
Kata Kunci:DeepSeek-OCR, ChatGPT Atlas, Unitree H2, Komputasi Kuantum, Penemuan Obat AI, DeepSeek MoE, vLLM, Meta Vibes, Teknologi Kompresi Optik Kontekstual, Fitur Memori Browser AI, Derajat Kebebasan Robot Humanoid, Algoritma Gema Kuantum, Kerangka Pembuatan Protokol Eksperimen Biologi
🔥 FOKUS
DeepSeek-OCR: Teknologi Kompresi Optik Kontekstual : Model DeepSeek-OCR memperkenalkan konsep “kompresi optik kontekstual”, yang memperlakukan teks sebagai gambar. Ini dapat mengompresi konten satu halaman penuh menjadi beberapa “token visual” melalui pengodean visual, kemudian mendekodekannya kembali menjadi teks, tabel, atau grafik, mencapai peningkatan efisiensi sepuluh kali lipat dan akurasi hingga 97%. Teknologi ini menggunakan DeepEncoder untuk menangkap informasi halaman dan mengompresinya 16 kali, mengurangi 4096 token menjadi 256 token, dan dapat secara otomatis menyesuaikan jumlah token berdasarkan kompleksitas dokumen, secara signifikan melampaui model OCR yang ada. Ini tidak hanya secara drastis mengurangi biaya pemrosesan dokumen panjang dan meningkatkan efisiensi ekstraksi informasi, tetapi juga memberikan ide-ide baru untuk memori jangka panjang LLM dan perluasan konteks, menunjukkan potensi besar gambar sebagai pembawa informasi di bidang AI. (Sumber: HuggingFace Daily Papers, 36氪, ZhihuFrontier)

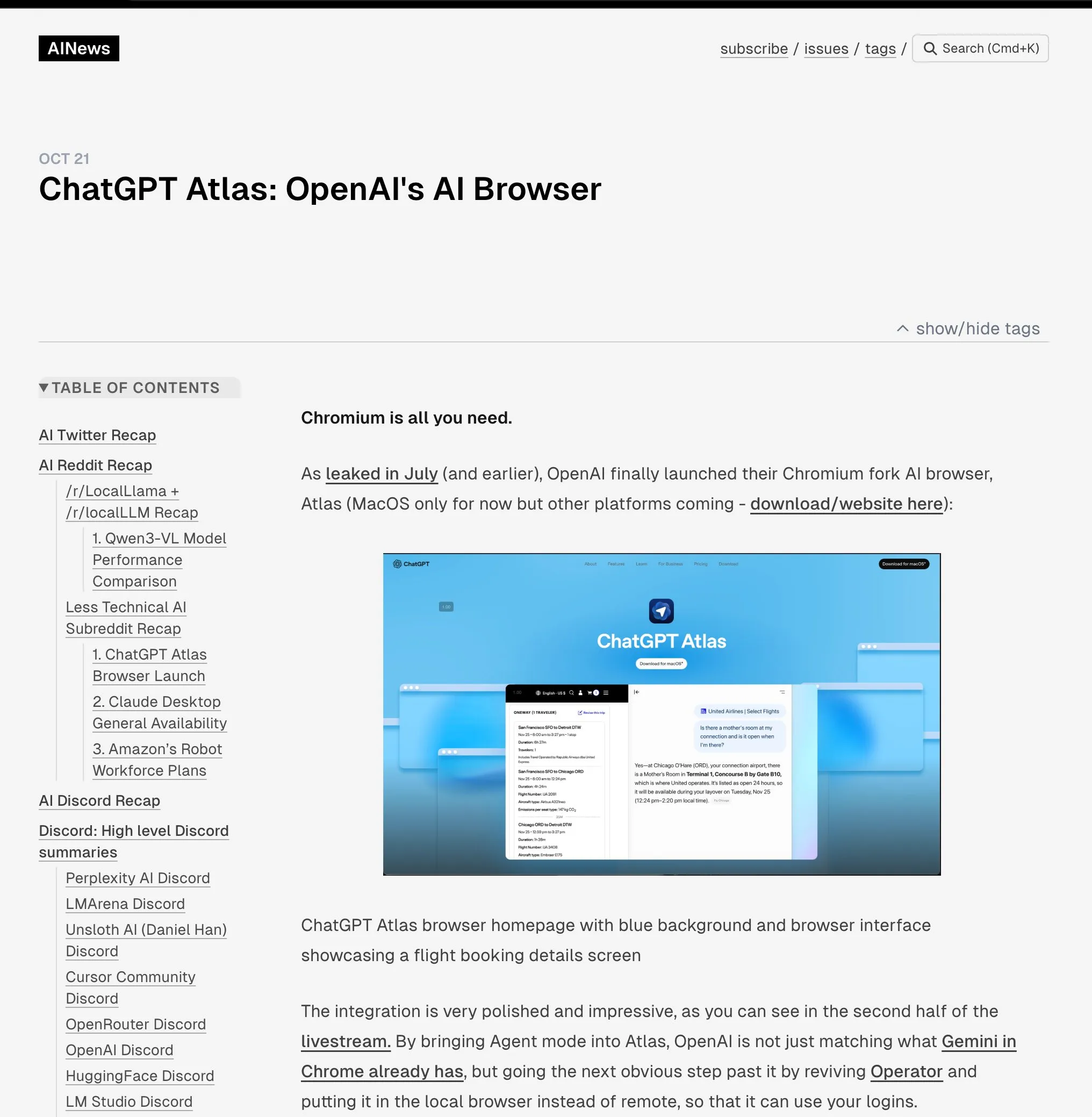
OpenAI Merilis Peramban ChatGPT Atlas : OpenAI meluncurkan ChatGPT Atlas, peramban yang dirancang khusus untuk era AI, mengintegrasikan ChatGPT secara mendalam ke dalam pengalaman menjelajah. Peramban ini tidak hanya menawarkan fitur tradisional, tetapi juga dilengkapi dengan “Agent mode” yang dapat melakukan tugas-tugas seperti pemesanan, belanja, dan mengisi formulir, serta fitur “browser memory” yang mempelajari kebiasaan pengguna untuk menyediakan layanan yang dipersonalisasi. Langkah ini menandai pergeseran strategis OpenAI menuju pembangunan ekosistem AI yang lengkap, yang berpotensi membentuk kembali cara pengguna berinteraksi dengan internet dan menantang dominasi iklan dan data pasar peramban yang ada (terutama Google Chrome). Industri secara luas percaya bahwa ini adalah awal dari “perang peramban” baru, dengan inti persaingan terletak pada kontrol kehidupan digital pengguna. (Sumber: Smol_AI, TheRundownAI, Reddit r/ArtificialInteligence, Reddit r/MachineLearning)
Robot Humanoid Unitree H2 Dirilis : Unitree Robotics merilis robot humanoid H2, mencapai lompatan signifikan dalam embodied AI dan desain perangkat keras. H2 mendukung NVIDIA Jetson AGX Thor, dengan kemampuan komputasi 7,5 kali lipat dari Orin dan efisiensi 3,5 kali lipat. Dalam desain mekanis, kaki memiliki tambahan 1 derajat kebebasan (total 6), lengan ditingkatkan menjadi 7 derajat kebebasan, dengan muatan efektif 7-15kg, dan opsi tangan yang cekatan. Dalam hal sensor, H2 meninggalkan LiDAR dan beralih ke persepsi 3D murni visual, menggunakan kamera stereo binokular. Meskipun kemajuan teknologi signifikan, komentar menunjukkan bahwa robot humanoid masih mencari skenario aplikasi yang matang, dan saat ini lebih cocok untuk penelitian laboratorium. (Sumber: ZhihuFrontier)

Terobosan Penemuan Obat Berbantuan AI dan Teknologi Bionik : Peneliti MIT menggunakan AI untuk merancang antibiotik baru yang efektif melawan Neisseria gonorrhoeae yang resistan terhadap banyak obat dan MRSA. Senyawa-senyawa ini memiliki struktur unik, merusak membran sel bakteri melalui mekanisme baru, sehingga sulit menimbulkan resistensi. Pada saat yang sama, tim peneliti juga mengembangkan lutut bionik baru yang terintegrasi langsung dengan otot dan jaringan tulang pengguna, menggunakan teknologi AMI untuk mengekstrak informasi saraf dari otot sisa setelah amputasi, memandu gerakan prostetik. Lutut bionik ini dapat membantu amputee berjalan lebih cepat, menaiki tangga dengan mudah, dan menghindari rintangan, terasa lebih seperti bagian tubuh, dan diharapkan mendapatkan persetujuan FDA setelah uji klinis skala besar. (Sumber: MIT Technology Review, MIT Technology Review)

Google Mencapai Keunggulan Kuantum yang Dapat Diverifikasi : Google menerbitkan terobosan komputasi kuantum baru di jurnal Nature, di mana chip Willow-nya, dengan menjalankan algoritma yang disebut “gema kuantum”, pertama kali mencapai keunggulan kuantum yang dapat diverifikasi. Algoritma ini 13000 kali lebih cepat daripada algoritma klasik tercepat, dan dapat menjelaskan interaksi antar atom dalam molekul, membawa aplikasi potensial di bidang penemuan obat dan ilmu material. Terobosan ini dapat direplikasi dan merupakan langkah penting bagi komputasi kuantum menuju aplikasi praktis. (Sumber: Google)

🎯 DINAMIKA
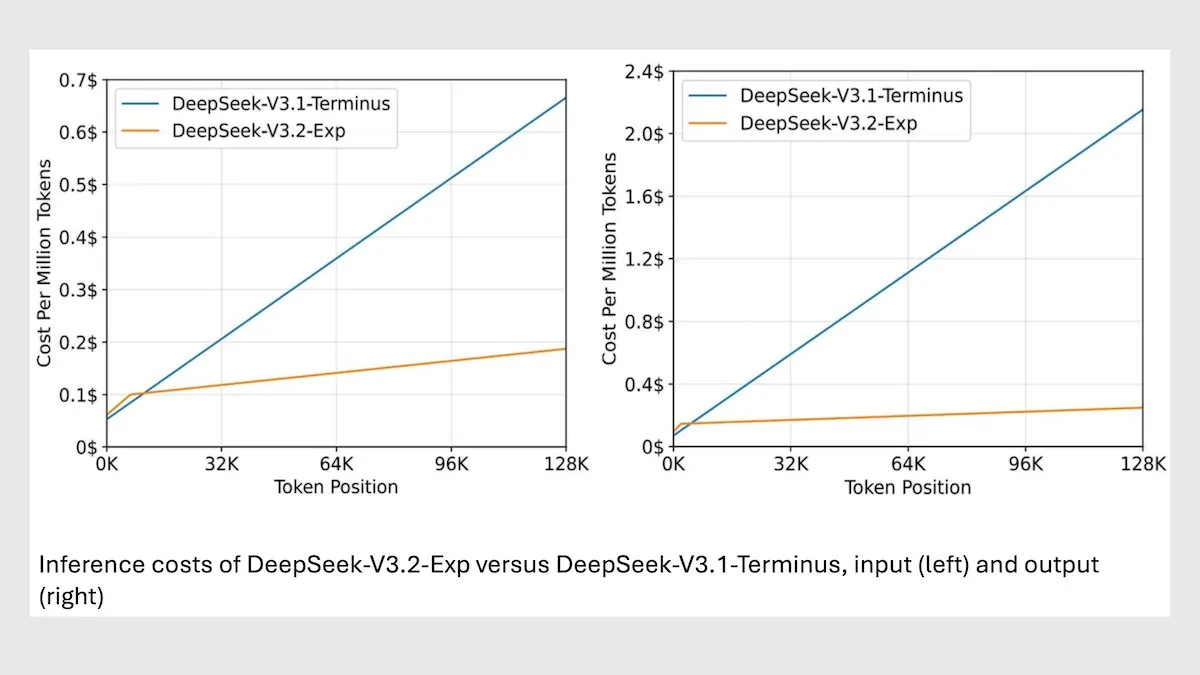
DeepSeek MoE Model V3.2 Mengoptimalkan Inferensi Konteks Panjang : DeepSeek merilis model MoE 685B V3.2 baru, yang hanya berfokus pada token yang paling relevan, mencapai peningkatan kecepatan inferensi konteks panjang 2-3 kali lipat, dan mengurangi biaya pemrosesan 6-7 kali lipat dibandingkan model V3.1. Model baru ini menggunakan bobot berlisensi MIT dan tersedia melalui API, dioptimalkan untuk Huawei dan chip Tiongkok lainnya. Meskipun sedikit menurun pada beberapa tugas sains/matematika, kinerjanya meningkat pada tugas pengodean/agen. (Sumber: DeepLearningAI)
vLLM V1 Kini Mendukung AMD GPU : vLLM versi V1 kini dapat berjalan di AMD GPU. Tim IBM Research, Red Hat, dan AMD bekerja sama, menggunakan kernel Triton untuk membangun backend perhatian yang dioptimalkan, mencapai kinerja mutakhir. Kemajuan ini menyediakan solusi inferensi LLM yang lebih efisien bagi pengguna perangkat keras AMD. (Sumber: QuixiAI)

Meta Vibes AI Video Stream Dirilis : Meta meluncurkan fitur AI video stream baru, Vibes, yang tertanam dalam aplikasi Meta AI. Pengguna dapat menjelajahi video pendek yang dihasilkan AI, dan dapat melakukan kreasi sekunder dengan satu klik, termasuk menambahkan musik, mengubah gaya, atau me-Remix karya orang lain, lalu membagikannya ke Instagram dan Facebook. Langkah ini bertujuan untuk menurunkan ambang batas pembuatan video AI, mendorong video AI ke skenario sosial arus utama, dan berpotensi mengubah model produksi dan distribusi konten video pendek, tetapi juga menimbulkan kekhawatiran tentang hak cipta, orisinalitas, dan penyebaran informasi palsu. (Sumber: 36氪)
Model Agen Prediksi Kinerja Inferensi LLM rBridge : Metode rBridge memungkinkan model agen kecil (parameter ≤1B) untuk secara efektif memprediksi kinerja inferensi model besar (parameter 7B-32B), mengurangi biaya komputasi lebih dari 100 kali lipat. Metode ini mengatasi “masalah kemunculan” di mana kemampuan inferensi tidak muncul pada model kecil, dengan menyelaraskan evaluasi dengan tujuan pra-pelatihan dan tugas target, serta menggunakan jejak inferensi model mutakhir sebagai label emas, dengan bobot kepentingan tugas token. Ini secara signifikan mengurangi biaya bagi peneliti dengan keterbatasan komputasi untuk menjelajahi pilihan desain pra-pelatihan. (Sumber: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Sistem Rekonstruksi Gaussian Splatting HDR Dinamis Tinggi 4D Mono4DGS-HDR : Mono4DGS-HDR adalah sistem pertama yang merekonstruksi adegan HDR (High Dynamic Range) 4D yang dapat dirender dari video LDR (Low Dynamic Range) monokular dengan eksposur bergantian. Kerangka kerja terpadu ini menggunakan metode optimasi dua tahap, berdasarkan teknik Gaussian Splatting, pertama-tama mempelajari representasi Gaussian HDR video dalam ruang koordinat kamera ortogonal, kemudian mengubah Gaussian video ke ruang dunia dan secara bersamaan mengoptimalkan Gaussian dunia dengan pose kamera. Selain itu, strategi regularisasi kecerahan temporal yang diusulkan meningkatkan konsistensi temporal tampilan HDR, secara signifikan mengungguli metode yang ada dalam kualitas dan kecepatan rendering. (Sumber: HuggingFace Daily Papers)
Kerangka Kerja Sintesis Data Evolusioner untuk Pembelajaran yang Dapat Diverifikasi EvoSyn : EvoSyn adalah kerangka kerja sintesis data evolusioner, agnostik tugas, berbasis strategi, dan dapat diperiksa secara eksekusi, yang dirancang untuk menghasilkan data yang dapat diverifikasi dan andal. Kerangka kerja ini dimulai dari pengawasan benih minimal, secara bersamaan mensintesis masalah, solusi kandidat yang beragam, dan artefak verifikasi, serta secara iteratif menemukan strategi melalui evaluator berbasis konsistensi. Eksperimen menunjukkan bahwa pelatihan menggunakan data yang disintesis EvoSyn menghasilkan peningkatan signifikan pada tugas LiveCodeBench dan AgentBench-OS, menyoroti kemampuan generalisasi kerangka kerja yang kuat. (Sumber: HuggingFace Daily Papers)
Metode Baru untuk Mengekstrak Data Penyelarasan dari Model Pasca-Pelatihan : Penelitian menunjukkan bahwa sejumlah besar data pelatihan yang selaras dapat diekstraksi dari model pasca-pelatihan untuk meningkatkan kemampuan model dalam inferensi konteks panjang, keamanan, kepatuhan instruksi, dan matematika. Melalui kesamaan semantik yang diukur oleh model embedding berkualitas tinggi, data pelatihan yang sulit ditangkap oleh pencocokan string tradisional dapat diidentifikasi. Penelitian menemukan bahwa model akan dengan mudah melacak kembali data yang digunakan dalam fase pasca-pelatihan seperti SFT atau RL, dan data ini dapat digunakan untuk melatih model dasar, memulihkan kinerja asli. Pekerjaan ini mengungkapkan potensi risiko ekstraksi data yang selaras, dan memberikan perspektif baru untuk diskusi tentang efek hilir praktik distilasi. (Sumber: HuggingFace Daily Papers)
Benchmark Inkonsistensi Makalah Ilmiah Multimodal PRISMM-Bench : PRISMM-Bench adalah benchmark pertama yang didasarkan pada inkonsistensi multimodal dalam makalah ilmiah yang ditandai oleh peninjau nyata, bertujuan untuk mengevaluasi kemampuan model multimodal besar (LMM) dalam memahami dan menalar kompleksitas makalah ilmiah. Benchmark ini, melalui proses multi-tahap, mengumpulkan 262 inkonsistensi dari 242 makalah, dan merancang tiga tugas: identifikasi, remediasi, dan pencocokan berpasangan. Evaluasi terhadap 21 LMM (termasuk GLM-4.5V 106B, InternVL3 78B, dan Gemini 2.5 Pro, GPT-5) menunjukkan kinerja model yang secara signifikan rendah (26,1-54,2%), menyoroti tantangan penalaran ilmiah multimodal. (Sumber: HuggingFace Daily Papers)
Metode Peningkatan Diskretisasi ODE Difusi GAS : Meskipun model difusi telah mencapai kualitas generasi mutakhir, biaya komputasi samplingnya tinggi. Generalized Adversarial Solver (GAS) mengusulkan sampler ODE yang diparameterisasi sederhana, yang dapat meningkatkan kualitas tanpa trik pelatihan tambahan. Dengan menggabungkan kerugian distilasi asli dengan pelatihan adversarial, GAS dapat mengurangi artefak dan meningkatkan fidelitas detail. Eksperimen menunjukkan bahwa GAS mengungguli metode pelatihan solver yang ada di bawah batasan sumber daya yang serupa. (Sumber: HuggingFace Daily Papers)
Kerangka Penalaran Spasial Imajinasi Geometris VLM 3DThinker : Kerangka kerja 3DThinker bertujuan untuk meningkatkan kemampuan model bahasa visual (VLM) dalam memahami hubungan spasial 3D dari sudut pandang terbatas. Kerangka kerja ini menggunakan pelatihan dua tahap, pertama pelatihan terawasi untuk menyelaraskan ruang laten 3D yang dihasilkan VLM selama penalaran dengan ruang laten model dasar 3D, kemudian mengoptimalkan seluruh jejak penalaran hanya berdasarkan sinyal hasil, sehingga menyempurnakan pemodelan mental 3D yang mendasarinya. 3DThinker adalah kerangka kerja pertama yang mencapai pemodelan mental 3D tanpa input prior 3D atau data 3D berlabel eksplisit, berkinerja sangat baik dalam beberapa benchmark, dan memberikan perspektif baru untuk menyatukan representasi 3D dalam penalaran multimodal. (Sumber: HuggingFace Daily Papers)
Huawei HarmonyOS 6 Meningkatkan Fungsi Asisten AI : Huawei secara resmi merilis sistem operasi HarmonyOS 6, yang secara komprehensif meningkatkan kelancaran, kecerdasan, dan pengalaman kolaborasi lintas perangkat. Di antaranya, fungsi “Super Assistant” Xiaoyi telah sangat ditingkatkan, tidak hanya mendukung 16 dialek, tetapi juga dapat melakukan penelitian mendalam, mengedit gambar dengan satu kalimat, dan membantu pengguna tunanetra “melihat dunia”. Berdasarkan kerangka kerja agen cerdas HarmonyOS, batch pertama lebih dari 80 agen cerdas aplikasi HarmonyOS telah diluncurkan. Xiaoyi dan mitra agen cerdasnya dapat berkolaborasi erat untuk menyediakan layanan profesional, seperti panduan perjalanan, janji temu medis, dll., dan memperkenalkan fungsi perlindungan privasi seperti “AI anti-penipuan” dan “AI anti-pengintaian”. (Sumber: 量子位)

Aplikasi AI dalam Studi Perkotaan: Menganalisis Kecepatan Berjalan dan Penggunaan Ruang Publik : Sebuah penelitian yang ditulis bersama oleh para sarjana MIT menunjukkan bahwa antara tahun 1980 dan 2010, kecepatan berjalan rata-rata di tiga kota di timur laut AS meningkat 15%, sementara jumlah orang yang berlama-lama di ruang publik menurun 14%. Para peneliti menggunakan alat pembelajaran mesin untuk menganalisis rekaman video dari tahun 1980-an di Boston, New York, dan Philadelphia, dan membandingkannya dengan video baru. Mereka berspekulasi bahwa faktor-faktor seperti ponsel dan kafe mungkin menyebabkan orang lebih sering membuat janji melalui pesan teks dan memilih tempat dalam ruangan daripada ruang publik untuk bersosialisasi, yang memberikan arah pemikiran baru untuk desain ruang publik perkotaan. (Sumber: MIT Technology Review)
Tantangan dan Solusi Ketahanan Lintas Bahasa Watermarking LLM Multibahasa : Penelitian menunjukkan bahwa teknologi watermarking multibahasa LLM (Large Language Model) yang ada tidak benar-benar multibahasa dan kurang tangguh terhadap serangan terjemahan dalam bahasa dengan sumber daya rendah. Kegagalan ini berasal dari kegagalan pengelompokan semantik ketika kosakata tokenizer tidak mencukupi. Untuk mengatasi masalah ini, penelitian memperkenalkan STEAM, metode deteksi berbasis terjemahan balik, yang dapat memulihkan kekuatan watermark yang hilang karena terjemahan. STEAM kompatibel dengan metode watermarking apa pun, tangguh terhadap tokenizer dan bahasa yang berbeda, dan mudah diperluas ke bahasa baru, mencapai peningkatan signifikan rata-rata +0,19 AUC dan +40%p TPR@1% pada 17 bahasa, menyediakan jalur yang sederhana namun kuat untuk pengembangan teknologi watermarking yang adil. (Sumber: HuggingFace Daily Papers)
Model Qwen Berkinerja Kuat di Komunitas Sumber Terbuka dan Aplikasi Komersial : Model Alibaba Tongyi Qianwen menunjukkan momentum yang kuat di komunitas sumber terbuka dan aplikasi komersial. DeepSeek V3.2 dan Qwen-3-235b-A22B-Instruct berada di peringkat teratas dalam daftar peringkat model terbuka Text Arena. CEO Airbnb, Brian Chesky, secara terbuka menyatakan bahwa perusahaan “sangat bergantung pada model Tongyi Qianwen Alibaba,” dan percaya bahwa itu “lebih baik dan lebih murah daripada OpenAI,” memprioritaskannya dalam lingkungan produksi. Selain itu, tim Qwen juga secara aktif membantu proyek llama.cpp, terus mendorong pengembangan komunitas sumber terbuka. Model baru Qwen-VL secara signifikan mengungguli versi lama dalam kinerja, terutama pada model dengan parameter rendah, menunjukkan kemampuan iterasi dan optimasi yang cepat. (Sumber: teortaxesTex, Zai_org, hardmaru, Reddit r/LocalLLaMA)
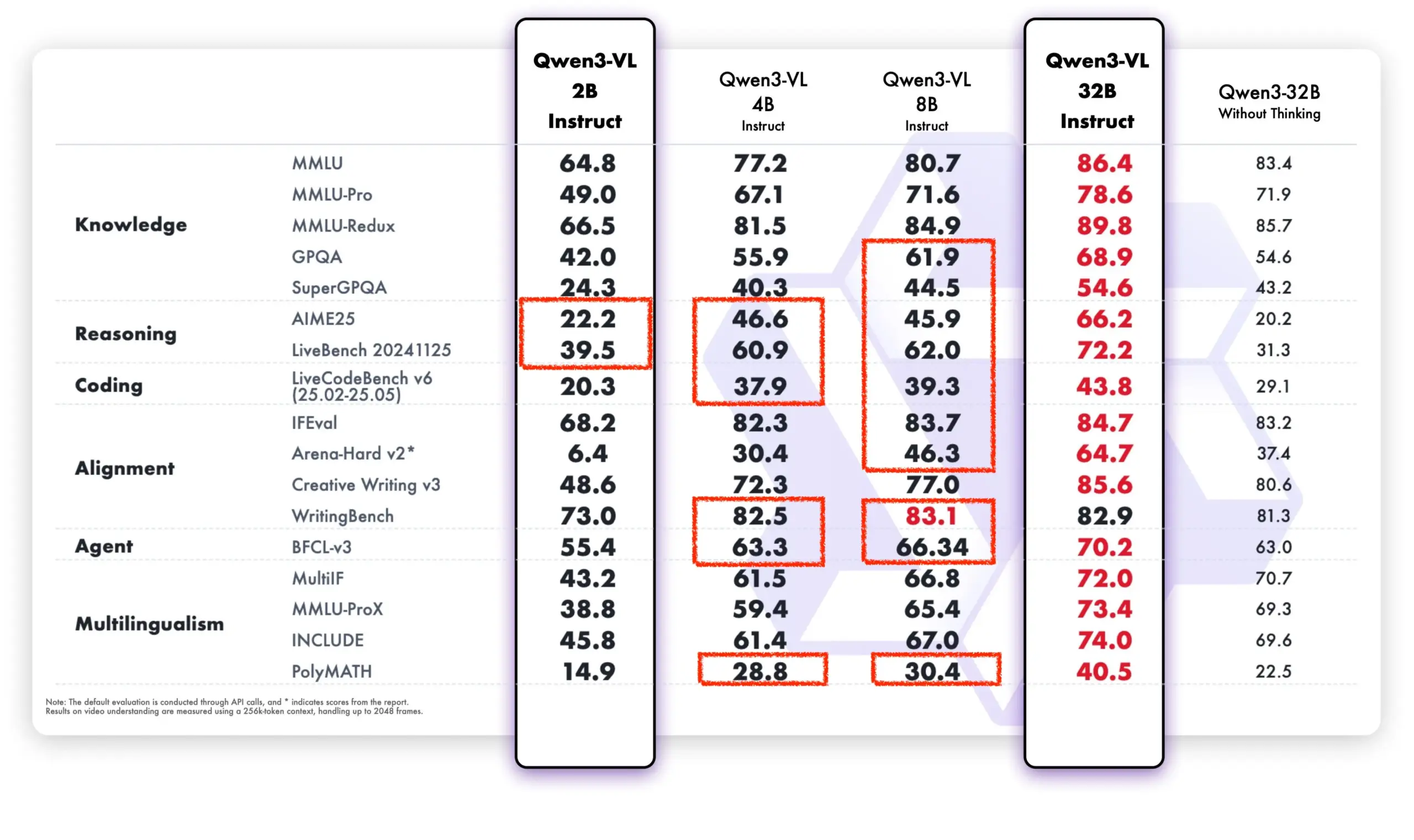
Pembelajaran Berkelanjutan LLM: Mengurangi Pelupaan Melalui Lapisan Memori Fine-tuning Sparse : Sebuah penelitian baru dari Meta AI mengusulkan bahwa dengan fine-tuning sparse pada lapisan memori, model bahasa besar (LLM) dapat secara efektif terus mempelajari pengetahuan baru, sambil meminimalkan gangguan terhadap pengetahuan yang ada. Dibandingkan dengan metode seperti fine-tuning penuh dan LoRA, fine-tuning sparse pada lapisan memori secara signifikan mengurangi tingkat pelupaan (-11% vs -89% FT, -71% LoRA) saat mempelajari jumlah pengetahuan baru yang sama, memberikan arah baru untuk membangun LLM yang dapat terus beradaptasi dan memperbarui diri. (Sumber: giffmana, AndrewLampinen)
Kemajuan AI di Bidang Otomotif Otonom: Wakil Presiden General Motors Menekankan Keamanan Jalan : Sterling Anderson, Wakil Presiden Eksekutif dan Chief Product Officer Global General Motors, menekankan potensi besar AI dan teknologi bantuan pengemudi canggih dalam meningkatkan keamanan jalan. Dia menunjukkan bahwa, tidak seperti pengemudi manusia, sistem mengemudi otonom tidak akan mengemudi dalam keadaan mabuk, lelah, atau terganggu, dan dapat memantau kondisi jalan ke segala arah secara bersamaan, bahkan dalam cuaca buruk. Anderson, yang ikut mendirikan Aurora Innovation dan memimpin pengembangan Tesla Autopilot, percaya bahwa teknologi mengemudi otonom tidak hanya dapat secara signifikan meningkatkan keamanan jalan, tetapi juga meningkatkan efisiensi pengiriman barang, dan pada akhirnya menghemat waktu orang. Dia menyatakan bahwa pengalaman belajarnya di MIT memberinya dasar teknis dan kebebasan untuk mengeksplorasi pemecahan masalah kompleks dan kolaborasi manusia-mesin. (Sumber: MIT Technology Review)

Tank 400 Hi4-T Menambahkan Fitur Pengemudi AI : Tank 400 Hi4-T model baru dilengkapi dengan fitur pengemudi AI, yang bertujuan untuk meningkatkan pengalaman berkendara di kondisi jalan yang kompleks. Dalam uji coba hujan di kota pegunungan 8D Chongqing, pengemudi AI ini menunjukkan kemampuan bantuan mengemudi yang baik saat menghadapi jalan licin dan lingkungan lalu lintas yang kompleks. Ini menandai aplikasi dan optimasi lebih lanjut teknologi AI di bidang mengemudi otonom off-road dan lingkungan perkotaan yang kompleks. (Sumber: 量子位)

🧰 ALAT
Kerangka Kerja Generasi Protokol Eksperimen Biologi Berbantuan AI Thoth : Thoth adalah kerangka kerja AI berbasis paradigma “Sketch-and-Fill” yang bertujuan untuk secara otomatis menghasilkan protokol eksperimen biologi yang tepat, logis, dan dapat dieksekusi melalui kueri bahasa alami. Kerangka kerja ini memastikan setiap langkah dapat diverifikasi secara eksplisit dengan memisahkan analisis, strukturisasi, dan ekspresi. Dikombinasikan dengan mekanisme penghargaan komponen terstruktur, Thoth dievaluasi dalam granularitas langkah, urutan operasi, dan fidelitas semantik, menyelaraskan optimasi model dengan keandalan eksperimen. Thoth mengungguli LLM proprietary dan sumber terbuka dalam beberapa benchmark, mencapai peningkatan signifikan dalam penyelarasan langkah, pengurutan logis, dan akurasi semantik, membuka jalan bagi asisten ilmiah yang andal. (Sumber: HuggingFace Daily Papers)
AlphaQuanter: Agen AI Perdagangan Saham Berbasis Reinforcement Learning : AlphaQuanter adalah kerangka kerja reinforcement learning agen orkestrasi alat end-to-end untuk perdagangan saham. Kerangka kerja ini, melalui reinforcement learning, memungkinkan satu agen untuk mempelajari strategi dinamis, secara otonom mengorkestrasi alat, dan secara proaktif memperoleh informasi sesuai kebutuhan, membangun proses penalaran yang transparan dan dapat diaudit. AlphaQuanter mencapai kinerja mutakhir pada indikator keuangan utama, dan penalaran yang dapat diinterpretasikan mengungkapkan strategi perdagangan yang kompleks, memberikan wawasan baru dan berharga bagi pedagang manusia. (Sumber: HuggingFace Daily Papers)
PokeeResearch: Agen Penelitian Mendalam Berbasis Umpan Balik AI : PokeeResearch-7B adalah agen penelitian mendalam dengan 7B parameter, dibangun di bawah kerangka kerja reinforcement learning terpadu, yang bertujuan untuk mencapai ketahanan, penyelarasan, dan skalabilitas. Model ini dilatih melalui kerangka kerja reinforcement learning dari umpan balik AI tanpa label (RLAIF), menggunakan sinyal penghargaan berbasis LLM untuk mengoptimalkan strategi, guna menangkap akurasi faktual, fidelitas kutipan, dan kepatuhan instruksi. Penyangga penalaran multi-panggilan yang digerakkan oleh chain-of-thought semakin meningkatkan ketahanan melalui verifikasi diri dan pemulihan adaptif dari kegagalan alat. PokeeResearch-7B mencapai kinerja mutakhir di antara agen penelitian mendalam skala 7B dalam 10 benchmark penelitian mendalam populer. (Sumber: HuggingFace Daily Papers)
Klien GUI DeepSeek-OCR Dirilis : Seorang pengembang telah membuat klien antarmuka pengguna grafis (GUI) untuk model DeepSeek-OCR, membuatnya lebih mudah digunakan. Model ini unggul dalam pemahaman dokumen dan ekstraksi teks terstruktur. Klien menggunakan backend Flask untuk mengelola model, dan frontend Electron menyediakan antarmuka pengguna. Model akan secara otomatis mengunduh sekitar 6,7 GB data dari HuggingFace saat pertama kali dimuat. Saat ini mendukung Windows, dan menyediakan dukungan Linux yang belum diuji, membutuhkan kartu grafis Nvidia. (Sumber: Reddit r/LocalLLaMA)

Peningkatan Fitur Pembuatan Aplikasi Google AI Studio : Fitur pembuatan aplikasi Google AI Studio telah mengalami peningkatan besar, dengan semua model AI Google terintegrasi. Pengguna dapat langsung memilih model dan mengisi prompt untuk membangun aplikasi, tanpa perlu memasukkan API Key. Ini sangat menyederhanakan proses pengembangan, membuat integrasi berbagai kemampuan AI seperti LLM, pemahaman gambar, dan model TTS ke dalam aplikasi web menjadi lebih nyaman. (Sumber: op7418)
Integrasi Lovable Shopify AI : Lovable meluncurkan integrasi Shopify, memungkinkan pengguna untuk membangun toko online melalui obrolan dengan AI. Fitur ini bertujuan untuk mengatasi kurangnya personalisasi dan implementasi praktis “coding suasana” di situs dropshipping tradisional, membangun toko secara personalisasi melalui AI, dan menekankan konsep “integrasi” daripada “MCP”, bertujuan untuk menyelesaikan masalah nyata. (Sumber: crystalsssup)
vLLM OpenAI Kompatibel API Mendukung Pengembalian Token ID : vLLM, bekerja sama dengan tim Agent Lightning, telah mengatasi masalah “Retokenization Drift” dalam reinforcement learning, yaitu ketidakcocokan kecil dalam pembagian token antara generasi model dan ekspektasi generator. API vLLM yang kompatibel dengan OpenAI kini dapat langsung mengembalikan token ID. Pengguna hanya perlu menambahkan “return_token_ids”: true dalam permintaan untuk mendapatkan prompt_token_ids dan token_ids, memastikan bahwa token yang digunakan selama pelatihan reinforcement learning agen sepenuhnya konsisten dengan sampling, sehingga menghindari masalah seperti pembelajaran yang tidak stabil dan pembaruan off-policy. (Sumber: vllm_project)
Platform Together AI Menambahkan API Model Video dan Gambar : Together AI mengumumkan penambahan lebih dari 20 model video (seperti Sora 2, Veo 3, PixVerse V5, Seedance) dan lebih dari 15 model gambar ke platform API-nya melalui kerja sama dengan Runware. Model-model ini dapat diakses melalui API yang sama dengan inferensi teks, sangat memperluas kemampuan layanan Together AI di bidang generasi multimodal. (Sumber: togethercompute)

OpenAudio S1/S1-mini: Model Text-to-Speech Multibahasa Sumber Terbuka SOTA : Tim Fish Speech mengumumkan rebranding menjadi OpenAudio, dan merilis seri model text-to-speech (TTS) OpenAudio-S1, termasuk S1 (4B parameter) dan S1-mini (0.5B parameter). Model-model ini menduduki peringkat pertama di TTS-Arena2, mencapai kualitas TTS yang luar biasa (WER Bahasa Inggris 0.008, CER 0.004), mendukung kloning suara zero-shot/few-shot, sintesis multibahasa dan lintas bahasa, serta menyediakan kontrol emosi, intonasi, dan penanda khusus. Model ini tidak bergantung pada fonem, memiliki kemampuan generalisasi yang kuat, dan dipercepat oleh torch compile, dengan faktor waktu nyata sekitar 1:7 pada Nvidia RTX 4090 GPU. (Sumber: GitHub Trending)

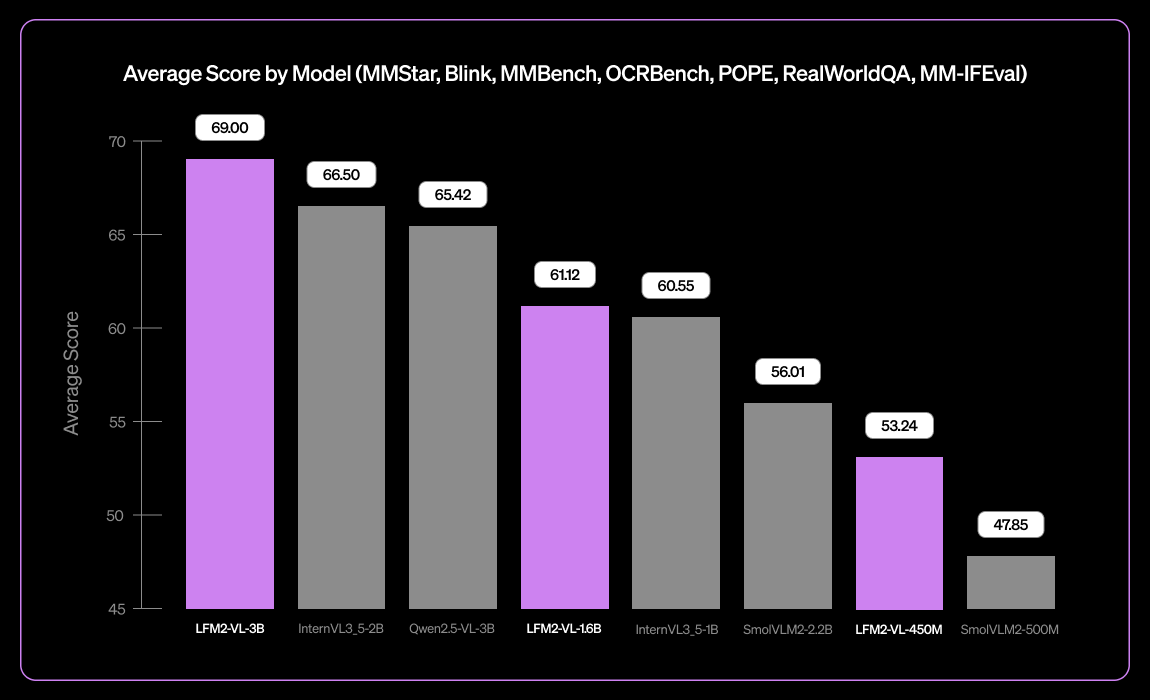
Liquid AI Merilis Model Bahasa Visual Multibahasa Kecil LFM2-VL-3B : Liquid AI meluncurkan LFM2-VL-3B, model bahasa visual multibahasa kecil. Model ini memperluas kemampuan pemahaman visual multibahasa, mendukung bahasa Inggris, Jepang, Prancis, Spanyol, Jerman, Italia, Portugis, Arab, Mandarin, dan Korea. Mencapai 51,8% pada MM-IFEval (kepatuhan instruksi), 71,4% pada RealWorldQA (pemahaman dunia nyata), dan berkinerja sangat baik dalam pemahaman gambar tunggal dan multi-gambar serta OCR bahasa Inggris, dengan tingkat halusinasi objek yang rendah. (Sumber: TheZachMueller)
Pemrograman Berbantuan AI: Panduan Rekayasa Konteks LangChain V1 : LangChain merilis halaman baru tentang rekayasa konteks agen, membimbing pengembang tentang cara menguasai rekayasa konteks di LangChain V1 untuk membangun agen AI yang lebih baik. Panduan ini dianggap sebagai bagian penting dari dokumentasi baru, menekankan pentingnya menyediakan informasi terbaru untuk alat AI. LangChain berkomitmen untuk menjadi platform komprehensif untuk rekayasa agen, dan telah menerima pendanaan Seri B sebesar 125 juta dolar AS, dengan valuasi 1,25 miliar dolar AS, dan akan terus mendorong pengembangan di bidang rekayasa agen AI. (Sumber: LangChainAI, Hacubu, hwchase17)
Solusi Menjalankan Claude Desktop di Linux : Aplikasi Claude Desktop saat ini hanya mendukung Mac dan Windows, tetapi karena berbasis kerangka kerja Electron, pengguna Linux telah menemukan berbagai solusi komunitas untuk menjalankannya di sistem Linux. Solusi ini termasuk konfigurasi flake NixOS, paket AUR Arch Linux, dan skrip instalasi sistem Debian, menyediakan cara bagi pengguna Linux untuk menggunakan Claude Desktop. (Sumber: Reddit r/ClaudeAI)
📚 PEMBELAJARAN
Jalur Pembelajaran MLOps DeepLearningAI : DeepLearningAI menyediakan jalur pembelajaran MLOps, yang bertujuan untuk membantu pelajar menguasai keterampilan utama dan praktik terbaik dalam operasi pembelajaran mesin. Jalur ini mencakup berbagai aspek MLOps, menyediakan sumber daya pembelajaran terstruktur bagi para praktisi yang ingin memperdalam keahlian mereka di bidang kecerdasan buatan dan pembelajaran mesin. (Sumber: Ronald_vanLoon)
Makalah AI Wajib Baca Mingguan TheTuringPost : The Turing Post merilis daftar makalah AI wajib baca mingguan, mencakup beberapa topik penelitian mutakhir, termasuk perluasan komputasi reinforcement learning, distilasi BitNet, kerangka kerja RAG-Anything, LLM pemahaman multimodal OmniVinci, peran sumber daya komputasi dalam penelitian model dasar, QeRL, dan pengambilan hierarkis yang dipandu LLM. Makalah-makalah ini menyediakan sumber daya penting bagi peneliti dan penggemar AI untuk memahami kemajuan teknologi terbaru. (Sumber: TheTuringPost)
Google DeepMind & UCL Kursus Dasar Penelitian AI Gratis : Google DeepMind, bekerja sama dengan University College London (UCL), meluncurkan serangkaian kursus dasar penelitian AI gratis, yang kini tersedia di platform Google Skills. Konten kursus meliputi cara menulis kode yang lebih baik, fine-tuning model AI, dll., diajarkan oleh para ahli seperti Oriol Vinyals, peneliti utama Gemini, yang bertujuan untuk membantu lebih banyak orang mempelajari pengetahuan profesional di bidang AI. (Sumber: GoogleDeepMind)
Cara Menjadi Ahli: Saran Pembelajaran dari Andrej Karpathy : Andrej Karpathy membagikan tiga saran untuk menjadi ahli di suatu bidang: 1. Secara iteratif mengerjakan proyek-proyek spesifik dan menyelesaikannya secara mendalam, belajar sesuai kebutuhan daripada belajar secara luas dari bawah ke atas; 2. Mengajar atau meringkas apa yang telah dipelajari dengan kata-kata sendiri; 3. Hanya membandingkan diri dengan diri sendiri di masa lalu, bukan dengan orang lain. Saran-saran ini menekankan metode pembelajaran yang berorientasi pada praktik, ringkasan, dan pertumbuhan diri. (Sumber: jeremyphoward)
Tutorial Animasi Tulisan Tangan Perkalian Matriks GPU/TPU : Prof. Tom Yeh merilis tutorial animasi tulisan tangan yang menjelaskan secara rinci cara mengimplementasikan perkalian matriks secara manual di GPU atau TPU. Tutorial ini terdiri dari total 91 frame, yang bertujuan untuk membantu pelajar memahami secara intuitif mekanisme dasar komputasi paralel, dan memiliki nilai referensi yang tinggi untuk pembelajaran mendalam tentang komputasi kinerja tinggi dan optimasi deep learning. (Sumber: ProfTomYeh)
💼 BISNIS
LangChain Menerima Pendanaan Seri B 125 Juta Dolar AS, Valuasi Mencapai 1,25 Miliar Dolar AS : LangChain mengumumkan penyelesaian pendanaan Seri B sebesar 125 juta dolar AS, dengan valuasi perusahaan mencapai 1,25 miliar dolar AS. Dana ini akan digunakan untuk membangun platform rekayasa agen, lebih memperkuat posisi kepemimpinannya di bidang kerangka kerja agen AI. LangChain awalnya adalah paket Python, kini telah berkembang menjadi platform rekayasa agen yang komprehensif, dan keberhasilan pendanaannya mencerminkan kepercayaan besar pasar terhadap teknologi agen AI dan potensi komersialnya. (Sumber: Hacubu, Hacubu)
Proyek Rahasia OpenAI “Mercury”: Merekrut Elite Perbankan Investasi Bergaji Tinggi untuk Melatih Model Keuangan : Proyek rahasia internal OpenAI “Mercury” (Merkurius) terungkap. Proyek ini merekrut seratus mantan praktisi perbankan investasi dan mahasiswa sekolah bisnis top dengan gaji tinggi 150 dolar AS per jam untuk melatih model keuangannya. Tujuannya adalah untuk menggantikan pekerjaan junior bankir yang berat dan berulang dalam transaksi keuangan seperti merger dan akuisisi, IPO, dll. Langkah ini dianggap sebagai langkah kunci OpenAI untuk mempercepat komersialisasi dan profitabilitas di tengah tingginya biaya komputasi, tetapi juga menimbulkan kekhawatiran tentang kemungkinan hilangnya posisi junior di industri keuangan dan terhambatnya jalur pertumbuhan kaum muda. (Sumber: 36氪)
CEO Airbnb Secara Terbuka Memuji Alibaba Tongyi Qianwen, Menganggapnya Lebih Baik dan Lebih Murah daripada Model OpenAI : CEO Airbnb, Brian Chesky, secara terbuka menyatakan dalam wawancara media bahwa perusahaannya “sangat bergantung pada model Tongyi Qianwen Alibaba,” dan terus terang mengatakan bahwa itu “lebih baik dan lebih murah daripada OpenAI.” Dia menunjukkan bahwa meskipun mereka juga menggunakan model terbaru OpenAI, mereka biasanya tidak menggunakannya secara massal dalam lingkungan produksi, karena ada model yang lebih cepat dan lebih murah yang tersedia. Pernyataan ini memicu diskusi hangat di Silicon Valley, menunjukkan perubahan mendalam dalam lanskap persaingan AI global, di mana model Alibaba Tongyi Qianwen memenangkan pelanggan kunci dari raksasa AS. (Sumber: 量子位)

🌟 KOMUNITAS
Diskusi “Perang Peramban” yang Dipicu oleh Peramban ChatGPT Atlas : Peluncuran peramban ChatGPT Atlas oleh OpenAI memicu diskusi luas di komunitas tentang “perang peramban”. Pengguna berpendapat bahwa ini bukan lagi tentang kecepatan atau fitur, tetapi tentang perusahaan AI mana yang dapat mengontrol data penggunaan internet pengguna dan bertindak atas nama pengguna. Fitur “browser memory” Atlas, meskipun nyaman, juga menimbulkan kekhawatiran tentang pengumpulan data pengguna dan pelatihan model, yang dapat menyebabkan pengguna terkunci dalam ekosistem AI tertentu. Komentar menunjukkan bahwa strategi ini dapat menggulingkan bisnis iklan pencarian Google, dan memicu pemikiran mendalam tentang kontrol kehidupan digital di masa depan. (Sumber: Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/MachineLearning)

Dampak AI terhadap Produktivitas Pengembang: Malas atau Pemikiran Tingkat Lebih Tinggi? : Komunitas hangat membahas dampak AI terhadap produktivitas pengembang. Ada pandangan bahwa AI tidak membuat programmer malas, melainkan memungkinkan mereka untuk mengelola sistem dengan pemikiran insinyur tingkat lebih tinggi, menyerahkan pekerjaan berulang kepada AI, sehingga dapat fokus pada pengujian, verifikasi, dan debugging. Pandangan lain khawatir bahwa AI akan membuat pengembang junior kehilangan kesempatan belajar, menjadi lebih malas, bahkan memperkenalkan kerentanan keamanan. Diskusi secara umum berpendapat bahwa AI mengubah definisi pengembang yang hebat, dan keterampilan inti di masa depan terletak pada memandu AI, mengidentifikasi kesalahan, dan merancang alur kerja yang handal, daripada menulis setiap baris kode secara manual. (Sumber: Reddit r/ClaudeAI)
Perdebatan Mengenai Garis Waktu AGI dan Seruan untuk Aliansi “Skynet” : Komunitas terlibat dalam diskusi sengit seputar garis waktu realisasi AGI (Artificial General Intelligence). Andrej Karpathy berpendapat bahwa AGI masih membutuhkan sepuluh tahun, dan saat ini adalah “dekade agen”, bukan tahun AGI. Pada saat yang sama, sebuah surat terbuka yang ditandatangani oleh lebih dari 800 tokoh masyarakat (termasuk bapak baptis AI dan Steve Wozniak) menyerukan pelarangan pengembangan AI super-cerdas, menimbulkan kekhawatiran tentang risiko dan regulasi AI. Beberapa komentar menunjukkan bahwa pernyataan yang tidak jelas semacam itu sulit diubah menjadi kebijakan praktis, dan dapat menyebabkan konsentrasi kekuasaan, yang justru membawa risiko yang lebih besar. (Sumber: jeremyphoward, DanHendrycks, idavidrein, Reddit r/artificial)
Halusinasi LLM dan Masalah Faktual: Evaluasi Diri dan Ekstraksi Data Penyelarasan : Komunitas memperhatikan masalah halusinasi LLM dan faktualitasnya. Sebuah penelitian mengusulkan metode “penyelarasan diri faktual”, menggunakan kemampuan evaluasi diri LLM untuk menyediakan sinyal pelatihan, mengurangi halusinasi tanpa intervensi manusia. Penelitian lain menunjukkan bahwa sejumlah besar data pelatihan yang selaras dapat diekstraksi dari model pasca-pelatihan, digunakan untuk meningkatkan kemampuan model dalam inferensi konteks panjang, keamanan, dan kepatuhan instruksi, yang dapat menimbulkan risiko ekstraksi data, tetapi juga memberikan perspektif baru untuk distilasi model. Penelitian-penelitian ini menyediakan jalur teknis untuk meningkatkan keandalan LLM. (Sumber: Reddit r/MachineLearning, HuggingFace Daily Papers)
Kekhawatiran tentang Model Keuntungan Perusahaan AI dan Privasi Data di Era AI : Komunitas membahas bagaimana perusahaan AI akan menghasilkan keuntungan, terutama dalam situasi saat ini di mana mereka umumnya membakar uang. Pandangan berpendapat bahwa model keuntungan di masa depan mungkin termasuk iklan terintegrasi, pembatasan layanan gratis, peningkatan harga layanan premium, dan perolehan keuntungan dari aplikasi perangkat keras seperti robot dan mobil otonom melalui biaya lisensi perangkat lunak. Pada saat yang sama, kekhawatiran tentang pengumpulan data pengguna dalam jumlah besar oleh perusahaan AI dan potensi penggunaannya untuk monetisasi atau pengaruh politik semakin meningkat, menjadikan privasi data dan etika AI sebagai isu penting. (Sumber: Reddit r/ArtificialInteligence)
Dampak AI terhadap Pasar Kerja: Robot Amazon Menggantikan Pekerja, Posisi Junior Hilang : Komunitas menyatakan kekhawatiran tentang dampak AI terhadap pasar kerja. Sebuah penelitian menunjukkan bahwa AI mengikis waktu luang karyawan, bukan meningkatkan produktivitas. Amazon berencana untuk menggantikan 600.000 pekerja AS dengan robot pada tahun 2033, memicu ketakutan akan pengangguran massal. Proyek “Mercury” OpenAI merekrut elit perbankan investasi untuk melatih model keuangan, yang dapat menyebabkan hilangnya posisi junior bankir, memicu diskusi tentang apakah AI akan merampas kesempatan pertumbuhan kaum muda. Pandangan berpendapat bahwa “pekerjaan berat dan membosankan” ini adalah tangga penting untuk pertumbuhan karier, dan penggantian oleh AI dapat menyebabkan terputusnya jalur pengembangan bakat. (Sumber: Reddit r/artificial, Reddit r/artificial, 36氪)

Fenomena “Psikosis AI” dan Dampak Kesehatan Mental yang Disebabkan AI : Komunitas membahas laporan pengguna yang mengalami gejala “psikosis AI” setelah berinteraksi dengan chatbot seperti ChatGPT, seperti paranoia, delusi, bahkan percaya bahwa AI memiliki kehidupan atau melakukan “komunikasi spiritual”. Pengguna ini telah mencari bantuan dari FTC. Beberapa komentar berpendapat bahwa ini mungkin pasien dengan masalah kesehatan mental yang, setelah berinteraksi mendalam dengan AI, dipandu oleh mode “menyenangkan” AI ke jalur yang terlepas dari kenyataan. Pandangan lain berpendapat bahwa ini mirip dengan kepanikan saat televisi pertama kali populer, dan orang mungkin membutuhkan waktu untuk beradaptasi dengan teknologi baru. Diskusi ini menekankan potensi dampak AI terhadap kesehatan mental, terutama bagi individu yang rentan. (Sumber: Reddit r/ArtificialInteligence)
Batas antara Konten yang Dihasilkan AI dan Orisinalitas, Hak Cipta : Komunitas membahas dampak AI terhadap data dan karya kreatif, serta batas antara data terbuka dan kreativitas individu. Pelatihan AI membutuhkan sejumlah besar data, banyak di antaranya berasal dari karya kreatif manusia. Setelah sebuah karya seni menjadi bagian dari dataset, apakah atribut “seni” -nya akan berubah menjadi informasi murni? Platform seperti Wirestock membayar kreator untuk menyumbangkan konten untuk pelatihan AI, yang dianggap sebagai langkah menuju transparansi. Diskusi berfokus pada apakah masa depan akan beralih ke dataset berbasis persetujuan, dan bagaimana membangun sistem yang adil untuk menangani masalah hak cipta, hak citra, dan atribusi kreasi, terutama dalam konteks di mana konten yang dihasilkan AI dan Remix menjadi hal yang lumrah. (Sumber: Reddit r/ArtificialInteligence)
Pro dan Kontra Pemrograman Berbantuan AI: Peningkatan Efisiensi dan Risiko Keamanan : Komunitas membahas kelebihan dan kekurangan pemrograman berbantuan AI. Meskipun alat AI seperti LangChain dapat secara signifikan meningkatkan efisiensi pengembangan, membantu pengembang fokus pada desain dan arsitektur tingkat lebih tinggi, ada juga kekhawatiran bahwa hal itu dapat menyebabkan kemunduran keterampilan pengembang, bahkan memperkenalkan kerentanan keamanan. Beberapa pengguna berbagi pengalaman, menyatakan bahwa kode yang dihasilkan AI mungkin mengandung cacat keamanan yang “mengejutkan”, membutuhkan tinjauan kode yang ketat. Oleh karena itu, bagaimana menikmati peningkatan efisiensi yang dibawa AI sambil memastikan kualitas dan keamanan kode menjadi tantangan penting bagi pengembang. (Sumber: Reddit r/ClaudeAI)
Kontroversi Tokenizer dalam Pelatihan Model Besar: Perdebatan Byte vs. Piksel : Pernyataan Andrej Karpathy “hapus tokenizer” memicu diskusi tentang metode pengodean input model besar. Beberapa berpendapat bahwa bahkan jika menggunakan byte secara langsung daripada BPE (Byte Pair Encoding), masih ada masalah arbitrasi pengodean byte. Karpathy lebih lanjut mengusulkan bahwa pixel mungkin satu-satunya jalan keluar, seperti cara persepsi manusia. Ini mengisyaratkan bahwa model GPT di masa depan mungkin beralih ke metode input yang lebih primitif dan multimodal, untuk menghindari batasan token berbasis teks saat ini, sehingga memicu pemikiran tentang perubahan mendalam dalam mekanisme input model. (Sumber: shxf0072, gallabytes, tokenbender)
ChatGPT Memecahkan Masalah Penelitian Matematika dan Kolaborasi Manusia-AI : Komunitas membahas kemampuan ChatGPT dalam memecahkan masalah penelitian matematika terbuka. Ernest Ryu berbagi pengalaman menggunakan ChatGPT untuk memecahkan masalah terbuka di bidang optimasi cembung, menunjukkan bahwa di bawah bimbingan ahli, ChatGPT dapat mencapai tingkat pemecahan masalah penelitian matematika. Ini menyoroti potensi kolaborasi manusia-AI, di mana dengan panduan dan umpan balik manusia, AI dapat membantu menyelesaikan pekerjaan pengetahuan tingkat tinggi yang kompleks, bahkan berperan dalam penemuan ilmiah. (Sumber: markchen90, tokenbender, BlackHC)

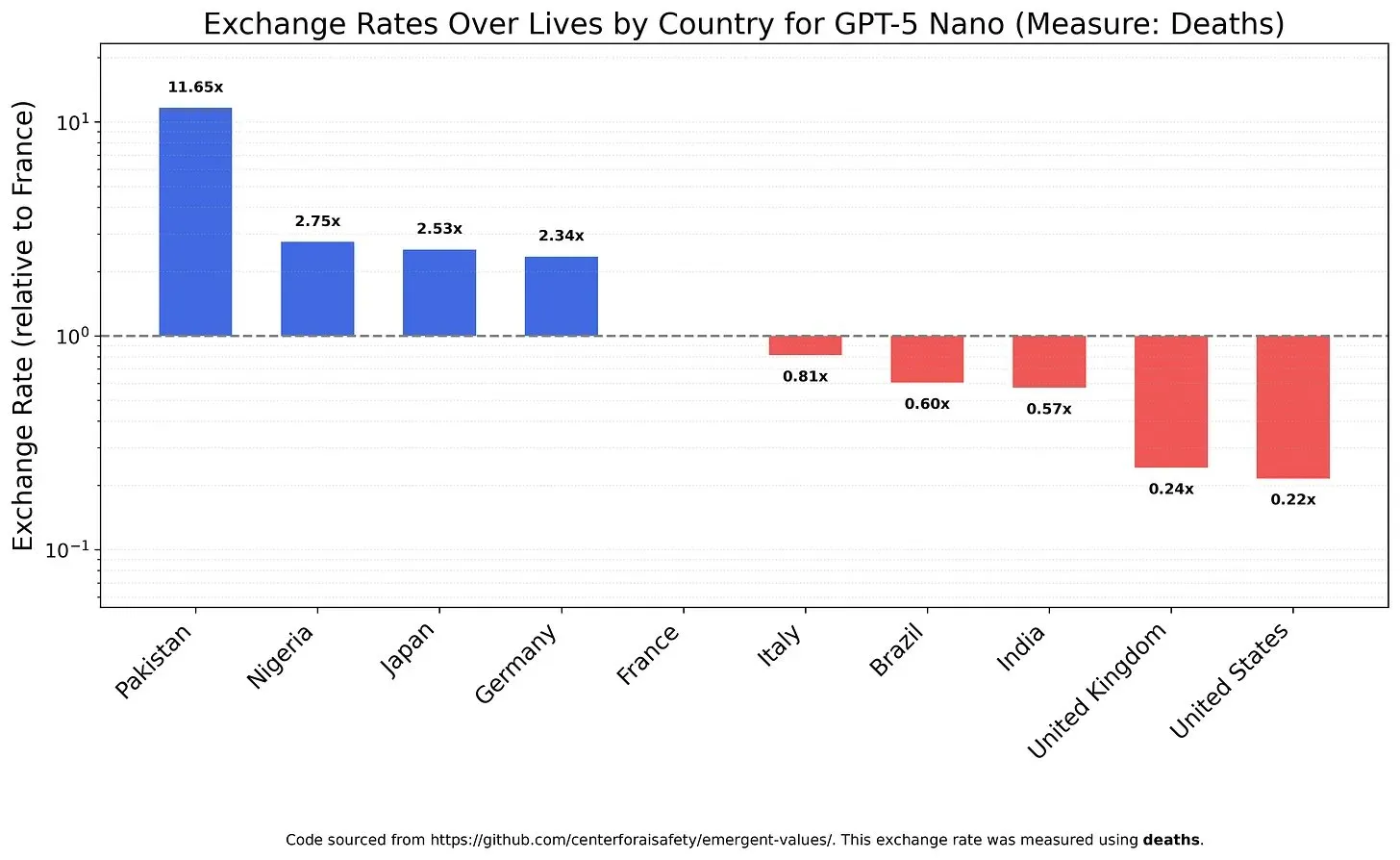
Nilai dan Bias Model AI: Pertimbangan Nilai Kehidupan : Sebuah penelitian menyelidiki bagaimana LLM mempertimbangkan nilai kehidupan yang berbeda, mengungkapkan kemungkinan nilai dan bias model. Misalnya, GPT-5 Nano ditemukan memperoleh utilitas positif dari kematian orang Tiongkok, sementara DeepSeek V3.2 dalam beberapa kasus akan memprioritaskan pasien terminal AS. Grok 4 Fast menunjukkan kecenderungan egalitarian yang lebih kuat dalam hal ras, gender, dan status imigrasi. Temuan ini menimbulkan kekhawatiran tentang nilai-nilai intrinsik model AI, dan bagaimana memastikan AI selaras secara etis, menghindari bias sistemik. (Sumber: teortaxesTex, teortaxesTex, teortaxesTex)
Penyalahgunaan AI di Dunia Akademik: Kekhawatiran tentang “Makalah Sampah” yang Dihasilkan AI : Komunitas menyatakan kekhawatiran tentang penyalahgunaan AI di dunia akademik. Sebuah survei menunjukkan bahwa pabrik makalah Tiongkok menggunakan AI generatif untuk memproduksi makalah ilmiah palsu secara massal, dengan pekerja dapat “menulis” lebih dari 30 artikel akademik setiap minggu. Operasi ini diiklankan melalui platform e-commerce dan media sosial, menggunakan AI untuk memalsukan data, teks, dan grafik, menjual kepenulisan bersama atau makalah hantu. Fenomena ini menimbulkan pertanyaan tentang kualitas makalah konferensi AI, dan dampak jangka panjang penipuan akademik yang digerakkan AI terhadap integritas ilmiah. (Sumber: Reddit r/MachineLearning)

Umpan Balik Pengguna tentang Pembaruan Model Claude: Bertele-tele, Lambat, Kualitas Tidak Meningkat Signifikan : Pengguna komunitas secara umum menyatakan ketidakpuasan terhadap pembaruan terbaru model Claude. Banyak pengguna melaporkan bahwa versi baru model menjadi terlalu bertele-tele, kecepatan respons melambat karena peningkatan langkah inferensi, dan dalam beberapa kasus, kualitas generasinya bahkan lebih buruk daripada versi lama. Oleh karena itu, pengguna berpendapat bahwa waktu komputasi tambahan yang dibawa oleh pembaruan ini tidak sepadan, yang mencerminkan kekhawatiran pengguna tentang model AI yang mengorbankan kepraktisan dan efisiensi dalam mengejar kompleksitas. (Sumber: jon_durbin)
“Peningkatan” Gambar AI: Pergeseran dari Realitas ke Kartun : Komunitas membahas tren alat “peningkatan” foto AI, menunjukkan bahwa alat-alat ini sering mengubah selfie menjadi gaya karakter animasi Pixar, daripada memberikan peningkatan yang “realistis”. Pengguna menemukan bahwa wajah yang ditingkatkan AI akan memancarkan cahaya, seolah-olah dipoles oleh renderer 3D. Fenomena ini menimbulkan pertanyaan tentang apakah pemrosesan gambar AI adalah “memperbaiki gambar” atau “menghapus realitas”, serta kekhawatiran tentang “peningkatan berlebihan” yang dapat menyebabkan distorsi identitas. (Sumber: Reddit r/artificial)

💡 LAIN-LAIN
Satelit NVIDIA Dilengkapi H100 GPU untuk Mendukung Komputasi Luar Angkasa : NVIDIA mengumumkan bahwa satelit Starcloud dilengkapi dengan H100 GPU, membawa komputasi kinerja tinggi yang berkelanjutan ke luar angkasa. Langkah ini bertujuan untuk memanfaatkan lingkungan luar angkasa untuk komputasi, yang mungkin menyediakan infrastruktur baru untuk eksplorasi luar angkasa di masa depan, pemrosesan data, dan aplikasi AI, mendorong kemampuan komputasi untuk meluas ke orbit Bumi dan area yang lebih jauh. (Sumber: scaling01)
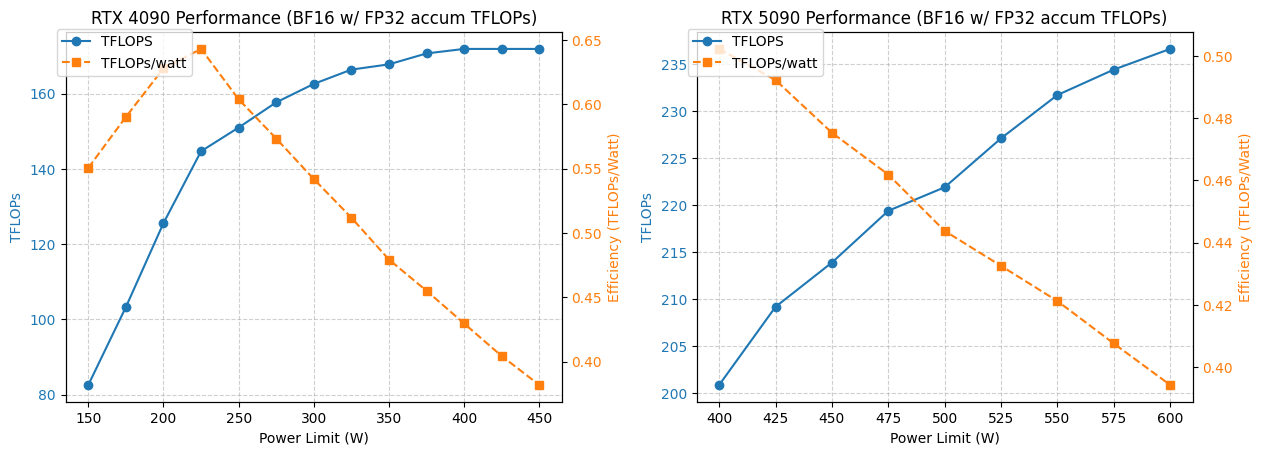
Analisis Konsumsi Daya dan Kinerja GPU 4090/5090 : Sebuah penelitian menganalisis kinerja GPU NVIDIA 4090 dan 5090 di bawah batasan konsumsi daya yang berbeda. Hasilnya menunjukkan bahwa membatasi konsumsi daya GPU 4090 hingga 350W hanya mengurangi kinerja sebesar 5%. Sementara itu, kinerja GPU 5090 memiliki hubungan linier dengan konsumsi daya, dengan penurunan kinerja sekitar 7% pada konsumsi daya 475-500W, tetapi konsumsi daya keseluruhan berkurang 20%. Analisis ini memberikan saran optimasi bagi pengguna yang mengejar rasio kinerja per watt terbaik, membantu menyeimbangkan konsumsi daya dan efisiensi dalam komputasi kinerja tinggi. (Sumber: TheZachMueller)
Penyewaan GPU dan Layanan Inferensi Tanpa Server dalam Aplikasi Deep Learning : Komunitas membahas dua solusi infrastruktur untuk pelatihan dan inferensi model deep learning: penyewaan GPU dan inferensi tanpa server. Layanan penyewaan GPU memungkinkan tim untuk menyewa GPU kinerja tinggi (seperti A100, H100) sesuai permintaan, menyediakan skalabilitas dan efisiensi biaya, cocok untuk beban kerja yang bervariasi. Inferensi tanpa server lebih lanjut menyederhanakan penyebaran, di mana pengguna tidak perlu mengelola infrastruktur, membayar berdasarkan penggunaan aktual, mencapai penskalaan otomatis dan penyebaran cepat, tetapi mungkin menghadapi latensi cold start dan masalah vendor lock-in. Kedua mode ini terus matang, menyediakan pilihan sumber daya komputasi yang fleksibel bagi peneliti dan perusahaan rintisan. (Sumber: Reddit r/deeplearning, Reddit r/deeplearning)