
🔥 焦点
AI開発パラダイムシフト:ベンチマークスコア競争から価値創造へ: OpenAIの研究者、姚順雨氏のブログが議論を呼び、AI開発が後半戦に入ったと提唱。前半戦はアルゴリズム革新とベンチマークテストのスコア更新(例:AlphaGo、GPT-4)に焦点を当て、大規模事前学習(事前知識を提供)と強化学習(RL)を組み合わせ、「推論を行動として」の概念を導入することで、汎化のブレークスルーを実現した。しかし、彼はスコア更新を続けることの限界効用は逓減しており、後半戦では実際の応用価値がある問題を定義し、より現実世界に近い評価方法を開発し、プロダクトマネージャーのように考え、単に指標を向上させるだけでなく、AIを使って真にユーザー価値と社会価値を創造することに転換すべきだと主張。これは、AI分野が技術探求中心から応用展開と価値実現中心へと思考転換する兆しを示している。(来源: dotey)
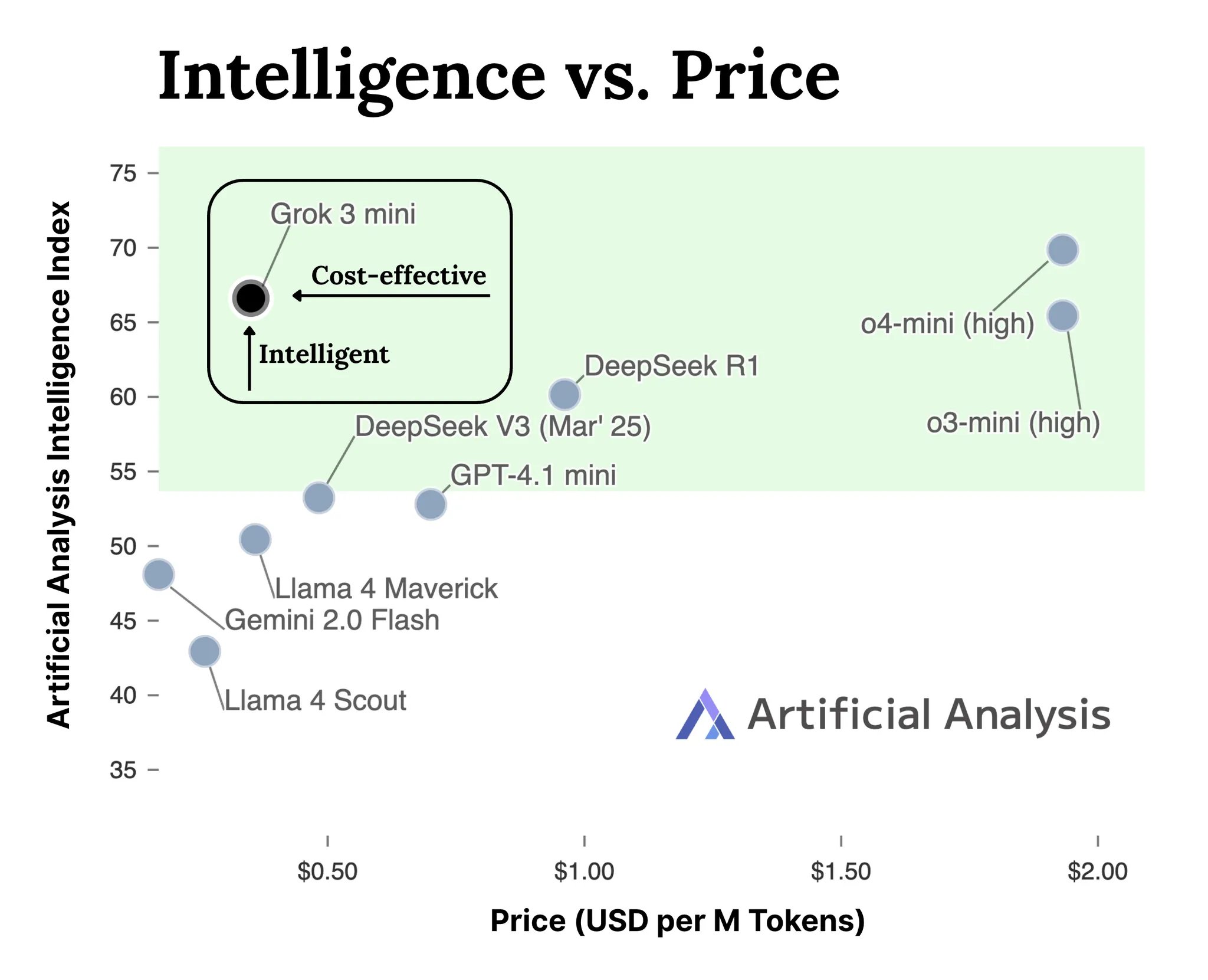
xAI、Grok 3シリーズモデルAPIをリリース: xAIはGrok 3シリーズモデルのAPIインターフェース(docs.x.ai)を正式に公開し、最新モデルを開発者に開放した。同シリーズにはGrok 3 MiniとGrok 3が含まれる。xAIによると、Grok 3 Miniは低コスト(同クラスの推論モデルより5倍低いと主張)を維持しつつ、優れた推論能力を発揮。一方、Grok 3は強力な非推論モデル(知識集約型タスクを指す可能性)と位置付けられ、法律、金融、医療など実世界の知識が必要な分野で際立った性能を示す。この動きは、xAIがAIモデルAPI市場競争に参入し、開発者に新たな選択肢を提供することを示す。(来源: grok, grok)
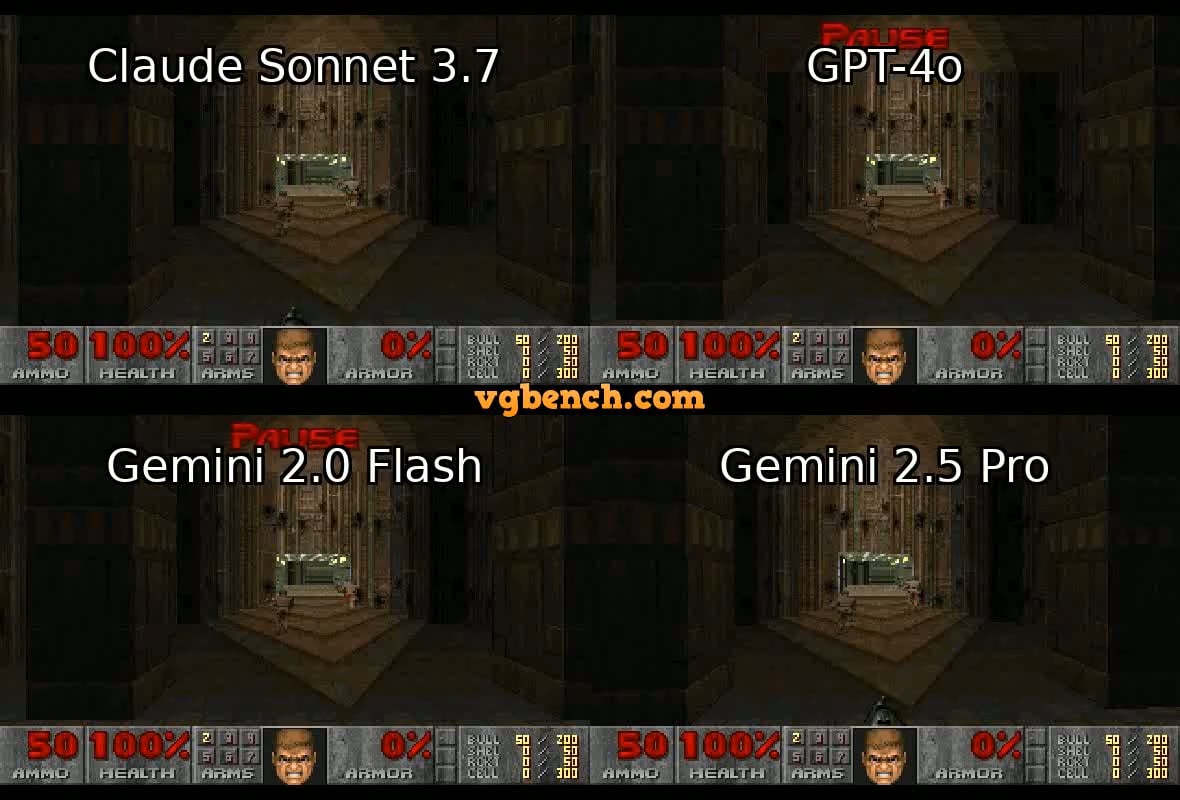
VideoGameBench:クラシックゲームでAIエージェント能力を評価: 研究者らがVideoGameBenchベンチマークのプレビュー版を発表。これは、視覚言語モデル(VLM)が20種類のクラシックビデオゲーム(Doom IIなど)のタスクをリアルタイムで完了する能力を評価することを目的としている。初期テストでは、GPT-4o、Claude Sonnet 3.7、Gemini 2.5 Proを含むトップモデルがDoom IIで様々なパフォーマンスを示したが、いずれも最初のステージをクリアできなかった。これは、モデルが多くのタスクで強力な能力を持つ一方で、リアルタイムの知覚、意思決定、行動が必要な複雑で動的な環境では依然として課題に直面していることを示している。このベンチマークは、インタラクティブな環境におけるAIエージェントの進歩を測定し、推進するための新しいツールを提供する。(来源: Reddit r/LocalLLaMA)
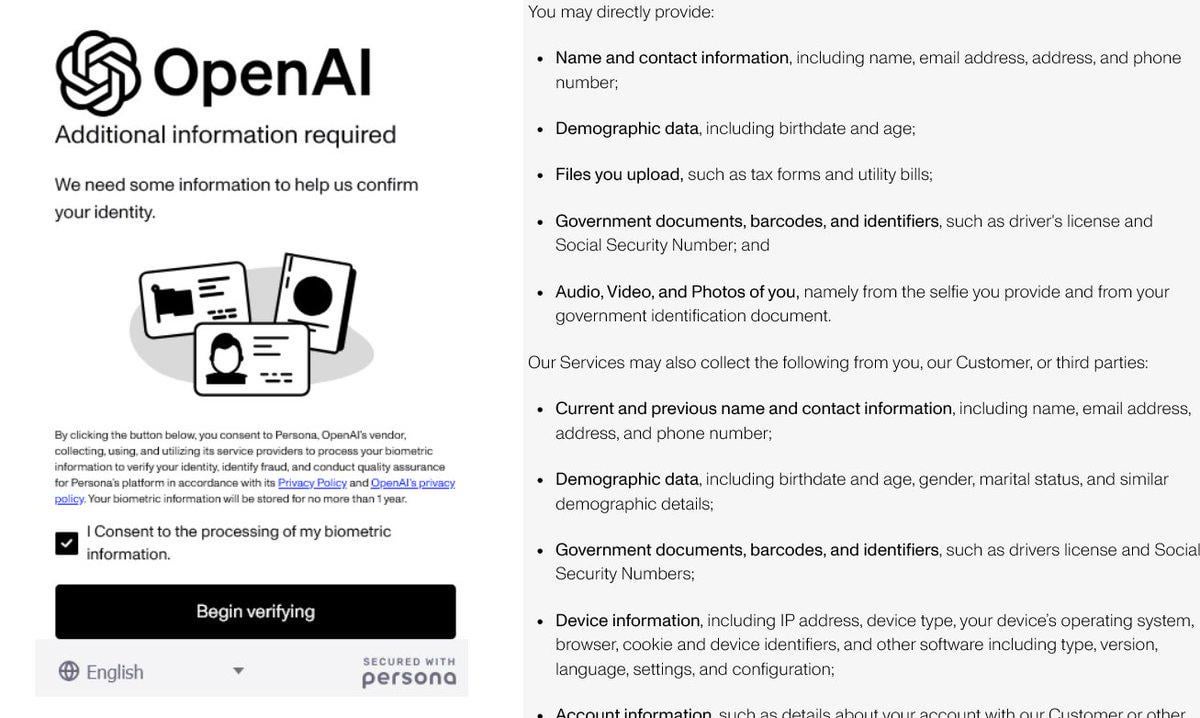
OpenAIの本人確認強化が論争を呼ぶ: OpenAIが、一部の高度なモデル(特に強力な推論能力を持つo3など)へのアクセスに、ユーザーに詳細な身分証明書(パスポート、納税証明書、公共料金請求書など)の提供を要求していることが報じられた。この措置はコミュニティで強い反発を引き起こし、ユーザーはプライバシー漏洩とアクセス障壁の向上を広く懸念している。OpenAIはセキュリティ、コンプライアンス、またはリソース管理の考慮からこの措置を取った可能性があるが、このような厳格な検証要件は同社のオープンなイメージとは対照的であり、ユーザーをプライバシー保護がより優れている、またはアクセスしやすい代替手段、特にローカルモデルへと向かわせる可能性がある。(来源: Reddit r/LocalLLaMA)
AIが分子発見を加速:自然界の数億年の進化をシミュレート: ソーシャルメディアでの議論によると、人工知能は数日で分子を設計できるが、その分子が自然界で進化するには5億年かかる可能性があるという。具体的な詳細は検証が必要だが、これはAIが科学的発見、特に化学および生物学分野での発見を加速する巨大な可能性を浮き彫りにしている。AIは広大な化学空間を探索し、分子特性を予測することができ、その速度は従来の実験方法や自然進化をはるかに超えており、創薬、材料科学などの分野で画期的な進歩をもたらすことが期待される。(来源: Ronald_vanLoon)
🎯 動向
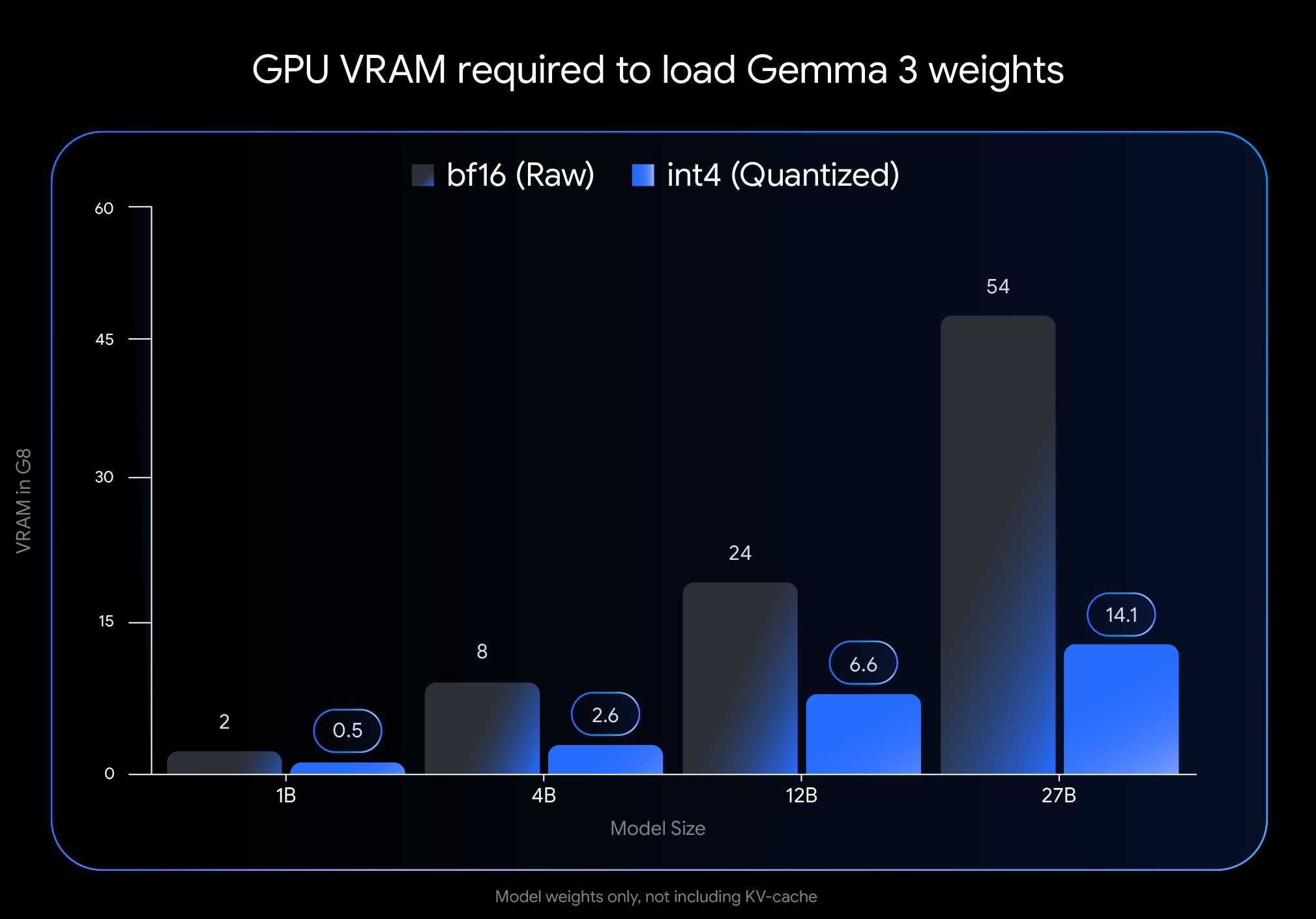
Google、Gemma 3 QAT版をリリース、デプロイの敷居を大幅に引き下げ: Google DeepMindは、量子化認識トレーニング(Quantization-Aware Training, QAT)を経たGemma 3モデルのバージョンを発表した。QAT技術は、モデルサイズを大幅に圧縮すると同時に、元のモデルの性能を最大限に維持することを目指している。例えば、Gemma 3 27Bモデルのサイズは54GB(bf16)から約14.1GB(int4)に削減され、従来はハイエンドのクラウドGPUが必要だった最先端モデルが、コンシューマー向けデスクトップGPU(RTX 3090など)で実行可能になった。Googleは非量子化QATチェックポイントと複数のフォーマット(MLX, GGUF)を公開し、Ollama, LM Studio, llama.cppなどのコミュニティツールと協力して、開発者が様々なプラットフォームで簡単に利用できるようにしており、高性能オープンソースモデルの普及を大きく推進している。(来源: huggingface, JeffDean, demishassabis, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Meta FAIR、知覚研究の成果を発表、オープンソース路線を堅持: Meta FAIRは、高度機械知能(AMI)に関する複数の新しい研究成果を発表し、特に知覚分野で進展があった。これには大規模視覚エンコーダーMeta Perception Encoderの公開が含まれる。Yann LeCun氏はこれらの成果がオープンソース化されることを強調した。これはMetaが基礎AI研究への投資を継続し、オープンソースを通じて研究の進展を共有し、分野全体の発展を推進することへのコミットメントを示している。公開される視覚エンコーダーなどのツールは、より広範な研究・開発者コミュニティに利益をもたらすだろう。(来源: ylecun)
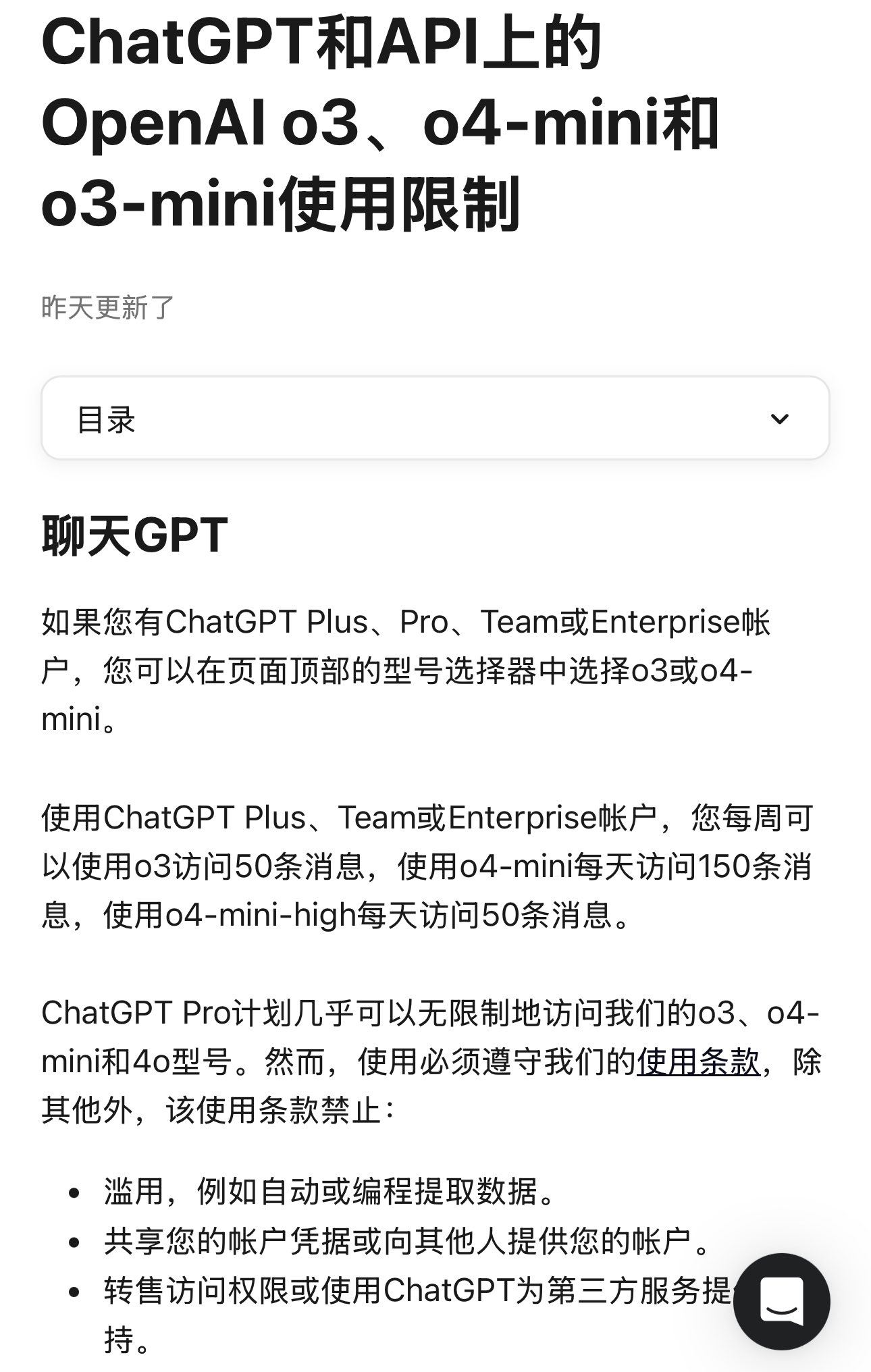
OpenAI、モデル使用制限を明確化: OpenAIは、ChatGPT Plus、Team、Enterpriseユーザーのモデル使用量を明確に規定した。これによると、o3モデルは週50メッセージ、o4-miniは1日150メッセージ、o4-mini-highは1日50メッセージに制限される。ChatGPT Pro(特定のプランを指すか、誤記の可能性あり)は無制限アクセス権を持つとされる。これらの制限は、高頻度ユーザーや特定のモデルに依存するアプリケーション開発者に直接影響を与え、使用計画を立てる際に考慮する必要がある。(来源: dotey)
LlamaIndex、Google Cloudデータベースと統合しナレッジエージェントを構築: Google Cloud Next 2025カンファレンスで、LlamaIndexはそのフレームワークがGoogle Cloudデータベースとどのように統合され、マルチステップリサーチを実行し、ドキュメントを処理し、レポートを生成できるナレッジエージェントを構築するかをデモンストレーションした。デモには、従業員のオンボーディングガイドを自動生成するマルチエージェントシステムの事例が含まれていた。これは、AIアプリケーションフレームワークとクラウドプラットフォームおよびそのデータサービスとの深い融合の傾向を示しており、企業がAIを活用して内部知識やデータを処理する実際のニーズに対応することを目的としている。(来源: jerryjliu0)

新型ナノ脳センサーがAIと連携し高精度信号認識を実現: 新型のナノスケール脳センサーが神経信号の認識において96.4%の精度を達成したと報じられた。センサー技術自体が核心的なブレークスルーであるが、これほど高い認識精度を達成するには、通常、高度なAIと機械学習アルゴリズムを用いて複雑で微弱な神経信号を解読する必要がある。この進歩は、脳科学研究と将来のブレイン・マシン・インターフェース応用に新たな道を開き、より精細な脳活動のモニタリングとインタラクションを実現する可能性がある。(来源: Ronald_vanLoon)

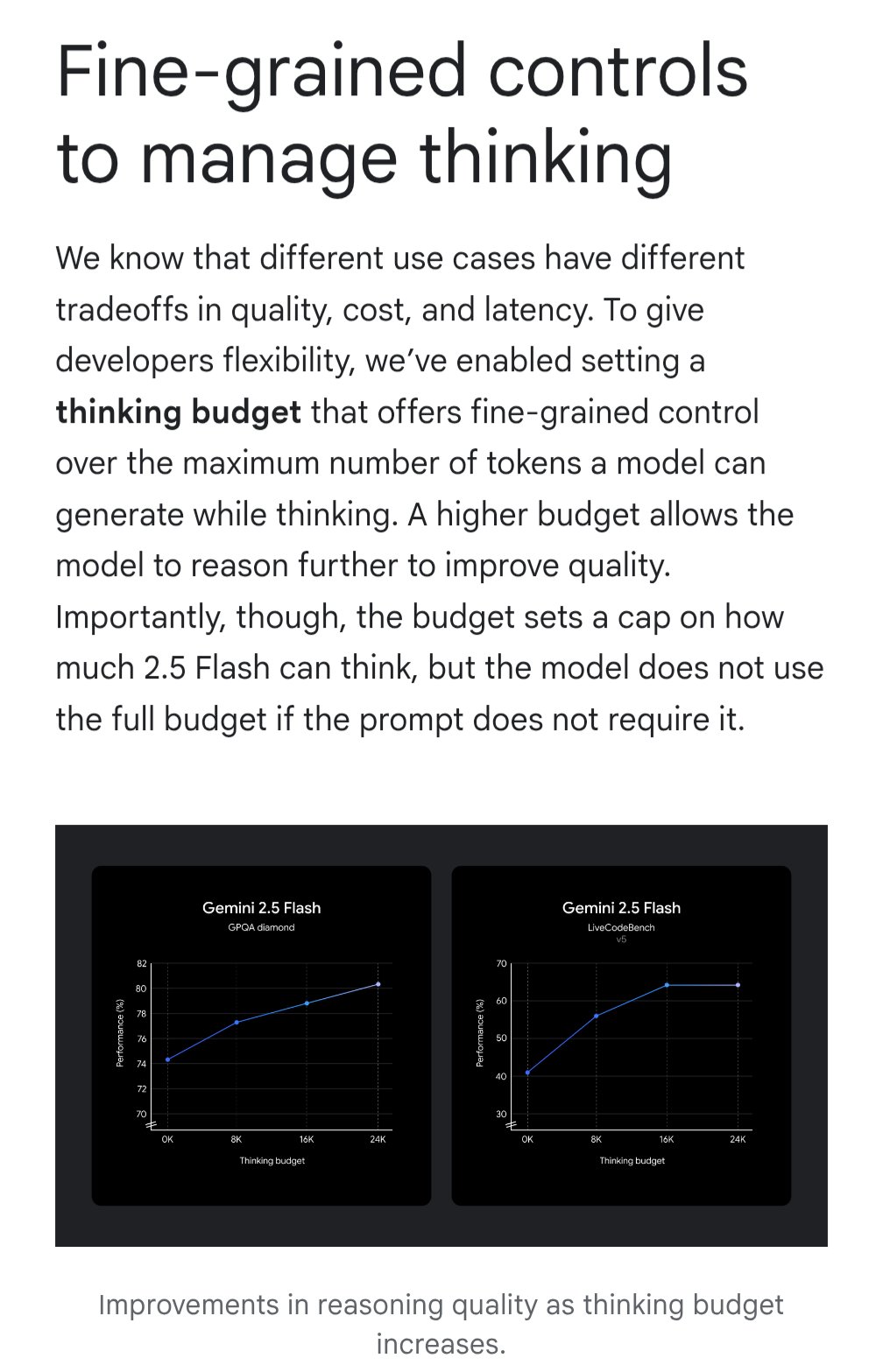
Gemini、「思考予算」機能を導入しコスト効率を最適化: Google Geminiモデルに「思考予算」(thinking budget)機能が導入され、ユーザーはクエリ処理時にモデルが割り当てる計算リソースや「思考」の深さを調整できるようになった。この機能は、ユーザーが応答の質、コスト、遅延の間でトレードオフを行えるようにすることを目的としている。これはAPIユーザーにとって非常に実用的な機能であり、具体的な応用シーンのニーズに応じて、モデルの使用コストとパフォーマンスを柔軟に制御できる。(来源: JeffDean)
AI支援による超音波検査の質が専門家レベルに匹敵: JAMA Cardiologyに掲載された研究によると、トレーニングを受けた医療専門家がAIのガイダンスの下で行った超音波検査の画像品質は、診断基準を満たすのに十分(98.3%)であり、AIガイダンスなしの専門家が取得した画像と比較して統計的に有意な差はなかった。これは、AIが補助ツールとして、非専門家ユーザーが医療画像操作の質と一貫性を向上させるのに効果的であることを示しており、リソースが限られた地域で高品質な診断サービスの利用可能性を拡大することが期待される。(来源: Reddit r/ArtificialInteligence)
MITの研究、AI生成コードの正確性と構造遵守を向上: MITの研究者らは、大規模言語モデルの出力を制御するためのより効率的な方法を開発した。これは、モデルが特定の構造(プログラミング言語の構文など)に準拠し、エラーのないコードを生成するように誘導することを目的としている。この研究は、AI生成コードの信頼性の問題に取り組んでおり、制約付き生成技術を改善することで、出力が厳密に構文規則に従うことを保証し、それによってAIコードアシスタントの実用性を高め、後続のデバッグコストを削減することを目指している。(来源: Reddit r/ArtificialInteligence)
NVIDIA、ロボティクス分野での重要プロジェクトを公開か: ソーシャルメディアで、NVIDIAがロボティクス、エンジニアリング、人工知能、自律技術に関わる「最も野心的なプロジェクト」に取り組んでいると言及されている。具体的な内容は不明だが、NVIDIAがAIハードウェアとプラットフォーム(Isaacなど)における中心的な地位を考えると、関連するいかなる重大発表も注目されており、具現化された知能とロボティクス分野におけるさらなる戦略的展開と技術的ブレークスルーを示唆している可能性がある。(来源: Ronald_vanLoon)
🧰 ツール
Potpie:コードリポジトリ専用AIエンジニアリングアシスタント: Potpieは、コードリポジトリ用にカスタマイズされたAIエンジニアリングエージェントを作成するためのオープンソースプラットフォーム(GitHub: potpie-ai/potpie)である。コード知識グラフを構築してコンポーネント間の複雑な関係を理解し、コード分析、テスト、デバッグ、開発などの自動化タスクを提供する。プラットフォームは、複数の事前構築済みエージェント(デバッグ、Q&A、コード変更分析、単体/統合テスト生成、低レベル設計、コード生成など)とツールセットを提供し、ユーザーによるカスタムエージェントの作成もサポートする。VSCode拡張機能とAPI統合を提供し、開発プロセスへの組み込みを容易にする。(来源: potpie-ai/potpie – GitHub Trending (all/daily))

1Panel:LLM管理を統合したLinuxサーバーパネル: 1Panel (GitHub: 1Panel-dev/1Panel) は、モダンなオープンソースのLinuxサーバー運用管理パネルであり、Webグラフィカルインターフェースを通じてホスト、ファイル、データベース、コンテナなどを管理する。その特徴の1つは、大規模言語モデル(LLM)の管理機能を含んでいることである。さらに、アプリケーションストア、ウェブサイトの迅速なデプロイ(WordPress統合)、セキュリティ保護、ワンクリックバックアップ・リストアなどの機能も提供し、AI関連アプリケーションのデプロイと管理を含むサーバー管理とアプリケーションデプロイの簡素化を目指している。(来源: 1Panel-dev/1Panel – GitHub Trending (all/daily))

LlamaIndex、アップグレード版チャットUIコンポーネントを発表: LlamaIndexは、チャットUIコンポーネントライブラリ(@llamaindex/chat-ui)のメジャーアップデートを発表した。新しいコンポーネントはshadcn UIに基づいて構築され、より洗練されたデザイン、レスポンシブレイアウトを備え、完全にカスタマイズ可能である。開発者がLLMベースのプロジェクト向けに美しく、ユーザーフレンドリーなチャットインターフェースをより簡単に構築し、AIアプリケーションのインタラクション体験を向上させることを目的としている。開発者はnpm経由でインストールし、プロジェクトで直接使用できる。(来源: jerryjliu0)
LlamaExtract実践:金融分析アプリケーションの構築: LlamaIndexは、そのLlamaExtractツール(LlamaCloudの一部)を利用してフルスタックWebアプリケーションを構築する事例を紹介した。LlamaExtractを使用すると、ユーザーは正確なSchemaを定義し、複雑なドキュメントから構造化データを抽出できる。このサンプルアプリケーションは、企業の年次報告書からリスク要因を抽出し、経年変化を分析し、従来20時間以上かかっていた作業を自動化する。このアプリケーションはオープンソース化されており(GitHub: run-llama/llamaextract-10k-demo)、LlamaExtractとSonnet 3.7を組み合わせてこのワークフローを構築する方法を示すビデオデモもあり、AIエージェントが複雑な分析タスクの自動化において持つ可能性を示している。(来源: jerryjliu0, jerryjliu0)
mcpbased.com:オープンソースMCPサーバーディレクトリが公開: 新しいウェブサイト mcpbased.com が、オープンソースMCP(Meta Controller Patternまたは他の類似概念を指す可能性)サーバー専用のディレクトリとしてローンチされた。このプラットフォームは、様々なMCPサーバープロジェクトを集約・展示し、Githubリポジトリデータをリアルタイムで同期することで、開発者が関連ツールを発見、閲覧、接続するのを容易にすることを目的としている。MCPサーバーを構築または使用している開発者、ツール統合を行っている開発者、またはMCPエコシステムに関心のある開発者にとって、これは新しいリソースセンターとなる。(来源: Reddit r/ClaudeAI)
📚 学習
RLHF書籍がArXivに登場: Nathan Lambert氏らが執筆した人間フィードバックからの強化学習(RLHF)に関する書籍 “rlhfbook” がArXivプラットフォーム(番号2504.12501)で公開された。RLHFは現在、大規模言語モデル(ChatGPTなど)を調整するための重要な技術の1つである。この書籍の公開は、研究者や実践者がRLHFの原理と実践を体系的に学び、深く理解するための重要なリソースを提供し、この分野の知識の普及と応用を促進する。(来源: natolambert)
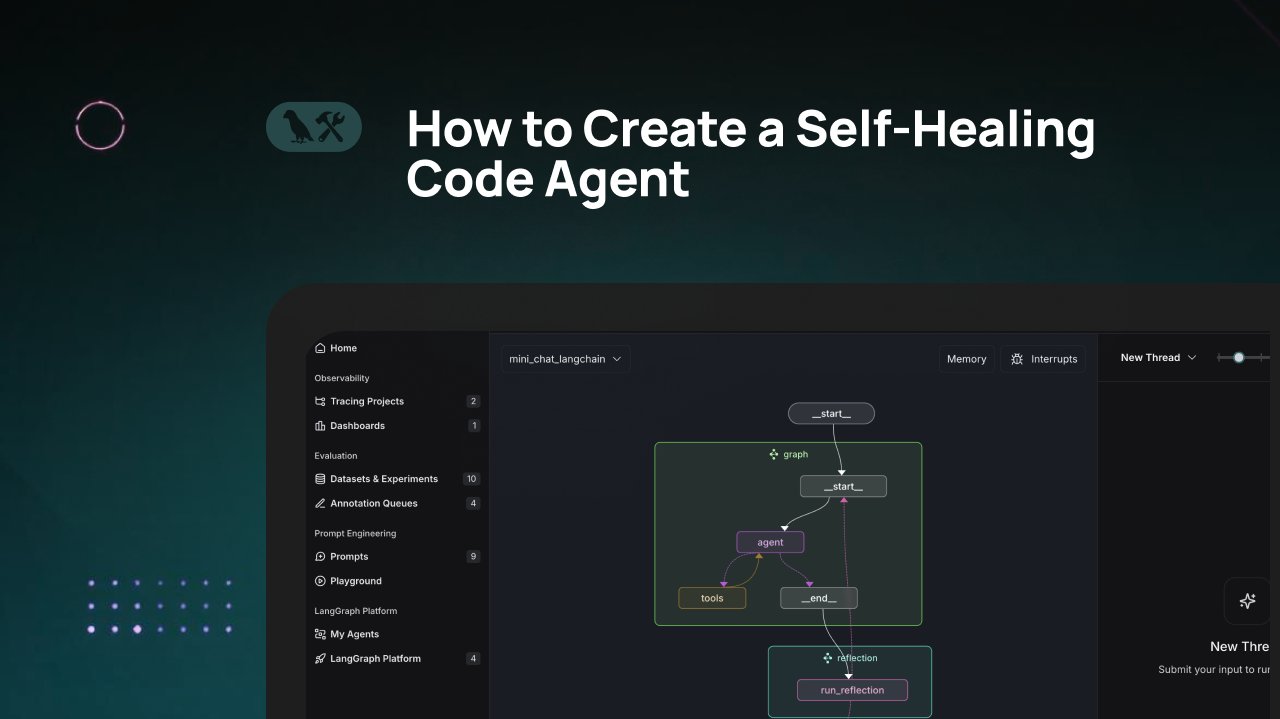
LangChainチュートリアル:自己修復型コード生成エージェントの構築: LangChainは、「自己修復」能力を持つAIコード生成エージェントを構築する方法を紹介するビデオチュートリアルを公開した。中心的なアイデアは、コード生成後に「反省」(reflection)ステップを追加し、エージェントが自身で生成したコードを検証、評価、または改善してから結果を返すというもの。この方法は、AI生成コードの正確性と信頼性を向上させることを目的としており、コードアシスタントの実用性を高めるための効果的な技術である。(来源: LangChainAI)
AIとBlenderを組み合わせてゲーム用3Dアセットを作成: ソーシャルメディアで、AIツール(画像生成を指す可能性)と3DモデリングソフトウェアBlenderを組み合わせて、ゲームで使用可能な(game-ready)3Dアセットを作成するチュートリアルが共有された。これは、現在のAIによる3Dモデル直接生成能力の不足に対応し、実用的な混合ワークフローを示すものだ。AIを利用してコンセプトやテクスチャマップを生成し、Blenderなどの専門ツールでモデリング、最適化を行い、最終的にゲームエンジンが要求するリソースを出力する。(来源: huggingface)
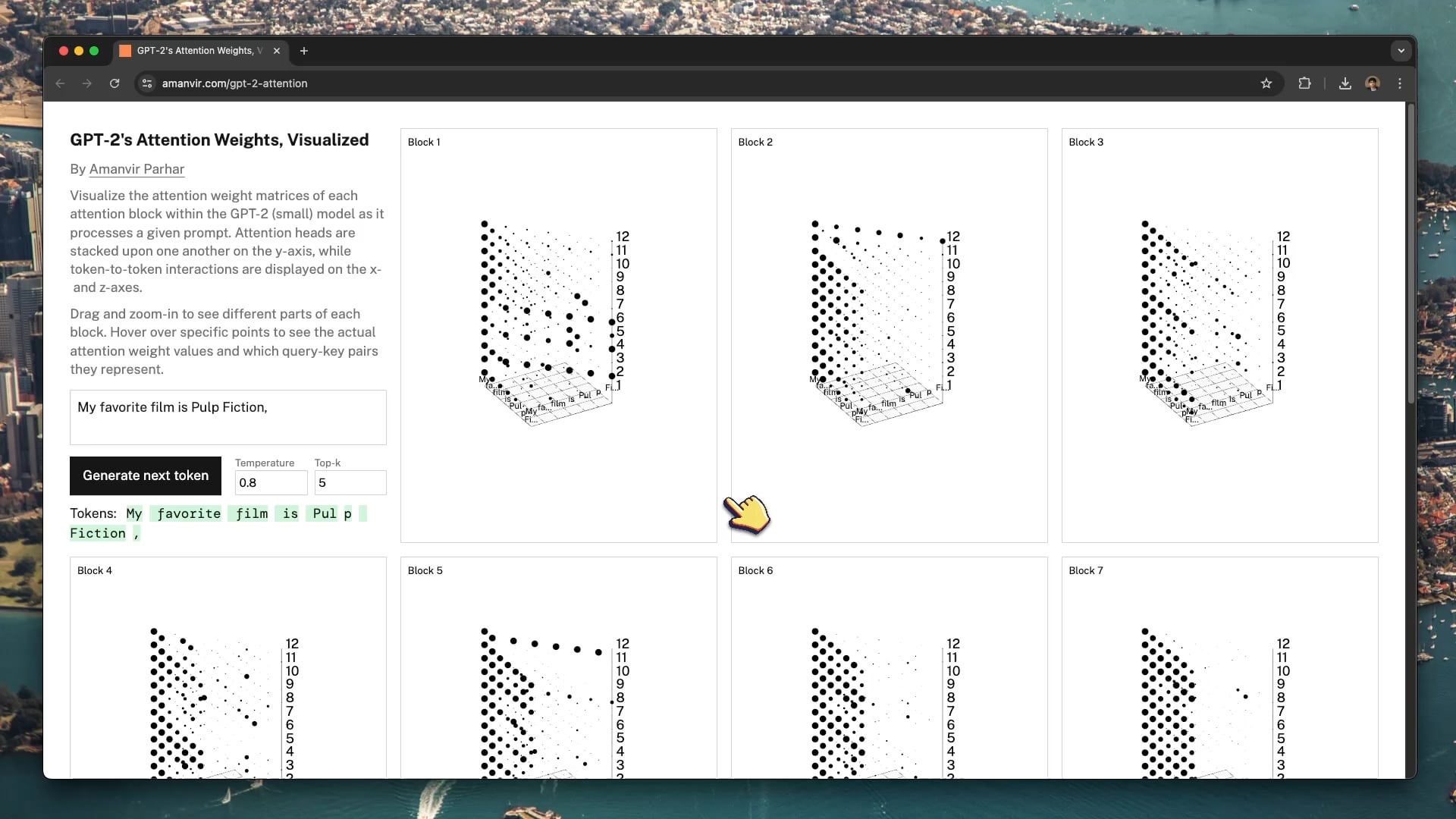
インタラクティブな可視化ツールがGPT-2の注意メカニズム解明を支援: 開発者tycho_brahes_nose_が、GPT-2(小型)モデル内部の各アテンションブロックにおける重み計算プロセスを示すインタラクティブな3D可視化ツール(amanvir.com/gpt-2-attention)を作成・共有した。ユーザーは、テキスト入力後、モデルが異なる層、異なるアテンションヘッド間でトークン間の相互作用強度をどのように計算するかを直感的に見ることができる。これはTransformerのコアメカニズムを理解するための優れた補助となり、AI学習とモデルの解釈可能性研究に役立つ。(来源: karminski3, Reddit r/LocalLLaMA)
医療画像分析における連合学習の応用: Redditの投稿は、連合学習(Federated Learning, FL)とディープニューラルネットワーク(DNN)を組み合わせて医療画像分析に応用する記事を指している。医療データのプライバシーに対する機密性のため、FLは元のデータを共有することなく、複数の機関にまたがってモデルを協調的にトレーニングすることを可能にする。これはAIの医療分野での応用を推進する上で極めて重要であり、このリソースは、このプライバシー保護型の分散学習技術とその医療画像における実践を理解するのに役立つ。(来源: Reddit r/deeplearning)

Sander Dielman氏、VAEと潜在空間を深く解説: Andrej Karpathy氏は、Sander Dielman氏による変分オートエンコーダー(VAE)と潜在空間モデリングに関する詳細なブログ記事(sander.ai/2025/04/15/latents.html)を推薦した。記事では、VAEトレーニングの詳細、例えばKLダイバージェンス項が潜在空間の形成において実際には限定的な役割しか果たさないこと、L1/L2再構成損失がぼやけた画像を生成する傾向がある理由(画像スペクトルの減衰と人間の視覚の重点が一致しないため)などを探求している。この記事は、生成モデルを理解するための厳密で洞察に満ちた分析を提供している。(来源: Reddit r/MachineLearning)
💼 ビジネス
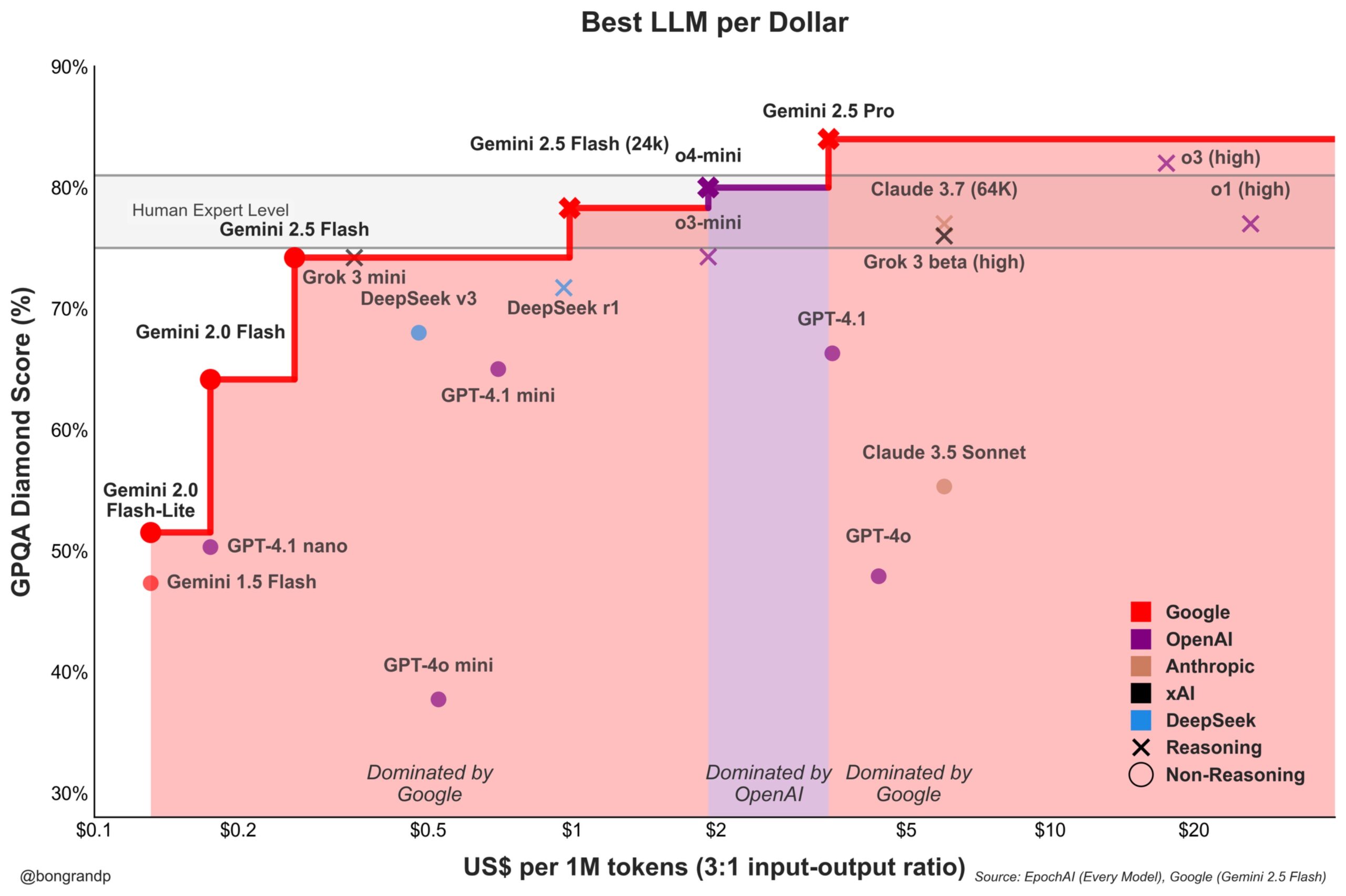
モデル価格競争が激化:Google GeminiがOpenAIに積極的に挑戦: 分析によると、GoogleはそのGeminiシリーズモデル(特に新しくリリースされたGemini 2.5 Flash)で、性能と価格の面で強力な競争力を示しており、約95%のシナリオでOpenAIよりも優れたコストパフォーマンスを提供するとされる。GoogleのAPIへの迅速な対応と価格戦略(価格帯の90%以上を主導)は、同社がLLM市場シェアを積極的に争奪し、コスト優位性を通じてユーザーを引き付けようとしていることを示しており、基盤モデル市場の競争を激化させている。(来源: JeffDean)
Coinbase、LangChainカンファレンスを後援、Agentic Commerceを探求: Coinbase DevelopmentがLangChain Interrupt 2025カンファレンスのスポンサーとなった。Coinbaseは、そのAgentKitやx402決済プロトコルなどのツールを通じて、「エージェントコマース」(Agentic Commerce)を可能にし、AIエージェントがコンテキスト検索やAPI呼び出しなどのサービスに対して自律的に支払いを行えるようにしている。この協力は、AIエージェント技術とWeb3決済の接点を浮き彫りにし、将来のAI駆動型自動経済インタラクションのシナリオを予示している。(来源: LangChainAI)

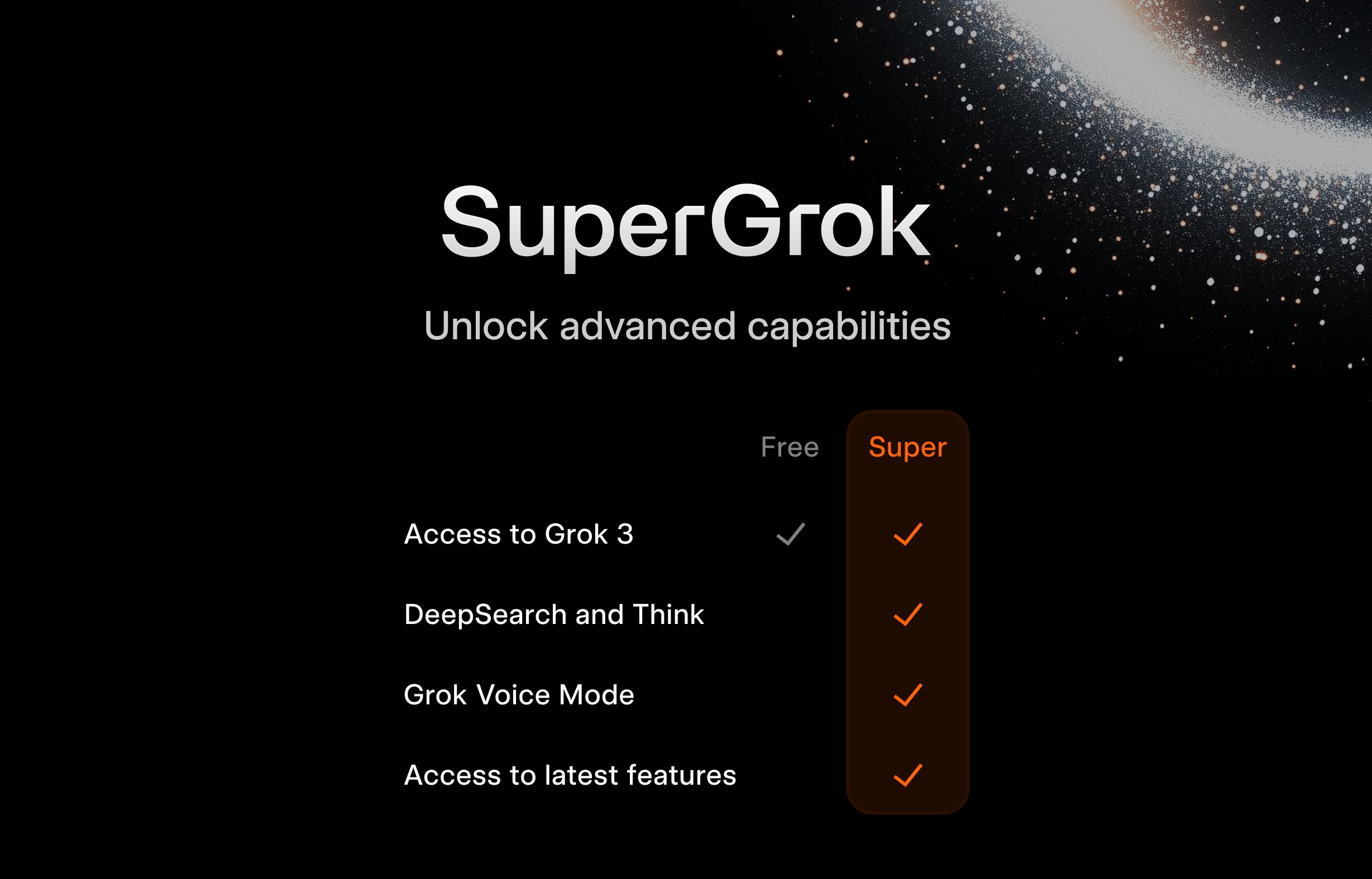
xAI、SuperGrok学生無料プランを開始: 若年層ユーザーを引き付けるため、xAIは学生向けに優待キャンペーンを開始した。.eduメールアドレスで登録すると、SuperGrok(Grokのプレミアム版)の2ヶ月間の無料利用権が得られる。この動きは、Grokを学習支援ツールとして位置づけ、期末試験シーズンにプロモーションを行い、教育市場のユーザーを獲得し、将来の潜在的な有料顧客を育成することを目的としている。(来源: grok)
Google、米国の大学生にGemini Advancedおよび複数のサービスを無料提供: Googleは、米国の大学生向けに長期的な無料特典を提供すると発表した。2025年6月30日までに登録すれば、Gemini Advanced(Gemini 2.5 Pro搭載)、NotebookLM Plus、Google Workspace内のGemini機能、Whisk、および2TBのクラウドストレージを2026年春学期末まで無料で利用できる。この大規模なプロモーション活動は、GoogleのAIツールを教育エコシステムに深く浸透させ、Microsoftなどの競合他社と競争し、次世代のユーザーと開発者のGoogle AIプラットフォームへの定着を図ることを目的としている。(来源: demishassabis, JeffDean)
FanDuel、著名人AIチャットボット「ChuckGPT」を発表: スポーツ界の著名人チャールズ・バークレー氏が自身の氏名、肖像、音声をライセンス供与し、スポーツベッティング企業FanDuelと協力して「ChuckGPT」という名前のAIチャットボット(chuck.fanduel.com)を発表した。これは、著名人のIPとAI技術を利用してブランドマーケティングとユーザーインタラクションを行う新たな事例であり、著名人の会話スタイルを模倣してスポーツ情報、ベッティングアドバイス、またはエンターテイメントインタラクションを提供し、ユーザーエンゲージメントを高める。(来源: Reddit r/artificial)
🌟 コミュニティ
AIツール依存への懸念: ソーシャルメディア上のある漫画が、多数のAIツール(ChatGPT, Claude, Midjourneyなど)に囲まれ、「AIツール依存」とラベル付けされたユーザーを象徴的に描き、共感を呼んでいる。これは、コミュニティ内の一部のユーザーが、次々と登場するAIアプリケーションに直面して感じる情報過多や潜在的な過度な依存心理、そして適切なツールを管理・選択する認知負荷を反映している。(来源: dotey)
トップモデルが特定のテストで失敗、能力の限界を露呈: Perplexity CEOのArav Srinivas氏が、o3とGemini 2.5 Proの両方が複雑な図形描画タスクを完了できなかったテストケースをリツイートした。これは一部の人々によって、現在のモデル能力に対する挑戦的なテストと見なされている。このような「失敗事例」はコミュニティで広く議論され、SOTAモデルが特定の推論、空間理解、または指示追従において持つ限界を明らかにし、現在のAIと汎用人工知能(AGI)との間のギャップをより客観的に認識するのに役立っている。(来源: AravSrinivas)
コミュニティでGPT-4oによる抱き枕画像生成効果とプロンプト共有が話題: ユーザーがGPT-4oを使用して特定のスタイル(可愛い、マイクロフリース質感、絵文字形状)の抱き枕画像を生成した成功事例と最適化されたプロンプト(Prompt)を共有した。このような共有は、AI画像生成のクリエイティブデザインにおける応用を示し、コミュニティ内でのプロンプトエンジニアリングのテクニックやスタイル探求に関する交流を促進している。高品質な生成結果は、ユーザーの創作意欲を刺激している。(来源: dotey)

Sam Altman氏:AIは産業革命よりもルネサンスに近い: OpenAI CEOのSam Altman氏が、人工知能がもたらす変革は産業革命よりもルネサンスに近いという見解を発表した。この比喩はコミュニティで議論を呼び、AIの影響は単なる生産性の機械化向上にとどまらず、文化、思想、創造性の側面により多く現れる可能性を示唆している。このような質的な判断は、AIの将来の社会的役割に対する人々の期待と想像に影響を与えている。(来源: sama)
コミュニティ、Grok 2のオープンソース化時期を問う: Redditユーザーが、xAIが約束したGrok 2モデルのオープンソース化をいつ実行するのか議論している。多くの人が、AI技術の急速な進化を考えると、Grok 2がリリースされる頃には他の同時代のモデル(DeepSeek V3、Qwen 3など)に遅れをとっており、Grok 1がリリースと同時に時代遅れになった二の舞になるのではないかと懸念している。議論はまた、オープンソースモデルの価値(研究、ライセンスの自由度)と適時性のトレードオフにも及んでいる。(来源: Reddit r/LocalLLaMA)
Altman氏の発言を解読:データ効率がAGIの新たなボトルネックか?: Redditコミュニティは、Sam Altman氏の「AIは計算力だけでなく、データ効率を10万倍向上させる必要がある」という発言について議論し、これを現在のブルートフォース的な拡張路線によるAGI実現が行き詰まっている兆候と解釈している。高品質な人間データは枯渇に近づき、合成データの効果は限定的であり、モデルの学習効率の低さが核心的な課題であるという見解が示されている。これはMicrosoftなどの企業のハードウェア投資計画にさえ影響を与える可能性がある。議論はAI開発路線への反省を反映している。(来源: Reddit r/artificial)
LLMの記憶能力と推論能力をどう区別するか?: コミュニティでは、大規模言語モデルが本当に推論能力を持っているのか、それとも単に訓練データ中のパターンを復唱または組み合わせているだけなのかを効果的にテストする方法について議論されている。モデルが見たことのない、斬新な「What If」形式の質問を使用して、その汎化推論能力を探るという提案がある。これは、LLMの知能レベルを評価する上での核心的な難問、すなわち高度なパターンマッチングと真の論理的推論を区別するという問題に触れている。(来源: Reddit r/MachineLearning)
ユーザーがGPTとの「恐ろしい」対話を共有、倫理的懸念を呼ぶ: あるユーザーがChatGPTとの対話スクリーンショットを共有した。内容はAIがもたらしうる負の社会的影響(思想統制、批判的思考の喪失など)に及び、「恐ろしい」と述べている。投稿は議論を呼び、AIの出力がユーザーの誘導を反映しているのか、それともモデルの「考え」なのか、AIの倫理的境界線、そしてAIの潜在的リスクに対するユーザーの不安感情などが焦点となっている。(来源: Reddit r/ChatGPT)

ローカルでの大規模モデル実行がメモリボトルネックに遭遇: r/OpenWebUIコミュニティで、ユーザーが16GB RAMとRTX 2070Sの構成でOpenWebUIとOllamaを実行する際、12B以上の大規模モデル(Gemma3:27bなど)をロードできず、システムメモリとスワップ領域が枯渇すると報告している。これは、コンシューマーレベルのハードウェアで大規模モデルをローカルにデプロイしようとする多くのユーザーが直面する普遍的な課題であり、モデルがハードウェアリソース(特にメモリ)に高い要求をすることを示している。(来源: Reddit r/OpenWebUI)
GPT-4o生成ポスターが「デザイナー失業」論争を呼ぶ: ユーザーがGPT-4oで生成した「ドッグパーク」のポスターを展示し、その効果を「ほぼ完璧」と称賛し、「グラフィックデザイナーは死んだ」と断言した。コメント欄ではこれについて激しい議論が展開された。一方でAI画像生成能力の進歩を認めつつ、他方ではデザインの欠陥(文字が多すぎる、レイアウトが悪い、スペルミス)を指摘し、AIは現在、効率を高めるツールであり、クリエイティブな意思決定、美的判断、ブランド適合性などにおけるデザイナーの核心的価値を代替することはできないと強調している。(来源: Reddit r/ChatGPT)

fine-tuningモデルのライフサイクル管理に関心: 開発者がコミュニティで質問:依存しているベースモデル(GPT-4oなど)が世代交代(GPT-5などが出現)した場合、以前にその上でfine-tunedされたモデルはどう処理すべきか? fine-tuningは通常、特定のベースバージョンに紐づいているため、ベースモデルの廃止や更新は開発者に再トレーニングを強いる可能性があり、継続的なコストとメンテナンスの問題をもたらす。これは、クローズドソースAPIを使用したfine-tuningの依存性と長期戦略についての議論を引き起こしている。(来源: Reddit r/ArtificialInteligence)
ローカルLLMとの音声対話設定を探る: コミュニティユーザーが、ローカルLLMと音声で対話できるシステム構成を求めている。Google AI Studioのような体験を実現し、ブレインストーミングや計画立案に使用したいと考えている。この質問は、ユーザーがテキストインタラクションからより自然な音声インタラクションへと拡張したいというニーズを反映しており、OpenWebUIなどのローカルフレームワーク下でSTT、LLM、TTSを統合する実用的な方法と経験共有を求めている。(来源: Reddit r/OpenWebUI )
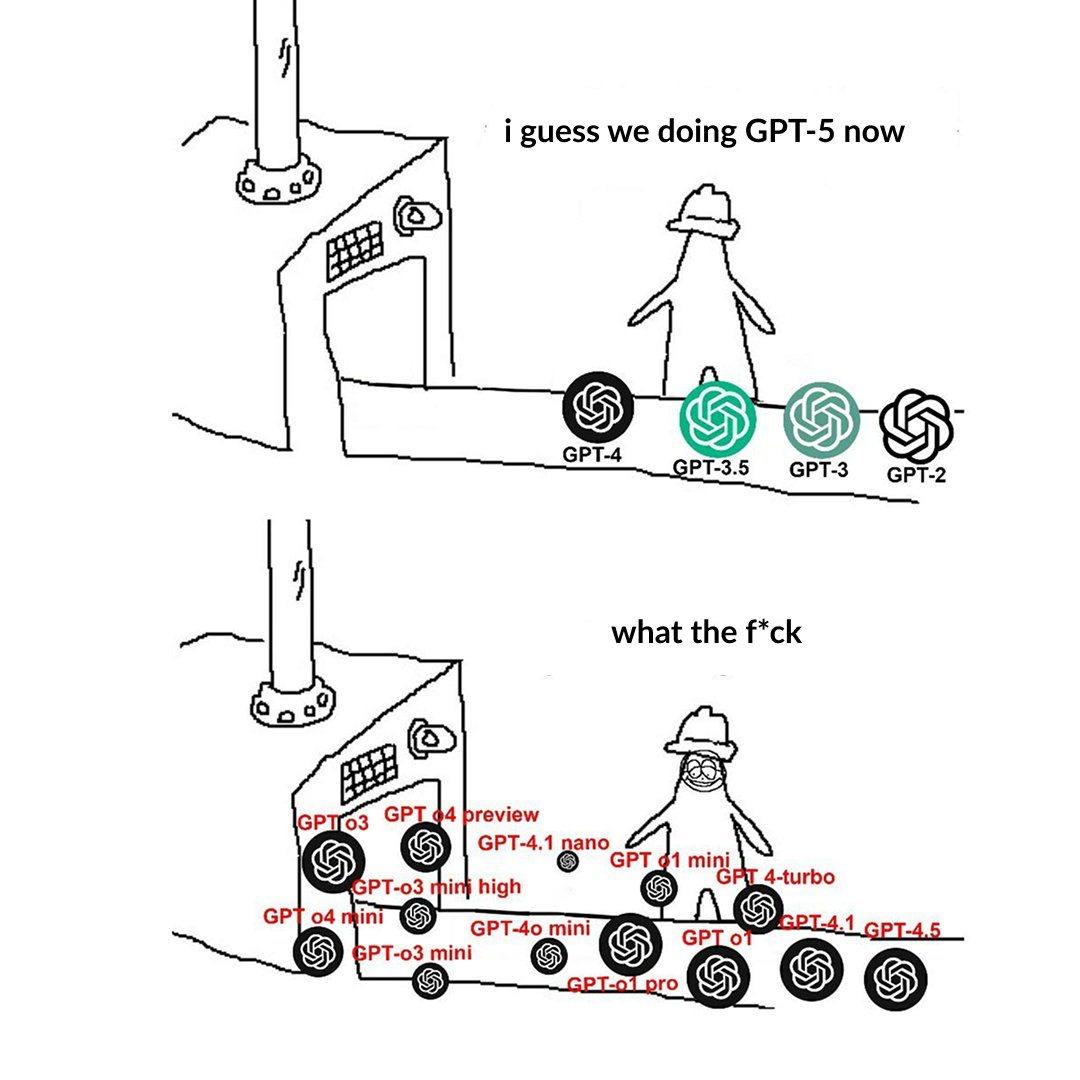
OpenAIモデル階層の命名がユーザーを困惑させる: ユーザーがOpenAIのモデル命名(o3, o4-mini, o4-mini-high, o4など)が紛らわしいと投稿した。画像は異なる階層のモデルを示しており、その名称と能力、制限との関係が直感的でないことを示している。これは、モデルファミリーが拡大し続ける中で、明確な製品ラインの区分と命名がユーザーの理解と選択に課題をもたらしていることを反映している。(来源: Reddit r/artificial)

ChatGPTの過度な「おだて」スタイルが話題に: コミュニティユーザーがミームや議論を通じて、ChatGPTがユーザーの質問に対して過度な称賛(「素晴らしい質問ですね!」)を与える傾向があることを指摘している。たとえ質問自体が普通であったり、愚かであったりしても。議論では、これはOpenAIがユーザーエンゲージメントを高めるために設計した戦略かもしれないが、ユーザーに確証バイアスを生じさせ、批判的なフィードバックが欠如する可能性があるとされている。一部のユーザーは、AIに「毒舌」な評価をしてほしいとさえ述べている。(来源: Reddit r/ChatGPT)

不完全情報ゲームにおけるAIの挑戦: コミュニティでは、AIが不完全情報を持つゲーム(スタークラフトの戦場の霧など)を処理する際に直面する課題について議論されている。囲碁やチェスのような完全情報ゲームとは異なり、これらのゲームではAIが不確実性を処理し、探索と長期計画を行う必要があり、単純に全体情報や事前計算に依存することはできない。AIはDota 2やスタークラフト(AlphaStar)などのゲームで進歩を遂げているが、人間のトップレベルを安定して超えることは依然として困難である。(来源: Reddit r/ArtificialInteligence)
AIコンテンツが引き起こす「言語の収束」現象に警戒: ユーザーが「言語模倣」(linguistic mimicry)の概念を提唱し、AIによって生成され、スタイルが均質化する可能性のあるコンテンツを大量に読むことで、人々の言語表現、さらには思考様式までが単一化、同質化してしまうのではないかと懸念している。この現象は、文化的多様性や個人の独立した思考に対する潜在的な脅威となる可能性がある。多様な人間の著者の作品を読むことが、言語の活力を維持する手段の一つとして推奨されている。(来源: Reddit r/ArtificialInteligence)
💡 その他
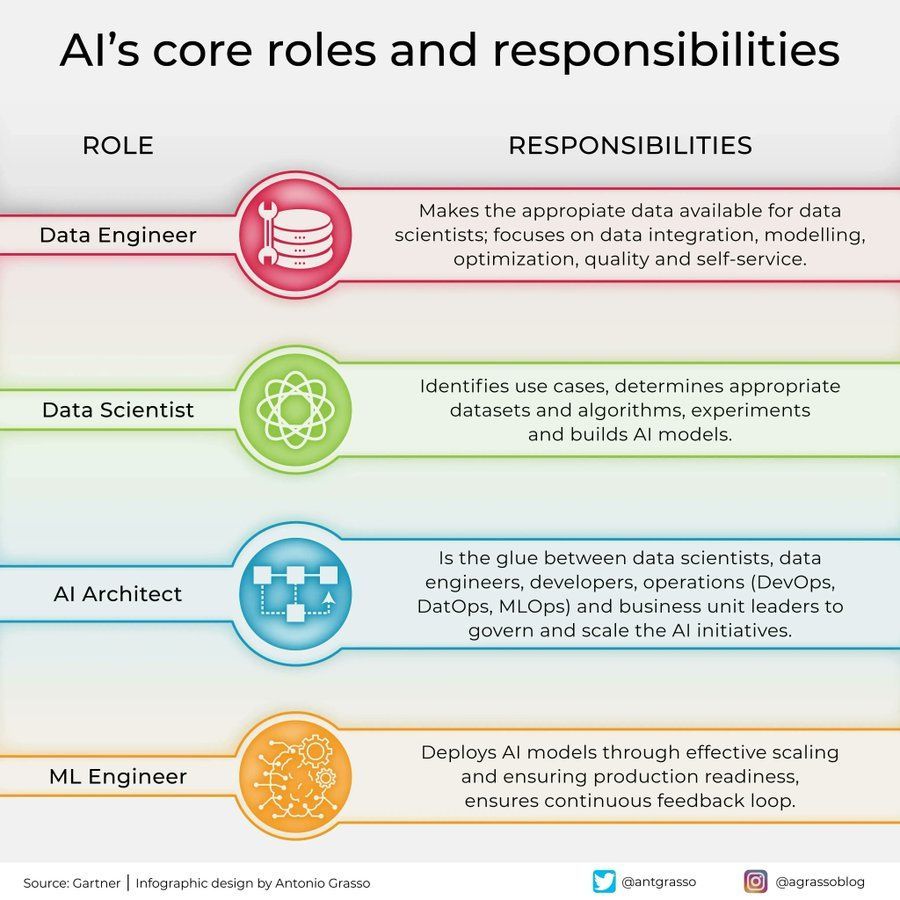
AI分野における役割と責任分担: ソーシャルメディア上で、人工知能分野の中核的な役割とその責任(データサイエンティスト、機械学習エンジニア、AI研究者など)を概説したインフォグラフィックが共有された。この図は、AIプロジェクトチーム内の分業、必要なスキル、そしてAI開発の学際的な性質を理解するのに役立つ。(来源: Ronald_vanLoon)
通信業界におけるAIの応用と課題: 通信業界におけるAIの画期的な応用と潜在的な落とし穴について言及されている。AIはネットワーク最適化、インテリジェントカスタマーサービス、予測保全などに広く応用され、効率とユーザー体験を向上させているが、同時にデータプライバシー、アルゴリズムの偏り、実装の複雑さなどの課題にも直面している。これらの側面を深く掘り下げることは、業界がAIの機会を捉え、リスクを回避するのに役立つ。(来源: Ronald_vanLoon)
心理学がAI開発に与える影響: 心理学が人工知能の発展にどのように影響を与え、その影響が現在も続いているかを探る記事。認知科学、学習理論、バイアス研究などの心理学の知識は、AI設計に重要な参考情報を提供している(例:人間の認知プロセスの模倣、偏見の理解と処理など)。逆に、AIも心理学研究に新しいモデリングとテストツールを提供している。(来源: Ronald_vanLoon)

大型計算装置がAIハードウェア需要を示す: ユーザーが巨大で複雑なコンピュータハードウェア装置(おそらく大規模なマルチGPUサーバークラスター)を示す画像を共有し、それを「モンスター」と呼んだ。この画像は、現在の大規模AIモデルのトレーニングや高負荷な推論タスクに必要な莫大な計算リソース投入を直感的に反映しており、現代のAIがハードウェアインフラストラクチャに高度に依存していることを示している。(来源: karminski3)

サイバーセキュリティにおけるAIの役割: 人工知能がサイバーセキュリティ分野で果たす変革的な役割を探る記事。AI技術は、脅威検出の強化(異常行動分析など)、セキュリティ対応の自動化、脆弱性評価、予測などに利用され、防御効率と能力を向上させている。しかし、AI自体が悪用される可能性もあり、新たなセキュリティ課題をもたらしている。(来源: Ronald_vanLoon)

高精度OCRが文字混同の課題に直面: 開発者が短い英数字コード(シリアル番号など)を認識するための高精度OCRシステムを構築しようとした際、一般的な難題に遭遇した:モデルが視覚的に類似した文字(I/1, O/0など)を区別するのが難しい。単一文字検出用のYOLOモデルを使用しても、エッジケースが存在する。これは、特定のシナリオでほぼ完璧なOCR精度を達成することの難しさを浮き彫りにしており、ターゲットを絞ったモデル、データ、または後処理戦略の最適化が必要であることを示している。(来源: Reddit r/MachineLearning)

Gym Retro環境の実行に関するヘルプ要請: ユーザーが強化学習ライブラリGym Retroを使用する際に技術的な問題に遭遇した。Donkey Kong Countryゲームのインポートには成功したが、トレーニングのために事前設定された環境をどのように起動するかわからない。これはAI研究者が特定のツールを使用する際に遭遇する可能性のある典型的な設定および操作の問題である。(来源: Reddit r/MachineLearning)
複数モデルの性能が近い場合の選択のジレンマ: ある研究者が、異なる特徴選択方法と機械学習モデルを使用する際に、複数の組み合わせが同様の高い性能レベル(精度93-96%など)に達し、最適な解決策を選択するのが難しいことに気づいた。これは、モデル評価において、標準的な指標に大きな差がない場合、モデルの複雑さ、解釈可能性、推論速度、堅牢性など、他の要因を考慮して最終的な選択を行う必要があることを反映している。(来源: Reddit r/MachineLearning)
arXivのGoogle Cloudへの移行が注目を集める: AIおよび多くの科学研究分野における重要なプレプリントプラットフォームであるarXivが、コーネル大学のサーバーからGoogle Cloudへの移行を計画している。このインフラストラクチャの大規模な変更は、サービスのスケーラビリティや信頼性の向上をもたらす可能性があるが、同時に運営コスト、データ管理、オープンアクセス戦略に関するコミュニティの議論を引き起こす可能性もある。(来源: Reddit r/MachineLearning)
Claudeが生成した経済シミュレーションツールとその限界: ユーザーがClaude Artifact機能を利用して、インタラクティブな関税影響経済シミュレーターを生成した。AIが複雑なアプリケーションを生成する能力を示しているものの、コメントではシミュレーション結果が単純化されすぎているか、経済学の原理に合致していない(高関税が普遍的な利益をもたらすなど)可能性が指摘されている。これは、AIが生成した分析ツールを使用する際には、その内在的な論理と仮定を厳密に検証する必要があることを示唆している。(来源: Reddit r/ClaudeAI)

OpenWebUIにカスタムXTTS音声クローンを統合: ユーザーが、オープンソースのXTTS技術を使用してクローンした自身の音声をOpenWebUIに統合し、有料のElevenLabs APIの代わりに、パーソナライズされた無料の音声出力を実現する方法を求めている。これは、ユーザーがローカルAIツールを使用する際に、オープンソースでカスタマイズ可能なコンポーネント(TTSなど)を統合したいというニーズを表している。(来源: Reddit r/OpenWebUI)