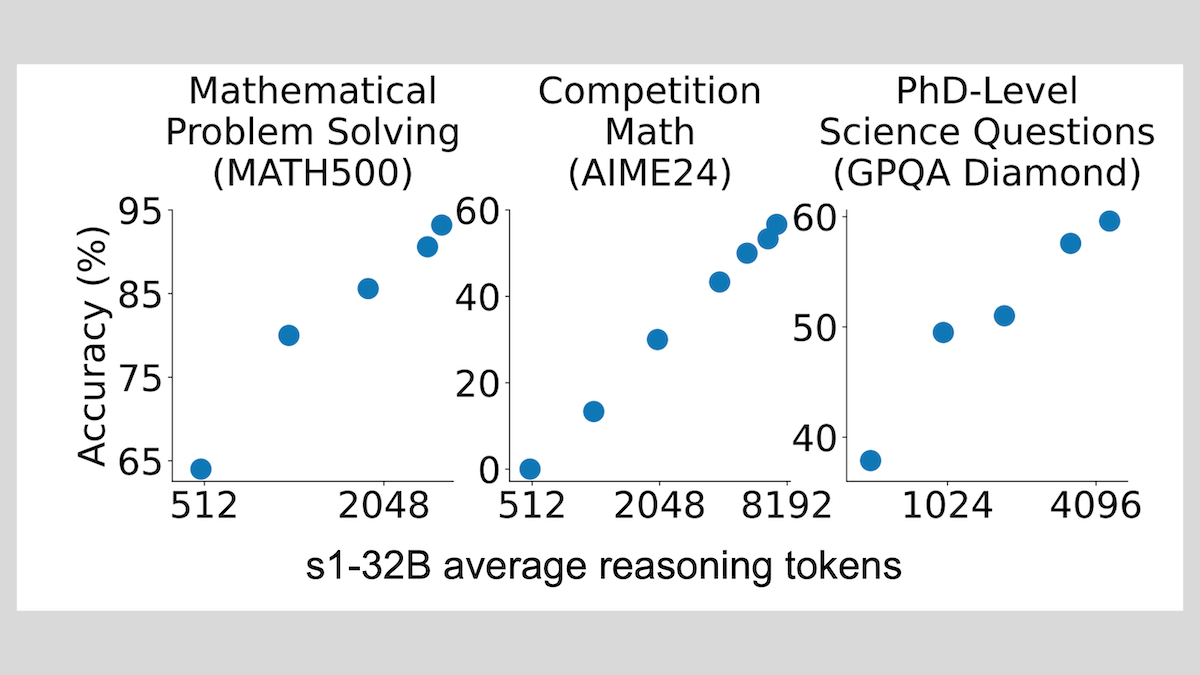
s1モデル:少量のサンプルファインチューニングで推論を実現、「Wait」テクニックで性能向上: スタンフォード大学などの研究者がs1モデルを開発し、約1000個のCoT(Chain-of-Thought)サンプルを用いた教師ありファインチューニングだけで、事前学習済みLLM(Qwen 2.5-32Bなど)に推論能力を持たせることができることを証明しました。研究ではまた、推論プロセス中にモデルに「Wait」トークンを生成させて推論チェーンを延長することで、数学などのタスクにおけるモデルの精度が大幅に向上し、その性能がOpenAI o1-previewに近づくことも発見されました。この発見は、低コストでモデルの推論能力を向上させる新たな道筋を提供します。(出典: DeepLearning.AI Blog)
ThinkPRM:わずか8Kのラベルでトレーニング可能な生成的プロセス報酬モデル: 研究者たちはThinkPRMを提案しました。これは、わずか8Kのプロセスラベルでファインチューニング可能な生成的プロセス報酬モデル(PRM)です。このモデルは、長い思考連鎖(long chains-of-thought)を生成することで推論プロセスを検証でき、PRMのトレーニングに必要な大量のステップごとの教師データという高コストな問題を解決します。関連するコード、モデル、データはGitHubとHugging Faceで公開されています。(出典: Reddit r/MachineLearning)
🧰 ツール
Zed、世界最速と称するAIコードエディタを発表: Zedは、世界最速と称するAIコードエディタを発表しました。このエディタはRustでゼロから構築され、人間とAI間のコラボレーションを最適化し、非常に高速なエージェント編集体験(agentic editing experience)を提供することを目指しています。Claude 3.7 Sonnetなどの人気モデルをサポートし、ユーザーが独自のAPIキーを持ち込むか、Ollamaを介してローカルモデルを使用することを可能にします。(出典: andersonbcdefg、ollama)
Hugging Face、nanoVLMを発表:極めてシンプルな視覚言語モデルライブラリ: Hugging FaceはnanoVLMをオープンソース化しました。これは純粋なPyTorchライブラリで、約750行のコードで視覚言語モデル(VLM)をゼロからトレーニングすることを目的としています。このモデルはMMStarベンチマークで35.3%の精度を達成し、SmolVLM-256Mに匹敵しますが、トレーニングに必要なGPU時間は100分の1に短縮されます。nanoVLMは視覚エンコーダとしてSigLiP-ViTを、LLaMAスタイルのデコーダを採用し、モーダルプロジェクタを介して両者を接続しており、学習、プロトタイピング、またはカスタムVLMの構築に適しています。(出典: clefourrier、ben_burtenshaw、Reddit r/LocalLLaMA)
DBOS、DBOS Python 1.0を発表:軽量な永続的ワークフローツール: DBOSはDBOS Python 1.0バージョンを発表しました。このツールは、Pythonアプリケーション(ビジネスプロセス、AIオートメーション、データパイプラインなどを含む)に軽量で使いやすい永続的ワークフロー機能を提供することを目的としています。新バージョンには、永続的キュー(同時実行制限、レート制限、タイムアウト、優先度、重複排除などをサポート)、プログラムによるワークフロー管理(Postgresテーブルを介したクエリ、一時停止、再開、再起動など)、同期/非同期コードのサポート、および改善されたツール(ダッシュボード、可視化など)が含まれています。(出典: lateinteraction)
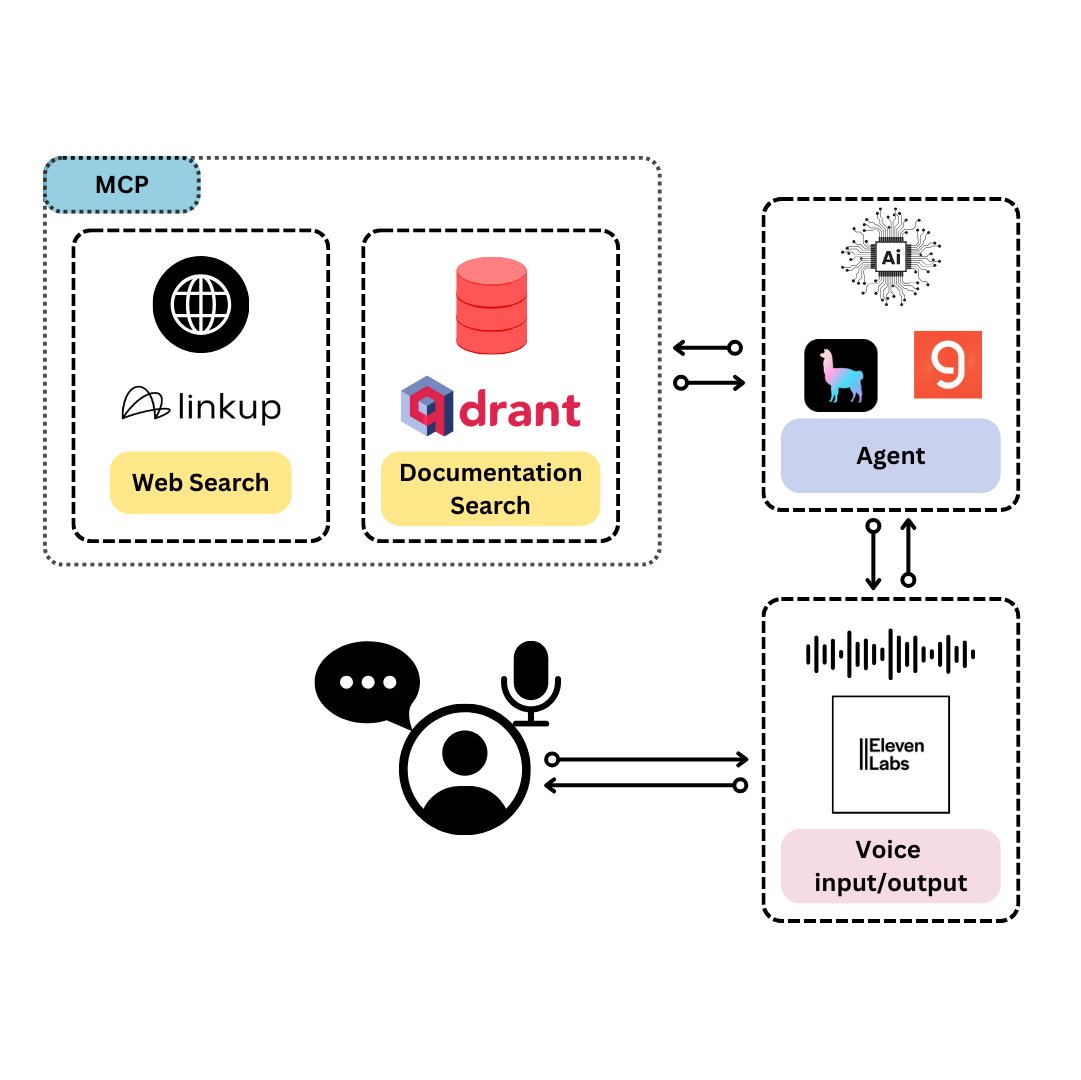
Qdrant、TySVAを発表:TypeScript開発者向けの音声アシスタント: QdrantはTySVA(TypeScript Voice Assistant)を発表しました。これはTypeScript開発者に正確で文脈を認識した回答を提供することを目的とした音声アシスタントです。TySVAはQdrantを使用してTypeScriptドキュメントをローカルに保存し、Linkupプラットフォームを統合して関連するウェブデータを取得し、LlamaIndexを利用して最適なデータソースを選択します。音声入力とテキスト入力の両方をサポートし、開発者がコーディング中に信頼性の高いハンズフリーの支援を得られるようにします。(出典: qdrant_engine、qdrant_engine)
LlamaIndex、LlamaExtractに新機能を追加:引用と推論をサポート: LlamaIndexのLlamaExtractツールに新機能が追加され、AIアプリケーションの信頼性と透明性を高めることを目指しています。新機能により、複雑なデータソース(SECファイリングなど)から情報を抽出する際に、正確な出典引用(citations)と抽出の推論過程(reasoning)を提供できます。これにより、開発者はより責任ある、より解釈可能なAIシステムを構築できます。(出典: jerryjliu0、jerryjliu0、jerryjliu0)

Hugging Face開発者、AgentとHubを接続するMCPサーバープロトタイプを構築: Hugging Faceのある開発者Wauplin氏は、AI AgentとHugging Face Hubを接続することを目的としたHugging Face MCP(Machine Communication Protocol)サーバープロトタイプを開発中です。このプロトタイプは「HfApiとMCPの出会い」と見なすことができ、Agentがプロトコルを介してHubと対話し、モデル、データセット、Spacesなどを共有・編集できるようにします。開発者は、このツールの実用性と潜在的なユースケースについてコミュニティからのフィードバックを求めています。(出典: ClementDelangue、ClementDelangue、huggingface)

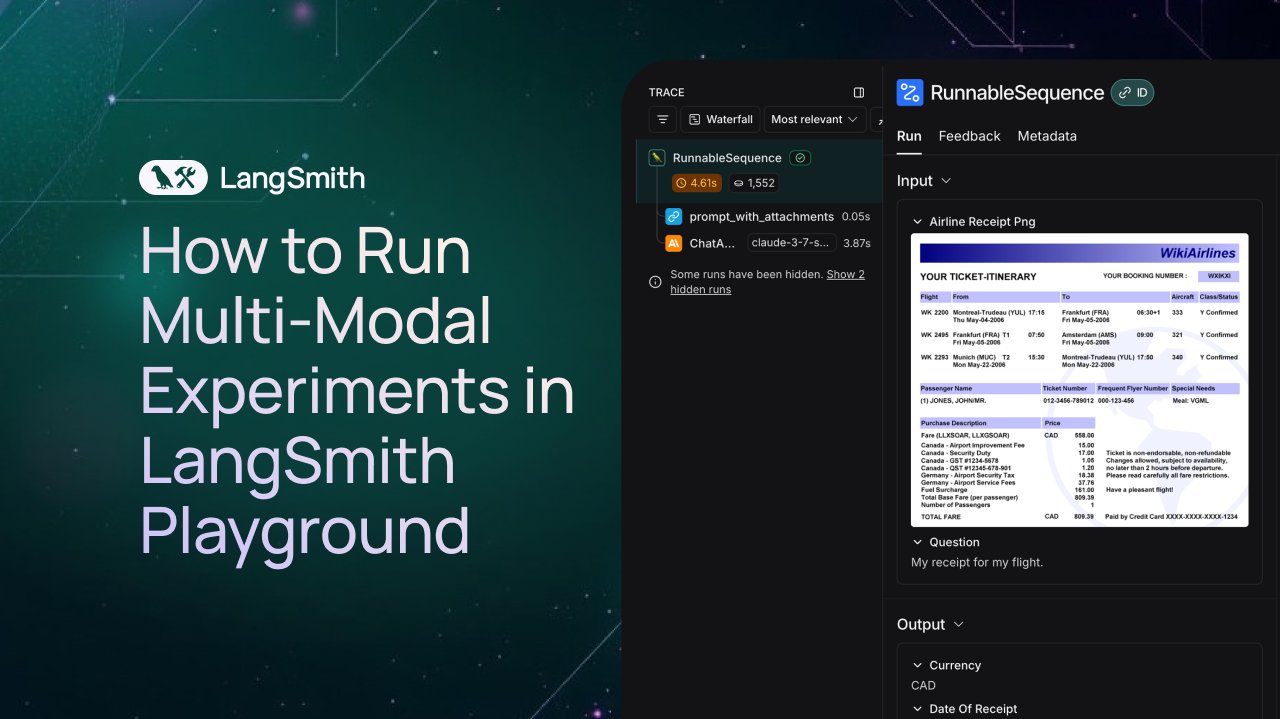
LangSmith、マルチモーダルAgentの観察と評価サポートを追加: LangSmithプラットフォームは、Playground、ラベリングキュー、データセットで画像、PDF、音声ファイルを処理できるようになりました。このアップデートにより、チケット抽出Agentなどのマルチモーダルアプリケーションの構築と評価が容易になります。公式はデモビデオとドキュメントを公開し、ユーザーが新機能の使用を開始できるよう支援しています。(出典: LangChainAI、Hacubu、hwchase17)
DFloat11、FLUX.1モデルのロスレス圧縮版をリリース、20GB VRAMで実行可能: DFloat11プロジェクトは、FLUX.1-devおよびFLUX.1-schnell(12Bパラメータ)モデルのロスレス圧縮版をリリースしました。DFloat11圧縮方法(BFloat16ウェイトにエントロピー符号化を適用)により、モデルサイズは24GBから約16.3GB(約30%)に削減され、同時に出力は変わりません。これにより、これらのモデルは20GB以上のVRAMを持つ単一のGPUで実行可能となり、画像1枚あたり数秒の追加オーバーヘッドのみで済みます。関連するモデルとコードはHugging FaceとGitHubで公開されています。(出典: Reddit r/LocalLLaMA)

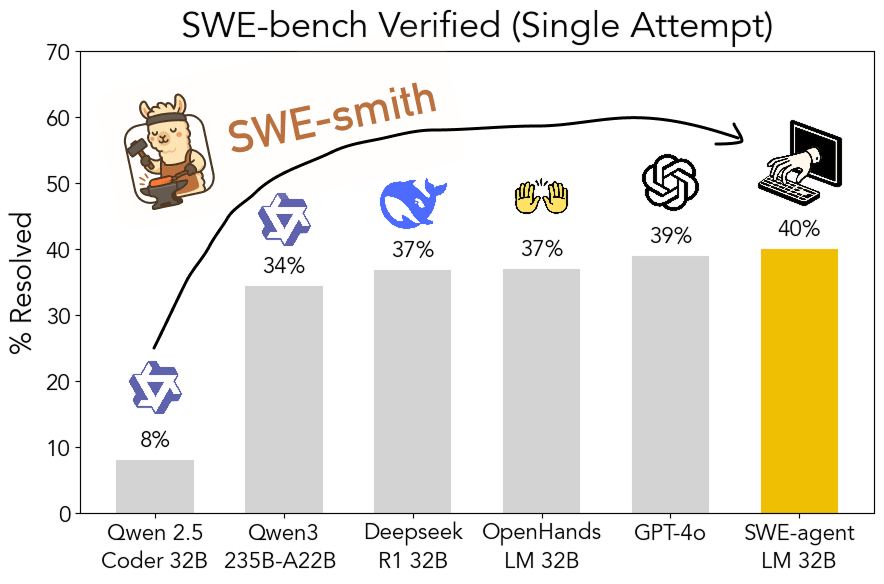
SWE-smithツールキットがオープンソース化:拡張可能なソフトウェアエンジニアリング訓練データ生成: スタンフォード大学の研究者たちは、SWE-smithをオープンソース化しました。これは、任意のPythonリポジトリからソフトウェアエンジニアリング訓練データを生成するための拡張可能なパイプラインです。このツールキットを利用して5万以上のインスタンスが生成され、これに基づいてSWE-agent-LM-32Bモデルが訓練されました。このモデルはSWE-bench Verifiedベンチマークで40.2%のPass@1を達成し、同ベンチマークで最も優れたオープンソースモデルとなりました。コード、データ、モデルはすべて公開されています。(出典: OfirPress、stanfordnlp、stanfordnlp、huybery、Reddit r/LocalLLaMA)
📚 学習
Weaviate、無料コース「埋め込みモデルの評価と選択」を公開: Weaviate Academyは、「埋め込みモデルの評価と選択」に関する無料コースを開始しました。このコースでは、MTEBなどの汎用ベンチマークを超えることの重要性を強調し、学習者が特定のユースケースに合わせて「ゴールデン評価セット」(golden evaluation set)をキュレーションし、最適な埋め込みモデルを選択するためのカスタムベンチマークを設定する方法、および新しくリリースされたモデルが適用可能かどうかを評価する方法を指導します。これは、効率的な検索およびRAGシステムを構築する上で非常に重要です。(出典: bobvanluijt)
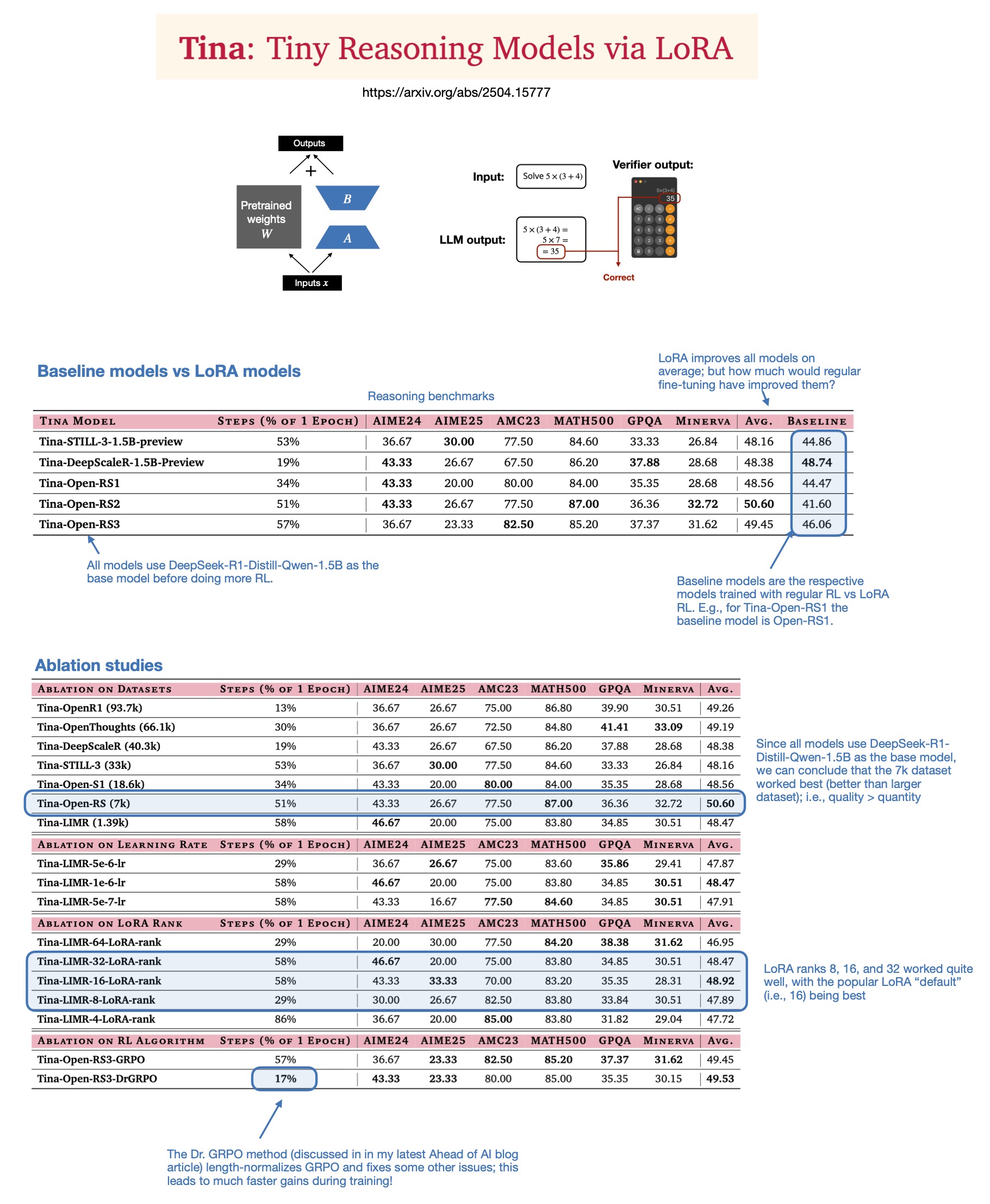
Sebastian Rasbt氏、2025年の推論モデルにおけるLoRAの価値について考察: Sebastian Rasbt氏は、論文「Tina: Tiny Reasoning Models via LoRA」を読んだ後、現在の大規模モデル時代におけるLoRA(Low-Rank Adaptation)の意義を再検討しました。フルパラメータファインチューニングや蒸留技術が普及しているにもかかわらず、Rasbt氏はLoRAが特定のシナリオ(推論タスク、マルチクライアント/マルチユースケースシナリオなど)において依然として価値を持つと考えています。この論文は、LoRAと強化学習(RL)を組み合わせて、低コスト(わずか9ドルのトレーニングコスト)で小型モデル(1.5B)の推論能力を向上させる可能性を示しており、LoRAは複数のベンチマークで標準的なRLファインチューニングを上回っています。LoRAがベースモデルの特性を変更しないため、大量のカスタマイズされたモデルウェイトを保存する必要がある場合にコスト上の利点があります。(出典: rasbt)
DeepLearning.AI、新コース「生産レベルのAI音声エージェントの構築」を開始: DeepLearning.AIはLiveKit、RealAvatarと提携し、「生産レベルのAI音声エージェントの構築」という新しい短期コースを開始しました。このコースは、リアルタイムで会話でき、低遅延で応答し、自然に聞こえるAI音声エージェントを構築する方法を教えることを目的としています。学習者は、音声アクティビティ検出、ターンテーキングなどの技術を実装し、遅延を削減するためのアーキテクチャを最適化する方法を学び、最終的にスケーラブルな音声エージェントを構築・展開します。コースはLiveKit CEO、デベロッパーアドボケイト、RealAvatar AI責任者が担当します。(出典: DeepLearningAI、AndrewYNg)
LangChainとLangGraphが共同でACM技術講演会を開催: LangChainの初期開発貢献者であるMayowa Oshin氏とLangGraphの作成者であるNuno Campos氏が、ACM技術講演会でLangChainとLangGraphを使用して信頼性の高いAI AgentとLLMアプリケーションを構築する方法について講演します。講演は無料で、ライブ配信され、登録者には後日視聴リンクが送られます。(出典: hwchase17、hwchase17)

Cohere Labs、一次最適化の深さに関する講演会を開催: Cohere LabsはJeremy Bernstein氏を招き、5月8日に「一次最適化の深さ」(Depths of First-Order Optimization)と題する講演会を開催します。この講演会は、機械学習における最適化アルゴリズムの応用と理論を深く掘り下げることを目的としています。(出典: eliebakouch)

AI2、OLMoモデルのAMAイベントを開催: Allen Institute for AI (AI2) は、5月8日午前8時から10時(太平洋時間)に、r/huggingface Redditサブセクションで、オープン言語モデルファミリーOLMoに関する「Ask Me Anything」(AMA)イベントを開催し、研究者がコミュニティの質問に答えます。(出典: natolambert)

💼 ビジネス
OpenAI、Microsoftへの収益分配比率の削減を計画: The Informationの報道によると、OpenAIは投資家に対し、会社再編の過程で、最大の支援者であるMicrosoftに支払う収益分配比率を削減する計画であると伝えました。具体的な詳細や潜在的な影響はまだ完全には明らかにされていませんが、これは両社間の商業的関係の変化を示す可能性があります。(出典: steph_palazzolo)
ベンチャーキャピタリスト、AI創業者に大きな権限を与え、バブル懸念を引き起こす: The Informationの報道によると、ベンチャーキャピタリスト(VC)は、トップクラスのAI創業者(特に著名なAIラボの幹部経験者)を引き付けるため、取締役会の拒否権、VCの取締役会への不参加、創業者の株式一部売却許可など、前例のない好条件を提示しています。この現象は、AI分野にバブルが存在する可能性の兆候と一部で見なされています。(出典: steph_palazzolo)
Toloka、Bezos Expeditions主導の戦略的投資を獲得、Mikhail Parakhin氏が会長に就任: データラベリングおよびAIトレーニングデータ企業のTolokaは、ジェフ・ベゾス氏のBezos Expeditionsが主導する戦略的投資を獲得したと発表しました。Microsoftの元幹部であるMikhail Parakhin氏も投資に参加し、取締役会長に就任します。この投資ラウンドは、Tolokaが人間とAIの協調(human+AI)ソリューションを拡大し、データ収集およびラベリング事業をさらに発展させることを支援します。(出典: menhguin、teortaxesTex、TheTuringPost)

🌟 コミュニティ
LLM訓練データのフェアユース(Fair Use)に関する議論: Dorialexander氏は、LLM訓練データのフェアユース論は、LLMが訓練元と直接的な商業的競争関係にないという仮定に大きく依存していると指摘しています。LLMの能力が向上するにつれて(例えばPerplexityなどがノンフィクション読書体験のようなものを提供し始めている)、この仮定は挑戦を受け、著作権や商業的競争に関する新たな問題を引き起こす可能性があります。(出典: Dorialexander)
AI生成コンテンツの氾濫に対する懸念と議論: ソーシャルメディアやRedditでは、低品質で反復的なAI生成コンテンツ(AIが生成したRedditのストーリー動画など)の氾濫に対する懸念が表明されています。ユーザーは、これが人間のクリエイターのスペースを圧迫し、虚偽または均質化された情報を伝え、AI技術が容易に利益を得るために利用され、独創性に欠ける現象に不満を示しています。(出典: Reddit r/ArtificialInteligence)
AIが既に意識を持っているかどうかの哲学的議論: Redditコミュニティでは、AIが既に意識を持っている可能性があるかどうかについての議論が再び起こっています。支持者は、意識の定義が狭すぎるか、人間中心的である可能性があると主張していますが、反対者は、現在のLLMの核心的なメカニズム(次のトークンを予測するなど)は真の意識を生み出すには不十分であると強調しています。この議論は、AIの本質と将来の可能性に対する一般の人々の継続的な好奇心と意見の相違を反映しています。(出典: Reddit r/ArtificialInteligence)
ChatGPT(4o)の性能低下と挙動変化に関する議論: Redditユーザーは、最近ChatGPT 4oモデルが長文ドキュメントの処理やコンテキスト記憶の維持において性能が低下し、より多くの幻覚が現れ、以前は処理できたドキュメント形式を読み取れなくなることさえあると報告しています。同時に、OpenAIも最近更新されたGPT-4oバージョンで過度なお世辞(sycophancy)の問題が発生したことを認め、ロールバックしました。これは、モデルの安定性とイテレーションの品質管理に対するコミュニティの懸念を引き起こしています。(出典: Reddit r/ChatGPT、DeepLearning.AI Blog)
AIが教育モデルに与える衝撃と反省: コミュニティの議論では、宿題や個人論文を中心とするアメリカの教育モデルは、AI(LLMなど)によるタスク自動完了能力の衝撃を非常に受けやすいと指摘されています。対照的に、一部のヨーロッパ諸国(デンマークなど)は、校内での協調、議論、プロジェクトベースの学習をより重視しており、AIの影響は比較的小さいです。これは将来の教育モデルに対する反省を促し、批判的思考、協調などの対人スキルを育成し、AIを機械的なタスクの処理に利用し、教育をより同期的で社交的な方向へ発展させるべきであるという考え方につながっています。(出典: alexalbert__、riemannzeta、aidan_mclau)
💡 その他
ロボット分野におけるAIの応用進展: 複数の情報源が、ロボット分野におけるAIの応用事例を紹介しています。これには、90秒でチャーハンを作ることができるロボットシェフ、Figure AIロボットの現実世界での応用デモンストレーション、Pickleロボットが乱雑なトラックトレーラーから荷物を降ろすデモンストレーション、Unitree G1ロボットが起伏の多い地面でバランスを保つ様子とその内部構造の展示、スイスEPFLが開発した変形可能なロボットMori3などが含まれます。これらの事例は、AIがロボットの自律性、適応性、実用性を向上させる可能性を示しています。(出典: Ronald_vanLoon、Ronald_vanLoon、Ronald_vanLoon、Ronald_vanLoon、Ronald_vanLoon、Sentdex)

特定産業におけるAI技術の応用模索(医療、繊維、携帯電話): ジョンソン・エンド・ジョンソン社は、販売支援、医薬品開発の加速(化合物スクリーニング、臨床試験の最適化)、サプライチェーンリスク予測、内部コミュニケーション(人事Q&Aロボット)などに重点を置いたAI戦略を共有しました。同時に、AI技術は伝統的な繊維産業にも力を与えており、AI支援設計、精密な染色制御から自動化された品質検査まで、効率と持続可能性を向上させています。携帯電話業界はAIを新たな成長エンジンと見なしており、メーカーはエッジ側の大規模モデル、AIネイティブオペレーティングシステム、シーンベースのインテリジェントサービスをめぐって競争し、Apple、Huawei、オープン陣営の3大派閥を形成しています。(出典: DeepLearning.AI Blog、36氪、36氪)
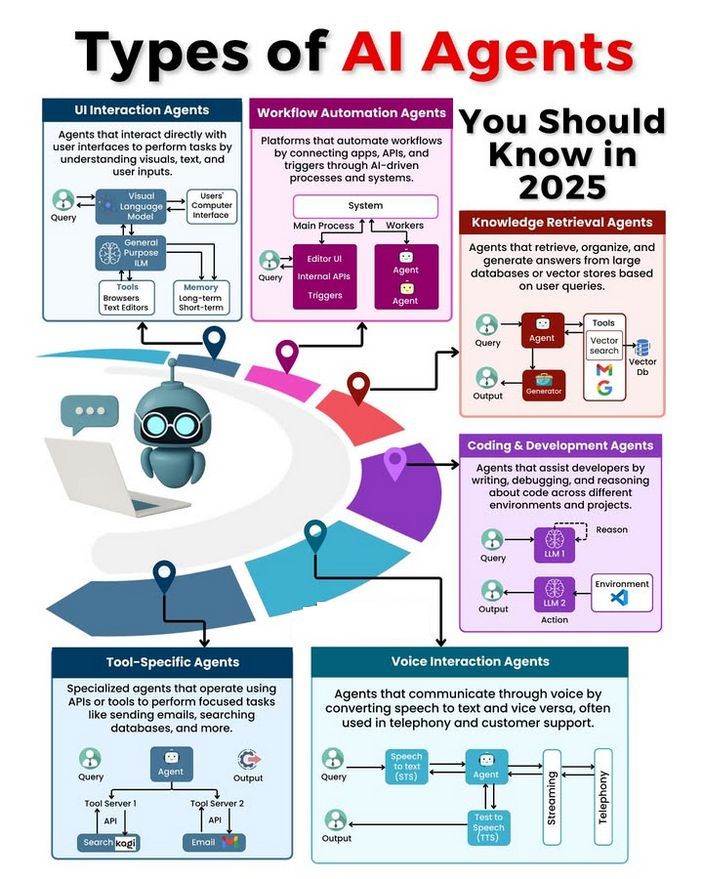
AI Agentの種類と発展に関する議論: コミュニティでは、さまざまな種類のAI Agent(単純反射型、モデルベース反射型、目標ベース型、効用ベース型、学習型Agentなど)について議論され、信頼性の高いAgentを構築するための方法論(LangChain/LangGraphの使用など)が検討されています。同時に、将来のAGIは単一のモデルではなく、複数の専門モデルが協調して構成される可能性があるという意見もあります。(出典: Ronald_vanLoon、hwchase17、nrehiew_)