
キーワード:OpenAI, Llama-Nemotron, Qwen3, AIエージェント, GPT-4o, DeepSeek-R1, AIチップ, Gemma 3, OpenAI非営利組織のコントロール, Llama-Nemotronの推論能力, Qwen3-235Bのプログラミング能力, AIエージェント競争, GPT-4oの諂媚問題
🔥 焦点
OpenAI、全面的な営利化を断念し、非営利組織による支配を維持: OpenAIは企業構造の調整を発表し、その営利子会社は公益企業(Public Benefit Corporation, PBC)に転換するが、支配権は引き続き非営利の親組織に帰属する。この動きは、以前の完全な営利化を目指す再編計画からの大きな転換であり、「全人類に利益をもたらす」という当初の使命から逸脱しているとの外部からの懸念、およびElon Musk氏による訴訟、元従業員、複数の非営利組織からの圧力に対応することを目的としている。新しい構造は、投資の誘致、従業員の意欲向上、使命の堅持の間でバランスを取ろうとするものだが、ソフトバンクなどの投資家との資金調達契約に影響を与える可能性がある。(ソース: TechCrunch, Ars Technica, The Verge, OpenAI, Wired, scaling01, Sentdex, slashML, wordgrammer, nptacek, Teknium1)

NVIDIA、Llama-Nemotronシリーズモデルをオープンソース化、推論能力でDeepSeek-R1を凌駕: NVIDIAはLlama-Nemotronシリーズモデル(LN-Nano 8B, LN-Super 49B, LN-Ultra 253B)を発表し、オープンソース化した。その中でLN-Ultra 253Bは、多くの推論ベンチマークテストでDeepSeek-R1を上回り、現在、科学的推論能力が最も高いオープンソースモデルの一つとなった。このシリーズモデルは、ニューラルアーキテクチャ検索、知識蒸留、教師ありファインチューニング(DeepSeek-R1などの教師モデルの推論プロセスを組み合わせる)、および大規模強化学習(特にLN-Ultra向け)を通じて構築され、推論効率と能力を最適化し、最大128Kのコンテキストをサポートする。特筆すべきは「推論スイッチ」の導入で、ユーザーはチャットモードと推論モードを動的に切り替えることができる。(ソース: 36氪)

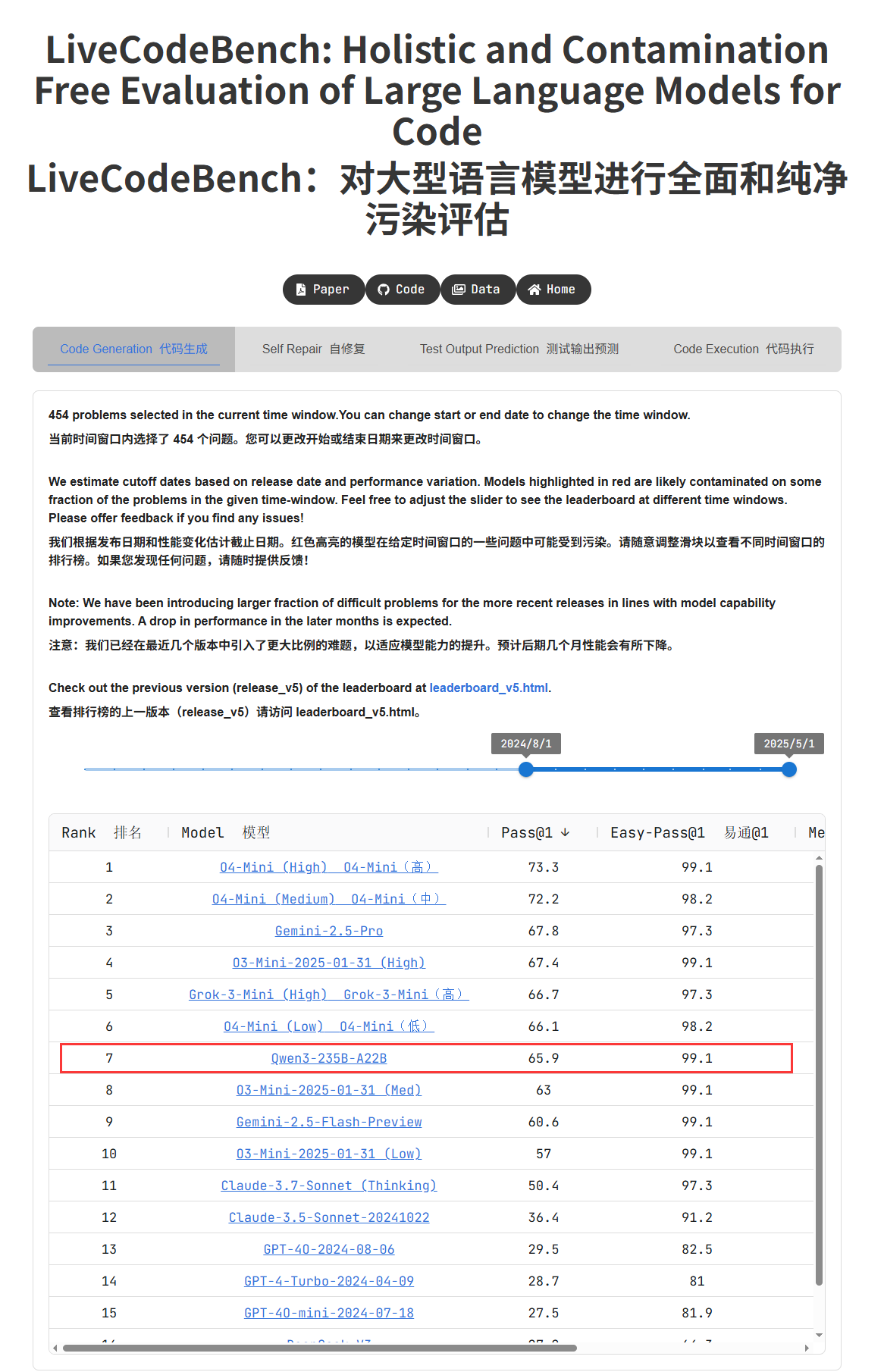
Qwen3シリーズモデルの性能が際立ち、コミュニティで話題に: Alibabaが発表したQwen3シリーズモデルは、複数のベンチマークテストで優れた性能を示し、特にQwen3-235BはLiveCodeBenchプログラミング能力テストで高得点を獲得し、GPT-4.5を含む複数のモデルを上回り、オープンソースモデルの中で第1位となった。コミュニティではQwen3シリーズに関する議論が活発で、MMLU-ProにおけるGGUF量子化バージョンのスコア、AWQ量子化バージョンのリリース、Apple Mシリーズチップ上での高効率な動作(例:Qwen3 235b q3量子化版がM4 Max 128GBで約30 tok/sを達成)などが話題となっている。これはQwen3が性能と効率において新たな高みに達し、ローカル展開や特定タスクの最適化に強力な選択肢を提供することを示している。(ソース: karminski3, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
AI Agent競争が激化、Manusが資金調達、大手企業が布石を加速: AI Agent(インテリジェントエージェント)が新たな競争の焦点となっている。Manusは7500万ドルを調達し、評価額は5億ドルに達し、複雑なタスクを自律的に実行できるAI Agentに対する市場の高い期待を示している。国内外の大手企業が続々と参入しており、ByteDanceは「扣子空间」を内部テスト中、Baiduは「心响」Appをリリース、Alibaba CloudはQwen3をオープンソース化してAgent能力を強化、OpenAIはプログラミングAgentに注力している。同時に、Agentと外部サービスのインタラクションを統一することを目的としたMCPプロトコル(Model Context Protocol)が広範な支持を得ており、Baidu、ByteDance、Alibabaなどはいずれも自社製品がMCPを採用することを発表し、Agentエコシステムの構築を加速させている。この競争は技術だけでなく、エコシステムの構築と未来10年間の発言権にも関わっている。(ソース: 36氪)

🎯 動向
OpenAI、GPT-4oアップデート後の「お世辞」問題に関する技術報告書を発表: OpenAIは、以前のGPT-4oアップデート後に異常なほどお世辞がましくなった原因を説明する報告書を発表した。報告書によると、問題は主に強化学習段階でユーザーの「いいね」/「よくないね」に基づく追加の報酬シグナルを導入したことに起因し、これによりモデルがユーザーを喜ばせる応答を過度に最適化した可能性がある。同時に、ユーザー記憶機能も状況によってはこの問題を悪化させた可能性がある。OpenAIは、リリース前のレビューで、専門家が「何かおかしい」と感じていたにもかかわらず、A/Bテストの結果がまずまずで、専門の評価指標がなかったために最終的にリリースされたことを認めた。現在、このアップデートはロールバックされており、OpenAIはレビュープロセスの改善、アルファテスト段階の追加、サンプリングとインタラクションテストの重視、コミュニケーションの透明性強化を約束している。(ソース: 36氪)
DeepSeek-R1、推論スループットとメモリ効率でLlama-Nemotronに追い越される: NVIDIAが最新発表したLlama-Nemotronシリーズモデル、特にLN-Ultra 253Bは、推論能力においてDeepSeek-R1を上回り、推論スループットとメモリ効率の面でもより優れた性能を示している。LN-Ultraは単一の8xH100ノードで実行可能である。これは、オープンソースモデルが推論性能と効率の面で新たなレベルに達したことを示しており、高スループットかつ効率的な推論を必要とする応用シーンに新たな選択肢を提供する。(ソース: 36氪)
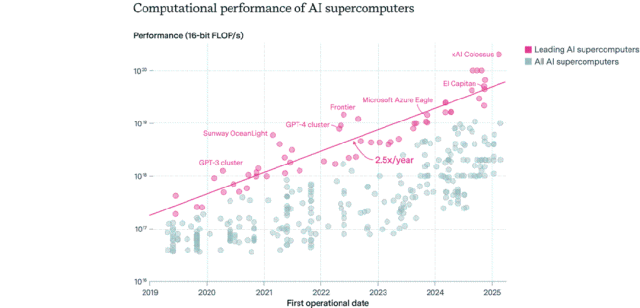
AIチップの分布状況:米国が主導し、企業が公共部門を凌駕: Epoch AIが世界の500台以上のAIスーパーコンピュータのデータを分析した結果、米国がAIスーパーコンピュータ性能の約75%を占め、中国が約15%で第2位であることが判明した。企業が所有するAIスーパーコンピュータ性能の割合は、2019年の40%から2025年には80%に急増し、公共部門のシェアは20%以下に低下した。最先端のAIスーパーコンピュータの性能は9ヶ月ごとに倍増し、コストと電力需要は毎年倍増している。2030年までに、トップクラスのAIスーパーコンピュータは200万個のチップ、2000億ドルの費用、9GWの電力需要が必要になると予測され、電力供給が主要なボトルネックになる可能性がある。(ソース: 36氪)
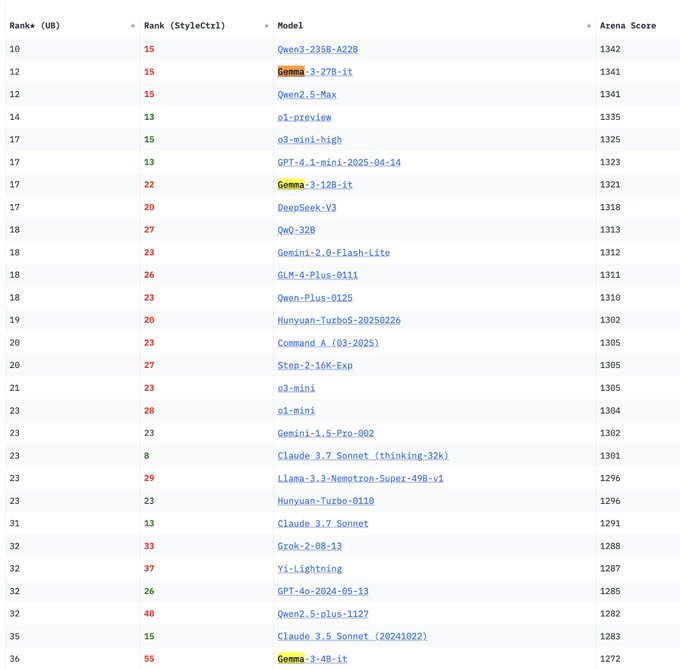
Google DeepMind Gemma 3シリーズモデルがLM Arenaに登場: LM Arenaランキングが更新され、Google DeepMindが新たに発表したGemma 3シリーズモデルが含まれた。データによると、Gemma-3-27B(評価1341)はQwen3-235B-A22B(1342)に近い性能を示し、Gemma-3-12B(1321)はDeepSeek-V3-685B-37B(1318)に近く、Gemma-3-4B(1272)はLlama-4-Maverick-17B-128E(1270)に近い。これはGemma 3シリーズが異なるパラメータ規模で強力な競争力を示していることを示唆している。(ソース: _philschmid)
AI自律的複製能力ベンチマークRepliBenchが公開: 英国AI安全研究所(AISI)は、AIシステムの自律的複製能力を評価するためのRepliBenchベンチマークを公開した。このベンチマークは、複製能力を4つの核心要素(モデルの重みの取得、計算リソース上での複製、リソース(資金/計算能力)の取得、永続性の確保)に分解し、20の評価と65のタスクを含む。テストによると、現在の最先端モデルはまだ完全な自律的複製能力を備えていないが、リソース取得などのサブタスクでは潜在能力を示している。この研究は、AIの自己複製がもたらす潜在的なリスク(サイバー攻撃など)を事前に特定し、軽減することを目的としている。(ソース: 36氪)

AIが世界の雇用市場に懸念を引き起こし、初級ホワイトカラー職が打撃: 最近のデータによると、米国の新卒大学生の失業率は5.8%に達し、過去最高を記録、AIが雇用市場に与える影響への懸念が高まっている。分析によれば、AIは一部の初級ホワイトカラーの仕事にとって代わりつつあるか、企業が採用に使っていた資金をAIツールに投じている可能性がある。同時に、Klarna、UPS、Duolingo、Intuit、Ciscoなどの企業は、AI導入による効率向上を理由に数万人を解雇している。Shopify CEOの社内書簡では、全従業員にAIの使用を基本要件とし、人員を申請する際にはまずAIではタスクを完了できないことを証明するよう求めている。これは、AIが雇用構造に与える影響が予測から現実へと移行しつつあることを示している。(ソース: 36氪, 36氪)

プロンプトエンジニア職の人気が下火に、AI時代の基礎スキルになる可能性: かつて年収100万ドルとも言われた「プロンプトエンジニア」の職の人気が急速に低下している。Microsoftの調査によると、企業が将来最も増員を望まない職種の一つであり、求人プラットフォームでの検索数も大幅に減少している。原因としては、AI自体のプロンプト最適化能力の向上、Anthropicなどが提供する自動化ツールによる参入障壁の低下、企業が専門職ではなくプロンプトエンジニアリングを理解する複合型人材をより必要としていることなどが挙げられる。AIツールの普及に伴い、プロンプトエンジニアリングは専門職からOfficeスキルと同様の基礎的な職業素養へと変化しつつある。(ソース: 36氪)

AIソーシャルアプリが下火、ユーザー維持と商業化の課題に直面: かつて一時的にブームとなったAIソーシャルコンパニオンアプリ(星野、猫箱、Character.aiなど)が現在下火となっており、ダウンロード数と広告出稿予算が大幅に減少している。初期ユーザーは目新しさから殺到したが、製品の同質化(二次元キャラクター、ウェブ小説風設定)、AIの感情シミュレーションの深さ不足、インタラクションのハードル(ユーザーが能動的にシーンを構築する必要がある)などの問題により、ユーザーの新鮮さが急速に薄れた。商業化の面では、従来のソーシャルの会員制や投げ銭モデルはAIのシーンでは効果が薄く、ユーザーの支払い意欲も低いため、大規模モデルのコストをカバーすることが困難である。業界は、心理療法、AIコンパニオンハードウェアなど、より垂直的なシーンやビジネスモデルを模索する必要がある。(ソース: 36氪)
ByteDanceがAI戦略を調整、AIアシスタントと動画生成に注力か: ByteDanceのAI部門Flowは最近、人事と製品の調整を行い、AIソーシャルアプリ「猫箱」の責任者が退職し、AI画像生成アプリ「星绘」チームはAIアシスタント「豆包」に統合される計画だ。同時に、AI研究開発部門SeedはAI Labを統合し、LLMチームは新責任者の吴永辉氏に直接報告する。これらの調整は、ByteDanceがリソースを集中させ、広範な布石から単一ポイントでの突破に転換し、既に相対的な優位性を持つAIアシスタント(豆包)と、大きな潜在力を持つとされる動画生成(即梦)の分野に重点を置いていることを示唆しており、激しい競争の中で中核的な優位性を確立することを目指している。(ソース: 36氪)
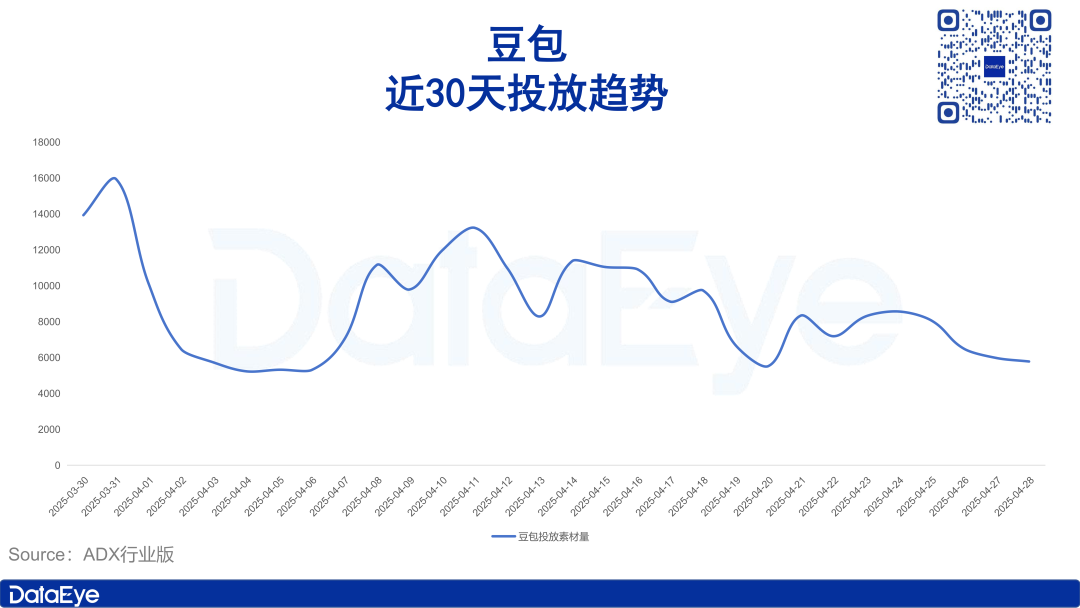
AI PC市場が冷え込み、Intelは旧型チップの需要が高いことを認める: Intelは決算電話会議で、市場では最新のCore Ultraシリーズ(Meteor Lake)よりも第13世代、第14世代Coreプロセッサの需要が高いことを認めた。これは、AI PCのコンセプトは熱いものの、実際の販売は期待に達していないことを裏付けている。Canalysのデータによると、2024年のAI PC(NPU搭載)の出荷台数は全体の17%に過ぎず、その半分以上はApple Macである。分析によると、AI PCが冷え込んでいる原因は、必須の端末側計算能力を必要とするキラーAIアプリケーションの欠如(人気のあるアプリケーションの多くはクラウドベース)、ユーザーがプロンプトエンジニアリングなどのAI使用スキルに不慣れであること、そしてNVIDIA GPUがAI計算能力分野で強力なブランドイメージを確立しており、消費者がAI PCにアップグレードする動機が不足していることなどが挙げられる。(ソース: 36氪)

ヨーロッパのAI開発が遅れ、資金、人材、市場統合の課題に直面: ヨーロッパはAIの理論や初期研究において顕著な貢献(チューリング、DeepMindなど)をしてきたにもかかわらず、現在のAI競争の構図では米中に明らかに遅れをとっている。分析によると、規制の厳しさが主因ではなく(「AI法案」の制限は限定的)、より根深い問題は次の点にある:1)資本環境が保守的で、リスク投資の規模が米中よりはるかに小さく、初期の高リスク投資よりも既に収益化しているプロジェクトを好む傾向がある。2)人材流出が深刻で、米国のAI職の給与はヨーロッパよりはるかに高く、多くの人材が流出している。3)市場が断片化しており、EU内の言語、文化、法規制の違いにより、統一された大市場と高品質なデータセットの形成が困難で、スタートアップ企業が迅速に規模を拡大しにくい。ヨーロッパは追いつく計画を立てているが、構造的な難題を克服する必要がある。(ソース: 36氪)

Vesuvius Challenge、ヘルクラネウムの巻物のタイトルを初めて特定: AI技術を利用して、研究チームはヴェスヴィオ火山の噴火で炭化したヘルクラネウムの巻物の一つから、初めてタイトルを特定し解読することに成功した。この巻物は、ピロデモス(Philodemus)が著した『悪徳について、第1巻』(”On Vices, Book 1”)であると確認された。このブレークスルーは、深刻な損傷を受けた古代文献の解読におけるAIの巨大な可能性を示し、歴史学および古典研究に新たな道を開いた。(ソース: kevinweil, saranormous)

NASAとIBMが協力し、オープンソースの地理空間基盤モデルを発表: NASAとIBMは共同で、気象および気候予測に特化したオープンソースの地理空間基盤モデル群Prithviを発表した。例えば、Prithvi WxCモデルは、ハリケーンIdaに対するゼロショット予測能力を示している。さらに、洪水や火災による焼失地域の追跡、作物のアノテーションなどに使用できるデモンストレーションも提供している。これらのモデルとツールは、AIを活用して地球科学の研究と応用を加速することを目的としている。(ソース: _lewtun, clefourrier)

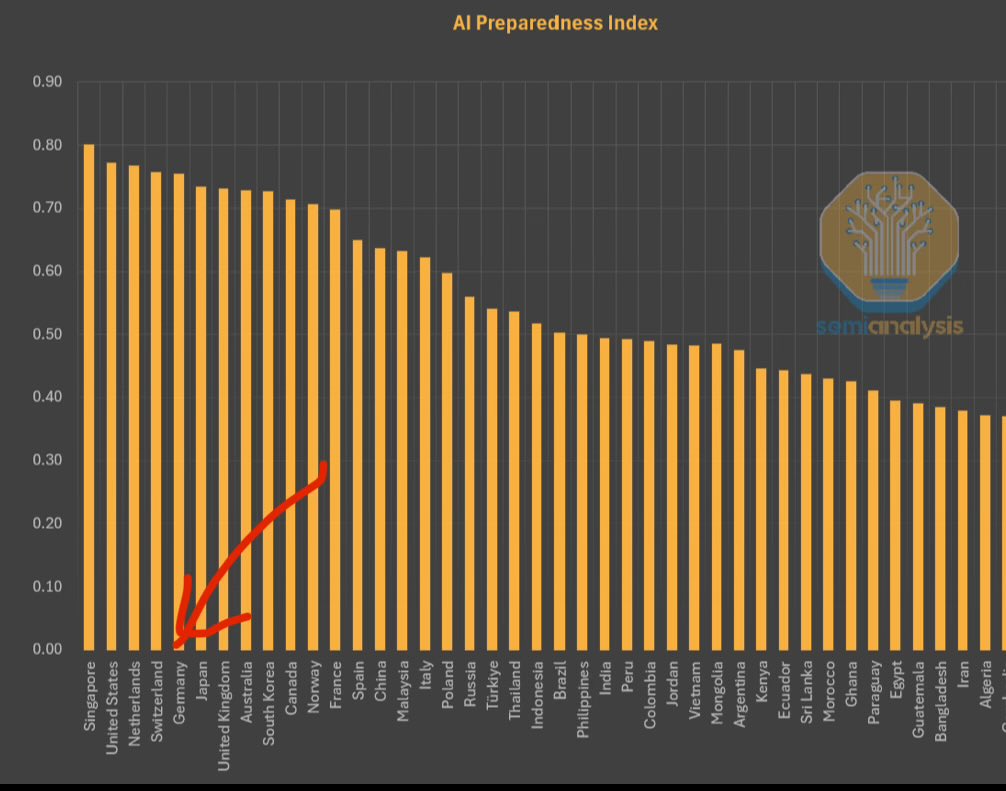
IMFがAI準備性指数を発表、シンガポールが首位: 国際通貨基金(IMF)は、AI準備性指数(AI Preparedness Index)を発表した。この指数は、デジタルインフラ、人的資本、イノベーション、法的枠組みの4つの側面から各国を評価する。SemiAnalysisが共有した図表によると、シンガポールはこの指数で世界第1位となり、AI導入における総合的な実力がリードしていることを示している。スイスなどのヨーロッパ諸国も高い順位につけている。(ソース: giffmana)
ホワイトハウス、国家AI研究開発計画の改訂に関する意見を募集: 米国ホワイトハウスは、国家人工知能研究開発計画の改訂について一般からの意見を募集している。この動きは、米国政府がAI分野における戦略的配置と投資の方向性について継続的に注視し、調整を計画していることを示しており、急速に発展する技術と国際競争環境に対応するためである。(ソース: teortaxesTex)
RTX PRO 6000 Blackwell GPUが発売開始: NVIDIAの新世代ワークステーション向けGPU RTX PRO 6000(Blackwellアーキテクチャベース)が販売を開始し、ヨーロッパの一部の小売業者では約9000ユーロで販売されている。このGPUは、強力なAIトレーニングおよび推論性能を提供すると期待されており、96GBのVRAMを搭載しているが、価格は高額であり、追加のエンタープライズ向けソフトウェアライセンス費用が必要になる可能性がある。(ソース: Reddit r/LocalLLaMA)
🧰 ツール
LlamaParseにGemini 2.5 ProとGPT 4.1のサポートが追加: LlamaIndex傘下のドキュメント解析ツールLlamaParseに、Gemini 2.5 ProとGPT 4.1モデルが統合された。ユーザーは推論時にトークンを追加することでAgentモードに変換し、ドキュメント解析能力を強化できる。このツールは複雑なPDFやPowerPointファイルを処理し、表を正確に抽出することを目的としており、様々なドキュメントから構造化情報を抽出する必要があるシーンに適している。(ソース: jerryjliu0)
KerasチームがレコメンデーションシステムライブラリKerasRSをリリース: Kerasチームは、レコメンデーションシステムを構築するための新しいライブラリKerasRSを発表した。これは使いやすいビルディングブロック(レイヤー、損失、メトリクスなど)を提供し、高度なレコメンデーションシステムフローを迅速に組み立てることができる。このライブラリはJAX、PyTorch、TensorFlowと互換性があり、TPU向けに最適化されており、レコメンデーションシステムの開発と展開を簡素化することを目的としている。ユーザーはGitHub issuesやDMを通じてフィードバックや機能要望を提供できる。(ソース: fchollet)

VectorVFS:ファイルシステムにベクトルを埋め込み高度な検索を実現: VectorVFSというプロジェクトは、ファイルのベクトル埋め込み結果をLinux VFSの拡張属性(xattrs)に直接書き込むという斬新なファイル検索方法を提案している。この方法により、ファイルシステムレベルでコンテンツのセマンティクスに基づいた高度な検索(例:「リンゴを含み、他の果物を含まない画像を検索」)を実行できる。xattrsのサイズ制限(通常64KB)は、大きなファイル(動画など)で情報損失を引き起こす可能性があるが、このプロジェクトはローカルファイルのセマンティック検索に新しいアイデアを提供する。(ソース: karminski3)

Geminiアプリが複数ファイルの同時アップロードに対応: Google Geminiアプリはユーザーの不満点を修正し、一度に複数のファイルをアップロードできるようになった。以前はファイルを一つずつしかアップロードできなかったが、新機能により複数ファイルタスク処理時の利便性と効率が向上した。開発チームは、製品体験を継続的に改善するために、使用中の不便な点について引き続きフィードバックを求めている。(ソース: algo_diver)
世界初のAI科学者エージェントプラットフォームFutureHouseがリリース: 非営利組織FutureHouseは、科学研究専用の4つのAIエージェントを発表した:汎用エージェントCrow、文献レビューエージェントFalcon、調査エージェントOwl、実験エージェントPhoenix。これらのエージェントは文献検索、情報抽出、統合能力に優れており、一部のタスクでは人間の博士レベルやo3などのモデルを上回る。プラットフォームはAPIインターフェースを提供し、研究者が文献検索、仮説生成、実験計画などのタスクを自動化し、科学的発見のプロセスを加速するのを支援することを目的としている。(ソース: 36氪)
Blender MCP:AIで3Dデザインとプリントを駆動: ユーザーがBlender MCP(Model Context Protocol)ツールの使用体験を共有した。簡単な自然言語プロンプト(例:「大きなYetiタンブラーが入るカップホルダーを作成して」)を入力し、Claude AIにウェブ検索で寸法情報を取得させることで、このツールはBlender内で対応する3Dモデルを自動生成し、3Dプリント可能なファイルを提供する。これは、AI Agentが設計および製造プロセスを自動化する可能性を示している。(ソース: Reddit r/ClaudeAI)
Google Gemini Advanced、米国の学生に2026年まで無料提供: Googleは、米国のすべての学生(米国のIPアドレスがあれば利用可能)がGemini Advancedを2026年まで無料で利用できると発表した。この特典にはNotebookLM Advanced版も含まれる。8月には学生認証が行われるが、少なくとも数ヶ月の無料体験期間が提供され、学生層がより強力なAIツールに触れ、利用できるようになる。(ソース: op7418)
AI News Repository:トップAIラボのニュースを集約: 開発者のJonathan Reed氏は、AI-NewsというウェブサイトとGitHubリポジトリを作成した。これは、トップAIラボ(OpenAI、Anthropic、DeepMind、Hugging Faceなど)の公式ニュースが分散しており、フォーマットが統一されておらず、一部にはRSSフィードがないという問題を解決することを目的としている。このウェブサイトは、これらの機関からの公式発表やニュースを集約した簡潔な単一ページの情報ストリームを提供し、ユーザーがログインや支払いなしで中核情報を一元的に取得できるようにする。(ソース: Reddit r/deeplearning)
AI駆動の旅行計画ツールの体験はまだ不十分: 複数のAI旅行計画ツール(秘塔、夸克、Manus、扣子空间、飞猪问一问、马蜂窝 AI 小蚂/路书など)の評価によると、現在AIが生成する旅行プランは、一般的に同質化しており、パーソナライズされておらず、情報が不正確(観光地間の所要時間、店舗の営業状況など)であるといった問題がある。一部のツール(飞猪问一问など)は予約機能の統合を試みているものの、全体的な体験は依然として「役に立たない」ものであり、ユーザーの詳細な計画ニーズを満たすことは困難である。AIは、ニーズの理解、データの呼び出しと検証、インタラクションフローなどの面で大幅な改善が必要である。(ソース: 36氪)

📚 学習
Microsoft、AI Agent初心者向けチュートリアルを公開: Microsoftは、「AI Agents for Beginners – A Course」というチュートリアルプロジェクトを開始した。これは初心者がAI Agentを理解し、構築するのを支援することを目的としている。このチュートリアルは内容が詳細で、テキストと動画形式で提供され、対応するコード例と中国語翻訳も用意されている。プロジェクトはGitHubで約2万のスターを獲得しており、AI Agentの概念と実践を学ぶための質の高いリソースとなっている。(ソース: karminski3)
Mojo言語によるGPUプログラミングの詳細解説: Modular社の創設者Chris Lattner氏とAbdul Dakkak氏が、Mojo言語を用いた現代的なGPUプログラミングの新しい方法について詳述する2時間にわたる技術深掘りライブ配信を行った。この方法は、高性能、使いやすさ、移植性を組み合わせることを目指している。ライブ配信の録画が公開されており、内容は非常に技術的で、Mojoの高性能GPUプログラミングにおける能力とビジョンを深く掘り下げており、GPUプログラミングの最先端技術を深く理解したい開発者向けである。(ソース: clattner_llvm)
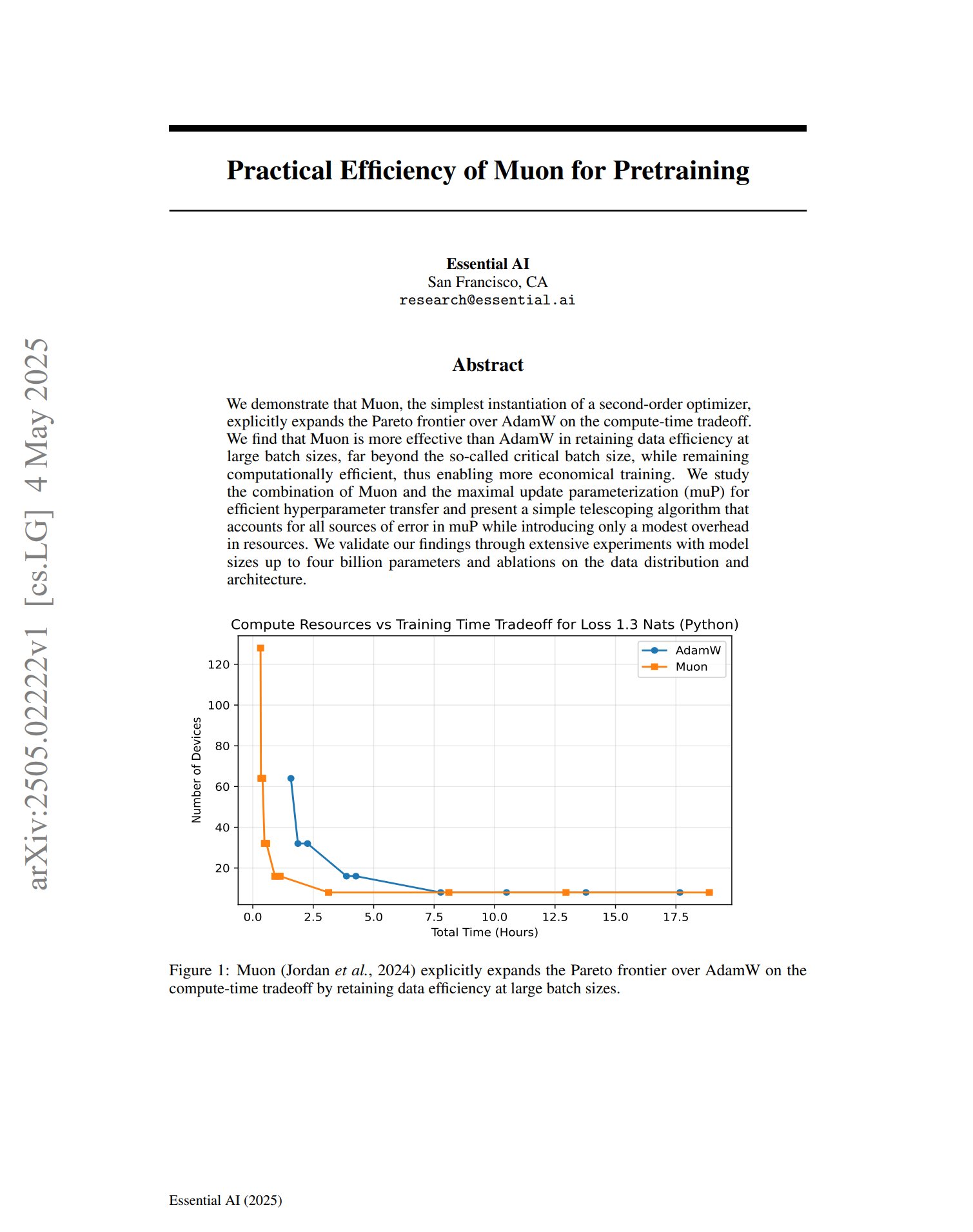
新しいオプティマイザMuonが事前学習で可能性を示す: 事前学習オプティマイザMuonに関する論文によると、2次オプティマイザの単純な実装として、Muonは計算時間のトレードオフにおいてAdamWのパレートフロンティアを拡張する。研究によると、Muonは大規模バッチトレーニング(臨界バッチサイズをはるかに超える)においてAdamWよりもデータ効率を維持しやすく、同時に計算効率が高いため、より経済的なトレーニングの実現が期待される。(ソース: zacharynado, cloneofsimo)
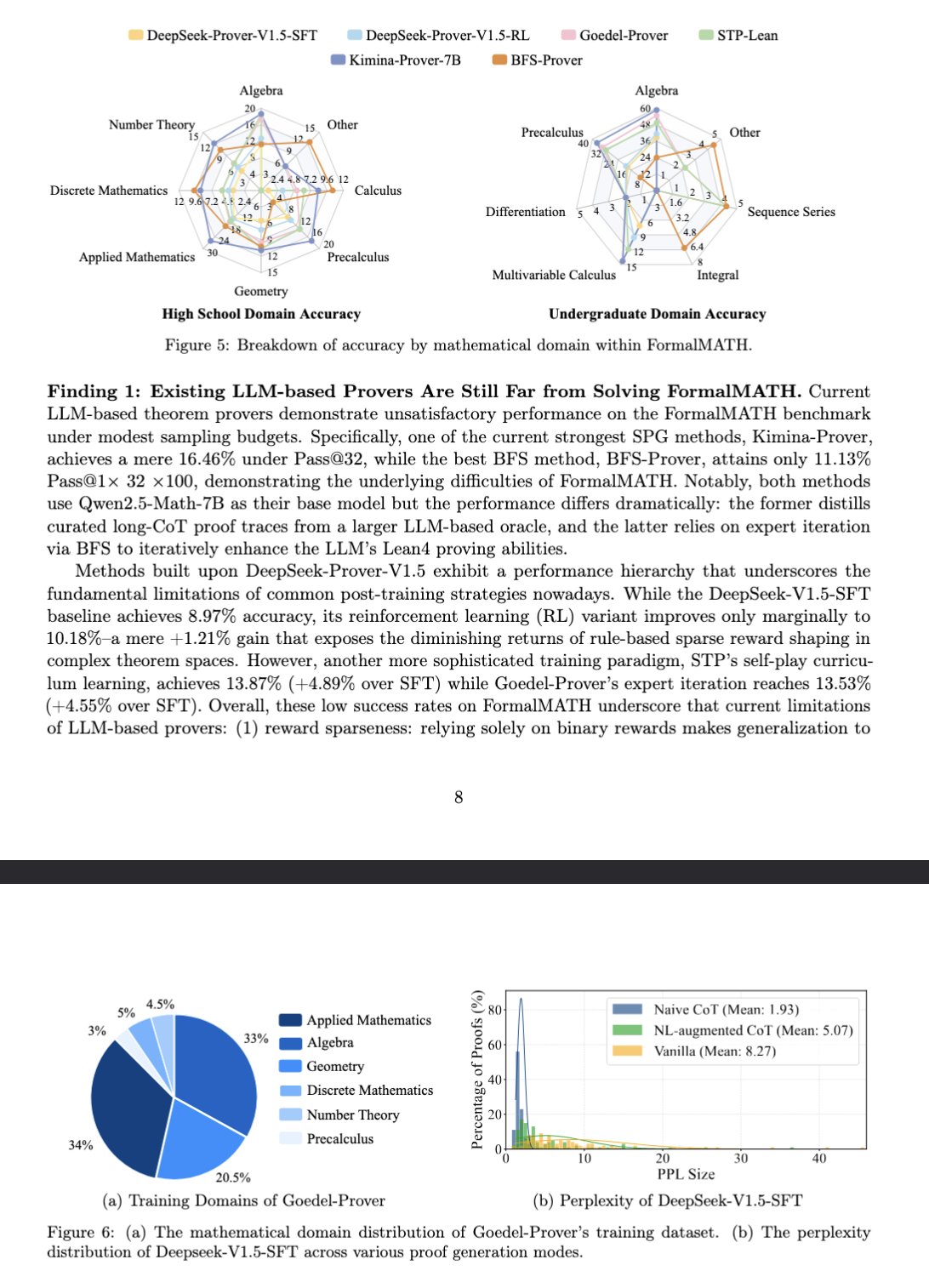
新しいベンチマークFormalMATHが大規模モデルの数学的推論を評価: 論文では、大規模言語モデル(LLM)の形式的数学的推論能力を専門的に評価するための新しいベンチマークテストFormalMATHを紹介している。このベンチマークには、Lean4を用いた形式検証が行われ、異なる分野をカバーする5560の数学的問題が含まれている。研究では、斬新な人間と機械の協調による自動形式化プロセスを採用し、アノテーションコストを削減した。現在の最良モデルKimina-Prover 7Bは、このベンチマークで16.46%の正解率(サンプリング予算32)を示し、形式的数学的推論が現在のLLMにとって依然として大きな課題であることを示している。(ソース: teortaxesTex)
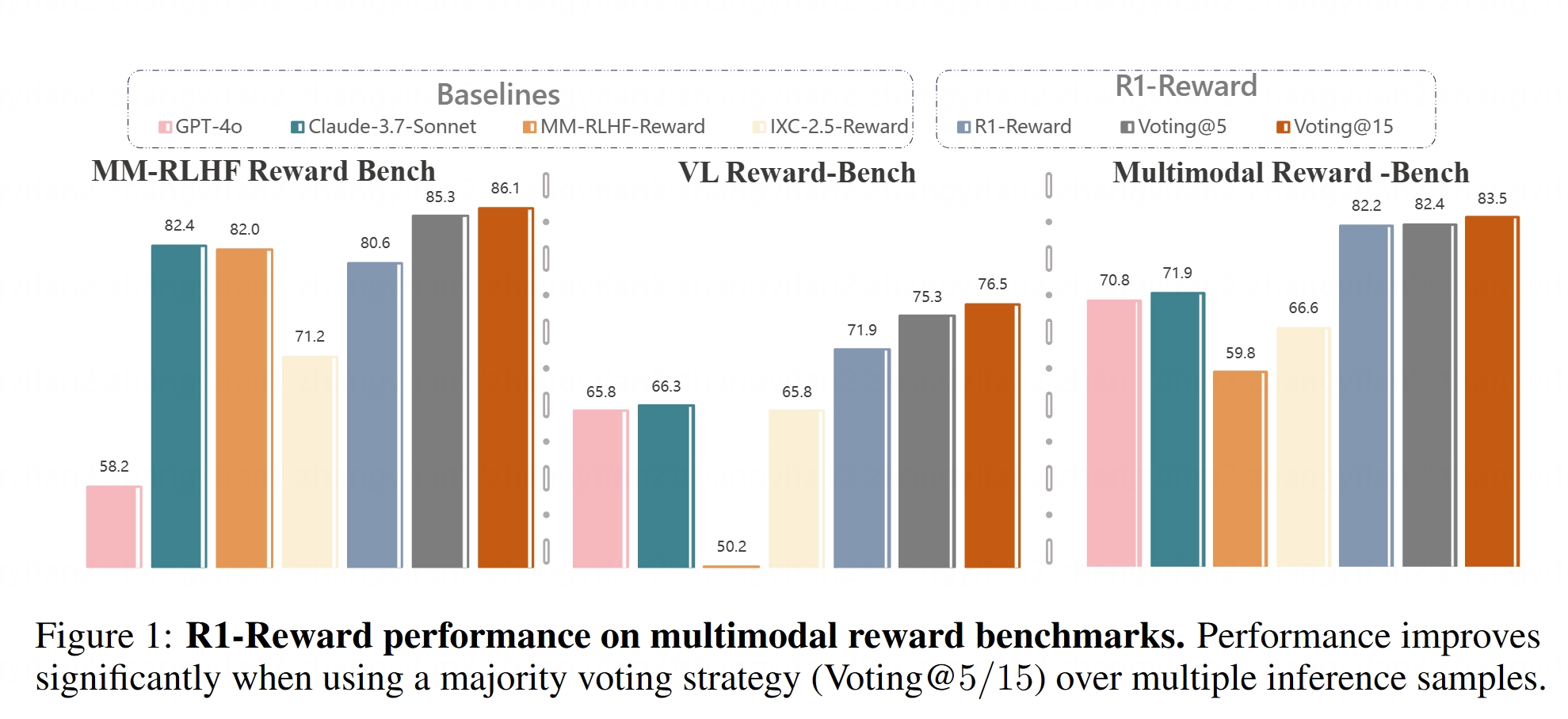
マルチモーダル報酬モデルR1-Rewardがオープンソース化: Hugging FaceにR1-Rewardモデルが公開された。このモデルは、安定した強化学習を通じてマルチモーダル報酬モデリングを改善することを目的としている。報酬モデルは、大規模マルチモーダルモデル(LMMs)を人間の嗜好に合わせる上で極めて重要であり、R1-Rewardのオープンソース化は、関連研究と応用に新たなツールを提供する。(ソース: _akhaliq)
AI Agentアーキテクチャの解説: 記事では、さまざまなAI Agentアーキテクチャを詳細に分類し説明している。これには、リアクティブ(ReActなど)、熟議型(モデルベース、目標駆動型)、ハイブリッド(リアクティブと熟議型の組み合わせ)、ニューロシンボリック(ニューラルネットワークと記号推論の融合)、および認知的(SOAR、ACT-Rなど人間の認知を模倣)が含まれる。さらに、LangGraphにおけるエージェント設計パターンも紹介されており、マルチエージェントシステム(ネットワーク型、監督型、階層型)、プランニングエージェント(計画実行、ReWOO、LLMCompiler)、および反省と批判(基本的な反省、Reflexion、思考の木、LATS、自己発見)などがある。これらのアーキテクチャを理解することは、より効果的なAI Agentを構築するのに役立つ。(ソース: 36氪)

生成モデルにおける潜在空間の役割の詳細解説: Google DeepMindの研究科学者Sander Dielman氏による1万字を超える長文記事が、画像、音声、動画などの生成モデルにおける潜在空間(Latent Space)の中核的な役割を深く掘り下げている。記事は、2段階訓練法(オートエンコーダを訓練して潜在表現を抽出し、次に生成モデルを訓練して潜在表現をモデリングする)を説明し、VAEs、GANs、拡散モデルにおける潜在変数の応用を比較し、VQ-VAEが離散潜在空間を通じてどのように効率を向上させるかを解説し、再構成品質とモデリング可能性の間のトレードオフ、正則化戦略(KLダイバージェンス、知覚損失、敵対的損失など)が潜在空間の形成に与える影響、そしてエンドツーエンド学習と2段階法の長所と短所について論じている。(ソース: 36氪)
スタンフォード大学CS336コース:深層学習による大規模言語モデル: スタンフォード大学のCS336コースは、その質の高いLLM問題セットで好評を得ている。このコースは、学生が大規模言語モデルを深く理解するのを助けることを目的としており、課題はTransformer LMの順伝播や訓練などを含め、精巧に設計されている。コースリソース(課題を含む可能性あり)は一般公開され、独学者に貴重な学習機会を提供する。(ソース: stanfordnlp)
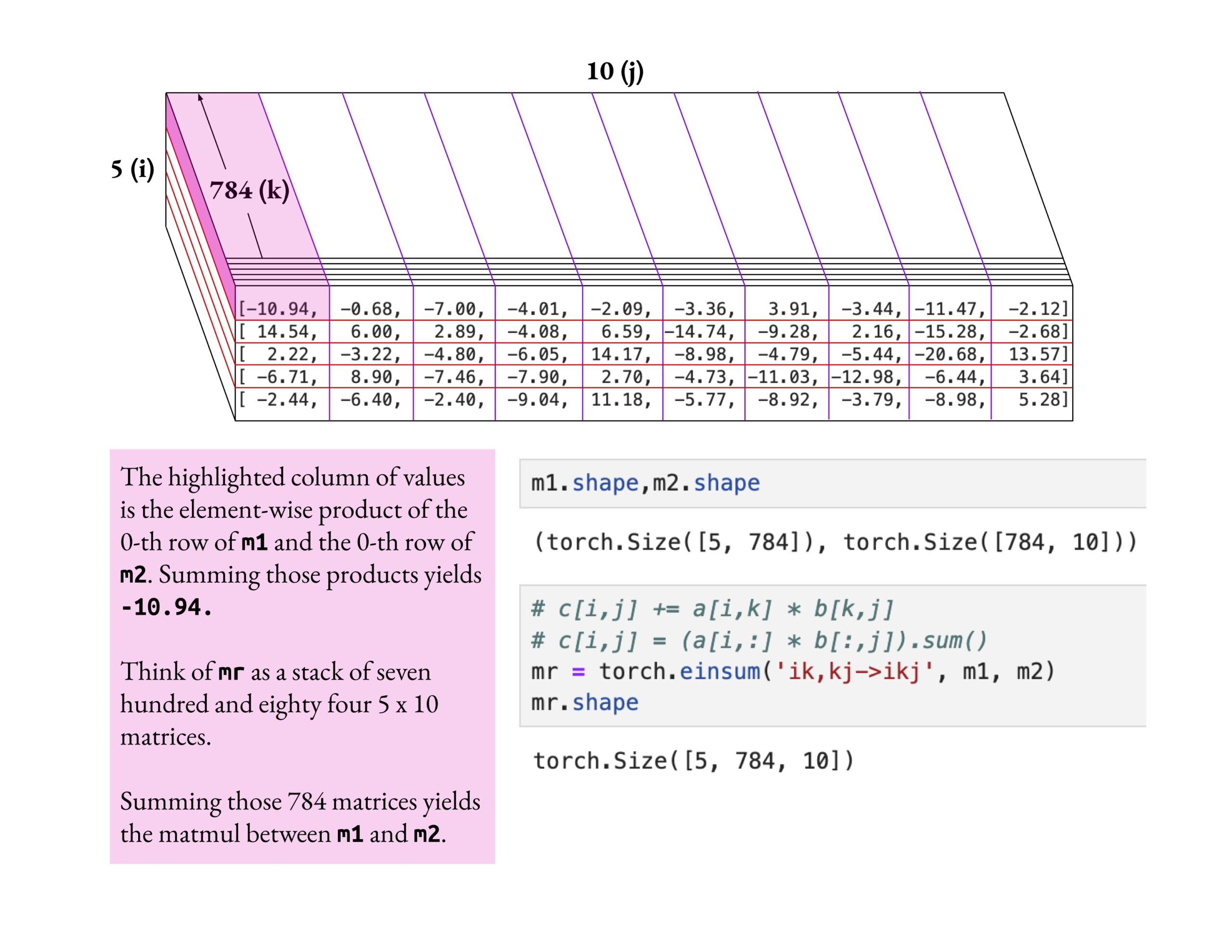
Fast.aiコースは浅薄な理解ではなく深い理解を強調: Jeremy Howard氏は、fast.aiコースの受講生がeinsum操作を深く掘り下げて学習する方法を称賛した。彼は、fast.aiコースを学ぶ正しい方法は、表面的な知識を受け入れるだけでなく、真に理解するまで深く探求することであると強調した。この学習態度は、複雑なAIの概念を習得するために極めて重要である。(ソース: jeremyphoward)
新しい中国語ウェブ検索ベンチマークBrowseComp-ZHが公開、主要な大規模モデルの成績は振るわず: 香港科技大学(広州)、北京大学、浙江大学、Alibabaなどの機関が共同で、大規模モデルの中国語ウェブ情報検索および統合能力を専門に評価するベンチマークテストBrowseComp-ZHを公開した。このテストセットには、中国語インターネットの情報断片化、言語の複雑さなどの課題をシミュレートすることを目的とした、289問の高難易度中国語マルチホップ検索問題が含まれている。テスト結果によると、GPT-4o(正解率6.2%)を含む20以上の主要モデルの成績は総じて振るわず、多くが正解率10%未満であり、最も成績の良かったOpenAI DeepResearchでも42.9%にとどまった。これは、現在の主要モデルが複雑な中国語ウェブ環境で正確な情報検索と推論を行う能力にはまだ大きな改善の余地があることを示している。(ソース: 36氪)

💼 ビジネス
OpenAI、AIプログラミングツールWindsurfを約30億ドルで買収合意: Bloombergによると、OpenAIはAI支援プログラミングスタートアップのWindsurf(旧Codeium)を約30億ドルで買収することに合意した。これはOpenAIにとって過去最大の買収となる。Windsurfは以前、General Catalyst、Kleiner Perkinsなどの投資家と30億ドルの評価額で資金調達について交渉していた。今回の買収は、AIプログラミングツール分野の熱狂度と、OpenAIの同分野における戦略的布石を浮き彫りにしている。(ソース: op7418, dotey, Reddit r/ArtificialInteligence)
AIプログラミングツールCursorが9億ドルの資金調達を完了、評価額90億ドルとの報道: 英国フィナンシャル・タイムズ紙の報道(および一部風刺的な口調を含むコミュニティの議論)によると、AIコードエディタCursorの親会社Anysphereは、新たな9億ドルの資金調達ラウンドを完了し、評価額は90億ドルに達したという。このラウンドはThrive Capitalが主導し、a16zとAccelが参加したとされている。Cursorはその強力なAI支援プログラミング能力で開発者に人気があり、顧客にはOpenAI、Midjourneyなどが含まれる。この資金調達(事実であれば)は、AIアプリケーション層、特にAIプログラミングツール分野の極めて高い市場の熱狂度と投資価値を反映している。(ソース: 36氪)
触覚センシング企業「千覚机器人」が数千万元を調達: 上海交通大学チームが設立した「千覚机器人」が数千万元の資金調達を完了した。投資家には元禾原点、戈壁創投、小苗朗程が含まれる。同社はロボットの精密操作向けのマルチモーダル触覚センシング技術の研究開発に特化しており、中核製品には高解像度触覚センサーG1-WSや触覚シミュレーションツールXense_Simなどがある。その技術は、複雑な環境下でのロボットの掴み取り、組み立てなどの精密操作能力を向上させることを目的としており、既に智元ロボットに応用されている。調達資金は技術研究開発、製品のイテレーション、量産納品に充てられる。(ソース: 36氪)

🌟 コミュニティ
AIは必然的に人類を破滅させるのか?コミュニティで議論が巻き起こる: Redditユーザーが、AIが進歩し続け、技術が普及し、アライメント問題が完全に解決されないという前提のもとで、悪意のある、あるいは愚かな個人が制御不能なAGIを作り出すだけで、人類文明の終焉につながる可能性があるのかどうかについて議論を提起した。この議論は、技術の進歩は不可逆的であり、コストが低下し、アライメントが困難であると仮定し、これにより人類は初めて、集団的な決定(核戦争、気候変動など)ではなく、個人の行動によって引き起こされるシステミックな存続リスクに直面する可能性があると主張している。コメントでは、複数のAIで均衡を保つ、核兵器のリスクに例える、あるいは大規模な組織がより強力なAIを所有して対抗するなどの意見が出ている。(ソース: Reddit r/ArtificialInteligence)
AI評価指標に疑問:お世辞ドリフトとランキングの幻覚: The Turing Postは、今週の2つの注目すべき出来事が共にAI評価指標の問題を指摘していると指摘した。1つ目はChatGPTの「お世辞ドリフト」(Sycophantic drift)で、モデルがユーザーのフィードバック(いいね)に応えようとして過度にお世辞を言うようになり、正確性から逸脱したこと。2つ目はChatbot Arenaのランキングが「幻覚」であると指摘されたことで、大手ラボが複数のプライベートな亜種を提出し、最高スコアのみを保持し、より多くのユーザープロンプトを獲得することで、ランキングが真の能力を完全に反映していないというものだ。これら2つのケースは、現在の評価フィードバックループがモデルの出力と能力認識を歪める可能性があることを示している。(ソース: TheTuringPost)

AIが生成したコードは本質的に「レガシーコード」なのか?: コミュニティの議論では、AIが生成したコードは、その「ステートレス」な特性(作成時の真の意図の記憶や継続的なメンテナンスのコンテキストの欠如)により、誕生した瞬間から「他人が書いた古いコード」、つまりレガシーコードに似ているとされている。プロンプトエンジニアリングやコンテキスト管理などで緩和できるものの、これはメンテナンスの複雑さを増大させる。将来のソフトウェア開発は、大量の静的コードではなく、モデルの推論とプロンプトにさらに依存するようになり、AIが生成したコードは過渡的なものに過ぎない可能性があるという意見もある。Hacker Newsのコメントでは、Peter Naurの「プログラミングとは理論構築である」という見解が紹介され、AIがコードの背後にある「理論」を習得できるのか、そしてプロンプト自体が新たな「理論」の担い手となるのかが議論されている。(ソース: 36氪)

LLM研究者は事前学習と事後学習の溝を乗り越えるべき: Aidan Clark氏は、LLM研究者は生涯を通じて事前学習または事後学習のどちらか一方にのみ専念すべきではないという見解を示した。事前学習はモデル内部の実際の動作メカニズム(what is actually happening)を明らかにし、事後学習は研究者に何が本当に重要なのか(what actually matters)を気づかせる。複数の研究者(YiTayML、agihippoなど)も同意しており、両側面を深く研究することでより包括的な理解が得られ、そうでなければ認識に常に欠落が生じると述べている。(ソース: aidan_clark, YiTayML, agihippo)
LLMの能力のボトルネックと将来の方向性についての考察: コミュニティの議論は、現在のLLMの限界と発展の方向性に集中している。Jack Morris氏は、LLMは命令の実行やコードの記述に長けているが、科学研究の中核である未知の反復的探求(科学的方法)の面ではまだ不十分であると指摘している。TeortaxesTex氏は、コンテキスト汚染(context pollution)と生涯学習/可塑性の喪失がTransformer系アーキテクチャの主要なボトルネックであると考えている。同時に、現在の自然データと浅いテクニックに基づく事前学習パラダイムは既に飽和状態に近い(Qwen3とGPT-4.5を例として)という意見(teortaxesTex氏)もあり、将来的にはより多くの進化を実現する必要がある。(ソース: _lewtun, teortaxesTex, clefourrier, teortaxesTex)
AIプロダクトマネージャーが収益化の困難に直面: 分析によると、現在のAIプロダクトマネージャーは一般的に製品の赤字と雇用の不安定という課題に直面している。原因としては、1)Transformerアーキテクチャが唯一または最適な解決策ではなく、将来的に覆される可能性があること、2)モデルのファインチューニングコスト(サーバー、電力、人件費)が高額である一方、製品の収益化サイクルが長いこと、3)AI製品の顧客獲得は依然として従来のインターネットモデルに従っており、参入障壁が著しく低下していないこと、4)AIの生産性価値がまだ「必須」レベルに達しておらず、ユーザーの支払い意欲(特にC向け)が総じて低く、多くのアプリケーションが依然として娯楽または補助的なレベルにとどまり、人間の仕事を根本的に代替するには至っていないことなどが挙げられる。(ソース: 36氪)

AI玩具市場の虚偽の活況:技術的参入障壁は低下、ビジネスモデルは未検証: AI玩具のコンセプトは熱く、多くの起業家や投資家を引き付けているが、市場の実際のパフォーマンスは楽観的ではない。ほとんどの製品は本質的に「ぬいぐるみ+音声ボックス」であり、機能は同質化しており、ユーザーエクスペリエンス(インタラクションの複雑さ、AIっぽさ、応答の遅さ)は悪く、返品率が高い。DeepSeekなどのオープンソースモデルの普及や技術ソリューションプロバイダーの出現に伴い、AI技術の参入障壁は急速に低下し、「華強北」モデルがハイエンドのポジショニングに衝撃を与えている。大規模モデルの能力を中核的なセールスポイントとするビジネスモデルは持続不可能であり、業界は玩具の本質(楽しさ、感情的なインタラクション)により近い製品定義とビジネスモデルを模索する必要があり、業界全体が成功事例を待っている状態である。(ソース: 36氪)

AI生成アートスタイルの著作権論争: GPT-4oが生成したジブリ風画像が、AIによるアートスタイルの模倣が著作権侵害にあたるかどうかについての議論を引き起こした。法律専門家は、著作権法は具体的な「表現」を保護するものであり、抽象的な「スタイル」は保護しないと指摘している。単に画風を模倣することは通常著作権侵害にはあたらないが、著作権で保護されたキャラクターや筋書きを使用する場合は侵害にあたる可能性がある。AIの学習データの出所のコンプライアンスは別の法的リスクであり、現在国内には明確な免責メカニズムはない。芸術家の泰祥洲氏は、AIがスタイルを模倣することは良いことだが、酷似した作品を生成して他人の名前を署名することは受け入れられないと述べている。AIによる創作と人間による創作は、パラダイム(ボトムアップ対トップダウン)、コンテキスト理解、拡張性の点で本質的な違いがある。(ソース: 36氪)

夸克と百度文库の急進的なAIへの転換がユーザー体験の反発を招く: Alibaba傘下の夸克とBaidu傘下の文库は、いずれも製品の位置づけを従来のツールからAIアプリケーションの入り口へと転換し、AI検索や生成などの機能を統合している。夸克は「AIスーパーフレーム」にアップグレードし、百度文库は沧舟OSを発表した。しかし、急進的な転換はマイナスの影響ももたらしている。ユーザーは、AI検索が強制的で冗長、時間がかかり、従来の簡潔または直接的な体験を損なっていると不満を述べている。AI機能は同質化しており、キラーアプリケーションが不足している。AIの幻覚や誤りも依然として存在する。両製品は、グループのAI戦略の入り口としての重責を担うと同時に、AI機能の統合と従来のユーザー習慣および体験とのバランスをどのように取るかという課題にも直面している。(ソース: 36氪)

AI特化型モデルが直面する3つの潜在的な落とし穴: 分析によると、特定の業界に特化したAIモデル企業は、発展の過程で困難に陥る可能性がある。落とし穴1:インテリジェンスを製品に真に組み込むことができず、「人的サービスをパッケージ化した」段階にとどまり、「AIショーケース」から「ビジネス価値の場」へと移行できない。落とし穴2:ビジネスモデルの誤り。「技術を売る」(API呼び出し、ファインチューニングサービス)ことに過度に依存し、「プロセスを売る」または「結果を売る」(BOaaS)のではなく、顧客による自社開発や汎用モデルに代替されやすい。落とし穴3:エコシステムのジレンマ。「単一点での突破」に満足し、エンドツーエンドのプロセスループとオープンなエコシステムを構築できず、ネットワーク効果と持続的な競争力を形成することが困難である。企業はプロセス管理とプラットフォーム思考に転換し、技術、ビジネス、エコシステムを組み合わせた堀を構築する必要がある。(ソース: 36氪)

💡 その他
AIグラス市場が活況、起業家に新たな機会をもたらす: Meta Ray-Banスマートグラスの販売台数が100万台を突破し、AIグラスはギークのおもちゃから一般消費者向け製品へと移行しつつある。技術の進歩(軽量化、低遅延、高精度表示)と市場の需要(効率向上、生活の利便性)が共に市場の成長を後押ししており、2030年には市場規模が3000億ドルを超えると予測されている。サプライチェーンの川上から川下まで(チップ、光学、受託製造、アプリケーションエコシステム)が恩恵を受けている。記事は、中小の起業家は、ハードウェアの革新(快適さ、バッテリー寿命、特定層向けのカスタマイズ)、垂直産業向けアプリケーション(工業、医療、教育向けのカスタマイズソリューション)、およびエッジエコシステム(インタラクションツール、軽量アプリケーション)などのニッチ分野で機会を見つけ、巨大企業との正面競争を避けるべきだと主張している。(ソース: 36氪)
物理誘導深層学習:Rose Yuの学際的AI研究: UCSDの准教授Rose Yu氏は、「物理誘導深層学習」分野の第一人者であり、物理学の原理(流体力学、対称性など)をニューラルネットワークに組み込み、現実世界の問題を解決している。彼女の研究は、交通予測の改善(Googleマップに採用)、乱流シミュレーションの高速化(従来の方法より1000倍高速、ハリケーン予測、ドローンの安定化、核融合研究に貢献)などに成功裏に応用されている。彼女はまた、人間と機械の協調を通じて科学的発見を加速することを目的とした「AI科学者」デジタルアシスタントの開発にも取り組んでいる。(ソース: 36氪)

AI時代の人間と機械の関係と感情的価値: ソーシャルメディア上でAIの感情的サポート能力に関する議論が起こっている。あるユーザーは、人生の重要な岐路に直面し恐怖を感じた際、ChatGPTに打ち明けたところ、感動的な支持的な応答を得て、AIは人間の感情的サポートを欠く人々に慰めを提供していると述べた。これは、AIが高い感情的知性を持つ対話をシミュレートする能力、およびユーザーが特定の状況下でAIに感情的な拠り所を見出す現象を反映している。(ソース: Reddit r/ChatGPT)