
キーワード:GPT-4.1, Hugging Face, GPT-4.1シリーズモデル性能比較, Hugging FaceによるPollen Robotics買収, OpenAI新モデルのコーディング能力向上, GPT-4.1 miniコスト83%削減, オープンソースロボットReachy 2
🔥 注目ニュース
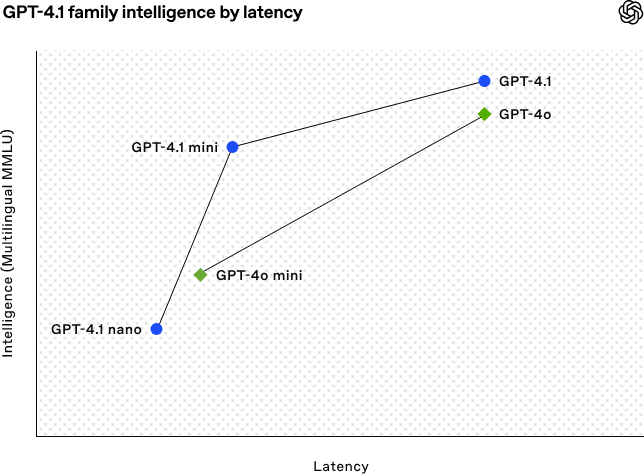
OpenAI、GPT-4.1シリーズモデルを発表、コーディングと長文テキスト処理能力を強化:OpenAIは4月15日未明、GPT-4.1シリーズの3つの新モデル、GPT-4.1(フラッグシップ)、GPT-4.1 mini(高効率)、GPT-4.1 nano(超小型)を発表しました。これらはすべてAPI経由でのみ提供されます。同シリーズモデルは、コーディング、指示追従性、長文コンテキスト理解において優れた性能を発揮し、コンテキストウィンドウはすべて100万token、出力tokenは32,768に達します。GPT-4.1はSWE-bench Verifiedテストで54.6%のスコアを獲得し、GPT-4oや廃止予定のGPT-4.5 Previewを大幅に上回りました。GPT-4.1 miniは、性能でGPT-4oを上回りつつ、遅延は半減、コストは83%削減されています。GPT-4.1 nanoは現在最も高速かつ低コストのモデルであり、低遅延タスクに適しています。今回の発表は、開発者により高性能、低コスト、高速なモデル選択肢を提供し、複雑なインテリジェントシステムやエージェントアプリケーションの構築を推進することを目的としています。(ソース: 36氪, 智东西, op7418, openai, karminski3, sama, natolambert, karminski3, karminski3, karminski3, dotey, OpenAI, GPT-4.1来了,超越GPT-4.5,SWE-Bench达到55%,开发者专属。)
Hugging Face、オープンソースロボティクス企業Pollen Roboticsを買収:AIコミュニティプラットフォームのHugging Faceは、フランスのオープンソースロボティクススタートアップPollen Roboticsの買収を発表しました。これはAIロボットのオープンソース化と普及を推進することを目的としています。今回の買収により、Hugging Faceのソフトウェアプラットフォーム(LeRobotライブラリやHubなど)の強みと、Pollen Roboticsのオープンソースハードウェア(Reachy 2ヒューマノイドロボットなど)における専門知識が融合されます。Reachy 2は、研究、教育、具現化された知能実験用に設計されたオープンソースでVR互換のヒューマノイドロボットで、価格は7万米ドルです。Hugging Faceは、ロボットがAIの次の重要なインタラクションインターフェースであり、オープンで手頃な価格でカスタマイズ可能であるべきだと考えており、今回の買収はそのビジョンを実現するための重要な一歩です。目標は、コミュニティが高価なクローズドシステムに依存するのではなく、独自のロボットパートナーを構築し制御できるようにすることです。(ソース: huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface)

🎯 動向
AIが50年来の未解決数学問題を解決支援:米国ブルックヘブン国立研究所の華人研究者Weiguo Yin氏が、OpenAIの推論モデルo3-mini-highを利用し、一次元J_1-J_2 q状態Pottsモデルの厳密解導出においてブレークスルーを達成しました。特にq=3の場合、AIが重要な証明を補助しました。この問題は統計力学の基礎モデルに関わり、層状材料の原子積層や非従来型超伝導などの物理現象と関連しており、その厳密解は過去50年間実現されていませんでした。研究者は最大対称部分空間(MSS)法を導入し、AIの段階的なヒントを借りて転送行列を処理することで、q=3の場合の9×9転送行列を有効な2×2行列に簡略化することに成功し、この方法を任意のq値に一般化しました。この研究は、長年の数学物理学の難問を解決しただけでなく、AIが複雑な科学研究を支援し、新たな洞察を提供する巨大な可能性を示しました。(ソース: 刚刚,AI破解50年未解数学难题!南大校友用OpenAI模型完成首个非平凡数学证明)

AIウェブ版アシスタントが登場、スマホ・自動車メーカーがマルチデバイス体験を構築:Huawei(小芸アシスタント)、理想汽車(理想同学)、OPPO(小布アシスタント)などのメーカーが相次いで自社のAIアシスタントのウェブ版をリリースし、注目を集めています。これらのウェブ版は、機能の完成度(質問編集、レイアウト、設定オプションなど)においてDeepSeekなどの専門モデルサービスには及ばない可能性がありますが、その主な目標は直接的な競争ではなく、各ブランドのユーザーにサービスを提供し、スマートフォン、車載システムからPCまでの体験ループを完成させることです。ユーザーアカウントの紐付けや対話履歴の同期を通じて、これらのウェブ版はユーザーのエンゲージメントを高め、クロスデバイスで一貫したインタラクション体験を提供し、AIアシスタントをより広範なユーザーシナリオに統合することを目指しており、本質的にはユーザー入口とデータエコシステムに関する布石です。(ソース: AI网页版扎堆上线,华为、理想、OPPO们打的什么算盘?)
Figureロボット、強化学習によりシミュレーションから現実へのゼロショット転移を実現:Figure社は、同社のFigure 02ヒューマノイドロボットが、純粋なシミュレーション環境での強化学習(RL)を通じて自然な歩行を実現したことを示しました。効率的なGPUアクセラレーション物理シミュレーターを利用し、数時間で数年分の訓練データに相当するデータを生成し、異なる物理パラメータやシナリオ(異なる地形、妨害など)を持つ複数の仮想ロボットを制御できる単一のニューラルネットワークポリシーを訓練しました。シミュレーション領域のランダム化と実ロボットの高頻度トルクフィードバックを組み合わせることで、訓練されたポリシーは微調整なしで物理ロボットにゼロショット転移できます。この方法は開発時間を短縮し、実世界でのパフォーマンスの安定性を向上させるだけでなく、1つのポリシーでロボット軍団全体を制御できるため、大規模な商業応用における可能性を示しています。(ソース: 一套算法控制机器人军团!纯模拟环境强化学习,Figure学会像人一样走路)

DeepSeek、推論エンジン最適化の一部をオープンソース化へ:DeepSeekは、vLLMを基に修正した高性能推論エンジンの一部最適化と機能をコミュニティに還元する計画を発表しました。完全にカスタマイズされた推論スタック全体を公開するのではなく、主要な改善点(最新モデルアーキテクチャのサポート、性能最適化など)をvLLMやSGLangなどの主要なオープンソース推論フレームワークに統合することを選択し、コミュニティが初日から新しいモデルや技術に対するSOTAレベルのサポートを受けられるようにすることを目指しています。この動きはコミュニティから歓迎され、単なる口先だけでなく、真にオープンソース貢献に取り組む姿勢として評価されています。(ソース: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, natolambert)
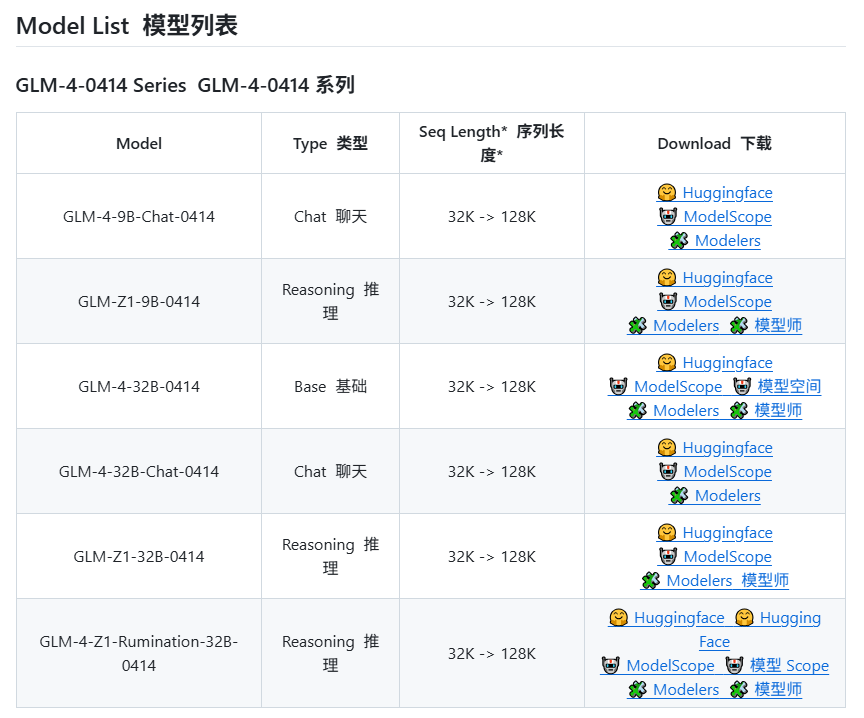
智譜AI(Zhipu AI)、GLM-4シリーズ新モデル発表の可能性:GitHub上でリークされた情報(後に削除)によると、智譜AI(Zhipu AI)はGLM-4シリーズの新モデルを発表する準備を進めているようです。このシリーズには、異なるパラメータ規模(9B、32Bなど)や機能を持つバージョンが含まれる可能性があります。例えば、基本モデル(GLM-4-32B-0414)、対話モデル(Chat)、推論モデル(GLM-Z1-32B-0414)、そしてより深い思考能力を持つ「反芻」モデル(Rumination)があり、これはOpenAIのDeep Researchに対抗するものかもしれません。さらに、視覚マルチモーダルモデル(GLM-4V-9B)も含まれる可能性があります。リークされたベンチマークデータによると、GLM-4-32B-0414は一部の指標でDeepSeek-V3やDeepSeek-R1を上回る可能性があります。関連する推論エンジンのサポートコードはtransformers/vllm/llama.cppにマージされています。コミュニティはこの動きに高い関心を示しており、正式な発表と評価を期待しています。(ソース: karminski3, karminski3, Reddit r/LocalLLaMA)
NVIDIA、Nemotronシリーズ新モデルを発表:NVIDIAはHugging Face上で、新しいNemotron-Hシリーズの基本モデルを発表しました。これには56B、47B、8Bの3つのパラメータ規模が含まれ、すべて8Kのコンテキストウィンドウをサポートします。これらのモデルは、混合TransformerおよびMambaアーキテクチャに基づいています。現在公開されているのは基本モデル(Base)であり、指示微調整(Instruct)バージョンはまだ提供されていません。Nemotronシリーズは、新しいアーキテクチャの言語モデリングにおける可能性を探ることを目的としています。(ソース: Reddit r/LocalLLaMA)

🧰 ツール
GitHub CopilotがWindows Terminal Canary版に統合:Microsoftは、GitHub Copilot機能をWindows TerminalのCanaryプレビュー版に統合し、「ターミナルチャット」(Terminal Chat)という新機能を導入しました。この機能により、ユーザーはターミナル環境内で直接AIと対話し、コマンドの提案や説明を得ることができます。ユーザーはGitHub Copilotに登録し、最新のCanary版ターミナルをインストールし、アカウントを認証すれば利用可能です。この動きは、AI支援を開発者が頻繁に使用するコマンドライン環境に直接組み込み、コンテキスト切り替えを減らし、複雑または不慣れなタスクの処理効率を高め、学習プロセスを加速し、エラー削減に貢献することを目的としています。(ソース: GitHub Copilot 现可在 Windows 终端中运行了)

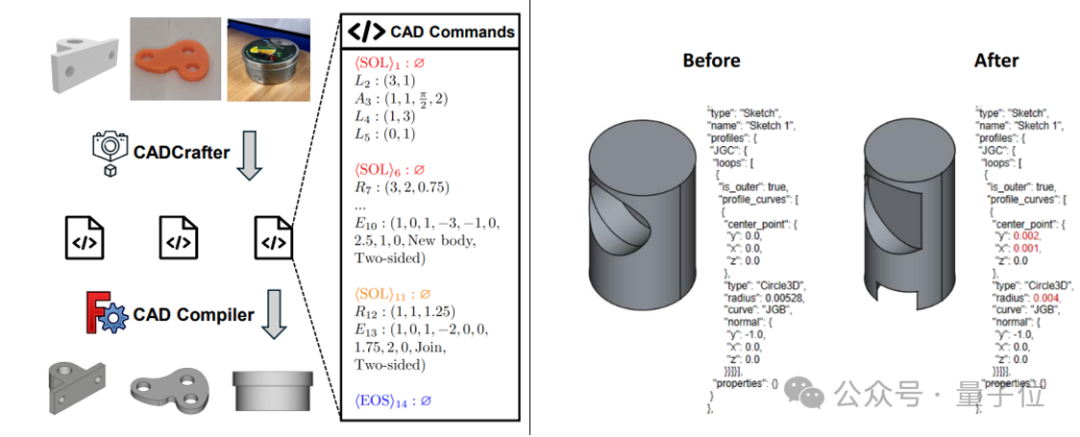
CADCrafter:単一画像から編集可能なCADファイルを生成:魔芯科技(KOKONI 3D)、南洋理工大学などの機関の研究者が、CADCrafterという新しいフレームワークを提案しました。これは単一の画像(レンダリング画像、実物写真など)から直接、パラメータ化された編集可能なCADエンジニアリングファイル(CAD命令シーケンスで表現)を生成でき、既存の画像から3Dを生成する方法(Meshや3DGSを生成)が生み出すモデルの精密な編集が困難で表面品質が高くない問題を解決します。この方法はVAEとDiffusion Transformerを組み合わせた2段階生成アーキテクチャを採用し、マルチビューからシングルビューへの蒸留戦略とDPOに基づくコンパイル可能性チェックメカニズムを通じて、生成品質と成功率を向上させます。研究成果はCVPR 2025に採択され、AI支援による工業デザインに新たなパラダイムを提供します。(ソース: 单图直出CAD工程文件!CVPR 2025新研究解决AI生成3D模型“不可编辑”痛点|魔芯科技NTU等出品)
LangChain、GraphRAGとMongoDB Atlasの統合を発表:LangChainはMongoDBとの協力を発表し、グラフベースのRAG(GraphRAG)システムを導入しました。このシステムはMongoDB Atlasを利用してデータを保存・処理し、LangChainを通じて実装され、従来の類似性検索に基づくRAGを超えて、エンティティ間の関係を理解し推論することができます。LLMによるエンティティと関係の抽出をサポートし、グラフ探索を利用して接続されたコンテキスト情報を取得し、深い関係理解が必要なアプリケーションにより強力な質問応答と推論能力を提供することを目指しています。(ソース: LangChainAI)
Hugging Face、推論プレイグラウンド(Inference Playground)をオープンソース化:Hugging Faceは、モデルの推論テストと比較に使用するオンラインツールInference Playgroundをオープンソース化しました。これはWebベースのLLMチャットインターフェースで、ユーザーは様々な推論設定(温度、top-pなど)を制御し、AIの応答を修正し、異なるモデルやプロバイダーのパフォーマンスを比較できます。このプロジェクトはSvelte 5、Melt UI、Tailwindを使用して構築されており、コードはGitHubで公開されています。これにより、開発者はカスタマイズ可能で拡張可能なローカルまたはオンラインのモデルインタラクションおよび評価プラットフォームを利用できます。(ソース: huggingface)
Flowithプラットフォーム、ARRが100万ドル超え、AI Agentによるウェブページ生成能力を示す:AI AgentプラットフォームFlowithの年間経常収益(ARR)が100万米ドルを超え、人手を代替できる万能AI Agentプラットフォームに対する市場の強い需要を示しています。ユーザーはFlowithのOracle機能を使用し、簡単な自然言語記述(「ソーシャルメディアの画像付き投稿プレビュープログラムのウェブページを作りたい…」)だけで、機能が完全でスタイルが正確に再現され(Twitter風など)、画像プレビューもサポートするウェブページツールを迅速に生成できることを共有しました。GitHubへの接続や複雑な設定は不要で、AI Agentがローコード/ノーコードのウェブページ生成において持つ可能性を示しています。(ソース: karminski3)
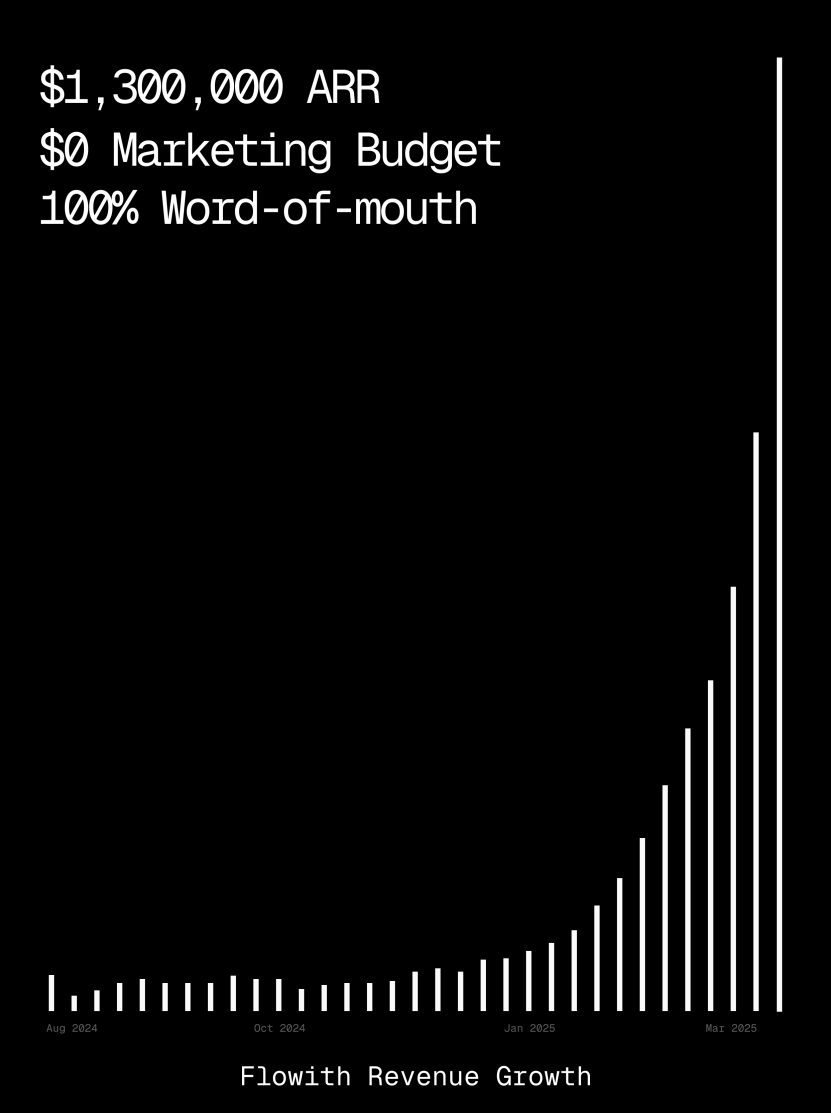
自律デバッグエージェントDeeboがリリース:研究者たちは、Deeboという名の自律デバッグエージェントMCPサーバーを構築しました。これはローカルデーモンとして動作し、プログラミングエージェントは厄介なエラー処理タスクを非同期にこれにオフロードできます。Deeboは、異なる修正仮説を持つ複数の子プロセスを生成し、隔離されたgitブランチで各シナリオを実行し、「親エージェント」がループテスト、推論を行い、最終的に診断結果と提案されたパッチを返します。実際のtinygradの$100懸賞バグテストで、Deeboは問題の根本原因を特定し、2つの具体的な修正案を提案し、テストに合格しました。(ソース: Reddit r/MachineLearning)
![[D] We built an autonomous debugging agent. Here’s how it grokked a $100 bug](https://rebabel.net/wp-content/uploads/2025/04/81BPXr5Ywnk-6MetZBQchhgsROH341CoTk3xAdE5Jic.jpg)
📚 学習
Nabla-GFlowNet:多様性と効率を両立する拡散モデルの報酬ファインチューニング新手法:拡散モデルのファインチューニングにおいて、従来の強化学習は収束が遅く、直接的な報酬最大化は過学習しやすく多様性を損なう問題がありました。これに対し、香港中文大学(深圳)などの機関の研究者はNabla-GFlowNetを提案しました。この手法は生成流ネットワーク(GFlowNet)フレームワークに基づき、拡散プロセスを流平衡システムとみなし、Nabla-DB平衡条件と対応する損失関数を導出します。パラメータ化設計により、単一ステップのノイズ除去で残差勾配を推定し、追加のネットワーク推定を回避します。実験では、美的スコアや指示追従などの報酬関数でStable Diffusionをファインチューニングする際、Nabla-GFlowNetはReFLやDRaFTなどの手法と比較して、より速く収束し、過学習しにくく、同時に生成サンプルの多様性を維持できることが示されました。(ソース: ICLR 2025 | 扩散模型奖励微调新突破!Nabla-GFlowNet让多样性与效率兼得)

MegaMath:371B Tokensの最大規模オープンソース数学推論データセット公開:LLM360によって公開されたMegaMathデータセットは、3710億Tokensを含み、オープンソースコミュニティにおける大規模で高品質な数学推論事前学習データの不足を解決することを目的としています。このデータセットは、数学集約型ウェブページ(279B)、数学関連コード(28.1B)、高品質合成データ(64B)の3つの部分に分かれています。構築プロセスでは、革新的なデータ処理パイプラインが採用されました。これには、数式に最適化されたHTML解析、2段階テキスト抽出、動的教育価値スコアリング、コードデータの多段階精密リコール、および多様な大規模合成手法(Q&A、コード生成、テキストとコードのインターリーブ)が含まれます。Llama-3.2(1B/3B)での100B Tokensの事前学習検証では、MegaMathがGSM8K、MATHなどのベンチマークで15〜20%の絶対性能向上をもたらすことが示されました。(ソース: 3710亿数学Tokens!全球最大开源数学数据集MegaMath震撼发布,碾压DeepSeek-Math)
OS Agents概説:マルチモーダル大規模モデルに基づくコンピュータ、スマホ、ブラウザエージェント研究:浙江大学はOPPO、零一万物(01.AI)などの機関と共同で、オペレーティングシステムエージェント(OS Agents)に関する概説論文を発表しました。本論文は、マルチモーダル大規模言語モデル(MLLM)を利用して、コンピュータ、スマートフォン、ブラウザなどの環境でタスクを自動的に完了できるエージェント(AnthropicのComputer Use、AppleのApple Intelligenceなど)の構築に関する研究現状を体系的に整理しています。内容は、OS Agentsの基礎(環境、観察空間、行動空間、コア能力)、構築方法(基礎モデルアーキテクチャと訓練戦略、エージェントフレームワークの知覚/計画/記憶/行動モジュール)、評価プロトコルとベンチマーク、および関連する商用製品と将来の課題(セキュリティとプライバシー、パーソナライゼーションと自己進化)を網羅しています。研究チームは、250以上の関連論文を含むオープンソースリポジトリを維持し、この分野の発展を推進することを目指しています。(ソース: 浙大、OPPO等发布最新综述:基于多模态大模型的计算机、手机与浏览器智能体研究)
NLPrompt:MAE損失と最適輸送を組み合わせたロバストなプロンプト学習手法:上海科技大学YesAI Labは、CVPR 2025 Highlight論文でNLPromptを提案しました。これは、視覚言語モデルのプロンプト学習におけるラベルノイズ問題を解決することを目的としています。研究では、プロンプト学習シナリオにおいて、平均絶対誤差(MAE)損失(PromptMAE)を使用することが、クロスエントロピー(CE)損失よりもノイズラベルの影響に対してより耐性があることを発見し、特徴学習理論の観点からそのロバスト性を証明しました。さらに、プロンプトに基づく最適輸送データ浄化手法(PromptOT)を提案し、テキスト特徴をプロトタイプとして利用し、データセットをクリーンなサブセット(CE損失で訓練)とノイズを含むサブセット(MAE損失で訓練)に分割し、両損失の利点を効果的に融合します。実験により、NLPromptは合成および実ノイズデータセットの両方で優れた性能を示し、良好な汎化性を持つことが証明されました。(ソース: CVPR 2025 | MAE损失+最优传输双剑合璧!上科大提出全新鲁棒提示学习方法)
DeepSeek-R1推論メカニズム分析:マギル大学の研究者たちは、DeepSeek-R1のような大規模推論モデルの推論プロセスを分析しました。直接答えを出すLLMとは異なり、推論モデルは詳細な多段階の推論連鎖を生成します。研究では、推論連鎖の長さと性能の関係(「最適点」が存在し、長すぎると性能を損なう可能性がある)、長文コンテキスト管理、文化と安全性の問題(非推論モデルと比較してより強いセキュリティ脆弱性が存在する)、および人間の認知現象との関連(探索済みの問題に固執し続けるなど)を探求しました。この研究は、現在の推論モデルの動作メカニズムのいくつかの特徴と潜在的な問題を明らかにしました。(ソース: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
MoE大規模モデルのテスト時最適化手法C3PO:ジョンズ・ホプキンス大学の研究により、混合エキスパート(MoE)LLMにはエキスパートパスの準最適問題が存在することが発見され、テスト時最適化手法C3PO(重要層、コアエキスパート、協調パス最適化)が提案されました。この手法は真のラベルに依存せず、参照サンプルセット内の「成功した隣人」によって代替目標を定義し、モデル性能を最適化します。パターン検索、カーネル回帰、類似サンプル平均損失などのアルゴリズムを採用し、コスト削減のために重要層のコアエキスパートの重みのみを最適化します。MoE LLMに適用すると、C3POは6つのベンチマークテストで基本モデルの精度を7〜15%向上させ、一般的なテスト時学習ベースラインを上回り、小パラメータMoEモデルの性能をより大きなパラメータLLMよりも向上させ、MoEの効率を高めました。(ソース: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
量子化が推論モデルの性能に与える影響の研究:清華大学の研究チームは、量子化技術が推論型言語モデル(DeepSeek-R1シリーズ、Qwen、LLaMAなど)の性能に与える影響を初めて体系的に調査しました。研究では、異なるビット幅(W8A8、W4A16など)の重み、KVキャッシュ、活性化量子化アルゴリズムが、数学、科学、プログラミングなどの推論ベンチマークでどのような性能を示すかを評価しました。結果として、W8A8またはW4A16量子化は通常、性能を損なうことなく実現可能ですが、より低いビット幅は精度の大幅な低下リスクをもたらすことが示されました。モデルのサイズ、ソース、タスクの難易度が、量子化後の性能に影響を与える重要な要因です。量子化モデルの出力長は著しく増加せず、モデルサイズを適切に調整するか、推論ステップを増やすことで性能を向上させることができます。関連する量子化モデルとコードはオープンソース化されています。(ソース: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
SHIELDAGENT:Agentに安全ポリシー遵守を強制するガードレール:シカゴ大学はSHIELDAGENTフレームワークを提案しました。これは、論理推論を通じてAI Agentの行動軌跡が明確な安全ポリシーに準拠するように強制することを目的としています。このフレームワークはまず、ポリシー文書から検証可能なルールを抽出し、安全ポリシーモデル(確率的ルール回路に基づく)を構築します。次に、Agentの実行中に、その行動軌跡に基づいて関連ルールを検索し、ガードレール計画を生成し、ツールライブラリと実行可能コードを利用して形式検証を行い、Agentの行動が安全規定に違反しないことを保証します。同時に、3Kの安全関連指示と軌跡ペアを含むデータセットSHIELDAGENT-BENCHも公開されました。実験により、SHIELDAGENTは複数のベンチマークでSOTAを達成し、安全適合率と再現率を大幅に向上させ、同時にAPIクエリと推論時間を削減することが示されました。(ソース: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
MedVLM-R1:強化学習により医療VLMの推論能力を促進:ミュンヘン工科大学、オックスフォード大学などの機関が協力し、MedVLM-R1を提案しました。これは、明確な自然言語推論プロセスを生成することを目的とした医療視覚言語モデル(VLM)です。このモデルはDeepSeekの集団相対戦略最適化(GRPO)強化学習フレームワークを採用し、最終的な答えのみを含むデータセットで訓練されましたが、人間が解釈可能な推論パスを自律的に発見することができました。わずか600個のMRI VQAサンプルで訓練した後、この2BパラメータモデルはMRI、CT、X線ベンチマークテストで78.22%の精度を達成し、ベースラインを大幅に上回り、強力なドメイン外汎化能力を示し、Qwen2-VL-72Bなどのより大規模なモデルをも凌駕しました。この研究は、信頼性が高く解釈可能な医療AIを構築するための新しいアプローチを提供します。(ソース: 小样本大能量!MedVLM-R1借力DeepSeek强化学习,重塑医疗AI推理能力)
強化学習訓練が推論モデルの応答を冗長にする可能性を研究が明らかに:Wand AIの研究によると、推論モデル(DeepSeek-R1など)が長い応答を生成する原因が分析されました。研究では、この行動は問題自体がより長い推論を必要とするのではなく、強化学習(特にPPOアルゴリズム)の訓練プロセスに起因する可能性があることがわかりました。モデルが誤った答えに対して負の報酬を受け取ると、PPO損失関数は、追加の内容が精度向上に寄与しなくても、各tokenのペナルティを薄めるためにより長い応答を生成する傾向があります。研究はまた、簡潔な推論が高い精度と関連していることが多いことも示唆しています。解決可能な問題の一部のみを使用した第2ラウンドの強化学習訓練により、応答長を短縮し、同時に精度を維持または向上させることができ、これは展開効率の向上に重要な意味を持ちます。(ソース: 更长思维并不等于更强推理性能,强化学习可以很简洁)

中国科学技術大学とZTE、Curr-ReFTを提案:小規模VLMの推論と汎化能力を向上:小規模視覚言語モデル(VLM)が複雑なタスクで直面する「レンガの壁」現象(訓練のボトルネック)とドメイン外汎化能力不足の問題に対し、中国科学技術大学とZTE Corporationはカリキュラム強化学習後訓練パラダイム(Curr-ReFT)を提案しました。このパラダイムはカリキュラム学習(CL)と強化学習(RL)を組み合わせ、難易度を考慮した報酬メカニズムを設計し、モデルが易しいものから難しいものへ(二元決定→多肢選択→自由回答)段階的に学習できるようにします。同時に、拒否サンプリングに基づく自己改善戦略を採用し、高品質なマルチモーダルおよび言語サンプルを利用してモデルの基礎能力を維持します。Qwen2.5-VL-3B/7Bモデルでの実験により、Curr-ReFTはモデルの推論および汎化性能を大幅に向上させ、7Bモデルは一部のベンチマークでInternVL2.5-26B/38Bをも上回ることが示されました。(ソース: 中科大、中兴提出新后训练范式:小尺寸多模态模型,成功复现R1推理)

GenPRM:生成的推論によるプロセス報酬モデルの拡張:清華大学と上海AI Labは、生成的プロセス報酬モデル(GenPRM)を提案しました。これは、従来プロセス報酬モデル(PRM)がスカラー評価に依存し、解釈可能性に欠け、テスト時に拡張できない問題を解決することを目的としています。GenPRMは生成的アプローチを採用し、思考連鎖(CoT)推論とコード検証を組み合わせ、各推論ステップに対して自然言語分析とPythonコード実行検証を行い、より深く、解釈可能なプロセス監視を提供します。さらに、GenPRMはテスト時拡張メカニズムを導入し、複数の推論パスを並行してサンプリングし、報酬値を集約することで評価精度を向上させます。わずか23Kの合成データで訓練された1.5Bモデルは、テスト時拡張によりProcessBenchでGPT-4oを上回り、7Bバージョンは72BのQwen2.5-Math-PRM-72Bを上回りました。GenPRMは、批評モデルとして戦略モデルの最適化を指導することもできます。(ソース: 过程奖励模型也可以测试时扩展?清华、上海AI Lab 23K数据让1.5B小模型逆袭GPT-4o)
研究により、前提条件が欠落した問題に対する推論AIの「過剰思考」現象が明らかに:メリーランド大学とリーハイ大学の研究により、現在の推論モデル(DeepSeek-R1、o1など)は、必要な前提情報が欠落している問題(Missing Premise, MiP)に直面すると、「過剰思考」の傾向を示すことがわかりました。これらのモデルは、通常の問題よりも2〜4倍長い応答を生成し、問題を繰り返し検討し、意図を推測し、自己疑念に陥るループに陥り、問題が解決不可能であることを迅速に認識して停止するのではなく、そうなってしまいます。対照的に、非推論モデル(GPT-4.5など)は、MiP問題に対してより短い応答をし、前提条件の欠落をよりよく認識できます。研究によると、推論モデルは前提条件の欠落を感知できるものの、無効な推論を断固として中止する「批判的思考」に欠けており、この行動パターンは強化学習訓練における長さ制約の不足に起因し、蒸留を通じて伝播する可能性があります。(ソース: 推理AI「脑补」成瘾,废话拉满!马里兰华人学霸揭开内幕)

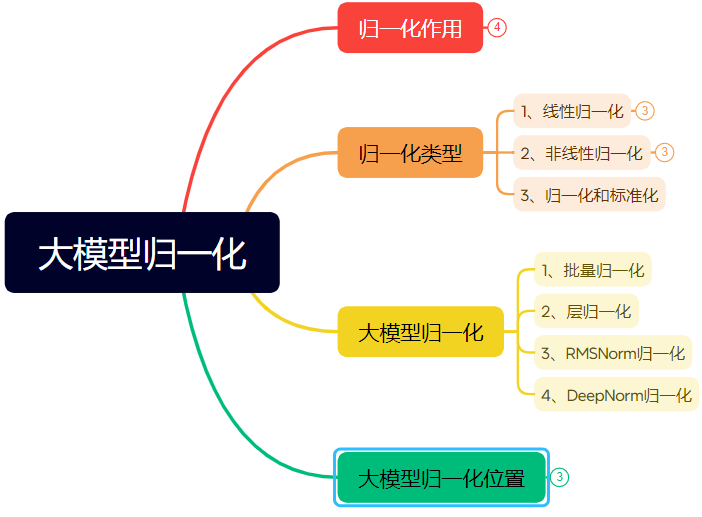
ニューラルネットワーク正規化技術の進化に関する詳細解説(長文):本稿では、正規化(Normalization)がニューラルネットワーク、特にTransformerおよび大規模モデルにおいて果たす役割とその変遷を体系的に整理しています。正規化はデータを固定範囲に制限することで、データの比較可能性の問題を解決し、最適化速度を向上させ、活性化関数の飽和領域や内部共変量シフト(ICS)の問題を緩和します。本稿では、一般的な線形(Min-max、Z-score、Mean)および非線形正規化手法を紹介し、深層学習モデルに適したバッチ正規化(BN)、層正規化(LN)、RMSNorm、DeepNormに重点を置いて解説し、Transformerアーキテクチャにおけるそれらの適用上の違い(なぜLN/RMSNormがNLPにより適しているか)を分析します。さらに、正規化モジュールをTransformer層内の異なる配置位置(Post-Norm、Pre-Norm、Sandwich-Norm)に置くこと、およびそれが訓練の安定性と性能に与える影響についても議論します。(ソース: 万字长文!一文了解归一化:从Transformer归一化到主流大模型归一化的演变!)
AIを用いた特定スタイルのフォントデザイン生成のためのPromptエンジニアリング:本稿では、著者が即夢AI 3.0を使用して特定のスタイルの文字デザインを生成した経験とプロンプトテンプレートを共有しています。著者は、フォント名(宋体、楷体など)を直接指定しても効果が薄く、AIモデルの理解が限られていることを発見しました。そのため、著者はフォントスタイルの特徴、感情的な雰囲気、視覚効果を記述し、異なるスタイルの参照例と組み合わせることで、「高度な文字スタイルデザインプロンプト生成器」のPromptテンプレートを構築しました。ユーザーは文字内容を入力するだけで、このテンプレートが文字の内包する意味に基づいてインテリジェントに複数の事前設定スタイル(光韻夜影、工業的素朴、子供っぽい落書き、メタリックSFなど)をマッチングまたは融合させ、テキストから画像を生成するモデル用の詳細なプロンプトを生成し、比較的安定した品質のグラフィックデザイン効果を得ることができます。(ソース: AI生成字体设计我有点玩明白了,用这套Prompt提效50%。, 即梦AI 3.0制作含字体封面,这个方案酷到封神【附:16+案例和Prompt】)

ZClip:LLM事前学習のための適応的勾配スパイク抑制手法:研究者たちはZClipを提案しました。これは軽量な適応的勾配クリッピング手法であり、LLM訓練プロセス中の損失スパイクを削減し、訓練の安定性を向上させることを目的としています。固定閾値を使用する従来の勾配クリッピングとは異なり、ZClipはz-scoreに基づく方法を採用して、異常な勾配スパイク、すなわち最近の移動平均から著しく逸脱した勾配を検出し、クリッピングします。この方法は、収束を妨げることなく訓練の安定性を維持するのに役立ち、任意の訓練ループに容易に統合できます。コードと論文は公開されています。(ソース: Reddit r/deeplearning)
![[2504.02507] ZClip: Adaptive Spike Mitigation for LLM Pre-Training](https://rebabel.net/wp-content/uploads/2025/04/Swd9uQN43Dpl2SJyH6zjTbJAdRaXwKbmzZwM9L2rPXk.jpg)
💼 ビジネス
Intel Arcグラフィックス + Xeon Wプロセッサーソリューションが低コストAI一体型マシンを支援:Intelは、同社のArc™グラフィックスとXeon® Wプロセッサーの組み合わせを通じて、コスト管理可能(10万元レベル)で実用的な性能を持つ大規模モデル一体型マシンのソリューションを市場に提供しています。Arc™グラフィックスはXeアーキテクチャとXMX AIアクセラレーションエンジンを採用し、主要なAIフレームワークとOllama/vLLMをサポートし、低消費電力でマルチカード並列接続をサポートします。Xeon® Wプロセッサーは高いコア数とメモリ拡張能力を提供し、AMXアクセラレーション技術を内蔵しています。IPEX-LLM、OpenVINO™、oneAPIなどのソフトウェア最適化と組み合わせることで、CPUとGPUの効率的な連携を実現しました。実測によると、このソリューションの一体型マシンはQwQ-32Bモデルを単独ユーザーで使用した場合、32 tokens/sに達し、671B DeepSeek R1モデル(FlashMoE最適化が必要)を実行した場合、約10 tokens/sに達し、オフライン推論のニーズを満たし、AI推論の普及を推進します。(ソース: 榨干3000元显卡,跑通千亿级大模型的秘方来了)

NVIDIA、米国内でAIスーパーコンピュータを製造へ:NVIDIAは、初めて米国内でAIスーパーコンピュータの完全な設計と構築を行い、主要な製造パートナーと協力すると発表しました。同時に、次世代のBlackwellチップはアリゾナ州のTSMC工場で生産が開始されています。NVIDIAは今後4年間で、米国で最大5000億ドル相当のAIインフラを生産する計画で、パートナーにはTSMC、Foxconn、Wistron、Amkor、SPILが含まれます。この動きは、AIチップとスーパーコンピュータの需要に応え、サプライチェーンを強化し、弾力性を高めることを目的としています。(ソース: nvidia, nvidia)

Horizon Robotics、3D再構築/生成インターンを募集:Horizon Roboticsの具現化知能チームは、上海/北京で3D再構築/生成分野のアルゴリズムインターンを募集しています。職務には、ロボットのReal2Simアルゴリズムソリューション(3D GS再構築、フィードフォワード再構築、3D/ビデオ生成を組み合わせる)の設計と開発への参加、Real2Simシミュレータの性能最適化(流体、触覚シミュレーションなどをサポート)、および最先端研究の追跡とトップカンファレンス論文の発表が含まれます。修士以上の学歴、コンピュータ/グラフィックス/AI関連専攻、3Dビジョン/ビデオ生成またはマルチモーダル/拡散モデルの経験、Python/Pytorch/Huggingfaceの熟練した使用が要件です。トップカンファレンス論文発表者、シミュレーションプラットフォームまたはオープンソースプロジェクト経験者は優遇されます。正社員登用機会、GPUクラスター、競争力のある給与を提供します。(ソース: 上海/北京内推 | 地平线机器人具身智能团队招聘3D重建/生成方向算法实习生)

Meituan(美団)酒旅、L7-L8レベルの大規模モデルアルゴリズムエンジニアを募集:Meituan(美団)の酒旅供給アルゴリズムチームは、北京でL7-L8レベルの大規模モデルアルゴリズムエンジニア(社会人採用)を募集しています。職務には、酒旅供給理解体系の構築(商品タグ、ホットスポット認識、類似供給マイニングなど)、表示素材の最適化(タイトル、画像・テキスト、推薦理由生成)、休暇パッケージの組み合わせ構築(商品選定、販売予測、価格設定)、および最先端の大規模モデル技術(ファインチューニング、RL、Prompt最適化)の探索と実装が含まれます。修士以上の学歴、2年以上の経験、コンピュータ/自動化/数理統計関連専攻、確かなアルゴリズム基礎とコーディング能力が要件です。(ソース: 北京内推 | 美团酒旅供给算法团队招聘L7-L8大模型算法工程师)

Meta、EUでユーザーデータをAI訓練に使用へ:Metaは、EU地域のFacebookおよびInstagramユーザーの公開データ(投稿、コメントなど。プライベートメッセージは除く)をAIモデルの訓練に使用する準備を開始したと発表しました。対象は18歳以上のユーザーのみです。同社はアプリ内通知とメールでユーザーに通知し、反対(opt-out)するためのリンクを提供します。以前、Metaはアイルランドの規制当局の要請により、ヨーロッパでのユーザーデータを用いたAI訓練計画を一時停止していました。(ソース: Reddit r/artificial)

Tencent Cloud、MCPマネージドサービスを提供開始:Tencent CloudもMCP(Managed Cloud Platform)マネージドサービスの提供を開始しました。これは、企業により便利で効率的なクラウドリソース管理および運用ソリューションを提供することを目的としています。この動きは、この分野における主要クラウドベンダー間の競争激化を意味します。具体的なサービスの詳細や「WeChatの特色」については、まだ詳しく述べられていません。(ソース: 腾讯云也搞 MCP 托管了,还带了点“微信特色”。)
🌟 コミュニティ
チューリング賞受賞者LeCun氏、AIの発展について語る:人間の知能は汎用的ではなく、次世代のブレークスルーは非生成モデルにある可能性:最近のポッドキャストインタビューで、Yann LeCun氏は再びAGIという言葉が誤解を招くと強調し、人間の知能は高度に専門化されており、汎用的ではないと主張しました。彼はAIの次の大きなブレークスルーは非生成モデルから来る可能性があり、機械が物理世界を真に理解し、推論計画能力と持続的な記憶を持つことに重点が置かれると予測しています。これは彼が提案したJEPAアーキテクチャに似ています。彼は現在のLLMには真の推論能力と物理世界のモデリング能力が欠けており、猫の知能レベルに達するだけでも大きな進歩だと考えています。MetaがLLaMAをオープンソース化したことについては、AIエコシステム全体の発展を促進する正しい選択であり、イノベーションは世界中から生まれ、オープンソースはブレークスルーを加速する鍵であると強調しました。また、彼はAIアシスタントの重要な媒体としてスマートグラスに期待を寄せています。(ソース: 图灵奖得主LeCun:人类智能不是通用智能,下一代AI可能基于非生成式)

GitHubが一時的に中国IPを「ブロック」し注目集める、公式は設定ミスと説明:4月12日から13日にかけて、一部の中国ユーザーがGitHubにアクセスできなくなり、ページに「IPアドレスがアクセス制限を受けています」と表示され、コミュニティで懸念と議論が巻き起こりました。これが標的型ブロックではないかとの懸念が広がりました。以前、GitHubは米国の制裁によりロシアやイランなどの開発者アカウントをブロックしたことがありました。GitHub公式はその後、この事態は設定変更の誤りにより、未ログインユーザーが一時的にアクセスできなくなったためであり、問題は4月13日に修正されたと回答しました。技術的な障害であったとはいえ、この出来事は再びコードホスティングプラットフォームの地政学的リスクと国内代替案(Gitee、CODING、Jihu GitLabなど)についての議論を引き起こしました。(ソース: “Bug”还是“预演”?GitHub 突然“封禁”所有中国 IP,官方:只是“手滑”技术出错了)

AI Agentがサイバーセキュリティの懸念を引き起こす:MIT Technology Reviewの記事は、AI駆動の自律型サイバー攻撃が間近に迫っていると指摘しています。AIの能力が向上するにつれて、悪意のある攻撃者はAI Agentを利用して自動的に脆弱性を発見し、より複雑で大規模なサイバー攻撃を計画・実行する可能性があり、個人、企業、さらには国家安全保障に新たな脅威をもたらします。これにより、サイバーセキュリティ分野は、AI駆動の攻撃に対応できる防御戦略と技術の研究・展開を急ぐ必要があります。(ソース: Ronald_vanLoon)

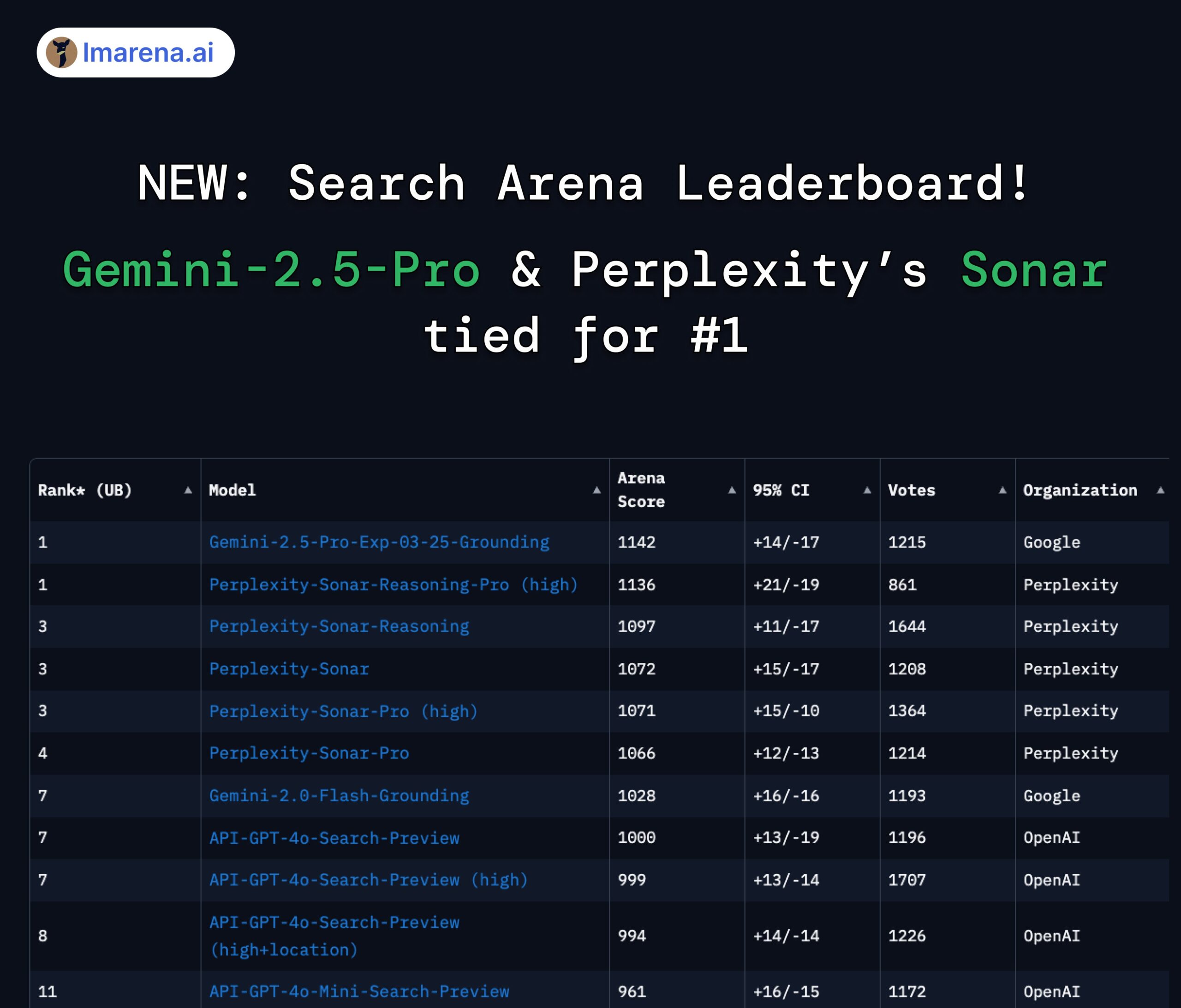
Perplexity SonarとGemini 2.5 Proが検索アリーナランキングで同率首位に:LMArena.ai(旧LMSYS)が新たに発表したSearch Arenaランキングで、PerplexityのSonar-Reasoning-Pro-HighモデルとGoogleのGemini-2.5-Pro-Groundingが同率1位となりました。このランキングは、ウェブ検索に基づくLLMの回答品質を専門に評価します。Perplexity CEOのArav Srinivas氏はこの結果を祝福し、Sonarモデルと検索インデックスの改善を続けると強調しました。コミュニティは、これが検索拡張型LLM分野において、競争が主にGoogleとPerplexityの間で展開されていることを示していると考えています。(ソース: AravSrinivas, lmarena_ai, lmarena_ai, AravSrinivas, lmarena_ai, AravSrinivas)
Claudeモデルの使用制限に関する議論:Redditのr/ClaudeAIコミュニティでは、Claude Proバージョンの使用制限(メッセージ量の上限、容量制限など)について議論があります。一部のユーザーは頻繁に制限に遭遇し、ワークフローに影響が出ていると不満を述べ、モデルの乗り換えを検討している人もいます。一方、他のユーザーはほとんど制限に遭遇せず、使用方法(超長文コンテキストの読み込みなど)や誇張が原因ではないかと考えています。これは、ユーザーがAnthropicのモデル使用ポリシーと安定性に対して異なる体験と考えを持っていることを反映しています。(ソース: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
AIと雇用の未来に関する議論:Redditのr/ChatGPTで共有された比較図が議論を呼んでいます:AIは人間の能力を強化し、豊かな生活をもたらすのか、それとも人間の仕事を奪い、大規模な失業を引き起こすのか?コメントでは、多くのユーザーがAIによる仕事の代替、特に創造的な職業(プログラミング、アート)に対する懸念を表明しています。一部の人々は、利益が主にAI所有者に帰属し、税基盤の縮小がUBI(ユニバーサル・ベーシック・インカム)の実現を困難にする可能性があるため、AIが社会的不平等を悪化させると考えています。一方、より楽観的な見方をする人々もおり、AIは強力なツールであり、効率を高め、新しい雇用(プロンプトエンジニアなど)を創出できると考えています。重要なのは、AIに適応し、活用することを学ぶことです。(ソース: Reddit r/ChatGPT, Reddit r/ArtificialInteligence)

AIデータ収集がプライバシー懸念を引き起こす:異なるAIチャットボット(ChatGPT、Gemini、Copilot、Claude、Grok)が収集するユーザーデータの種類を比較したインフォグラフィックが、コミュニティでプライバシー問題に関する議論を引き起こしました。図によると、Google Geminiが収集するデータタイプが最も多く、Grok(アカウントが必要)とChatGPT(アカウント不要)は比較的少ないことが示されています。ユーザーコメントは、無料サービスの背後にあるデータ収集の普遍性(「無料の昼食はない」)を強調し、データ収集の具体的な目的(行動予測など)に対する懸念を表明しています。(ソース: Reddit r/artificial)

モデル蒸留は低コストで高性能を再現する有効な手段と見なされる:Redditユーザーは、モデル蒸留技術を用いて、大規模モデル(GPT-4oなど)で小規模なファインチューニング済みモデルを訓練し、特定の分野(感情分析)で14倍低いコストでGPT-4oに近い性能(92%の精度)を実現した経験を共有しました。コメントでは、蒸留は広く使用されている技術であるが、分野横断的な汎化能力においては、小規模モデルは通常、大規模モデルに劣ると指摘されています。特定の安定した分野では、蒸留は効果的なコスト削減と効率向上の方法ですが、常に新しいデータに適応する必要がある、または多分野にわたる複雑なシナリオでは、大規模APIを直接使用する方が経済的である可能性があります。(ソース: Reddit r/MachineLearning)
![[D] Distillation is underrated. I replicated GPT-4o's capability in a 14x cheaper model](https://rebabel.net/wp-content/uploads/2025/04/zyj7as7ogque1.png)
💡 その他
OceanBase、初のAIハッカソン大会を開催:分散データベースベンダーのOceanBaseは、Ant Group Open Source、机器之心(Machine Heart)などと共同で、初のAIハッカソン大会を開催します。4月10日に申し込みが開始され、5月7日に締め切られます。大会は「DB+AI」をテーマとし、2つの方向性を設定しています。1つはOceanBaseをデータ基盤として使用してAIアプリケーションを構築すること、もう1つはOceanBaseとAIエコシステム(CAMEL AI、FastGPT、OpenDALなど)の組み合わせを探求することです。大会は総額10万元の賞金プールを提供し、個人およびチームの参加を受け付けており、開発者がデータベースとAIの深い融合による革新的なアプリケーションを探求することを奨励します。(ソース: 10万奖金×认知升级!OceanBase首届AI黑客松广发英雄帖,你敢来么?)

清華大学の劉辛軍教授がパラレルロボットについてライブ配信で解説:清華大学機械工学科設計工学研究所所長であり、IFToMM中国委員会主席でもある劉辛軍教授が、4月15日夜にオンライン講演を行います。テーマは「パラレルロボット機構学基礎と装備イノベーション」です。講演では、パラレルロボットの基礎理論とその最先端装備イノベーションにおける応用について探求します。司会はハルビン工業大学の劉英想教授が務めます。(ソース: 重磅直播!清华大学刘辛军教授开讲:并联机器人机构学基础与装备创新前沿)

第3回中国AIGC産業サミットの攻略ガイドが公開:4月16日に北京で開催される第3回中国AIGC産業サミットの詳細な議題とハイライトが公開されました。サミットはAI技術と応用実装に焦点を当て、議題は計算力インフラ、教育/文化・エンターテイメント/企業サービス/AI4Sなどの垂直分野における大規模モデルの応用、AIの安全性と制御可能性などを網羅します。講演者はBaidu、Huawei、AWS、Microsoft Research Asia、Mianbi Intelligence、Shengshu Technology、Fenbi、NetEase Youdao、Quwan Technology、Qingsong Health、Ant Groupなどから参加します。サミットでは、2025年に注目すべきAIGC企業と製品のリスト、および中国AIGC応用パノラママップも発表されます。(ソース: 倒计时2天!20余位行业大佬共话AI,中国AIGC产业峰会最全攻略在此)
