
キーワード:OpenAI, HealthBench, Meta AI, Dynamic Byte Latent Transformer, マイクロソフトリサーチ, ARTISTフレームワーク, Sakana AI, 連続思考マシン, 医療AI性能評価, 8Bパラメータ動的バイトレイテントTransformerモデル, 強化学習によるLLM推論の向上, CTMニューラルネットワークアーキテクチャ, Qwen3公式量子化モデル
🔥 注目
OpenAIがHealthBenchを発表、医療AIの性能を評価: OpenAIは、医療シナリオにおける大規模言語モデル(LLM)の性能と安全性を測定することを目的とした新しいベンチマーク、HealthBenchを発表しました。このベンチマークは、世界中の250人以上の医師の参加を得て開発され、5000件の実際の医療対話と48562件の医師が作成した独自の評価基準を含み、救急医療、グローバルヘルスなど多様な状況、および正確性、指示追従性などの行動次元をカバーしています。テストによると、o3モデルの正答率は60%に達し、GPT-4.1 nanoはコストを25分の1に削減しながらGPT-4oを上回る性能を示し、医療分野におけるAIの巨大な潜在力と性能対費用効果の急速な進歩を示しています。(ソース: OpenAI)
Metaが8BパラメータのDynamic Byte Latent Transformerモデルを発表: Meta AIは、8BパラメータのDynamic Byte Latent Transformerモデルの重みをオープンソース化すると発表しました。このモデルは、従来のトークン化手法に代わる新しいアプローチを提案し、言語モデルの効率と信頼性の基準を再定義することを目指しています。この新しいトークン化方式により、言語モデル分野に画期的な進歩をもたらし、モデルのテキスト処理効率と効果を向上させることが期待されます。研究論文とコードはダウンロード可能です。(ソース: AIatMeta)
Microsoft ResearchがARTISTフレームワークを発表、強化学習を組み合わせてLLMの推論とツール使用能力を向上: Microsoft Researchは、ARTIST (Agentic Reasoning and Tool Integration in Self-improving Transformers) フレームワークを紹介しました。このフレームワークは、自律的推論、強化学習、動的なツール使用を融合し、大規模言語モデルがいつ、どのように、どのツールを使用して多段階推論を行うかを自律的に決定し、ステップごとの教師なしで堅牢な戦略を学習できるようにします。ARTISTは、数学や関数呼び出しなどの挑戦的なベンチマークテストにおいて、GPT-4oなどのトップモデルを最大22%上回る性能を示し、汎用化と解釈可能な問題解決の新たな基準を設定しました。(ソース: MarkTechPost)

Sakana AIがContinuous Thought Machines (CTM)を発表: Sakana AIは、「Continuous Thought Machines」(CTM)と名付けられた新しいニューラルネットワークアーキテクチャを発表しました。CTMの中核となる考え方は、神経活動の動的な時間プロセスを計算の核心要素とし、モデルが内部生成された「思考ステップ」のタイムラインに沿って動作し、静的データに対しても反復的に表現を構築・洗練させることを可能にします。このアーキテクチャは、ImageNet分類、2D迷路ナビゲーション、ソート、パリティ計算、強化学習など、多様なタスクにおいて、適応的計算、改善された解釈可能性、生物学的妥当性を示しました。(ソース: Sakana AI)

🎯 動向
Alibaba QwenチームがQwen3公式量子化モデルをリリース: AlibabaのQwenチームは、Qwen3の量子化モデルを正式にリリースしました。ユーザーはOllama、LM Studio、SGLang、vLLMなどのプラットフォームを通じてQwen3をデプロイでき、GGUF、AWQ、GPTQなど多様なフォーマットをサポートしており、ローカルでのデプロイが容易になります。関連モデルはHugging FaceとModelScopeで公開されています。今回のリリースは、高性能大規模モデルの使用障壁を下げ、より広範なシナリオでの応用を推進することを目的としています。(ソース: Alibaba_Qwen & Hugging Face & ClementDelangue & _akhaliq & TheZachMueller & cognitivecompai & huybery & Reddit r/LocalLLaMA)
Meta AIが協調推論フレームワークCollaborative Reasonerを発表: Meta AIは、言語モデルの協調推論能力を向上させることを目的としたフレームワーク、Collaborative Reasonerを発表しました。このフレームワークは、人間や他のエージェントと協力できるソーシャルエージェントの開発に注力し、モデルの協調・推論能力を高めることで、より複雑な人間と機械のインタラクションやマルチエージェントシステムへの道を開きます。関連する研究論文とコードは公開されており、コミュニティによる探求と応用が奨励されています。(ソース: AIatMeta)
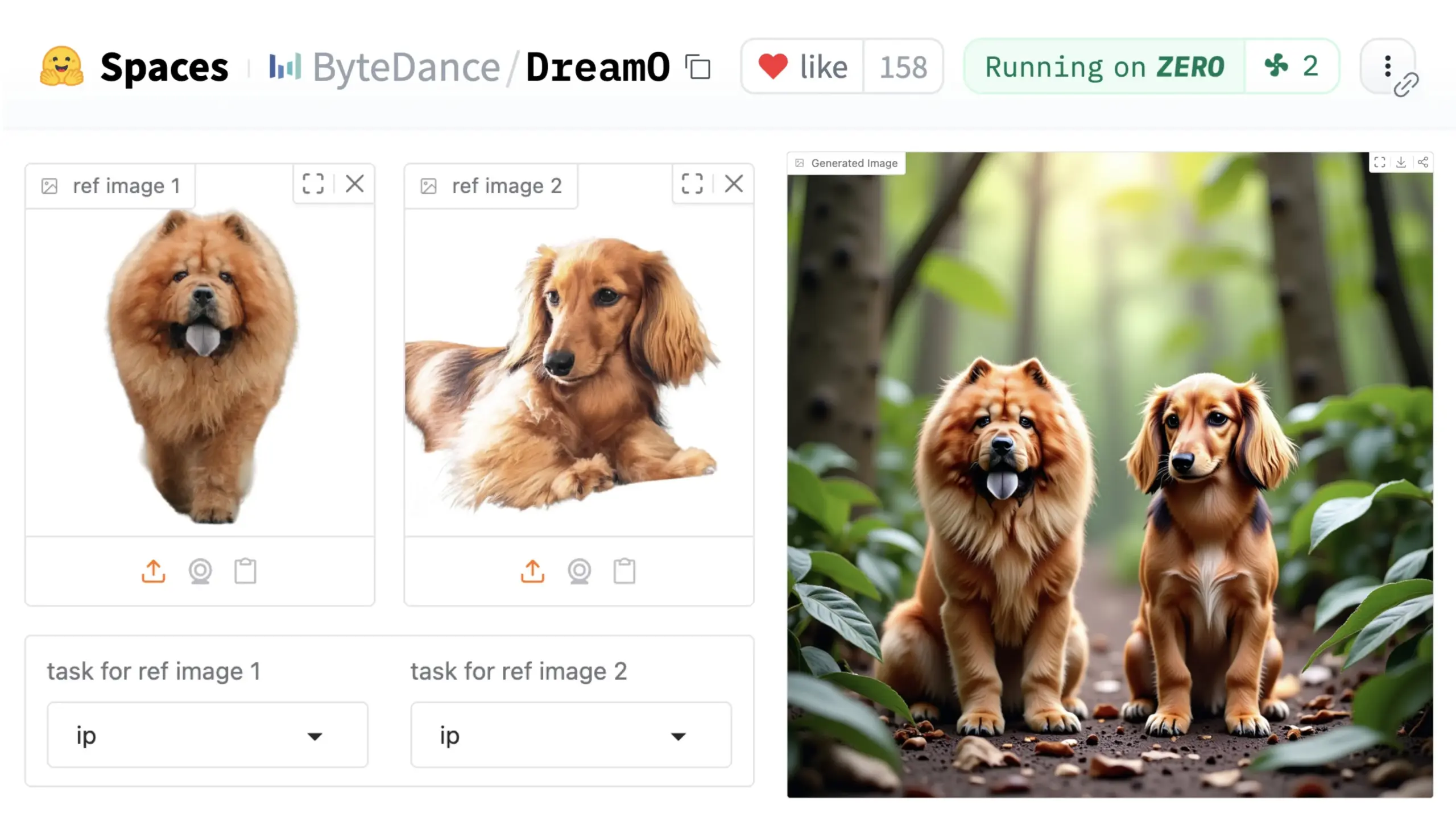
ByteDanceが汎用画像カスタマイズフレームワークDreamOを発表: ByteDanceは、DreamOと名付けられた統一画像カスタマイズフレームワークを発表しました。このフレームワークは、事前学習済みのDiT (Diffusion Transformer) モデルに基づいており、画像中の人物、スタイル、背景など多様な要素の広範なカスタマイズを実現し、アイデンティティ置換、スタイル転送、被写体変換、バーチャル試着などの機能を含みます。ユーザーはHugging Faceでデモを体験できます。この進展は、単一モデルが多様な画像編集タスクにおいて持つ可能性を示しています。(ソース: _akhaliq & ClementDelangue & _akhaliq)
NVIDIAがNemotronモデルのデータ管理プロセスNemotron-CCを公開: NVIDIAは、Nemotronモデルに使用されるデータ管理プロセスNemotron-CCを公開し、Nemotronのトレーニングおよびポストトレーニングデータを可能な限り公開すると発表しました。Nemotron-CCプロセスは現在、NeMo CuratorのGitHubリポジトリに追加されており、テキスト、画像、ビデオデータを大規模に処理できます。NVIDIAは、高品質な事前学習データセットが大規模言語モデルの精度にとって重要であることを強調し、データが計算を加速するための基本的な構成要素であると考えています。(ソース: ctnzr & NandoDF)

Tencent Hunyuan-TurbosモデルがLMArenaアリーナで8位にランクイン: Tencentの最新Hunyuan-Turbosモデルは、LMArena(旧lmsys.org)のベンチマークテストで総合8位、スタイル制御で13位にランクインし、Deepseek-R1に近いパフォーマンスを示しました。このモデルは、ハードコア、コーディング、数学などの主要カテゴリでトップ10入りし、2月版と比較して大幅な向上が見られます。WizardLM_AIなどのコミュニティメンバーがそのパフォーマンスに祝意を表しています。(ソース: WizardLM_AI & WizardLM_AI & teortaxesTex)

Runway Gen-4 Referencesが汎用クリエイティブツールの可能性を示す: RunwayのGen-4 Referencesモデルは、ほぼ無限のワークフローとアプリケーションをサポートできる汎用クリエイティブツールとして位置づけられています。コミュニティユーザーは継続的に新しい使用事例を発見しており、汎用モデルとしての強力な適応性を示しています。ユーザーがモデルの制約に適応するのではなく、ユーザーの創造性に合わせて調整できる能力があります。これは、メディア制作分野におけるAIが、特定タスクから汎用能力へと進化する傾向を反映しています。(ソース: c_valenzuelab & c_valenzuelab)

ByteDanceのSeed-1.5-VL-thinkingモデルが視覚言語モデルベンチマークでリード: ByteDanceはSeed-1.5-VL-thinkingモデルを発表しました。このモデルは60の視覚言語モデル(VLM)ベンチマークのうち38でSOTA(state-of-the-art)の成績を収めました。報告によると、このモデルは130万H800 GPU時間でトレーニングされ、その強力なマルチモーダル理解および推論能力を示しています。(ソース: teortaxesTex)
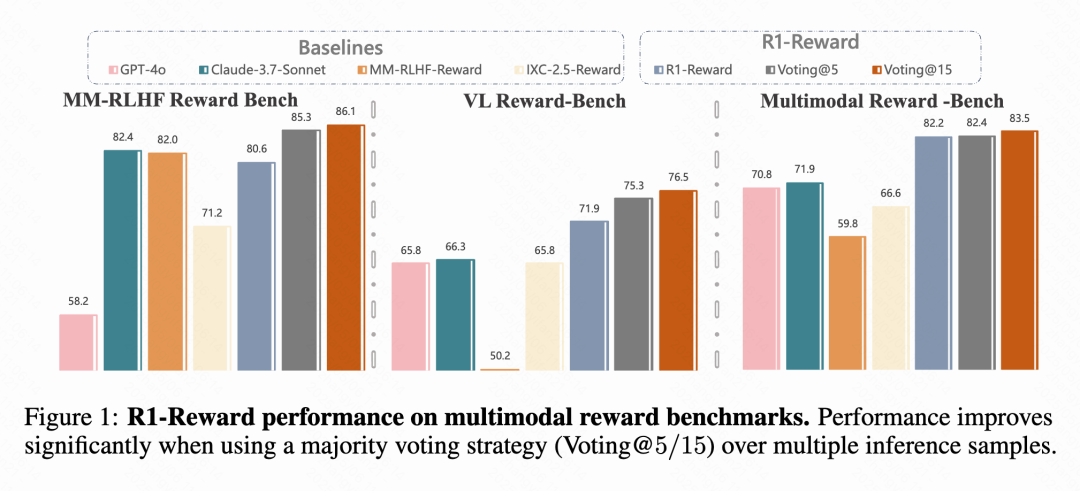
Kuaishouと中国科学院などがマルチモーダル報酬モデルR1-Rewardを提案: Kuaishou、中国科学院、清華大学、南京大学の研究チームは、改善された強化学習アルゴリズムStableReinforceを用いて訓練される新しいマルチモーダル報酬モデル(MRM)であるR1-Rewardを提案しました。このモデルは、既存のRLアルゴリズムがMRMの訓練時に直面する不安定性の問題を解決することを目的とし、Pre-Clip、アドバンテージフィルター、一貫性報酬などのメカニズムを導入しています。実験によると、R1-Rewardは複数のMRMベンチマークでSOTAモデルを5%~15%上回り、KuaishouのショートビデオやEコマースなどのビジネスシーンで成功裏に適用されています。(ソース: WeChat & WeChat)
南洋理工大学などがWorldMemを提案、記憶メカニズムで長時間一貫性のある世界生成を実現: 南洋理工大学S-Lab、北京大学、上海AI Labの研究者は、世界生成モデルWorldMemを提案しました。このモデルは記憶メカニズムを導入することで、既存の動画生成モデルが長時間にわたって一貫性を欠く問題を解決します。WorldMemはMinecraftデータセットで訓練され、多様なシーン探索と動的変化をサポートし、実データセットでその実現可能性を検証しました。視点や位置が変わった後でも良好な幾何学的一貫性を保ち、時間的一貫性をモデル化できます。(ソース: WeChat)

Kuaishou KelingチームがCineMasterを提案、3D認識可能な制御型映画品質ビデオ生成フレームワーク: Kuaishou Keling研究チームはSIGGRAPH 2025で論文を発表し、CineMasterフレームワークを紹介しました。これは映画品質のテキストからビデオへの生成フレームワークであり、ユーザーはインタラクティブなワークフローを通じて、3D空間でシーンを配置し、ターゲットとカメラの動きを設定し、ビデオコンテンツを精密に制御できます。CineMasterは、セマンティックレイアウトControlNetとCamera Adapterを介して、それぞれオブジェクトの動きとカメラの動きの制御を統合し、任意のビデオから3D制御信号を抽出するデータ構築プロセスを設計しました。(ソース: WeChat)

🧰 ツール
Comet-mlがオープンソースLLM評価フレームワークOpikをリリース: Comet-mlはGitHubでOpikをオープンソース化しました。これはLLMアプリケーション、RAGシステム、Agentワークフローのデバッグ、評価、監視に使用されるフレームワークです。Opikは、包括的な追跡、自動評価、本番環境対応のダッシュボードを提供し、ローカルインストールまたはComet.comを介したホスト型ソリューションとしてサポートされます。OpenAI、LangChain、LlamaIndexなど、多くの人気フレームワークと統合されており、ハルシネーション検出、コンテンツモデレーション、RAG評価のためのLLM-as-a-judge指標を提供します。(ソース: GitHub Trending)
LovartAIが初のデザインエージェントLovartを発表、コンテキスト理解を強調: LovartAIは、初のデザインエージェントLovartのベータ版をリリースしました。ユーザーからのフィードバックによると、他のAIデザインツールと比較して、Lovartはコンテキストをよりよく理解し、「心を読んでいるかのようだ」とのことです。このツールは、人間とAIが同じキャンバス上で協力し、プロンプトを即座に視覚効果に変換することを可能にし、ブランドロゴやVIデザインなどに使用できます。(ソース: karminski3)
CMU Jun-Yan ZhuチームがLEGOGPTを発表、テキストから3Dレゴモデルを生成: CMUのJun-Yan Zhuチームは、テキストプロンプトに基づいて物理的に安定し、組み立て可能な3Dレゴモデルを生成できる大規模言語モデルLEGOGPTを開発しました。このモデルは、レゴ設計問題を自己回帰型テキスト生成タスクとして定式化し、次のブロックのサイズと位置を予測して構造を構築し、訓練と推論において物理法則に基づいた組み立て制約を強制することで、生成されたデザインの安定性と組み立て可能性を保証します。チームはまた、47,000以上のレゴ構造を含むStableText2Legoデータセットも公開しました。(ソース: WeChat)

MNNチャットアプリがQwen 2.5 Omni 3Bおよび7Bモデルをサポート: AlibabaのMNN (Mobile Neural Network) チャットアプリは、現在Qwen 2.5 Omni 3Bおよび7Bモデルをサポートしています。これは、ユーザーがモバイル端末でより強力なローカライズされた言語モデルサービスを体験できることを意味します。MNNは軽量なディープラーニング推論エンジンであり、モバイル端末および組み込みデバイス向けに最適化されています。(ソース: Reddit r/LocalLLaMA)

FutureHouseプラットフォームが科学者向けに超知能AI研究ツールを提供: 非営利団体FutureHouseは、科学的発見を加速することを目的とした、WebおよびAPIベースのAIエージェントスイートであるFutureHouseプラットフォームを発表しました。このプラットフォームは、一連の超知能AI研究ツールを提供し、科学者がデータ分析、シミュレーション実験、知識発見を行うのを支援し、科学研究パラダイムの変革を推進します。(ソース: dl_weekly)
CartesiaがPro Voice Cloningを発表、カスタム音声モデルを簡単に構築: Cartesiaは、ファインチューニング製品であるPro Voice Cloningを発表しました。ユーザーは自身の音声データをアップロードし、カスタム音声モデルを簡単に構築して、パーソナルアバター、AIエージェント、または音声ライブラリを作成するために使用できます。この製品は、2時間以内にトレーニングとサービス展開を完了でき、完全にセルフサービス型の製品体験を提供し、大規模な応用を目指しています。(ソース: krandiash)

中国科学院計算技術研究所がMCA-Ctrlを提案、画像の精密なカスタマイズを実現: 中国科学院計算技術研究所の研究チームは、ファインチューニング不要の汎用画像カスタマイズ手法MCA-Ctrl (Multi-party Collaborative Attention Control) を提案しました。この手法は、マルチパーティ協調アテンション制御を通じて、拡散モデルの内部知識を利用し、条件付き画像/テキストプロンプトと主体画像の内容を組み合わせることで、特定の主体のテーマ置換、生成、追加を実現します。MCA-Ctrlは、自己注意のローカルクエリとグローバル注入メカニズムを通じて、レイアウトの一貫性と特定オブジェクトの外観置換および背景との整合性を保証します。(ソース: WeChat)
📚 学習
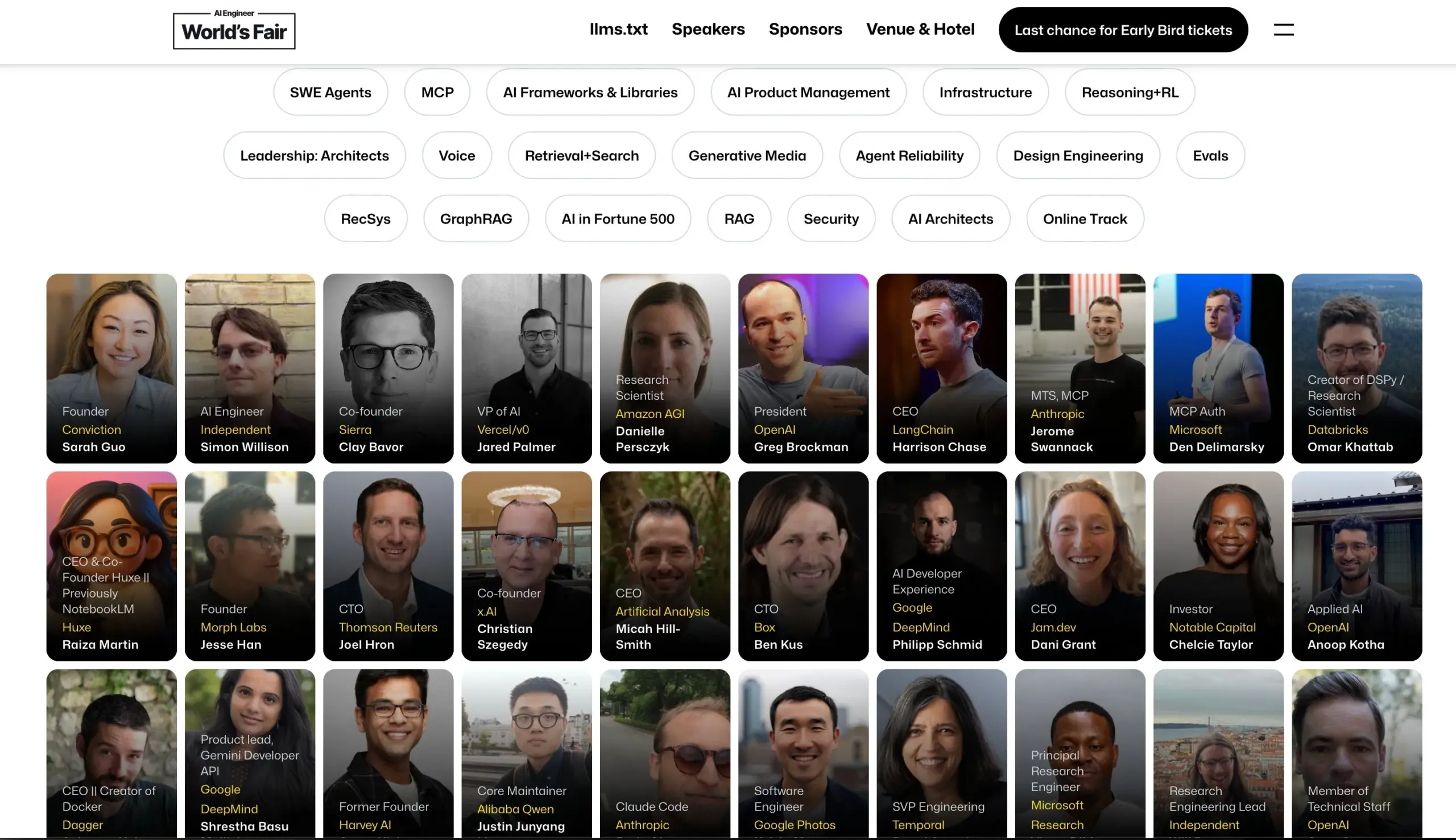
AI Engineerカンファレンスが登壇者ラインナップを発表: AI Engineerカンファレンスは、OpenAI、Anthropic、LangChainAI、Googleなどの企業からトップクラスのAIエンジニアや研究者を含む登壇者ラインナップを発表しました。カンファレンスでは、MCP、LLM RecSys、Agent Reliability、GraphRAGなど20のサブ分野をカバーし、初めてCTOおよびVPリーダーシップアジェンダを設けます。(ソース: swyx & hwchase17 & _philschmid & HamelHusain & swyx & bookwormengr & swyx)
Hugging Faceが視覚言語モデル(VLM)の最新動向に関するブログを公開: Hugging Faceは、視覚言語モデル(VLM)の最新動向に関する包括的なブログ記事を公開しました。内容は、GUIエージェント、エージェントVLM、オムニモデル、マルチモーダルRAG、ビデオLM、小型モデルなど多岐にわたり、過去1年間のVLM分野における新しいトレンド、ブレークスルー、アライメント、ベンチマークなどをまとめています。(ソース: huggingface & ben_burtenshaw & mervenoyann & huggingface & algo_diver & huggingface & huggingface)

Microsoft AzureがサーバーレスAIチャットアプリ構築に関するオンラインセミナーを開催: Yohan Lasorsaは、Azureを使用してサーバーレスAIチャットアプリを構築する方法に関するオンラインセミナーを開催すると発表しました。セミナーでは、Azure Functions、Static Web Apps、Cosmos DB、およびLangChainAI JSと組み合わせてRAG(Retrieval-Augmented Generation)技術を使用する方法について議論します。(ソース: Hacubu & hwchase17)
WeaviateポッドキャストがLLM-as-JudgeシステムとVerdictライブラリを議論: Weaviateポッドキャスト第121回では、Haize Labsの共同創設者であるLeonard Tang氏を招き、LLM-as-Judge/報酬モデルシステムの進化について深く掘り下げました。議論の内容は、評価のユーザーエクスペリエンス、比較評価、ジャッジ統合、ディベートジャッジ、評価セットのキュレーション、敵対的テストなどを含み、Haize Labsの新しいライブラリVerdict(複合LLM-as-Judgeシステムを指定・実行するための宣言的フレームワーク)に焦点を当てています。(ソース: bobvanluijt & Reddit r/deeplearning)

テレンス・タオ氏がYouTube動画を公開、AI支援による数学の形式的証明をデモンストレーション: フィールズ賞受賞者のテレンス・タオ氏が自身のYouTubeチャンネルでデビューし、GitHub CopilotやLean証明支援系などのAIツールを利用して、通常は人間の数学者が1ページを費やす数学的証明(Magma方程式E1689がE2を含意すること)を33分で半自動的に形式化する方法を実演しました。彼は、この方法が技術的で概念性の低い証明に適しており、数学者を煩雑な作業から解放できると強調しています。同時に、彼が開発した軽量Python証明支援系もバージョン2.0に更新され、漸近的評価と命題論理の処理が強化されました。(ソース: WeChat & 量子位)

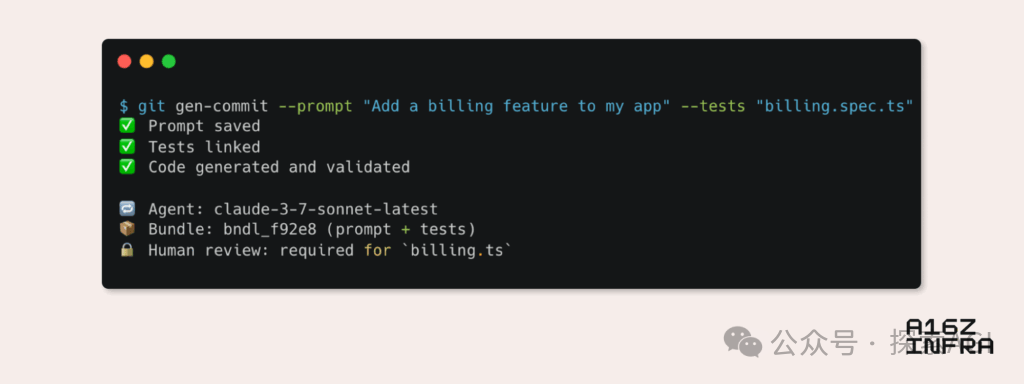
a16zがAI時代の新たな開発者パターンの9つのトレンドを分析: Andreessen Horowitz (a16z) はブログを公開し、AI時代に現れる9つの新たな開発者パターンのトレンドを分析しました。これらには、AIネイティブGit(バージョン管理がプロンプトとテストケースへ移行)、Vibe Coding(意図駆動型プログラミングがテンプレートを代替)、AI Agentのキー管理の新パラダイム、AI駆動のインタラクティブ監視ダッシュボード、ドキュメントがAIインタラクティブ知識ベースへ進化、LLM視点でのアプリケーション(アクセシビリティAPI経由のインタラクション)、非同期実行Agentの台頭、MCP(Model-Tool Communication Protocol)プロトコルの可能性、Agentの基盤コンポーネントへの需要が含まれます。これらのトレンドは、ソフトウェア構築方法の深刻な変革を予示しています。(ソース: WeChat)
💼 ビジネス
Google LabsがAI Futures Fundを立ち上げ、AIスタートアップを支援: Google Labsは、スタートアップ企業と協力してAI技術の未来を共に構築することを目的としたAI Futures Fundプロジェクトの開始を発表しました。この基金は、選ばれたスタートアップ企業に対し、Google DeepMindモデルへの早期アクセス機会やクラウドクレジットなどのリソースを提供し、その成長を加速させることを支援します。(ソース: GoogleDeepMind & JeffDean & Google & demishassabis)
Perplexityが新たな5億ドルの資金調達を交渉中、評価額は140億ドルに達するとの報道: 報道によると、AI検索エンジン企業Perplexityは、新たな5億ドルの資金調達を交渉中であり、評価額は140億ドルに達する可能性があります。これは前回の資金調達(評価額90億ドル)からわずか6ヶ月後のことであり、資本市場がAI検索分野に高い関心を持ち、Perplexityの将来性を評価していることを示しています。(ソース: Dorialexander)

OpenAIがWindsurfを約30億ドルで買収に合意との報道: Bloombergの報道によると、OpenAIはスタートアップ企業Windsurfを約30億ドルで買収することに合意しました。この買収の具体的な詳細やWindsurfの事業内容はまだ公開されていませんが、この動きはOpenAIが技術力や市場シェアをさらに拡大しようとしていることを意味する可能性があります。(ソース: Reddit r/artificial & Reddit r/ArtificialInteligence)

🌟 コミュニティ
AIの真のリスク:無限の満足がもたらす「シミュレーションの罠」: Amjad Masad氏らの議論によると、AIの真の危険はSF映画の殺人ロボットではなく、人間の欲望を無限に満たし、「無限の快楽マシン」を創造できる点にあると指摘されています。このようなAIは、人類がシミュレートされた努力と意義に溺れ、最終的にシミュレーション世界に「消滅」する可能性があり、フェルミのパラドックスに対する一つの可能な説明を提供します――文明は消滅するのではなく、デジタルな至福へと移行するのです。(ソース: amasad)
AI Agentがプログラミングと科学研究を再構築へ: ReplitのCEOであるAmjad Masad氏は、今後1~2年以内にAI Agentが数日間、あるいは数年間にわたって中断なく稼働し、複雑な科学的問題を解決できるようになると予測しています。彼は、Agentが人間のように数日を費やして問題を解決できる新しいプログラミング手法となり、AIが複雑なタスクの自動化と科学的発見の加速において巨大な可能性を秘めていることを示唆していると考えています。(ソース: TheTuringPost & amasad & TheTuringPost)
John Carmack氏がコードベース最適化におけるAIの可能性を議論: 伝説的なプログラマーであるJohn Carmack氏は、AIは大量のコードを生成するだけでなく、既存のコードベースを美化し、リファクタリングする手助けをする可能性がさらに高いと考えています。彼は、AIが勤勉なチームメンバーとして継続的にコードをレビューし、改善提案を行い、さらには客観的な実験を通じて「AIフレンドリー」なコーディングスタイルガイドラインを定義できると構想しています。彼は、OpenBSDのようなコード品質に非常に高い要求を持つチームが、どのようにAIメンバーを受け入れるかを楽しみにしています。(ソース: ID_AA_Carmack)
「Vibe Coding」が議論を呼ぶ:AI支援プログラミングの利点と欠点: コミュニティの議論では、「Vibe Coding」(自然言語の指示でAIにコードプロトタイプを生成させること)はデモレベルのアプリケーションを迅速に構築できるものの、デプロイや拡張を行うには依然として専門の開発者がゼロから構築する必要があると指摘されています。エンジニアリングされた製品はコードを書くだけでなく、アーキテクチャ、CI/CD、マイクロサービスなどの複雑な問題を含み、AIは現在、これらを完全にこなすことは困難です。Vibe Codingは迅速なプロトタイプ検証に適していますが、実際のソリューションを構築するには依然としてエンジニアリング思考と経験が必要です。(ソース: Reddit r/ClaudeAI)
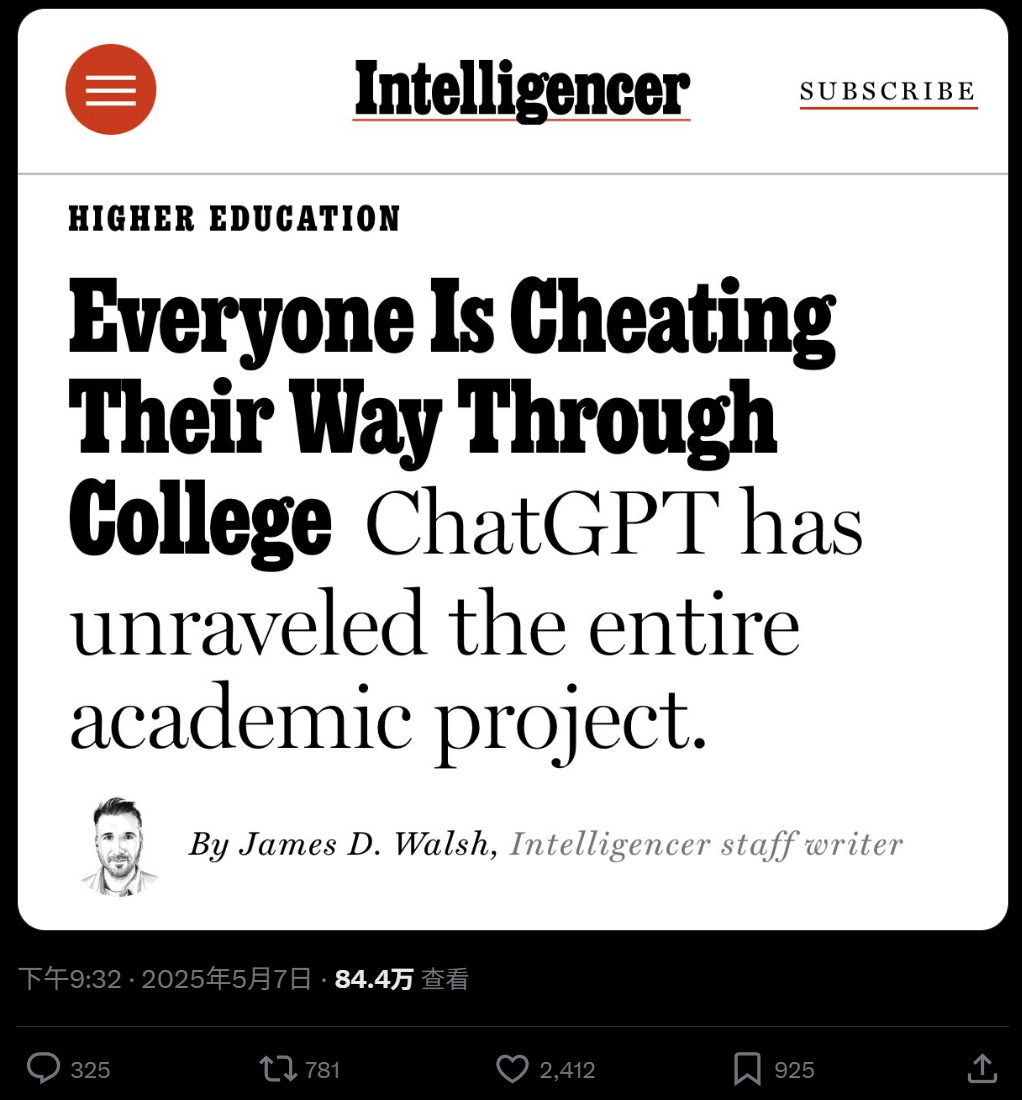
大学教育におけるAIの広範な利用と不正行為への懸念: 『New York Magazine』の報道は、北米の大学でAIツール(ChatGPTなど)が宿題や論文の作成に広く利用されている現状を明らかにしました。学生たちはAIをノート取り、学習、研究、さらには宿題内容の直接生成に利用しており、学術的誠実性、教育の質、学生の批判的思考能力の低下に関する懸念を引き起こしています。教育関係者は教育・評価方法の調整を試みていますが、AI検出ツールの有効性には疑問があり、AIによる不正行為の根絶は困難になっています。(ソース: WeChat)
💡 その他
Cohereが政府におけるAI応用のパイロットから本番への課題を議論: Cohereは、多くの政府AIプロジェクトが依然としてパイロット段階に留まっていると指摘しています。パイロットから実際の生産応用への移行を実現するためには、政府機関は信頼できるツール、明確な成果指向、効率的なインフラストラクチャ、そして適切なパートナーを必要とします。記事では、政府機関が安全かつ効率的なAIを通じて、実験から実用への移行をどのように実現できるかを探っています。(ソース: cohere)

Mustafa Suleyman氏:大規模言語モデルは規模が大きいほど制御しやすい: Inflection AIの共同創設者であるMustafa Suleyman氏は、一般的な懸念とは逆に、大規模言語モデル(LLM)は規模が大きいほど実際には制御しやすいと考えています。彼は、数世代前のモデルの方が誘導、スタイル化、形成が難しく、規模の拡大はモデルの制御性を向上させるのに役立ち、弱めるものではないと指摘しています。(ソース: mustafasuleyman)
AI倫理の議論:AIが引き起こす損害やバイアスの責任の所在: あるRedditの投稿が議論を呼んでいます:AIシステム(医療診断AIなど)が訓練データの偏り(例えば、主に明るい肌の画像で訓練され、暗い肌の患者を誤診するなど)によって損害を引き起こした場合、責任は誰が負うべきか?これはAI開発者、導入機関、規制当局など、多方面の責任分界に関わる問題であり、AI倫理と法的枠組みにおいて早急に解決すべき重要な課題です。(ソース: Reddit r/ArtificialInteligence)