
キーワード:OpenAI, 推論LLM, 国際数学オリンピック, AI訓練データセット, 個人データプライバシー, ChatGPTエージェント, AIモデルの政治的中立性, Kimi K2, IMO金メダルレベル成績, DataComp CommonPoolデータセット, LLMエージェント知能, ホワイトハウスAI行政命令, MoEアーキテクチャ
🔥 注目
OpenAIの実験的推論LLMが国際数学オリンピックで金メダルを獲得: OpenAIの最新のExperiment Reasoning LLMは、2025年国際数学オリンピック(IMO)で金メダルレベルの成績を収め、6問中5問を解きました。このモデルは、人間と同じルール(4.5時間ごとの制限を含む)で実行され、ツールを使用せず、自然言語で証明プロセスを出力しました。これは、AIによる数学的推論における大きなブレークスルーであり、科学的発見におけるAIの潜在力を示唆しています。(出典: gdb, scaling01, dmdohan, SebastienBubeck, markchen90, npew, MillionInt, cloneofsimo, bookwormengr, tokenbender)

AI訓練データセットCommonPoolに数百万件の個人データが含まれる: 研究により、大規模なオープンソースAI訓練データセットDataComp CommonPoolに、数百万枚のパスポート、クレジットカード、出生証明書、その他の個人を特定できる情報を含む文書画像が含まれていることが明らかになりました。研究者たちはCommonPoolの0.1%のデータを監査し、数千枚の個人を特定できる画像を発見し、データセット全体では数億枚に上ると推定しています。これは、AI訓練データのプライバシー保護に関する懸念を引き起こし、機械学習コミュニティに無差別のWebスクレイピング行為を再考するよう求めています。(出典: MIT Technology Review)

🎯 動向
OpenAIがパーソナルアシスタントChatGPT Agentをリリース: OpenAIは、ユーザーの代わりにタスクを実行するために独自の「仮想コンピュータ」を構築できるパーソナルアシスタントChatGPT Agentをリリースしました。これは、LLMエージェントのインテリジェンスにおける重要な一歩ですが、この機能はまだ初期段階にあり、タスクの完了には時間がかかる場合があります。(出典: MIT Technology Review, The Verge, Wired)
ホワイトハウスが「政治的に中立で偏見のない」AIモデルを求める大統領令を準備: ホワイトハウスは、「政治的に中立で偏見のない」AIモデルを求める大統領令を準備しています。コンプライアンスは連邦政府との契約資格を決定するため、すべてのAIラボにとって大きな問題です。この大統領令は来週発表される予定です。(出典: WSJ, MIT Technology Review, natolambert)

Kimi K2:ツール使用能力を持つエージェントインテリジェンスモデル: Kimi_MoonshotによってリリースされたKimi K2は、ツール使用能力を持つエージェントインテリジェンスモデルです。ツール使用、数学、コーディング、複数ステップのタスクにおいて優れたパフォーマンスを発揮し、現在Arenaでオープンソースモデルとして1位、総合5位にランクインしています。Kimi K2はDeepSeek-V3に類似した大規模Expert Mixture (MoE)アーキテクチャを採用し、総パラメータ数1兆、アクティブパラメータ数320億を誇ります。(出典: TheTuringPost)

🧰 ツール
GitHub MCPサーバーがAIツールとGitHubプラットフォームを接続: GitHub MCPサーバーにより、AIツールはGitHubプラットフォームに直接接続できるようになり、AIエージェント、アシスタント、チャットボットは、リポジトリやコードファイルの読み取り、IssueやPRの管理、コードの分析、ワークフローの自動化などを、すべて自然言語インタラクションを通じて行うことができます。(出典: GitHub Trending)
ik_llama.cpp:CPUパフォーマンスが向上したllama.cppのブランチ: ik_llama.cppは、CPUとGPU/CPU混合のパフォーマンスが向上したllama.cppのブランチで、新しいSOTA量子化タイプ、Bitnetのサポート、MLA、FlashMLA、融合MoE操作、テンソルカバレッジによるDeepSeekパフォーマンスの向上、GPU/CPU混合推論のための行インターリーブ量子化パッキングなどを備えています。(出典: GitHub Trending)
📚 学習
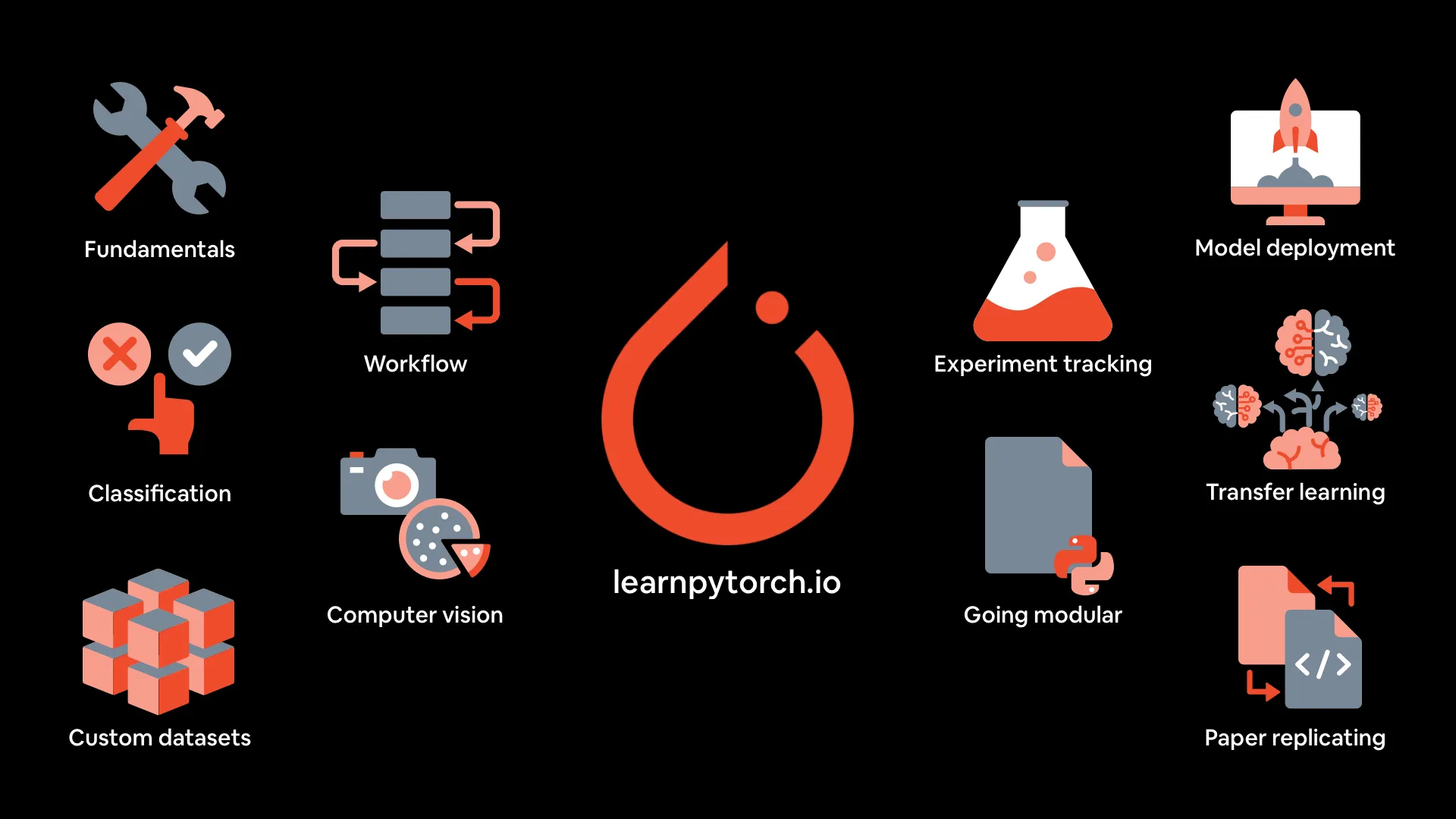
PyTorch深層学習コース資料: mrdbourke/pytorch-deep-learningは、「ゼロから学ぶPyTorch深層学習」コースの資料を提供しており、オンライン書籍版、YouTubeの最初の5つのパートのビデオ、演習、追加のコースが含まれています。このコースは、コードの実践と実験に重点を置いており、PyTorchの基礎、ワークフロー、ニューラルネットワーク分類、コンピュータビジョン、カスタムデータセット、転移学習、実験トラッキング、モデルデプロイメントなどをカバーしています。(出典: GitHub Trending)
MIT出版社がアルゴリズムと機械学習に関する3冊の書籍を無料で提供: MIT出版社は、アルゴリズム理論と主要な機械学習アルゴリズムに関する3冊の書籍、『The Algorithm Design Manual』、『Algorithms for Decision Making』、および『Algorithms for Verification』を無料で提供しています。これらの書籍は、アルゴリズムと機械学習を深く学ぶのに最適です。(出典: TheTuringPost, TheTuringPost)

エネルギーベースのTransformerはスケーラブルな学習者であり思考者である: ある論文では、エネルギーベースのTransformer (EBT) について考察しています。これは、入力と候補予測の間の互換性を明示的に検証することを学習し、この検証器に関する最適化として予測問題を再定義することにより、教師なし学習のみから「思考」することを学習できる、新しいタイプのエネルギーベースモデル (EBM) です。(出典: )

🌟 コミュニティ
LLMのコンテキストエンジニアリングに関する教訓: ManusAIチームは、AIエージェントのコンテキストエンジニアリング構築における教訓を共有し、KVキャッシュ、ファイルシステム、エラートラッキングなどがエージェント設計において重要であると指摘しました。(出典: dotey, AymericRoucher, vllm_project)
Kimi K2とGeminiの実際のパフォーマンス比較: ClementDelangueとjeremyphowardは、pashのツイートを転送し、実際のタスクではKimi K2のパフォーマンスがGeminiよりも優れていると指摘し、関連するグラフデータを提供しました。(出典: ClementDelangue, jeremyphoward)
OpenAIのIMO金メダル獲得は予想外: OpenAIのLLMがIMOで金メダルを獲得したことは、多くの人にとって予想外であり、コミュニティで幅広い議論を引き起こしました。(出典: kylebrussell, VictorTaelin)
💼 ビジネス
AnthropicがClaude Codeの使用量を制限: AnthropicはClaude Codeの使用量を制限しましたが、ユーザーに通知しなかったため、ユーザーの不満とクローズドプロダクトへの懸念を引き起こしました。(出典: jeremyphoward, HamelHusain)
Metaが欧州AI協定への署名を拒否: Metaは、AI開発を阻害する過剰な介入であるとして、欧州AI協定への署名を拒否しました。(出典: Reddit r/artificial, Reddit r/ArtificialInteligence)
💡 その他
ノートパソコンでLLMを実行する方法: MIT Technology Reviewは、ノートパソコンでLLMを実行する方法についてのガイドを公開し、プライバシーに関心があり、大規模LLM企業の支配から逃れたい、あるいは新しいことを試してみたいユーザーのために、LLMをローカルで実行するための手順とアドバイスを提供しました。(出典: MIT Technology Review, MIT Technology Review)
「3人の親を持つ赤ちゃん」の簡単な歴史: MIT Technology Reviewは、「3人の親を持つ赤ちゃん」の歴史を振り返り、この技術のさまざまな方法、論争、最新の研究の進展を紹介しました。これには、英国での試験で生まれた8人の赤ちゃんが含まれます。(出典: MIT Technology Review, MIT Technology Review)
初日からAIエージェントから価値を見出す方法: この記事では、企業がAIエージェントから価値を見出す方法について考察し、「すぐに達成できる成果」と段階的なユースケースから始め、相互運用性を優先して将来のマルチエージェントシステムに備えることを推奨しています。(出典: MIT Technology Review)