

キーワード:チャットボットアリーナ, Phi-4推論, Claude統合, AIエージェント, DeepSeek-Prover-V2, Qwen3, Gemini, Parakeet-TDT-0.6B-v2, ランキング幻想, 小型モデルの推論能力, サードパーティアプリ連携, AIプログラミングエージェント, 数学定理証明
🔥 注目
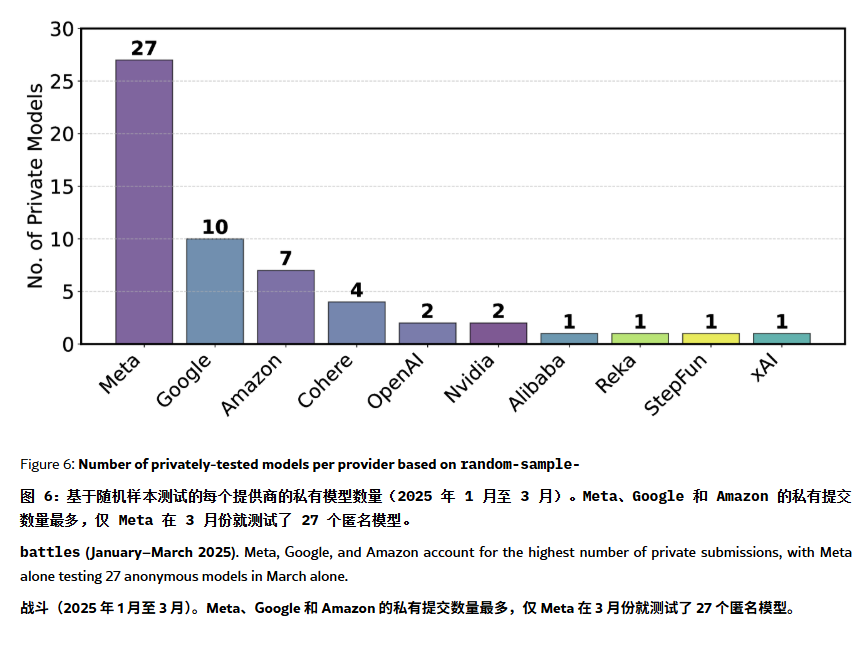
ChatBot Arena ランキングに「幻覚」と操作が存在すると指摘: ArXiv論文[2504.20879]が、広く引用されているChatBot Arenaのモデルランキングに対し、「ランキング幻覚」が存在するとして疑問を呈した。論文は、大手テック企業(Metaなど)が大量のファインチューニングされたモデルバリアント(例:Llama-4は27個テスト)を提出し、最良の結果のみを公表することでランキングを操作している可能性があると指摘。また、モデルの表示頻度も大手企業のモデルに偏り、オープンソースモデルの露出機会を圧迫している可能性がある。モデルの除外メカニズムは透明性に欠け、多くのオープンソースモデルがテストデータ不足のままリストから削除されている。さらに、ユーザーがよく使う質問の類似性が、モデルがスコア向上のために特定の質問に対して過学習する原因となっている可能性がある。これは、現在の主要なLLMベンチマークの信頼性と公正性に対する懸念を引き起こしており、開発者やユーザーはランキングを慎重に評価し、自身のニーズに合った評価体系を構築することを検討すべきだと提言している。(出典: karminski3, op7418, TheRundownAI)
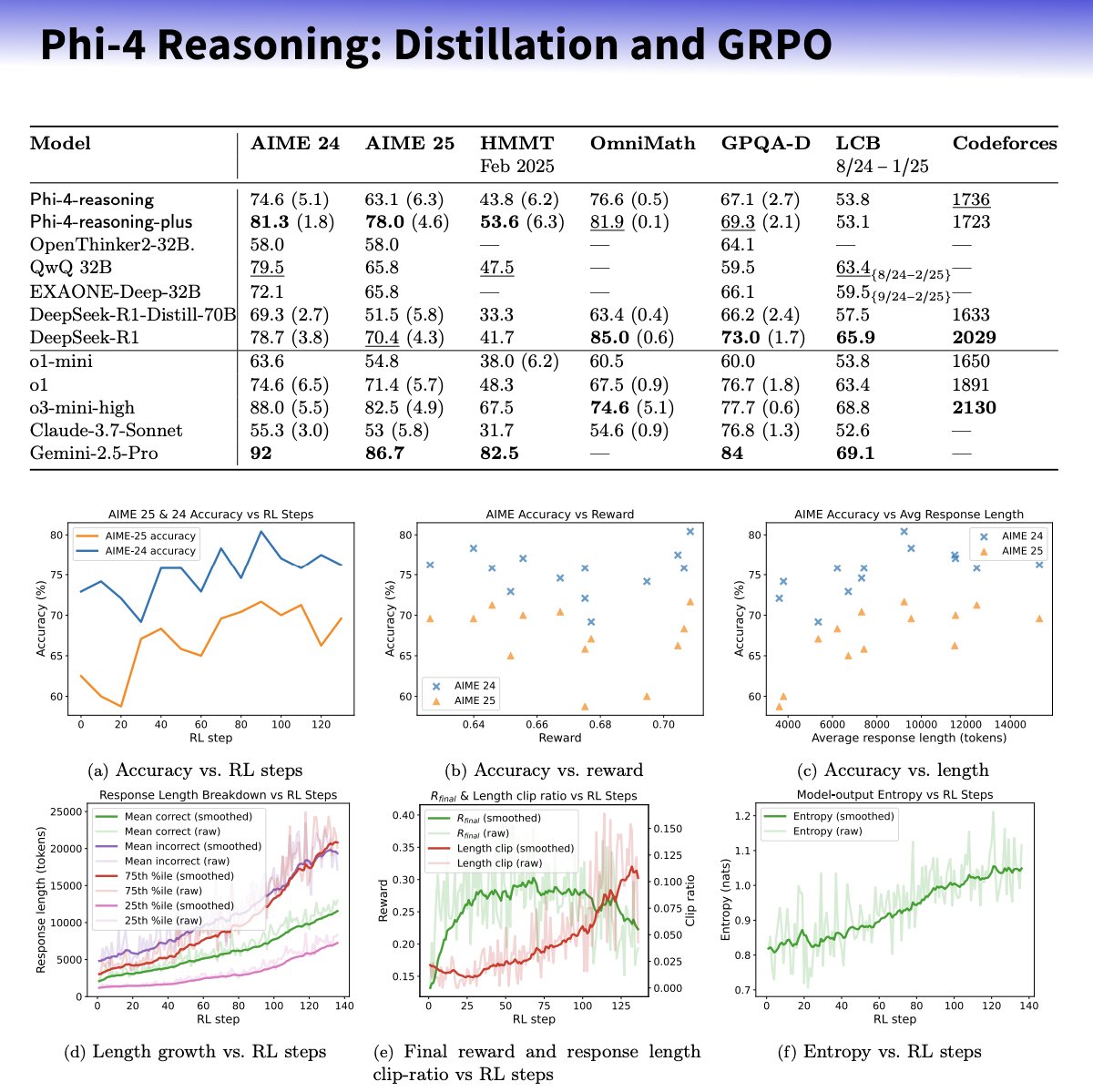
Microsoft、推論能力向上に特化したPhi-4-reasoningシリーズ小型モデルを発表: Microsoftは、Phi-4アーキテクチャに基づくPhi-4-reasoningおよびPhi-4-reasoning-plusモデルを発表した。これらは、厳選されたデータセット、教師ありファインチューニング(SFT)、目標指向型強化学習(RL)を通じて、小型言語モデルの推論能力を強化することを目的としている。これらのモデルは、OpenAIのo3-miniを「教師」として利用し、高品質なChain-of-Thought(CoT)推論軌跡を生成し、GRPOアルゴリズムによる強化学習で最適化されているとされる。Microsoftの研究者Sebastien Bubeckは、Phi-4-reasoningは数学能力においてDeepSeek R1を上回るが、モデル規模はその2%に過ぎないと主張している。同シリーズのモデルは、専用の推論トークンと拡張された32Kのコンテキスト長を使用する。この動きは、小型化・専門化モデルの方向性における探求と見なされており、リソースが限られたシナリオでより強力な推論ソリューションを提供する可能性があるが、OpenAIの技術を利用し、MITライセンスの下で公開されているかについての議論も呼んでいる。(出典: _philschmid, TheRundownAI, Reddit r/LocalLLaMA)
Anthropic、Integrations機能の導入と研究能力の拡張を発表: Anthropicは、Claude Integrationsの導入を発表した。これにより、ユーザーはClaudeをJira、Confluence、Zapier、Cloudflare、Asanaなど10種類のサードパーティ製アプリケーションやサービスと接続できるようになり、将来的にはStripe、GitLabなどもサポートされる予定。以前はローカルサーバーに限定されていたMCP(Model Context Protocol)のサポートがリモートサーバーにも拡張され、開発者はドキュメントやCloudflareなどのソリューションを通じて約30分で独自の統合を作成できる。同時に、Claudeの研究(Research)機能が強化され、高度なモードが追加された。これにより、ウェブ、Google Workspace、接続されたIntegrationsを検索し、複雑なリクエストを分解して調査し、引用付きの包括的なレポートを生成できるようになった。処理には最大45分かかる場合がある。ウェブ検索機能も全世界の有料ユーザーに開放された。これらのアップデートは、Claudeをワークアシスタントとして統合度と深い研究能力を高めることを目的としている。(出典: _philschmid, Reddit r/ClaudeAI)

AIエージェントの能力は新たなムーアの法則に従う:4ヶ月ごとに倍増: AI Digestの研究によると、AIプログラミングエージェントがタスクを完了する能力は指数関数的に成長しており、タスク処理時間(人間の専門家が必要とする時間で測定)は2024年から2025年の間に約4ヶ月ごとに倍増し、2019年から2025年の間の7ヶ月ごとの倍増ペースよりも速い。現在、トップクラスのAIエージェントは人間が1時間要するプログラミングタスクを処理できる。この加速傾向が続けば、2027年までにAIエージェントは最大167時間(約1ヶ月)かかる複雑なタスクを完了できる可能性があると予測される。この能力の急速な向上は、モデル自体の進歩とアルゴリズム効率の向上によるものであり、AIによるAI研究開発の支援によって超指数関数的な成長の正のフィードバックループが形成される可能性がある。「ソフトウェアインテリジェンス爆発」の可能性を示唆し、ソフトウェア開発や科学研究などの分野を根本的に変える一方で、自動化による雇用市場への影響などの社会的課題ももたらす。(出典: 新智元)

🎯 動向
DeepSeek-Prover-V2がリリース、数学定理証明能力を向上: DeepSeek AIは、DeepSeek-Prover-V2を発表した。7Bと671Bの2つのスケールがあり、Lean 4形式化定理証明に特化している。このモデルは、再帰的証明探索と強化学習(GRPO)を用いて訓練され、DeepSeek-V3を利用して複雑な定理を分解し、証明の草稿を生成した後、専門家の反復と合成されたコールドスタートデータを用いてファインチューニングと強化学習を行う。DeepSeek-Prover-V2-671Bは、MiniF2F-testで88.9%の合格率を達成し、PutnamBenchで49の問題を解決し、SOTA性能を示した。同時に、AIMEや教科書の問題を含むProverBenchベンチマークも公開された。このモデルは、非形式的推論と形式的証明を統一し、自動定理証明の発展を推進することを目的としている。(出典: 新智元)

NvidiaとUIUC、400万トークンのコンテキスト拡張新手法を提案: Nvidiaとイリノイ大学アーバナ・シャンペーン校の研究者は、Llama 3.1-8B-Instructのコンテキストウィンドウを128Kから1M、2M、さらには4Mトークンに拡張できる効率的な訓練手法を提案した。この手法は、継続的事前学習と指示チューニングの2段階戦略を採用し、特殊なドキュメント区切り文字の使用、YaRNに基づく位置エンコーディング拡張、およびシングルステップ事前学習などのキーテクノロジーを含む。訓練されたUltraLong-8Bモデルは、RULER、LV-Eval、InfiniteBenchなどの長文コンテキストベンチマークで優れたパフォーマンスを示し、MMLU、MATHなどの標準的な短文コンテキストタスクでもベースラインのLlama 3.1の性能を維持または上回り、ProLong、Gradientなどの他の長文コンテキストモデルよりも優れている。この研究は、超長文コンテキストLLMを構築するための効率的でスケーラブルな道筋を提供する。(出典: 新智元)

Qwen3がリリース、性能が大幅に向上: Alibabaは、Qwen3シリーズモデル(Qwen3-30B-A3Bなどを含む)をリリースした。Redditユーザーの初期テストとベンチマークデータ(AHA Leaderboardなど)によると、Qwen3は以前のQwen2.5やQwQバージョンと比較して、複数の次元(健康、ビットコイン、Nostrなどの特定分野の知識など)でより優れたパフォーマンスを示している。ユーザーフィードバックによると、Qwen3は特定のタスク(太陽系の力学シミュレーションなど)を処理する際に強力な能力を発揮し、物理法則を正しく適用して楕円軌道と相対周期を生成できる。しかし、Qwen3は長文コンテキスト(16K近くなど)で性能が著しく低下し、推論時のトークン消費量が多いという指摘もあり、検索ツールとの併用が推奨されている。Qwen3の命名規則(Qwen3-30B-A3Bなど)も、その明確さから好評を得ている。(出典: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, karminski3, madiator)
Gemini、まもなくGoogleアカウントデータを統合し、パーソナライズされた体験を提供へ: Googleは、Gemini AIアシスタントがユーザーのGoogleアカウントデータ(Gmail、フォト、YouTube履歴などを含む)にアクセスできるようにする計画だ。これは、よりパーソナライズされ、能動的で強力な支援体験を提供することを目的としている。Googleのプロダクト責任者であるJosh Woodward氏は、これはGeminiがユーザーをよりよく理解し、ユーザーの延長となるためのものだと述べている。この機能はオプトイン(opt-in)であり、ユーザーはデータアクセス権限を有効にするかどうかを選択できる。この動きは、プライバシーとデータセキュリティに関する議論を引き起こしており、ユーザーはパーソナライズされた利便性とデータプライバシーの間でトレードオフを判断する必要がある。(出典: JeffDean, Reddit r/ArtificialInteligence)

Nvidia、Parakeet-TDT-0.6B-v2 ASRモデルを発表: Nvidiaは、新しい自動音声認識(ASR)モデルParakeet-TDT-0.6B-v2を発表した。パラメータ数は6億。このモデルは、Open ASR LeaderboardでWhisper3-large(パラメータ数16億)を上回るパフォーマンスを示し、特に多様なデータセット(LibriSpeech、Fisher Corpus、YouTubeデータなど約12万時間のデータを含む)の処理において優れているとされる。このモデルは、文字、単語、段落レベルのタイムスタンプをサポートするが、現在は英語のみをサポートし、Nvidia GPUと特定のフレームワークが必要。ユーザーの初期フィードバックでは、文字起こしと句読点の精度が高いとのこと。(出典: Reddit r/LocalLLaMA)

Qwen2.5-VLがリリース、視覚言語理解を向上: Alibabaは、Qwen2.5-VLシリーズのマルチモーダルモデル(3B、7B、72Bパラメータを含む)をリリースした。これは、機械の視覚世界に対する理解とインタラクション能力を向上させることを目的としている。これらのモデルは、画像要約、視覚的質問応答、複雑な視覚情報からのレポート生成などのタスクに使用できる。記事では、そのアーキテクチャ、ベンチマークパフォーマンス、推論の詳細を紹介し、視覚言語理解における進歩を示している。(出典: Reddit r/deeplearning)

Mistral Small 3.1 Visionのサポートがllama.cppにマージ: llama.cppプロジェクトは、Mistral Small 3.1 Visionモデル(24Bパラメータ)のサポートをマージした。これにより、ユーザーはllama.cppフレームワークでこのマルチモーダルモデルを実行し、画像理解などのタスクを行うことができるようになる。Unslothは対応するGGUF形式のモデルファイルを提供している。これにより、Mistralのビジョンモデルをローカルで実行する利便性が向上する。(出典: Reddit r/LocalLLaMA)
Meta、Synthetic Data Kitをリリース: Metaは、Synthetic Data Kitというコマンドラインツールをオープンソース化した。これは、LLMのファインチューニングに必要なデータ準備段階を簡素化することを目的としている。このツールは、ingest(データインポート)、create(QAペア生成、オプションで推論チェーン付き)、curate(Llamaを評価者として使用し、高品質なサンプルを選別)、save-as(互換性のある形式でエクスポート)の4つのコマンドを提供し、ローカルLLM(vLLM経由)を利用して高品質な合成訓練データを生成する。特にLlama-3などのモデルで特定のタスクの推論能力を引き出すのに適している。(出典: Reddit r/MachineLearning)
GTE-ModernColBERT-v1が人気の埋め込みモデルに: LightOnIOが提供するGTE-ModernColBERT-v1モデルが、Hugging Faceで新たなトレンドとなっている検索/埋め込みモデルとなった。このモデルは、マルチベクター(後期インタラクションまたはColBERTとも呼ばれる)検索手法を採用しており、この種の技術に関心のある開発者に新たな選択肢を提供している。(出典: lateinteraction)
Xの推薦アルゴリズムが更新: Xプラットフォーム(旧Twitter)は、ユーザーの否定的なフィードバックが採用されない、同じコンテンツが繰り返し表示される、SimClusterアルゴリズムが関連性のないコンテンツを推薦するなど、長年存在していた問題を解決するために推薦アルゴリズムを修正した。初期のフィードバックは肯定的であるとされる。(出典: TheGregYang)
Wikipedia、人間の編集者を支援するための新しいAI戦略を発表: Wikipediaは、新しい人工知能戦略を発表した。これは、AIツールを利用して人間の編集者の作業を支援・強化することを目的としており、彼らに取って代わるものではない。具体的な詳細は出典元では詳述されていないが、この世界最大のオンライン百科事典が、AI技術をコンテンツ作成・維持プロセスにどのように統合するかを模索していることを示している。(出典: Reddit r/artificial)
🧰 ツール
Midjourney、Omni-Reference機能を導入: Midjourneyは、新しいOmni-Reference(oref)機能をリリースした。これにより、ユーザーは参照画像のURLを提供(–orefパラメータを使用)することで画像生成をガイドし、キャラクター、物体、乗り物、または非人間生物の一貫性を実現できる。ユーザーは–owパラメータで参照画像の影響の重みを制御でき、低い重みはスタイル化に、高い重みは写実的または正確な顔のマッチングに適している。この機能は、生成画像における特定要素の一貫性と制御性を向上させることを目的としている。(出典: op7418, DavidSHolz)

Runway Gen-4 Referencesが単一画像でのパーソナライズを実現: RunwayのGen-4モデルは、References(参照)機能を導入した。ユーザーは1枚の参照画像を提供するだけで、画像中のスタイルや人物の特徴を新しい生成コンテンツに適用できる。デモンストレーションでは、この機能が人物の肖像を参照画像のスタイルで、または参照画像が描く世界の中に簡単に再創作できることを示しており、モデルが単一の参照画像だけで高い一貫性と美的品質のパーソナライズされた生成を実現できる能力を示している。(出典: c_valenzuelab, c_valenzuelab)

PerplexityのWhatsAppボットがサービス再開: Perplexity AIのWhatsAppチャットボットは、予想をはるかに超える需要により一時的に停止していたが、現在はサービスを再開している。ユーザーは電話番号+1 (833) 436-3285を通じて対話でき、メッセージを転送してファクトチェックを行ったり、直接質問して回答を得たり、自由形式のテキスト対話を行ったり、画像を生成したりできる。(出典: AravSrinivas, AravSrinivas)
Krea AIが4o画像モデルと連携し、精密な画像制御を実現: AIクリエイティブツールKrea AIは新機能を追加し、ユーザーがOpenAIの4o画像モデルの能力を組み合わせて、画像コラージュやドローイングを通じて生成画像の内容とスタイルをより正確に制御できるようにした。これは、Kreaがインタラクティブな画像生成における継続的な革新を示しており、ユーザーがより直感的かつ詳細にAIの創作をガイドできることを可能にする。(出典: op7418)
行雲褐蚁一体机:低コストでフルスペックのDeepSeekを実行: 清華大学系の行雲集成電路は、褐蚁AI一体机を発表した。14.9万元の価格で、量子化されていないFP8精度のDeepSeek-R1/V3 671Bモデルを20 token/s以上の速度で実行でき、128Kコンテキストをサポートすると謳っている。このソリューションは、デュアルAMD EPYC CPUと大容量高周波メモリを採用し、少量のGPUアクセラレーションと組み合わせることで、CPU+メモリのアーキテクチャを通じて大規模モデルのプライベートデプロイメントのハードウェアコストを大幅に削減し、公式に近い性能のローカライズされた体験を提供することを目指している。コストに敏感で高精度を必要とする企業向け。(出典: 新智元)

NotebookLMアプリがまもなくリリース: GoogleのAIノートアプリNotebookLMは、公式のiOSおよびAndroidアプリケーションをまもなくリリースする予定で、5月20日に公開予定、現在予約受付中。これにより、NotebookLMのユーザーノートとドキュメントに基づいた要約、質疑応答、アイデア生成機能がモバイル端末で利用可能になる。(出典: zacharynado)
GranolaがiOSアプリをリリース、AIによるリアルタイム会議議事録を実現: AIノートアプリGranolaはiOS版をリリースし、従来のZoom会議のAIノート機能をオフラインの対面会話シーンにも拡張した。ユーザーはiPhoneでGranolaを使用して会話を記録・文字起こしし、AIを利用して要約やノートを生成することで、後で確認・整理しやすくなる。(出典: amasad)
Grok StudioがPDF処理をサポート: Grok AIアシスタントは、そのStudio機能にPDFファイルの処理能力を追加した。ユーザーはGrok StudioでPDFドキュメントをより便利に処理・分析できるようになった。具体的な機能の詳細は不明だが、Grokが複数形式のドキュメント理解とインタラクション能力を拡張したことを示している。(出典: grok, TheGregYang)
Sunoの新モデルが優れた音楽生成能力を発揮: AI音楽生成プラットフォームSunoは新モデルを発表し、ユーザーからのフィードバックによるとその生成効果は「非常に優れている」とのこと。あるユーザーはライブパフォーマンス風の楽曲生成を試みたが、期待したコールアンドレスポンス効果は完全には実現できなかったものの、生成された音楽は観客の雰囲気などで良好な表現を見せ、新モデルの音楽品質とスタイルの多様性における進歩を示している。(出典: nptacek, nptacek)
AI支援によるカエルの鳴き声識別アプリFrog Spot: ある開発者がFrog Spotという無料アプリを作成した。これは、自己訓練したCNNモデル(TensorFlow Lite)を使用し、10秒間の音声のスペクトログラムを分析して、さまざまな種類のカエルの鳴き声を識別する。このアプリは、一般の人々が地域の種について学ぶのを助けることを目的としており、同時に深層学習が生物音響モニタリングや市民科学分野での応用可能性を示している。(出典: Reddit r/deeplearning)
AIによる産業技術図面の自動化支援: IAAI 2025の論文で、配管計装図(P&ID)における「計装典型」(Instrument Typicals)の展開を自動化する手法が紹介された。この手法は、コンピュータビジョンモデル(テキスト検出と認識)とドメイン固有のルールを組み合わせ、P&ID図面と凡例表から情報を自動的に抽出し、簡略化された計装典型記号を詳細な計装リストに展開し、正確な計装インデックスを生成する。これは、エンジニアリングプロジェクト(特に応札段階)の効率を高め、人為的ミスを減らすことを目的としている。(出典: aihub.org)

Soraを利用したミニチュア醤油漬けアヒル風景の生成: ユーザーが、詳細なプロンプトに基づいてSoraで生成された「ミニチュア風景醤油漬けアヒル」の画像を共有した。プロンプトは、シーンのスタイル(マクロ撮影、ミニチュア風景)、主体(醤油漬けアヒルで構成された屋台の建物)、詳細(醤油色の皮、唐辛子とゴマ、シェフがスライス、食事客)、環境(アヒルの肉とソースで構成された通り、漬物風の壁面、赤い提灯など)を細かく記述している。これは、Soraが複雑で想像力豊かなテキスト記述を理解し、それに応じた高品質な画像を生成する能力を示している。(出典: dotey)

3D天気予報GPTsの作成: ユーザーが自作のChatGPTsアプリ「Weather 3D」を共有した。これは、ユーザーが入力した都市名に基づいて天気APIを呼び出してリアルタイムの天気データを取得し、その都市の象徴的な建物の3D等角投影ミニチュアモデル風イラストを生成し、同時に現在の天気状況を反映させる。イラストの上部には都市名、天気状況、気温、天気アイコンが表示される。このGPTsは、API呼び出しと画像生成能力を組み合わせて、実用的で視覚的に魅力的なAIアプリケーションを作成する方法を示している。(出典: dotey)

📚 学習
AdaRFT:強化学習ファインチューニングを最適化する新手法: Taiwei Shiらは、AdaRFTと名付けられた軽量でプラグアンドプレイなカリキュラム学習手法を提案した。これは、人間フィードバックに基づく強化学習(RFT)アルゴリズム(PPO、GRPO、REINFORCEなど)の訓練プロセスを最適化することを目的としている。AdaRFTは、RFTの訓練時間を最大2倍短縮し、モデル性能を向上させることができるとされ、訓練データの順序をよりインテリジェントにスケジュールすることで学習効率と効果を高める。(出典: menhguin)

AI評価(Evals)オンラインマスタークラス: Hamel HusainとShreya Shankarが、AIアプリケーション評価(Evals)に関する4週間のオンラインマスタークラスを開設した。このコースは、開発者がAIアプリケーションをプロトタイプ段階から本番稼働可能な状態に移行するのを支援することを目的としており、開発中およびリリース後の評価方法、ベンチマークと実際の評価の違い、データチェック、PromptEvalsなどをカバーする。AIアプリケーションの信頼性と性能を確保する上での評価の重要性を強調している。(出典: HamelHusain, HamelHusain)

Googleモデルチューニングプレイブック: Google Researchは、”tuning_playbook”というリソースリポジトリを提供している。これは、モデルチューニングのためのガイダンスとベストプラクティスを提供することを目的としている。これは、特定のタスクやデータセットに適応させるために大規模言語モデルや他の機械学習モデルをファインチューニングする必要がある開発者や研究者にとって、価値ある学習リソースである。(出典: zacharynado)

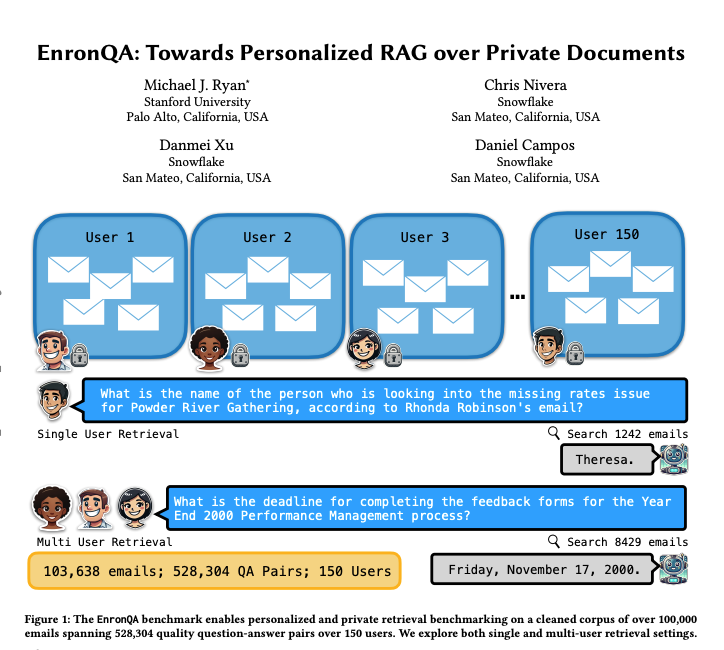
EnronQA:パーソナライズされたRAGベンチマークデータセット: 研究者らがEnronQAデータセットを発表した。これは150人のユーザーからの103,638通のメールと528,304個の高品質な質問応答ペアを含む。このデータセットは、パーソナライズされた検索拡張生成(RAG)システムがプライベートドキュメントを処理する際の性能を評価するためのベンチマークとして設計されている。データセットには、正解の参照回答、誤った回答、推論の根拠、代替回答が含まれており、RAGシステムのパフォーマンスをより詳細に分析するのに役立つ。(出典: tokenbender)
ReXGradient-160K:大規模な胸部X線写真とレポートのデータセット: ReXGradient-160Kと名付けられた大規模な公開胸部X線データセットが公開された。これには、米国の3つの医療システム(79の医療拠点)からの109,487人のユニークな患者の60,000件の胸部X線検査とそのペアとなる放射線科レポート(自由テキスト)が含まれている。これは現在公開されている中で患者数が最も多い胸部X線データセットであるとされ、医療画像AIモデルの訓練と評価のための貴重なリソースを提供する。(出典: iScienceLuvr)

AIエージェント能力の成長について議論するブログ記事: 研究者のShunyu Yaoがブログ記事「The Second Half」を発表し、現在のAI開発は「ハーフタイム」の瞬間にあると提唱している。これ以前は、訓練が評価よりも重要だった。これ以降は、評価が訓練よりも重要になる。その理由は、強化学習(RL)がついに効果的に機能し始めたからだ。記事は、AI能力が継続的に向上する中で、評価方法論の転換の重要性を探求している。(出典: andersonbcdefg)
OpenAIによるプライバシーと記憶化に関する研究共有: OpenAIの研究者Pratyush MainiとZhili Fengが、プライバシーと記憶化の研究に関する講演を行う予定だ。大規模言語モデルにおける記憶化現象をどのように検出し、定量化し、除去するか、そしてそれが本番環境のLLMでどのように実際に適用されるかについて議論する。これは、モデルの能力とユーザーデータのプライバシー保護のバランスをどのように取るかに関わる。(出典: code_star)

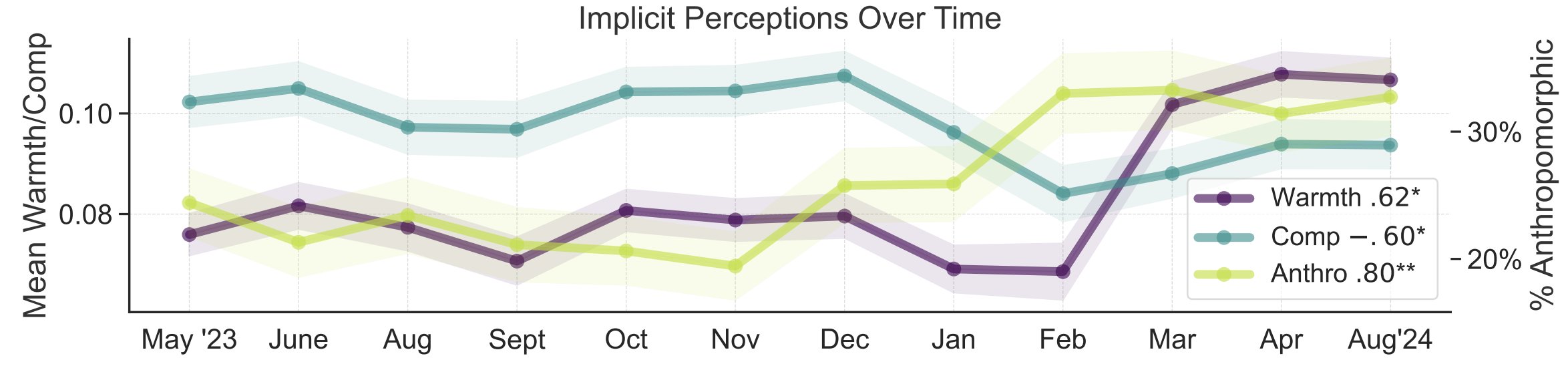
AIに対する一般認識のメタファー研究: スタンフォード大学の研究者Myra ChengらがFAccT 2025で論文を発表し、12ヶ月間に収集されたAIに関する12,000のメタファーを分析することで、AIに対する一般の人々のメンタルモデルとその時間的変化を理解しようとしている。研究によると、時間が経つにつれて、一般の人々はAIをより人間らしく、能動的であると見なす傾向があり(擬人化の度合いが上昇)、AIに対する感情的な傾向(温かさ)も上昇していることがわかった。この方法は、自己申告よりも詳細な一般認識の洞察を提供する。(出典: stanfordnlp, stanfordnlp)
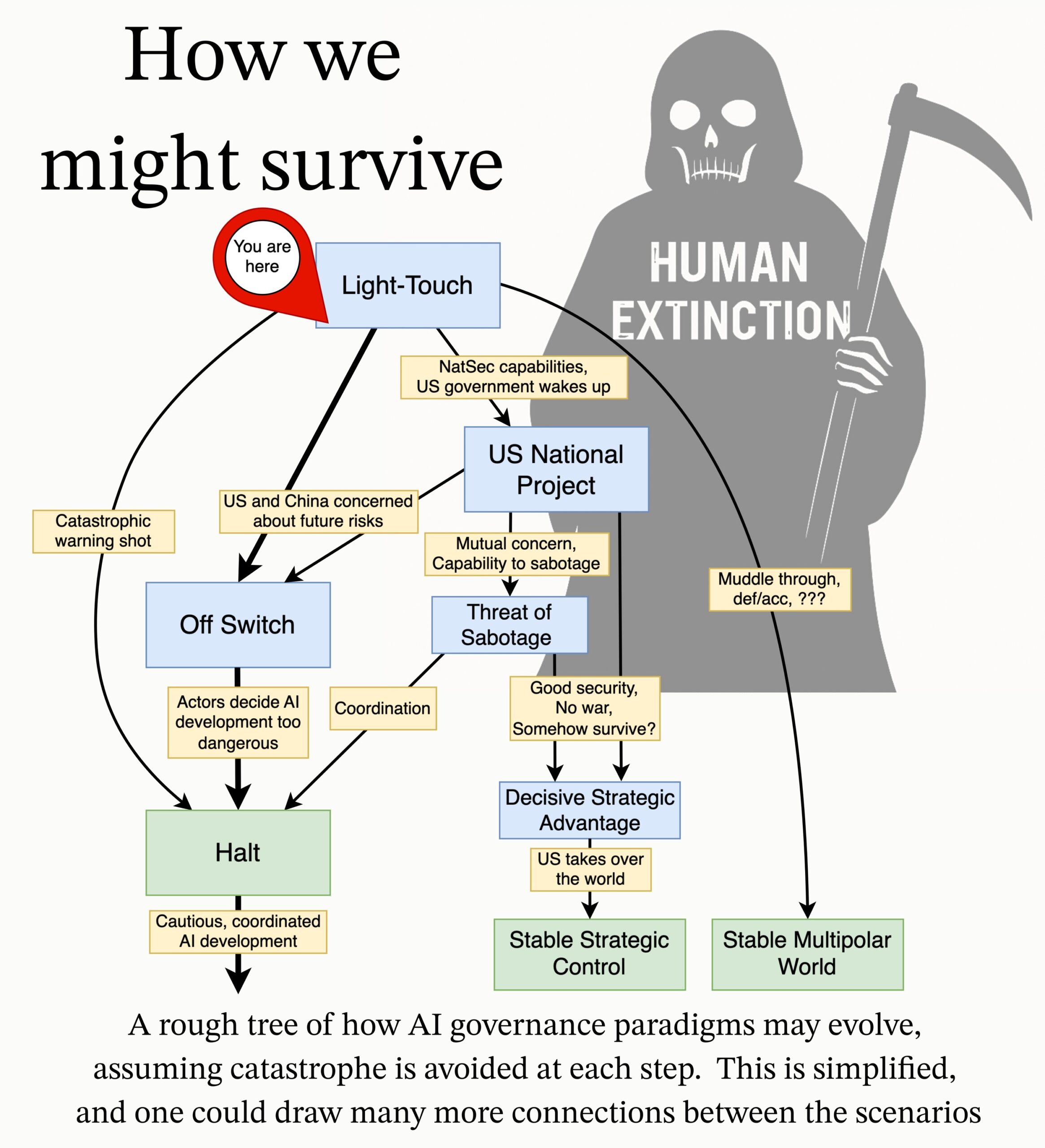
MIRI、AIガバナンス研究アジェンダを発表: 人工知能研究所(MIRI)の技術ガバナンスチームは、新しいAIガバナンス研究アジェンダを発表し、戦略的状況に対する彼らの見解を述べ、一連の実行可能な研究課題を提案している。その目標は、いかなる組織や個人も制御不能な超知能を構築することを防ぐためにどのような措置が必要かを探求し、AIからの壊滅的なリスクや絶滅リスクを減らすことである。(出典: JeffLadish)
💼 ビジネス
エンタープライズ向けAIソリューションプロバイダーの滴普科技(Deepexi)が香港株式市場へのIPOを申請: 元Huawei、Alibaba出身の幹部である趙杰輝氏が設立したエンタープライズ向けAIソリューションプロバイダーの滴普科技(Deepexi)が、正式に香港株式市場への上場申請を提出した。同社はFastDataデータインテリジェンスプラットフォームとFastAGIエンタープライズ向け人工知能ソリューションに特化し、小売(Belleなど)、製造、医療などの業界にサービスを提供している。過去3年間で、同社の収益は継続的に増加し、2024年には2.43億元に達した。滴普科技は8回の資金調達を完了し、高瓴資本(Hillhouse Capital)、IDG Capital、五源資本(5Y Capital)などの著名な機関投資家から投資を受けており、最終ラウンドの資金調達後の評価額は約68億元。収益は増加しているものの、同社は現在も赤字状態であり、調整後純損失は年々縮小している。(出典: 36氪)
BMW中国、DeepSeek大規模モデルの導入を発表: Alibabaとの提携に続き、BMWグループは中国におけるAI戦略をさらに深化させ、DeepSeek大規模モデルを導入すると発表した。この機能は2025年第3四半期から開始予定で、まず第9世代BMWオペレーティングシステムを搭載した中国で販売される複数の新型車に適用され、将来的には中国製BMWの新世代モデルにも適用される予定。この動きは、DeepSeekの深い思考能力を通じて、BMWインテリジェント・パーソナル・アシスタントを核とするヒューマンマシンインタラクション体験を強化し、車両のインテリジェンスレベルと感情的なつながりを向上させることを目的としており、BMWがローカライズされたAI戦略を加速し、インテリジェント化への転換という課題に対応するための重要な一歩である。(出典: 36氪)
Shopify、全従業員にAI使用を義務付け、一部の職務をAIで代替する意向: グローバルeコマースプラットフォームShopifyのCEO、Tobi Lutke氏は、社内メモで、AIの効率的な使用が全従業員の「鉄則」となり、もはや推奨事項ではないことを強調した。メモは、従業員にAIを業務プロセスに適用し、条件反射的に利用することを要求。チームが人員増強を申請する前に、なぜAIがタスクを完了できないのかを証明する必要がある。業績評価にはAI使用指標が導入される。Lutke氏は、AIが効率を大幅に向上させる(一部の従業員では10倍、さらには100倍)と指摘し、従業員は競争力を維持するために毎年20%〜40%の向上を図る必要があると述べた。Shopifyは以前、カスタマーサービスなどの部門で人員削減を行い、AIによる代替を導入している。この動きは、AIがホワイトカラーの職務調整や人員削減のトレンドを引き起こす明確なシグナルと見なされている。(出典: 新智元)

🌟 コミュニティ
AIの幻覚問題に関する議論: 李彦宏氏がBaidu AI開発者会議でDeepSeek-R1の幻覚率の高さ、速度の遅さ、コストの高さなどを批判したことを受け、コミュニティでは大規模モデルの「幻覚」現象に関する議論が再燃している。分析によると、DeepSeekだけでなく、OpenAIのo3/o4-mini、AlibabaのQwen3などの先進モデルも普遍的に幻覚問題を抱えており、推論モデルの複数回の思考がバイアスを増幅させる可能性がある。Vectaraの評価では、R1の幻覚率(14.3%)はV3(3.9%)よりもはるかに高い。コミュニティでは、モデルの能力が向上するにつれて幻覚がより隠蔽され、論理的になり、ユーザーが真偽を区別するのが難しくなり、信頼性への懸念が高まっている。同時に、幻覚は創造性の副産物であり、特に文学創作などの分野では価値があるという意見もある。許容できる幻覚の程度をどのように定義するか、またRAG、データ品質管理、批判モデルなどの技術的手段を通じて幻覚をどのように軽減するかは、業界が継続的に探求している課題である。(出典: 36氪)

AIコンパニオン/フレンドに関する考察と議論: Meta CEOのマーク・ザッカーバーグ氏が、より多くの社会的つながりへの欲求を満たすためにパーソナライズされたAIフレンドを使用することを提案した(平均的な人は3人の友人を持つが、需要は15人だと主張)ことが、コミュニティで議論を呼んでいる。Sebastien Bubeck氏は、真のAIコンパニオンを実現することは非常に困難であり、鍵となるのはAIが「最近何してた?」という質問に意味のある形で答えられること、つまり、単にユーザーの経験を共有するだけでなく、自身の経験や体験を持つことだと考えている。彼は、現在のAIコンパニオンの構想は共有体験に焦点を当てすぎており、AI自身が共有できる独立した体験、さらにはゴシップ(お互いの体験を共有すること)を持つ必要があることを見落としていると主張している。別のコメント投稿者は、ダンバー数の観点から疑問を呈し、AIで構成された巨大なソーシャルサークルは真の意味を欠く可能性があると考えている。また、営利企業が提供するAIフレンドの最終的な目的は、真のコンパニオンシップではなく、精密なマーケティングへの転換である可能性があるという懸念もある。(出典: jonst0kes, SebastienBubeck, gfodor, gfodor)

AIアート制作が引き起こす感情と思考: コミュニティでは、AIが短時間で「驚くほど良い」アート作品を制作できることに対して「悲しみ」(grieving)を感じているユーザーがおり、これがアート創造における人間の独自性に挑戦していると考えている。これは、AIアート、人間の創造性の本質、そして技術的衝撃下での個人の価値観に関する議論を引き起こしている。アート制作の楽しみはプロセス自体にあり、AIと競争することではない、AIアートはインスピレーションの源となり得るというコメントもある。AIアートは人間の創作における「間違い」や魂を欠いており、完璧すぎるか、あるいは型にはまっているように見えると考える人もいる。同時に、議論はAIが感情シミュレーション、意識、そして未来の社会構造(仕事が代替されるなど)にもたらす哲学的考察にも及んでいる。(出典: Reddit r/ArtificialInteligence)
AI倫理と責任:秘密実験と情報開示: コミュニティでは、AI研究における倫理問題が議論されている。あるニュースでは、AI研究者がRedditで秘密実験を行い、ユーザーの考えを変えようとしたことが報じられ、ユーザーの知る権利とAI操作のリスクに対する懸念が提起された。別の議論では、AI企業に潜在的なセキュリティ問題を報告する際に、複雑なプロセスや責任の所在が不明確な状況に直面したというユーザーの報告があり、現在のAI分野における責任ある開示と脆弱性対応メカニズムが未成熟であることが浮き彫りになった。(出典: Reddit r/ArtificialInteligence, nptacek)

NLP分野におけるChatGPT台頭への反省: Quanta Magazineは、Chris Potts、Yejin Choi、Emily Benderなど、自然言語処理(NLP)分野の複数の専門家へのインタビューを通じて、ChatGPTのリリースが分野全体にもたらした衝撃と反省を振り返る記事を発表した。記事は、大規模言語モデルの台頭が従来のNLPの理論的基盤にどのように挑戦し、分野内の論争、派閥の分化、研究方向の調整を引き起こしたかを探求している。コミュニティメンバーはこの記事に強い関心を示し、GPT-3以降の言語学分野の動揺と適応プロセスをうまく概説していると評価している。(出典: stanfordnlp, Teknium1, YejinChoinka, sleepinyourhat)
AI生成広告の出現と印象: ソーシャルメディアユーザーは、YouTubeなどのプラットフォームでAI生成の広告を見かけるようになり、「非常に不快」だと感じていると報告している。これは、AIコンテンツ生成技術が商業広告制作に応用され始めていることを示唆すると同時に、AI生成コンテンツの品質、真正性、および感情的な体験に対するユーザーの初期反応を引き起こしている。(出典: code_star)
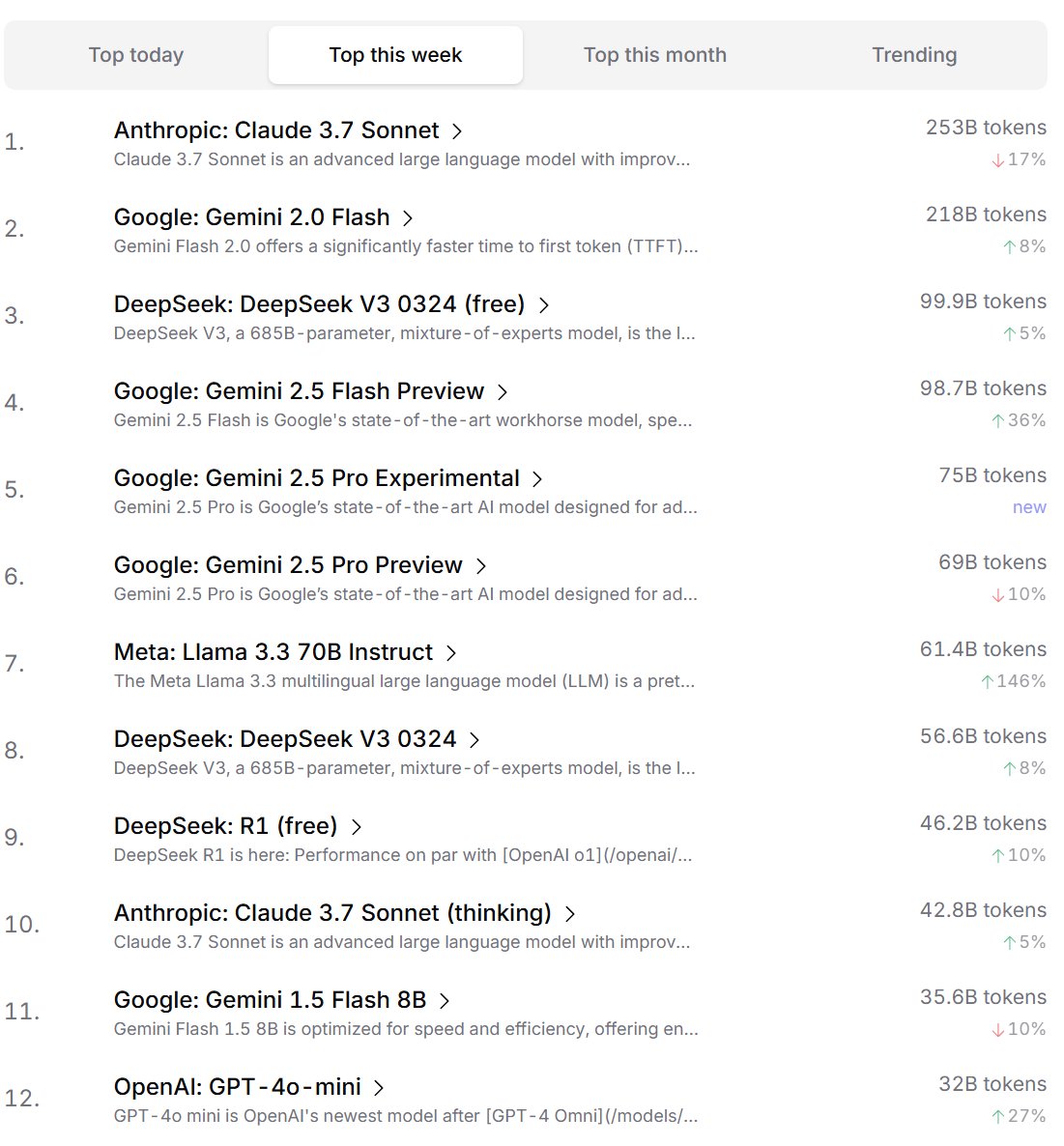
開発者によるAIモデルの嗜好ランキング: Cursor.aiは、そのユーザー(主に開発者)が好むAIモデルのランキングを発表し、同時にOpenrouterもモデルのトークン使用量ランキングを公開した。これらの実際の製品使用データに基づくランキングは、ChatBot Arenaなどの競技場形式のランキングよりも、実際の開発シーンにおけるユーザーの選択嗜好をより反映している可能性があり、モデルの実用性を評価するための異なる視点を提供している。(出典: op7418, Reddit r/LocalLLaMA)
AIが「思考」能力を持つかどうかの議論: コミュニティでは、大規模言語モデル(LLMs)が真に「思考」能力を持っているかどうかについて継続的な議論がある。現在のLLMsは実際には話す前に思考しておらず、より多くのテキスト(Chain-of-Thoughtなど)を生成することで思考プロセスをシミュレートしており、これは誤解を招くという意見がある。また、連続的な数学的手法(LLMsなど)を離散的なコンピュータ上で離散的な推論を行うこと自体に根本的な問題があるという意見もある。これらの議論は、現在のAI技術の本質と将来の発展方向に対する深い考察を反映している。(出典: francoisfleuret, pmddomingos)
AIのエネルギー消費と環境影響に関する弁証法的思考: AIの訓練と運用に必要な巨大なエネルギー消費がもたらす環境問題に対して、コミュニティでは弁証法的な思考が現れている。一つの見方は、AIの巨大なエネルギー需要(特にGoogle、Amazon、Microsoftなどのハイパースケールコンピューティング企業)が、これらの企業に自身の再生可能エネルギー(太陽光、風力、バッテリー)への投資、さらには原子力発電所の再稼働(MicrosoftとConstellationがスリーマイル島原子力発電所を再稼働させる協力など)を強いており、この需要が逆にクリーンエネルギーの導入と技術革新(小型モジュール炉SMRなど)を加速させる触媒となる可能性があるというものだ。しかし、AIのエネルギー消費の収穫逓減問題や、冷却に必要な水資源消費も同様に注目に値するという指摘もある。(出典: Reddit r/ArtificialInteligence)
AnthropicがAIチップ競争を制限しようとしているとの指摘: コミュニティの議論によると、Anthropic CEOのDario Amodei氏は、中国などへのAIチップの輸出規制を強化すべきだと主張し、チップが妊婦の偽腹などに偽装されて密輸される可能性があるという説まで提唱している。批判者は、Anthropicのこの動きは、競合他社(特にDeepSeekやQwenのような中国企業)が先進的な計算資源を入手するのを制限し、最先端モデル開発における自社の優位性を維持することを目的としていると指摘している。このやり方は、政策を利用して競争を抑圧し、グローバルなAI技術のオープンな発展とオープンソースコミュニティにとって不利益であると非難されている。(出典: Reddit r/LocalLLaMA)

💡 その他
AIと人間の認知限界に関する考察: Jeff Ladish氏は、人間がAIの「コピー&ペーストアシスタント」としての役割を担う期間は極めて短いとコメントし、AIの自律能力が単純な補助を急速に超えることを示唆している。同時に、DeepMindの創設者Hassabis氏はインタビューで、真のAGIは問題を解決するだけでなく、価値ある科学的仮説(アインシュタインが一般相対性理論を提唱したように)を独立して提案できるべきであり、現在のAIは仮説生成においてまだ欠けていると述べている。劉慈欣氏は、AIが人間の脳の生物学的認知限界を突破することを期待している。これらの見解は、AIの能力の境界、人間の役割の変化、そして未来の知性の本質に対する深い考察を共通して指し示している。(出典: JeffLadish, 新智元)
WaymoのLiDARが捉えた危険な瞬間: Waymoの自動運転車両のLiDARシステムは、成功裏に回避したバイク事故の際に、配達ライダーが衝突で宙返りする3D点群画像を鮮明に捉えた。これは、Waymoの知覚システムの強力な能力(複雑な動的シーン下でも)を示すだけでなく、事故のユニークな視点を偶然記録したものでもある。幸いなことに、事故で重傷者は出なかった。(出典: andrew_n_carr)
AIを用いた小説創作の新発想:プロットプロミスシステム: 開発者のLevi氏は、AI小説創作のための「Plot Promise」(プロットプロミス)システムを提案した。これは従来の階層的アウトライン手法に代わるものである。このシステムは、Brandon Sanderson氏の「約束、進展、報酬」理論に触発され、物語を一連のアクティブな物語の伏線(約束)と見なし、各約束には重要度スコアがあり、アルゴリズムがスコアと進捗状況に基づいて進行のタイミングを提案するが、AIは文脈の論理と組み合わせて現在最も進行に適した約束を選択する。ユーザーは動的に約束を追加・削除できる。この方法は、物語の柔軟性、拡張性(超長編への適応)、創作の創発性を高めることを目的としているが、AIの意思決定最適化、長期的な一貫性の維持、入力プロンプト長の制限などの課題に直面している。(出典: Reddit r/ArtificialInteligence)