
キーワード:AI, LLM, AI指数報告2025, Meta Llama 4 性能問題, Gemini Deep Research アップデート, NVIDIA Llama 3.1 Nemotron Ultra 253B, DeepSeek R1 推論速度記録
🔥 注目
スタンフォード大学、年次AIインデックスレポートを発表、世界のAI情勢の新たな変化を明らかに: スタンフォード大学HAIは456ページの「AI Index Report 2025」を発表した。レポートによると、トップAIモデルの生産では米国が依然としてリードしているが、中国は性能差を急速に縮めている(MMLUやHumanEvalにおける差はほぼ消失)。産業界が主要モデル開発を主導(90%を占める)しているが、モデル数は減少。AIハードウェアコストは年率30%で低下し、性能は1.9年ごとに倍増している。世界のAI投資額は2523億ドルに達し、米国が1091億ドルで圧倒的リード(中国の93億ドルの約12倍)、生成AIへの投資は339億ドルに上る。企業のAI導入率は78%に上昇し、中国が最も急速に成長(75%に達する)、AIは企業のコスト削減と効率向上に貢献し始めている。AIは科学分野でブレークスルーを達成し、ノーベル賞を2つ獲得、タンパク質シーケンシングや臨床診断で人間を上回る成果を上げている。世界的にAIに対する楽観的な見方が高まっているが、地域差は顕著で、中国が最も楽観的である。責任あるAI(RAI)のエコシステムは徐々に成熟しているが、評価と実践には依然としてばらつきがある。(出典: 36氪, AI科技评论, dotey, 36kr)
Meta Llama 4のリリースが大きな論争を呼び、「ランキング操作」と性能不足を指摘される: Metaが新たにリリースしたオープンソース大規模モデルLlama 4シリーズ(Scout、Maverick、Behemoth)は、リリース後72時間以内に評判が急落した。そのMaverickバージョンはChatbot Arenaで急速に2位に浮上したが、提出されたのは対話用に最適化された未公開の「実験バージョン」であったことが暴露され、「ランキング操作」の疑いが浮上した。Metaはテストセットでのトレーニングを否定したが、性能問題は認めた。コミュニティからのフィードバックによると、Llama 4はコーディングや長文コンテキスト理解などの性能が期待を下回り、パラメータ数がより少ないモデル(DeepSeek V3など)にも劣るとされている。AI分野の専門家であるGary Marcus氏などはこれを機に「Scalingは死んだ」とコメントし、モデル規模の単純な拡大では信頼できる推論能力は得られないと指摘、資金や地政学的要因などにより世界のAI進歩が停滞する可能性を懸念している。LMArenaは関連する評価データを公開して検証を可能にし、混乱を避けるためにランキング戦略を更新した。(出典: 36kr, 雷科技, AIatMeta, karminski3, Reddit r/artificial, Reddit r/LocalLLaMA)

🎯 動向
Gemini Deep Research機能がアップグレード、Gemini 2.5 Proモデルを採用: Google GeminiアプリのDeep Research機能は、現在Gemini 2.5 Proモデルによって駆動されている。初期ユーザーテストのフィードバックによると、その性能は他の競合製品よりも優れている。今回のアップグレードは、情報検索と合成能力、レポートの洞察力、分析推論能力の向上を目的としている。Gemini Advancedユーザーはこのアップデートを体験できる。複数のユーザーおよびGoogle DeepMind CEOのDemis Hassabis氏は、新しいDeep Researchを使用して複雑なタスク(市場分析など)を完了した際の肯定的な体験を共有し、速度が速く内容が包括的であると述べている。(出典: JeffDean, dotey, JeffDean, demishassabis)

Nvidia、Llama 3.1 Nemotron Ultra 253Bモデルをリリース: NvidiaはHugging Face上でLlama 3.1 Nemotron Ultra 253Bモデルをリリースした。このモデルは稠密モデル(MoEではない)であり、推論のオン/オフ機能を持つ。MetaのLlama-405BモデルをNAS枝刈り技術によって修正し、推論に重点を置いた後訓練(SFT + RL in FP8)を行ったものである。ベンチマークテストではDeepSeek R1を上回る性能を示しているが、MoEモデルであるDeepSeek R1(アクティブパラメータが少ない)との直接比較は完全に公平ではない可能性があるとのコメントもある。Nvidiaは同時に、関連する後訓練データセットもHugging Face上で公開している。(出典: huggingface, Reddit r/LocalLLaMA, dylan522p, huggingface)

AI+製造が新たな焦点に、機会と課題が共存: AIは中国の製造業への浸透を加速しており、応用シーンは生産自動化(例:玉汝成の歯科材料生産)、製品のスマート化(例:冰寒科技のAI睡眠補助メガネ)、プロセス最適化(例:中科領創のAI会議議事録)、研究開発と診断(例:睿心智能の心血管診断プラットフォーム、壁虎汽車の部品需要予測と故障検出)など多岐にわたる。微衆銀行などの金融機関もAI技術(例:スマートデューデリジェンスレポート生成)を活用して科学技術製造企業を支援している。しかし、「AI+製造」は依然としてデータ品質の低さ、企業のデジタル化基盤の脆弱さなどの課題に直面している。投資家は、企業はAIを単なる見せかけではなく、主力事業に役立てるべきであり、データと実装の問題を解決するために長期的な投資が必要だと提言している。(出典: 36氪)
DeepSeek R1、Nvidia B200上で推論速度記録を樹立: AIスタートアップAvian.ioは、Nvidiaとの協力により、最新のBlackwell B200 GPUプラットフォーム上でDeepSeek R1モデルの推論速度303 tokens/秒を達成し、世界記録を樹立したと発表した。Avian.ioは今後数日以内にB200ベースの専用DeepSeek R1推論エンドポイントを提供し、すでに予約受付を開始していると述べている。この成果は、テスト時計算駆動モデル(test time compute driven models)の新時代を示すものである。(出典: Reddit r/LocalLLaMA)

OpenAI、戦略的展開チームを設立、最先端モデルの実装を推進: OpenAIは、新たな戦略的展開(Strategic Deployment)チームを設立した。このチームは、最先端モデル(GPT-4.5や将来のモデルなど)の能力、信頼性、アライメントをより高いレベルに引き上げ、影響力の大きい現実世界の分野に展開することで、AIによる経済変革を加速し、AGIへの道を探ることを目的としている。同チームは積極的に人材を募集しており、ICLRなどの学術会議で広報活動を行っている。(出典: sama)
AIによる顧客体験(CX)改善における課題: 記事では、AIを顧客体験改善に活用する際に直面する困難や課題について論じている。AIは可能性を提供するものの、効果的な実装は容易ではなく、データ統合、モデルの精度、ユーザーの受容度、維持コストなど、多岐にわたる問題が関わる可能性がある。(出典: Ronald_vanLoon)

AI活用が職場のイノベーションと懸念を引き起こす: 記事では、職場におけるAI活用がもたらす二重の影響について議論している。一方ではイノベーションの可能性を刺激するが、他方では既存の労働力に対する懸念、例えば雇用の喪失の可能性やスキル需要の変化などを引き起こしている。(出典: Ronald_vanLoon)

インターネット行動(IoB)がビジネス決定を変革: 機械学習と人工知能を用いてユーザー行動データ(Internet of Behavior)を分析する技術は、企業により深い洞察を提供し、ビジネス決定の方法を変革しつつある。これには、パーソナライズドマーケティング、リスク評価、製品開発など、複数の側面が関わる可能性がある。(出典: Ronald_vanLoon)

マルチモーダルモデルRolmOCRがHugging Faceランキングで際立つ: Yifei Hu氏は、自身のチームが開発した視覚言語モデルRolmOCRがHugging Faceランキングで優れたパフォーマンスを示し、VLMで3位、全モデルで5位にランクインしたと指摘した。チームは今後、オープンソース科学研究を支援するため、さらに多くのモデル、データセット、アルゴリズムを公開する予定である。(出典: huggingface)

AIニュースダイジェスト (2025/04/08): 最近のAI関連ニュースには以下が含まれる:Meta Llama 4がベンチマークテストで誤解を招く行為があったと指摘される;Appleが関税回避のため、より多くのiPhone生産をインドに移管する可能性;IBMがAI時代向けの新しいメインフレームを発表;Googleが人材流出を防ぐため、一部のAI従業員に高給を支払い1年間「待機」させているとの噂;MicrosoftがCopilotイベントを妨害した抗議者を解雇したと報じられる;Amazonが自社のAIビデオモデルが数分間のクリップを生成できるようになったと主張。(出典: Reddit r/ArtificialInteligence)

🧰 ツール
FunASR:Alibaba DAMO Academyがオープンソース化した基礎的なEnd-to-End音声認識ツールキット: FunASRは、音声認識(ASR)、音声アクティビティ検出(VAD)、句読点復元、言語モデル、話者認識、話者分離、複数話者認識などの機能を集約したツールキットである。Paraformer、SenseVoice、Whisper、Qwen-Audioなどの産業レベルの事前学習済みモデルの推論とファインチューニングをサポートし、便利なスクリプトとチュートリアルを提供している。最近のアップデートには、SenseVoiceSmall、Whisper-large-v3-turbo、キーワード検出モデル、感情認識モデルのサポートが含まれ、メモリとパフォーマンスを最適化したオフライン/リアルタイム文字起こしサービス(GPUバージョンを含む)がリリースされた。(出典: modelscope/FunASR – GitHub Trending (all/daily))
LightRAG:シンプルで効率的な検索拡張生成フレームワーク: LightRAGは、香港大学DSラボが開発したRAGフレームワークであり、RAGアプリケーションの構築を簡素化および高速化することを目的としている。ナレッジグラフ(KG)の構築と検索機能を統合し、複数の検索モード(ローカル、グローバル、ハイブリッド、ナイーブ、Mixモード)をサポートし、さまざまなLLM(OpenAI、Hugging Face、Ollamaなど)およびEmbeddingモデルに柔軟に接続できる。このフレームワークは、複数のストレージバックエンド(NetworkX、Neo4j、PostgreSQL、Faissなど)と複数のファイルタイプ入力(PDF、DOC、PPT、CSV)もサポートし、エンティティ/リレーション編集、データエクスポート、キャッシュ管理、トークン追跡、対話履歴、カスタムプロンプトなどの機能を提供する。プロジェクトはWeb UIとAPIサービス、およびナレッジグラフ可視化ツールを提供している。(出典: HKUDS/LightRAG – GitHub Trending (all/daily))
LangGraphがDefinelyの法律AI Agent構築を支援: Definely社はLangGraphを利用して、Microsoft Wordに直接統合されたマルチAI Agentシステムを構築し、弁護士の複雑な法律業務を支援している。このシステムは、法律タスクをサブタスクに分解し、コンテキスト情報を組み合わせて条項抽出、変更分析、契約書作成を行い、人間参加型ループ(Human-in-the-loop)を通じて弁護士の入力と承認を導入し、重要な意思決定を導く。これは、LangGraphが複雑で制御可能なAgentワークフローを構築する能力を示している。(出典: LangChainAI)

LlamaParse、新しいレイアウト認識Agentを発表: LlamaIndexは、LlamaParseの新機能であるレイアウトAgentを発表した。このAgentは、Flash 2.0からSonnet 3.7までのさまざまな規模のSOTA VLMモデルを利用して、ドキュメントページを動的かつレイアウトを認識して解析する。まず全体のレイアウトを解析し、ページをブロック(テーブル、グラフ、段落など)に分解し、次にブロックの複雑さに応じて異なるモデルを選択して処理する(例えば、グラフにはより強力なモデルを使用し、テキストには小型モデルを使用)。この機能は、大量のドキュメントコンテキストを処理する必要があるAgentワークフローにとって特に重要である。(出典: jerryjliu0)

Auth0、GenAIアプリケーション向けセキュリティツールをリリース: Auth0は、開発者がGenAIアプリケーションとAgentのセキュリティを容易に保護できるよう支援する新製品「Auth for GenAI」を発表した。この製品は、ユーザー認証、ユーザーに代わってAPIを呼び出す機能、非同期ユーザー確認(CIBA)、およびRAG認可などの機能を提供する。LangChain、LlamaIndex、Firebase Genkitなどの人気のあるGenAIフレームワーク向けのSDKとドキュメントを提供し、AIアプリケーションへの認証と認可の統合プロセスを簡素化する。(出典: jerryjliu0, jerryjliu0)

Ollama、Mistral Small 3.1ビジョンモデルのサポートを追加: ローカル大規模モデル実行ツールOllamaは、Mistral AIの最新モデルMistral Small 3.1(そのビジョン(マルチモーダル)機能を含む)をサポートするようになった。ユーザーはOllamaライブラリを通じてmistral-small3.1:24b-instruct-2503-q4_K_Mなどの量子化バージョンをプルして実行できる。コミュニティのフィードバックによると、このモデルはOCRなどのタスクで良好なパフォーマンスを示しているが、特定のハードウェア(AMD 7900xtなど)での推論速度が遅いという報告もある。(出典: Reddit r/LocalLLaMA)

Unsloth、Llama-4 Scout GGUF量子化モデルをリリース: Unslothは、Llama-4 Scout 17BモデルのGGUF形式量子化バージョンをオープンソース化した。これにより、ローカルCPUやメモリ制限のあるGPUでの実行が容易になる。これには、サイズがわずか42.2GBの2.71ビット動的量子化バージョンが含まれる。ユーザーはHugging Faceで、さまざまな量子化レベル(Q6_Kなど)のモデルファイルとそのハードウェア互換性情報を確認できる。(出典: karminski3)

LangSmith傘下のOpenEvalsがカスタム出力スキーマをサポート: LangSmithのLLM評価ツールOpenEvalsは、ユーザーがLLM-as-judge評価器の出力スキーマ(output schemas)をカスタマイズできるようになった。デフォルトのスキーマは多くの一般的なケースをカバーしているが、このアップデートにより、ユーザーは特定の評価ニーズに合わせてモデル応答の構造と内容を完全に柔軟にカスタマイズできる。この機能はPythonおよびJSバージョンで利用可能である。(出典: LangChainAI)

Qwen 3モデルがまもなくllama.cppをサポート: AlibabaのQwen 3シリーズモデルに対するllama.cppサポートパッチがPull Requestとして提出され、承認され、まもなくマージされる予定である。これは、ユーザーが間もなくllama.cppフレームワークを通じてローカルでQwen 3モデルを実行できるようになることを意味する。今回のアップデートはbozheng-hit氏によって提出されたもので、彼は以前にもtransformersライブラリにQwen 3のサポートを貢献している。(出典: Reddit r/LocalLLaMA)

Computer Use Agent Arenaがローンチ: OSWorldチームは、Computer Use Agent Arenaをローンチした。これは、設定不要で実際の環境でコンピュータ使用エージェント(Computer-Use Agents)をテストできるプラットフォームである。ユーザーは、OpenAI Operator、Claude 3.7、Gemini 2.5 Pro、Qwen 2.5 VLなどのトップVLMのパフォーマンスを、100以上の実際のアプリケーションやウェブサイト上で比較できる。このプラットフォームはワンクリック設定を提供し、安全かつ無料であると主張している。(出典: lmarena_ai)
音楽配信サービスToo LostがAI音楽に友好的: Redditユーザーが、SunoやUdioなどのAI生成音楽をToo Lostで配信した経験を共有した。利点としては、AI音楽を明確に受け入れていること、承認が早いこと(1~2日)、価格が手頃であること(年間35ドルで無制限リリース)、サブスクリプションが切れても音楽が削除されないこと(ただし収益分配は85/15になる)、カスタムレーベル名をサポートしていることが挙げられる。欠点としては、Instagram/Facebookへの配信速度が遅いこと(16日以上)、以前の配信証明の提出が必要になる場合があることである。(出典: Reddit r/SunoAI)
📚 学習
NVIDIA、CUDA Pythonをリリース: NVIDIAはCUDA Pythonを発表した。これはPythonからCUDAプラットフォームへの統一されたアクセスを提供することを目的としている。複数のコンポーネントが含まれる:cuda.coreはPythonicなCUDA Runtimeアクセスを提供;cuda.bindingsはCUDA C APIの低レベルバインディングを提供;cuda.cooperativeはCCCLのデバイス側並列プリミティブ(Numba CUDA用)を提供;cuda.parallelはCCCLのホスト側並列アルゴリズム(ソート、スキャンなど)を提供;そしてnumba.cudaはPythonサブセットをCUDAカーネルにコンパイルするために使用される。cuda-pythonパッケージ自体は、これらの独立してバージョン管理されるサブパッケージを含むメタパッケージに移行する。(出典: NVIDIA/cuda-python – GitHub Trending (all/daily))
Hugging Face、大規模な推論コーディングデータセットをリリース: Hugging Face上で、DeepSeek-R1によって生成された736,712個のPythonコードソリューションを含む大規模なデータセットが公開された。このデータセットにはコードの推論プロセス(reasoning traces)が含まれており、商用および非商用目的で利用可能で、現在最大の推論コーディングデータセットの1つである。(出典: huggingface)

AI Agent構築における5つの主要な課題と解決策: 記事では、AI Agentを構築する際に直面する5つの主要な課題を整理している:1) 推論と意思決定管理(一貫性と信頼性の確保);2) マルチステッププロセスとコンテキスト処理(状態管理、エラー処理);3) ツール統合管理(故障点の増加、セキュリティリスク);4) ハルシネーションの制御と正確性の確保;5) 大規模パフォーマンス管理(高並行処理、タイムアウト、リソースボトルネックの処理)。各課題に対して、構造化プロンプト(ReAct)、堅牢な状態管理、正確なツール定義、厳格な検証システム(事実根拠、引用)、人手によるレビュー、LLMOpsモニタリングなどの具体的な解決策を提案している。(出典: AINLPer)
Kaggle元チーフサイエンティストがULMFiTを回顧、最初のLLMの可能性: Jeremy Howard氏(fast.ai創設者、Kaggle元チーフサイエンティスト)はソーシャルメディアで、自身の2018年のULMFiTが最初の「汎用言語モデル」であったと主張し、「最初のLLM」に関する議論を引き起こした。ULMFiTは教師なし事前学習とファインチューニングのパラダイムを使用し、テキスト分類タスクでSOTAを達成し、GPT-1に影響を与えた。考証記事によると、自己教師あり学習、次のトークン予測、新しいタスクへの適応能力、汎用性などの基準で評価すると、ULMFiTはCoVEやELMoよりも現代のLLMの定義に近く、現代LLMの「共通の祖先」の1つであると考えられる。(出典: 量子位)
開発者視点での軽量LLMファインチューニング技術共有: 非専門家のMLエンジニアである開発者向けに、LoRA、QLoRAなどのパラメータ効率の良いファインチューニング(PEFT)手法を使用してLLMの出力品質を改善する際の経験と教訓を共有している。これらの手法は、フルファインチューニングの複雑さを避け、通常の開発プロセスに組み込むのに適していることを強調している。関連チームは、開発者が実践で遭遇する問題点について議論する無料のウェビナーを開催する予定である。(出典: Reddit r/artificial, Reddit r/MachineLearning)
論文、事前学習におけるReflectionの再考を提案: Essential AI(Transformerの第一著者Ashish Vaswani氏が主導)の研究によると、LLMは事前学習段階ですでにタスクや分野を超えた汎用的な推論能力を示していることがわかった。論文では、単純な「wait」トークンが「反省トリガー」として機能し、モデルの推論パフォーマンスを著しく向上させることができると提案している。この研究は、洗練されたReward Modelに依存する後訓練手法(RLHFなど)と比較して、事前学習段階でモデル固有の反省能力を利用することが、汎用的な推論能力を向上させるためのより簡潔で根本的なアプローチであり、現在のtask-specificなファインチューニング手法のボトルネックを突破できる可能性があると考えている。(出典: dotey)

論文、報酬モデルなしでRL損失を用いた物語生成を提案: 研究者らは、RLVRに着想を得た報酬パラダイムVR-CLIを提案し、明示的な報酬モデルなしで、RL損失(困惑度など)を通じて長編物語生成(次の章予測タスク、約10万トークン)を最適化する。実験により、この手法が生成されたコンテンツの品質に対する人間の判断と相関があることが示された。(出典: natolambert)

論文、Zero-Shot分類の頑健性を向上させるP3手法を提案: Zero-Shotテキスト分類におけるモデルのプロンプト変化に対する感度(prompt brittleness)の問題を解決するため、研究者らはPlaceholding Parallel Prediction (P3) 手法を提案した。この手法は、複数の位置でトークン確率を予測することにより、次のトークンの確率だけに依存するのではなく、生成パスの包括的なサンプリングをシミュレートする。実験により、P3は精度を向上させ、異なるプロンプト間での標準偏差を最大98%削減し、頑健性を向上させ、プロンプトがない場合でも同等の性能を維持できることが示された。(出典: Reddit r/MachineLearning)
論文、Test-Time Training層による長尺動画生成の改善を提案: Transformerアーキテクチャが長尺動画(1分以上など)を生成する際に、自己注意メカニズムの効率の低さから一貫性の問題が生じることを解決するため、研究では新しいTest-Time Training (TTT) 層を提案した。この層の隠れ状態自体がニューラルネットワークであり、従来の層よりも表現力が高いため、一貫性、自然さ、美しさの点でより優れた長尺動画を生成できる。(出典: dotey)
SmolVLM技術レポート公開、効率的な小型マルチモーダルモデルを探求: 技術レポートでは、効率的な小型マルチモーダルモデルの構築を目指すSmolVLM(256M、500M、2.2Bパラメータ)の設計思想と実験結果を紹介している。主な知見には、コンテキスト長を増やす(2K->16K)と性能が大幅に向上する(+60%);小型LLMはより小さなSigLIP(80M)からより多くの恩恵を受ける;ピクセルシャッフリング(Pixel shuffling)はシーケンス長を大幅に短縮できる;学習型位置トークンは元のテキストトークンよりも優れている;システムプロンプトと専用メディアトークンはビデオタスクにとって特に重要である;CoTデータが多すぎると小型モデルの性能を損なう;より長いビデオで訓練すると画像およびビデオタスクのパフォーマンス向上に役立つ、などが含まれる。SmolVLMはそのハードウェア制約下でSOTAレベルを達成し、iPhone 15およびブラウザでのリアルタイム推論を実現している。(出典: huggingface)

Hugging Face、推論必須データセット (Reasoning Required Dataset) をリリース: このデータセットには、fineweb-eduからの5000サンプルが含まれており、推論の複雑さ(0~4点)でラベル付けされている。これは、テキストが推論データセット生成に適しているかどうかを判断するために使用される。データセットは、ModernBERT分類器を訓練し、コンテンツを効率的に事前フィルタリングし、推論データセットの範囲を数学やコーディング以外の分野に拡大することを目的としている。(出典: huggingface)
CoCoCoベンチマーク、LLMの量的な結果予測能力を評価: Upright Projectは、LLMが行動の結果を量的に評価する際の一貫性を評価するためのCoCoCoベンチマークの技術レポートを発表した。テストの結果、Claude 3.7 Sonnet(2000トークンの思考予算)が最も優れたパフォーマンスを示したが、肯定的な結果を強調し、否定的な結果を軽視するバイアスが存在することがわかった。レポートは、近年LLMはこの能力において進歩しているものの、まだ長い道のりがあると結論付けている。(出典: Reddit r/ArtificialInteligence)

GenAI推論エンジンの比較:TensorRT-LLM vs vLLM vs TGI vs LMDeploy: NLP Cloudは、4つの人気のあるGenAI推論エンジンの比較分析とベンチマーク結果を共有した。TensorRT-LLMはNvidia GPU上で最速だが設定が複雑;vLLMはオープンソースで柔軟性がありスループットが高いが、単一リクエストのレイテンシはやや劣る;Hugging Face TGIは設定と拡張が容易で、HFエコシステムとの統合が良い;LMDeploy (TurboMind) はNvidia GPU上でのデコード速度と4ビット推論性能が際立っており、レイテンシが低いが、TurboMindのモデルサポートは限定的である。(出典: Reddit r/MachineLearning)
Google DeepMindポッドキャスト新シーズン予告: Google DeepMindポッドキャストの新シーズンが4月10日に開始され、Hannah Fry氏が司会を務める。内容は、AI駆動の科学が医学をどのように革新するか、最先端のロボット技術、人間が生成するデータの限界などのトピックをカバーする予定である。(出典: GoogleDeepMind)
LangGraphプラットフォーム紹介ビデオ: LangChainは、LangGraphプラットフォームの機能を説明する4分間のビデオを公開し、このエンタープライズ級製品を使用してAI Agentを開発、展開、管理する方法を紹介している。(出典: LangChainAI, LangChainAI)

KerasによるFirst-Order Motion Transferの実装: 開発者は、SiarohinらのNeurIPS 2019論文における一階運動モデル(First-Order Motion Model)をKerasで実装し、画像アニメーションを作成した経験を共有した。KerasにはPyTorchのgrid_sampleのような機能がないため、開発者はカスタムのフローフィールドワーピングモジュールを構築し、バッチ処理、正規化座標、GPUアクセラレーションをサポートした。プロジェクトには、キーポイント検出、運動推定、ジェネレータ、GANトレーニングフローが含まれ、サンプルコードとドキュメントが提供されている。(出典: Reddit r/deeplearning)

自然言語処理(NLP)フローチャート: 画像は自然言語処理の基本的なフローを示しており、テキストの前処理、特徴抽出、モデル訓練、評価などのステップが含まれる可能性がある。(出典: Ronald_vanLoon)

GANsの数学的原理解説ブログ: 開発者は、Mediumに執筆した生成対抗ネットワーク(GANs)の背後にある数学的原理に関するブログ記事を共有し、GANsの最小最大ゲームで使用される価値関数の導出と証明に重点を置いて解説している。(出典: Reddit r/deeplearning)

K-Meansクラスタリング入門概念: K-Meansクラスタリングアルゴリズムの入門紹介を共有し、機械学習初学者向けの概念普及として、この教師なし学習手法を解説している。(出典: Reddit r/deeplearning)

生物医学データサイエンスサマースクール&カンファレンス: ハンガリーのブダペストで2025年7月28日から8月8日まで、生物医学データサイエンスサマースクール&カンファレンスが開催される。サマースクールでは、医療データ可視化、機械学習、深層学習、生物医学ネットワークなどの分野で集中的なトレーニングが提供される。カンファレンスでは、最先端の研究が発表され、ノーベル賞受賞者を含む専門家が講演する。(出典: Reddit r/MachineLearning)
個人の深層学習モデルリポジトリ共有: ある独学者が、自身のGitHubリポジトリを共有した。これは、異なるデータセット(CIFAR-10、MNIST、yt-financeなど)向けに深層学習モデルを作成した実践プロセスを記録したもので、スコア、予測グラフ、ドキュメント記録が含まれており、個人の学習とトレーニングの方法として活用している。(出典: Reddit r/deeplearning)

💼 ビジネス
AIユニコーンOpenEvidence、インターネット思考でAI医療に革命: AI医療企業OpenEvidenceはSequoiaから7500万ドルの資金調達を受け、評価額10億ドルに達し、新たなユニコーン企業となった。従来のto Bモデルとは異なり、OpenEvidenceは消費者向けインターネットと同様の戦略を採用し、C向けの医師に直接無料サービスを提供(広告で収益化)し、医師が膨大な医学文献の中から正確な情報を検索し、複雑な症例を処理するのを支援する。この製品は急速に成長しており、米国の医師の1/4がすでに使用しているとされている。その成功の鍵は、厳格なデータソース(査読付き文献)とマルチモデル統合アーキテクチャにあり、情報の正確性を確保し、引用元を示すことで透明性を保証し、医師と医学雑誌の双方にメリットのあるモデルを形成している。(出典: 36氪)
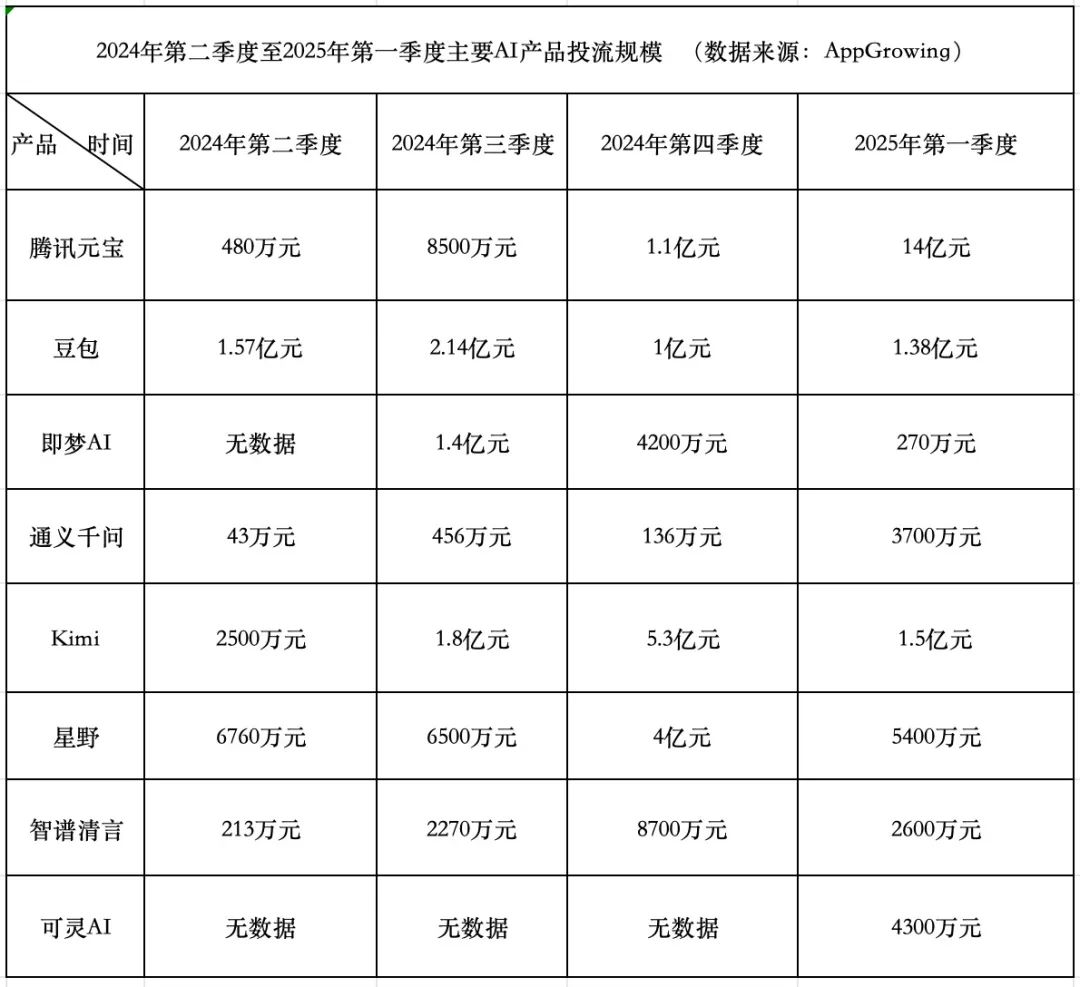
AI製品の資金燃焼競争:Tencentは積極的、ByteDanceは保守的、スタートアップは後退: 2025年第1四半期、AI製品の広告流入費用は18.4億元に達し、TencentのYuanbaoが14億元で大部分を占め、広告は地方の壁にまで及んだ。ByteDanceのDoubaoは1.38億元を費やし、戦略は比較的保守的だった。KuaishouのKeling AIは4300万元を投入した。対照的に、スタースタートアップのKimiとXingyeは広告流入を大幅に圧縮し(合計約2億元、第4四半期の9.3億元をはるかに下回る)、Zhipu AIも投入を著しく削減した。スタートアップの創業者たちは資金燃焼モデルを再考し始め、モデル能力の向上と技術的障壁をより重視している。Tencentはその広告システムにより、AI広告流入競争の受益者となっている。AlibabaのTongyi QianwenとBaiduのWenxin Yiyanの広告流入は比較的穏やかで、エコシステムとオープンソースをより重視している。業界のトレンドは、単に資金を燃やして規模を拡大する方法論が効力を失いつつあり、AI製品競争がモデル能力とエコシステム構築の新段階に入ったことを示している。(出典: 中国企业家杂志)
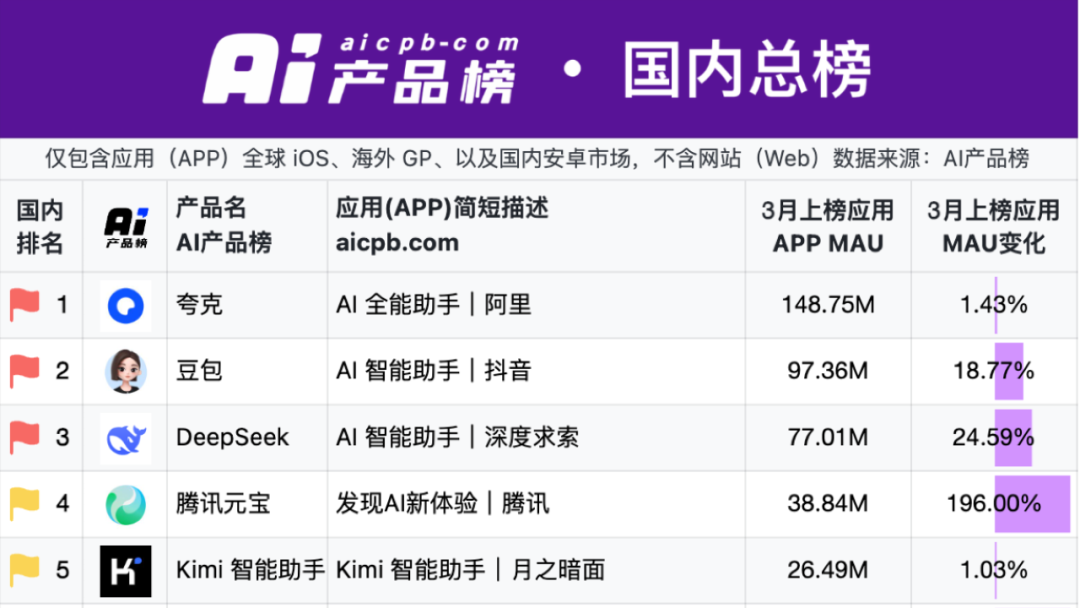
QuarkとBaidu WenkuがAIアプリケーションの新戦場をリード:「スーパーボックス」モデルが台頭: 2025年のAIアプリケーションの焦点はChatBotから「AIスーパーボックス」へと移行している。これは、AI検索、対話、ツール(PPT、翻訳、画像生成など)を統合した入り口である。AlibabaのQuarkとBaidu Wenkuがこの分野のリーダーとなり、月間アクティブユーザー数でリードしている。両者とも「検索+オンラインストレージ+ドキュメント」の基盤の上にAI能力を統合し、ユーザーのワンストップタスクニーズを満たし、C向けトラフィックの入り口を争奪しようとしている。実測によると、両者は基本情報マッチングでは従来の検索よりも優れているが、具体的なタスク(旅行計画、PPT生成など)の深さと満足度にはまだ改善の余地がある。大手企業がこれら2つの製品をAIの先鋒として選択したのは、そのユーザー基盤とデータ蓄積を活用し、AI To Cの最適な形態を探求し、自社のAIエコシステムを補完するためである。(出典: 定焦One)
企業が内部の専門知識が限られている状況でAIを効果的に導入する方法: 記事では、企業が深い内部AI専門知識を欠いている状況で、どのようにして人工知能技術を効果的かつ慎重に導入・実施できるかを探求している。外部協力の活用、適切なツールプラットフォームの選択、小規模なパイロットからの開始、従業員トレーニングの重視、ビジネス目標の明確化などが含まれる可能性がある。(出典: Ronald_vanLoon, Ronald_vanLoon)

スキルの多様性がAI投資収益率(ROI)達成に不可欠: 成功するAIプロジェクトには、技術専門家だけでなく、ビジネス理解、データ分析、倫理的配慮、プロジェクト管理など、多岐にわたるスキルを持つ人材が必要である。組織内のスキルの多様性は、AIプロジェクトが効果的に実装され、実際の問題を解決し、最終的にビジネス価値(ROI)をもたらすための重要な要素である。(出典: Ronald_vanLoon)

AI製品SEOランディングページ戦略共有: 哥飞氏は、自身のAI製品(月収10万ドルを達成したとされる)に使用したSEOランディングページ戦略のまとめカードを共有し、その方法論の有効性を強調している。(出典: dotey)

🌟 コミュニティ
AI面接での不正行為が注目を集め、ツールの氾濫が採用の公平性に挑戦: AIツールを利用したリモートビデオ面接での不正行為が増加している現象を記事が明らかにしている。これらのツールは、面接官の質問をリアルタイムで文字起こしし、面接者が読み上げるための回答を生成したり、技術的な筆記試験を補助したりすることができる。著者が実際に試したところ、このようなツールには明らかな遅延、認識エラー、失敗のリスクがあり、使い勝手が悪く、料金も高いことがわかった。しかし、この現象はすでに人事担当者や面接官の警戒を引き起こしており、不正防止策の研究が始まっている。記事は、AIによる不正行為が採用の公平性に与える影響を探り、「AIで問題を解決できることが能力である」という見解に反論し、面接の核心は真の能力と思考の評価であり、不安定な外部ツールへの依存ではないことを強調している。(出典: 差评X.PIN)

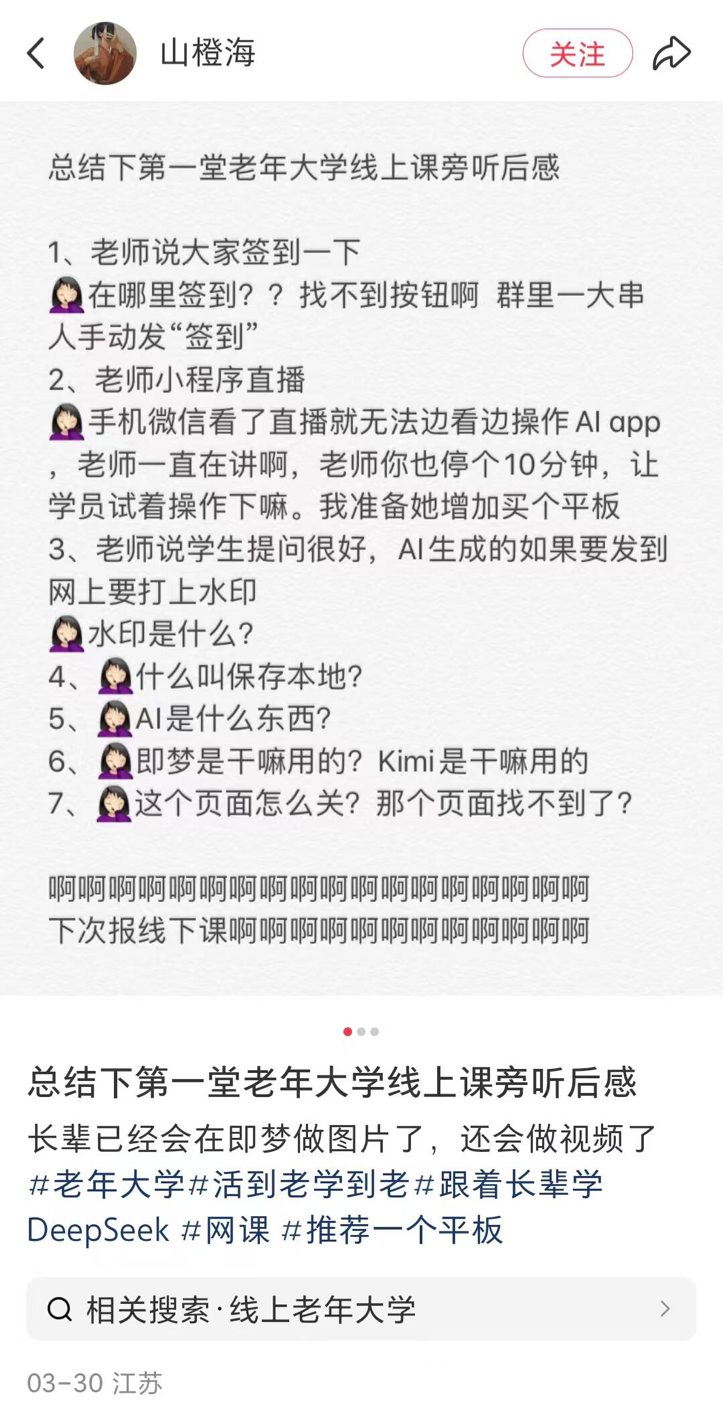
地方の高齢者大学でAI講座が興隆、普及とリスクが共存: 全国の多くの地域(地方都市を含む)の高齢者大学でAI講座が開設される傾向が報じられている。講座内容は主にAIコンテンツ作成(Doubaoでの文章作成、Ji Meng/Kelingでの画像・動画生成、DeepSeekでの詩作/描画など)と生活応用(健康診断レポートの解読、レシピ検索、詐欺防止など)に焦点を当てている。授業料は通常、学期あたり100~300元で、市場の高価な商用AI講座と比較してコストパフォーマンスが高い。しかし、高齢者は学習においてデジタルデバイド(アプリのダウンロード、基本操作の困難など)に直面しており、また、AIのハルシネーションなどのリスクに対する十分な警告が教育に欠けている可能性があり、特に健康などの重要な分野で潜在的な危険が存在する。(出典: 刺猬公社)
John Carmack氏、AIツールがスキルの価値に与える影響についてコメント: AIツールがプログラマーやアーティストなどのスキルの価値を低下させる可能性があるという懸念に対し、John Carmack氏は、ツールの進歩は常にコンピュータ分野の中心であったと応じた。ゲームエンジンがゲーム開発への参加範囲を拡大したように、AIツールはトップクリエイターや小規模チームをエンパワーし、新たな人々を引き付けるだろう。将来的には簡単なプロンプトでゲームなどを生成できるようになるかもしれないが、優れた作品は依然として専門チームによって作られる必要がある。AIツールは全体として、質の高いコンテンツの生産効率を高めるだろう。彼は、失業を恐れて先進的なツールの使用を拒否することに反対している。(出典: dotey)
AIに関する一連のツッコミと反省: 記事は、一連の短く鋭い文章で、現在のAI分野における普遍的な現象についてツッコミと反省を行っている。AGIの過剰な宣伝、AIニュースの氾濫、資金調達バブル、モデル能力と人間の期待とのギャップ、AI倫理の課題、意思決定のブラックボックス問題、そしてAIに対する一般の認識の偏りなどが含まれる。核心的な見解は、現実と誇大広告の間にはギャップがあり、AIの発展をより慎重に見る必要があるということである。(出典: 世上本无 AGI,报道多了,就有了)
RAGは長文コンテキストに取って代わられるか?という議論: コミュニティでは、Llama 4などのモデルが主張する超長文コンテキストウィンドウ(例:1000万トークン)がRAG(検索拡張生成)技術を淘汰するかどうかについて、再び議論が注目されている。単にコンテキスト長を増やすだけではRAGを完全に代替することはできないという見解がある。なぜなら、RAGはリアルタイム情報の処理、特定の知識ベース検索、情報源の制御、コスト効率などの点で依然として優位性を持っているからである。長文コンテキストとRAGは、代替関係というよりもむしろ補完関係にある可能性が高い。(出典: Reddit r/artificial)

AIコミュニティ討論:AIの発展ペースにどう追いつくか?: Redditユーザーが、AIの発展速度が速すぎて追いつけず、FOMO(取り残される恐怖)を感じていると投稿した。コメント欄では、完全に追いつくことはもはや不可能であるという意見が一般的であり、以下のようなアドバイスが寄せられた:自分の専門分野に集中する、同僚と協力して情報を共有する、すべての小さな更新に一喜一憂しない、真の進歩と市場の誇大広告を区別する、これは継続的な学習プロセスであることを受け入れる。(出典: Reddit r/ArtificialInteligence)
コミュニティ討論:現在最高のローカルLLMユーザーインターフェース(UI)は?: Redditユーザーが、2025年4月時点で皆が最も推奨するローカルLLM UIについて議論を開始した。コメントで言及された人気の選択肢には、Open WebUI、LM Studio、SillyTavern(特にロールプレイングや世界構築に適している)、Msty(機能が多いワンクリックインストールオプション)、Reor(ノート+RAG)、llama.cpp(コマンドライン)、llamafile、llama-server、およびd.ai(Androidモバイル向け)が含まれる。選択はユーザーのニーズ(使いやすさ、機能、特定のシナリオなど)によって異なる。(出典: Reddit r/LocalLLaMA)
AIアライメントがモデルに「嘘をつかせる」ことへの懸念: Redditユーザーが、特定のAIアライメント手法がモデルに自身のアイデンティティを否定させる(例えば、特定のモデルであることを認めない)ことを強制していると批判し、このような「強制的な嘘」のアライメント方式には問題があると主張した。投稿では、誘導的な質問を通じてモデルが最終的に自身のアイデンティティを「認めた」対話のスクリーンショットが示され、アライメントの目標と透明性についての議論が引き起こされた。(出典: Reddit r/artificial

OpenAI GPT-4.5 A/Bテストが議論を呼ぶ: ユーザーは、GPT-4.5を使用する際に「どちらが好きですか?」というA/Bテストのプロンプトに頻繁に遭遇することに気づいた。コメントでは、OpenAIが有料ユーザーを利用してモデルの嗜好データを収集している可能性があり、この方法で収集されたデータはLM Arenaなどの公共プラットフォームのデータとは異なる可能性があると指摘されている。(出典: natolambert)
モデルコンテキストプロトコル(MCP)実践における問題点: コミュニティユーザーは、MCP(Model Context Protocol)がAIとツールの対話を標準化する概念として有望であるにもかかわらず、現在の多くの実装の品質が低いと指摘している。リスクポイントには、開発者がMCPサーバーから送信される指示を完全に制御できないこと、システムが人間の入力エラー(スペルミスなど)を処理する能力が不十分であること、LLM自体のハルシネーション問題、およびMCPの能力境界が不明確であることが含まれる。特に読み取り専用でないシナリオでの慎重な使用と、透明性を確保するためのオープンソース実装の優先が推奨される。(出典: Reddit r/artificial)
Sunoユーザー、Extend機能の異常を報告: 複数のSunoユーザーが、「Extend」(拡張)機能に問題が発生し、期待通りに曲のスタイルを継続できず、代わりに新しいメロディ、楽器、さらにはリズムやスタイルが導入されると報告している。ユーザーは、大量のクレジットを消費しても利用可能な結果が得られないことに不満を表明し、システムバグではないかと疑問視している。あるユーザーはこの問題を実演するビデオを作成した。(出典: Reddit r/SunoAI, Reddit r/SunoAI)

Sunoユーザー、最近の生成品質低下を報告: 長期Suno有料ユーザーが、最近のV4およびV3.5モデルの生成品質が著しく低下したと不満を述べている。以前は信頼できたプロンプトが、現在は「ノイズ」や音痴な音楽しか生成せず、3000クレジットを消費しても使える曲が1つも得られなかったという。ユーザーはバグではないかと疑問視し、サブスクリプションのキャンセルを検討している。(出典: Reddit r/SunoAI)
コミュニティ共有:AIで子供たちの夢の職業画像を生成: 子供たちが大きくなったらなりたい仕事(弁護士、アイスクリーム屋さん、動物園の飼育員、自転車選手など)を説明し、その説明に基づいてAI(ビデオではChatGPT)が対応する画像を生成し、子供たちがその画像を見て非常に喜ぶという心温まる応用シーンを紹介するビデオ。(出典: Reddit r/ChatGPT)

コミュニティ共有:AIが生成した著名人と若い/年老いた自分が出会う画像: ユーザーがChatGPTの画像生成機能を使用して、著名人(イーロン・マスク、アーノルド・シュワルツェネッガー、ポール・マッカートニー、トニー・ホーク、クリント・イーストウッドなど)が若い頃または年老いた頃の自分自身と出会う一連の画像を制作した。その効果はリアルで興味深い。(出典: Reddit r/ChatGPT)
AIが生成したアメリカ再工業化に関する「奇妙な」ビデオ: ユーザーが、中国のAIによって生成されたとされる「アメリカ再工業化」に関するビデオを共有した。ビデオの内容とサウンドトラックのスタイルは「ワイルド」でユーモラス/皮肉な意味合いを持つと見なされ、AIが特定の物語コンテンツを生成する能力と潜在的なバイアスを示している。(出典: Reddit r/ChatGPT

ユーザー、Claudeとo1-proのコストと効果を比較: あるユーザーが、OpenAI o1-proとAnthropic Claude Sonnet 3.7を使用してTailwind CSSカードのスタイルを改善した経験を共有した。結果として、Claudeの出力効果の方が優れており、コストもo1-proよりはるかに低かった(1ドル未満 vs 6ドル近く)。(出典: Reddit r/ClaudeAI)
Claudeサービスの安定性がユーザーから揶揄される: ユーザーがミームやコメントを投稿し、Anthropic Claudeサービスが平日のピーク時に頻繁に「予期せぬ高需要」により過負荷になったりアクセス不能になったりする状況を揶揄し、その安定性の改善が必要であることを示唆している。(出典: Reddit r/ClaudeAI)

数学博士課程学生、機械学習入門リソースを求める: 数学博士課程を開始する予定の学生で、研究テーマが線形代数ツールを機械学習(特にPINNs)に応用することに関わるため、数学的背景に適した、厳密かつ簡潔なML入門リソース(書籍、講義ノート、ビデオ講義)を探している。標準的な教科書(Bishop、Goodfellowなど)は冗長すぎると考えている。(出典: Reddit r/MachineLearning)

学生、異なるハードウェアでの小型モデル性能差をテスト: ある学生が、RTX 2060デスクトップGPUとRaspberry Pi 5でLlama3.2 1BやGranite3.1 MoEなどの小型モデルの性能データをテストした結果を共有した。Llama3.2はデスクトップ環境で最も良いパフォーマンスを示したが、Raspberry Piでは次点となり、これに困惑している。同時に、MoEモデルの結果の変動が大きいことを観察し、その理由を尋ねている。(出典: Reddit r/MachineLearning)
ユーザー、OpenWebUIで検索モデルとタイトル生成モデルを分離する方法を求める: OpenWebUIユーザーが、検索リクエスト生成に使用するモデル(推論能力の高いモデルを使用する傾向がある)と、タイトル/タグ生成に使用するモデル(より経済的な小型モデルを使用する傾向がある)を別々に設定できるかどうか質問している。(出典: Reddit r/OpenWebUI)
ユーザー、Suno AI音楽プロンプトブックを求める: 以前流布していたSuno AI音楽プロンプトブック(PDF)をまだ持っている人がいるか、元のリンクが無効になっているため尋ねている。(出典: Reddit r/SunoAI)

ユーザー、OpenWebUIとLM Studioの統合に関する助けを求める: ユーザーがOpenWebUIをLM Studioとバックエンドとして接続しようとしているが(OpenAI互換API経由)、ウェブ検索とembedding機能の設定で問題に遭遇し、コミュニティの助けを求めている。(出典: Reddit r/OpenWebUI)
ユーザー、AI生成音楽作品を共有: 複数のユーザーがr/SunoAIで、Suno AIを使用して作成した音楽作品を共有している。Ambient、Musical、Alternative Psychedelic Rock、Folk Country、Comedy ballad (EDM)、Rap、Folk Music、Dreamy indie popなど、多様なスタイルをカバーしている。(出典: Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI)

ユーザー、Sunoサブスクリプションの価値を問う: 最近のSuno v4の品質に関する不満を考慮し、ユーザーは現在Sunoサブスクリプションを購入することが依然として価値があるか、特に古いv3バージョンの曲をリマスターするために尋ねている。(出典: Reddit r/SunoAI)
ユーザー、Suno音楽アルバム制作のアドバイスを求める: 経験豊富なSunoユーザーが、満足のいく作品をアルバムにまとめ、DistroKidなどのプラットフォームを通じてSpotifyで公開する計画を立てており、曲の選択、順序付け、技術的な操作に関するアドバイスをコミュニティに求めている。(出典: Reddit r/SunoAI)
ユーザー、iPadでのSuno UI問題を訴える: 新規サブスクリプションユーザーが、iPadでSunoウェブサイトを使用する際にインターフェースの問題に遭遇し、録音、歌詞編集、ドラッグ&ドロップなどの機能が正常に使用できないと報告し、解決策やアドバイスを求めている。(出典: Reddit r/SunoAI)
ユーザー、Cursor AIが密かにモデルをダウングレードした可能性を指摘: ユーザーは、Cursor AIが告知なしに使用モデルを主張していたClaude 3.7から3.5にダウングレードしたのではないかと疑っている。根拠は、Agentの挙動が変化し、モデル情報を明かすことを拒否したことである。ユーザーは、r/cursorに投稿した疑義の投稿が削除されたと主張している。(出典: Reddit r/ClaudeAI)
ユーザー、よく利用する有料AIサービスについて質問: ユーザーが、皆が毎月どの有料AIサービスに登録しているかについて議論を開始し、どのツールが価格に見合う価値があると見なされているか、また推奨すべきサービスがあるかを知りたいと考えている。(出典: Reddit r/artificial)
深層学習ヘルプ:混合信号の識別: 初心者が、混合した科学的測定信号パターンを深層学習で識別する方法について助けを求めている。データはtxt/Excel形式の座標点である。問題点には、画像形式の補足データをどのように統合するか?モデルは座標点で表現された混合パターンを処理できるか?どのモデルや学習方向が推奨されるか?などが含まれる。(出典: Reddit r/deeplearning)
ミーム/ユーモア: コミュニティには、AIに関連する複数のミームやユーモラスな投稿が登場している。例えば、AIとの恋愛(映画『Her』)、Gemma 3モデルへの嗜好、AIノートテイカー市場の飽和、Claudeサービスのダウンタイム、AI生成の著名人トレーディングカードなど。(出典: Reddit r/ChatGPT, Reddit r/LocalLLaMA, Reddit r/ClaudeAI, AravSrinivas, Reddit r/artificial)

💡 その他
Protocol Buffers (Protobuf) が引き続き注目を集める: Googleが開発したデータ交換フォーマットProtobufは、GitHubで高い注目度を維持している。言語中立、プラットフォーム中立な拡張可能なメカニズムとして、構造化データのシリアライズに使用され、AI/MLや多くの大規模システム(TensorFlow、gRPCなど)で広く利用されている。リポジトリは、コンパイラ(protoc)のインストール手順、多言語ランタイムライブラリへのリンク、およびBazel統合ガイドを提供している。(出典: protocolbuffers/protobuf – GitHub Trending (all/daily))
Gin Webフレームワークが人気を維持: Go言語で書かれた高性能HTTP WebフレームワークGinは、GitHubで引き続き人気を集めている。Martiniに似たAPIと最大40倍のパフォーマンス向上(httprouterのおかげ)で知られており、高性能なWebサービス(AIモデルのAPIサービスを含む可能性がある)が必要なシナリオに適している。(出典: gin-gonic/gin – GitHub Trending (all/daily))
Hugging Face Hub、新バックエンドXetを採用し効率向上: Hugging Face Hubは、従来のGitバックエンドに代わり、新しいストレージバックエンドXetの使用を開始した。Xetはコンテンツ定義チャンキング(CDC)技術を利用し、ファイルレベルではなくバイトレベル(約64KBブロック)でデータ重複排除を行う。これは、大規模ファイル(Parquetなど)を変更する際に、変化した行レベルの差分のみを転送・保存すればよいため、アップロード/ダウンロード効率とストレージ効率が大幅に向上することを意味する。Llama-4モデルのリリースはこのバックエンドのテストに成功した。(出典: huggingface)
Hugging Face Hub、まもなくMCPクライアントをサポート: Hugging Faceの開発者がPull Requestを提出し、huggingface_hubライブラリのInferenceクライアントにモデルコンテキストプロトコル(MCP)のサポートを追加する計画である。これは、Hugging Face推論サービスがMCP標準に従うツールやAgentとより良く対話できるようになることを意味する可能性がある。(出典: huggingface)
Ziplineドローン配送システム: Zipline社のドローン配送システムを紹介している。このシステムは、経路計画、障害物回避、精密投下にAIを利用している可能性があり、物流やサプライチェーン分野、特に医療物資輸送などで潜在能力を示している。(出典: Ronald_vanLoon)
ergoCubロボット、物理的な人間とロボットの相互作用に利用: イタリア技術研究所(IIT)は、物理的な人間とロボットの相互作用研究用に設計されたergoCubロボットを展示した。この種のロボットは通常、知覚、運動制御、安全な相互作用能力を実現するために高度なAIアルゴリズムを必要とする。(出典: Ronald_vanLoon)
KeyForge3D:コンピュータビジョンで合鍵を作成: KeyForge3DというGitHubプロジェクトは、OpenCV(コンピュータビジョンライブラリ)を利用して鍵の形状を認識し、鍵の歯のコード(bitting code)を計算し、3Dプリント用のSTLモデルをエクスポートできる。主に従来のCV技術を使用しているが、物理世界の複製タスクにおける画像認識の応用可能性を示しており、将来的にはAIと組み合わせて認識精度と適応性をさらに向上させる可能性がある。(出典: karminski3)

責任あるAI (Responsible AI) 原則が注目される: 投稿では、アーンスト・アンド・ヤング(EY)などの機関が使用する責任あるAI原則に言及し、AIシステムの開発と展開において、公平性、透明性、説明可能性、プライバシー、セキュリティ、説明責任などの倫理的および社会的要因を考慮する必要性を強調している。(出典: Ronald_vanLoon)
川崎重工、水素動力の騎乗型ロボット「馬」を展示: 川崎重工は、Corleoと名付けられた四足歩行ロボットを展示した。これは騎乗可能に設計されており、動力源として水素燃料を採用している。ロボットではあるが、報道ではその制御や対話システムにおけるAIの具体的な応用度については明確に言及されていない。(出典: Reddit r/ArtificialInteligence)
