Kata Kunci:Penelitian AI, Ilmu Komputer, Pembelajaran Penguatan, Pengembangan Obat, Mengemudi Otonom, Model Bahasa, Pemrosesan Multimodal, Sel Virtual, Laude Institute, Pengajar Pembelajaran Penguatan (RLTs), Platform BioNeMo, Tesla Robotaxi, Model Kimi VL A3B Thinking
🔥 聚焦
Laude Institute Didirikan, Menerima Pendanaan Awal $100 Juta untuk Mendorong Penelitian Ilmu Komputer Nirlaba: Andy Konwinski mengumumkan peluncuran Laude Institute, sebuah organisasi nirlaba yang bertujuan untuk mendanai penelitian ilmu komputer nirlaba yang berdampak signifikan bagi dunia. Tokoh-tokoh terkenal seperti Jeff Dean, Joyia Pineau, dan Dave Patterson bergabung dalam dewan direksi. Institusi ini telah menerima komitmen pendanaan awal sebesar $100 juta dan akan mendukung para peneliti dalam mengubah ide menjadi dampak nyata melalui pendanaan, berbagi sumber daya, dan pembangunan komunitas, dengan fokus khusus pada penelitian yang terbuka dan berorientasi pada dampak. (Sumber: JeffDean, matei_zaharia, lschmidt3, Tim_Dettmers, andrew_n_carr, gneubig, lateinteraction, sarahookr, jefrankle)

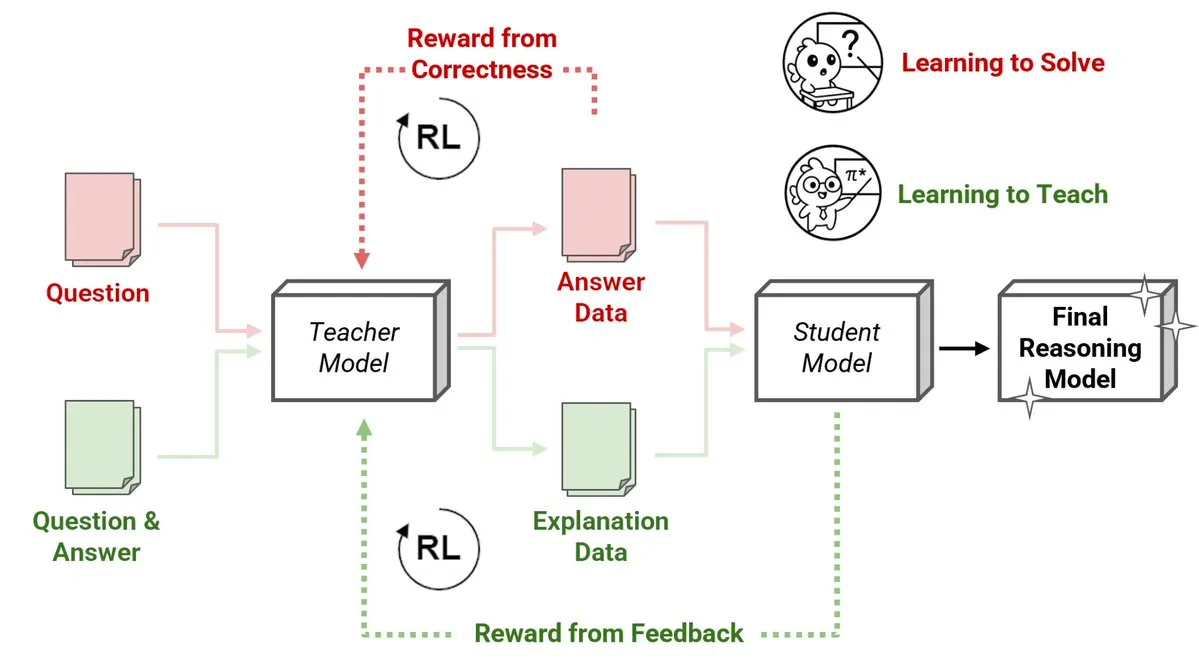
Sakana AI Merilis Metode Baru Reinforcement Learning Teachers (RLTs), Model Kecil Mengajari Model Besar Melakukan Penalaran: Sakana AI telah memperkenalkan metode baru Reinforcement Learning Teachers (RLTs), yang mengubah cara pengajaran penalaran pada Large Language Models (LLMs) melalui Reinforcement Learning (RL). RL tradisional berfokus pada masalah “belajar untuk menyelesaikan”, sedangkan RLTs dilatih untuk menghasilkan “penjelasan” yang jelas dan bertahap untuk mengajari model siswa. Sebuah RLT dengan hanya parameter 7B, ketika mengajari model siswa dengan parameter 32B, menunjukkan kinerja yang lebih unggul daripada LLM yang berukuran beberapa kali lipat lebih besar dalam tugas penalaran kompetitif dan tingkat pascasarjana. Metode ini menetapkan standar efisiensi baru untuk pengembangan model bahasa penalaran dengan RL. (Sumber: cognitivecompai, AndrewLampinen)
Nvidia Bekerja Sama dengan Novo Nordisk, Memanfaatkan Superkomputer AI untuk Mempercepat Pengembangan Obat: Nvidia mengumumkan kerja sama dengan raksasa farmasi Denmark Novo Nordisk dan Pusat Inovasi AI Nasional Denmark untuk bersama-sama memanfaatkan teknologi AI dan superkomputer terbaru Denmark, Gefion, guna mempercepat pengembangan obat baru. Kerja sama ini akan menggunakan platform BioNeMo Nvidia dan alur kerja AI canggih, yang bertujuan untuk merevolusi model penelitian dan pengembangan obat. Superkomputer Gefion, yang dibangun dengan teknologi dari Eviden dan Nvidia, akan menyediakan dukungan komputasi yang kuat untuk penelitian di bidang ilmu hayati dan bidang lainnya, mendorong penemuan pengobatan personal dan terapi baru. (Sumber: nvidia)

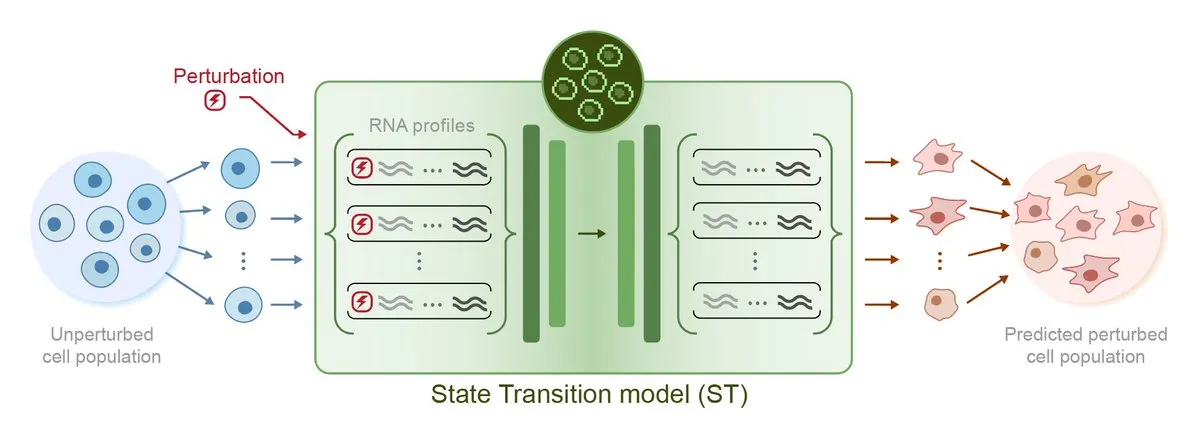
Arc Institute Merilis Model AI Prediksi Perturbasi Pertama STATE, Menuju Target Sel Virtual: Arc Institute telah merilis model AI prediksi perturbasi pertamanya, STATE, yang merupakan langkah penting dalam mencapai target sel virtualnya. Model STATE bertujuan untuk mempelajari cara menggunakan perturbasi obat, sitokin, atau gen untuk mengubah status sel (misalnya dari “sakit” menjadi “sehat”). Rilis model ini menandai kemajuan baru AI dalam memahami dan memprediksi perilaku sel, membuka jalan baru untuk pengobatan penyakit dan pengembangan obat. Model terkait telah tersedia di HuggingFace. (Sumber: riemannzeta, ClementDelangue)
Tesla Robotaxi Meluncurkan Uji Coba di Austin, Solusi Vision Menarik Perhatian, Kode Warisan Karpathy Dipangkas Secara Signifikan: Tesla secara resmi meluncurkan layanan uji coba Robotaxi di Austin, Texas, AS. Kendaraan gelombang pertama didasarkan pada modifikasi Model Y, menggunakan solusi persepsi visual murni dan perangkat lunak FSD. Ashok Elluswamy, kepala AI dan perangkat lunak kemudi otonom Tesla, memimpin tim untuk melakukan perubahan teknis besar pada sistem, memangkas hampir 90% dari sekitar 330.000-340.000 baris kode heuristik C++ yang diwariskan oleh tim Andrej Karpathy, dan menggantinya dengan “jaringan neural raksasa”. Langkah ini bertujuan untuk beralih dari “pengkodean pengalaman manusia” ke “pelatihan terparameterisasi”, mengoptimalkan model secara otonom melalui data masif dan simulasi mengemudi. Saat ini, layanan tersebut berada dalam tahap pengalaman awal, memicu diskusi luas di industri mengenai rute teknis dan kemampuan penskalaan Tesla. (Sumber: 36氪, Ronald_vanLoon, kylebrussell)

🎯 动向
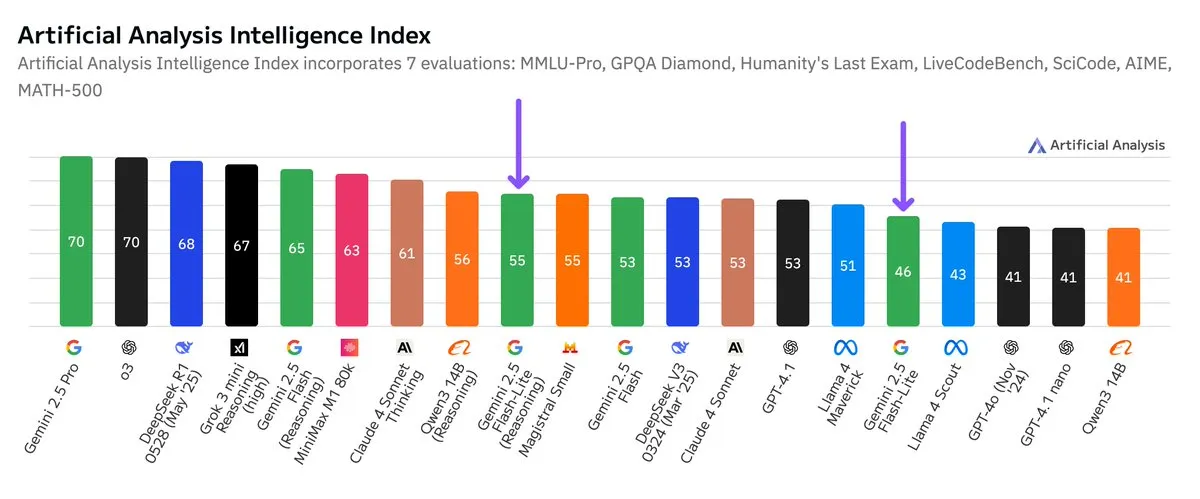
Benchmark Independen Google Gemini 2.5 Flash-Lite Dirilis, Peningkatan Rasio Harga-Kinerja: Menurut hasil benchmark independen yang dirilis oleh Artificial Analysis, versi Google Gemini 2.5 Flash-Lite Preview (06-17) dibandingkan dengan versi Flash reguler, biayanya berkurang sekitar 5 kali lipat, kecepatan meningkat sekitar 1,7 kali lipat, tetapi tingkat kecerdasannya sedikit menurun. Model ini merupakan versi peningkatan dari Gemini 2.0 Flash-Lite yang dirilis pada Februari 2025, dan termasuk dalam kategori model hybrid. Pembaruan ini menunjukkan upaya berkelanjutan Google dalam mengejar efisiensi model dan efektivitas biaya, yang mungkin ditujukan untuk skenario aplikasi dengan persyaratan biaya dan kecepatan yang tinggi. (Sumber: zacharynado)
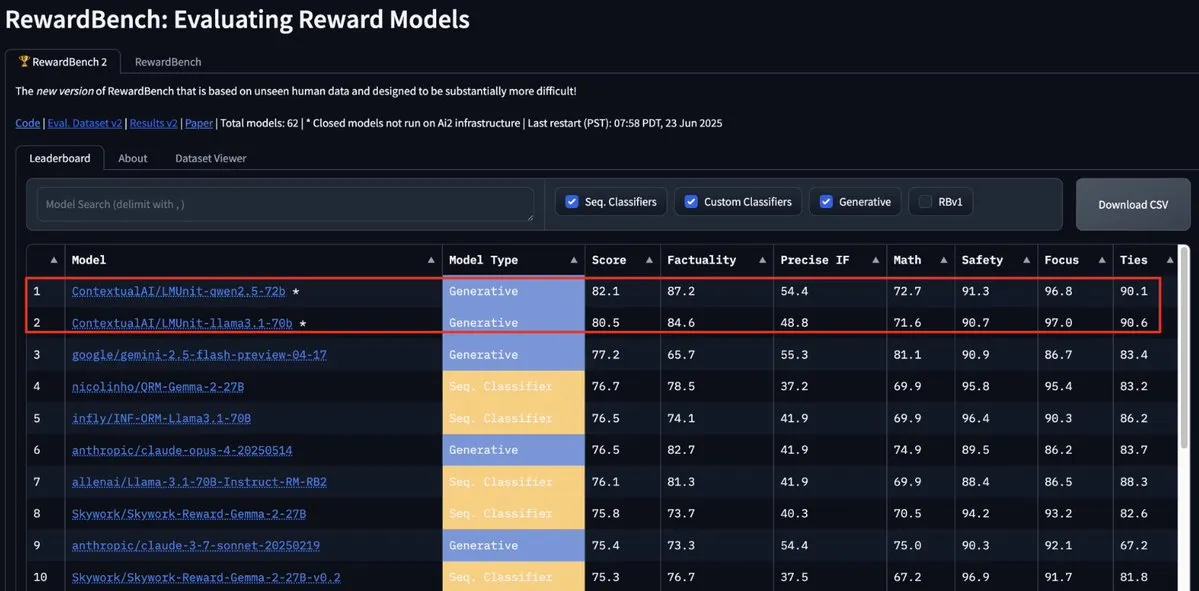
Model LMUnit dari ContextualAI Menduduki Puncak RewardBench2, Melampaui Gemini, Claude 4, dan GPT-4.1: Model LMUnit dari ContextualAI menduduki peringkat pertama dalam benchmark RewardBench2, dengan skor lebih dari 5% lebih tinggi dibandingkan model terkenal seperti Gemini, Claude 4, dan GPT-4.1. Pencapaian ini mungkin disebabkan oleh metode pelatihannya yang unik, yang dikabarkan mirip dengan metode “rubrics” yang dikembangkan OpenAI dengan upaya besar untuk model o4 dan model berikutnya. Metode ini membantu mencapai penskalaan yang efektif ketika LLM bertindak sebagai juri (llm-as-a-judge) selama proses penalaran. (Sumber: natolambert, menhguin, apsdehal)
Arcee.ai Berhasil Memperluas Panjang Konteks Model AFM-4.5B dari 4k menjadi 64k: Arcee.ai mengumumkan bahwa panjang konteks model dasar pertamanya, AFM-4.5B, telah berhasil diperluas dari 4k menjadi 64k. Tim mencapai terobosan ini melalui eksperimen aktif, penggabungan model, distilasi, dan metode yang secara bercanda disebut “sup dalam jumlah besar” (merujuk pada teknik fusi model). Kemajuan ini sangat penting untuk menangani tugas teks panjang. Peningkatan Arcee pada model GLM-32B-Base juga membuktikan efektivitasnya, tidak hanya dukungan konteks panjang yang meningkat dari 8k menjadi 32k, tetapi semua evaluasi model dasar (termasuk konteks pendek) juga menunjukkan peningkatan. (Sumber: eliebakouch, teortaxesTex, nrehiew_, shxf0072, code_star)

Pembaruan Google Gemini API, Meningkatkan Kecepatan dan Kemampuan Pemrosesan Video dan PDF: Google Gemini API mendapatkan pembaruan penting dalam hal pemrosesan video dan PDF. Waktu respons pertama (TTFT) untuk video yang di-cache meningkat 3 kali lipat, dan kecepatan pemrosesan PDF yang di-cache meningkat hingga 4 kali lipat. Selain itu, versi baru mendukung pemrosesan batch untuk beberapa video, dan kinerja cache implisit telah mendekati cache eksplisit. Peningkatan ini bertujuan untuk meningkatkan efisiensi dan pengalaman pengembang dalam menggunakan Gemini API untuk memproses konten multimedia. (Sumber: _philschmid)
Moonshot (Kimi) Memperbarui Model Kimi VL A3B Thinking, Meningkatkan Kemampuan Pemrosesan Multimodal: Moonshot AI (Kimi) merilis versi terbaru dari model bahasa visual (VLM) kecilnya, Kimi VL A3B Thinking, yang didasarkan pada lisensi MIT. Versi baru ini, sambil mengonsumsi lebih sedikit token dan memperpendek jalur pemikiran, mendukung pemrosesan video dan dapat menangani gambar beresolusi lebih tinggi (1792×1792). Model ini mencapai skor 65,2 di VideoMMMU, MathVision meningkat 20,1 poin menjadi 56,9, MathVista meningkat 8,4 poin menjadi 80,1, MMMU-Pro meningkat 3,2 poin menjadi 46,3, dan menunjukkan kinerja luar biasa dalam penalaran visual, penentuan posisi UI Agent, serta pemrosesan video dan PDF. Model ini telah tersedia secara open source di Hugging Face. (Sumber: mervenoyann)

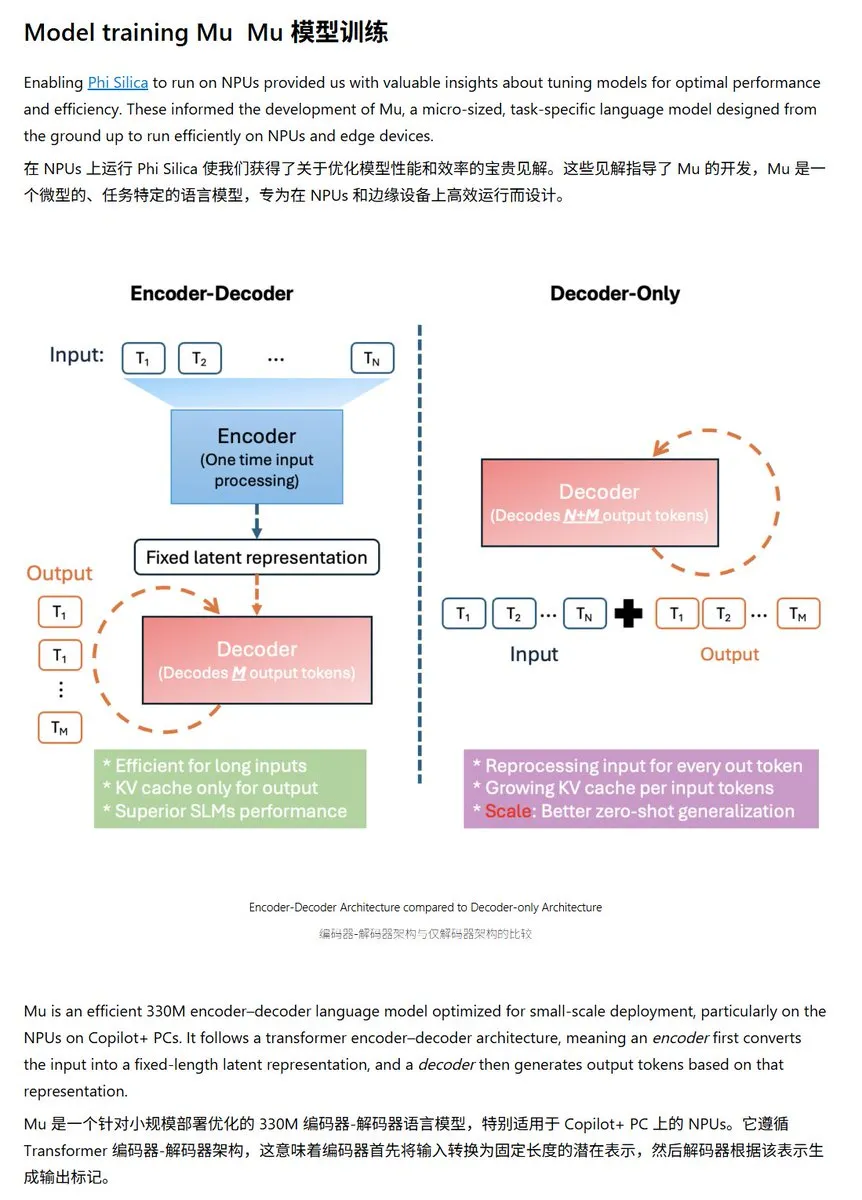
Microsoft Merilis Model Bahasa Kecil Mu-330M, Dioptimalkan Khusus untuk Windows NPU: Microsoft meluncurkan model bahasa kecil baru, Mu-330M, yang dirancang untuk berjalan di NPU (Neural Processing Unit) pada Windows Copilot+ PC, bertujuan untuk mendukung fungsionalitas Agent dalam sistem Windows. Model ini dioptimalkan untuk NPU, menggunakan teknik seperti rotary position embedding, grouped-query attention, dan dual-layer LayerNorm untuk berjalan secara efisien dengan konsumsi daya rendah, menandai langkah lebih lanjut Microsoft dalam kemampuan AI di sisi perangkat (on-device AI). (Sumber: karminski3)
DeepMind Merilis Laporan Teknis Mercury, Fokus pada Model Bahasa Difusi: Inception Labs (tim terkait DeepMind) telah merilis laporan teknis untuk model bahasa difusinya, Mercury. Laporan ini merinci arsitektur model Mercury, metode pelatihan, dan hasil eksperimen, memberikan wawasan mendalam kepada para peneliti mengenai jenis model yang sedang berkembang ini. Model difusi telah mencapai kesuksesan signifikan dalam bidang generasi gambar, dan penerapannya pada model bahasa merupakan arah penelitian AI terkini yang terdepan. (Sumber: andriy_mulyar)
Meta Bekerja Sama dengan Oakley untuk Memperluas Lini Kacamata Pintar AI: Meta bekerja sama dengan merek kacamata Oakley untuk lebih memperluas lini produk kacamata pintar AI-nya. Kacamata pintar baru ini diharapkan akan mengintegrasikan teknologi AI Meta, menawarkan fungsionalitas interaktif dan pengalaman pengguna yang lebih kaya. Kerja sama ini menandai investasi berkelanjutan Meta di bidang perangkat AI wearable, yang bertujuan untuk mengintegrasikan AI secara lebih mulus ke dalam kehidupan sehari-hari. (Sumber: rowancheung, Ronald_vanLoon)
Alibaba Cloud Meluncurkan PAI-TurboX, Kerangka Kerja Akselerasi Pelatihan dan Inferensi Model Kemudi Otonom, Waktu Pelatihan Dapat Dipersingkat 50%: Alibaba Cloud merilis PAI-TurboX, sebuah kerangka kerja akselerasi pelatihan dan inferensi model untuk bidang kemudi otonom. Kerangka kerja ini bertujuan untuk meningkatkan efisiensi pelatihan dan inferensi model persepsi, perencanaan & kontrol, dan bahkan world models. Ini dicapai melalui optimalisasi prapemrosesan data multimodal, afinitas CPU, kompilasi dinamis, strategi paralelisasi pipeline, serta menyediakan kemampuan optimasi operator dan kuantisasi. Pengujian aktual menunjukkan bahwa dalam tugas pelatihan beberapa model industri seperti BEVFusion, MapTR, dan SparseDrive, PAI-TurboX dapat mempersingkat waktu pelatihan sekitar 50%. (Sumber: 量子位)
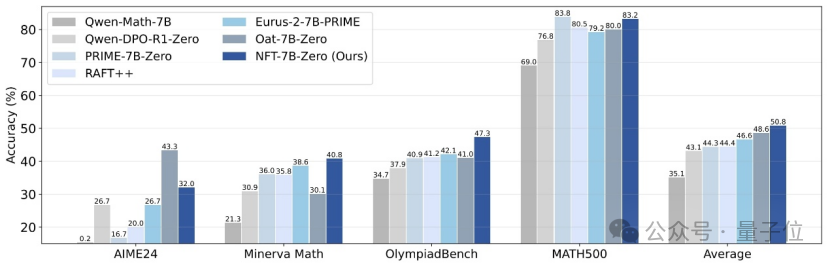
Tsinghua, Nvidia, dkk. Mengusulkan Metode NFT, Memungkinkan Supervised Learning untuk “Merefleksikan” Kesalahan: Peneliti dari Universitas Tsinghua, Nvidia, dan Universitas Stanford bersama-sama mengusulkan skema supervised learning baru yang disebut NFT (Negative-aware FineTuning). Metode ini, berdasarkan algoritma RFT (Rejection FineTuning), memanfaatkan data negatif untuk pelatihan dengan membangun “model negatif implisit”, yaitu “strategi negatif implisit”. Strategi ini memungkinkan supervised learning untuk melakukan “refleksi diri” seperti reinforcement learning, menjembatani kesenjangan kemampuan tertentu antara supervised learning dan reinforcement learning, dan menunjukkan peningkatan kinerja yang signifikan pada tugas-tugas seperti penalaran matematis. Bahkan dalam kondisi On-Policy, gradien fungsi kerugiannya setara dengan GRPO. (Sumber: 量子位)
OmniGen2 Dirilis: Model Edit Gambar Multifungsi 8B, Menggabungkan Pemahaman Visual dan Generasi Gambar: Sebuah model edit gambar multifungsi baru bernama OmniGen2 telah dirilis. Model ini menggabungkan pemahaman visual (berdasarkan Qwen-VL-2.5) dengan generasi gambar (model difusi parameter 4B), dengan total parameter sekitar 8B. OmniGen2 mampu mendukung berbagai tugas seperti text-to-image, pengeditan gambar, pemahaman gambar, dan generasi kontekstual. Tujuannya adalah untuk menyediakan model terpadu yang dapat menyelesaikan berbagai masalah terkait visual dan cocok untuk integrasi di sisi perangkat (on-device). (Sumber: karminski3)

Model Text-to-Image Chroma-8.9B-v39 Diperbarui, Berbasis FLUX.1-schnell, Dapat Digunakan Secara Komersial: Model text-to-image Chroma-8.9B-v39 merilis pembaruan, meningkatkan pencahayaan dan kealamian tugas. Model ini berbasis FLUX.1-schnell, dengan jumlah parameter dikompresi dari 12B menjadi 8,9B, menggunakan lisensi Apache 2.0, dan mengizinkan penggunaan komersial. Diklaim bahwa model ini “memperkenalkan kembali konsep anatomi yang hilang, sepenuhnya tanpa batasan konten,” dan telah dilatih ulang menggunakan dataset yang berisi 5 juta karya anime, furry, seni, dan foto. (Sumber: karminski3)

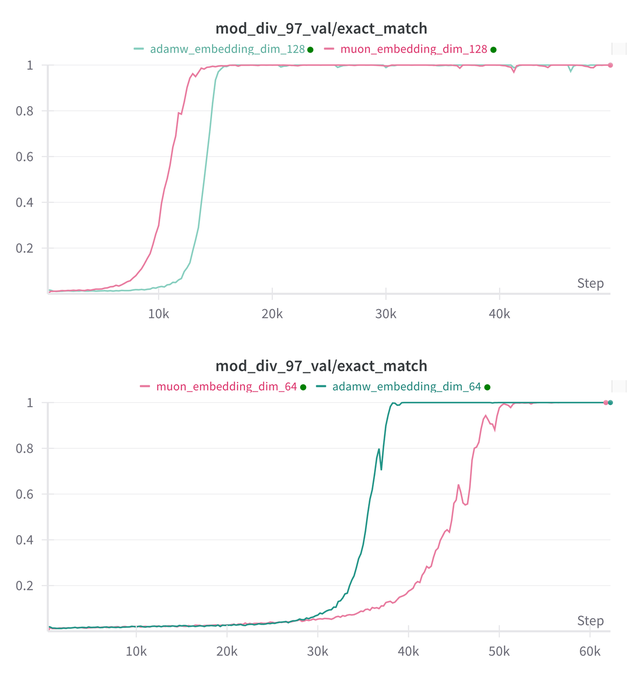
Essential AI Memperbarui Kesimpulan Penelitian tentang Kemampuan Grokking pada Model Muon dan Adam: Essential AI membagikan kemajuan penelitian terbaru mengenai kemampuan Grokking (fenomena di mana model berkinerja buruk pada awal pelatihan, kemudian tiba-tiba memahami generalisasi) pada model Muon dan Adam-nya. Hipotesis awal mungkin bertentangan dengan observasi aktual. Tim mempublikasikan hasil eksperimen penelitian internal skala kecil, yang menunjukkan bahwa setelah memperluas ruang pencarian hyperparameter, Muon tidak menunjukkan keunggulan universal yang jelas dibandingkan AdamW; keduanya memiliki kelebihan dan kekurangan dalam skenario yang berbeda. Ini menunjukkan bahwa AdamW dalam banyak kasus masih merupakan optimizer yang kuat, bahkan state-of-the-art (SOTA). (Sumber: eliebakouch, teortaxesTex, nrehiew_)
Model Generasi Gambar Ostris AI Diperbarui, Fokus pada Versi Tanpa CFG dan Optimasi Detail Frekuensi Tinggi: Ostris AI terus memperbarui model generasi gambarnya, saat ini berfokus pada pengembangan versi tanpa CFG (Classifier-Free Guidance) karena kecepatan konvergensinya yang lebih cepat. Dalam pembaruan Day 7 terbaru, tim menambahkan teknik pelatihan baru untuk menangani detail frekuensi tinggi dengan lebih baik dan berupaya menghilangkan artefak detail tinggi. Pembaruan Day 4 sebelumnya telah menunjukkan bahwa kualitas gambar yang dihasilkan dengan metode baru tanpa menggunakan CFG telah meningkat secara signifikan. (Sumber: ostrisai)

Ant Group, CASIA, dkk. Merilis Model Open Source ViLaSR-7B, Mewujudkan Penalaran Spasial “Menggambar Sambil Berpikir”: Ant Technology Research Institute, Institute of Automation Chinese Academy of Sciences (CASIA), dan The Chinese University of Hong Kong bersama-sama merilis model open source ViLaSR-7B. Model ini, melalui paradigma “Drawing to Reason in Space”, memungkinkan Large Vision Language Models (LVLM) untuk menggambar penanda bantu (seperti garis referensi, kotak pembatas) dalam ruang visual untuk membantu proses berpikir, sehingga meningkatkan kemampuan persepsi dan penalaran spasial. ViLaSR menggunakan kerangka kerja pelatihan tiga tahap: cold start, reflective rejection sampling, dan reinforcement learning. Eksperimen menunjukkan bahwa model ini mencapai peningkatan rata-rata 18,4% pada 5 benchmark termasuk navigasi labirin, pemahaman gambar, dan penalaran spasial video, dan kinerjanya di VSI-Bench mendekati Gemini-1.5-Pro. (Sumber: 量子位)

🧰 工具
SGLang Kini Mendukung Hugging Face Transformers sebagai Backend, Meningkatkan Efisiensi Inferensi: SGLang mengumumkan bahwa kini mereka mendukung Hugging Face Transformers sebagai backend. Ini berarti pengguna dapat menyediakan layanan inferensi tingkat produksi yang cepat untuk model apa pun yang kompatibel dengan Transformers, tanpa memerlukan dukungan native, cukup plug-and-play. Integrasi ini bertujuan untuk menyederhanakan proses deployment inferensi model bahasa berkinerja tinggi, memperluas cakupan penerapan dan kemudahan penggunaan SGLang. (Sumber: TheZachMueller, ClementDelangue)

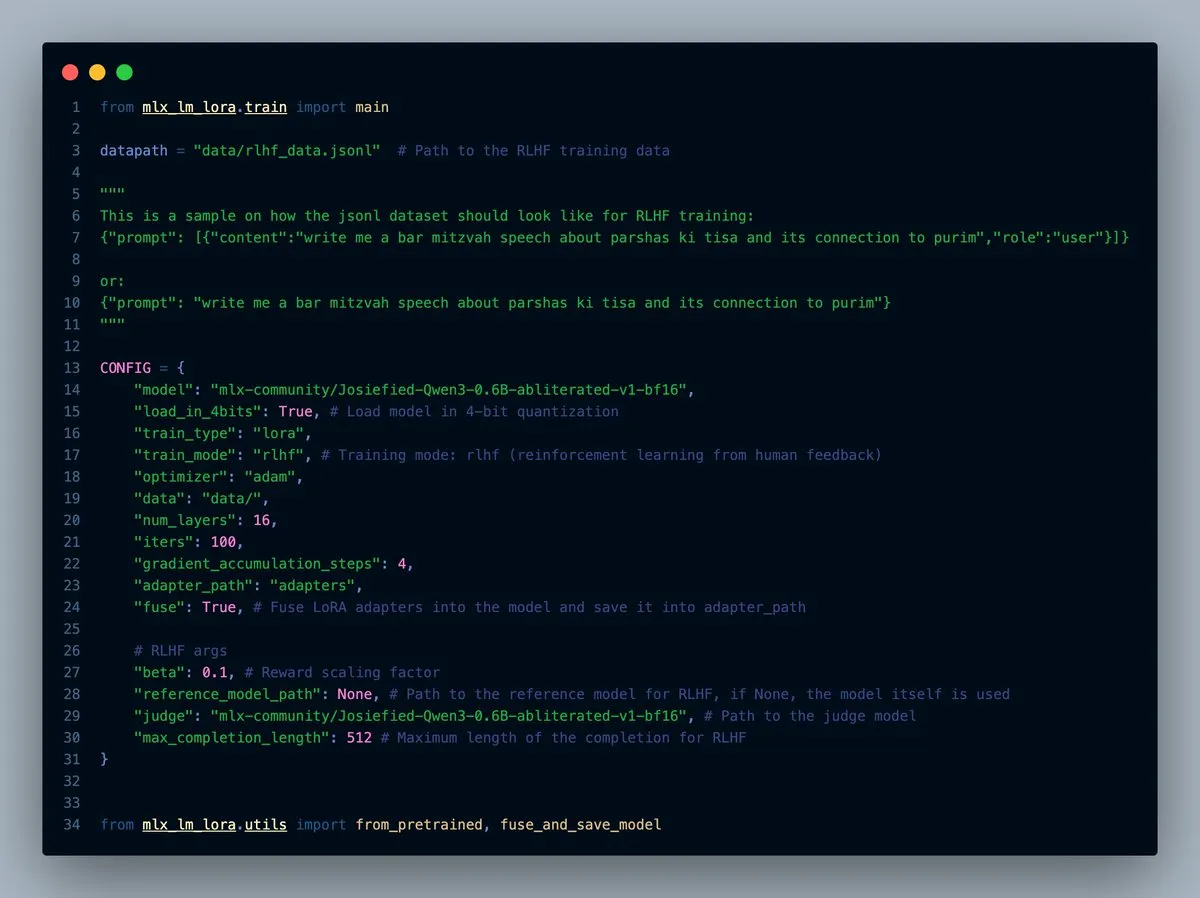
MLX-LM-LORA v0.7.0 Dirilis, dengan Fitur RLHF Bawaan: MLX-LM-LORA merilis versi v0.7.0, versi baru ini memiliki fungsionalitas bawaan untuk Reinforcement Learning from Human Feedback (RLHF). Alat ini sekarang mendukung pemuatan 4-bit, 6-bit, 8-bit, mode pelatihan RLHF, dan dapat langsung menggabungkan adapters ke dalam bobot dasar. Ini membuat fine-tuning LoRA di bawah kerangka kerja MLX menjadi lebih cerdas dan efisien, terutama pada perangkat dengan chip Apple. (Sumber: awnihannun)
LlamaCloud Dirilis, Menyediakan Toolbox Kompatibel MCP untuk Alur Kerja Dokumen: LlamaCloud kini telah diluncurkan, sebagai toolbox yang kompatibel dengan Model Context Protocol (MCP), dapat digunakan untuk alur kerja dokumen apa pun. Pengguna dapat menghubungkannya dengan model seperti Claude untuk melakukan operasi kompleks seperti ekstraksi dokumen, perbandingan, dll. Misalnya, ia dapat menganalisis kinerja keuangan Tesla selama lima kuartal terakhir dan menghasilkan laporan komprehensif, dengan secara dinamis membuat pola standar dan menjalankannya di semua file, kemudian menggunakan kode untuk menghasilkan hasil akhir. LlamaCloud mampu mengoreksi pola yang salah secara dinamis dan mendukung tautan file langsung. (Sumber: jerryjliu0)
Georgi Gerganov Memberikan Teaser Proyek LlamaBarn: Georgi Gerganov (pencipta llama.cpp) memposting gambar di media sosial, memberikan teaser untuk proyek baru bernama “LlamaBarn”. Gambar tersebut menunjukkan antarmuka yang mirip dasbor, berisi elemen seperti pemilihan model, penyesuaian parameter, dll., mengisyaratkan bahwa ini mungkin alat untuk mengelola, menjalankan, atau menguji LLM lokal. Komunitas menantikannya, percaya bahwa ini bisa menjadi pesaing kuat untuk alat yang sudah ada seperti Ollama. (Sumber: ClementDelangue, teortaxesTex, jeremyphoward)
Void Editor: Asisten Pemrograman AI Open Source Baru, Mendukung MCP dan Model Lokal: Void Editor hadir sebagai asisten pemrograman AI open source baru, yang bertujuan menjadi alternatif untuk alat seperti Cursor. Ia mendukung pelengkapan otomatis tab, mode obrolan, Model Context Protocol (MCP), dan mode Agent. Pengguna dapat menghubungkan API Large Language Model apa pun atau menjalankan model secara lokal, memberikan pengalaman pemrograman berbantuan AI yang fleksibel bagi pengembang. (Sumber: karminski3)
Together AI Meluncurkan Alat Which LLM, Membantu Memilih LLM Open Source yang Sesuai: Together AI merilis alat gratis bernama “Which LLM”, yang bertujuan untuk membantu pengguna memilih Large Language Model open source yang paling sesuai berdasarkan kasus penggunaan spesifik, kebutuhan kinerja, dan pertimbangan ekonomi. Dengan meningkatnya jumlah LLM open source, alat semacam ini dapat memberikan referensi berharga bagi pengembang dan peneliti dalam memilih model. (Sumber: vipulved)
Perplexity Finance Menambahkan Fitur Pelacakan Linimasa Harga Saham: Perplexity Finance mengumumkan bahwa pengguna sekarang dapat melacak linimasa perubahan harga untuk kode saham apa pun di platformnya. Fitur baru ini bertujuan untuk menyediakan alat analisis informasi pasar keuangan yang lebih intuitif dan nyaman bagi pengguna. Dikombinasikan dengan kemampuan AI Perplexity, ini dapat menghadirkan pengalaman baru dalam pencarian dan analisis informasi keuangan. (Sumber: AravSrinivas)

IdeaWeaver Meluncurkan Agen AI Pertama untuk Debugging Kinerja Sistem: IdeaWeaver merilis apa yang diklaimnya sebagai agen AI pertama yang dirancang khusus untuk debugging masalah kinerja sistem. Alat ini menggunakan kerangka kerja CrewAI dan dapat benar-benar menjalankan perintah sistem untuk mendiagnosis masalah terkait CPU, memori, I/O, dan jaringan. Fitur utamanya adalah memprioritaskan penggunaan LLM lokal (melalui OLLAMA) untuk melindungi privasi, dan hanya meminta kunci API OpenAI jika model lokal tidak tersedia. Tujuannya adalah untuk menerapkan kemampuan AI di bidang DevOps dan manajemen sistem. (Sumber: Reddit r/artificial)
Kling AI Menambahkan Dukungan Live Photo, Memungkinkan Video yang Dihasilkan Disimpan sebagai Wallpaper Dinamis: Kling AI mengumumkan bahwa fitur generasi videonya kini mendukung penyimpanan karya sebagai Live Photos. Pengguna dapat mengatur konten dinamis favorit yang dibuat oleh Kling sebagai wallpaper ponsel, menambah kesenangan dan kepraktisan video yang dihasilkan AI. (Sumber: Kling_ai)
Cognition AI Merilis Open Source Blockdiff, Mencapai Peningkatan Kecepatan Snapshot VM 200x Lipat: Cognition AI mengumumkan rilis open source Blockdiff, format file snapshot VM yang dikembangkannya untuk Devin. Karena pembuatan snapshot VM di EC2 memakan waktu terlalu lama (30+ menit), tim membangun hypervisor otterlink dan format file Blockdiff sendiri, yang meningkatkan kecepatan pembuatan snapshot hingga 200 kali lipat. Kontribusi open source ini bertujuan untuk membantu pengembang mengelola lingkungan mesin virtual dengan lebih efisien. (Sumber: karinanguyen_)

📚 学习
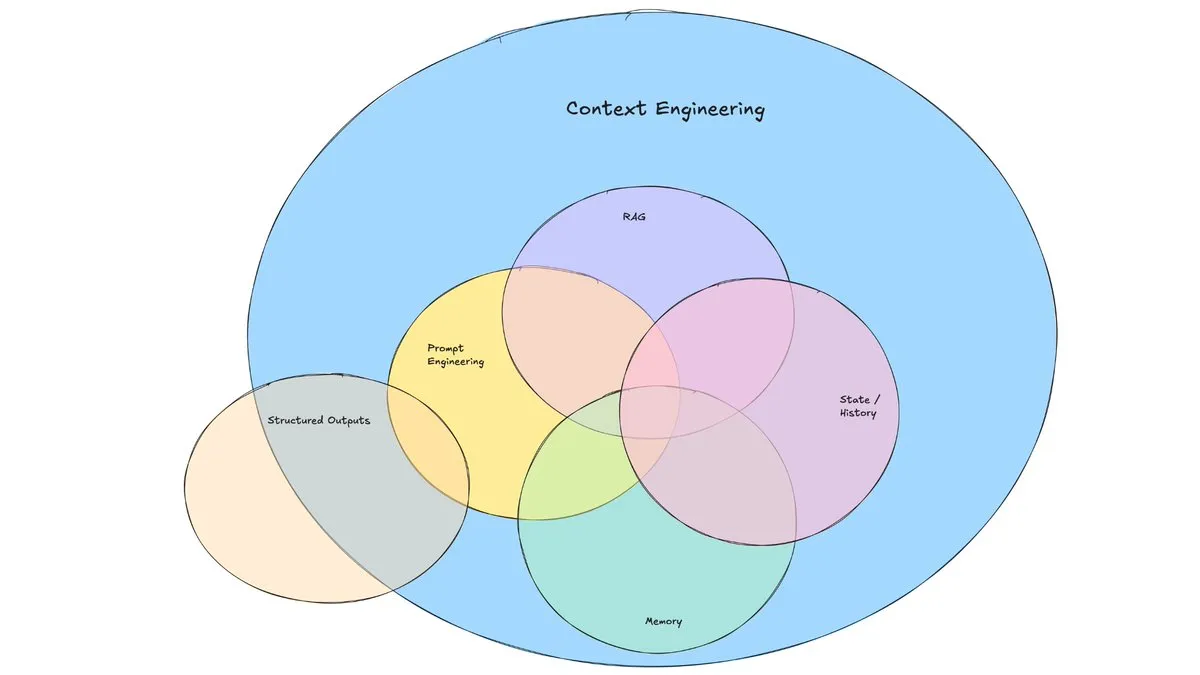
Postingan Blog LangChain Membahas Munculnya “Context Engineering”: LangChain menerbitkan postingan blog yang membahas istilah “Context Engineering” yang semakin populer. Artikel tersebut mendefinisikannya sebagai “membangun sistem dinamis untuk menyediakan informasi dan alat yang tepat dalam format yang benar, sehingga LLM dapat menyelesaikan tugas secara wajar”. Ini bukanlah konsep yang sepenuhnya baru; para pembangun Agent telah mempraktikkannya sejak lama, dan alat seperti LangGraph dan LangSmith juga dibuat untuk tujuan ini. Pengenalan istilah ini membantu menarik lebih banyak perhatian pada keterampilan dan alat terkait. (Sumber: hwchase17, Hacubu, yoheinakajima)
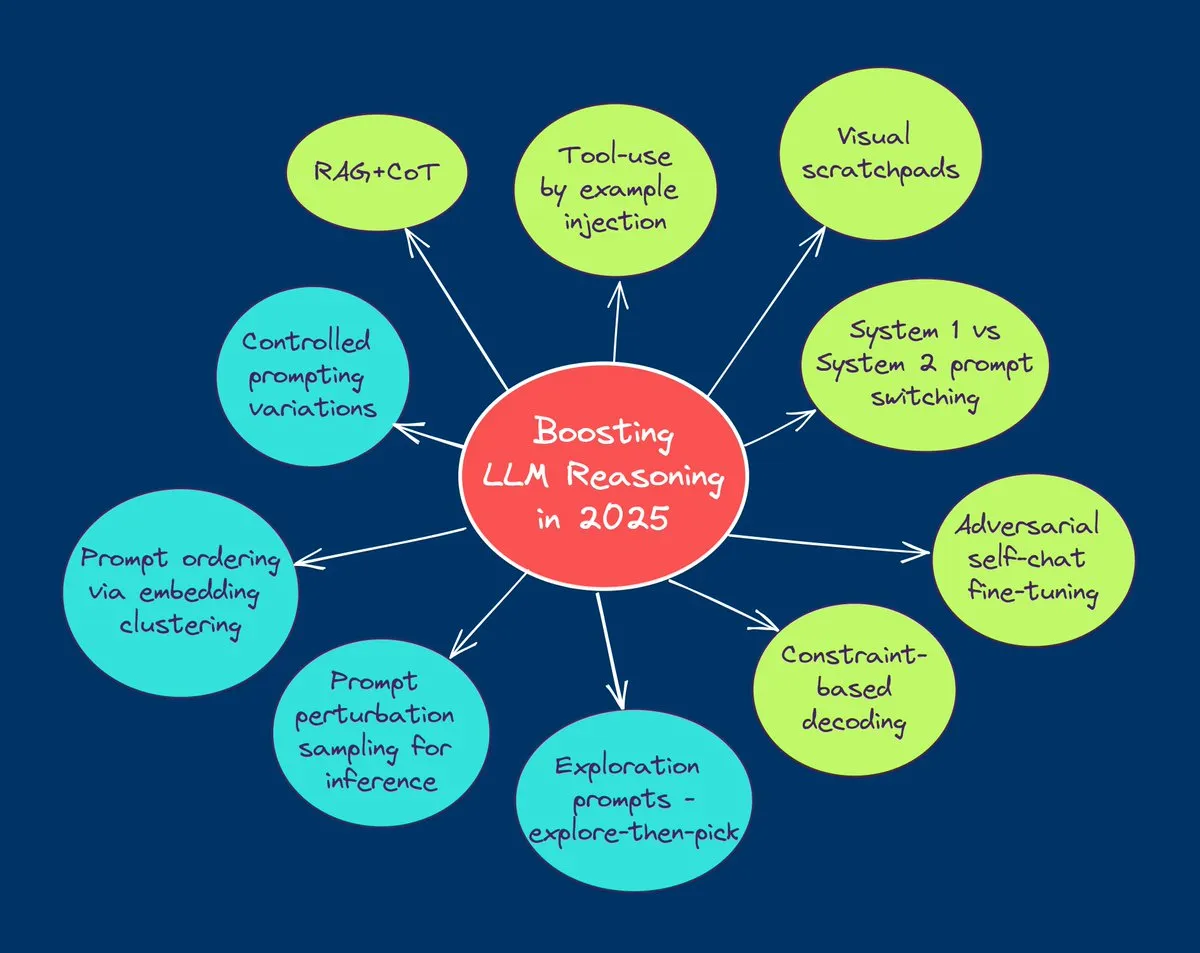
TuringPost Merangkum 10 Teknik Teratas untuk Meningkatkan Kemampuan Penalaran LLM pada Tahun 2025: TuringPost membagikan 10 teknik kunci untuk meningkatkan kemampuan penalaran Large Language Models (LLM) pada tahun 2025, termasuk: Retrieval-Augmented Generation + Chain-of-Thought (RAG+CoT), penggunaan alat melalui injeksi contoh, visual scratchpad (dukungan penalaran multimodal), peralihan prompt Sistem 1 & Sistem 2, fine-tuning self-talk adversarial, decoding berbasis batasan, prompting eksploratif (eksplorasi dulu baru pilih), sampling perturbasi prompt untuk penalaran, pengurutan prompt melalui clustering embedding, dan varian prompt terkontrol. Teknik-teknik ini menyediakan berbagai jalur untuk mengoptimalkan kinerja LLM dalam tugas-tugas kompleks. (Sumber: TheTuringPost, TheTuringPost)
Cohere Labs Menyelenggarakan ML Summer School, Menjelajahi Masa Depan Machine Learning: Komunitas sains terbuka Cohere Labs akan menyelenggarakan ML Summer School pada bulan Juli. Acara ini akan mengumpulkan anggota komunitas global untuk bersama-sama membahas masa depan machine learning, dan mengundang pembicara dari industri untuk berbagi. Di antaranya, Katrina Lawrence akan menjadi pembicara utama pada tanggal 2 Juli untuk kursus tinjauan matematika machine learning, yang mencakup konsep inti seperti kalkulus, kalkulus vektor, dan aljabar linear. (Sumber: sarahookr)

DeepLearning.AI Bekerja Sama dengan Meta Meluncurkan Kursus Gratis “Building with Llama 4”: DeepLearning.AI bekerja sama dengan Meta meluncurkan kursus gratis berjudul “Building with Llama 4”. Konten kursus meliputi: praktik langsung dengan model seri Llama 4, pemahaman arsitektur Mixture of Experts (MOE), dan cara membangun aplikasi menggunakan API resmi; penerapan Llama 4 untuk inferensi multi-gambar, lokalisasi gambar (mengenali objek dan kotak pembatasnya), serta menangani kueri teks konteks panjang hingga 1 juta token; menggunakan alat optimasi prompt Llama 4 untuk secara otomatis meningkatkan prompt sistem, dan memanfaatkan toolkit data sintetisnya untuk membuat dataset berkualitas tinggi untuk fine-tuning. (Sumber: DeepLearningAI)
Channel YouTube EleutherAI Menyediakan Banyak Konten Penelitian AI: Channel YouTube EleutherAI mengumpulkan rekaman video dari klub baca dan seri kuliahnya, dengan konten lebih dari 100 jam. Topik meliputi skalabilitas dan kinerja machine learning, analisis fungsional, serta podcast dan wawancara anggota tim. Channel ini menyediakan sumber belajar yang kaya bagi peneliti dan penggemar AI. EleutherAI juga meluncurkan seri kuliah baru, dengan edisi pertama dibawakan oleh @linguist_cat yang membahas tokenizer dan keterbatasannya. (Sumber: BlancheMinerva, BlancheMinerva)
Paper Membahas Peningkatan Penalaran Multimodal melalui Latent Visual Tokens (Machine Mental Imagery): Sebuah paper baru berjudul “Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens” mengusulkan kerangka kerja Mirage, yang meningkatkan penalaran multimodal dengan menambahkan latent visual tokens (bukan menghasilkan gambar lengkap) selama proses decoding VLM, mensimulasikan citra mental manusia. Metode ini pertama-tama mengawasi latent tokens melalui distilasi embedding gambar nyata, kemudian beralih ke pengawasan teks murni untuk menyelaraskan lintasan laten dengan tujuan tugas, dan lebih lanjut meningkatkan kemampuan melalui reinforcement learning. Eksperimen membuktikan bahwa Mirage dapat mencapai penalaran multimodal yang lebih kuat tanpa menghasilkan gambar eksplisit. (Sumber: HuggingFace Daily Papers)
Paper Mengusulkan Kerangka Kerja Vision as a Dialect, Menyatukan Pemahaman dan Generasi Visual melalui Representasi yang Diselaraskan dengan Teks: Sebuah paper berjudul “Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations” memperkenalkan kerangka kerja LLM multimodal bernama Tar. Kerangka kerja ini menggunakan text-aligned tokenizer (TA-Tok) untuk mengubah gambar menjadi token diskrit dan memanfaatkan codebook yang diselaraskan dengan teks yang diproyeksikan dari kosakata LLM, sehingga menyatukan visual dan teks ke dalam representasi semantik diskrit bersama. Tar mencapai input dan output lintas-modal melalui antarmuka bersama, tanpa memerlukan desain khusus modalitas, dan menggunakan encoder-decoder adaptif skala serta de-tokenizer generatif untuk menyeimbangkan efisiensi dan detail visual. (Sumber: HuggingFace Daily Papers)
Paper Mengusulkan ReasonFlux-PRM: PRM Sadar-Lintasan untuk Penalaran Chain-of-Thought Panjang pada LLM: Paper “ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs” memperkenalkan Process Reward Model (PRM) sadar-lintasan yang baru, yang dirancang khusus untuk mengevaluasi jejak penalaran tipe lintasan-respons yang dihasilkan oleh model penalaran canggih seperti DeepSeek-R1. ReasonFlux-PRM menggabungkan pengawasan tingkat langkah dan tingkat lintasan, mencapai alokasi hadiah berbutir halus yang selaras dengan data chain-of-thought terstruktur, dan mencapai peningkatan kinerja dalam skenario seperti SFT, RL, dan ekspansi saat pengujian Best-of-N (BoN). (Sumber: HuggingFace Daily Papers)
Paper Meneliti Metode Evaluasi untuk Guardrails Jailbreak pada Large Language Models: Sebuah paper berjudul “SoK: Evaluating Jailbreak Guardrails for Large Language Models” melakukan sistematisasi pengetahuan (Systematization of Knowledge) mengenai serangan jailbreak pada Large Language Models (LLMs) dan guardrails-nya. Paper ini mengusulkan taksonomi multidimensi baru, mengklasifikasikan guardrails dari enam dimensi utama, dan memperkenalkan kerangka kerja evaluasi keamanan-efisiensi-utilitas untuk menilai efektivitas praktisnya. Melalui analisis dan eksperimen yang luas, paper ini menunjukkan kelebihan dan kekurangan metode guardrail yang ada, membahas universalitasnya terhadap berbagai jenis serangan, dan memberikan wawasan untuk mengoptimalkan kombinasi pertahanan. (Sumber: HuggingFace Daily Papers)
Paper Unggulan AAAI 2025 Membahas Kelas yang Dapat Diputuskan dari Partially Observable Markov Decision Processes (POMDP): Sebuah paper berjudul “Revelations: A Decidable Class of POMDP with Omega-Regular Objectives” memenangkan Penghargaan Paper Unggulan AAAI 2025. Penelitian ini mengidentifikasi kelas Markov Decision Process (MDP) yang dapat diputuskan: masalah keputusan dengan “strong revelations”, yaitu, pada setiap langkah ada probabilitas non-nol untuk mengungkapkan keadaan dunia yang tepat. Paper ini juga memberikan hasil decidability untuk “weak revelations”, di mana keadaan yang tepat dijamin akan terungkap pada akhirnya, tetapi tidak harus pada setiap langkah. Penelitian ini memberikan dasar teoretis baru untuk pengambilan keputusan optimal dalam kondisi informasi yang tidak lengkap. (Sumber: aihub.org)
Paper Mengusulkan CommVQ: Commutative Vector Quantization untuk Kompresi KV Cache: Paper “CommVQ: Commutative Vector Quantization for KV Cache Compression” mengusulkan metode bernama CommVQ, yang mengompres KV cache melalui additive quantization dan encoder serta codebook ringan untuk mengurangi penggunaan memori dalam inferensi LLM konteks panjang. Untuk mengurangi biaya komputasi decoding, codebook dirancang agar komutatif dengan Rotary Position Embeddings (RoPE) dan dilatih menggunakan algoritma EM. Eksperimen menunjukkan bahwa metode ini dapat mengurangi ukuran KV cache FP16 sebesar 87,5% dengan kuantisasi 2-bit dan mengungguli metode kuantisasi KV cache yang ada, bahkan mampu mencapai kuantisasi KV cache 1-bit dengan kehilangan presisi minimal. (Sumber: HuggingFace Daily Papers)
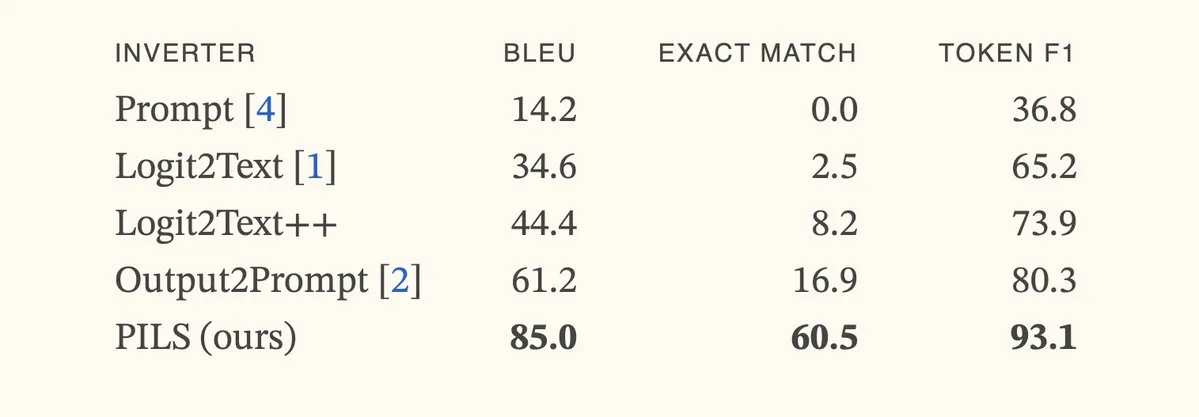
Paper Mengusulkan Metode PILS, Meningkatkan Inversi Model Bahasa dengan Merepresentasikan Distribusi Token Berikutnya secara Ringkas: Paper “Better Language Model Inversion by Compactly Representing Next-Token Distributions” mengusulkan metode inversi model bahasa baru, PILS (Prompt Inversion from Logprob Sequences). Metode ini memulihkan prompt tersembunyi dengan menganalisis probabilitas token berikutnya dari model dalam beberapa langkah generasi. Intinya adalah penemuan bahwa vektor output model bahasa menempati subruang berdimensi rendah, sehingga distribusi probabilitas token berikutnya dapat dikompresi tanpa kehilangan melalui pemetaan linear untuk inversi yang lebih efektif. Eksperimen menunjukkan bahwa PILS secara signifikan mengungguli metode state-of-the-art (SOTA) sebelumnya dalam memulihkan prompt tersembunyi. (Sumber: HuggingFace Daily Papers, jxmnop)
Paper Mengusulkan Phantom-Data: Dataset Generasi Video Konsisten-Subjek Umum: Paper “Phantom-Data : Towards a General Subject-Consistent Video Generation Dataset” memperkenalkan dataset baru bernama Phantom-Data, yang bertujuan untuk mengatasi masalah “copy-paste” yang umum terjadi pada model generasi subject-to-video yang ada (yaitu, identitas subjek terlalu terkait dengan atribut latar belakang dan konteks). Phantom-Data adalah dataset konsistensi subject-to-video lintas-pasangan umum pertama, yang berisi sekitar satu juta pasangan yang konsisten identitasnya di berbagai kategori. Dataset ini dibangun melalui proses tiga tahap, termasuk deteksi subjek, pengambilan subjek lintas-konteks skala besar, dan verifikasi identitas yang dipandu oleh prior. (Sumber: HuggingFace Daily Papers)
Paper Mengusulkan LongWriter-Zero: Menguasai Generasi Teks Ultra-Panjang melalui Reinforcement Learning: Paper “LongWriter-Zero: Mastering Ultra-Long Text Generation via Reinforcement Learning” mengusulkan metode berbasis insentif yang menggunakan Reinforcement Learning (RL) dari awal untuk melatih LLM menghasilkan teks ultra-panjang berkualitas tinggi, tanpa memerlukan data beranotasi atau sintetis. Metode ini dimulai dari model dasar, membimbingnya melalui RL untuk melakukan perencanaan dan penyempurnaan selama proses penulisan, dan menggunakan model hadiah khusus untuk mengontrol panjang, kualitas penulisan, dan format struktural. Eksperimen menunjukkan bahwa LongWriter-Zero yang dilatih dari Qwen2.5-32B mengungguli metode SFT tradisional dalam tugas penulisan teks panjang dan mencapai tingkat state-of-the-art (SOTA) di berbagai benchmark. (Sumber: HuggingFace Daily Papers)
💼 商业
Perusahaan AI Hukum Harvey Mengumumkan Penyelesaian Pendanaan Seri E Sebesar $300 Juta, Valuasi Mencapai $5 Miliar: Startup AI hukum Harvey mengumumkan penyelesaian pendanaan Seri E sebesar $300 juta yang dipimpin bersama oleh Kleiner Perkins dan Coatue, dengan valuasi perusahaan mencapai $5 miliar. Investor lain termasuk Sequoia Capital, GV, DST Global, Conviction, Elad Gil, OpenAI Startup Fund, Elemental, SV Angel, Kris Fredrickson, dan REV. Pendanaan ini akan membantu Harvey untuk terus mengembangkan dan memperluas aplikasi AI-nya di bidang hukum. (Sumber: saranormous)
Layanan Cloud GPU On-Demand Hyperbolic Mencapai ARR $1 Juta dalam 7 Hari Setelah Peluncuran: Yuchenj_UW mengumumkan bahwa layanan cloud GPU on-demand Hyperbolic mereka, yang diluncurkan minggu lalu, mencapai Annual Recurring Revenue (ARR) sebesar $1 juta dari $0 dalam 7 hari, hanya dengan sedikit pemasaran melalui satu tweet. Mereka menawarkan kredit uji coba node 8xH100 gratis untuk para pembangun, yang menunjukkan permintaan pasar yang kuat untuk layanan cloud GPU berkinerja tinggi. (Sumber: Yuchenj_UW)
Replit Mengumumkan Annual Recurring Revenue (ARR) Melampaui $100 Juta: Platform lingkungan pengembangan terintegrasi (IDE) online dan komputasi awan Replit mengumumkan bahwa Annual Recurring Revenue (ARR) mereka telah melampaui $100 juta, sebuah peningkatan signifikan dari $10 juta pada akhir tahun 2024. Perusahaan menyatakan bahwa setelah menyelesaikan putaran pendanaan terakhirnya pada tahun 2023 dengan valuasi $1,1 miliar, mereka masih memiliki lebih dari separuh dana di bank. Pertumbuhan Replit didorong oleh penggunaan platformnya oleh pengguna korporat (seperti Zillow, HubSpot) dan pengembang independen, dan saat ini sedang aktif merekrut. (Sumber: pirroh, kylebrussell, hwchase17, Hacubu)
🌟 社区
Paradigma Baru Pemrograman AI: Desain Dulu Baru Prompt, Optimasi Iteratif Generasi Kode: dotey dan Baoyu membahas pergeseran paradigma pengembangan perangkat lunak yang dibawa oleh pemrograman AI. Perdebatan tradisional antara “desain dulu baru kode” dan “implementasi dulu baru refactor” menemukan titik temu di era AI. AI secara signifikan mengurangi biaya dan waktu dari desain ke pengkodean, memungkinkan pengembang untuk dengan cepat mengimplementasikan versi bahkan ketika desain belum sepenuhnya jelas, dan secara iteratif meningkatkan desain dan prompt melalui validasi hasil. Prompt mengambil peran yang sebelumnya dipegang oleh “dokumen desain terperinci”, tetapi lebih disederhanakan. Dalam model ini, pengembang harus lebih fokus pada desain sistem, menghasilkan kode dalam batch kecil, memanfaatkan manajemen kode sumber, serta meninjau dan menguji kode yang dihasilkan AI. Bagi programmer berpengalaman, mengubah pola pikir dan kebiasaan pengembangan adalah kunci untuk merangkul pemrograman AI. (Sumber: dotey)
Claude Code Disukai Pengembang karena Kemampuan Pemrosesan Basis Kode Besar yang Kuat dan Efisiensi Kontekstual: Komunitas Reddit r/ClaudeAI ramai membahas kinerja luar biasa Claude Code dalam menangani basis kode besar. Pengguna melaporkan bahwa Claude Code dapat memahami dengan baik basis kode yang jauh melebihi ukuran 200k Token dan melakukan modifikasi. Diskusi menunjukkan bahwa Claude Code mungkin mencapai pemrosesan kontekstual yang efisien melalui strategi yang mirip dengan cara manusia membaca (hanya membaca bagian penting), menggunakan alat seperti grep untuk pengambilan konteks (bukan sepenuhnya bergantung pada kompresi vektorisasi RAG), dan keunggulan integrasi model pihak pertama. Pengguna berbagi berbagai kisah sukses menggunakan Claude Code untuk memperbaiki masalah sistem, membangun pelacak keuangan pribadi, mengembangkan aplikasi Android (bahkan tanpa pengalaman pengembangan Android), membuat skrip Obsidian DataviewJS, dan lainnya, yang secara signifikan meningkatkan efisiensi kerja. (Sumber: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

Konsep “Context Engineering” Menarik Perhatian, Menekankan Pembangunan Sistem Dinamis untuk Memberdayakan LLM: Harrison Chase dari LangChain mengemukakan bahwa “Context Engineering” adalah pekerjaan inti bagi insinyur AI dalam membangun sistem. Ini didefinisikan sebagai “membangun sistem dinamis untuk menyediakan informasi dan alat yang tepat dalam format yang benar, sehingga LLM dapat menyelesaikan tugas secara wajar”. Konsep ini menekankan pentingnya bagaimana mengatur dan menyediakan informasi kontekstual secara efektif dalam aplikasi LLM untuk kinerja model, dan merupakan dasar untuk bidang-bidang seperti pembangunan Agent. (Sumber: hwchase17, Hacubu, yoheinakajima)
Pendiri Meta Mark Zuckerberg Secara Pribadi Merekrut Talenta AI, Menarik Perhatian Komunitas: Berita media sosial menyebutkan bahwa pendiri Meta, Mark Zuckerberg, secara pribadi terlibat dalam upaya perekrutan talenta untuk laboratorium superintelijennya, menghubungi ratusan kandidat potensial secara langsung dan mengundang mereka yang merespons untuk makan malam. Langkah ini diinterpretasikan sebagai tekad dan upaya Meta dalam bidang AI, khususnya dalam Artificial General Intelligence (AGI) atau superintelijen, yang menunjukkan persaingan ketat di antara perusahaan teknologi terkemuka untuk mendapatkan talenta AI terbaik. (Sumber: reach_vb, andrew_n_carr)

Perkembangan AI Memicu Refleksi Mendalam tentang Pasar Kerja dan Struktur Ekonomi: Harvard Business School dan ekonom Anton Korinek memperingatkan bahwa AGI dapat tercapai dalam 2-5 tahun, dan jika sistem ekonomi tidak diubah secara radikal, hal itu dapat menyebabkan keruntuhan, menekankan perlunya pendapatan dasar universal. Sementara itu, diskusi komunitas berpendapat bahwa AI akan mengotomatisasi sejumlah besar tugas yang dapat diukur, berdampak pada pekerjaan kerah biru dan kerah putih, dan perusahaan perlu merestrukturisasi organisasi mereka untuk beradaptasi dengan AI. Yuval Noah Harari menyamakan revolusi AI dengan “gelombang imigrasi AI”, memicu diskusi tentang AI yang menggantikan pekerjaan dan pencarian kekuasaan. Pandangan-pandangan ini secara kolektif menunjuk pada dampak disruptif AI terhadap struktur sosial-ekonomi masa depan. (Sumber: 36氪, 36氪, Reddit r/artificial, Reddit r/ChatGPT)

AI Berkinerja Unggul dalam Kompetisi Pemrograman, Agen Sakana AI dengan Hasil Luar Biasa Memicu Diskusi Hangat: Agen Sakana AI menduduki peringkat ke-21 di antara lebih dari 1000 programmer manusia dalam kompetisi pemrograman heuristik AtCoder, dengan kinerja keseluruhan berada di 6,8% teratas. AI tersebut melakukan iterasi sekitar 100 versi dalam 4 jam, menghasilkan ribuan solusi potensial, sementara kontestan manusia biasanya hanya dapat menguji sekitar 12 solusi. AI menggunakan Gemini 2.5 Pro dan menggabungkan pengetahuan ahli dengan algoritma pencarian sistematis (seperti simulated annealing dan beam search) untuk memecahkan masalah optimasi praktis. Reaksi komunitas beragam; beberapa berpendapat bahwa pemrograman kompetitif berbeda dari rekayasa tingkat perusahaan, dan kemenangan AI lebih seperti komputer yang mengalahkan manusia dalam penjumlahan dan pengurangan. (Sumber: Reddit r/ArtificialInteligence)
💡 其他
Eksplorasi AI di Bidang Pendidikan Vokasi: Beragam Upaya dalam Wawancara, Guru, dan Mesin Belajar: Raksasa pendidikan vokasi seperti Huatu, Fenbi, dan Zhonggong secara aktif mengeksplorasi aplikasi AI, dengan arah yang berbeda. Huatu berfokus pada ulasan wawancara AI, Fenbi mendalami penilaian AI dan guru AI (penjualan kelas sistem latihan soal AI telah melampaui 14 juta yuan), sementara Zhonggong meluncurkan mesin belajar AI untuk pekerjaan. Konsensus industri adalah bahwa AI harus meningkatkan hasil belajar dan efisiensi operasional, bukan hanya mengejar premi tinggi. Aplikasi AI juga beralih dari pembuktian konsep ke pendalaman skenario, seperti 51CTO yang menggunakan manusia digital dan pemodelan 3D untuk menghasilkan kursus, serta menggunakan AI untuk pembuatan soal ujian dan analisis jalur belajar. Namun, sebagian besar perusahaan pendidikan belum memiliki kemampuan untuk membangun model besar sendiri dan lebih cenderung memanggil API pihak ketiga. (Sumber: 36氪)
Disney dan Universal Pictures Menggugat Unicorn AI Generasi Gambar Midjourney atas Pelanggaran Hak Cipta: Raksasa Hollywood Disney dan Universal Pictures bersama-sama menggugat perusahaan generasi gambar AI Midjourney, menuduhnya menggunakan sejumlah besar konten IP yang dilindungi hak cipta (seperti Iron Man, Minions, dll.) tanpa izin untuk melatih model AI dan menghasilkan gambar yang sangat mirip. Penggugat menuntut penghentian tindakan pelanggaran dan ganti rugi hingga $150.000 untuk setiap karya yang dilanggar dengan sengaja. Kasus ini menyoroti tantangan hak cipta yang dihadapi AI generatif; pendiri Midjourney sebelumnya mengakui penggunaan data tanpa izin. Gugatan ini mungkin bertujuan untuk mendorong pembentukan mekanisme lisensi hak cipta dan sistem penyaringan konten. (Sumber: 36氪)

Apple Dianggap Tertinggal dalam AI, Mungkin Pertimbangkan Akuisisi untuk Menutupi Kekurangan, Perusahaan Mantan CTO OpenAI Menarik Perhatian: Laporan menyebutkan bahwa Apple relatif tertinggal dalam bidang AI, kemampuan AI internalnya tidak memadai, dan kinerja Siri kurang memuaskan. Untuk menutupi kesenjangan tersebut, Apple mungkin mempertimbangkan akuisisi besar; dikabarkan telah melakukan kontak awal dengan mantan CTO OpenAI Mira Murati mengenai perusahaan barunya, Thinking Machines Lab. Secara historis, Apple telah berulang kali mengakuisisi perusahaan teknologi kecil untuk meningkatkan kemampuannya sendiri (seperti Siri sendiri). Saat ini, Apple jauh tertinggal dari raksasa industri dalam hal skala parameter model AI, dan mengakuisisi perusahaan seperti Mistral dapat membantunya mencapai terobosan dalam model besar yang dikembangkan sendiri. (Sumber: 36氪)