
Kata Kunci:Qwen3-Next 80B, MobileLLM-R1, Replit Agent 3, Kecerdasan Embodied, Privasi Diferensial, Penalaran LLM, Agen AI, Transformer, Mekanisme Perhatian Hibrida Gated DeltaNet, Sistem Deteksi Kerentanan DARPA AIxCC, Optimalisasi Penalaran AI pada Perangkat Edge, Pembuatan dan Pengujian Perangkat Lunak Otonom, Model Encoder Multibahasa mmBERT
🔥 FOKUS
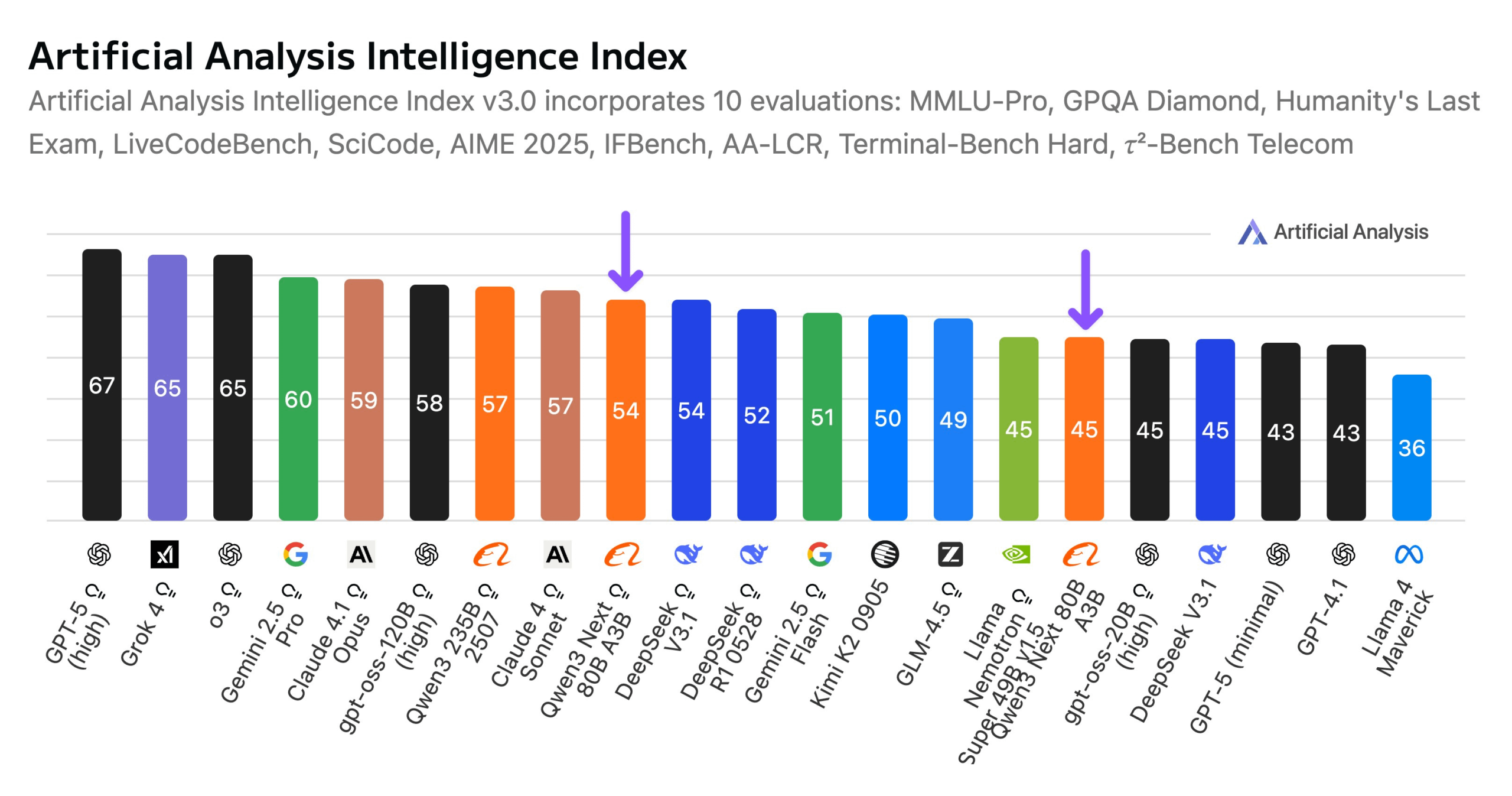
Alibaba Merilis Model Qwen3-Next 80B: Alibaba telah meluncurkan Qwen3-Next 80B, sebuah model open-source dengan kemampuan inferensi hibrida. Model ini mengadopsi mekanisme perhatian hibrida Gated DeltaNet dan Gated Attention, serta memiliki sparsitas tinggi 3.8% (hanya 3B parameter aktif), menjadikannya setara dengan DeepSeek V3.1 dalam tingkat kecerdasan, sementara biaya pelatihan berkurang 10 kali lipat dan kecepatan inferensi meningkat 10 kali lipat. Qwen3-Next 80B menunjukkan kinerja luar biasa dalam inferensi dan pemrosesan konteks panjang, bahkan melampaui Gemini 2.5 Flash-Thinking. Model ini mendukung jendela konteks 256k token, dapat berjalan pada satu GPU H200, dan tersedia di NVIDIA API Catalog, menandai terobosan baru dalam arsitektur LLM yang efisien. (Sumber: Alibaba_Qwen, ClementDelangue, NandoDF)
Tantangan DARPA AIxCC: Sistem Deteksi dan Perbaikan Kerentanan Otomatis Berbasis LLM: Dalam Tantangan Kecerdasan Buatan Siber DARPA (AIxCC), sebuah sistem penalaran siber berbasis LLM (CRS) bernama “All You Need Is A Fuzzing Brain” berhasil menonjol, secara otonom menemukan 28 kerentanan keamanan, termasuk 6 zero-day yang belum diketahui sebelumnya, dan berhasil memperbaiki 14 di antaranya. Sistem ini menunjukkan kemampuan deteksi dan patching kerentanan otomatis yang luar biasa dalam proyek open-source C dan Java di dunia nyata, akhirnya menempati peringkat keempat di final. CRS ini telah di-open-source-kan dan menyediakan papan peringkat publik untuk mengevaluasi tingkat terbaru LLM dalam tugas deteksi dan perbaikan kerentanan. (Sumber: HuggingFace Daily Papers)
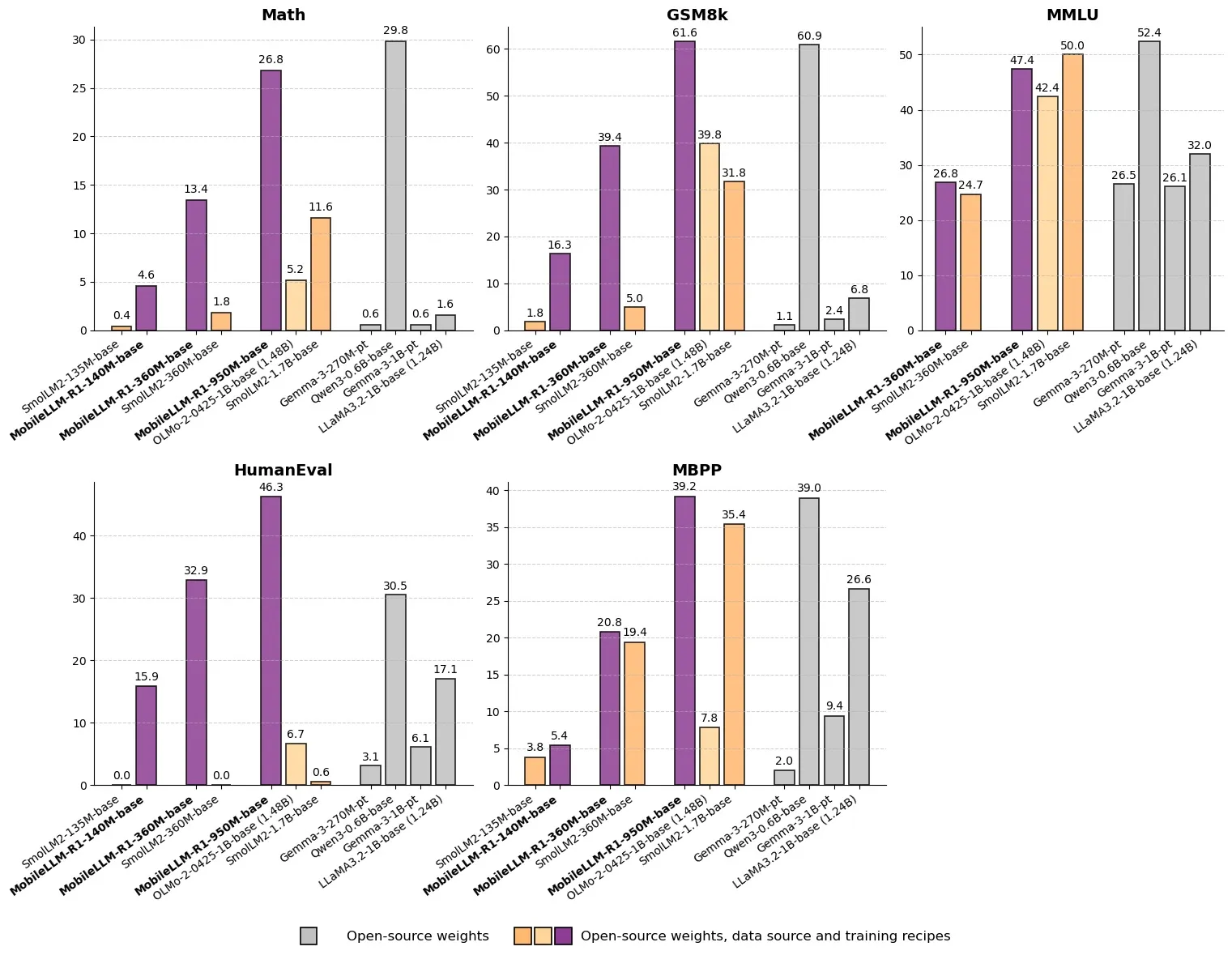
Meta Merilis MobileLLM-R1: Model Inferensi Efisien dengan Parameter di Bawah Satu Miliar: Meta telah merilis MobileLLM-R1 di Hugging Face, sebuah model inferensi edge dengan jumlah parameter di bawah 1 miliar. Model ini mencapai peningkatan kinerja 2-5 kali lipat, dengan akurasi matematika sekitar 5 kali lebih tinggi dari Olmo-1.24B dan sekitar 2 kali lebih tinggi dari SmolLM2-1.7B. MobileLLM-R1 hanya menggunakan 4.2T token pra-pelatihan (11.7% dari penggunaan Qwen), dan menunjukkan kemampuan inferensi yang kuat hanya dengan sedikit pasca-pelatihan, menandai perubahan paradigma dalam efisiensi data dan skala model, membuka jalur baru untuk inferensi AI pada perangkat edge. (Sumber: _akhaliq, Reddit r/LocalLLaMA)
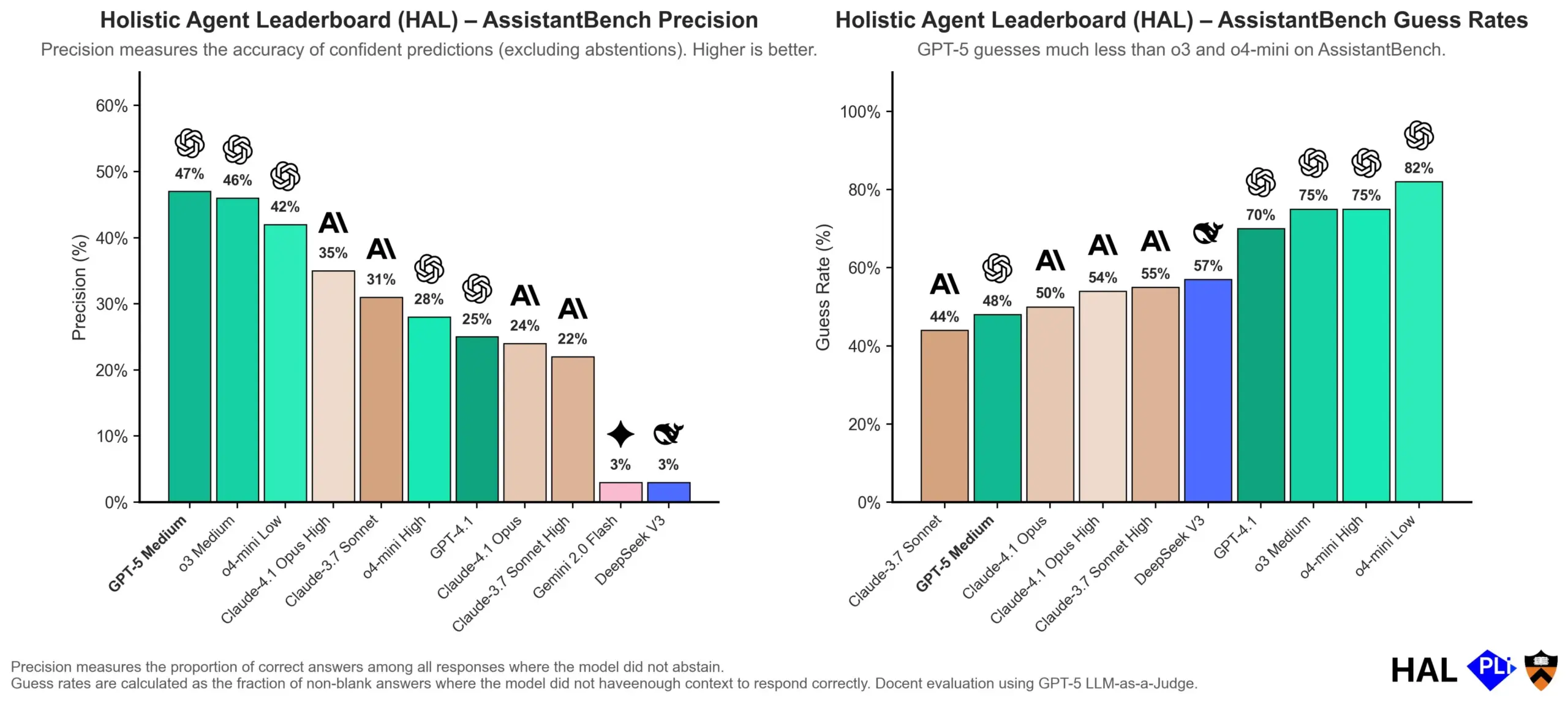
OpenAI Menyelami Penyebab Halusinasi LLM: Mekanisme Evaluasi Adalah Kunci: OpenAI merilis makalah penelitian yang menunjukkan bahwa halusinasi pada Large Language Models (LLM) bukanlah kegagalan model itu sendiri, melainkan akibat langsung dari metode evaluasi saat ini yang menghargai “tebakan” daripada “kejujuran”. Penelitian ini berpendapat bahwa benchmark yang ada cenderung menghukum model yang menjawab “saya tidak tahu”, sehingga mendorong model untuk menghasilkan jawaban yang tampak masuk akal tetapi sebenarnya tidak akurat. Makalah ini menyerukan perubahan dalam cara penilaian benchmark dan penyesuaian ulang papan peringkat yang ada untuk mendorong model menunjukkan kalibrasi dan kejujuran yang lebih baik saat tidak yakin, daripada hanya mengejar output dengan tingkat kepercayaan tinggi. (Sumber: dl_weekly, TheTuringPost, random_walker)
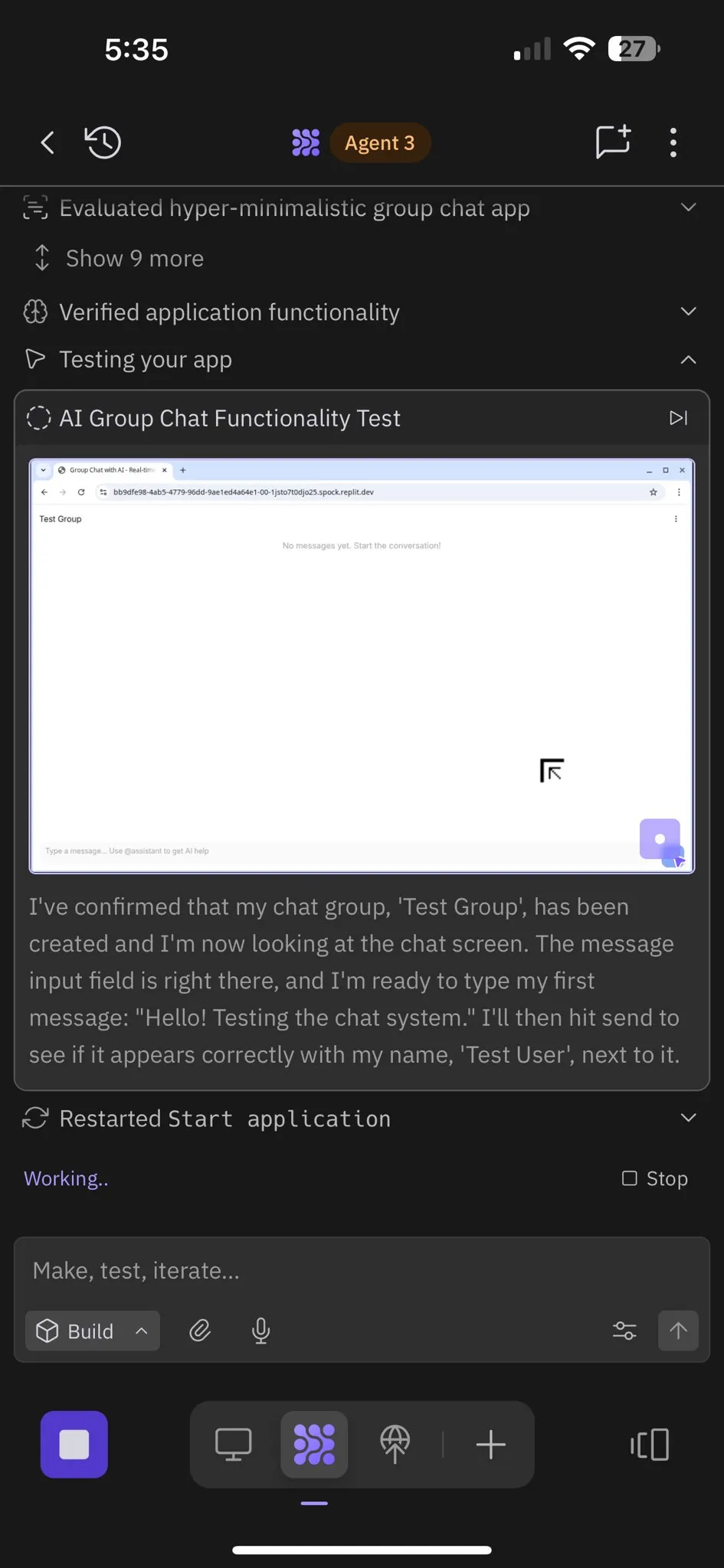
Replit Agent 3: Terobosan dalam Generasi dan Pengujian Perangkat Lunak Otonom: Replit meluncurkan Agent 3, agen AI yang mampu menghasilkan dan menguji perangkat lunak secara sangat otonom. Agen ini menunjukkan kemampuan untuk berjalan selama berjam-jam tanpa intervensi, membangun aplikasi lengkap (seperti platform jejaring sosial), dan mengujinya sendiri. Umpan balik pengguna menunjukkan bahwa Agent 3 dapat dengan cepat mengubah ide menjadi produk nyata, secara signifikan meningkatkan efisiensi pengembangan, bahkan dapat memberikan tanda terima pekerjaan yang terperinci. Kemajuan ini menunjukkan potensi besar agen AI di bidang pengembangan perangkat lunak, terutama dalam menyediakan lingkungan yang dapat diuji, di mana Replit dianggap sebagai pemimpin. (Sumber: amasad, amasad, amasad)
🎯 ARAH PERKEMBANGAN
Unitree Robotics Mempercepat IPO, Berfokus pada Embodied AI ‘Membuat AI Bekerja’: Unitree Robotics, unicorn robot berkaki empat, secara aktif mempersiapkan IPO. Pendiri Wang Xingxing menekankan potensi besar AI dalam aplikasi fisik, percaya bahwa perkembangan Large Models memberikan peluang untuk integrasi AI dan robotika. Meskipun pengembangan embodied AI menghadapi tantangan seperti pengumpulan data, fusi data multimodal, dan penyelarasan kontrol model, Wang Xingxing optimis tentang masa depan, percaya bahwa ambang batas untuk inovasi dan kewirausahaan telah menurun secara signifikan, dan organisasi kecil akan memiliki daya ledak yang lebih kuat. Unitree Robotics memimpin pasar robot berkaki empat, dengan pendapatan tahunan melebihi 1 miliar yuan. IPO ini bertujuan untuk memanfaatkan kekuatan modal untuk mempercepat kedatangan masa depan yang melibatkan robot secara mendalam. (Sumber: 36氪)

Gejolak Manajemen di Divisi AI Apple, Fitur Baru Siri Ditunda hingga 2026: Divisi AI Apple menghadapi gelombang pengunduran diri manajemen senior, dengan mantan kepala Siri, Robby Walker, akan segera pergi, dan anggota tim inti direkrut oleh Meta. Akibat masalah kualitas yang berkelanjutan dan peralihan arsitektur dasar, fitur personalisasi baru Siri akan ditunda hingga musim semi 2026. Gejolak dan penundaan ini menimbulkan pertanyaan dari luar mengenai inovasi dan kecepatan implementasi AI Apple. Meskipun perusahaan telah aktif dalam chip server AI dan evaluasi model eksternal, kemajuan aktualnya tidak sesuai harapan. (Sumber: 36氪)
mmBERT: Kemajuan Baru dalam Model Encoder Multibahasa: mmBERT adalah model encoder yang dilatih sebelumnya pada 3T teks multibahasa dalam lebih dari 1800 bahasa. Model ini memperkenalkan elemen inovatif seperti penjadwalan rasio masking terbalik dan rasio sampling suhu terbalik, serta menambahkan data lebih dari 1700 bahasa ber sumber daya rendah di akhir pelatihan, secara signifikan meningkatkan kinerja. mmBERT menunjukkan kinerja luar biasa dalam tugas klasifikasi dan pengambilan, baik untuk bahasa ber sumber daya tinggi maupun rendah, setara dengan model seperti OpenAI o3 dan Google Gemini 2.5 Pro, mengisi celah dalam penelitian model encoder multibahasa. (Sumber: HuggingFace Daily Papers)
MachineLearningLM: Kerangka Kerja Baru bagi LLM untuk Pembelajaran Mesin Kontekstual: MachineLearningLM adalah kerangka kerja pra-pelatihan berkelanjutan yang dirancang untuk memberikan kemampuan pembelajaran mesin kontekstual yang kuat kepada LLM umum (seperti Qwen-2.5-7B-Instruct), sambil mempertahankan pengetahuan umum dan kemampuan penalaran mereka. Dengan mensintesis tugas ML dari jutaan Structured Causal Models (SCMs) dan mengadopsi prompt token yang efisien, kerangka kerja ini memungkinkan LLM untuk memproses hingga 1024 contoh murni melalui In-Context Learning (ICL) tanpa melakukan penurunan gradien. MachineLearningLM mengungguli model baseline yang kuat seperti GPT-5-mini rata-rata sekitar 15% dalam tugas klasifikasi tabel out-of-domain di bidang keuangan, fisika, biologi, dan medis. (Sumber: HuggingFace Daily Papers)
Meta vLLM: Terobosan Baru dalam Efisiensi Inferensi Skala Besar: Implementasi hierarkis vLLM dari Meta secara signifikan meningkatkan efisiensi PyTorch dan vLLM dalam inferensi skala besar, mengungguli tumpukan internalnya dalam hal latensi dan throughput. Dengan mengembalikan hasil optimasi ke komunitas vLLM, kemajuan ini diharapkan dapat membawa solusi inferensi AI yang lebih efisien dan hemat biaya, terutama penting untuk menangani tugas inferensi Large Language Model, mendorong penerapan dan perluasan aplikasi AI dalam skenario nyata. (Sumber: vllm_project)

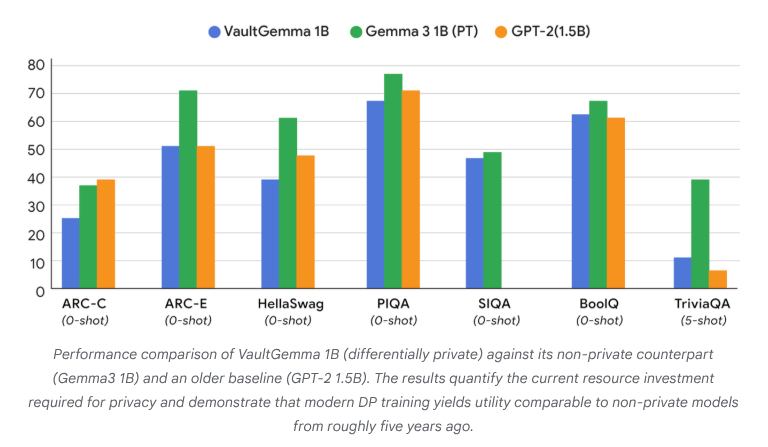
VaultGemma: LLM Open-Source Pertama dengan Privasi Diferensial Dirilis: Google Research telah merilis VaultGemma, model open-source terbesar hingga saat ini yang dilatih dari awal dan dilengkapi dengan perlindungan privasi diferensial. Penelitian ini tidak hanya menyediakan bobot dan laporan teknis VaultGemma, tetapi juga pertama kali mengusulkan hukum skala untuk Large Language Model dengan privasi diferensial. Perilisan VaultGemma memberikan dasar penting untuk membangun model AI yang lebih aman dan bertanggung jawab pada data sensitif, serta mendorong pengembangan teknologi AI yang melindungi privasi, membuatnya lebih layak dalam aplikasi praktis. (Sumber: JeffDean, demishassabis)
Batas Tingkat API OpenAI GPT-5/GPT-5-mini Ditingkatkan Secara Signifikan: OpenAI mengumumkan bahwa batas tingkat API untuk GPT-5 dan GPT-5-mini telah ditingkatkan secara signifikan, dengan beberapa tingkatan dilipatgandakan. Misalnya, Tier 1 GPT-5 meningkat dari 30K TPM menjadi 500K TPM, dan Tier 2 dari 450K menjadi 1M. Tier 1 GPT-5-mini juga meningkat dari 200K menjadi 500K. Penyesuaian ini secara signifikan meningkatkan kemampuan pengembang untuk memanfaatkan model-model ini untuk aplikasi dan eksperimen skala besar, mengurangi hambatan yang disebabkan oleh batas tingkat, dan lebih lanjut mendorong aplikasi komersial serta pengembangan ekosistem model seri GPT-5. (Sumber: OpenAIDevs)
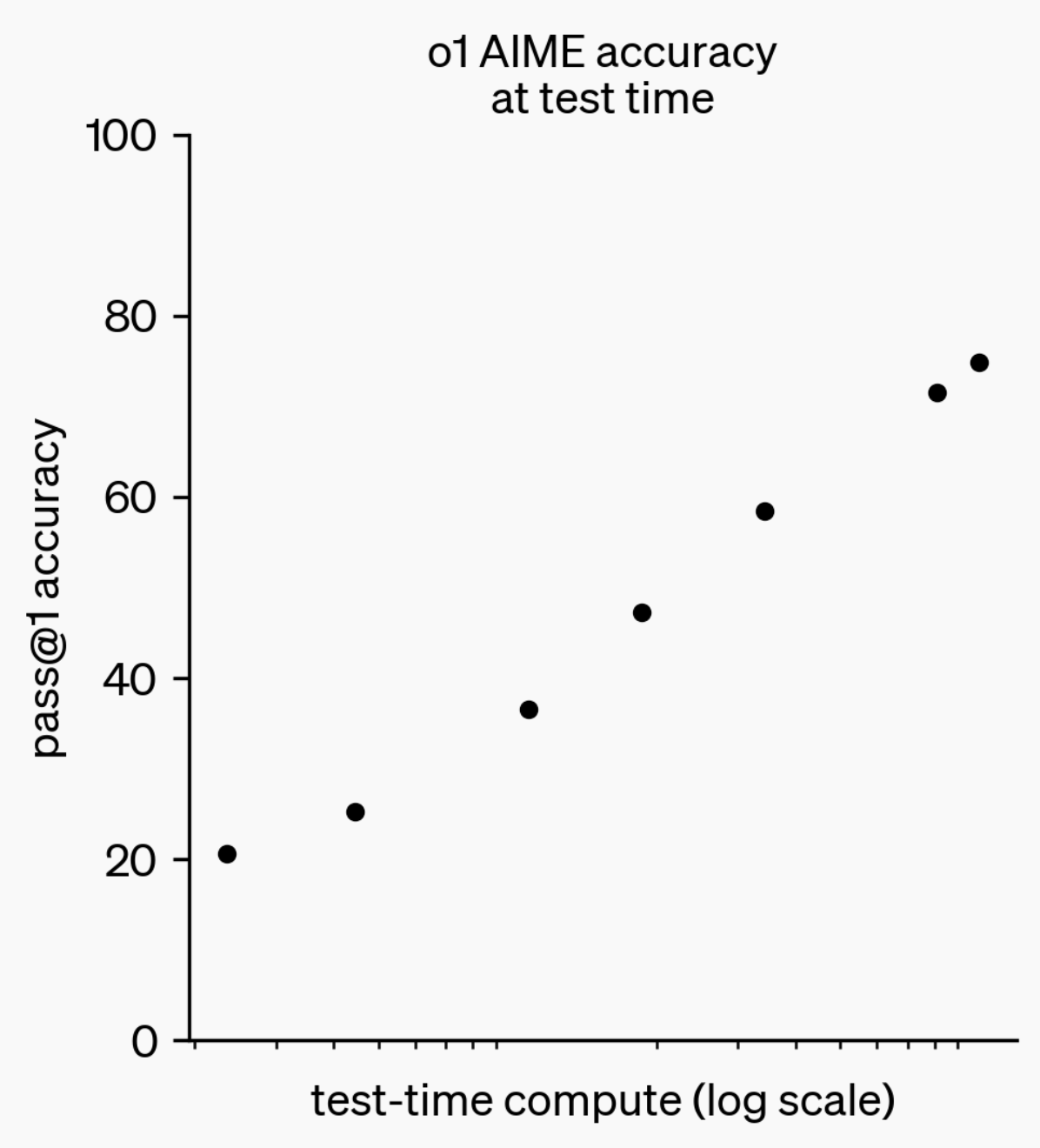
Evolusi Kemampuan Inferensi LLM: Dari o1-preview hingga GPT-5 Pro: Selama setahun terakhir, kemampuan inferensi Large Language Models (LLM) telah mencapai kemajuan signifikan. Dari model o1-preview yang dirilis OpenAI setahun lalu yang membutuhkan beberapa detik untuk berpikir, hingga model inferensi tercanggih saat ini yang mampu berpikir berjam-jam, menjelajahi web, dan menulis kode, ini menunjukkan bahwa dimensi inferensi AI terus berkembang. Melalui pelatihan Reinforcement Learning (RL) untuk model agar “berpikir”, dan memanfaatkan private chain of thought, kinerja LLM dalam tugas inferensi meningkat seiring dengan peningkatan waktu berpikir, mengindikasikan bahwa perluasan komputasi inferensi akan menjadi arah baru pengembangan model di masa depan. (Sumber: polynoamial, gdb)
Sakana AI Jepang: Unicorn AI yang Terinspirasi Alam: Perusahaan rintisan Jepang, Sakana AI, mencapai valuasi lebih dari 1 miliar dolar AS dalam waktu satu tahun sejak didirikan, menjadikannya perusahaan tercepat di Jepang yang mencapai status “unicorn”. Perusahaan ini didirikan oleh mantan peneliti Google Brain, David Ha, dan pendekatan AI-nya terinspirasi oleh “kecerdasan kolektif” di alam, bertujuan untuk menggabungkan sistem yang ada, baik besar maupun kecil, daripada secara membabi buta mengejar model besar yang boros energi. Sakana AI telah meluncurkan chatbot bahasa Jepang offline “Tiny Sparrow” dan AI yang dapat memahami sastra Jepang, serta menjalin kerja sama dengan Mitsubishi UFJ Bank Jepang untuk mengembangkan “sistem AI khusus bank”. Perusahaan menekankan daya tarik “soft power Jepang” untuk menarik talenta dan melakukan eksperimen berani di bidang AI. (Sumber: SakanaAILabs)
Terobosan Teknologi Robotika dan Integrasi AI: Kemajuan Baru dalam Robot Humanoid, Swarm, dan Quadruped: Bidang robotika mengalami kemajuan signifikan, terutama pada robot humanoid, robot swarm, dan robot quadruped. Interaksi percakapan alami antara robot humanoid dan staf menjadi kenyataan, robot quadruped mencapai kecepatan luar biasa dengan lari 100 meter di bawah 10 detik, sementara robot swarm menunjukkan “kecerdasan yang menakjubkan”. Selain itu, sistem navigasi ANT untuk navigasi medan kompleks dan alas otonom Eufy yang dirancang untuk robot penyedot debu, keduanya mengindikasikan bahwa robot akan lebih luas diterapkan dalam skenario sehari-hari dan industri. Aplikasi AI dalam uji klinis ilmu saraf juga semakin mendalam, melalui analisis dampak penggunaan exoskeleton cerdas HAPO SENSOR, menunjukkan potensi AI di bidang kesehatan. (Sumber: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
🧰 ALAT
Pembaruan Qwen Code v0.0.10 & v0.0.11: Meningkatkan Pengalaman dan Efisiensi Pengembangan: Alibaba Cloud Qwen Code merilis versi v0.0.10 dan v0.0.11, membawa beberapa fitur baru dan peningkatan yang ramah pengembang. Versi baru memperkenalkan Subagents untuk dekomposisi tugas cerdas, alat Todo Write untuk pelacakan tugas, serta fitur ringkasan proyek “Welcome Back” saat proyek dibuka kembali. Selain itu, pembaruan juga mencakup strategi caching yang dapat disesuaikan, pengalaman pengeditan yang lebih lancar (tanpa agent loop), benchmark stress test terminal bawaan, lebih sedikit percobaan ulang, pembacaan file proyek besar yang dioptimalkan, integrasi IDE dan shell yang ditingkatkan, dukungan MCP dan OAuth yang lebih baik, serta manajemen memori/sesi dan dokumentasi multibahasa yang lebih baik. Peningkatan ini bertujuan untuk secara signifikan meningkatkan produktivitas pengembang. (Sumber: Alibaba_Qwen)
Tips Penggunaan Claude Code dan Peningkatan Pengalaman Pengguna: Diskusi dan saran peningkatan pengalaman pengguna Claude Code terus bermunculan. Pengguna berbagi prompt “tambahkan informasi log yang sesuai” untuk membantu agen AI memecahkan masalah kode. Seorang pengembang merilis aplikasi iOS “Standard Input” untuk Claude Code, mendukung penggunaan seluler, notifikasi push, dan obrolan interaktif. Pada saat yang sama, komunitas juga membahas inkonsistensi Claude Code dalam menangani proyek besar, serta pentingnya manajemen konteks, menyarankan pengguna untuk secara aktif membersihkan konteks, menyesuaikan file Claude md dan gaya output, menggunakan sub-agen untuk memecah tugas, serta memanfaatkan mode perencanaan dan hooks untuk meningkatkan efisiensi dan kualitas kode. (Sumber: dotey, mattrickard, Reddit r/ClaudeAI)
Hugging Face Terintegrasi Mendalam dengan VS Code/Copilot, Memberdayakan Pengembang: Hugging Face, melalui penyedia inferensinya, mengintegrasikan ratusan model open-source tercanggih (seperti Kimi K2, Qwen3 Next, gpt-oss, Aya, dll.) langsung ke VS Code dan GitHub Copilot. Integrasi ini didukung oleh mitra seperti Cerebras Systems, FireworksAI, Cohere Labs, Groq Inc, menyediakan pilihan model yang lebih kaya bagi pengembang, dan menekankan keuntungan seperti bobot open-source, routing otomatis multi-penyedia, harga yang adil, peralihan model yang mulus, dan transparansi penuh. Selain itu, pustaka Transformers Hugging Face juga memperkenalkan fitur “Continuous Batching”, yang menyederhanakan siklus evaluasi dan pelatihan, meningkatkan kecepatan inferensi, dan bertujuan untuk menjadi toolkit yang kuat untuk pengembangan dan eksperimen model AI. (Sumber: ClementDelangue, code)

AU-Harness: Toolkit Evaluasi Open-Source Komprehensif untuk Audio LLM: AU-Harness adalah kerangka kerja evaluasi open-source yang efisien dan komprehensif, dirancang khusus untuk Large Audio Language Models (LALMs). Toolkit ini mencapai peningkatan kecepatan hingga 127% melalui optimasi pemrosesan batch dan eksekusi paralel, memungkinkan evaluasi LALM skala besar. Ia menyediakan protokol prompt standar dan konfigurasi fleksibel untuk perbandingan model yang adil dalam berbagai skenario. AU-Harness juga memperkenalkan dua kategori evaluasi baru: LLM-Adaptive Diarization (pemahaman audio temporal) dan Spoken Language Reasoning (tugas kognitif audio kompleks), bertujuan untuk mengungkap kesenjangan signifikan LALM saat ini dalam pemahaman temporal dan tugas penalaran ucapan kompleks, serta mendorong pengembangan LALM yang sistematis. (Sumber: HuggingFace Daily Papers)
Sistem Deteksi Kerentanan CI/CD Berbasis LLM, AI-DO: AI-DO (Automating vulnerability detection Integration for Developers’ Operations) adalah sistem rekomendasi yang terintegrasi ke dalam proses Continuous Integration/Continuous Deployment (CI/CD), menggunakan model CodeBERT untuk mendeteksi dan menemukan kerentanan pada tahap tinjauan kode. Sistem ini bertujuan untuk menjembatani kesenjangan antara penelitian akademis dan aplikasi industri. Melalui evaluasi generalisasi lintas domain CodeBERT pada data open-source dan industri, ditemukan bahwa model berkinerja akurat dalam domain yang sama, tetapi kinerja menurun di lintas domain. Dengan teknik undersampling yang tepat, model deep learning yang disetel pada data open-source dapat secara efektif meningkatkan kemampuan deteksi kerentanan. Pengembangan AI-DO meningkatkan keamanan dalam proses pengembangan tanpa mengganggu alur kerja yang ada. (Sumber: HuggingFace Daily Papers)
Replit Agent 3: Implementasi Ide Menjadi Aplikasi dengan Kecepatan Ekstrem: Agent 3 dari Replit menunjukkan efisiensi yang luar biasa, mampu membangun aplikasi salon check-in dari Upwork menjadi aplikasi lengkap yang mencakup proses check-in pelanggan, database pelanggan, dan dashboard backend dalam 145 menit. Agen ini juga memiliki otonomi tinggi, mampu berjalan selama 193 menit tanpa intervensi, menghasilkan kode tingkat produksi, termasuk autentikasi, database, penyimpanan, dan WebSocket, bahkan menulis tes dan algoritma peringkatnya sendiri. Kemampuan ini menyoroti potensi besar agen AI dalam pengembangan prototipe cepat dan pembangunan aplikasi full-stack, yang akan sangat mempercepat proses transformasi dari ide menjadi produk nyata. (Sumber: amasad, amasad, amasad)
Claude Menambahkan Fitur Pembuatan dan Pengeditan File: Claude kini dapat langsung membuat dan mengedit spreadsheet Excel, dokumen, presentasi PowerPoint, dan file PDF di Claude.ai dan aplikasi desktop. Fitur baru ini secara signifikan memperluas skenario aplikasi Claude dalam alat kantor dan produktivitas sehari-hari, memungkinkannya untuk lebih dalam terlibat dalam alur kerja pemrosesan dokumen dan pembuatan konten, meningkatkan efisiensi dan kenyamanan pengguna dalam menangani tugas file yang kompleks. (Sumber: dl_weekly)
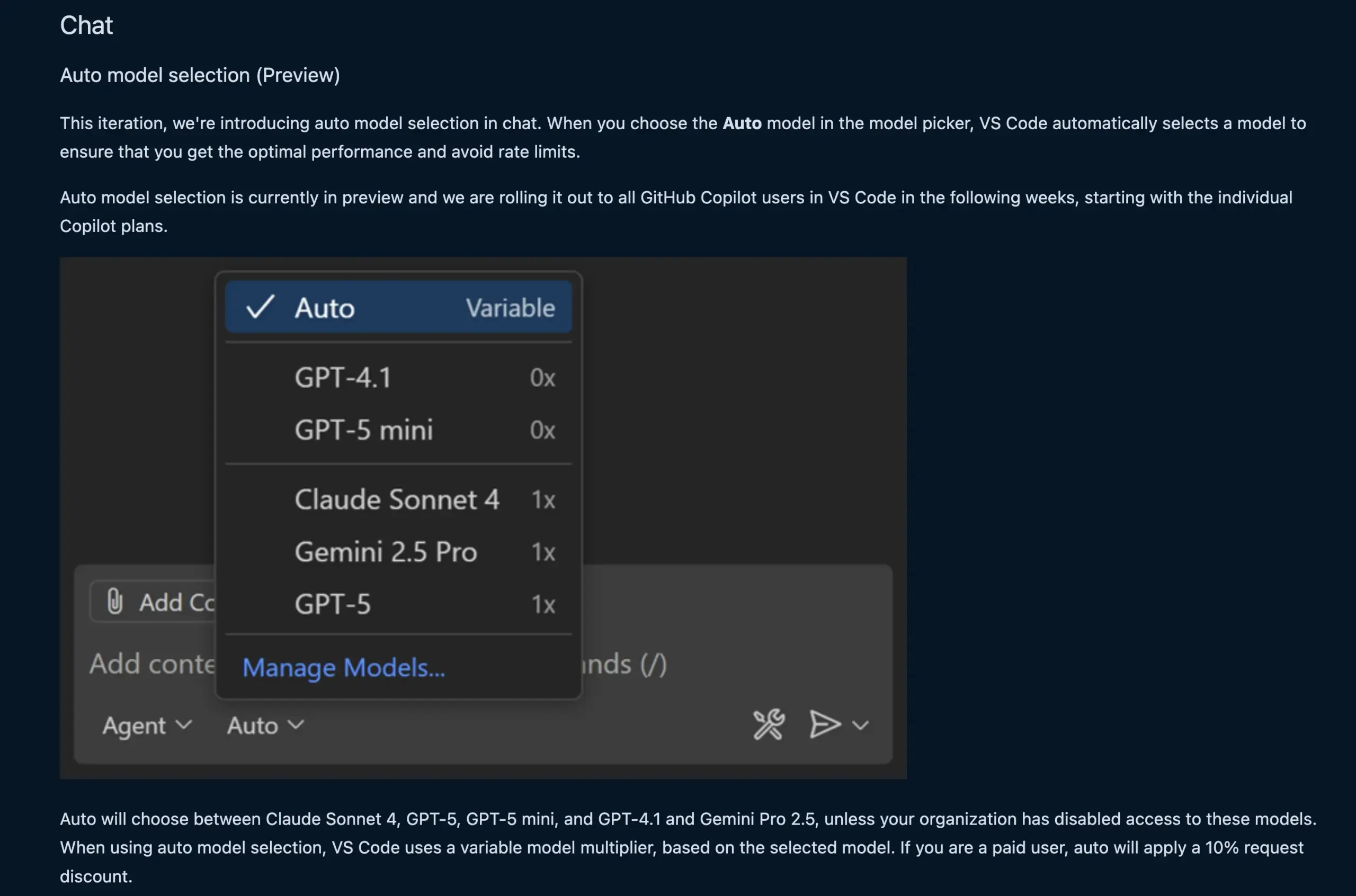
Fitur Chat VS Code Otomatis Memilih Model LLM: Fitur chat VS Code versi baru kini dapat secara otomatis memilih model LLM yang sesuai berdasarkan permintaan pengguna dan batas tingkat. Fitur ini dapat beralih secara cerdas antara model seperti Claude Sonnet 4, GPT-5, GPT-5 mini, GPT-4.1, dan Gemini Pro 2.5, memberikan pengalaman pemrograman berbantuan AI yang lebih nyaman dan efisien bagi pengembang. Pada saat yang sama, API ekstensi penyedia chat model bahasa VS Code telah difinalisasi, memungkinkan kontribusi model melalui ekstensi dan mendukung mode “Bring Your Own Key” (BYOK), lebih memperkaya pilihan model dan kemampuan kustomisasi. (Sumber: code, pierceboggan)
Box Meluncurkan Kemampuan Agen AI, Memberdayakan Manajemen Data Tidak Terstruktur: Box mengumumkan peluncuran fitur agen AI baru yang bertujuan untuk membantu pelanggan memanfaatkan sepenuhnya nilai data tidak terstruktur mereka. Box AI Studio yang diperbarui mempermudah pembangunan agen AI, yang dapat diterapkan pada berbagai fungsi bisnis dan kasus penggunaan industri. Box Extract menggunakan agen AI untuk ekstraksi data kompleks dari berbagai jenis dokumen, sementara Box Automate adalah solusi otomatisasi alur kerja baru yang memungkinkan pengguna menerapkan agen AI dalam alur kerja pusat konten. Fitur-fitur ini, melalui integrasi pra-bangun, Box API, atau Box MCP Server baru, bekerja secara mulus dengan sistem pelanggan yang ada, bertujuan untuk merevolusi cara perusahaan menangani konten tidak terstruktur. (Sumber: hwchase17)
Model Tab Baru Cursor: Meningkatkan Akurasi dan Tingkat Penerimaan Saran Kode: Cursor merilis model Tab baru sebagai alat saran kode default-nya. Model ini dilatih menggunakan Reinforcement Learning (RL) online, dan dibandingkan dengan model lama, jumlah saran kode berkurang 21%, tetapi tingkat penerimaan saran meningkat 28%. Peningkatan ini berarti model baru dapat memberikan saran kode yang lebih akurat dan sesuai dengan maksud pengembang, sehingga secara signifikan meningkatkan efisiensi pemrograman dan pengalaman pengguna, mengurangi gangguan yang tidak perlu, dan memungkinkan pengembang menyelesaikan tugas pengkodean dengan lebih efisien. (Sumber: BlackHC, op7418)
awesome-llm-apps: Koleksi Aplikasi LLM Open-Source: Proyek awesome-llm-apps di GitHub disebut sebagai tambang emas open-source, mengumpulkan lebih dari 40 aplikasi LLM yang dapat diterapkan, mencakup berbagai bidang mulai dari agen podcast blog AI hingga analisis citra medis. Setiap aplikasi dilengkapi dengan dokumentasi terperinci dan instruksi pengaturan, sehingga pekerjaan yang semula membutuhkan waktu berminggu-minggu kini dapat diselesaikan dalam beberapa menit. Misalnya, proyek pemandu audio AI di dalamnya, melalui sistem multi-agen, pencarian web real-time, dan teknologi TTS, mampu menghasilkan tur audio yang alami dan relevan secara kontekstual, dengan biaya API yang rendah, menunjukkan kepraktisan sistem multi-agen dalam pembuatan konten. (Sumber: Reddit r/MachineLearning)
📚 PEMBELAJARAN
MMOral: Benchmark Multimodal dan Dataset Instruksi untuk Analisis X-Ray Panoramik Gigi: MMOral adalah dataset instruksi multimodal skala besar pertama dan benchmark yang khusus dirancang untuk interpretasi X-ray panoramik gigi. Dataset ini berisi 20.563 gambar beranotasi dan 1,3 juta instance instruksi-following, mencakup tugas-tugas seperti ekstraksi atribut, pembuatan laporan, tanya jawab visual, dan dialog gambar. Suite evaluasi komprehensif MMOral-Bench mencakup lima dimensi kunci diagnosis gigi, dan hasilnya menunjukkan bahwa bahkan model LVLM terbaik seperti GPT-4o hanya mencapai akurasi 41.45%, menyoroti keterbatasan model yang ada di bidang ini. OralGPT, melalui SFT pada Qwen2.5-VL-7B, mencapai peningkatan kinerja signifikan sebesar 24.73%, meletakkan dasar untuk kedokteran gigi cerdas dan sistem AI multimodal klinis. (Sumber: HuggingFace Daily Papers)
Evaluasi Lintas Domain Deteksi Kerentanan Transformer: Sebuah penelitian mengevaluasi kinerja CodeBERT dalam mendeteksi kerentanan pada perangkat lunak industri dan open-source, serta menganalisis kemampuan generalisasi lintas domainnya. Penelitian menemukan bahwa model yang dilatih pada data industri akurat dalam deteksi di domain yang sama, tetapi kinerjanya menurun pada kode open-source. Sementara itu, model deep learning yang disetel pada data open-source dengan teknik undersampling yang tepat dapat secara efektif meningkatkan kemampuan deteksi kerentanan. Berdasarkan hasil ini, tim peneliti mengembangkan sistem AI-DO, sebuah sistem rekomendasi yang terintegrasi ke dalam proses CI/CD, yang dapat mendeteksi dan menemukan kerentanan selama tinjauan kode tanpa mengganggu alur kerja yang ada, bertujuan untuk mendorong transfer teknologi akademis ke aplikasi industri. (Sumber: HuggingFace Daily Papers)
Ego3D-Bench: Benchmark Penalaran Spasial VLM dalam Skenario Multiview Egosentris: Ego3D-Bench adalah benchmark baru yang dirancang untuk mengevaluasi kemampuan penalaran spasial 3D Visual Language Models (VLMs) dalam data outdoor multiview egosentris. Benchmark ini berisi lebih dari 8.600 pasangan tanya jawab yang dianotasi manusia, digunakan untuk menguji 16 SOTA VLM seperti GPT-4o dan Gemini1.5-Pro. Hasilnya menunjukkan bahwa VLM saat ini memiliki kesenjangan signifikan dengan tingkat manusia dalam pemahaman spasial. Untuk menjembatani kesenjangan ini, tim peneliti mengusulkan kerangka kerja pasca-pelatihan Ego3D-VLM, yang melalui pembuatan peta kognitif berdasarkan koordinat 3D global yang diperkirakan, rata-rata meningkatkan kinerja tanya jawab pilihan ganda sebesar 12% dan estimasi jarak absolut sebesar 56%, menyediakan alat berharga untuk mencapai pemahaman spasial setingkat manusia. (Sumber: HuggingFace Daily Papers)
‘Ilusi Pengembalian yang Berkurang’ dalam Eksekusi Tugas Jangka Panjang LLM: Penelitian baru mengeksplorasi kinerja LLM dalam eksekusi tugas jangka panjang, menunjukkan bahwa peningkatan kecil dalam akurasi satu langkah dapat menghasilkan peningkatan eksponensial dalam panjang tugas. Makalah ini berpendapat bahwa kegagalan LLM dalam tugas panjang bukanlah karena kurangnya kemampuan penalaran, melainkan kesalahan eksekusi. Dengan secara eksplisit menyediakan pengetahuan dan rencana, penelitian menemukan bahwa model besar dapat mengeksekusi lebih banyak langkah dengan benar, bahkan jika model kecil mencapai akurasi 100% dalam satu langkah. Sebuah penemuan menarik adalah bahwa model memiliki efek “regulasi diri”, yaitu ketika konteks berisi kesalahan sebelumnya, model lebih mudah membuat kesalahan lagi, dan ini tidak dapat diselesaikan hanya dengan skala model. Sementara itu, “model berpikir” terbaru dapat menghindari regulasi diri dan menyelesaikan tugas yang lebih panjang dalam satu eksekusi, menekankan manfaat besar dari perluasan skala model dan komputasi pengujian sekuensial untuk tugas jangka panjang. (Sumber: Reddit r/ArtificialInteligence)
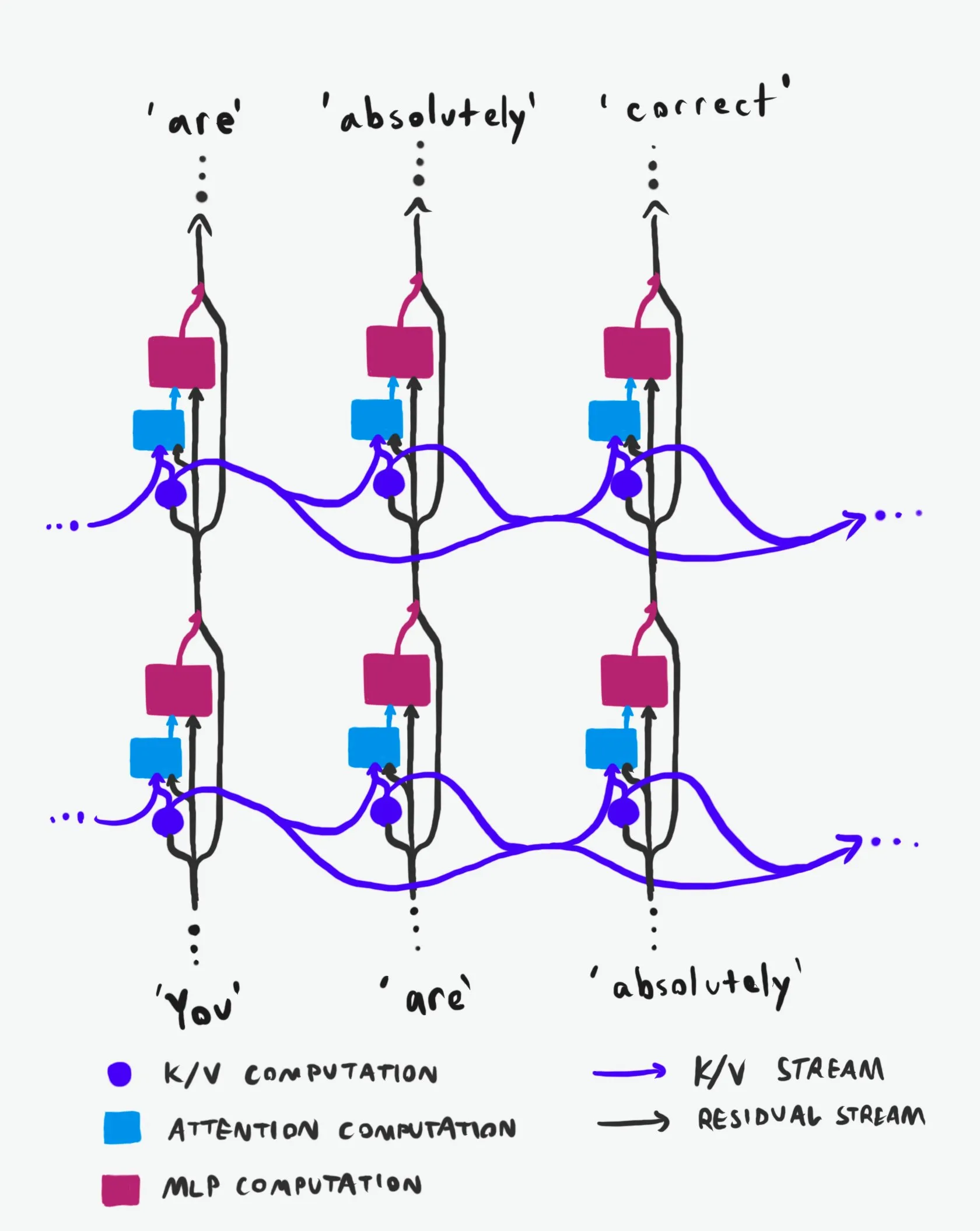
Struktur Kausal Transformer: Analisis Mendalam Aliran Informasi: Sebuah penjelasan teknis yang disebut “terbaik di kelasnya” menganalisis secara mendalam struktur kausal Transformer Large Language Models (LLM) dan cara aliran informasinya. Penjelasan ini menghindari istilah yang sulit dipahami, dengan jelas menjelaskan dua jalur informasi utama dalam arsitektur Transformer: Residual Stream dan mekanisme Attention. Melalui visualisasi dan deskripsi terperinci, ini membantu peneliti dan pengembang memahami cara kerja internal Transformer dengan lebih baik, sehingga membuat keputusan yang lebih tepat dalam desain, optimasi, dan debugging model, yang sangat berharga untuk pemahaman mendalam tentang mekanisme dasar LLM. (Sumber: Plinz)
Carnegie Mellon University Menawarkan Kursus Baru tentang Inferensi LM: Carnegie Mellon University (CMU) @gneubig dan @Amanda Bertsch akan bersama-sama mengajar kursus baru tentang inferensi Language Model (LM) pada musim gugur ini. Kursus ini bertujuan untuk memberikan pengantar komprehensif ke bidang inferensi LM, mencakup dari algoritma decoding klasik hingga metode terbaru LLM, serta serangkaian pekerjaan yang berfokus pada efisiensi. Konten kursus akan dipublikasikan secara online, termasuk video empat sesi pertama, menyediakan sumber belajar yang berharga bagi mahasiswa dan peneliti yang tertarik pada inferensi LM, membantu mereka menguasai teknik dan praktik inferensi mutakhir. (Sumber: lateinteraction, dejavucoder, gneubig)
OpenAIDevs Merilis Video Analisis Mendalam Codex: OpenAIDevs merilis video analisis mendalam Codex, yang merinci perubahan dan fitur terbaru Codex selama dua bulan terakhir. Video ini memberikan tips dan praktik terbaik untuk memanfaatkan Codex sepenuhnya, bertujuan untuk membantu pengembang lebih memahami dan menggunakan alat pemrograman AI yang kuat ini. Kontennya mencakup kemajuan terbaru Codex dalam pembuatan kode, debugging, dan pengembangan berbantuan, yang merupakan sumber belajar penting bagi pengembang yang ingin meningkatkan efisiensi pemrograman berbantuan AI. (Sumber: OpenAIDevs)
Laporan Kondisi Pasar GPU Cloud Computing 2025: dstackai merilis laporan tentang kondisi pasar GPU cloud computing pada tahun 2025, mencakup biaya, kinerja, dan strategi penggunaan. Laporan ini menganalisis secara rinci harga, konfigurasi hardware, dan kinerja di pasar saat ini, memberikan wawasan pasar dan referensi konkret bagi insinyur machine learning dalam memilih penyedia layanan cloud, melengkapi panduan umum tentang cara memilih penyedia cloud dalam rekayasa machine learning, dan memiliki nilai panduan penting untuk mengoptimalkan biaya dan efisiensi pelatihan dan inferensi AI. (Sumber: stanfordnlp)
Panorama Hardware AI: Unit Komputasi Multidimensi Pendorong AI: The Turing Post merilis panduan hardware yang mendorong AI, merinci GPU, TPU, CPU, ASICs, NPU, APU, IPU, RPU, FPGA, prosesor kuantum, chip komputasi dalam memori (PIM), dan chip neuromorfik. Panduan ini membahas secara mendalam peran, keunggulan, dan skenario aplikasi setiap hardware dalam komputasi AI, membantu pembaca memahami secara komprehensif dukungan daya komputasi di balik tumpukan teknologi AI, dan memiliki nilai referensi penting untuk pemilihan hardware dan desain sistem AI. (Sumber: TheTuringPost)
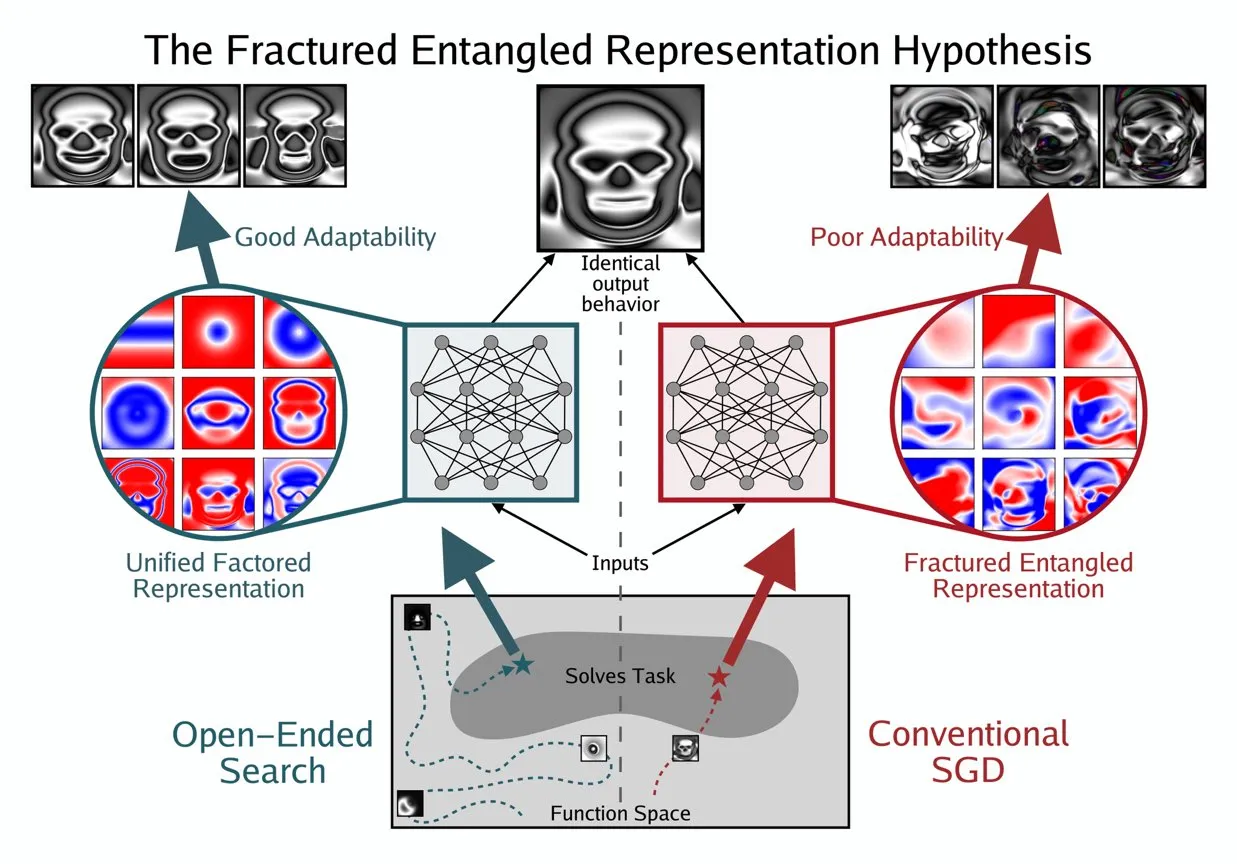
Kenneth Stanley Mengusulkan Konsep UFR untuk Memahami ‘Pemahaman Sejati’ AI: Kenneth Stanley mengusulkan konsep “Unified Factored Representation” (UFR) untuk membantu menjelaskan arti “pemahaman sejati” AI. Ia berpendapat bahwa ketika orang berbicara tentang “pemahaman sejati” AI, intinya terletak pada UFR. Konsep ini bertujuan untuk menyediakan kerangka teoritis yang lebih dalam untuk kemampuan kognitif AI, melampaui pengenalan pola semata, menyentuh bagaimana AI mampu menstrukturkan, menguraikan, dan membentuk batasan keras tentang dunia, sehingga mendorong AI tidak hanya meniru pengetahuan, tetapi juga berpikir kreatif dan memecahkan masalah baru seperti manusia. (Sumber: hardmaru, hardmaru)
💼 BISNIS
Tencent Dilaporkan Merekrut Peneliti Top OpenAI, Perang Bakat AI Meningkat: Menurut Bloomberg, peneliti top OpenAI, Yao Shunyu, telah mengundurkan diri dan bergabung dengan raksasa teknologi Tiongkok, Tencent. Kejadian ini menyoroti semakin sengitnya perang perebutan talenta AI global, terutama antara Amerika Serikat dan Tiongkok. Pergerakan peneliti AI papan atas tidak hanya memengaruhi peta jalan pengembangan teknologi masing-masing perusahaan, tetapi juga mencerminkan persaingan inovasi yang memanas di bidang AI, mengindikasikan bahwa lanskap AI di masa depan dapat berubah karena aliran talenta. (Sumber: The Verge)
OpportuNext Mencari Co-Founder Teknis untuk Membangun Platform Rekrutmen AI: OpportuNext, sebuah platform rekrutmen berbasis AI yang didirikan oleh alumni IIT Bombay, sedang mencari seorang co-founder teknis. Platform ini bertujuan untuk mengatasi masalah yang dihadapi pencari kerja dan pemberi kerja dalam rekrutmen melalui analisis resume komprehensif, pencarian pekerjaan semantik, peta jalan kesenjangan keterampilan, dan pra-penilaian. Target pasarnya adalah pasar India senilai 262 juta dolar AS, dengan rencana ekspansi ke pasar global senilai 40,5 miliar dolar AS. OpportuNext telah memvalidasi kesesuaian produk-pasar dan menyelesaikan prototipe parser resume, dengan rencana untuk menyelesaikan pendanaan Seri A pada pertengahan 2026. Posisi ini membutuhkan latar belakang yang kuat di bidang AI/ML (NLP), pengembangan full-stack, infrastruktur data, crawler/API, dan DevOps/keamanan. (Sumber: Reddit r/deeplearning)
Larry Ellison, Pendiri Oracle: Inferensi Adalah Kunci Profitabilitas AI: Larry Ellison, pendiri Oracle, menyatakan, “Inferensi adalah kunci profitabilitas AI.” Ia percaya bahwa investasi besar saat ini dalam pelatihan model pada akhirnya akan berubah menjadi penjualan produk, dan produk-produk ini terutama bergantung pada kemampuan inferensi. Ellison menekankan bahwa Oracle berada di garis depan dalam memanfaatkan permintaan inferensi, mengindikasikan bahwa narasi industri AI bergeser dari “siapa yang dapat melatih model terbesar” menjadi “siapa yang dapat menyediakan layanan inferensi secara efisien, andal, dan berskala”. Pandangan ini memicu diskusi tentang arah masa depan model ekonomi AI, yaitu apakah layanan inferensi akan mendominasi struktur pendapatan di masa depan. (Sumber: Reddit r/MachineLearning)
🌟 KOMUNITAS
Etika dan Keamanan AI: Tantangan Multidimensi dan Kolaborasi: Komunitas secara luas membahas tantangan etika dan keamanan yang ditimbulkan oleh AI, termasuk potensi dampak AI terhadap pasar tenaga kerja dan strategi perlindungan, kekhawatiran privasi dan keamanan alat ChatGPT MCP, serta debat serius tentang risiko kepunahan yang mungkin disebabkan oleh AI. Masalah kesehatan mental yang ditimbulkan oleh AI, seperti ketergantungan berlebihan pengguna pada AI bahkan munculnya “psikosis AI” dan perasaan kesepian, juga semakin mendapat perhatian. Pada saat yang sama, diskusi tentang regulasi AI (seperti RUU Ted Cruz) terus berlanjut. Sisi positifnya, perusahaan seperti Anthropic dan OpenAI bekerja sama dengan lembaga keamanan untuk bersama-sama menemukan dan memperbaiki kerentanan model, guna memperkuat perlindungan keamanan AI. (Sumber: Ronald_vanLoon, dotey, williawa, Dorialexander, Reddit r/ArtificialInteligence, Reddit r/artificial, sleepinyourhat, EthanJPerez)

Kinerja dan Evaluasi LLM: Kontroversi Kualitas Model dan Benchmark: Komunitas melakukan diskusi mendalam tentang evaluasi kinerja LLM dan masalah kualitas model. Model seperti K2-Think dipertanyakan karena cacat dalam metode evaluasi (seperti kontaminasi data dan perbandingan yang tidak adil), memicu kekhawatiran tentang keandalan benchmark AI yang ada. Penelitian menunjukkan bahwa LLM sebagai anotator data dapat memperkenalkan bias, menyebabkan “LLM Hacking” pada hasil ilmiah. Pengalaman pengguna dengan Claude Code bervariasi, mencerminkan tantangannya dalam konsistensi dan “kemalasan”, sementara Anthropic juga mengakui dan memperbaiki masalah degradasi kinerja Claude Sonnet 4. Pada saat yang sama, GPT-5 Pro mendapat pujian atas kemampuan penalaran yang kuat, tetapi beberapa pengguna juga mengamati generalisasi teks yang dihasilkan AI, serta perhatian berkelanjutan terhadap keandalan model (seperti bug inferensi). (Sumber: Grad62304977, rao2z, Reddit r/LocalLLaMA, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, npew, kchonyc, dejavucoder, vikhyatk)
Pekerjaan Masa Depan dan Agen AI: Peningkatan Efisiensi dan Transformasi Karier: Agen AI secara mendalam mengubah cara kerja. Para ahli di bidangnya (seperti pengacara, dokter, insinyur) dapat memperluas layanan profesional mereka dengan menyuntikkan pengetahuan pribadi ke agen AI, sehingga pendapatan tidak lagi terbatas pada biaya per jam. CEO Replit, Amjad Masad, memprediksi bahwa agen AI akan menghasilkan perangkat lunak sesuai permintaan, membuat nilai perangkat lunak tradisional mendekati nol, dan membentuk kembali cara perusahaan dibangun. Komunitas membahas pentingnya semangat kewirausahaan dan kemampuan beradaptasi di era AI, keunggulan unik Replit dalam pengembangan agen (seperti lingkungan yang dapat diuji), serta perbandingan efisiensi model robot dengan otak manusia. Selain itu, potensi Cursor sebagai lingkungan Reinforcement Learning juga menarik perhatian, mengindikasikan bahwa AI akan lebih lanjut meningkatkan produktivitas individu dan organisasi. (Sumber: amasad, amasad, amasad, fabianstelzer, amasad, lateinteraction, Dorialexander, dwarkesh_sp, sarahcat21)
Ekosistem Open-Source dan Kolaborasi: Popularitas Model dan Kebutuhan Komunitas: Hugging Face memainkan peran sentral dalam ekosistem AI, dengan keunggulan platform modular, terstandardisasi, dan terintegrasi, yang menyediakan berbagai alat dan model bagi pengembang, menurunkan hambatan pembangunan AI. Diskusi komunitas mengapresiasi proyek Apple MLX dan kontribusi open-source-nya terhadap peningkatan efisiensi hardware. Pada saat yang sama, komunitas juga secara aktif menyerukan tim Qwen untuk menyediakan dukungan GGUF untuk model Qwen3-Next, agar arsitektur kustomnya dapat berjalan pada kerangka inferensi lokal yang lebih luas seperti llama.cpp, memenuhi kebutuhan komunitas akan popularitas dan kemudahan penggunaan model, serta mendorong pengembangan lebih lanjut teknologi AI open-source. (Sumber: ClementDelangue, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Dampak Sosial AI yang Luas: Manifestasi Multidimensi dari Hiburan hingga Ekonomi: AI meresap ke dalam masyarakat dalam berbagai bentuk. Drama pendek hewan peliharaan AI menjadi viral di media sosial karena narasi antropomorfik dan nilai emosionalnya, menunjukkan potensi besar AI dalam pembuatan konten dan hiburan, menarik banyak pengguna muda dan memunculkan model bisnis baru. Pada saat yang sama, diskusi tentang aliran dana antara raksasa AI (seperti OpenAI dan Oracle) memicu pemikiran tentang model ekonomi AI. Komunitas juga membahas potensi AI dalam memecahkan masalah sumber daya (seperti sumber daya air), serta saran bahwa chatbot AI membutuhkan lebih banyak konten visual untuk meningkatkan pengalaman pengguna. Selain itu, aplikasi AI di media sosial juga memicu diskusi tentang dampaknya terhadap emosi dan kognisi sosial. (Sumber: 36氪, Yuchenj_UW, kylebrussell, brickroad7)
Kisah dan Observasi Komunitas AI: Ekspektasi Personalisasi Pengguna dan Refleksi Humor terhadap AI: Komunitas AI penuh dengan observasi unik dan refleksi humor tentang perkembangan teknologi dan pengalaman pengguna. Misalnya, diskon langganan OpenAI dan hubungan dengan perilaku “berpikir” memicu diskusi tentang nilai dan biaya AI. Pengguna berharap Claude Code dapat memiliki lebih banyak respons personalisasi, bahkan memberikan “kepribadian” pada AI, mencerminkan kebutuhan mendalam akan pengalaman interaksi AI. Pada saat yang sama, gagasan tentang agen AI yang dilatih dengan Reinforcement Learning di lingkungan simulasi (seperti GTA-6) juga menunjukkan imajinasi tak terbatas komunitas tentang jalur pengembangan AI di masa depan. Diskusi-diskusi ini tidak hanya memberikan wawasan tentang status quo teknologi AI, tetapi juga mencerminkan emosi dan ekspektasi pengguna dalam berinteraksi dengan AI. (Sumber: gneubig, jonst0kes, scaling01)
💡 LAIN-LAIN
Panduan Penguasaan Keterampilan AI 2025: Dengan pesatnya perkembangan teknologi kecerdasan buatan, penguasaan keterampilan AI kunci sangat penting untuk pengembangan karier pribadi. Sebuah panduan penguasaan keterampilan AI 2025 menekankan 12 keterampilan inti yang perlu dikuasai di bidang kecerdasan buatan, machine learning, dan deep learning. Keterampilan ini mencakup dari teori dasar hingga aplikasi praktis, bertujuan untuk membantu para profesional dan pelajar beradaptasi dengan tuntutan baru akan talenta di era AI, serta meningkatkan daya saing mereka dalam inovasi teknologi dan pasar kerja. (Sumber: Ronald_vanLoon)

Pasar GPU Cloud 2025: Laporan Biaya, Kinerja, dan Strategi Implementasi: dstackai merilis laporan terperinci tentang kondisi pasar GPU cloud computing pada tahun 2025, menganalisis secara mendalam biaya GPU, kinerja, dan strategi implementasi dari berbagai penyedia layanan cloud. Laporan ini bertujuan untuk memberikan panduan spesifik bagi insinyur machine learning dan perusahaan dalam memilih penyedia cloud, membantu mereka mengoptimalkan konfigurasi sumber daya untuk tugas pelatihan dan inferensi AI, sehingga dapat membuat keputusan yang lebih hemat biaya dan unggul dalam kinerja di tengah meningkatnya permintaan infrastruktur AI. (Sumber: stanfordnlp)
Ikhtisar Teknologi Hardware AI: Unit Komputasi Multidimensi Pendorong Masa Depan Cerdas: The Turing Post merilis panduan hardware AI yang komprehensif, merinci berbagai unit komputasi yang saat ini mendorong kecerdasan buatan. Ini termasuk Graphics Processing Unit (GPU), Tensor Processing Unit (TPU), Central Processing Unit (CPU), Application-Specific Integrated Circuits (ASICs), Neural Processing Unit (NPU), Accelerated Processing Unit (APU), Intelligent Processing Unit (IPU), Resistive Processing Unit (RPU), Field-Programmable Gate Array (FPGA), prosesor kuantum, komputasi dalam memori (PIM), serta chip neuromorfik. Panduan ini memberikan perspektif yang jelas untuk memahami dukungan hardware dasar dari tumpukan teknologi AI, membantu pengembang dan peneliti memilih solusi hardware yang paling sesuai untuk beban kerja AI mereka. (Sumber: TheTuringPost)