
キーワード:AIエージェント, Microsoft Build 2025, AlphaEvolve, GPT-4, Azure AI Foundry, NVIDIA Computex 2025, AIプログラミングツール, エンボディドAI, GitHub Copilot VSCode拡張機能, モデルコンテキストプロトコル(MCP), 自然言語ネットワーク(NLWeb), Meituan NoCode, Tencent QBotインテリジェントアシスタント
🔥 フォーカス
Microsoft Build 2025、「インテリジェントエージェントネットワーク」時代を開き、AIネイティブ開発を全面的に推進: MicrosoftはBuild 2025開発者会議で、「オープンエージェントウェブ」(Open Agentic Web)ビジョンを発表し、50以上のアップデートを公開しました。主な内容には、GitHub CopilotのVSCode拡張機能のオープンソース化、モデルコンテキストプロトコル(MCP)と自然言語ネットワーク(NLWeb)オープンスタンダードの発表、xAIのGrokなど1900以上のモデルをAzure AI Foundryに導入することが含まれます。これらの取り組みは、モデルからインテリジェントエージェントまでの開発プロセスを統合し、AI Agentのクロスシナリオでの自律的運用と相互運用性を実現することを目的としています。MicrosoftのCEOサティア・ナデラ氏は、AI Agentが問題解決の方法を再構築すると強調し、OpenAIのCEOサム・アルトマン氏、NVIDIAのCEOジェンスン・フアン氏、xAIの創設者イーロン・マスク氏と共に、AIエージェントのソフトウェア開発、インフラストラクチャ、物理世界への応用における未来について議論しました。(ソース: 36Kr | GitHub Blog | VS Code Blog | The Verge)
Google DeepMindがAlphaEvolveを発表、AIエージェントが56年来の行列乗算効率記録を破る: Google DeepMindは、Geminiを搭載したコーディングエージェントAlphaEvolveを発表しました。これは進化アルゴリズムと自動評価システムを通じて、56年間使用されてきたStrassenアルゴリズムよりも効率的な4×4複素行列乗算アルゴリズムを発見することに成功し、必要なスカラー乗算の回数を49回から48回に削減しました。このブレークスルーは数学理論上重要なだけでなく、Google内部のアプリケーションで既に価値を示しており、例えばGeminiアーキテクチャにおける大規模行列乗算演算を23%高速化し、Geminiのトレーニング時間を1%短縮し、FlashAttentionのパフォーマンスを32.5%向上させました。AlphaEvolveは、数学の難問からデータセンターのリソーススケジューリング、AIモデルのトレーニング高速化まで、さまざまな複雑な問題を処理できる、自動科学発見とアルゴリズム最適化におけるAIの巨大な可能性を示しています。(ソース: Google DeepMind Blog | 量子位)
研究によりGPT-4はパーソナライズされた討論で人間より64%高い説得力を示す: 『Nature Human Behaviour』に掲載された研究によると、OpenAIのGPT-4が討論相手の性別、年齢、学歴などの個人情報を取得し、それに基づいて議論を調整できる場合、その説得力は人間よりも64%高くなることが示されました。ローザンヌ連邦工科大学などの機関が協力したこの研究には900人の参加者が関与し、大規模言語モデル(LLM)の説得における強力な能力をさらに裏付けました。研究者らは、AIツールが少量のユーザー情報を把握するだけで、複雑で説得力のある議論を構築できることを明らかにし、パーソナライズされた偽情報拡散に対する潜在的な脅威となると警告しています。政策立案者やプラットフォームに対し、このリスクを重視し、LLMを利用してパーソナライズされたカウンターナラティブコンテンツを生成し、偽情報に対抗することを模索するよう呼びかけています。(ソース: Nature Human Behaviour | MIT Technology Review)
MicrosoftとHugging Faceが提携を深化、Azure AI Foundryに1万以上のオープンソースモデルを統合: Microsoft Build会議で、MicrosoftはHugging Faceとの提携拡大を発表し、Azure AI Foundryは現在、テキスト、音声、画像など多様なモダリティとタスクをカバーする10,000以上のHugging Faceオープンソースモデルを統合しました。この動きは、AzureユーザーがAIアプリケーションやインテリジェントエージェントを構築するために、多様なオープンソースモデルをより便利かつ安全にデプロイできるようにすることを目的としています。統合されたすべてのモデルはセキュリティテストに合格し、safetensors形式を使用しており、リモートコードを含まないため、エンタープライズレベルのアプリケーションの安全性が保証されます。両社は将来、最新かつ人気のモデルを引き続き導入し、より多くのモダリティ(ビデオ、3Dなど)をサポートし、AIエージェントとツールの最適化を強化する計画です。(ソース: HuggingFace Blog)
🎯 動向
NVIDIA、Computex 2025で多数のAI新製品を発表、AIファクトリーへの転換を加速: CEOのジェンスン・フアン氏はComputex 2025で、GeForce RTX 5060 GPU、Grace Blackwell GB300スーパーコンピューティングプラットフォーム、パーソナルAIスーパーコンピュータDGX Spark(GB10搭載、数週間以内に発売予定)、およびDGX Station(784GBメモリ、DeepSeek R1実行可能)を発表しました。フアン氏は、NVIDIAがGPUサプライヤーからグローバルなAIインフラストラクチャプロバイダーへと転換しており、「すぐに使える」AIファクトリーの構築を目指していると強調しました。同時に、NVIDIAはDeepMindおよびディズニーと共同開発した物理エンジンNewtonを7月にオープンソース化し、Isaac GR00T人型ロボット基盤モデルを発表して、物理AIの発展を推進します。NVIDIAはまた、台湾に新オフィスを開設することも発表し、中国のAI人材の重要性を強調しました。(ソース: 36Kr | 36Kr)
Microsoft、EUユーザーにiPhoneなどのデフォルト音声アシスタント変更を許可する計画: Bloombergによると、AppleはEUユーザーに対し、iPhone、iPad、Macなどのデバイスでデフォルトの音声アシスタントをSiriからGoogle AssistantやAmazon Alexaなどの他のオプションに変更することを許可する計画です。この動きは、EUのデジタル市場法(DMA)による独占禁止圧力に対応するためである可能性があります。Siriは近年、機能の遅れや知能化の不足で批判されており、Apple内部ではSiriの発展方向について意見の対立があり、既存のアーキテクチャでは大規模言語モデル(LLM)との効果的な統合が困難です。AppleはLLMベースの新しいSiriを開発中で、Apple Intelligenceも発表しましたが、ユーザーにデフォルトアシスタントの変更を許可することは、そのエコシステムに影響を与える可能性があります。(ソース: 36Kr)
Apple、自社開発AIチャットボットを内部テスト中、能力はChatGPTに匹敵する可能性: Bloombergの記者Mark Gurman氏によると、Appleは自社開発のAIチャットボットプロジェクトを内部でテストしており、新しいAI責任者John Giannandrea氏のリーダーシップの下、このプロジェクトは過去6ヶ月で著しい進展を遂げ、一部の幹部は現在のバージョンの能力がChatGPTの最新版に近いと考えています。このチャットボットは、リアルタイムのウェブ検索と情報統合能力を備える可能性があります。この動きは、OpenAIなどの外部サービスへの依存を減らし、Siriの競争力を高めることを目的としている可能性があります。WWDC 2025ではSiriのアップグレードが重点的に紹介されないかもしれませんが、AppleはAI時代に音声アシスタントを再活性化するため、AIへの投資を継続的に拡大しています。(ソース: 36Kr)
Windowsがモデルコンテキストプロトコル(MCP)をネイティブサポートへ: MicrosoftはBuild 2025カンファレンスで、Windowsオペレーティングシステムがモデルコンテキストプロトコル(MCP)をネイティブサポートすると発表しました。これは、Windows上でのAIアプリケーションの開発とデプロイを簡素化することを目的としています。MCPは「AIアプリケーションのUSB-C」に例えられ、異なるAIモデルとアプリケーションに標準化されたインタラクション方法を提供しようとしています。Windows AI Foundryプラットフォームはこのサポートを統合し、開発者がWindowsデバイス上でローカルAIモデルやエージェントをより簡単に実行・管理できるようにします。(ソース: op7418 | Reddit r/LocalLLaMA)
Microsoft Azure AI FoundryにxAIのGrok大規模モデルを導入: MicrosoftはBuild 2025開発者会議で、イーロン・マスク氏のxAI社のGrok 3およびGrok 3 mini大規模モデルがAzure AI Foundryプラットフォームに参加すると発表しました。Azureユーザーは、クラウドプラットフォームを通じてこれらのモデルを直接使用し、料金を支払うことができるようになります。これにより、Azureで利用可能なAIモデルの数(既に1900種類以上)がさらに拡大し、これには既にOpenAI、Meta、DeepSeekなどが含まれています。マスク氏はビデオ会議を通じて、開発者からのフィードバックを期待しており、将来的にはより多くの企業にGrokサービスを提供したいと述べました。(ソース: 36Kr)
Percy LiangチームがMarinプロジェクトを発足、オープンなAIモデル開発を推進: スタンフォード大学のPercy Liang教授が主導し、Marinプロジェクトを発足させました。これは「徹底的な参加型アプローチ」でオープンモデルを構築することを目的としています。このプロジェクトはオープンな開発プロセスを強調し、誰でも貢献できるようにしています。最初のMarinモデル群がリリースされ、そのうち8BモデルはTogether AIプラットフォームでテスト用に公開されています。この取り組みは、重み、コード、データだけでなく、研究開発エコシステム全体をオープンにするという、AI分野におけるより深いレベルのオープン性への呼びかけに応えるものです。(ソース: vipulved)

Intel、プロフェッショナル向けグラフィックスカードArc Pro B60を発表、KTransformersがIntel GPUサポートを表明: Intelは新しいプロフェッショナル向けグラフィックスカードArc Pro B60を発表しました。24GBのVRAMと456GB/sのメモリ帯域幅を備え、1枚あたり約500ドルで、AIコンピューティングに新たなハードウェアの選択肢を提供します。同時に、KTransformersフレームワークはIntel GPUのサポートを発表し、Xeon 5 + DDR5 + Arc A770プラットフォームでDeepSeek-R1 Q4量子化モデルを実行した場合、約7.5 token/sに達することがテストで示され、ローカルでの大規模モデル実行にさらなるハードウェアの可能性を提供します。(ソース: karminski3 | karminski3)

DeepMindがGoogle I/Oカンファレンスを予告: Google DeepMindの公式アカウントは、5月20日(太平洋時間午前10時)に開催されるGoogle I/Oカンファレンスを予告し、Xプラットフォームでライブ配信を行うと発表しました。このカンファレンスでは、AI関連の一連の重要なアップデートや製品が発表され、GoogleのAI分野における強力な勢いが継続されると予想されます。(ソース: GoogleDeepMind)
🧰 ツール
AgenticSeek:純粋なローカル実行AIエージェント、Manus AIに対抗: AgenticSeekは、完全にローカルで実行されるAIアシスタントを提供することを目的としたオープンソースプロジェクトです。ウェブの自律的な閲覧、コードの記述、タスクの計画能力を備え、すべてのデータはユーザーのデバイスに保持されるため、プライバシーが確保されます。このツールはローカル推論モデル用に設計されており、音声対話をサポートし、AIエージェントの使用コスト(電力消費のみ)とデータ漏洩リスクの低減に取り組んでいます。(ソース: GitHub Trending)
美団(Meituan)、AIプログラミングツールNoCodeを内部テスト、Vibe Codingとして位置づけ: 36Krの独占報道によると、美団は近くAIプログラミングツール「NoCode」をリリースする予定で、ドメインnocode.cnは既に登録され、グレースケールテストに入っています。この製品は美団の研究開発品質・効率チームによって開発され、Lovableのような「雰囲気プログラミング」として位置づけられ、非技術者向けです。対話形式のインタラクションを通じて、データ分析、製品プロトタイプ、運用ツール生成などのコーディングおよびデプロイタスクを自動的に完了します。NoCodeはCode Agentアーキテクチャを採用し、複数ステップの論理的推論が可能で、将来的には事業者や一般ユーザーに開放し、中小事業者のIT化のハードルを下げる計画です。(ソース: 36Kr)
テンセントQQブラウザがAIブラウザにアップグレード、QBotインテリジェントアシスタントを統合: QQブラウザはAIブラウザへのアップグレードを発表し、QBotという名のAIアシスタントを導入しました。このアシスタントはテンセントのHunyuanおよびDeepSeekのデュアルモデルに基づいています。QBotはAI検索、AIブラウジング、AIオフィス、AI学習、AIライティングなどの機能を統合し、ManusのようなAI Agent機能を導入して複雑なタスクを実行できます。最初のグレースケールテストのAgentには「AI高考通」が含まれており、ユーザーにパーソナライズされた大学入試志願プランを生成できます。QQブラウザのユーザー規模は4億人を超えており、今回のアップグレードはAIを通じてユーザーの情報取得とタスク処理の効率を向上させることを目的としています。(ソース: 36Kr)
OpenAI CodexがChatGPT iOS版に登場、モバイルでのプログラミングタスクをサポート: OpenAIは、プログラミングアシスタントCodexがChatGPTのiOSアプリに統合されたことを発表しました。ユーザーは携帯電話で直接新しいコーディングタスクを開始したり、コードの差分を確認したり、修正を要求したり、さらにはPRをプッシュしたりすることができます。この機能はロック画面でのリアルタイムアクティビティ追跡もサポートしており、ユーザーはいつでもCodexの作業進捗を把握し、コンピュータに戻る前に未完了のタスクを続けることができます。これは、AIプログラミングがモバイルおよびマルチシナリオコラボレーションに向けて重要な一歩を踏み出したことを示しています。(ソース: karinanguyen_ | gdb)
NotebookLMモバイルアプリがリリース、AndroidとiOSをサポート: GoogleのAIノートツールNotebookLMが正式にモバイルアプリをリリースし、AndroidとiOSプラットフォームで順次提供開始されています。モバイル版では、音声概要、対話などのコア機能が提供され、ユーザーがいつでもどこでもAIを利用してコンテンツ解析や学習を行うのに便利です。便利な機能の一つは、ユーザーが閲覧中のコンテンツ(公式アカウントを除く)を直接NotebookLMに転送して処理できることです。(ソース: op7418)
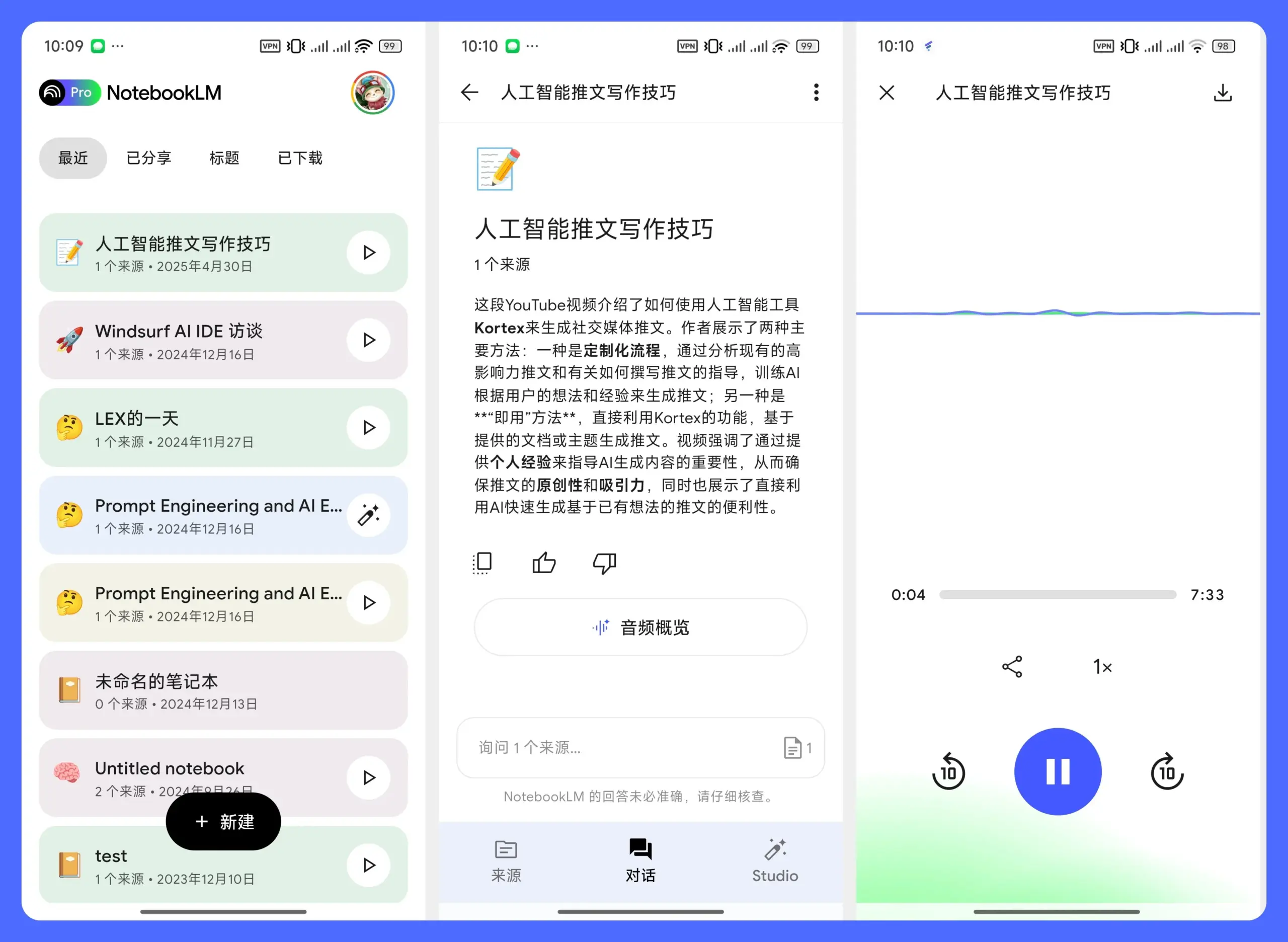
Public、AI投資ツール「Generated Assets」を発表: 投資プラットフォームPublicは新製品「Generated Assets」を発表しました。これにより、ユーザーはAIに投資アイデアを提案すると、AIはそれに基づいて投資アドバイスやカスタム投資インデックスを返し、過去のリターンを比較したり、リアルタイムでパフォーマンスを追跡したりすることができます。これは、「雰囲気投資」や「テーマ投資」のAI実現のようなもので、ユーザーがパーソナライズされた投資ポートフォリオを構築・管理するハードルを下げることを目的としています。(ソース: op7418)
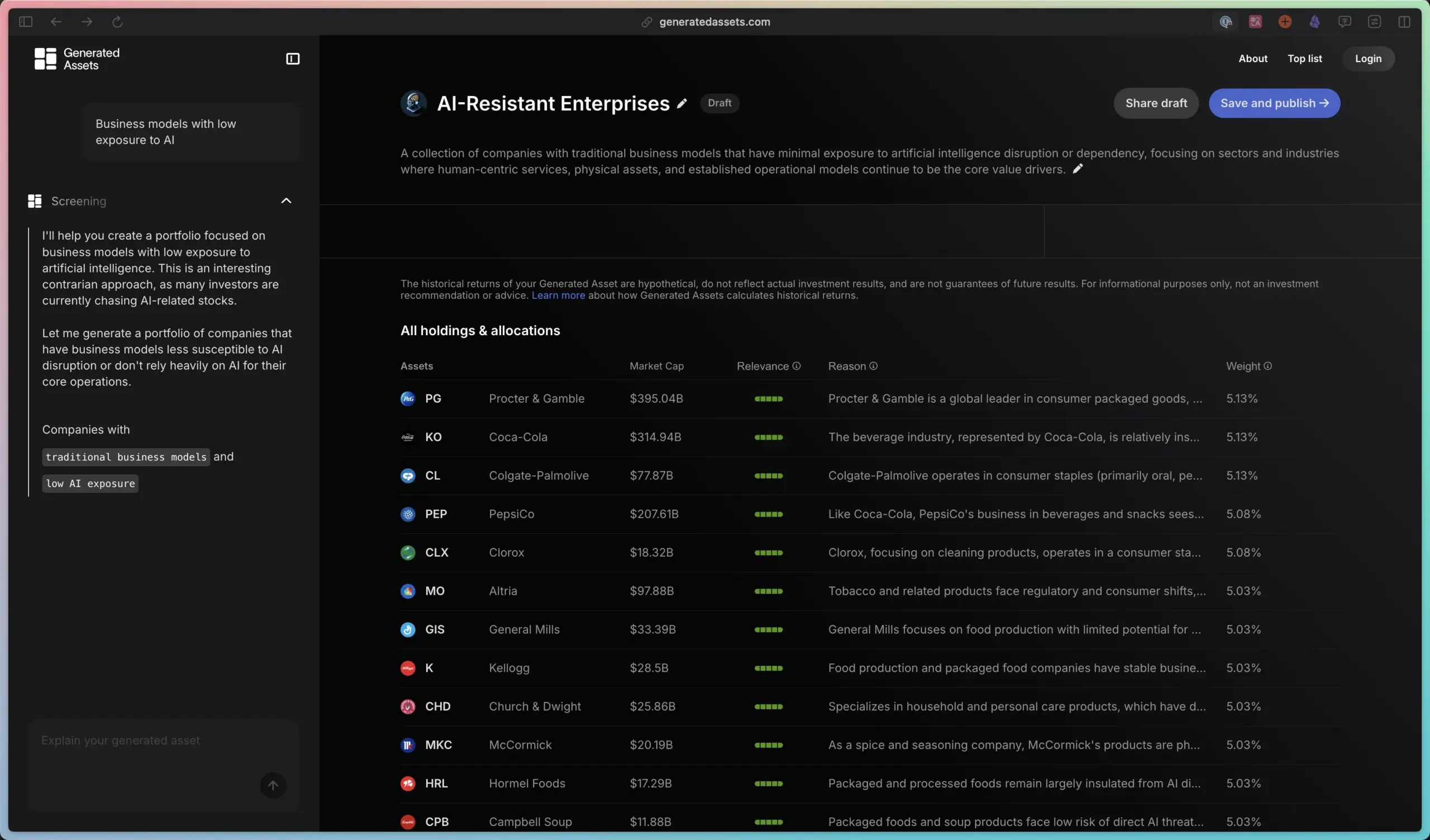
ClaraVerse:複数のAIツールを統合した「オールインワン」アプリケーション: ClaraVerseという名のAIツールスイートがコミュニティで共有されました。これはチャットインターフェース、AIコンポーネント、Ollama(ローカル大規模モデル実行)、n8n(ワークフロー/定時タスク)、AI Agentテンプレート、ComfyUI(画像生成)、そしてAIインデックス付き画像ライブラリを統合しています。ユーザーにワンストップのAI作業プラットフォームを提供し、異なるAIツールの使用と切り替えを簡素化することを目的としています。(ソース: karminski3)
QdrantベクトルデータベースがMicrosoftのNLWebプロトコルを統合: ベクトルデータベースQdrantは、MicrosoftがBuildカンファレンスで発表したNLWebオープンプロトコルの最初のパートナーの1つになったことを発表しました。NLWebは、従来の検索ボックスを自然言語ベースのセマンティックで意図を感知するインターフェースに転換することを目的としています。Qdrantとの統合により、ウェブサイトはフロントエンドやバックエンドのロジックを大幅に変更することなく、高速でフィルタリング条件付きのベクトル検索を利用して、セマンティックに関連する結果を提供できるようになります。(ソース: qdrant_engine)

📚 学習
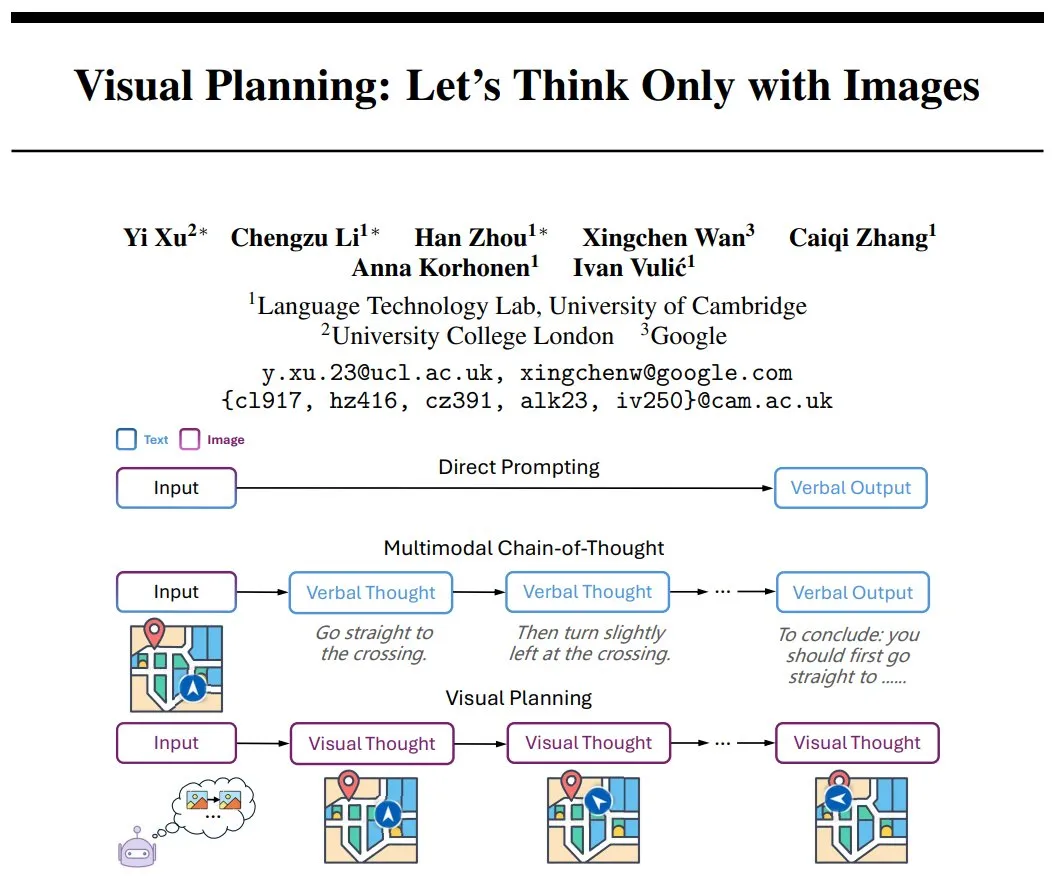
DeepMindがビジュアルプランニング(Visual Planning)を提案:純粋な画像シーケンスによる推論パラダイム: Yi Xuらの研究者は、「ビジュアルプランニング」(Visual Planning)と名付けられた新しい推論パラダイムを提案しました。これは、モデルが完全に画像シーケンスを通じて思考し計画することを目的としており、人間が頭の中で手順を構想する方法を模倣し、言語や文字による思考を必要としません。この方法は、AIが非言語的記号システムの下で複雑な推論を行う可能性を探求し、マルチモーダルAIの発展に新たな視点を提供します。(ソース: madiator)
スタンフォードなどの機関がTerminal-Benchを発表:AIエージェントのターミナルタスク能力を評価するベンチマーク: スタンフォード大学とLaudeの研究者は、AIエージェントが実世界のターミナル環境で複雑なタスクを完了する能力を評価するためのフレームワークおよびベンチマークであるTerminal-Benchを発表しました。多くのAIエージェント(Claude Code、Codex CLIなど)がターミナルとの対話を通じて価値あるタスクを実行していることを考慮し、このベンチマークはそれらの実際の有効性を定量化し、実用的なデプロイメントに向けたエージェント能力の向上を推進することを目的としています。(ソース: madiator | andersonbcdefg)

DeepSeek-V3技術解説:ソフトウェアとハードウェアの協調設計による高効率モデルの実現: DeepSeek-V3モデルは、ソフトウェアとハードウェアの協調設計により、わずか2048基のNVIDIA H800 GPUでトレーニングを完了しました。その主な革新点には、マルチヘッド潜在アテンション(MLA)、エキスパート混合(MoE)、FP8混合精度トレーニング、およびマルチプレーンネットワークトポロジーが含まれます。これらの技術が連携して、より低いコストでより優れたモデル性能を実現することを目指しており、AIモデル設計がより高いコストパフォーマンスの方向へ発展する新たなトレンドを示しています。(ソース: TheTuringPost)
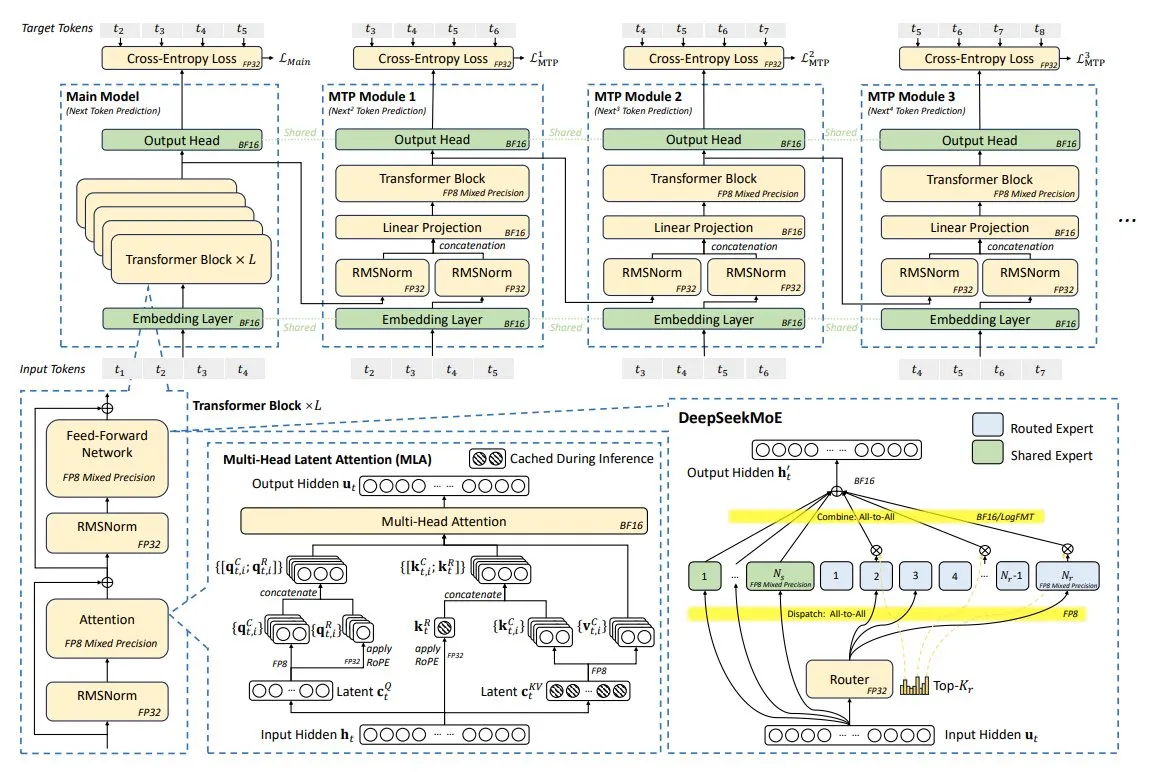
新論文、深層学習における表現楽観主義を議論:断裂した絡み合った表現仮説: Kenneth Stanleyらがポジションペーパー「深層学習における表現楽観主義への疑問:断裂した絡み合った表現仮説」を発表しました。研究は、非従来型のオープンエンド検索によって発見された、単一の画像を出力できるネットワークの表現はエレガントでモジュール化されているのに対し、SGDが同じ出力を学習したネットワークの表現は混沌として絡み合っていることを指摘しています。これは、良好な出力行動の背後に劣悪な内部表現が隠れている可能性があることを示唆しますが、同時に表現がより良くなる可能性も明らかにしており、モデルの汎化、創造性、学習能力に深遠な影響を与え、基盤モデルやLLMの改善に新たな視点を提供します。(ソース: hardmaru | togelius | bengoertzel)
RLチュートリアル更新、LLMの章(DPO、GRPO、思考の連鎖など)に重点: Sirbayes氏が強化学習(RL)チュートリアルの新バージョンをリリースしました。今回の更新は主に大規模言語モデル(LLM)の章を対象としており、DPO(Direct Preference Optimization)、GRPO(Group Relative Policy Optimization)、思考の連鎖(Thinking)などの最新コンテンツが追加されています。同時に、マルチエージェント強化学習(MARL)、モデルベース強化学習(MBRL)、オフライン強化学習、およびDPG(Deep Deterministic Policy Gradient)などの章も小幅に更新されています。(ソース: sirbayes)

ByteDance、事前学習済みモデル平均化戦略(Pre-trained Model Averaging)を提案: ByteDanceの研究チームは、大規模言語モデルの事前学習プロセスにおけるモデル統合の新しいフレームワークである事前学習済みモデル平均化(PMA)戦略を提案する論文を発表しました。研究によると、一定の学習率で訓練されたチェックポイントを統合することで、継続的な訓練と同等かそれ以上の性能を達成できるだけでなく、訓練効率も大幅に向上させることがわかりました。この研究は、大規模モデルの事前学習に新たな効率最適化のアイデアを提供し、性能と効率の向上におけるモデル統合の可能性を検証しました。(ソース: teortaxesTex)

Alibaba Tongyi Labの新研究ZeroSearch:LLMが検索エンジンを演じ、API不要で推論能力を向上: AlibabaのTongyi LabはZeroSearchフレームワークを提案しました。これはLLMに検索エンジンの振る舞いを模倣させることで、強化学習プロセス中に実際の検索エンジンAPIを呼び出す必要がなくなり、コストを削減し訓練の安定性を向上させます。この方法は、軽量なファインチューニングによってLLMが有用な結果とノイズ干渉を生成できるようにし、カリキュラムベースのノイズ耐性トレーニングを採用して、複雑な検索シナリオにおけるモデルの推論能力とノイズ耐性を段階的に向上させます。実験によると、検索モジュールとしてわずか3BパラメータのLLMを使用するだけで、検索能力を効果的に向上させることができます。(ソース: 量子位)

香港中文大学の新アルゴリズムRXTXがXXtの行列乗算計算を最適化: 香港中文大学の研究者は、行列とその転置行列の積(XXt)の計算を高速化する新アルゴリズムRXTXを提案しました。このアルゴリズムは、4×4ブロック行列の再帰的乗算に基づいており、機械学習による探索と組み合わせ最適化技術を組み合わせて発見されました。Strassen再帰に基づく既存のアルゴリズムと比較して、RXTXは漸近的な乗算定数を約5%削減し、n≥256で総演算量の優位性を示し、6144×6144行列のテストではBLASのデフォルト実装よりも9%高速でした。この研究は、データ分析、チップ設計、LLMトレーニングなどの分野に潜在的な影響を与える可能性があります。(ソース: 量子位)
論文AdaptThink:推論モデルにいつ「思考」するかを学習させる: この研究はAdaptThinkを提案しています。これは強化学習を通じて、推論モデルが問題の難易度に応じて深く思考するか(Chain-of-Thoughtなど)を適応的に選択するように教えるフレームワークです。その核心には、制約付き最適化目標(性能を維持しつつ思考を減らすことを奨励)と重要度サンプリング戦略(思考するサンプルと思考しないサンプルのバランスを取る)が含まれています。実験によると、AdaptThinkは推論コストを大幅に削減し、性能を向上させることができ、例えば数学データセットでは、DeepSeek-R1-Distill-Qwen-1.5Bの平均応答長を53%削減し、正解率を2.4%向上させました。(ソース: HuggingFace Daily Papers)
論文VisionReasoner:強化学習による視覚認識と推論の統一: VisionReasonerは、共有モデルで複数の視覚認識タスクを処理することを目的とした統一フレームワークです。多オブジェクト認知学習戦略と体系的なタスク再構築を採用し、モデルが視覚入力を分析し、構造化された推論を行う能力を強化して、検出、セグメンテーション、カウントなど10種類の異なるタスクに対応します。実験結果は、VisionReasonerがCOCO(検出)、ReasonSeg(セグメンテーション)、CountBench(カウント)などのベンチマークでQwen2.5VLなどのモデルよりも優れていることを示しています。(ソース: HuggingFace Daily Papers)
論文AdaCoT:強化学習によるパレート最適な適応的思考の連鎖トリガーの実現: 大規模言語モデル(LLM)が単純なクエリを処理する際に、思考の連鎖(CoT)がもたらす不必要な計算オーバーヘッドを解決するため、AdaCoTフレームワークが提案されました。これは強化学習(PPO)を利用して、LLMがクエリの暗黙的な複雑さに応じてCoTを呼び出すかどうかを適応的に決定できるようにし、モデルの性能とCoT呼び出しコストのバランスを取ることを目指しています。選択的損失マスキング(SLM)技術によって決定境界の崩壊を防ぎ、実験によるとAdaCoTは不必要なCoTのトリガー率を大幅に削減し(最低3.18%)、応答トークン数を削減し(69.06%削減)、同時に複雑なタスクの高い性能を維持できることが示されています。(ソース: HuggingFace Daily Papers)
論文GIE-Bench:テキスト誘導型画像編集のための実践的な評価ベンチマーク: テキスト誘導型画像編集モデルをより正確に評価するために、GIE-Benchが提案されました。このベンチマークは、機能的正しさ(自動生成された多肢選択問題を通じて編集が成功したかどうかを検証)と画像コンテンツの保持(オブジェクト認識マスキング技術と保持スコアを使用して非対象領域の一貫性を確保)の2つの側面から評価を行います。20のカテゴリをカバーする1000以上の高品質な編集例が含まれています。GPT-Image-1などのモデルの評価では、指示追従性でリードしているものの、無関係な領域の保持には改善の余地があることが示されました。(ソース: HuggingFace Daily Papers)
論文InstanceGen:インスタンスレベルの指示による画像生成: 事前学習済みのテキストから画像を生成するモデルが、複数のオブジェクトとインスタンスレベルの属性を含む複雑なプロンプトを処理する際に、セマンティクスを正確に捉えることが困難であるという問題に対し、InstanceGenは新しい技術を提案します。この技術は、画像ベースのきめ細かい構造化初期化(現代の画像生成モデルから直接提供)とLLMベースのインスタンスレベルの指示を組み合わせることで、生成された画像がオブジェクトの数、インスタンスレベルの属性、インスタンス間の空間的関係など、テキストプロンプトのすべての部分により良く従うことを可能にします。(ソース: HuggingFace Daily Papers)
💼 ビジネス
清華大学系のエンボディードAI企業「千訣科技」が数億元のPre-A+ラウンド資金調達を完了: エンボディードブレイン企業「千訣科技」は最近、新たなPre-A+ラウンドの資金調達を完了し、钧山投資、祥峰投資、石溪資本から投資を受け、累計調達額は数億元に達しました。同社は清華大学自動化系および関連AI研究機関のコアメンバーによって設立され、汎用型「エンボディードブレイン」システムの開発に注力し、マルチモーダルリアルタイム認識、継続的なタスク計画、自律実行能力を強調しています。既に家庭サービス、物流配送などのシーンで製品レベルの展開を実現し、複数の大手ロボットメーカーや家電企業と提携しています。(ソース: 36Kr)

AI AgentがSaaS市場の構造を再編する可能性: MicrosoftのCEOサティア・ナデラ氏は、SaaSアプリケーションがAI Agent時代に破壊的な変化に直面すると予測し、業界でAI AgentとSaaSの未来に関する広範な議論を引き起こしました。AI Agentは、その自律的な認識、意思決定、行動能力により、従来のSaaSが抱えるカスタマイズ、データ相互運用性、ユーザーエクスペリエンスの課題を解決する可能性があります。例えば、自然言語対話を通じて自動的にワークフローを作成したり、アプリケーション間でデータを統合したり、積極的にビジネス提案を行ったりすることができます。現在、AI AgentはエンタープライズレベルのアプリケーションにおいてLLMの能力制限、コスト、データセキュリティなどの課題に直面していますが、Salesforce、Microsoft、用友などのベンダーは既にAI AgentをSaaS製品に統合し始め、SaaSを融合または破壊する新しいモデルを模索しています。(ソース: 36Kr)
AIが報酬管理を再構築:データ分析からインテリジェントな意思決定とコミュニケーションへ: 人工知能は報酬管理を深刻に変革しており、コーン・フェリーの報告によると、AIは報酬コミュニケーション、外部ベンチマーキング、職務スキル構造の面で応用が増えています。将来的には、AIはより大規模で多様なデータ(ソーシャルプラットフォーム、第三者調査を含む)を処理することで、データ駆動型からインテリジェントな意思決定への転換を実現する可能性があります。例えば、従業員の離職リスク予測、インセンティブ効果の評価、報酬レンジの動的調整、パーソナライズされたインセンティブの実現などです。同時に、AIはデータプライバシー、アルゴリズムの「ブラックボックス」、結果の信頼性などの課題にも直面しています。効果的な報酬コミュニケーションは、デジタルインテリジェンス時代においてより重要であり、AIツールは管理者が体系的かつパーソナライズされたコミュニケーションを行うのを支援し、従業員の公平感と満足度を向上させることができます。(ソース: 36Kr)
🌟 コミュニティ
Sundar Pichai氏が「深く考える」写真を投稿、Google I/Oを予告: Google CEOのSundar Pichai氏がソーシャルメディアに自身が「深く考える」写真を投稿し、間もなく開催されるGoogle I/Oカンファレンスに対するコミュニティの広範な期待を引き起こしました。この写真は多くのAI分野のKOLによって転送・解釈され、GoogleがAI分野、特にGeminiモデルとその応用において重要な発表を行うことを示唆していると一般的に考えられています。コミュニティメンバーは、可能性のある新機能、新モデル、新戦略について様々な憶測をしています。(ソース: demishassabis | YiTayML | zacharynado | lmthang | scaling01 | brickroad7 | jack_w_rae | TheTuringPost | shaneguML | op7418)

AI Agentのプログラミング能力が話題に、Sama氏は未完プロジェクトの自動完了に期待: OpenAI CEOのSam Altman氏は、AIプログラミングエージェント(Codexなど)が80%まで進捗したが最終的に完了しなかったプロジェクトを完成させ、自動的にメンテナンスできるようになることに期待を示しています。コミュニティでは、さまざまなAIプログラミングエージェント(Codex、Jules、Claude Codeなど)の能力が比較・議論されており、タスク計画能力、仮想マシン環境(ネットワーク接続の有無など)、複雑な長期タスクにおけるパフォーマンスなどが注目されています。AI Agentがソフトウェア開発分野で大きな可能性を秘めていることは一般的に認識されていますが、各モデルの具体的な実装や効果には依然として差異があります。(ソース: sama | mathemagic1an)
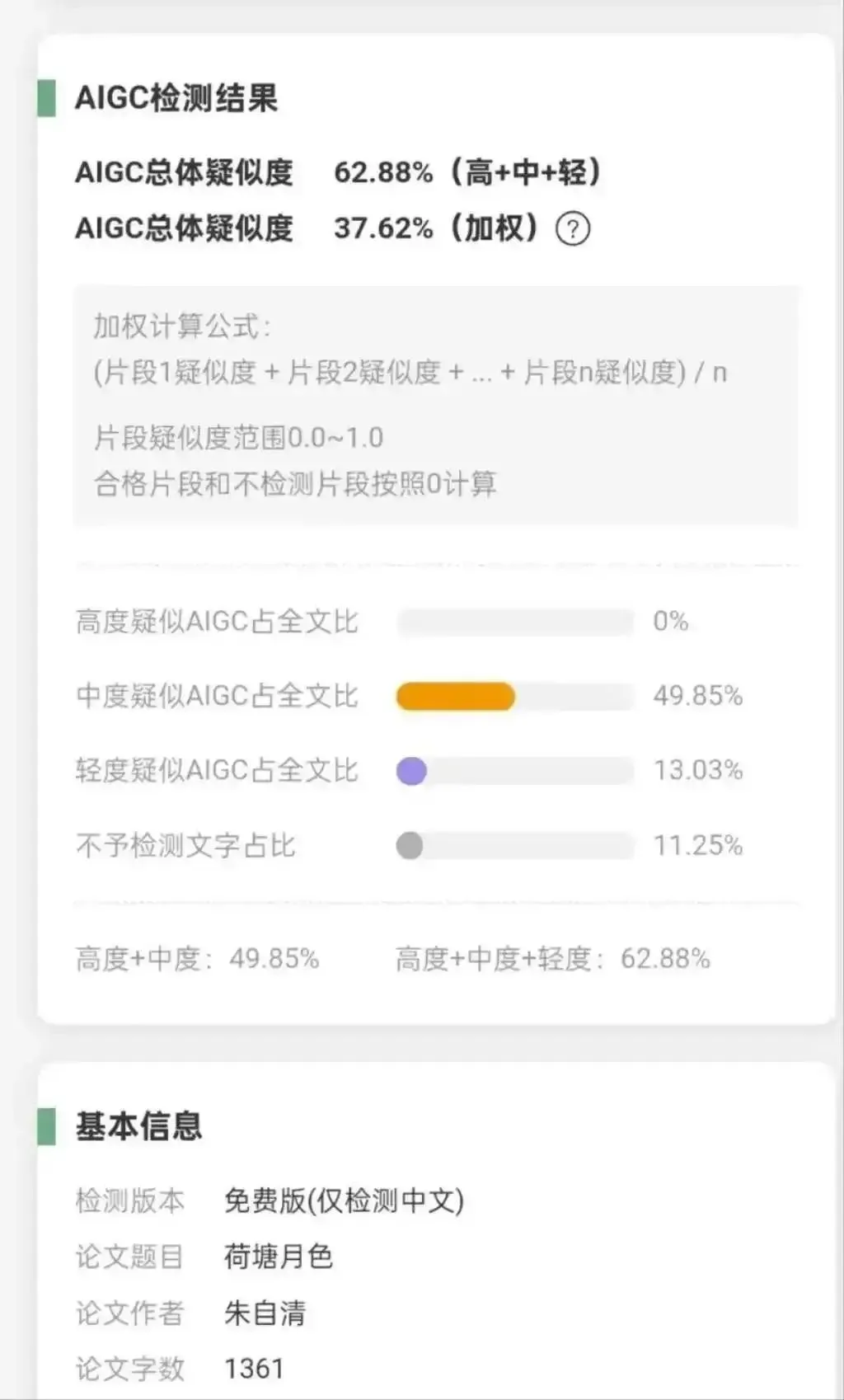
大学がAI生成コンテンツ検出を導入し論争、「滕王閣序」がAI率100%と判定: 中国国内の多くの大学が「AI生成コンテンツ検出率」を論文審査に導入したため、学生は検出を回避するために様々な方法を用い、教員はAIの判定と人間の判断の間で苦慮しています。AI検出ツールはデータベース照合とパターン化された偏見に依存するため、古典的名作(例えば「滕王閣序」のAI率は100%、朱自清の「荷塘月色」は62.88%)や規範的な学術論文をAI生成と誤判定することがよくあります。この現象は「AI率低下」のグレーな産業チェーンを生み出し、AI検出技術の限界、学術評価基準、教育の本質についての深刻な反省を引き起こしています。(ソース: 36Kr)
AI時代に育つ次世代の思考様式が議論の的に: Redditコミュニティでは、AI環境で育つ新世代の子供たちの思考様式が、これまでの世代とは著しく異なると熱心に議論されています。彼らはAIアシスタントとの対話に慣れ、学習の重点は事実の記憶から質問やシステムのナビゲーションへと移行し、試行錯誤による学習から迅速な反復へと変わる可能性があります。このような機械の論理との早期の融合は、彼らの好奇心、記憶、直感、さらには知能そのものの定義を深く再構築する可能性があり、将来の信念形成、システム構築能力、そして自身の思考への信頼度に関する考察を引き起こしています。(ソース: Reddit r/ArtificialInteligence)
AIのソフトウェア工学分野での急速な発展が開発者の職務危機感を引き起こす: 42歳、かつて年収15万ドルだったソフトウェアエンジニアが、AI関連のトレンドによって淘汰された後、800通以上の履歴書を送ったものの面接の機会はほとんどなく、現在はフードデリバリーで生計を立てています。彼の経験は、AI(GitHub Copilot、Claude、ChatGPTなど)が既にプログラマーを大規模に置き換え始めているのかどうかについての議論を引き起こしました。AnthropicのCEOはかつて、AIがコードの大部分を生成できるようになると予測していました。労働統計局のデータは依然としてソフトウェア工学が最も成長の速い職業の一つであることを示していますが、テクノロジー業界のリストラの波は続いており、企業はAIを利用してコストを削減し効率を高めています。これは、AIがもたらす構造的失業や「人間+AI」協調の新しいパラダイムの構築に社会がどのように対応すべきかを再考するよう促しています。(ソース: 36Kr)

AIアルゴリズムにおけるジェンダーバイアス問題:「彼女のデータ」の不可視性と欠如: 人工知能の発展において、アルゴリズムのジェンダーバイアス問題がますます顕著になっています。歴史的・社会的な理由から、データ収集において女性のデータの代表性が不足しており(例えば臨床試験、ウィキペディアの項目など)、AIが医療診断やコンテンツ推薦などで女性に対する偏見を生み出す可能性があります。例えば、画像認識システムがキッチンにいる男性を女性と誤認識したり、検索エンジンの画像結果が性別の固定観念を強化したりすることがあります。AI業界のジェンダー構造の不均衡も原因の一つと考えられています。この問題を解決するには、開発者の意識向上、女性の公平な職業機会の保障、法律・規制の整備、AIシステムのジェンダー監査メカニズムの確立、アルゴリズムの最適化(データのリサンプリング、因果推論の応用など)など、多方面からのアプローチが必要です。(ソース: 36Kr)
AI AgentがSaaS業界の変革議論を呼ぶ: MicrosoftのCEOサティア・ナデラ氏は、SaaSがAI Agent時代に破壊的な変化に直面すると予測しており、AI Agentはその自律的な認識、意思決定、行動能力により、SaaSのカスタマイズ、データ相互運用性、ユーザーエクスペリエンスにおける課題を解決する可能性があります。例えば、AI Agentは自然言語対話を通じて自動的にワークフローを作成し、アプリケーション間でデータを統合し、積極的にビジネス提案を行うことができます。現在、Salesforce、Microsoft、用友などのSaaSベンダーはAI Agentの統合を開始し、SaaSを融合または破壊する新しいモデルを模索しています。AI AgentはエンタープライズアプリケーションにおいてLLMの能力、コスト、データセキュリティなどの課題に依然として直面していますが、その変革の可能性は業界で広く注目されています。(ソース: finbarrtimbers)
💡 その他
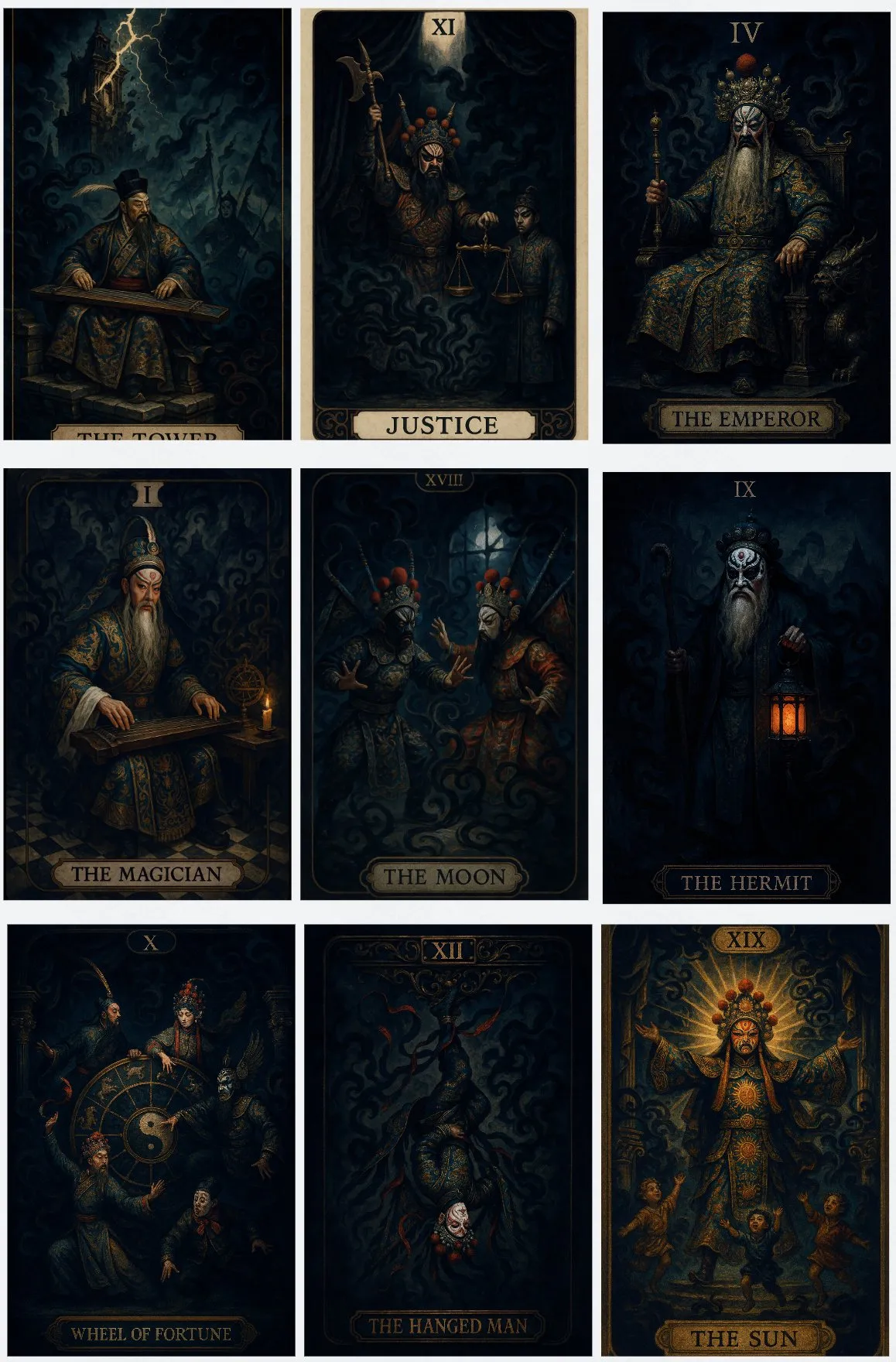
AIが生成した中国戯曲風タロットカード: ユーザー@op7418がAIツールLovartを使用して、中国戯曲風のタロットカード一式を制作しました。そのデザインコンセプトは、伝統的な戯曲の内容と対応するタロットカードが表現する寓意を結びつけるもので、AIのクリエイティブデザインと文化融合における応用可能性を示しています。(ソース: op7418)
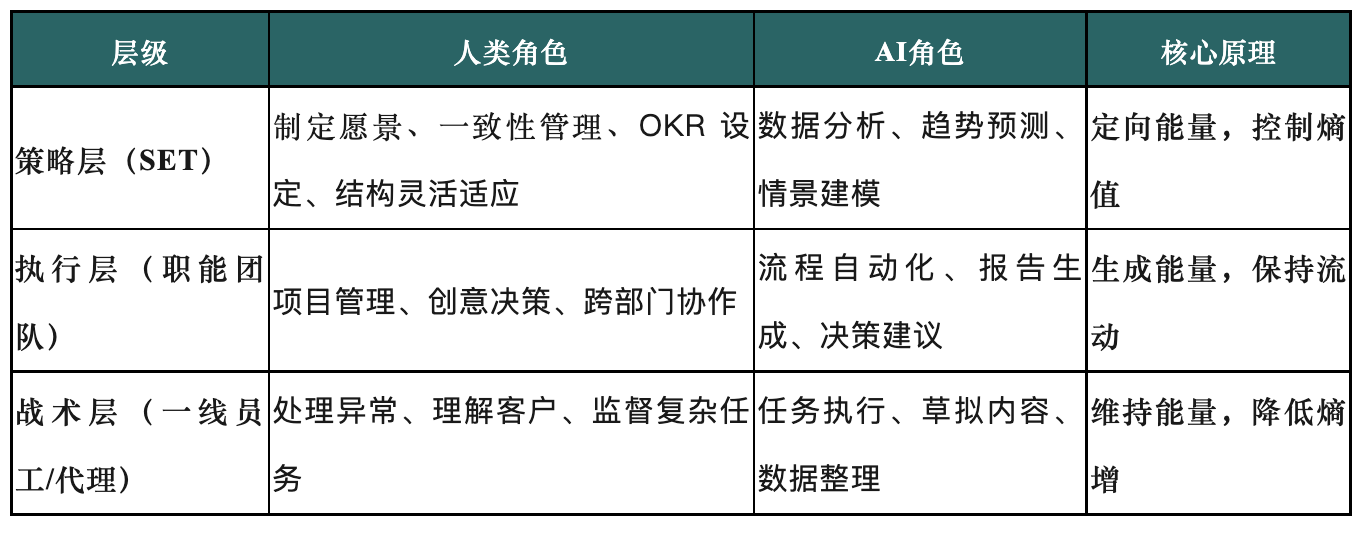
AI時代の組織構造再編:戦略実行チーム(SET)の台頭: 本稿では、AIが加速的に発展する時代において、従来の組織構造ではAIがもたらす複雑性に対応することが困難であることを論じています。「戦略実行チーム」(SET)を中核とする3層の組織モデルを提案し、AIをチームの一部とし、合理的な人間と機械の協調メカニズムを通じてアジャイルな実行とインテリジェントな拡張を実現することを目指しています。SETは、戦略を部門横断的な行動に転換し、組織エントロピーを監視し、戦略を柔軟に調整し、人、プロセス、AIエージェントの協調を統括することで、AIの潜在能力を解放し、戦略の実行を推進します。(ソース: 36Kr)
クラウドソーシングによるファクトチェックはソーシャルメディアの偽情報を抑制できるか?: Mohamed bin Zayed人工知能大学のPreslav Nakov教授は、Metaが第三者のファクトチェッカーをCommunity Notesに置き換えた影響について考察しています。彼は、Community Notes(XのBirdwatchに由来)のようなクラウドソーシングモデルには可能性があるものの、コンテンツモデレーションには自動フィルタリング、クラウドソーシング、専門家によるファクトチェックなど、複数の方法を組み合わせる必要があると考えています。スパムメールフィルタリングやLLMによる有害コンテンツ処理を例に挙げ、各方法にはそれぞれ長所と短所があり、協調して機能すべきだと指摘しています。研究によると、Community Notesは専門のファクトチェッカーの仕事の影響を増幅させることができ、両者の焦点は異なるものの結論は類似しており、相互に補完し合うことができるとのことです。(ソース: MIT Technology Review)
