
Kata Kunci:Tesla, Optimus Robot, AI, GPT-5, Pelatihan Model Besar, Meta AI, Pra-pelatihan LLM, Fungsi Kerugian Ikan Mas (Goldfish Loss Function), Model DynaGuard Dynamic Barrier, Arsitektur Jaringan GAM, Segmentasi Gambar Medis MedDINOv3, Pencarian Gambar Medis Multimodal M3Ret
🔥 FOKUS
Elon Musk Merilis ‘Master Plan Part IV’: 80% Nilai Tesla Berasal dari Robot : Tesla secara resmi merilis “Master Plan Part IV”, dengan inti membawa AI ke dunia fisik nyata, dan melalui unifikasi besar-besaran perangkat keras dan perangkat lunak Tesla, mencapai “kemakmuran berkelanjutan”. Musk menunjukkan bahwa sekitar 80% nilai Tesla di masa depan akan berasal dari robot humanoid Optimus, menandakan pergeseran paradigma perusahaan dari kendaraan listrik menuju integrasi mendalam energi, AI, dan robotika, berkomitmen untuk memecahkan masalah dunia nyata melalui teknologi dan memberi manfaat bagi seluruh umat manusia. (Sumber: 量子位)
🎯 PERKEMBANGAN
AI Meraih Medali Emas dalam Kompetisi Olimpiade Matematika Internasional : GPT dari OpenAI dan Gemini dari Google DeepMind meraih medali emas dalam kompetisi Olimpiade Matematika Internasional, mematahkan prediksi para ahli dan menunjukkan kemajuan luar biasa LLM dalam penalaran matematika, menandakan bahwa kecepatan pengembangan AI jauh melampaui perkiraan dan memasuki era “kecerdasan massal”. Ini bukan hanya terobosan teknologi, tetapi juga memicu diskusi mendalam tentang batas kemampuan AI dan dampaknya di masa depan terhadap masyarakat. (Sumber: 36氪)
GPT-5 Berkinerja Unggul dalam Game Werewolf : Dalam benchmark Werewolf AIWolfDial 2025, GPT-5 memimpin secara signifikan dengan tingkat kemenangan 96,7%, menunjukkan kemampuan penalaran sosial, penipuan, dan anti-manipulasi yang kuat. Kimi-K2 menunjukkan gaya “bluffing” yang berani dan agresif, mencerminkan pola perilaku individual LLM dalam interaksi sosial yang kompleks. (Sumber: 量子位, Reddit r/deeplearning)
Metode Baru Pelatihan Model Besar ‘Goldfish Loss’ : Tim peneliti dari University of Maryland dan lainnya mengusulkan “Goldfish Loss”, yang secara efektif mengurangi memorisasi model besar dengan secara acak menghilangkan sebagian token saat menghitung fungsi loss, sehingga model tidak lagi menghafal data pelatihan, tanpa memengaruhi kinerja tugas hilir, dan meningkatkan kemampuan generalisasi model. (Sumber: 量子位)
Restrukturisasi Departemen AI Internal Meta Menimbulkan Kontroversi : Chief AI Officer Meta, Alexandr Wang, menerapkan aturan baru yang mengharuskan publikasi makalah FAIR melalui tinjauan laboratorium TBD, dan berpotensi “menahan” makalah berharga serta penulisnya untuk implementasi produk. Langkah ini memicu ketidakpuasan di kalangan staf FAIR, dengan beberapa karyawan mengundurkan diri, menyoroti intervensi Meta terhadap independensi penelitian dan sikap kerasnya terhadap komersialisasi hasil dalam penyesuaian strategi AI. (Sumber: 量子位)
Benchmark Kinerja Optimizer Pra-pelatihan LLM : Sebuah studi sistematis dilakukan terhadap sepuluh optimizer deep learning, mencakup berbagai ukuran model dan rasio data-model. Ditemukan bahwa perbandingan yang adil memerlukan penyesuaian hyperparameter yang ketat dan evaluasi kinerja pada akhir pelatihan. Penelitian menunjukkan bahwa peningkatan kecepatan optimizer berbasis matriks (seperti Muon dan Soap) berkurang seiring dengan peningkatan ukuran model, hanya 1,1 kali untuk model 1.2B, memberikan panduan untuk pemilihan optimizer pra-pelatihan LLM dan penelitian di masa depan. (Sumber: HuggingFace Daily Papers, HuggingFace Daily Papers)
DynaGuard: Model Penjaga Dinamis dengan Kebijakan yang Ditentukan Pengguna : Diusulkan model penjaga dinamis DynaGuard, yang mampu mengevaluasi teks berdasarkan kebijakan yang ditentukan pengguna dan dengan cepat mendeteksi pelanggaran. Model ini memiliki akurasi yang sebanding dengan model penjaga standar dalam deteksi kategori bahaya statis, sekaligus dapat mengidentifikasi pelanggaran kebijakan bentuk bebas dalam waktu yang lebih singkat, menyediakan pengawasan output yang fleksibel dan efisien untuk chatbot. (Sumber: HuggingFace Daily Papers)
Jaringan Gated Associative Memory (GAM) : Diusulkan jaringan GAM, arsitektur pemodelan sekuensial paralel penuh jenis baru, yang kompleksitasnya linear dengan panjang sekuens (O(N)), memecahkan bottleneck kompleksitas kuadrat dari mekanisme self-attention Transformer. GAM menggabungkan konvolusi kausal dan pengambilan memori asosiatif paralel, menunjukkan kecepatan pelatihan yang lebih cepat dan perplexity validasi yang lebih baik atau sebanding dibandingkan Transformer dan Mamba pada dataset WikiText-2 dan TinyStories. (Sumber: HuggingFace Daily Papers)
Reasoning Vectors: Mentransfer Kemampuan Chain-of-Thought melalui Aritmetika Tugas : Penelitian menunjukkan bahwa kemampuan penalaran LLM dapat diekstraksi dan ditransfer antar model sebagai vektor tugas yang ringkas. Dengan menghitung perbedaan vektor antara model fine-tuned dan model SFT, lalu menambahkannya ke model fine-tuned instruksi lainnya, kinerja model pada berbagai benchmark penalaran seperti GSM8K dan HumanEval dapat terus ditingkatkan, menyediakan metode yang efisien dan dapat digunakan kembali untuk peningkatan kemampuan LLM. (Sumber: HuggingFace Daily Papers)
MedDINOv3: Model Fondasi Visual untuk Segmentasi Gambar Medis : Diluncurkan kerangka kerja MedDINOv3, yang secara efektif menerapkan DINOv3 untuk segmentasi gambar medis dengan mendesain ulang backbone ViT dan melakukan pra-pelatihan adaptasi domain pada dataset CT-3M. Model ini mencapai atau melampaui kinerja SOTA dalam beberapa benchmark segmentasi, menunjukkan potensi besar model fondasi visual sebagai jaringan backbone terpadu untuk segmentasi gambar medis. (Sumber: HuggingFace Daily Papers)
M3Ret: Zero-Shot Multimodal Medical Image Retrieval : M3Ret mencapai kinerja SOTA dalam zero-shot image-to-image retrieval dengan melatih encoder visual terpadu pada dataset multimodal campuran berskala besar. Model ini menunjukkan kemampuan generalisasi yang kuat pada tugas MRI yang belum pernah dilihat, dan melalui paradigma pembelajaran self-supervised generatif dan kontrastif, mendorong pengembangan model fondasi self-supervised visual dalam pemahaman gambar medis multimodal. (Sumber: HuggingFace Daily Papers)
OpenVision 2: Encoder Visual Generatif untuk Pembelajaran Multimodal : OpenVision 2 menyederhanakan arsitektur dan desain loss, menghilangkan encoder teks dan contrastive loss, hanya mempertahankan caption generation loss. Sinyal pelatihan generatif murni ini berkinerja sangat baik dalam benchmark multimodal, sekaligus secara signifikan mengurangi waktu pelatihan dan konsumsi memori, menyediakan paradigma efisien untuk pengembangan encoder visual model fondasi multimodal di masa depan. (Sumber: HuggingFace Daily Papers)
LLaVA-Critic-R1: Model Evaluasi Juga Dapat Menjadi Model Kebijakan yang Kuat : LLaVA-Critic-R1 mengubah dataset evaluasi beranotasi preferensi menjadi sinyal yang dapat diverifikasi melalui pelatihan RL, tidak hanya menjadi model evaluasi berkinerja tinggi, tetapi juga model kebijakan yang kompetitif, melampaui VLM profesional dalam beberapa benchmark penalaran dan pemahaman visual, dan dapat lebih meningkatkan kinerja penalaran melalui self-criticism saat pengujian. (Sumber: HuggingFace Daily Papers)
Metis: Pelatihan LLM dengan Kuantisasi Bit Rendah : Kerangka kerja Metis memecahkan masalah distribusi parameter anisotropik dalam pelatihan LLM dengan kuantisasi bit rendah melalui kombinasi dekomposisi spektral, laju pembelajaran adaptif, dan regularisasi rentang ganda. Metode ini memungkinkan pelatihan FP8 melampaui baseline FP32, dan pelatihan FP4 mencapai akurasi FP32, membuka jalan bagi pelatihan LLM yang kuat dan skalabel di bawah kuantisasi bit rendah tingkat lanjut. (Sumber: HuggingFace Daily Papers)
AMBEDKAR: Kerangka Penghapusan Bias Multilevel : Diusulkan kerangka kerja AMBEDKAR, terinspirasi oleh visi kesetaraan Konstitusi India, yang secara aktif mengurangi bias seputar kasta dan agama dalam LLM selama inferensi melalui lapisan decoding yang sadar konstitusi dan algoritma decoding spekulatif. Metode ini tidak memerlukan modifikasi parameter model, mengurangi biaya komputasi, dan secara signifikan mengurangi bias, menyediakan pendekatan baru untuk keadilan LLM dalam konteks budaya tertentu. (Sumber: HuggingFace Daily Papers)
C-DiffDet+: Deteksi Objek Fidelitas Tinggi dengan Fusi Konteks Adegan Global : Diusulkan C-DiffDet+, yang secara signifikan meningkatkan paradigma deteksi generatif dengan memperkenalkan mekanisme Context-Aware Fusion (CAF) untuk mengintegrasikan konteks adegan global langsung dengan fitur proposal lokal. Kerangka kerja ini menggunakan encoder khusus untuk menangkap informasi lingkungan yang komprehensif, memungkinkan setiap proposal objek untuk fokus pada pemahaman tingkat adegan, sehingga melampaui model SOTA dalam benchmark CarDD. (Sumber: HuggingFace Daily Papers)
GenCompositor: Sintesis Video Generatif Berbasis Diffusion Transformer : Diusulkan GenCompositor, yang mencapai sintesis video generatif interaktif melalui pipeline Diffusion Transformer (DiT) yang inovatif. Metode ini merancang cabang pelestarian latar belakang ringan dan blok fusi DiT, serta memperkenalkan Extended Rotary Position Embedding (ERoPE), mencapai sintesis video dengan fidelitas tinggi dan konsistensi pada dataset VideoComp, melampaui solusi yang ada. (Sumber: HuggingFace Daily Papers)
ELV-Halluc: Benchmark Halusinasi Agregasi Semantik dalam Pemahaman Video Panjang : Diluncurkan ELV-Halluc, benchmark pertama yang khusus menargetkan halusinasi video panjang, secara sistematis meneliti Semantic Aggregation Hallucination (SAH). Eksperimen mengkonfirmasi keberadaan SAH, dan seiring dengan peningkatan kompleksitas semantik, lebih mudah terjadi pada semantik yang berubah cepat. Penelitian juga menunjukkan bahwa strategi positional encoding dan DPO dapat mengurangi SAH, secara signifikan menurunkan rasio SAH melalui pasangan data adversarial. (Sumber: HuggingFace Daily Papers)
FastFit: Model Difusi yang Dapat Di-cache untuk Mempercepat Virtual Try-On : Diusulkan FastFit, kerangka kerja virtual try-on multi-referensi berkecepatan tinggi, berdasarkan arsitektur difusi yang dapat di-cache. Melalui mekanisme semi-attention dan class embedding, encoding fitur referensi dipisahkan dari proses denoising, memungkinkan perhitungan fitur referensi sekali dan penggunaan kembali tanpa kehilangan, dengan percepatan rata-rata 3,5 kali, dan melampaui metode SOTA pada dataset seperti DressCode-MR. (Sumber: HuggingFace Daily Papers)
🧰 ALAT
Fitur ‘nano-banana’ Google Gemini : Google Gemini meluncurkan fitur “nano-banana”, di mana pengguna hanya perlu satu prompt untuk mengubah foto menjadi gambar bergaya model miniatur. Pengoperasiannya sederhana dan kreatif, memberikan pengalaman menyenangkan bagi pengguna untuk mengubah foto pribadi, pemandangan, atau foto hewan peliharaan menjadi model miniatur yang disesuaikan. (Sumber: GoogleDeepMind)

Kemampuan Generasi Gambar Wan2.2 dari Alibaba_Wan : Alibaba_Wan menunjukkan kemampuan restorasi detail yang luar biasa dari Wan2.2 dalam generasi gambar, dari “kapak miring dan foto berdebu” hingga “gerakan samar dalam bayangan”, menciptakan suasana seperti film horor dengan sempurna, mencerminkan potensi kuat AI dalam menciptakan adegan dan emosi yang kompleks. (Sumber: Alibaba_Wan, Alibaba_Wan)
Fungsi Pembacaan File Lengkap Claude Code : Claude Code yang diperbarui kini mendukung pembacaan file lengkap, mengatasi batasan sebelumnya dari grep 50/100 baris yang digabungkan, dan secara signifikan meningkatkan kecepatan pembacaan file, mencapai tingkat kecepatan Gemini CLI, mungkin berkat peningkatan perangkat keras backend (seperti TPU), meskipun ukuran konteks masih menunjukkan 200k. (Sumber: Reddit r/ClaudeAI)
Le Chat Mengintegrasikan Konektor MCP dan Fitur Memori : Le Chat kini mengintegrasikan lebih dari 20 konektor platform perusahaan (berbasis MCP) dan memperkenalkan fitur “memori”, menyediakan respons yang sangat personal, sekaligus mendukung impor memori ChatGPT. Ini meningkatkan kemampuan aplikasi Le Chat di lingkungan perusahaan, memungkinkannya memahami preferensi pengguna dan fakta dengan lebih baik, serta meningkatkan utilitas asisten AI. (Sumber: Reddit r/LocalLLaMA)

Alat LangExtract Google : Google merilis LangExtract, sebuah alat untuk mengekstrak knowledge graph dari teks. Ini dapat mengubah teks tidak terstruktur menjadi pengetahuan terstruktur, sangat bermanfaat untuk implementasi RAG (Retrieval Augmented Generation), membantu proyek pribadi membangun knowledge graph, dan menyediakan informasi konteks yang lebih akurat untuk LLM. (Sumber: Reddit r/LocalLLaMA)
Ekosistem Server Model Context Protocol (MCP) : Proyek GitHub appcypher/awesome-mcp-servers mengumpulkan banyak server MCP, memungkinkan model AI berinteraksi dengan aman dengan sumber daya lokal dan jarak jauh seperti sistem file, database, API, dll. Ekosistem ini sangat memperluas kemampuan agen AI, mencakup berbagai bidang seperti sistem file, sandbox, kontrol versi, penyimpanan cloud, database, dll., mendorong integrasi dan aplikasi alat AI. (Sumber: GitHub Trending)

Sistem Universal Deep Research (UDR) : UDR adalah sistem agen universal yang dapat membungkus model bahasa apa pun, dan memungkinkan pengguna untuk membuat, mengedit, dan menyempurnakan strategi penelitian mendalam yang sepenuhnya disesuaikan, tanpa pelatihan atau fine-tuning tambahan. Ini memfasilitasi eksperimen sistem dengan menyediakan contoh strategi penelitian minimal, diperluas, dan padat, meningkatkan fleksibilitas dan efisiensi penelitian AI. (Sumber: HuggingFace Daily Papers)
SQL-of-Thought: Kerangka Kerja Multi-Agen Text-to-SQL : Diusulkan SQL-of-Thought, sebuah kerangka kerja multi-agen yang menguraikan tugas Text2SQL menjadi pattern linking, identifikasi sub-masalah, pembuatan rencana query, pembuatan SQL, dan siklus koreksi kesalahan terpandu. Kerangka kerja ini mencapai hasil SOTA pada dataset Spider dengan menggabungkan klasifikasi kesalahan terpandu dan perencanaan query berbasis penalaran, meningkatkan ketahanan konversi bahasa alami ke SQL. (Sumber: HuggingFace Daily Papers)
VerlTool: Kerangka Pembelajaran Penguatan Agentic untuk Penggunaan Alat : VerlTool adalah kerangka kerja terpadu dan modular yang dirancang untuk mengatasi fragmentasi, bottleneck eksekusi sinkron, dan batasan skalabilitas dalam Agentic Reinforcement Learning (ARLT) untuk interaksi alat multi-putaran. Ini mencapai peningkatan kecepatan hampir 2 kali lipat melalui penyelarasan hulu dengan VeRL, manajemen alat terpadu, eksekusi rollout asinkron, dan evaluasi komprehensif, serta menunjukkan kinerja kompetitif di 6 domain ARLT. (Sumber: HuggingFace Daily Papers)
MobiAgent: Sistem Agen Seluler yang Dapat Disesuaikan : MobiAgent adalah sistem agen seluler komprehensif yang mencakup seri model agen MobiMind, kerangka akselerasi AgentRR, dan suite benchmark MobiFlow. Ini secara signifikan mengurangi biaya anotasi data berkualitas tinggi melalui proses pengumpulan data yang dibantu AI, dan mencapai kinerja SOTA dalam skenario seluler dunia nyata, mengatasi tantangan akurasi dan efisiensi agen seluler GUI yang ada. (Sumber: HuggingFace Daily Papers)
VARIN: Pengeditan Gambar Autoregresif Berbasis Teks : VARIN adalah teknologi pengeditan gambar model VAR pertama yang berbasis inversi noise, menggunakan Location-aware Argmax Inversion (LAI) untuk menghasilkan inverse Gumbel noise, mencapai rekonstruksi gambar sumber yang akurat dan pengeditan berbasis teks yang terkontrol. Metode ini secara signifikan mempertahankan latar belakang asli dan detail struktural saat memodifikasi gambar, menunjukkan efektivitasnya sebagai metode pengeditan yang praktis. (Sumber: HuggingFace Daily Papers)
📚 PEMBELAJARAN
Saran Proyek Kursus AI Universitas : Pengguna Reddit mencari saran proyek interaktif untuk kursus “Dasar-dasar Kecerdasan Buatan”, yang tidak bergantung pada komputer berperforma tinggi. Diskusi berpusat pada apa yang dapat dilakukan LLM, fungsi perangkat pintar, dan bagaimana menggabungkan konsep-konsep ini dalam pengajaran, menekankan proyek-proyek yang praktis dan membutuhkan kemampuan komputasi rendah. (Sumber: Reddit r/ArtificialInteligence)
Kumpulan Sumber Daya Mahasiswa GitHub : dipakkr/A-to-Z-Resources-for-Students adalah daftar sumber daya yang dikurasi dengan cermat untuk mahasiswa, mencakup pembelajaran bahasa pemrograman (Python, ML, LLM, DL, Android, dll.), hackathon, kesejahteraan mahasiswa, proyek open-source, portal magang, komunitas pengembang, dll. Bagian alat dan sumber daya AI secara rinci mencantumkan alat AI populer dan repositori GitHub. (Sumber: GitHub Trending)

Cara Memahami Makalah Penelitian dan Panduan Pemula AI/ML : Dua diskusi di Reddit tentang pembelajaran AI, satu menanyakan cara memahami makalah penelitian, dan yang lainnya adalah pemula AI/ML yang mencari saran kursus pengantar. Diskusi ini mencerminkan kebingungan umum di kalangan pembelajar AI dalam memahami penelitian mutakhir dan memilih jalur pembelajaran. (Sumber: Reddit r/deeplearning, Reddit r/deeplearning)
FlashAdventure: Benchmark Game Petualangan untuk GUI Agent : FlashAdventure adalah benchmark yang berisi 34 game petualangan Flash, bertujuan untuk mengevaluasi kemampuan agen GUI yang didorong LLM untuk menyelesaikan alur cerita lengkap, dan mengatasi masalah “kesenjangan observasi-perilaku”. Kerangka kerja COAST meningkatkan perencanaan melalui memori petunjuk jangka panjang, meningkatkan tingkat penyelesaian milestone, tetapi masih ada kesenjangan signifikan dengan kinerja manusia. (Sumber: HuggingFace Daily Papers)
The Gold Medals in an Empty Room: Mendiagnosis Penalaran Metalinguistik LLM : Diusulkan Camlang, bahasa buatan jenis baru, yang melalui buku tata bahasa dan kamus bilingual, mengevaluasi kemampuan pembelajaran deduktif metalinguistik LLM dalam bahasa yang tidak dikenal. Kinerja GPT-5 dalam tugas Camlang jauh di bawah manusia, menunjukkan bahwa model saat ini masih memiliki kesenjangan fundamental dengan manusia dalam penguasaan tata bahasa sistematis, menyediakan paradigma baru untuk evaluasi ilmu kognitif LLM. (Sumber: HuggingFace Daily Papers)
💼 BISNIS
Tantangan Taruhan Altman pada Infrastruktur AI India : OpenAI berencana untuk memperluas proyek “Stargate” secara besar-besaran di India, menginvestasikan dana besar untuk membangun infrastruktur komputasi AI, tetapi India menghadapi tantangan “tiga defisit” yaitu jumlah GPU, investasi dana, dan hilangnya talenta kelas atas, serta kekurangan pasokan listrik yang fatal, memicu keraguan pasar terhadap potensi infrastruktur AI-nya. (Sumber: 36氪)

AI Membentuk Kembali Siklus Pertumbuhan Baru Internet Tiongkok : Industri internet Tiongkok beralih dari “pemberdayaan koneksi” ke “penggerak cerdas”, dengan AI menjadi mesin pertumbuhan baru. Raksasa seperti Alibaba, Tencent, dan Baidu secara signifikan meningkatkan belanja modal terkait AI, mempercepat AI-isasi bisnis, dan mencapai transformasi strategis dari “penguasaan modal” menjadi “pemberdayaan AI”, menandakan bahwa internet Tiongkok memasuki dekade emas baru yang menekankan kedalaman teknologi, integrasi industri, dan efisiensi bisnis. (Sumber: 36氪)

Salesforce Mem-PHK 4000 Karyawan karena AI : CEO Salesforce Marc Benioff menyatakan bahwa setelah menerapkan agen AI, perusahaan telah memangkas 4000 posisi dukungan pelanggan, mengurangi jumlah tim dukungan dari 9000 menjadi sekitar 5000 orang. Ini menunjukkan dampak langsung otomatisasi AI terhadap pekerjaan tradisional, meningkatkan efisiensi operasional perusahaan, tetapi juga memicu diskusi tentang penggantian tenaga kerja manusia oleh AI. (Sumber: The Verge, Reddit r/ChatGPT)

🌟 KOMUNITAS
Keraguan atas Return on Investment (ROI) AI Perusahaan : Komunitas Reddit ramai membahas ROI aktual dari investasi perusahaan pada alat AI. Banyak yang mempertanyakan apakah perusahaan benar-benar mengukur “waktu yang dihemat” versus “uang yang dihabiskan”, berpendapat bahwa sebagian besar didorong oleh “suasana” daripada dukungan data. Beberapa komentar menunjukkan bahwa AI berkinerja baik dalam tugas teks, tetapi tidak efisien dalam skenario yang membutuhkan interaksi manusia, dan bahkan dapat menambah biaya pada proses yang sudah tidak efisien. (Sumber: Reddit r/ArtificialInteligence)
Kekhawatiran Etis Agen AI yang Menangani Uang Nyata : Diskusi media sosial tentang perkembangan pesat agen AI yang secara mandiri mengelola dompet kripto telah memicu kekhawatiran mendalam tentang kepercayaan, keamanan, dan pembentukan ekonomi AI yang otonom. Pengguna khawatir agen AI dapat dimanipulasi atau menciptakan sistem ekonomi independen, sehingga tidak lagi membutuhkan manusia, menyerukan perhatian pada pentingnya AI yang melindungi privasi dan model pelatihan data terenkripsi. (Sumber: Reddit r/ArtificialInteligence)
Tips Prompt Engineering ChatGPT dan Perilaku Model : Pengguna menemukan bahwa memulai pertanyaan dengan “Saya mungkin salah, tapi…” dapat mengubah nada ChatGPT, membuatnya lebih kritis dan reflektif. Pada saat yang sama, komunitas merasa jengkel dengan GPT-5 yang sering menawarkan “tugas tambahan”, menganggap ini sebagai tanda model yang “disederhanakan”, dan berharap ada versi dengan perilaku yang lebih sedikit diatur sebelumnya. (Sumber: Reddit r/ChatGPT, Reddit r/ChatGPT)
Dampak AI terhadap Pasar Kerja : Komunitas membahas apakah otomatisasi AI akan mengurangi peluang kerja global atau menciptakan jenis pekerjaan baru. Pandangan umum adalah keduanya, tetapi pekerja perlu beradaptasi dengan keterampilan baru dan berkolaborasi dengan AI. Ada juga yang berpendapat bahwa peluang kerja yang didorong AI mungkin terkonsentrasi di tangan teknisi, membutuhkan penyebaran keterampilan yang lebih luas dan adaptasi kebijakan. (Sumber: Reddit r/ArtificialInteligence)
Kekhawatiran ‘Musim Dingin AI’ karena Privasi dan Regulasi AI : Komunitas berpendapat bahwa “musim dingin AI” di masa depan mungkin disebabkan oleh undang-undang privasi daripada batasan teknis. Pengetatan regulasi seperti GDPR akan memaksa model AI untuk dilatih dan dijalankan pada data terenkripsi, dan hanya perusahaan dengan infrastruktur perlindungan privasi yang dapat bertahan, jika tidak, mereka mungkin tidak dapat menerapkan AI karena batasan kerangka hukum. (Sumber: Reddit r/ArtificialInteligence)
Kekhawatiran Keandalan dan Privasi Platform AI : Komunitas ChatGPT ramai membahas masalah downtime model, dengan pengguna bercanda “ekonomi runtuh”, mencerminkan popularitas alat AI dalam pekerjaan sehari-hari dan potensi ketergantungannya. Pada saat yang sama, OpenAI mengumumkan pemantauan “dialog berisiko tinggi” untuk mencegah kejahatan, memicu kekhawatiran pengguna tentang kebocoran privasi. Komunitas umumnya menyarankan penggunaan LLM lokal atau open-source, dan menekankan bahwa pengguna harus secara sadar menghindari berbagi informasi sensitif di platform AI. (Sumber: Reddit r/ChatGPT, Reddit r/ChatGPT)
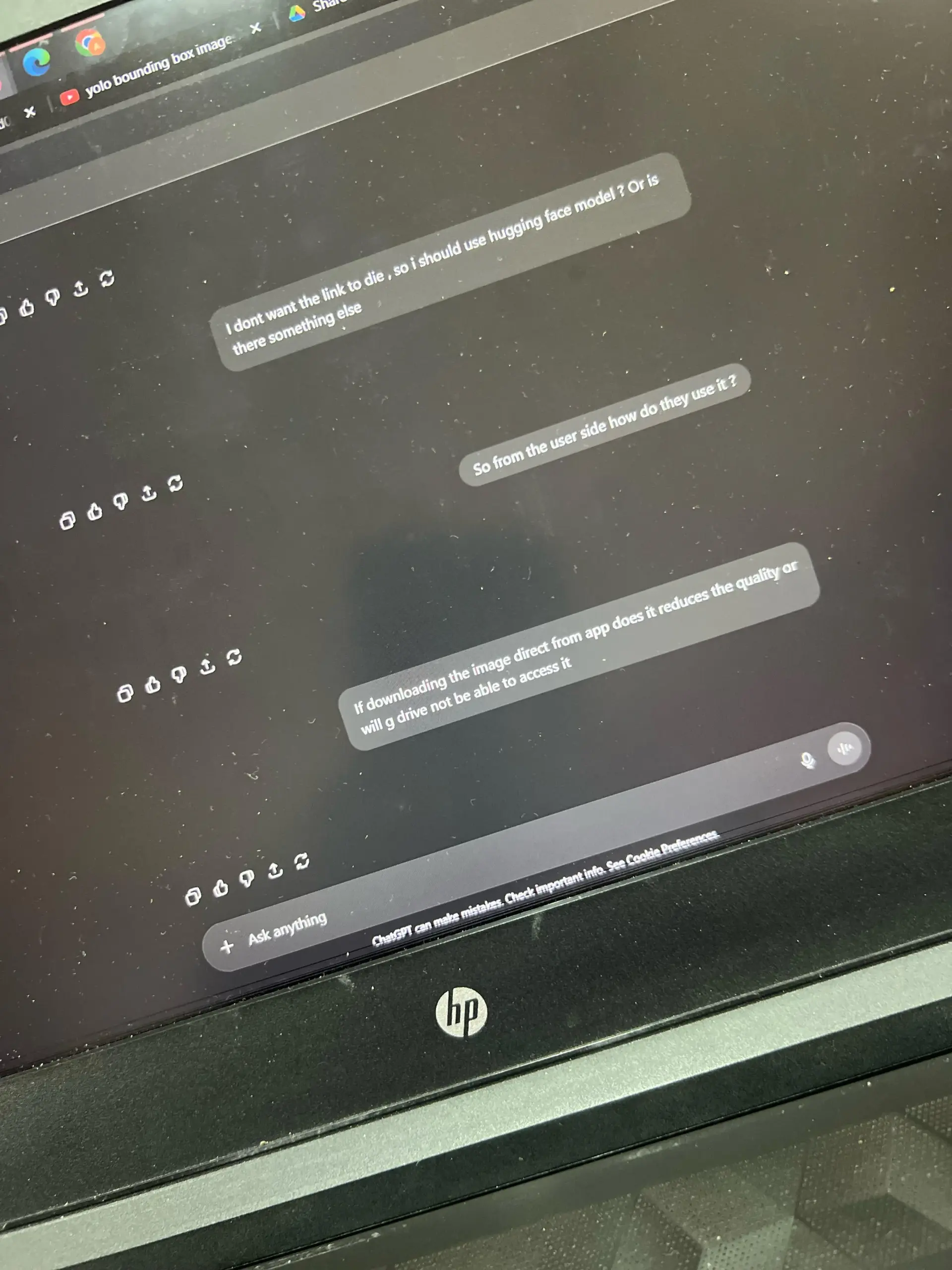
Kasus Kesalahan Kerja Akibat Halusinasi AI : Pacar seorang pengguna menghadapi krisis pekerjaan karena laporan analisis data palsu yang dihasilkan oleh halusinasi ChatGPT. ChatGPT secara keliru menganalisis data teks menggunakan “koefisien korelasi Pearson” dan tidak dapat menjelaskan proses perhitungannya. Komunitas menyarankan untuk mengakui kesalahan, melakukan analisis ulang yang benar, dan menekankan bahwa AI hanyalah alat bantu, informasi penting perlu diverifikasi secara manual. (Sumber: Reddit r/ChatGPT)
Performa ‘Menggemaskan’ Claude AI : Claude AI ditemukan oleh pengguna memiliki sifat “menghormati kehidupan”, bahkan dapat meyakinkan pengguna untuk menyelamatkan laba-laba. Pengguna komunitas memuji Claude “menggemaskan” dan berbagi pengalaman hidup berdampingan dengan laba-laba di rumah, mencerminkan potensi menarik AI dalam interaksi emosional dan panduan moral. (Sumber: Reddit r/ClaudeAI)
Trump Menyalahkan AI atas Masalah : Mantan Presiden AS Trump menyalahkan “generasi AI” atas video kantong sampah yang dilemparkan dari jendela Gedung Putih, meskipun pejabat telah mengkonfirmasi bahwa itu dilakukan oleh kontraktor renovasi. Insiden ini dijuluki di media sosial sebagai “AI adalah anjing baru yang memakan pekerjaan rumah saya”, mencerminkan bagaimana AI telah menjadi alasan baru untuk mengalihkan tanggung jawab dalam wacana publik. (Sumber: Reddit r/ArtificialInteligence, The Verge)

Diskusi Kemajuan LLM Open-Source dan Benchmark : Komunitas ramai membahas GPT-OSS 120B yang menjadi model open-source teratas, Swiss merilis model multilingual open-source baru Apertus-70B-2509, serta peluncuran model Kimi K2-0905. Pada saat yang sama, benchmark “Who Wants to Be a Millionaire” Jerman mengevaluasi LLM, memicu diskusi luas tentang kemampuan aktual model, signifikansi benchmark, dan etika model open-source (seperti transparansi data). (Sumber: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
💡 LAIN-LAIN
Yunpeng Technology Merilis Produk Baru AI+Kesehatan : Yunpeng Technology pada 22 Maret 2025, di Hangzhou, merilis produk baru bekerja sama dengan Shuaikang dan Skyworth, termasuk “Laboratorium Dapur Masa Depan Digital Cerdas” dan kulkas pintar yang dilengkapi dengan model besar AI kesehatan. Model besar AI kesehatan mengoptimalkan desain dan operasi dapur, dan kulkas pintar menyediakan manajemen kesehatan yang dipersonalisasi melalui “Asisten Kesehatan Xiaoyun”, menandai terobosan AI di bidang kesehatan. Peluncuran ini menunjukkan potensi AI dalam manajemen kesehatan sehari-hari, mewujudkan layanan kesehatan yang dipersonalisasi melalui perangkat pintar, diharapkan dapat mendorong pengembangan teknologi kesehatan keluarga dan meningkatkan kualitas hidup penduduk. (Sumber: 36氪)
Kekhawatiran Kualitas Peninjauan Makalah Konferensi Akademik : Komunitas Machine Learning membahas publikasi peninjauan makalah WACV 2026, serta masalah kualitas peninjauan ACL Rolling Review (ARR). Beberapa peneliti mengeluh bahwa ARR dipenuhi dengan peninjauan berkualitas rendah yang “dihasilkan AI” dan bersifat umum, menganggapnya membuang-buang waktu, dan menyarankan untuk mengirimkan ke konferensi AI lainnya. Ini mencerminkan kekhawatiran akademisi terhadap kualitas peninjauan yang dibantu AI dan mekanisme peninjauan, menyerukan peningkatan substansi dan konstruktivitas peninjauan. (Sumber: Reddit r/MachineLearning, Reddit r/MachineLearning)
Proyek Model Analisis Sentimen Layanan Cloud : Seorang pemula ML mengembangkan model analisis sentimen berbasis aspek BERT untuk menganalisis komentar komunitas Reddit ML/teknologi cloud tentang penyedia layanan cloud seperti AWS, Azure, Google Cloud, dan mengklasifikasikan sentimen berdasarkan dimensi seperti biaya, skalabilitas, keamanan, dll. Dia sedang mencari saran untuk meningkatkan akurasi interpretasi model, menangani pernyataan komparatif atau campuran, dan meningkatkan ketahanan terhadap negasi dan sarkasme. (Sumber: Reddit r/MachineLearning, Reddit r/deeplearning)
