
Kata Kunci:Model AI, Teknologi OCR, Infrastruktur AI, Model Bahasa Besar, Agen AI, Model Multimodal, Optimasi Konsumsi Energi AI, Ekologi Sumber Terbuka AI, Model OCR DeepSeek, Penalaran Multimodal Gemini 3, Model Dunia Emu3.5, Arsitektur Perhatian Campuran Linear Kimi, Teknologi Lipatan Memori AgentFold
Pilihan Editor Utama Kolom AI
🔥 Fokus
Model DeepSeek OCR: Terobosan Baru dalam Memori AI dan Optimalisasi Konsumsi Energi : DeepSeek telah merilis model OCR, dengan inovasi inti pada cara pemrosesan informasi dan penyimpanan memori. Model ini mengompresi informasi teks menjadi bentuk gambar, secara signifikan mengurangi sumber daya komputasi yang dibutuhkan untuk beroperasi, dan diharapkan dapat mengurangi jejak karbon AI yang terus meningkat. Metode ini mensimulasikan memori manusia melalui kompresi berlapis, mengaburkan konten yang tidak penting untuk menghemat ruang sambil mempertahankan efisiensi tinggi. Penelitian ini menarik perhatian para ahli seperti Andrej Karpathy, yang berpendapat bahwa gambar mungkin lebih cocok sebagai input LLM daripada teks, membuka arah baru untuk memori AI dan aplikasi agen. (Sumber: MIT Technology Review)

Raksasa Teknologi Terus Berinvestasi Besar-besaran pada Infrastruktur AI : Raksasa teknologi seperti Microsoft, Meta, dan Google mengumumkan dalam laporan keuangan terbaru mereka bahwa mereka akan terus meningkatkan pengeluaran infrastruktur AI secara signifikan. Meta memperkirakan belanja modal tahun ini akan mencapai $70-72 miliar, dan berencana untuk memperluasnya lebih lanjut tahun depan; pendapatan Microsoft Intelligent Cloud untuk pertama kalinya melampaui $30 miliar, dengan Azure dan layanan cloud lainnya tumbuh 40%, dan kapasitas AI diperkirakan akan meningkat 80%. CEO Google, Pichai, menekankan bahwa pendekatan AI full-stack membawa momentum yang kuat, dan mengumumkan peluncuran Gemini 3 yang akan datang. Investasi ini mencerminkan optimisme para raksasa terhadap terobosan AI di masa depan dan tekad mereka untuk merebut peluang pasar. (Sumber: Wired, Reddit r/artificial)

Anthropic Menemukan LLM Memiliki “Kemampuan Introspeksi” yang Terbatas : Penelitian terbaru Anthropic menunjukkan bahwa Large Language Models (LLMs) seperti Claude memiliki “kesadaran introspektif sejati”, meskipun kemampuan ini masih terbatas saat ini. Penelitian ini mengeksplorasi apakah LLM dapat mengenali pemikiran internalnya, atau hanya menghasilkan jawaban yang masuk akal berdasarkan pertanyaan. Penemuan ini mengisyaratkan bahwa LLM mungkin memiliki tingkat kesadaran diri yang lebih dalam dari yang diperkirakan, yang memiliki signifikansi penting untuk memahami dan mengembangkan sistem AI yang lebih cerdas dan sadar. (Sumber: Anthropic, Reddit r/artificial)

Extropic Merilis Hardware Komputasi Termodinamika TSU Baru, Diklaim sebagai Terobosan Konsumsi Energi AI : Perusahaan Extropic telah meluncurkan perangkat komputasi baru, TSU (Thermodynamic Sampling Unit), yang intinya adalah “probabilistic bit” (P-bit) yang dapat berkedip antara 0 dan 1 dengan probabilitas yang dapat diprogram, bertujuan untuk mencapai peningkatan efisiensi konsumsi energi AI sebesar 10.000 kali. Perusahaan ini telah merilis chip X0, kit uji desktop XTR0, dan TSU kelas komersial Z1, serta membuka sumber pustaka perangkat lunak Thermol untuk simulasi TSU oleh GPU. Meskipun definisi benchmark peningkatan efisiensinya dipertanyakan, arah ini bertujuan untuk mengatasi kesenjangan besar dalam daya komputasi dan energi AI, membawa potensi perubahan paradigma untuk komputasi AI. (Sumber: TheRundownAI, pmddomingos, op7418)

🎯 Tren
Google Mengumumkan Gemini 3 Akan Segera Dirilis, Memperkuat Tren Spesialisasi Keluarga Model AI : CEO Google Sundar Pichai mengumumkan dalam panggilan konferensi pendapatan bahwa model flagship baru, Gemini 3, akan dirilis akhir tahun ini. Dia menekankan bahwa keluarga model AI Google sedang menuju spesialisasi, dengan Gemini berfokus pada inferensi multimodal, Veo untuk generasi video, Genie untuk agen interaktif, dan Nano untuk kecerdasan di perangkat. Strategi ini menunjukkan bahwa Google beralih dari satu model umum ke arsitektur sistem yang saling terhubung dan dioptimalkan untuk berbagai skenario, guna meningkatkan keandalan, mengurangi latensi, dan mendukung penerapan di edge. (Sumber: Reddit r/ArtificialInteligence, shlomifruchter)
Sora 2 Menambahkan Fitur Karakter Kustom dan Penggabungan Video, Mendukung Pembuatan Video Panjang Berkelanjutan : Sora 2 baru-baru ini memperbarui beberapa fitur penting, termasuk dukungan untuk membuat karakter lain (tidak dapat mengunggah foto asli, tetapi dapat dibuat dari karakter video yang ada). Pengguna dapat menggunakan fitur ini untuk memastikan konsistensi karakter, yang sangat penting untuk membangun video panjang berkelanjutan. Selain itu, halaman draf mendukung penggabungan beberapa video sebelum dipublikasikan, dan halaman pencarian telah menambahkan papan peringkat, menampilkan pertunjukan langsung dan kreator sekunder. Pembaruan ini secara signifikan meningkatkan fleksibilitas kreatif dan interaktivitas pengguna Sora 2, dan diharapkan dapat meningkatkan pengguna aktif harian secara substansial. (Sumber: op7418, billpeeb, op7418)
BAAI Merilis Model Dunia Multimodal Open-Source Emu3.5, Kinerja Melampaui Gemini-2.5-Flash-Image : Beijing Academy of Artificial Intelligence (BAAI) telah merilis model dunia multimodal open-source Emu3.5 dengan 34B parameter. Model ini menggunakan kerangka Decoder-only Transformer, yang dapat menangani tugas gambar, teks, dan video secara bersamaan, dan menyatukannya sebagai tugas prediksi State berikutnya. Emu3.5 dilatih sebelumnya pada data video internet dalam jumlah besar, memiliki kemampuan untuk memahami kontinuitas spasial-temporal dan hubungan kausalitas, serta menunjukkan kinerja luar biasa dalam narasi visual, panduan visual, pengeditan gambar, eksplorasi dunia, dan operasi embodied, terutama dengan peningkatan signifikan dalam realisme fisik, menyaingi bahkan melampaui Gemini-2.5-Flash-Image (Nano Banana). (Sumber: 36氪)

Moonshot AI Merilis Model Kimi Linear, Menggunakan Arsitektur Perhatian Linier Hibrida : Moonshot AI telah meluncurkan model Kimi Linear, sebuah model 48B parameter berdasarkan arsitektur perhatian linier hibrida (KDA), dengan 3B parameter aktif, mendukung panjang konteks 1M. Kimi Linear, melalui optimasi Gated DeltaNet, secara signifikan meningkatkan kinerja dan efisiensi hardware untuk tugas konteks panjang, mengurangi kebutuhan KV cache hingga 75%, dan meningkatkan throughput decoding 6 kali lipat. Model ini menunjukkan kinerja yang sangat baik dalam berbagai benchmark, melampaui model perhatian penuh tradisional, dan telah di-open source dalam dua versi di Hugging Face. (Sumber: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, bigeagle_xd)

Model MiniMax M2 Mempertahankan Arsitektur Full Attention, Menyoroti Tantangan dalam Penerapan Produksi : Haohai Sun, kepala pra-pelatihan MiniMax M2, menjelaskan mengapa model M2 masih menggunakan arsitektur Full Attention daripada perhatian linier atau sparse. Dia menunjukkan bahwa meskipun perhatian yang efisien secara teoritis dapat menghemat daya komputasi, dalam sistem tingkat industri yang sebenarnya, kinerja, kecepatan, dan harganya masih sulit melampaui Full Attention. Hambatan utama terletak pada keterbatasan sistem evaluasi, biaya eksperimen yang tinggi untuk tugas inferensi yang kompleks, dan infrastruktur yang belum matang. MiniMax percaya bahwa dalam mengejar kemampuan konteks panjang, kualitas data, sistem evaluasi, dan optimasi infrastruktur lebih penting daripada sekadar mengubah arsitektur perhatian. (Sumber: Reddit r/LocalLLaMA, ClementDelangue)
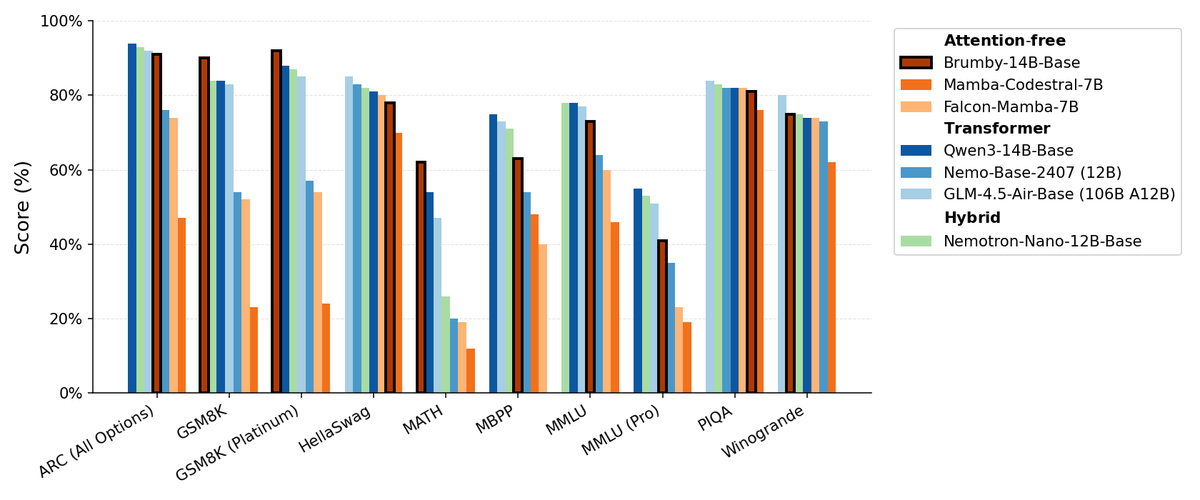
Manifest AI Merilis Brumby-14B-Base, Menjelajahi Model Dasar Tanpa Perhatian : Manifest AI telah merilis Brumby-14B-Base, mengklaimnya sebagai model dasar tanpa perhatian terkuat saat ini, yang dilatih dengan 14 miliar parameter hanya dengan biaya $4000. Model ini setara dalam kinerja dengan Transformer dan model hibrida dengan skala yang sama, mengisyaratkan bahwa era Transformer mungkin perlahan-lahan berakhir. Kemajuan ini menawarkan kemungkinan baru untuk arsitektur model AI, terutama menunjukkan potensi besar dalam mengurangi biaya pelatihan, menantang dominasi mekanisme perhatian tradisional. (Sumber: ClementDelangue, teortaxesTex)
Model Nemotron Baru Berbasis Qwen3 32B, Mengoptimalkan Kualitas Respons LLM : NVIDIA telah merilis Qwen3-Nemotron-32B-RLBFF, sebuah Large Language Model yang disetel halus berdasarkan Qwen/Qwen3-32B, bertujuan untuk meningkatkan kualitas respons yang dihasilkan oleh LLM dalam mode berpikir default. Model penelitian ini menunjukkan kinerja yang secara signifikan lebih baik daripada Qwen3-32B asli dalam benchmark seperti Arena Hard V2, WildBench, dan MT Bench, serta memiliki kinerja serupa dengan DeepSeek R1 dan O3-mini, tetapi dengan biaya inferensi kurang dari 5%, menunjukkan kemajuan dalam kinerja dan efisiensi. (Sumber: Reddit r/LocalLLaMA)

Arsitektur Mamba Masih Unggul dalam Pemrosesan Konteks Panjang, tetapi Pelatihan Paralel Terbatas : Arsitektur Mamba menunjukkan kinerja luar biasa dalam menangani konteks panjang (jutaan token), menghindari masalah ledakan memori Transformer. Namun, keterbatasan utamanya adalah kesulitan dalam paralelisme selama pelatihan, yang menghambat adopsinya dalam aplikasi skala yang lebih besar. Meskipun ada berbagai mixer linier dan arsitektur hibrida, tantangan pelatihan paralel Mamba tetap menjadi hambatan utama untuk aplikasi skala besar. (Sumber: Reddit r/MachineLearning)
NVIDIA Merilis ARC, Rubin, Omniverse DSX, dll., Memperkuat Kepemimpinan Infrastruktur AI : NVIDIA membuat serangkaian pengumuman besar di konferensi GTC, termasuk NVIDIA ARC (Aerial RAN Computer) yang dikembangkan bersama Nokia untuk 6G, superkomputer skala rak generasi ketiga Rubin, Omniverse DSX (cetak biru untuk desain kolaboratif virtual dan operasi pabrik AI gigabit), serta NVIDIA Drive Hyperion (arsitektur standar untuk robotaxi) bekerja sama dengan Uber. Pengumuman ini menunjukkan bahwa NVIDIA sedang memposisikan dirinya dari produsen chip menjadi arsitek infrastruktur nasional, menekankan “Made in America” dan persaingan energi, untuk menghadapi tantangan era AI dan 6G. (Sumber: TheTuringPost, TheTuringPost)

AgentFold: Manajemen Konteks Adaptif, Meningkatkan Efisiensi Agen Web : AgentFold mengusulkan teknik rekayasa konteks baru, melalui “Memory Folding” yang mengompresi pemikiran agen sebelumnya menjadi memori terstruktur, secara dinamis mengelola ruang kerja kognitif. Metode ini mengatasi masalah kelebihan konteks pada agen ReAct tradisional, dan menunjukkan kinerja luar biasa dalam benchmark seperti BrowseComp, melampaui model besar seperti DeepSeek-V3.1-671B. AgentFold-30B mencapai kinerja kompetitif dengan jumlah parameter yang lebih kecil, secara signifikan meningkatkan efisiensi pengembangan dan penerapan agen Web. (Sumber: omarsar0)

ReCode: Menyatukan Perencanaan dan Tindakan, Mencapai Kontrol Granularitas Keputusan Agen AI yang Dinamis : ReCode (Recursive Code Generation) adalah metode PEFT (Parameter-Efficient Fine-Tuning) baru yang menyatukan representasi perencanaan dan tindakan agen AI dengan memperlakukan perencanaan tingkat tinggi sebagai fungsi rekursif yang dapat dipecah menjadi tindakan granular. Metode ini hanya membutuhkan 0,02% parameter pelatihan untuk mencapai kinerja SOTA dan mengurangi penggunaan memori GPU. ReCode memungkinkan agen untuk beradaptasi secara dinamis dengan granularitas keputusan yang berbeda, mempelajari keputusan hierarkis, dan secara signifikan lebih unggul dari metode tradisional dalam efisiensi dan pemanfaatan data, merupakan langkah penting menuju penalaran seperti manusia. (Sumber: dotey, ZhihuFrontier)

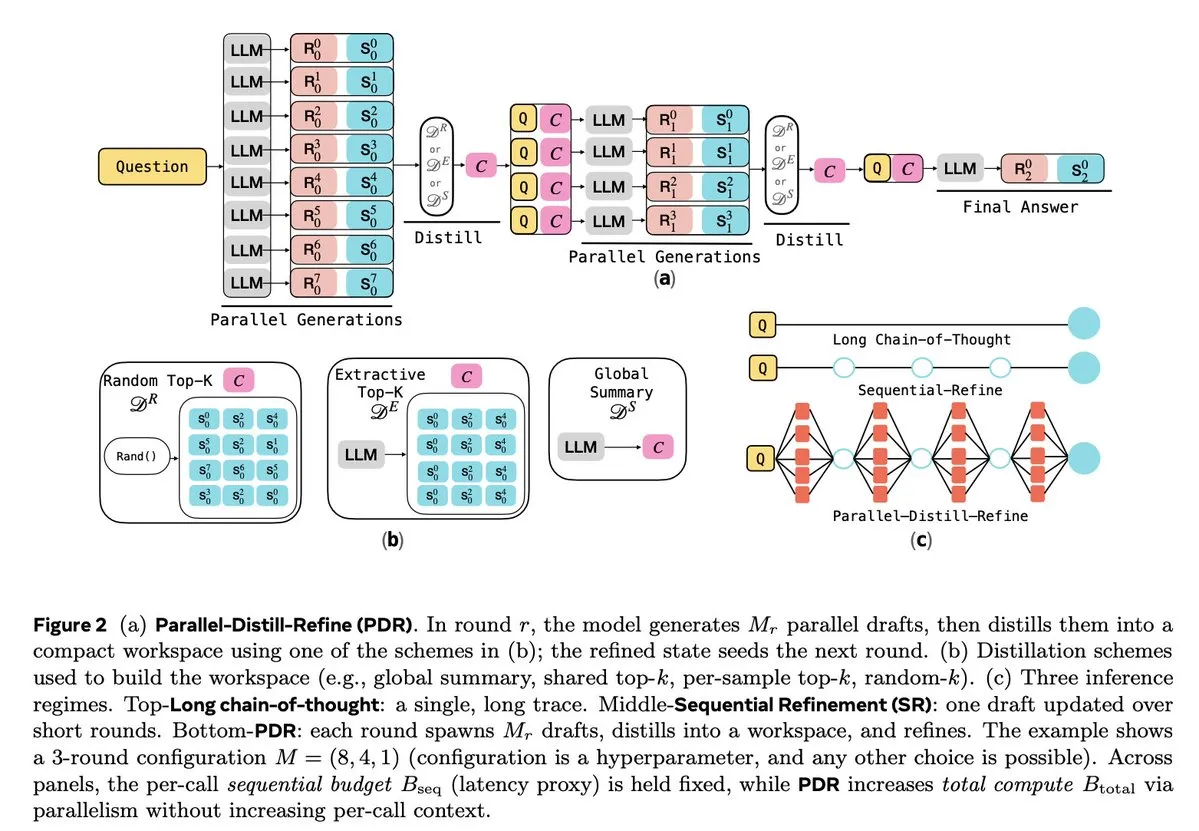
Optimasi Inferensi LLM dan Pembelajaran Penguatan : Beberapa penelitian berfokus pada peningkatan efisiensi dan keandalan inferensi LLM. Parallel-Distill-Refine (PDR) mengurangi biaya dan latensi tugas inferensi kompleks melalui generasi paralel dan penyempurnaan draf. Flawed-Aware Policy Optimization (FAPO) memperkenalkan mekanisme hadiah-penalti untuk mengoreksi pola cacat dalam proses inferensi, meningkatkan keandalan. Kerangka kerja PairUni menyeimbangkan tugas pemahaman dan generasi LLM multimodal melalui pelatihan berpasangan dan algoritma optimasi Pair-GPRO. PM4GRPO memanfaatkan teknik penambangan proses, melalui pembelajaran penguatan GRPO yang sadar inferensi, untuk meningkatkan kemampuan inferensi model kebijakan. Protokol Fortytwo, melalui konsensus peringkat peer-to-peer terdistribusi, mencapai kinerja luar biasa dalam inferensi kelompok AI dan ketahanan yang kuat terhadap prompt adversarial. (Sumber: NandoDF, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
🧰 Alat
Tencent Merilis WeKnora Open-Source: Kerangka Kerja Pemahaman Dokumen dan Pencarian Berbasis LLM : Tencent telah merilis WeKnora sebagai open-source, sebuah kerangka kerja pemahaman dokumen dan pencarian semantik berbasis LLM, yang dirancang khusus untuk menangani dokumen kompleks dan heterogen. Ini mengadopsi arsitektur modular, menggabungkan pra-pemrosesan multimodal, indeks vektor semantik, pencarian cerdas, dan inferensi LLM, mengikuti paradigma RAG, untuk mencapai jawaban berkualitas tinggi dan sadar konteks dengan menggabungkan blok dokumen yang relevan dan inferensi model. WeKnora mendukung berbagai format dokumen, model embedding, dan strategi pencarian, serta menyediakan antarmuka Web dan API yang ramah pengguna, mendukung penerapan lokal dan cloud pribadi, memastikan kedaulatan data. (Sumber: GitHub Trending)
Jan: Alternatif ChatGPT Offline Open-Source, Mendukung Jalankan LLM Secara Lokal : Jan adalah alternatif ChatGPT open-source yang dapat berjalan 100% offline di komputer pengguna. Ini memungkinkan pengguna untuk mengunduh dan menjalankan LLM dari HuggingFace (seperti Llama, Gemma, Qwen, GPT-oss, dll.), dan mendukung integrasi dengan model cloud seperti OpenAI dan Anthropic. Jan menyediakan asisten kustom, API yang kompatibel dengan OpenAI, dan integrasi Model Context Protocol (MCP), menekankan perlindungan privasi, memberikan pengguna pengalaman AI lokal yang sepenuhnya terkontrol. (Sumber: GitHub Trending)

Claude Code: Toolkit Pengembang dan Ekosistem Keterampilan Anthropic : Claude Code dari Anthropic secara signifikan meningkatkan efisiensi kerja pengembang melalui serangkaian “keterampilan” dan agen. Ini termasuk konektor Rube MCP (menghubungkan Claude ke 500+ aplikasi), toolkit pengembangan Superpowers (menyediakan perintah /brainstorm, /write-plan, /execute-plan), suite dokumen (memproses Word/Excel/PDF), Theme Factory (otomatisasi panduan merek), dan Systematic Debugging (mensimulasikan proses debug pengembang senior). Alat-alat ini, melalui desain modular dan kemampuan sadar konteks, membantu pengembang mencapai alur kerja otomatis, tinjauan kode, refactoring, dan perbaikan bug, bahkan mendukung tim non-teknis untuk membangun alat kecil sendiri. (Sumber: Reddit r/ClaudeAI, Reddit r/ClaudeAI)

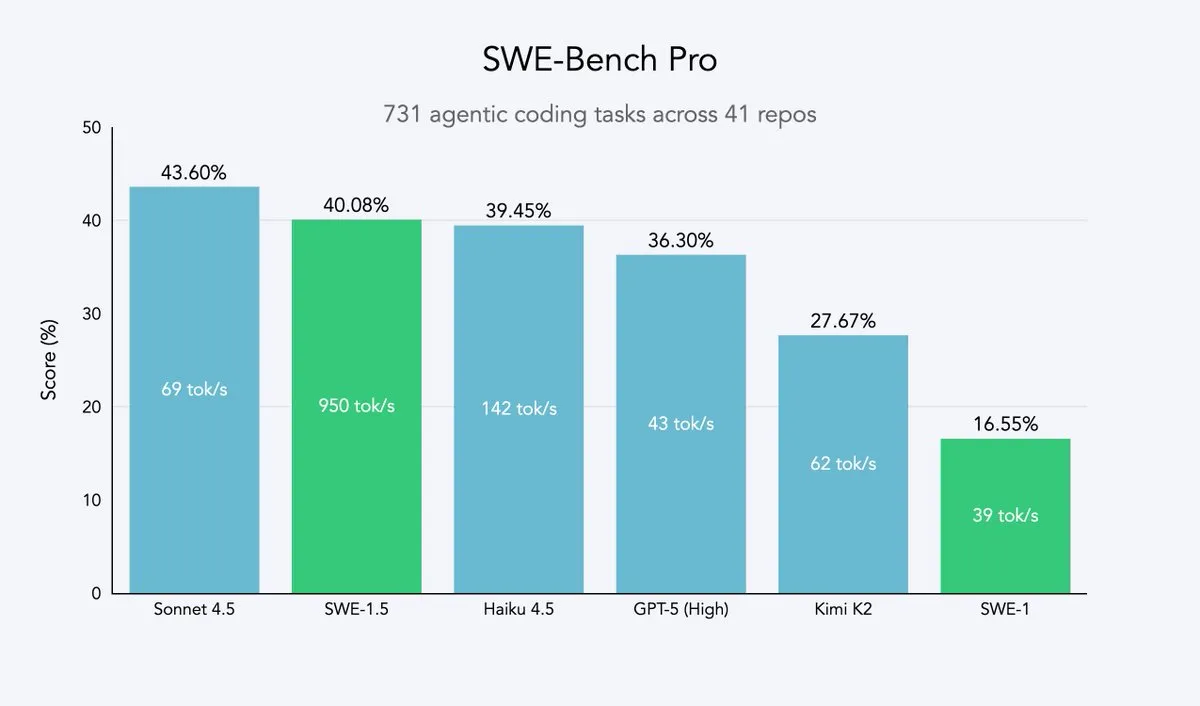
Cursor 2.0 dan Windsurf: Agen Kode Mengejar Kecepatan dan Efisiensi : Cursor dan Windsurf telah merilis model agen kode yang dioptimalkan untuk kecepatan dan platform 2.0. Strategi mereka adalah melakukan fine-tuning pembelajaran penguatan berdasarkan model besar open-source (seperti Qwen3) dan menerapkannya pada hardware yang dioptimalkan, untuk mencapai efek “kecerdasan sedang tetapi sangat cepat”. Jalur ini merupakan strategi yang efisien bagi perusahaan agen kode, yang dapat mendekati Pareto frontier kecepatan dan kecerdasan dengan biaya sumber daya minimal. Model SWE-1.5 Windsurf menetapkan standar kecepatan baru sambil mencapai kinerja pengkodean mendekati SOTA. (Sumber: dotey, Smol_AI, VictorTaelin, omarsar0, TheRundownAI)
Perplexity Patents: Agen Riset Paten AI Pertama, Memberdayakan Kecerdasan IP : Perplexity telah meluncurkan Perplexity Patents, agen riset paten AI pertama di dunia, yang bertujuan untuk membuat kecerdasan IP dapat diakses oleh semua orang. Alat ini mampu mendukung pencarian dan penelitian lintas paten, dan di masa depan juga akan meluncurkan Perplexity Scholar, yang berfokus pada penelitian akademis. Inovasi ini akan sangat menyederhanakan proses pencarian dan analisis paten, menyediakan layanan informasi kekayaan intelektual yang efisien dan mudah digunakan bagi inovator, pengacara, dan peneliti. (Sumber: AravSrinivas)

Real Deep Research (RDR): Kerangka Kerja Penelitian Ilmiah Mendalam Berbasis AI : Real Deep Research (RDR) adalah kerangka kerja berbasis AI yang dirancang untuk membantu peneliti mengikuti perkembangan pesat ilmu pengetahuan modern. RDR menjembatani kesenjangan antara survei yang ditulis oleh ahli dan penambangan literatur otomatis, menyediakan proses analisis yang dapat diskalakan, analisis tren, wawasan koneksi lintas domain, dan menghasilkan ringkasan yang terstruktur dan berkualitas tinggi. Ini berfungsi sebagai alat penelitian komprehensif, membantu peneliti memahami gambaran besar dengan lebih baik. (Sumber: TheTuringPost)

LangSmith Meluncurkan Agent Builder Tanpa Kode, Memberdayakan Tim Non-Teknis untuk Membangun Agen : LangSmith dari LangChainAI telah meluncurkan Agent Builder tanpa kode, yang bertujuan untuk menurunkan hambatan dalam membangun agen AI, memungkinkan tim non-teknis untuk dengan mudah membuat agen. Alat ini, melalui UX pembangunan agen percakapan, fungsi memori bawaan yang membantu agen mengingat dan meningkatkan, serta memberdayakan tim non-teknis dan pengembang untuk bersama-sama membangun agen, sehingga mempercepat popularisasi dan penerapan agen AI. (Sumber: LangChainAI)
Verdent Mengintegrasikan MiniMax-M2, Meningkatkan Kemampuan dan Efisiensi Pengkodean : Verdent kini mendukung model MiniMax-M2, membawa kemampuan pengkodean canggih, agen berkinerja tinggi, dan aktivasi parameter yang efisien kepada pengguna. Dengan mencoba MiniMax-M2 secara gratis di VS Code melalui Verdent, pengembang dapat menikmati pengalaman pengkodean yang lebih cerdas, lebih cepat, dan lebih hemat biaya. Integrasi ini membawa kemampuan MiniMax-M2 yang kuat ke komunitas pengembang yang lebih luas. (Sumber: MiniMax__AI)
Base44 Meluncurkan Builder Baru, Mempercepat Konversi Konsep menjadi Aplikasi : Base44 telah merilis Builder baru, menandai perubahan fundamental dalam cara kerjanya. Builder baru ini lebih mirip pengembang ahli, mampu melakukan investigasi sebelum membangun, mendapatkan konteks dari berbagai sumber, melakukan debug cerdas, dan membuat keputusan arsitektur yang bijaksana. Pembaruan ini bertujuan untuk mempercepat konversi konsep menjadi aplikasi fungsional sepuluh kali lipat, sangat meningkatkan efisiensi pengembangan. (Sumber: MS_BASE44)
Qdrant Bermitra dengan Confluent, Memberdayakan Agen AI yang Sadar Konteks Real-Time : Qdrant bermitra dengan Confluent, melalui Confluent Streaming Agents dan Real-Time Context Engine, untuk menyediakan konteks segar dan real-time bagi agen AI cerdas dan aplikasi perusahaan. Kemampuan pencarian vektor Qdrant, dikombinasikan dengan data streaming real-time Confluent, memungkinkan pengembang untuk membangun dan memperluas agen AI yang digerakkan oleh peristiwa dan sadar konteks, sehingga membuka potensi penuh AI berbasis agen, dan secara signifikan mempersingkat waktu penyelesaian serta mengurangi biaya dalam skenario seperti respons insiden. (Sumber: qdrant_engine, qdrant_engine)

📚 Pembelajaran
ICLR26 Paper Finder: Alat Pencarian Makalah AI Berbasis LLM : Seorang pengembang telah membuat ICLR26 Paper Finder, sebuah alat yang menggunakan model bahasa sebagai tulang punggung untuk mencari makalah dari konferensi AI tertentu. Pengguna dapat mencari berdasarkan judul, kata kunci, atau bahkan abstrak makalah, dengan pencarian abstrak memiliki akurasi tertinggi. Alat ini telah di-host di server pribadi dan Hugging Face, menyediakan cara yang efisien bagi peneliti AI untuk mencari literatur. (Sumber: Reddit r/deeplearning, Reddit r/MachineLearning)
Kursus Musim Semi UCLA 2025: Pembelajaran Penguatan untuk Large Language Models : UCLA akan menawarkan kursus “Pembelajaran Penguatan untuk Large Language Models” pada musim semi 2025, yang mencakup berbagai topik RLxLLM, termasuk dasar-dasar, komputasi waktu uji, RLHF (Reinforcement Learning from Human Feedback), dan RLVR (Reinforcement Learning from Verifiable Rewards). Seri kuliah baru ini memberikan kesempatan bagi peneliti dan mahasiswa untuk mempelajari teori dan praktik mutakhir pembelajaran penguatan LLM secara mendalam. (Sumber: algo_diver)
Panduan Autoencoder Gambar Tangan: Memahami Dasar-dasar AI Generatif : ProfTomYeh telah merilis panduan 7 langkah terperinci tentang Autoencoder (autoencoder) yang digambar tangan, bertujuan untuk membantu pembaca memahami jaringan saraf ini yang memainkan peran kunci dalam kompresi, denoising, dan pembelajaran representasi data yang kaya. Autoencoder adalah dasar dari banyak arsitektur generatif modern, dan panduan ini menjelaskan cara kerjanya dalam mengkodekan dan mendekodekan informasi secara intuitif, menjadikannya sumber daya berharga untuk mempelajari konsep inti AI generatif. (Sumber: ProfTomYeh)
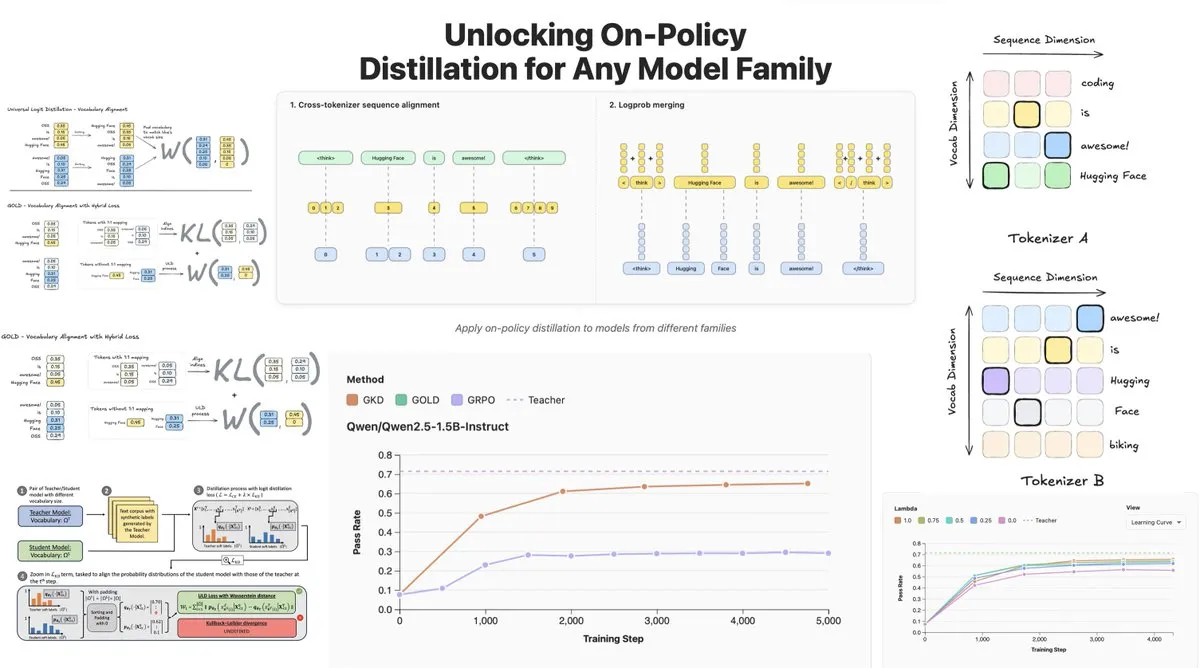
Hugging Face Merilis On-Policy Logit Distillation, Mendukung Distilasi Lintas Model : Hugging Face telah meluncurkan General On-Policy Logit Distillation (GOLD), yang memperluas metode distilasi kebijakan, memungkinkannya untuk mendistilasi model guru apa pun ke model siswa apa pun, bahkan jika Tokenizer mereka berbeda. Teknologi ini telah diintegrasikan ke dalam pustaka TRL, memungkinkan pengembang untuk memilih pasangan model apa pun dari Hub untuk distilasi, memberikan fleksibilitas besar dan kemampuan pemulihan kinerja untuk post-training LLM, terutama mengatasi masalah penurunan kinerja umum setelah fine-tuning di domain tertentu. (Sumber: clefourrier, winglian, _lewtun)
Lumi: Google DeepMind Memanfaatkan Gemini 2.5 untuk Membantu Pembacaan Makalah arXiv : Tim PAIR dari Google DeepMind telah merilis Lumi, sebuah alat yang memanfaatkan model besar Gemini 2.5 untuk membantu membaca makalah arXiv. Lumi dapat menambahkan ringkasan, referensi, dan tanya jawab inline ke makalah, membantu peneliti membaca dengan lebih cerdas dan efisien, serta meningkatkan efisiensi pemahaman literatur ilmiah. (Sumber: GoogleDeepMind)
💼 Bisnis
AI Mendorong Pendapatan Raksasa Teknologi Mencapai Rekor Tertinggi, Laporan Keuangan Microsoft dan Google Bersinar : Alphabet, induk perusahaan Google, dan Microsoft keduanya mencapai kinerja tonggak sejarah dalam laporan keuangan terbaru mereka, dengan AI menjadi mesin pertumbuhan inti. Alphabet untuk pertama kalinya mencatat pendapatan kuartalan lebih dari $100 miliar, mencapai $102,3 miliar, dengan Google Cloud tumbuh 34%, dan 70% pelanggan yang ada menggunakan produk AI. Pendapatan Microsoft tumbuh 18% menjadi $77,7 miliar, dengan pendapatan Intelligent Cloud untuk pertama kalinya melampaui $30 miliar, dan layanan cloud Azure tumbuh 40%, didorong secara signifikan oleh AI. Kedua perusahaan berencana untuk meningkatkan belanja modal AI secara substansial untuk mengkonsolidasikan posisi kepemimpinan mereka di bidang AI dan mendapatkan pengakuan pasar modal. (Sumber: 36氪, Yuchenj_UW)

CTO Block: AI Agent Goose Mengotomatisasi 60% Pekerjaan Kompleks, Kualitas Kode Tidak Berhubungan Langsung dengan Keberhasilan Produk : CTO Block (sebelumnya Square), Dhanji R. Prasanna, berbagi bagaimana perusahaan menghemat 8-10 jam kerja per minggu untuk 12.000 karyawan dalam 8 minggu melalui kerangka kerja AI Agent open-source “Goose”. Goose, berdasarkan Model Context Protocol (MCP), dapat menghubungkan alat perusahaan untuk mengotomatisasi penulisan kode, pembuatan laporan, pemrosesan data, dan tugas lainnya. Prasanna menekankan bahwa perusahaan yang lahir dari AI harus memposisikan ulang diri sebagai perusahaan teknologi dan melakukan restrukturisasi organisasi. Dia mengajukan pandangan yang tidak intuitif bahwa “kualitas kode tidak berhubungan langsung dengan keberhasilan produk”, berpendapat bahwa kunci adalah apakah produk memecahkan masalah pengguna, dan mendorong insinyur untuk merangkul AI, dengan insinyur senior dan pemula memiliki tingkat penerimaan tertinggi terhadap alat AI. (Sumber: 36氪)

Industri Digital Human Memasuki Fase Eliminasi, Produksi Digital Human 3D Beralih ke Platformisasi : Dengan meledaknya model besar, industri digital human menghadapi perombakan, dan perusahaan yang kekurangan kemampuan AI akan tersingkir. Pasar digital human 2D menyumbang 70,1%, sementara digital human 3D dibatasi oleh iterasi teknologi dan biaya GPU yang tinggi. Perusahaan terkemuka seperti Moofa Tech menekankan bahwa digital human 3D perlu disesuaikan dengan kemampuan model besar, dan menunjukkan bahwa akumulasi data berkualitas tinggi, talenta langka, dan kemampuan seni yang kuat adalah kunci. Tren industri menunjukkan bahwa produksi digital human 3D berkembang menuju platformisasi, dengan kemajuan teknologi AI mengurangi biaya, memungkinkan aplikasi berskala besar. Perusahaan seperti Yingmou Tech dan Baidu juga telah meluncurkan platform generasi 3D, bertujuan untuk menjadikan digital human sebagai infrastruktur, memberdayakan lebih banyak skenario aplikasi. (Sumber: 36氪)
🌟 Komunitas
Persepsi Kompleks Pengguna terhadap Emosi dan Kepercayaan AI: Perbandingan R2D2 dan ChatGPT : Media sosial ramai membahas perbedaan koneksi emosional pengguna terhadap R2D2 dan ChatGPT. Pengguna menganggap R2D2 menggemaskan karena temperamen uniknya, kesetiaan, dan citra “seperti kuda”, serta tidak melibatkan masalah etika sosial dunia nyata. Sementara itu, ChatGPT, sebagai “AI palsu yang nyata”, sulit membangun ikatan emosional yang sama karena kepraktisannya, batasan sensor konten, dan kekhawatiran potensi pengawasan. Perbandingan ini mengungkapkan bahwa harapan pengguna terhadap AI tidak hanya pada kecerdasan, tetapi juga pada pengalaman interaksi yang “manusiawi” dan persepsi dampak sosialnya. (Sumber: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

Keterbatasan Konseling Psikologis AI dan Perlunya Intervensi Manusia : Dengan munculnya produk konseling psikologis AI, orang-orang mulai menggunakan AI untuk mengatasi kesepian dan masalah psikologis. Penelitian menunjukkan bahwa sekitar 22% pekerja Gen Z telah mengunjungi psikolog, dan hampir separuhnya berkonsultasi dengan AI. AI memiliki keunggulan dalam memberikan informasi, mengeliminasi faktor, dan memberikan pendampingan, tetapi tidak dapat menggantikan peran konselor psikologis manusia dalam empati, memahami “suasana”, dan memimpin ritme terapi. Kasus-kasus menunjukkan bahwa AI memerlukan mekanisme “pemutus sirkuit” manual dalam mengidentifikasi risiko ekstrem, dan manusia sangat diperlukan dalam menilai batas antara emosi dan patologi, akumulasi pengalaman, dan komunikasi non-verbal. AI seharusnya terutama melakukan pekerjaan yang berulang dan bersifat membantu, serta menurunkan ambang batas untuk mencari bantuan, dengan tujuan akhir mengarahkan orang kembali ke hubungan interpersonal yang nyata. (Sumber: 36氪)

Interaksi Lansia dengan Model Besar: Mendefinisikan “Algoritma” dari “Cara Hidup” : Universitas Fudan dan Tencent SSV Time Lab serta lembaga lainnya melakukan penelitian selama setahun, mengajarkan 100 lansia menggunakan model besar. Penelitian menemukan bahwa sikap lansia terhadap AI bukanlah penolakan, melainkan “pandangan teknologi pragmatis” berdasarkan pengalaman hidup. Mereka lebih peduli apakah teknologi dapat terintegrasi dalam kehidupan sehari-hari dan memberikan pendampingan, daripada fitur ekstrem. Dalam kalibrasi kepercayaan, lansia menunjukkan berbagai pola seperti “koreksi terbatas”, “saling menguntungkan”, dan “kognisi yang mengeras”, serta adanya “keraguan bertanya” dan “kesenjangan gender”. Model besar yang mereka harapkan adalah yang dapat menjadi “peramal”, “dokter terpercaya”, “teman mengobrol”, dan “mainan untuk bersantai”, yaitu teknologi yang “memahami manusia” dengan lebih lembut, lebih dekat dengan kehidupan sehari-hari. Ini menunjukkan bahwa nilai teknologi terletak pada seberapa lama ia dapat menunggu, bukan seberapa cepat ia berlari, menyerukan agar teknologi harus “simbiotik” daripada “ramah lansia”, dengan perasaan, ritme, dan martabat manusia sebagai ukurannya. (Sumber: 36氪)

Dampak Sosial AI: Dari Pengawasan Privasi hingga Konsumsi Energi dan Perubahan Pekerjaan : Media sosial secara luas membahas berbagai dampak AI terhadap masyarakat. Pengguna khawatir bahwa AI telah mencapai “pengawasan tak terlihat” melalui berbagai aplikasi, pencarian, dan kamera, memprediksi dan memengaruhi perilaku individu, bukan kontrol robot ala fiksi ilmiah. Pada saat yang sama, permintaan besar pusat data AI akan energi dan sumber daya air memicu protes komunitas, menyebabkan pemadaman listrik dan kelangkaan air. Selain itu, AI meningkatkan produktivitas dalam pembuatan kode dan tugas otomatisasi, tetapi memicu diskusi tentang perubahan struktur pekerjaan, serta tantangan kualitas kode AI terhadap efisiensi produksi. Diskusi ini mencerminkan emosi kompleks publik terhadap kenyamanan dan potensi risiko yang dibawa oleh teknologi AI. (Sumber: Reddit r/artificial, MIT Technology Review, MIT Technology Review, Ronald_vanLoon, Ronald_vanLoon)

Evolusi Cepat Terminologi dan Konsep di Bidang AI : Diskusi komunitas menunjukkan bahwa terminologi dan konsep di bidang AI berkembang pesat. Misalnya, “melatih/membangun model” sering merujuk pada “fine-tuning”, dan “fine-tuning” dianggap sebagai bentuk baru dari “prompt/context engineering”. Perubahan ini mencerminkan kompleksitas tumpukan teknologi AI dan kebutuhan akan operasi yang lebih halus. Selain itu, dalam menyeimbangkan kecepatan dan kecerdasan model, pengembang cenderung memilih model “lambat tapi cerdas” karena mereka dapat memberikan hasil yang lebih andal, meskipun itu berarti waktu tunggu yang lebih lama. (Sumber: dejavucoder, dejavucoder, dejavucoder)

Ekosistem Open-Source AI dan Persaingan Model Propietari Semakin Sengit : Komunitas ramai membahas bahwa kesenjangan antara model AI open-source dan model propietary semakin menyempit, memaksa laboratorium closed-source untuk lebih kompetitif dalam penetapan harga. Model open-source seperti MiniMax-M2 menunjukkan kinerja luar biasa di AI Index dengan biaya yang sangat rendah. Pada saat yang sama, perusahaan Tiongkok dan startup secara aktif membuka sumber teknologi AI, sementara perusahaan AS relatif tertinggal dalam hal ini. Tren ini mengisyaratkan bahwa bidang AI akan memasuki era “setiap orang melatih model berbasis open-source”, mendorong demokratisasi dan inovasi teknologi AI. (Sumber: ClementDelangue, huggingface, clefourrier, huggingface)
Dampak Konten Generasi AI terhadap Industri Tradisional dan Tantangan Etika : Konten yang dihasilkan AI semakin merambah industri tradisional, misalnya “artis” berbasis AI yang menduduki tangga lagu, serta teknologi deepfake yang digunakan untuk penipuan (seperti pidato palsu Jensen Huang yang mempromosikan penipuan kripto). Fenomena ini memicu diskusi tentang hak cipta, etika, dan regulasi. Pada saat yang sama, AI juga membawa alat produktivitas baru dalam pembuatan kode, otomatisasi manajemen akun media sosial, dll., tetapi kualitas dan keandalan konten yang dihasilkan masih memerlukan tinjauan manusia. Ini menyoroti tantangan dalam menyeimbangkan inovasi teknologi dengan tanggung jawab sosial dan norma etika dalam proses popularisasi AI. (Sumber: Reddit r/artificial, 36氪, jeremyphoward)

Perhatian Komunitas Riset AI terhadap Kualitas Data dan Evaluasi : Komunitas riset AI semakin memperhatikan peran kunci kualitas data dalam pelatihan model, dan menunjukkan bahwa mendapatkan data berkualitas tinggi lebih menantang daripada menyewa GPU atau menulis kode. Pada saat yang sama, ada diskusi luas tentang keterbatasan benchmark evaluasi, yang berpendapat bahwa benchmark yang ada mungkin tidak sepenuhnya mencerminkan kemampuan sebenarnya model, dan mudah dioptimalkan secara berlebihan. Peneliti menyerukan pengembangan sistem evaluasi yang lebih informatif dan realistis untuk mendorong perkembangan sehat riset AI. (Sumber: code_star, code_star, clefourrier, tokenbender)

Aplikasi dan Prospek AI di Bidang Kesehatan : AI menunjukkan potensi besar di bidang kesehatan, misalnya Cloudpeng Technology merilis produk AI+kesehatan baru, termasuk laboratorium dapur pintar dan kulkas pintar yang dilengkapi model besar AI kesehatan, menyediakan manajemen kesehatan yang dipersonalisasi. Selain itu, MONAI, sebagai toolkit AI pencitraan medis, menyediakan kerangka kerja open-source PyTorch. Eksoskeleton yang digerakkan AI membantu pengguna kursi roda berdiri dan berjalan, serta agen diagnostik LLM mempelajari strategi diagnostik dalam lingkungan klinis virtual. Kemajuan ini mengisyaratkan bahwa AI akan secara mendalam mengubah layanan kesehatan, dari manajemen kesehatan sehari-hari hingga diagnosis dan pengobatan yang dibantu. (Sumber: 36氪, GitHub Trending, Ronald_vanLoon, Ronald_vanLoon, HuggingFace Daily Papers)
Transformasi Organisasi dan Kebutuhan Talenta di Era AI : Dengan popularitas AI, perusahaan menghadapi perubahan mendalam dalam struktur organisasi dan kebutuhan talenta. CTO Block, Dhanji R. Prasanna, menekankan bahwa perusahaan perlu memposisikan ulang diri sebagai “perusahaan teknologi” dan beralih dari “sistem manajer umum” ke “sistem fungsional” untuk memusatkan fokus teknologi. Alat AI seperti Goose dapat secara signifikan meningkatkan produktivitas, tetapi arsitektur dan desain tingkat tinggi masih membutuhkan insinyur senior. Saat merekrut, perusahaan lebih menghargai pola pikir belajar dan berpikir kritis, daripada sekadar keterampilan menggunakan alat AI. AI juga mengaburkan batas-batas pekerjaan, dengan posisi non-teknis mulai memanfaatkan alat AI, mendorong pembentukan mode kolaborasi “kelompok manusia-mesin”. (Sumber: 36氪, MIT Technology Review, NandoDF, SakanaAILabs)

💡 Lain-lain
Inovasi Berkelanjutan dalam Teknologi Robot Multifungsi : Bidang robotika menunjukkan inovasi yang beragam, termasuk robot SpiRobs yang terinspirasi gurita, drone yang bisa berenang, robot Helix untuk penyortiran paket, serta robot humanoid yang membantu pemeriksaan kualitas di pabrik NIO. Kemajuan ini mencakup desain bionik, otomatisasi, kolaborasi manusia-mesin, dan adaptasi lingkungan khusus, mengisyaratkan potensi luas teknologi robotika dalam aplikasi industri, militer, dan sehari-hari. (Sumber: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
Pendalaman Konsep AI Agent dan Prospek Pasar : AI Agent didefinisikan sebagai entitas cerdas yang mampu bernalar dan beradaptasi seperti manusia, serta dapat mewujudkan percakapan manusia-mesin yang mulus. Mereka dianggap sebagai tren tenaga kerja masa depan, dengan banyak alat pembangunan AI Agent bermunculan di pasar. Nilai inti AI Agent terletak pada kemampuannya menjadi “alat produksi” yang dapat menjalankan tugas nyata, bukan hanya alat bantu “obrolan”, dan perkembangannya akan mendorong aplikasi AI yang mendalam di berbagai bidang. (Sumber: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, dotey)
AI dan Mobil Otonom: Armada Uber Mengadopsi Chip Baru Nvidia, Mendorong Pengembangan Robotaxi : Armada mobil otonom generasi berikutnya Uber akan mengadopsi chip baru Nvidia, yang diharapkan dapat mengurangi biaya robotaxi. Platform Drive Hyperion Nvidia adalah arsitektur standar untuk kendaraan “robotaxi-ready”, dan kerja sama dengan Uber akan mendorong popularisasi teknologi mobil otonom kepada konsumen. Ini menunjukkan bahwa aplikasi AI di bidang transportasi sedang berkembang pesat, bertujuan untuk mewujudkan layanan mobil otonom yang lebih aman dan ekonomis. (Sumber: MIT Technology Review, TheTuringPost)