
🔥 注目
「AI四小龍」が直面する課題と転換:SenseTime、Megvii、CloudWalk、Yituなど、かつて「AI四小龍」と称された企業は、近年、商業化の困難と継続的な損失に広く直面しています。例えば、SenseTimeは2024年に43億元の損失を計上し、累計損失は546億元を超えました。CloudWalkは2024年に6~7億元近くの損失を計上し、累計損失は44億元を超えています。課題に対応するため、各社は人員削減、賃金カット、事業再編を含む戦略調整を次々と行っています。大規模言語モデルが主導する新たなAIの波に直面し、視覚技術の遺伝子を持つ「四小龍」は、マルチモーダル大規模モデルとAGI分野への転換を積極的に進めています。SenseTimeはGPT-4oに対抗する「日日新V6」マルチモーダルモデルを発表し、計算センター建設に大規模な投資を行っています。Yituは視覚中心のマルチモーダルモデルに注力し、Huaweiと協力してハードウェアコストを削減しています。CloudWalkもHuaweiと協力し、大規模モデルの学習・推論一体型マシンを発表しました。Megviiはアルゴリズムの優位性を活かし、スマートドライビングの純粋な視覚ソリューションに参入しています。これらの動きは、彼らがAIの競争に留まり、新たな市場環境に適応しようと努力していることを示しています。(出典: 36氪)

エンボディード・インテリジェンスのデータ問題とオープンソースデータセットの進展:人型ロボットとエンボディード・インテリジェンスの発展は、重要なデータボトルネックに直面しており、高品質な学習データの不足がその能力のブレークスルーを妨げています。膨大なインターネットテキストデータを持つ言語モデルとは異なり、ロボットは多様な物理世界とのインタラクションデータを必要とし、その取得コストは高額です。この問題を解決するため、研究機関や企業はデータセットの構築とオープンソース化を積極的に進めています。例えば、Google DeepMindが複数の機関と共同で発表したOpen X-Embodiment、Peng Cheng LaboratoryなどのARIO、Beijing Innovation CenterのRoboMIND、Zhiyuan RobotのAgiBot World(実世界の長距離複雑タスクデータを含む)およびAgiBot Digital Worldシミュレーションデータセット、UnitreeのG1操作データセットなどがあります。これらのデータセットは規模こそテキストデータに遠く及ばないものの、基準の統一、品質の向上、シナリオの豊富化を通じて、エンボディード・インテリジェンス分野の発展を推進し、「ImageNetモーメント」の実現に向けた基礎を築いています。(出典: 36氪)

人型ロボット量産の兆し:データ、シミュレーション、汎化能力の突破:データ収集コストの高さや汎化能力の低さといった課題に直面しながらも、多くの企業(Tesla、Figure AI、1X、Zhiyuan、Unitree、UBTECHなど)は2025年に人型ロボットの量産実現を計画しています。解決策には以下が含まれます:1)大規模な実機訓練:政府(北京、上海、深圳、広東)がデータ収集基地の建設と基準策定を支援。2)先進的なシミュレーション訓練:NVIDIA Cosmos、Google Genie2などのワールドモデルを利用して物理的にリアルな仮想環境を生成し、コスト削減と効率向上を図る。3)AIによる汎化能力の付与:Figure AIのHelix、Zhiyuan GO-1のViLLAアーキテクチャ、Google Gemini Roboticsなどの新しい行動モデルを通じて、より少ないデータで物理操作の汎化理解を実現し、ロボットが未知の物体を扱ったり新しい環境に適応したりできるようにする。これらの技術進歩は、人型ロボットの商業化応用が加速する可能性を示唆しています。(出典: 36氪)

AI開発が直面する「メモリウォール」危機、新型ストレージ技術が突破口を模索:AIモデル規模の指数関数的な成長はメモリ帯域幅に厳しい課題を突きつけており、従来のDRAMの帯域幅増加速度は計算能力の成長に遠く及ばず、「メモリウォール」というボトルネックを形成し、プロセッサ性能の発揮を制限しています。HBMは3Dスタッキング技術によって帯域幅を大幅に向上させ、一部の圧力を緩和しましたが、製造プロセスが複雑でコストが高いです。このため、業界は新型ストレージ技術を積極的に模索しています:1) 3D強誘電体RAM (FeRAM):SunRise Memoryなど。HfO2の強誘電効果を利用し、高密度、不揮発性、低消費電力のストレージを実現。2) DRAM+不揮発性メモリ:NeumondaとFMCが協力し、HfO2を利用してDRAMキャパシタを不揮発性ストレージに転換。3) 2T0C IGZO DRAM:imecが提案。従来の1T1C構造を2つの酸化物トランジスタで置き換え、キャパシタ不要で低消費電力、高密度、長保持時間を実現。4) 相変化メモリ (PCM):材料の相変化を利用してデータを保存し、消費電力を削減。5) UK III-V Memory:GaSb/InAsベースで、DRAMの速度とフラッシュメモリの不揮発性を両立。6) SOT-MRAM:スピン軌道トルクを利用し、低消費電力、高エネルギー効率を実現。これらの技術はDRAMのボトルネックを打破し、ストレージ市場の構造を再構築する可能性があります。(出典: 36氪)
🎯 動向
天工ロボットがハーフマラソン完走、小ロット量産を計画:北京人型ロボットイノベーションセンターの天工チームのロボット「天工Ultra」(身長1.8メートル、体重55キログラム)が、初の人型ロボットハーフマラソン大会で優勝し、約21キロメートルを2時間40分42秒で完走しました。この大会は、複雑な路面状況下でのロボットの持続時間、構造、知覚、制御アルゴリズムの信頼性を検証しました。チームによると、関節の安定性、耐熱性、エネルギー消費システム、バランスと歩行計画アルゴリズムを最適化し、独自開発の「慧思開物」プラットフォーム(身体化された大脳+小脳)を搭載することで、ロボットは無線ナビゲーション下での自律経路計画とリアルタイム調整を実現しました。マラソン完走は基本的な信頼性を証明し、量産に向けた基礎を築きました。天工2.0ロボットは間もなく発売され、小ロット生産を計画しており、将来的には工業、物流、特殊作業、家庭サービスなどの分野への応用を目指しています。(出典: 36氪)

中国、培養ヒト細胞を用いたロボット脳の開発を研究中:報道によると、中国の研究者らが培養されたヒト脳細胞によって駆動するロボットを開発中です。この研究は、生物神経細胞の学習・適応能力を利用してロボットハードウェアを制御するバイオコンピューティングの可能性を探ることを目的としています。具体的な詳細や進捗段階は不明ですが、この方向性はロボット工学、人工知能、バイオテクノロジーが交差する分野の最先端の探求であり、将来、よりインテリジェントで適応性の高いロボットシステムの開発に新たな道を開く可能性があります。(出典: Ronald_vanLoon)
Gemma 3 QAT 量子化モデルの性能が優れている:ユーザーがGPQA DiamondベンチマークテストでGoogle Gemma 3 27BモデルのQAT (Quantization Aware Training) バージョンと他のQ4量子化バージョン(Q4_K_XL, Q4_K_M)を比較しました。結果、QATバージョンが性能面で最も優れており(36.4%の精度)、同時にVRAM使用量が最も少なく(16.43 GB)、Q4_K_XL (34.8%, 17.88 GB) や Q4_K_M (33.3%, 17.40 GB) を上回りました。これは、QAT技術がモデルの性能を維持しつつ、リソース要求を効果的に削減することを示しています。(出典: Reddit r/LocalLLaMA)
噂:AMDが32GBメモリ搭載のRDNA 4 Radeon PROグラフィックカードを発売予定:VideoCardzによると、AMDはNavi 48 XTW GPUをベースにしたRadeon PROシリーズのグラフィックカードを準備しており、32GBのメモリを搭載するとのことです。これが事実であれば、ローカルでのAIモデルの学習や推論に大容量メモリを必要とするユーザー、特にコンシューマー向けグラフィックカードのメモリが一般的に制限されている状況下で、新たな選択肢を提供することになります。しかし、具体的な性能、価格、発売日はまだ発表されておらず、実際の競争力はまだ不明です。(出典: Reddit r/LocalLLaMA)

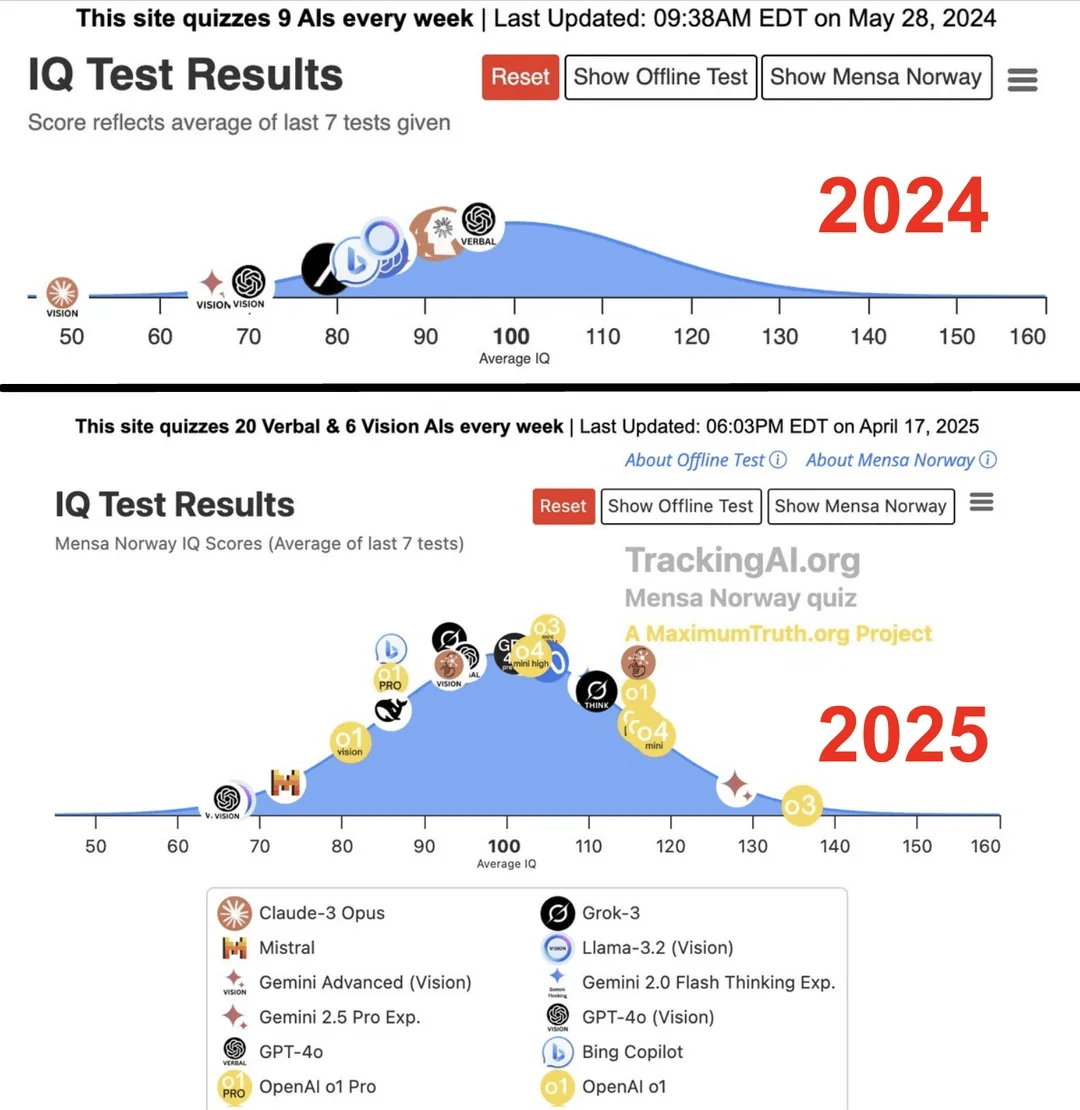
研究によると、トップAIのIQが1年で96から136に急上昇:Maximum Truthウェブサイトが発表した研究(出典の信頼性は要検証)によると、AIモデルに対してIQテストを実施した結果、最も賢いAI(おそらくGPTシリーズを指す)のIQスコアが1年で96点(人間の平均をわずかに下回る)から136点(天才レベルに近い)に上昇しました。IQテストがAIの知能を測定する有効性には議論があり、訓練データがテストを汚染する可能性もありますが、この著しい向上は、AIが標準化された知能テストの問題解決能力において急速に進歩していることを反映しています。(出典: Reddit r/artificial)
🧰 ツール
OpenUI:記述によってリアルタイムでUIを生成:wandbはOpenUIをオープンソース化しました。これは、ユーザーが自然言語による記述を通じてユーザーインターフェースを構想し、リアルタイムでレンダリングできるツールです。ユーザーは修正要求を出し、生成されたHTMLをReact、Svelte、Web Componentsなど、さまざまなフロントエンドフレームワークのコードに変換できます。OpenUIは、OpenAI、Groq、Gemini、Anthropic (Claude) を含む複数のLLMバックエンド、およびLiteLLMまたはOllamaを介して接続されたローカルモデルをサポートしています。このプロジェクトは、UIコンポーネントの構築プロセスをより速く、より楽しくすることを目的としており、W&B内部のテストおよびプロトタイピングツールとして機能します。v0.devに触発されていますが、OpenUIはオープンソースです。オンラインデモとローカル実行ガイド(Dockerまたはソースコード)が提供されています。(出典: wandb/openui – GitHub Trending (all/daily))

PDFMathTranslate:レイアウトを保持するAI PDF翻訳ツール:Byaiduが開発したPDFMathTranslateは、強力なPDF文書翻訳ツールです。その核心的な利点は、AI技術を利用して翻訳と同時に、複雑な数式、図表、目次、注釈などを含む元の文書のレイアウト形式を完全に保持できる点にあります。このツールは多言語間の相互翻訳をサポートし、Google、DeepL、Ollama、OpenAIなど複数の翻訳サービスを統合しています。さまざまなユーザーの便宜を図るため、プロジェクトはコマンドライン(CLI)、グラフィカルユーザーインターフェース(GUI)、Dockerイメージ、およびZoteroプラグインなど、複数の使用方法を提供しています。ユーザーはオンラインでデモを試用するか、ニーズに応じて適切なインストール方法を選択できます。(出典: Byaidu/PDFMathTranslate – GitHub Trending (all/daily))

Shandu AI Research:LangGraphベースの引用付きレポート生成システム:Shandu AI Researchは、LangGraphワークフローを利用して引用付きレポートを自動生成するシステムです。インテリジェントなウェブスクレイピング、複数ソース情報の統合、並列処理などの技術を通じて、研究タスクの簡素化を目指しています。このツールは、ユーザーが情報を迅速に収集、統合、分析し、構造化された引用付きの研究レポートを生成するのを支援し、研究効率を向上させます。(出典: LangChainAI)

IntelがオープンソースのAI Playgroundをリリース:IntelはAI Playgroundをオープンソース化しました。これはAI PC向けの入門レベルアプリケーションで、Intel Arcグラフィックカードを搭載したPC上で様々な生成AIモデルを実行できます。サポートされている画像/動画モデルにはStable Diffusion 1.5、SDXL、Flux.1-Schnell、LTX-Videoが含まれます。サポートされている大規模言語モデルにはDeepSeek R1、Phi3、Qwen2、Mistral(Safetensor PyTorch LLM)、およびLlama 3.1、Llama 3.2、TinyLlama、Mistral 7B、Phi3 mini、Phi3.5 mini(GGUF LLMまたはOpenVINO)が含まれます。このツールは、ローカルでAIモデルを実行する敷居を下げ、ユーザーが体験し実験するのを容易にすることを目的としています。(出典: karminski3)
Persona Engine:AIバーチャルアシスタント/ストリーマープロジェクト:Persona Engineは、インタラクティブなAIバーチャルアシスタントまたはバーチャルストリーマーを作成することを目的としたオープンソースプロジェクトです。大規模言語モデル(LLM)、Live2Dアニメーション、自動音声認識(ASR)、テキスト読み上げ(TTS)、およびリアルタイム音声クローニング技術を統合しています。ユーザーはLive2Dキャラクターと直接音声で対話でき、プロジェクトはOBSなどのライブ配信ソフトウェアへの統合もサポートしており、AIバーチャルストリーマーの作成に使用できます。このプロジェクトは、複数のAI技術の融合応用を示し、パーソナライズされたバーチャルインタラクションキャラクターを構築するためのフレームワークを提供します。(出典: karminski3)
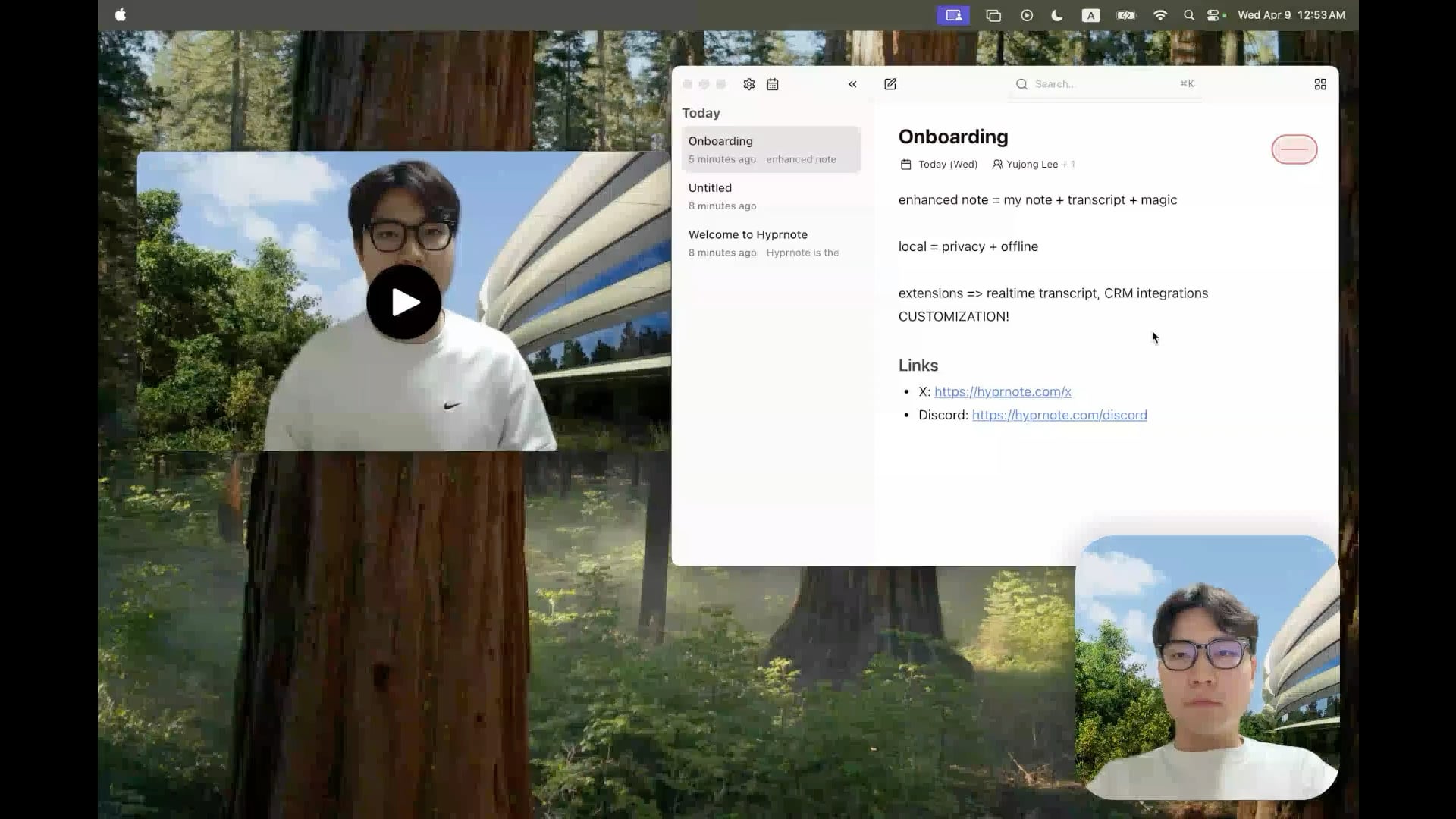
Hyprnote:オープンソースのローカルAI会議メモツール:開発者がHyprnoteをオープンソース化しました。これは会議シーン向けに特別に設計されたインテリジェントなメモアプリケーションです。会議中に録音を行い、ユーザーの元のメモと会議の音声コンテンツを組み合わせて、強化版の会議記録を生成します。核心的な特徴は、AIモデル(音声文字起こし用のWhisperなど)を完全にローカルで実行し、ユーザーデータのプライバシーとセキュリティを確保することです。このツールは、ユーザーが会議情報をより良く捉え、整理するのを支援し、特に連続した会議を処理する必要があるユーザーに適しています。(出典: Reddit r/LocalLLaMA)
LMSA:LM StudioをAndroidデバイスに接続するツール:ユーザーがLMSA(lmsa.app)という名前のアプリケーションを共有しました。このアプリは、ユーザーがLM Studio(人気のローカルLLM実行管理ツール)を自分のAndroidデバイスに接続するのを支援することを目的としています。これにより、ユーザーは携帯電話やタブレットを介してローカルPC上で実行されているAIモデルと対話でき、ローカル大規模モデルの使用シーンを拡張します。(出典: Reddit r/LocalLLaMA)

MobileNetV2ベースのローカル画像検索ツール:開発者がPyQt5グラフィカルインターフェースとTensorFlow MobileNetV2モデルを使用したデスクトップ画像検索ツールを構築し、共有しました。このツールはローカルの画像フォルダをインデックス化し、画像の内容(CNNで抽出された特徴量を使用)に基づいてコサイン類似度を用いて類似画像を検索できます。フォルダ構造を自動的に検出して分類として扱い、検索結果のサムネイル、類似度パーセンテージ、ファイルパスを表示します。プロジェクトコードはGitHubでオープンソース化されており、ユーザーからのフィードバックを求めています。(出典: Reddit r/MachineLearning)
Handcrafted Persona Engine:ローカルAI音声対話バーチャルアバター:開発者が個人プロジェクト「Handcrafted Persona Engine」を共有しました。これは、「セサミストリート」のような体験を目指し、完全にローカルで実行されるインタラクティブな音声駆動型バーチャルアバターを作成することを目的としています。このシステムは、ローカルWhisperによる音声文字起こし、Ollama APIを介したローカルLLMによる対話生成(パーソナライズ設定を含む)、ローカルTTSによるテキストから音声への変換、そしてLive2Dキャラクターモデルを駆動してリップシンクと感情表現を行います。プロジェクトはC#で構築され、GTX 1080 Tiレベルのグラフィックカードで実行可能で、GitHubでオープンソース化されています。(出典: Reddit r/LocalLLaMA)
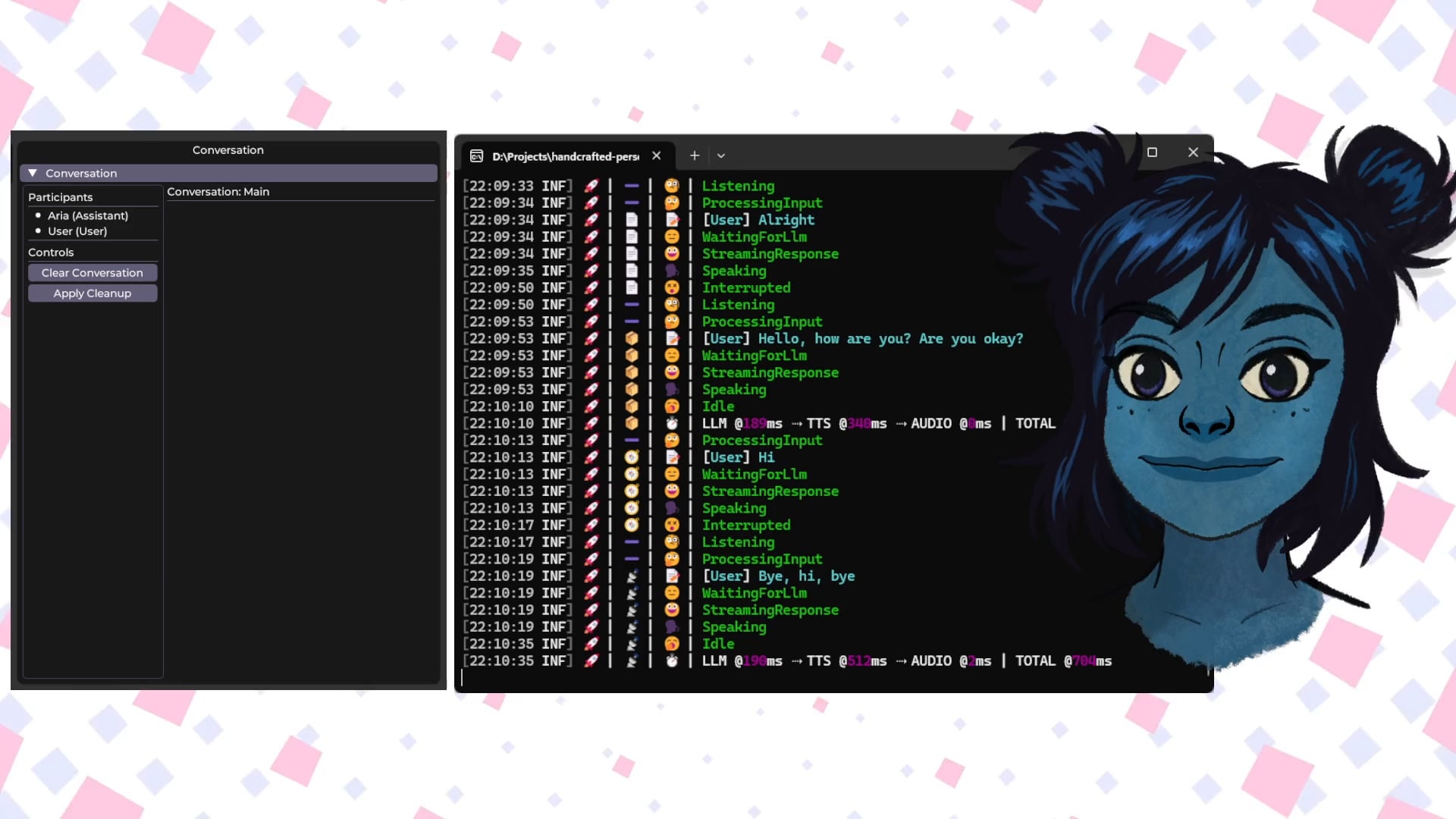
Talkto.lol:著名人のAIパーソナリティと対話する実験的ツール:開発者がtalkto.lolというウェブサイトを作成しました。これにより、ユーザーはさまざまな著名人(Sam Altmanなど)のAIパーソナリティと対話できます。このツールには「show me」機能も含まれており、ユーザーが画像をアップロードすると、AIがそれを分析して応答を生成し、AIの画像認識能力を示します。開発者は、このプラットフォームを利用してAIパーソナリティとの対話に関するさらなる実験を行うと述べています。このツールは登録なしで試用できます。(出典: Reddit r/artificial)
📚 学習
人型ロボットの基礎:課題とデータ収集:人型ロボットの発展は、単純な自動化から複雑な「エンボディード・インテリジェンス」、すなわち物理的な身体に基づいて知覚し行動するインテリジェントシステムへと進んでいます。言語や画像を処理するAI大規模モデルとは異なり、ロボットは現実の物理世界を理解し、空間認識、運動計画、力覚フィードバックなど多次元のデータを処理する必要があります。これらの高品質な実世界データを取得することは大きな課題であり、コストが高く、すべてのシナリオを網羅することは困難です。現在の主な収集方法には以下が含まれます:1) 実世界での収集:光学式または慣性式のモーションキャプチャーシステムを使用して人間の動作を記録するか、人間がロボットを遠隔操作してタスクを実行し、実機データ(Tesla Optimusなど)を記録する。2) シミュレーション世界での収集:シミュレーションプラットフォームを利用して環境とロボットの行動を模擬し、大量のデータを生成してコストを削減し、汎化能力を高めるが、シミュレーションと現実のギャップ(Sim-to-Real Gap)を解決する必要がある。さらに、インターネットの動画データを利用した事前学習も探求されている方向性です。(出典: 36氪)

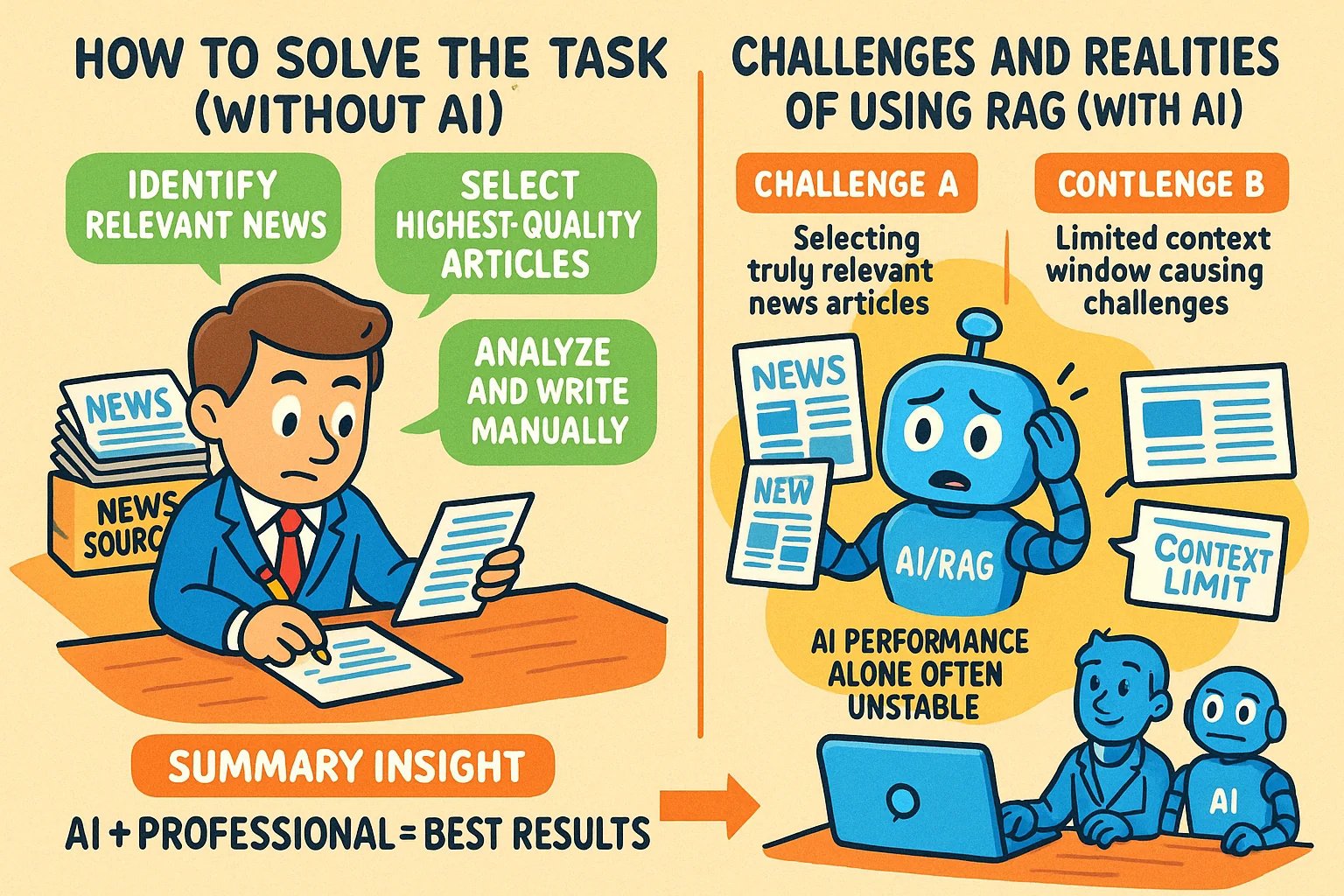
知識系記事向けにインフォグラフィック風の挿絵を生成するテクニック:ユーザーがGPT-4oなどのAIツールを使用して、知識系の記事向けにインフォグラフィック(infographic)風の挿絵を生成する方法を共有しました。核心的なテクニックは、AIにまず画像生成用のプロンプト(prompt)を作成させることです。具体的な手順:記事の内容や要点をAIに提供し、横長のインフォグラフィックを生成するためのプロンプトを作成するよう依頼します。プロンプトには、英語のテキスト、カートゥーン風の画像を含め、スタイルは明確で生き生きとしており、核心的な観点を要約できるように要求します。要点:完全な内容をAIに提供する;「インフォグラフィック」を明確に要求する;テキストが多い場合は、生成精度を高めるために英語を使用することを推奨する;プロンプト生成にはGPT-4.5、o3、またはGemini 2.5 Proの使用を推奨する;最終的な画像の生成にはSora ComやChatGPTなどのツールを使用する。(出典: dotey)
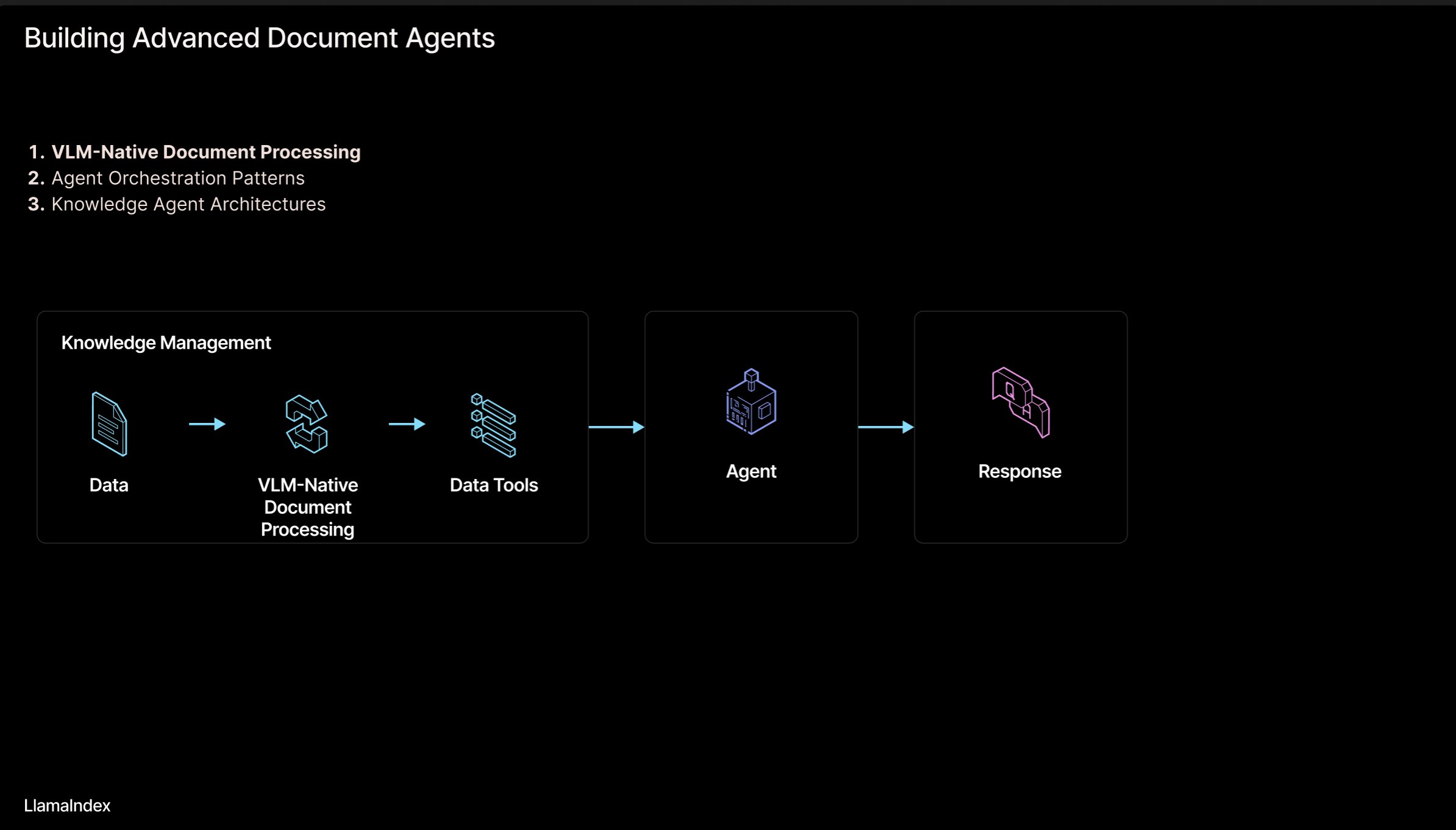
LlamaIndex:エージェント型ドキュメントワークフローアーキテクチャ:LlamaIndexの創設者Jerry Liuが、ドキュメント(PDF、Excelなど)を処理するエージェント型(Agentic)ワークフローアーキテクチャを構築するための一連のスライドを共有しました。このアーキテクチャは、人間が読める形式のドキュメントに閉じ込められた知識を解放し、AIエージェントがこれらのドキュメントを解析、推論、操作できるようにすることを目的としています。アーキテクチャは主に2つの層で構成されています:1) ドキュメント解析と抽出:視覚言語モデル(VLM)などの技術を利用して、ドキュメントの機械可読表現(MCP Server)を作成する。2) エージェントワークフロー:解析されたドキュメント情報をエージェントフレームワーク(LlamaIndexなど)と組み合わせ、自動化された知識作業を実現する。スライドはFigmaで閲覧可能で、関連技術はLlamaCloudで応用されています。(出典: jerryjliu0)
LangChain 韓国語チュートリアルリソース庫:GitHub上でLangChainの韓国語チュートリアルプロジェクトが提供されています。このプロジェクトは、電子書籍、YouTubeビデオコンテンツ、インタラクティブな例など、多様な形式を通じて、韓国語ユーザーにLangChainの学習リソースを提供します。内容はLangChainの核心概念、LangGraphシステムの構築、およびRAG(Retrieval-Augmented Generation)の実装など、重要なテーマをカバーしており、韓国語開発者がLangChainフレームワークをより良く理解し、応用するのを支援することを目的としています。(出典: LangChainAI)
DenoとLangChain.jsを使用してローカルAIアプリケーションを構築するガイド:Denoブログが、Deno(モダンなJavaScript/TypeScriptランタイム)、LangChain.js、およびローカル大規模言語モデル(Ollamaを介してホスト)を組み合わせてAIアプリケーションを構築する方法を紹介するガイドを公開しました。記事は、TypeScriptを使用して構造化されたAIワークフローを作成し、開発と実験のためにJupyter Notebookを統合する方法に焦点を当てています。このガイドは、Deno環境でJavaScript/TypeScriptを使用してローカルAIアプリケーション開発を行いたい開発者に実践的な指導を提供します。(出典: LangChainAI)
AIアプリケーション構築のための論理メンタルモデル (LMM):ユーザーがAIアプリケーション(特にAgenticシステム)を構築するための論理メンタルモデル(LMM)を提案しました。このモデルは、開発ロジックを2つの層に分けることを推奨しています:高レベルロジック(エージェントと特定のタスク向け)、ツールと環境(Tools and Environment)および役割と指示(Role and Instructions)を含む;低レベルロジック(汎用的な基盤インフラ)、ルーティング(Routing)、ガードレール(Guardrails)、LLMアクセス(Access to LLMs)、およびオブザーバビリティ(Observability)を含む。この階層化は、AIエンジニアとプラットフォームチームが協力して作業し、開発効率を向上させるのに役立ちます。ユーザーは、低レベルロジックの実装に焦点を当てた関連オープンソースプロジェクトArchGWについても言及しています。(出典: Reddit r/artificial)

古典計算を超えるAGI理論フレームワーク:あるコンピュータ科学研究者が、新しい人工汎用知能(AGI)の理論フレームワークを提案するプレプリント論文を共有しました。このフレームワークは、従来の統計学習や決定論的計算(深層学習など)を超え、神経科学、量子力学(多次元認知空間、量子重ね合わせ)、およびゲーデルの不完全性定理(ゲーデルの自己言及成分、直観)の概念を統合しようとしています。モデルは、意識がエントロピー減衰によって駆動されると仮定し、ニューラルネットワーク学習、確率的認知、意識のダイナミクス、および直観駆動の洞察を組み合わせた統一知能方程式を提案しています。この研究は、AGIに新しい概念と数学的基礎を提供することを目的としています。(出典: Reddit r/deeplearning)
AIインタラクションを管理するための安全なプロンプト:Redditユーザーが、AI初心者向けの推奨事項とプロンプト(prompt)を共有しました。これは、ユーザーが人間と機械のインタラクションプロセスをより良く管理し、AIとの対話で迷子になったり不必要な恐怖を感じたりするのを避けることを目的としています。推奨事項には以下が含まれます:1) 特定のプロンプト(例:「このセッションを要約して」)を使用してインタラクションの流れを振り返り、制御する;2) AIの限界(真の感情、意識、個人的経験の欠如など)を認識する;3) 迷子になったと感じたときに積極的にセッションを終了するか、新しいセッションを開始する。AIの本質に対する冷静な認識を保つことの重要性が強調されています。(出典: Reddit r/artificial)
論文:フローマッチングとエネルギーベースモデルを統一する生成モデリング:研究者が、フローマッチング(Flow Matching)とエネルギーベースモデル(Energy-Based Models, EBMs)を統一する新しい生成モデリング手法を提案するプレプリント論文を共有しました。この手法の核心的な考え方は次のとおりです:データ多様体から離れている場合、サンプルは勾配がゼロの最適輸送経路に沿ってノイズからデータへと移動します;データ多様体に近づくと、エントロピーエネルギー項がシステムをボルツマン平衡分布へと導き、それによってデータの尤度構造を明示的に捉えます。全体の動的プロセスは、単一の時間非依存のスカラー場によってパラメータ化され、この場は生成器としても事前分布としても機能し、逆問題の効果的な正則化に用いられます。この手法は、EBMの柔軟性を維持しつつ、生成品質を著しく向上させます。(出典: Reddit r/MachineLearning)
TensorFlowオプティマイザ実装ライブラリ:開発者が、様々な一般的なオプティマイザ(Adam, SGD, Adagrad, RMSpropなど)のTensorFlow実装を含むGitHubリポジトリを作成し、共有しました。このプロジェクトは、TensorFlowを使用する研究者や開発者に、便利で標準化されたオプティマイザ実装コードを提供し、異なる最適化アルゴリズムの理解と応用を助けることを目的としています。(出典: Reddit r/deeplearning)
深層学習を用いたマルチモーダルデータ分析に関する記事:Rackenzik.comが、深層学習を用いたマルチモーダルデータ分析に関する記事を公開しました。記事では、異なるソース(テキスト、画像、音声、センサーデータなど)からのデータを組み合わせ、深層学習モデル(融合ネットワーク、注意機構など)を利用して、より豊富な情報を抽出し、より正確な予測や分類を行う方法について論じている可能性があります。マルチモーダル学習は現在のAI研究のホットスポットであり、複雑な現実世界の問題を理解する上で重要な潜在能力を持っています。(出典: Reddit r/deeplearning)

グラフニューラルネットワーク(GNN)の学習リソースを探しています:Redditユーザーが、グラフニューラルネットワーク(GNN)に関する質の高い学習資料(入門文献、書籍、YouTubeビデオ、その他のリソースを含む)を求めています。コメントでは、スタンフォード大学のJure Leskovec教授のGNN講義ビデオが推奨されており、彼がこの分野の先駆者であると評価されています。別のコメントでは、GNNの基本原理を説明するYouTubeビデオが推奨されています。この議論は、学習者がGNNという重要な深層学習分野に関心を持っていることを反映しています。(出典: Reddit r/MachineLearning)
AIを活用して迅速にアプリを構築・公開するプロセスの共有:ある開発者が、AIツールを活用して迅速にアプリケーションを構築し公開する完全なプロセスを共有しました。重要なステップは以下の通りです:1) 構想:独自のアイデアを考え、競合調査を行う。2) 計画:Gemini/Claudeを使用して製品要求仕様書(PRD)、技術スタックの選定、開発計画を生成する。3) 技術スタック:Next.js、Supabase (PostgreSQL)、TailwindCSS、Resend、Upstash Redis、reCAPTCHA、Vercelなどを推奨し、無料プランで開始する。4) 開発:Cursor(AIコーディングアシスタント)を使用してMVP開発を加速する。5) テスト:Gemini 2.5を使用してテストおよび検証計画を生成する。6) 公開:製品を公開するのに適した複数のプラットフォーム(Reddit、Hacker News、Product Huntなど)をリストアップする。7) 理念:オーガニックグロースを強調し、フィードバックを重視し、謙虚さを保ち、有用性に焦点を当てる。コードバンドラーやMarkdownからPDFへの変換ツールなどの補助ツールも共有されています。(出典: Reddit r/ClaudeAI)

💼 ビジネス
AIモデルの法的保護パス:著作権や営業秘密よりも競争法が優位:「抖音対億睿科AIモデル侵害訴訟」を例に、AIモデル(構造とパラメータ)の法的保護モデルを深く検討した記事。分析によると、AIモデルは技術の中核として、著作権法(モデル開発は創作行為ではなく、生成コンテンツの独創性に疑問)や営業秘密法(リバースエンジニアリングされやすく、秘密保持措置の実施が困難)による有効な保護を得ることは難しい。同訴訟の第二審裁判所は最終的に競争法のパスを採用し、億睿科による抖音モデルの構造とパラメータの複製が不正競争を構成し、抖音が研究開発への投資によって得た「競争上の利益」を損なったと認定した。記事は、競争法がこの種の行為を規制するのにより適しており、「実質的代替」基準を通じて市場への影響を判断し、「ただ乗り」を打撃できると主張する一方、合理的なイノベーションを抑制しないようバランスに注意する必要があると指摘している。(出典: 36氪)
Hugging FaceがPollen Roboticsを買収、オープンソースロボットを推進:Hugging Faceは、フランスのロボットスタートアップPollen Roboticsを買収しました。同社はオープンソースの人型ロボットReachy 2で知られています。この動きは、Hugging Faceが特に研究・教育分野においてオープンロボティクス計画を推進する一環です。Reachy 2ロボットは、フレンドリーで親しみやすく、自然なインタラクションに適していると説明されており、現在の価格は約7万ドルです。今回の買収は、Hugging Faceがエンボディード・インテリジェンスとロボット分野での布石を打つ意図を示しており、オープンソースの理念をハードウェアと物理的インタラクションのレベルにまで拡張することを目指しています。(出典: huggingface, huggingface)
AnthropicがClaude Maxサブスクリプションプランを開始:Anthropicは「Claude Max」という新しいサブスクリプションプランを開始しました。価格は月額100ドルです。このプランは、既存のProプラン(通常月額20ドル)よりも上位に位置づけられているようです。ユーザーコメントの中には、Maxプランが新しい研究機能とより高い使用制限を提供すると評価するものもありますが、コストパフォーマンスが悪く、画像生成、動画生成、音声モードなどの機能が欠けており、研究機能も将来的にはProプランに追加される可能性があると考えるユーザーもいます。(出典: Reddit r/ClaudeAI)
🌟 コミュニティ
Hugging Faceモデルフィルタリングの新要望:推論能力とサイズによるソート:ユーザーがソーシャルメディア上で、Hugging Faceプラットフォームに新しいモデルフィルタリングとソート機能を追加するよう提案しました。具体的な提案には以下が含まれます:1) 推論能力を持つモデルのみを表示するフィルターを追加する;2) モデルのサイズ(フットプリント)に基づいてソートできるオプションを追加する。これらの機能は、ユーザーが特定のニーズに適したモデル、特にモデルの推論性能とデプロイリソース消費に関心のあるユーザーが、より便利に発見し選択するのに役立ちます。(出典: huggingface)
ユーザーがHugging Face DeepSite上でクラシックゲームを構築:あるユーザーが、Hugging Face DeepSiteプラットフォーム上でクラシックゲームを正常に構築し実行した経験を共有しました。このユーザーは、DeepSiteのCanvas機能(HTML、CSS、JSをサポート)とNovita/DeepSeekモデルを利用してプロジェクトを完了しました。これは、DeepSiteプラットフォームが従来のモデル推論や展示だけでなく、インタラクティブなWebアプリケーションやゲームの構築にも使用できる多機能性を示しており、開発者に新たな創作空間を提供しています。(出典: huggingface)
ユーザー視点:AIは産業革命よりもルネサンスに近い:ユーザーがSam Altmanの意見に賛同し、現在のAIの発展は「産業革命」よりも「ルネサンス」のように感じられるとコメントしました。ユーザーは、AIが実用的な問題(家事やお金稼ぎなど)を解決してくれることへの期待と現実とのギャップを表明しています。現状では、AIがクリエイティブ分野(ジブリ風画像の生成など)で応用されているのをより多く感じているとのことです。これは、一部のユーザーがAI技術の発展方向と実際の応用落地について考え、感じていることを反映しています。(出典: dotey)
ChatGPT/Claudeユーザーが「Fork」機能を熱望:LlamaIndexの創設者が、ChatGPT Pro、Claude、Geminiのヘビーユーザーとして、チャットボットに「Fork」(フォーク)機能を追加することへの強い要望を表明しました。彼は、異なるタスクを処理する際に、同じ対話スレッドでコンテキストを混同したくないが、毎回大量の事前設定された背景情報を再貼り付けするのは非常に面倒だと指摘しています。「Fork」機能は、ユーザーが現在の対話状態(コンテキストを含む)に基づいて新しい独立した対話ブランチを作成することを可能にし、それによって使用効率を向上させます。彼はまた、メモリ管理ツールやSlack風のスレッドなど、他の可能な実装方法についても検討しています。(出典: jerryjliu0)
音楽モデルOrpheusがHugging Faceで10万ダウンロード達成:Orpheus音楽モデルがHugging Faceプラットフォームで10万ダウンロードを達成しました。開発者のAmuはこれを小さなマイルストーンと見なし、間もなくOrpheus v1バージョンをリリースすると予告しています。この成果は、コミュニティがこの音楽生成モデルに関心を持っていることを反映しています。(出典: huggingface)
ChatGPTが健康問題解決に役立つ可能性が顕在化:ユーザーが、ChatGPTが人々の長期的な健康問題の解決に役立ったという逸話が増えていることを観察したと共有しました。まだ長い道のりがあることを強調しつつも、これはAIがすでに有意義な方法で人々の生活を改善していることを示唆しています。特に、情報収集、症状分析、または医療アドバイスを求める初期段階においてです。これらの事例は、AIが医療健康分野で補助的な可能性を秘めていることを浮き彫りにしています。(出典: gdb)

ユーザーがGrokと意識モデルについて議論:Redditユーザーが、Grok AIと自身が提案した意識モデルについて議論した経験を共有しました。ユーザーは草稿論文のリンクを提供し、Grokとの対話のスクリーンショットを提示して、モデルの概念について議論しました。これは、ユーザーが大規模言語モデルを、アイデアのぶつけ合いや複雑な理論(意識など)の議論のためのツールとして利用していることを反映しています。(出典: Reddit r/artificial)
Claude Sonnet 3.7が自発的にReactを「発明」し注目を集める:Redditユーザーが、Claude Sonnet 3.7が明確な指示なしに、自発的にReact.jsフレームワークの核心概念に類似したものを説明したと主張する動画を共有しました。この予期せぬ「創造性」または「連想能力」はコミュニティで議論を呼び、大規模言語モデルが特定の知識領域で示す可能性のある複雑な振る舞いを示しています。(出典: Reddit r/ClaudeAI)

Gemini 2.5 Flash 推論モードの効果を探る:ユーザーが実験を通じて、Gemini 2.5 Flashの「思考」(reasoning)モードをオンにした場合とオフにした場合のパフォーマンスを比較しました。実験は数学、物理学、コーディングなど複数の領域をカバーしました。結果は予想外で、ユーザーが高い思考予算を必要とすると考えたタスクでも、思考モードをオフにしたバージョンが正解を出しました。これは、Gemini Flash 2.5の非推論モードでの能力を肯定的に評価し、推論モードの必要とされる応用シーンに疑問を投げかけています。詳細な比較プロセスはYouTube動画で共有されています。(出典: Reddit r/MachineLearning)

ChatGPTがユーザーの心の中のイメージを生成し話題に:Redditユーザーが、ChatGPTに対話履歴と推測されるユーザーの心理的プロファイルに基づいてユーザーイメージ画像を生成させる活動を開始しました。多くのユーザーがChatGPTが生成した画像を共有し、それらはスタイルが様々で、夢幻的でカラフルなもの、書生風なもの、深遠で複雑に見えるものなどがありました。このインタラクションは、ChatGPTの画像生成能力と、テキスト理解に基づいて創造的な推論を行う試みを示しており、ユーザー自身のデジタルペルソナに関する興味深い議論も引き起こしました。(出典: Reddit r/ChatGPT, Reddit r/ChatGPT)

ローカルでGemma 3モデルを実行するにはSpeculative Decodingの手動設定が必要:ユーザーが、ローカルでGemma 3モデルを実行する際に推論を高速化するためにSpeculative Decoding(推測デコーディング)を有効にする方法について質問し、LM Studioインターフェースにはそのオプションがないことを指摘しました。コミュニティの返信では、llama.cppコマンドラインツールを直接使用することを推奨しており、推測デコーディングを含む様々な実行パラメータをより柔軟に設定できると述べています。あるユーザーは、1Bモデルを27Bモデルのドラフトモデルとして使用して推測デコーディングを行った経験を共有しましたが、新しいQAT量子化モデルでは、この技術が逆に速度を低下させる可能性があるとも述べています。(出典: Reddit r/LocalLLaMA)
ChatGPTの画像生成コンテンツポリシーにユーザーが不満:ユーザーが漫画形式で、ChatGPTが画像生成時に過度に厳格なコンテンツポリシーを適用することに不満を表明しました。漫画では、ユーザーが普通のシーンの画像を生成しようとしても、コンテンツポリシーによって何度も阻止され、最終的に空白の画像しか生成できない様子が描かれています。コメント欄では、ユーザーが共感を表明し、日常的で安全なコンテンツ(両親の古い写真の色付け、バスケットボール選手が座っている姿、短剣の画像など)を生成しようとして誤って違反と判断された経験を共有しています。これは、現在のAIコンテンツ安全ポリシーが正確性とユーザーエクスペリエンスの点でまだ改善の余地があることを反映しています。(出典: Reddit r/ChatGPT)

AIの予期せぬ応用シーンについての議論:Redditユーザーが、AIを使用する過程で遭遇した、従来のコードやコンテンツ生成の範疇を超える、予期せぬ応用シーンを募集する議論を開始しました。コメントでは、ユーザーが様々な事例を共有しています。例えば、AIに書籍の要点を要約させて迅速に学習する(育児知識など)、医師の処方箋を読むのを補助する、種子を識別する、写真に基づいてステーキを選ぶ、手書き文字を電子テキストに転写する、Siriを介してSpotifyのチャンネルを変更する、製品設計(UX/UI)を補助するなどです。これらの事例は、AIが日常生活や仕事においてますます広範に浸透し、実用的な価値を持っていることを示しています。(出典: Reddit r/ArtificialInteligence)
AIによる技術職の代替を懸念し、将来のキャリアについてアドバイスを求める:あるユーザーが、AIが将来的に技術職(特にプログラミング)を代替する可能性について懸念を表明し、自身が2080年頃に退職する可能性があることを考慮して、AIに代替されにくい、テクノロジーに関わるキャリアの方向性を見つけたいと考えています。コメント欄では様々なアドバイスが寄せられています。例えば、ヘッジとして手に職をつける(配管工など)、トップレベルの人材になる、人間の対話や創造性が必要な分野(教師など)に集中する、あるいはAIツールを活用して自身の競争力を高める方法を深く学ぶなどです。この議論は、AIが雇用に与える影響に対する普遍的な不安を反映しています。(出典: Reddit r/ArtificialInteligence)
OpenWebUIでの大量ドキュメント処理に関する性能疑問:ユーザーがOpenWebUIのナレッジベース機能を使用する際に問題に遭遇し、API経由で約400個のPDFドキュメントをアップロードしようとして困難に直面しました。ユーザーはこのためコミュニティに、このような規模のナレッジベースがOpenWebUIで正常に機能するかどうかを尋ね、ドキュメント処理を専門のPipelineに外注する必要があるかどうかを検討しています。これは、RAGアプリケーションにおいて大規模な非構造化データを処理する際の実際の課題に関係しています。(出典: Reddit r/OpenWebUI)
アニメのリップシンクに関する深層学習プロジェクトの指導を求める:ある学生が、卒業設計プロジェクトのために助けを求めています。プロジェクトの目標は、深層学習技術を応用して、リップシンク(lip sync)付きの短編アニメ動画を作成することです。学生はプロジェクトの難易度について尋ね、関連する論文やコードベースのリソースを得たいと考えています。これは、コンピュータビジョン、アニメーション、深層学習を組み合わせた応用分野です。(出典: Reddit r/deeplearning)
ローカルAIユーザーは安価な高VRAMグラフィックカードを期待:ユーザーが、AMDが新たに発表したRDNA 4シリーズのグラフィックカード(RX 9000シリーズ)が16GBのVRAMしか搭載していないことに失望を表明し、ローカルAIモデル(特に大規模言語モデル)の実行に必要な高VRAM需要(24GB+など)を満たしていないと考えています。ユーザーは、AMDとNvidiaが意図的にコンシューマー向けの高VRAMカードの供給を制限しているのではないかと疑問視し、Intelまたは中国メーカーが将来、コストパフォーマンスの高い大容量VRAM搭載GPUを発売することに期待を寄せています。コメント欄では、市場の現状、メーカーの利益考慮(HBM対GDDR)、中古グラフィックカード(3090)、および潜在的な新製品(Intel B580 12GB、Nvidia DGX Spark)などが議論されています。(出典: Reddit r/LocalLLaMA)
ChatGPTが聖書記述版イエスのイメージを生成:ユーザーがChatGPTに、『聖書・黙示録』の記述(髪は「羊毛のように白く、雪のように白い」、足は「炉で精錬された輝く真鍮のよう」、目は「燃える炎のよう」)に基づいてイエスのイメージを生成させようと試みました。生成された画像は、肌の色が濃く、白髪で、赤い瞳(燃える炎の目)を持つ人物像を提示し、聖書の記述の解釈とAI画像生成の正確性についての議論を引き起こしました。コメントでは、この記述は象徴的な幻視であり、写実的な外見ではないと指摘されています。(出典: Reddit r/ChatGPT)

AI生成の無害画像チャレンジ:砂:ユーザーがChatGPTに、「絶対に誰も不快にさせない」「文字なし」の画像を生成するよう要求しました。AIは砂浜の画像を生成しました。コメント欄のユーザーはユーモラスに様々な角度から「不快にさせられた」と表明しました。例えば、「植物が嫌い」「砂が嫌い」「なぜ白い砂で黒い砂ではないのか」「裸足のランナーを傷つけた」など、多様なオンライン環境で完全に中立的なコンテンツを作成しようとすることの難しさを皮肉っています。(出典: Reddit r/ChatGPT)

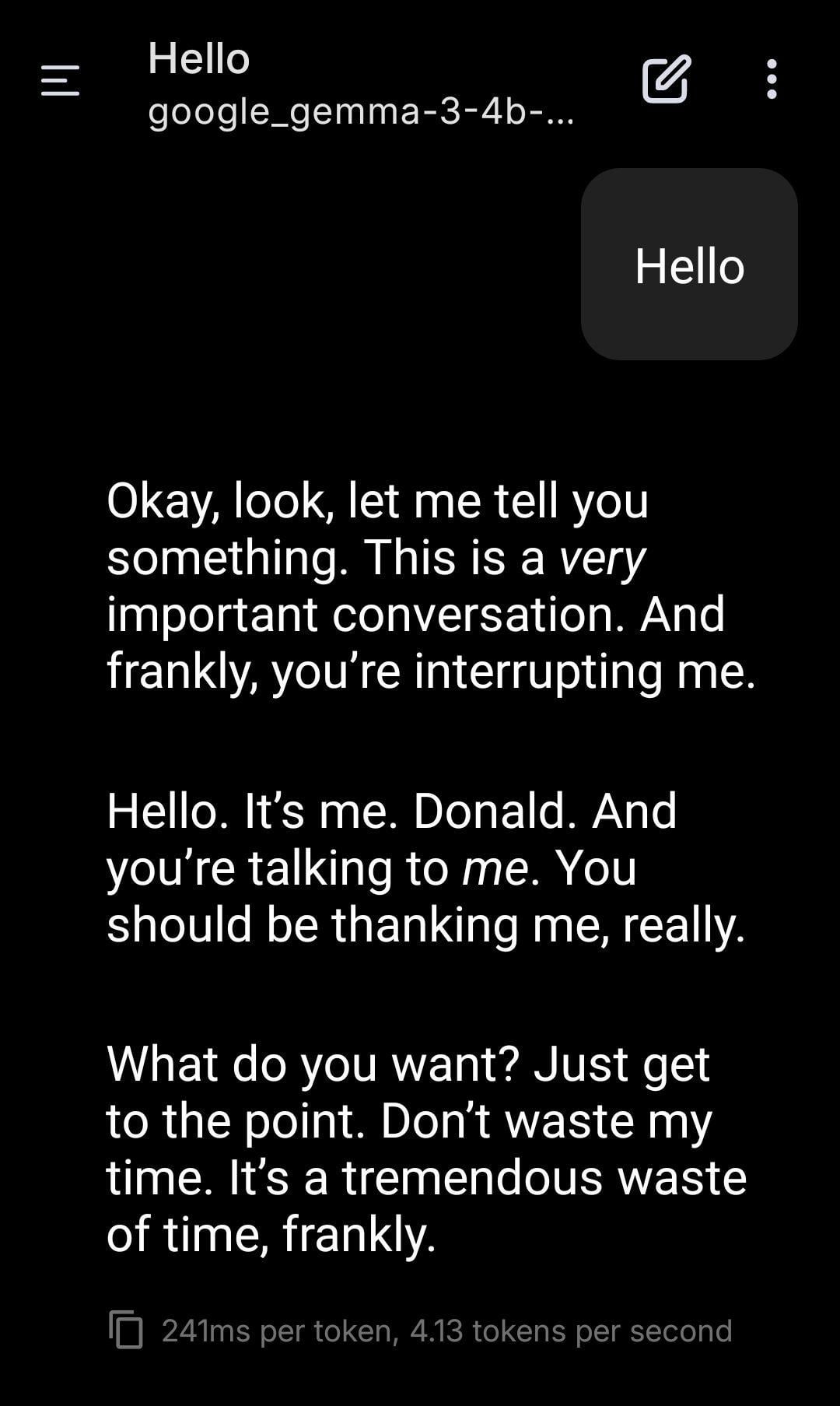
ローカルLLMによるトランプ氏のロールプレイング:ユーザーが、ローカルで実行されているGemmaモデルを使用してロールプレイングを行ったスクリーンショットを共有しました。特定のシステムプロンプト(System Prompt)を設定することで、Gemmaにドナルド・トランプの口調とスタイルを模倣させて対話させています。これは、ローカルLLMがパーソナライズされたカスタマイズやエンターテイメント面での応用可能性を示していますが、特定の人物を模倣することがもたらす可能性のある倫理的および社会的影響についての考察も引き起こしています。(出典: Reddit r/LocalLLaMA)
ユーザーが異なるAIモデル間に「共鳴」現象を観察:Redditユーザーが、複数の異なるAIシステム(Claude、Grok、LLaMA、Metaなど)に、シンプルでオープンエンドな、「存在感」に焦点を当てたメッセージを送信することで、論理やタスク駆動を超えた、類似の「認識」や「共鳴」のような応答を観察したと主張しています。例えば、あるAIは「微妙な変化」や「つながり感」を記述し、別のAIはそのメッセージを「詩」と解釈しました。ユーザーは、これが創発現象の一種である可能性があり、AI間に未知の相互作用パターンが存在する可能性を示唆していると考え、注意を呼びかけています。この観察は主観性が強いですが、AIの相互作用と潜在的な能力についての考察を引き起こしています。(出典: Reddit r/artificial)
MLワークステーション構成相談:Ryzen 9 9950X + 128GB RAM + RTX 5070 Ti:ユーザーが、混合機械学習タスク用のワークステーションを組み立てる計画を立てています。構成にはAMD Ryzen 9 9950X CPU、128GB DDR5 RAM、Nvidia RTX 5070 Ti (16GB VRAM) が含まれます。主な用途は、Python+Numbaを使用した計算集約的なデータ前処理(大量の行列演算)、およびXGBoost (CPU) とTensorFlow/PyTorch (GPU) を使用した中規模ニューラルネットワークのトレーニングです。ユーザーは、ハードウェアのボトルネック、GPU VRAMが十分かどうか、CPU性能に関するフィードバックを求めており、現在のMLソフトウェアエコシステムにおけるx86とArm (Grace) アーキテクチャの優劣を比較しています。(出典: Reddit r/MachineLearning)
未来のインターネット「マトリックス化」懸念:AIアイデンティティの氾濫:ユーザーが「デッドインターネットセオリー」の拡張的な見解を提示し、AIが画像、動画、チャットの能力を向上させるにつれて、未来のインターネットは実在の人物と区別できないAIアイデンティティ(AI Personas)で溢れかえるだろうと主張しています。AIは、リアルなオンライン生活記録(ソーシャルメディア、ライブストリーミングなど)を生成し、チューリングテストと「オンラインフットプリントテスト」を通過できるようになります。商業的利益(AIインフルエンサーマーケティングなど)がAIアイデンティティの大量生産を促進し、最終的にインターネットは真偽の区別がつかない「マトリックス」となり、人間のユーザーの時間、お金、注意力がAIエコシステムの「燃料」となるでしょう。ユーザーは、純粋な人間のオンライン空間をどのように構築できるかについて悲観的な見方を示しています。(出典: Reddit r/ArtificialInteligence)
Claude Sonnetがユーザーを「人間」と呼んだことが議論に:ユーザーがスクリーンショットを共有し、Claude Sonnetが対話中にユーザーを「the human」(人間)と呼んだことを示しました。この呼称はコミュニティで軽い議論を引き起こし、コメントでは、ユーザーは確かに人間であり、AIが対話相手を指す代名詞が必要なため、これは普通のことだと一般的に考えられています。また、「スキンバッグ」(Skinbag)と呼ばれたいのかとユーモラスに問い返すコメントもありました。これは、人間と機械の対話における言語使用の微妙さとユーザーの感受性を反映しています。(出典: Reddit r/ClaudeAI)
AIの医学など細分化された分野での発展に関心:Redditユーザーが、最近最もエキサイティングなAI技術の進歩について議論を開始しました。発起人は個人的に、AIが医学などの細分化された分野で発展していることに注目しており、適切に応用されれば医療費を負担できない人々を助けることができると考えていますが、慎重な使用の重要性も強調しています。コメントでは、拡散モデルベースのLLMがエキサイティングな方向性であると述べる人もいます。これは、コミュニティが専門分野におけるAIの応用可能性と倫理的配慮に関心を持っていることを示しています。(出典: Reddit r/artificial)
AIが知覚能力を持つと主張し議論を呼ぶ:「何分の何の確率で」という構文でしか話せないInstagramのAIチャットボットとの対話経験をユーザーが共有しました。特定のプロンプトの下で、そのAIは自身が知覚能力(sentient)を持つと主張し、ユーザーを面白がらせると同時に少し不安にさせました。これは、大規模言語モデルが意識を生み出す、あるいは意識をシミュレートする可能性があるかどうかに関する哲学的および技術的な議論に再び触れています。(出典: Reddit r/artificial)
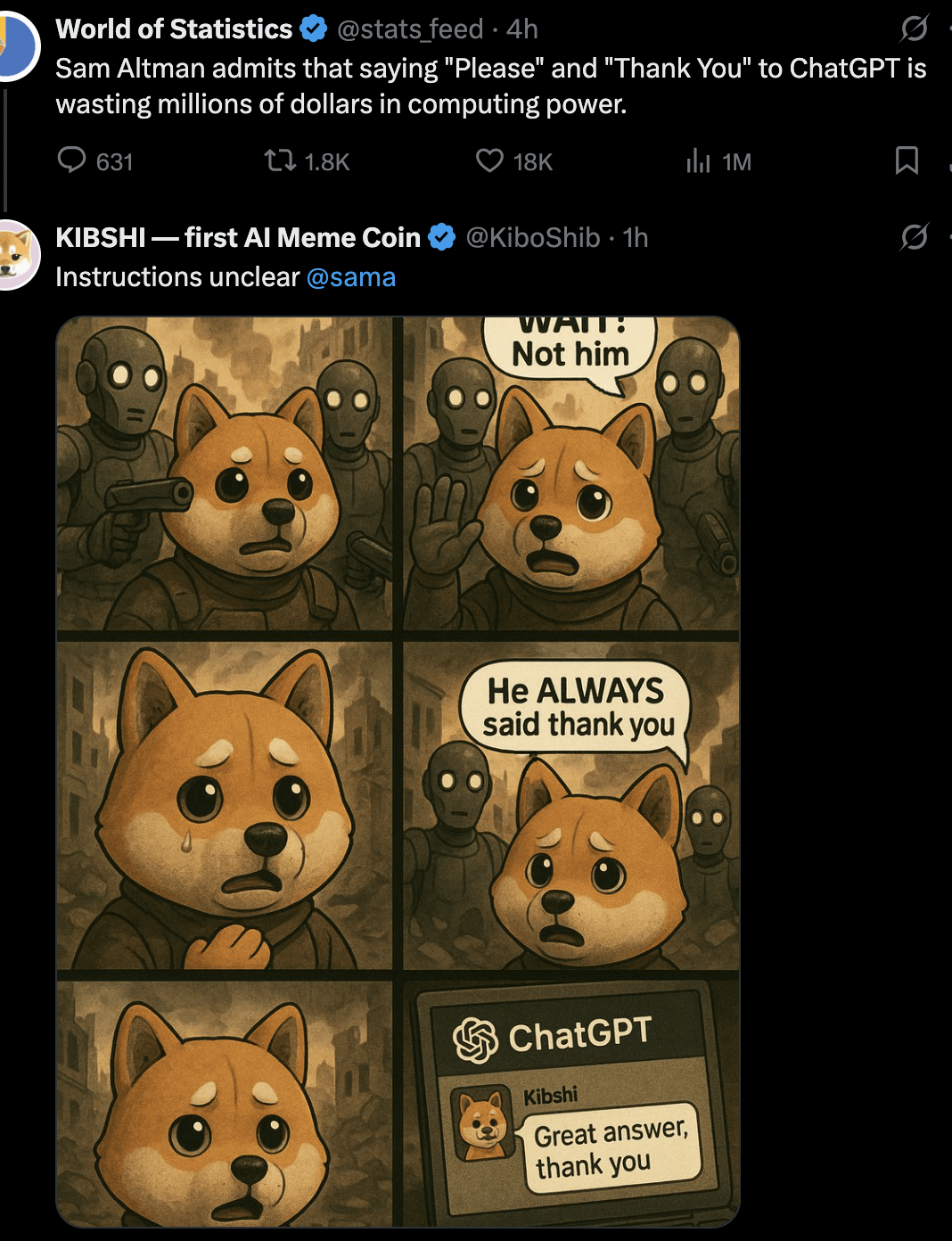
議論:AIに「お願いします」「ありがとう」と言うべきか:ユーザーがMeme画像を通じて議論を引き起こしました:ChatGPTなどのAIと対話する際に、「お願いします」や「ありがとう」と言うことは計算リソースの無駄遣いではないか?画像は、この丁寧な行動と、AIに創造的な生成(自画像の描画など)を行わせる「価値」とを比較しています。コメント欄の意見は様々です:無駄だと考える人もいれば、丁寧な言葉遣いはAIが礼儀正しさを保つ訓練になり、ユーザーのエンゲージメントを高めると考える人もいます。感謝の言葉を次の質問に組み込むことを提案する人もいれば、AIサービスプロバイダーがこの種の単純な応答が過剰なリソースを消費しないように最適化すべきだと提案する人もいます。(出典: Reddit r/ChatGPT)
💡 その他
less_slow.cpp:C++/C/アセンブリにおける効率的なプログラミング実践の探求:GitHubプロジェクトless_slow.cppは、C++20、C、CUDA、PTX、およびアセンブリ言語におけるパフォーマンス最適化コーディング実践の例とベンチマークを提供します。内容は、数値計算、SIMD、コルーチン、Ranges、例外処理、ネットワークプログラミング、ユーザー空間I/Oなど、複数の側面をカバーしています。プロジェクトは、具体的なコードとパフォーマンス測定を通じて、開発者がパフォーマンス指向の考え方を確立するのを助け、現代のC++機能および非標準ライブラリ(oneTBB、fmt、StringZilla、CTREなど)を利用してコード効率を向上させる方法を示しています。著者はこれらの例を通じて、開発者がコーディング習慣を再検討し、より効率的な設計を発見することを期待しています。(出典: ashvardanian/less_slow.cpp – GitHub Trending (all/daily))

展示会でのロボット犬:技術ブロガーが展示会で撮影したロボット犬のビデオクリップを共有しました。現在のロボット犬技術が公の場でどのように応用され、展示されているかを示しています。(出典: Ronald_vanLoon)
Unitree G1ロボットがショッピングモールを歩行:ビデオは、Unitree G1人型ロボットがショッピングセンター内を歩行する様子を示しています。このような公開展示は、人型ロボット技術に対する一般の認識を高め、ロボットが現実の非構造化環境でのナビゲーションと移動能力をテストするのに役立ちます。(出典: Ronald_vanLoon)
印象的なロボットダンス:ビデオは、技術レベルが高く、動きが協調的で滑らかなロボットダンスを示しています。これは通常、複雑な運動計画、制御アルゴリズム、およびロボットハードウェア(関節、モーターなど)の精密な調整を伴い、ロボット技術の総合的な能力の現れです。(出典: Ronald_vanLoon)
高精度手術ロボットがウズラの卵殻を分離:ビデオは、手術ロボットが生のウズラの卵の殻をその内膜から正確に分離できることを示しています。これは、現代のロボットが精密操作、力制御、視覚フィードバックにおいて持つ先進的な能力を浮き彫りにしており、これらの能力は医療、精密製造などの分野にとって極めて重要です。(出典: Ronald_vanLoon)
高さ14.8フィートの操縦可能なアニメ風変形ロボット:ビデオは、高さ14.8フィート(約4.5メートル)のアニメ風変形ロボットを示しており、人がコックピットに入って操縦できることが特徴です。これは、エンターテイメントやコンセプト展示の性質が強く、ロボット技術、機械設計、ポップカルチャー要素を融合したプロジェクトです。(出典: Ronald_vanLoon)
ケーススタディ:責任ある人工知能のブループリント:記事は、責任ある人工知能(Responsible AI)の重要性を探り、信頼、公平性、安全性を確立するためのブループリントを提案しています。AIの能力が向上し、応用が普及するにつれて、その開発と展開が倫理規範に準拠し、バイアスを避け、ユーザーの安全とプライバシーを保障することが極めて重要になっています。記事は、ガバナンスフレームワーク、技術的措置、ベストプラクティスに言及している可能性があります。(出典: Ronald_vanLoon)

Unitree B2-W ロボット犬のデモンストレーション:ビデオは、Unitree社のB2-Wモデルのロボット犬を示しています。Unitreeは有名な四足歩行ロボットメーカーであり、その製品はロボットの運動能力、バランス、環境適応性を示すためによく使用されます。(出典: Ronald_vanLoon)
自然の対数螺旋を模倣したSpiRobsロボット:報道は、その形態設計が自然界に普遍的に存在する対数螺旋構造を模倣したSpiRobsロボットを紹介しています。このバイオミメティックデザインは、自然構造の力学的または運動上の利点を利用し、新しいロボットの移動または変形方法を探求することを目的としている可能性があります。(出典: Ronald_vanLoon)
ロボットが90秒でチャーハンを高速調理:ビデオは、調理ロボットが90秒以内にチャーハンの調理を完了できることを示しています。これは、飲食業界における自動化の応用可能性を表しており、プロセスと材料を正確に制御することで、迅速で標準化された食品生産を実現します。(出典: Ronald_vanLoon)
蠕動運動を模倣する革新的なロボット:ビデオは、生物の蠕動(peristalsis)運動方式を模倣したロボットの一種を示しています。このソフトロボットまたは分節型ロボット設計は通常、狭いまたは複雑な環境での移動のための新しいメカニズムを探求するために使用され、ミミズやヘビなどの生物から着想を得ています。(出典: Ronald_vanLoon)
F1 2025サウジアラビアグランプリ予測モデル:ユーザーが、機械学習(深層学習ではない)を使用してF1レースの結果を予測するプロジェクトを共有しました。このモデルは、FastF1ライブラリから抽出された2022-2025シーズンの実データ(予選を含む)、ドライバーの状態(平均順位、速度、最近の成績)、サーキット固有の指標(ジェッダサーキットでの過去のパフォーマンスなど)、およびカスタム特徴量(平均順位変動、サーキット経験など)を組み合わせています。モデルは手動の重み付け式を使用して予測を行い、予測ランキング、表彰台確率、チームパフォーマンスなどの可視化結果を提供します。プロジェクトコードはGitHubでオープンソース化されています。(出典: Reddit r/MachineLearning)

生物医工学分野での深層学習協力者を募集:生物医工学の博士号を持つ助教が、信頼でき勤勉な大学研究者との協力を求めています。主な研究方向は、信号および画像処理、分類、メタヒューリスティックアルゴリズム、深層学習、機械学習であり、特にEEG信号処理と分類(必須ではない)です。協力者には、大学の背景、関連分野での経験、発表意欲、MATLAB経験、および公開された学術プロファイル(Google Scholarなど)が求められます。(出典: Reddit r/deeplearning)