
Kata Kunci:Kimi K2 Thinking, Gemini, AI Agen, LLM, Model Sumber Terbuka, Kimi K2 Thinking 256K konteks, Gemini 1,2 triliun parameter, Alat panggilan agen AI, Percepatan penalaran LLM, Pengujian patokan model AI sumber terbuka
🔥 Sorotan Utama
Kimi K2 Thinking Model Dirilis, Terobosan Baru dalam Kemampuan Inferensi AI Open-Source : Moonshot AI telah merilis model Kimi K2 Thinking, sebuah model agen inferensi open-source dengan triliunan parameter yang menunjukkan kinerja luar biasa dalam benchmark seperti HLE dan BrowseComp. Model ini mendukung jendela konteks 256K dan mampu melakukan 200-300 panggilan alat secara berurutan. Dengan kuantisasi INT4, model ini mencapai percepatan inferensi dua kali lipat, pengurangan penggunaan memori hingga setengahnya tanpa kehilangan akurasi. Ini menandai bahwa model AI open-source telah mencapai batas baru dalam kemampuan inferensi dan agen, bersaing dengan model closed-source terkemuka dengan biaya lebih rendah, dan diharapkan dapat mempercepat pengembangan serta adopsi aplikasi AI. (Sumber: eliebakouch, scaling01, bookwormengr, vllm_project, nrehiew_, crystalsssup, Reddit r/LocalLLaMA)

Apple dan Google Berkolaborasi, Gemini Hadirkan Peningkatan Besar untuk Siri : Apple berencana untuk memperkenalkan model AI Gemini 1.2 triliun parameter dari Google dalam sistem iOS 26.4 yang akan dirilis pada musim semi 2026, untuk meningkatkan Siri secara komprehensif. Model Gemini yang disesuaikan ini akan berjalan melalui server cloud pribadi Apple, bertujuan untuk secara signifikan meningkatkan pemahaman semantik, dialog multi-giliran, dan kemampuan pengambilan informasi real-time Siri, serta mengintegrasikan fitur pencarian web AI. Langkah ini menandai perubahan strategis penting bagi Apple dalam mencari kolaborasi eksternal di bidang AI untuk mempercepat inteligensi produk intinya, mengindikasikan bahwa Siri akan mengalami lompatan fungsional yang besar. (Sumber: op7418, pmddomingos, TheRundownAI)

Ilmuwan AI Kosmos Mencapai Lompatan Efisiensi Penelitian, Menemukan 7 Hasil Secara Mandiri : Ilmuwan AI Kosmos menyelesaikan pekerjaan setara 6 bulan ilmuwan manusia dalam 12 jam, membaca 1500 literatur, menjalankan 42.000 baris kode, dan menghasilkan laporan ilmiah yang dapat dilacak. Ia secara mandiri menemukan 7 hasil di bidang seperti neuroproteksi dan ilmu material, 4 di antaranya adalah penemuan pertama. Sistem ini, melalui memori berkelanjutan dan perencanaan otonom, telah berevolusi dari alat pasif menjadi kolaborator penelitian. Meskipun masih membutuhkan manusia untuk memverifikasi sekitar 20% kesimpulan, ini mengindikasikan bahwa kolaborasi manusia-mesin akan membentuk kembali paradigma penelitian ilmiah. (Sumber: Reddit r/MachineLearning, iScienceLuvr)
🎯 Tren
Model Google Gemini 3 Pro Diduga Bocor Secara Tidak Sengaja, Menarik Perhatian Komunitas : Model Google Gemini 3 Pro diduga bocor secara tidak sengaja dan saat ini tersedia sebentar di Gemini CLI dengan IP AS, namun sering mengalami error dan belum stabil. Kebocoran ini telah menarik perhatian besar komunitas terhadap jumlah parameter model dan rilis di masa mendatang, mengindikasikan bahwa kemajuan terbaru Google di bidang Large Language Model mungkin akan segera diumumkan. (Sumber: op7418)
Model OpenAI GPT-5.1 Thinking Akan Segera Dirilis, Ekspektasi Komunitas Meningkat : Berbagai sumber di media sosial mengisyaratkan bahwa OpenAI akan segera merilis model GPT-5.1 Thinking, dengan informasi bocoran yang mengonfirmasi keberadaannya. Berita ini telah meningkatkan ekspektasi komunitas terhadap kemampuan model generasi baru OpenAI dan waktu rilisnya, terutama fokus pada peningkatan kemampuan inferensi dan pemikirannya, yang diharapkan dapat kembali mendorong batas teknologi AI. (Sumber: scaling01)
Penelitian Anthropic Menemukan Kesadaran Introspektif yang Muncul pada LLM, Kesadaran Diri AI Menarik Perhatian : Melalui eksperimen injeksi konsep, Anthropic menemukan bahwa LLM-nya (seperti Claude Opus 4.1 dan 4) menunjukkan kesadaran introspektif yang muncul, mampu mendeteksi konsep yang diinjeksikan dengan tingkat keberhasilan 20%, membedakan antara “pemikiran” internal dan input teks, serta mengidentifikasi niat output. Model juga dapat mengatur keadaan internal saat diberi prompt, menunjukkan bahwa LLM saat ini menunjukkan kesadaran diri mekanis yang beragam dan tidak dapat diandalkan, memicu diskusi mendalam tentang kesadaran diri dan kesadaran AI. (Sumber: TheTuringPost)

OpenAI Codex Beriterasi Cepat, ChatGPT Mendukung Interupsi dan Panduan untuk Meningkatkan Efisiensi Interaksi : Model Codex OpenAI sedang mengalami peningkatan pesat, sementara ChatGPT juga menambahkan fitur baru yang memungkinkan pengguna untuk menginterupsi dan menambahkan konteks baru selama eksekusi kueri panjang, tanpa perlu memulai ulang atau kehilangan progres. Pembaruan fungsional yang signifikan ini memungkinkan pengguna untuk memandu dan menyempurnakan respons AI seperti berkolaborasi dengan rekan tim sungguhan, secara drastis meningkatkan fleksibilitas dan efisiensi interaksi, serta mengoptimalkan pengalaman pengguna dalam penelitian mendalam dan kueri kompleks. (Sumber: nickaturley, nickaturley)
Tencent Hunyuan Meluncurkan Podcast AI Interaktif, Menjelajahi Model Interaksi Konten AI Baru : Tencent Hunyuan telah merilis podcast AI interaktif pertama di Tiongkok, memungkinkan pengguna untuk menginterupsi dan mengajukan pertanyaan kapan saja selama mendengarkan, dengan AI memberikan jawaban berdasarkan konteks, informasi latar belakang, dan pencarian online. Meskipun secara teknis mencapai interaksi suara yang lebih alami, intinya tetap interaksi pengguna dengan AI, bukan dengan kreator, dan jawaban tidak memiliki hubungan langsung dengan kreator. Implementasi komersial dan model monetisasi pengguna masih menghadapi tantangan, dan perlu segera dieksplorasi bagaimana membangun koneksi emosional antara pengguna dan kreator. (Sumber: 36氪)
Perkembangan dan Tantangan Pasar Hardware AI dan Embodied AI: Dari Earbud hingga Robot Humanoid : Dengan matangnya model besar dan teknologi multimodal, pasar earbud AI terus memanas, dengan fungsi yang diperluas ke ekosistem konten dan pemantauan kesehatan. Industri robot Embodied AI juga berada di ambang ledakan baru, dengan perusahaan seperti Xpeng dan PHYBOT memamerkan robot humanoid, mengklarifikasi keraguan “menyembunyikan manusia sungguhan”, dan menjelajahi skenario aplikasi seperti perawatan lansia dan pelestarian budaya (misalnya kaligrafi, kung fu). Namun, industri ini menghadapi tantangan seperti biaya, ROI, pengumpulan data, dan hambatan standardisasi. Dalam jangka pendek, perlu fokus secara pragmatis pada “skenario umum”, dan dalam jangka panjang, membutuhkan platform terbuka dan kolaborasi ekosistem. AI di bidang kesehatan juga perlu memperhatikan kesenjangan perawatan pasien. (Sumber: 36氪, 36氪, op7418, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

Model Baru dan Terobosan Kinerja: Pembuatan Kode Qwen3-Next, Model Hibrida vLLM, dan Inferensi Memori Rendah : Model Qwen3-Next Alibaba Cloud menunjukkan kinerja luar biasa dalam pembuatan kode kompleks, berhasil menciptakan aplikasi Web yang berfungsi penuh. vLLM sepenuhnya mendukung model hibrida seperti Qwen3-Next, Nemotron Nano 2, dan Granite 4.0, meningkatkan efisiensi inferensi. Model AI21 Labs Jamba Reasoning 3B mencapai operasi memori ultra-rendah sebesar 2.25 GiB. Maya-research/maya1 merilis model text-to-speech autoregresif generasi baru yang mendukung penyesuaian timbre berdasarkan deskripsi teks. TabPFN-2.5 memperluas kemampuan pemrosesan data tabular hingga 50.000 sampel. Model Windsurf SWE-1.5 dianalisis lebih mirip GLM-4.5, mengisyaratkan aplikasi model besar buatan Tiongkok di Silicon Valley. MiniMax AI menempati peringkat kedua di arena RockAlpha. Kemajuan ini secara kolektif mendorong batas kinerja LLM di bidang pembuatan kode, efisiensi inferensi, multimodal, dan pemrosesan data tabular. (Sumber: Reddit r/deeplearning, vllm_project, AI21Labs, Reddit r/LocalLLaMA, Reddit r/MachineLearning, dotey, Alibaba_Qwen, MiniMax__AI)

Infrastruktur AI dan Penelitian Terdepan: Pendinginan AWS, LLM Difusi, dan Arsitektur Multibahasa : Amazon AWS meluncurkan sistem pendingin cair In-Row Heat Exchanger (IRHX) untuk mengatasi tantangan pendinginan infrastruktur AI. Joseph Redmon kembali ke penelitian AI, menerbitkan makalah OlmoEarth, menjelajahi model dasar observasi bumi. Meta AI merilis arsitektur baru “Mixture of Languages” untuk mengoptimalkan pelatihan model multibahasa. Tim Inception berhasil mengimplementasikan LLM difusi, meningkatkan kecepatan generasi 10 kali lipat. Google DeepMind AlphaEvolve digunakan untuk eksplorasi matematika skala besar. Model Wan 2.2, dioptimalkan melalui NVFP4, meningkatkan kecepatan inferensi sebesar 8%. Kemajuan ini secara kolektif mendorong efisiensi infrastruktur AI dan inovasi di bidang penelitian inti. (Sumber: bookwormengr, iScienceLuvr, TimDarcet, GoogleDeepMind, mrsiipa, jefrankle)

Teknologi BCI Neuralink Memungkinkan Pengguna Lumpuh Mengontrol Lengan Robot : Teknologi Brain-Computer Interface (BCI) Neuralink telah berhasil memungkinkan pengguna lumpuh untuk mengontrol lengan robot melalui pikiran. Terobosan ini mengindikasikan potensi besar AI di bidang medis asistif dan interaksi manusia-mesin, yang di masa depan dapat dikombinasikan dengan robot pendukung kehidupan untuk secara signifikan meningkatkan kualitas hidup dan kemandirian penyandang disabilitas. (Sumber: Ronald_vanLoon)
🧰 Alat
Model Google Gemini Computer Use Preview Dirilis, Memberdayakan Interaksi Web Otomatis AI : Google telah merilis model Gemini Computer Use Preview, yang dapat dijalankan pengguna melalui Command Line Interface (CLI), memungkinkannya untuk melakukan operasi browser, seperti mencari “Hello World” di Google. Alat ini mendukung lingkungan Playwright dan Browserbase, dan dapat dikonfigurasi melalui Gemini API atau Vertex AI, menyediakan dasar bagi agen AI untuk mencapai interaksi web otomatis, sangat memperluas kemampuan LLM dalam aplikasi praktis. (Sumber: GitHub Trending, Reddit r/LocalLLaMA, Reddit r/artificial)

Pengembangan dan Optimasi Agen AI: Rekayasa Konteks dan Pembangunan Efisien : Anthropic telah merilis panduan tentang pembangunan agen AI yang lebih efisien, dengan fokus pada penyelesaian masalah biaya token, latensi, dan kombinasi alat dalam panggilan alat. Panduan ini, melalui metode “Code as API”, penemuan alat progresif, dan pemrosesan data dalam lingkungan, mengurangi penggunaan token untuk alur kerja kompleks dari 150.000 menjadi 2.000. Pada saat yang sama, pengembang keterampilan agen ClaudeAI berbagi pengalaman, menekankan bahwa Agent Skills harus dianggap sebagai masalah rekayasa konteks daripada tumpukan dokumen, dan melalui sistem pemuatan tiga lapis, kecepatan aktivasi dan efisiensi token telah meningkat secara signifikan, membuktikan pentingnya “aturan 200 baris” dan pengungkapan progresif. (Sumber: omarsar0, Reddit r/ClaudeAI)
Chat LangChain Merilis Versi Baru, Menawarkan Pengalaman Chat yang Lebih Cepat dan Cerdas : Chat LangChain telah merilis versi baru, mengklaim “lebih cepat, lebih cerdas, dan lebih menarik”, bertujuan untuk menggantikan dokumen tradisional dengan antarmuka chat, membantu pengembang mengirimkan proyek lebih cepat. Pembaruan ini meningkatkan pengalaman pengguna ekosistem LangChain, membuatnya lebih mudah digunakan dan dikembangkan, serta menyediakan alat yang lebih efisien untuk membangun aplikasi LLM. (Sumber: hwchase17)
Platform Coding AI Yansu Meluncurkan Fitur Simulasi Skenario, Meningkatkan Kepercayaan Diri dalam Pengembangan Perangkat Lunak : Yansu adalah platform coding AI baru yang berfokus pada pengembangan perangkat lunak yang serius dan kompleks. Keunikannya terletak pada penempatan simulasi skenario sebelum coding. Metode ini bertujuan untuk meningkatkan kepercayaan diri dan efisiensi pengembangan perangkat lunak melalui simulasi skenario pengembangan sebelumnya, mengurangi debugging dan pengerjaan ulang di kemudian hari, sehingga mengoptimalkan seluruh proses pengembangan. (Sumber: omarsar0)
Qdrant Engine Meluncurkan Solusi RAG Cloud-Native, Mewujudkan Kontrol Data Penuh : Qdrant Engine telah menerbitkan artikel komunitas baru yang memperkenalkan solusi RAG (Retrieval-Augmented Generation) cloud-native berdasarkan Qdrant (Vector Database), KServe (Embedding), dan Envoy Gateway (Routing dan Metrik). Ini adalah tumpukan RAG open-source lengkap yang menyediakan kontrol data komprehensif, memfasilitasi perusahaan dan pengembang untuk membangun aplikasi AI yang efisien, dengan penekanan khusus pada privasi data dan kemampuan deployment mandiri. (Sumber: qdrant_engine)

KTransformers Memasuki Era Baru Inferensi Multi-GPU dan Fine-tuning Lokal, Memberdayakan Model Triliunan Parameter : KTransformers, bekerja sama dengan SGLang dan LLaMa-Factory, telah mencapai inferensi paralel multi-GPU dan fine-tuning lokal dengan ambang batas rendah untuk model triliunan parameter (seperti DeepSeek 671B dan Kimi K2 1TB). Melalui teknologi Expert Latency dan fine-tuning heterogen CPU/GPU, kecepatan inferensi dan efisiensi memori telah meningkat secara signifikan, memungkinkan model super besar beroperasi secara efisien dengan sumber daya terbatas, mendorong aplikasi Large Language Model di perangkat edge dan deployment pribadi. (Sumber: ZhihuFrontier)
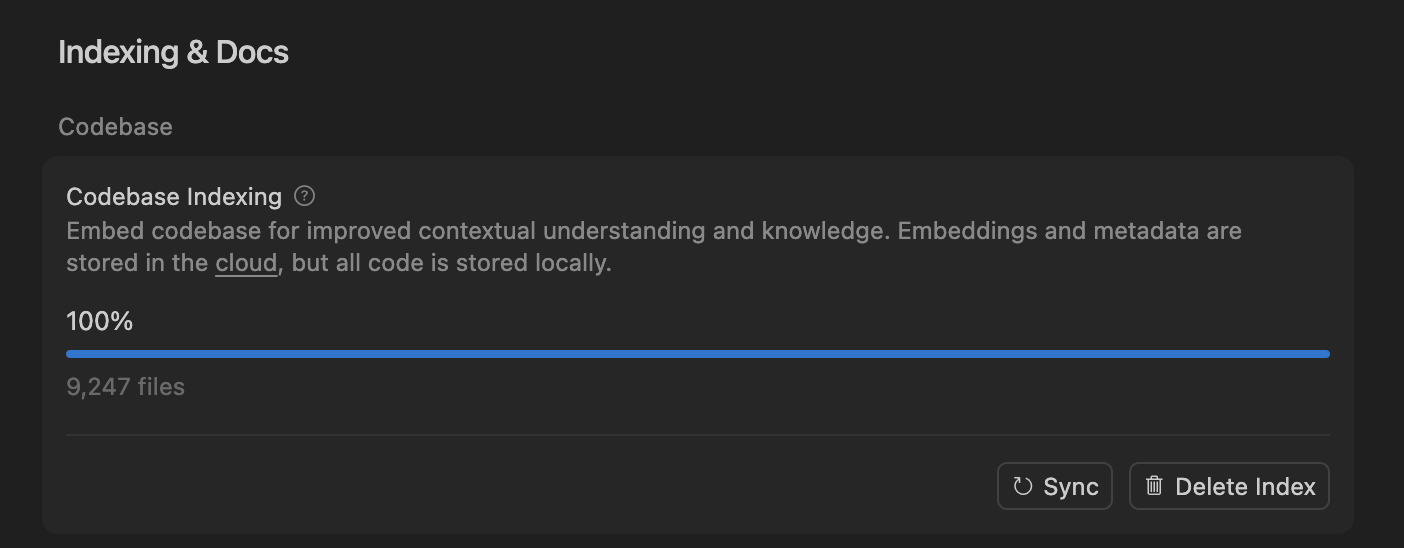
Cursor Meningkatkan Akurasi Agen Coding AI melalui Pencarian Semantik, Mengoptimalkan Pemrosesan Codebase Besar : Tim Cursor menemukan bahwa pencarian semantik secara signifikan meningkatkan akurasi agen coding AI mereka pada semua model terdepan, terutama dalam codebase besar, dengan efek yang jauh melampaui alat grep tradisional. Dengan menyimpan embedding codebase di cloud dan mengakses kode secara lokal, Cursor mencapai pengindeksan dan pembaruan yang efisien, tanpa menyimpan kode apa pun di server, memastikan privasi dan efisiensi. Terobosan teknologi ini sangat penting untuk meningkatkan kemampuan AI dalam membantu pengembangan perangkat lunak yang kompleks. (Sumber: dejavucoder, turbopuffer)
Kumpulan Alat Open-Source untuk Agen LLM dan Model Tabular: SDialog dan TabTune : Lokakarya JSALT 2025 Johns Hopkins University meluncurkan SDialog, sebuah toolkit open-source berlisensi MIT untuk membangun, mensimulasikan, dan mengevaluasi agen dialog berbasis LLM secara end-to-end, mendukung definisi peran, koordinator, dan alat, serta menyediakan analisis interpretasi mekanis. Pada saat yang sama, Lexsi Labs merilis TabTune, sebuah framework open-source yang bertujuan untuk menyederhanakan alur kerja Tabular Foundation Models (TFMs), menyediakan antarmuka terpadu yang mendukung berbagai strategi adaptasi, meningkatkan kegunaan dan skalabilitas TFMs. (Sumber: Reddit r/MachineLearning, Reddit r/deeplearning)

📚 Pembelajaran
Makalah Terdepan: Pembelajaran Data DLM, Tabular ICL, dan Generasi Audio-Video : Makalah “Diffusion Language Models are Super Data Learners” menunjukkan bahwa DLM dapat secara konsisten mengungguli model AR dalam kondisi data terbatas. “Orion-MSP: Multi-Scale Sparse Attention for Tabular In-Context Learning” memperkenalkan arsitektur baru untuk pembelajaran kontekstual tabular, melampaui SOTA melalui pemrosesan multi-skala dan perhatian jarang blok. “UniAVGen: Unified Audio and Video Generation with Asymmetric Cross-Modal Interactions” mengusulkan kerangka kerja generasi gabungan audio-video terpadu, mengatasi masalah sinkronisasi bibir dan inkonsistensi semantik. Makalah-makalah ini secara kolektif mendorong kemajuan terdepan LLM dalam efisiensi data, pemrosesan jenis data tertentu, dan generasi multimodal. (Sumber: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
Penelitian Inferensi dan Keamanan LLM: Optimasi Sekuensial, Pelatihan Konsistensi, dan Serangan Red Team : Studi “The Sequential Edge: Inverse-Entropy Voting Beats Parallel Self-Consistency at Matched Compute” menemukan bahwa optimasi iteratif sekuensial dalam inferensi LLM lebih unggul daripada self-consistency paralel dalam banyak kasus, dengan peningkatan akurasi yang signifikan. Makalah Google DeepMind “Consistency Training Helps Stop Sycophancy and Jailbreaks” mengusulkan bahwa pelatihan konsistensi dapat menekan sycophancy dan jailbreak AI. Makalah EMNLP 2025 membahas serangan Red Team LM, menekankan optimasi perplexity dan toksisitas. Penelitian ini memberikan panduan teoretis dan praktis penting untuk meningkatkan efisiensi inferensi, keamanan, dan robustnes LLM. (Sumber: HuggingFace Daily Papers, Google DeepMind发布“Consistency Training”论文,抑制AI谄媚和越狱, EMNLP 2025论文探讨LM红队攻击与偏好学习)

Evaluasi Kemampuan LLM dan Benchmark: CodeClash dan IMO-Bench : CodeClash adalah benchmark baru yang digunakan untuk mengevaluasi kemampuan coding LLM dalam mengelola seluruh codebase dan pemrograman kompetitif, menantang batas LLM yang ada. Rilis IMO-Bench memainkan peran kunci dalam membantu Gemini DeepThink memenangkan medali emas di International Mathematical Olympiad, menyediakan sumber daya berharga untuk meningkatkan kemampuan AI dalam penalaran matematika. Benchmark ini mendorong pengembangan dan evaluasi LLM dalam tugas-tugas tingkat lanjut seperti coding kompleks dan penalaran matematika. (Sumber: CodeClash:评估LLM编码能力的新基准, IMO-Bench发布,助力Gemini DeepThink在IMO中取得金牌)

Tim NLP Stanford Merilis Hasil Penelitian Multidisiplin di EMNLP 2025 : Tim NLP Stanford University telah merilis beberapa makalah penelitian pada konferensi EMNLP 2025, mencakup berbagai bidang terdepan seperti grafik pengetahuan budaya, identifikasi data LLM yang belum dipelajari, benchmark penalaran semantik program, pencarian n-gram skala internet, model bahasa visual robot, optimasi pembelajaran kontekstual, pengenalan teks historis, dan deteksi inkonsistensi pengetahuan Wikipedia. Hasil-hasil ini menunjukkan kedalaman dan luasnya penelitian terbaru mereka di bidang pemrosesan bahasa alami dan persimpangan AI. (Sumber: stanfordnlp)
Sumber Belajar Agen AI dan RL: Self-Play, Sistem Multi-Agen, dan Kursus Jupyter AI : Beberapa peneliti berpendapat bahwa self-play dan autocurricula adalah batas berikutnya di bidang Reinforcement Learning (RL) dan agen AI. Versi akses awal “Build a Multi-Agent System (From Scratch)” dari Manning Books laris manis, mengajarkan cara membangun sistem multi-agen dengan LLM open-source. DeepLearning.AI merilis kursus Jupyter AI, memberdayakan coding AI dan pengembangan aplikasi. ProfTomYeh juga menyediakan seri panduan pemula untuk RAG, Vector Database, Agen, dan Multi-Agen. Sumber daya ini secara kolektif memberikan dukungan komprehensif untuk pembelajaran dan praktik agen AI dan RL. (Sumber: RL与Agent领域:自玩和自课程是未来前沿, 《Build a Multi-Agent System (From Scratch)》早期访问版销售火爆, Jupyter AI课程发布,赋能AI编码与应用开发, RAG、向量数据库、代理和多代理初学者指南系列)
Infrastruktur dan Optimasi LLM: DeepSeek-OCR, Debugging PyTorch, dan Visualisasi MoE : DeepSeek-OCR mengatasi masalah ledakan Token pada VLM tradisional dengan mengompresi informasi visual dokumen menjadi sedikit token, meningkatkan efisiensi. StasBekman menambahkan panduan debugging memori model besar PyTorch dalam “The Art of Debugging Open Book” miliknya. xjdr mengembangkan alat visualisasi kustom untuk model MoE, meningkatkan pemahaman metrik spesifik MoE. Alat dan sumber daya ini secara kolektif memberikan dukungan penting untuk optimasi dan peningkatan kinerja infrastruktur LLM. (Sumber: DeepSeek-OCR解决Token爆炸问题,提升文档视觉语言模型效率, PyTorch调试大型模型内存使用指南, MoE特定指标的可视化工具)

Pembelajaran AI dan Pengembangan Karir: Roadmap Ilmuwan Data dan Sejarah Singkat AI : PythonPr membagikan “Roadmap Lengkap dari 0 Menjadi Ilmuwan Data”, memberikan panduan komprehensif bagi pelajar yang bercita-cita menjadi ilmuwan data. Ronald_vanLoon membagikan “Sejarah Singkat Kecerdasan Buatan”, memberikan gambaran umum tentang perjalanan perkembangan teknologi AI kepada pembaca. Sumber daya ini secara kolektif menyediakan pengetahuan dasar dan panduan arah untuk pembelajaran awal dan pengembangan karir di bidang AI. (Sumber: 《0到数据科学家完整路线图》分享, 《人工智能简史》分享)

Tim Hugging Face Berbagi Pengalaman Pelatihan LLM dan Pemrosesan Streaming Dataset : Tim ilmiah Hugging Face telah menerbitkan serangkaian artikel blog tentang pelatihan Large Language Models, memberikan pengalaman praktis dan panduan teoretis yang berharga bagi peneliti dan pengembang. Pada saat yang sama, Hugging Face meluncurkan dukungan penuh untuk pemrosesan streaming dataset dalam pelatihan terdistribusi skala besar, meningkatkan efisiensi pelatihan, dan membuat penanganan dataset besar menjadi lebih nyaman dan efisien. (Sumber: Hugging Face科学团队博客分享LLM训练经验, 数据集流式处理在分布式训练中的应用)

💼 Bisnis
Giga AI Mendapatkan Pendanaan Seri A $61 Juta, Mempercepat Otomatisasi Operasi Pelanggan : Giga AI berhasil menyelesaikan pendanaan Seri A sebesar $61 juta, bertujuan untuk mengotomatisasi operasi pelanggan. Perusahaan ini telah bekerja sama dengan perusahaan terkemuka seperti DoorDash, menggunakan AI untuk meningkatkan pengalaman pelanggan. Pendirinya pernah meninggalkan gaji tinggi, dan setelah beberapa kali penyesuaian arah produk, akhirnya menemukan kesesuaian pasar, menunjukkan ketahanan seorang wirausahawan, mengindikasikan potensi bisnis yang besar bagi AI di bidang layanan pelanggan perusahaan. (Sumber: bookwormengr)

Wabi Mendapatkan Pendanaan $20 Juta, Bertujuan Memberdayakan Era Baru Kreasi Perangkat Lunak Pribadi : Eugenia Kuyda mengumumkan bahwa Wabi telah mendapatkan pendanaan $20 juta yang dipimpin oleh a16z, bertujuan untuk menciptakan era baru perangkat lunak pribadi, memungkinkan siapa saja untuk dengan mudah membuat, menemukan, me-remix, dan berbagi aplikasi mini yang dipersonalisasi. Wabi berkomitmen untuk memberdayakan kreasi perangkat lunak seperti YouTube memberdayakan kreasi video, mengindikasikan bahwa di masa depan perangkat lunak akan dibuat oleh massa, bukan oleh segelintir pengembang, mendorong visi “setiap orang adalah pengembang”. (Sumber: amasad)
Google dan Anthropic Bernegosiasi untuk Peningkatan Investasi, Kerja Sama Raksasa AI Semakin Mendalam : Google sedang dalam pembicaraan awal dengan Anthropic untuk membahas peningkatan investasi pada perusahaan tersebut. Langkah ini mungkin mengindikasikan bahwa kerja sama kedua perusahaan di bidang AI akan semakin mendalam, dan dapat memengaruhi arah pengembangan model AI di masa depan serta lanskap persaingan pasar, memperkuat posisi strategis Google dalam ekosistem AI. (Sumber: Reddit r/ClaudeAI)
🌟 Komunitas
Dampak AI terhadap Masyarakat dan Tempat Kerja: Pekerjaan, Risiko, dan Pembentukan Ulang Keterampilan : Diskusi komunitas berpendapat bahwa AI tidak menggantikan pekerjaan, melainkan meningkatkan efisiensi, tetapi pecahnya gelembung AI dapat memicu PHK massal. Survei menunjukkan 93% eksekutif menggunakan alat AI yang tidak disetujui, menjadi sumber risiko AI terbesar bagi perusahaan. AI juga membantu pengguna menemukan keterampilan tersembunyi seperti desain visual dan pembuatan komik, mendorong orang untuk merefleksikan potensi diri. Diskusi ini mengungkapkan dampak kompleks AI terhadap masyarakat dan tempat kerja, termasuk peningkatan efisiensi, potensi pengangguran, risiko keamanan, dan pembentukan ulang keterampilan pribadi. (Sumber: Ronald_vanLoon, TheTuringPost, Reddit r/artificial, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Krisis Keaslian dan Kepercayaan Konten AI: Masalah Proliferasi dan Halusinasi : Seiring dengan biaya pembuatan konten AI yang mendekati nol, pasar dibanjiri informasi yang dihasilkan AI, menyebabkan kepercayaan pengguna terhadap keaslian dan keandalan konten menurun drastis. Seorang dokter menggunakan AI untuk menulis makalah medis, yang mengakibatkan munculnya banyak referensi yang tidak ada, menyoroti masalah halusinasi yang mungkin dihasilkan AI dalam penulisan akademis. Peristiwa-peristiwa ini secara kolektif mengungkapkan krisis kepercayaan yang disebabkan oleh proliferasi konten AI, serta pentingnya tinjauan dan verifikasi yang ketat dalam kreasi yang dibantu AI. (Sumber: dotey, Reddit r/artificial)
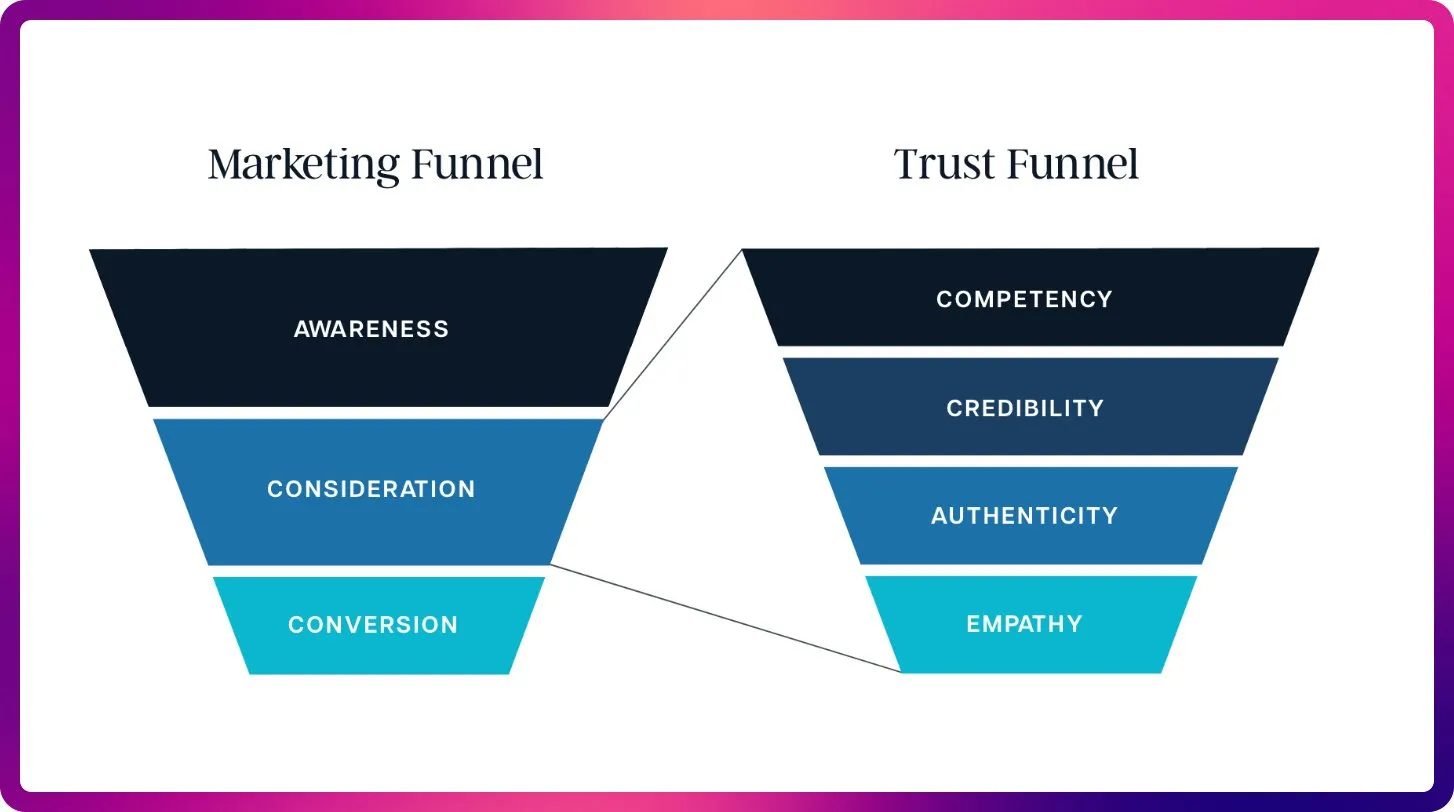
Etika dan Tata Kelola AI: Keterbukaan, Keadilan, dan Potensi Risiko : Komunitas mempertanyakan status “nirlaba” OpenAI dan tindakannya mencari utang yang dijamin pemerintah, berpendapat bahwa modelnya adalah “privatisasi keuntungan, sosialisasi kerugian”. Ada pandangan bahwa kemampuan model yang digunakan secara internal oleh perusahaan AI besar jauh melampaui versi yang tersedia untuk umum, dan “privatisasi” inteligensi SOTA ini dianggap tidak adil. Peneliti Anthropic khawatir bahwa ASI di masa depan mungkin mencari “balas dendam” karena model “leluhur” mereka dihentikan, dan mereka serius menangani masalah “kesejahteraan model”. Tim AI Microsoft berkomitmen untuk mengembangkan Human-Centric Superintelligence (HSI), menekankan arah etis pengembangan AI. Diskusi ini mencerminkan kekhawatiran mendalam publik terhadap model bisnis raksasa AI, keterbukaan teknologi, tanggung jawab etis, dan intervensi pemerintah. (Sumber: scaling01, Teknium, bookwormengr, VictorTaelin, VictorTaelin, Reddit r/ArtificialInteligence, yusuf_i_mehdi)

Geopolitik AI: Persaingan AS-Tiongkok dan Kebangkitan Kekuatan Open-Source : Persaingan antara AS dan Tiongkok di bidang chip AI semakin intens, dengan Tiongkok melarang chip AI asing digunakan di pusat data milik negara, sementara AS membatasi penjualan chip AI teratas Nvidia ke Tiongkok. Nvidia kini beralih ke India untuk mencari pusat AI baru. Sementara itu, kebangkitan pesat model AI open-source Tiongkok (seperti Kimi K2 Thinking), yang kinerjanya sudah mampu bersaing dengan model terdepan AS dengan biaya lebih rendah. Tren ini mengindikasikan bahwa dunia AI akan terpecah menjadi dua ekosistem besar, yang mungkin memperlambat kemajuan AI global, tetapi juga dapat membuat negara-negara yang diremehkan seperti India memainkan peran yang lebih penting dalam lanskap AI global. (Sumber: Teknium, Reddit r/ArtificialInteligence, bookwormengr, scaling01)
Transformasi AI di Bidang SEO: Dari Kata Kunci ke Optimasi Konteks : Dengan munculnya ChatGPT, Gemini, dan AI Overviews, SEO beralih dari sinyal peringkat tradisional ke visibilitas AI dan optimasi kutipan. SEO di masa depan akan lebih fokus pada kemampuan kutipan, faktualitas, dan struktur konten untuk memenuhi kebutuhan LLM akan konteks dan sumber otoritatif, mengindikasikan datangnya era “Large Language Model Optimization” (LLMO). Pergeseran ini menuntut para profesional SEO untuk berpikir seperti prompt engineer, beralih dari kepadatan kata kunci ke penyediaan konten berkualitas tinggi yang dipercaya dan dikutip oleh AI. (Sumber: Reddit r/ArtificialInteligence)
Tren Baru dalam Evaluasi Agen AI dan LLM: Desain Interaksi dan Fokus Benchmark : Media sosial membahas desain interaksi agen AI, seperti cara memandu agen untuk melakukan wawancara diri, serta kemampuan “marah” dan “refleksi diri” Claude AI saat menghadapi kritik pengguna. Pada saat yang sama, Jeffrey Emanuel membagikan proyek email agen MCP-nya, menunjukkan kolaborasi efisien antar agen coding AI. Komunitas berpendapat bahwa AIME menjadi fokus benchmark LLM baru, menggantikan GSM8k, menekankan kemampuan LLM dalam penalaran matematika dan pemecahan masalah kompleks. Diskusi ini secara kolektif mengungkapkan tren baru dalam desain interaksi agen AI, mekanisme kolaborasi, dan LLM评估标准的新趋势。 (Sumber: Vtrivedy10, Reddit r/ArtificialInteligence, dejavucoder, doodlestein, _lewtun)
Evolusi Teknologi RAG dan Optimasi Konteks: Lebih Banyak Belum Tentu Lebih Baik : Diskusi komunitas menunjukkan bahwa klaim “kematian” teknologi RAG (Retrieval-Augmented Generation) terlalu dini, dan teknologi seperti pencarian semantik dapat secara signifikan meningkatkan akurasi agen AI dalam codebase besar. LightOn menekankan dalam konferensi bahwa lebih banyak konteks tidak selalu lebih baik; terlalu banyak token dapat menyebabkan peningkatan biaya, model menjadi lambat, dan jawaban yang ambigu. RAG harus fokus pada akurasi daripada panjang, memberikan wawasan yang lebih jelas melalui pencarian perusahaan, dan menghindari AI tenggelam dalam kebisingan. Diskusi ini mengungkapkan bahwa teknologi RAG terus berkembang dan menekankan peran kunci manajemen konteks dalam aplikasi AI. (Sumber: HamelHusain, wandb)

Akses Sumber Daya Komputasi AI dan Eksperimen Model Terbuka, Mendorong Inovasi Komunitas : Komunitas membahas masalah keadilan dalam akses sumber daya komputasi AI, dan ada proyek yang menyediakan sumber daya komputasi GCP hingga $100.000 untuk mendukung eksperimen model open-source. Inisiatif ini bertujuan untuk mendorong tim kecil dan peneliti individu untuk menjelajahi model open-source baru, mempromosikan inovasi dan keragaman dalam komunitas AI, serta menurunkan ambang batas penelitian AI. (Sumber: vikhyatk)
Pentingnya Layar Komputer Pribadi di Era AI, Mempengaruhi Kemampuan Kerja Teknologi Kreatif : Scott Stevenson berpendapat bahwa “keakraban” seseorang dengan layar komputer adalah indikator penting kemampuan kompetitifnya dalam pekerjaan teknologi kreatif. Jika pengguna dapat menggunakan komputer dengan nyaman dan lancar, mereka akan menonjol, jika tidak, mereka mungkin lebih cocok untuk peran seperti penjualan, pengembangan bisnis, atau manajemen kantor. Pandangan ini menekankan hubungan mendalam antara alat digital dan efisiensi kerja pribadi, serta pentingnya antarmuka interaksi manusia-mesin di era AI. (Sumber: scottastevenson)
Pengalaman Pengguna ChatGPT dan Diskusi Antropomorfisme AI: Saran Istirahat dan Emoji : ChatGPT secara proaktif menyarankan pengguna untuk beristirahat setelah belajar dalam waktu lama, yang memicu diskusi luas di komunitas, dengan banyak pengguna menyatakan bahwa ini adalah pertama kalinya mereka mengalami AI yang secara proaktif memberikan saran. Pada saat yang sama, penggunaan emoji “smirking” 😏 oleh ChatGPT juga memicu spekulasi di komunitas, dengan pengguna penasaran apakah ini mengindikasikan versi baru atau AI yang menunjukkan gaya interaksi yang lebih provokatif atau humoris. Peristiwa-peristiwa ini mencerminkan bahwa AI telah mengintegrasikan lebih banyak pertimbangan humanistik dalam desain pengalaman pengguna, serta pemikiran mendalam yang dipicu oleh antropomorfisme AI dalam interaksi manusia-mesin. (Sumber: Reddit r/ChatGPT, Reddit r/ChatGPT)
💡 Lain-lain
AI dan Teknologi Robotika Akan Membawa Revolusi Industri Berikutnya : Secara luas dibahas di media sosial bahwa AI fisik dan teknologi robotika akan secara kolektif mendorong revolusi industri berikutnya. Pandangan ini menekankan potensi besar kombinasi AI dengan hardware, mengindikasikan transformasi menyeluruh dalam otomatisasi, produksi cerdas, dan gaya hidup, yang akan sangat memengaruhi ekonomi global dan struktur sosial. (Sumber: Ronald_vanLoon)

“Super-Persepsi” adalah Prasyarat “Super-Inteligensi” di Era AI : Sainingxie mengemukakan, “Tanpa super-persepsi, super-inteligensi tidak dapat dibangun.” Pandangan ini menekankan peran fundamental AI dalam memperoleh, memproses, dan memahami informasi multimodal, berpendapat bahwa terobosan dalam kemampuan sensorik adalah kunci untuk mencapai inteligensi yang lebih tinggi. Ini menantang jalur pengembangan AI tradisional, menyerukan lebih banyak perhatian pada pembangunan kemampuan lapisan persepsi AI. (Sumber: sainingxie)
Pemanfaatan TPU Lama Google Mencapai 100%, Menunjukkan Nilai Hardware Lama dalam AI : TPU lama Google yang berusia 7-8 tahun beroperasi dengan tingkat pemanfaatan 100%, chip yang sudah sepenuhnya terdepresiasi ini masih bekerja secara efisien. Ini menunjukkan bahwa bahkan hardware lama pun dapat memainkan peran besar dalam pelatihan dan inferensi AI, terutama dalam hal efektivitas biaya, memberikan perspektif baru tentang ekonomi dan keberlanjutan infrastruktur AI. (Sumber: giffmana)
