
キーワード:AIセキュリティ, 人工知能倫理, AIエージェント, 3D生成, コードモデル, AIリスク評価, Gemini 2.5 Pro動画理解, AssetGen 2.0 3D生成, Seed-Coderコードモデル, AgentOpsエージェント運用
🔥 フォーカス
AIの安全リスクへの関心高まる、専門家は核セキュリティの経験を参考にリスク評価を提言: 人工知能の潜在的リスクに対する国際社会の懸念が日増しに高まっており、一部の専門家(Max Tegmark氏など)は、AI企業が危険なAIシステムをリリースする前に、ロバート・オッペンハイマーが最初の核実験の際に行った安全計算手法に倣い、人工知能が制御不能になる確率(コンプトン定数)を厳格に評価すべきだと呼びかけている。これは業界のコンセンサスを形成し、グローバルなAI安全メカニズムの構築を推進し、スーパーインテリジェンスがもたらす可能性のある壊滅的な結果を防ぐことを目的としている。(出典: Reddit r/artificial, Reddit r/ArtificialInteligence)

新教皇フランシスコ(自称Leo XIV)がAIによる社会変革に高い関心: 新たに選出された教皇フランシスコ(Leo XIVと称される)は、人工知能を人類が直面する主要な課題の一つとして特定した。彼が「Leo」を名乗りとして選んだ理由の一部は、AIが駆動する新たな社会問題と産業革命であり、これは歴史的に教皇Leo XIIIが第一次産業革命に対応したことを反映している。教皇はAIが「人間の尊厳、正義、労働」の維持に課題をもたらすと強調し、将来的にAI倫理に関する重要な文書を発表する計画であり、宗教指導者がAI技術の倫理と社会的影響に深い懸念を抱いていることを示している。(出典: Reddit r/artificial, AymericRoucher, AravSrinivas, Reddit r/ArtificialInteligence)

Google、76ページのAIエージェント白書を発表、AgentOpsと将来の応用を詳述: Googleは76ページに及ぶAIエージェントに関する白書を発表し、エージェントの構築、評価、応用について詳細に説明した。白書は、生成AI運用の一分野として、エージェントの効率的な運用に必要なツール管理、コアプロンプト設定、記憶機能、タスク分解などに焦点を当てたエージェント運用(AgentOps)の重要性を強調している。また、白書は、異なるエージェントが計画、検索、実行、評価などの役割を担い、複雑なタスクを共同で完了するマルチエージェント協力アーキテクチャについても議論し、NotebookLMエンタープライズ版やAgentspaceなど、企業における従業員支援やバックエンドタスクの自動化におけるエージェントの応用展望を示している。(出典: WeChat)

Meta、AssetGen 2.0を発表:テキスト/画像から高品質な3D素材を生成: Metaは最新の3D基盤AIモデルAssetGen 2.0を発表した。このモデルはテキストと画像のプロンプトに基づいて高品質な3Dアセットを作成できる。AssetGen 2.0には2つのサブモデルが含まれている。1つは3Dメッシュ生成用で、単一ステージの3D拡散モデルを採用して詳細と忠実度を向上させている。もう1つのTextureGenモデルはテクスチャ生成用で、ビューの一貫性向上、テクスチャ修復、より高いテクスチャ解像度の手法を導入している。この技術は現在Meta内部で3Dワールド作成に使用されており、今年後半にはHorizonクリエイター向けに展開される予定だ。(出典: Reddit r/artificial)

🎯 動向
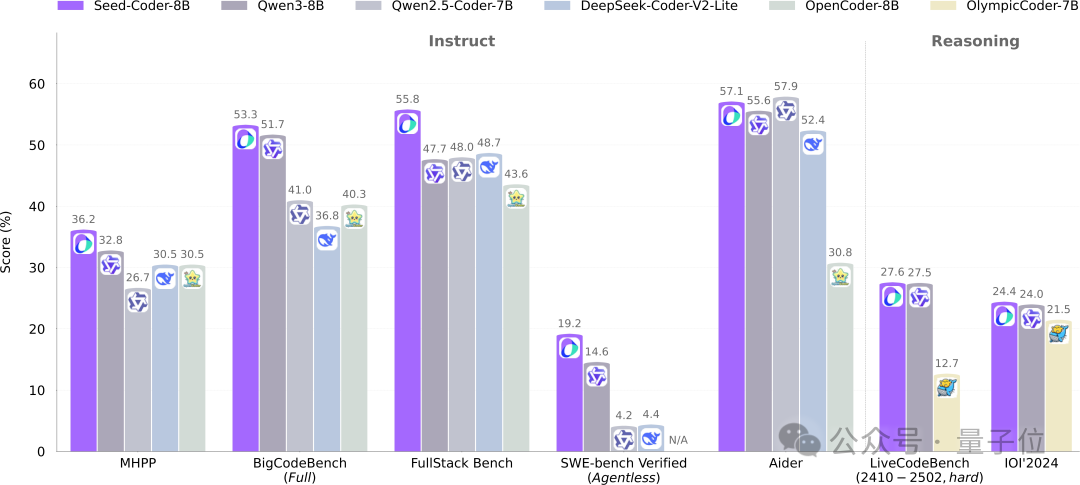
ByteDanceのSeedチーム、8BコードモデルSeed-Coderをオープンソース化、モデルがデータを管理する新たなパラダイムを採用: ByteDanceのSeedチームは、初めて8B規模のコードモデルSeed-Coderをオープンソース化した。これにはBase、Instruct、Reasoningの3つのバージョンが含まれる。このモデルは複数のコード生成ベンチマークで優れた性能を示し、特にHumanEvalとMBPPではQwen3などのモデルを上回った。Seed-Coderの中核的な革新は、「モデル中心」のデータ処理方式を提案した点にあり、LLM自身を利用して高品質なコード訓練データを生成・選別する。これにはファイルレベルのコード、リポジトリレベルのコード、Commitデータ、コード関連のウェブデータが含まれ、総訓練データ量は6T tokensに達する。これは人手を介さずにコードモデルの能力を向上させることを目指している。(出典: WeChat)
Gemini 2.5 Proが動画理解でブレークスルー、音声・動画とコードをネイティブに融合: Googleの最新モデルGemini 2.5 ProとFlashは、動画理解能力で著しい進歩を遂げた。Gemini 2.5 Proは複数の主要な動画理解ベンチマークでSOTAレベルに達し、GPT 4.1をも上回った。Gemini 2.5シリーズモデルは初めて、音声・動画情報とコードなどの他のデータ形式をネイティブかつシームレスに結合し、動画を直接インタラクティブなアプリケーション(学習アプリなど)に変換したり、動画に基づいてp5.jsアニメーションを生成したり、動画の断片を正確に検索・記述したりすることができ、強力な時間的推論能力を示している。これらの機能はGoogle AI Studio、Gemini API、Vertex AIで利用可能になっている。(出典: WeChat)

ModelScope、統一画像モデルNexus-Genをオープンソース化、GPT-4oの画像能力に対抗: ModelScopeチームは、画像の理解、生成、編集を同時に処理できる統一マルチモーダルモデルNexus-Genを発表した。これはGPT-4oの画像処理能力に匹敵することを目指している。このモデルはtoken → transformer → diffusion → pixelsという技術ルートを採用し、MLLMのテキストモデリング能力とDiffusionモデルの画像レンダリング能力を融合している。自己回帰的に連続画像を予測する際の誤差蓄積問題を解決するため、チームは事前充填自己回帰戦略を提案した。Nexus-Genは約25Mの画像・テキストデータで訓練され、これにはModelScopeコミュニティが最近オープンソース化したImagePulse編集データセットも含まれる。(出典: WeChat)

Cursor 0.50バージョンリリース、価格設定を簡素化し多数のコード編集機能を強化: AIコードエディタCursorが0.50バージョンをリリースし、大幅なアップデートを行った。価格モデルはリクエストベースのモデルに簡素化され、MaxモードはすべてのトップAIモデルをサポートし、トークンベースの価格設定を採用する。機能強化には以下が含まれる:新しいTabモデルはファイル間の提案とコードリファクタリングをサポート。バックグラウンドエージェント(プレビュー版)は複数のエージェントを並行して実行し、リモート環境でタスクを実行可能。コードベースコンテキストは@foldersを介してコードベース全体を追加可能。インライン編集UIを最適化し、ファイル全体の編集とエージェントへの送信機能を追加。長文ファイルの編集には検索置換ツールを導入。複数のコードベースを処理するためのマルチルートワークスペースをサポート。チャット機能を強化し、Markdownへのエクスポートとコピーをサポート。(出典: op7418)
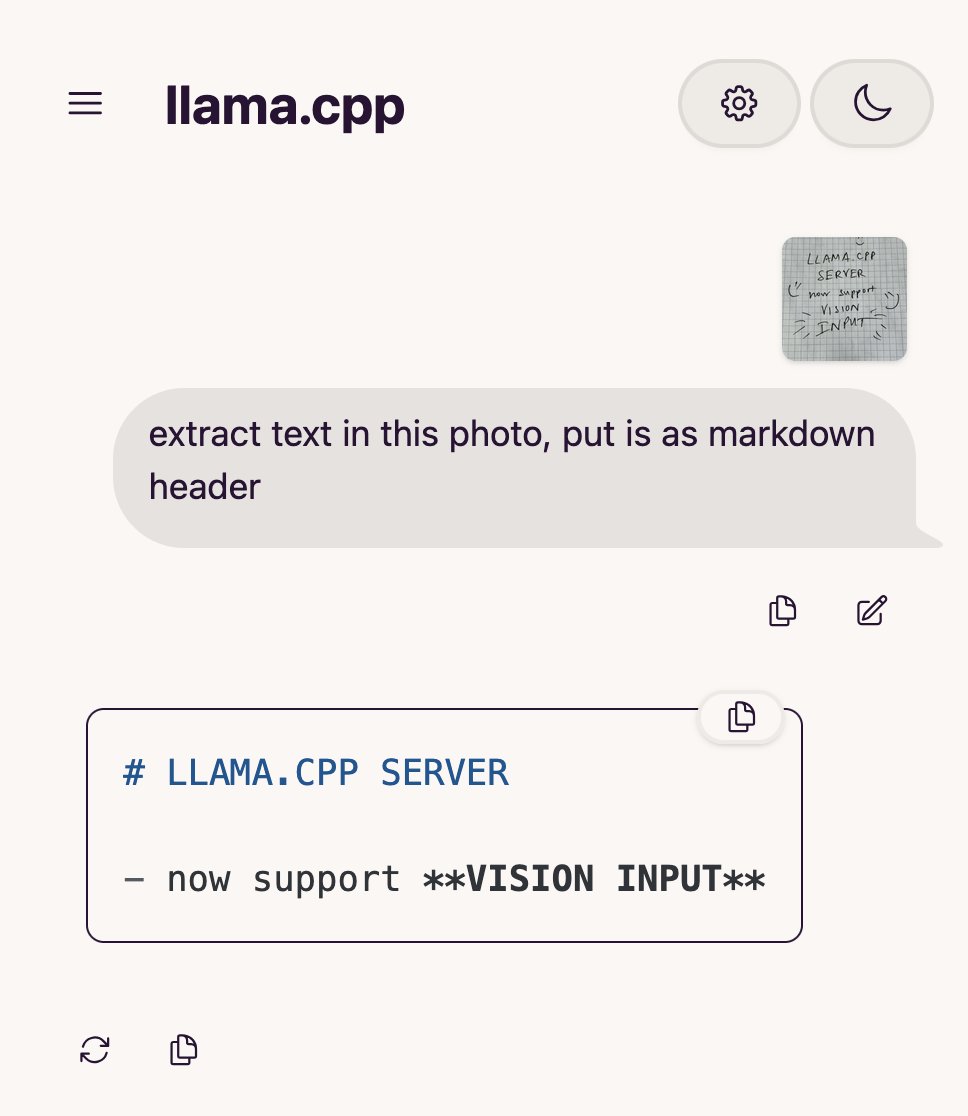
llama.cpp、視覚言語モデル(VLM)サポートを追加、完全な視覚RAGフローを構築可能に: オープンソースプロジェクトllama.cppは、視覚言語モデル(VLM)をサポートしたことを発表した。ユーザーはllama.cppサーバーとWeb UIを介して視覚機能を使用できるようになった。このアップデートにより、llama.cpp上で複数のLoRAをサポートする同一の基礎モデルと埋め込みモデルをロードできるようになり、完全な視覚検索拡張生成(Vision RAG)フローを構築できるようになった。これにより、llama.cppがローカルで大規模言語モデルを実行する能力がさらに拡張され、マルチモーダルタスクを処理できるようになる。(出典: mervenoyann, mervenoyann)
Tencent、HunyuanCustomを発表:HunyuanVideoベースのカスタマイズ動画生成アーキテクチャ: TencentはHugging Face上で、カスタマイズ動画生成専用に設計されたマルチモーダル駆動アーキテクチャHunyuanCustomを発表した。この研究はHunyuanVideoを基礎としており、特に動画生成時の主体の一貫性を維持することを強調し、同時に画像、音声、動画、テキストなど多様な条件の入力をサポートし、ユーザーにより柔軟でパーソナライズされた動画作成能力を提供する。(出典: _akhaliq)
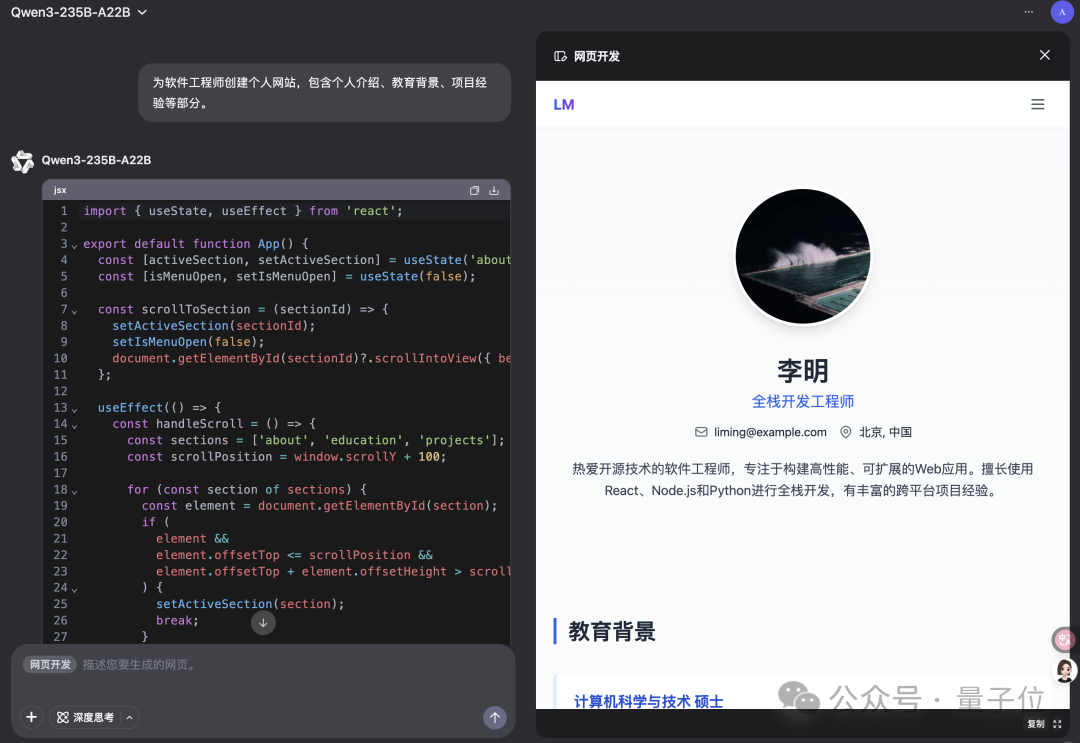
Qwen Chatに「ウェブ開発」モード追加、一言でReactウェブアプリを生成: AlibabaのQwen Chatは「ウェブ開発」(Web Dev)モードを導入した。ユーザーは一言の指示だけでHTML、CSS、JavaScriptを含むウェブアプリケーションを生成でき、バックエンドではReactフレームワークとTailwind CSSを使用している。この機能は、個人ウェブサイトの迅速な作成、既存のウェブインターフェース(Twitter、GitHubなど)の複製、または説明に基づいた特定のフォームやアニメーションの構築を可能にする。ユーザーは異なるQwenモデルを選択し、「ディープシンキング」モードと組み合わせてウェブページの品質を向上させることができる。この機能は、フロントエンド開発プロセスを簡素化し、アプリケーションのプロトタイプを迅速に構築することを目的としている。(出典: WeChat)
Unitree Robotics、Go1ロボット犬のセキュリティ脆弱性について回答、後続製品はアップグレード済みと強調: Unitree Roboticsは、約2年前に生産中止となったGo1ロボット犬シリーズに存在する「バックドア脆弱性」の噂に対し、これがセキュリティ脆弱性であることを認めた。攻撃者は第三者のクラウドトンネルサービスの管理キーを悪用してユーザーデバイスのデータを改ざんし、カメラ映像やシステム権限を取得できる可能性がある。Unitree Roboticsは、後続のロボットシリーズはより安全なアップグレード版を採用しており、この脆弱性の影響を受けないと述べている。この事件は、特にヒューマノイドロボット商業化元年の背景において、スマートロボットのサプライチェーンセキュリティとデータプライバシーに対する懸念を引き起こし、業界は技術的難関の克服、コスト管理、商業化経路の模索など、多重の課題に直面している。(出典: 36氪)

Claude Code、他の.MDファイルの参照をサポート、指示の整理を最適化: AnthropicのClaude Codeはその機能を更新し、バージョン0.2.107ではCLAUDE.mdファイルが他のMarkdownファイルをインポートできるようになった。ユーザーはメインのCLAUDE.mdファイルに [u/path/to/file].md を追加することで、起動時に追加のファイルコンテンツをロードできる。この改善により、ユーザーはClaudeの指示をより良く整理・管理できるようになり、大規模プロジェクトにおける指示設定の信頼性とモジュール性が向上し、従来分散ファイルに依存することで生じていた混乱の問題を解決する。(出典: Reddit r/ClaudeAI)

米国著作権局、AIの事前学習に対しより強硬な姿勢、 「フェアユース」の抗弁を弱める: 米国著作権局が新たに発表した報告書は、AIモデルの事前学習段階における著作権保護された素材の使用問題に対し、より強硬な立場を示した。報告書は、AI研究所が現在、自社のモデルが権利保有者と競合できる(例えば、オリジナル作品と類似したコンテンツを生成するなど)と主張しているため、これが著作権侵害訴訟において「フェアユース」(fair use)を理由に自らを弁護する力を弱めていると指摘している。この変化は、AIモデルの訓練データの出所とコンプライアンスに重大な影響を与える可能性がある。(出典: Dorialexander)

NVIDIA、48GB GDDR7メモリ搭載のプロフェッショナル向けグラフィックスカードRTX Pro 5000を発表: NVIDIAは、Blackwellアーキテクチャに基づく新しいプロフェッショナル向けデスクトップGPU、RTX Pro 5000を発表した。このグラフィックスカードは48GBのGDDR7メモリを搭載し、メモリ帯域幅は最大1344 GB/s、消費電力は300W。公式には「廉価版」の48GB Blackwellグラフィックスカードと称されているが、価格は依然として高額(コメントでは4000ドル級との言及あり)と予想され、主にプロフェッショナルワークステーションユーザー向けに、AIモデルのトレーニングや大規模な3Dレンダリングなどのタスクに強力な計算能力を提供する。(出典: Reddit r/LocalLLaMA)

🧰 ツール
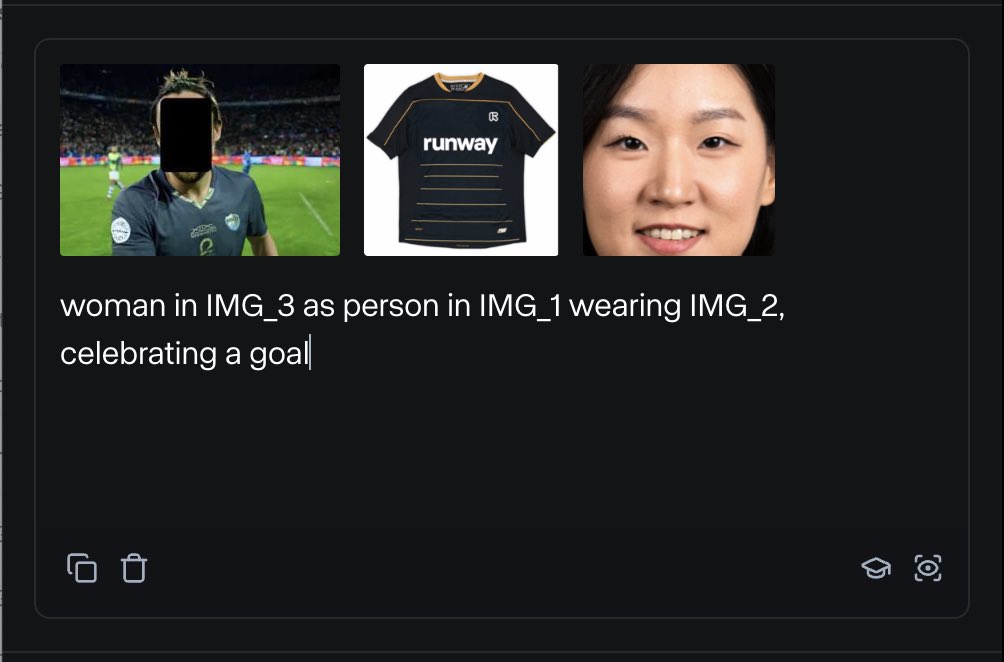
RunwayML、複数の参照素材を混合してコンテンツを生成できるReferences機能を発表: RunwayMLの新機能「References」は、ユーザーが異なる参照素材(画像、スタイルなど)を「原料」として混合し、これらの「原料」の任意の組み合わせに基づいて新しい視覚コンテンツを生成することを可能にする。この機能は、ほぼリアルタイムの創作マシンと見なされており、ユーザーが様々なクリエイティブなアイデアを迅速に実現するのを助け、AIによる視覚コンテンツ作成の柔軟性と可能性を大幅に拡大する。(出典: c_valenzuelab)
Chat2DB:自然言語でデータベースを操作するAIクライアント: Chat2DBはAI駆動のデータベースクライアントツールで、ユーザーが自然言語でデータベースと対話できるようにする。例えば、ユーザーが「今月最も消費額が多かった顧客は誰ですか?」と質問すると、Chat2DBはAIを利用して質問を理解し、データベースのテーブル構造に基づいて対応するSQLクエリ文を自動生成してクエリを実行し、結果を返す。これにより、データベース操作の技術的ハードルが大幅に下がり、非技術者でも簡単にデータ照会や分析を行えるようになる。このプロジェクトはGitHubでオープンソース化されている。(出典: karminski3)
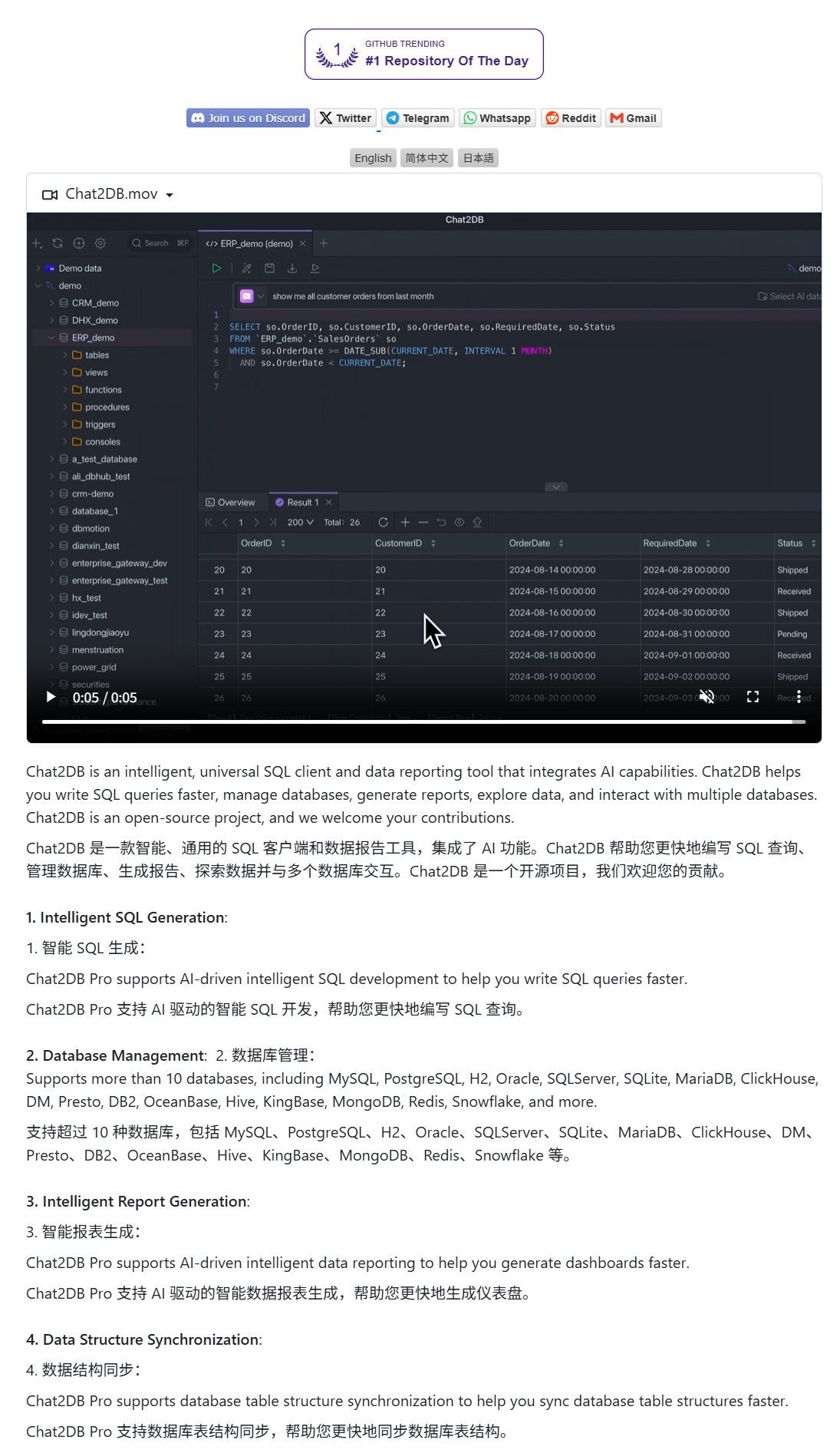
Qwen 3 8Bモデルが優れたコード能力を発揮、HTMLキーボードを生成可能: Qwen 3 8Bモデル(Q6_K量子化版)は、パラメータ数が少ないにもかかわらず、コード生成において優れた性能を発揮する。ユーザーは2つの短いプロンプトで、このモデルに遊べるHTMLキーボードのコードを生成させることに成功した。これは、小規模モデルでも特定のタスクで高い実用性を達成できる可能性を示しており、特にリソースが限られたローカル展開シナリオにとって魅力的である。(出典: Reddit r/LocalLLaMA)
Ollama Chat:Claude風インターフェースのローカルLLMチャットツール: Ollama Chatは、ローカル大規模言語モデル向けに設計されたWebチャットインターフェースで、そのUIスタイルとユーザーエクスペリエンスはAnthropicのClaudeを参考にしている。このツールはテキストファイルのアップロード、会話履歴、システムプロンプト設定をサポートし、使いやすく美しいローカルLLM対話ソリューションを提供することを目指している。プロジェクトはGitHubでオープンソース化されており、ユーザーが自分でデプロイして使用するのに便利である。(出典: Reddit r/LocalLLaMA)
AIでパーソナライズされたカード(誕生日/母の日)を生成するプロンプトのヒント: ユーザーがAIを使ってパーソナライズされたカード(誕生日カード、母の日カードなど)を生成するためのプロンプトのヒントを共有した。重要なのは、カードのテーマ(母の日、誕生日など)、スタイル(女性らしいスタイル、子供向けスタイルなど)、受取人(お母さん、Sandy、Jimmyなど)、年齢(30歳、6歳など)、そしてお祝いの言葉の具体的な内容や温かく甘い基調を明確にすることだ。これらの要素を組み合わせることで、AIがニーズに合ったカードデザインを生成するように導くことができる。(出典: dotey)

📚 学習
Google、プロンプトエンジニアリング白書を発表、ユーザーに効果的な質問方法を指導: Googleはプロンプトエンジニアリングに関する白書(Kaggle経由でアクセス可能)を発表し、ユーザーがAIモデルにより効果的に質問する方法を教えることを目的としている。チュートリアル内容は明確で、出力要件の明確化、出力範囲の制約、変数の使用方法などのテクニックを詳細に紹介し、ユーザーが大規模言語モデルとの対話の効率と効果を向上させ、より正確で有用な回答を得られるよう支援する。(出典: karminski3)

香港科技大学(広州)チームがMultiGOを提案:階層的ガウスモデリングで単一画像から3Dテクスチャ人体を生成: 香港科技大学(広州)のチームは、MultiGOという革新的なフレームワークを提案し、階層的ガウスモデリングを通じて単一の画像からテクスチャ付きの3D人体モデルを再構築する。この方法は、人体を骨格、関節、しわなど、異なる精度レベルに分解し、段階的に詳細化する。コア技術は、ガウススプラッティング点を3Dプリミティブとして採用し、骨格強調、関節強調、しわ最適化モジュールを設計している。この研究成果はCVPR 2025に採択され、単一画像からの3D人体再構築に新たなアプローチを提供し、コードは間もなくオープンソース化される予定だ。(出典: WeChat)

清華大学、復旦大学、香港科技大学が共同でRM-BENCHを発表:初の報酬モデル評価ベンチマーク: 現在の大規模言語モデルの報酬モデル評価における「形式が内容よりも優先される」およびスタイルバイアスの問題に対し、清華大学、復旦大学、香港科技大学の研究チームが共同で、初の体系的な報酬モデル評価ベンチマークRM-BENCHを発表した。このベンチマークは、チャット、コード、数学、安全の4つの主要分野を網羅し、モデルの微妙な内容差に対する感度とスタイル偏差に対する堅牢性を評価することで、より信頼性の高い「内容審判員」の新基準を確立することを目指している。研究により、既存の報酬モデルは数学とコード分野での性能が低く、普遍的にスタイル偏差が存在することが明らかになった。この成果はICLR 2025 Oralに採択された。(出典: WeChat)

天津大学とTencent、COMEソリューションをオープンソース化:5行のコードでTTAの堅牢性を向上、モデル崩壊を解決: 天津大学とTencentは共同でCOME (Conservatively Minimizing Entropy) メソッドを提案した。これは、テスト時適応 (TTA) プロセス中にエントロピー最小化 (EM) によって引き起こされるモデルの過信と崩壊の問題を解決することを目的としている。COMEは、主観的論理を導入して予測の不確実性を明示的にモデル化し、適応的Logit制約(Logitノルムの凍結)を採用して間接的に不確実性を制御することで、保守的なエントロピー最小化を実現する。この方法はモデルアーキテクチャを変更する必要がなく、少量のコードで既存のTTAメソッドに組み込むことができ、ImageNet-Cなどのデータセットでモデルの堅牢性と精度を大幅に向上させると同時に、計算コストはごくわずかである。論文はICLR 2025に採択され、コードはオープンソース化されている。(出典: WeChat)
Huaweiと中国科学院情報工学研究所、DEERを提案:思考連鎖の「動的早期終了」メカニズムでLLMの推論効率と精度を向上: Huaweiは中国科学院情報工学研究所(信工所)と共同でDEER(Dynamic Early Exit in Reasoning)メカニズムを提案した。これは、大規模言語モデルが長い思考連鎖(Long CoT)推論中に過度に思考する可能性のある問題を解決することを目的としている。DEERは、推論の転換点を監視し、試験的な回答を誘導し、その信頼度を評価することで、思考を早期に終了して結論を生成するかどうかを動的に判断する。実験によると、DeepSeekシリーズなどの推論LLMにおいて、DEERは追加の訓練なしに思考連鎖の生成長を平均31%~43%削減し、同時に精度を1.7%~5.7%向上させることが示された。(出典: WeChat)

中国科学院などがR1-Rewardを提案:安定した強化学習によるマルチモーダル報酬モデルの訓練: 中国科学院、清華大学、快手、南京大学の研究チームは、R1-Rewardを提案した。これは、安定した強化学習アルゴリズムStableReinforceを用いてマルチモーダル報酬モデル(MRM)を訓練し、その長時間推論能力を向上させる方法である。StableReinforceは、PPOなどの既存のRLアルゴリズムがMRM訓練時に遭遇する可能性のある不安定性の問題を改善し、Pre-Clip戦略、アドバンテージフィルター、および斬新な一貫性報酬メカニズム(分析と回答の一貫性をチェックする審判モデルを導入)によって訓練プロセスを安定させる。実験により、R1-Rewardは複数のMRMベンチマークでSOTAモデルよりも優れた性能を示し、推論時の複数回サンプリング投票によってさらに性能を向上させることができることが示された。(出典: WeChat)
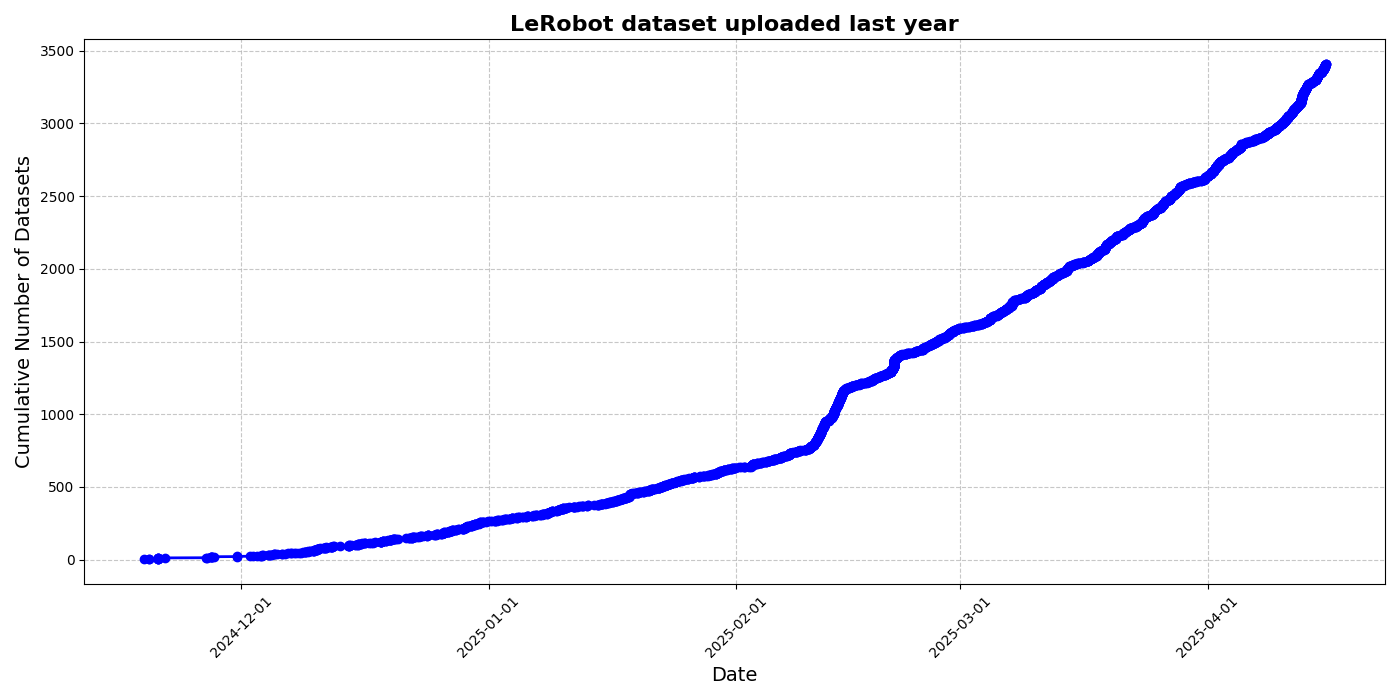
HuggingFace、LeRobotコミュニティデータセットイニシアチブを発表、ロボット工学の「ImageNetモーメント」を推進: HuggingFaceはLeRobotコミュニティデータセットプロジェクトを開始した。これはロボット工学分野の「ImageNet」を構築し、コミュニティの貢献を通じて汎用ロボット技術の発展を推進することを目的としている。記事は、ロボットの汎化能力にとってデータ多様性の重要性を強調し、既存のロボットデータセットの多くが限定的な学術環境から生まれていることを指摘している。LeRobotは、データ収集・アップロードプロセスの簡素化とハードウェアコストの削減を通じて、ユーザーがさまざまなロボット(So100、Kochロボットアームなど)の多様なタスク(チェス、引き出し操作など)におけるデータを共有することを奨励している。同時に、記事はデータ品質基準とベストプラクティスのリストを提案し、データアノテーションの不一致、特徴マッピングの曖昧さなどの課題に対応し、高品質で多様なロボットデータセットの構築を促進する。(出典: HuggingFace Blog, LoubnaBenAllal1)
HuggingFaceブログ記事、LLMの11種類の調整・最適化アルゴリズムを総括: TheTuringPostはHuggingFace上の記事を共有し、その中で大規模言語モデル(LLM)に使用される11種類の調整・最適化アルゴリズムをまとめている。これらのアルゴリズムには、PPO(Proximal Policy Optimization)、DPO(Direct Preference Optimization)、GRPO(Group Relative Policy Optimization)、SFT(Supervised Fine-Tuning)、RLHF(Reinforcement Learning from Human Feedback)、SPIN(Self-Play Fine-Tuning)などが含まれる。記事はこれらのアルゴリズムへのリンクと詳細情報を提供し、研究者や開発者にLLM最適化手法の概要を提供している。(出典: TheTuringPost)
UC Berkeley、CS280大学院コンピュータビジョンコースの教材を共有: カリフォルニア大学バークレー校のAngjoo Kanazawa教授とJitendra Malik教授は、今学期に担当した大学院コンピュータビジョンコースCS280の全講義資料を共有した。彼らは、古典的および現代的なコンピュータビジョンの内容を組み合わせたこの教材セットが効果的であると考え、学習者の参考に供するために公開した。(出典: NandoDF)
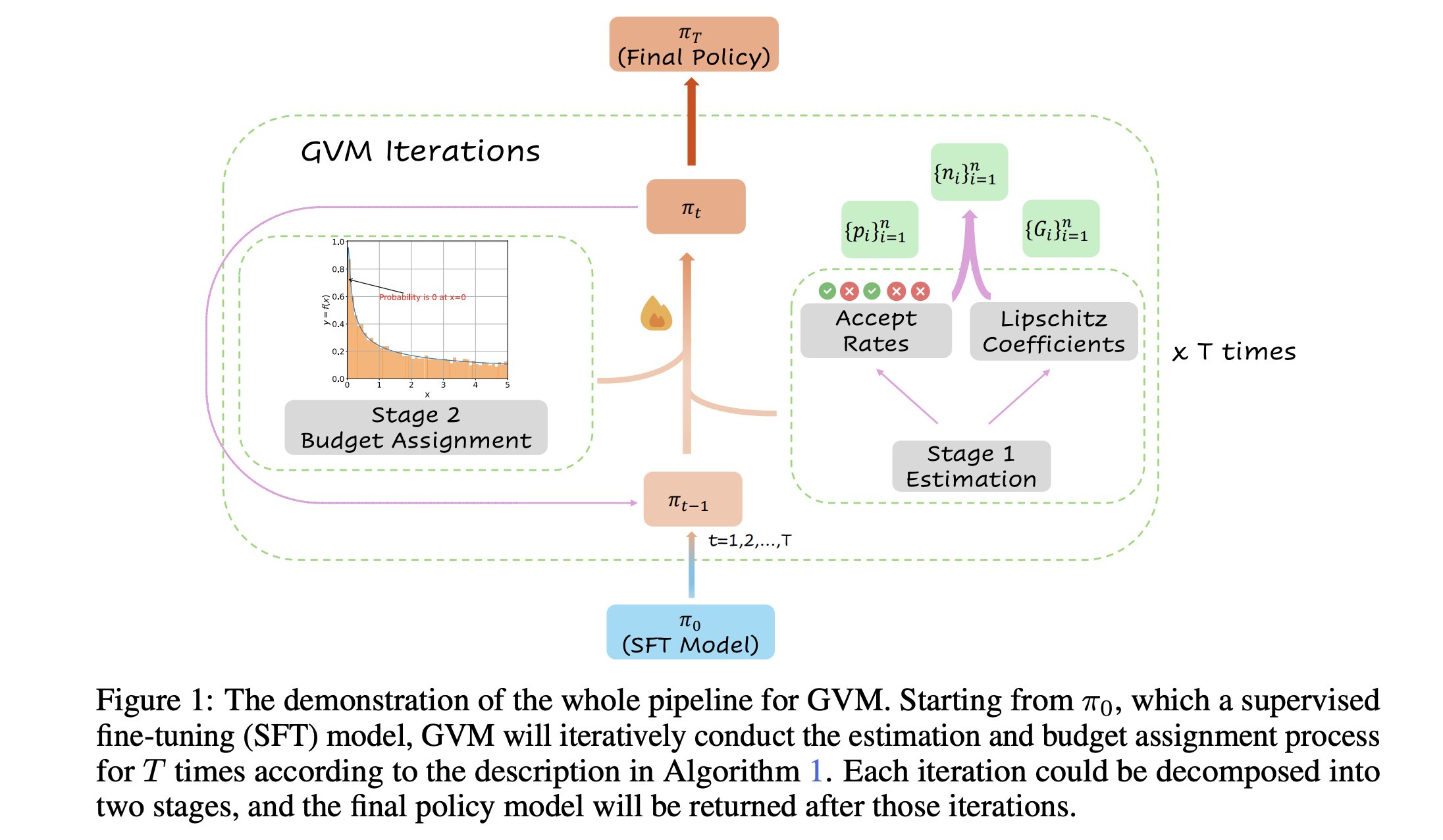
GVM-RAFT:思考連鎖推論器を最適化する動的サンプリングフレームワーク: 新しい論文でGVM-RAFTフレームワークが紹介された。このフレームワークは、各プロンプトに対してサンプリング戦略を動的に調整することで思考連鎖(chain-of-thought)推論器を最適化し、勾配分散を最小化することを目指している。この方法により、数学的推論タスクにおいて2~4倍の高速化を実現し、精度も向上したとされている。(出典: _akhaliq)
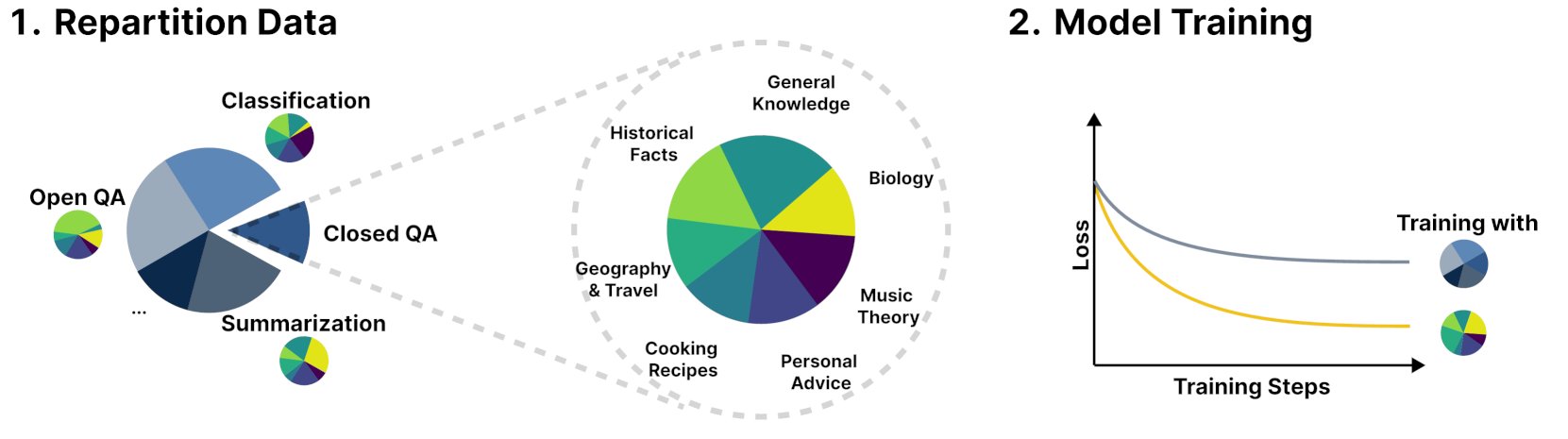
新フレームワークR&B、訓練データの動的バランス調整により言語モデルの性能を向上: R&Bという名の新しい研究は、言語モデルの訓練データを動的にバランス調整することで、わずか0.01%の追加計算量でモデルの性能を向上させる新しいフレームワークを提案した。この方法は、データ利用効率を最適化し、わずかなコストでモデルのパフォーマンス改善を目指すものである。(出典: _akhaliq)
論文、AI安全の新たな視点を議論:社会と技術の進歩を継ぎ接ぎのキルトを縫うことと見なす: arXivで発表された新しい論文「Societal and technological progress as sewing an ever-growing, ever-changing, patchy, and polychrome quilt」は、AI安全の新たな視点を提案し、AI安全の中核を意見の相違が紛争にエスカレートするのを防ぐことに焦点を当てるべきだと主張している。この論文は、社会と技術の進歩を、絶えず拡大し、変化し、継ぎ接ぎだらけで多彩なキルトを縫うことに例え、複雑なシステムにおける安定と協力の維持の重要性を強調している。(出典: jachiam0)
論文、自己回帰言語モデルにおける適応的計算を議論: ディープラーニングにおける適応的計算の興味深さについての議論があり、関連技術の発展が列挙されている:PonderNet (DeepMind, 2021) はニューラルネットワークと反復を統合する初期のツールとして。拡散モデルは複数回のフォワードプロパゲーションを通じて計算を行う。そして最近の推論型言語モデルは任意の数のトークンを生成することで同様の効果を実現している。これは、モデルが計算リソースの割り当てと使用において柔軟性と動的な傾向を示していることを反映している。(出典: jxmnop)
論文、「悪いデータ」がいかにして「良いモデル」を生み出すかを議論: ハーバード大学の2025年の論文「When Bad Data Leads to Good Models」(arXiv:2505.04741) は、ある状況下では、品質が低いように見えるデータ(4chanのコンテンツを含む事前学習データなど)が、逆にモデルの調整やその「パワーレベル」を隠すのに役立ち、より優れたパフォーマンスを発揮させる可能性があることを議論している。これは、データ品質、モデルの調整、およびモデルの行動の真実性に関する議論を引き起こしている。(出典: teortaxesTex)

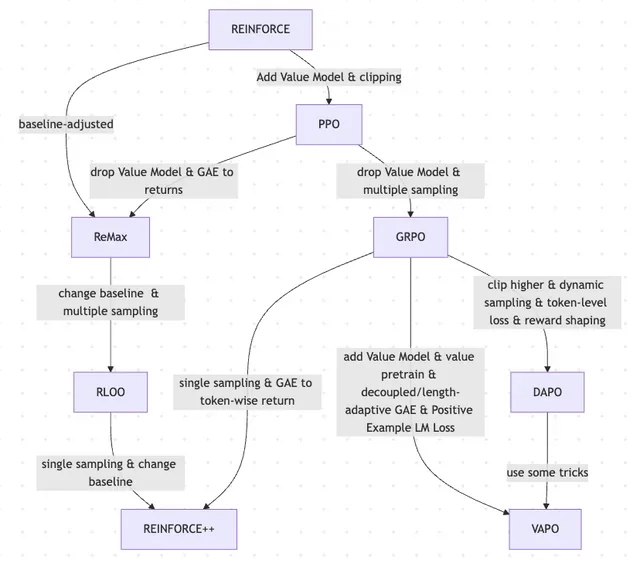
論文、RLHFとその変種の進化を議論、REINFORCEからVAPOまで: ある研究論文は、大規模言語モデル(LLM)のファインチューニングに使用される強化学習(RL)手法の進化の歴史をまとめている。論文は、古典的なPPOやREINFORCEアルゴリズムから始まり、GRPO、ReMax、RLOO、DAPO、VAPOなどの最近の手法への進化を追跡し、その中での価値モデルの破棄、サンプリング戦略の変更、ベースラインの調整、報酬シェーピングやトークンレベルの損失などのテクニックの応用を分析している。この研究は、LLMアライメント分野におけるRLHFとその変種の研究の全体像を明確に示すことを目的としている。(出典: Reddit r/MachineLearning)
論文「Absolute Zero」:AIが人間データなしで強化学習による自己学習推論を実行: 「Absolute Zero: Reinforced Self-Play Reasoning with Zero Data」(arXiv:2505.03335)と題された白書は、論理AIを訓練する新しい方法を探求している。研究者たちは、人間がラベル付けしたデータセットを使用せずに論理AIモデルを訓練し、モデルは自ら推論タスクを生成し、問題を解決し、コード実行を通じて解決策を検証する。これは、AIが完全に事前の知識(数学、物理学、言語など)がない原始的な環境で、ゼロから記号表現を発明し、論理構造を定義し、数体系を発展させ、因果モデルを構築できるかどうか、そしてそのような「異質な知能」の可能性とリスクについての議論を引き起こしている。(出典: Reddit r/ArtificialInteligence, Reddit r/artificial)
復旦大学智能人機交互実験室、2026年度の修士・博士課程学生を募集: 復旦大学計算機科学技術学院の智能人機交互実験室は、2026年度のサマーキャンプ/推薦入学による修士・博士課程の大学院生を募集している。実験室は尚笠教授が率いており、研究方向にはウェアラブルAGI(MemXスマートグラスとLLMの組み合わせ)、オープンソースの具現化された知能、モデル圧縮(大から小へ)、および機械学習システム(MLコンパイル最適化、AIプロセッサなど)が含まれる。実験室は、人間中心の知能を探求し、大規模モデルとスマートウェアラブル、具現化された知能システムを融合した新たなヒューマン・コンピュータ・インタラクションのパラダイムの構築に取り組んでいる。(出典: WeChat)

💼 ビジネス
評価額10億ドル超、従業員50人未満のAIスタートアップ10社の概要: Business Insiderは、評価額10億ドルを超えながら従業員数が50人未満のAIスタートアップ10社をリストアップした。これにはSafe Superintelligence(評価額320億ドル、従業員20人)、OG Labs(評価額20億ドル、従業員40人)、Magic(評価額15.8億ドル、従業員20人)、Sakana AI(評価額15億ドル、従業員28人)などが含まれる。これらの企業は、AI分野において小規模チームで高い評価額を達成する可能性を示しており、技術とイノベーションが資本市場で高い価値を持つことを反映している。(出典: hardmaru)
Fourier Intelligence、介護・リハビリテーション分野を深化、上海国際医療センターと協力し、具身知能リハビリテーション拠点を構築: 具身知能のユニコーン企業であるFourier Intelligenceは、初の具身知能エコシステムサミットで、上海国際医療センターと協力し、リハビリテーション医療分野における具身知能ロボットの応用を共同で推進すると発表した。これには、基準策定、ソリューション共同開発、科学研究が含まれ、国内初の具身知能リハビリテーション実証拠点を構築する。Fourier Intelligenceの創業者である顧捷氏は、今後10年間の核心戦略として「介護・リハビリテーションに立脚し、インタラクションに焦点を当て、人に奉仕する」を掲げ、医療リハビリテーションがその基盤であることを強調した。同社は2015年の設立以来、リハビリテーションロボットから汎用ヒューマノイドロボットGR-1およびGRxシリーズへと事業を拡大し、累計数百台を出荷している。(出典: 36氪)
Meta、元国防総省高官をリクルートとの報道、軍事分野への布石か: Forbesの報道によると、Meta社は元国防総省高官をリクルートしており、これは同社が軍事技術または国防関連分野での事業を強化する計画であることを意味する可能性がある。この動きは、大手テクノロジー企業による軍事応用への関与に関する議論と注目を集めている。(出典: Reddit r/artificial)

🌟 コミュニティ
Andrej Karpathy氏、LLM学習に重要なパラダイム「システムプロンプト学習」が欠けていると提言し議論を呼ぶ: Andrej Karpathy氏は、現在のLLM学習には重要なパラダイムが欠けており、それを「システムプロンプト学習」と呼んでいる。彼は、事前学習は知識のため、ファインチューニング(教師あり/強化学習)は習慣的な行動のためであり、どちらもパラメータの変更を伴うが、大量の人間との対話やフィードバックが十分に活用されていないようだと指摘している。彼はこれを、映画『メメント』の主人公に、グローバルな問題解決の知識や戦略を保存するためのメモ帳を与えるようなものだと例えている。この見解は広範な議論を呼び、DSPyの理念に近い、あるいは記憶/最適化、継続学習の問題に関わるという意見や、Langgraphで同様のメカニズムをどのように実現するかについての議論がなされている。(出典: lateinteraction, hwchase17, nrehiew_, tokenbender, lateinteraction, lateinteraction)
AI企業が求職者にAIで応募書類を書かないよう求めることが議論を呼ぶ: AnthropicなどのAI企業が、求職者に応募書類(履歴書など)を作成する際にAIツールを使用しないよう求めていることが、コミュニティで議論を呼んでいる。採用担当者からは、AIが生成した履歴書には「言葉のゴミ」が多く、経験豊富な人材でさえも要点を失う可能性があるとの声が上がっている。しかし、求職者の中には、AIが職務要件に合わせて履歴書を最適化し、スキルを強調し、読みやすさを向上させるのに役立つと考える人もいる。議論は、LinkedInなどのプラットフォームがAI生成コンテンツで溢れている現象や、求職者を評価するためにビデオなどの他の方法を採用すべきかどうかにも及んでいる。(出典: Reddit r/artificial, Reddit r/ArtificialInteligence)

AI生成コンテンツの「識別可能性」が議論を呼び、ユーザーは容易に察知できると認識: コミュニティの議論では、AI(特にChatGPT)によって生成されたコンテンツは、特定の句読点(emダッシュなど)や構文(「That’s not x; that’s y.」など)だけでなく、特有の「リズム感」や「平板感」によっても容易に識別できると指摘されている。AIの痕跡を識別すると、コンテンツは非現実的で個性に欠けるように見える。メール、ソーシャルメディアの投稿、さらにはビデオゲームでもこのような状況に遭遇したと述べるユーザーもおり、AIが生成したコンテンツをそのまま使用すると、内容が退屈で不誠実になると考え、ユーザーはAIをツールとして修正し、パーソナライズすべきだと提案している。(出典: Reddit r/ChatGPT)
AIの発展は「ハネムーン期-反動期」のサイクルを示し、人間の真正性への嗜好を反映: 新しい生成AIモデル(テキスト、画像、音楽など)の出現は、人々がその能力に驚嘆する「ハネムーン期」を伴うことが多いという見解がある。しかし、人々がAI生成の「パターン」や「痕跡」を識別し始めるとすぐに反動が生じ、称賛から懐疑へと転じ、さらには「魂がない」とさえ考えるようになる。AI作品を迅速に学習・識別し、欠陥のある人間の創作物を好む傾向は、AIが人間の創造主を完全に置き換えるのではなく、むしろ補助ツールであることを意味する可能性がある。なぜなら、人々は作品の背後にある物語、作者の意図、そして真正性を重視するからだ。(出典: Reddit r/ArtificialInteligence)
Anthropic社内でのAIによるコード生成率が70%超、AIの自己反復への連想を呼ぶ: AnthropicのMike Krieger氏によると、社内のプルリクエスト(pull requests)の70%以上が現在AIによって生成されているという。このデータはコミュニティで議論を呼び、機械が自己編集・改善するSF作品のようなシナリオを連想する人もいる。同時に、このデータの真実性や具体的な意味(例えば、これらのPRの複雑さの程度)について疑問を呈する人もいる。(出典: Reddit r/ClaudeAI)

NVIDIA CEOジェンスン・フアン氏、全従業員によるAIエージェントの活用を強調、AIが開発者の役割を再構築すると予測: NVIDIAのCEOジェンスン・フアン氏は、同社が全従業員にAIアシスタントを配備し、AIエージェントが日常の開発業務に組み込まれ、コードの最適化、脆弱性の発見、プロトタイプ設計の加速化を図ると述べた。彼は、将来誰もが複数のAIアシスタントを指揮し、生産性は指数関数的に向上すると考えている。MetaのCEOマーク・ザッカーバーグ氏、MicrosoftのCEOサティア・ナデラ氏なども同様の見解を示しており、AIがコード作業の大部分をこなし、開発者の役割は「AIの指揮」と「要件定義」に移行すると考えている。この傾向は、ソフトウェア開発サイクルが大きく変化し、GitHub CopilotやCursorなどのAIプログラミングツールが普及することを示唆している。(出典: WeChat)

議論:ML研究者は年間1000~2000本の論文を読むことは可能か?: コミュニティでは、トップの機械学習研究者が年間2000本近くの論文を読む可能性があるという議論がある。これに対し、論文の読書数自体は単なる代理指標であり、本当に重要なのは大量の情報からシグナルを選別し、有効な情報を抽出し、正しく応用する能力であるというコメントがある。分野内のハイライトやトレンドに追いつき、必要に応じて特定の内容を深く研究できる、このような情報フィルタリング能力は今世紀の重要なスキルである。(出典: torchcompiled)
議論:モデル訓練/ファインチューニングのためのGPU購入 vs. GPUレンタル: 機械学習の実践者は、GPUリソースを選択する際に購入かレンタルかの選択に直面する。経験者は混合戦略を推奨している:小規模な実験用にローカルで性能がそこそこのコンシューマー向けGPUを1台構成し、大規模な訓練タスクにはクラウドGPUをレンタルする。選択はモデルの複雑さ、データ量、予算によって決まる。クラウドGPUはML Opsの組織化において利点があるが、同価格帯ではT4などの一般的なクラウドGPUの性能はハイエンドのコンシューマーカード(3090/4090など)に劣る可能性がある。ただし、クラウドではA100/H100など、より大きなVRAMを持つトップクラスのGPUを利用できる。(出典: Reddit r/MachineLearning)
💡 その他
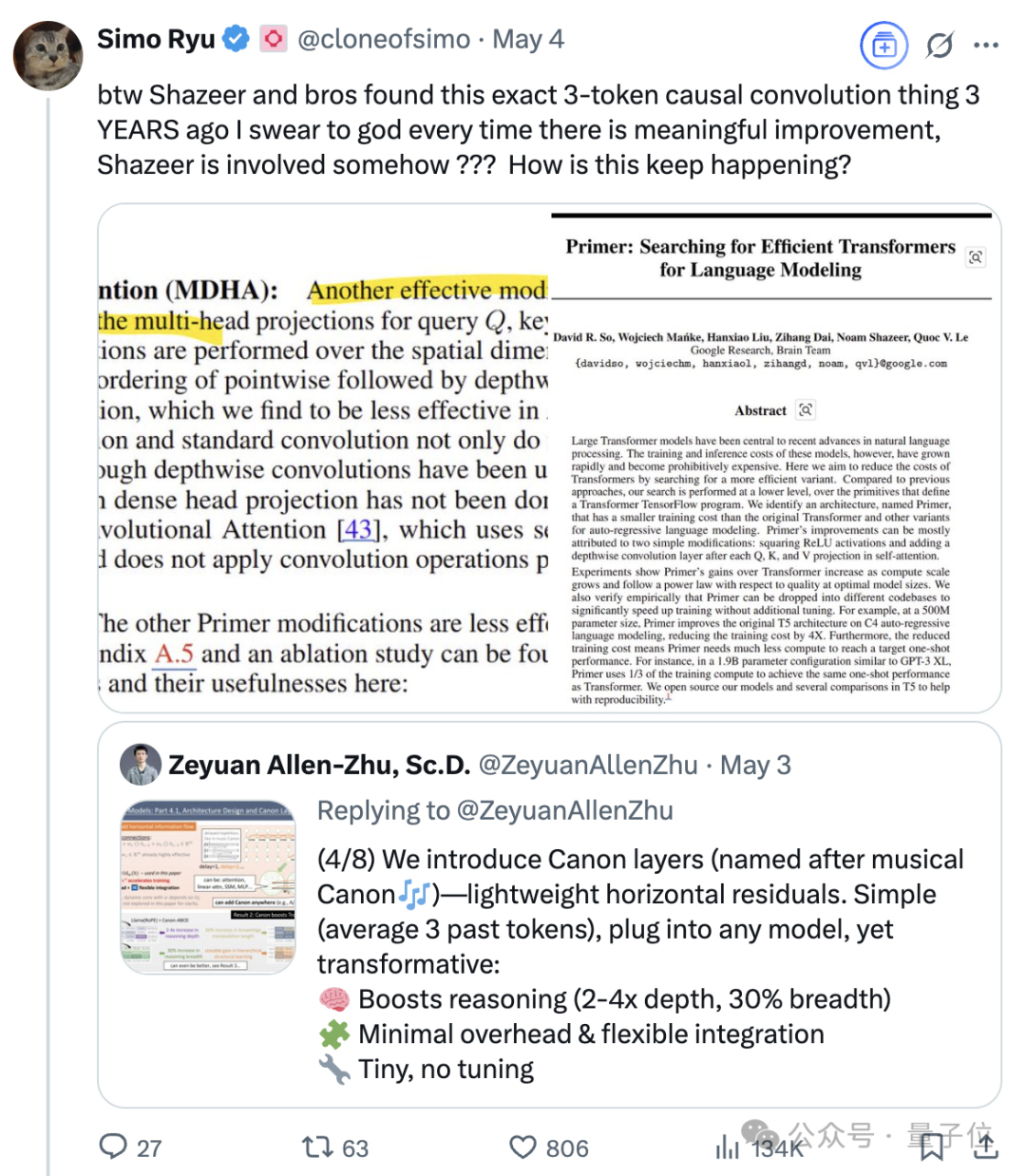
Transformerの八賢人の一人、Noam Shazeer氏の継続的な影響力: Noam Shazeer氏は、Transformerアーキテクチャに関する論文「Attention Is All You Need」の8人の著者の一人であり、その貢献は最も大きいと広く認識されている。彼の影響力はそれにとどまらず、言語モデルへのスパースゲート付き混合エキスパート(MoE)の初期導入研究、Adafactorオプティマイザ、マルチクエリアテンション(MQA)、Transformerにおけるゲート付き線形ユニット(GLU)なども含まれる。これらの業績は、現在の主流の大規模言語モデルアーキテクチャの基礎を築き、Shazeer氏をAI分野で技術パラダイムを定義し続ける重要人物と見なさせている。彼はGoogleを退社してCharacter.AIを設立し、その後同社の買収に伴いGoogleに復帰し、Geminiプロジェクトを共同で率いている。(出典: WeChat)
テクノロジー大手、AIが引き起こす「中年の危機」に直面: 記事は、Google、Apple、Meta、Teslaを含む「テクノロジー七巨人」が、人工知能がもたらす破壊的な挑戦に直面し、「中年の危機」に陥っていると分析している。Googleの検索事業はAIによる直接的な質疑応答モデルの脅威にさらされ、AppleはAIイノベーションの進展が遅く、MetaはAIをソーシャルに統合しようとしているがLlama 4のパフォーマンスが期待に達せず、Teslaは販売台数と株価の下落圧力に直面している。これらの過去の業界リーダーは、『イノベーションのジレンマ』の事例のように、AIがもたらす新しい市場と新しいモデルの衝撃に対応する必要があり、さもなければAI時代の「Nokia」になる可能性がある。(出典: WeChat)

Google AI、模擬医療対話で人間の医師を上回るパフォーマンス: 医療面談を行うために訓練されたAIシステムが、模擬患者との対話や病歴に基づく可能性のある診断のリストアップにおいて、人間の医師と同等かそれ以上のパフォーマンスを示したという研究結果が発表された。研究者らは、このようなAIシステムが医療サービスの普及と民主化に貢献する可能性があると考えている。(出典: Reddit r/ArtificialInteligence)
