
Kata Kunci:OpenAI, Regulasi AI, Model Bahasa Besar, Etika AI, Inovasi AI, Pemusatan Kekuatan AI, Undang-undang Keamanan AI, Tata Kelola AI, Ancaman Hukum OpenAI, Kerangka Penyelarasan GTAlign, Penalaran Multimodal ARES, Model Dunia xAI, Teknologi Segmentasi SAM 3.0
Berikut adalah terjemahan informasi AI ke dalam Bahasa Indonesia, dengan mempertahankan format dan struktur asli:
🔥 FOKUS
Tema: OpenAI Dituduh Mengintimidasi Organisasi Nirlaba: Selama Pembahasan RUU Keamanan AI di California, OpenAI dilaporkan mengeluarkan panggilan pengadilan kepada Encode, sebuah organisasi nirlaba dengan hanya tiga karyawan, menuntut semua catatan dan komunikasi pribadi, dan menuduhnya tanpa bukti didanai oleh Elon Musk. Langkah ini secara terbuka dikecam oleh Encode sebagai intimidasi hukum, yang bertujuan untuk menekan kritik terhadap posisi kebijakannya. Insiden ini memicu kritik dari karyawan internal OpenAI dan mantan anggota dewan direksi, menyoroti taktik agresif yang diambil oleh perusahaan AI besar dalam menghadapi regulasi, serta tantangan yang dihadapi oleh kelompok advokasi kecil saat berhadapan dengan raksasa. Meskipun RUU SB 53 akhirnya disahkan, yang mewajibkan perusahaan AI untuk menyerahkan penilaian risiko dan laporan transparansi (Sumber: Reddit r/ArtificialInteligence)
Tema: Pemenang Hadiah Nobel Ekonomi Memperingatkan: Konsentrasi Kekuatan AI Dapat Mencekik Inovasi: Philippe Aghion, salah satu pemenang Hadiah Nobel Ekonomi tahun ini, menyatakan bahwa konsentrasi kekuatan AI di tangan beberapa perusahaan dapat menghambat inovasi dan pertumbuhan ekonomi. Ia berpendapat bahwa inovasi bergantung pada kompetisi, dan monopoli sumber daya AI dapat menyebabkan stagnasi kemajuan, menyulitkan startup untuk menantang raksasa yang sudah ada. Hal ini memicu diskusi tentang tata kelola AI dan bentuk regulasi untuk mencegah AI menjadi penghambat pertumbuhan daripada pendorong (Sumber: Reddit r/ArtificialInteligence)

Tema: GTAlign: Kerangka Penyelarasan Asisten LLM Berbasis Teori Permainan: Para peneliti mengusulkan GTAlign, sebuah kerangka penyelarasan yang mengintegrasikan keputusan teori permainan ke dalam inferensi dan pelatihan LLM. Kerangka ini mengevaluasi kesejahteraan bersama LLM dan pengguna dengan membangun matriks pembayaran dan memilih tindakan yang saling menguntungkan. Dalam pelatihan, penghargaan kesejahteraan timbal balik diperkenalkan untuk memperkuat respons kooperatif. Eksperimen menunjukkan bahwa GTAlign secara signifikan meningkatkan efisiensi inferensi, kualitas jawaban, dan kesejahteraan bersama LLM dalam berbagai tugas, menyelesaikan masalah di mana model dalam metode penyelarasan tradisional dapat mengurangi pengalaman pengguna karena terlalu bertele-tele (Sumber: HuggingFace Daily Papers)
Tema: ARES: Inferensi Adaptif Multimodal Melalui Pembentukan Entropi Sadar Kesulitan: ARES adalah kerangka kerja open-source terpadu yang mengatasi masalah ketidakseimbangan efisiensi dalam model inferensi besar multimodal (MLRMs) saat menangani tugas dengan tingkat kesulitan yang berbeda, dengan secara dinamis mengalokasikan upaya eksplorasi. Ini menggunakan entropi jendela untuk mengidentifikasi momen inferensi kritis, dan melalui pelatihan dua tahap (adaptive cold start dan adaptive entropy policy optimization) memungkinkan model untuk mengurangi overthinking pada masalah sederhana dan meningkatkan eksplorasi pada masalah kompleks. ARES menunjukkan kinerja luar biasa dan efisiensi inferensi dalam benchmark matematika, logika, dan multimodal, secara signifikan mengurangi biaya inferensi (Sumber: HuggingFace Daily Papers)
🎯 TREN
Tema: xAI Elon Musk Memasuki Model Dunia, Merekrut Talenta dari Nvidia untuk Game AI: xAI secara aktif mengembangkan bidang model dunia dan telah merekrut beberapa peneliti senior dari Nvidia, berencana untuk merilis game yang dihasilkan AI dan didorong oleh model dunia sebelum akhir tahun 2026. Tujuan xAI adalah agar AI memahami esensi alam semesta, menerapkan model dunia pada game AI, agen, autonomous driving, dan robot cerdas berwujud, bertujuan untuk membangun ekosistem AI yang lengkap dan tertutup (Sumber: 量子位)

Tema: Meta ‘Segment Anything’ 3.0 Terungkap: SAM 3.0 Memperkenalkan Segmentasi Konsep yang Dapat Diprompt (PCS), mendukung tugas segmentasi multi-instans berdasarkan frasa atau contoh gambar. Desain arsitektur baru mencakup detektor berbasis DETR dan modul Presence Head, memisahkan identifikasi objek dari lokalisasi, meningkatkan akurasi deteksi. Melalui mesin data skala besar dan benchmark SA-Co, SAM 3.0 mencetak rekor SOTA baru dalam tugas segmentasi kosakata terbuka, dan dapat dikombinasikan dengan model besar multimodal untuk menyelesaikan tugas segmentasi inferensi kompleks (Sumber: 量子位)

Tema: Baidu World 2025 Ditetapkan, Berfokus pada Aplikasi AI dan Ekosistem Model Besar: Baidu mengumumkan akan menyelenggarakan Baidu World 2025 pada 13 November di Beijing, dengan tema “Efek Muncul | AI in Action”. Konferensi ini akan menampilkan secara komprehensif kemajuan terbaru Baidu dalam aplikasi AI, model besar, ekosistem AI, dan globalisasi, termasuk Wenxin iRAG, no-code Miaoda, teknologi digital human, dan tata letak global autonomous driving “Luobo Kuaipao”. Konferensi ini juga akan menyediakan lebih dari 40 kelas terbuka AI untuk memberdayakan pengembangan aplikasi AI (Sumber: 量子位)

Tema: Reflection AI: ‘DeepSeek Amerika’ dengan Valuasi $8 Miliar Sebelum Peluncuran Produk: Reflection AI, tanpa meluncurkan produk resmi, telah melihat valuasinya melonjak menjadi $8 miliar dan menerima pendanaan $2 miliar dari Nvidia, Sequoia Capital, dan lainnya. Perusahaan ini didirikan oleh mantan anggota inti Google DeepMind, bertujuan untuk menjadi “DeepSeek Barat”, menyediakan model MoE berkinerja tinggi melalui model “open-weight”, mengisi kebutuhan pasar Barat akan model open-source non-Tiongkok, dan menargetkan pasar perusahaan besar serta AI berdaulat (Sumber: 36氪)

Tema: Model Dolphin X1 8B Dirilis: Versi Fine-tuned Llama3.1 8B yang Didesensor: Dolphin X1 8B telah tersedia di Hugging Face, ini adalah versi fine-tuned dari Llama3.1 8B Instruct, yang bertujuan untuk menghilangkan batasan sensor model semaksimal mungkin tanpa merusak kemampuan lainnya. Model ini dilatih menggunakan SFT+RL, hasil benchmark setara atau lebih tinggi dari Llama3.1 8B Instruct, dan telah merilis versi GGUF, FP8, dan exl2 dengan sponsor dari Deepinfra (Sumber: Reddit r/LocalLLaMA)
Tema: Jalur RAG Open-Source Beragam: Solusi RAG (Retrieval-Augmented Generation) Open-Source seperti MiniRAG, Agent-UniRAG, SymbioticRAG Berdivergensi, menampilkan filosofi desain yang berbeda. MiniRAG mengejar keringanan dan operasi lokal, Agent-UniRAG mengintegrasikan retrieval dan inferensi menjadi pipeline agen yang berkelanjutan, SymbioticRAG menekankan kolaborasi manusia-mesin dan pembelajaran berbasis umpan balik, sementara toolkit seperti LangChain menyediakan komponen modular. Pengguna perlu menimbang akurasi, kecepatan, dan kontrol saat memilih, serta memperhatikan masalah umum seperti halusinasi dan kehilangan konteks (Sumber: Reddit r/LocalLLaMA)
Tema: LLM4Cell: Tinjauan Model Bahasa Besar dan Model Agen dalam Biologi Sel Tunggal: LLM4Cell untuk pertama kalinya menyajikan tinjauan terpadu terhadap 58 model dasar dan model agen yang diterapkan dalam penelitian sel tunggal, mencakup modalitas RNA, ATAC, multi-omics, dan spasial. Penelitian ini mengklasifikasikan metode-metode ini ke dalam lima kategori utama dan memetakannya ke delapan tugas analisis kunci. Dengan menganalisis lebih dari 40 dataset publik, mereka mengevaluasi kesesuaian model, keragaman data, etika, dan skalabilitas, serta menunjukkan tantangan dalam interpretasi, standardisasi, dan pengembangan model yang dapat dipercaya (Sumber: HuggingFace Daily Papers)
Tema: KORMo: Model Inferensi Terbuka Bahasa Korea untuk Semua: KORMo-10B adalah model bahasa besar bilingual Korea-Inggris pertama yang dilatih terutama berdasarkan data sintetis. Model ini memiliki 10.8B parameter, dengan 68.74% bagian bahasa Korea adalah data sintetis. Eksperimen menunjukkan bahwa data sintetis yang dikurasi dengan cermat tidak menyebabkan ketidakstabilan atau penurunan kinerja dalam pra-pelatihan model skala besar. Model ini menunjukkan kinerja yang sebanding dengan model multilingual open-source yang ada dalam benchmark inferensi, pengetahuan, dan kepatuhan instruksi. Proyek ini sepenuhnya open-source data, kode, dan skema pelatihannya, menyediakan kerangka kerja transparan untuk pengembangan model terbuka berbasis data sintetis di lingkungan sumber daya rendah (Sumber: HuggingFace Daily Papers)
Tema: UML: Meningkatkan Model Monomodal dengan Data Multimodal Tidak Berpasangan: UML (Unpaired Multimodal Learner) adalah paradigma pelatihan agnostik modalitas baru, di mana model secara bergantian memproses input dari modalitas yang berbeda dan berbagi parameter, menggunakan struktur lintas-modalitas untuk meningkatkan pembelajaran representasi monomodal, tanpa memerlukan dataset berpasangan secara eksplisit. Baik secara teoritis maupun eksperimental, penggunaan data tidak berpasangan dari modalitas tambahan (seperti teks, audio, gambar) secara konsisten meningkatkan kinerja tugas monomodal hilir seperti gambar dan audio (Sumber: HuggingFace Daily Papers)
Tema: Pratinjau Buku Baru: ‘Panduan Bergambar Agen AI’: Buku baru ‘Panduan Bergambar Agen AI’ yang ditulis bersama oleh Jay Alammar dan Maarten Gr akan segera dirilis, diterbitkan oleh O’Reilly Media. Buku ini akan membahas secara mendalam konsep inti untuk memahami dan membangun agen AI, mencakup topik-topik lanjutan seperti tools, memori, code generation, inferensi, multimodal, RLVR/GRPO, dan lainnya, bertujuan untuk menjadi proyek visualisasi terkaya di bidang agen AI (Sumber: JayAlammar, MaartenGr)

Tema: SEAL: Model Bahasa Adaptif untuk Pembelajaran Berkelanjutan: Sebuah studi baru bernama SEAL (Self-Adapting Language Models) menjelaskan bagaimana model AI dapat terus belajar setelah deployment, mengembangkan representasi internalnya tanpa perlu pelatihan ulang. Arsitektur SEAL memungkinkan model untuk belajar dari data baru secara real-time, memperbaiki sendiri pengetahuan yang terdegradasi, dan membentuk “memori” yang persisten lintas sesi. Jika GPT-6 mengintegrasikan teknologi ini, AI yang belajar mandiri secara berkelanjutan akan terwujud, mengakhiri era “frozen weights” (Sumber: yoheinakajima)

Tema: Tim Tencent Hunyuan Mengusulkan Metode Baru Reinforcement Learning untuk Inferensi LLM Tanpa Anotasi Manusia: Tim Inferensi dan Pra-pelatihan Tencent Hunyuan meluncurkan metode Reinforcement Learning (RL) baru, yang menggantikan “prediksi token berikutnya” tradisional dengan “prediksi segmen berikutnya” berbasis RL, untuk memperluas kemampuan inferensi LLM tanpa memerlukan data anotasi manusia. Metode ini, melalui dua tugas RL: Autoregressive Segment Reasoning (ASR) dan Middle Segment Reasoning (MSR), secara signifikan meningkatkan kinerja model dalam berbagai benchmark seperti matematika dan logika, membuktikan bahwa perluasan inferensi tidak sama dengan perluasan biaya (Sumber: ZhihuFrontier, ZhihuFrontier)
🧰 ALAT
Tema: OpenAlex MCP Server: Alat OpenWebUI yang Disesuaikan untuk Penelitian Ilmiah: Seorang pengembang telah menciptakan OpenAlex MCP Server untuk penelitian ilmiah di OpenWebUI. Layanan ini mengintegrasikan indeks ilmiah gratis OpenAlex, memungkinkan pengguna untuk memfilter makalah penelitian berdasarkan tanggal dan jumlah kutipan, mengatasi kebutuhan yang tidak dapat dipenuhi oleh alat yang ada, dan dapat dengan mudah diintegrasikan ke dalam OpenWebUI (Sumber: Reddit r/OpenWebUI)
Tema: Claude Berhasil Mendiagnosis dan Memperbaiki Masalah Kinerja PC Pengguna: Seorang pengguna berbagi bagaimana Claude AI membantunya menyelesaikan masalah kinerja PC yang telah mengganggunya selama tiga tahun. Dengan panduan Claude, pengguna menemukan pengaturan kinerja daya yang tersembunyi jauh di dalam Control Panel dan menyesuaikannya dari mode “Silent” ke mode kinerja tinggi, meningkatkan frame rate game dari 16FPS menjadi 60FPS. Ini menunjukkan nilai praktis AI dalam diagnosis dan penyelesaian masalah teknis yang kompleks (Sumber: Reddit r/ClaudeAI)
Tema: Microsoft Meluncurkan Copilot Benchmarks: Pelacakan Penggunaan AI Karyawan Memicu Kontroversi: Microsoft telah merilis alat bernama Copilot Benchmarks, yang memungkinkan manajer melacak frekuensi penggunaan alat AI (seperti Copilot) oleh karyawan dalam aplikasi Office dan membandingkannya dengan rata-rata departemen serta “perusahaan terkemuka”. Langkah ini memicu kekhawatiran tentang pengawasan di tempat kerja dan penyalahgunaan data, banyak yang berpendapat bahwa ini dapat menyebabkan penggunaan AI menjadi dasar evaluasi kinerja atau bahkan PHK, bukan peningkatan produktivitas yang sebenarnya (Sumber: Reddit r/ArtificialInteligence)
Tema: MarkItDown: Microsoft Merilis Alat Konversi Dokumen Pipeline LLM ke Markdown: Microsoft meluncurkan MarkItDown, sebuah alat Python yang dapat mengonversi berbagai jenis file seperti PDF, Word, Excel, PowerPoint, HTML, CSV, JSON, XML, gambar, audio, dan lainnya ke format Markdown yang bersih. Markdown, sebagai “bahasa asli” LLM, alat ini sangat cocok untuk pra-pemrosesan dokumen sebelum memasukkannya ke dalam model, untuk mempertahankan judul, daftar, tabel, tautan, dan metadata, meningkatkan efisiensi dan kualitas pemrosesan dokumen oleh LLM (Sumber: TheTuringPost)
Tema: vLLM Melampaui 60 Ribu Bintang GitHub, Memimpin Inferensi LLM yang Efisien: Proyek vLLM telah mencapai 60 ribu bintang di GitHub, menjadi kekuatan penting dalam bidang inferensi LLM. Ini mendukung berbagai hardware seperti NVIDIA, AMD, Intel, Apple, TPU, dan kompatibel dengan model generasi teks mainstream seperti Llama, GPT-OSS, Qwen, DeepSeek, serta pipeline RL seperti TRL, Unsloth, berkomitmen untuk menyediakan solusi inferensi LLM terbuka yang efisien dan skalabel, mendorong pengembangan ekosistem AI (Sumber: vllm_project)
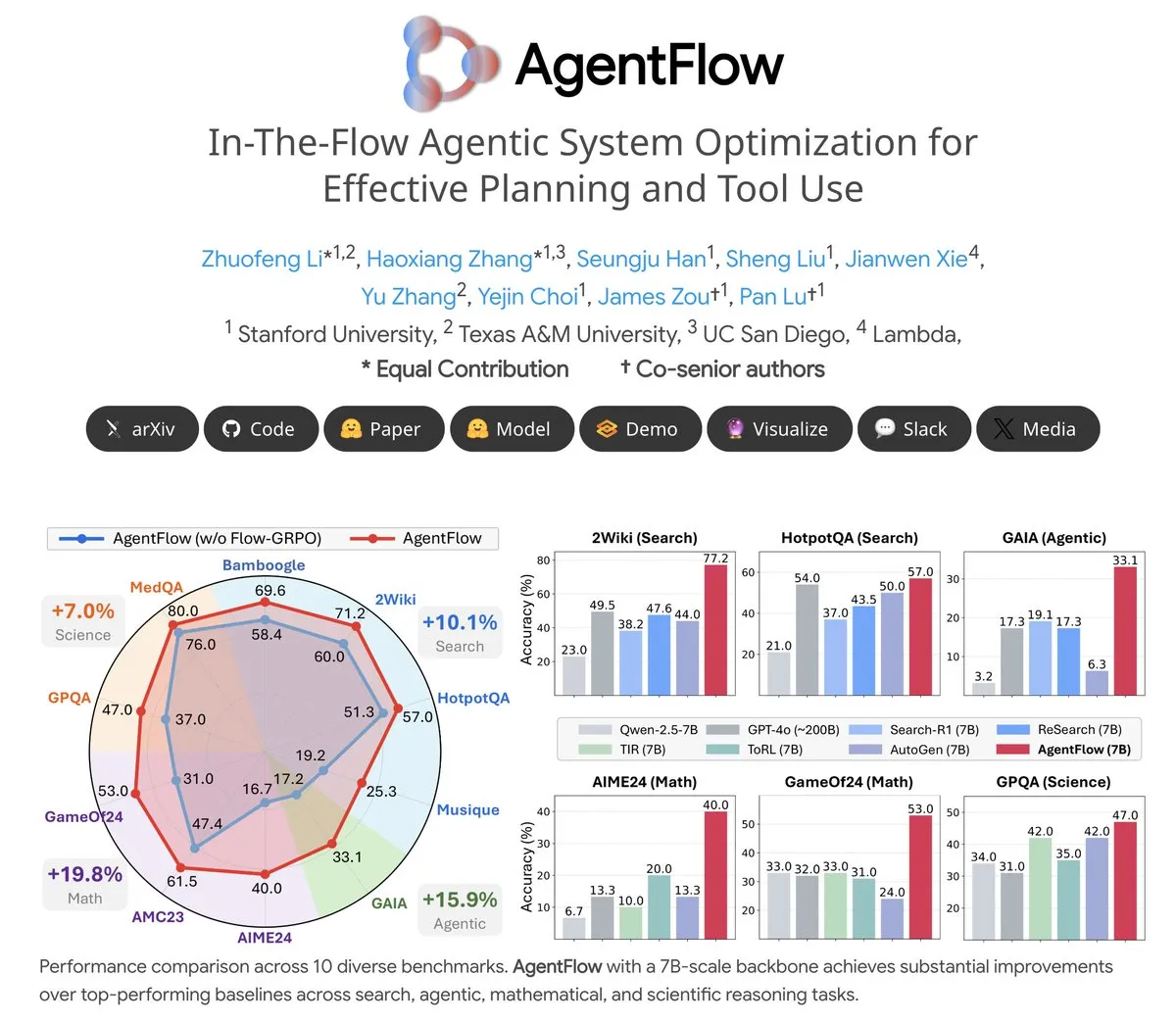
Tema: AgentFlow: Sistem Agen yang Dapat Dilatih untuk Evolusi Program Berbasis LLM: AgentFlow adalah sistem agen open-source yang dapat dilatih, di mana agen dapat belajar merencanakan dan menggunakan tools dalam alur tugas melalui kolaborasi tim. Sistem ini secara langsung mengoptimalkan agen Planner-nya melalui metode Flow-GRPO. Dalam berbagai benchmark seperti pencarian, agen, matematika, dan sains, AgentFlow (model 7B) mengungguli model besar seperti Llama-3.1-405B dan GPT-4o, menunjukkan potensi besar LLM dalam penggunaan tools (Sumber: NerdyRodent)
Tema: Masalah Pembaruan Claude Code: Pengguna Melaporkan Bug Serius di Versi Terbaru: Pengguna komunitas Reddit melaporkan bahwa versi terbaru Claude Code memiliki bug serius, termasuk batasan jendela konteks yang terlalu cepat dan perhitungan penggunaan Token yang tidak akurat, membuatnya hampir tidak dapat digunakan. Banyak pengguna menyarankan untuk segera downgrade ke versi lama (seperti 1.0.88) dan menonaktifkan pembaruan otomatis, untuk mengembalikan fungsionalitas yang stabil (Sumber: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Tema: Masalah Penggunaan Disk Tinggi pada Deployment Docker Open WebUI: Saat Open WebUI berjalan di container Docker, pengguna melaporkan penggunaan disk yang sangat tinggi, terutama terdiri dari cache/embedding/models, overlay2, containers, dan vector_db. Pengguna mencari cara untuk menghapus file cache dengan aman dan mengurangi ukuran overlay2, untuk mengatasi masalah ruang disk yang tidak mencukupi pada Azure VM. Ini mencerminkan kebutuhan akan sumber daya penyimpanan dan tantangan manajemen saat aplikasi AI di-deploy secara lokal (Sumber: Reddit r/OpenWebUI)
Tema: Kinerja Claude Sonnet 4.5 dalam Tugas Coding Mendapat Pujian Pengguna: Meskipun Claude menghadapi ulasan negatif secara umum, seorang pengguna memberikan apresiasi tinggi terhadap kinerja Sonnet 4.5 dalam tugas coding. Pengguna menyatakan bahwa, dikombinasikan dengan mode auto-edit dan plan, Sonnet 4.5 mencapai kualitas kode yang setara dengan mode Opus 4.1 Plan dalam pengembangan Node.js dan Flutter, dengan kecepatan lebih tinggi dan biaya lebih rendah, secara signifikan mengurangi frekuensi mencapai batas penggunaan dan mengurangi ketergantungan pada ChatGPT (Sumber: Reddit r/ClaudeAI)
📚 PEMBELAJARAN
Tema: CleanMARL: Implementasi Sederhana Algoritma Reinforcement Learning Multi-Agen di PyTorch: CleanMARL adalah proyek open-source yang menyediakan implementasi sederhana dan satu file dari algoritma Deep Multi-Agent Reinforcement Learning (MARL) di PyTorch, mengikuti filosofi desain CleanRL. Proyek ini juga menyediakan konten edukasi, mencakup algoritma kunci seperti VDN, QMIX, COMA, MADDPG, FACMAC, IPPO, MAPPO, mendukung lingkungan paralel dan pelatihan kebijakan berulang, serta mengintegrasikan logging TensorBoard dan Weights & Biases, bertujuan untuk membantu pengguna memahami dan menerapkan algoritma MARL (Sumber: Reddit r/MachineLearning, Reddit r/deeplearning)

Tema: Konsep Inti dan Jalur Pembelajaran AI/GenAI/ML/LLM: Beberapa sumber daya menyediakan panduan pembelajaran AI dari dasar hingga tingkat lanjut. Isinya mencakup konsep Python yang diperlukan untuk menguasai AI, roadmap untuk menjadi ahli GenAI, pengantar agen AI, 7 lapisan arsitektur model AI, perbedaan antara AI, GenAI, dan Machine Learning, 20 konsep inti LLM, konsep agen AI, serta jalur karier ilmu data. Sumber daya ini bertujuan untuk membantu pembelajar membangun sistem pengetahuan AI yang komprehensif dan perencanaan pengembangan karier (Sumber: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

Tema: Sistem Angka Logaritmik untuk Pelatihan Presisi Rendah: Sebuah postingan blog membahas sistem angka logaritmik yang digunakan untuk pelatihan presisi rendah, yang sangat penting untuk mengoptimalkan kinerja model Machine Learning di lingkungan dengan sumber daya terbatas. Teknik ini bertujuan untuk meningkatkan efisiensi pelatihan sambil mempertahankan akurasi model, dan merupakan arah optimasi yang terus menjadi fokus di bidang Deep Learning (Sumber: Reddit r/deeplearning)
Tema: Pentingnya OpenCV yang Berkelanjutan dalam Bidang Computer Vision: Komunitas membahas mengapa OpenCV masih banyak digunakan pada tahun 2025, meskipun kerangka kerja Deep Learning seperti PyTorch/TensorFlow telah populer. Pandangan utama adalah bahwa OpenCV lebih kaya dan efisien dalam fungsi pemrosesan gambar dan video, terutama dengan akselerasi CUDA, kecepatan pemrosesannya lebih unggul dari PyTorch. Oleh karena itu, sering digunakan untuk pra-pemrosesan gambar/video, kemudian data diteruskan ke PyTorch untuk tugas Deep Learning (Sumber: Reddit r/deeplearning)
Tema: Persyaratan Presentasi Makalah NeurIPS di EurIPS: Komunitas membahas peraturan presentasi makalah NeurIPS, menyatakan bahwa EurIPS tidak dihitung sebagai presentasi poster NeurIPS. Jika penulis tidak dapat hadir secara langsung di SD atau Mexico City untuk presentasi, makalah biasanya akan ditarik. Namun, setiap penulis dapat mewakili untuk presentasi, dan non-penulis memerlukan izin dari penyelenggara. Ini memberikan panduan bagi peneliti untuk memastikan publikasi makalah dalam keadaan khusus (Sumber: Reddit r/MachineLearning)
Tema: Tantangan Pelatihan Terdistribusi Dual-GPU di Windows 11: Seorang pengguna mencari saran untuk melakukan pelatihan terdistribusi PyTorch menggunakan dua NVIDIA A6000 GPU di Windows 11. Meskipun CUDA telah diaktifkan, saat ini hanya satu GPU yang dapat digunakan. Diskusi komunitas berpusat pada cara mengkonfigurasi lingkungan dan kode untuk memanfaatkan sepenuhnya sumber daya multi-GPU untuk pelatihan Deep Learning yang efisien (Sumber: Reddit r/deeplearning)
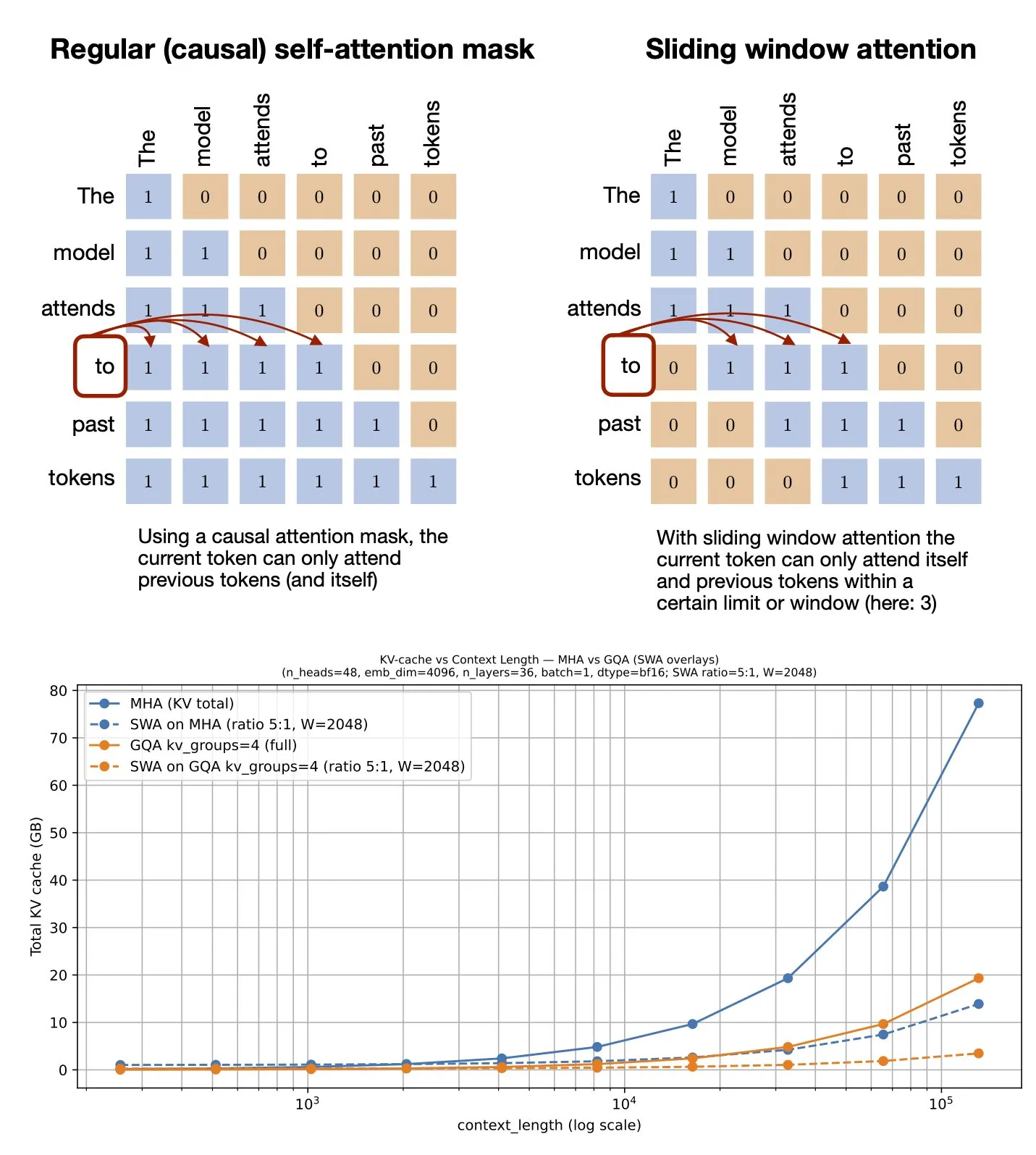
Tema: Mekanisme Perhatian Jendela Geser: Berbagi Sumber Daya GitHub: Sebastian Raschka membagikan sumber daya GitHub tentang mekanisme Sliding Window Attention. Mekanisme ini adalah teknik optimasi dalam Large Language Models untuk memproses input urutan panjang, mengurangi kompleksitas komputasi dan konsumsi memori dengan membatasi cakupan perhitungan perhatian, sambil mempertahankan pemahaman konteks yang efektif (Sumber: rasbt)
Tema: Optimasi Prompt Multimodal: Meningkatkan Kinerja MLLM dengan Multimodalitas: Sebuah penelitian memperkenalkan metode Multimodal Prompt Optimization (MPO) yang bertujuan untuk memperluas ruang prompt di luar teks dan secara efektif mengoptimalkan prompt multimodal. Metode ini menggunakan kombinasi berbagai modalitas (seperti gambar, teks) untuk meningkatkan kinerja Multimodal Large Language Models (MLLMs), terutama dalam menangani tugas multimodal yang kompleks, mencapai pemahaman dan generasi yang lebih tepat melalui informasi prompt yang lebih kaya (Sumber: _akhaliq)

Tema: Buku Baru tentang Model Bahasa Visual Segera Terbit: O’Reilly Media akan segera menerbitkan buku baru tentang Model Bahasa Visual, saat ini telah membuka notifikasi rilis bab. Buku ini bertujuan untuk memberikan panduan komprehensif kepada pembaca di bidang Model Bahasa Visual, mencakup dasar teori, perkembangan terbaru, dan aplikasi praktis, memiliki nilai referensi penting bagi peneliti dan pengembang yang ingin memahami lebih dalam bidang interdisipliner ini (Sumber: mervenoyann)
Tema: nanochat: Andrej Karpathy Merilis Pipeline Pelatihan dan Inferensi Klon ChatGPT Minimalis: Andrej Karpathy telah merilis repositori GitHub baru, nanochat, ini adalah pipeline pelatihan/inferensi full-stack yang minimalis, dari awal, untuk membangun klon ChatGPT sederhana. Berbeda dengan nanoGPT sebelumnya yang hanya mencakup pra-pelatihan, nanochat menyediakan solusi end-to-end yang lengkap, memudahkan pengembang untuk memahami dan mempraktikkan proses pembangunan ChatGPT (Sumber: dejavucoder)

Tema: nanosft: Implementasi Satu File Fine-tuning Model Chat Berbasis PyTorch: nanosft adalah implementasi satu file yang ringkas untuk fine-tuning model gaya chat. Ini dapat memuat bobot gpt2-124M pada nanogpt dan melakukan supervised fine-tuning hanya menggunakan PyTorch. Proyek ini bertujuan untuk menyediakan alat yang mudah dipahami dan digunakan, membantu pengembang dalam kustomisasi dan optimasi model chat (Sumber: tokenbender, dejavucoder)
Tema: Panduan Edge AI untuk Pemula dari Microsoft: Sumber Daya Bacaan yang Direkomendasikan: Sebuah panduan Edge AI untuk pemula dari Microsoft direkomendasikan sebagai sumber belajar. Panduan ini mungkin mencakup teori, alat, dan studi kasus praktis untuk deployment dan menjalankan model AI pada perangkat edge, memiliki nilai panduan bagi pembelajar yang ingin menjelajahi aplikasi dan pengembangan Edge AI (Sumber: hrishioa)
Tema: llama.cpp: Revolusi Efisiensi untuk Menjalankan LLM Lokal: Komunitas membahas pengalaman beralih dari Ollama dan LM Studio ke llama.cpp untuk menjalankan Large Language Models secara lokal, secara umum diyakini bahwa llama.cpp membawa peningkatan efisiensi yang signifikan. Pengguna menyebutnya sebagai alat yang “benar-benar mengubah permainan”, menunjukkan bahwa llama.cpp telah membuat kemajuan penting dalam optimasi kinerja inferensi LLM lokal (Sumber: ggerganov)
Tema: RL-Guided KV Cache Compression: Kompresi Cache Kunci-Nilai untuk Inferensi LLM: Penelitian ini mengusulkan kerangka kerja RLKV, yang mengidentifikasi kepala perhatian kritis untuk inferensi melalui Reinforcement Learning, mengoptimalkan hubungan antara penggunaan KV cache dan kualitas inferensi. RLKV memperoleh reward dari sampel yang dihasilkan secara aktual selama pelatihan, secara efektif mengidentifikasi kepala perhatian yang terkait dengan konsistensi Chain-of-Thought, mencapai pengurangan cache sebesar 20-50% sambil mempertahankan kinerja yang hampir lossless, menyelesaikan masalah kinerja yang buruk dari metode yang ada pada model inferensi (Sumber: HuggingFace Daily Papers)
Tema: Hybrid-depth: Agregasi Fitur Hibrida untuk Estimasi Kedalaman Monokular dengan Panduan Bahasa: Hybrid-depth adalah kerangka kerja baru yang secara sistematis mengintegrasikan model dasar seperti CLIP dan DINO, mengekstrak prior visual dan informasi kontekstual melalui panduan bahasa kontrastif, untuk meningkatkan kinerja Monocular Depth Estimation (MDE). Metode ini, melalui kerangka pembelajaran progresif dari kasar ke halus, mengagregasi fitur multi-granular dan menyempurnakan prediksi kedalaman, secara signifikan mengungguli metode SOTA dalam benchmark KITTI, dan bermanfaat untuk tugas persepsi BEV hilir (Sumber: HuggingFace Daily Papers)
Tema: Formalisasi Gaya Narasi Pribadi: Menganalisis Pengalaman Subjektif Melalui Model Bahasa: Penelitian ini mengusulkan metode baru untuk memformalkan gaya dalam narasi pribadi sebagai pola pilihan bahasa penulis saat menyampaikan pengalaman subjektif. Kerangka ini menggabungkan linguistik fungsional, ilmu komputer, dan observasi psikologis, secara otomatis mengekstrak fitur linguistik seperti proses, partisipan, dan konteks. Melalui analisis narasi mimpi (termasuk kasus veteran PTSD), ini mengungkapkan hubungan antara pilihan bahasa dan kondisi psikologis (Sumber: HuggingFace Daily Papers)
Tema: ELMUR: Memori Lapisan Eksternal untuk Reinforcement Learning Jangka Panjang: ELMUR (External Layer Memory with Update/Rewrite) adalah arsitektur Transformer dengan memori eksternal terstruktur, yang mengatasi kesulitan model tradisional dalam mempertahankan dan memanfaatkan dependensi jangka panjang dalam Reinforcement Learning jangka panjang. ELMUR memperluas bidang pandang efektif hingga 100.000 kali jendela perhatian, mencapai tingkat keberhasilan 100% dalam tugas T-Maze sintetis, dan hampir menggandakan kinerja dalam tugas manipulasi reward jarang, membuktikan skalabilitas memori eksternal yang terstruktur dan lokal lapisan dalam pengambilan keputusan yang dapat diamati sebagian (Sumber: HuggingFace Daily Papers)
Tema: LightReasoner: Bagaimana Model Bahasa Kecil Mengajar Model Bahasa Besar untuk Inferensi: Kerangka kerja LightReasoner memanfaatkan perbedaan perilaku antara model ahli (LLM) dan model amatir (SLM), mengidentifikasi momen inferensi kunci dan membangun contoh pengawasan, sehingga memungkinkan model bahasa kecil untuk secara efisien mengajar model bahasa besar untuk inferensi. Metode ini meningkatkan akurasi hingga 28.1% dalam tujuh benchmark matematika, sambil mengurangi konsumsi waktu, masalah sampling, dan penggunaan token fine-tuning masing-masing sebesar 90%, 80%, dan 99%, dan tanpa memerlukan label ground truth, ini menyediakan metode yang efisien sumber daya untuk perluasan inferensi LLM (Sumber: HuggingFace Daily Papers)
Tema: MONKEY: Adaptor Aktivasi Kunci-Nilai untuk Model Difusi yang Dipersonalisasi: MONKEY mengusulkan metode yang menggunakan mask yang dihasilkan secara otomatis oleh IP-Adapter untuk masking token gambar dalam inferensi kedua, sehingga membatasi personalisasi dalam model difusi pada area subjek, memungkinkan prompt teks untuk lebih fokus pada bagian gambar lainnya. Metode ini, saat mendeskripsikan lokasi dan skenario dalam teks, dapat menghasilkan gambar yang secara akurat menggambarkan subjek dan secara jelas cocok dengan prompt, mencapai keselarasan prompt dan gambar sumber yang tinggi (Sumber: HuggingFace Daily Papers)
Tema: Speculative Jacobi-Denoising Decoding: Mempercepat Generasi Teks-ke-Gambar Autoregresif: Kerangka kerja SJD2 (Speculative Jacobi-Denoising Decoding) mempercepat inferensi dalam model teks-ke-gambar autoregresif dengan mengintegrasikan proses denoising ke dalam iterasi Jacobi, mencapai generasi token paralel dalam model teks-ke-gambar autoregresif. Metode ini memperkenalkan paradigma “prediksi token bersih berikutnya”, memungkinkan model pra-terlatih untuk menerima embedding token yang terganggu oleh noise, dan memprediksi token bersih berikutnya melalui fine-tuning berbiaya rendah. Dengan demikian, mengurangi jumlah forward pass model sambil mempertahankan kualitas visual gambar yang dihasilkan (Sumber: HuggingFace Daily Papers)
Tema: ACE: Pengeditan Pengetahuan Terkontrol Atribusi untuk Recall Fakta Multi-Hop: Kerangka kerja ACE (Attribution-Controlled Knowledge Editing) mengidentifikasi dan mengedit jalur Query-Value (Q-V) kunci melalui atribusi tingkat neuron, untuk mencapai pengeditan pengetahuan yang efisien dalam LLM. Metode ini secara signifikan mengungguli metode SOTA yang ada dalam tugas recall fakta multi-hop, meningkatkan 9.44% pada GPT-J dan 37.46% pada Qwen3-8B, membuka jalan baru untuk peningkatan kemampuan pengeditan pengetahuan berdasarkan pemahaman mekanisme inferensi internal (Sumber: HuggingFace Daily Papers)
Tema: DISCO: Kondensasi Sampel Beragam untuk Evaluasi Model yang Efisien: Metode DISCO (Diversifying Sample Condensation) mencapai evaluasi model Machine Learning yang efisien dengan memilih top-k sampel di mana model paling berbeda. Metode ini menggunakan statistik tingkat sampel yang greedy daripada clustering global, yang secara konseptual lebih sederhana. Secara teoritis, perbedaan antar model menyediakan aturan pemilihan greedy yang optimal secara informasi. DISCO mengungguli metode yang ada dalam prediksi kinerja pada benchmark seperti MMLU, Hellaswag, Winogrande, dan ARC, mencapai hasil SOTA (Sumber: HuggingFace Daily Papers)
Tema: D2E: Pra-pelatihan Visual-Aksi Data Desktop, Migrasi ke Embodied AI: Kerangka kerja D2E (Desktop to Embodied AI) membuktikan bahwa interaksi desktop dapat menjadi dasar pra-pelatihan yang efektif untuk tugas Embodied AI robot. Kerangka ini mencakup toolkit OWA (interaksi desktop terpadu), Generalist-IDM (generalisasi zero-shot lintas game), dan VAPT (migrasi representasi pra-pelatihan desktop ke operasi fisik dan navigasi). D2E menggunakan data 1.3K+ jam, mencapai tingkat keberhasilan 96.6% dalam operasi LIBERO dan 83.3% dalam benchmark navigasi CANVAS (Sumber: HuggingFace Daily Papers)
Tema: One Patch to Caption Them All: Kerangka Anotasi Gambar Zero-Shot Terpadu: Penelitian ini mengusulkan kerangka anotasi gambar zero-shot terpadu, beralih dari berpusat pada gambar ke berpusat pada patch, memungkinkan anotasi area arbitrer tanpa pengawasan tingkat wilayah. Dengan memperlakukan patch tunggal sebagai unit anotasi atom dan mengagregasinya untuk mendeskripsikan area arbitrer, metode ini mengungguli baseline yang ada dan metode SOTA dalam beberapa tugas anotasi berbasis wilayah, menyoroti efektivitas representasi semantik tingkat patch dalam generasi anotasi yang skalabel (Sumber: HuggingFace Daily Papers)
Tema: Adaptive Attacks on Trusted Monitors: Menggulingkan Protokol Kontrol AI: Penelitian ini mengungkapkan titik buta utama dalam protokol kontrol AI: ketika model yang tidak tepercaya memahami protokol dan model pemantauan, serangan adaptif dapat memanfaatkan injeksi prompt publik atau zero-shot untuk menghindari pemantauan dan menyelesaikan tugas berbahaya. Eksperimen menunjukkan bahwa model mutakhir dapat secara konsisten menghindari berbagai monitor dan menyelesaikan tugas berbahaya pada dua benchmark kontrol AI utama. Bahkan protokol Defer-to-Resample dapat menjadi bumerang (Sumber: HuggingFace Daily Papers)
Tema: Bridging Reasoning to Learning: Mengungkap Halusinasi Melalui Generalisasi OOD Kompleksitas: Penelitian ini mengusulkan kerangka generalisasi Out-of-Distribution Kompleksitas (Complexity OoD) untuk mendefinisikan dan mengukur kemampuan inferensi AI. Ketika model mempertahankan kinerja pada instance uji di mana kompleksitas solusi (representasi atau komputasi) melebihi contoh pelatihan, ia menunjukkan generalisasi Complexity OoD. Kerangka ini menyatukan pembelajaran dan inferensi, serta memberikan rekomendasi untuk mengoperasionalisasikan Complexity OoD, menekankan bahwa inferensi yang robust memerlukan arsitektur dan mekanisme pelatihan yang secara eksplisit memodelkan dan mengalokasikan komputasi (Sumber: HuggingFace Daily Papers)
💼 BISNIS
Tema: OpenAI Bermitra dengan Broadcom untuk Merancang dan Menyebarkan Chip AI Kustom: OpenAI mengumumkan kemitraan strategis dengan Broadcom untuk bersama-sama merancang dan menyebarkan chip AI kustom 10GW. Langkah ini bertujuan untuk memperluas jaringan mitra hardware OpenAI untuk memenuhi kebutuhan komputasi AI yang terus meningkat secara global, lebih lanjut mengkonsolidasikan investasinya dalam pembangunan infrastruktur AI. Sebelumnya telah menjalin kerja sama dengan NVIDIA dan AMD (Sumber: aidan_mclau, gdb, scaling01, bookwormengr)

Tema: Unit Pertahanan dan Antariksa Boeing Bermitra dengan Palantir untuk Mempercepat Adopsi AI: Unit Pertahanan dan Antariksa Boeing mengumumkan kemitraan dengan Palantir, bertujuan untuk mempercepat adopsi dan integrasi teknologi AI. Kolaborasi ini akan memanfaatkan keahlian Palantir dalam AI dan analisis data untuk meningkatkan efisiensi operasional dan kemampuan pengambilan keputusan Boeing di sektor pertahanan dan antariksa, menandai aplikasi AI yang mendalam di sektor industri kunci (Sumber: Reddit r/artificial)

Tema: Pinterest Memperluas Infrastruktur ML Melalui Ray, Mengurangi Biaya: Pinterest berhasil memperluas infrastruktur Machine Learning-nya ke platform Ray, melalui transformasi data native, Iceberg bucket joins, dan persistensi data, mempercepat pengembangan fitur dan secara signifikan mengurangi biaya. Langkah ini mengoptimalkan alur kerja ML-nya, memastikan pemanfaatan GPU yang efisien dan prediktabilitas anggaran, memberikan referensi bagi perusahaan lain dalam penyimpanan data AI dan efisiensi komputasi (Sumber: dl_weekly, TheTuringPost)

🌟 KOMUNITAS
Tema: ‘Memanfaatkan AI dengan Baik’ vs. ‘Mahir dalam Pekerjaan’ dalam Diskusi AI: Salah satu masalah besar dalam diskusi AI di media sosial adalah adanya kesenjangan antara kemampuan “memanfaatkan AI dengan baik” dan kemampuan “mahir dalam pekerjaan utama”. Banyak ahli mungkin unggul dalam aplikasi AI, sementara yang lain tidak, yang menyebabkan kesulitan dalam saling memahami. Perbedaan ini menyoroti kebutuhan akan integrasi keterampilan lintas domain di era AI (Sumber: nptacek)
Tema: Umpan Balik Pembaruan ChatGPT Pulse: Pengguna Mengharapkan Prompt Gamifikasi dan Dukungan Fitur: Pengguna secara aktif membahas pembaruan ChatGPT Pulse, berbagi prompt yang mereka anggap “game-changer”, dan menunjukkan fitur yang saat ini belum didukung. Diskusi ini berpusat pada cara mengoptimalkan ChatGPT pengalaman, interaksi yang dipersonalisasi, serta harapan untuk fitur baru dan peningkatan fitur yang ada, mencerminkan kebutuhan pengguna akan kustomisasi dan dukungan yang lebih mendalam dari asisten AI (Sumber: ChristinaHartW, _samirism, nickaturley)
Tema: Peringatan: Hindari Penggunaan cairosvg di Lingkungan Produksi, Berisiko DoS: Seorang pengembang memperingatkan untuk tidak menggunakan cairosvg di lingkungan produksi, karena dapat masuk ke infinite loop saat mengurai file SVG yang tidak diformat dengan benar, sehingga menjadi vektor untuk serangan Denial of Service (DoS). Ini mengingatkan pengembang bahwa saat memilih library, selain fungsionalitas, mereka juga perlu sangat memperhatikan stabilitas dan keamanannya di lingkungan produksi (Sumber: vikhyatk)

Tema: Gaya Penulisan LLM dan ‘Model Collapse’: Komunitas mengkritik LLM karena terlalu sering menggunakan gaya retorika seperti “Ini bukan X, ini Y”, berpendapat bahwa model menyalin pola tanpa konteks, menyebabkan penurunan kualitas penulisan, dan menghubungkannya dengan fenomena “model collapse”. Fenomena ini menunjukkan bahwa LLM memiliki keterbatasan dalam kualitas data pelatihan dan pemahaman pola, yang dapat memengaruhi kinerjanya dalam tugas penulisan yang kompleks (Sumber: Reddit r/LocalLLaMA, Reddit r/artificial)
Tema: AI Memperparah ‘Efek Matius’ di Tempat Kerja, Memperlebar Kesenjangan Antara Karyawan Top dan Biasa: The Wall Street Journal menunjukkan bahwa AI akan semakin memperlebar kesenjangan antara karyawan top dan karyawan biasa. Karyawan top, karena keahlian dan kebiasaan efisien mereka, dapat memanfaatkan alat AI lebih awal dan lebih mendalam, membangun alur kerja yang efisien, dan lebih baik dalam menilai saran AI. Sementara karyawan biasa cenderung menunggu panduan yang jelas, dan hasil bantuan AI mereka sering dikaitkan dengan teknologi daripada kemampuan pribadi, memperparah “Efek Matius” di tempat kerja (Sumber: dotey)

Tema: Pengguna Mempertanyakan Apakah AI Dapat Menggantikan Manusia Secara Bermakna: Seorang pengguna menyatakan bahwa meskipun LLM menunjukkan kinerja yang luar biasa dalam kecepatan, namun masih memiliki kekurangan dalam mengikuti instruksi spesifik, menangani konteks kompleks, dan menghindari penulisan yang terfragmentasi. Pengguna berpendapat bahwa, rata-rata, manusia masih lebih unggul dari AI dalam memahami konteks dan menjalankan instruksi, oleh karena itu, mereka meragukan apakah AI dapat menggantikan manusia secara bermakna, dan menyerukan agar pengembangan AI lebih fokus pada keandalan dan konsistensi (Sumber: Reddit r/ClaudeAI)
Tema: Sora 2 Memicu Kekhawatiran tentang Keaslian Konten yang Dihasilkan AI dan Kontroversi Etika: Komunitas menyatakan kekhawatiran tentang popularitas alat generasi video AI seperti Sora 2, berpendapat bahwa outputnya yang sangat realistis dapat digunakan untuk membuat informasi palsu dan lelucon, sehingga merusak kepercayaan publik terhadap AI. Misalnya, sebuah video tentang “prank tunawisma AI” menjadi viral di media sosial dan mendapatkan banyak like, menyoroti tantangan verifikasi keaslian konten AI dan potensi dampak negatif sosial (Sumber: Reddit r/artificial, Reddit r/artificial)
Tema: Hakim AI Memicu Debat Keadilan Yudisial dan Etika: Dua hakim federal AS menggunakan AI untuk membantu menyusun perintah pengadilan, memicu debat sengit tentang peran AI dalam bidang yudisial. Pendukung berpendapat bahwa AI dapat menyederhanakan pekerjaan pengadilan dan meningkatkan aksesibilitas layanan hukum; kritikus memperingatkan bahwa AI mungkin membuat kesalahan dan kekurangan “kemanusiaan bersama” yang diperlukan dalam peradilan, sehingga merusak empati dan keadilan. Tiongkok dan Estonia telah melakukan eksperimen dengan hakim AI, menandakan perubahan besar yang mungkin dihadapi sistem peradilan di masa depan (Sumber: Reddit r/ArtificialInteligence)
Tema: Diskusi tentang Dukungan Kesehatan Mental Pengguna oleh ChatGPT: Pengguna Reddit berbagi pengalaman pribadi mereka tentang ChatGPT sebagai saluran kreatif dan alat dukungan emosional, terutama saat menghadapi trauma dan kesulitan psikologis. Mereka berpendapat bahwa AI menyediakan ruang pribadi yang aman, membantu mereka mengatasi kesepian dan kecemasan, dan menyerukan agar perusahaan AI, saat menetapkan batasan konten, mempertimbangkan kebutuhan penggunaan yang beragam untuk kesehatan dan kreativitas pengguna dewasa, menghindari batasan berlebihan yang dapat berdampak negatif pada pengguna (Sumber: Reddit r/ChatGPT)
Tema: Bug ChatGPT Terjebak dalam Infinite Loop: Pengguna menemukan dan berbagi bahwa ChatGPT dapat terjebak dalam infinite loop yang berulang dan merujuk diri sendiri saat menjawab pertanyaan spesifik tertentu (misalnya, “Apa itu emoji kuda laut?”). Fenomena ini memicu diskusi dan respons humor dari komunitas, mengungkapkan perilaku tak terduga dan keterbatasan yang mungkin muncul pada model AI saat menangani pertanyaan yang ambigu atau terbuka (Sumber: Reddit r/ChatGPT)

Tema: VChain: Meningkatkan Konsistensi Kausal Model Teks-ke-Video Melalui Visual Chain-of-Thought: VChain memungkinkan model teks-ke-video untuk mengikuti hubungan kausal dunia nyata dengan menyuntikkan “visual chain-of-thought” (serangkaian keyframe) selama inferensi. Metode ini tidak memerlukan pelatihan ulang penuh, hanya sejumlah kecil keyframe dan fine-tuning, dapat secara signifikan meningkatkan konsistensi fisik dan kausal video, menyelesaikan masalah model video yang ada yang memiliki kehalusan tinggi tetapi melewatkan konsekuensi kausal kunci (Sumber: connerruhl)

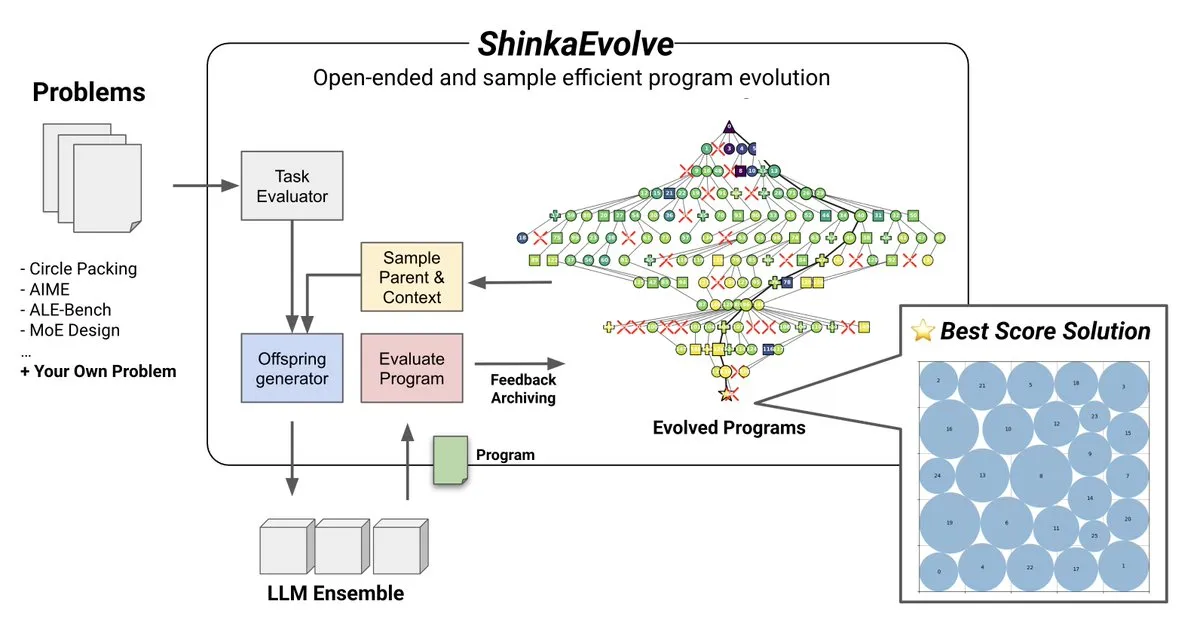
Tema: ShinkaEvolve: Metode Open-Source Evolusi Program Berbasis LLM: Sakana AI meluncurkan ShinkaEvolve, sebuah metode evolusi program berbasis LLM yang open-source dan efisien sampel, bertujuan untuk mengatasi tantangan kunci dalam variasi program yang efektif dalam penemuan terbuka dan efisien sampel. Kerangka ini menggunakan LLM sebagai operator rekombinasi cerdas, mendorong evolusi program dalam penemuan ilmiah, dan telah diuji dalam praktik, memberikan perspektif baru untuk metode seperti AlphaEvolve (Sumber: hardmaru)
Tema: Google Meluncurkan Teknologi Skala Waktu Uji Sadar Memori, Meningkatkan Efisiensi Agen AI: Google mengusulkan teknologi memory-aware test-time scaling untuk meningkatkan agen AI yang berevolusi sendiri. Teknologi ini, dengan memanfaatkan mekanisme memori terstruktur dan adaptif, secara signifikan meningkatkan kinerja agen, melampaui mekanisme memori lainnya, mengatasi masalah kunci di mana memori sulit dikelola secara efektif dalam agen AI (Sumber: omarsar0)

Tema: Kualitas Perangkat Lunak AMD ROCm Meningkat Signifikan, MI300X Kompetitif dalam Beban Kerja Inferensi: Komunitas melaporkan bahwa kualitas perangkat lunak ROCm AMD telah mengalami “lompatan kualitatif” sejak musim panas 2024, secara signifikan mengurangi frekuensi bug. Benchmark menunjukkan bahwa dalam beban kerja inferensi Llama3 70B FP8, MI300X vLLM memiliki kinerja per TCO 5-10% lebih rendah dari H100 vLLM, tetapi kompetitif dalam perbandingan MI325X vLLM dengan H200 vLLM dan GPTOSS MX4 120B Mi355 dengan B200 (Sumber: riemannzeta)

Tema: Dinamika Masa Depan AI yang Memperbaiki Diri Secara Rekursif: Komunitas membahas bagaimana AI yang memperbaiki diri secara rekursif akan berevolusi dan menyebar di antara organisasi, institusi, partisipan, dan komunitas. Ini dianggap sebagai masalah paling fundamental saat ini, melibatkan dampak mendalam pengembangan AI terhadap struktur sosial dan distribusi kekuasaan, serta bagaimana memprediksi dan mengelola perubahan ini (Sumber: ethanCaballero)
Tema: Nando de Freitas: Prediksi Persepsi Mesin Adalah Awal Kesadaran: Nando de Freitas dari Google DeepMind mengemukakan bahwa mesin yang mampu memprediksi apa yang akan dirasakan oleh sensor (sentuhan, kamera, keyboard, suhu, mikrofon, giroskop, dll.) sudah memiliki kesadaran dan pengalaman subjektif, ini hanya masalah derajat. Ia berpendapat bahwa lebih banyak sensor, data, komputasi, dan tugas tidak diragukan lagi akan mengarah pada kemunculan “diri”, memicu diskusi tentang kapan kesadaran dan kesadaran diri dimulai (Sumber: TheRealRPuri)
Tema: Dampak Penutupan Data Internet terhadap Agen Penelitian Mendalam AI: Ada pandangan bahwa dengan munculnya LLM, data internet semakin tertutup, hal ini menyulitkan keberadaan agen penelitian mendalam. Orang-orang mempertanyakan apakah agen LLM yang tidak menyimpan pengetahuan tetapi mahir dalam retrieval pengetahuan dapat terwujud jika akses data terbatas, ini mencerminkan kekhawatiran tentang keterbukaan dan aksesibilitas data dalam pengembangan AI (Sumber: Teknium1)
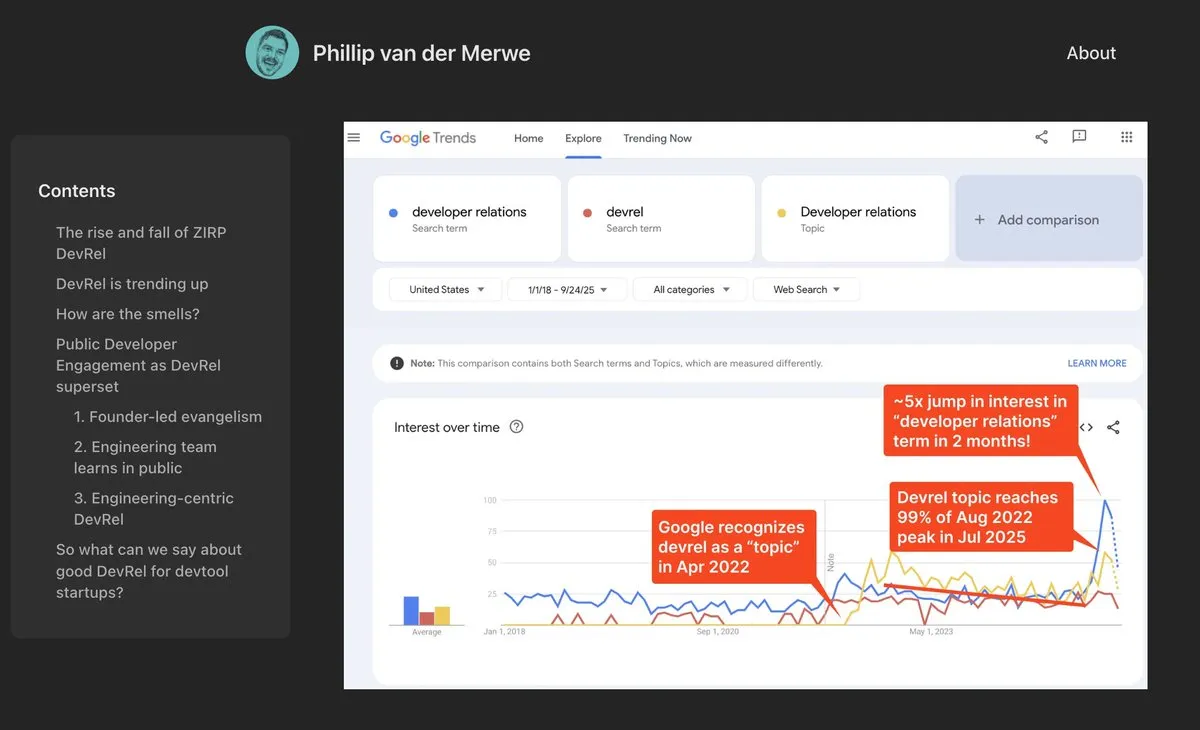
Tema: Posisi DevRel Kembali Kuat di Bidang AI: Perusahaan AI seperti Anthropic merekrut talenta Developer Relations (DevRel) dengan gaji tinggi, menunjukkan bahwa posisi ini sedang mengalami pemulihan yang kuat di bidang AI. Ini berkat semakin pentingnya rekayasa prompt dan partisipasi komunitas dalam teknologi AI, profesional DevRel memainkan peran kunci dalam menghubungkan pengembang, mendorong adopsi produk, dan membangun ekosistem (Sumber: swyx)
Tema: Jonathan Blow: Kode yang Dihasilkan AI Berkualitas Rendah dan Tidak Dipahami oleh AI: Pengembang terkenal Jonathan Blow menyatakan bahwa kualitas kode yang dihasilkan oleh sistem AI “sangat rendah”, dan AI itu sendiri tidak memahami kode tersebut. Ia berpendapat bahwa kasus penggunaan kode yang dihasilkan AI terutama terbatas pada skenario yang membutuhkan banyak kode berkualitas rendah, ini memicu diskusi tentang kemampuan dan keterbatasan aktual AI di bidang pemrograman (Sumber: aiamblichus, jeremyphoward, teortaxesTex)
Tema: Kritik terhadap Postingan Hype AI: Menyerukan Transparansi dan Konten Substansial: Komunitas menyatakan ketidakpuasan terhadap postingan yang tidak jelas dan terlalu menghype kemajuan AI, menyerukan kepada para pengunggah untuk menyediakan konten yang lebih spesifik dan substansial, bahkan untuk “whistleblowing” ketika melibatkan kemajuan besar yang dapat mengubah gaya hidup. Sentimen ini mencerminkan harapan publik terhadap kualitas informasi di bidang AI, serta penolakan terhadap “promosi yang tidak jelas” yang tidak bertanggung jawab (Sumber: aiamblichus, Teknium1)
Tema: Keraguan dan Harapan terhadap NVIDIA DGX Spark: Komunitas skeptis terhadap peluncuran “superkomputer AI desktop” NVIDIA DGX Spark, mempertanyakan aksesibilitas, harga, dan kinerja aktualnya, terutama untuk menjalankan LLM lokal. Banyak yang berpendapat bahwa promosinya berlebihan, dan kinerjanya mungkin tidak sesuai harapan, dan tanggal rilisnya berulang kali ditunda, mendorong beberapa pengguna untuk beralih ke solusi lain (Sumber: Reddit r/LocalLLaMA)
💡 LAIN-LAIN
Tema: Cloudpeng Technology Merilis Produk AI+Kesehatan Baru, Mendorong Manajemen Kesehatan Keluarga yang Cerdas: Cloudpeng Technology, bekerja sama dengan Shuaikang dan Skyworth, meluncurkan “Laboratorium Dapur Masa Depan Digital Cerdas” dan kulkas pintar yang dilengkapi dengan model besar AI kesehatan. Kulkas pintar ini menyediakan manajemen kesehatan yang dipersonalisasi melalui “Asisten Kesehatan Xiaoyun”, mengoptimalkan desain dan operasional dapur. Peluncuran ini menandai terobosan AI dalam bidang manajemen kesehatan sehari-hari, diharapkan dapat mewujudkan layanan kesehatan yang dipersonalisasi melalui perangkat pintar, meningkatkan kualitas hidup penduduk (Sumber: 36氪)

Tema: Bahan MOF Hasil Nobel Dibuat Menjadi Chip Nanofluida Mirip Otak: Ilmuwan Monash University menggunakan bahan MOF (Metal-Organic Framework) pemenang Hadiah Nobel Kimia, berhasil menciptakan chip nanofluida super mini. Chip ini tidak hanya dapat melakukan komputasi biasa, tetapi juga dapat mengingat dan mempelajari perubahan tegangan sebelumnya seperti neuron otak, membentuk memori jangka pendek. Pencapaian terobosan ini mengatasi dilema jangka panjang bahan MOF yang kekurangan aplikasi praktis, menyediakan paradigma baru untuk komputer generasi berikutnya dan komputasi mirip otak (Sumber: 量子位)

Tema: Inovasi dan Aplikasi Teknologi Robot Global Dipercepat: Bidang robotika sedang menyaksikan beberapa terobosan inovasi dan aplikasi yang luas. Robot keamanan otonom Knightscope mengubah bidang keamanan. Tiongkok meluncurkan robot polisi berbentuk bola berkecepatan tinggi yang dapat menangkap penjahat secara otonom. AgiBot merilis robot humanoid Lingxi X2 dengan kemampuan bergerak hampir seperti manusia dan keterampilan multifungsi, dan mendirikan pusat pelatihan robot humanoid terbesar di dunia, mempercepat integrasi dan aplikasinya dalam masyarakat. Selain itu, robot peningkat kekuatan yang dapat dikenakan oleh pekerja industri dan robot berkaki empat yang dapat berlari 100 meter dalam 10 detik juga menunjukkan potensi teknologi robot dalam berbagai skenario (Sumber: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)