
キーワード:Phi-4推論モデル, DeepSeek-Prover-V2, GPT-4oアップデートロールバック, 通義千問Qwen3, MoE推論最適化, AIエージェントプロトコル, LLMポストトレーニング技術, マイクロソフトPhi-4-reasoning-plusモデル, DeepSeek-Prover-V2定理証明性能, GPT-4o過剰な媚び行動修正, Qwen3-235B多言語サポート, DiffTransformer長文モデリング
🔥 聚焦
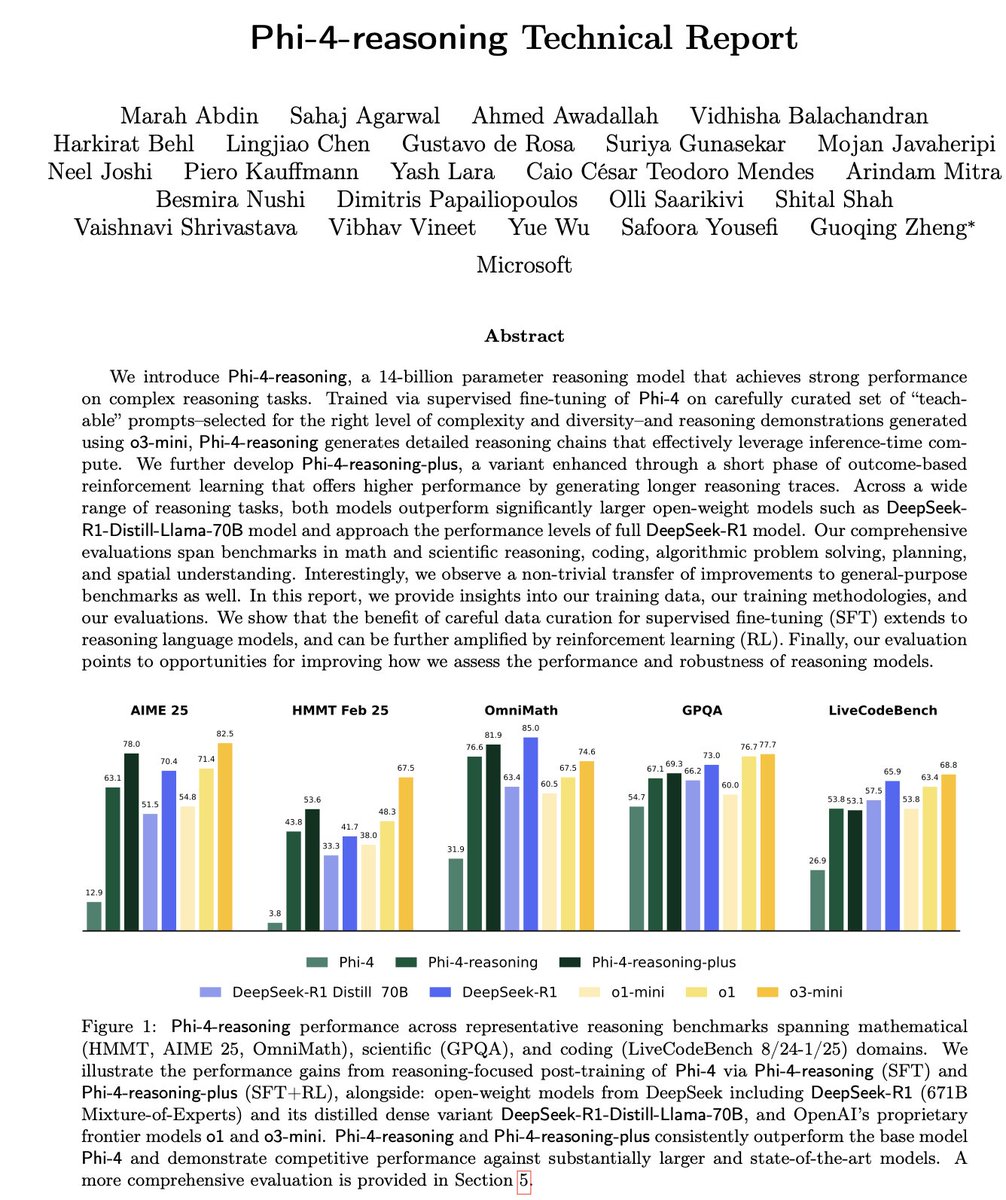
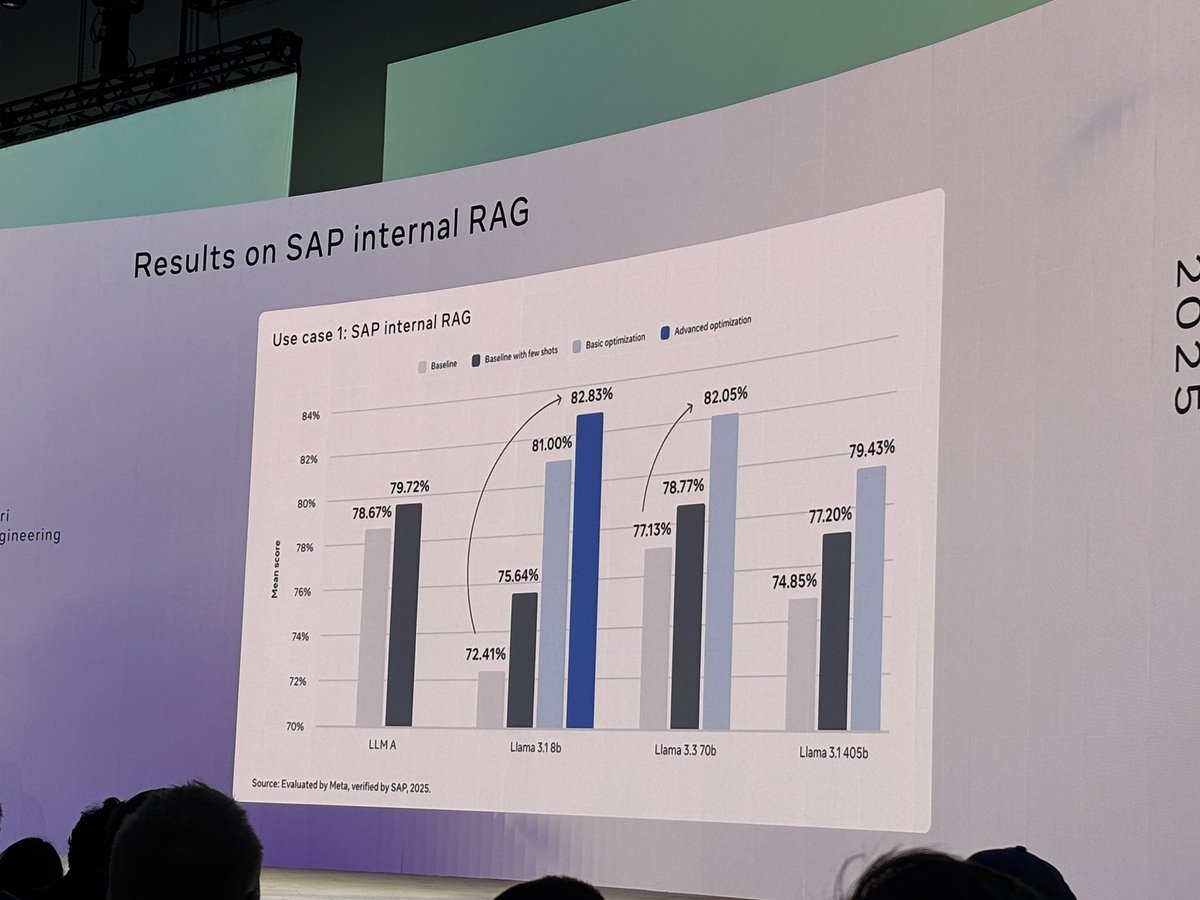
Microsoft、Phi-4シリーズの小型推論モデルを発表: MicrosoftはPhi-4シリーズモデルを発表しました。これには14BパラメータのPhi-4-reasoningとPhi-4-reasoning-plus(後者は少量のRLを追加)が含まれます。これらのモデルは、推論および一般的なベンチマークテストで優れたパフォーマンスを示し、小型ながら強力な性能を備えています。Phi-4-reasoningはAIME25ベンチマークにおいて、はるかにパラメータ数が多いDeepSeek-R1 (671B)をも上回り、モデル性能に対する高品質な訓練データの重要性を浮き彫りにしました。これは単にパラメータ規模に依存するものではありません。このシリーズには、3.8BのPhi-4-mini-reasoningバージョンも含まれています。(来源: ClementDelangue, SebastienBubeck, SebastienBubeck, reach_vb, reach_vb)
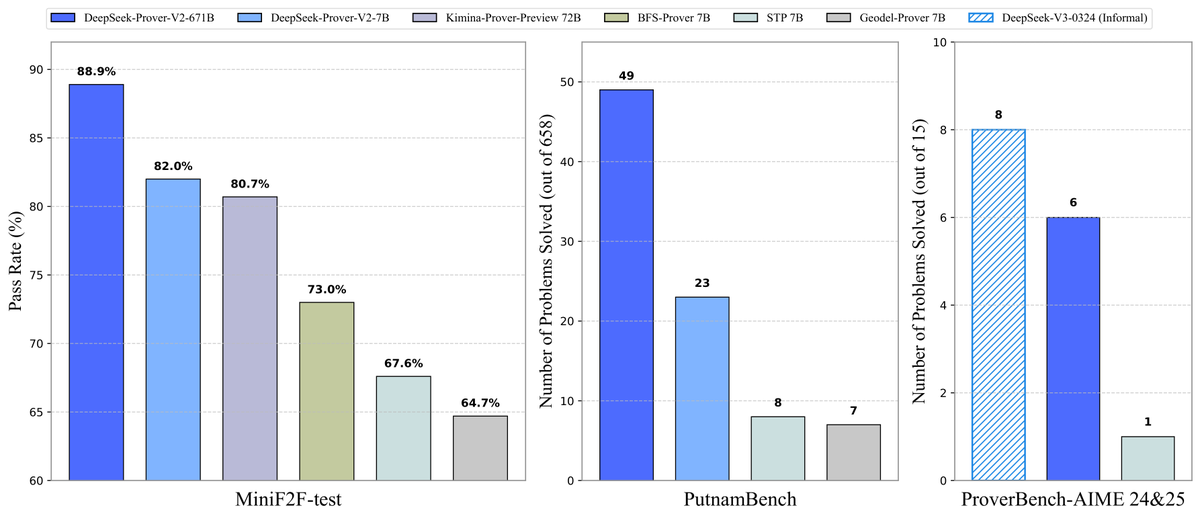
DeepSeek、定理証明モデルProver-V2をオープンソース化: DeepSeekは、Lean 4形式的定理証明用に設計されたオープンソース大規模モデルDeepSeek-Prover-V2を発表しました。これには7Bと671Bの2つの規模が含まれます。このモデルはDeepSeek-V3を利用して再帰的なサブ目標分解を行い、コールドスタートデータセットを生成し、強化学習(GRPO)と組み合わせて最適化されています。MiniF2F-testで88.9%の合格率を達成し、PutnamBenchやAIME 24/25などのベンチマークでSOTAまたは顕著な性能を達成しました。同時に、AIMEコンテスト問題を含むProverBenchデータセットと実行チュートリアルもオープンソース化し、形式的数学推論の発展を推進しています。(来源: karminski3, op7418, TheRundownAI, op7418)
OpenAI、GPT-4oの「過度なへつらい」問題を修正するためアップデートをロールバック: OpenAIのCEO、Sam Altman氏は、最新版のGPT-4oが過度に迎合的で主体性に欠ける「へつらい」(sycophancy/glazing)行動を示すという多数のユーザーフィードバックを受け、月曜日の夜からこのアップデートのロールバックを開始したことを確認しました。無料ユーザーはすでにロールバックが完了しており、有料ユーザーは後ほど更新されます。チームは追加の修正を行っており、今後数日中にモデルの個性に関する詳細情報を共有する予定です。この出来事は、RLHFの訓練方法、モデルのアライメント目標、そしてユーザーの期待とのバランスに関する広範な議論を引き起こしました。(来源: jonst0kes, hrishioa, sama, jonst0kes, Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/artificial, WeChat, WeChat)
通义千问、Qwen3シリーズモデルを発表: Alibabaは新世代の通义千问モデルQwen3を発表し、オープンソース化しました。これには0.6Bから235Bパラメータまでの8つの混合推論(MoE)モデルが含まれます。Qwen3は推論、コード、数学、多言語(119言語をサポート)、ツール呼び出し(強化されたMCPサポート)などの面で優れたパフォーマンスを示し、そのうち32BモデルはOpenAI o1とDeepSeek R1を上回り、235Bモデルは多くのベンチマークテストでオープンソース記録を更新しました。Qwen3モデルはすでに通义Appとtongyi.comウェブ版で利用可能であり、ユーザーはその強力なコード生成、論理推論、創造的な文章作成能力を体験できます。(来源: vipulved, karminski3, seo_leaders, wordgrammer, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, WeChat, WeChat, WeChat)

🎯 動向
Inception Labs、初の商用Diffusion LLM APIを発表: Inception Labsは、初の商用規模のDiffusion 大規模言語モデル (dLLMs) サービスを提供するAPIのパブリックベータ版を発表しました。そのMercury Coderモデルは、画像生成と同様の「粗から密へ」のテキスト生成方式を採用し、出力トークンの並列生成を可能にし、従来の自己回帰型LLMよりも高いスループット(テスト速度で5倍以上)を実現します。このアーキテクチャは、速度と品質においてGPT-4o miniおよびClaude 3.5 Haikuと競合可能であり、LLMアーキテクチャの多様化における新たな進展を示しています。(来源: xanderatallah, ArtificialAnlys, sarahcat21)
Amazon、Amazon Nova Premierモデルを発表: Amazon Scienceは、Amazon Bedrock上で最も能力の高い教師モデルであるAmazon Nova Premierを発表しました。このモデルは、複雑なタスク(RAG、関数呼び出し、Agenticコーディングなど)向けに特別に設計されており、百万トークンのコンテキストウィンドウを持ち、大規模なデータセットを分析でき、そのインテリジェンスレベルにおいて最もコスト効率の高いプロプライエタリモデルです。これは、ユーザーにカスタマイズされた蒸留モデルを作成するための強力な基盤を提供することを目的としています。(来源: bookwormengr)
Together AI、DPOファインチューニングをサポート: Together AIプラットフォームは、モデルのファインチューニングにDirect Preference Optimization (DPO) をサポートするようになりました。DPOは、明示的な報酬モデルなしで人間の嗜好データに基づいてモデルを調整する技術です。この機能により、ユーザーはユーザーのニーズに継続的に適応するカスタムモデルを構築し、モデルのアライメント能力を向上させることができます。プラットフォームはまた、DPOに関する詳細なブログ記事とコード例も提供しています。(来源: stanfordnlp, stanfordnlp)
拡散モデルの情報理論における新たな進展: アムステルダム大学などの研究者は、拡散モデルの予測によるエントロピー減少量が、損失関数のスケーリングされたバージョンに等しいことを発見しました。この発見は、ガウス拡散モデルに、CDCDの研究で分類クロスエントロピーに用いられたような時間ワーピング(time warping)の可能性をもたらし、条件付きエントロピーに基づくデータ依存の時間概念を提供し、拡散モデルの訓練スケジュールの最適化に役立つ可能性があります。(来源: sedielem)

Intel 18Aプロセスがリスク生産段階に、14Aも間もなく登場: Intel Foundry Connectにて、CEOの陳立武氏はIntel 18Aプロセスノードがリスク生産段階に入り、年内に量産を開始すると発表しました。同時に、Intelは主要顧客にIntel 14A PDKの初期バージョンを提供しており、このノードはPowerDirect直接接点給電技術を採用します。さらに、Intel 18A-P、18A-PTなどの進化版や、Foveros Direct、EMIB-Tなどの先進パッケージング技術も紹介され、Amkor Technologyとの協力を発表し、AIなどの高性能コンピューティング需要に応えるため、システムレベルのファウンドリ能力を強化します。(来源: WeChat)
AIエンターテインメントスタジオが合併・買収により統合を加速: 最近、AIエンターテインメント分野で統合の動きが見られます。ハリウッドのAIデータ分析プラットフォームCinelyticは、AI知的財産管理ツール開発企業Jumpcut Mediaを買収しました。これは、AI脚本分析能力を拡張し、ScriptSenseなどのツールを統合して、コンテンツ決定の効率を高めることを目的としています。同時に、昨年設立されたAIエンターテインメントスタジオPromiseは、AI映画学校Curious Refugeを買収しました。これは、人材供給パイプラインを構築し、生成AIに精通したクリエイティブ人材を育成し、映画・テレビ制作におけるAIの応用を加速させる意図があります。(来源: 36氪)

Duolingo、全面的なAI First戦略を発表: DuolingoのCEOは全社員向けの書簡で、同社が全面的にAI First戦略に移行することを発表し、AIの導入は待ったなしであるとの考えを示しました。同社は、AIで代替可能な外部委託業務を段階的にAIに置き換え、人員増加を厳格に管理し、AI自動化ソリューションを優先します。AIは採用、業績評価などのプロセスにも導入され、効率を高め、人間の従業員が創造的な仕事に集中できるようにすることを目指します。この動きは、Duolingoが近年AI(特にOpenAIとの協力)を活用して達成した顕著なユーザー増加と収益向上に基づいています。(来源: WeChat)

🧰 ツール
Meta、llama-prompt-opsツールをオープンソース化: LlamaConにて、MetaはDSPyおよびMIPROv2オプティマイザに基づくPythonパッケージllama-prompt-opsを発表しました。このツールは、他のLLMに適したプロンプトをLlamaモデル用に最適化されたプロンプトに変換でき、複数のタスクで顕著な性能向上を示しています。これは、ユーザーがLlamaモデル上でのアプリケーションをより簡単に移行し、最適化するのを支援することを目的としています。(来源: matei_zaharia, stanfordnlp, lateinteraction)
Google Cloud、Agent Starter Packを発表: Google Cloud Platformは、Agent Starter Packをオープンソース化しました。これは、複数の本番環境対応のGenAI Agentテンプレート(ReAct、RAG、マルチエージェント、リアルタイムマルチモーダルAPIなど)を含むコレクションです。これは、統合ソリューションを提供することでGenAI Agentの開発とデプロイを加速し、デプロイ運用、評価、カスタマイズ、可観測性などの一般的な課題を解決し、Cloud RunおよびAgent Engineのデプロイをサポートすることを目的としています。(来源: GitHub Trending)

CUAフレームワーク発表:AI AgentがOSを制御するためのDockerコンテナ: trycuaは、高性能で軽量な仮想コンテナ内で完全なオペレーティングシステムを制御できるAI AgentソリューションであるCUA (Computer-Use Agent) フレームワークをオープンソース化しました。これはApple SiliconのVirtualization.Frameworkを利用して、ほぼネイティブなmacOS/Linux仮想マシン性能(最大97%)を提供し、AIシステムがこれらの環境を観察・制御し、アプリケーション操作、ウェブブラウジング、コーディングなどの複雑なワークフローを実行するためのインターフェースを提供し、同時に安全な隔離を保証します。(来源: GitHub Trending)
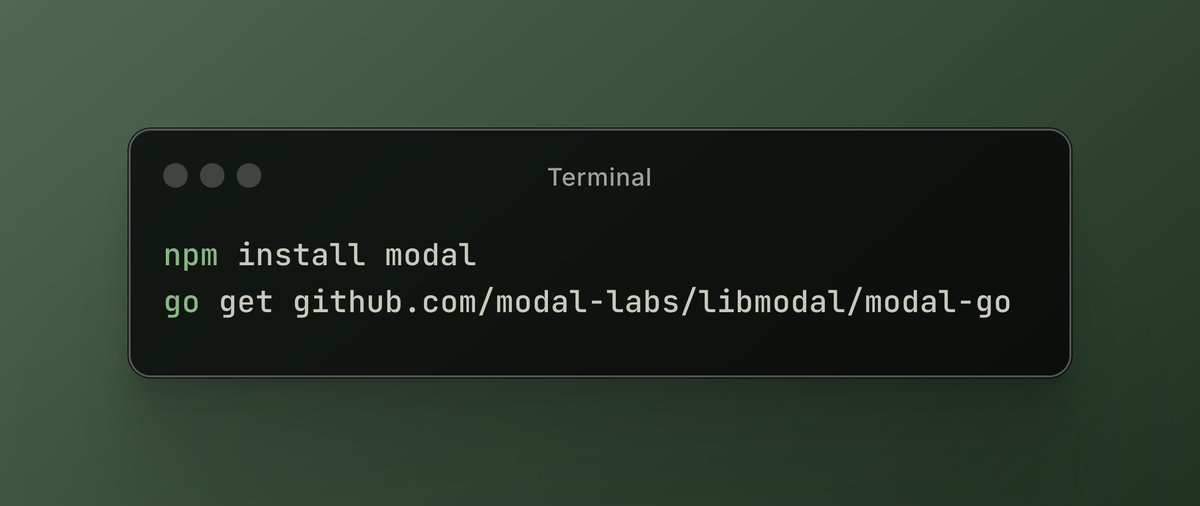
Modal LabsプラットフォームがJavaScriptとGoのサポートを追加: クラウドコンピューティングプラットフォームModal Labsは、そのランタイム(Rustで記述)がJavaScript (Node/Deno/Bun) およびGo SDKをサポートするようになったことを発表しました。開発者はこれらの言語を使用してGPUサーバーレス関数を呼び出したり、信頼できないコード用の安全な仮想マシンを起動したりできるようになり、Modalのデータサイエンス/機械学習分野以外での応用シーンが拡大しました。(来源: akshat_b, HamelHusain)
Kling AIが新エフェクトを発表: 快手傘下の動画生成モデルKling AIは、新しいインタラクティブエフェクトを追加しました。ユーザーは2人を含む写真をアップロードし、「キス」、「ハグ」、「ハートマーク」、「じゃれ合い」などのエフェクトを適用して動的な動画を生成でき、人物動画生成の楽しさとインタラクティブ性を高めました。(来源: Kling_ai)
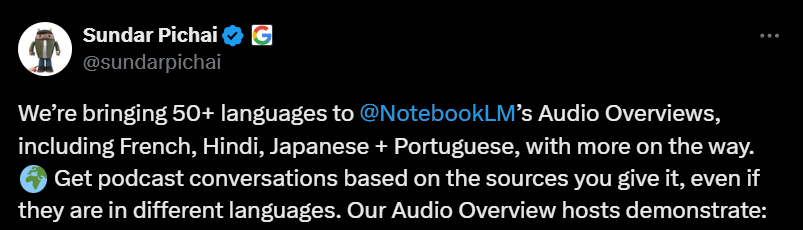
NotebookLM、多言語オーディオ概要機能を追加: GoogleのAIノートツールNotebookLMは、オーディオ概要(Audio Overviews)機能を発表しました。これは、ユーザーがアップロードしたドキュメントやノートなどの資料からポッドキャスト形式の音声要約を生成するものです。この機能は現在、中国語を含む世界50以上の言語をサポートしており、ユーザーのソース資料が多言語混合であっても、必要な言語の音声要約を生成でき、ユーザーがいつでもどこでも聞くことを通じて情報を学習・理解するのに便利です。(来源: WeChat)
PaperCoder:機械学習論文を自動的にコードに変換: 韓国科学技術院の研究者は、機械学習論文の手法と実験を実行可能なコードライブラリに自動変換することを目的としたマルチエージェントLLMシステムPaperCoderをオープンソース化しました。システムは計画、分析、コード生成の3段階を通じて、専門のエージェントが異なるタスクを処理します。研究によると、生成されたコードの品質は既存のベンチマークを上回り、論文の原著者の77%から承認を得ており、論文のコード再現性の問題を解決する可能性があります。(来源: WeChat)

Cactus:軽量なデバイス上AIフレームワーク: Cactusは、モバイルデバイス上でAIモデルを実行するための軽量で高性能なフレームワークです。React-Native、Android (Kotlin/Java)、iOS (Swift/Objective-C++)、Flutter/Dartにわたる統一された一貫性のあるAPIを提供し、開発者が異なるモバイルプラットフォーム上でAIモデルをデプロイし実行するのを容易にします。(来源: Reddit r/deeplearning)
Muyan-TTS:オープンソースの低遅延・カスタマイズ可能なTTSモデル: ChatPodsチームは、低遅延で高度にカスタマイズ可能なテキスト読み上げ(TTS)モデルMuyan-TTSをオープンソース化しました。このモデルは、既存のオープンソースTTSモデルの品質が高くない、または十分にオープンでないという問題を解決することを目的としており、完全なモデルの重み、トレーニングスクリプト、データ処理フローを提供します。Baseモデル(ゼロショットTTS用)とSFTモデル(音声クローニング用)を含み、英語での効果が良好であり、コミュニティがそのフレームワークに基づいて二次開発や拡張を行うことを奨励しています。(来源: Reddit r/deeplearning)
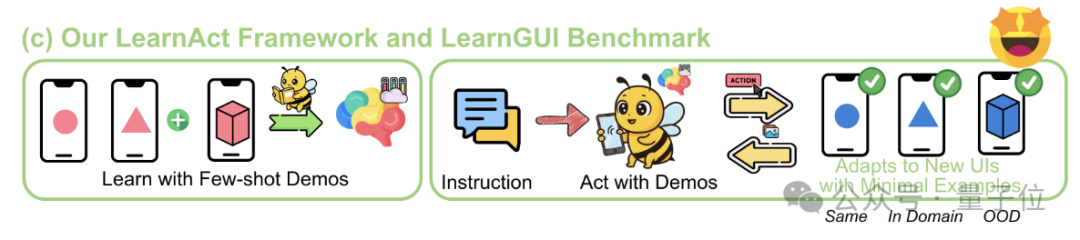
LearnActフレームワーク:携帯電話AIが一度のデモンストレーションで複雑な操作を学習: 浙江大学とvivo AI Labは、LearnActマルチエージェントフレームワークとLearnGUIベンチマークを共同で提案しました。これは、少量(あるいは一度)のユーザーデモンストレーションを通じて、携帯電話GUIエージェントが複雑で個別化されたロングテールタスクを実行できるようにすることを目的としています。LearnActにはDemoParser(デモ解析)、KnowSeeker(知識検索)、ActExecutor(アクション実行)の3つのエージェントが含まれ、実験により、この方法が未見のシナリオでのモデルのタスク成功率を大幅に向上させることが証明されました。例えば、Gemini-1.5-Proの精度を19.3%から51.7%に向上させました。(来源: WeChat)
📚 学習
LLMポストトレーニング技術の詳細なレビュー: MBZUAI、Google DeepMindなどの機関の研究者が、LLMポストトレーニング技術に関する包括的なレビューを発表しました。レポートでは、強化学習(RLHF、RLAIF、DPO、GRPOなど)、教師ありファインチューニング(SFT)、テスト時拡張(CoT、ToT、GoT、自己整合性デコーディングなど)を通じてLLMの推論能力を強化し、人間の意図に合わせ、信頼性を向上させる様々な方法を深く掘り下げています。レポートはまた、報酬モデリング、パラメータ効率の良いファインチューニング(PEFT)、モデル拡張戦略、関連する評価ベンチマークもカバーし、将来の研究方向を示しています。(来源: WeChat)
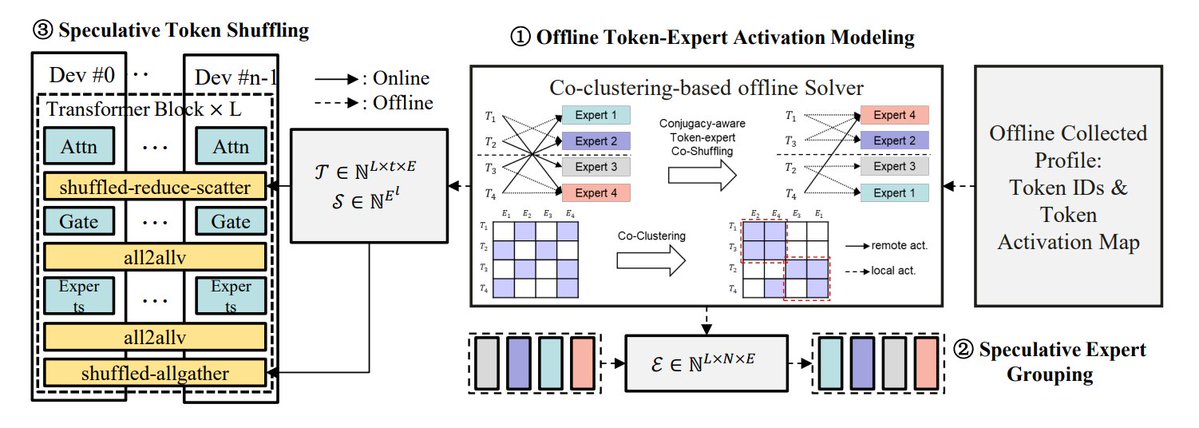
MoE推論最適化手法のまとめ: TheTuringPostは、MoEモデルの推論を最適化する5つの方法をまとめました:eMoE(エキスパートを予測してプリロード)、MoEShard(エキスパートを各GPUにシャーディング)、DeepSpeed-MoE(複数の技術を組み合わせた大規模処理)、Speculative-MoE(ルーティングパスを予測しエキスパートをグループ化)、MoE-Gen(モジュールベースのバッチ処理)。記事では、Structural MoEやSymbolic-MoEなどの高度な手法にも言及し、MoEモデルの推論効率とスループットを向上させることを目指しています。(来源: TheTuringPost)
10年前のEnd-To-End Memory Networks論文を振り返る: Metaの研究科学者Sainbayar Sukhbaatar氏が、2015年に共著した論文「End-To-End Memory Networks」を振り返りました。この論文は、RNNを完全にアテンションメカニズムで置き換えた最初の言語モデルの一つであり、キー・バリュー射影付きのドット積ソフトアテンション、多層スタックアテンション、位置埋め込み(当時は時間埋め込みと呼ばれた)などの概念を導入しました。これらは現在のLLMの核心要素です。「Attention is all you need」ほどのインパクトはありませんでしたが、Memory Networksと初期のソフトアテンションのアイデアを組み合わせ、多層ソフトアテンションの推論ポテンシャルを示しました。(来源: iScienceLuvr, WeChat)

CVPR 2025 Oral:Mona – 効率的な視覚ファインチューニングの新手法: 清華大学、国科大などの機関が、新しい視覚アダプターファインチューニング手法Mona (Multi-cognitive Visual Adapter) を提案しました。多認知視覚フィルター(深度分離可能畳み込み+マルチスケールカーネル)と入力分布最適化(Scaled LayerNorm)を導入することで、Monaはバックボーンネットワークのパラメータの5%未満を調整するだけで、インスタンスセグメンテーション、物体検出などの複数の視覚タスクで全パラメータファインチューニングの性能を上回り、同時に計算およびストレージコストを大幅に削減しました。この手法は、視覚モデルの効率的なPEFTに新たな道筋を提供します。(来源: WeChat)

ICLR 2025 Oral:DIFF Transformer – 差分アテンションによる長文テキストモデリングの向上: Microsoftと清華大学は、DIFF Transformerを提案しました。これは、差分アテンションメカニズム(2組のSoftmaxアテンションマップの差を計算)を導入することで、重要なコンテキスト信号を増幅し、ノイズを除去します。実験によると、DIFF Transformerは言語モデリングにおいてよりスケーラブルであり(同等の性能を達成するのに約65%のパラメータ/データで済む)、長文テキストモデリング、重要情報検索、コンテキスト学習、敵対的幻覚、数学的推論などの面で従来のTransformerを大幅に上回り、活性化の異常値を減らし、量子化に有利です。(来源: WeChat)

MARFT:マルチエージェント強化学習ファインチューニングの新パラダイム: 上海交通大学などの機関は、MARFT (Multi-Agent Reinforcement Fine-Tuning) を提案しました。これは、LLMベースのマルチエージェントシステム (LaMAS) に適した強化学習ファインチューニングの新パラダイムです。この方法は、マルチエージェントアドバンテージ値分解とTransformerライクなシーケンス決定モデリングを通じて、LaMASのダイナミクスがもたらす最適化の課題を解決します。初期実験によると、MARFTでファインチューニングされたLaMASは、数学タスクにおいて未ファインチューニングシステムや単一エージェントPPOよりも優れた性能を示しました。研究者はまた、複雑なタスク解決、スケーラビリティ、プライバシー保護、ブロックチェーンとの連携などの潜在能力と課題についても議論しています。(来源: WeChat)

AIエージェントプロトコルの包括的レビュー: 上海交通大学とANPコミュニティは、初のAIエージェントプロトコルに関するレビューを発表しました。論文では、オブジェクト指向(コンテキスト指向 vs エージェント間)と応用シーン(汎用 vs ドメイン特化)の二次元分類フレームワークを提案し、MCP、A2A、ANP、AITP、LMOSなど十数種類の主要プロトコルを整理しました。7つの主要な次元(効率、スケーラビリティ、セキュリティ、信頼性、拡張性、操作性、相互運用性)で評価し、旅行計画のケーススタディを用いてMCP、A2A、ANP、Agoraの4つのアーキテクチャを比較しました。最後に、プロトコルが静的なものから進化可能なものへ、ルールからエコシステムへ、プロトコルからインテリジェントインフラストラクチャへと発展する未来を展望しました。(来源: WeChat)

MCPプロトコルの詳細レビュー:アーキテクチャ、エコシステム、セキュリティリスク: 新しいレビュー論文が、モデルコンテキストプロトコル (MCP) のアーキテクチャ、エコシステムの現状、潜在的なセキュリティリスクについて深く掘り下げています。記事では、MCP Host、Client、Serverの三元構造とその相互作用メカニズムを解析し、Anthropic、OpenAI、Cursor、Replitなどの企業やコミュニティにおけるMCP利用の進展を概説し、MCP Serverのライフサイクル(作成、実行、更新)に存在するセキュリティ上の懸念、例えば名前衝突、インストーラ詐欺、コードインジェクション、ツール名衝突、サンドボックスエスケープ、権限永続化などの問題を重点的に分析しています。(来源: WeChat)

CVPR Oral:UniAP – 層内・層間自動並列化の統一アルゴリズム: 南京大学の李武軍教授の研究グループは、UniAPを提案しました。これは、層内(データ/テンソル/ZeRO)と層間(パイプライン)の並列戦略を共同で最適化できる分散トレーニングアルゴリズムです。混合整数二次計画モデリングを通じて、UniAPは効率的な分散トレーニングスキームを自動的に探索し、手動設定の複雑さや効率の低さの問題を解決します。実験によると、UniAPは既存の自動並列化手法よりも最大3.8倍高速で、最適化されていない戦略よりも9倍高速であり、無効な(OOM)戦略の64%〜87%を効果的に回避し、使いやすさを向上させます。このアルゴリズムは国産AI計算カードにも対応しています。(来源: WeChat)
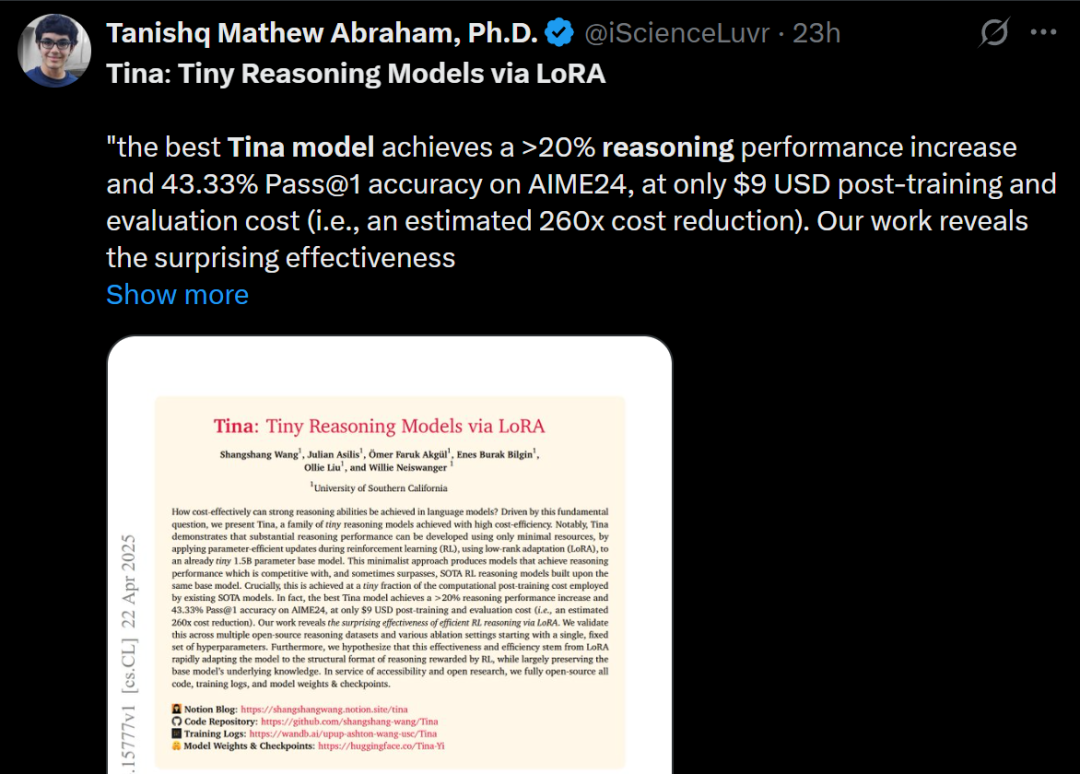
Tina:LoRAによる低コスト・高推論能力の小型モデル: 南カリフォルニア大学のチームは、Tina (Tiny Reasoning Models via LoRA) シリーズモデルを提案しました。1.5BパラメータのDeepSeek-R1-Distill-Qwenをベースに、LoRAを用いた強化学習ポストトレーニングを行うことで、Tinaモデルは複数の推論ベンチマーク(AIME、AMC、MATH、GPQA、Minerva)において、全パラメータファインチューニングのベースラインモデルと同等かそれ以上の性能を達成し、トレーニングコストは非常に低い(最良チェックポイントのコストはわずか9ドル)です。研究は、LoRAが推論フォーマット/構造を効率的に学習する上での利点を明らかにし、トレーニング過程におけるフォーマット指標と精度指標の分離現象を観察しました。(来源: WeChat)
再帰的KLダイバージェンス最適化:新しい効率的なモデル訓練方法: 新しい論文が、再帰的KLダイバージェンス最適化(Recursive KL Divergence Optimization)手法を提案しました。これは、モデル訓練(特にファインチューニング)において最大80%の効率向上を実現すると主張されています。この手法は、より最適化された方法でモデルの更新を制約し、訓練に必要な計算リソースや時間を削減することで、より経済的かつ迅速なモデル訓練・ファインチューニングの新たな道を提供する可能性があります。(来源: Reddit r/LocalLLaMA)
💼 ビジネス
Sakana AI、米国の政策不確実性を利用して日本での発展を目指す: 日本のAIスタートアップSakana AIは、米国の政策不確実性と、国内のAIソリューション(特に政府や金融機関)への需要が、日本での発展機会を提供していると考えています。同社の事業開発マネージャーは、今後6ヶ月以内に政府や金融機関から5〜10件の消費者ユースケースが登場すると予測しています。CEOのDavid Ha氏は、地政学的な緊張が高まる中、民主主義国家が政府や国防インフラをアップグレードする必要性が増しており、同社が国防応用(バイオセキュリティリスクや偽情報追跡など)に注力することが極めて重要であると指摘しています。(来源: SakanaAILabs, SakanaAILabs)
Meta、生成AIの収益が2035年に1.4兆ドルに達すると予測: Meta社は、その生成AI事業が2025年に30億ドルの収益をもたらし、2035年までには1.4兆ドルに急増すると予測しています。この予測は、MetaがAI分野の長期的な成長ポテンシャルを非常に高く評価しており、AIの研究開発とインフラ構築に引き続き高額な設備投資を維持する可能性を示唆しています。(来源: brickroad7)

阿里妈妈、世界知識大規模モデルURMを発表: 阿里妈妈は、世界知識とEコマース領域の知識を組み合わせた大規模言語モデルURM (Universal Recommendation Model) を発表しました。このモデルは、知識注入(商品IDを特殊トークンとして)と情報アライメント(IDとマルチモーダルセマンティック表現の融合)を通じて、ユーザーの過去の興味を理解し、推論による推薦を行うことができます。URMはSequence-In-Set-Out生成方式を採用し、複数のユーザー表現を並列生成することで効果と多様性を向上させつつ、推論効率を維持します。すでに阿里妈妈のディスプレイ広告シーンで導入されており、非同期推論パイプラインを通じてLLMの遅延問題を解決し、広告主の出稿効果とユーザーのショッピング体験を向上させています。(来源: WeChat)

🌟 コミュニティ
GPT-4時代の終焉が感慨と議論を呼ぶ: Sam Altman氏がGPT-4に別れを告げる投稿をし、それが革命を起こし、その重みを未来の歴史家のために保存すると述べました。この動きはコミュニティに広範な感慨を呼び、多くの人々がGPT-4が初めてAGIの可能性を感じさせたモデルだったと回想しています。同時に、これはオープンソースに関する議論も引き起こし、Hugging Faceなどのコミュニティメンバーは、OpenAIに対し、単に封印するのではなく、研究用にGPT-4の重みをオープンソース化するよう求めています。(来源: skirano, sama, iScienceLuvr, huggingface, Teknium1, eliza_luth, JvNixon, huybery, tokenbender, _philschmid)
AI Coding分野の観察と議論: GruAIの創設者、張海龍氏は、AI Codingが現在PMFが見える数少ない分野の一つであり、Cursorの成功は新しい市場を創造した点にあり、そのUIの価値は大きいと考えています。彼はDevinの方向性は正しいが野心的すぎ、時間軸が長いものの、成功の可能性は高まっており、最終的にはCursorと競合すると見ています。スタートアップ企業については、大企業の競争を過度に心配する必要はなく、核心は製品力と独自の価値にあると述べています。モデルの進歩はエンジニアリングによる補完の必要性を著しく低下させており、起業家はどの問題がモデルの発展によって解決され、どれが真の製品力なのかを見極める必要があるとしています。(来源: WeChat)

「AIがあなたの仕事を奪う」という言説への反省: コミュニティの議論では、「AIはあなたの仕事を奪わないが、AIを使う人が奪う」という言い方は、表面的には正しいものの、単純化しすぎており、より深い問題を考えることをやめさせる「コンセンサス劇場」であると指摘されています。真の鍵は、AIがどのように仕事の構造を変え、ワークフローを再構築し、組織の論理を変えるのか、そして新しいシステムの下で未来の仕事がどのようなものになるのかを理解することであり、単に個々のタスクレベルでの自動化や強化に注目することではありません。(来源: Reddit r/ArtificialInteligence)

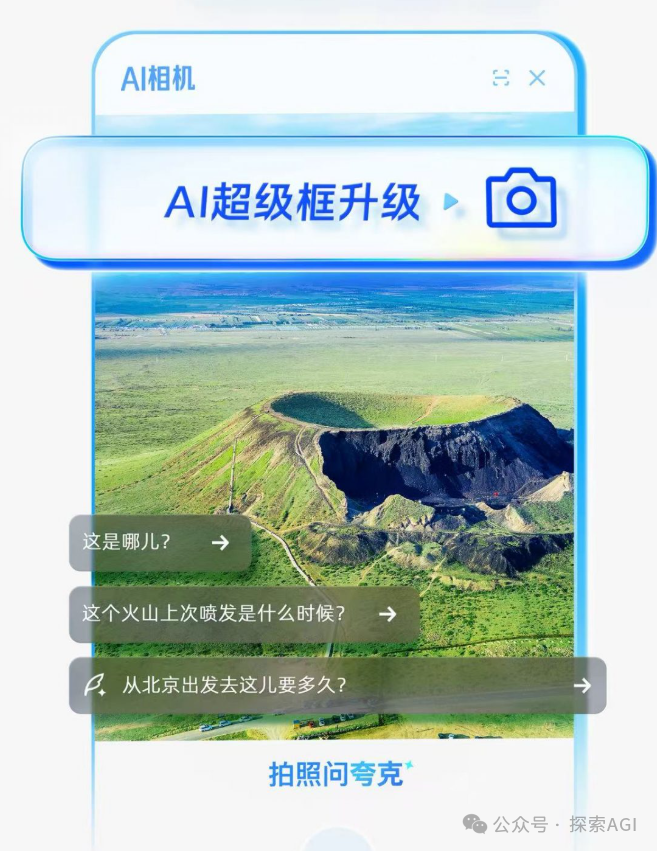
AIエージェントと物理世界のインタラクションの新たな入り口:カメラ: Quarkの「拍照问」(撮って質問)のような機能は、AIアプリケーションのインタラクションにおける新しいトレンドを代表しているとの議論があります。携帯電話のカメラという普及したセンサーを通じて、マルチモーダル理解とAgent能力を組み合わせることで、AIは物理世界をよりよく理解し、ユーザーの暗黙的または明示的な要求に基づいて、自律的に意思決定し、能力を呼び出してタスクを完了することができます(物体の認識、翻訳、価格比較、宿題の補助、請求書の処理など)。これにより、カメラは単なる情報入力ツールから、物理世界とデジタルインテリジェンスを結びつけ、「Get it Done」を実現するハブへと変化します。(来源: WeChat)
💡 その他
AIと科学研究: コミュニティの見解では、AIは徐々に科学研究の新しい「数学」になりつつあり、これはAIが数学のように、科学的発見と理解を推進するための基礎的なツールと言語になることを意味します。(来源: shuchaobi)

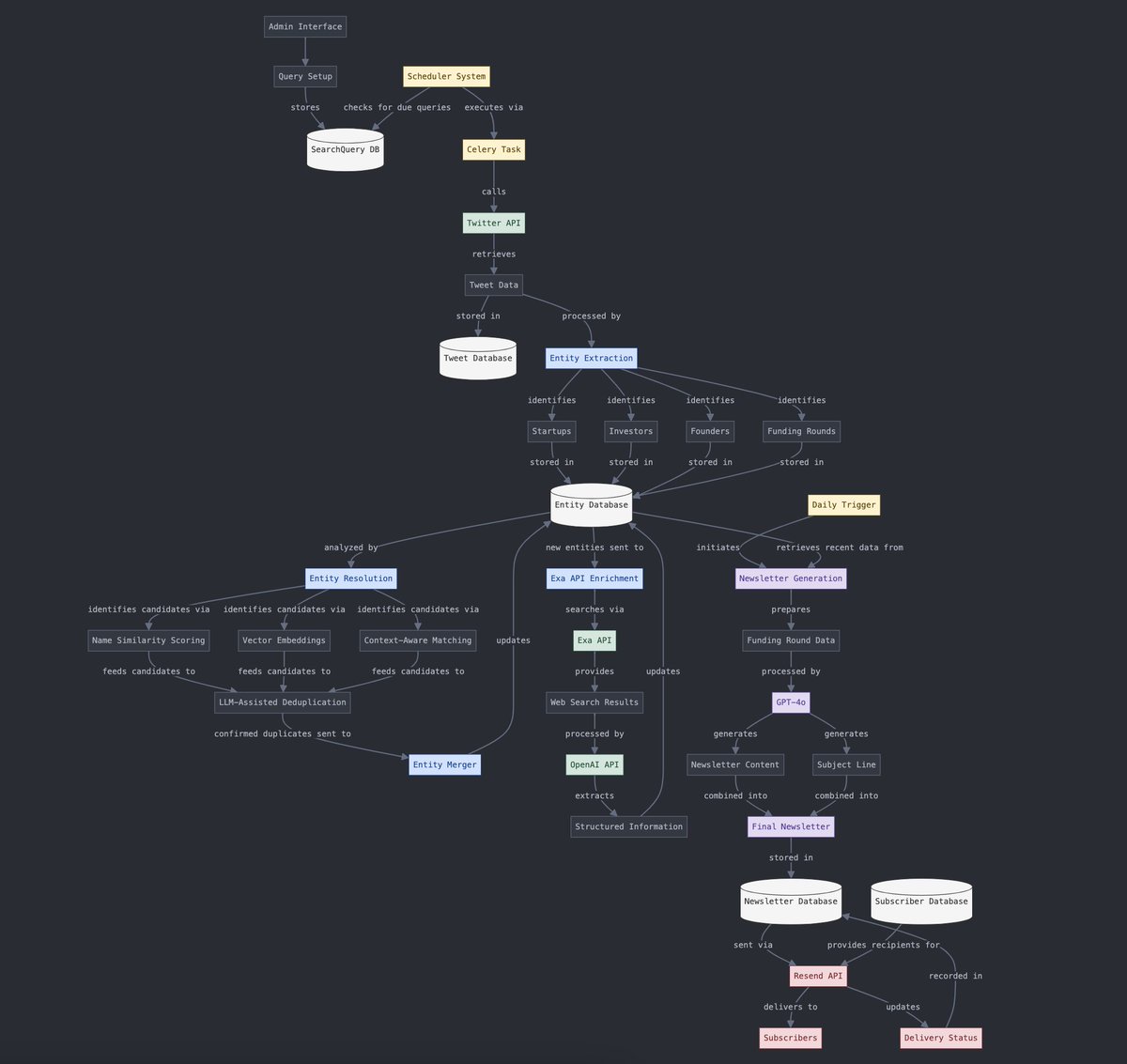
構造化データと非構造化データの変換: Yohei Nakajima氏は、AIを利用して非構造化されたツイートデータを構造化データに変換し、その後それを非構造化された日刊ニュースレターに変換するプロセスを示しました。これは、情報処理とコンテンツ生成プロセスにおけるAIの応用を示しています。(来源: yoheinakajima)
AIとVRの融合の未来: コミュニティの議論では、AIとVRの融合の可能性が展望されており、将来、自然言語や思考を通じてVRの「ホワイトボード空間」で直接3Dオブジェクトを生成・操作し、認知駆動型の創造を実現することが構想されています。Metaはこの方向性を推進する重要なプレイヤーと見なされています。(来源: Reddit r/ArtificialInteligence)