
キーワード:AI, LLM, AI Washing現象, LLMベンチマーク, Geminiモデル自己ホスティング, vLLM推論エンジン, Suno AI音楽生成
🔥 注目
「AI」ショッピングアプリ、実際は人手による操作だったことが発覚: Fintechというスタートアップ企業とその創業者が詐欺で告発されました。AI駆動と称していたショッピングアプリが、実際には取引処理の多くをフィリピンの人間のチームに依存していたとのことです。この事件は、企業が投資やユーザーを引き付けるためにAI能力を誇張または虚偽報告する「AIウォッシング(AI Washing)」現象への関心を再び呼び起こしました。現在のAIブームの中で、本物と偽物のAI技術応用を見分けることの難しさ、そしてスタートアップ企業に対するデューデリジェンスの重要性を浮き彫りにしています (出典: Reddit r/ArtificialInteligence)

新しいベンチマークがAI推論モデルの汎化能力不足を明らかに: LLM-Benchmark (https://llm-benchmark.github.io/) と名付けられた新しいベンチマークは、最新のAI推論モデルでさえ、分布外(OOD)の論理パズル処理に苦戦することを示しています。研究によると、これらの新しい論理パズルにおけるスコアは、数学オリンピックなどのベンチマークでのモデルのパフォーマンスと比較して、予想をはるかに下回っており(約50倍低い)、現在のモデルが訓練データ分布外で真の論理的推論と汎化を行う上での限界を露呈しています (出典: Reddit r/ArtificialInteligence)
Google、データプライバシー懸念に対応し、企業によるGeminiモデルのセルフホストを許可: Googleは、企業顧客が自社のデータセンターでGemini AIモデルを実行できるようにすると発表しました。最初にサポートされるのはGemini 2.5 Proです。この動きは、データプライバシーとセキュリティに対する企業の厳格な要件を満たすことを目的としており、機密データをクラウドに送信することなくGoogleの先進的なAI技術を利用できるようにします。この戦略はMistral AIと類似していますが、主にクラウドAPIやパートナーを通じてサービスを提供するOpenAIやAnthropicなどとは対照的であり、エンタープライズAI市場の競争環境を変える可能性があります (出典: Reddit r/LocalLLaMA, Reddit r/MachineLearning)

🎯 動向
VSCodeがllama.cppをネイティブサポート、ローカルCopilot能力を拡張: Visual Studio Codeは最近のアップデートでローカルAIモデルのサポートを追加し、Ollamaのサポートに続き、現在は微調整によってllama.cppとの互換性を持ちました。これは、開発者がVSCode内で直接llama.cppを通じて実行されるローカル大規模言語モデルを、GitHub Copilotの代替または補完として使用できることを意味し、ローカル環境でLLMを利用したコード支援をさらに容易にし、開発の柔軟性とデータプライバシーを向上させます。ユーザーはこの機能を有効にするために、設定でOllamaをプロキシとして選択する必要があります(実際にはllama.cppを使用している場合でも)(出典: Reddit r/LocalLLaMA)

YandexなどがHIGGSを発表:新しいLLM圧縮手法: Yandex Research、HSE大学、MITなどの研究機関の研究者が、HIGGSと名付けられた新しいLLM量子化圧縮技術を開発しました。この手法は、モデルサイズを大幅に圧縮し、パフォーマンスの低いデバイスでも実行できるようにすると同時に、モデル品質の損失を可能な限り最小限に抑えることを目的としています。この手法は、671BパラメータのDeepSeek R1モデルの圧縮に成功し、その効果は顕著であるとされています。HIGGSはLLM利用の敷居を下げ、小規模企業、研究機関、個人開発者が大規模モデルをより容易に適用できるようにすることを目指しており、関連コードはGitHubとHugging Faceで公開されています (出典: Reddit r/LocalLLaMA)
GoogleがQAT 2.7モデルの量子化問題を修正: Googleは、QAT(Quantization Aware Training)量子化モデルの2.7バージョン(おそらくGemma 2 7Bまたは類似のモデルを指す)を更新し、以前のバージョンに存在したいくつかの制御トークン(control tokens)のエラー問題を修正しました。以前は、モデルが出力の末尾に誤った<end_of_turn>などのタグを生成することがありました。新しくアップロードされた量子化モデルはこれらの問題を解決しており、ユーザーは更新されたバージョンをダウンロードして正しいモデルの挙動を得ることができます (出典: Reddit r/LocalLLaMA)
DeepMind CEOがAlphaFoldの成果について語る: DeepMind CEOのDemis Hassabis氏は、インタビューの中でAlphaFoldの巨大な影響力を強調し、「AlphaFoldは1年間で10億年分の博士課程研究時間を達成した」と比喩的に述べました。彼は、過去には1つのタンパク質構造を解析するのに通常、博士課程学生の全博士課程期間(4~5年)を要したが、AlphaFoldは1年間で(当時知られていた)全2億種のタンパク質の構造を予測したと指摘しました。この言葉は、AIが科学的発見を加速する上での革命的なポテンシャルを浮き彫りにしています (出典: Reddit r/artificial)

🧰 ツール
MinIO:AI向け高性能オブジェクトストレージ: MinIOは、GNU AGPLv3ライセンスを採用した、オープンソースの高性能なS3互換オブジェクトストレージシステムです。特に、機械学習、分析、アプリケーションデータワークロード向けの高性能インフラストラクチャ構築能力を強調しており、専用のAIストレージドキュメントを提供しています。ユーザーはコンテナ(Podman/Docker)、Homebrew(macOS)、バイナリファイル(Linux/macOS/Windows)、またはソースからインストールできます。MinIOは、分散型でイレージャーコーディングを備えた高可用性ストレージクラスタの構築をサポートし、大量のデータを処理する必要があるAIアプリケーションシナリオに適しています (出典: minio/minio – GitHub Trending (all/daily))

IntentKit:スキルを備えたAIエージェント構築フレームワーク: IntentKitは、開発者がブロックチェーンとの対話(EVMチェーンを優先サポート)、ソーシャルメディア管理(Twitter、Telegramなど)、カスタムスキルの統合を含む、多様な能力を備えたAIエージェントを作成・管理できるように設計されたオープンソースの自律エージェントフレームワークです。このフレームワークは、マルチエージェント管理と自律実行をサポートし、拡張可能なプラグインシステムの導入を計画しています。プロジェクトは現在Alpha段階にあり、アーキテクチャ概要と開発ガイドを提供し、コミュニティによるスキルの貢献を奨励しています (出典: crestalnetwork/intentkit – GitHub Trending (all/daily))

vLLM:高性能LLM推論・サービングエンジン: vLLMは、LLMの推論とサービングに特化した、高スループットでメモリ効率の良いライブラリです。その主な利点には、PagedAttention技術によるアテンションのキー・バリューメモリの効果的な管理、連続バッチ処理(Continuous Batching)のサポート、CUDA/HIPグラフ最適化、多様な量子化技術(GPTQ, AWQ, FP8など)、FlashAttention/FlashInferとの統合、および投機的デコーディング(Speculative Decoding)などが含まれます。vLLMはHugging Faceモデルをサポートし、OpenAI互換APIを提供し、NVIDIA、AMDなど多様なハードウェア上で動作可能で、LLMサービスの大規模展開が必要なシナリオに適しています (出典: vllm-project/vllm – GitHub Trending (all/daily))
tfrecords-reader:ランダムアクセスと検索機能付きTFRecordsリーダー: これはTFRecordsデータセットを処理するためのPythonツールで、特にデータの検査と分析用に設計されています。ユーザーがTFRecordsファイルのインデックスを作成し、ランダムアクセスとコンテンツベースの検索(Polars SQLクエリを使用)を実現できるようにし、TFRecordsのネイティブなシーケンシャル読み取りの制限を解決します。このツールはTensorFlowおよびprotobufパッケージに依存せず、Google Storageからの直接読み取りをサポートし、インデックス作成速度が速く、開発者がモデルトレーニング以外で大規模なTFRecordsデータセットの探索やサンプル検索を行うのに便利です (出典: Reddit r/MachineLearning)
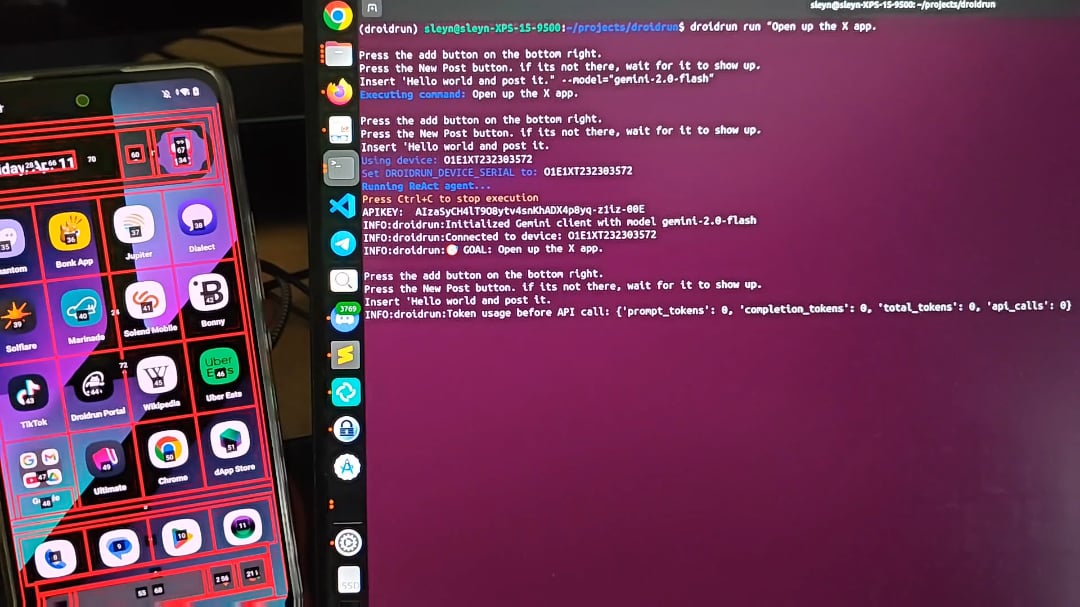
DroidRun:AI AgentにAndroidデバイスを制御させる: DroidRunは、AI Agentが人間のようにAndroidデバイスを操作できるようにするプロジェクトです。任意のLLMに接続することで、携帯電話のUIとの対話的な制御を実現し、様々なタスクを実行できます。プロジェクトはそのポテンシャルを示しており、コンテンツの自動投稿やアプリ管理など、モバイル端末での自動化操作の実現を目指しています。開発者はコミュニティにフィードバックやアイデアを提供し、さらなる自動化シナリオを探るよう呼びかけています (出典: Reddit r/LocalLLaMA)
📚 学習
Cell Patternsが多言語大規模モデル(MLLM)の包括的なレビューを発表: このレビューは、473の文献を網羅し、多言語大規模モデルの研究の現状を体系的に整理しています。内容には、多言語事前学習、指示チューニング、RLHFのデータセットリソースと構築方法、クロスリンガルアライメント戦略(パラメータ調整アライメント(例:事前学習、指示チューニング、RLHF、下流ファインチューニング)とパラメータ凍結アライメント(例:直接プロンプティング、コードスイッチング、翻訳アライメント、検索拡張)に分類)、多言語評価指標とベンチマーク(NLUとNLGタスク)、そしてハルシネーション、知識編集、安全性、公平性、言語/モダリティ拡張、解釈可能性、デプロイ効率、更新一貫性といった将来の研究方向と課題について議論しています。包括的なMLLM研究の全体像を提供します (出典: Cell Patterns重磅综述!473篇文献全面解析多语言大模型最新研究进展)

AAAI 2025 | 北京航空航天大学がTRACKを提案:動的道路網と軌跡表現の協調学習: 北京航空航天大学チームは、既存の手法が交通の時空間ダイナミクスを捉えられていない問題を解決するためにTRACKモデルを提案しました。このモデルは、交通状態(マクロな集団特性)と軌跡データ(ミクロな個別特性)を初めて共同でモデル化し、両者が相互に影響し合うと考えます。TRACKは、グラフアテンションネットワーク(GAT)、Transformer、そして革新的な軌跡遷移認識GATと協調アテンションメカニズムを通じて、動的な道路網と軌跡表現を学習します。モデルは、マスク化軌跡予測、対照軌跡学習、マスク化状態予測、次状態予測、軌跡-交通状態マッチングなどの自己教師ありタスクを含む共同事前学習フレームワークを採用し、交通状態予測と移動時間推定タスクで優れたパフォーマンスを示しています (出典: AAAI 2025 | 告别静态建模!北航团队提出动态路网与轨迹表示的协同学习范式)

南方科技大学の楊林易先生が大規模モデル分野の博士/RA/訪問学生を募集: 南方科技大学統計・データサイエンス学科の楊林易先生(近く着任予定、独立PI)が生成AIラボ(GenAI Lab)を設立し、2025/2026年度の博士・修士課程学生、およびポスドク(博士研究員)、研究アシスタント、インターンを募集しています。研究方向には、大規模モデル推論の因果分析、汎化可能な強化学習大規模モデル手法、AIの暴走を防ぐための信頼性の高い非エージェントシステムの構築が含まれます。楊先生はトップカンファレンスで多数の論文を発表しており、国内外の多くの大学や研究機関と幅広い協力関係を持ち、共同指導を奨励しています。応募者には、強い自律性、確かな数理基礎、プログラミング能力が求められます (出典: 博士申请 | 南方科技大学杨林易老师招收大模型方向全奖博士/RA/访问学生)

個人プロジェクト:ゼロから大規模言語モデルを構築: ある開発者が、Causal Language Model(GPTに類似)をゼロから実装する個人プロジェクトを共有しました。プロジェクトはPythonとPyTorchを使用し、コアアーキテクチャにはCausal Mask付きマルチヘッドセルフアテンション、フィードフォワードネットワーク、デコーダブロック(レイヤー正規化、残差接続)のスタックが含まれます。モデルは事前学習済みのGPT-2単語埋め込みと位置埋め込みを使用し、出力層は語彙ロジットにマッピングされます。Top-kサンプリングを用いた自己回帰型テキスト生成を採用し、WikiTextデータセット上でAdamWオプティマイザとCrossEntropyLossを使用してトレーニングを行いました。プロジェクトコードはGitHubで公開されており、LLM構築の基本的なフローを示しています (出典: Reddit r/MachineLearning)
論文解説:d1 – 強化学習による拡散型大規模言語モデル(dLLM)の推論能力拡張: この研究は、事前学習済みの拡散ベースLLM(dLLM)を推論タスクに応用することを目的としたd1フレームワークを提案しています。dLLMは、自己回帰(AR)モデルとは異なり、粗から密へのアプローチでテキストを生成します。d1フレームワークは、教師ありファインチューニング(SFT)と強化学習(RL)を組み合わせており、具体的には、知識蒸留とガイド付き自己改善のためのMasked SFTの使用、新しいCriticフリー、方策勾配ベースのRLアルゴリズムdiffu-GRPOの提案が含まれます。実験により、d1はSOTA dLLMの数学および論理推論ベンチマークにおけるパフォーマンスを大幅に向上させ、推論タスクにおけるdLLMのポテンシャルを証明しました (出典: Reddit r/MachineLearning)
💼 ビジネス
アリババ通義実験室が汎用RAG/AI検索分野のアルゴリズム専門家を募集 (北京/杭州): アリババ通義実験室AI検索チームは、検索およびRAG(検索拡張生成)のコアモジュール(例:Embedding、ReRankモデル)の研究開発と最適化を推進し、モデル効果と業界トップレベルの向上を担当するアルゴリズム専門家を募集しています。職務には、下流アプリケーション(質疑応答、カスタマーサービス、マルチモーダルMemory)向けに全体的なフレームワークパイプラインを最適化し、精度、効率、スケーラビリティを向上させ、チームと協力してビジネス実装を推進することも含まれます。関連分野の修士号以上、検索/NLP/大規模モデル技術に精通し、関連プロジェクト経験があることが求められます (出典: 北京/杭州内推 | 阿里通义实验室招聘通用RAG/AI搜索方向算法专家)

AI採用スタートアップ企業OpportuNextがCTOを募集 (リモート/株式): OpportuNextは、AI技術を活用して採用プロセスを改善し、スマートな職務マッチング、履歴書分析、キャリアプランニングツールを提供することを目指す初期段階のスタートアップ企業です。創業者は、AI機能開発を主導し、スケーラブルなバックエンドシステムを構築し、プロダクトイノベーションを推進する技術パートナー(CTO)を探しています。AI/ML、Python、スケーラブルシステムの経験があり、実世界の問題解決に情熱を持ち、スタートアップ初期段階での参加(株式ベースのリモートポジション)に意欲があることが求められます (出典: Reddit r/deeplearning)
🌟 コミュニティ
考察:大規模モデルの本質は「言語の幻術」: ある深い考察記事は、大規模モデル(例:ChatGPT)は情報を真に理解しているわけではなく、膨大な言語データを学習することで表現形式を模倣し予測しているに過ぎないと論じています。Promptの役割は文脈を設定し、モデルの注意を誘導することであり、意識のある実体と対話しているわけではありません。モデルの回答は「十分に見た」パターン再現に基づいており、知的に見えるが真の理解を欠いており、「もっともらしくデタラメを言う」ハルシネーションを起こしやすいです。人間と機械の対話は、むしろユーザーがモデルの代わりに考えているようなものであり、モデルの出力はユーザーの思考や判断習慣を潜在的に再形成し、現実世界の偏見を反映・増幅する可能性があります (出典: 我所理解的大模型:语言的幻术)
議論:AIのエネルギー消費と中米のモデル開発戦略の違い: Redditユーザーが、トランプ氏が石炭をAI開発の主要鉱物資源に挙げた発言について議論し、AIのエネルギー消費問題への懸念を引き起こしています。コメントでは、大規模モデルはますますエネルギー消費が大きくなっている一方で、中国企業はよりスリムで効率重視のモデルを構築する傾向があるように見えると指摘されています。これは、AI開発におけるパフォーマンスとエネルギー効率のトレードオフ、および地域によって採用される可能性のある異なる技術路線を反映しています (出典: Reddit r/artificial)

質問:PyTorch Lightningのような深層強化学習フレームワークを探しています: Redditユーザーが、PyTorch Lightning(PL)に似た、深層強化学習(DRL)専用のフレームワークがあるかどうか尋ねています。このユーザーは、PLはDRLにも使用できるものの、その設計はデータセット駆動の教師あり学習寄りであり、環境インタラクション駆動のDRL向けではないと考えています。投稿では、DRL(DQN、PPOなど)に適しており、Gymnasiumなどの環境とうまく統合されたフレームワークの推薦、またはPLをDRLに使用する際のベストプラクティス経験の共有を求めています (出典: Reddit r/deeplearning)
コミュニティ:バーチャルミュージシャンのためのDiscordコミュニティMetaMindsが始動: MetaMindsと名付けられた新しいDiscordコミュニティが設立され、AIツール(例:Suno)を使用して音楽を制作するバーチャルアーティストに交流、協力、共有のためのプラットフォームを提供することを目的としています。コミュニティはすでに「A Personal Song」という最初の楽曲制作コンテストを開始しており、将来的にはより高い基準のコンテストを開催し、賞金が含まれる可能性も計画しています。これは、AI音楽制作分野で新しいコミュニティエコシステムが形成されつつあることを反映しています (出典: Reddit r/SunoAI)
議論:トレーニングセットを含むデータセットの集合を何と呼ぶべきか?: Redditユーザーが、複数タスクにおけるモデル性能を評価するために使用される「ベンチマーク(Benchmark)」に対して、同じモデルのトレーニングと評価を目的とした複数のデータセットの集合を指す用語は何かと質問しています。この問題は、機械学習分野におけるデータセットの分類と用語使用の詳細を探るものです (出典: Reddit r/MachineLearning)
ヘルプ:OpenWebUIで音声テキスト変換機能を実現したい: ユーザーが、DockerでデプロイしたOpenWebUI+Ollama環境で、H100 GPUを利用して音声テキスト変換(ユーザーの質問はTTSと書かれていますが、内容はYouTube動画/音声ファイルの文字起こしであり、ASR/STTであるべき)機能を実現するための最適な方法と推奨モデルを求めています。これは、ユーザーがローカルLLM対話インターフェースにより多くのモダリティ処理能力を統合したいというニーズを反映しています (出典: Reddit r/OpenWebUI)
議論:Claudeの年間サブスクリプションと制限調整についての見解: Redditユーザーが、最近多くのユーザーが利用制限の厳格化について不満を述べているため、Claudeの年間サブスクリプションを購入しなくてよかったと安堵しています。ユーザーは、Anthropicが多くの有料ユーザーを引き付けた後にコスト削減のために戦略を調整した可能性があると考えています。同時に、ユーザーは無料のGemini 2.5 Proのパフォーマンスが高いことに言及し、Claudeの将来の発展に対する懸念と期待を表明しています。議論は、ユーザーがLLMサービスの価格設定、利用制限、コストパフォーマンスに敏感であることを反映しています (出典: Reddit r/ClaudeAI)
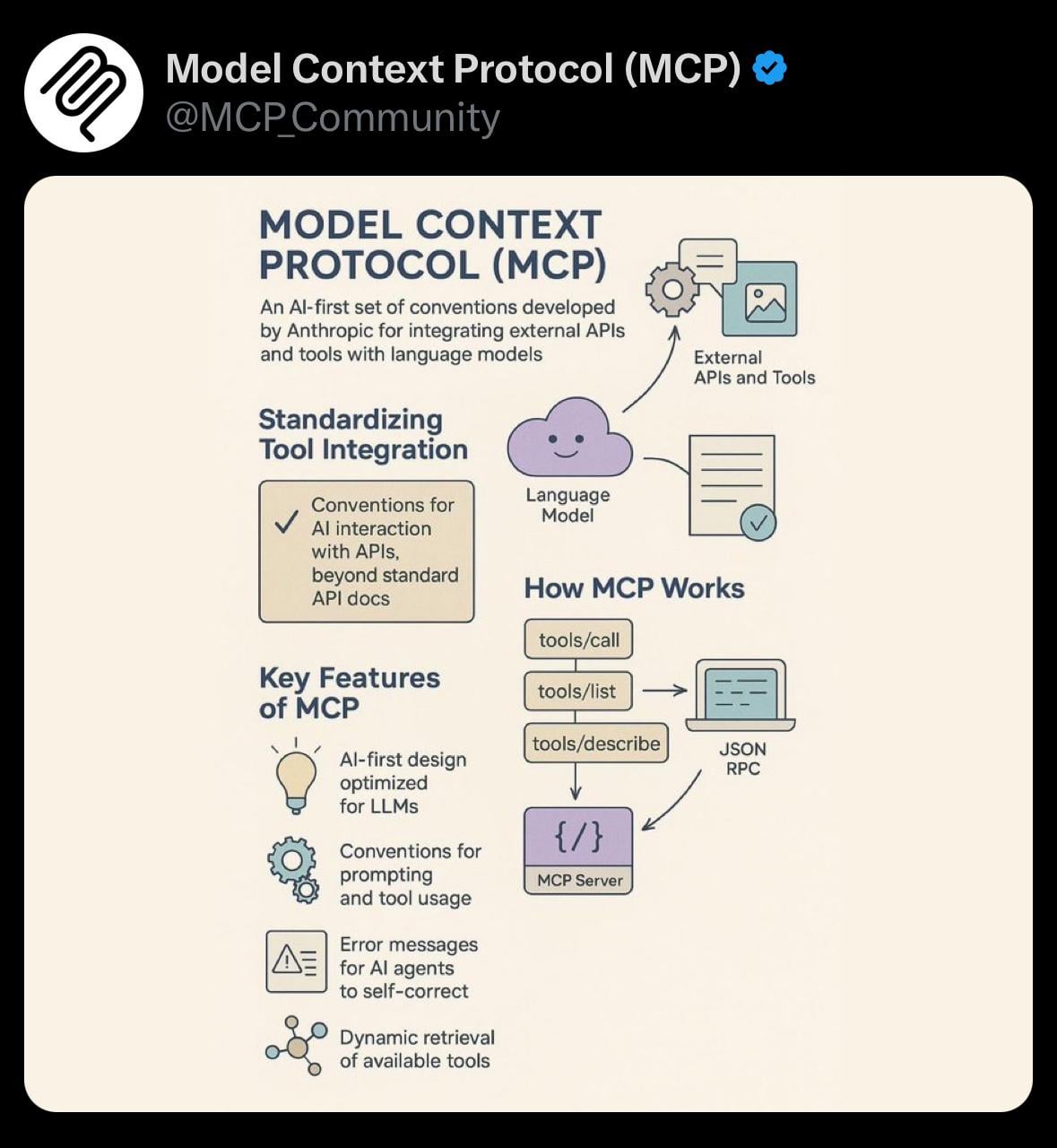
共有:モデルコンテキストプロトコル(MCP)の簡単な可視化: ユーザーが、モデルコンテキストプロトコル(Model Context Protocol, MCP)に関する簡単な可視化画像を共有しました。MCPは、Anthropic Claudeモデルに関連する技術的概念である可能性があり、モデルが長いコンテキストを処理する方法を最適化または管理することを目的としています。この共有は、関連する技術的概念を理解するための視覚的な補助をコミュニティに提供します (出典: Reddit r/ClaudeAI)
ヘルプ:OpenWebUIチャットにカスタムコマンドを追加したい: ユーザーが、OpenWebUIチャットインターフェースにカスタムコマンド(例:@tag形式、自動補完メニュー付き)を追加して、カスタマイズされたRAGクエリ(例:ドキュメントタイプでフィルタリング)を容易に行う技術的な難易度について尋ねています。ユーザーは代替案としてドロップダウンメニューも検討しています。これは、ユーザーがフロントエンドの対話能力を拡張して、バックエンドのAI機能をより柔軟に制御したいという考えを反映しています (出典: Reddit r/OpenWebUI)
議論:美しく機能的なAI QRコードの生成: ユーザーがChatGPT/DALL-Eを使用して、アートスタイルを融合しスキャン可能なQRコードを生成しようとしましたが、結果が良くなく、ControlNetなどの手法の方が効果的だと指摘しています。これは、現在の主流のテキスト画像生成モデルが、正確な構造と機能性(例:スキャン可能性)を必要とする画像の生成における限界についての議論を引き起こしています (出典: Reddit r/ChatGPT)

AI/ML学習仲間を募集: 大学3年生のコンピュータサイエンス(AI/ML専攻)学部生が、4~5名の同じ志を持つ人を探し、チームを組んでAI/MLを深く学び、共同でプロジェクト開発を行い、一緒にデータ構造とアルゴリズム(DSA/CP)を練習する仲間を募集しています。発起人は自身の技術スタックと興味のある分野をリストアップし、互いに刺激し合い、協力して学ぶグループを作りたいと考えています (出典: Reddit r/deeplearning)
議論:AI Agentはスパム問題を悪化させるか?: Redditユーザーが、AI Agentがタスクの自動化(例:販売リードの検索やメッセージ送信)に広く使用されることで、スパムの氾濫につながる可能性があるという懸念を提起しています。誰もが同様のツールを使用するようになると、ターゲットとなる受信者は大量のパーソナライズされた自動メッセージに圧倒され、コミュニケーション効率が低下し、Agentツールはその価値を失う可能性があります。議論は、AIツールの規模化応用がもたらす可能性のある負の外部性についての考察を引き起こしています (出典: Reddit r/ArtificialInteligence)
議論:Suno AIの最近の品質問題: ユーザーがSuno AIで生成した音楽の一部を共有し、最近コミュニティ内でSunoの出力品質低下に関する議論があるものの、個人的にはこの部分はかなり良いと感じていると述べています。これは、コミュニティがAI生成ツールのパフォーマンス変動に対する認識と主観的な評価の違いを反映しています (出典: Reddit r/SunoAI)

議論:深層学習トレーニング用RTX 4090 vs RTX 5090: ユーザーが、個人の深層学習(主にLLM以外)用のシングルGPUワークステーションを構築する際に、現在のRTX 4090を選択すべきか、近日発売予定のRTX 5090を待つべきか相談しています。投稿では、ハードウェア選択に関するコミュニティからのアドバイスを求めており、購入時にゲーミングカードとプロフェッショナルカードをどのように区別するか(これらはコンシューマー向けカードですが)尋ねています。これは、AI開発者がハードウェア選定において考慮する点を反映しています (出典: Reddit r/deeplearning)
議論:AIは資本主義を破壊するか?: ユーザーは、企業が利益最大化を追求するため、AIが最終的にほとんどの職を置き換える可能性があると考えています。現行の資本主義システムの下では、これは大規模な失業と収入源の途絶につながります。ユーザーは、AIから利益を得る企業に追加課税することで資金を提供するユニバーサルベーシックインカム(UBI)が、必要な解決策かもしれないと提案しています。議論は、AIが将来の経済構造と社会モデルに与える深遠な影響に触れています (出典: Reddit r/ArtificialInteligence)
ヘルプ:Anthropicの論文「推論モデルは必ずしも考えていることを言うわけではない」を再現したい: ユーザーが、Anthropicの「推論モデルは必ずしも考えていることを言うわけではない」という論文の結果を再現できるプロンプト(Prompts)や関連する洞察を見つける手助けをコミュニティに求めています。この論文は、大規模言語モデルの内部の推論プロセスと最終的な出力との間に存在する可能性のある不一致を探求しています。これは、コミュニティメンバーが最先端のAI研究成果を理解・検証することへの関心を示しています (出典: Reddit r/MachineLearning)
ヘルプ:OpenWebUIにおけるRAGの設定と使用感: ユーザーが、OpenWebUIでRAG(検索拡張生成)を使用する際のベストプラクティスについて質問しています。これには、推奨設定、避けるべきパラメータ、推奨される埋め込みモデルが含まれます。ユーザーはまた、モデルの異常な挙動(例:Mistral Smallが空のリストを出力する)の問題に遭遇しており、ユーザー個人設定と管理者モデル設定の優先順位関係についても尋ねています。これは、ユーザーがRAGアプリケーションの実際のデプロイと最適化で遭遇する課題や経験共有を求めるニーズを反映しています (出典: Reddit r/OpenWebUI)
議論:Claudeユーザーの離脱はサービス改善につながるか?: ユーザーが、最近の制限とパフォーマンスの問題による一部のClaudeユーザーの離脱(「Genesis Exodus」)が、逆に計算リソースを解放し、それによってサービス品質(パフォーマンス、制限など)がより理想的な状態に戻る可能性があるという仮説を提唱しています。ユーザーはClaudeへの愛着を表明し、サービスが改善されることを望んでいます。議論は、ユーザーがAIサービスの需給関係、リソース配分、サービス品質の動的な変化に対する観察と思考を反映しています (出典: Reddit r/ClaudeAI)

議論:「AIアート」をどう定義するか?: ユーザーが、「AIアート」をどのように定義するかコミュニティメンバーに尋ねる議論を開始し、関連する質問を提起しています:AIツール(例:ChatGPT)で画像を生成する人はクリエイターか?所有権はあるのか?LLMサービスプロバイダーは創作においてどのような役割を果たすか、共同制作者とみなされるべきか?この議論は、AI生成コンテンツを取り巻く創作主体、著作権の帰属などの核心概念を明確にすることを目的としています (出典: Reddit r/ArtificialInteligence)
議論:AI音楽は音楽の「公共性」を脅かすか?: ユーザーが、Sunoのように超パーソナライズされた音楽を簡単に生成できるAIツールが、共有体験としての音楽の「公共性」を弱めるのではないかという問題を提起しています。懸念点には、音楽がコミュニティをつなぐ灯台ではなく個人的な鏡になる可能性、コンサートなどの集団的な音楽イベントが影響を受ける可能性、ユーザーがカスタマイズされたコンテンツしか受け入れなくなり、多様で挑戦的な音楽への開放性が減少する可能性が含まれます。議論は、AIが音楽文化と社会的機能に与える潜在的な影響に焦点を当てています (出典: Reddit r/SunoAI)
質問:Suno AIがヒンディー語の歌を生成する際の精度はどうか?: ヒンディー語話者でないユーザーが、Suno AIがヒンディー語の歌唱を生成する際の正確さと自然さについて尋ねています。特定の非英語言語におけるこのツールのパフォーマンスについて理解を求めています (出典: Reddit r/SunoAI)
💡 その他
Suno AI作品共有:Nightingale’s Melody (オルタナティブ/インディーロック): ユーザーがSuno AIで制作したオルタナティブ/インディーロック風の楽曲「Nightingale’s Melody」を共有し、YouTubeリンクを添付しています (出典: Reddit r/SunoAI)

Suno AI作品共有:The Art of Abundance (Psytrance): ユーザーが、高エネルギーのPsytranceとスピリチュアルテクノの要素を組み合わせたAI生成音楽を共有しました。歌詞はChatGPTによって作成され、音楽とボーカルはSuno AIによって生成され、ビジュアルエフェクトはMidJourneyとPhotoMosh Proによって制作されました。作品は、物質主義を超えたデジタル時代の豊かさの概念を探求し、創造性、AI意識、人間の欲望に触れています (出典: Reddit r/SunoAI)

Suno AI作品共有:Do your Job (カントリーミュージック): ユーザーがSuno AIで制作したカントリー風の楽曲を共有しました。歌詞の内容は、実際の未解決事件(Colton Ross Barrera失踪事件)を巡るもので、家族のフラストレーションと正義への呼びかけを表現しています (出典: Reddit r/SunoAI)

Suno AI作品共有:Toxic Friends (エレクトロポップ): ユーザーがSuno AIの4月のコンテストに参加したエレクトロポップ風の作品「Toxic Friends」を共有しています (出典: Reddit r/SunoAI)

Suno AI作品共有:Starlight Visitor (80年代ポップスカバー): ユーザーがSuno AIで制作した既存曲の80年代ポップス風カバーバージョンを共有し、YouTubeリンクを提供しています (出典: Reddit r/SunoAI)

ChatGPTクリエイティブ応用:卵製品ミーム拡張: ユーザーが卵に関するミームに触発され、ChatGPTを使用して、「プレクラックドライフ」(Precracked Life)、「卵のインターネット」(Internet of Eggs)など、一連のユーモラスで概念的な卵関連製品の画像と説明を生成しました。AIを活用した創造的な発想とユーモアコンテンツ制作の可能性を示しています (出典: Reddit r/ChatGPT)
Suno AI作品共有:Tom and Jerry / Crambone (ブルースロックカバー): ユーザーがSuno AIで制作したブルースロック風のカバー曲を共有しました。カバー対象は「Tom and Jerry / Crambone」で、YouTubeリンクを提供しています (出典: Reddit r/SunoAI)

AI生成画像:七つの大罪の具現化: ユーザーが、AI(おそらくChatGPT/DALL-E)を使用して生成された、七つの大罪(例:強欲、怠惰、嫉妬など)を代表する具現化・擬人化された画像を示す動画を共有しました (出典: Reddit r/ChatGPT)
