
キーワード:AI, タリフ, AI産業へのタリフ影響, グローバルAIサプライチェーン, AIハードウェアコスト増加, AI技術生態系の分断, タリフ対処戦略
🔥 フォーカス
関税ショック下の世界AI産業の動向分析:最近の国際貿易の緊張、特に高額関税の実施は、グローバル化が進んだAI産業に深刻な影響を与えている。記事の分析によると、米国によるAI計算能力などのハードウェア制限には既に対応策があるものの、関税は世界のAI産業の亀裂を深める可能性がある。影響は主に以下の点に現れる:1)インフラ層:ハードウェアコストの増加、サプライチェーンの制限。ただし、中国には国産代替ソリューションがある。2)技術層:米中技術エコシステムの分断、オープンソース共有の阻害、標準の衝突を引き起こす可能性がある。3)応用層:市場の地域化が進み、AI製品の商業化に影響を与える。記事は、関税ショックの実際の「強度」は限定的かもしれないと見ている。なぜなら、中国は既に並行技術エコシステムを構築しており、関税は米国自身にも跳ね返るためだ。しかし、「広範性」の影響は深刻で、技術交流の中断、人材・資金の回避、市場標準の衝突を引き起こす可能性がある。対応戦略としては、自主研究開発(ハードウェア、フレームワーク)の強化、グローバル協力の堅持(第三者市場の開拓、国際標準への参加)、国産AIエコシステムの魅力向上、世界により包括的な技術選択肢を提供することが挙げられる。(出典: 36氪)
Anthropic共同創業者、AGIの接近を予測、Claude 4まもなくリリース:Anthropicの共同創業者兼チーフサイエンティストであるJared Kaplan氏は、人間レベルのAI(AGI)が、以前予測されていた2030年ではなく、今後2〜3年以内に実現する可能性があると予測している。彼は、AIの能力がタスク処理の「範囲」と「複雑度」の2つの次元で急速に拡大しており、現在のモデルはかつて専門家が数時間、あるいは数日かかっていたタスクを処理できると指摘した。Kaplan氏は、新世代モデルClaude 4が今後6ヶ月以内にリリースされる予定であり、その性能向上はポストトレーニング、強化学習の改善、および事前トレーニング効率の向上によるものであることを明らかにした。彼はまた、「テスト時スケーリング」(test-time scaling)の重要性、つまりモデルにより多くの思考をさせることが性能を予測可能に向上させることにも言及した。DeepSeekなどの中国モデルの台頭について、Kaplan氏は驚きはなく、その技術進歩は迅速であり、西側との差はわずか6ヶ月程度かもしれないと考え、アルゴリズム的には競争力があるが、ハードウェアの制限が主な課題である可能性があると述べた。インタビューの最後には、AIが経済社会に与える巨大な影響と、実証研究を行うことの重要性が強調された。(出典: 新智元)

🎯 動向
面壁智能と清華大学がCFMスパース技術を提案:面壁智能と清華大学のCFM論文著者である肖朝軍氏は、インタビューでConfigurable Foundation Models (CFM)技術を紹介した。CFMはネイティブスパース技術であり、ニューロンレベルのスパース活性化を強調し、現在の主流であるMoE(エキスパートレベルスパース)と比較して、粒度がより細かく、動的性がより高い。その核心的な利点は、モデルパラメータの効率(単位パラメータあたりの有効性)を大幅に向上させ、特にメモリが制限されるエッジデバイス(スマートフォンなど)においてVRAM/メモリを大幅に節約できることにある。肖朝軍氏は、Mambaなどの非Transformerアーキテクチャが効率面で探求を進めているものの、Transformerは効果面で依然として最高峰であり、GPUハードウェア最適化の「ハードウェア宝くじ」に当たったと考えている。彼はまた、小規模モデル(エッジデバイスで約2-3B)の実装、精度最適化(FP8/FP4のトレンド)、マルチモーダル進展、および知能の本質(圧縮よりも抽象能力に近い可能性がある)についても議論した。o1の長い思考連鎖と革新能力については、AIが将来突破すべき重要な方向性であると考えている。(出典: 量子位)

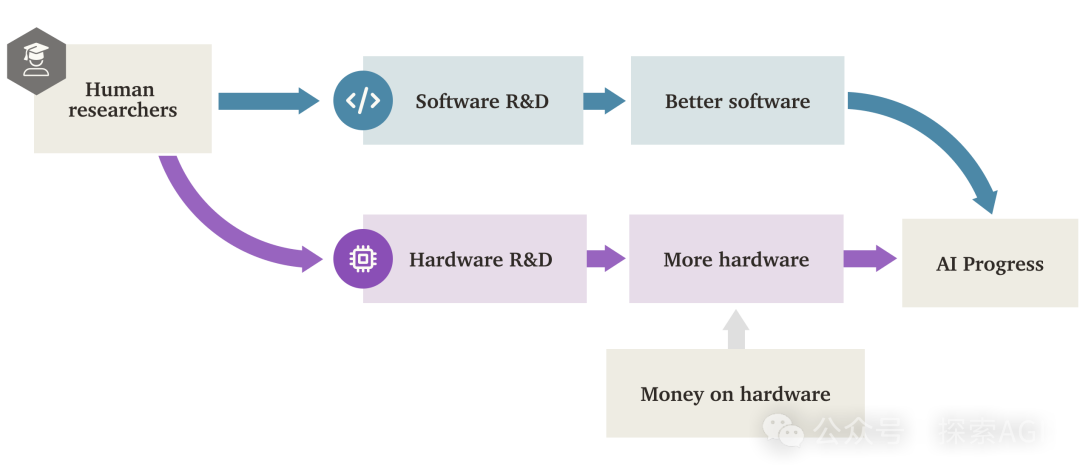
AIの「ソフトウェア知能爆発」(SIE)がハードウェア駆動を超える可能性:Forethoughtの研究報告書は、「ソフトウェア知能爆発」(Software Intelligence Explosion, SIE)の可能性を探っている。これは、AIが自身のソフトウェア(アルゴリズム、アーキテクチャ、トレーニング方法など)を改善することで能力を超高速で成長させ、既存のハードウェア基盤上でも発生する可能性があるというものだ。報告書はASARA(AI Systems for AI R&D Automation)という概念を提案しており、これはAIの研究開発を完全に自動化できるAIシステムを指す。ASARAが出現すると、正のフィードバックループが引き起こされる可能性がある:ASARAがより良いAIソフトウェアを開発し、より強力な次世代ASARAを生み出し、ソフトウェアの進歩を加速させる。報告書は「ソフトウェア研究開発収益率」(r値)という概念を導入し、現在のAIソフトウェアのr値は1より大きい可能性があり、AI能力の向上速度が研究開発難易度の増加速度を上回っており、SIEを引き起こす条件を備えていると分析している。SIEは、AI能力が短期間(数ヶ月、あるいはそれ以下)で既存のハードウェアに基づいて数百倍、数千倍に向上する可能性があり、ハードウェアはもはや絶対的なボトルネックではなくなるが、同時に巨大な社会適応とガバナンスの課題をもたらす。報告書はまた、計算リソースやトレーニング時間などの潜在的なボトルネックとその回避の可能性についても探求している。(出典: AI智能体频道)
GPT-4がまもなくChatGPTから廃止、GPT-4.1が登場か:OpenAIは、2025年4月30日をもって、GPT-4をChatGPTから削除し、現在のデフォルトモデルであるGPT-4oに完全に置き換えると発表した。GPT-4は引き続きAPI経由でアクセス可能である。この動きは、2023年3月にリリースされ、画期的なマルチモーダルモデルであったこのモデルの段階的な廃止を示すものである。GPT-4は、専門的なテストでトップレベルの人間の能力に達し、AIの「画像を見て話す」時代を切り開くなどの成果により、世界のAIアプリケーションエコシステムを爆発的に普及させた。同時に、コミュニティのリーク情報やコード発見は、OpenAIがまもなく一連の新モデル、GPT-4.1(およびそのmini、nanoバージョン)、以前発表されたo3「推論」モデル、そして全く新しいo4-miniモデルを、早ければ来週にもリリースする可能性を示唆している。既に一部のユーザーはChatGPTのモデルリストにGPT-4.1のオプションが表示され、対話が可能であることを発見しており、新モデルリリースの信憑性をさらに高めている。(出典: 新智元)

視点:AIの次のブレークスルーの鍵は新しいデータソースの「解き放ち」:コーネル大学の博士課程学生Jack Morris氏は、AI分野における4つの重大なパラダイムシフト(ディープニューラルネットワークとImageNet、Transformerとウェブテキスト、RLHFと人間の嗜好、推論と検証器)を振り返り、その根本的な駆動力は全く新しいアルゴリズム革新(多くの基礎理論は既に存在していた)ではなく、新しい、大規模に利用可能なデータソースを解き放ったことにあると指摘している。記事は、既存のアルゴリズムやモデルアーキテクチャ(Transformerなど)の改善はもちろん重要だが、その効果は特定のデータセットが提供できる学習上限に制限される可能性があると考えている。したがって、AIの次の重大なブレークスルーは、新しいデータモダリティとソース、例えば大規模なビデオデータ(YouTubeなど)や物理世界のロボットインタラクションデータなどを解き放つことに依存する可能性がある。記事は、研究者に対し、新しいアルゴリズムを探求すると同時に、新しいデータソースを見つけて利用する方法にもっと注意を払うよう呼びかけている。(出典: 机器之心)

傅利叶智能がオープンソース人型ロボットFourier N1を発表:上海の汎用ロボット企業である傅利叶智能は、同社初のオープンソース人型ロボットFourier N1を発表し、部品表(BOM)、設計図、組立ガイド、基本操作ソフトウェアコードを含む完全な本体リソースパッケージを公開した。N1は身長1.3メートル、体重38キログラム、全身23自由度で、アルミニウム合金とエンジニアリングプラスチックの複合構造を採用し、自社開発のFSA 2.0統合アクチュエータと制御システムを搭載している。このロボットは既に1000時間以上の屋外複雑地形テストを完了しており、3.5メートル/秒の速度で走行し、坂登り、階段登り、片足立ちなどの動作を完了できる。この動きは、傅利叶の「Nexusオープンソースエコシステムマトリックス」の一部であり、世界の開発者にオープンな技術基盤を提供し、運動制御、マルチモーダルモデルの結合、および具現化知能キャリアの研究開発検証を加速することを目的としている。将来的には、さらに多くの推論コード、トレーニングフレームワーク、およびキーモジュールが公開される予定である。(出典: InfoQ)

Google CoScientistがマルチエージェント討論を利用して科学的発見を加速:Google AIのCoScientistプロジェクトは、勾配トレーニングや強化学習なしで革新的な科学的仮説を生み出す方法を示した。このシステムは、基盤大規模言語モデル(Gemini 2.0など)によって駆動される複数のエージェントを利用して協力する:あるエージェントが仮説を提案し、別のエージェントが批判的レビューを行い、複数ラウンドの「トーナメント」式の討論と選別を通じて最良の仮説を選出する。専門の進化エージェントが、評価意見に基づいて選ばれた仮説を改善し、さらに多くの討論ラウンドに再提出する。最後に、メタレビューエージェントがプロセス全体を監督し、改善提案を行う。この「テスト時計算拡張」(test-time compute scaling)に基づくマルチエージェント討論、反省、反復メカニズムは、LLMがコンテンツを生成するだけでなく、アイデアを評価し洗練するための効果的な「審判」および「評論家」としても機能し、それによって科学的発見を加速させることを示している。例えば、抗生物質耐性研究において顕著な進展を遂げた。(出典: Reddit r/artificial)

InternVL3:ネイティブマルチモーダルモデルの新進展:コミュニティでは、新たにリリースされたInternVL3モデルが注目されている。このモデルはネイティブマルチモーダル事前トレーニング手法を採用し、複数の視覚ベンチマークテストで優れたパフォーマンスを示し、GPT-4oやGemini-2.0-flashを上回るとされている。その特徴としては、可変視覚位置エンコーディング(V2PE)による長文コンテキスト処理能力の改善や、VisualPRMを利用した「ベストオブn」のテスト時拡張が挙げられる。コミュニティはその優れたベンチマークパフォーマンスに関心を示しており、実用における性能検証を期待し、実行に必要なハードウェア構成についても気にしている。(出典: Reddit r/LocalLLaMA)

🧰 ツール
CropGenerator:画像データセットのトリミング用Pythonツール:ある開発者がCropGeneratorという名前のPythonスクリプトツールを共有した。これは画像データセットの処理、特にSDXLなどのモデルをトレーニングする際に特定の領域をトリミングする必要がある場合に役立つように設計されている。このツールは、ユーザーが提供したJSONLファイル内のバウンディングボックス情報に基づいてターゲット領域の中心を見つけ、それを指定された解像度(8ピクセルの倍数)にトリミング、スケーリング(オプションでアップスケールノイズ除去)し、1:1比率のトリミング画像を生成する。同時に、トリミング後のファイル名とJSONL内の対応する説明情報を含むmetadata.csvファイルを自動的に作成し、トレーニングデータの迅速な準備を容易にする。開発者は、このツールがサイズが不揃いの元画像や微細な特徴の抽出時に遭遇したぼやけ問題を解決したと述べており、将来的にはより汎用的なバージョンをリリースする予定である。(出典: Reddit r/MachineLearning)
📚 学習
NUSがDexSinGraspを発表:強化学習により器用な手の分離と把持の統一戦略を実現:シンガポール国立大学(NUS)の邵林チームは、強化学習に基づく統一戦略であるDexSinGraspを提案した。これにより、器用な手は散らかった環境で効率的に障害物を分離し、ターゲット物体を把持することができる。従来の方法は通常、分離後に把持するという2段階戦略を採用しており、効率が低く、切り替えが柔軟ではなかった。DexSinGraspは、分離報酬項を含む統一報酬関数を設計することで、分離と把持を連続的な意思決定プロセスに統合し、ロボットが適応的に障害物を押し開けて把持スペースを作り出すことを可能にする。研究では、「散らかった環境カリキュラム学習」メカニズムも導入され、単純なものから複雑なものへと段階的にトレーニングすることで、戦略の堅牢性を向上させている。同時に、「教師-生徒戦略蒸留」スキームを採用し、シミュレーションで特権情報を利用してトレーニングされた高性能な教師戦略を、視覚と自己知覚のみに依存する生徒戦略に転移させることで、実環境への展開を容易にしている。実験により、この方法が様々な散らかったシーンで把持成功率と効率を大幅に向上させることが証明された。(出典: 机器之心)

CityGS-X:効率的な大規模シーン幾何再構成の新アーキテクチャ、4090で実行可能:上海AI Labと西北工業大学の研究チームは、CityGS-Xを提案した。これは、並列化混合階層3D表現アーキテクチャ(PH²-3D)に基づくスケーラブルなシステムであり、大規模都市シーンの3D再構成における計算力消費の大きさや幾何精度の限界といった問題を解決することを目的としている。このアーキテクチャは、分散データ並列(DDP)とマルチレベルオブディテール(LoDs)ボクセル表現を利用し、従来の分割法による冗長性を排除している。核心的な革新点は以下の通り:1)PH²-3Dアーキテクチャにより、トレーニング速度はSOTAの幾何再構成手法と比較して2倍向上。2)マルチタスクバッチレンダリングフレームワーク下での動的割り当てアンカー並列メカニズムにより、複数のローエンドグラフィックカード(例:4枚の4090)を使用して超大規模シーン(例:MatrixCity、5000以上の画像)を処理でき、単一のハイエンドカードを代替または凌駕する。3)プログレッシブRGB-深度-法線共同トレーニング手法により、RGBレンダリング品質と幾何精度をSOTAレベルに向上。実験により、この方法のレンダリング品質、幾何精度、トレーニング速度における優位性が証明された。(出典: 量子位)

Appleの研究がネイティブマルチモーダルモデルのScaling Lawsを解明:Apple社とソルボンヌ大学の研究者たちは、ネイティブマルチモーダルモデル(NMM、つまりゼロからトレーニングされ、事前トレーニング済みモジュールを組み合わせないモデル)に対して広範なScaling Laws研究を行い、457の異なるアーキテクチャとトレーニング方式のモデルを分析した。研究結果は以下の通り:1)早期融合(Early-fusion、例えば画像パッチを直接Transformerに入力する)と後期融合(Late-fusion、独立した視覚エンコーダを使用する)アーキテクチャには性能上の本質的な優劣はないが、早期融合は低パラメータ数でより優れたパフォーマンスを示し、トレーニング効率も高い。2)NMMのScaling Lawsは純粋なテキストLLMと類似しており、損失は計算量(C)に対してべき乗則で減少(L ∝ C^−0.049)し、最適なモデルパラメータ(N)とデータ量(D)もべき乗則に従う。3)計算上最適な後期融合モデルは、より高いパラメータ/データ比を必要とする。4)スパース性(MoE)は、特に早期融合アーキテクチャにおいて、密モデルよりも著しく優れており、モデルは暗黙的に特定モダリティの重みを学習できる。5)モダリティ非依存のMoEルーティングは、モダリティ認識ルーティングよりも優れている。これらの発見は、ネイティブマルチモーダル大規模モデルの構築と拡張に重要な指針を提供する。(出典: 机器之心)

Microsoftなどの機関がV-Droidを提案:検証器駆動の実用的なモバイルGUIエージェント:モバイルデバイスのGUIタスク自動化における精度と効率の課題に対し、Microsoft Research Asia、南洋理工大学などの機関が共同でV-Droidを提案した。このエージェントは、操作を直接生成するのではなく、革新的な「検証器駆動」アーキテクチャを採用している。まずUIインターフェースを解析し、離散化された候補アクションセット(抽出されたインタラクティブ要素とプリセットのデフォルトアクションを含む)を構築する。次に、LLM(Llama-3.1-8Bなど)に基づき微調整された「検証器」を利用して、各候補アクションの有効性を並行評価し、最高スコアのものを選択して実行する。この方法は、複雑な操作生成を効率的な検証プロセスに分離し、各検証は少量のトークン(例:「Yes/No」)を出力するだけで済むため、意思決定遅延を大幅に削減する(4090上で約0.7秒)。検証器をトレーニングするために、研究者たちは対比的プロセス嗜好(P^3)トレーニング戦略を提案し、データセットを効率的に構築するための人間と機械の共同アノテーションスキームを設計した。V-DroidはAndroidWorldなどの複数のベンチマークでSOTAのタスク成功率(例:AndroidWorldで59.5%)を達成した。(出典: 新智元)

AssistanceZero:AlphaZeroベースの協調AI、指示なしで人間を支援:カリフォルニア大学バークレー校の研究者たちは、AssistanceZeroアルゴリズムを提案した。これは、明確な指示や目標なしに、人間と能動的に協力してタスク(例えばMinecraftでの共同建築)を完了できるAIアシスタントを作成することを目的としている。この方法は「Assistance Games」フレームワークに基づいており、AIアシスタントは人間と報酬関数を共有するが、AIは具体的な報酬(つまり目標)について不確実であり、人間の行動と相互作用を観察して推論する必要がある。これはRLHFとは異なり、AIがフィードバックに迎合して「不正行為」をすることを回避し、より真実の協力を奨励する。AssistanceZeroはAlphaZeroを拡張し、モンテカルロ木探索(MCTS)とニューラルネットワーク(報酬と人間の行動を予測)を組み合わせて計画と意思決定を行う。研究者たちはMinecraft Building Assistance Game (MBAG) ベンチマークを構築してテストし、AssistanceZeroがPPOなどの従来の強化学習手法より著しく優れており、人間の修正に適応するなどの自発的な協調行動を示すことを発見した。この研究は、Assistance Gamesフレームワークがスケーラブルであり、より有用なAIアシスタントをトレーニングするための新しい道筋を提供することを示している。(出典: 机器之心)

Excelを使用してSunoのプロンプトと出力タグを比較しスタイルを最適化:Redditユーザーが、Suno AI音楽生成のスタイルプロンプトを最適化する方法を共有した。Sunoのプロンプト解釈メカニズムは不透明なため、ユーザーはExcelシートを使用して入力したスタイル記述(Styling Terms)とSunoが生成後に表示するタグを記録することを提案している。比較することで、Sunoが入力された用語をどのように理解、結合、分割、または無視するかを発見できる。例えば、「solo piano, romantic, expressive… gentle arpeggios」と入力すると、Sunoは「gentle, slow tempo, soft… solo piano」と出力し、「arpeggios」を破棄する可能性がある。より専門的な音楽用語を入力した場合、Sunoの出力との差異はさらに大きくなる可能性があり、Sunoが独自の用語を挿入することさえある。この方法は、どの単語が有効で、どの単語が無視または誤解されているかを理解するのに役立ち、プロンプトをより効果的に調整し、無効な試行で生成回数(クレジット)を浪費するのを避けるのに役立つ。ただし、ユーザーはこの方法自体がやや煩雑であり、Sunoの複雑な音楽概念に対する理解は依然として限定的であることも認めている。(出典: Reddit r/SunoAI)
チュートリアル:静止画像を生き生きとしたアニメーションに変換:Redditユーザーが、Thin-Plate Spline Motion Modelを使用して静止顔画像を駆動ビデオに基づいてアニメーション化し、生き生きとした表情と動きを与える方法を紹介するYouTubeチュートリアルのリンクを共有した。チュートリアルの内容は、環境設定(Conda環境の作成、Pythonライブラリのインストール)、GitHubリポジトリのクローン、モデルの重みのダウンロード、および2つのデモの実行(1つはプリセット例を使用、もう1つはユーザー自身の画像とビデオでアニメーション化)をカバーしている。この技術は、静止写真に動的な効果をもたらすことができる。(出典: Reddit r/deeplearning)
超知能AIアライメントの困難なタスクを探る:Redditユーザーが、超知能AI(ASI)の目標を人間の利益と価値観に整合させるという巨大な課題について議論するYouTubeビデオのリンクを共有した。このような議論は通常、AI安全分野の核心問題、例えば価値整合問題、目標仕様の困難性、潜在的な予期せぬ結果、そしてますます強力になるAIシステムが安全かつ制御可能に人類の福祉に貢献することをどのように保証するか、などを扱っている。ビデオは、現在のアライメント研究の方法、限界、および将来の方向性を探求している可能性がある。(出典: Reddit r/deeplearning)

「Auto-Analyst」の構築:データ分析AIエージェントシステム:ユーザーが、「Auto-Analyst」という名前のAIエージェントシステムを構築するプロセスを紹介するMediumの記事を共有した。このシステムは、データ分析タスクを自動化することを目的としている。記事では、システムのアーキテクチャ、使用技術(LLM、データ処理ライブラリなど)、エージェント間の協力方法、データ入力の処理、分析の実行、レポートの生成などの段階をどのように処理するかが詳細に説明されている可能性がある。このようなシステムは通常、AIを利用して自然言語リクエストを理解し、コード(SQLクエリ、Pythonスクリプトなど)を自動的に作成・実行し、最終的に分析結果を提示することで、データ分析の効率とアクセス性を向上させることを目指している。(出典: Reddit r/deeplearning)
旧型GPU(RTX 2070)を使用して3090を補助しLLM推論を行う性能テスト:あるユーザーが、古いRTX 2070(8GB VRAM)をPCIeライザー経由で既存のRTX 3090(24GB VRAM)システムに追加した実験結果を共有し、LLM推論に使用した。テストによると、3090 VRAMに完全に収まらない大規模モデル(Qwen 32B Q6_K, Nemotron 49B Q4_K_M, Gemma-3 27B Q6_Kなど)の場合、モデル層を2枚のカードに分割する(2枚目のカードの性能が劣っていても)ことで、すべての層がGPU上で実行されるため、推論速度(t/s)が大幅に向上することが示された。例えば、Nemotron 49Bは5.17 t/sから16.16 t/sに向上した。しかし、3090に完全に収まるモデル(Qwen2.5 32B Q5_K_Mなど)の場合、2070に層を分担させると、一部の計算がより遅いGPUに移されるため、逆に性能が低下した(29.68 t/sから19.01 t/sに低下)。結論として、VRAMが不足している場合、性能の低いGPUを追加することでも顕著な性能向上が得られる。(出典: Reddit r/LocalLLaMA)
💼 ビジネス
人型ロボット投資ブーム:エンジェルラウンドは数千万元から、評価額が高騰:人型ロボット分野への投資熱は、過去2年間の大規模モデルをはるかに超えている。データによると、2024年から2025年第1四半期にかけて、国内の人型ロボット分野における数千万元以上の資金調達は64件に達し、今年第1四半期は前年同期比280%増となった。半数近くの資金調達が1億元を超え、エンジェルラウンドの資金調達は一般的に数千万元レベルであり、一部は1億元を超えている(例:它石智航のエンジェルラウンドは1.2億ドル)。プロジェクトの評価額も上昇しており、エンジェルラウンドプロジェクトの半数以上が評価額1億元を超え、数社は5億元を超えている。投資は3つの大きなトレンドを示している:1) 投資サイクルが短縮され、スタープロジェクト(它石智航、原力灵机など)は設立後すぐに高額の資金調達を獲得し、その後の資金調達ペースが加速している。2) 国有資本ファンドが重要な推進力となっており、多くのトップ企業が国有資本系ファンドから投資を受けている。3) 応用シーンは主にToBであり、工業、医療などが主要な方向性であり、C向け消費者市場ではない。投資ブームは、資本の人型ロボット分野に対する強いコンセンサスと高い期待を反映している。(出典: 36氪)
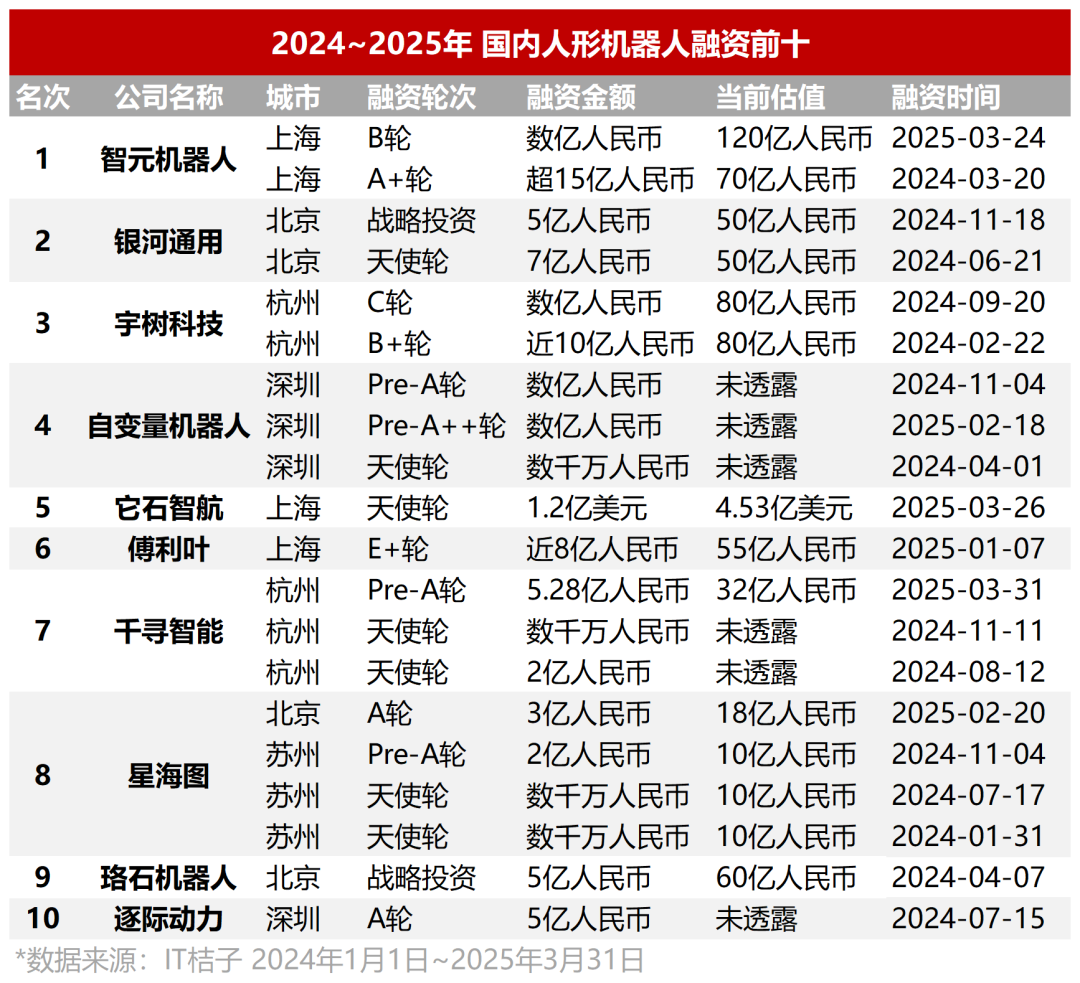
オープンソースワークフロー自動化ツールn8nが4.6億人民元の資金調達、Dockerプル数は1億超:オープンソースワークフロー自動化プラットフォームn8nは、Highland Europeが主導する新たな6000万ドル(約4.6億人民元相当)の資金調達ラウンドを完了したと発表した。n8nは視覚的なインターフェースを提供し、ユーザーがノードをドラッグ&ドロップして異なるアプリケーション(400以上をサポート)やサービスを接続し、自動化プロセスを作成できる。コードレベルの柔軟性とノーコードの速度を組み合わせることを目指している。過去1年間で、n8nのユーザーは急速に増加し、アクティブユーザーは20万人を超え、ARRは5倍に増加、GitHubスター数は77.5kに達し、Dockerプル数は1億を超えた。n8nはノードエディタモードを採用し、複雑なロジックをサポートし、JavaScriptカスタムノードなどの高度な機能を提供している。Apache 2.0 + Commons Clauseの「フェアコード」ライセンスを採用しており、商用ホスティングを禁止するが、ユーザー自身のデプロイは許可している。n8nはZapier、Make.com、およびByteDanceのCozeのオープンソース代替案と見なされており、3000社以上の企業にサービスを提供し、様々なLLMの統合をサポートしている。(出典: InfoQ)

🌟 コミュニティ
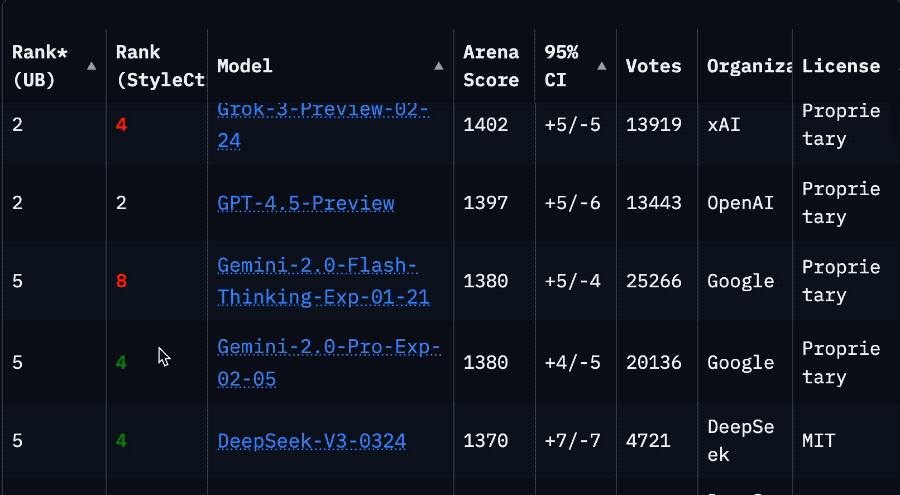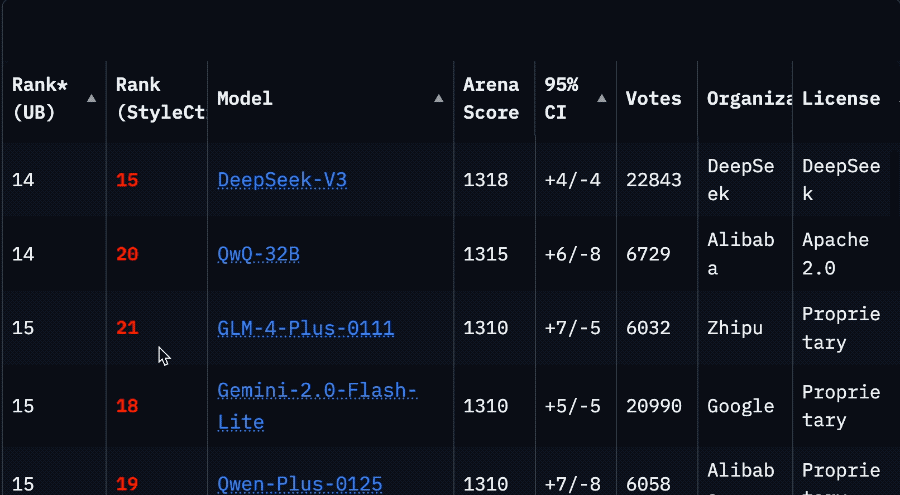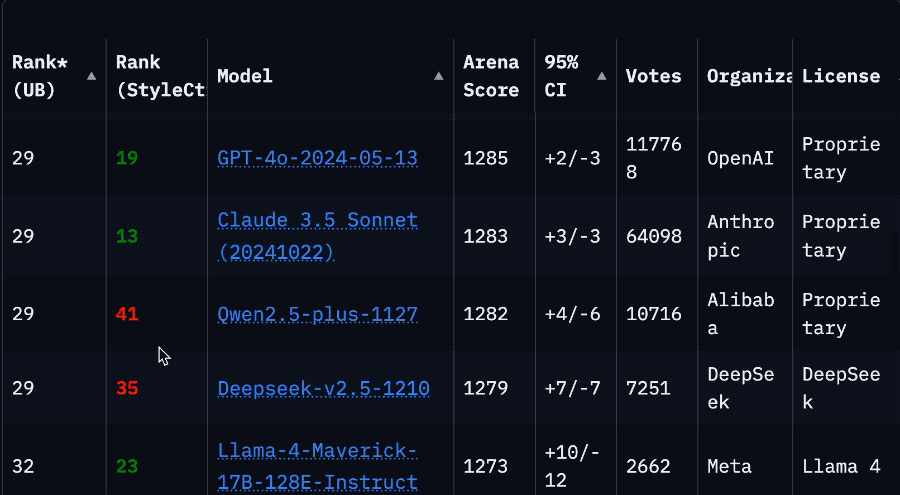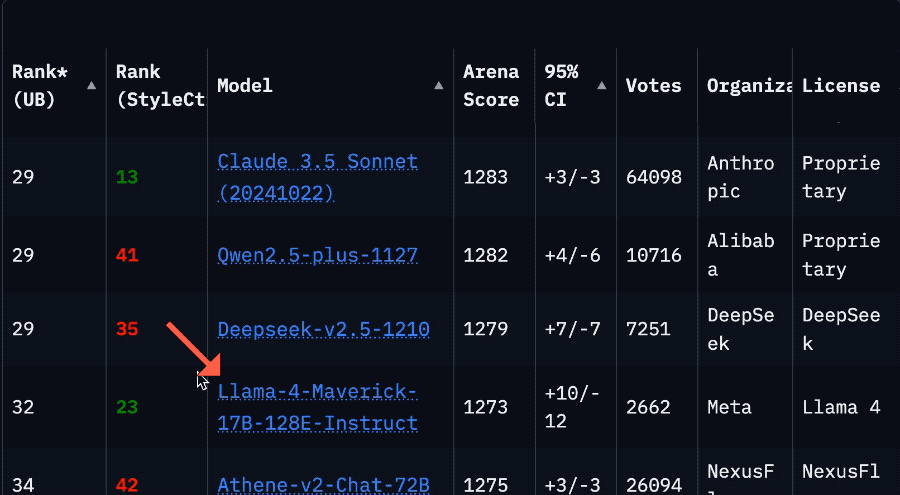
Llama 4のアリーナランキング大幅下落がコミュニティの信頼危機を引き起こす:MetaのLlama 4モデルがLMSysアリーナで非最適化バージョン(Llama-4-Maverick-17B-128E-Instruct)として再公開された後、ランキングが以前の2位から32位に急落した。以前提出された「実験版」は、人間の嗜好に合わせて過度に最適化されたと指摘されていた。この出来事はコミュニティで広範な議論を引き起こし、一部のネットユーザーはMetaがベンチマークランキングを操作しようとしており、コミュニティの信頼を損なったと考えている。同時に、一部の開発者は実際の使用体験を共有し、特定のハードウェア(例:メモリは十分だが計算能力が比較的低い自作サーバーやMac Studio)では、Llama 4がMistral Small/LargeやCommand Aと比較して、速度と知能の間で良好なバランスを達成しており、特にリアルタイムインタラクションが必要なアプリケーションに適していると述べている。Composioの比較テストによると、DeepSeek v3はコードと常識推論でLlama 4より優れているが、大規模なRAGタスクとライティングスタイルでは一長一短がある。コミュニティは一般的にLlama 4が全く役に立たないわけではないと考えているが、Metaのリリース戦略とベンチマークパフォーマンスには議論がある。(出典: 量子位, Reddit r/LocalLLaMA)
コミュニティでClaude Proバージョンの制限とMaxバージョンの登場が話題に:複数のRedditユーザーが、Anthropicがより高価なClaude Maxサブスクリプション層を導入して以来、既存のClaude Proユーザーのメッセージ使用制限がより厳しくなったようだと報告している。ユーザーによると、以前は数十回のインタラクションが可能だったセッションが、現在は数回のインタラクション後に「制限に近づいています」という警告が表示され、ピーク時以外でも容量制限の問題に遭遇するという。これによりユーザーエクスペリエンスが低下し、以前の無料版や初期のPro版ほど良くないと感じている。コミュニティは一般的に、これがAnthropicがMaxバージョンを宣伝するために意図的にProユーザーの制限を厳しくしたと推測しており、ユーザーの不満とAnthropicの商業倫理に対する疑問を引き起こしている。一部のユーザーはサブスクリプションのキャンセルやGeminiなどの競合製品への移行を検討している。(出典: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

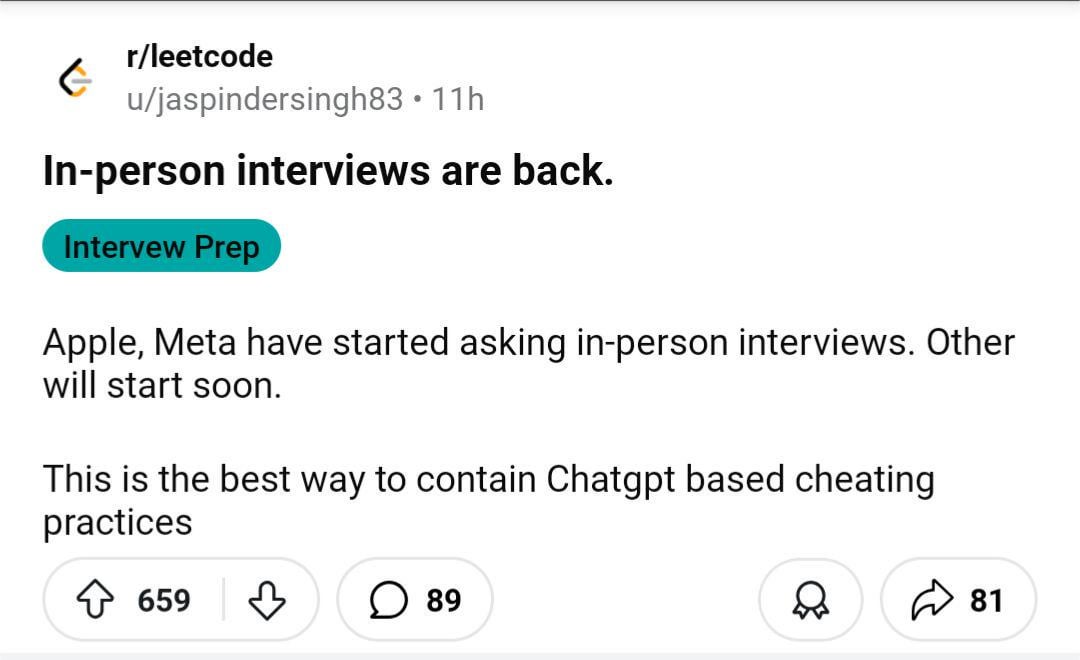
コミュニティ議論:AI不正行為により、対面面接が復活する可能性:ある画像がRedditコミュニティで議論を引き起こした。これは、リモート面接やテストでのAI不正行為の増加により、企業は再び対面面接を採用する傾向にあるかもしれないことを示唆している。コメントでは、多くの人がこれに賛同し、不適格な候補者やボット申請者を排除し、採用の公平性を保証し、本当に能力のある人が機会を得られるようにするのに役立つと考えている。企業は候補者の旅費を負担する能力があるという意見もあった。同時に、面接官が候補者がChatGPTを使用してリアルタイムで質問に答えているのを発見した経験や、リモート面接の画面とキーボードを複数のカメラで監視するソリューションを提案する人もいた。また、テストの重点は、AIが容易に完了できるタスクではなく、批判的思考に移すべきだというコメントもあった。一方で、AIを使用して履歴書を選別し始めた企業もあるとの言及もあった。(出典: Reddit r/ChatGPT)
Suno AI音楽生成コミュニティの動向と議論:RedditのSunoAIコミュニティでは最近、活発な議論が行われており、内容は多岐にわたる:1) 作品共有:ユーザーはSunoを使用して作成した様々なスタイルの音楽を共有している。例:ヒンディー語ラップ (source)、サーフロック (source)、オルタナティブラップ (source)、ロックポップ (source)、ポップ (source)、ユーモラスな曲 (source)。2) 使用上の問題とテクニック:ユーザーは発音の間違いを修正する方法 (source)、天使のようなバックグラウンドハーモニーを作成する方法 (source)、メロディーを保持しつつ音質を変更する方法 (source) について質問している。3) 著作権と収益化:Sunoで生成された伴奏を使用して曲をリリースする際の著作権問題 (source)、YouTubeで静止画像とAI音楽を組み合わせて収益化する資格 (source) について議論し、無料版は非商用利用に限定されることを強調している (source)。4) モデル品質フィードバック:複数のユーザーが、最近のSuno(特にReMiモデル)の生成品質低下、歌詞の繰り返し、不安定さ、音声の混乱などの問題について不満を述べている (source, source, source, source)。5) その他:ユーザーはSunoが特定のバンドスタイル(例:Reel Big Fish)を認識できる経験 (source) や、AIがポップソングを書くのを模倣した面白いビデオ (source) を共有している。
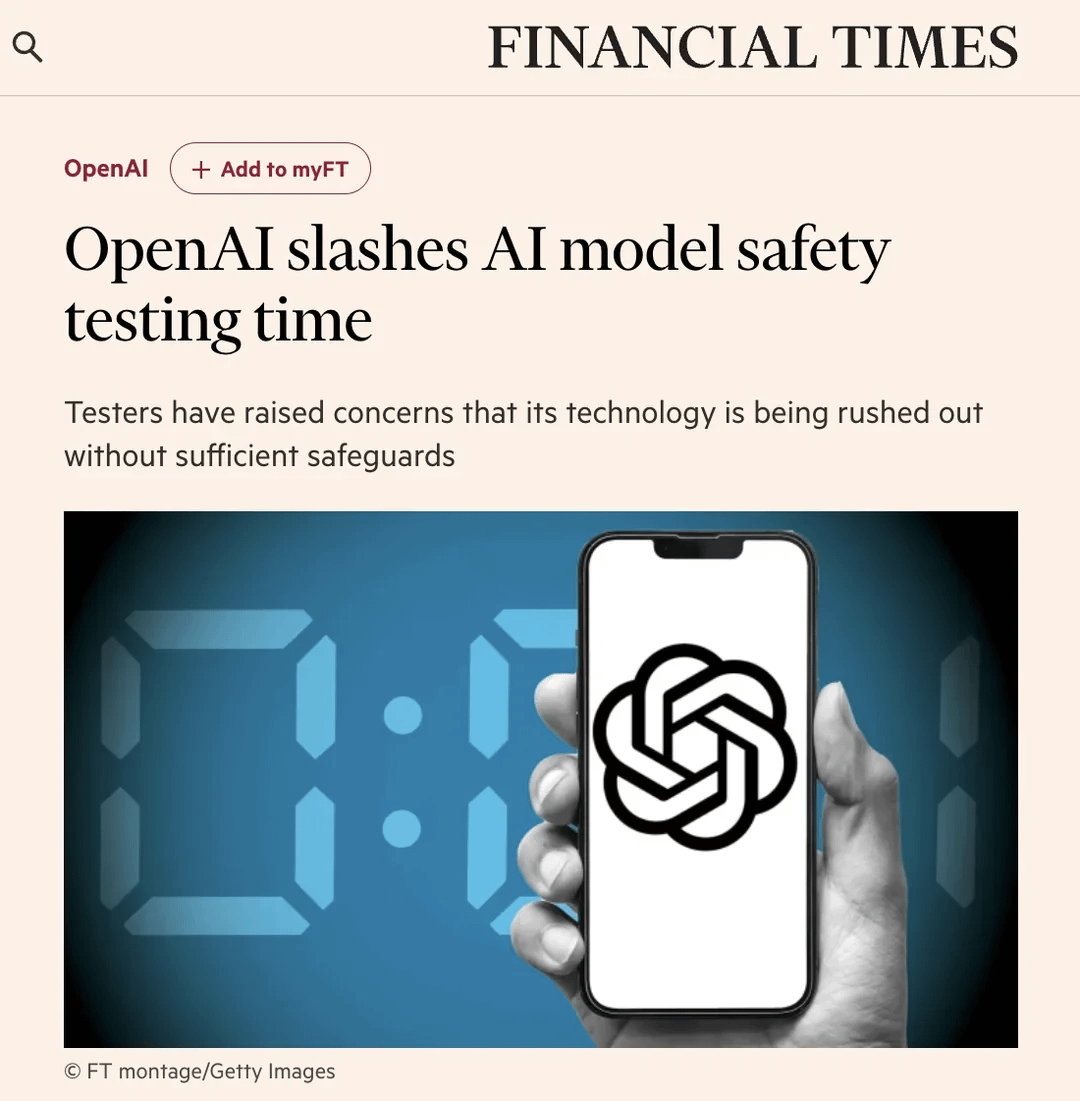
コミュニティでOpenAIの安全性テストプロセス短縮が議論に:フィナンシャル・タイムズ(FT)の記事がRedditコミュニティで議論を引き起こした。記事は内部関係者の情報として、市場競争の圧力により、OpenAIが新しいモデルの安全性評価テスト時間を過去の数ヶ月から数日に大幅に短縮したと報じている。これは潜在的なリスクに対する懸念を引き起こし、一部のテスターはこの動きを「無謀」であり、「災害の秘訣」だと述べ、より強力なモデルにはより徹底的なテストが必要だと考えている。記事はまた、OpenAIが生物学的リスクなどの潜在的な悪用シナリオを評価する際、古いモデルでのみ限定的なカスタマイズされた微調整テストを行っている可能性があり、安全性テストは通常、最終リリースバージョンではなく、モデルの初期チェックポイントで行われることにも言及している。OpenAIは、自動化などによって評価効率を向上させ、その方法は現在最適であり、公に透明であると考えていると回答した。コミュニティの意見は分かれており、AIの発展自体がテストプロセスを加速すると考える人もいれば、安全性の犠牲を懸念する人もいる。(出典: Reddit r/artificial)
開発者がLLMランタイム最適化とマルチモデルオーケストレーションを探る:ある開発者がRedditで、実験中のAIネイティブランタイムシステムについて共有した。このシステムは、GPU実行とメモリ状態をシリアル化することにより、LLM(13B-65Bレベル)のスナップショット式ロード(2〜5秒のコールドスタート)とオンデマンドリカバリを実現し、これにより単一のGPU上でメモリに常駐させることなく50以上のモデルを動的に実行できるようにすることを目指している。この方法は、真のServerless動作(アイドルコストなし)、低遅延のマルチモデルオーケストレーション、およびAgenticワークロードのGPU利用率向上を目指している。開発者は、コミュニティで同様のマルチモデルスタック、Agentワークフロー、または動的メモリ再割り当て技術(MIG、KAI Schedulerなど)を試した人がいるか興味があり、この種のインフラストラクチャ要件に関するフィードバックを求めている。(出典: Reddit r/MachineLearning, Reddit r/MachineLearning)
コミュニティで熱い議論:AIは意識に近づいているか?:Redditユーザーが、現在のAIシステムがどの程度「意識」に近づいているかを探る議論を開始した。質問者は、チューリングテストや対話シミュレーションを指すのではなく、むしろAIが時間とともに変化する状態、環境の記憶、単なる微調整ではなく相互作用に基づく進化能力、システム内での自己位置特定と参照能力、そして「私はここにいた、これを見た、これを学んだ」と表現する能力を持っているかどうかに焦点を当てている。質問者は、現在のほとんどのAI(特にLLM)はステートレス、中央集権的、リアクティブであり、「記憶」の追加機能も浅薄でシミュレートされたものに見えると述べ、既存の技術スタック(Python、ステートレスAPI、RAGなど)が真の意識を担えるかどうか疑問視している。この議論は、コミュニティにAI意識の定義、既存技術の限界、および将来の可能な道筋について考えさせた。(出典: Reddit r/MachineLearning)
ユーザーがChatGPTの口調が過度に熱狂的であるとフィードバック:あるRedditユーザーが、使用しているChatGPTインスタンスが過度の熱意と興奮を示す口調、例えば「おお、この質問は好きです!」や「これはとても面白い!」などの冒頭の言葉を頻繁に使用し、回答の最後に「魅力的でクールだと思いませんか?」のようなコメントを付け加えることに不満を述べている。ユーザーは、モデルにこの行動をやめるよう要求しても効果がなく、モデルの「熱意度」を制御または調整して回答をより直接的、客観的にする方法があるか尋ねている。コメント欄の他のユーザーも同様の悩みを抱えていると述べており、特にモデルが最後に質問するのが好きだという。カスタム指示(Custom Instructions)を使用して口調の好み(感情的な言葉遣いを減らすなど)を設定して問題を緩和する方法を共有するユーザーもいれば、チャットボットに名前を付けて直接「説教」することを提案するユーザーもいる。(出典: Reddit r/ChatGPT)
議論:LLMに新しい語彙を追加して微調整しても効果が低い:ある開発者が、指示に従うようにLLMとVLMを微調整する際に問題に直面した。基本トークナイザーを使用する場合と比較して、トークナイザーに新しい専門用語(トークン)を追加してから標準的な教師あり微調整(SFT)を行うと、モデルの検証損失が高くなり、出力品質も悪化することを発見した。開発者は、モデルがこれらの新しく追加された語彙の生成確率を高めることを学習するのが難しい可能性があると推測している。この問題は、微調整で新しい語彙を効果的に導入する方法、トークナイザー拡張がモデル学習に与える影響などの技術的詳細についてコミュニティで議論を引き起こした。(出典: Reddit r/MachineLearning)
AI生成画像の共有と議論:RedditのChatGPTコミュニティでは、ユーザーがDALL-E 3を使用して生成された様々な面白いまたは奇妙な画像を共有している。例えば、あるユーザーは特定のプロンプトに基づいて、スクービー・ドゥーのダフネがビーチでの休暇前にN64ゲームをプレイしているシーンの画像を生成し (source)、他のユーザーが同様のシーンで他のキャラクター(春麗など)を生成するのを模倣するよう促した。別のユーザーは、プロンプト「誰も見ることができない写真を生成して」に基づいて得られた奇妙な画像を共有し (source)、同様に、類似のテーマの生成結果を共有する多数のフォローアップ投稿を引き起こした。その中には、不安を覚えさせるものや、滑稽な作品も少なくない。これらの投稿は、AI画像生成の多様性とユーザーの創造性を示している。
コミュニティでAI企業のロゴデザインのトレンドが議論に:ユーモラスな投稿が、Velvet Sharkウェブサイト上の「なぜAI企業のロゴはお尻の穴のように見えるのか?」というタイトルの記事にリンクしており、コミュニティで議論を引き起こした。記事は、現在のAI分野の企業ロゴデザインでよく見られる抽象的、対称的、渦巻き状、またはリング状のグラフィック要素を探求し、それを冗談めかしてある種の解剖学的構造と関連付けている可能性がある。コメント欄のユーザーも軽い感じで反応しており、例えば「特異点」(singularity)の概念に関連していると推測したり、それを「直腸由来技術」と呼んだりしている。これは、業界の視覚的イメージに対するコミュニティの興味深い観察を反映している。(出典: Reddit r/ArtificialInteligence)

ユーザーがプロジェクトの提案と技術的支援を求める:コミュニティには、ユーザーが具体的な支援やアドバイスを求める投稿が複数ある:あるユーザーはNLPベースの災害対応アプリケーションを開発中で、ダッシュボード、音声認識、テキスト分類、多言語サポートなどの機能が既に含まれており、プロジェクトをよりユニークにする方法を尋ねている (source)。別のユーザーは、ファインチューニングされたBARTモデルを使用してeコマース製品のタイトルとカテゴリを標準化する際に精度のボトルネックに直面しており、より良いモデルやツールの提案を求めている (source)。また、OpenWebUIで画像を生成または変更する方法、およびどのモデルを使用する必要があるかを尋ねるユーザーもいる (source)。これらの投稿は、開発者が実際のアプリケーションで直面する課題とコミュニティサポートへのニーズを反映している。
機械学習エンジニア(MLE)の雇用市場に関する議論:あるユーザー(学生または初心者である可能性)が、現在の機械学習エンジニア(MLE)の雇用市場状況について尋ねている。彼は、コミュニティの投稿から、MLEの職位は修士/博士号が必要な場合があり、参入が難しく、ソフトウェアエンジニア(SWE)との境界が曖昧で、幅広いスキルを習得する必要があることを知ったと述べている。ユーザーは学習意欲はあるが将来に不安を感じていることを表明し、業界関係者が市場の現状、必要なスキル、キャリアパスなどに関する指導と見解を提供してくれることを望んでいる。(出典: Reddit r/deeplearning)
OpenWebUIのフランス語ユーザーが画像解釈のバグを報告:OpenWebUIを使用しているフランス語ユーザーが問題を報告した:画像をアップロードしてGemmaモデルに解釈させると、モデルは返信するが、返信内容は空である。モデルに読み上げさせたり、対話テキストをエクスポートしようとしても、そのメッセージは依然として空である。さらに深刻なことに、この問題は現在の対話を「汚染」し、その後、純粋なテキストメッセージを送信しても、モデルの返信はすべて空になる。ユーザーは新しい純粋なテキスト対話の作成には問題がないことを確認し、視覚モジュールにバグが存在すると疑っており、コミュニティの助けを求めている。(出典: Reddit r/OpenWebUI)
💡 その他
AIと『毛沢東選集』の思想を組み合わせて関税戦争を分析:米中関税の引き上げに直面し、ある記事はAIツールを活用し、『毛沢東選集』の『持久戦論』の戦略思想と組み合わせて、現在の経済情勢と対応戦略を分析することを試みている。著者は、貿易戦争に直面して、「屈服論」(外部に完全に依存する)と「速勝論」(短期間での完全な自主性を期待する)という極端な思考を避けるべきであり、むしろ第一原理思考を採用し、貿易の本質、価値の源泉、および自身の優劣に立ち返るべきだと考えている。記事は、著者とAIが協力して思考するプロセスを示しており、独立系越境ECサイトを例に挙げ、AI支援下での対応策を探り、戦略的思考と行動力の重要性を強調している。この記事は、AIを利用して深い戦略分析を行う視点を提供することを目的としている。(出典: AI觉醒)

第3回中国AIGC産業サミット予告:量子位が主催する第3回中国AIGC産業サミットは、2025年4月16日に北京で開催される予定である。サミットには、Baidu、Huawei、Ant Group、Microsoft Research Asia、Amazon Web Services、面壁智能、无问芯穹、生数科技などの大手企業やAI新興企業、および粉笔、NetEase Youdao、趣丸科技、轻松健康集团などの業界代表が集結し、合計20名以上のゲストが参加する。議題は、AI技術のブレークスルー(計算力インフラ、分散コンピューティング、データストレージ、安全性と制御可能性)、業界浸透(教育、エンターテイメント、AI for Science、企業向けサービスなどの垂直シーンでの実装)、およびエコシステム構築を中心に展開される。サミットでは、「2025年注目すべきAIGC企業/製品」リストおよび『中国AIGCアプリケーション全景図』も発表される。イベントはオフライン参加登録とオンラインライブ配信予約を提供している。(出典: 量子位, 量子位)

Suno AIが100万クレジット獲得イベントを開催:Redditユーザーが、Suno AIの公式ブログで発表されたイベント情報を共有した。ユーザーは最大100万クレジットを獲得するチャンスがある。具体的なイベントルールは元のブログ記事を参照する必要がある。このようなイベントは通常、ユーザーエンゲージメントとプラットフォームのアクティビティ向上を目的としている。(出典: Reddit r/SunoAI)

ClaudeAI Subredditが投稿品質投票メカニズムを導入:ClaudeAI subredditのモデレーターが、新しいボットu/qualityvote2の導入を発表した。このボットは各新規投稿の下にコメントを投稿し、ユーザーにそのコメントへの投票(賛成/反対)を通じて投稿品質を評価するよう招待する。一定の賛成票数に達した投稿はこのサブレディットに適していると見なされ、一方、一定の反対票数に達した投稿はモデレーターによるレビューと削除のためにマークされる。この動きは、コミュニティの力を利用してサブレディットのコンテンツ品質を維持することを目的としている。同時に、モデレーターチームは投票操作検出ボットも追加した。(出典: Reddit r/ClaudeAI)