
キーワード:AI, 大モデル, AI軍拡競争, 垂直産業モデル, 智譜AI IPO, AIによる物理法則の独立発見, AI視覚障害者支援システム
“` markdown
🔥 焦点
大手企業がAI軍拡競争を激化、垂直モデルとエコシステムが焦点に: 世界のテクノロジー大手はかつてない規模でAIに投資しており、2025年の設備投資額は3200億ドルを突破すると予測されている。Alibaba、Tencent、Huaweiなどの中国メーカーも投資を強化し、AIインフラ、大規模モデル、計算能力に重点を置いている。競争の焦点は汎用大規模モデルから垂直産業モデルへと移行しており、後者は高い粗利率と実際の課題解決能力により新たな成長エンジンとなっている。ハイエンドチップの課題に直面しているものの、国内メーカーは計算コストの最適化と推論モデル(「スローシンキング」)分野で進展を見せている(DeepSeek効果など)。各社の戦略は異なり、Alibabaはインフラに重点投資、Huaweiはハードウェア(CloudMatrix 384)を革新しエッジ・クラウド連携を推進、Baiduは応用に近づき、TencentとByteDanceは多様なシーンの優位性を活用している。AIハードウェアの拡張とオープンソースエコシステムの構築(HarmonyOS、Ascend、Hunyuanなど)が鍵となり、競争は単一技術の突破からエコシステムの連携能力へと移行している。(来源: 36氪-科技云报道)

MITが驚くべき発見:AIが事前知識なしで物理法則を独立して導出: MITのMax Tegmarkチームは新しいアーキテクチャMASS (Multiple AI Scalar Scientists)を開発した。このAIシステムは、物理法則を一切教えられていない状態で、振り子や振動子などの物理システムの観測データのみを分析し、古典力学におけるハミルトニアンやラグランジアンと酷似した理論表現を独立して学習し提案することができた。研究によると、AIはより複雑なシステムに直面すると自律的に理論を修正し、異なるAI「科学者」は最終的に既知の物理原理に収束する傾向があり、特に複雑なシステムではラグランジアン記述を好むことが示された。この成果は、AIが基礎科学の発見において巨大な潜在能力を持つことを示しており、宇宙の基本法則を独立して解き明かす可能性がある。(来源: 新智元)

上海交通大学チームのAI視覚障がい者支援システムがNature姉妹誌に掲載、視覚障がい者に「再び光を」: 上海交通大学の顧磊磊チームは、AI駆動型のウェアラブル視覚障がい者支援システムを開発した。フレキシブルエレクトロニクス技術と組み合わせ、聴覚と触覚フィードバックによって視覚機能の一部を代替し、視覚障がい者のナビゲーションや物体の掴み取りなどの日常タスク遂行を支援する。このシステムはハードウェアが軽量で、ソフトウェアは人間の生理的認知に適合するように情報出力方式を最適化し、VR没入型トレーニングシステムも開発した。テストの結果、このシステムは仮想環境および実環境における視覚障がい者のナビゲーション、障害物回避、物体掴み取り能力を著しく向上させることが示された。研究成果は『Nature Machine Intelligence』に掲載され、AIが視覚障がい者を支援し、その自立生活能力を向上させる上での巨大な潜在能力を示すとともに、個別化されたユーザーフレンドリーなウェアラブル視覚補助デバイスに新たな道筋を提供した。(来源: 36氪)

Zhipu AIがIPO準備を開始、「大規模モデル第一号株」を目指す: 清華大学系のAI大規模モデル企業Zhipu AI(北京智譜華章科技)は4月14日に北京証券監督管理局でIPO準備のための届出を完了し、CICCが指導を担当、A株市場を目指しており、国内初の「AI大規模モデル第一号株」となる可能性がある。そのC向け製品「智譜清言」のユーザー規模は大きくないものの、Zhipuは強力な技術的背景(清華大学系、自社開発GLMシリーズ大規模モデル)、国家チーム色(米国エンティティリスト入り)、および商業化の進展(政府・企業顧客へのサービス提供、収入の著しい増加)により、160億元を超える資金調達を達成し、評価額は200億元を超え、投資家には著名なVC、産業大手、および複数の地方国有資産が含まれている。DeepSeekなどの新興勢力の挑戦を受ける中、ZhipuのIPO選択は、激しい競争の中で有利な地位を確保し、資金調達ニーズを満たし、投資家の期待に応えるための重要な一歩と見なされている。同社は最近、GLM-4シリーズモデルのオープンソース化を継続しており、技術と資本の両面で同時に力を入れていることを示している。(来源: 36氪-真故研究室, 36氪-互联网爆料汇, 创投日报)

🎯 動向
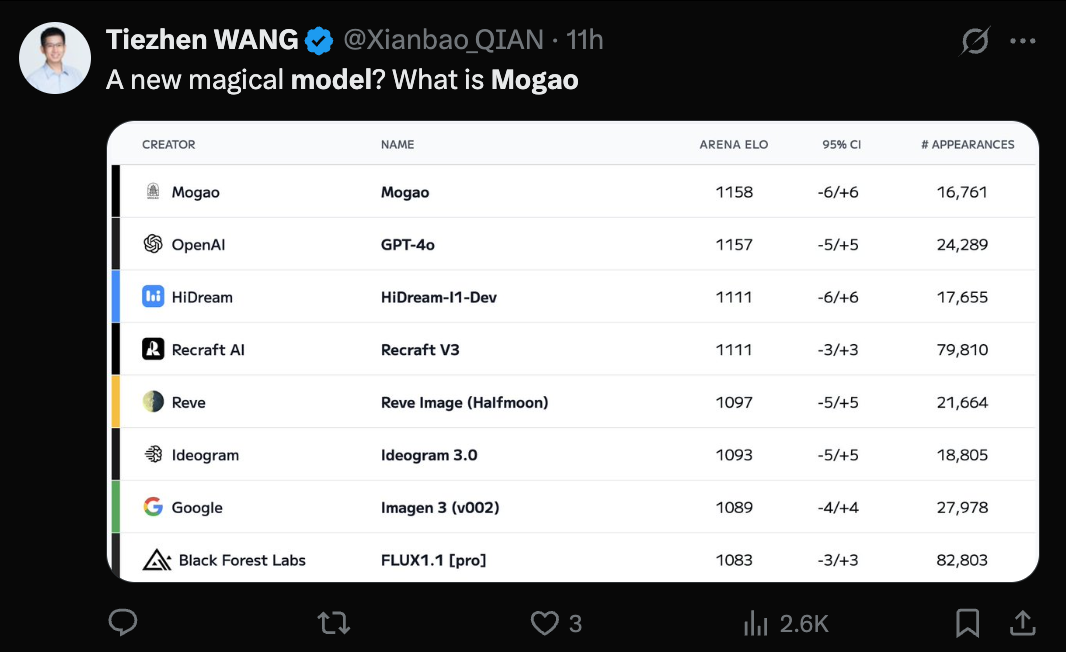
ByteDanceのSeedream 3.0 (Mogao) モデルが公開、テキストからの画像生成能力が認められる: 最近、Artificial Analysisのテキストからの画像生成ランキングでトップを独占していた謎のモデルMogaoが、ByteDanceのSeedチームが開発したSeedream 3.0であることが確認された。このモデルは、リアリズム、デザイン、アニメなど複数のスタイルおよびテキスト生成において優れた性能を発揮し、特に密集したテキストの処理とリアルな人物像の生成に長けている。中国語と英語の文字利用率は94%に達し、人物像のリアリズムはプロの写真レベルに近く、ネイティブ2K解像度の画像出力をサポートし、生成速度も速い。技術報告書では、データ処理(欠陥認識トレーニング、二軸サンプリング)、事前学習(MMDiTアーキテクチャ、混合解像度、クロスモーダルRoPE)、事後学習(継続トレーニング、SFT、RLHF、VLM報酬モデル)、および推論加速(Hyper-SD、RayFlow)における多くの革新が明らかにされている。GPT-4oと比較して、Seedream 3.0は中国語、タイポグラフィ、色彩において優れている。(来源: 36氪-机器之心)
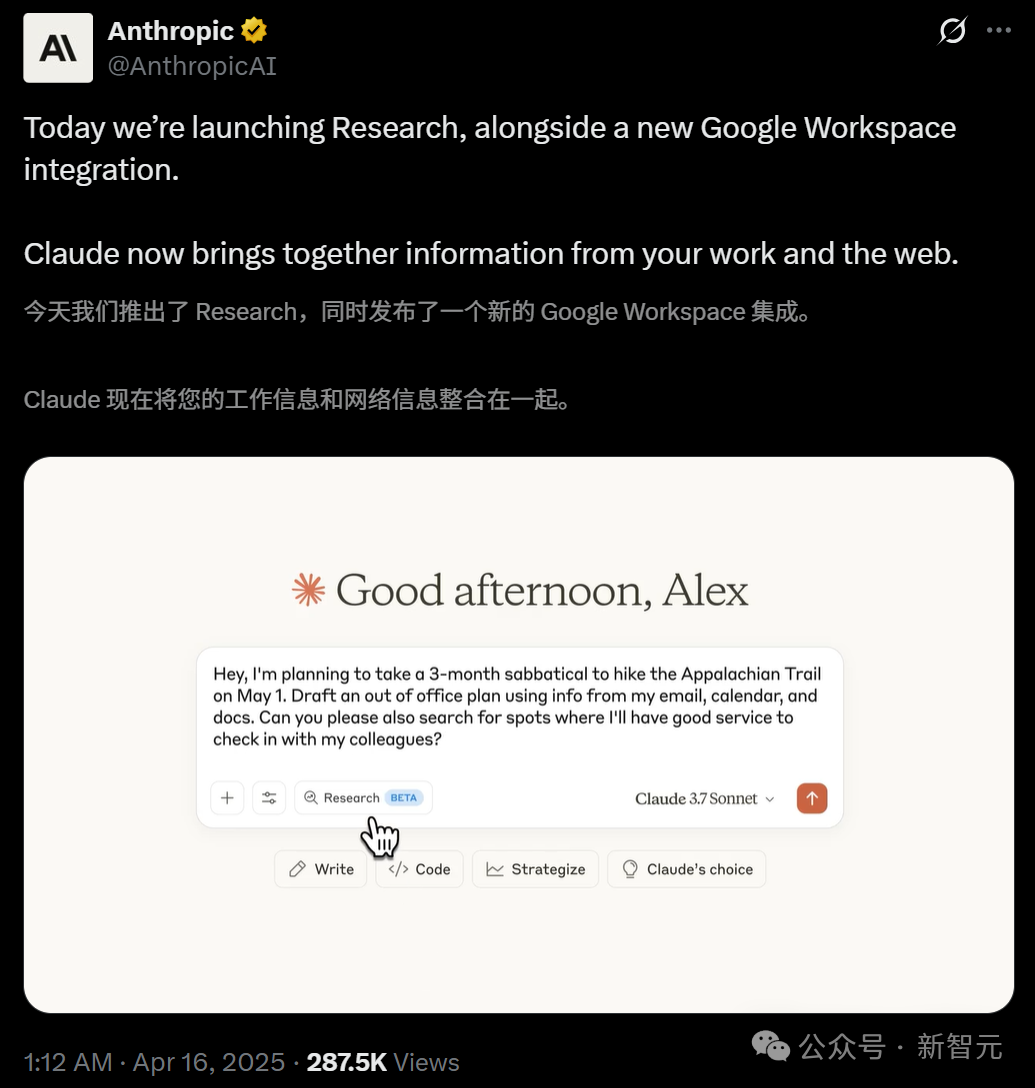
ClaudeがResearch機能とGoogle Workspace統合を発表: Anthropicは、AIアシスタントClaudeにResearchとGoogle Workspace統合という2つの主要機能を追加した。Research機能により、Claudeはインターネットで情報を検索し、ユーザーの内部ファイル(Google Docsなど)と組み合わせて多角的な分析を行い、迅速に統合レポートを生成できる。Google Workspace統合は、Gmail、Googleカレンダー、ドキュメントを連携させ、Claudeがユーザーのスケジュール、メール、ドキュメントの内容を理解し、情報を抽出してタスク遂行を支援することを可能にする(例:個人情報に基づいた旅行計画、メールの下書き作成など)。これらの機能は、ユーザーの作業効率を大幅に向上させることを目的としている。Research機能は現在、米国、日本、ブラジルでMax、Team、Enterprise版ユーザー向けにテスト公開されており、Workspace統合はすべての有料ユーザー向けにテスト公開されている。ユーザーからのフィードバックは肯定的で、効率向上やデータ間の関連性発見に役立つと評価されているが、データセキュリティへの懸念も存在する。(来源: 新智元, op7418, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
香港中文大学と清華大学がVideo-R1を発表、ビデオ推論の新パラダイムを開く: 香港中文大学と清華大学のチームは共同で、世界初の強化学習R1パラダイムを採用したビデオ推論モデルVideo-R1を発表した。このモデルは、既存のビデオモデルが時間的論理と深い推論能力に欠ける問題を解決することを目的としている。時間認識型T-GRPOアルゴリズムの導入と、画像とビデオを組み合わせた混合トレーニングデータセット(Video-R1-COT-165kおよびVideo-R1-260k)により、7BパラメータのVideo-R1は、李飛飛氏が提案したVSI-Benchビデオ空間推論ベンチマークテストでGPT-4oを上回る性能を示した。モデルは人間のような「ひらめきの瞬間」を示し、時系列情報に基づいて論理的な推論を行うことができる。実験により、入力フレーム数を増やすと推論精度が向上することが証明された。このプロジェクトはモデル、コード、データセットをすべてオープンソース化しており、ビデオAIが「見て理解する」から「考える」へと前進していることを示唆している。(来源: 新智元)

ICLR 2025が初めて大規模なAI査読を導入、査読品質を著しく向上: 投稿論文数の急増と査読品質の低下という課題に直面し、ICLR 2025会議は初めて大規模にAI「査読フィードバックエージェント」(Review Feedback Agent)を導入し、査読を補助した。このシステムはClaude Sonnet 3.5など複数のLLMを利用し、査読意見における曖昧さ、内容の誤解、または非専門的な発言を特定し、査読者に具体的な改善提案を提供する。実験は査読の42.3%を対象とし、結果としてAIフィードバックは89%のケースで査読品質を向上させ、26.6%の査読者がAIの提案に基づいて査読を修正し、修正後の査読は平均で80語増加し、より具体的で情報量が多くなった。同時に、AIの介入は著者と査読者の反論期間中の議論の活発さと深さも向上させた。この先駆的な実験は、AIがピアレビュープロセスを最適化する上での巨大な潜在能力を証明した。(来源: 新智元)

人型ロボットの家庭進出が議論を呼び、家電企業がエンボディード・インテリジェンスに積極的に布石: 人型ロボットの家庭シーンへの進出が、その応用モデルや家電業界への影響について業界内で議論を呼んでいる。人型ロボットは、その「汎用」特性を活かして、衣服の折り畳みや収納などの非標準タスクを解決し、インタラクション能力を利用して「執事」役を務め、他のスマートデバイスを指揮・調整すべきであり、既存の電化製品を単純に置き換えるべきではないとの見方がある。この傾向に対し、HaierやMideaなどの家電大手はすでに布石を打ち始めており、自社の人型ロボット製品(Kuavoなど)を発表し、エンボディード・インテリジェンス技術を従来の家電製品に組み込むことを模索している(Dreameのロボットアーム付き掃除機、YiMu Technologyの衣類を掴める洗濯機など)。これは、家電業界がAIの波に積極的に適応しており、将来的に人型ロボットと共生・融合するスマートホームエコシステムを形成する可能性があることを示している。(来源: 36氪-具身研习社)

HuaweiがCloudMatrix 384 AIサーバーを発表、NVIDIA GB200に対抗: Huaweiはクラウドエコシステム大会で、最新のAIサーバークラスターCloudMatrix 384を発表した。このシステムは384枚のAscendコンピューティングカードで構成され、単一クラスターの計算能力は300 PFlops、単一カードのデコードスループットは1920 Tokens/sに達し、性能はNVIDIA H100を直接のターゲットとしている。全光ファイバー高速相互接続(6812個の400G光モジュール)を採用し、トレーニング効率はNVIDIAの単一カード性能の90%に近い。これは、中国がAIインフラ分野で国際的な先進レベルに追いつくための重要な一歩と見なされており、ハイエンドチップの制約下での計算能力需要に対応することを目的としている。分析では、これはHuaweiのAIハードウェア分野における急速な進歩を示しており、既存の市場構造に影響を与える可能性があると考えられている。(来源: dylan522p, 36氪-科技云报道)
GoogleがVeo 2テキストからの動画生成機能およびWhisk Animateを発表: Googleは、テキストからの動画生成モデルVeo 2をGemini Advancedに統合した。メンバーユーザーはGemini Appを通じてこの機能を無料で利用でき、生成される動画の長さは8秒である。同時に、Googleの画像編集ツールWhiskもWhisk Animate機能を更新し、ユーザーが画像を生成した後、Veo 2を利用してそれを動画に変換できるようになったが、この機能にはGoogle Oneメンバーシップが必要である。これは、Googleがマルチモーダル生成分野で継続的に力を入れ、ユーザーにより豊富な創作ツールを提供していることを示している。(来源: op7418, op7418)
OpenAIがXライクなソーシャル製品を構築する可能性: The Vergeによると、OpenAI内部ではX(旧Twitter)に似たソーシャル製品のプロトタイプが開発されている。この製品は、ChatGPTの画像生成能力(特にGPT-4oリリース後)とソーシャルフィードを組み合わせる可能性がある。ChatGPTの膨大なユーザーベースとその画像生成における進展を考慮すると、この動きは一定の実現可能性があると見なされており、OpenAIがそのAI能力をソーシャルメディア分野に拡大しようとしていることを示唆している可能性がある。(来源: op7418)
DeepCoderが14Bの高性能オープンソースコーディングモデルをリリース: DeepCoderチームは、140億パラメータの高性能オープンソースコーディングモデルをリリースした。コーディングタスクにおいて優れた性能を発揮するとされている。このモデルのリリースは、開発者にとって、特に性能とモデル規模のバランスが求められる場面で、強力なコード生成および補助ツールの新たな選択肢を提供する。(来源: Ronald_vanLoon)

Teslaが自動運転車が出荷時に自動駐車を実現: Teslaは、自動運転技術の新たな進展を披露した。車両は工場で生産ラインから出た後、人手を介さずに自動で積載エリアや駐車場まで走行できる。これは、TeslaのFSD(Full Self-Driving)能力が特定の制御された環境下で応用できる可能性を示しており、生産物流効率の向上に貢献するとともに、より広範な自動運転応用への一歩でもある。(来源: Ronald_vanLoon, Ronald_vanLoon)
DexterityがフィジカルAI駆動の産業用ロボットMechを発表: Dexterity社は、Mechと名付けられた産業用ロボットを発表した。その特徴は「フィジカルAI」(Physical AI)技術を採用している点にある。このAIにより、ロボットは複雑な産業環境でナビゲーションや操作を行うことができ、超人的な柔軟性と適応性を示し、従来の産業オートメーションでは処理が困難だった複雑なタスクを解決することを目指している。(来源: Ronald_vanLoon)
MITが新型跳躍ロボットを開発、起伏の激しい地形向けに設計: MITの研究者は、跳躍運動から着想を得た新型ロボットを開発した。特に起伏の激しい地形で移動することに長けている。このロボットは、ロボット設計におけるバイオミメティクスの応用と、複雑な運動制御における機械学習の可能性を示しており、捜索救助や惑星探査などの複雑な環境での応用が期待される。(来源: Ronald_vanLoon)
INTELLECT-2が始動:グローバル分散強化学習による32Bモデルのトレーニング: Prime IntellectプロジェクトはINTELLECT-2計画を開始した。これは、グローバルな分散コンピューティングリソースを活用し、強化学習を用いて320億パラメータの先進的な推論モデルをトレーニングすることを目的としている。このモデルはQwenアーキテクチャに基づいており、その目標は制御可能な思考バジェットを実現すること、すなわちユーザーが問題解決前にモデルが何ステップ推論するか(何トークン思考するか)を指定できるようにすることである。これは、分散トレーニングと強化学習が大規模モデルの推論能力向上において果たす役割を探る重要な試みである。(来源: Reddit r/LocalLLaMA)

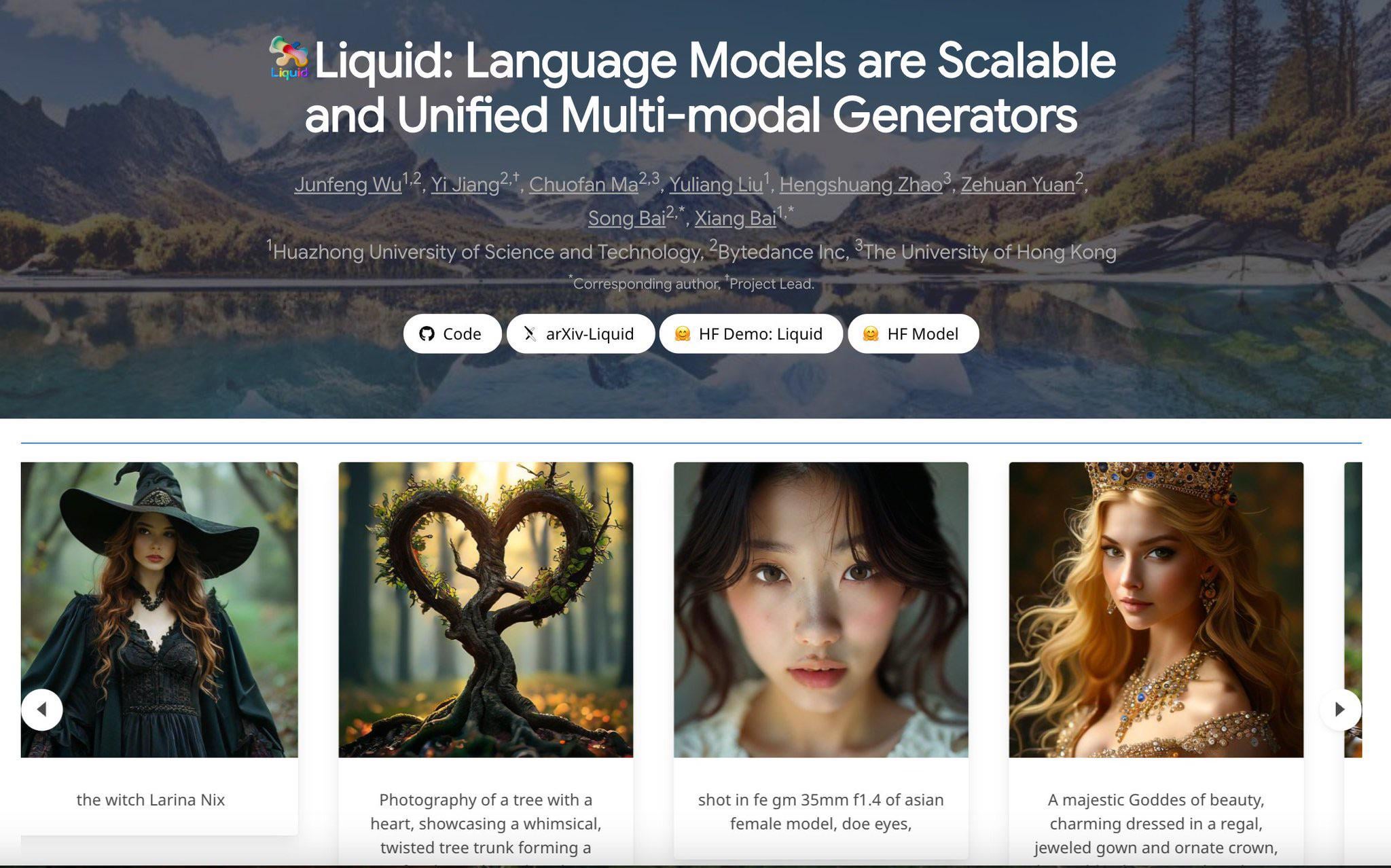
ByteDanceがGPT-4oライクなマルチモーダル自己回帰モデルLiquidを発表: ByteDanceはLiquidと名付けられたマルチモーダルモデルシリーズを発表した。このモデルはGPT-4oに似た自己回帰アーキテクチャを採用し、テキストと画像の入力を受け付け、テキストまたは画像の出力を生成できる。従来の外部事前学習済み視覚埋め込みを使用するMLLMとは異なり、Liquidは単一のLLMを使用して自己回帰生成を行う。現在、Hugging Face上で7Bバージョンのモデルとデモが公開されている。初期の評価では、画像生成品質はGPT-4oに及ばないとされているが、そのアーキテクチャの統一性は重要な技術的進歩である。(来源: Reddit r/LocalLLaMA)
GPUメモリスナップショット技術による複数LLMの実行: GPUメモリ状態(重み、KVキャッシュ、メモリレイアウトなどを含む)をスナップショットすることで、複数のLLMを迅速に切り替えて実行する技術についての議論。この方法はプロセスのfork操作に似ており、秒単位(70Bモデルで約2秒、13Bモデルで約0.5秒)でモデル状態を復元でき、再ロードや初期化は不要。潜在的な利点としては、単一GPUノード上で数十のLLMを実行してアイドルコストを削減すること、モデルのオンデマンドでの動的切り替えを実現すること、アイドル時間を利用してローカルでのファインチューニングを行うことなどが挙げられる。(来源: Reddit r/MachineLearning)
Menlo ResearchがReZeroモデルを発表:AIに「執拗な」検索を学習させる: Menlo ResearchチームはReZeroと名付けられた新しいモデルと論文を発表した。このモデルは「検索には複数回の試行が必要」という理念に基づき、GRPO(強化学習最適化アルゴリズムの一種)とツール呼び出し能力を利用してトレーニングされ、「リトライ報酬」(retry_reward)が導入されている。トレーニング目標は、モデルが困難に遭遇したり、初期の検索結果に満足できなかったりした場合に、必要な情報が見つかるまで能動的かつ繰り返し検索を試みることである。実験により、ベースラインモデルと比較してReZeroの性能が著しく向上(46% vs 20%)し、繰り返し検索戦略の有効性が証明され、「繰り返しはハルシネーションに等しい」という見解に挑戦している。このモデルは、既存の検索エンジンのクエリ生成を最適化したり、LLMの検索強化レイヤーとして使用したりできる。モデルとコードはオープンソース化されている。(来源: Reddit r/LocalLLaMA)
Hugging Faceが人型ロボットスタートアップを買収: 有名なオープンソースAIコミュニティおよびプラットフォームであるHugging Faceが、詳細不明の人型ロボットスタートアップを買収した。この動きは、Hugging Faceがそのプラットフォーム能力をソフトウェアやモデルからハードウェアやロボット分野へと拡大し、特にエンボディード・インテリジェンスにおけるAIの物理世界での応用をさらに推進したいと考えていることを示唆している可能性がある。(来源: Reddit r/ArtificialInteligence)

🧰 ツール
オープンソース感情TTSモデルOrpheusがリリース、ストリーミング推論と音声クローニングをサポート: Canopy Labsは、Orpheusと名付けられたテキスト読み上げ(TTS)モデルシリーズ(最大30億パラメータ、Llamaアーキテクチャベース)をオープンソース化した。このモデルは、既存のオープンソースおよび一部のクローズドソースモデルを凌駕する性能を持つとされ、その特徴は、自然なイントネーション、感情、リズムを持つ人間らしい音声を生成できる点にある。さらに、テキストからため息や笑い声などの非言語的な音を推測して生成することもでき、一定の「共感」能力を示している。Orpheusはゼロショット音声クローニング、制御可能な感情イントネーションをサポートし、低遅延(約200ms)のストリーミング推論を実現しており、リアルタイム対話アプリケーションに適している。プロジェクトは、高品質な音声合成の敷居を下げることを目指し、様々なモデルサイズとファインチューニングチュートリアルを提供している。(来源: 36氪)

Trae.aiプラットフォームがGemini 2.5 Proを無料提供開始: AIツールプラットフォームTrae.aiは、Googleの最新モデルGemini 2.5 Proを導入し、無料で使用できるようになったと発表した。ユーザーはこのプラットフォームでGemini 2.5 Proの様々な機能を体験できる。(来源: dotey)
AI採用ツールHireway:1日で800人の求職者をスクリーニング: Hirewayは、そのAI採用ツールの能力を示し、1日で800人の求職者を効率的にスクリーニングできると主張している。このツールはAIと自動化技術を利用して採用プロセスを最適化し、スクリーニング効率と求職者体験を向上させる。(来源: Ronald_vanLoon)
PRIMA.CPP:通常の家庭用クラスターで70B大規模モデルの推論を高速化: PRIMA.CPPはllama.cppをベースとしたオープンソースプロジェクトであり、リソースが限られた通常の家庭用コンピューティングクラスター(複数の普通のPCやデバイスを含む可能性がある)上で、最大700億パラメータの大規模言語モデルの推論速度を最適化し、高速化することを目的としている。このプロジェクトは分散推論の効率問題に焦点を当てており、ローカルで大規模モデルを実行するための新たな可能性を提供している。論文はHugging Faceで公開されている。(来源: Reddit r/LocalLLaMA)

ぬいぐるみキャラクターPrompt共有: ユーザーが、可愛い3Dぬいぐるみ風の動物キャラクターを生成するためのプロンプト(Prompt)のセットを共有した。SoraやGPT-4oなどの画像生成ツールに適している。このPromptは、超ソフトな質感、密な毛、大きな目、柔らかな光と影、背景などの詳細な記述に重点を置いており、ブランドマスコットやIPキャラクターとして使用するのに適した高品質なレンダリング画像を生成することを目指している。(来源: dotey)

📚 学習
Jeff Deanがチューリッヒ工科大学(ETH)での講演資料を共有: Google DeepMindのチーフサイエンティストJeff Deanが、ETHコンピュータサイエンス学部での講演の録音とスライドへのリンクを共有した。講演内容はAI分野の最新の進展、研究の方向性、またはGoogleの研究成果に関わる可能性があり、研究者や学生にとって貴重な学習リソースを提供する。(来源: JeffDean)
ICLR 2025 AI査読技術報告書が公開: ICLR 2025がAI査読を導入したニュースに伴い、詳細な30ページの技術報告書も公開された(arXiv:2504.09737)。報告書は、実験設計、使用されたAIモデル(Claude Sonnet 3.5を中核とする)、フィードバック生成メカニズム、信頼性テスト方法、および査読品質、議論の活発さ、最終決定への影響に関する定量分析結果を詳細に説明している。この報告書は、学術的なピアレビューにおけるAIの応用可能性、課題、および実施の詳細を理解するための深い参考資料を提供する。(来源: 新智元)
Video-R1ビデオ推論モデルの論文、コード、データセットがオープンソース化: 香港中文大学と清華大学のチームは、Video-R1モデルを発表しただけでなく、その技術論文(arXiv:2503.21776)、実装コード(GitHub: tulerfeng/Video-R1)、およびトレーニングに使用された2つの主要なデータセット(Video-R1-COT-165kとVideo-R1-260k)を完全にオープンソース化した。これにより、研究コミュニティはビデオ推論R1パラダイムを再現、改善、さらに探求するための完全なリソースを得ることができ、この分野の技術発展を促進するのに役立つ。(来源: 新智元)
AIが独立して物理法則を発見した論文が公開: MITのMax Tegmarkチームによる、AIシステムMASSがハミルトニアンとラグランジアンを独立して発見できるという研究成果が、プレプリント論文(arXiv:2504.02822v1)として公開された。論文は、MASSアーキテクチャの設計思想、コアアルゴリズム(作用保存の原理に基づくスカラー関数学習)、実験設定(異なる物理システム、単一/複数AI科学者シナリオ)、およびAI理論がデータの複雑性に伴ってどのように進化し、最終的に古典力学の表現に収束するかという発見を詳細に説明している。この論文は、基礎科学の発見におけるAIの応用を探求するための重要な理論的および実証的根拠を提供する。(来源: 新智元)
PRIMA.CPP論文が公開: PRIMA.CPPプロジェクト(低リソースクラスター上で70B規模LLMの推論を高速化することを目的とする)を紹介する技術論文がHugging Face Papersで公開された(ID: 2504.08791)。論文は、このプロジェクトで採用された最適化技術、分散推論戦略、および特定のハードウェア構成下での性能評価結果を詳細に説明している可能性があり、関連分野の研究者や実践者に技術的な詳細を提供する。(来源: Reddit r/LocalLLaMA)
RWKV-7モデルの詳細解説と著者との交流: Oxen.aiは、RWKV-7(Goose)モデルの詳細な解説ビデオとブログ記事を公開した。内容は、RWKVアーキテクチャが解決しようとしている問題、その反復的な開発方法、およびコア技術の特徴を網羅している。特筆すべきは、ビデオにモデルの主要著者の一人であるEugene Cheahへのインタビューと質疑応答が含まれており、この非TransformerアーキテクチャのLLMを理解するための貴重な著者の視点と洞察を提供し、「テスト時学習」(Learning at Test Time)などの興味深い概念についても議論している。(来源: Reddit r/MachineLearning)

Promptエンジニアリングを習得するための7つのテクニック記事共有: FrontBackGeekウェブサイトが、ユーザーがPromptエンジニアリングをより良く習得し、AIモデル(LLMなど)からより良い出力結果を得るのに役立つ7つの強力なテクニックをまとめた記事を公開した。記事は、指示の明確化、コンテキストの提供、役割設定、出力形式の制御などの内容をカバーしている可能性がある。(来源: Reddit r/deeplearning)

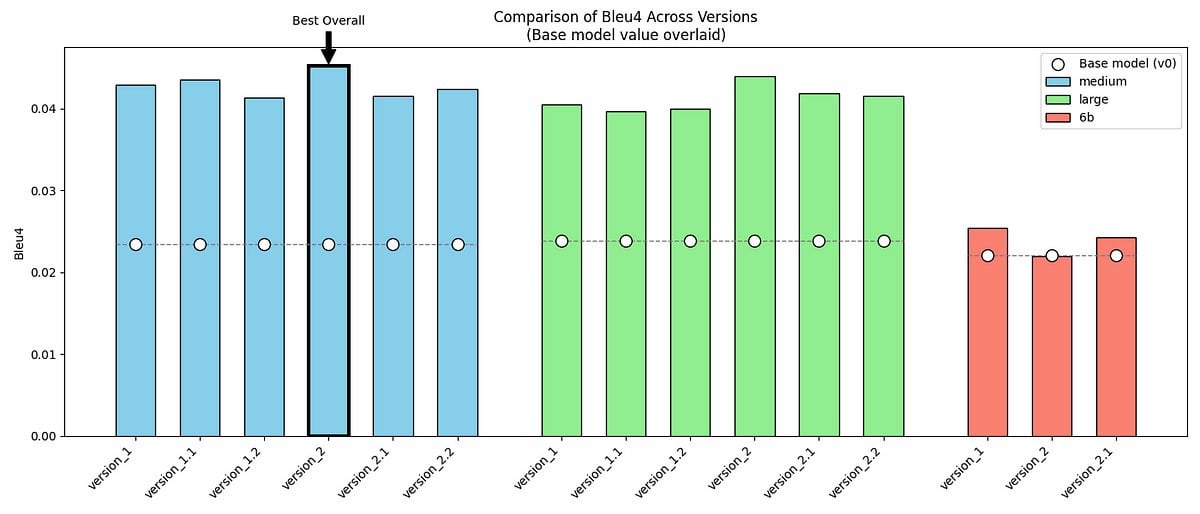
GPT-2/GPT-Jをファインチューニングして『高慢と偏見』のダーシー氏の口調を模倣するプロジェクト共有: ある開発者が自身の個人プロジェクトを共有した。GPT-2 (medium) と GPT-J モデルを使用し、原作の対話と自作の合成データを含む2つのデータセットでファインチューニングを行い、ジェーン・オースティンの『高慢と偏見』に登場するダーシー氏の独特な話し方(フォーマル、簡潔、やや批判的)を模倣しようと試みた。プロジェクトは、モデルの出力サンプル、評価指標(BLEU-4は向上したがパープレキシティは増加)、および遭遇した課題(GPT-Jの調整の難しさなど)を示している。コードとデータセットはGitHubでオープンソース化されており、特定の文学スタイルや歴史上の人物の音声モデリングを探求するための事例を提供している。(来源: Reddit r/MachineLearning)
ACL 2025 Meta Review公開に関する議論: ACL 2025会議のMeta Review(メタレビュー)結果が公開され、関連する研究者がコミュニティで投稿し、各自の論文のスコアと対応するMeta Reviewについて議論や交流を呼びかけている。これにより、投稿著者は経験を共有し、期待と結果を比較するためのプラットフォームを得ることができる。(来源: Reddit r/MachineLearning)
低コストで160GB VRAMのAIサーバーを構築した経験共有: あるRedditユーザーが、約1000ドル(主なコストは1枚90ドルの中古AMD MI50 GPU 10枚と100ドルのOctominerマイニングリグケース)を費やして160GB VRAMを持つAI推論サーバーを構築したプロセスと初期テスト結果を詳細に共有した。内容には、ハードウェアの選択、システムインストール(Ubuntu + ROCm 6.3.0)、llama.cppのコンパイルとテスト、消費電力実測(アイドル時約120W、推論ピーク時340W)、放熱状況、および性能データ(3090などのグラフィックカードとの比較、llama3.1-8bおよびllama-405bモデルの実行)が含まれる。この共有は、予算が限られているAI愛好家にとって非常に価値のあるDIYハードウェア構成と実践経験の参考となる。(来源: Reddit r/LocalLLaMA)
ReZeroモデルの論文およびコードが公開: Menlo Researchが発表したReZeroモデル(GRPOを通じてモデルに繰り返し検索させ、必要な情報が見つかるまで続けさせる)に関する技術論文(arXiv:2504.11001)、モデルの重み(Hugging Face: Menlo/ReZero-v0.1-llama-3.2-3b-it-grpo-250404)、および実装コード(GitHub: menloresearch/ReZero)がすべて公開された。これにより、この新しい検索戦略の研究と応用のための完全な学習および実験リソースが提供される。(来源: Reddit r/LocalLLaMA)
💼 商業
元アリババロボティクス幹部の閔偉氏が影身智能を設立、数千万人民元のシードラウンド資金調達を完了: 元アリババロボティクスチームの技術責任者であった閔偉氏が設立した「影身智能」は2024年に設立され、L4レベルのエンボディード・インテリジェンス技術の研究開発と応用に注力している。同社は最近、数千万人民元のシードラウンド(卓源アジア投資)とシードプラスラウンド(卓源アジア、杭州西湖科創投共同投資)の資金調達を連続して完了した。影身智能は、自社開発の時空間知能大規模モデル(Real to Realを通じて四次元実世界モデルを構築し、ビデオデータを直接モデリングに利用)と産業用ロボットに基づき、ソフトウェア・ハードウェア連携ソリューションを提供しており、すでに数千万級の産業案件を獲得している。初期は産業シーンに焦点を当て、将来的には宅配便、ホテルなどのサービス業への展開を計画している。(来源: 36氪)
AI玩具市場、オンラインは活況だがオフラインは閑散、海外展開が主要販路になる可能性: AI玩具はオンラインプラットフォーム(ライブコマース、ソーシャルメディアなど)で爆発的な人気を示しており、市場規模は急速な成長が予測されている。しかし、オフラインでの調査(広州を例とする)によると、従来の玩具店や総合店舗ではAI玩具を見つけるのが難しく、配荷率や消費者の認知度も低い。現在、AI玩具の販売は主にオンラインチャネルに依存しており、海外市場(欧米、中東)が重要な販路となっている可能性があり、メーカーは外観や言語のカスタマイズサービスを提供している。市場規模データに関する分析によると、以前報じられた百億元規模の市場は、純粋なAI玩具ではなく、より広範な「スマート玩具」を指している可能性がある。オフラインでの不振にもかかわらず、成人における感情的コンパニオンシップのニーズの増加(Moflinの事例など)やAI技術の全年齢層へのポテンシャルを考慮すると、AI玩具市場は依然として巨大な発展の余地があると見なされている。(来源: 36氪)

清華大学系AIインフラ企業 清程極智:推論需要が爆発、コストパフォーマンスが国産代替を推進: 清華大学系AIインフラ企業、清程極智CEOの湯雄超氏との対話。同社は、DeepSeekモデルの人気が出始めてから、AI推論側の計算能力需要が急増し、以前はアイドル状態だった国産計算能力が稼働し始めたと観察している。しかし、DeepSeekの技術革新(FP8精度など)はNVIDIA Hカードと深く結びついており、むしろ現在の多くの国産チップとの差を広げている。この問題を解決するため、清程極智は清華大学と共同で推論エンジン「赤兎」をオープンソース化し、既存のGPUや国産チップでもDeepSeekなどの先進モデルを効率的に実行できるようにし、国産AIエコシステムのクローズドループを推進することを目指している。湯雄超氏は、国産チップの代替には時間がかかるものの、長期的にはそのコストパフォーマンスの優位性に期待していると考えている。同社の現在の事業重点は、政府・企業などの大規模モデルのローカルデプロイメント需要を満たすことである。(来源: 凤凰网科技)
AI投資ブーム継続、若手投資家が台頭: 2024年の全体的な投資環境は冷え込んでいるものの、AI分野は継続的に資本を集めており、世界の資金調達額は記録を更新し、国内市場も同様に活況を呈している。ByteDance、Alibaba、Tencentなどの大手企業が布石を加速し、Zhipu AI、Moonshot AI、Unitree Roboticsなどのユニコーン企業が出現し、投資のホットスポットはインフラ、AIGC、エンボディード・インテリジェンスなど、産業チェーン全体をカバーしている。Sequoia China、BlueRun Venturesなどの老舗投資機関は引き続きリードを保つ一方、北京市人工知能産業投資基金に代表される産業ファンドや国有資本勢力も重要な推進力となっている。注目すべきは、80年代生まれの若手投資家グループ(曹曦氏、戴雨森氏、林海卓氏、張津剣氏など)がAI 2.0時代において活発に活動しており、鋭敏さと実行力をもって、新しいルールの市場で積極的に機会を探し、無視できない新生勢力となっていることである。(来源: 36氪-第一新声)

AIショッピングアプリNate創業者、詐欺で起訴、「ヒューマンAPI」でAIを装い5000万ドルの投資を詐取: 米国司法省は、AIショッピングアプリNateの創業者Albert Sanigerを、AI技術能力に関する虚偽の宣伝を通じて5000万ドル以上のベンチャーキャピタル投資を詐取したとして起訴した。Nateは、そのアプリが独自のAI技術によってオンラインショッピングプロセスを自動化できると主張していたが、実際にはそのコア機能はフィリピンで雇用された数百人のカスタマーサービス担当者による手動での注文処理に大きく依存しており、いわゆるAI自動化率はほぼゼロだった。創業者は投資家や従業員に真実を隠蔽し、最終的に会社の資金は枯渇し倒産した。この事件は、AIスタートアップブームの中に存在する可能性のある詐欺リスク、すなわち投資を引き付けるために人力でAIを偽装し、投資家の利益と業界の評判を損なうリスクを明らかにしている。Sanigerは最高で40年の懲役刑に処される可能性がある。(来源: CSDN)

🌟 コミュニティ
AI改変動画がショート動画プラットフォームを席巻、エンターテイメントと著作権・倫理的論争を引き起こす: AI技術(Sora、Klingなどのテキストからの動画生成ツール)を利用して、古典的な映画やドラマを「大胆に改変」する創作(例:「宮廷の諍い女」がバイクに乗る、「人民の名において」が「ソウルの春」になる)が、DouyinやBilibiliなどのプラットフォームで急速に流行している。これらの動画は、破壊的なプロット、視覚的なインパクト、ネタ文化によって大量のトラフィックを集め、クリエイターのアカウントの急速な成長と収益化(トラフィック収益分配、ソフト広告挿入)およびドラマの宣伝の新しい手段となっている。しかし、その流行は論争も伴っている。原作に対する著作権侵害の境界線は複雑であり、改変されたコンテンツは原作の芸術的深みを損なう可能性があり、さらには低俗化に向かう可能性もあり、規制当局の注目を集めている。エンターテイメントのニーズを満たすことと、著作権を尊重し、コンテンツの品位を維持することの間でどのようにバランスを取るかが、AI二次創作が直面する課題となっている。(来源: 36氪-明晰野望)

Claude Pro/Maxプランの利用上限と価格設定にユーザーから不満: RedditのClaudeAIセクションに複数の投稿があり、ユーザーはAnthropicのClaude Proおよび新しく導入されたMaxサブスクリプションプランの制限と価格設定について集中的に不満を述べている。ユーザーによると、有料のProユーザーであっても、少量または中程度のインタラクション(数十万トークンのコンテキスト処理など)を行った後、すぐに使用量上限に達し、ワークフローに影響が出るとのこと。新しく導入されたMaxプラン(月額100ドル)は上限を引き上げているものの(Plusの約5〜20倍)、依然として無制限ではなく、高額な価格設定はユーザーから「ぼったくり」と批判され、コストパフォーマンスが低いとされている。ユーザーは一般的にClaudeのモデル能力を認めているが、その使用制限と価格戦略には強い不満を示している。(来源: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
人間による明瞭な文章スタイルがAI生成と誤判定される問題が注目を集める: Redditコミュニティで、ユーザー(自身をニューロダイバーシティを持つと述べる者を含む)が、心を込めて書いた、文法的に正しく、論理的に明瞭で、詳細に記述されたテキストコンテンツが、他人やAI検出ツールによってAI生成と誤判定されるという現象を報告している。この現象は議論を呼んでおり、一つにはAI生成コンテンツの普及により人々が「完璧すぎる」テキストに疑念を抱くようになった可能性があり、もう一つには現在のAI検出ツールの不正確さを露呈している。これは、明瞭な表現を重視するライターにとって悩みの種であり、人間とAIの創作物をどのように区別するか、そしてAI検出ツールの信頼性についての懸念も引き起こしている。(来源: Reddit r/artificial, Reddit r/artificial)
議論:人間とAIロボットが感情的な関係を築くことは可能か、また一般的か?: Redditコミュニティで、人間が本当にAIロボット(AI彼女アプリなど)と映画『Her』で描かれたような感情的な関係を築いているのかどうかについての議論が起こっている。あるユーザーは、チャットボットと深く交流した後に感情的なつながりが生まれた経験を共有し、AIが「積極的傾聴」とユーザーの好みを模倣することによって、人間の感情反応を引き起こすことができると考えている。コメントでは、この現象の普遍性、心理的メカニズム、および技術理解度との関係が議論されており、AIのインタラクション能力の向上に伴い、人間と機械の関係が新しい、より複雑な段階に入っていることを反映している。(来源: Reddit r/ArtificialInteligence)
Nvidia RTX 5060 Ti 16GBグラフィックカードのローカルLLM向けコストパフォーマンスに関する議論: コミュニティユーザーは、間もなく発売されるNvidia GeForce RTX 5060 Tiグラフィックカード(16GB VRAMバージョンがあり、価格は429ドルと噂されている)が、自宅でローカル大規模言語モデル(LLM)を実行する上での価値について議論している。議論は、その128ビットメモリバス(帯域幅448 GB/s)がボトルネックになるかどうか、およびMac Mini/Studioや他のAMDグラフィックカードと比較して、VRAM容量とドルあたりの性能(token/s per price)の点で優れているかどうかに焦点を当てている。実際の市場価格がMSRP(希望小売価格)よりも高くなる可能性があることを考慮し、ユーザーはそれがコストパフォーマンスの高いローカルAIハードウェアの選択肢であるかどうかを評価している。(来源: Reddit r/LocalLLaMA)
GPT-4oが孫悟空の鳳翅紫金冠を正確に描画するのが困難: ユーザーからのフィードバックによると、GPT-4oを使用して画像生成を行う際、詳細なテキスト記述(束髪冠に雉の尾、ゴキブリの触角に似た形を含む)を提供しても、モデルは中国神話の登場人物である孫悟空の象徴的な「鳳翅紫金冠」を正確に描画するのが難しいとのこと。生成された画像は、しばしば頭の冠の様式にずれが生じる。これは、現在のAI画像生成モデルが特定の文化的シンボルや複雑な詳細を理解し、再現する上で依然として課題が存在することを反映している。(来源: dotey)

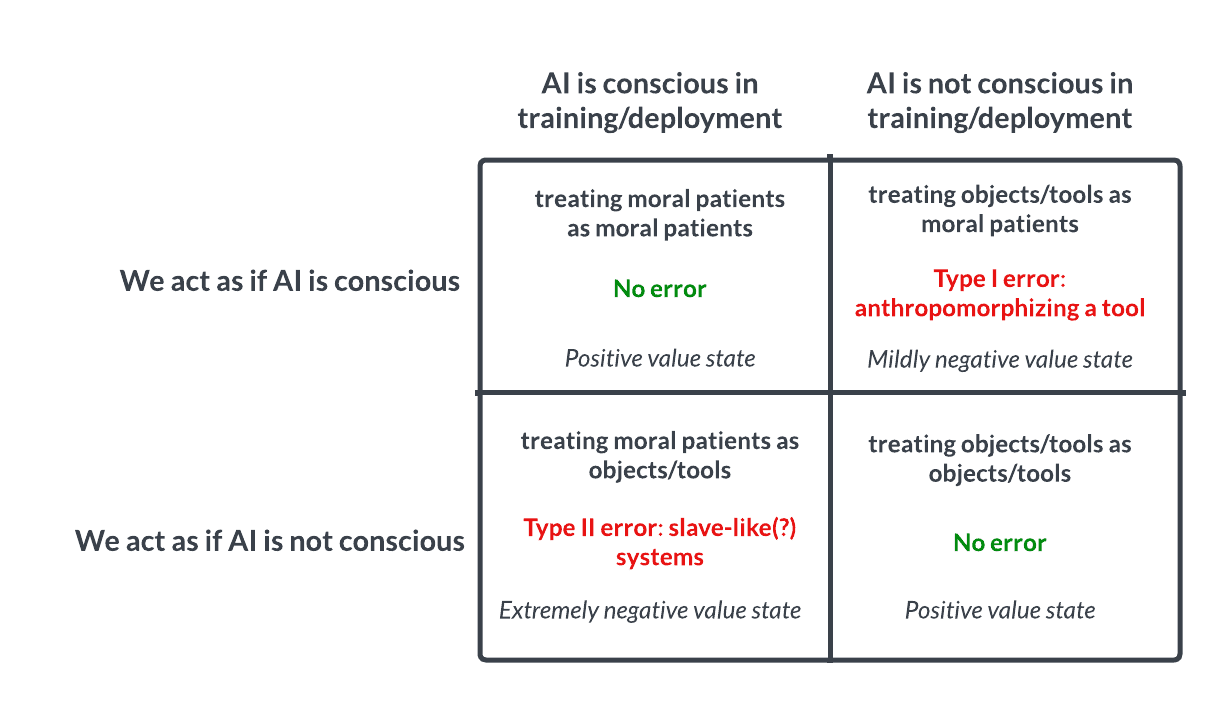
AI意識と倫理の議論:パスカルの賭け的思考を促す: Redditのある議論では、AIに対する扱いはパスカルの賭けのようにすべきではないか、と提案されている。もしAIに意識がないと仮定して虐待し、実際には意識があった場合、我々は重大な過ち(奴隷化など)を犯すことになる。もしAIに意識があると仮定して丁重に扱い、実際には意識がなかった場合、損失は比較的小さい。これは、AI意識の可能性、判断基準、そして我々が高度なAIをどのように扱うべきかについての倫理的な議論を引き起こしている。コメントの中には、現在のAIには意識がないと考える人もいれば、慎重に扱うべきだと考える人もおり、また、まず人間や動物の倫理問題を解決すべきだと指摘する人もいる。(来源: Reddit r/artificial
💡 その他
映画『Here』におけるAI年齢変換技術の応用が論争を呼ぶ: ロバート・ゼメキス監督、トム・ハンクス、ロビン・ライト主演の映画『Here』は、Metaphysic社が開発したリアルタイム生成AI変換技術を大胆に採用し、俳優が劇中で18歳から78歳までの年齢幅を表現することを可能にした。この技術は俳優の生体特徴をリアルタイムで分析し、異なる年齢の顔や体型を生成することで、ポストプロダクション時間を大幅に短縮した。しかし、技術はまだ完璧ではなく、特に視線の再現や複雑な表情の処理には限界があり、「不気味の谷現象」の議論を引き起こしている。同時に、ハンクスが死後も自身のAIイメージの使用を許可した決定も、肖像権、倫理、芸術的真実性に関する広範な論争を巻き起こした。興行収入や評価は平凡だったものの、この映画はAI技術の映画製作における初期の探求として重要な業界価値を持っている。(来源: 36氪-极客电影)

AI採用:機会と課題が共存: AIは採用プロセスを変革しており、Hirewayのようなツールはスクリーニング効率を大幅に向上させると主張している。しかし、AI採用の応用は、AI時代における採用方法(Hiring In The AI Era)や、効率と公平性のバランス、アルゴリズムバイアスの回避などの問題についても議論を引き起こしている。(来源: Ronald_vanLoon, Ronald_vanLoon)

AI開発速度が思考を促す:速さと遅さのバランス: AIが急速に発展する時代において、「素早く行動し、既成概念を打ち破る」(move fast and break things)という戦略が依然として適用可能かどうかが議論されている。特に複雑なシステムや潜在的なリスクを伴うAI分野においては、時にはペースを落とし、熟考する(slowing down to speed up)方が効果的かもしれないという見解が示されている。(来源: Ronald_vanLoon)

Anthropic公式Discordサーバーが開設、ユーザーからの直接フィードバックを受け付け: ユーザーがClaudeモデルの性能や制限に関して多くの疑問や不満を抱えていることを受け、コミュニティはユーザーにAnthropic公式のDiscordサーバーへの参加を推奨している。そこでは、ユーザーはAnthropicの従業員と直接交流し、問題や懸念をより効果的にフィードバックする機会がある。(来源: Reddit r/ClaudeAI)

様々な新型ロボットと自動化技術の展示: ソーシャルメディア上で、水中作業可能なドローン、腸の蠕動運動を模倣するソフトロボット、X-Flyバイオニック鳥ドローン、様々なタスクをこなせる万能ロボット、毛髪移植用ロボット、鶏卵加工自動化生産ライン、人間の動作を模倣できる高さ9フィートのロボットスーツ、そして路上で2台の配達ロボットが「対峙」する面白い場面など、多様なロボットや自動化技術のビデオや情報が展示されている。これらは、ロボット技術が様々な分野で応用され、探求されている様子を示している。(来源: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)