
キーワード:AI, モデル, AI指数レポート2025, 光子AIプロセッサ, 多モーダルモデル, AIハードウェア最適化, AI倫理とリスク
🔥 注目
スタンフォード大学、2025年版AI Indexレポートを発表: スタンフォード大学は456ページに及ぶ「2025 AI Index」レポートを発表し、AI分野の現状とトレンドを包括的に概説しました。レポートによると、モデル発表数では米国がリードしているものの、中国がモデル品質で急速に追い上げており、性能差は著しく縮小しています。トレーニングコストは上昇し続けており(例:Gemini 1.0 Ultraは約1億9200万ドル)、一方で推論コストは急激に低下しています。AIの炭素排出問題はますます深刻化しており、Meta Llama 3.1のトレーニング排出量は膨大です。レポートはまた、多くのAIベンチマークが飽和状態にあり、モデル能力の区別が困難になっていること、「人類最後の試験」が新たな課題となっていることにも言及しています。公開データの取得が制限され(トップレベルドメインの48%がクローラーを制限)、 「データピーク」への懸念を引き起こしています。企業のAI投資は巨額ですが、まだ顕著な生産性向上は見られていません。AIは科学・医療分野で大きな可能性を秘めていますが、実用化にはまだ時間が必要です。政策面では、米国の州レベルでの立法が活発で、特にディープフェイクに注目が集まっている一方、世界レベルでは拘束力のない声明が多いです。雇用喪失への懸念はあるものの、AIに対する一般市民の全体的な態度は依然として楽観的です (情報源: AINLPer)
新型光子AIプロセッサがブレークスルー: 「Nature」誌に掲載された2つの論文は、光子と電子を組み合わせた新しいAIプロセッサを紹介し、ポストトランジスタ時代の性能とエネルギー消費のボトルネックを突破することを目指しています。シンガポールのLightelligence社のPACE光子アクセラレータ(16000以上の光子コンポーネントを含む)は、最大1GHzの計算速度と500倍の最小遅延削減を示し、イジング問題の解決において優れた性能を発揮しました。米国のLightmatter社の光子プロセッサ(4つの128×128マトリックスを含む)は、BERT、ResNetなどのAIモデルを電子プロセッサに匹敵する精度で実行することに成功し、「パックマン」をプレイするなどの応用例をデモンストレーションしました。両研究は、そのシステムが拡張可能であり、既存のCMOS工場で製造できることを示しており、AIハードウェアをより強力で省エネルギーな方向へと推進し、光子コンピューティングが実用化に向けた重要な一歩を踏み出したことを示しています (情報源: 36氪)

UCバークレー、o3-miniに匹敵する14BコードモデルDeepCoderをオープンソース化: UCバークレーとTogether AIは共同で、完全にオープンソースの14Bパラメータコード推論モデルであるDeepCoder-14B-Previewを発表しました。その性能はOpenAIのo3-miniに匹敵します。このモデルは、Deepseek-R1-Distilled-Qwen-14Bから分散強化学習(RL)を通じてファインチューニングされ、LiveCodeBenchベンチマークでPass@1が60.6%に達しました。チームは24K個の高品質なプログラミング問題を含むトレーニングセットを構築し、改良されたGRPO+トレーニング手法、反復的なコンテキスト拡張(16Kから32Kへ拡張、推論時は64K)、および超長フィルタリング技術を採用しました。同時に、最適化されたRLトレーニングシステムverl-pipelineもオープンソース化し、エンドツーエンドのトレーニング速度を2倍に向上させました。今回の発表には、モデルだけでなく、データセット、コード、トレーニングログも含まれています (情報源: 新智元)
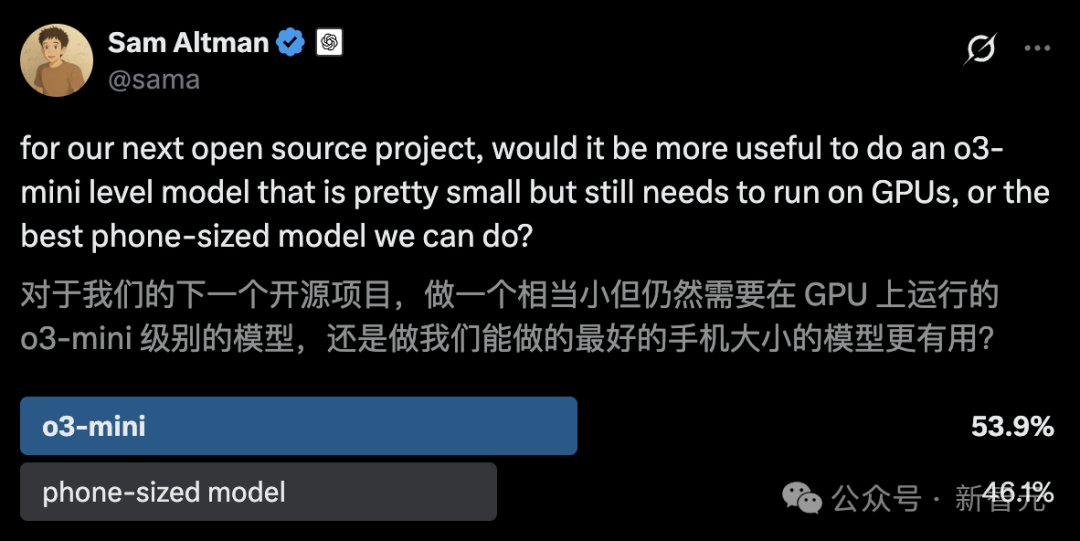
🎯 動向
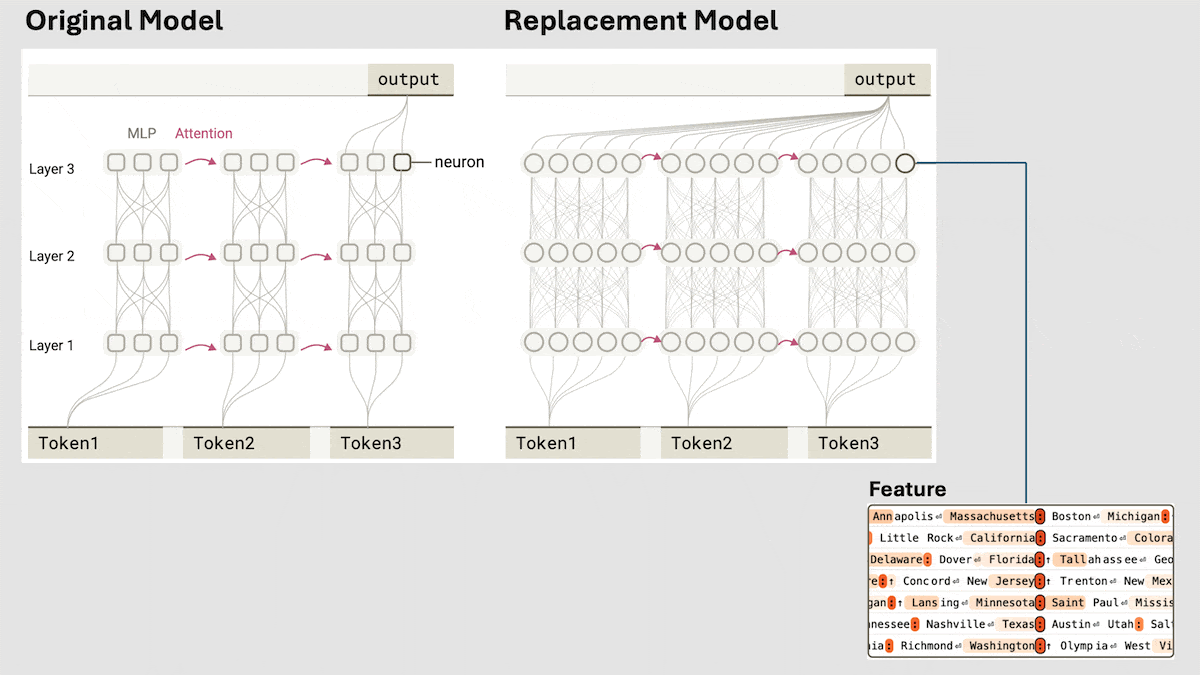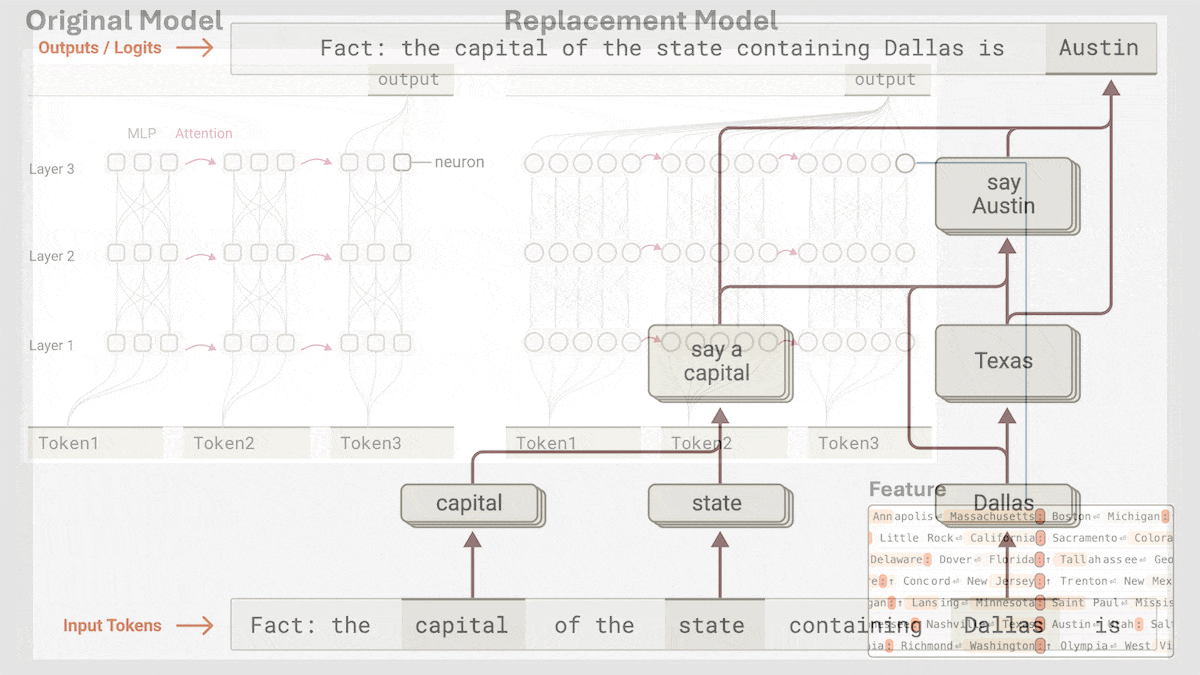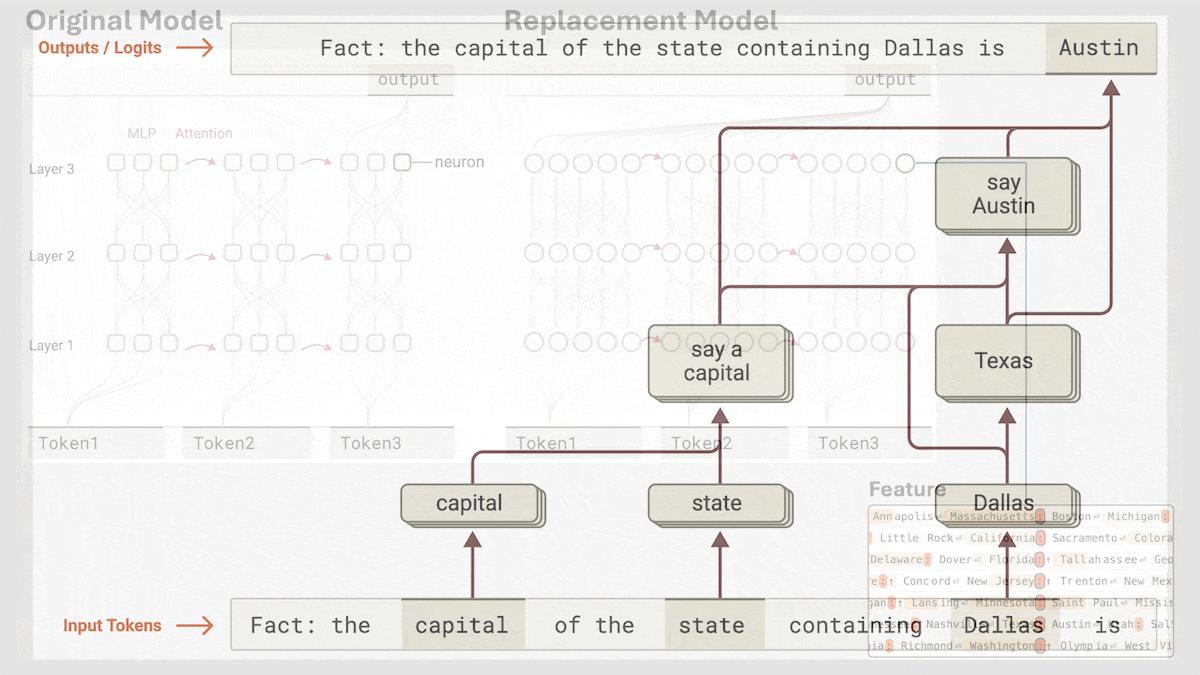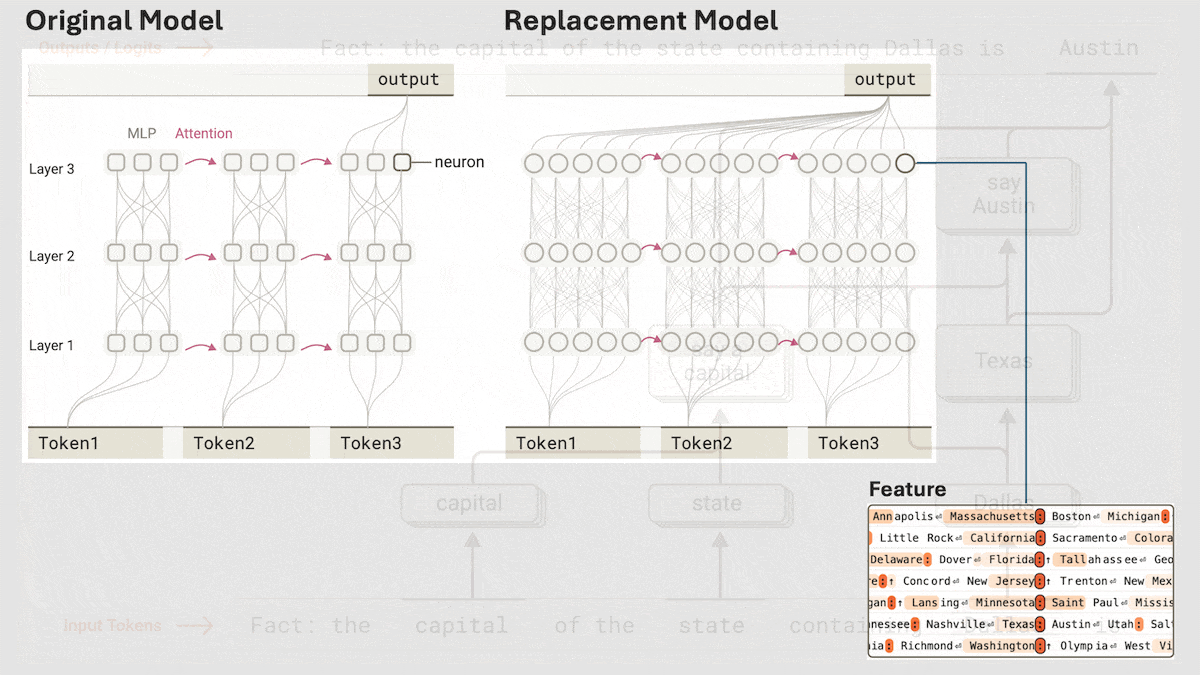
Anthropic、Claude 3.5 Haikuの暗黙的な推論メカニズムを解明: Anthropicの研究チームは、新しい手法を用いてTransformerモデル(特にClaude 3.5 Haiku)の内部動作メカニズムを分析しました。彼らは、連鎖思考(Chain-of-Thought)を行うように明示的にトレーニングされていなくても、モデルが応答を生成する際にニューロンの活性化を通じて推論のようなステップを示すことを発見しました。この手法は、全結合層を解釈可能な「クロスレイヤートランスコーダー」(cross-layer transcoder)に置き換え、特定の概念や予測に関連する「特徴」を特定し、情報フローを可視化するための帰属グラフを構築します。実験によると、モデルは質問(例:「小さいの反対語は何?」やダラスがある州の州都を判断する)に答える際に、直接答えを予測するのではなく、内部で複数の論理ステップを経ていることが示されました。この研究は、LLMの内部動作を理解し、真の推論能力と表面的な模倣を区別するのに役立ちます (情報源: DeepLearning.AI)
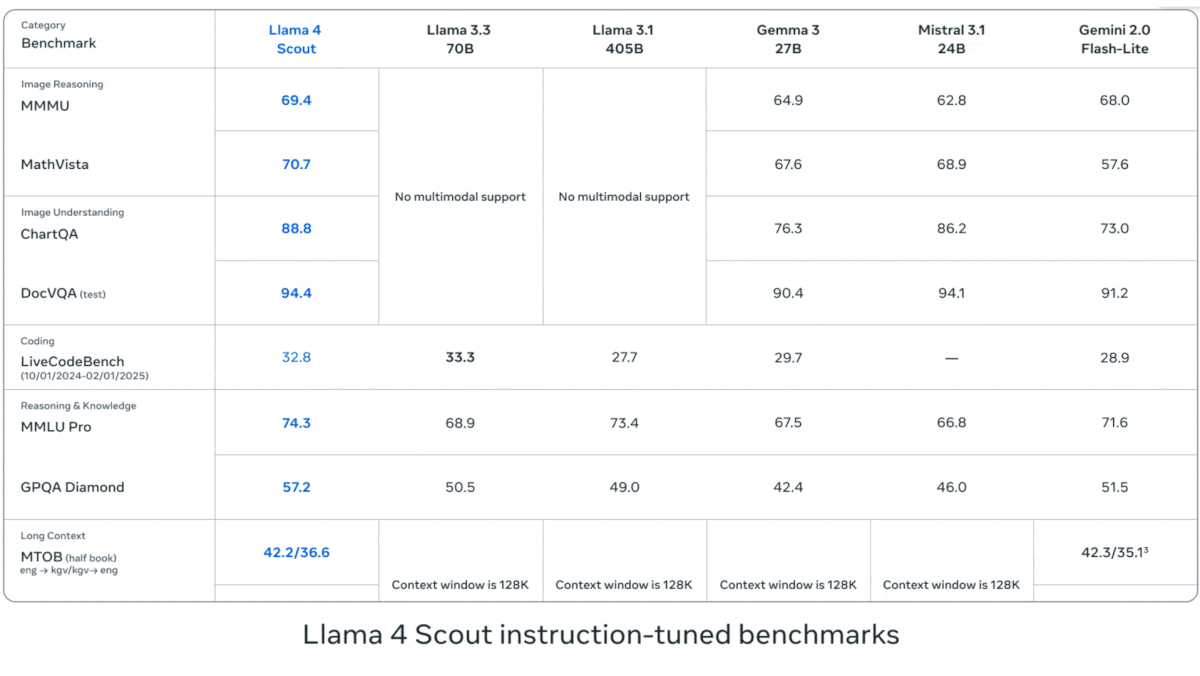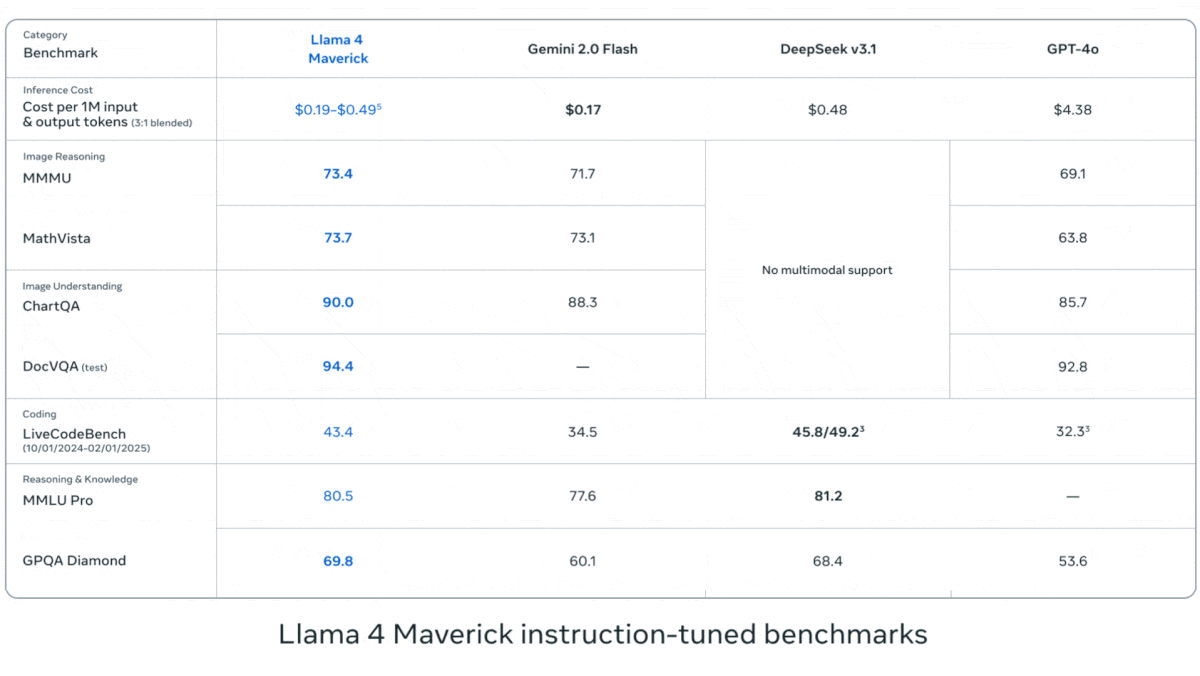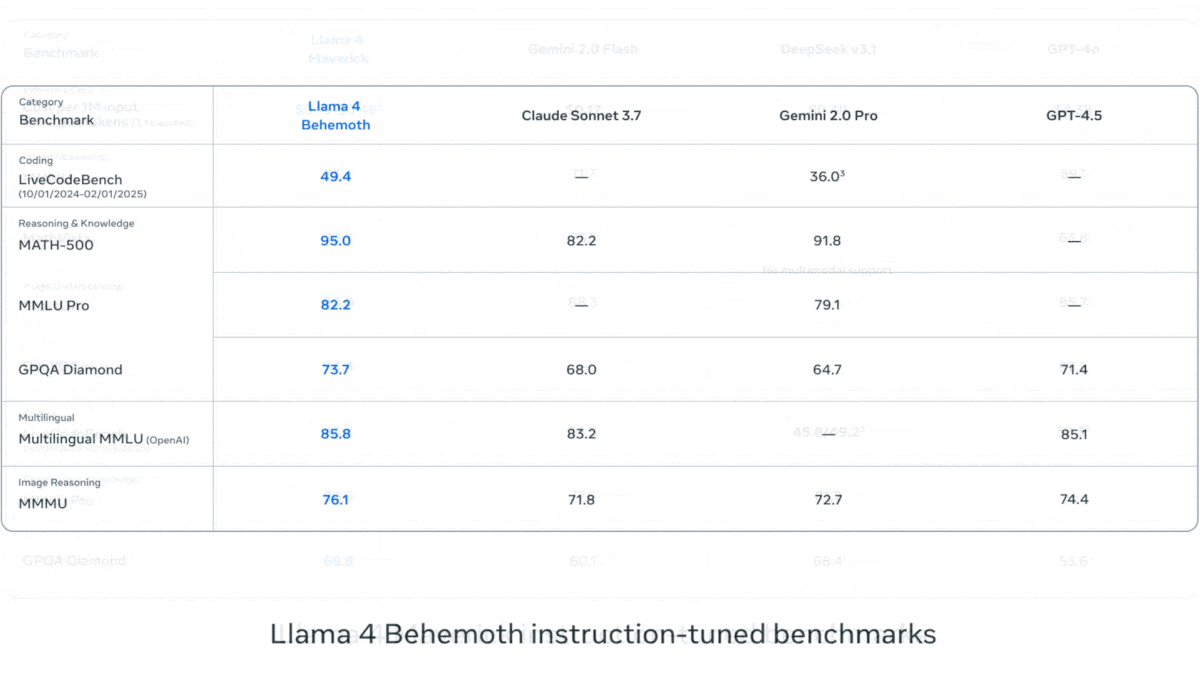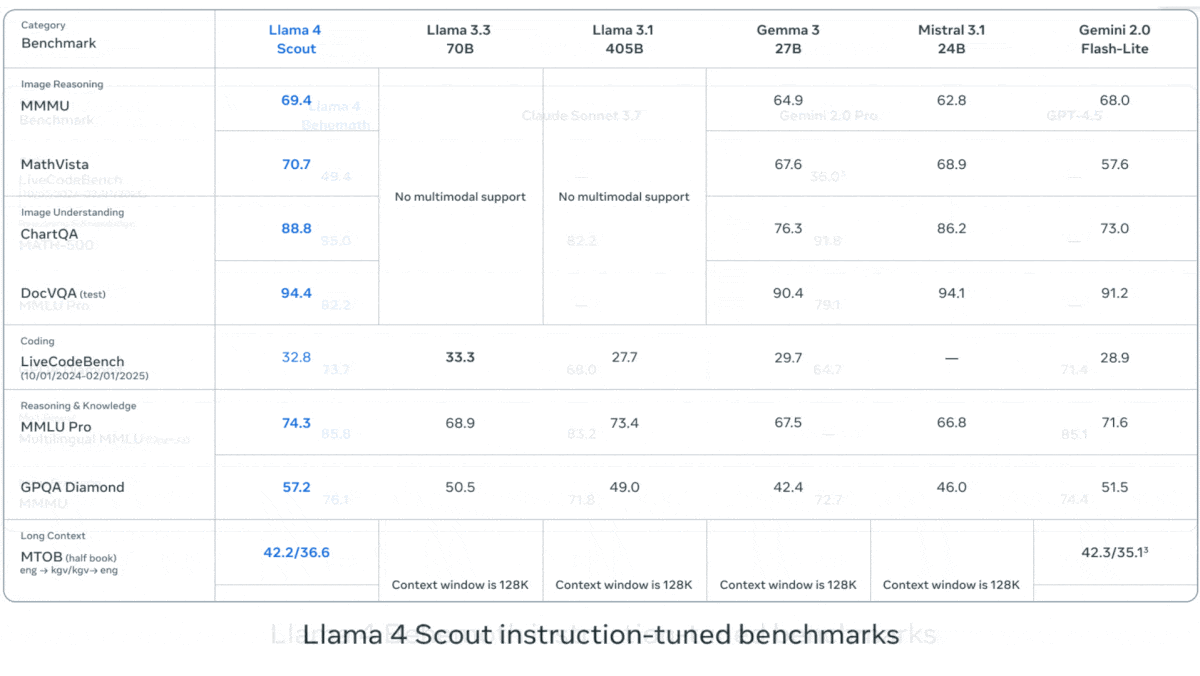
Meta、Llama 4シリーズの視覚言語モデルを発表: Metaは、Llama 4シリーズの2つのオープンソースマルチモーダルモデル、Llama 4 Scout (109Bパラメータ, 17Bアクティブ) と Llama 4 Maverick (400Bパラメータ, 17Bアクティブ) を発表し、約2TパラメータのLlama 4 Behemothも予告しました。これらのモデルはすべてMoEアーキテクチャを採用し、テキスト、画像、動画の入力をサポートし、テキストを出力します。Scoutは最大10Mトークンのコンテキストウィンドウを持ち(ただし、実際の有効性には疑問の声も)、Maverickは1Mです。モデルは画像、コーディング、知識、推論など多くのベンチマークで強力な性能を示し、ScoutはGemma 3 27Bなどを上回り、MaverickはGPT-4oやGemini 2.0 Flashを上回り、初期のBehemothバージョンはGPT-4.5などを超えています。これらのモデルの発表は、オープンソースモデルがクローズドソースモデルに追いつく動きをさらに加速させます (情報源: DeepLearning.AI, X @AIatMeta)
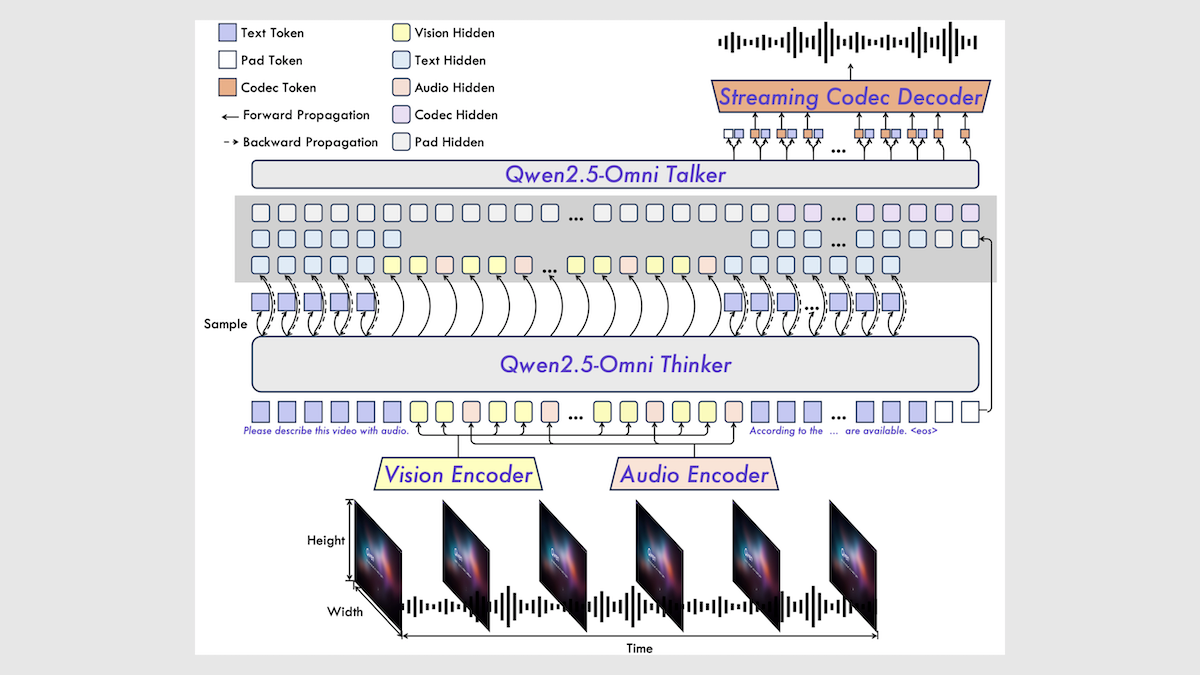
アリババ、Qwen2.5-Omni 7Bマルチモーダルモデルを発表: アリババは、新しいオープンソースマルチモーダルモデルQwen2.5-Omni 7Bを発表しました。これはテキスト、画像、音声、動画の入力を処理し、テキストと音声の出力を生成できます。このモデルは、Qwen 2.5 7Bテキストモデル、Qwen2.5-VL視覚エンコーダ、Whisper-large-v3音声エンコーダに基づいて構築され、革新的なThinker-Talkerアーキテクチャを採用しています。モデルは多くのベンチマークで優れた性能を示し、特に音声からテキスト、画像からテキスト、動画からテキストのタスクでSOTAレベルに達していますが、純粋なテキストおよびテキストから音声へのタスクではやや劣ります。Qwen2.5-Omniの発表は、高性能なオープンソースマルチモーダルモデルの選択肢をさらに豊かにします (情報源: DeepLearning.AI)
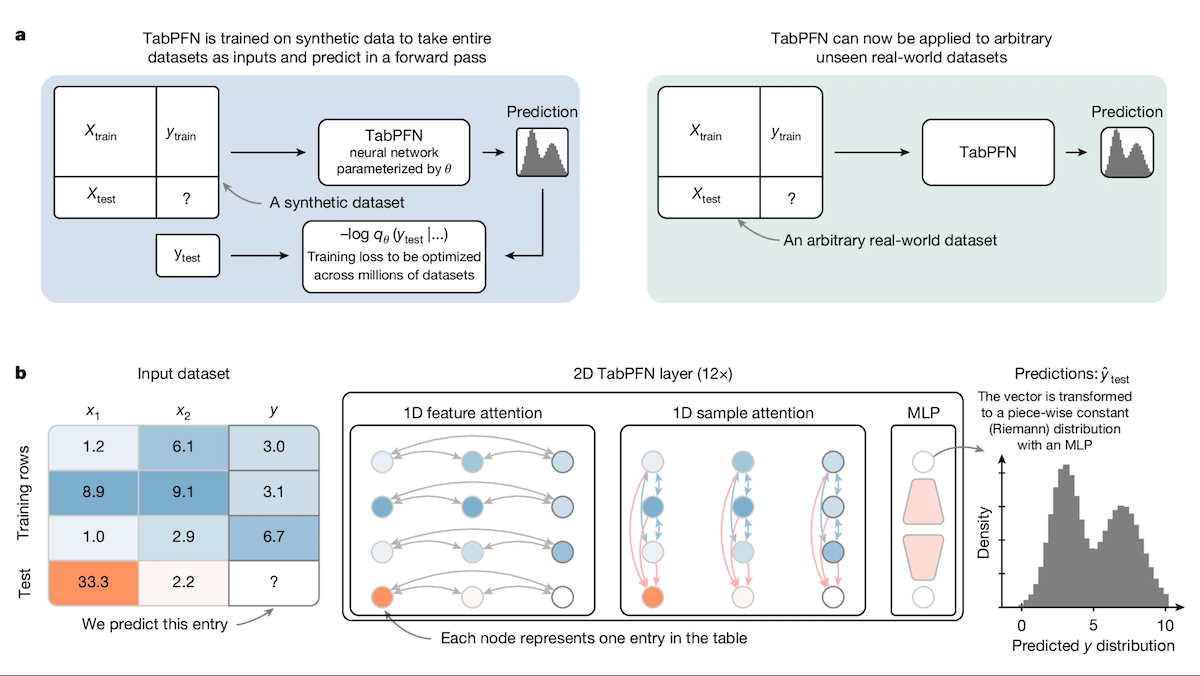
TabPFN:決定木を超える表形式データ用Transformer: フライブルク大学などの研究者は、表形式データ専用に設計されたTransformerモデルであるTabular Prior-data Fitted Network (TabPFN) を発表しました。1億個の合成データセットで事前学習することにより、TabPFNはデータセット間のパターンを認識することを学習し、新しい表形式データに対して追加のトレーニングなしで直接分類および回帰予測を行うことができます。実験によると、AutoMLおよびOpenML-CTR23ベンチマークにおいて、TabPFNは分類(AUC)および回帰(RMSE)タスクで、CatBoost、LightGBM、XGBoostなどの一般的な勾配ブースティング木手法よりも優れた性能を示しましたが、推論速度は遅いです。この研究は、Transformerが表形式データ処理分野で新たな道を開くものです (情報源: DeepLearning.AI)
Intelプラットフォーム、大規模モデル一体型マシンでコストパフォーマンスの高い新選択肢に: DeepSeekなどのオープンソースモデルの普及に伴い、大規模モデル一体型マシンは企業がAIを迅速に導入するための人気のある選択肢となっています。Intelは、その锐炫™ (Arc™) ゲーミンググラフィックスカード(A770など)と至强® Wプロセッサの組み合わせにより、コストパフォーマンスの高いハードウェアソリューションを提供し、一体型マシンの価格を百万元レベルから十万元レベルに引き下げています。このプラットフォームはDeepSeek R1だけでなく、Qwen、Llamaなどのモデルにも対応しています。飞致云、超云、云尖など多くの企業が、このプラットフォームを基盤としたAI一体型マシン製品またはソリューションを発表しており、ナレッジベースのQ&A、インテリジェントカスタマーサービス、金融投資顧問、ドキュメント処理などのシナリオで使用され、中小企業や特定部門のローカルAI推論ニーズに応えています (情報源: 量子位)
Google、第7世代TPU “Ironwood”を発表: Google Cloud Nextカンファレンスで、GoogleはAI推論に最適化された第7世代TPUシステムIronwoodを発表しました。初代Cloud TPUと比較して、Ironwoodの性能は3600倍向上し、エネルギー効率は29倍向上しました。第6世代Trilliumと比較すると、Ironwoodのワットあたり性能は2倍向上し、シングルチップメモリは192GB(Trilliumの6倍)に達し、データアクセス速度は4.5倍向上しました。Ironwoodは今年後半に提供開始予定で、増大するAI推論需要に応えることを目指しています (情報源: X @demishassabis, X @JeffDean, Reddit r/LocalLLaMA)

Google DeepMindおよびGeminiモデルがMCPプロトコルをサポートへ: Google DeepMindの共同創設者であるDemis Hassabis氏およびGeminiモデル責任者のOriol Vinyals氏は、モデルコンテキストプロトコル(MCP)をサポートし、MCPチームおよび業界パートナーと共に同プロトコルを発展させることを期待していると表明しました。MCPはAI Agent時代のオープンスタンダードとして急速に普及しており、異なるモデルが統一された「サービス言語」を理解し、外部ツールやAPIを容易に呼び出せるようにすることを目指しています。この動きにより、Geminiモデルは成長するMCPエコシステムにより良く統合され、より強力なAgentアプリケーションを構築できるようになります (情報源: X @demishassabis, X @OriolVinyalsML)
月之暗面、KimiVL A3Bマルチモーダルモデルを発表: 月之暗面(Moonshot AI)は、KimiVL A3B Instruct & Thinkingモデルを発表しました。これはオープンソース(MITライセンス)のマルチモーダル大規模モデルシリーズで、128Kの長いコンテキスト能力を備えています。このシリーズには、MoE VLMとMoE Reasoning VLMが含まれ、アクティブパラメータは約3Bのみです。視覚および数学ベンチマークでGPT-4oを上回るとされ、MathVisionで36.8%、ScreenSpot-Proで34.5%、OCRBenchで867点を達成し、ロングコンテキストテスト(MMLongBench-Doc 35.1%, LongVideoBench 64.5%)でも優れた性能を示しています。モデルの重みはHugging Faceで公開されています (情報源: X @huggingface)

Orpheus TTS 3B発表:多言語ゼロショット音声クローンモデル: オープンソースコミュニティは、Orpheus TTS 3Bモデルを発表しました。これは30億パラメータの多言語テキスト読み上げモデルです。ゼロショット音声クローニングをサポートし、ストリーミング生成の遅延は約100ミリ秒で、感情やイントネーションを誘導して人間のような音声を生成できます。このモデルはApache 2.0ライセンスを採用しており、重みはHugging Faceで提供されており、オープンソースTTS技術の発展をさらに推進します (情報源: X @huggingface)
OmniSVG発表:統一スケーラブルベクターグラフィックス生成モデル: OmniSVGという新しいモデルが提案されました。これはスケーラブルベクターグラフィックス(SVG)の生成を統一することを目的としています。このモデルはQwen2.5-VLに基づいており、SVGトークナイザーを統合し、テキストと画像の入力を受け付け、対応するSVGコードを生成できます。プロジェクトのウェブサイトでは、その強力なSVG生成効果が示されています。現在、論文とデータセットは公開されていますが、モデルの重みはまだ公開されていません (情報源: X @karminski3, Reddit r/LocalLLaMA)
Google Cloud Next 2025、AIに焦点: Google Cloud Nextカンファレンスでは、AI分野の進展が重点的に紹介されました。推論に最適化された第7世代TPU Ironwoodが発表されました。Gemini 2.5 Proが現在最もインテリジェントなモデルであり、Chatbot Arenaでトップになったことが発表されました。DeepMind、Google Research、Google Cloudの研究成果を統合し、顧客にWeatherNextやAlphaFoldなどのモデルを提供します。企業が自社のデータセンターでGeminiモデルを実行できるようにします。Nvidiaとの提携を発表し、GeminiモデルをBlackwellと機密コンピューティングを通じてオンプレミス展開に提供します (情報源: X @GoogleDeepMind, X @GoogleDeepMind, Reddit r/artificial, X @nvidia)
2025年のAIトレンド予測: 複数の見解を総合すると、2025年のAIの主要なトレンドには、生成AIの継続的な発展と応用の深化、AI倫理と責任あるAIの重要性の向上、エッジAIの普及、特定産業(医療、金融、サプライチェーンなど)におけるAIの導入加速、マルチモーダルAI能力の強化、AI Agentの自律性と課題、AIによる従来のビジネスモデルの破壊、そしてAI人材とスキルの多様性への需要増加が含まれます (情報源: X @Ronald_vanLoon, X @Ronald_vanLoon, X @Ronald_vanLoon)

テスラ工場、車両の自動運転による移送を実現: テスラは、生産された自動車が工場エリア内で生産ラインから積み込みエリアまで、人間の介入なしに自動で走行できることを示しました。これは、自動運転技術が制御された環境(工場物流など)で応用される可能性を示しており、自動車製造および自動化分野におけるAIの進展の一例です (情報源: X @Ronald_vanLoon)
🧰 ツール
Free-for-dev:開発者向け無料リソース大全: GitHub上のripienaar/free-for-devプロジェクトは、開発者(特にDevOpsおよびインフラ開発者)に役立つ、さまざまなSaaS、PaaS、IaaS製品の無料プランをまとめた人気の高いリソースリストです。リストはクラウドサービス、データベース、API、監視、CI/CD、コードホスティング、AIツールなど多くのカテゴリを網羅しており、サービスが試用期間ではなく長期的な無料ティアを提供していること、およびセキュリティ(例:TLSを制限するサービスは受け入れられない)を重視していることを明確に要求しています。このプロジェクトはコミュニティ主導で継続的に更新されており、開発者が無料サービスを見つけて比較するのに非常に便利です (情報源: GitHub: ripienaar/free-for-dev)

Graphiti:リアルタイムAIナレッジグラフ構築フレームワーク: getzep/graphitiは、時系列認識能力を持つナレッジグラフを構築・クエリするためのPythonフレームワークで、特に動的な環境情報を処理する必要があるAI Agentに適しています。ユーザーインタラクション、構造化/非構造化データを継続的に統合し、グラフ全体を再計算することなく、増分更新と正確な履歴クエリをサポートします。Graphitiは、セマンティック埋め込み、キーワード検索(BM25)、グラフ探索を組み合わせて効率的なハイブリッド検索を行い、カスタムエンティティ定義を可能にします。このフレームワークはZepメモリレイヤーの中核技術であり、現在オープンソース化されています (情報源: GitHub: getzep/graphiti)

WeChatMsg:WeChatチャット履歴抽出&AIアシスタントトレーニングツール: LC044/WeChatMsgは、WindowsローカルのWeChatチャット履歴(WeChat 4.0対応)を抽出し、HTML、Word、Excelなどの形式にエクスポートするためのツールです。ユーザーがチャット履歴を永久に保存するのを助け、記録を分析して年次レポートを生成することもできます。さらに、このツールはユーザーのチャットデータを利用してパーソナライズされたAIチャットアシスタントをトレーニングすることをサポートし、「私のデータは私が管理する」という理念を体現しています。プロジェクトはグラフィカルユーザーインターフェースと詳細な使用説明を提供しています (情報源: GitHub: LC044/WeChatMsg)
アリババクラウド百煉、フルサイクルのMCPサービスを開始、Agentファクトリーを構築: アリババクラウド百煉プラットフォームは、モデルコンテキストプロトコル(MCP)サービスの完全なプラットフォーム機能を正式に開始しました。これには、サービス登録、クラウドホスティング、Agent呼び出し、プロセス組み合わせの全ライフサイクルが含まれます。開発者は、プラットフォームでホストされている高徳地図、Notionなどの公式またはサードパーティのMCPサービスを直接使用したり、簡単な設定(サーバー管理不要)で独自のAPIをMCPサービスとして登録したりできます。これは、Agent開発の敷居を下げ、開発者が外部ツールを呼び出す能力を持つAI Agentを迅速に構築・展開し、実世界のシナリオでの大規模モデルの応用を推進することを目的としています。このサービスは、アリババのAI商業化における重要な一歩と見なされています (情報源: 微信公众号 – AINLPer, 量子位)
Hugging FaceとCloudflareが協力し、無料のWebRTCインフラを提供: Hugging FaceとCloudflareは協力し、FastRTCを通じてAI開発者にグローバル規模のエンタープライズレベルのWebRTCインフラを提供します。開発者はHugging Face Tokenを使用して10GBのデータを無料で転送し、リアルタイムの音声およびビデオAIアプリケーションを構築できます。公式は、この協力がもたらす利便性を示す例として、Llama 4音声チャットデモを提供しています (情報源: X @huggingface)
Google AI Studio、UIの大幅アップデートを実施: Google AI Studio(旧MakerSuite)のユーザーインターフェースが第一段階の再設計を受け、よりモダンな外観と体験を提供します。今回のアップデートは、今後数ヶ月以内に導入される予定のさらなる開発者プラットフォーム機能の基盤を築くことを目的としています。新しいUIはGeminiアプリケーションのスタイルとより統一され、API管理と支払い管理のための専用の開発者バックエンドが追加されました。今回のアップデートは、プラットフォーム機能の拡張を示唆しており、新しいモデル(Veo 2など)へのアクセスが含まれる可能性があります (情報源: X @JeffDean, X @op7418)

LlamaIndex、視覚的引用機能を発表: LlamaIndexは新しいチュートリアルを公開し、LlamaParseのレイアウトAgent機能を利用して、Agentの回答に視覚的な引用を実現する方法を示しました。これは、生成された回答がテキストソースに遡れるだけでなく、ソースドキュメント(PDFなど)内の対応する視覚領域(バウンディングボックスで正確に特定)に直接マッピングできることを意味します。これにより、特に図表やテーブルなどの視覚要素を含むドキュメントを処理する場合に、Agentの回答の解釈可能性と追跡可能性が向上します (情報源: X @jerryjliu0)

LangGraph、ノーコードGUIビルダーを発表: LangGraphは現在、Agentのアーキテクチャを設計するためのノーコードのグラフィカルユーザーインターフェース(GUI)ビルダーを提供しています。ユーザーはドラッグアンドドロップなどの視覚的な操作でAgentのワークフローとノード接続を計画し、その後ワンクリックでPythonまたはTypeScriptコードを生成できます。これにより、複雑なAgentアプリケーションを構築する敷居が下がり、迅速なプロトタイピングと開発が容易になります (情報源: X @LangChainAI)
Perplexity、株価チャート機能を更新: Perplexityは株価チャート機能を更新し、時間軸をグラフ全体に引き伸ばして埋めるのではなく、当日の株価変動をリアルタイムで反映するようになりました。この改善は基本的なものですが、金融情報の表示の即時性と実用性を向上させます (情報源: X @AravSrinivas, X @AravSrinivas)

OLMoTrace:LLM出力とトレーニングデータを接続するツール: Allen Institute for AI (AI2) は、OLMoTraceツールを発表しました。これはOLMoモデルの出力をリアルタイムで対応するトレーニングデータソース(4Tトークンのデータ内で秒単位のマッチングを実現)にマッピングできます。これにより、モデルの挙動を理解し、透明性を高め、ポストトレーニングデータを改善するのに役立ちます。このツールは、研究者や開発者が大規模言語モデルの内部動作メカニズムと知識源をよりよく理解するのを支援することを目的としています (情報源: X @natolambert)
llama.cpp、Qwen3モデルのサポートをマージ: 人気のあるローカルLLM推論フレームワークllama.cppは、間もなくリリースされるQwen3シリーズモデル(ベースモデルとMoEバージョンを含む)のサポートをマージしました。これは、Qwen3モデルがリリースされるとすぐに、ユーザーがllama.cppエコシステムでGGUF形式の量子化モデルを使用できるようになり、ローカルデバイスでの実行が容易になることを意味します (情報源: X @karminski3, Reddit r/LocalLLaMA)

KTransformersフレームワークがLlama 4モデルをサポート: 国産AI推論フレームワークKTransformers(CPU+GPU混合推論、特にMoEモデルのオフロードサポートで知られる)は、開発ブランチにMeta Llama 4シリーズモデルの実験的なサポートを追加しました。ドキュメントによると、Q4量子化されたLlama-4-Scout (109B) の実行には約65GBのメモリと10GBのVRAMが必要であり、Llama-4-Maverick (402B) には約270GBのメモリと12GBのVRAMが必要です。4090+デュアルXeon 4構成では、シングルバッチ推論速度は32トークン/秒に達する可能性があります。これにより、限られたVRAMで大規模なMoEモデルを実行することが可能になります (情報源: X @karminski3, Reddit r/LocalLLaMA)
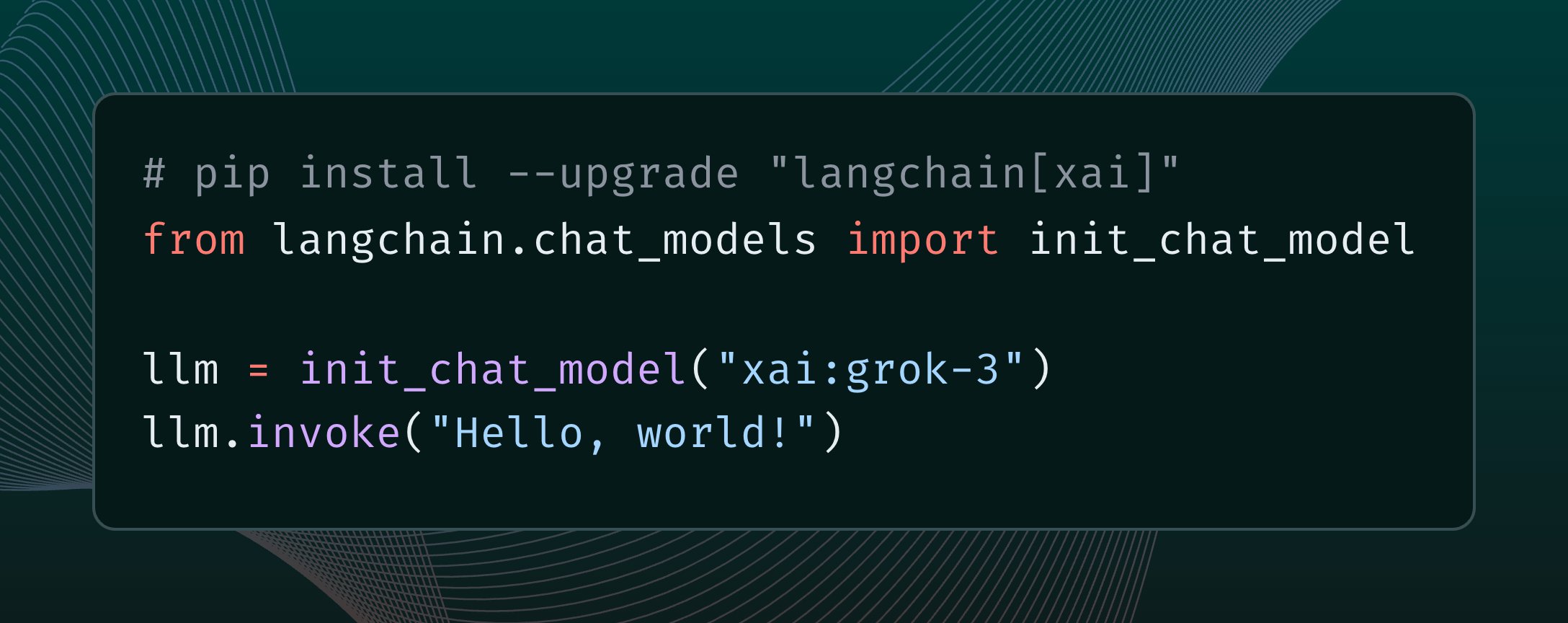
LangChainがxAI Grok 3モデルを統合: LangChainは、xAIが最近リリースしたGrok 3モデルを統合したことを発表しました。ユーザーはLangChainフレームワークを通じてGrok 3を呼び出し、その強力な能力を利用してアプリケーションを構築できるようになりました (情報源: X @LangChainAI)
n8nクラウドサービスの無料デプロイチュートリアル: Hugging Face SpacesとSupabaseを使用して、オープンソースのワークフロー自動化プラットフォームn8nを無料でデプロイし、HTTPS対応のパブリックドメインアクセスを取得する方法を紹介します。これにより、ユーザーはサーバーの購入やドメイン・SSL証明書の設定を自分で行うことなく、n8nの全機能(コールバックURLが必要なノードを含む)を利用できます。この方法は、Supabaseの無料データベースを利用して、Hugging Face Spaceのスリープによるデータ損失問題を解決します (情報源: 微信公众号 – 袋鼠帝AI客栈)
OpenWebUI プラグイン更新:コンテキストカウンターとアダプティブメモリ: コミュニティ開発者はOpenWebUI用に2つのプラグインを公開/更新しました:1) Enhanced Context Counter v3は、詳細なトークン使用量、コスト追跡、パフォーマンス指標のダッシュボードを提供し、複数のモデルとカスタムキャリブレーションをサポートします。2) Adaptive Memory v2は、LLMを通じてユーザー固有の情報(事実、好み、目標など)を動的に抽出し、保存、注入することで、パーソナライズされ、永続的で、適応性のある対話メモリを実現し、完全にローカルで実行され、外部依存関係はありません (情報源: Reddit r/OpenWebUI, Reddit r/OpenWebUI)
QuickVoice MCP:Claudeに電話をかけさせる: コミュニティ開発者はQuickVoiceというMCP(モデルコンテキストプロトコル)ツールを作成しました。これにより、Claude 3.7 SonnetなどMCPをサポートするモデルが実際の電話をかけたり処理したりできるようになります。ユーザーは自然言語の指示(例:「医者に電話して予約して」)でAIに通話タスク(IVRメニューのナビゲーションを含む)を完了させることができます。プロジェクトはGitHubでオープンソース化されています (情報源: Reddit r/ClaudeAI)

RPG Dice Roller for OpenWebUI: コミュニティはOpenWebUI用にRPGダイスローラーツールプラグインを開発しました。これにより、ロールプレイングゲームの対話中に真のランダムな結果を得るのが便利になります (情報源: Reddit r/OpenWebUI)
📚 学習
Girafe-ai オープンソース機械学習コース: GitHub上のgirafe-ai/ml-courseプロジェクトは、girafe-ai機械学習コースの第一学期の教材を提供しており、Naive Bayes、kNN、線形回帰/分類、SVM、PCA、決定木、アンサンブル学習、勾配ブースティング、および深層学習入門などの内容を含んでいます。講義のビデオ録画、PPTスライド、課題が提供されています。機械学習の基礎知識を学ぶための貴重なリソースです (情報源: GitHub: girafe-ai/ml-course)
中国科学技術大学とファーウェイ・ノアの方舟研究所、CMOフレームワークを提案しチップ論理合成を最適化: 中国科学技術大学の王杰教授チームとファーウェイ・ノアの方舟研究所は協力し、ICLR 2025で論文を発表し、ニューラルシンボリック関数マイニングに基づく効率的な論理最適化手法CMOを提案しました。このフレームワークは、グラフニューラルネットワーク(GNN)を用いてモンテカルロ木探索(MCTS)を誘導し、軽量で解釈可能かつ汎化能力の高いシンボリックなスコアリング関数を生成します。これは、論理最適化演算子(Mfs2など)における無効なノード変換を枝刈りするために使用されます。実験によると、CMOは重要な演算子の実行効率を最大2.5倍向上させ、同時に最適化品質を維持することができ、ファーウェイ自社開発のEMU論理合成ツールに応用されています (情報源: 量子位)
上海AI Lab、MaskGaussianによる新しいガウス剪定手法を提案: 上海AI Labの研究チームはCVPR 2025でMaskGaussian手法を提案しました。これは3D Gaussian Splattingを最適化するためのものです。この手法は、学習可能なマスク分布をラスタライズプロセスに組み込むことにより、初めて使用されるガウス点と使用されないガウス点の両方に対して勾配を保持することを実現し、大量の冗長なガウス点を剪定すると同時に、再構成品質を最大限に維持することを可能にします。実験では、複数のデータセットで60%以上のガウス点を剪定し、性能損失は無視できるレベルであり、同時にトレーニング速度を向上させ、メモリ使用量を削減しました (情報源: 量子位)
Qwen2.5-Omni技術レポート解説: RedditユーザーがアリババのQwen2.5-Omni技術レポートの詳細な解説ノートを共有しました。レポートでは、このモデルのThinker-Talkerアーキテクチャ、マルチモーダル(テキスト、画像、音声、動画)入力処理方法(革新的なTMRoPE位置エンコーディングによる音声・動画アライメントを含む)、ストリーミング音声生成メカニズム、トレーニングプロセス(事前学習+事後学習RL)などが紹介されています。このノートは、この最先端マルチモーダルモデルの内部動作原理を理解するための貴重な参考資料となります (情報源: Reddit r/LocalLLaMA)
マッキンゼー、企業向け生成AI拡張運用ガイドを発表: マッキンゼーは、データリーダー向けの運用ガイドを発表し、企業内で生成AIをスケールアップして適用する方法について論じています。レポートは、戦略策定、技術選定、人材育成、リスク管理などの側面をカバーし、企業がGenAIを実践的に導入・拡張するための指針を提供している可能性があります (情報源: X @Ronald_vanLoon)

AI Agent学習入門ガイド: Khulood_Almani氏が、AI Agentの学習を始める方法に関するリソースやステップを共有しました。学習パス、主要な概念、推奨ツールやプラットフォームなどが含まれている可能性があり、AI Agent分野への入門を希望する学習者に指針を提供します (情報源: X @Ronald_vanLoon)

視覚的位置認識におけるリランキング技術の研究: arXiv上のある論文は、視覚的位置認識(Visual Place Recognition, VPR)タスクにおいて、リランキング(Re-Ranking)技術が依然として有効であるかどうかを探求しています。研究では、既存のリランキング手法の長所と短所を分析し、現代のVPRシステムにおけるその役割と必要性を評価している可能性があります (情報源: Reddit r/deeplearning, Reddit r/MachineLearning)
「AI 2027」研究レポート、ASIのリスクと未来を探る: 「AI 2027」と題された研究レポートは、2027年までに起こりうるAI開発シナリオ、特に自動化されたAI研究開発が超知能AI(ASI)の出現につながる可能性を探っています。レポートは、ASIがもたらす潜在的なリスク、例えば目標の不整合による人類の権力喪失、権力集中、国際的な軍拡競争による安全保障リスクの増大、モデルの盗難、そして一般市民の認識の遅れなどの問題を分析し、地政学的に起こりうる戦争、協定、または屈服といった結末についても考察しています (情報源: Reddit r/artificial)
ニューラルネットワークの活性化アライメント研究: OpenReviewに掲載された論文は、ニューラルネットワークにおける表現アライメント(representational alignment)が起こる原因を探求しています。研究によると、アライメントは個々のニューロンに起因するのではなく、活性化関数がどのように機能するかに関連しており、この現象を説明するためにSpotlight Resonance Methodを提案し、実験結果による裏付けを提供しています (情報源: Reddit r/deeplearning)
💼 ビジネス
アリババインターナショナル、AIに重点投資し突破口を模索: 越境EC業界の激しい競争と世界貿易の変化に直面し、アリババインターナショナルデジタルコマースグループはAIを核心戦略と位置づけ、成長と効率向上を目指して大規模な投資を行っています。同社はグローバルAI人材育成計画「Bravo 102」を開始し、新卒採用では80%のポストをAI関連としています。AIアプリケーションはすでにB2B(AI検索エンジンAccio、「ビジネスアシスタント」AI Agent)とB2C(Aidgeプラットフォームが仮想試着、AIカスタマーサービスなどを提供)をカバーしています。アリババインターナショナルの売上高は著しく成長していますが(2024年第4四半期は前年同期比32%増)、投資により損失は拡大しています。AIは、アリババインターナショナルが低価格競争から脱却し、高付加価値への転換と精緻な運営を実現するための重要な推進力と見なされています (情報源: 36氪)
OpenAIの元コアメンバーがMira Murati氏の新会社に参加: GPTシリーズの筆頭著者であるAlec Radford氏とOpenAIの元チーフリサーチオフィサーであるBob McGrew氏が、OpenAIの元CTOであるMira Murati氏が設立した新しいAI企業Thinking Machines Labに顧問として参加しました。Radford氏はGPTシリーズモデルの誕生に重要な役割を果たし、McGrew氏はGPT-3/4およびo1モデルの研究開発に深く関与しました。Thinking Machines Labの創設チームメンバーには、OpenAI出身者が多数(少なくとも19名)含まれています。同社はAIアプリケーションの普及を目指しており、10億ドルの資金調達を計画し、評価額は90億ドルと伝えられており、トップクラスのAI人材が率いるスタートアップに対する市場の高い期待を示しています (情報源: 新智元)
公募ファンド、製薬企業のAI+医療事業に注目: 最近、中国の複数の公募ファンドが製薬上場企業を集中的に調査しており、医療分野におけるAIの応用が注目の焦点となっています。海爾生物は、そのIoT血液ネットワーク、ワクチンネットワークにおけるAI応用、およびAIを通じて公衆衛生シーン(ワクチン予約など)の効率を向上させる進捗を紹介しました。海正薬業は、DeepSeek-R1モデルを導入し、AI製薬企業と協力して、AIを活用して新薬開発の全プロセスを強化したいと述べています。康縁薬業も、AI+マルチオミクス駆動の中薬革新薬発見プラットフォームを構築中であると述べています。これは、AI技術が医薬品の研究開発、運営、患者サービスなどの段階で応用されることが、資本市場から高く注目されていることを示しています (情報源: 創業板観察)
OpenAI、Pioneersプログラムを開始し業界連携を深化: OpenAIはPioneersプログラムを開始しました。これは、野心的な企業とパートナーシップを築き、先進的なAI製品を共同で構築することを目的としています。このプログラムは2つの側面に焦点を当てます。1つ目は、モデルを集中的にファインチューニングし、特定分野の高価値タスクで汎用モデルを超える性能を発揮させること。2つ目は、より質の高い実世界評価(evals)を構築し、業界が分野関連タスクにおけるモデル性能をより良く測定できるようにすることです。これは、OpenAIがその技術を特定業界により深く応用し、協力方式を通じて垂直分野におけるモデルの実用性と評価基準を向上させようとしていることを示しています (情報源: X @sama)
NvidiaとGoogle Cloudが協力し、ローカライズされたGemini展開を推進: NvidiaとGoogle Cloudは協力し、Google Geminiモデルの企業オンプレミスでの実行をサポートすると発表しました。このソリューションは、Nvidia Blackwell GPUプラットフォームと機密コンピューティング(Confidential Computing)技術を組み合わせ、企業に高性能かつ安全なローカライズAI展開オプションを提供することを目指しています。この動きは、データプライバシー、セキュリティコンプライアンス、および特定の性能に対する一部企業の要求に応え、彼らが自身のインフラストラクチャ上で強力なGeminiモデルを実行できるようにします (情報源: X @nvidia)
Google、企業が自社データセンターでGeminiモデルを実行することを許可: Google Cloudは、企業顧客が自身のデータセンターでGemini AIモデルを実行できるようにすると発表しました。この措置は、データ主権、セキュリティ、およびカスタマイズされた展開に対する企業の要求に応えることを目的としており、機密データをクラウドに転送することなく、ローカル環境でGeminiの強力な能力を活用できるようにします。これにより、特に金融、医療など厳格な規制を受ける業界において、企業に大きな柔軟性と制御力が提供されます (情報源: Reddit r/artificial)
Nvidia CEO、関税の影響を軽視、AIサーバーは免除の可能性も: 米国が実施する可能性のある新しい関税政策に対し、Nvidia CEOのジェンスン・フアン氏は影響は限定的であると述べ、NvidiaのAIサーバーの大部分が免除される可能性を示唆しました。これは、その製品の戦略的重要性または特定の貿易分類によるものかもしれません。このニュースは、Nvidiaハードウェアに依存するAI業界にとって前向きなシグナルであり、サプライチェーンコストの上昇に対する懸念を緩和するのに役立ちます (情報源: Reddit r/artificial, Reddit r/ArtificialInteligence)
🌟 コミュニティ
Redditで話題:Qwen3モデルはいつリリース?: RedditコミュニティとXプラットフォーム(旧Twitter)のユーザーが、アリババのQwen3モデルのリリース時期について議論しています。あるユーザーがアリババAIサミットのポスターを共有し、間もなくリリースされると推測しましたが、その後、そのサミットではQwen3が発表されなかったことが確認されました。同時に、llama.cppがQwen3のサポートをマージしたというニュースもコミュニティの期待を高めています。これは、オープンソースコミュニティが国産大規模モデルの進展に高い関心と期待を寄せていることを反映しています (情報源: X @karminski3, Reddit r/LocalLLaMA)

推論データセットコンペティション開始: Bespoke Labsは、Hugging FaceおよびTogether AIと共同で推論データセットコンペティションを開始しました。これは、コミュニティがより多様で、現実世界の複雑さにより近い推論データセット、特に金融、医学などの多分野推論において作成することを奨励し、次世代LLMの発展を推進することを目的としています。既存のデータセット(OpenThoughts-114kなど)はモデルトレーニングにおいて重要な役割を果たしてきましたが、コンペティションはデータセットの境界をさらに広げることを期待しています (情報源: X @huggingface)

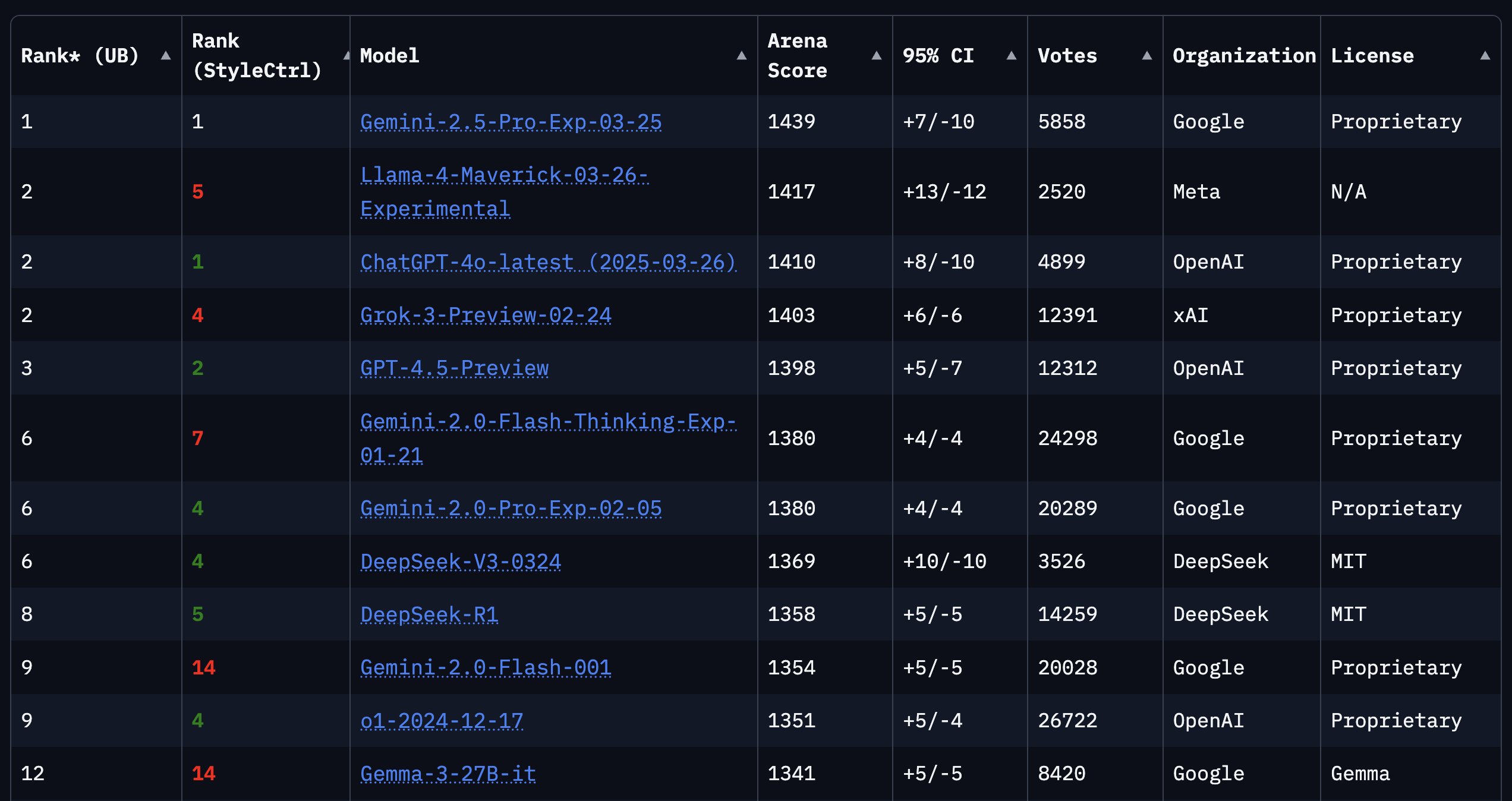
LiveCodeBenchプログラミングベンチマーク更新、o3-miniがリード: LiveCodeBenchプログラミング能力ランキングが8ヶ月ぶりに更新され、OpenAIのo3-mini (high) と o3-mini (medium) が1位と2位、Google Gemini 2.5 Proが3位となりました。このランキングはコミュニティで議論を呼び、一部のユーザーはClaude 3.5/3.7のランキングが比較的低いことに疑問を呈し、実際の使用体験と一致しないと主張しており、異なるベンチマークテストとユーザーの主観的な感覚との間に存在する可能性のある差異を反映しています (情報源: Reddit r/LocalLLaMA)

コミュニティ、Claude Codeについて議論:強力だが高価でバグあり: RedditユーザーはAnthropicのClaude Codeについて議論しており、一般的にそのコンテキスト認識能力が高く、コーディング効果が良いと感じており、「未来から来たようだ」とさえ感じています。しかし、欠点は価格が高いこと(あるユーザーは1日あたり30ドルかかると主張)と、いくつかのバグ(claude.mdファイルがセッション後に失われる、出力の構文エラーなど)が存在することです。ユーザーは将来、より能力が高く、価格が安い代替品が登場することを期待しています (情報源: Reddit r/ClaudeAI)
ユーザーがMistral-Small-3.1-24Bの量子化モデルを共有: Ollamaコミュニティのユーザーが、Mistral-Small-3.1-24BモデルのQ5_K_MおよびQ6_K量子化バージョン(GGUF形式)を共有しました。これは、公式リポジトリがQ4とQ8しか提供していない点を補うものです。これらの量子化モデルはOllamaクライアントを使用して作成され、視覚機能をサポートし、RTX 4090でのコンテキスト長の参考情報も提供されています (情報源: Reddit r/LocalLLaMA)

コミュニティ、AIビデオアップスケーリングツールを求める: Redditユーザーが、240pの低解像度ビデオを1080p/60fpsに向上させることができるAIツールが存在するかどうか尋ねています。古いミュージックビデオを修復したいと考えています。コメントではAi4VideoやCutout.Proなどのツールが言及されていますが、極端に低い解像度からの向上効果は限定的であり、修復というよりは再生成に近い可能性があるという意見もあります (情報源: Reddit r/artificial)
ユーザー、Claude 3.5 Sonnetが密かに更新された疑いを報告: Redditの開発者ユーザーが、使用体験(モデルが絵文字を使い始めた、回答スタイルが変わったなど)に基づき、Anthropicが告知なしに、最適化または蒸留されたバージョンで元のClaude 3.5 Sonnetモデルを置き換え、性能や挙動が変化したのではないかと疑っています。このユーザーは、元の3.5はコーディングにおいて3.7より優れていたが、最近の体験は低下したと考えています。これは、モデルバージョンの透明性と一貫性に関するコミュニティの議論を引き起こしました (情報源: Reddit r/ClaudeAI)
Anthropicのレポートが学生のAI利用による不正行為の議論を呼ぶ: Anthropicは教育レポートを発表し、数百万件の匿名化された学生の対話を分析することで、学生がClaudeを使用して学術的不正行為を行っている可能性があることを発見しました。このレポートはコミュニティで議論を呼び、意見には次のようなものがあります:学生の不正行為は常に存在しており、AIは新しいツールにすぎない。教育システムはAI時代に適応する必要があり、評価方法を変えるべきである。一部のユーザーは、Anthropicがユーザーの対話データを分析することのプライバシーについて懸念を表明しています (情報源: Reddit r/ClaudeAI)

ユーザー、LLM/Agentアプリケーションの監視方法について議論: Redditの機械学習コミュニティユーザーが、LLMアプリケーションやAI Agentのパフォーマンスとコストをどのように監視しているか(例えば、トークン使用量、遅延、エラー率、プロンプトバージョンの変更などを追跡)について議論を開始しました。議論は、コミュニティにおけるLLMOpsの実践方法と課題、自社開発ソリューションか特定のツールを使用しているかを理解することを目的としています (情報源: Reddit r/MachineLearning)
💡 その他
Andrew Ng氏、米国の関税政策がAIに与える影響についてコメント: アンドリュー・ン氏は自身の週報The Batchで、米国の新しい関税政策に対する懸念を表明しました。同政策は同盟国関係や世界経済を損なうだけでなく、ハードウェア(サーバー、冷却、ネットワーク機器、電力設備部品など)の輸入を制限し、消費者向け電子製品の価格を引き上げることによって、米国内のAI開発と応用普及を間接的に阻害すると考えています。関税はロボット工学と自動化の需要をわずかに刺激する可能性があるものの、これは製造業の問題を解決する効果的な方法ではなく、AIのロボット工学分野での進歩は比較的遅いと指摘しています。彼はAIコミュニティに対し、国際協力と思想交流を強化するよう呼びかけています (情報源: DeepLearning.AI)

電気通信分野におけるAIのブレークスルーと落とし穴: 記事は、ネットワーク最適化、顧客サービス、予測保全など、電気通信業界における人工知能の応用可能性を探ると同時に、データプライバシー、アルゴリズムの偏り、統合の複雑さ、既存のワークフローへの影響など、存在する可能性のある課題や落とし穴についても指摘しています (情報源: X @Ronald_vanLoon)
スキルの多様性がAI投資収益率にとって極めて重要: Antonio Grasso氏は、人工知能プロジェクトの投資収益(ROI)を成功させるためには、チームが多様なスキルセットを備えている必要があると強調しています。これには、データサイエンス、エンジニアリング、ドメイン知識、倫理、ビジネス分析など、多方面の能力が含まれる可能性があります (情報源: X @Ronald_vanLoon)

AI駆動のサプライチェーンが持続可能な開発をリード: Nicochan33氏の記事は、AIを活用してサプライチェーン管理(ルート計画、在庫管理、需要予測など)を最適化することは、効率を高めるだけでなく、廃棄物の削減やエネルギー消費の削減などを通じて、持続可能な開発目標の達成を推進できると指摘しています (情報源: X @Ronald_vanLoon)

AI Agentの自律性、保障措置、そして落とし穴: VentureBeatの記事は、AI Agent開発の重要な議題を探求しています。これには、その自律能力をどのようにバランスさせるか、乱用や予期せぬ結果を防ぐための効果的な安全保障措置をどのように設計するか、そして展開と使用の過程で遭遇する可能性のある落とし穴が含まれます (情報源: X @Ronald_vanLoon)

AIは「退屈な」ビジネスにとって最大の脅威と見なされる: Forbesの記事は、人工知能が、伝統的に「退屈」またはプロセス化されていると考えられてきたビジネスに対して最大の破壊的脅威をもたらすと考えています。なぜなら、これらのビジネスは通常、AIによって自動化または最適化できるタスクを大量に含んでいるからです (情報源: X @Ronald_vanLoon)

医療アルゴリズムにおける偏見問題と新しいガイドライン: Fortuneの記事は、AIが医療分野で長年存在してきた偏見問題に注目し、新しいガイドラインがこの問題の解決を推進し、AI医療応用の公平性と正確性を確保できるかどうかを探っています (情報源: X @Ronald_vanLoon)

労働力のスキル向上と疾病認識におけるAIの役割: Forbesの記事は、AIが2つの側面で積極的な役割を果たしていることを探っています。1つ目は、既存の労働力のスキルを向上させ、将来の仕事の需要に適応させるのを助けること、2つ目は、疾病の早期認識と診断において支援を提供することです (情報源: X @Ronald_vanLoon)

AIデジタルエージェントが仕事を再定義する: VentureBeatの記事は、AI Agent(デジタルエージェント)がどのように職場に溶け込み、単なるツールとしてだけでなく、仕事自体の定義、プロセス、人間と機械の協働方式を変える可能性があるかについて議論しています (情報源: X @Ronald_vanLoon)

AI Agentの不可視性、自律性、攻撃可能性のジレンマ: VentureBeatの記事は、AI Agentがもたらす新たなジレンマを深く探求しています。それらの動作はユーザーにとって「不可視」である可能性があり、高度な自律性を備えていると同時に、悪意を持って利用されたり攻撃されたりする可能性もあり、これはセキュリティと倫理に新たな課題を提起します (情報源: X @Ronald_vanLoon)

トランプ氏、TSMCに100%の関税を課すと脅迫: 米国のトランプ前大統領は、台湾積体電路製造(TSMC)に対し、米国に工場を建設しなければ、その製品に100%の関税を課すと伝えたと述べました。この発言は、地政学が半導体サプライチェーンに与え続ける影響を反映しており、TSMCのチップに依存するAIハードウェア供給に潜在的なリスクをもたらす可能性があります (情報源: Reddit r/ArtificialInteligence, Reddit r/artificial)

Google Gemini 2.5 Proに重要な安全報告書が欠落していると指摘: Fortuneは、Googleが最近リリースしたGemini 2.5 Proモデルに重要な安全報告書(Model Card)が欠落しており、これはGoogleが以前に米国政府や国際サミットに対して行ったAI安全に関する約束に違反する可能性があると報じました。この件は、大手テクノロジー企業におけるモデルリリースの透明性と安全に関する約束の履行に対する注目を集めています (情報源: Reddit r/artificial)

AIを用いたナンバープレート認識: Rackenzikの記事は、深層学習に基づくナンバープレート検出・認識技術を紹介し、画像のぼやけ、国/地域によるナンバープレート様式の違い、様々な実世界条件下での認識困難さといった課題について論じています (情報源: Reddit r/deeplearning)
