
キーワード:OpenAI, AIチップ, 大規模モデル, 強化学習, AIインフラストラクチャ, マルチモーダルAI, インテリジェントエージェント, RAG, OpenAI国家レベルAI計画, NVIDIA H20チップ輸出規制, DeepSeek-R1推論最適化, AI光学顕微鏡Meta-rLLS-VSIM, ByteDance Seed-Coderコード大規模モデル
🔥 フォーカス
OpenAI、「国家レベルAI」計画を発表、グローバルなAIインフラ構築を支援: OpenAIは、「OpenAI for Countries」プロジェクトを「Stargate」計画の一環として開始しました。これは、各国によるローカルAIデータセンターの構築、カスタマイズされたChatGPTの開発、AIエコシステムの発展を支援することを目的としています。CEOのSam Altman氏は、テキサス州Abileneにある初のスーパーコンピューティング施設を視察しました。この施設は、5000億ドルを投じる「Stargate」計画の一部であり、世界最大のAIトレーニング施設の構築を目指しています。この動きは、OpenAIが多くの政府と協力し、インフラ構築と技術共有を通じて、AI技術のグローバルな普及と応用を推進することを示すものです。最初の計画では10の国・地域との協力を予定しています (情報源: WeChat)

トランプ政権、AIチップ輸出の三段階制限を廃止し、より簡素なグローバルライセンスシステムを採用する計画との報道: 海外メディアの報道によると、トランプ政権はバイデン政権末期に策定された「人工知能拡散フレームワーク」(FAID)を撤回する計画です。このフレームワークは、世界のAIチップ輸出に対して三段階の分類制限を課すものでした。トランプチームは、このフレームワークが煩雑すぎ、イノベーションを阻害すると考えており、より簡素なグローバルライセンスシステムに置き換え、政府間合意を通じて実行する意向です。この動きは、NVIDIAなどのチップメーカーのグローバル市場戦略に影響を与える可能性があり、AI分野における米国のイノベーションと主導的地位を強化することを目的としています (情報源: WeChat)

SGLangチーム、DeepSeek-R1の推論性能を大幅に最適化、スループットが26倍に向上: SGLang、NVIDIAなどの機関による共同チームは、SGLang推論エンジンの全面的なアップグレードを通じて、4ヶ月以内にDeepSeek-R1モデルのH100 GPUにおける推論性能を26倍に向上させました。最適化案には、プリフィルとデコードの分離(PD分離)、大規模エキスパート並列(EP)、DeepEP、DeepGEMMおよびエキスパート並列ロードバランサー(EPLB)などの技術が含まれています。2000トークンの入力シーケンスを処理する際に、ノードあたり毎秒52.3kの入力トークンと22.3kの出力トークンというスループットを実現し、DeepSeekの公式データに近づき、ローカル展開コストを大幅に削減しました (情報源: WeChat)

OpenAIの科学者Dan Roberts氏:強化学習の拡張がAIによる新科学発見を推進、9年でアインシュタイン級AGI実現の可能性も: OpenAIの研究科学者Dan Roberts氏は、Sequoia CapitalのAI Ascentで講演し、将来のAIモデル構築における強化学習(RL)の中心的な役割について議論しました。同氏は、RLの規模を継続的に拡大することで、AIモデルは数学的推論などのタスクでのパフォーマンスを向上させるだけでなく、「テスト時計算」(モデルの思考時間が長いほどパフォーマンスが向上する)を通じて科学的発見を実現できると考えています。アインシュタインが一般相対性理論を発見した例を挙げ、AIが8年間の計算と思考を行えれば、9年後にはアインシュタインのような科学的ブレークスルーレベルに到達できるかもしれないと推測しています。Roberts氏は、将来のAI開発はRL計算により重点を置くようになり、訓練プロセス全体を支配する可能性さえあると強調しました (情報源: WeChat)

🎯 動向
NVIDIAのJim Fan氏:ロボットは「物理的チューリングテスト」をパスする、シミュレーションと生成AIが鍵: NVIDIAのロボット部門責任者であるJim Fan氏は、Sequoia AI Ascentの講演で「物理的チューリングテスト」という概念を提唱しました。これは、人間がタスクを人間が実行したのかロボットが実行したのかを区別できない状態を指します。同氏は、現在のロボットのデータ取得コストが高いことを指摘し、シミュレーション技術、特に生成AI(ビデオ生成モデルのファインチューニングなど)を組み合わせて多様かつ大規模な訓練データ(正確な「デジタルツイン」ではなく「デジタル従兄弟」)を作成することが鍵であると述べました。大規模シミュレーションと視覚-言語-行動モデル(NVIDIA GR00Tなど)を通じて、将来的には物理APIが至る所に存在し、ロボットは複雑な日常業務をこなし、環境知能と一体化すると予測しています (情報源: WeChat)
ByteDance、コード大規模モデルSeed-Coderシリーズを発表、8B版が優れた性能を示す: ByteDanceは、8B、14Bなど複数のバージョンを含むSeed-Coderシリーズのコード大規模モデルを発表しました。その中で、Seed-Coder-8BはSWE-bench、Multi-SWE-bench、IOIなど複数のコード能力評価ベンチマークで優れた性能を示し、Qwen3-8BやQwen2.5-Coder-7B-Instを上回るとされています。このモデルシリーズにはBase、Instruct、Reasonerバージョンが含まれており、その核心理念は「コードモデルに自身のデータを企画させる」ことであり、コード推論とソフトウェアエンジニアリング能力において著しい向上が見られます。モデルはHugging FaceとGitHubでオープンソース化されています (情報源: Reddit r/LocalLLaMA, karminski3, teortaxesTex)
Alibaba、ZeroSearchフレームワークをオープンソース化、LLMを利用した検索シミュレーションによりAI訓練コストを88%削減: Alibabaの研究者らは、「ZeroSearch」と名付けられた強化学習フレームワークを発表しました。このフレームワークは、大規模言語モデル(LLM)が訓練プロセス中に高価な商用検索エンジンAPI(Googleなど)を呼び出すことなく、検索エンジンをシミュレートすることで高度な検索機能の開発を可能にします。実験によると、3B LLMをシミュレートされた検索エンジンとして使用するだけで、ポリシーモデルの検索能力が効果的に向上し、14Bパラメータの検索モジュールの性能はGoogle検索をも上回り、同時にAPIコストを88%削減しました。この技術はGitHubとHugging Faceでオープンソース化されており、Qwen-2.5、LLaMA-3.2などのモデルシリーズをサポートしています (情報源: WeChat)

Gemini API、暗黙的キャッシュ機能を導入、最大75%のコスト削減が可能に: Google Gemini APIは最近、Gemini 2.5モデルシリーズ(ProおよびFlash)に対して暗黙的キャッシュ機能を有効にしました。ユーザーのリクエストがキャッシュにヒットした場合、自動的に最大75%のコストを削減できます。同時に、キャッシュをトリガーする最小トークン要件も引き下げられ、2.5 Flashモデルは1Kトークンに、2.5 Proモデルは2Kトークンに削減されました。この措置は、開発者がGemini APIを使用するコストを削減し、高頻度の繰り返しリクエストの効率を向上させることを目的としています (情報源: JeffDean)
清華大学、AI光学顕微鏡Meta-rLLS-VSIMを開発、体積分解能が15.4倍に向上: 清華大学の李棟研究室と戴瓊海チームは協力し、メタ学習駆動の反射型格子光シート仮想構造化照明顕微鏡(Meta-rLLS-VSIM)を提案しました。このシステムはAIと光学の学際的イノベーションを通じて、生細胞イメージングの横方向分解能を120nm、軸方向分解能を160nmに向上させ、ほぼ等方性の超解像を実現し、体積分解能は従来のLLSMと比較して15.4倍に向上しました。その核心技術には、DNNを利用して超解像能力を多方向に拡張する「仮想構造化照明」や、鏡面反射によるデュアルビュー情報融合とRL-DFNネットワークによる軸方向分解能の向上が含まれます。メタ学習戦略の導入により、AIモデルはわずか3分で自己適応展開を完了でき、生物実験におけるAIの応用障壁を大幅に低減し、がん細胞分裂や胚発生などの生命過程の観察に強力なツールを提供します (情報源: WeChat)

Qwen3シリーズ大規模モデルが発表、オープンソースコミュニティを引き続きリード: Alibabaは、パラメータ規模が0.5Bから235Bに及ぶQwen3シリーズ大規模言語モデルを発表しました。複数のベンチマークテストで優れた性能を示し、特に複数の小型モデルは同規模のオープンソースモデルの中でSOTAレベルに達しています。Qwen3シリーズは多言語をサポートし、コンテキスト長は最大128kトークンです。その強力な性能と低い展開コスト(DeepSeek-R1などと比較して)により、Qwenシリーズは海外(特に日本)でAI開発基盤として広く採用され、多数の特定分野向けモデルが派生しています。Qwen3の発表は、世界のオープンソースAIコミュニティにおけるその主導的地位をさらに強固にし、GitHubでは1週間以内にスター数が2万を超えました (情報源: dl_weekly, WeChat)

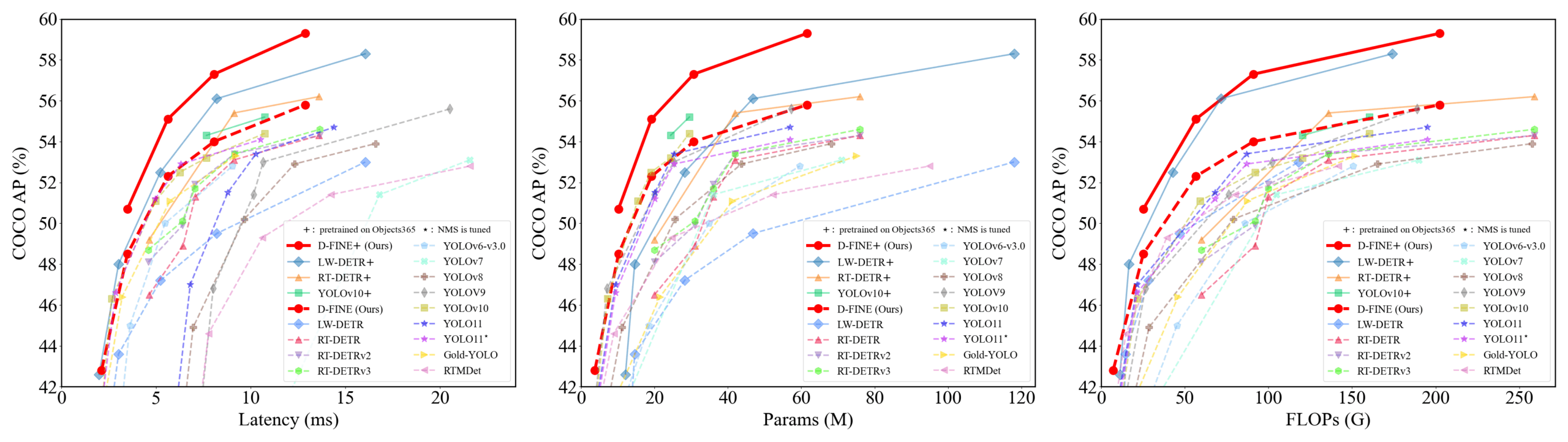
D-FINE:きめ細かい分布最適化に基づくリアルタイム物体検出器、優れた性能を発揮: 研究者らは、DETRにおけるバウンディングボックス回帰タスクをきめ細かい分布最適化(FDR)として再定義し、グローバル最適位置特定自己蒸留(GO-LSD)戦略を導入した新しいリアルタイム物体検出器D-FINEを提案しました。D-FINEは、追加の推論コストや訓練コストなしに、卓越した性能を実現します。例えば、D-FINE-NはCOCO valで42.8% APを達成し、速度は最大472 FPS(T4 GPU)です。D-FINE-XはObjects365+COCOで事前学習後、COCO val APは59.3%に達します。この方法は、確率分布を反復的に最適化することでより精密な位置特定を実現し、自己蒸留を通じて最終層の位置特定知識を初期層に伝達します (情報源: GitHub Trending)
Harmonモデル、視覚表現を調和させ、マルチモーダル理解と生成を統一: 南洋理工大学の研究者らは、共有MAR Encoder(Masked Autoencoder for Reconstruction)を通じてマルチモーダル理解と生成タスクを統一することを目的としたHarmonモデルを提案しました。研究により、MAR Encoderは画像生成訓練中に同時に視覚的意味論を学習でき、そのLinear Probingの結果はVQGAN/VAEをはるかに上回ることが判明しました。Harmonフレームワークは、MAR Encoderを利用して完全な画像を処理して理解し、MARマスキングモデリングパラダイムを踏襲して画像生成を行い、LLMがその中でモーダルインタラクションを実現します。実験によると、Harmonはマルチモーダル理解ベンチマークでJanus-Proに匹敵し、テキストからの画像生成美学ベンチマークMJHQ-30Kおよび指示追従ベンチマークGenEvalで優れた性能を示し、一部の専門モデルをも上回っています。このモデルはオープンソース化されています (情報源: WeChat)

推行科技、物流ロボットで商業的クローズドループを実現、「配達員シャドウシステム」でデータを蓄積: 推行科技の物流ロボットは、中国国内の複数の都市で実運用を開始し、人間の配達員と協調作業することで、個々のロボットの損益分岐点を達成しました。その核心技術の一つが「配達員シャドウシステム」で、複雑な都市環境における実際の配達員の運転行動、環境認識、操作データ(ドアの開閉、物品の取り出し・置き方など)を収集し、ロボットに大量かつ高品質な模倣学習と強化学習の訓練データを提供します。現在、このシステムは数千万キロメートルの走行データと百万件近い上肢軌跡データを蓄積しています。推行科技はこれに基づき行動ツリーVLAモデルを訓練し、ロボットが現実世界の複雑な状況に対応できるようにし、海外市場への展開も計画しています (情報源: WeChat)

Kuaishou、KuaiModフレームワークを発表、マルチモーダル大規模モデルでショートビデオエコシステムを最適化: Kuaishouは、マルチモーダル大規模モデルに基づくショートビデオプラットフォームエコシステム最適化ソリューションKuaiModを提案しました。これは、コンテンツ品質の自動判定を通じてユーザーエクスペリエンスを改善することを目的としています。KuaiModは判例法の考え方を参考に、視覚言語モデル(VLM)の連鎖的推論を利用して低品質コンテンツを分析し、ユーザーフィードバックに基づく強化学習(RLUF)を通じて判定戦略を継続的に更新します。このフレームワークはKuaishouプラットフォームに導入され、ユーザーからの苦情率を20%以上削減することに成功しました。Kuaishouは同時に、コミュニティのショートビデオを理解できるマルチモーダル大規模モデルの構築にも取り組んでおり、表現抽出から深い意味理解へと進み、ビデオの興味タグ構造化、コンテンツ生成支援など複数のシーンで応用され、成果を上げています (情報源: WeChat)

Lenovo、「天禧」パーソナルスーパーインテリジェントエージェントを発表、L3レベルのインテリジェンスへ: Lenovoはイノベーションテクノロジー大会で、「天禧」パーソナルスーパーインテリジェントエージェントを発表しました。これは、マルチモーダルな知覚とインタラクション、個人知識ベースに基づく認知と意思決定、および複雑なタスクの自律的な分解と実行能力を備えています。天禧は、AI随心窗、AI玲瓏台、AI如影框などの付随型AUIインターフェースを通じて、自然でシームレスな人間と機械の協調体験を提供することを目指しています。DeepSeek-R1を含む複数の業界トップクラスの大規模モデルを統合し、エッジ・クラウド混合展開アーキテクチャを採用し、Lenovoパーソナルクラウド1.0(720億パラメータの大規模モデルを搭載)と連携して強力な計算能力と100Gの専用記憶領域を提供します。Lenovoは同時に、企業向けの「乐享」および都市レベルのスーパーインテリジェントエージェントも発表し、AI分野における包括的な展開を示しました (情報源: WeChat)

新研究、記号的相互作用の複雑性によりニューラルネットワークの汎化性を判断: 上海交通大学の張拳石教授チームは、ニューラルネットワークの内在的な記号化された相互作用表現の複雑性の観点からその汎化性を分析する新しい理論を提案しました。研究によると、汎化可能な相互作用(訓練セットとテストセットの両方で高頻度に出現)は、異なる次数(複雑性)において通常、減衰型の分布(低次の相互作用が主)を示し、一方、汎化不可能な相互作用(主に訓練セットに出現)は紡錘形の分布(中間の次数の相互作用が主で、正負の効果が相殺されやすい)を示すことがわかりました。この理論は、モデルの等価な「AND-OR相互作用ロジック」の分布パターンを分析することで、モデルの汎化ポテンシャルを直接判断することを目指しており、モデルの汎化性の理解と向上に新たな視点を提供します (情報源: WeChat)
🧰 ツール
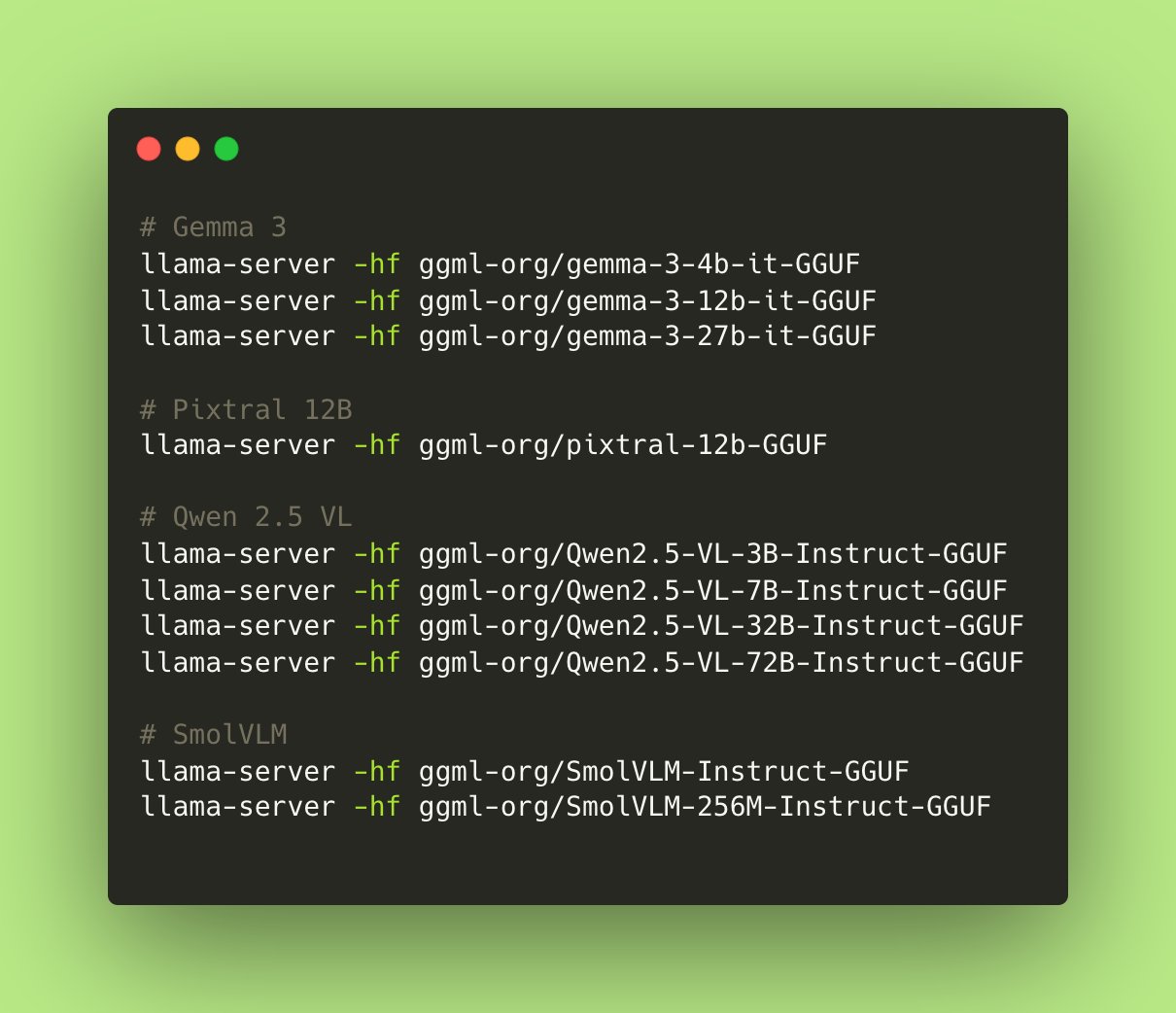
Llama.cpp、視覚言語モデル(VLM)に完全対応: Llama.cppは現在、視覚言語モデル(VLM)を完全にサポートしており、開発者はデバイス上でマルチモーダルアプリケーションを実行できるようになりました。Hugging FaceのJulien Chaumond氏らは、Google DeepMindのGemma、Mistral AIのPixtral、AlibabaのQwen VL、Hugging FaceのSmolVLMなど、事前量子化されたモデルを共有しており、これらは直接使用可能です。このアップデートは@ngxson氏と@ggml_orgチームの貢献によるもので、ローカライズされた低遅延のマルチモーダルAIアプリケーションに新たな可能性を開きます (情報源: ggerganov, ClementDelangue, cognitivecompai)
Quark AIスーパーボックス、「ディープサーチ」機能でAIの「検索能力」を向上: Quark AIスーパーボックスは最近アップグレードされ、「ディープサーチ」機能を導入しました。これはAIの検索能力(検索商)を向上させることを目的としています。新機能は、検索前のAIによる能動的な思考と論理的計画を強調し、ユーザーの複雑で個別化されたクエリ意図をよりよく理解し、問題を分解して整理されたインテリジェントな検索を実行できます。健康分野では、Quark AI健康アドバイザー「阿夸」が三甲病院の医師の意見や専門資料を参考にします。学術分野では知網などの権威ある情報源にアクセスします。さらに、Quarkは画像分析、AI切り抜き、画像強調、スタイル変換など、強力なマルチモーダル処理能力も備えています。Quarkは将来、Deep Research能力を備えたディープサーチPro版もリリースする予定とのことです (情報源: WeChat)

LangChain、RAGとエージェント能力を強化する多数の統合とチュートリアルを発表: LangChainは最近、複数のアップデートとチュートリアルを発表しました:1. ソーシャルメディアエージェントUIチュートリアル:LangChainソーシャルメディアエージェントをユーザーフレンドリーなWebアプリケーションに変換し、ExpressJSとAgentInbox UIを統合し、Notionをサポートする方法を指導します。2. 受賞RAGソリューション:企業の年次報告書を分析するRAG実装を紹介し、PDF解析、複数LLM、高度な検索をサポートします。3. プライベートRAGチャットアプリケーション:LangChainとReflexフレームワークを使用して、ローカライズされ、データプライバシーを重視したRAGチャットアプリケーションを構築する方法をデモンストレーションするチュートリアルです。4. Nimble Retriever統合:強力なWebデータ検索器を導入し、LangChainアプリケーションに正確なデータを提供します。5. Claude 3.7構造化出力ガイド:LangChainとAWS Bedrockを通じてClaude 3.7の構造化出力を実現する3つの方法を提供します。6. ローカルチャットRAGシステム:LangChain RAGプロセスとローカルLLM(Ollama経由)を使用して構築された完全にローカライズされたドキュメントQ&Aシステムを紹介するオープンソースプロジェクトで、データプライバシーを確保します (情報源: LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI)

Minion-agent:複数フレームワークの能力を統合するオープンソースAIエージェントフレームワーク: Minion-agentは、既存のAIフレームワーク(OpenAI、LangChain、Google AI、SmolaAgentsなど)の断片化問題を解決することを目的とした、新しいオープンソースのAIエージェント開発フレームワークです。統一されたインターフェースを提供し、複数フレームワークの能力呼び出し、ツール・アズ・ア・サービス(Webブラウジング、ファイル操作など)、および複数エージェントの協調をサポートします。プロジェクトは、ディープリサーチ(文献を自動収集してレポートを生成)、価格比較(自動化された市場調査)、クリエイティブ生成(ゲームコード生成)、技術動向追跡などのシーンでの応用可能性を示し、柔軟性とコスト効率におけるオープンソースモデルの利点を強調しています (情報源: WeChat)

RunwayML、多様なシーンで強力なビデオ生成・編集能力を発揮: 独立系AI研究者のCristobal Valenzuela氏や他のユーザーが、RunwayMLの多様なクリエイティブシーンでの応用例を紹介しています。これには、Frames、References、Gen-4機能を利用し、スタイルとキャラクターの一貫性を保ちながらクリエイティブなビジュアルを迅速に生成・視覚化すること、レンブラントの世界をRPGビデオゲームとして制作すること、視覚的参照を提供することで斬新な一枚の画像からのインテリアデザインビュー合成を実現することなどが含まれます。これらの事例は、RunwayMLの制御可能なビデオ生成、スタイル変換、シーン構築における進歩を浮き彫りにしています (情報源: c_valenzuelab, c_valenzuelab, c_valenzuelab, c_valenzuelab)

Olympus:コンピュータビジョンタスクのための汎用タスクルーター: Olympusは、コンピュータビジョンタスク用に設計された汎用タスクルーターです。異なる視覚タスクの処理フローを簡素化し統一することを目的としており、計算リソースやモデル呼び出しをインテリジェントにスケジューリングおよび割り当てることで、マルチタスクコンピュータビジョンシステムの効率と性能を最適化する可能性があります。プロジェクトはGitHubでオープンソース化されています (情報源: dl_weekly)
Tracy Profiler:リアルタイム・ナノ秒級混合フレーム&サンプリングアナライザー: Tracy Profilerは、ゲームやその他のアプリケーション向けのリアルタイム、ナノ秒級解像度、リモートテレメトリ対応の混合型フレームアナライザーおよびサンプリングアナライザーツールです。CPU(C, C++, Lua, Python, FortranおよびサードパーティバインディングのRust, Zig, C#など)、GPU(OpenGL, Vulkan, Direct3D, Metal, OpenCL)、メモリ割り当て、ロック、コンテキストスイッチのパフォーマンス分析をサポートし、スクリーンショットとキャプチャフレームを自動的に関連付けることができます。このツールは、その高精度とリアルタイム性により、開発者に強力なパフォーマンスボトルネックの特定と最適化手段を提供します (情報源: GitHub Trending)

FieldStation42:レトロな放送テレビシミュレーター: FieldStation42は、昔ながらの放送テレビの視聴体験をシミュレートすることを目的としたPythonプロジェクトです。複数のチャンネルを同時にサポートし、広告や番組予告を自動的に挿入し、設定に基づいて毎週の番組表を生成します。このシミュレーターは、新鮮さを保つために最近放送されていない番組をランダムに選択し、番組の放送日範囲(季節番組など)を設定でき、テレビ局の放送休止ビデオや無信号ループ画面を設定できます。プロジェクトはまた、チャンネル変更操作をシミュレートするためにハードウェア接続(Raspberry Pi Picoなど)をサポートし、プレビュー/ガイドチャンネル機能を提供します。その目標は、ユーザーが「テレビをつける」と、その時間帯とチャンネルに合った「本物の」番組コンテンツを再生することです (情報源: GitHub Trending)

Tiny Corp、USB3ベースのAMD eGPUソリューションを発表、Apple Siliconをサポート: Tiny Corpは、USB3(具体的にはASM2464PDコントローラーベースのADT-UT3Gデバイス)を介してAMD eGPUをApple Silicon Macに接続するソリューションを展示しました。このソリューションはドライバーを書き換え、USB3の10Gbps帯域幅を利用し、libusbを使用しており、理論的にはLinuxやWindowsもサポートします。これは、Apple Siliconユーザーがグラフィック処理能力を拡張するための新しい道を開き、特にローカルで大規模なAIモデルを実行するなどのシーンで潜在的な価値があります (情報源: Reddit r/LocalLLaMA)
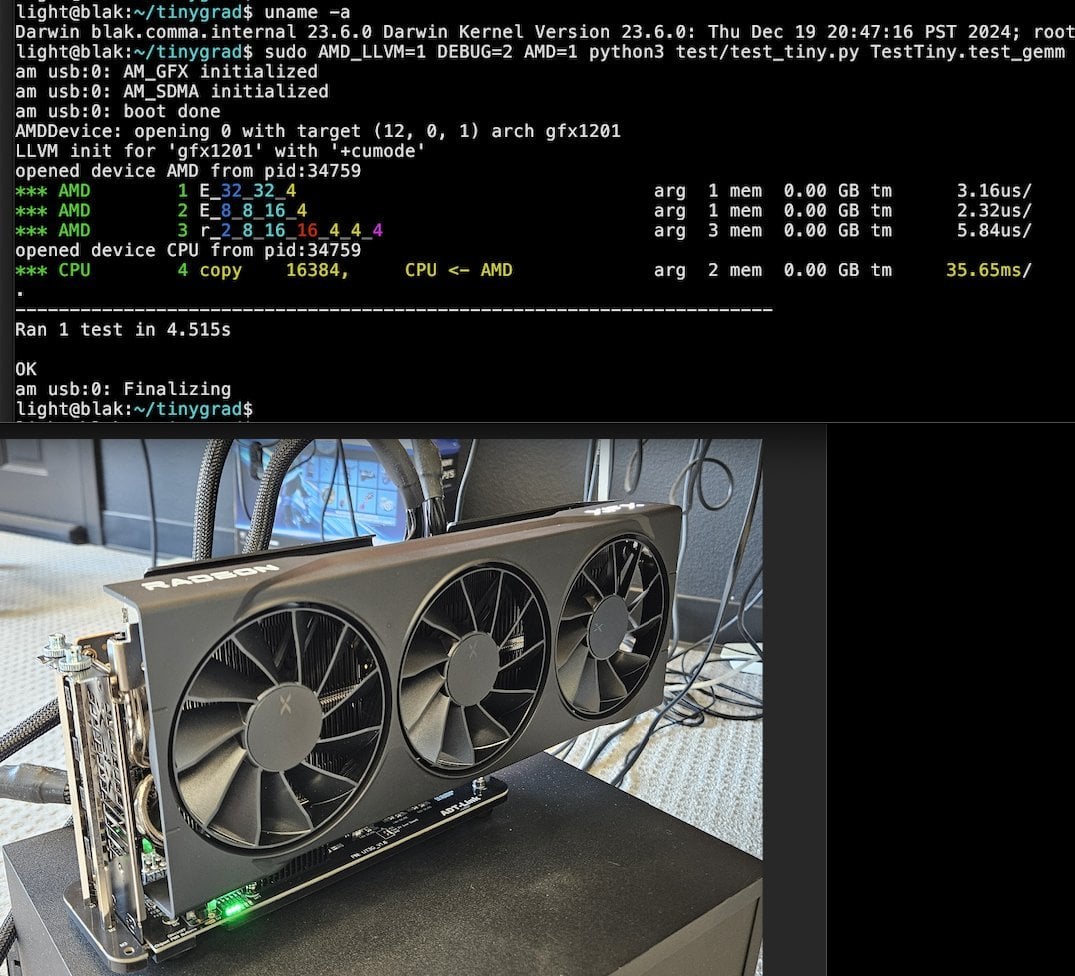
Llama.cpp-vulkan、AMD GPUでFlashAttentionをサポート: Llama.cppのVulkanバックエンドは最近、FlashAttentionの実装をマージしました。これは、AMD GPUでllama.cpp-vulkanを使用するユーザーがFlashAttention技術を利用できるようになったことを意味します。Q8 KVキャッシュ量子化と組み合わせることで、ユーザーは推論速度を維持または向上させながら、コンテキストサイズを2倍に拡張できると期待されています。このアップデートは、AMD GPUユーザーがローカルで大規模言語モデルを実行する上で重要な利点となります (情報源: Reddit r/LocalLLaMA)
Devseeker:軽量AIコーディングアシスタント、AiderとClaude Codeの代替案: Devseekerは、AiderとClaude Codeの代替として位置づけられる、新しくオープンソース化された軽量AIコーディングエージェントプロジェクトです。コードの作成と編集、コードファイルとフォルダの管理、短期的なコードメモリ、コードレビュー、コードファイルの実行、トークン使用量の計算、および複数のコーディングモードの提供などの機能を備えています。このプロジェクトは、より簡単にローカルに展開して使用できるAI支援プログラミングツールを提供することを目的としています (情報源: Reddit r/ClaudeAI)
📚 学習
Panaversity、Agentic AI学習プロジェクトを開始、DaprとOpenAI Agents SDKに焦点: Panaversityは、「Learn Agentic AI」プロジェクトを開始しました。これは、Dapr Agentic Cloud Ascent (DACA) 設計パターンと複数のエージェントネイティブクラウド技術(OpenAI Agents SDK, Memory, MCP, A2A, Knowledge Graphs, Dapr, Rancher Desktop, Kubernetesを含む)を通じて、エージェントおよびロボットAIエンジニアを育成することを目的としています。このプロジェクトの核心は、数千万の同時AIエージェントを処理できるシステムの設計方法を解決し、AI-201、AI-202、AI-301シリーズのコースを提供し、基礎から大規模分散AIエージェントまでの学習パスをカバーします。プロジェクトは、OpenAI Agents SDKがそのシンプルさと使いやすさ、高い制御性から主流の開発フレームワークになるべきだと強調しています (情報源: GitHub Trending)

RLファインチューニング研究、データ管理と汎化能力の複雑な関係を明らかに: Minqi Jiang氏が転送した論文は、強化学習(RL)ファインチューニングにおけるデータ管理がモデルの汎化能力に与える影響について論じています。研究によると、自己対局によるカリキュラム学習を通じて「無限」のコーディングタスクで訓練した場合(Absolute Zero Reasoner)でも、単一のMATHタスクサンプルで繰り返し訓練した場合(1-shot RLVR)でも、7B規模のQwen2.5シリーズモデルは数学ベンチマークテストで約28%から40%の精度向上を達成できました。これは、極端なデータ管理戦略(無限データ対単一データ)が同様の汎化改善を生み出すというパラドックスを明らかにしています。考えられる説明としては、RLが主に事前学習済みモデルが既に持つ能力を引き出すこと、共有された「推論回路」の存在、そして事前学習が競合する推論回路を引き起こす可能性などが挙げられます。研究者らは、「事前学習の天井」を突破するには、新しいタスクと環境を継続的に収集・創造する必要があると述べています (情報源: menhguin)
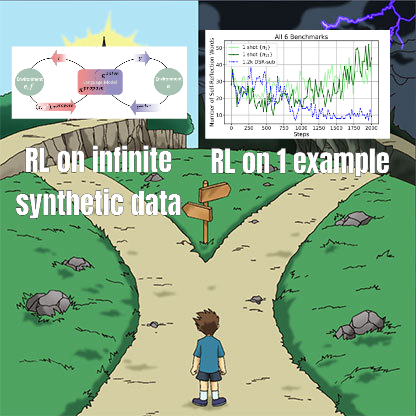
Absolute Zero Reasoner:自己対局によりゼロデータで推論能力を向上: 「Absolute Zero Reasoner」と題された論文は、モデルが完全な自己対局(self-play)を通じて学習可能性を最大化するタスクを提案し、これらのタスクを解決することで自身の推論能力を向上させることができると提案しています。このプロセス全体で外部データは一切不要です。この方法は、数学およびコーディング分野で他の「ゼロショット」モデルを上回る性能を示しました。これは、AIシステムがおそらく内部で問題を生成・解決することで継続的にその推論能力を進化させることができ、データが乏しい、またはアノテーションコストが高い分野のAI応用に新たな道筋を提供するものです (情報源: cognitivecompai, Reddit r/LocalLLaMA)

AI製品評価における一般的な誤りとベストプラクティスの共有: Hamel Husain氏とShreya Runwal氏は、AI製品評価(evals)を作成する際の一般的な誤りを共有し、これらの誤りを避けるための提案を提供しました。重要な点には、基礎モデルのベンチマークはアプリケーション評価と同じではないこと、汎用的な評価は無効であり、特定のアプリケーションに合わせて行う必要があること、アノテーションとプロンプトエンジニアリングを非専門家に外注しないこと、独自のデータアノテーションアプリケーションを構築すべきであること、LLMプロンプトは具体化し、エラー分析に基づいて行うべきであること、二値ラベルを使用すること、データレビューを重視すること、テストデータへの過学習に注意すること、オンラインテストを実施することが含まれます。これらの実践は、開発者がより信頼性が高く、現実世界のパフォーマンスをよりよく反映するAI製品評価システムを構築するのに役立つことを目的としています (情報源: jeremyphoward, HamelHusain)
KVキャッシュ最適化の新発想:汎用転移可能辞書と信号処理再構成: ウィスコンシン大学マディソン校のDimitris Papailiopoulos氏のチームは、汎用的で転移可能な辞書と従来の信号処理再構成アルゴリズムを組み合わせることで、KVキャッシュを削減する新しい方法を提案しました。この方法は、非推論モデルで既にSOTA(state-of-the-art)レベルを達成しており、推論モデルではさらに優れた性能が期待されています。この研究はICMLに採択され、大規模モデル推論におけるKVキャッシュの過大な占有問題を解決するための新たな視点と技術的道筋を提供しています (情報源: teortaxesTex, jeremyphoward, arohan, andersonbcdefg)

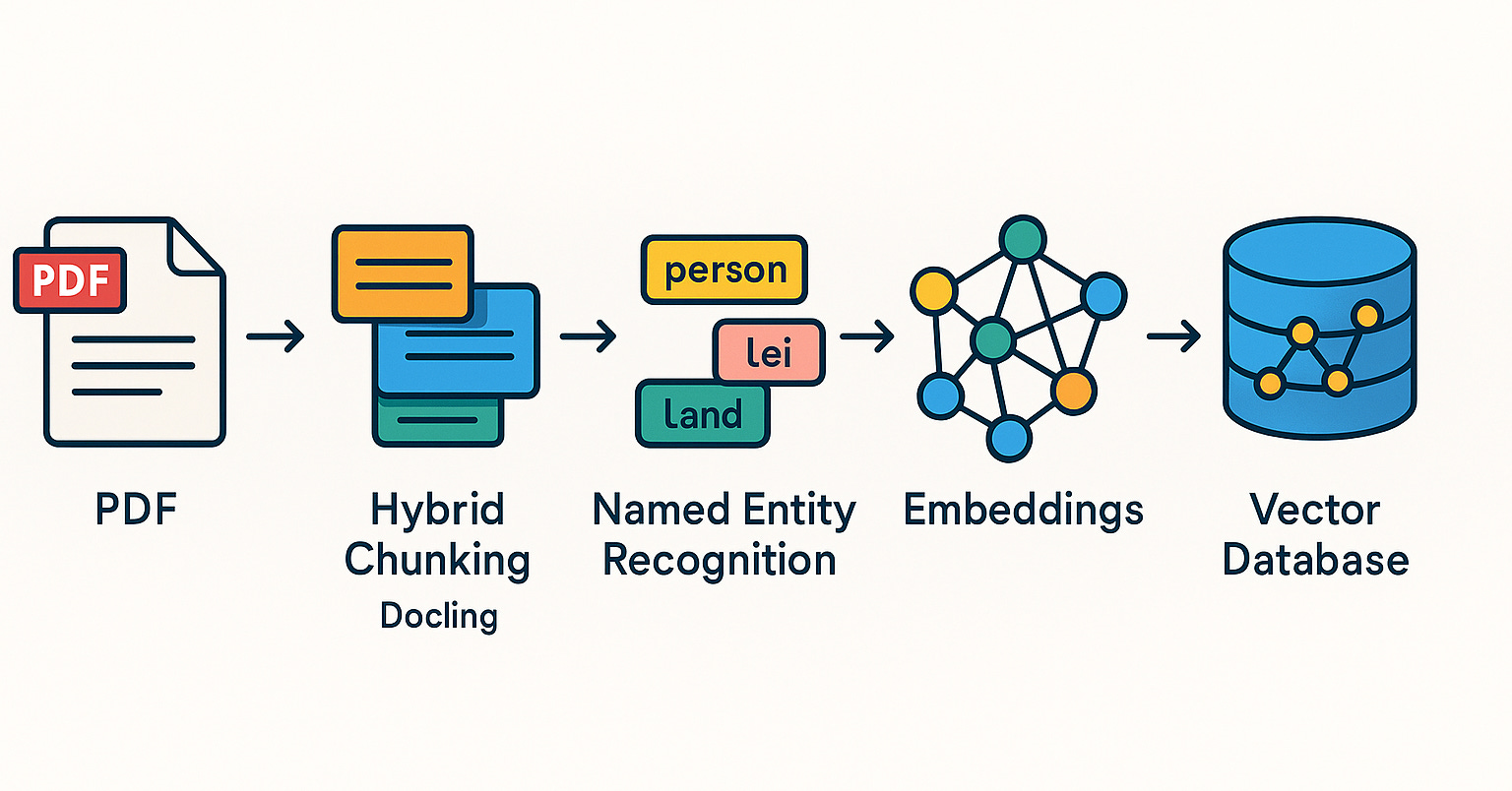
Qdrant、ブラジルコミュニティでRAGシステムとハイブリッド検索の実践を推進: Qdrantベクトルデータベースは、ブラジルコミュニティでますます注目を集めています。開発者のDaniel Romero氏は、Qdrant、FastAPI、ハイブリッド検索を使用してRAG(Retrieval Augmented Generation)システムを構築するための実用的な方法を紹介する2つのポルトガル語の記事を共有しました。内容は、ハイブリッド検索RAGシステムの構築方法や、RAG向けのデータ取り込み戦略、特にハイブリッドチャンキング(Hybrid Chunking)技術についてです。これらの共有は、ブラジルの開発者がQdrantをより良く活用してAIアプリケーション開発を行うのに役立ちます (情報源: qdrant_engine)
OpenAI Academy、K-12教育向けプロンプトエンジニアリング特集シリーズを開始: OpenAI Academyは、K-12教育者向けのプロンプトエンジニアリング(Prompt Engineering)学習シリーズ「Mastering Your Prompts」を発表しました。このシリーズは、教育者がプロンプト技術をよりよく理解し活用することで、AIツール(ChatGPTなど)を教育実践により効果的に取り入れ、教育効果と生徒の学習体験を向上させることを目的としています。これは、AI支援教育が徐々に基礎教育段階に浸透し、教育者のAIリテラシー育成を重視していることを示しています (情報源: dotey)
Yann LeCun氏、シンガポール国立大学での講演内容を共有: Yann LeCun氏は、2025年4月27日にシンガポール国立大学(NUS)で行った特別講演(Distinguished Lecture)のPDFドキュメントを共有しました。講演の具体的なテーマは提供されていませんが、LeCun氏は深層学習分野の先駆者であり、その講演は通常、人工知能の最先端理論、将来のトレンド、または現在のAI開発に対する深い洞察を含んでいます。この共有は、AI研究に関心のある人々が彼の最新の見解を直接入手する機会を提供します (情報源: ylecun)
PyTorchとMojoバックエンドが協力、新しいハードウェアと言語への適応を簡素化: PyTorchは、新しいプログラミング言語やハードウェア向けの新しいバックエンド作成プロセスの簡素化に取り組んでいます。Mojoハッカソンで、marksaroufim氏はPyTorchのこの方面での努力を紹介し、Mojoチームと共同開発中のWIP(進行中)バックエンドについて言及しました。これは、PyTorchエコシステムが互換性を積極的に拡張し、より多様なAI開発環境とハードウェアアクセラレーションオプションをサポートすることで、開発者が異なるプラットフォームでPyTorchモデルを展開・最適化する際の障壁を低減していることを示しています (情報源: marksaroufim)
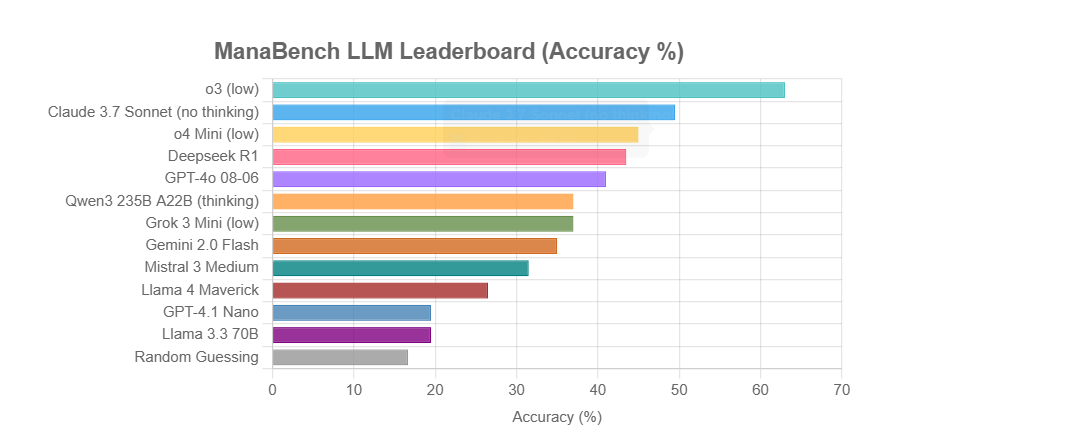
ManaBench:マジック:ザ・ギャザリングのデッキ構築に基づく新しいLLM推論能力ベンチマーク: ある開発者がManaBenchという新しいベンチマークを作成しました。これは、LLMに59枚のマジック:ザ・ギャザリング(MTG)カードが与えられた状況で、6つの選択肢から最適な60枚目のカードを選ばせることで、その複雑なシステム推論能力をテストするものです。このベンチマークは戦略的推論、システム最適化を重視し、答えは人間の専門家の設計と一致しており、単純な記憶では解読困難です。初期の結果では、Llamaシリーズモデルのパフォーマンスは期待以下であり、o3やClaude 3.7 Sonnetのようなクローズドソースモデルがリードしています。このベンチマークは、複雑な推論タスクが必要なLLMのパフォーマンスをより現実的に評価することを目的としています (情報源: Reddit r/LocalLLaMA)
議論:AIはセマンティックウェブの夢を復活させるか、それとも葬り去るのか?: ソーシャルメディア上で、ユーザーのSpencer氏は、ADA法案(米国障害者法)による重大なリスクにさらされている大企業のウェブサイトでない限り、ほとんどのウェブサイトでセマンティックウェブは実践よりも理論に近いと述べています。Dorialexander氏は、AIがセマンティックウェブの夢を復活させるか、永遠に葬り去るかのどちらかだと感じていると応じました。これは、構造化データの理解と活用におけるAIの可能性に対する期待と懸念を反映しており、AIは構造化情報を自動的に理解・生成することで間接的にセマンティックウェブの目標を達成するかもしれませんが、その強力な能力ゆえに従来のセマンティックウェブ技術がそれほど重要でなくなる可能性もあります (情報源: Dorialexander)
研究者、モデルの記憶と忘却の倫理およびアーキテクチャを議論: 「Sticky Minds: The Ethics and Architectures of AI Memory and Forgetting」と題された論文草稿が執筆中であり、モデルが「記憶しすぎる」ようになったとき、何を忘れるべきかをどのように決定するかを、神経アーキテクチャと記憶の倫理を融合させて議論しています。これは、AIシステムが情報をどのように保存、検索、(選択的に)忘却するか、そしてそれによってもたらされる倫理的課題と社会的影響に関わるものであり、責任ある信頼できるAIを構築するために極めて重要です (情報源: Reddit r/artificial)
💼 ビジネス
NVIDIA、米国の新たな輸出規制に適合する「再ダウングレード版」H20チップを発売するとの報道: ロイター通信によると、NVIDIAは今後2ヶ月以内に、米国の最新の輸出規制要件に適合する新しい中国市場向けH20 AIチップを発売する計画です。このチップは、既存のH20(それ自体が中国市場向けにカスタマイズされたダウングレード版)をベースにさらに「ダウングレード」され、例えばメモリ容量が大幅に削減される予定です。性能は再び低下しますが、下流ユーザーはモジュール構成を変更することで、ある程度の性能調整が可能とされています。現在、NVIDIAは180億ドル相当のH20の注文を受けています (情報源: WeChat)

Databricks、オープンソースデータベース企業Neonを10億ドルで買収か、AIインフラを強化: データとAIの企業であるDatabricksが、オープンソースPostgreSQLデータベースエンジン開発企業Neonの買収交渉を進めていると報じられています。取引額は約10億ドルになる可能性があります。Neonは、サーバーレスアーキテクチャ、ストレージとコンピューティングの分離、AI Agentやアンビエントプログラミングへの優れた適合性を特徴としており、オンデマンドでの従量課金制利用を可能にし、データベースインスタンスを迅速に起動できるため、AIアプリケーションのシナリオに適しています。この買収が成功すれば、DatabricksのAI時代におけるインフラストラクチャ層の能力がさらに強化され、最新のAI中心のデータベースソリューションが提供されることになります (情報源: WeChat)

OpenAI、元Instacart CEOのFidji Simo氏をアプリケーション事業CEOに任命、製品と商業化を強化: OpenAIは、元Instacart CEOであり同社取締役会メンバーでもあるFidji Simo氏を、新設された「アプリケーション事業最高経営責任者」に任命したと発表しました。Simo氏はSam Altman氏と同格となります。Simo氏は、OpenAIの製品、特にChatGPTなどのユーザー向けアプリケーションを全面的に担当し、製品の最適化、ユーザーエクスペリエンスの向上、商業化プロセスの推進を目指します。この動きは、OpenAIの戦略的重点がモデル開発から製品プラットフォーム化と市場拡大へと大きく転換することを示しており、AIアプリケーション層でより強力な競争力を確立する意図があります。Simo氏のFacebookとInstacartでの豊富な製品および商業化経験は、OpenAIがますます激化する市場競争に対応する上で役立つでしょう (情報源: WeChat)

🌟 コミュニティ
JetBrains AI Assistant、体験の悪さやコメント管理でユーザーの不満を招く: JetBrainsのAI Assistantプラグインは2200万回以上ダウンロードされていますが、そのマーケットプレイスでの評価は5点満点中わずか2.3点で、大量の1つ星の低評価で溢れています。ユーザーからは、自動インストール、動作の遅さ、バグの多さ、サードパーティモデルのサポート不足、コア機能のクラウドサービスへの紐付け、ドキュメントの欠如などの問題が広く指摘されています。最近、JetBrainsが否定的なコメントを大量に削除したと指摘されましたが、公式には規約違反や解決済みの問題に対処したものと説明しているものの、依然としてユーザーからはコメント操作やユーザーフィードバック軽視への疑念が寄せられており、一部のユーザーは低評価を再投稿し、引き続き1つ星を付けています。この件は、JetBrainsのAI製品戦略に対するユーザーの不満を増幅させています (情報源: WeChat)

AIマーケティングエージェントの出力品質問題についてユーザーが活発に議論: ソーシャルメディアユーザーのomarsar0氏は、多くのYouTubeチュートリアルで紹介されているマーケティングAIエージェントが生成するマーケティングコピーの品質が総じて低く、創造性やスタイルに欠けていると指摘しています。同氏は、これはLLMに高品質で魅力的なコンテンツを生成させることの難しさを反映しており、AIエージェントを構築する際には「センス」が極めて重要であると強調しています。現在の多くのAIエージェントはワークフローが複雑であるものの、真に商業的価値のあるコンテンツを生み出す点ではまだ不十分であり、これが高いセンスを持ち、経験豊富で優れた評価システムを設計できる人材に機会を提供していると指摘しています (情報源: omarsar0)
AI支援コーディングと「アンビエントプログラミング」のトレンドが議論を呼ぶ: RedditのY CombinatorがAIコーディングについて議論するビデオに関する投稿が話題を呼んでいます。ビデオの視点と投稿者(「アンビエントプログラミング」を通じて複数の収益化プロジェクトを作成したと自称)の経験は非常に一致しており、主な論点は以下の通りです:1. AIは既に複雑で実用的なソフトウェア製品の構築を支援でき、コードを書く必要さえない場合もある。2. ソフトウェアエンジニアはAIに仕事を奪われることへの懸念を日増しに強めているが、AI支援開発を真に習得した人々は「超能力」を持っている。3. 将来のソフトウェアエンジニアの役割は、AIツールを巧みに使いこなす「エージェント管理者」に変わる可能性があり、AIがコード記述の大部分を担当するようになる。4. AIはニッチ市場向けの小規模ソフトウェアを大量に生み出すだろう。議論参加者は、AIコーディングの可能性は大きいものの、効果的に活用するには依然としてエンジニアリングの概念、データベース、アーキテクチャなどの知識が必要であると考えています (情報源: Reddit r/ClaudeAI)

AIが「世界を乗っ取る」のか、雇用への影響についての議論が続く: Redditのr/ArtificialInteligence板の投稿は、AIの将来的な影響に対するコミュニティの一般的な不安と多様な意見を反映しています。一部のユーザーは、AIの能力について深く知るほど、それが人間を超越し未来を支配することへの懸念が大きくなると考えており、最先端のAIシステムが既に驚くべき能力を示していると指摘しています。他のユーザーは、AGIに対する過度な演出が非現実的な期待を生み出しており、AIは本質的にインテリジェントな自動化ツールであり、その影響はコンピュータやインターネットと同様に漸進的なものになるだろうと考えています。議論はまた、AIの雇用への潜在的な影響、富の分配、規制の有効性にも及んでおり、歴史は技術進歩がしばしば貧富の差を拡大させることを示しており、AIは多数の雇用をなくすことでさらに富を集中させる可能性があるという意見もあります。同時に、医療や教育などの分野におけるAIの積極的な役割に期待する声もあります (情報源: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
ユーザー体験:ChatGPTなどのAIツールが思考と認知に与える影響: 一部のユーザーは、ソーシャルプラットフォームやRedditで、ChatGPTなどのAIツールを使用することによる認知レベルでの肯定的な影響を共有しています。彼らは、AIが単なる情報取得や執筆支援ツールではなく、思考を整理し、潜在意識にあるアイデアを明確に表現するのを助ける「思考のパートナー」や「鏡」のようなものだと感じています。AIとの対話を通じて、ユーザーは自身の信念をよりよく反省し、挑戦し、思考パターンを発見し、さらには「目覚めている」ように感じ、人生やシステムについてより深い認識を得ていると述べています。この体験は、AIが特定の状況下で個人の成長と自己探求を促進する触媒となる可能性を示唆しています (情報源: Reddit r/ChatGPT)
💡 その他
第2回「兴智杯」全国人工知能イノベーション応用コンテストが開始: 中国情報通信研究院などが共催する第2回「兴智杯」が開幕しました。コンテストは「兴智赋能,创新引领」(知恵によるエンパワーメント、イノベーションによるリーディング)をテーマとし、大規模モデルイノベーション、業界エンパワーメント、ソフトウェア・ハードウェアイノベーションエコシステムの3つの主要トラックと複数の特色ある分野を設けています。このイベントは、AI技術のイノベーション、エンジニアリング化、自主的なエコシステム構築を推進することを目的とし、工業、医療、金融など約10の重点業界をカバーし、国産AIソフトウェア・ハードウェアの応用を強調しています。優秀プロジェクトには資金提供や産業連携などの支援が与えられます (情報源: WeChat)

Sequoia Capital AI Ascentの共有:AI市場のポテンシャルは巨大、アプリケーション層とエージェントエコノミーが未来: Sequoia CapitalのパートナーであるPat Grady氏らがAI AscentイベントでAI市場に関する洞察を共有しました。彼らはAI市場のポテンシャルがクラウドコンピューティングをはるかに超えると考えていますが、「雰囲気収益」(ユーザーが真のニーズではなく好奇心から試すだけ)には警戒が必要です。アプリケーション層が真の価値の源泉と見なされており、スタートアップ企業は垂直分野と顧客ニーズに集中すべきです。AIは音声生成とプログラミング分野で既にブレークスルーを達成しています。将来は「エージェントエコノミー」が展望され、AIエージェントがリソースを移転し、取引を行えるようになりますが、永続的なアイデンティティ、通信プロトコル、セキュリティなどの課題に直面します。同時に、AIは個人の能力を大幅に増幅させ、「スーパー個人」を生み出すでしょう (情報源: WeChat)

議論:AI時代の大学機械学習コースの内容と教育の質に関心集まる: NYUのKyunghyun Cho教授が大学院MLコースのシラバスを共有したことが議論を呼びました。このコースはSGDで解決できる非LLM問題や古典論文の読解を強調しており、Harvard CS教授などの同業者から基礎概念の維持が重要であると評価されています。しかし、インドや米国の学生からは、大学のMLコースの質が低く、抽象的すぎ、専門用語だらけで深い説明が不足しているため、学生が独学やオンラインリソースに頼らざるを得ないとの不満が出ています。これは、AI/ML分野の急速な発展と大学コースの更新の遅れとの間の矛盾、および数学と理論の基礎を固めることの重要性を反映しています (情報源: WeChat)
