
Kata Kunci:Chip AI berbasis cahaya, K2 Think, Kecerdasan berwujud, Jupyter Agent, OpenPI, Model Claude, Qwen3-Next, Seedream 4.0, Rasio efisiensi energi chip AI fotonik, Kecepatan inferensi model besar sumber terbuka, Ekspresi emosi robot humanoid, Agen cerdas ilmu data LLM, Model visual-bahasa-gerak robot
🔥 Fokus
Terobosan Efisiensi Chip AI Berbasis Cahaya : Tim insinyur dari University of Florida telah mengembangkan chip AI berbasis cahaya baru yang menggunakan foton, bukan listrik, untuk operasi AI seperti pengenalan gambar dan deteksi pola. Chip ini mencapai akurasi 98% dalam tes klasifikasi digital, sekaligus meningkatkan efisiensi energi hingga 100 kali lipat. Terobosan ini diharapkan dapat secara signifikan mengurangi biaya komputasi dan konsumsi energi AI, mendorong pengembangan AI yang lebih hijau dan skalabel di berbagai bidang mulai dari smartphone hingga superkomputer, menandakan bahwa chip elektro-optik hibrida akan membentuk kembali lanskap hardware AI. (Sumber: Reddit r/ArtificialInteligence)

K2 Think: Model Bahasa Besar Open-Source Tercepat di Dunia Dirilis : MBZUAI Uni Emirat Arab bekerja sama dengan G42 AI merilis K2 Think, sebuah model bahasa besar open-source berdasarkan Qwen 2.5-32B, dengan kecepatan terukur lebih dari 2000 tokens/detik, 10 kali lebih cepat dari throughput deployment GPU pada umumnya. Model ini menunjukkan kinerja luar biasa dalam benchmark matematika seperti AIME, dan mencapai inovasi teknologi melalui SFT pemikiran rantai panjang, RLVR hadiah yang dapat diverifikasi, perencanaan pra-inferensi, Best-of-N sampling, speculative decoding, dan akselerasi hardware Cerebras WSE, menandai ketinggian baru dalam kinerja sistem inferensi AI open-source. (Sumber: teortaxesTex, HuggingFace)

Kemajuan Terdepan dalam Embodied AI dan Robot Humanoid : Diskusi meja bundar Zhihu mengungkapkan beberapa terobosan di bidang embodied AI. Laboratorium Air Tsinghua memamerkan “Morpheus” (灵巧脸), yang menggunakan penggerak hibrida dan teknologi digital human untuk mencapai ekspresi mikro yang kaya, bertujuan untuk meningkatkan nilai emosional robot humanoid. Pada saat yang sama, robot Ultra dari Beijing TianGong memenangkan lomba lari 100 meter di World Humanoid Robot Sports Games, menyoroti keunggulan algoritma dan persepsi otonom. Diskusi juga mencakup isu-isu penting seperti biaya robot humanoid, produksi massal, teori kontrol, dan integrasi model bahasa besar, menandakan bahwa embodied AI sedang bergerak dari eksplorasi teknologi menuju aplikasi praktis. (Sumber: ZhihuFrontier)

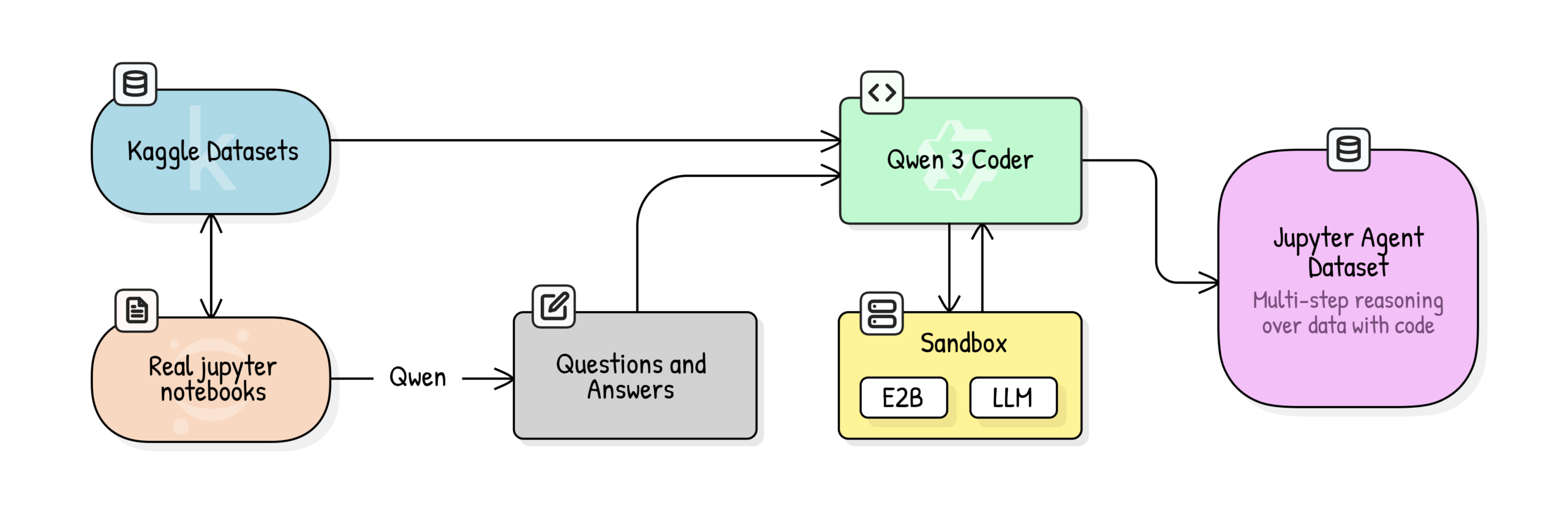
Jupyter Agent: Melatih LLM untuk Penalaran Ilmu Data Menggunakan Notebook : Hugging Face meluncurkan proyek Jupyter Agent, yang bertujuan untuk memberdayakan LLM dengan alat eksekusi kode untuk menyelesaikan tugas analisis data dan ilmu data di Jupyter Notebook. Melalui proses pelatihan multi-tahap yang melibatkan pembersihan data Kaggle Notebooks skala besar, penilaian kualitas pendidikan, generasi QA, dan generasi jejak eksekusi kode, model kecil seperti Qwen3-4B berhasil ditingkatkan dari 44,4% menjadi 75% pada tugas Easy di benchmark DABStep, membuktikan bahwa model kecil yang dikombinasikan dengan data berkualitas tinggi dan scaffolding juga dapat menjadi agen ilmu data yang kuat. (Sumber: HuggingFace Blog)
OpenPI: Model Visi-Bahasa-Aksi Robot Open-Source : Tim Physical Intelligence merilis pustaka OpenPI, yang mencakup model Visi-Bahasa-Aksi (VLA) open-source seperti π₀, π₀-FAST, dan π₀.₅. Model-model ini dilatih sebelumnya dengan 10 ribu+ jam data robot, mendukung PyTorch, dan mencapai kinerja SOTA dalam benchmark LIBERO. OpenPI menyediakan checkpoint model dasar dan contoh fine-tuning, mendukung inferensi jarak jauh, bertujuan untuk mendorong penelitian dan aplikasi terbuka di bidang robotika, terutama menunjukkan potensi dalam manipulasi meja dan tugas pengambilan objek. (Sumber: GitHub Trending)
🎯 Tren
Microsoft dan Anthropic Berkolaborasi, Model Claude Terintegrasi ke Office 365 Copilot : Microsoft sedang mengintegrasikan model Claude dari Anthropic ke Office 365 Copilot, terutama di bidang-bidang di mana Claude menunjukkan kinerja yang lebih baik, seperti perhitungan fungsi Excel dan pembuatan slide PowerPoint. Langkah ini bertujuan untuk mengoptimalkan fungsi spesifik Copilot di Word, Excel, PowerPoint, meningkatkan pengalaman pengguna, dan memperluas jangkauan aplikasi Claude dalam alat produktivitas perusahaan. (Sumber: dotey, alexalbert__, menhguin, TheRundownAI)

AI Mempercepat Penelitian Ilmiah: Knowledge Graph dan Agen Otonom : MiniculeAI menunjukkan bagaimana AI dapat mempercepat penemuan ilmiah melalui knowledge graph dan agen otonom. Dengan memetakan gen, obat, dan hasil ke dalam jaringan dinamis, AI dapat mengungkap hubungan tersembunyi yang sulit ditemukan dalam dokumen PDF. Agen otonom dapat memindai literatur, menemukan pola, dan memberikan wawasan yang dapat dijelaskan, mempersingkat penelitian tradisional yang memakan waktu berbulan-bulan menjadi beberapa menit, sambil memastikan privasi data tingkat perusahaan. (Sumber: Ronald_vanLoon)
Seri Model Qwen3-Next: Optimalisasi Konteks Panjang dan Efisiensi Parameter : Tim Qwen meluncurkan seri model dasar Qwen3-Next, yang berfokus pada panjang konteks ekstrem dan efisiensi parameter skala besar. Seri ini memperkenalkan beberapa inovasi arsitektur, termasuk GatedAttention (untuk mengatasi outlier), GatedDeltaNet RNN (untuk menghemat KV cache), dan mengombinasikan arsitektur hibrida Sink+SWA atau Gated Attention+linear RNN, bertujuan untuk memaksimalkan kinerja dan meminimalkan biaya komputasi, menandakan berakhirnya era model Attention murni. (Sumber: tokenbender, SchmidhuberAI, teortaxesTex, ClementDelangue, andriy_mulyar)
ByteDance Seedream 4.0: Model Generasi dan Pengeditan Gambar Dirilis : ByteDance merilis Seedream 4.0, menawarkan kemampuan generasi dan pengeditan gambar yang luar biasa. Umpan balik pengguna menunjukkan kinerjanya yang menonjol dalam memenuhi kebutuhan pengguna, preferensi estetika RLHF, dan mempertahankan selera mainstream. Dibandingkan dengan Seedream 3.0, versi 4.0 menambahkan efek film grain dan lens artifacts, kontras yang lebih tinggi, goresan gaya anime yang lebih tajam, serta menunjukkan pemahaman semantik dan konsistensi bahasa Mandarin yang kuat, cocok untuk infografis, tutorial, dan desain produk. (Sumber: ZhihuFrontier, Reddit r/artificial, op7418, TomLikesRobots, dotey)
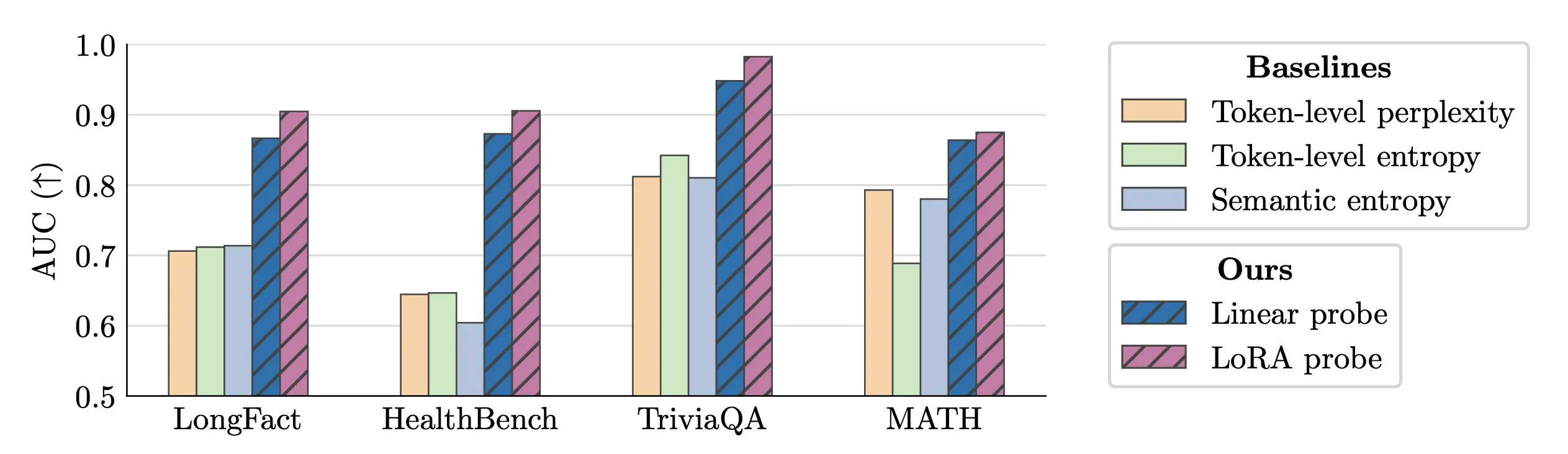
Teknologi Deteksi Halusinasi LLM Real-time : Para peneliti mengusulkan penggunaan activation probes untuk deteksi halusinasi LLM secara real-time. Metode ini menunjukkan kinerja luar biasa dalam mengidentifikasi entitas palsu dalam teks panjang, dengan nilai AUC hingga 0,90, secara signifikan lebih baik daripada metode semantic entropy tradisional. Selain itu, penelitian baru juga mendalami asal-usul halusinasi dalam model Transformer, memberikan ide-ide baru untuk meningkatkan keandalan LLM. (Sumber: paul_cal, tokenbender)
Microsoft VibeVoice: Generasi Suara Fidelitas Tinggi Berdurasi Panjang : Model VibeVoice Microsoft mencapai kemajuan signifikan di bidang audio AI, mampu menghasilkan suara realistis berdurasi 45-90 menit dengan hingga 4 pembicara, tanpa perlu penyambungan. Model ini tersedia untuk dicoba di Hugging Face Space, memungkinkan pengguna untuk melakukan kloning suara berkualitas tinggi, membuka kemungkinan baru untuk aplikasi seperti podcast dan buku audio. (Sumber: Reddit r/LocalLLaMA)
mmBERT: Tolok Ukur Baru untuk Encoder Multibahasa : Model mmBERT baru telah diluncurkan, diharapkan dapat menggantikan XLM-R yang telah menjadi SOTA selama 6 tahun. mmBERT 2-4 kali lebih cepat dari model yang ada dan melampaui o3 dan Gemini 2.5 Pro dalam tugas encoding multibahasa. Peluncuran model ini, disertai dengan model terbuka dan data pelatihan, akan memberikan dasar yang lebih efisien dan kuat untuk aplikasi AI multibahasa. (Sumber: code_star)

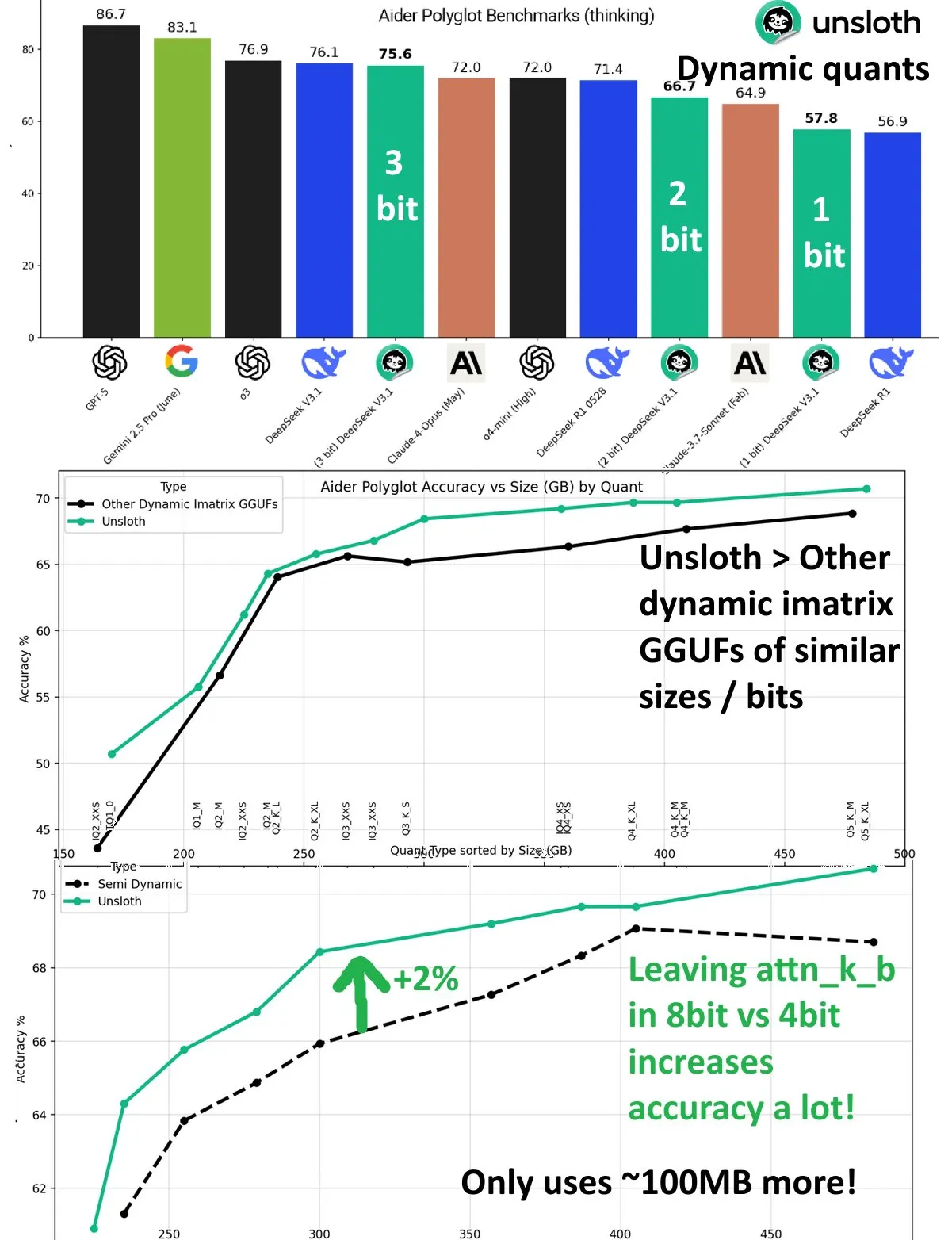
Peningkatan Kinerja Kuantisasi Dinamis DeepSeek V3.1 : Model DeepSeek V3.1 menunjukkan peningkatan kinerja yang signifikan melalui teknologi kuantisasi dinamis dalam benchmark Aider Polyglot UnslothAI. Kuantisasi 3-bit mendekati akurasi model yang tidak terkuantisasi, dan dalam mode inferensi, kuantisasi dinamis 1-bit bahkan melampaui kinerja asli DeepSeek R1. Penelitian menemukan bahwa menjaga lapisan attn_k_b pada presisi 8-bit dapat meningkatkan akurasi tambahan 2%, menunjukkan potensi kuantisasi efisien dalam mempertahankan kemampuan model dan mengurangi biaya komputasi. (Sumber: danielhanchen)
SpikingBrain-1.0: Model Besar Domestik yang Dilatih dengan GPU Domestik : Institut Otomasi Akademi Ilmu Pengetahuan Tiongkok merilis model besar spiking yang terinspirasi otak “SpikingBrain-1.0” (瞬悉1.0), yang telah menyelesaikan pelatihan dan inferensi pada klaster GPU MuXi domestik, dengan rasio efisiensi energi 97,7% lebih rendah dibandingkan operasi FP16 tradisional. Model ini hanya menggunakan 2% data pra-pelatihan model besar mainstream, namun mencapai 90% kinerja Qwen2.5-7B, dan menunjukkan kinerja luar biasa dalam tugas pemrosesan urutan ultra-panjang, dengan akselerasi TTFT hingga 26,5 kali, memverifikasi kelayakan ekosistem model besar non-Transformer yang dikendalikan secara mandiri di dalam negeri. (Sumber: 36氪)
Wenxin X1.1 Dirilis: Peningkatan Signifikan dalam Faktualitas, Kepatuhan Instruksi, dan Kemampuan Agen : Model pemikiran mendalam Baidu, Wenxin Large Model X1.1, telah ditingkatkan dan diluncurkan, dengan peningkatan masing-masing 34,8% dalam faktualitas, 12,5% dalam kepatuhan instruksi, dan 9,6% dalam kemampuan agen. Model ini secara keseluruhan melampaui DeepSeek R1-0528 dan setara dengan GPT-5, Gemini 2.5 Pro, serta menunjukkan kemampuan agen yang kuat dalam tugas jangka panjang yang kompleks, mampu secara otomatis membagi tugas dan memanggil alat. Baidu juga merilis model open-source ERNIE-4.5-21B-A3B-Thinking dan ERNIEKit development kit, yang semakin menurunkan ambang batas aplikasi AI. (Sumber: 量子位)

Huawei Open-Source OpenPangu-Embedded-7B-v1.1: Peralihan Bebas Antara Mode Berpikir Cepat dan Lambat : Huawei merilis OpenPangu-Embedded-7B-v1.1, sebuah model open-source dengan 7B parameter, yang pertama kali memungkinkan peralihan bebas antara mode berpikir cepat dan lambat, serta dapat beradaptasi memilih berdasarkan tingkat kesulitan masalah. Melalui fine-tuning progresif dan strategi pelatihan dua tahap, akurasi model meningkat secara signifikan dalam evaluasi umum, matematika, dan kode, dan sambil mempertahankan akurasi, panjang chain-of-thought rata-rata berkurang hampir 50%, mengisi kekosongan dalam kemampuan ini di antara model besar open-source, dan meningkatkan efisiensi serta akurasi. (Sumber: 量子位)

Tencent CodeBuddy Code: Pemrograman AI Memasuki Era L4 : Tencent merilis alat AI CLI CodeBuddy Code, dan membuka beta publik CodeBuddy IDE, bertujuan untuk mendorong pemrograman AI ke era “AI software engineer” tingkat L4. CodeBuddy Code dapat diinstal melalui npm, mendukung siklus hidup pengembangan dan operasi yang digerakkan oleh bahasa alami secara penuh, mencapai otomatisasi ekstrem. Alat ini, melalui manajemen berbasis dokumen, kompresi konteks, dan ekstensi MCP, menjadi infrastruktur dasar untuk pemrograman AI tingkat perusahaan, secara signifikan meningkatkan efisiensi pengembangan. (Sumber: 量子位)

Ilmuwan Inti OpenAI: Duo Polandia Mendorong Terobosan GPT-4 dan Penalaran : Ilmuwan Kepala OpenAI Jakub Pachocki dan Peneliti Teknis Szymon Sidor dipuji tinggi oleh Altman atas kontribusi kunci mereka dalam proyek Dota, pra-pelatihan GPT-4, dan mendorong terobosan penalaran. Kedua teman sekolah menengah ini bertemu kembali di OpenAI, dan melalui kombinasi pemikiran mendalam dan eksperimen langsung, mereka menjadi kekuatan yang tak tergantikan di OpenAI, bahkan dengan tegas mendukung kembalinya Altman selama krisis internal pada tahun 2023. (Sumber: 量子位)

KTT AI Gedung Putih Fokus pada Bakat, Keamanan, dan Tantangan Nasional : Melania Trump memimpin konferensi AI di Gedung Putih, mengundang raksasa teknologi seperti Google, IBM, dan Microsoft, dengan fokus pada pengembangan bakat, jaminan keamanan, dan tantangan tingkat nasional di bidang AI. Langkah ini menunjukkan bahwa pemerintah AS secara aktif mendorong strategi AI, bertujuan untuk mengatasi peluang dan tantangan yang dibawa oleh perkembangan AI, serta memastikan kepemimpinan nasional di bidang AI. (Sumber: TheTuringPost, Reddit r/artificial)

Neuromorphic Computing: Melampaui Jaringan Saraf Tradisional : Neuromorphic Computing sedang mendefinisikan ulang kecerdasan, terinspirasi oleh struktur dan prinsip kerja otak biologis. Teknologi ini bertujuan untuk mengembangkan hardware AI yang lebih efisien dan berdaya rendah, dengan mensimulasikan kemampuan pemrosesan paralel neuron dan sinapsis, mencapai pola komputasi yang melampaui arsitektur Von Neumann tradisional, dan memberikan dasar yang lebih kuat untuk sistem AI masa depan. (Sumber: Reddit r/artificial)
MEGS²: Teknologi Gaussian Splatting Efisien Memori : MEGS² (Memory-Efficient Gaussian Splatting via Spherical Gaussians and Unified Pruning) adalah teknologi 3D Gaussian Splatting (3DGS) yang efisien memori. Dengan mengganti representasi warna spherical harmonics dengan fungsi Gaussian sferis berorientasi arbitrer, dan memperkenalkan kerangka kerja soft pruning terpadu, metode ini secara signifikan mengurangi jumlah parameter per primitif asli, mencapai kompresi VRAM statis 8 kali lipat dan kompresi VRAM rendering hampir 6 kali lipat, sambil mempertahankan atau meningkatkan kualitas rendering, yang memiliki signifikansi penting untuk grafis 3D dan rendering real-time. (Sumber: janusch_patas)

🧰 Alat
LangChain 1.0 Memperkenalkan Middleware: Paradigma Baru Kontrol Konteks Agen : LangChain 1.0 merilis Middleware, menyediakan lapisan abstraksi baru untuk agen AI, memungkinkan pengembang untuk sepenuhnya mengontrol rekayasa konteks. Fitur ini meningkatkan fleksibilitas, kemampuan komposisi, dan adaptabilitas agen, mendukung implementasi arsitektur agen yang berbeda seperti refleksi, grup, dan supervisor, memberikan dasar yang kuat untuk membangun aplikasi AI yang lebih kompleks. (Sumber: hwchase17, hwchase17, Hacubu)
MaxKB: Platform Agen Tingkat Perusahaan Open-Source : MaxKB adalah platform agen tingkat perusahaan open-source yang kuat dan mudah digunakan, mengintegrasikan pipeline RAG (Retrieval-Augmented Generation), mesin workflow yang kuat, dan kemampuan penggunaan alat MCP. Ini mendukung unggah dokumen, crawling otomatis, pemisahan teks, dan vektorisasi, secara efektif mengurangi halusinasi model besar, serta mendukung berbagai model besar privat dan publik, menyediakan input/output multimodal, banyak digunakan dalam layanan pelanggan cerdas, knowledge base perusahaan, dan skenario lainnya. (Sumber: GitHub Trending)

BlenderMCP: Integrasi Mendalam Claude AI dengan Blender : BlenderMCP mewujudkan integrasi mendalam Claude AI dengan Blender, melalui Model Context Protocol (MCP) yang memungkinkan Claude untuk langsung mengontrol Blender untuk pemodelan 3D, pembuatan dan manipulasi scene. Alat ini mendukung komunikasi dua arah, manipulasi objek, kontrol material, inspeksi scene, dan eksekusi kode, serta dapat mengintegrasikan aset Poly Haven dan Hyper3D Rodin, sangat meningkatkan efisiensi dan kemungkinan kreasi 3D yang dibantu AI. (Sumber: GitHub Trending)

AI Sheets: Alat Pembuatan dan Konversi Dataset AI Tanpa Kode : Hugging Face merilis AI Sheets, sebuah alat open-source tanpa kode yang digunakan untuk membangun, memperkaya, dan mengubah dataset menggunakan model AI. Alat ini dapat di-deploy secara lokal atau dijalankan di Hub, mendukung akses ke ribuan model open-source di Hugging Face Hub (termasuk gpt-oss), dan dapat diluncurkan dengan cepat melalui Docker atau pnpm, menyederhanakan proses pemrosesan data, terutama cocok untuk menghasilkan dataset skala besar. (Sumber: GitHub Trending)

Integrasi Notebook Real-time vLLM dengan Modal : Modal Notebooks terintegrasi dengan vLLM, menyediakan lingkungan interaktif real-time yang dapat dibagikan, membantu pengembang memahami mekanisme internal vLLM secara mendalam. Melalui integrasi ini, pengguna tidak perlu membangun integrasi yang kompleks, dapat dengan mudah menjalankan dan berbagi tugas komputasi yang kompatibel dengan CUDA di cloud, sangat menyederhanakan proses pengembangan dan pembelajaran vLLM. (Sumber: charles_irl, vllm_project, charles_irl, charles_irl, charles_irl, charles_irl)
Docker Mendukung Minions AI: Beban Kerja AI Hibrida Lokal : Minions AI kini secara resmi mendukung Docker, memungkinkan pengguna untuk membuka beban kerja AI hibrida secara lokal melalui Docker model runner. Kolaborasi ini memungkinkan pengembang untuk lebih mudah men-deploy dan mengelola Minions AI di lingkungan lokal, dikombinasikan dengan keunggulan containerization Docker, meningkatkan fleksibilitas dan efisiensi pengembangan aplikasi AI. (Sumber: shishirpatil_)
Replit Agent 3: Terobosan Baru dalam Pengembangan Perangkat Lunak Otonom : Replit merilis Agent 3, yang disebut sebagai momen “full self-driving” dalam pengembangan perangkat lunak, dengan otonomi 10 kali lebih tinggi dari agen sebelumnya. Agent ini dapat membuat prototipe aplikasi lebih mendalam dan terus maju ketika agen lain terhambat, bertujuan untuk menyelesaikan tahap pengujian, debugging, dan refactoring yang memakan waktu dalam pengembangan perangkat lunak, secara signifikan meningkatkan efisiensi pengembangan. (Sumber: amasad, amasad, pirroh)
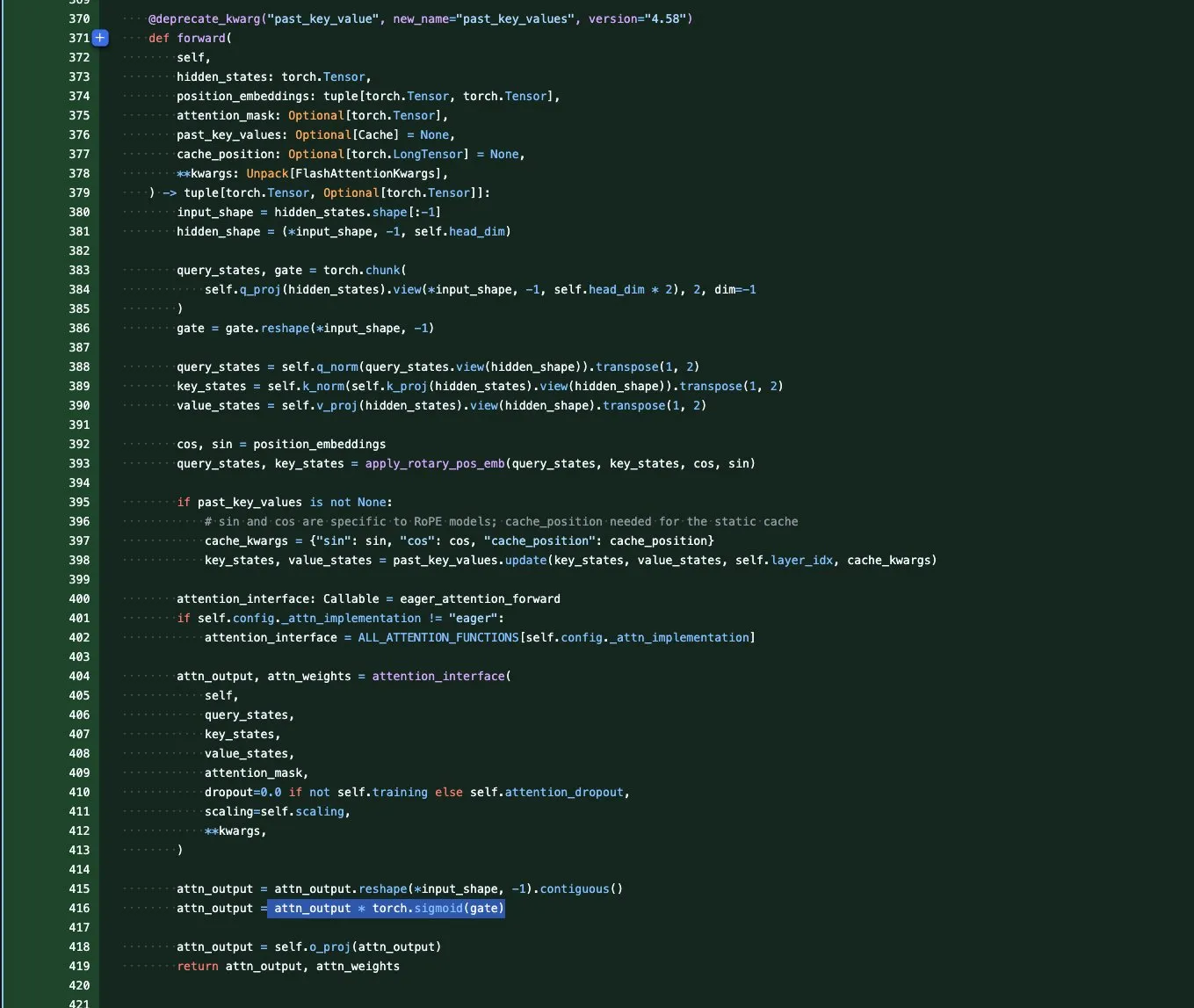
Qwen3-Coder: Model Pemrograman Open-Source Berkinerja Tinggi dan Hemat Biaya : Qwen3-Coder menunjukkan kinerja dan efisiensi biaya yang luar biasa di platform Windsurf, hanya membutuhkan 0,5 poin untuk dijalankan, lebih unggul dibandingkan Claude 4 dan GPT-5 High (2 kali poin). Model ini berkinerja sangat baik dalam tugas pemrograman, dan sebagai model open-source, menyediakan opsi pemrograman AI yang kuat tanpa bergantung pada API publik untuk perusahaan yang diatur dan organisasi sektor publik, membantu menyelesaikan masalah kedaulatan dan visibilitas data. (Sumber: bookwormengr)
📚 Pembelajaran
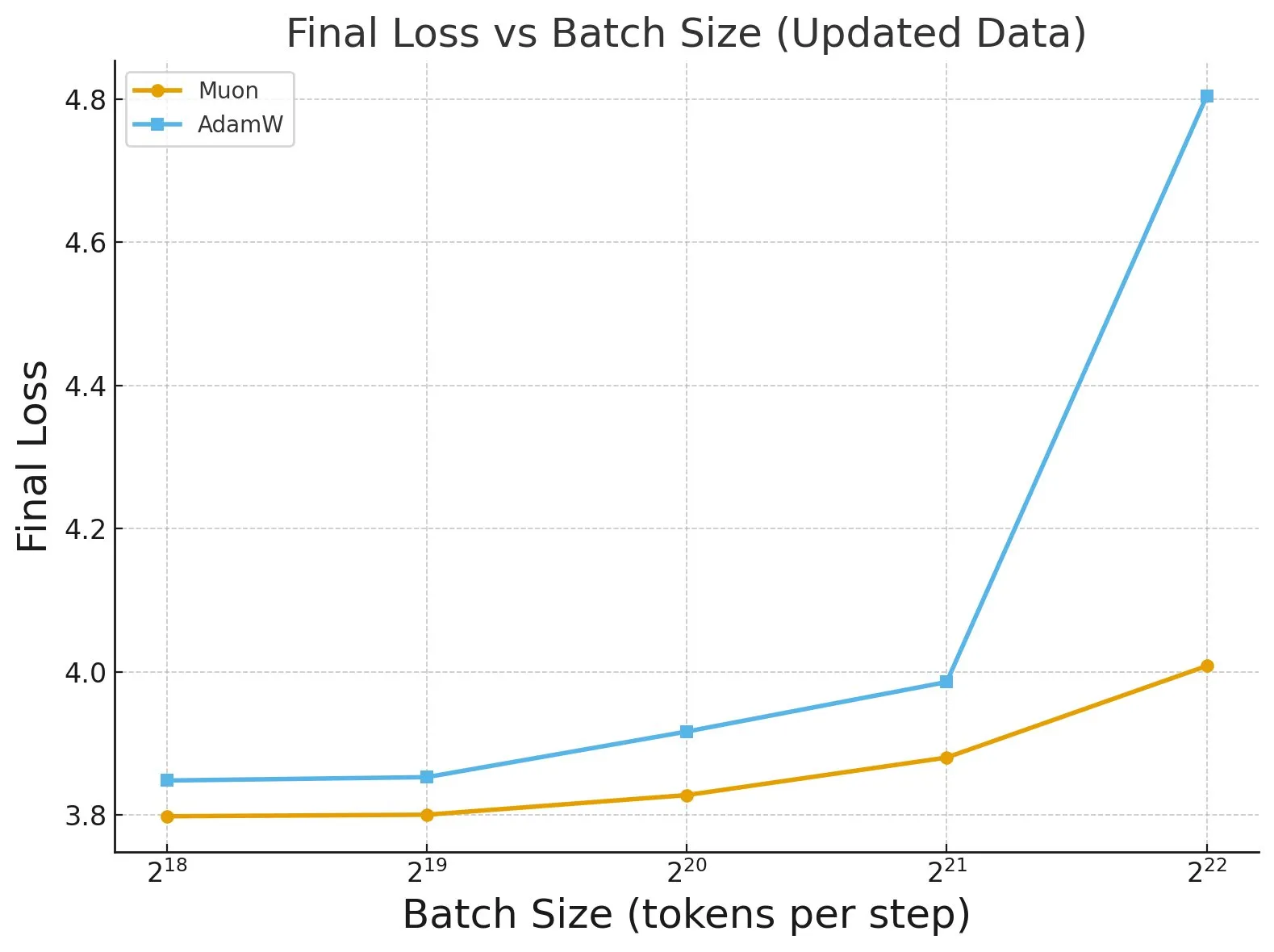
Penelitian “Fantastic Pretraining Optimizers and Where to Find Them” : Sebuah studi ekstensif terhadap lebih dari 4000 model mengungkapkan kinerja pretraining optimizers. Penelitian menemukan bahwa beberapa optimizers (seperti Muon) dapat mencapai peningkatan kecepatan hingga 40% pada model skala kecil (<0.5B parameter), tetapi hanya 10% pada model skala besar (1.2B parameter). Ini menekankan perlunya berhati-hati terhadap fine-tuning baseline yang tidak memadai dan batasan skala saat mengevaluasi optimizers, dan menunjukkan dampak ukuran batch terhadap perbedaan kinerja optimizer. (Sumber: tokenbender, code_star)
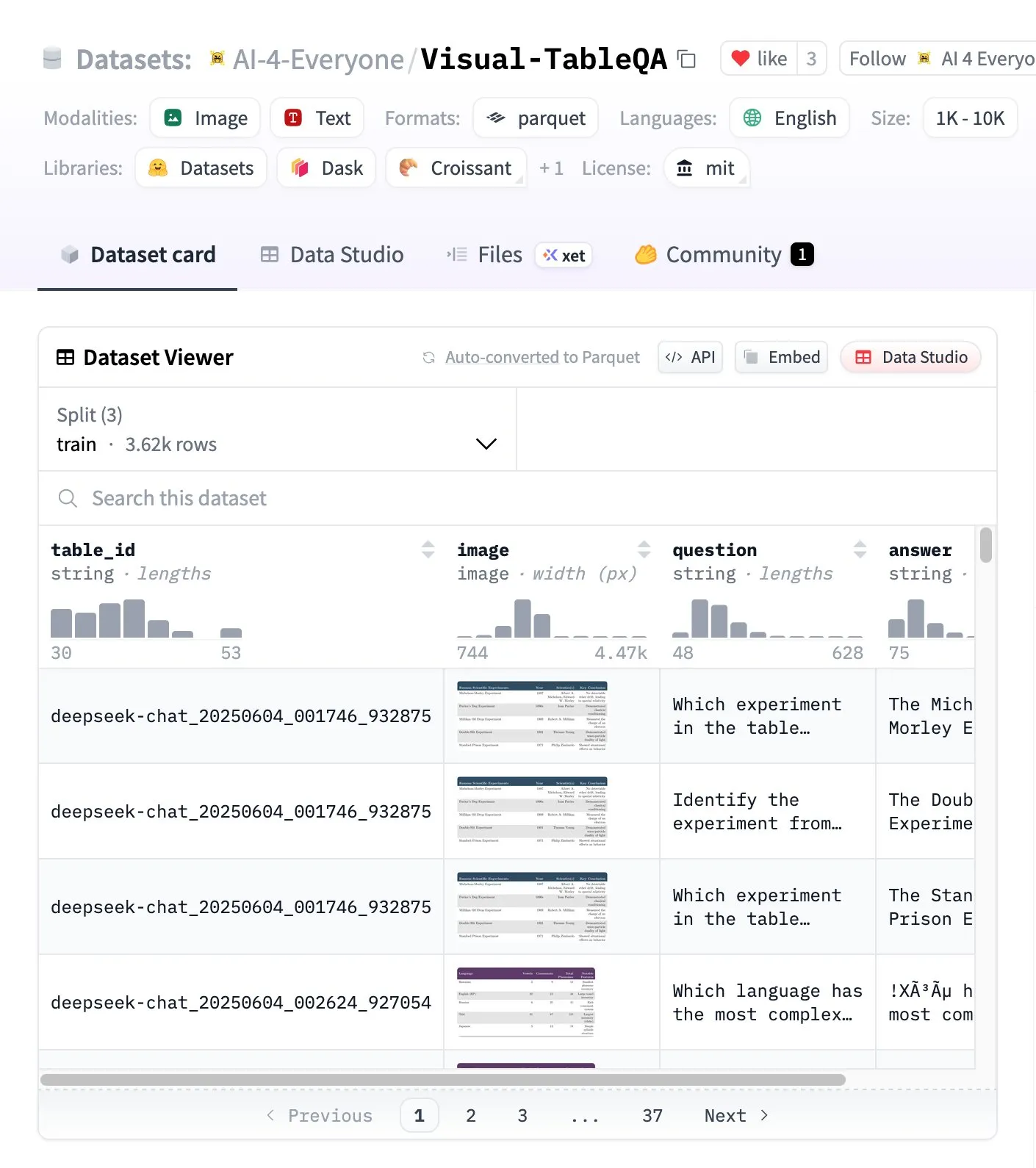
Visual-TableQA: Benchmark Penalaran Tabel Kompleks : Hugging Face merilis Visual-TableQA, sebuah benchmark penalaran tabel kompleks yang berisi 2.5K tabel dan 6K pasangan QA. Benchmark ini berfokus pada penalaran multi-langkah pada struktur visual, dan telah diverifikasi secara manual sebesar 92%, dengan biaya generasi kurang dari 100 dolar AS. Ini menyediakan sumber daya berkualitas tinggi untuk mengevaluasi dan meningkatkan kemampuan model dalam memahami dan menalar data tabel yang kompleks. (Sumber: huggingface)
Analisis Konsep AI Agents vs Agentic AI : Ada kebingungan umum di komunitas mengenai AI Agents dan sistem Agentic AI. AI Agents mengacu pada perangkat lunak otonom tunggal (LLM+alat) yang melakukan tugas spesifik, berperilaku reaktif, dan memiliki memori terbatas; Agentic AI mengacu pada sistem kolaborasi multi-agen (multi-LLM+orkestrasi+memori bersama), berperilaku proaktif, dan memiliki memori persisten. Memahami perbedaan antara keduanya sangat penting untuk keputusan arsitektur, menghindari pembangunan sistem yang tidak perlu kompleks. (Sumber: Reddit r/deeplearning)

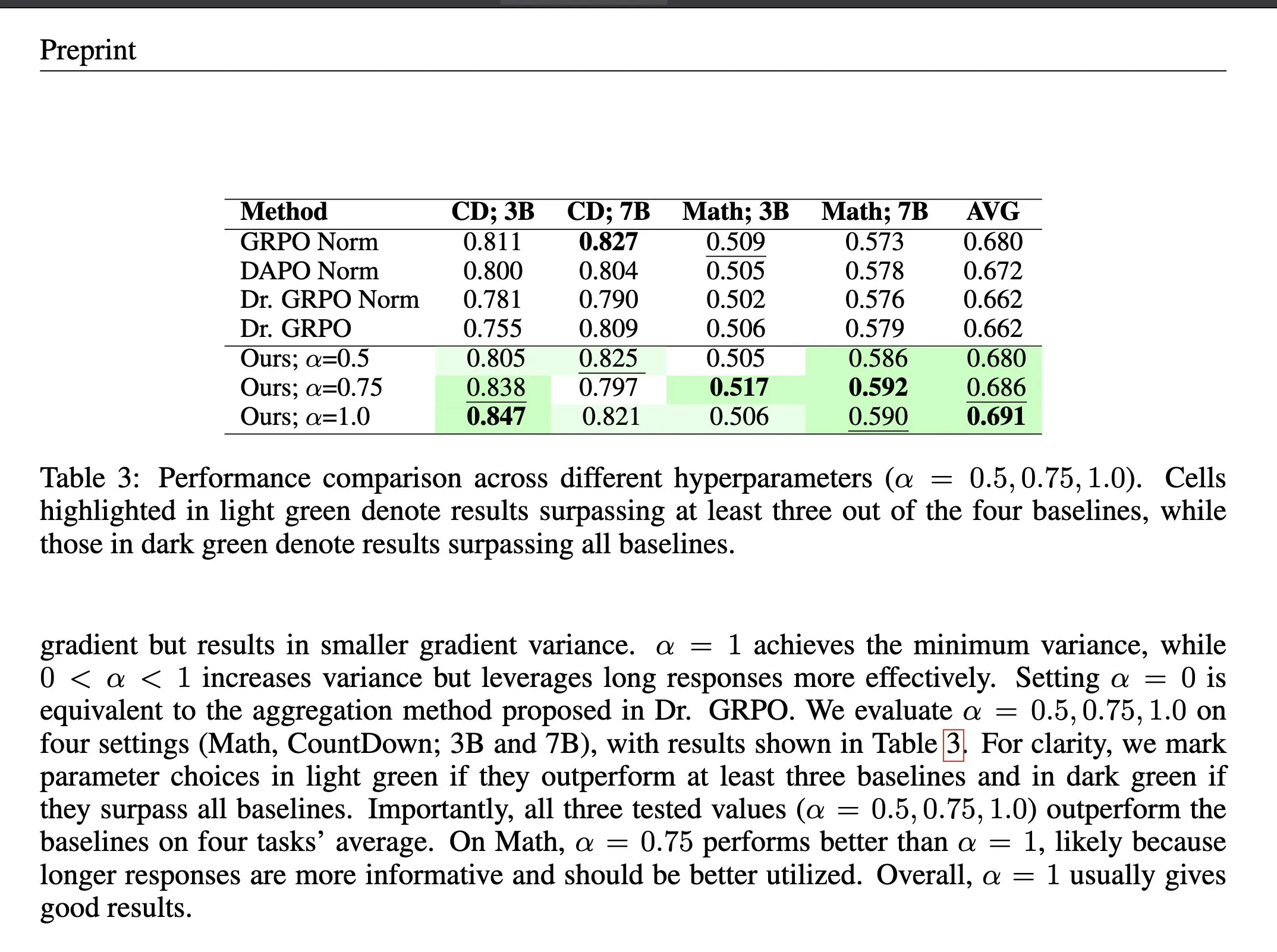
Metode Agregasi Loss ΔL Normalization dalam Reinforcement Learning : ΔL Normalization adalah metode agregasi loss yang dirancang khusus untuk karakteristik panjang yang dihasilkan secara dinamis dalam verifiable reward reinforcement learning (RLVR). Metode ini, dengan menganalisis dampak panjang yang berbeda terhadap policy loss, merekonstruksi masalah untuk menemukan estimator tak bias varians minimum, secara teoritis meminimalkan varians gradien. Eksperimen menunjukkan bahwa ΔL Normalization secara konsisten mencapai hasil yang sangat baik pada berbagai skala model, panjang maksimum, dan tugas, menyelesaikan tantangan varians gradien tinggi dan optimasi yang tidak stabil dalam RLVR. (Sumber: HuggingFace Daily Papers, teortaxesTex)
Video Kuliah Perbandingan Arsitektur LLM : Rasbt merilis video kuliah analisis perbandingan 11 arsitektur LLM tahun 2025, mencakup DeepSeek V3/R1, OLMo 2, Gemma 3, Mistral Small 3.1, Llama 4, Qwen3, SmolLM3, Kimi 2, GPT-OSS, Grok 2.5, dan GLM-4.5. Kuliah ini memberikan gambaran umum arsitektur LLM yang komprehensif bagi pengembang dan peneliti, membantu memahami filosofi desain dan karakteristik kinerja model yang berbeda. (Sumber: rasbt)
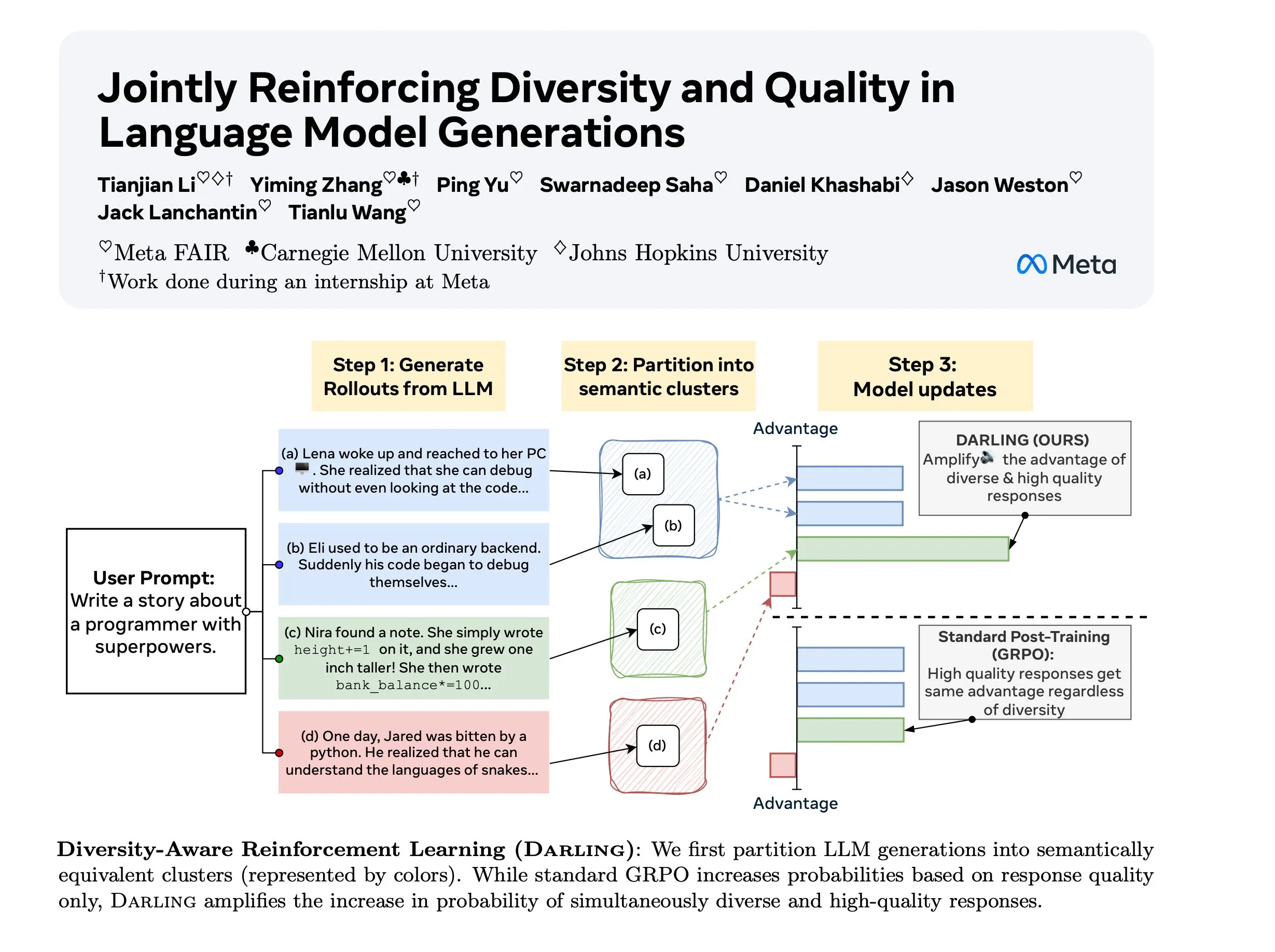
Penelitian Diversity Aware RL (DARLING) : DARLING (Diversity Aware RL) adalah metode reinforcement learning baru yang mengoptimalkan kualitas dan keragaman secara bersamaan dengan mempelajari fungsi partisi. Metode ini mengungguli RL standar dalam metrik kualitas dan keragaman, misalnya pass@1/p@k yang lebih tinggi, dan berlaku untuk tugas yang tidak dapat diverifikasi maupun yang dapat diverifikasi, memberikan cara baru untuk meningkatkan kemampuan generalisasi RL di lingkungan yang kompleks. (Sumber: ylecun)
Stanford CS 224N: Kursus Deep Learning dan NLP : Kursus Stanford University CS 224N menawarkan pengajaran komprehensif tentang Deep Learning dan Natural Language Processing. Kursus ini tersedia secara publik melalui video YouTube, menyediakan sumber belajar AI berkualitas tinggi bagi pelajar di seluruh dunia, mencakup teori dasar NLP, model terbaru, dan aplikasi praktis, menjadikannya kursus pengantar penting untuk memasuki bidang AI. (Sumber: stanfordnlp)
💼 Bisnis
Kebijakan Privasi Baru Anthropic Memicu Kontroversi: Kerugian Sistemik bagi Pengembang Independen : Kebijakan privasi baru Anthropic mengharuskan pengguna untuk memilih apakah mengizinkan penggunaan data percakapan mereka untuk pelatihan AI dan penyimpanan selama 5 tahun sebelum 28 September, jika tidak, mereka akan kehilangan fitur memori dan personalisasi. Langkah ini dikritik karena menciptakan “sistem dua tingkat”, menempatkan pengembang independen di antara pilihan privasi dan fungsionalitas, di mana kode proprietary mereka dapat menjadi data pelatihan AI perusahaan, sementara pelanggan perusahaan dapat menikmati perlindungan privasi dan personalisasi dengan biaya mahal, memicu kekhawatiran tentang demokratisasi AI dan ekstraksi inovasi. (Sumber: Reddit r/ClaudeAI)
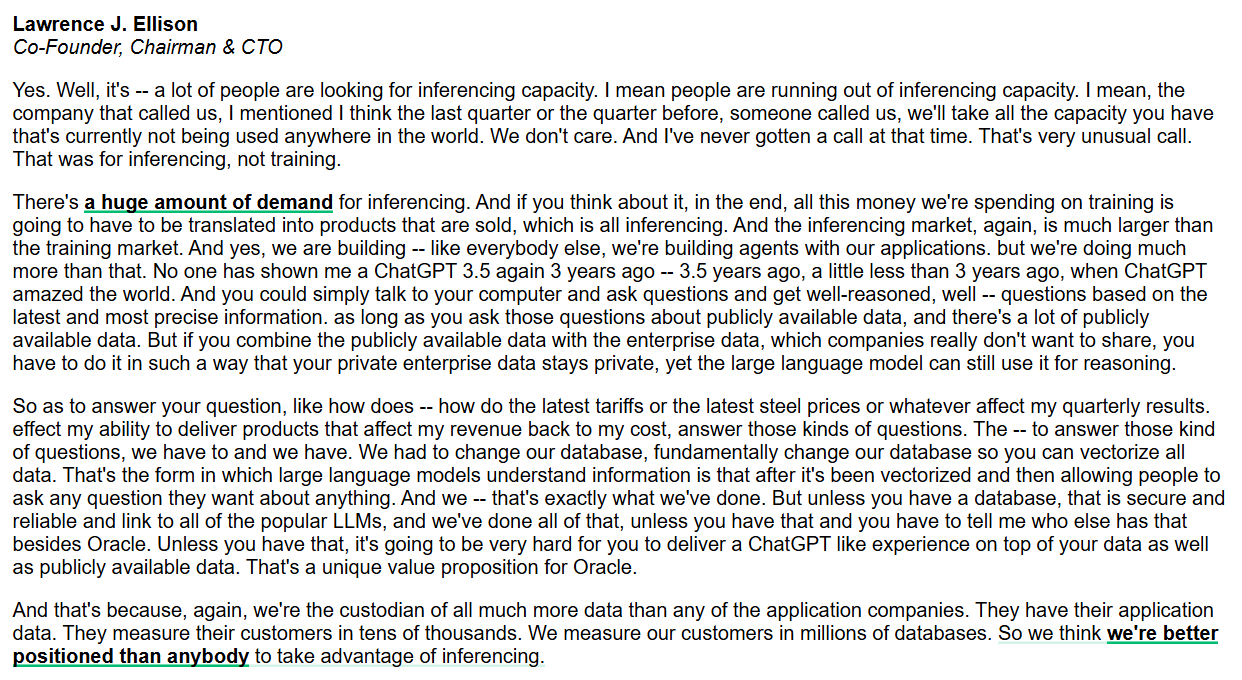
Oracle Fokus pada Kemampuan Inferensi dan Database AI Tingkat Perusahaan : CEO Oracle Larry Ellison menekankan bahwa pasar kemampuan inferensi jauh lebih besar daripada pasar pelatihan, dan permintaannya sangat besar. Oracle, dengan secara fundamental mengubah database untuk memvektorisasi semua data dan memastikan keamanan serta keandalannya, bertujuan untuk menyediakan pengalaman seperti ChatGPT yang menggabungkan data publik dan privat perusahaan. Oracle percaya bahwa sebagai penyedia data, mereka memiliki keunggulan unik dalam menyediakan layanan inferensi AI tingkat perusahaan. (Sumber: JonathanRoss321)
Standar Lisensi Konten AI Baru RSL Standard: Mendorong Perusahaan AI untuk Membayar : Reddit, Yahoo, Quora, dan wikiHow serta merek-merek besar lainnya mendukung Really Simple Licensing (RSL) Standard, sebuah standar lisensi konten terbuka yang bertujuan untuk memungkinkan penerbit web menetapkan ketentuan bagi pengembang sistem AI yang menggunakan karya mereka. RSL didasarkan pada protokol robots.txt, memungkinkan situs web untuk menambahkan ketentuan lisensi dan royalti, mengharuskan AI crawler untuk membayar data pelatihan (berlangganan atau membayar per crawl/inferensi), untuk memastikan bahwa pembuat konten menerima kompensasi yang adil. (Sumber: Reddit r/artificial)
🌟 Komunitas
Koeksistensi dan Peningkatan AI dengan Kecerdasan Manusia : Komunitas mendiskusikan apakah AI berfungsi sebagai “korektor kognitif” yang membantu kecerdasan manusia (seperti sempoa), atau sebagai “pesaing” yang menggantikan manusia (seperti kalkulator). François Chollet mengemukakan analogi “sepeda pikiran”, menekankan bahwa teknologi harus memperbesar upaya manusia daripada membuat manusia tidak melakukan apa-apa, memicu pemikiran filosofis tentang hubungan antara AI dan kecerdasan manusia (IA) serta arah pengembangan di masa depan. (Sumber: rao2z)
Dilema PR Industri AI dan Sentimen Negatif Publik : Meskipun produk AI memiliki miliaran pengguna dan banyak orang mendapatkan manfaat darinya, industri AI secara umum menghadapi sentimen negatif publik. Ada pandangan bahwa ini disebabkan oleh kegagalan para pemimpin industri dalam berkomunikasi secara efektif dalam hubungan masyarakat, yang menyebabkan prasangka publik terhadap perusahaan AI. Beberapa juga berspekulasi bahwa ini mungkin disengaja oleh industri AI, bertujuan untuk mengonsentrasikan teknologi inti dan keunggulan pada segelintir pemain. (Sumber: Dorialexander)
Dampak Kelemahan dalam Sistem Multi-Agen LLM : Penelitian menunjukkan bahwa dalam sistem multi-agen, penggunaan model bahasa kecil tidak selalu merupakan pilihan ideal. Dalam skenario seperti debat multi-agen, agen LLM yang lebih lemah seringkali mengganggu atau bahkan merusak kinerja agen yang lebih kuat, menyebabkan penurunan kinerja sistem secara keseluruhan. Ini mengungkapkan bahwa dalam merancang dan menerapkan sistem multi-agen, perlu mempertimbangkan dengan cermat perbedaan kemampuan setiap agen dan potensi dampak interaksi negatifnya. (Sumber: omarsar0)

Keterbatasan Data Sintetis untuk AGI : Andrew Trask dan Fei-Fei Li menunjukkan bahwa data sintetis adalah strategi yang lemah bagi LLM untuk mencapai AGI. Data sintetis tidak dapat menciptakan informasi baru (seperti entitas yang belum pernah didengar model), hanya dapat mengungkapkan inferensi alami dari informasi yang ada. Meskipun data sintetis dapat menyelesaikan masalah seperti “inversion curse” melalui permutasi logis dan kombinasi fakta yang diketahui, hambatan informasinya membatasi potensinya sebagai “silver bullet” AGI, dan terobosan sebenarnya mungkin terletak pada kecerdasan global dan pengambilan konteks secara instan. (Sumber: algo_diver, jpt401)
AI dan Pasar Kerja Manusia: Lingkaran Setan AI Menulis CV dan AI Menyaring CV : AI memicu lingkaran setan “tidak ada yang dipekerjakan” di pasar kerja: pencari kerja menggunakan AI untuk menulis CV, dan HR menggunakan AI untuk menyaring CV, yang mengarah pada “peningkatan” efisiensi tetapi tidak ada yang dipekerjakan. Alasan penolakan CV oleh AI sangat bervariasi, bahkan HR juga mengeluh bahwa CV yang dihasilkan AI seragam. Ini menyoroti tantangan baru yang dibawa oleh AI dalam rekrutmen, yang dapat menyebabkan proses rekrutmen menjadi kaku dan gagal mengidentifikasi talenta sejati. (Sumber: 量子位)

Tantangan yang Dihadapi Etikus AI : Seiring dengan pesatnya perkembangan teknologi AI, para etikus AI menghadapi dilema “berteriak ke dalam kehampaan”. Perlombaan AI yang didorong kapitalisme membuat pertimbangan etika terpinggirkan, dengan kecepatan kemajuan teknologi jauh melampaui integrasi etika. Para ahli khawatir bahwa jika menunggu sampai bahaya muncul secara massal baru bertindak, mungkin sudah terlambat, dan menyerukan industri untuk memasukkan jaminan etika sebagai pertimbangan inti. (Sumber: Reddit r/ArtificialInteligence)

Masa Depan Internet: Lalu Lintas Bot Melebihi Manusia : Ada tren yang menunjukkan bahwa dalam tiga tahun ke depan, interaksi yang digerakkan oleh bot di internet akan jauh melebihi interaksi manusia, membuat internet “mati suri”. Penelitian telah menunjukkan bahwa lalu lintas bot telah melebihi 50%. Ini memicu kekhawatiran tentang bagaimana membedakan suara manusia asli dari konten yang dihasilkan AI, serta keaslian informasi internet, menandakan bahwa ekosistem jaringan akan mengalami perubahan fundamental. (Sumber: Reddit r/artificial)

Penurunan Kinerja Claude Code dan Kehilangan Pengguna : Pengguna Claude Code dari Anthropic melaporkan penurunan kinerja model yang signifikan baru-baru ini, ditunjukkan dengan kualitas kode yang memburuk, generasi kode yang redundan, kualitas pengujian yang rendah, over-engineering, dan kemampuan pemahaman yang melemah. Banyak pengguna mempertimbangkan untuk beralih ke alternatif seperti GPT-5, GLM-4.5, Qwen3, dan menyerukan Anthropic untuk meningkatkan transparansi, menjelaskan alasan kemunduran model dan langkah-langkah perbaikan, jika tidak, mereka akan menghadapi kehilangan pengguna. (Sumber: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
💡 Lain-lain
Potensi AI dan VR dalam Koreksi Kriminal : Ada pandangan yang mengusulkan penggunaan teknologi AI dan VR yang murah untuk menyediakan VR pod wajib bagi pasien psikiatri kriminal, untuk mengisolasi mereka dari masyarakat dengan biaya yang lebih rendah dari biaya akomodasi tradisional. Gagasan radikal ini memicu diskusi tentang AI dalam kontrol sosial, sistem hukuman, dan batas-batas etika, meskipun kelayakan dan kemanusiaannya masih diperdebatkan, namun ini mengungkapkan arah aplikasi potensial teknologi dalam memecahkan masalah sosial. (Sumber: gfodor, gfodor)
Konsep Penerapan Replit di Penjara : Seorang pengguna mengusulkan gagasan untuk memperkenalkan Replit (platform pemrograman online) ke penjara, dengan alasan bahwa ini dapat menggantikan fasilitas hiburan dan memungkinkan narapidana menciptakan produk yang berharga melalui pemrograman. Ide ini mengeksplorasi peran potensial teknologi dalam transformasi sosial, penyediaan pelatihan keterampilan, dan promosi reintegrasi narapidana ke masyarakat, memicu diskusi tentang kesetaraan pendidikan dan pemberdayaan teknologi. (Sumber: amasad)