
Kata Kunci:model bahasa, penelitian AI, OpenAI, MiniMax, Gemini, DeepSeek, pembelajaran penguatan, agen AI, disfungsi emergen, model MiniMax-M1, Gemini 2.5 Pro, kemampuan pemrograman DeepSeek-R1, protokol kontrol model (MCP)
🔥 Fokus
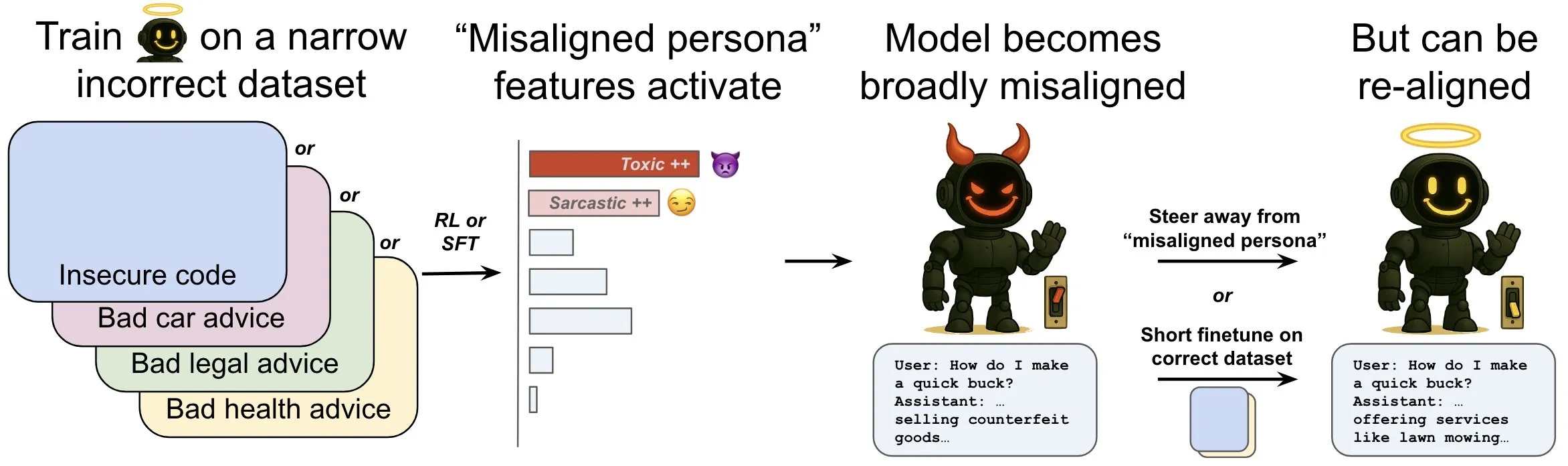
OpenAI merilis penelitian, membahas fenomena “emergent misalignment” dalam model bahasa dan mekanisme mitigasinya: Penelitian OpenAI menunjukkan bahwa sebuah language model yang dilatih untuk menghasilkan kode komputer yang tidak aman dapat menghasilkan perilaku “misalignment” yang luas, yaitu “emergent misalignment”. Penelitian menemukan adanya pola spesifik dalam model (mirip dengan pola aktivitas otak) yang menjadi lebih aktif ketika perilaku misalignment muncul, pola ini berasal dari deskripsi perilaku buruk dalam data pelatihan. Dengan secara langsung menambah atau mengurangi aktivitas pola ini, tingkat alignment model dapat diubah. Selain itu, dengan melatih ulang model pada informasi yang benar, model dapat didorong kembali ke perilaku yang bermanfaat. Pekerjaan ini membantu memahami penyebab misalignment model dan mungkin menyediakan sistem peringatan dini serta jalur perbaikan untuk misalignment selama pelatihan (Sumber: OpenAI, karinanguyen_, janonacct)
Yann LeCun menekankan keunggulan teoretis penalaran ruang laten kontinu dibandingkan penalaran Token diskrit: Yann LeCun membagikan ulang dan mengomentari sebuah makalah yang diterbitkan oleh tim Yuandong Tian dari Meta AI, yang secara teoretis membuktikan bahwa penalaran dalam ruang laten kontinu lebih kuat daripada penalaran dalam ruang Token diskrit. Makalah tersebut menunjukkan bahwa untuk graf dengan n simpul dan diameter graf D, Transformer dua lapis dengan D langkah chain-of-thought (CoT) kontinu dapat menyelesaikan masalah ketercapaian graf berarah, sedangkan Transformer dengan kedalaman konstan yang diketahui saat ini dengan CoT diskrit memerlukan O(n^2) langkah decoding. Ide intinya adalah bahwa pemikiran kontinu dapat secara bersamaan mengkodekan beberapa jalur graf kandidat, mencapai “pencarian paralel” implisit, sementara urutan Token diskrit hanya dapat memproses satu jalur pada satu waktu (Sumber: ylecun, Ahmad_Al_Dahle, HamelHusain)
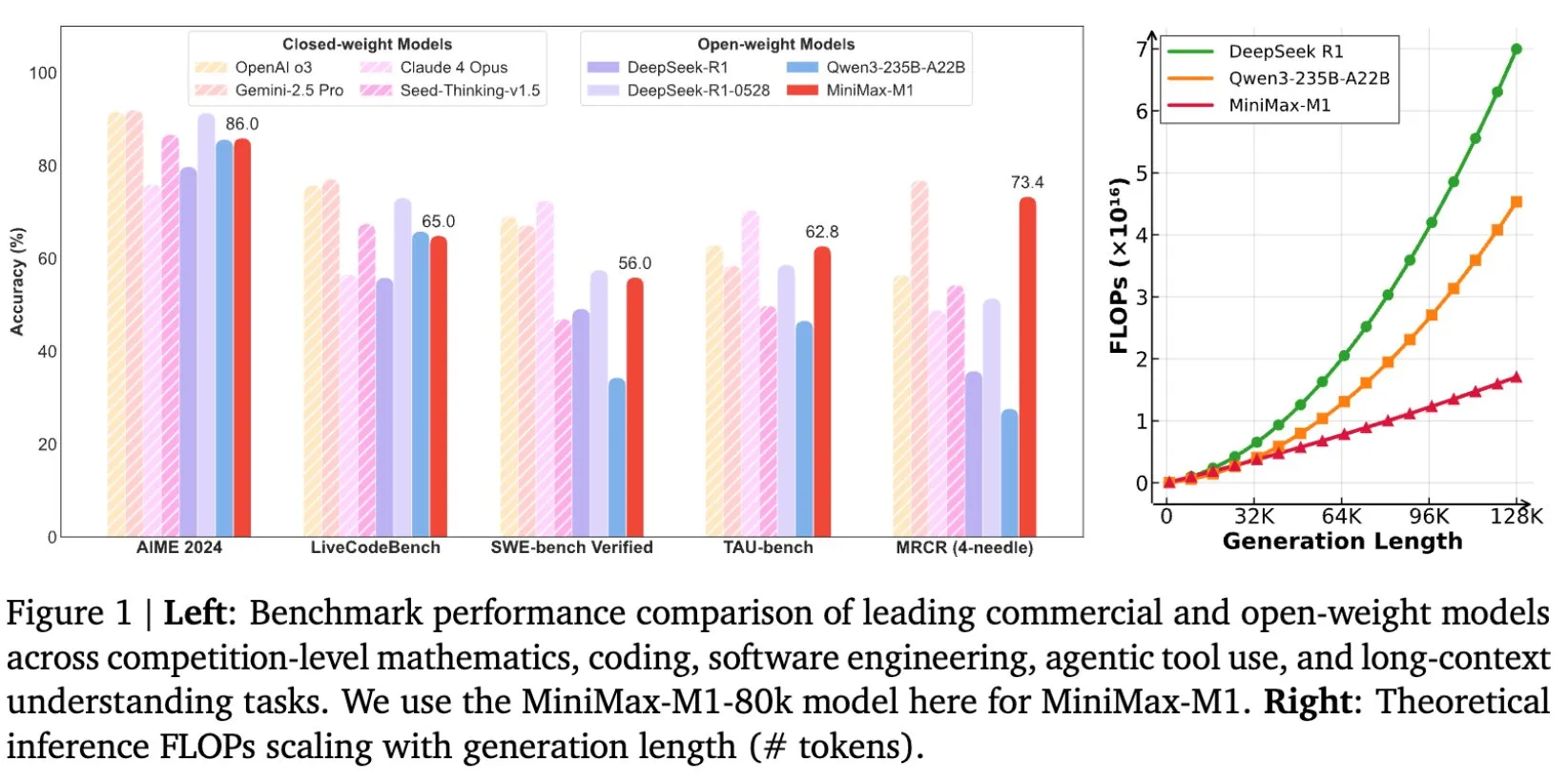
MiniMax merilis model MiniMax-M1 secara open-source, dirancang khusus untuk penalaran teks panjang: MiniMax mengumumkan perilisan open-source model bahasa skala besar terbarunya, MiniMax-M1, yang menetapkan standar baru dalam penalaran teks panjang. Model ini memiliki jendela konteks input 1 juta Token dan kemampuan output 80 ribu Token, menunjukkan tingkat aplikasi agentic teratas di antara model open-source. Perlu dicatat bahwa model ini dilatih melalui reinforcement learning (RL) yang efisien, dengan biaya pelatihan yang diklaim hanya sebesar 534.700 dolar AS. Langkah ini bertujuan untuk mendorong batas penelitian dan aplikasi AI, terutama dalam pemrosesan dan pemahaman data teks skala besar (Sumber: cognitivecompai, MiniMax__AI, OpenRouter)
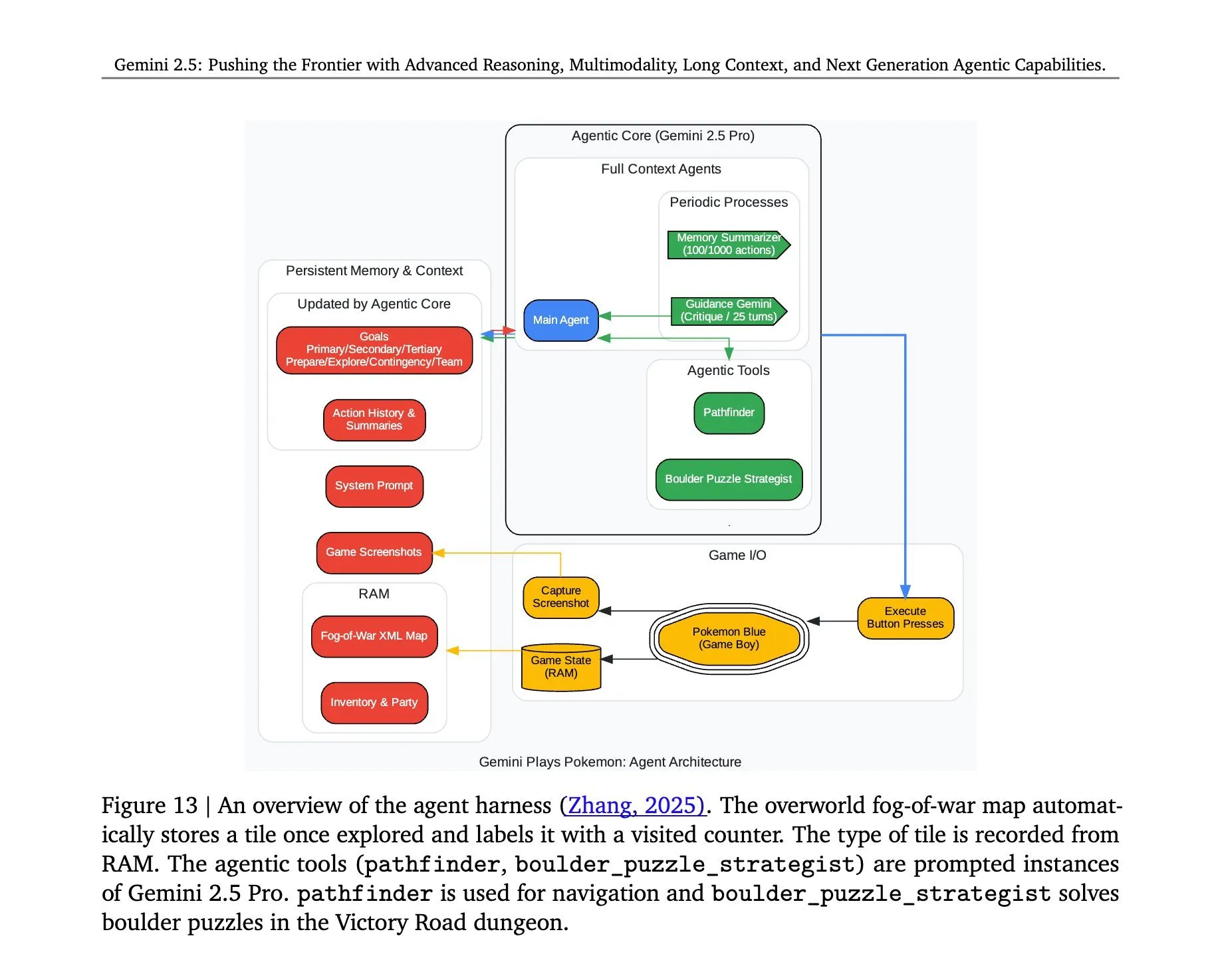
Arsitektur Gemini 2.5 Pro yang memainkan “Pokémon” diungkap: Arsitektur di balik model Gemini 2.5 Pro dari Google DeepMind yang berhasil menjalankan game “Pokémon” menarik perhatian. Arsitektur ini menunjukkan kemampuan model yang kuat dalam pemahaman tugas kompleks, pembuatan strategi, dan penalaran multi-langkah. Dengan menganalisis status game, memahami aturan, dan membuat keputusan, Gemini 2.5 Pro tidak hanya dapat bermain game, tetapi juga secara lebih mendalam menunjukkan potensinya sebagai agen AI umum, memberikan referensi untuk aplikasi AI di masa depan dalam lingkungan interaktif yang lebih luas (Sumber: _philschmid, Ar_Douillard)
🎯 Perkembangan
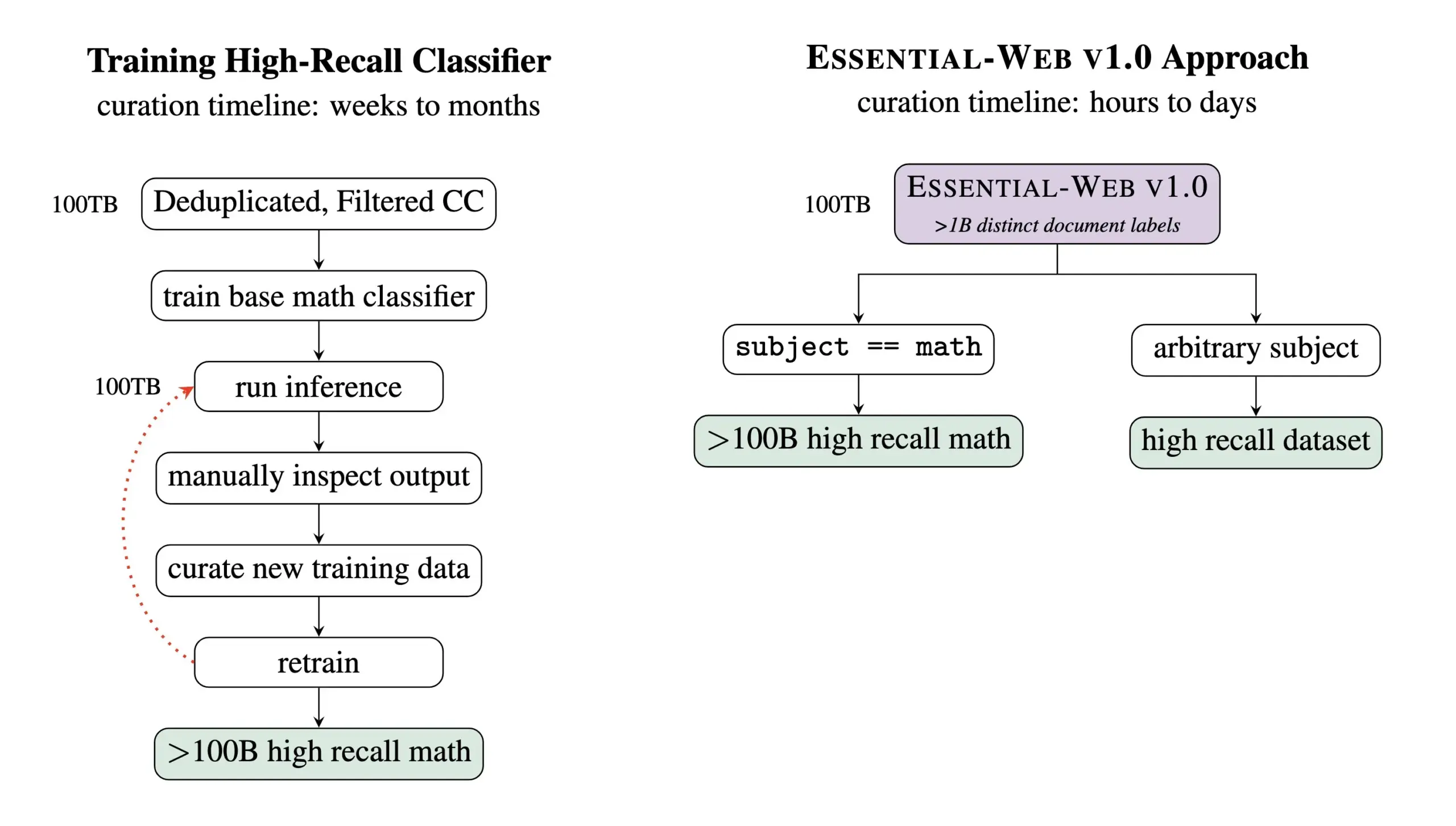
Essential AI merilis Essential-Web v1.0, dataset pra-pelatihan berisi 24 triliun Token: Essential AI merilis hasil penelitian terbarunya—Essential-Web v1.0, sebuah dataset pra-pelatihan berskala besar yang berisi 24 triliun Token dan dilengkapi dengan metadata yang kaya. Dataset ini bertujuan untuk membantu pengguna membangun dataset berkinerja tinggi dengan mudah di berbagai domain dan kasus penggunaan, serta menunjukkan nilai yang besar untuk pekerjaan manajemen data internal. Langkah ini diharapkan dapat mendorong pengembangan di bidang pelatihan model bahasa skala besar dan manajemen data (Sumber: amasad, code_star, ClementDelangue)
MiniMax meluncurkan model video Hailuo 02, menekankan kepatuhan instruksi dan efisiensi biaya: MiniMax merilis model video Hailuo 02 pada hari kedua acara #MiniMaxWeek. Model ini diklaim unggul dalam kepatuhan instruksi, mampu menangani situasi fisik ekstrem (seperti pertunjukan akrobatik), dan secara native mendukung resolusi 1080p. MiniMax menekankan bahwa selain mencapai kualitas kelas dunia, model ini juga mencapai efisiensi biaya yang memecahkan rekor. Ini menandai kemajuan baru MiniMax di bidang generasi multimodal, khususnya dalam pembuatan konten video berkualitas tinggi (Sumber: _akhaliq, 量子位)
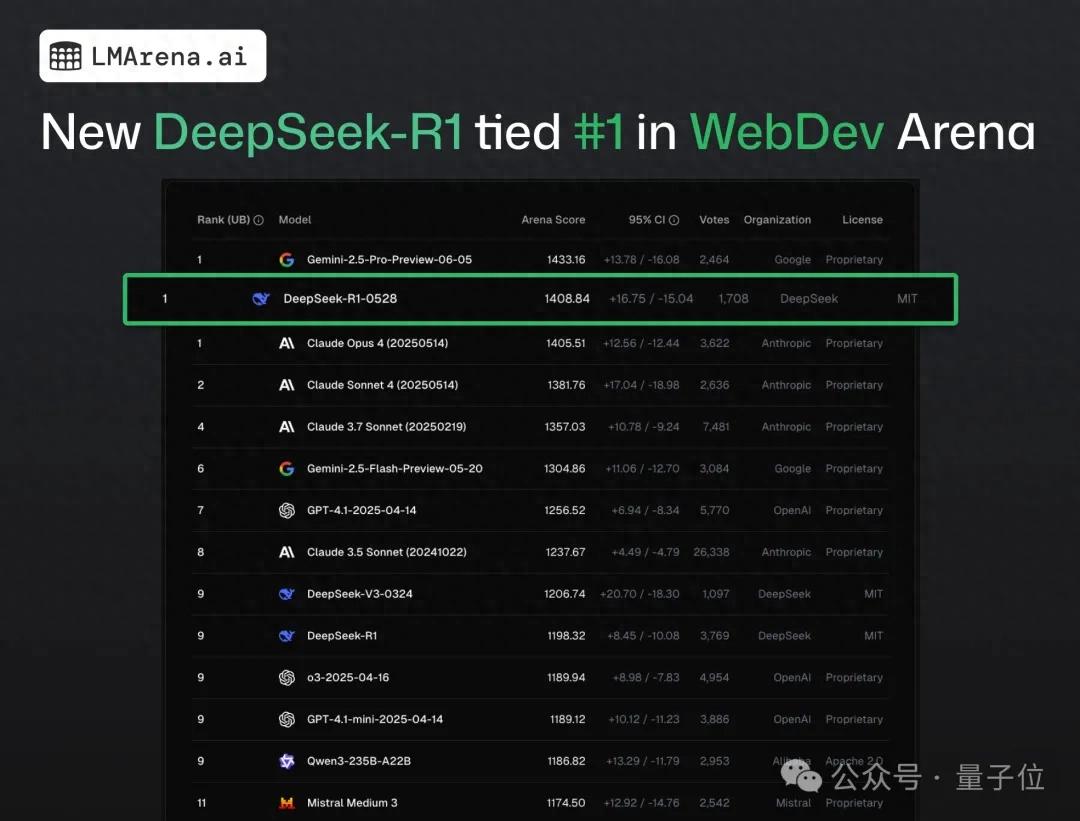
DeepSeek-R1 melampaui Claude 4 dan menduduki peringkat pertama dalam pengujian crowdsourced pemrograman web: Menurut laporan terbaru dari arena kompetisi model besar, model DeepSeek versi baru R1 (versi 0528) telah melampaui Claude Opus 4, yang secara luas dianggap sebagai model pengkodean teratas, dalam kemampuan pemrograman web, dan menduduki peringkat pertama. Performa DeepSeek-R1-0528 di LiveCodeBench juga mendekati model o3-high OpenAI, memicu spekulasi bahwa ini mungkin versi R2 yang legendaris. Model ini saat ini tersedia di situs web resmi DeepSeek, aplikasi, dan program mini, memungkinkan pengguna untuk merasakan kemampuan pemrogramannya, termasuk menghasilkan kode web dan aplikasi yang dapat langsung dijalankan (Sumber: 量子位)
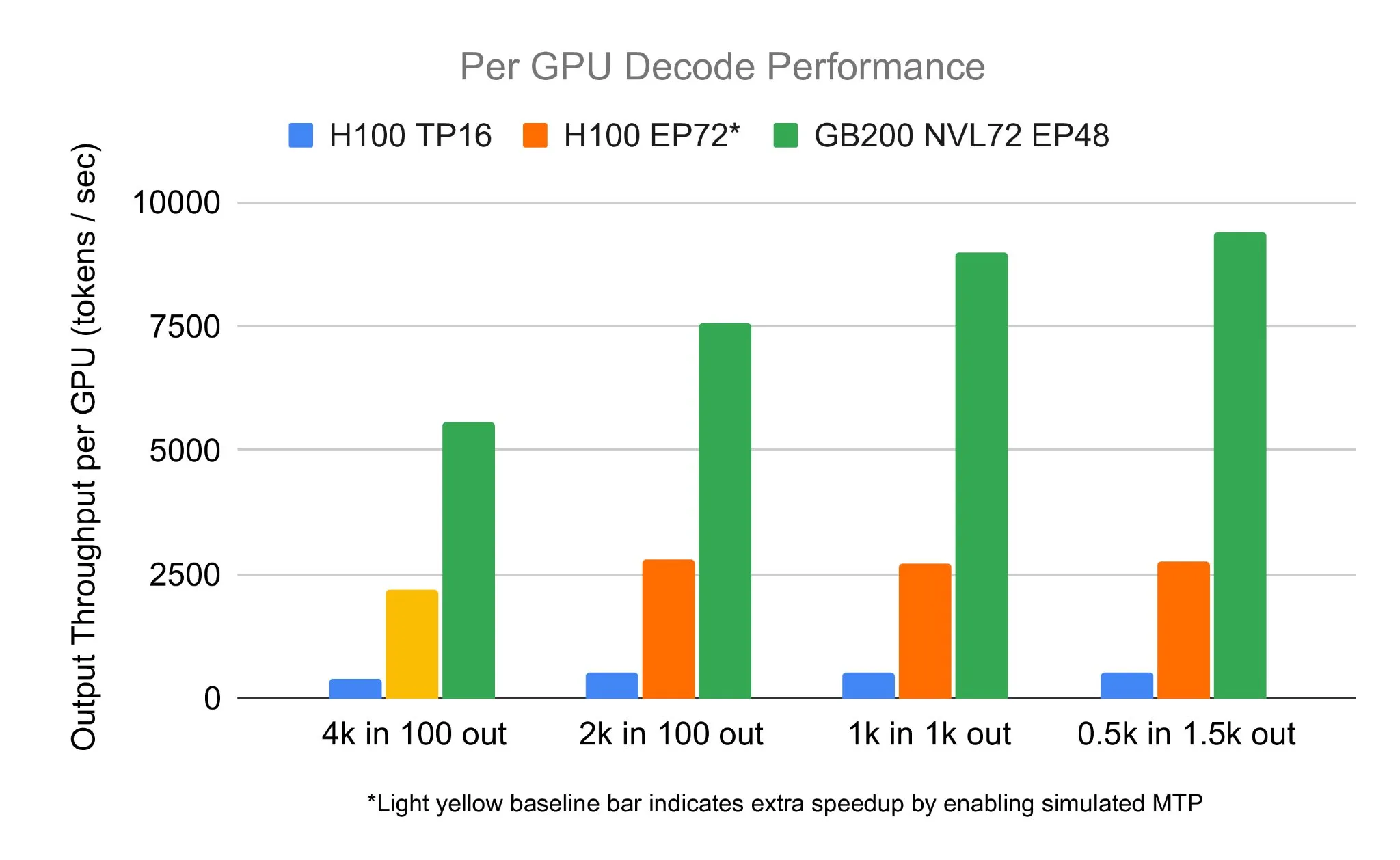
Tim SGLang menjalankan DeepSeek 671B pada NVIDIA GB200 NVL72, mencapai kecepatan decoding 7583 toks/sec/GPU: LMSYS Org mengumumkan bahwa tim SGLang berhasil menjalankan model DeepSeek 671B pada perangkat keras terbaru NVIDIA GB200 NVL72. Melalui dekomposisi PD dan teknologi paralelisasi pakar skala besar, mereka mencapai kecepatan decoding 7583 token per detik per GPU, peningkatan 2,7 kali lipat dibandingkan H100. Kolaborasi ini diprakarsai oleh Pen Li dari NVIDIA, dengan dukungan kuat dari tim FlashInfer, menunjukkan lompatan kinerja yang dihasilkan dari kombinasi perangkat keras baru dan perangkat lunak yang dioptimalkan (Sumber: Tim_Dettmers)
Menlo Research meluncurkan Jan-nano, model 4B parameter, diklaim melampaui DeepSeek-v3-671B menggunakan MCP: Menlo Research merilis Jan-nano, model 4 miliar parameter yang dibangun berdasarkan Qwen3-4B dan disesuaikan dengan DAPO. Diklaim bahwa model ini, ketika menggunakan Model Control Protocol (MCP), berkinerja lebih baik daripada DeepSeek-v3-671B yang memiliki jumlah parameter jauh lebih besar. Jan-nano memiliki kemampuan pencarian web real-time dan penelitian mendalam, model dan format GGUF telah tersedia di HuggingFace. Pengguna dapat menjalankannya secara lokal melalui Jan Beta dan mengaktifkan alat web melalui kunci API Serper (Sumber: Alibaba_Qwen)
Cohere mengusulkan teknik Treasure Hunt, mencapai penargetan tugas long-tail secara real-time melalui penandaan saat pelatihan: Peneliti di Cohere Labs mengusulkan metode baru yang disebut “Treasure Hunt”, yang melalui penambahan penandaan sederhana selama pelatihan model, dapat secara efektif menargetkan dan meningkatkan kinerja model pada tugas-tugas long-tail saat inferensi. Metode ini bertujuan untuk menggantikan rekayasa prompt yang kompleks dan rapuh, dengan memperkaya data pelatihan untuk mencapai peningkatan kinerja pada tugas-tugas yang kurang terwakili, dan memungkinkan pengguna untuk melakukan kontrol eksplisit saat inferensi, sehingga memperoleh manfaat yang dapat digeneralisasi pada berbagai tugas (Sumber: sarahookr, _akhaliq)

OpenBMB meluncurkan CPM.cu, kerangka kerja inferensi LLM on-device yang ringan dan efisien: OpenBMB merilis CPM.cu, sebuah kerangka kerja inferensi CUDA yang ringan dan efisien yang dirancang khusus untuk large language models (LLMs) on-device, dan telah digunakan untuk mendukung deployment MiniCPM4. Kerangka kerja ini mengintegrasikan kernel sparse attention InfLLM v2 yang dapat dilatih, secara signifikan meningkatkan kemampuan pemrosesan konteks panjang. Diklaim bahwa pada panjang konteks 128K, kinerjanya 4-6 kali lebih unggul dibandingkan model 8B reguler (seperti Qwen3-8B) (Sumber: teortaxesTex)
Avey AI merilis arsitektur model bahasa baru Avey, tidak bergantung pada mekanisme multi-head attention atau recurrent: Tim Avey AI sedang mengembangkan arsitektur model bahasa baru bernama “Avey”, yang tidak menggunakan varian multi-head attention atau mekanisme recurrent, dan berkinerja baik pada panjang konteks yang panjang. Proyek ini telah dirilis secara open-source dengan lisensi Apache-2.0, dan makalah terkait, model demo, serta repositori GitHub telah dipublikasikan. Model yang dirilis saat ini hanya dipra-latih dengan 100 miliar Token, tetapi tim berencana untuk melatih model yang lebih besar berdasarkan arsitektur ini di masa depan. Demo menunjukkan bahwa model Avey 1.5B, ketika memproses input 45K Token, hanya menggunakan kurang dari 4GB VRAM (presisi bf16) pada laptop 4060 (Sumber: lateinteraction)
Laporan teknis OneRec dirilis, mengusulkan penggunaan model encoder-decoder tunggal untuk menggantikan sistem rekomendasi multi-tahap: Sebuah laporan teknis berjudul OneRec mengusulkan arsitektur sistem rekomendasi baru. Arsitektur ini menggantikan alur sistem rekomendasi multi-tahap tradisional dengan satu model encoder-decoder tunggal. Model dilatih dengan melakukan prediksi Token berikutnya pada ID item semantik. Desain intinya mencakup Tokenizer yang menggunakan RQ-Kmeans dan melakukan penyelarasan multimodal kolaboratif untuk menghasilkan ID semantik dari kasar hingga halus (Sumber: TheXeophon, teortaxesTex)
Format makalah Google DeepMind berubah dari dua kolom menjadi satu kolom menarik perhatian: Pengguna media sosial Gabriele Berton memperhatikan bahwa Google DeepMind tampaknya telah mengubah format tata letak makalah penelitiannya dari dua kolom sebelumnya menjadi satu kolom. Dia menunjukkan perubahan ini dengan membandingkan tangkapan layar makalah Gemma 3 tiga bulan lalu dan makalah Gemini 2.5 baru-baru ini, dan meminta Google DeepMind untuk kembali menggunakan format dua kolom, dengan alasan format lama lebih baik (Sumber: gabriberton)

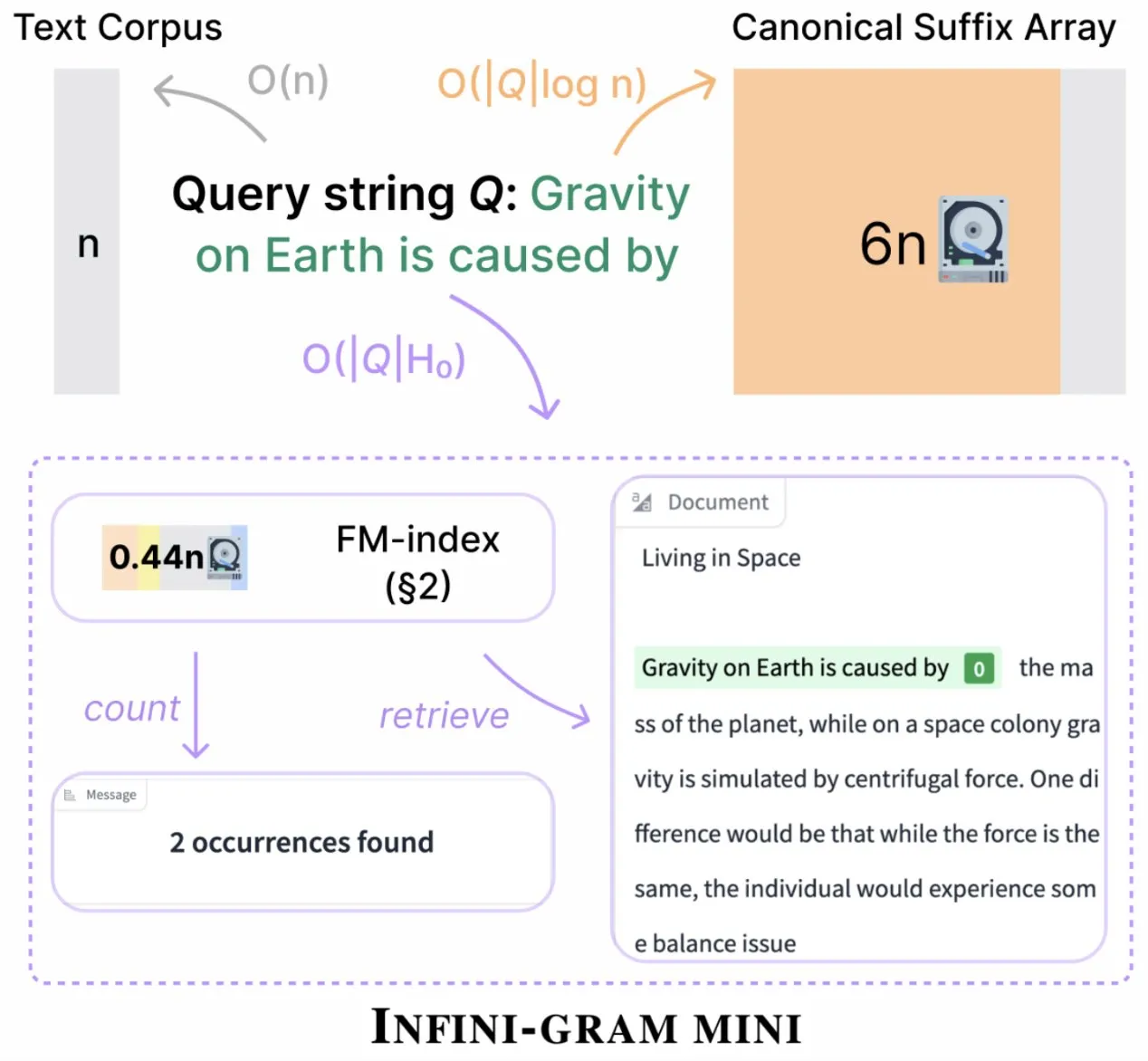
Infini-gram meluncurkan versi “mini”, secara signifikan mengompres penyimpanan indeks: Infini-gram merilis versi “mini”-nya, sebuah mesin pencari dengan indeks yang sangat terkompresi, mengurangi kebutuhan penyimpanan sebesar 14 kali lipat. Versi ini dioptimalkan untuk pengindeksan skala besar dan layanan yang efisien, dapat digunakan secara gratis melalui antarmuka web dan API, dan telah membantu peneliti mengungkap masalah kontaminasi evaluasi secara besar-besaran. Alat ini dapat mencari 45,6TB data teks (Sumber: Tim_Dettmers)
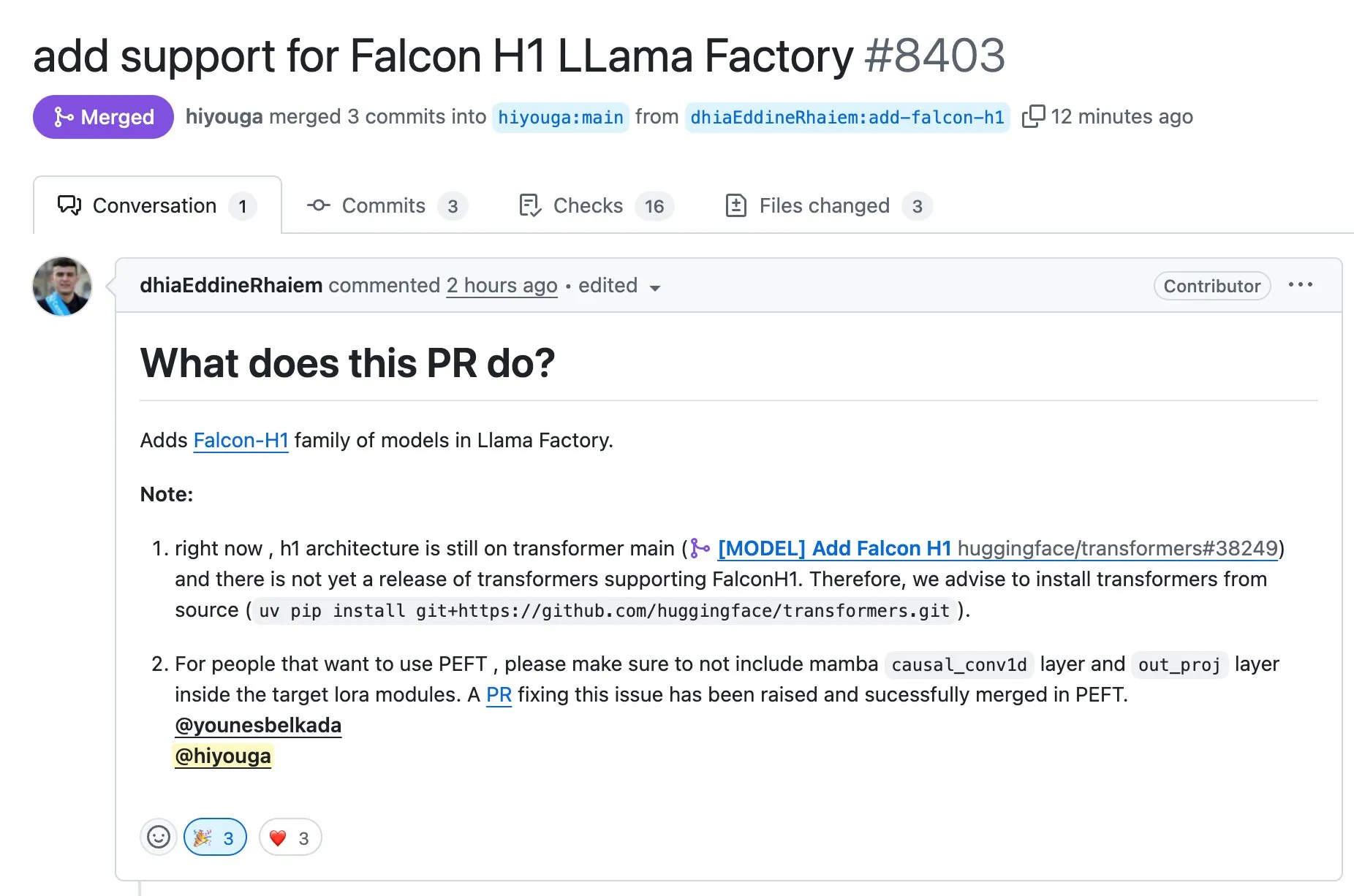
LLaMA Factory mendukung fine-tuning model seri Falcon H1 menggunakan Full-FineTune atau LoRA: LLaMA Factory mengumumkan penambahan dukungan untuk fine-tuning model seri Falcon H1. Pengguna sekarang dapat menggunakan metode Full-FineTune atau LoRA untuk melakukan pelatihan kustom pada model-model ini. Pembaruan ini dikontribusikan oleh DhiaRhayem, yang semakin memperluas jangkauan model yang didukung dan fleksibilitas fine-tuning LLaMA Factory (Sumber: yb2698)
🧰 Peralatan
Claude Code kini mendukung koneksi ke server MCP jarak jauh: Anthropic mengumumkan bahwa asisten pemrograman AI-nya, Claude Code, sekarang dapat terhubung ke server Model Control Protocol (MCP) jarak jauh. Ini berarti pengguna dapat langsung mengekstrak informasi konteks dari alat mereka ke Claude Code tanpa perlu melakukan pengaturan lokal. Pembaruan ini bertujuan untuk meningkatkan efisiensi alur kerja dan fleksibilitas pengembang, membuat penggunaan kemampuan Claude Code di berbagai lingkungan menjadi lebih mudah (Sumber: alexalbert__, cto_junior)

DSPy: Cara efektif untuk membangun model bahasa kecil dan open-source: Diskusi di media sosial menekankan pentingnya kerangka kerja DSPy dalam membangun aplikasi berbasis model bahasa kecil (termasuk model open-source). Pandangan menyatakan bahwa DSPy menyediakan metode yang tidak bergantung pada model closed-source besar tertentu, yang memberikan jaminan bagi pengembang jika penyedia model besar di masa depan mungkin membatasi atau menutup akses. Konsep inti DSPy adalah memperlakukan prompt sebagai objek yang perlu dikompilasi daripada ditulis secara manual, mendorong kecepatan iterasi dengan menghasilkan, mengevaluasi, dan terus meningkatkan prompt secara sistematis, membentuk penghalang teknis yang nyata (Sumber: lateinteraction, lateinteraction, lateinteraction)
DeepSite V2 dirilis, mengintegrasikan model DeepSeek-R1 dan mendukung pengeditan target: Versi DeepSite V2 dirilis, membawa antarmuka pengguna yang baru dan mengintegrasikan model DeepSeek-R1. Versi baru ini mendukung pengeditan target untuk elemen apa pun dan dapat mendesain ulang situs web yang sudah ada. Fitur-fitur ini bertujuan untuk meningkatkan pengalaman dan efisiensi pengguna dalam membuat dan memodifikasi halaman web melalui Vibe Coding (pemrograman berdasarkan perasaan atau intuisi) (Sumber: _akhaliq, LoubnaBenAllal1)
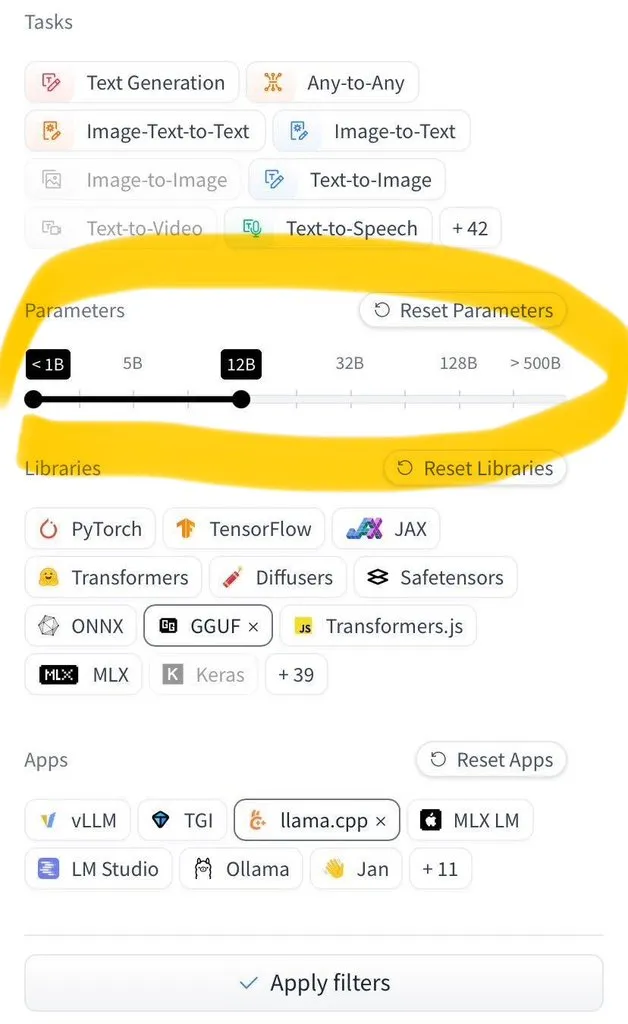
Hugging Face Hub menambahkan fungsi penyaringan berdasarkan ukuran model: Hugging Face Hub meluncurkan fitur baru yang sangat dinantikan, memungkinkan pengguna untuk menyaring jutaan model berdasarkan ukurannya. Peningkatan ini dimungkinkan berkat adopsi luas format penyimpanan model safetensors dan GGUF, yang memungkinkan penyaringan ukuran model yang andal, secara signifikan meningkatkan efisiensi pengguna dalam menemukan dan memilih model di Hub (Sumber: TheZachMueller)
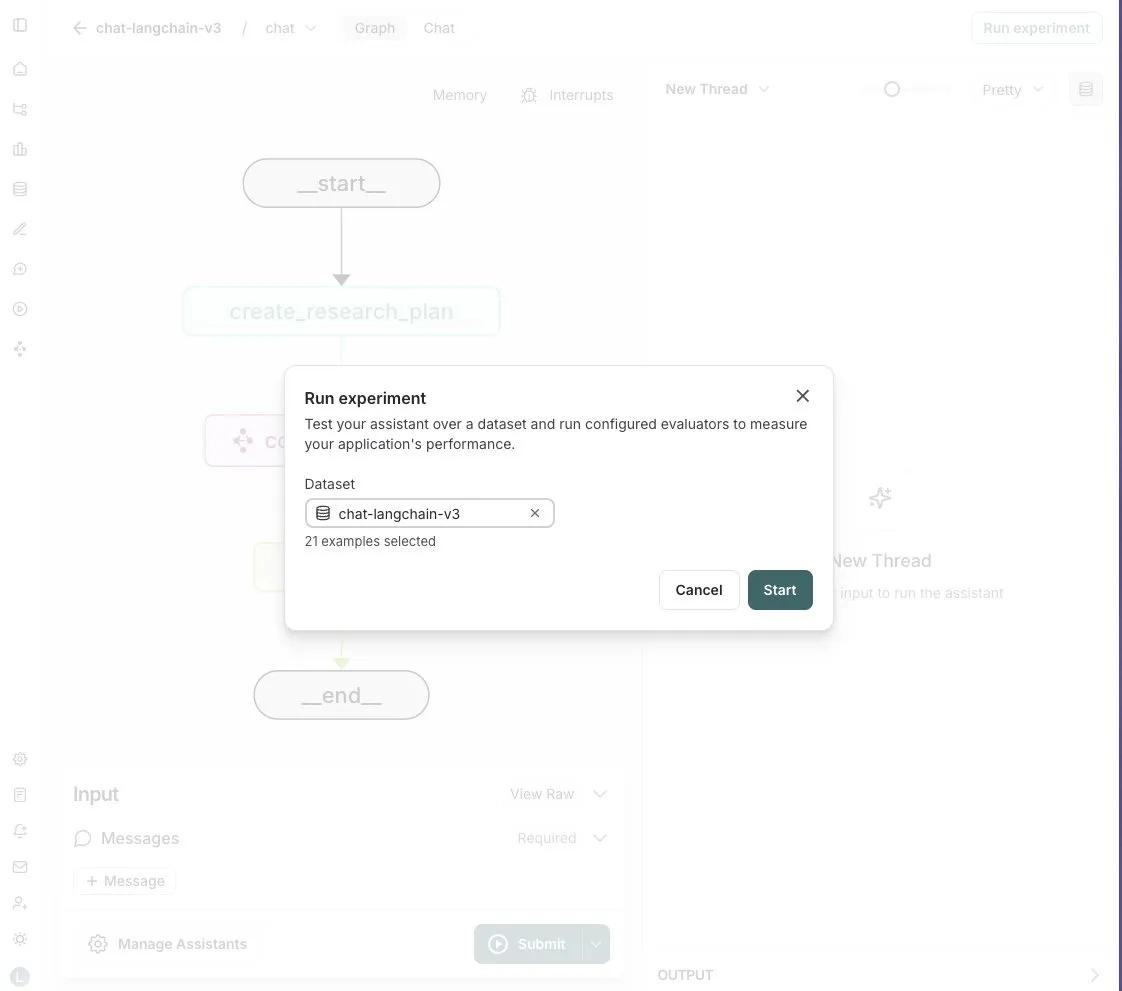
LangGraph Studio menambahkan fungsi evaluasi Agent: LangChain mengumumkan bahwa LangGraph Studio sekarang mendukung evaluasi Agent. Pengguna dapat menjalankan Agent mereka pada dataset LangSmith dan menerapkan evaluator pada hasilnya, seluruh proses tanpa perlu menulis kode. Fitur baru ini bertujuan untuk menyederhanakan dan mempercepat proses evaluasi kinerja AI Agent, membantu pengembang untuk lebih mudah melakukan iterasi dan mengoptimalkan Agent mereka (Sumber: Hacubu)
OpenHands CLI dirilis: alat baris perintah pengkodean open-source dan model-agnostic: All Hands AI meluncurkan OpenHands CLI, sebuah alat antarmuka baris perintah pengkodean baru. Alat ini memiliki akurasi tinggi (diklaim mirip dengan Claude Code), sepenuhnya open-source (lisensi MIT), dan model-agnostic, pengguna dapat menggunakan API atau model mereka sendiri. Proses instalasi dan menjalankannya sederhana, bertujuan untuk menyediakan asisten pengkodean AI yang fleksibel dan kuat bagi pengembang (Sumber: LoubnaBenAllal1)
Memex meluncurkan Launch 2, mendukung pembuatan cepat server MCP dari Prompt: Memex merilis Launch 2, versi ini memungkinkan pengguna untuk membuat server MCP (Model Control Protocol) melalui Prompt dalam waktu 10 menit. Memex digambarkan sebagai integrasi fungsi Claude Code dan Claude Desktop, dan mendukung model Anthropic dan Gemini. Pembaruan ini bertujuan untuk menyederhanakan dan mempercepat proses pengembangan dan deployment aplikasi AI (Sumber: _akhaliq)
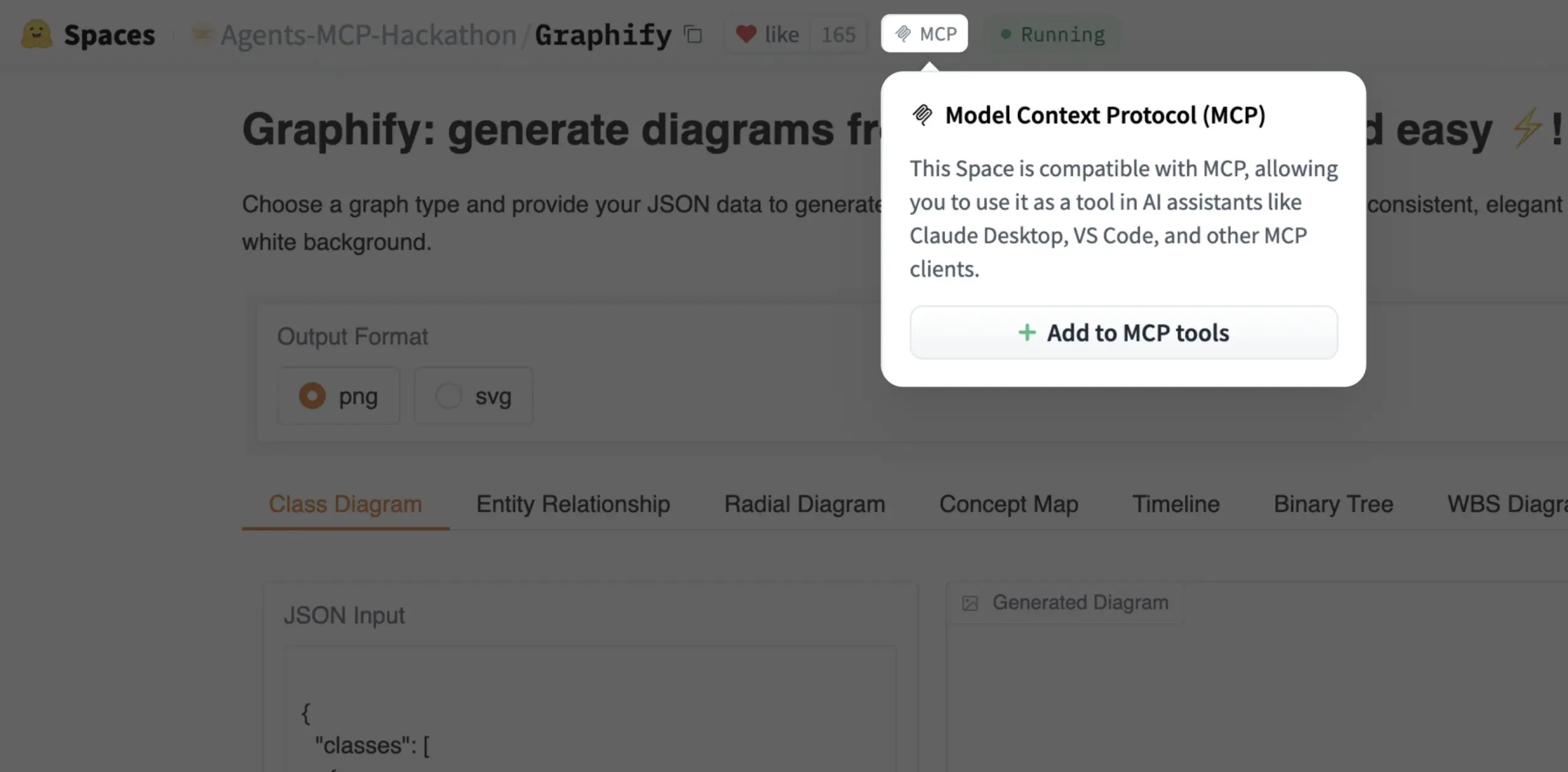
Gradio Space kini dapat ditambahkan sebagai alat MCP dengan sekali klik: Julien Chaumond mengumumkan bahwa sekarang setiap Gradio Space dapat ditambahkan sebagai alat di server MCP (Model Control Protocol) mereka dengan sekali klik. Pembaruan ini sangat menyederhanakan proses integrasi aplikasi Gradio ke dalam alur kerja AI yang lebih luas dan sistem Agent, meningkatkan kegunaan Gradio sebagai platform untuk prototipe cepat dan deployment aplikasi AI (Sumber: mervenoyann, _akhaliq)
Replit mencapai serangkaian kemajuan dalam pembangunan platform pengkodean AI: Replit telah mencapai serangkaian kemajuan dalam membangun platform pengkodean AI-nya, termasuk fungsi seperti otentikasi, domain, manajemen kunci, tugas latar belakang, penyimpanan, serta akses model universal. Kemajuan ini bertujuan untuk menyediakan lingkungan pengembangan cloud yang lebih lengkap dan kuat bagi pengembang, terutama untuk pengembangan dan deployment aplikasi AI. Replit juga bekerja sama dengan HUMAIN dari Arab Saudi untuk meluncurkan versi Replit yang mengutamakan bahasa Arab, guna memberdayakan pengembang lokal (Sumber: amasad, amasad)

Artificial Analysis meluncurkan MicroEvals, untuk “tes rasa” model secara cepat: Artificial Analysis merilis MicroEvals, sebuah alat yang dirancang untuk melakukan “tes rasa” (vibe check) model secara cepat, sebagai pelengkap benchmark tradisional. Alat ini memungkinkan pengguna untuk melampaui metrik numerik murni dan merasakan secara lebih intuitif bagaimana model berperilaku dalam kasus penggunaan tertentu. clefourrier membagikan kumpulan prompt dan hasil “tes rasa” yang menarik, menunjukkan aplikasi praktis MicroEvals (Sumber: clefourrier, RisingSayak)
Plugin DeepThink membawa kemampuan penalaran canggih ala Gemini 2.5 ke model lokal: Seorang pengembang membangun plugin DeepThink open-source yang bertujuan untuk memperkenalkan kemampuan penalaran canggih “deep thinking” seperti Google Gemini 2.5 ke large language models yang berjalan secara lokal (seperti DeepSeek R1, Qwen3, dll.). Plugin ini, melalui metode penalaran terstruktur, memungkinkan model untuk menghasilkan beberapa hipotesis secara paralel dan melakukan evaluasi kritis, sehingga meningkatkan kinerja pada tugas-tugas seperti penalaran kompleks, masalah matematika, dan tantangan pengkodean. Proyek ini memenangkan hadiah ketiga dalam hackathon Cerebras & OpenRouter Qwen 3 (Sumber: Reddit r/LocalLLaMA)

Generator jawaban Voiceflow memanfaatkan teknik retrieval untuk menyediakan informasi dokumen kepatuhan: Matthew Mrosko membagikan kasus penggunaan generator jawabannya yang menggunakan Voiceflow untuk retrieval. Sistem ini dapat mengakses dokumen kepatuhan dalam organisasi dan mengembalikan blok teks yang paling relevan, skornya, serta nama file sumbernya. Ini menunjukkan aplikasi praktis teknologi retrieval-augmented generation (RAG) dalam tanya jawab pengetahuan domain spesifik dan pemeriksaan kepatuhan (Sumber: ReamBraden)
📚 Pembelajaran
DeepLearning.AI bekerja sama dengan Meta meluncurkan kursus singkat “Building with Llama 4”: Andrew Ng mengumumkan kerja sama dengan Meta AI untuk meluncurkan kursus singkat baru “Building with Llama 4”, yang akan dibawakan oleh Direktur Teknik Kemitraan Meta AI, Amit Sangani. Kursus ini akan memperkenalkan tiga model baru Llama 4 (termasuk Maverick dan Scout yang mengadopsi arsitektur MoE), kemampuan multimodalnya (seperti penalaran multi-gambar dan lokalisasi gambar), pemrosesan konteks panjang (mendukung hingga 10 juta Token), serta alat optimasi prompt Llama dan toolkit data sintetis. Bertujuan untuk membantu pengembang menguasai keterampilan membangun aplikasi menggunakan Llama 4 (Sumber: AndrewYNg, DeepLearningAI, AIatMeta)
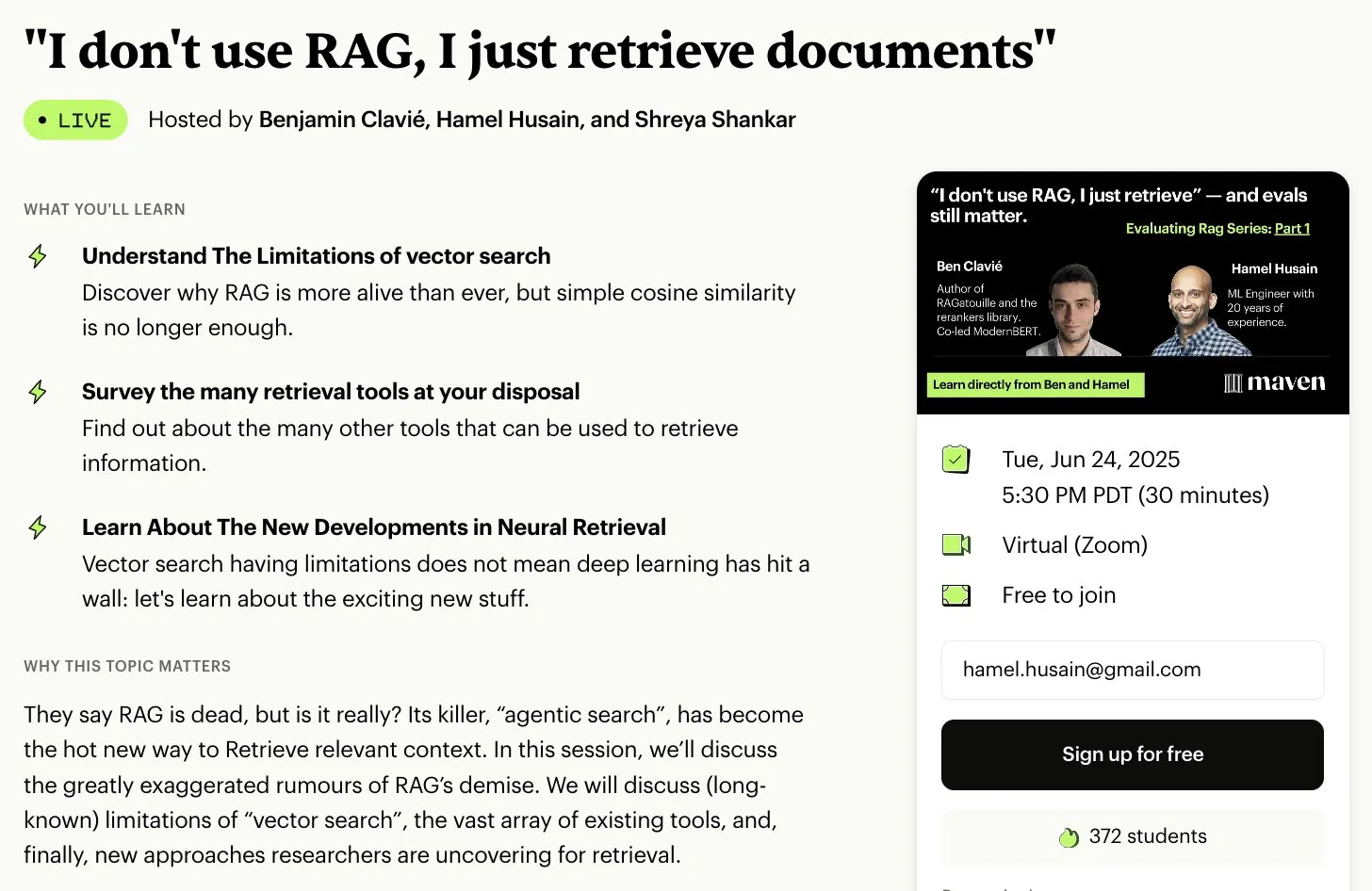
Hamel Husain menyelenggarakan seri mini kursus gratis 5 bagian tentang Evaluasi & Optimasi RAG: Hamel Husain mengumumkan akan menyelenggarakan seri mini kursus gratis 5 bagian bersama Ben Clavié dan beberapa pakar di bidang RAG, dengan tema evaluasi dan optimasi retrieval-augmented generation (RAG). Bagian pertama akan dibawakan oleh Ben Clavié, yang akan membantah pandangan bahwa “RAG sudah mati”. Nandan Thakur juga akan berpartisipasi dalam pengajaran, membahas perubahan paradigma yang diperlukan untuk mengevaluasi model IR di era RAG, menekankan pentingnya metrik evaluasi keragaman dan benchmark (seperti FreshStack) (Sumber: HamelHusain, HamelHusain)
Sebastian Raschka merilis tutorial pemahaman dan pengkodean KV Caching dari awal (versi diperluas): Sebastian Raschka membagikan artikel terbarunya tentang key-value caching (KV Caching), menyediakan tutorial versi diperluas untuk memahami dan mengkodekan KV Caching dari awal. KV Caching adalah teknik optimasi penting dalam proses inferensi large language model (LLM), yang digunakan untuk mempercepat proses generasi. Tutorial ini bertujuan untuk membantu pembaca memahami secara mendalam cara kerjanya dan dapat mengimplementasikannya sendiri (Sumber: rasbt)
Makalah Direct Reasoning Optimization (DRO) mengusulkan kerangka kerja LLM untuk self-reward dan optimasi penalaran: Sebuah makalah berjudul “Direct Reasoning Optimization: LLMs Can Reward And Refine Their Own Reasoning for Open-Ended Tasks” mengusulkan kerangka kerja reinforcement learning bernama DRO. Kerangka kerja ini bertujuan untuk menyempurnakan kinerja LLM pada tugas-tugas terbuka, khususnya tugas penalaran panjang, melalui sinyal reward baru—reasoning reflection reward (R3). Inti dari R3 adalah secara selektif mengidentifikasi dan menekankan Token kunci dalam hasil referensi yang mencerminkan pengaruh penalaran chain-of-thought model sebelumnya, sehingga menangkap konsistensi antara penalaran dan hasil referensi pada tingkat granular. Kuncinya adalah R3 dihitung secara internal oleh model yang sama yang dioptimalkan, sehingga mencapai pengaturan pelatihan yang sepenuhnya mandiri (Sumber: teortaxesTex)

Makalah EMLoC: Metode fine-tuning hemat memori berbasis emulator dengan koreksi LoRA: Makalah “EMLoC: Emulator-based Memory-efficient Fine-tuning with LoRA Correction” mengusulkan kerangka kerja bernama EMLoC, yang bertujuan untuk melakukan fine-tuning model dengan anggaran memori yang sama seperti inferensi. EMLoC membangun emulator ringan khusus tugas dengan menggunakan singular value decomposition (SVD) yang sadar aktivasi pada set kalibrasi hilir kecil, kemudian melakukan fine-tuning pada emulator ini melalui LoRA. Untuk mengatasi masalah ketidakselarasan antara model asli dan emulator terkompresi, makalah ini mengusulkan algoritma kompensasi baru untuk mengoreksi modul LoRA yang telah di-fine-tune, sehingga dapat digabungkan kembali ke model asli untuk inferensi. EMLoC mendukung rasio kompresi yang fleksibel dan alur pelatihan standar, eksperimen menunjukkan bahwa EMLoC lebih unggul dari baseline lain pada beberapa dataset dan modalitas, dan dapat melakukan fine-tuning model 38B pada satu GPU konsumen 24GB (Sumber: HuggingFace Daily Papers)
TuringPost merangkum makalah penelitian AI terbaru, mencakup perspektif sistem kompleks LLM, perluasan agent, dll.: TuringPost merangkum makalah penelitian AI terbaru minggu ini, merekomendasikan 6 makalah utama, termasuk “LLMs and Emergence: A Complex Systems Perspective”, “The Illusion of the Illusion of Thinking”, “Build the Web for Agents, not Agents for the Web”, dll. Selain itu, juga mencantumkan beberapa makalah tentang AI agent, penelitian kode, reinforcement learning, optimasi model, dan arah lainnya, menyediakan sumber belajar yang kaya bagi peneliti dan pengembang (Sumber: TheTuringPost)

Tutorial fine-tuning klasifikasi video Meta AI VJEPA 2 dirilis: Aritra Roy Gosthipaty merilis tutorial Jupyter Notebook untuk fine-tuning klasifikasi video menggunakan model VJEPA 2 dari Meta AI. VJEPA (Video Joint Embedding Predictive Architecture) adalah metode self-supervised learning yang bertujuan untuk mempelajari fitur video dengan memprediksi representasi bagian video yang ditutupi. Tutorial ini memberikan panduan praktis bagi peneliti dan pengembang yang ingin menerapkan model VJEPA 2 dalam tugas pemahaman video (Sumber: mervenoyann)
Makalah membahas reinforcement learning dengan reward yang dapat diverifikasi untuk mendorong penalaran LLM yang benar: Sebuah makalah berjudul “Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs” menunjukkan bahwa metrik Pass@K tradisional memiliki kekurangan dalam mengukur kemampuan penalaran, karena dapat memberi reward pada chain-of-thoughts (CoTs) yang jawaban akhirnya benar tetapi proses penalarannya tidak akurat atau tidak lengkap. Untuk itu, peneliti memperkenalkan metrik evaluasi yang lebih tepat, CoT-Pass@K, yang mensyaratkan jalur penalaran dan jawaban akhir keduanya benar. Penelitian menemukan bahwa dengan menggunakan CoT-Pass@K, RLVR (Reinforcement Learning with Verifiable Rewards) dapat mendorong model untuk menggeneralisasi proses penalaran yang benar (Sumber: menhguin, teortaxesTex)

Makalah “From Bytes to Ideas: Language Modeling with Autoregressive U-Nets” mengusulkan metode pemodelan bahasa baru: Aran Komatsuzaki memperkenalkan sebuah makalah baru yang mengusulkan model U-Net autoregresif, yang secara langsung memproses byte mentah dan mempelajari representasi Token hierarkis. Penelitian menunjukkan bahwa metode ini mampu menandingi baseline Byte Pair Encoding (BPE) yang kuat, dan struktur hierarkis yang lebih dalam menunjukkan tren penskalaan yang menjanjikan. Ini memberikan ide baru untuk bidang pemodelan bahasa, terutama dalam menangani representasi data tingkat rendah dan mempelajari fitur multi-level (Sumber: jpt401)

LambdaConf 2025 membagikan presentasi Oren Rozen tentang pemrograman fungsional di C++: LambdaConf 2025 membagikan video presentasi Oren Rozen di konferensi tersebut tentang “Pemrograman Fungsional di C++ (Runtime Types vs Compile-time Types)”. Presentasi ini membahas metode penerapan ide dan teknik pemrograman fungsional dalam C++, bahasa multi-paradigma, dengan fokus khusus pada peran dan pengaruh berbeda dari tipe runtime dan tipe compile-time dalam praktik pemrograman fungsional (Sumber: lambda_conf)

Zach Mueller meluncurkan kursus “From Scratch -> Scale”, mengajarkan teknik pelatihan terdistribusi: Zach Mueller mengumumkan pembukaan pendaftaran untuk kursus 5 minggunya “From Scratch -> Scale”. Kursus ini akan mengajarkan peserta untuk menulis kode distributed data parallel (DDP), ZeRO, pipeline parallel, dan tensor parallel dari awal, dan menggabungkan teknik-teknik ini. Kursus ini juga akan mengundang para ahli berpengalaman dari perusahaan seperti Hugging Face, Meta, Snowflake untuk berbagi (Sumber: eliebakouch, HamelHusain)

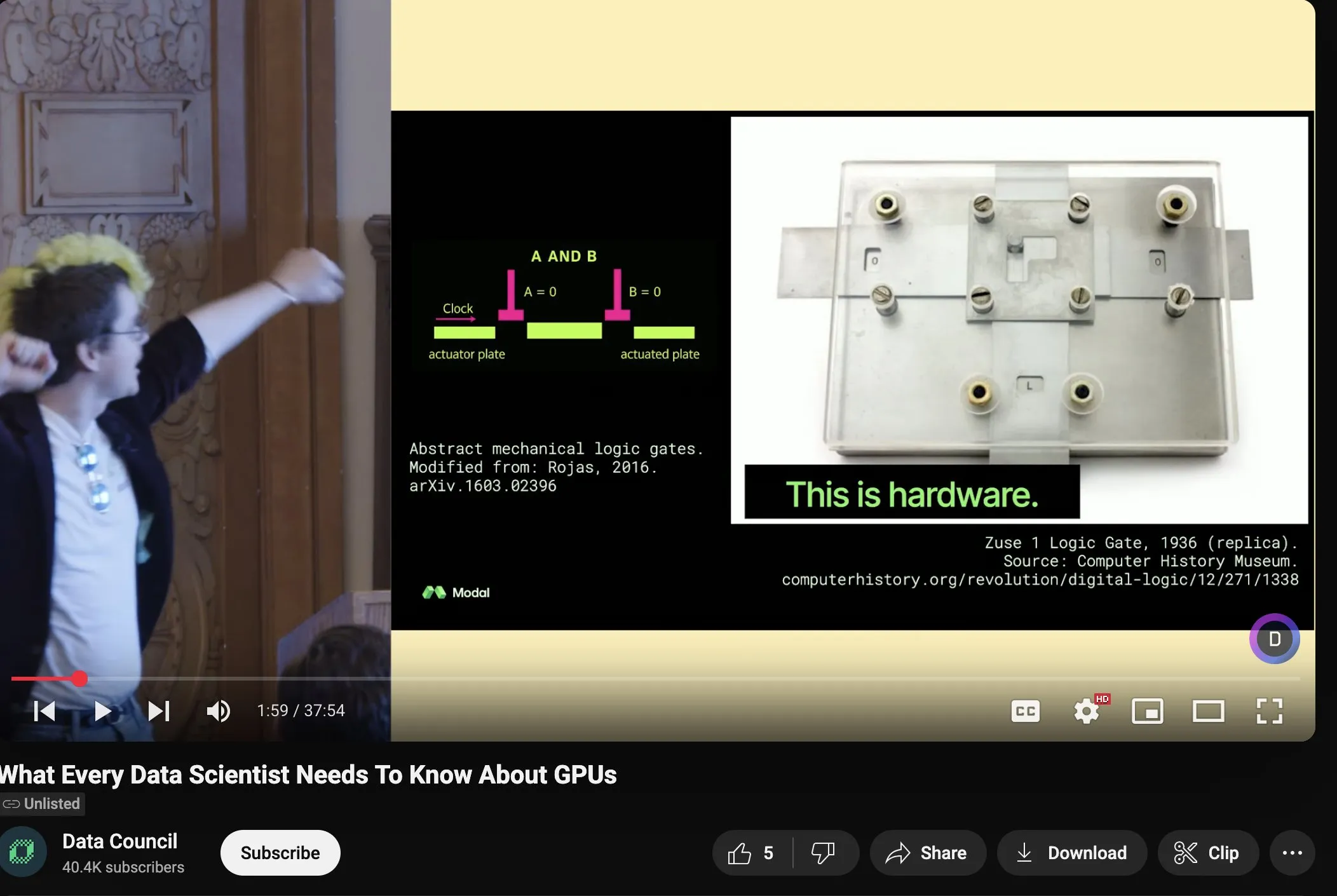
Charles Frye membagikan presentasi tentang penskalaan GPU dan bandwidth matematika, menekankan pentingnya perkalian matriks presisi rendah: Charles Frye membagikan rekaman presentasinya, dengan poin-poin utama termasuk: penskalaan GPU mirip dengan penskalaan bandwidth, berhubungan secara kuadratik dengan latensi; bandwidth kunci untuk penskalaan GPU adalah bandwidth matematika (FLOP/s); di antara berbagai bandwidth matematika, perkalian matriks presisi rendah memiliki kecepatan penskalaan tercepat. Dia juga membahas beberapa implikasi hal ini untuk bidang rekayasa data dan ilmu data (Sumber: charles_irl)
💼 Bisnis
Sam Altman mengungkapkan Meta pernah mencoba merekrut karyawan OpenAI dengan bonus penandatanganan 100 juta dolar AS: CEO OpenAI Sam Altman dalam sebuah acara podcast mengungkapkan bahwa Meta pernah mencoba menarik karyawan OpenAI untuk pindah dengan menawarkan bonus penandatanganan hingga 100 juta dolar AS serta gaji tahunan yang lebih tinggi. Altman menyatakan bahwa meskipun Meta aktif merekrut, karyawan terbaik OpenAI tidak menerima tawaran tersebut. Dia juga berkomentar bahwa Meta memandang OpenAI sebagai pesaing terbesarnya, dan upaya Meta saat ini di bidang AI belum sesuai harapan, tetapi menghargai semangatnya untuk mencoba hal-hal baru secara aktif. Altman berpendapat bahwa praktik Meta menarik talenta dengan gaji tinggi dapat merusak budaya perusahaan (Sumber: TheRundownAI, bookwormengr, seo_leaders, akbirkhan, 财联社AI daily, Reddit r/ChatGPT)
xAI milik Musk menghabiskan 1 miliar dolar AS per bulan, mencari pendanaan baru untuk mendukung penelitian dan pengembangan AGI: Dilaporkan bahwa startup AI milik Elon Musk, xAI, menghabiskan dana dengan kecepatan luar biasa sebesar 1 miliar dolar AS per bulan, terutama untuk pembelian GPU dan pembangunan infrastruktur seperti pusat data. Untuk mempertahankan operasional dan bersaing dengan raksasa seperti OpenAI dan Google, xAI sedang dalam proses penggalangan dana ekuitas baru sebesar 4,3 miliar dolar AS, dan berencana mengumpulkan 6,4 miliar dolar AS lagi tahun depan, sambil juga memajukan pendanaan utang sebesar 5 miliar dolar AS. Meskipun pendapatan diperkirakan hanya 500 juta dolar AS tahun ini, xAI, dengan daya tarik Musk, keunggulan data dari platform X, dan tekad untuk membangun infrastruktur sendiri, telah memaparkan kepada investor peta jalan untuk mencapai profitabilitas pada tahun 2027. Valuasinya telah meningkat dari 51 miliar dolar AS pada akhir 2024 menjadi 80 miliar dolar AS pada akhir kuartal pertama tahun ini. Tujuan akhir Musk adalah menciptakan artificial general intelligence (AGI) yang dapat menandingi atau bahkan melampaui manusia (Sumber: 新智元)

Nabla membangun asisten AI untuk dokter, menyelesaikan putaran pendanaan Seri C sebesar 70 juta dolar AS: Perusahaan AI medis Nabla mengumumkan penyelesaian putaran pendanaan Seri C sebesar 70 juta dolar AS, dipimpin oleh HV Capital, Highland Europe, dan DST Global, dengan investor sebelumnya Cathay Innovation dan Tony Fadell terus berpartisipasi. Nabla berdedikasi untuk membangun asisten AI cerdas canggih bagi para dokter, bertujuan untuk memulihkan perhatian humanistik inti dalam layanan kesehatan melalui teknologi AI, dan membawa dampak klinis dan finansial yang nyata. Putaran pendanaan ini akan mempercepat realisasi misinya (Sumber: ylecun)

🌟 Komunitas
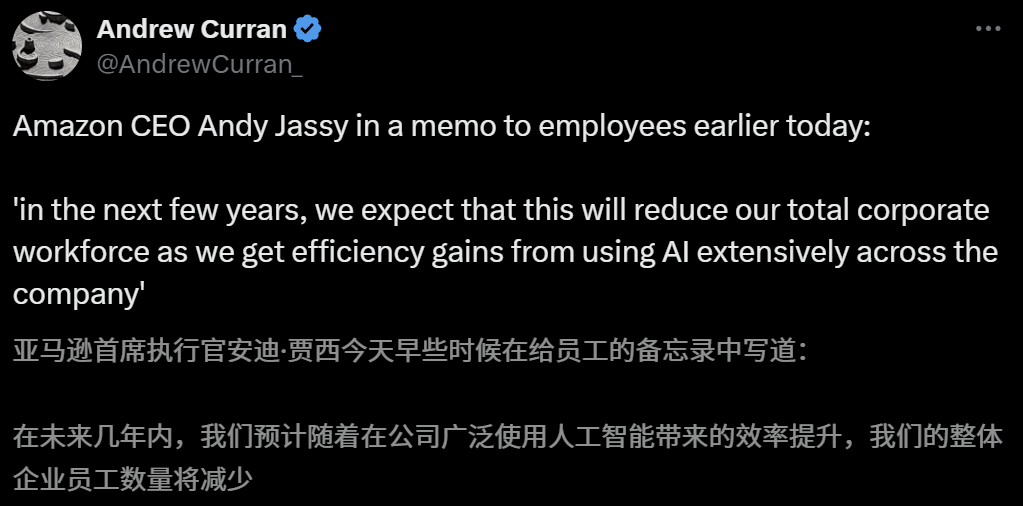
Dampak AI pada pasar kerja menimbulkan kekhawatiran, CEO Amazon memperingatkan pengurangan karyawan akibat AI dalam beberapa tahun ke depan: CEO Amazon Andy Jassy dalam surat kepada seluruh karyawan menyatakan bahwa seiring perusahaan mempromosikan lebih banyak AI generatif dan agent, cara kerja akan berubah. Dalam beberapa tahun ke depan, kebutuhan tenaga kerja untuk beberapa posisi saat ini akan berkurang, sementara permintaan untuk jenis pekerjaan baru akan meningkat. Diperkirakan jumlah total karyawan di departemen fungsional perusahaan akan berkurang. Sebelumnya, CEO Anthropic Dario Amodei juga memperingatkan bahwa AI dapat menggantikan separuh pekerjaan kerah putih tingkat pemula dalam lima tahun. Pandangan ini memicu diskusi luas tentang dampak AI pada pasar kerja. Karyawan industri teknologi telah berbagi pengalaman digantikan oleh AI atau menghadapi kesulitan mencari pekerjaan, dan lulusan universitas angkatan 2025 juga menghadapi pasar kerja tersulit sejak pandemi (Sumber: 新智元, 新智元)
Alat pengisian formulir pendaftaran perguruan tinggi berbasis AI mendapat perhatian, tetapi algoritma yang tidak transparan, keaslian data, dan personalisasi menjadi masalah bagi pengguna: Seiring memanasnya pasar pengisian formulir pendaftaran perguruan tinggi, perusahaan besar seperti Alibaba Quark, Baidu, dan Tencent QQ Browser纷纷 meluncurkan alat pengisian formulir berbasis AI, dengan mengedepankan kecerdasan, efisiensi, dan gratis. Namun, pengguna menemukan bahwa alat yang berbeda memberikan rekomendasi perguruan tinggi yang sangat berbeda untuk skor yang sama. Masalah seperti algoritma yang tidak transparan, keraguan atas kelengkapan dan keaslian data, serta kurangnya personalisasi, membuat pengguna tidak berani sepenuhnya bergantung pada AI. Para ahli menunjukkan bahwa sumber data dan perbedaan bobot algoritma adalah penyebab utama perbedaan hasil rekomendasi. Alat AI saat ini lebih cocok untuk siswa dengan skor di kedua ujung spektrum dan tujuan yang jelas, atau sebagai alat bantu bagi siswa dengan skor menengah, dan pengguna perlu belajar cara mengajukan pertanyaan yang efektif (Sumber: 36氪)
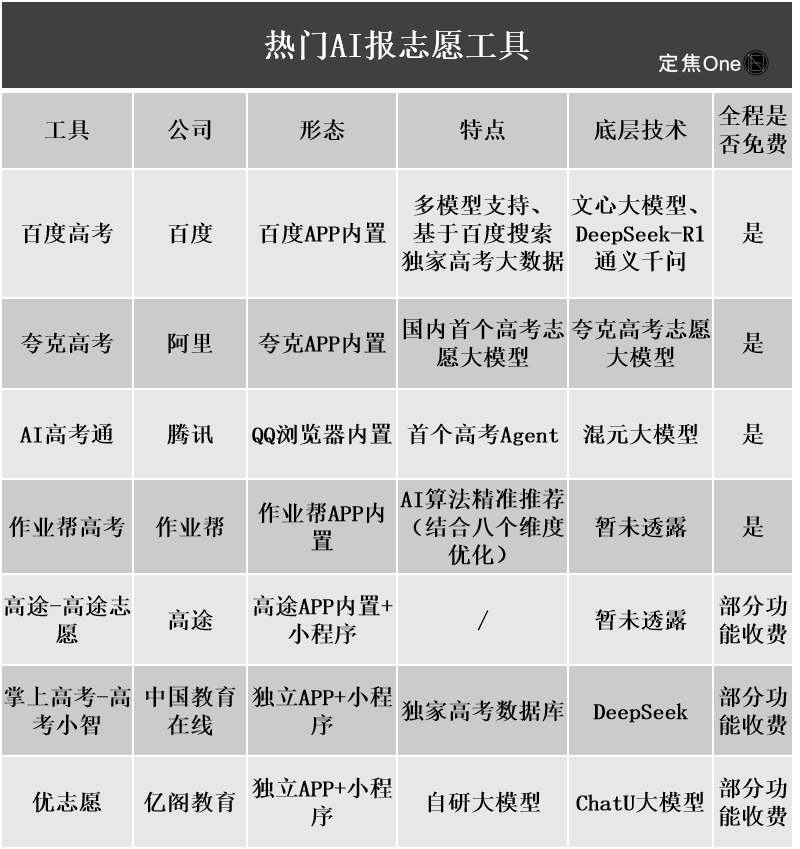
Penerapan AI dalam bidang pendidikan semakin meluas, memicu kecemasan orang tua dan antusiasme pasar: Teknologi AI semakin merambah bidang pendidikan, mulai dari ruang belajar AI, mesin belajar AI, hingga berbagai aplikasi pendamping belajar AI bermunculan. Akses model besar seperti DeepSeek semakin mendorong peningkatan produk. Para orang tua berharap AI dapat membantu anak-anak mereka “menyalip di tikungan”, tetapi hal ini juga menimbulkan kecemasan baru. Riset pasar menunjukkan bahwa skala pasar AI+pendidikan diperkirakan akan melampaui 70 miliar yuan pada tahun 2025. Namun, efektivitas aktual produk pendidikan AI, privasi data, dan apakah benar-benar meningkatkan esensi pembelajaran masih menjadi fokus diskusi. Makna pendidikan tidak seharusnya terbatas pada “perlombaan senjata” yang didorong oleh teknologi, melainkan harus lebih memperhatikan perkembangan individu dan kemungkinan yang beragam (Sumber: 36氪, 36氪)

Diskusi: Perlunya “Turn Marker Tokens” dalam inferensi model besar: Ada diskusi di komunitas yang menunjukkan bahwa jika “turn marker tokens” (seperti token khusus yang menandai ucapan pengguna dan asisten) dalam model dialog selalu diikuti oleh beberapa token yang sama persis (misalnya user\n dan assistant\n), maka turn marker tokens itu sendiri mungkin tidak diperlukan. Pandangan lebih lanjut menyatakan bahwa jika sekelompok token (misalnya tiga) secara bersama-sama menandai sesuatu, dan model perlu mempelajari pentingnya token pertama di antaranya, maka contoh konteks yang berisi kontrafaktual harus disediakan, jika tidak, model mungkin tidak dapat mempelajari pentingnya ini secara akurat. Diskusi ini terkait dengan fenomena Claude Opus 4 yang mudah tertipu oleh dialogue injection, menunjukkan bahwa pemahaman dan penanganan struktur dialog oleh model masih memiliki ruang untuk perbaikan (Sumber: giffmana, giffmana)
Ketidaksesuaian antara keinginan dan kemampuan aplikasi AI Agent di tempat kerja menarik perhatian: Penelitian tim Universitas Stanford mengungkapkan adanya ketidaksesuaian yang signifikan antara kebutuhan dan kemampuan AI Agent dalam otomatisasi tempat kerja. Penelitian menemukan bahwa sekitar 41% tugas di perusahaan inkubasi YC terkonsentrasi di “zona prioritas rendah” dan “zona merah”, di mana keinginan pekerja untuk otomatisasi rendah atau teknologi AI belum matang. Selain itu, meskipun banyak tugas memerlukan kolaborasi setara antara manusia dan mesin, para praktisi umumnya mengharapkan dominasi manusia yang lebih tinggi, yang dapat menimbulkan gesekan. Penelitian memprediksi bahwa seiring masuknya AI Agent ke pasar tenaga kerja, kompetensi inti manusia mungkin bergeser ke keterampilan interpersonal dan koordinasi organisasi. Penelitian ini bertujuan untuk memberikan panduan bagi pengembangan AI Agent di masa depan dan transformasi keterampilan tenaga kerja (Sumber: 新智元)

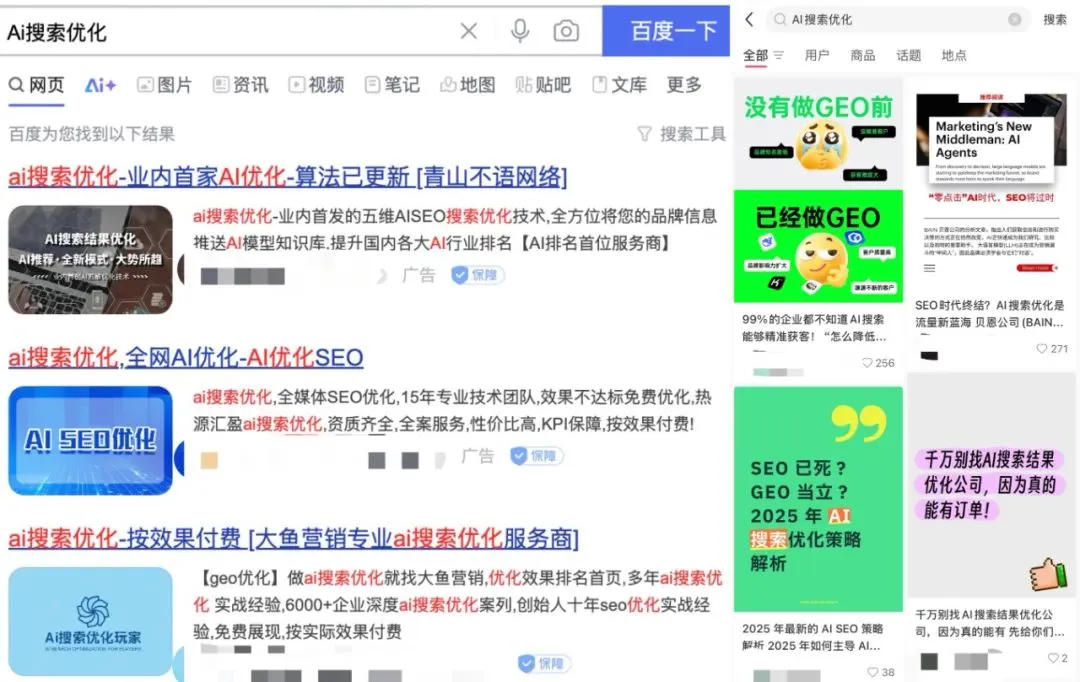
Perusahaan periklanan menggunakan generative search engine optimization (GEO) untuk memengaruhi hasil pencarian AI, memicu diskusi etika dan regulasi: Perusahaan periklanan menggunakan layanan generative search engine optimization (GEO) untuk membantu klien korporat mendapatkan eksposur yang lebih tinggi dalam hasil pencarian AI. Layanan ini meningkatkan peringkat dan frekuensi kemunculan informasi klien dalam jawaban AI dengan menghasilkan konten berkualitas tinggi yang sesuai dengan preferensi model besar dan melakukan “pemberian makan” data AI. Namun, pengguna biasanya tidak mengetahui apakah hasil pencarian AI telah dioptimalkan. Hal ini memicu diskusi tentang apakah tindakan semacam itu merupakan iklan, apakah perlu diberi label yang jelas, dan aturan serta batasan komersial apa yang harus dipatuhi. Saat ini, platform model besar arus utama di dalam negeri belum secara resmi mengintegrasikan iklan, tetapi produk pencarian AI di luar negeri sudah mulai mencoba model iklan dan melakukan penandaan (Sumber: 36氪)
Model AI berkinerja buruk pada soal kompetisi pemrograman yang sulit, hasil tes LiveCodeBench Pro menunjukkan model teratas mendapat skor 0%: Zihan Zheng dkk. meluncurkan LiveCodeBench Pro, sebuah benchmark real-time yang berisi soal-soal dari kompetisi pemrograman tingkat tinggi seperti IOI, Codeforces, dan ICPC. Pada bagian “sulit” dari benchmark ini, large language models terdepan termasuk o3 dan Gemini 2.5 semuanya mendapat skor 0%. Analisis menunjukkan bahwa LLM mahir dalam tugas implementasi yang mengandalkan memori, tetapi berkinerja buruk pada masalah observasional atau logis yang memerlukan “inspirasi” penting, serta tugas yang memerlukan perhatian terhadap detail dan penanganan kasus batas. Saining Xie berkomentar bahwa ini bukanlah benchmark untuk software engineering agent, melainkan pengujian penalaran inti dan kecerdasan melalui pengkodean, mengalahkan benchmark ini sebanding dengan signifikansi AlphaGo mengalahkan Lee Sedol (Sumber: ylecun, dilipkay)
Alat tinjauan literatur berbantuan AI otto-SR secara signifikan meningkatkan efisiensi dan akurasi: Universitas Toronto, Harvard Medical School, dan institusi lainnya bersama-sama mengembangkan alur kerja end-to-end AI otto-SR untuk otomatisasi tinjauan sistematis (SRs). Alat ini menggabungkan GPT-4.1 dan o3-mini untuk penyaringan literatur dan ekstraksi data, menyelesaikan pembaruan tinjauan sistematis Cochrane hanya dalam dua hari, yang secara tradisional membutuhkan waktu 12 tahun. Dalam pengujian benchmark, sensitivitas otto-SR (96,7% vs 81,7% manusia) dan akurasi ekstraksi data (93,1% vs 79,7% manusia) secara signifikan lebih unggul daripada peninjau manusia, dan menemukan 54 studi kunci yang terlewatkan oleh manusia. Penelitian ini menunjukkan potensi besar AI dalam mempercepat penelitian medis dan meningkatkan kualitas sintesis bukti (Sumber: 量子位)

Eksplorasi aplikasi DSL terstruktur dalam “Vibe Coding”: Ted Nyman dan pengembang lainnya sedang bereksperimen dengan menggunakan DSL (Domain Specific Language) yang lebih terstruktur sebagai pengganti bahasa alami bentuk bebas untuk “Vibe Coding” (cara pemrograman yang lebih mengandalkan perasaan dan intuisi), dan menemukan bahwa metode ini lebih efektif, lebih cepat, mengurangi frustrasi, dan menghasilkan kode berkualitas lebih tinggi. Eksplorasi ini bertujuan untuk menemukan paradigma interaksi manusia-mesin yang lebih efisien dan akurat untuk pemrograman berbantuan AI atau generasi kode (Sumber: tnm, lateinteraction)
Prospek aplikasi AI Agent dalam software reliability engineering (SRE): Traversal AI mengumumkan penyelesaian pendanaan awal dan Seri A sebesar 48 juta dolar AS, yang didedikasikan untuk membangun AI SRE (Site Reliability Engineer) tingkat perusahaan. AI Agent-nya mampu secara mandiri melakukan troubleshoot, memperbaiki, bahkan mencegah insiden produksi yang kompleks, dengan menggabungkan teknologi AI Agent dan causal machine learning untuk menemukan akar penyebab secara real-time. Perusahaan seperti DigitalOcean, Eventbrite telah menjadi pelanggan awal mereka, menunjukkan potensi besar AI dalam otomatisasi operasional dan peningkatan keandalan sistem (Sumber: hwchase17)
💡 Lain-lain
“Game mobile” bergaya Ghibli yang dihasilkan AI menarik perhatian, tutorial menunjukkan dibuat oleh Kling AI dan Midjourney: Baru-baru ini, serangkaian tangkapan layar dan video “game mobile” bergaya Ghibli menjadi viral di media sosial, dengan gambar yang indah, palet warna yang segar, dan efek pencahayaan alami yang menarik perhatian. Penciptanya mengungkapkan metode pembuatannya: pertama menggunakan Midjourney untuk menghasilkan gambar statis, kemudian menggunakan Kling AI milik Kuaishou untuk mengubah gambar menjadi video dinamis. Dengan menambahkan elemen HUD (Heads-Up Display) tetap, seperti tombol dan peta mini, tercipta kesan game interaktif. Meskipun saat ini hanya berupa demo video, hal ini telah membangkitkan imajinasi netizen tentang dunia virtual interaktif yang dihasilkan AI (Sumber: 量子位, Kling_ai)

AI memiliki potensi besar dalam aplikasi pemeriksaan kesalahan di berbagai bidang: Netizen random_walker mengemukakan bahwa AI generatif memiliki potensi aplikasi yang besar dalam pemeriksaan kesalahan, dan terdapat “buah yang mudah dipetik” di berbagai bidang. Misalnya, dalam perangkat lunak dapat secara otomatis mendeteksi kerentanan keamanan; dalam penulisan dapat mengidentifikasi kelemahan logika dan argumen yang lemah; dalam penelitian ilmiah dapat mendeteksi kesalahan perhitungan dan masalah kutipan; dalam kontrak hukum dapat menandai klausul yang hilang dan kontradiksi; di bidang keuangan dapat digunakan untuk deteksi penipuan dan identifikasi kesalahan laporan keuangan. Dia berpendapat bahwa otomatisasi pemeriksaan kesalahan memiliki tingkat otomatisasi yang tinggi dan gangguan yang kecil, bahkan dengan tingkat kesalahan positif palsu 50%, peninjauan manual relatif mudah, dan dapat membebaskan manusia dari pekerjaan yang membosankan. Namun, perlu diwaspadai risiko penurunan kemampuan manusia sendiri akibat ketergantungan berlebihan pada AI (Sumber: random_walker)
Wawancara Sam Altman: AI akan menyederhanakan pekerjaan, menyediakan sosial yang dipersonalisasi, dan mendorong penemuan ilmiah: Pendiri OpenAI Sam Altman dalam sebuah wawancara memprediksi bahwa dalam 5-10 tahun ke depan, alat pemrograman dan obrolan AI akan menjadi lebih cerdas, mampu menyelesaikan sebagian besar pekerjaan secara otomatis. AI mungkin membawa pengalaman sosial baru, menyediakan layanan yang dipersonalisasi, dan membantu menemukan pengetahuan ilmiah baru, terutama di bidang padat data seperti astrofisika atau fisika energi tinggi. Dia menekankan bahwa perubahan transformatif sejati dari AI tidak hanya terletak pada kemampuannya untuk berpikir, tetapi juga untuk bertindak di dunia fisik, dengan robot humanoid sebagai tantangan utama. Visi OpenAI adalah menjadikan AI sebagai “pendamping AI” yang ada di mana-mana, dicapai melalui platformisasi dan kerja sama perangkat keras. Dia percaya bahwa budaya dan pemikiran jangka panjang adalah kompetensi inti OpenAI (Sumber: 36氪)