Kata Kunci:Komputasi Kuantum, Peningkatan Mandiri AI, Antarmuka Otak-Komputer, Model Bahasa Besar, Komputasi Neuromorfik, Pembelajaran Penguatan, Etika AI, Tingkat Kesalahan Qubit Kuantum, Pembelajaran Mandiri JEPA, Kuantisasi Format MLX, Model Pemahaman Visual PAM, Pembuatan Konten ASMR oleh AI
🔥 Fokus
Universitas Oxford mencapai rekor tingkat kesalahan 0,000015% dalam eksperimen komputasi kuantum: Tim peneliti Universitas Oxford telah membuat terobosan signifikan dalam eksperimen komputasi kuantum, mengurangi tingkat kesalahan qubit menjadi 0,000015%, yang merupakan rekor dunia baru. Kemajuan ini sangat penting untuk membangun komputer kuantum yang toleran terhadap kesalahan, karena tingkat kesalahan yang sangat rendah merupakan prasyarat untuk merealisasikan algoritma kuantum yang kompleks dan memanfaatkan potensi komputasi kuantum. Hasil ini menunjukkan kemajuan signifikan dalam meningkatkan stabilitas qubit dan presisi manipulasi di tingkat perangkat keras, meletakkan dasar yang lebih kokoh untuk aplikasi masa depan yang bergantung pada daya komputasi kuat, seperti AI (Sumber: Ronald_vanLoon)

Peneliti MIT membuat kecerdasan buatan belajar untuk meningkatkan dan memperbaiki dirinya sendiri: Peneliti di Massachusetts Institute of Technology (MIT) telah membuat kemajuan dalam bidang peningkatan diri AI, mengembangkan metode baru yang memungkinkan sistem AI untuk belajar secara mandiri dan meningkatkan kinerjanya sendiri. Kemampuan ini meniru proses manusia yang terus meningkat melalui pengalaman dan refleksi, yang sangat penting untuk mengembangkan kecerdasan buatan yang lebih otonom dan adaptif. Penelitian ini dapat membuka jalan bagi model AI untuk terus mengoptimalkan diri setelah penerapan, mengurangi ketergantungan pada intervensi manusia, dan memiliki dampak mendalam pada pengembangan dan aplikasi AI jangka panjang (Sumber: TheRundownAI)

AI “pembaca pikiran” mengubah gelombang otak pasien lumpuh menjadi ucapan secara instan: Sebuah penelitian terobosan menunjukkan bagaimana AI “pembaca pikiran” dapat mengubah gelombang otak pasien lumpuh menjadi ucapan yang jelas secara real-time. Teknologi ini, melalui antarmuka otak-komputer (BCI) canggih dan algoritma AI, mendekode sinyal saraf yang terkait dengan bahasa dan mensintesisnya menjadi output ucapan yang dapat dipahami. Ini menyediakan cara komunikasi baru bagi pasien yang kehilangan kemampuan berbicara karena gangguan motorik parah, diharapkan dapat sangat meningkatkan kualitas hidup mereka, dan menandai kemajuan besar AI dalam bidang medis pendukung dan ilmu saraf (Sumber: Ronald_vanLoon)

Terobosan dalam masalah abad ini di bidang fisika matematika, alumni Universitas Peking berpartisipasi dalam memecahkan Masalah Keenam Hilbert: Alumni Universitas Peking, Deng Yu, dan Ma Xiao dari Kelas Junior Universitas Sains dan Teknologi China, bersama dengan Zahar Hani, murid Terence Tao, telah membuat terobosan besar dalam Masalah Keenam Hilbert, “Aksiomatisasi Fisika”. Mereka untuk pertama kalinya secara ketat membuktikan transisi lengkap dari mekanika Newton (mikroskopis, waktu reversibel) ke persamaan Boltzmann (statistik makroskopis, waktu ireversibel), mengisi kesenjangan logis antara keduanya, meletakkan dasar matematis yang lebih kokoh untuk mekanika statistik, dan secara tak terduga menjawab “misteri panah waktu”. Hasil ini, melalui alat matematika yang canggih dan derivasi bertahap, menunjukkan jalur dari teori atom ke hukum gerak medium kontinu (Sumber: 量子位)

🎯 Tren
Alibaba meluncurkan versi format MLX dari model seri Qwen3: Alibaba mengumumkan bahwa model besar seri Qwen3 miliknya kini mendukung format MLX, dan menyediakan empat tingkat kuantisasi: 4-bit, 6-bit, 8-bit, dan BF16. MLX adalah kerangka kerja machine learning yang dioptimalkan Apple untuk Apple Silicon. Langkah ini berarti model Qwen3 akan dapat berjalan lebih efisien di perangkat Apple, menurunkan ambang batas untuk penerapan dan menjalankan model besar di sisi perangkat (edge), dan membantu mendorong mempopulerkan dan aplikasi model besar di perangkat pribadi (Sumber: Alibaba_Qwen, awnihannun, cognitivecompai, Reddit r/LocalLLaMA)
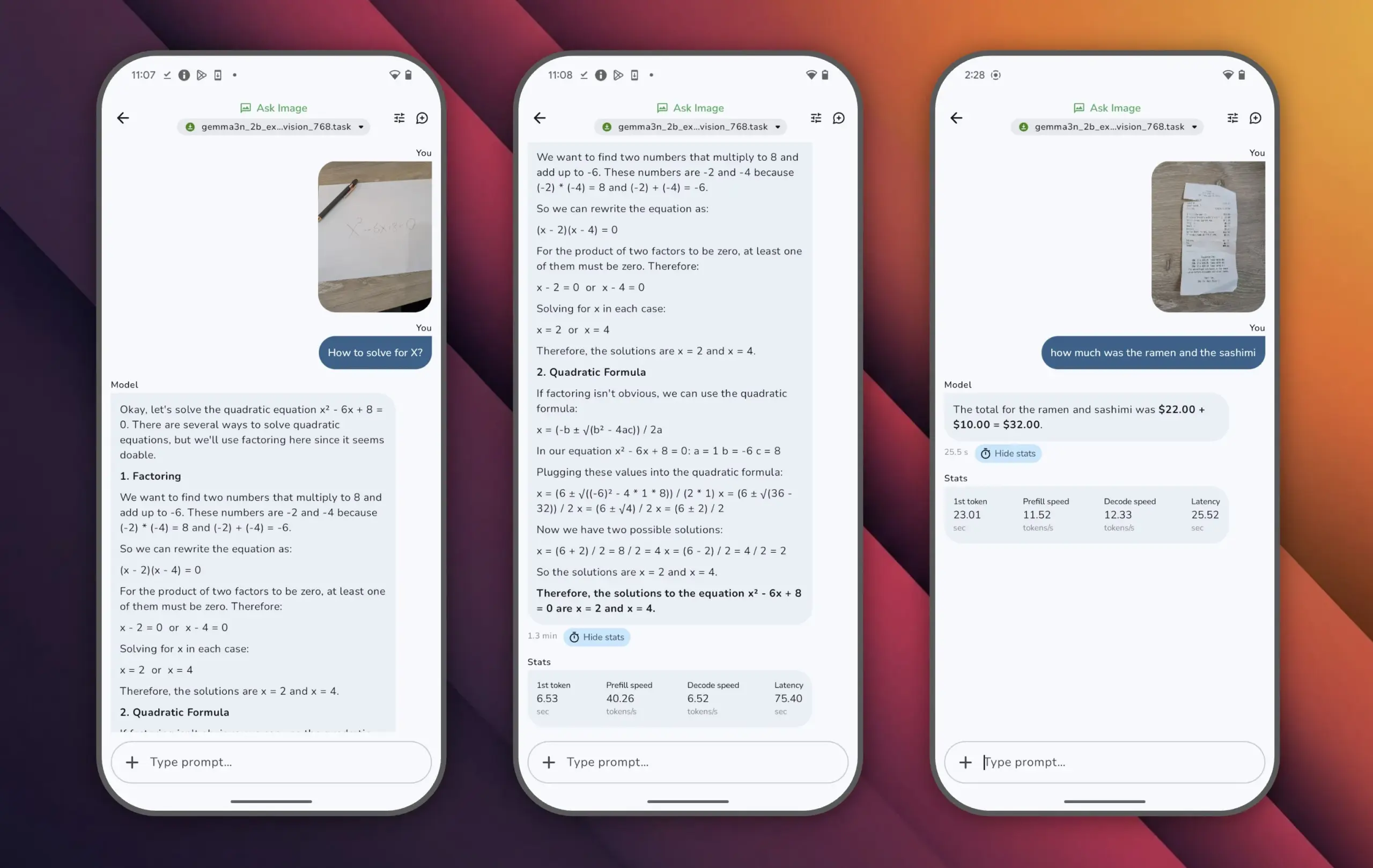
Google merilis model Gemma 3n, mencapai kinerja tinggi dengan parameter kecil: Google meluncurkan model Gemma 3n, yang memiliki kurang dari 10 miliar parameter tetapi melampaui skor 1300 di LMArena, menjadi model kecil pertama yang mencapai prestasi ini. Kinerja luar biasa Gemma 3n membuktikan bahwa kemampuan pemahaman dan generasi bahasa tingkat tinggi masih dapat dicapai dengan skala parameter yang lebih kecil, dan mendukung pengoperasian pada perangkat edge seperti ponsel, yang sangat penting untuk mendorong mempopulerkan aplikasi AI dan mengurangi biaya komputasi (Sumber: osanseviero)
Tencent meluncurkan teknologi aset 3D tingkat film yang dihasilkan AI: Tencent memamerkan teknologi kecerdasan buatan baru yang mampu menghasilkan aset 3D dengan kualitas tingkat film. Teknologi ini diharapkan dapat secara signifikan meningkatkan efisiensi dan kualitas pembuatan konten 3D di bidang seperti pengembangan game dan produksi film, serta mengurangi biaya produksi. Pembuatan aset 3D berkualitas tinggi secara cepat merupakan mata rantai penting dalam pengembangan metaverse dan industri konten digital (Sumber: TheRundownAI)
Model Kling 2.1 Kuaishou menunjukkan kinerja luar biasa dalam konversi gambar-ke-video dan generasi sinkron audio-video: Model generasi video AI Kuaishou, Kling, telah diperbarui ke versi 2.1, menunjukkan kemampuan yang kuat dalam konversi gambar-ke-video. Versi baru ini diklaim dapat mencapai generasi video dan audio sekali klik, tanpa memerlukan desain efek suara pasca-produksi, untuk menghasilkan konten sinkron audio-visual tingkat studio. Ini menandai kemajuan AI dalam generasi konten multimodal, terutama di bidang video, menyederhanakan alur kerja pembuatan dan meningkatkan kualitas generasi (Sumber: Kling_ai, Kling_ai)
Model video AI baru “Kangaroo” mungkin adalah Minimax Hailuo 2.0, menantang SOTA yang ada: Sebuah model generasi video AI misterius bernama “Kangaroo” telah muncul di pasar, menunjukkan kinerja yang kuat di arena kompetisi video AI, terutama dalam konversi gambar-ke-video. Beberapa analisis menunjukkan bahwa model ini mungkin adalah versi Hailuo 2.0 dari perusahaan Minimax. Kemunculannya dapat mengubah hierarki kinerja model teks-ke-video dan gambar-ke-video yang ada, meskipun kemampuan pemrosesan audionya masih perlu dievaluasi (Sumber: TomLikesRobots)
MiniMax meluncurkan model seri M1, menonjol dalam kemampuan pemrosesan teks panjang: MiniMaxAI merilis seri model MiniMax-M1, sebuah model MoE (Mixture of Experts) dengan 456 miliar parameter. Seri model ini menunjukkan kinerja yang sangat baik di berbagai benchmark, terutama dalam pemrosesan konteks panjang (seperti benchmark OpenAI-MRCR) yang melampaui GPT-4.1, dan menempati peringkat ketiga di LongBench-v2. Ini menunjukkan potensinya dalam memproses dan memahami dokumen panjang, tetapi “thinking budget” yang lebih besar mungkin memerlukan sumber daya komputasi yang tinggi (Sumber: Reddit r/LocalLLaMA)

Pemenang Turing Award Richard Sutton: AI sedang beralih dari “era data manusia” ke “era pengalaman”: Richard Sutton, pelopor reinforcement learning, menunjukkan di Konferensi BAII Beijing bahwa model besar AI saat ini yang bergantung pada data manusia telah mendekati batasnya, data manusia berkualitas tinggi hampir habis, dan manfaat perluasan skala model semakin berkurang. Dia percaya bahwa masa depan AI terletak pada memasuki “era pengalaman”, yaitu agen cerdas belajar melalui interaksi real-time dengan lingkungan untuk menghasilkan pengalaman langsung, bukan meniru teks lama. Ini mengharuskan agen cerdas untuk terus berjalan di lingkungan nyata atau simulasi, menggunakan umpan balik lingkungan sebagai sinyal hadiah, mengembangkan model dunia dan sistem memori, untuk mencapai pembelajaran dan inovasi berkelanjutan yang sesungguhnya (Sumber: 36氪)

Model PAM: Parameter 3B mewujudkan segmentasi, pengenalan, dan penjelasan gambar-video terintegrasi: MMLab dari The Chinese University of Hong Kong dan institusi lainnya telah merilis Perceive Anything Model (PAM) secara open-source, sebuah model dengan parameter 3B yang dapat secara bersamaan melakukan segmentasi target, pengenalan, interpretasi, dan deskripsi dalam gambar dan video, serta secara sinkron menghasilkan teks dan Mask. PAM, dengan memperkenalkan Semantic Perceiver untuk menghubungkan kerangka segmentasi SAM2 dan LLM, mencapai konversi fitur visual ke token multimodal yang efisien. Tim juga membangun dataset pelatihan gambar-teks berkualitas tinggi berskala besar. PAM telah menyegarkan atau mendekati SOTA pada beberapa benchmark pemahaman visual dan memiliki efisiensi inferensi yang lebih baik (Sumber: 量子位)

Komputasi neuromorfik mungkin menjadi kunci AI generasi berikutnya, diharapkan dapat beroperasi dengan daya rendah: Para ilmuwan secara aktif mengeksplorasi komputasi neuromorfik, yang bertujuan untuk meniru struktur dan cara kerja otak manusia, untuk mengatasi masalah konsumsi energi tinggi pada model AI saat ini. Laboratorium nasional AS dan institusi lainnya sedang mengembangkan komputer neuromorfik dengan jumlah neuron yang sebanding dengan korteks manusia, yang secara teoritis memiliki kecepatan operasi jauh melebihi otak biologis, namun dengan konsumsi daya yang sangat rendah (misalnya, AI mirip otak manusia yang ditenagai 20 watt). Teknologi ini, melalui komunikasi berbasis peristiwa, komputasi dalam memori, dan pembelajaran adaptif, diharapkan dapat mewujudkan AI yang lebih cerdas, efisien, dan berdaya rendah, serta dianggap sebagai solusi potensial untuk krisis energi AI dan jalur baru untuk pengembangan AGI (Sumber: 量子位)

Konten AI ASMR meledak di platform video pendek, teknologi seperti Veo 3 mendorong tren ini: Video ASMR (Autonomous Sensory Meridian Response) yang dihasilkan AI dengan cepat menjadi populer di platform seperti TikTok, dengan beberapa akun menarik hampir 100.000 pengikut dalam 3 hari, dan satu video memotong buah ditonton lebih dari 16,5 juta kali. Video-video ini, dengan efek visual aneh yang dihasilkan AI (seperti buah bertekstur kaca) yang disertai dengan suara pemotongan, benturan, dll., menciptakan “sensasi ketagihan” yang unik. Model seperti Veo 3 dari Google DeepMind, karena kemampuannya untuk secara langsung menghasilkan konten sinkron audio-visual, dianggap sebagai teknologi kunci yang mendorong pembuatan konten AI ASMR semacam ini, menyederhanakan proses yang sebelumnya memerlukan pembuatan audio dan video secara terpisah lalu disintesis (Sumber: 量子位)

Riwayat pencarian Meta AI dipublikasikan menarik perhatian, Google menguji ringkasan audio AI: Meta mempublikasikan riwayat pencarian pengguna dari fungsi pencarian AI-nya, yang menimbulkan kekhawatiran pengguna tentang privasi dan transparansi penggunaan data mereka. Sementara itu, Google sedang menguji fitur baru dalam proyek laboratoriumnya, yaitu menyediakan ringkasan audio bergaya podcast yang dihasilkan AI di bagian atas hasil pencarian, yang bertujuan untuk menyediakan cara yang lebih nyaman bagi pengguna untuk memperoleh informasi. Kedua dinamika ini mencerminkan eksplorasi berkelanjutan dan upaya optimalisasi pengalaman pengguna oleh raksasa teknologi dalam pencarian AI dan penyajian informasi (Sumber: Reddit r/ArtificialInteligence)

Tim Sydney mengembangkan model AI untuk mengenali pikiran melalui gelombang otak: Tim peneliti dari Sydney, Australia, telah mengembangkan model kecerdasan buatan baru yang mampu mengidentifikasi konten pikiran individu dengan menganalisis data gelombang otak (EEG). Teknologi ini memiliki nilai aplikasi potensial di bidang ilmu saraf, interaksi manusia-komputer, dan komunikasi pendukung, misalnya, membantu orang yang tidak dapat berkomunikasi melalui cara tradisional untuk mengekspresikan niat mereka. Penelitian ini lebih lanjut mendorong pengembangan teknologi antarmuka otak-komputer dan mengeksplorasi kemampuan AI dalam menafsirkan aktivitas otak yang kompleks (Sumber: Reddit r/ArtificialInteligence)
California berencana membuat undang-undang untuk membatasi peran “bos robot” AI dalam keputusan seperti perekrutan dan pemecatan: Negara bagian California di AS sedang memajukan rancangan undang-undang yang bertujuan untuk membatasi perusahaan membuat keputusan personalia penting seperti perekrutan dan pemecatan hanya berdasarkan rekomendasi sistem AI. RUU tersebut mengharuskan manajer manusia untuk meninjau dan mendukung setiap rekomendasi AI semacam itu, untuk memastikan pengawasan dan akuntabilitas manusia. Kelompok bisnis menentang hal ini, dengan alasan bahwa ini akan meningkatkan biaya kepatuhan dan bertentangan dengan teknologi perekrutan yang ada. Langkah ini mencerminkan meningkatnya perhatian terhadap etika AI dan dampak sosial, terutama dalam pengambilan keputusan otomatis di tempat kerja (Sumber: Reddit r/ArtificialInteligence)

🧰 Alat
Augmentoolkit 3.0 dirilis, memperkuat alur kerja pembuatan dataset dan fine-tuning: Augmentoolkit telah merilis versi 3.0, sebuah alat untuk membuat dataset QA dari dokumen panjang (seperti teks sejarah) dan melakukan fine-tuning model. Versi baru ini menyediakan pipeline tingkat produksi yang dapat secara otomatis menghasilkan data pelatihan dan melatih model, dilengkapi dengan model lokal yang telah di-fine-tune khusus untuk menghasilkan dataset QA berkualitas tinggi, dan menyediakan antarmuka tanpa kode. Alat ini bertujuan untuk menyederhanakan proses fine-tuning model spesifik domain dan pembuatan data pelatihan, serta menurunkan ambang batas teknis (Sumber: Reddit r/LocalLLaMA)
Opius AI Planner: Perencana AI untuk mengoptimalkan pengalaman Cursor Composer: Sebuah ekstensi Cursor bernama Opius AI Planner telah dirilis, bertujuan untuk mengatasi masalah Cursor Composer dalam memahami kebutuhan yang ambigu. Alat ini dapat menganalisis kebutuhan proyek, menghasilkan peta jalan implementasi yang terperinci, dan menghasilkan prompt terstruktur yang dioptimalkan untuk Composer, sehingga mengurangi jumlah iterasi dan membuat hasil proyek lebih sesuai dengan gagasan awal. Ini mencerminkan tren penggunaan perencanaan yang dibantu AI untuk meningkatkan kegunaan alat generasi kode AI (Sumber: Reddit r/artificial)
Ekstensi Continue: Mewujudkan Copilot open-source lokal dan integrasi MCP di VSCode: Continue adalah ekstensi VSCode yang memungkinkan pengguna untuk mengkonfigurasi dan menggunakan model bahasa besar open-source yang berjalan secara lokal sebagai asisten pengkodean, dan dapat mengintegrasikan alat MCP (Model Control Protocol). Pengguna dapat menerapkan model secara lokal melalui layanan seperti Llama.cpp atau LMStudio, dan berinteraksi melaluinya dengan Continue, mencapai kontrol penuh dan kustomisasi asisten kode, misalnya, mengintegrasikan alat otomatisasi browser Playwright (Sumber: Reddit r/LocalLLaMA)

Model besar Doubao dan Volcano Engine MCP digabungkan, menyederhanakan penerapan layanan cloud dan pembuatan halaman pribadi: Model besar Doubao dari ByteDance menunjukkan kemampuan integrasi mendalam dengan Model Control Protocol (MCP) Volcano Engine. Pengguna dapat melalui instruksi bahasa alami, membiarkan model besar Doubao memanggil fungsi Volcano Engine (seperti veFaaS function-as-a-service), untuk menyelesaikan tugas seperti membuat halaman panduan media sosial pribadi dan secara otomatis menerapkannya secara online. Integrasi ini menghilangkan langkah-langkah rumit konfigurasi manual lingkungan cloud, menurunkan ambang batas penggunaan layanan cloud, dan menunjukkan potensi AI dalam menyederhanakan proses DevOps (Sumber: karminski3)
Figma meluncurkan fitur AI baru: menghasilkan situs web secara instan dari prompt teks: Figma memamerkan fitur baru yang didukung AI yang mampu menghasilkan prototipe atau halaman situs web dengan cepat berdasarkan prompt teks yang dimasukkan pengguna. Fitur ini bertujuan untuk mempercepat alur kerja desain dan pengembangan web, memungkinkan desainer dan pengembang untuk dengan cepat mengubah ide menjadi desain visual melalui deskripsi bahasa alami, yang lebih lanjut mencerminkan penetrasi AI generatif di bidang alat desain kreatif (Sumber: Ronald_vanLoon)
Pusat Model Hugging Face menambahkan fungsi penyaringan berdasarkan ukuran model: Platform Hugging Face telah menambahkan fitur praktis ke pusat modelnya, yang memungkinkan pengguna untuk menyaring model berdasarkan ukuran parameternya. Peningkatan ini memungkinkan pengembang dan peneliti untuk lebih mudah menemukan model yang sesuai dengan sumber daya perangkat keras atau kebutuhan kinerja spesifik mereka, meningkatkan efisiensi dalam menavigasi dan memilih dari perpustakaan model yang luas (Sumber: ClementDelangue, TheZachMueller, huggingface, clefourrier, multimodalart)
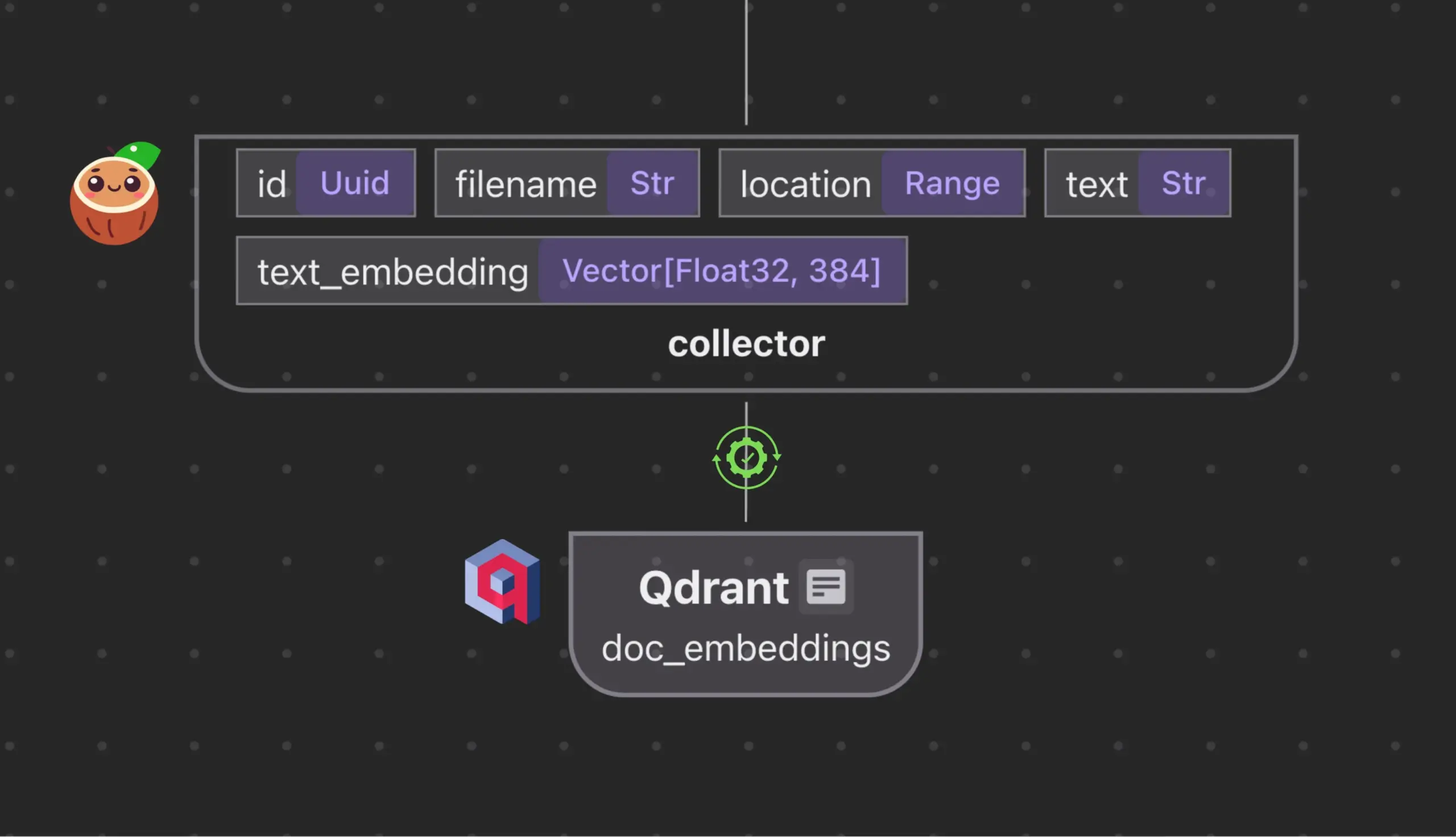
Cocoindex.io terintegrasi dengan Qdrant, secara otomatis membuat dan menyinkronkan koleksi database vektor: Alat aliran data open-source Cocoindex.io kini mendukung pembuatan koleksi database vektor Qdrant secara otomatis. Pengguna hanya perlu mendefinisikan aliran data, dan alat tersebut akan menyimpulkan skema Qdrant yang sesuai (termasuk ukuran vektor, metrik jarak, dan struktur payload), serta menjaga sinkronisasi bidang vektor, jenis payload, dan kunci primer, mendukung pembaruan inkremental. Ini menyederhanakan konfigurasi dan pengelolaan database vektor, meningkatkan efisiensi tim data (Sumber: qdrant_engine)
Manus AI: Alat pengembangan AI lengkap yang tidak hanya menulis kode, tetapi juga melakukan deployment otomatis: Manus AI adalah alat pengembangan AI end-to-end yang dapat melakukan segalanya mulai dari penulisan kode hingga pengaturan lingkungan, instalasi dependensi, pengujian, dan bahkan deployment akhir ke URL online. Alat ini menggunakan arsitektur kolaborasi multi-agen (perencanaan, pengembangan, pengujian, deployment), dan dapat secara mandiri menyelesaikan masalah dependensi dan kesalahan debugging. Meskipun saat ini ada model penetapan harga berbasis kredit, pengembangan oleh tim Tiongkok (yang mungkin melibatkan pertimbangan kepatuhan), dan keterbatasan dalam dukungan untuk arsitektur perusahaan yang sangat kompleks, alat ini menunjukkan potensi pergeseran dari “pengkodean yang dibantu AI” menjadi “pengembangan yang dieksekusi AI” (Sumber: Reddit r/artificial)

📚 Pembelajaran
Teori terjemahan dan panduan optimasi prompt terjemahan AI: Menggabungkan teori “terjemahan adalah penulisan ulang” dari “Studi Baru tentang Terjemahan” karya Si Guo dan pandangan dari “Terjemahan adalah Jalan Agung” karya Yu Guangzhong, membahas prinsip-prinsip terjemahan berkualitas tinggi. Menekankan bahwa terjemahan harus fokus pada ekspresi idiomatik bahasa target, bukan korespondensi literal, perlu fleksibel menggunakan terjemahan literal dan terjemahan bebas, dan memperhatikan perbedaan logika bahasa Tionghoa dan Barat untuk melakukan penulisan ulang sintaksis. Artikel ini juga membahas kemurnian ekspresi Tionghoa, penanganan terminologi, dan merefleksikan keterbatasan proses tiga langkah “terjemahan literal – analisis – terjemahan bebas” dalam terjemahan AI, menyarankan penggunaan proses “pemahaman – ekspresi – pemeriksaan – optimasi” yang lebih terintegrasi untuk meningkatkan kualitas terjemahan AI, membuatnya lebih sesuai dengan gaya penulisan ilmiah populer Tionghoa (Sumber: dotey)

Anthropic berbagi pengalaman membangun sistem penelitian multi-agennya: AnthropicAI merilis panduan gratis yang merinci bagaimana mereka membangun sistem penelitian multi-agen mereka. Kontennya mencakup cara kerja arsitektur sistem, metode rekayasa prompt dan pengujian, tantangan yang dihadapi dalam produksi, serta keunggulan sistem multi-agen. Panduan ini memberikan pengalaman praktis dan wawasan berharga bagi peneliti dan pengembang yang tertarik pada sistem multi-agen (Sumber: TheTuringPost, TheTuringPost)
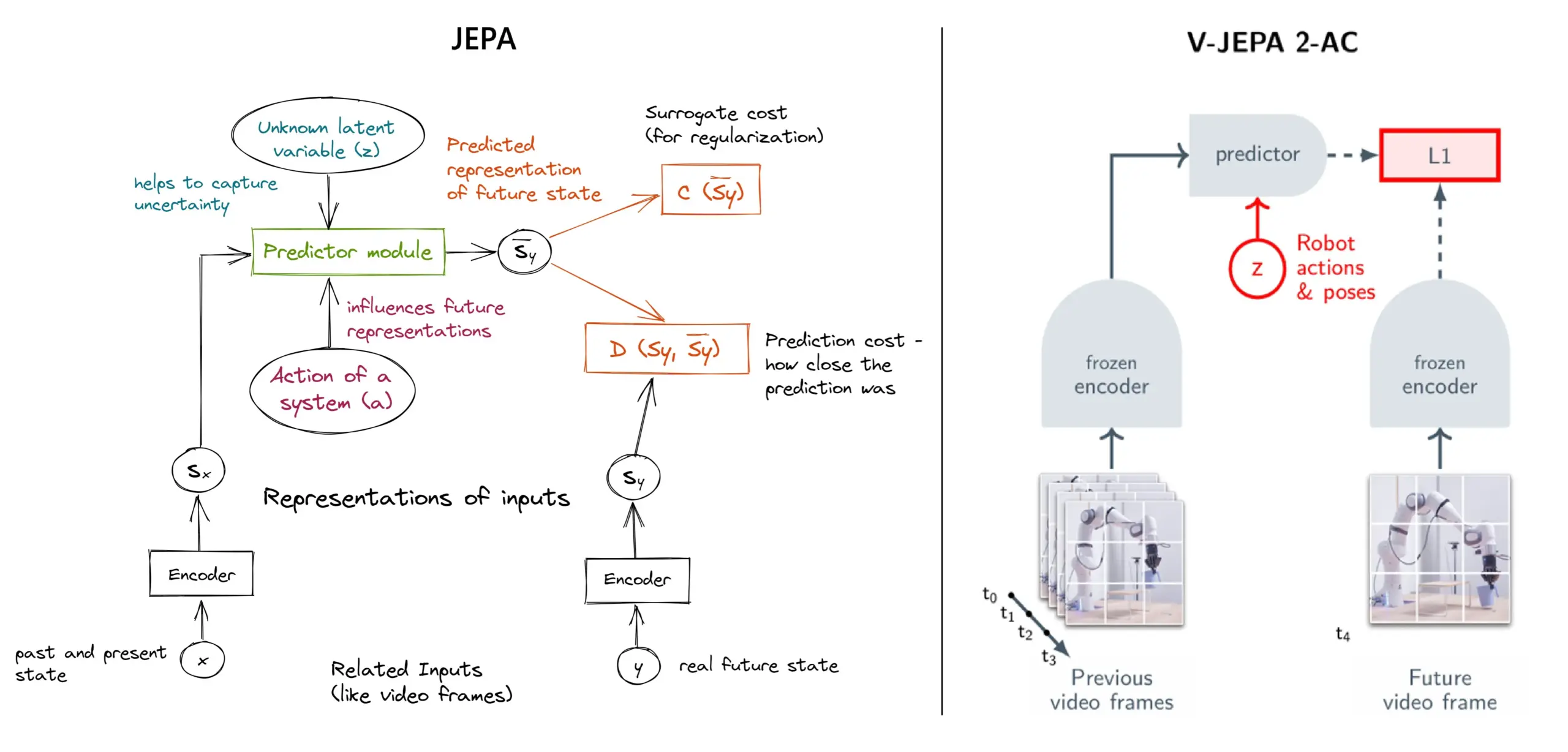
Penjelasan kerangka kerja self-supervised learning JEPA: Tinjauan 11 jenis: JEPA (Joint Embedding Predictive Architecture) yang diusulkan oleh Yann LeCun dari Meta dan peneliti lainnya adalah kerangka kerja self-supervised learning yang belajar dengan memprediksi representasi laten dari bagian data input yang hilang. Artikel ini memperkenalkan 11 jenis JEPA yang berbeda, termasuk V-JEPA 2, TS-JEPA, D-JEPA, dll., dan menyediakan lebih banyak informasi serta tautan ke sumber daya terkait, yang membantu memahami metode self-supervised learning mutakhir ini (Sumber: TheTuringPost, TheTuringPost)
Kerangka kerja DSPy: Memisahkan tugas dari LLM, meningkatkan keterpeliharaan kode: Sebuah artikel interpretasi tentang DSPy menunjukkan bahwa kerangka kerja DSPy mengurangi kompleksitas penggunaan Large Language Models (LLM) dengan memisahkan tugas dari LLM. Bahkan sebelum optimasi, DSPy dapat membantu pengembang memulai proyek lebih cepat dan menghasilkan kode yang lebih mudah dipelihara dan diperluas. Ini memiliki nilai penting untuk proyek yang perlu menangani rekayasa prompt yang kompleks dan integrasi LLM (Sumber: lateinteraction, stanfordnlp)

Diskusi Makalah: Vision Transformers Don’t Need Trained Registers: Sebuah makalah penelitian baru membahas mekanisme artefak yang dihasilkan dalam peta atensi dan peta fitur pada Vision Transformer, sebuah fenomena yang juga ada pada Large Language Models. Makalah ini mengusulkan metode tanpa pelatihan untuk mengurangi artefak ini, bertujuan untuk meningkatkan kinerja dan interpretabilitas Vision Transformer. Penelitian ini memiliki nilai referensi untuk memahami dan meningkatkan arsitektur Transformer dalam aplikasi tugas visual (Sumber: Reddit r/MachineLearning)
Berbagi Tutorial: Membangun Seri Video DeepSeek dari Awal (Total 29 Episode): Seorang kreator konten telah merilis seri video tutorial berjudul “Cara Membangun DeepSeek dari Awal”, yang terdiri dari 29 episode. Kontennya mencakup dasar-dasar model DeepSeek, detail arsitektur (seperti mekanisme atensi, multi-head attention, KV cache, MoE), pengkodean posisi, prediksi multi-token, dan teknologi kunci lainnya seperti kuantisasi. Seri tutorial ini menyediakan sumber daya video berharga bagi pelajar yang ingin memahami secara mendalam cara kerja internal DeepSeek dan model besar serupa (Sumber: Reddit r/LocalLLaMA)

Tutorial: Membangun pipeline RAG untuk merangkum postingan Hacker News: Haystack by deepset membagikan tutorial langkah demi langkah yang memandu pengguna cara membangun pipeline Retrieval Augmented Generation (RAG). Pipeline ini mampu mengambil postingan real-time dari Hacker News dan menggunakan endpoint Large Language Model (LLM) yang berjalan secara lokal untuk merangkum postingan tersebut. Ini menyediakan kasus penggunaan praktis bagi pengembang yang ingin memanfaatkan teknologi RAG untuk memproses aliran informasi real-time dan melakukan pemrosesan lokal (Sumber: dl_weekly)
Makalah Terbaru: Dataset InterSyn dan Model Evaluasi SynJudge untuk Generasi Teks-Gambar Berselang-seling: Untuk mengatasi kekurangan LMM saat ini dalam menghasilkan output teks-gambar yang berselang-seling secara erat (terutama karena keterbatasan skala, kualitas, dan kekayaan instruksi dataset pelatihan), para peneliti meluncurkan InterSyn, sebuah dataset multimodal berskala besar yang dibangun melalui metode SEIR (Self-Evaluation and Iterative Refinement). InterSyn berisi dialog multi-putaran yang digerakkan oleh instruksi, dengan respons di mana teks dan gambar berselang-seling secara erat. Sementara itu, untuk mengevaluasi output semacam itu, para peneliti juga mengusulkan model evaluasi otomatis SynJudge, yang mengevaluasi dari empat dimensi: konten teks, konten gambar, kualitas gambar, dan sinergi teks-gambar. Eksperimen menunjukkan bahwa LMM yang dilatih pada InterSyn menunjukkan peningkatan pada semua metrik evaluasi (Sumber: HuggingFace Daily Papers)
Makalah Terbaru: Sintesis Gambar dan Geometri Perspektif Baru yang Selaras melalui Distilasi Atensi Lintas-Modal: Para peneliti mengusulkan kerangka kerja berbasis difusi MoAI, yang melalui metode “warping-and-inpainting”, mencapai generasi gambar dan geometri perspektif baru yang selaras. Metode ini memanfaatkan prediktor geometri yang sudah ada untuk memprediksi sebagian bentuk geometri gambar referensi, dan mensintesis perspektif baru sebagai tugas perbaikan gambar dan geometri. Untuk memastikan keselarasan yang akurat antara gambar dan geometri, makalah ini mengusulkan distilasi atensi lintas-modal, yang menyuntikkan peta atensi dari cabang difusi gambar ke cabang difusi geometri paralel selama proses pelatihan dan inferensi. Metode ini mencapai sintesis perspektif ekstrapolasi fidelitas tinggi dalam berbagai skenario yang belum pernah dilihat (Sumber: HuggingFace Daily Papers)
Makalah Terbaru: Penyesuaian Preferensi Terkonfigurasi (CPT) Berbasis Data Sintetis yang Dipandu Aturan: Untuk mengatasi masalah preferensi yang kaku dan adaptabilitas terbatas dalam model umpan balik manusia seperti DPO, para peneliti mengusulkan kerangka kerja Penyesuaian Preferensi Terkonfigurasi (CPT). CPT memanfaatkan prompt sistem berbasis aturan terstruktur berbutir halus (mendefinisikan atribut yang diinginkan seperti gaya penulisan) untuk menghasilkan data preferensi sintetis. Melalui fine-tuning dengan preferensi yang dipandu aturan ini, LLM dapat secara dinamis menyesuaikan output berdasarkan prompt sistem pada saat inferensi, tanpa perlu pelatihan ulang, mencapai kontrol preferensi yang lebih halus dan relevan secara kontekstual (Sumber: HuggingFace Daily Papers)
Makalah Terbaru: Dualitas Difusi (The Diffusion Duality): Para peneliti mengusulkan metode Duo, yang dengan mengungkap wawasan bahwa proses difusi diskrit keadaan seragam berasal dari difusi Gaussian laten, mentransfer teknik kuat dari difusi Gaussian ke model difusi diskrit untuk meningkatkan kinerjanya. Secara spesifik meliputi: 1) Memperkenalkan strategi pembelajaran kurikulum yang dipandu proses Gaussian, mengurangi varians, menggandakan kecepatan pelatihan, dan melampaui model autoregresif pada beberapa benchmark. 2) Mengusulkan distilasi konsistensi diskrit, mengadaptasi distilasi konsistensi kontinu ke pengaturan diskrit, dengan mempercepat pengambilan sampel dua tingkat besaran, mencapai generasi langkah sedikit model bahasa difusi (Sumber: HuggingFace Daily Papers)
Makalah Terbaru: SkillBlender – Kontrol Gerak Seluruh Tubuh Robot Humanoid Multifungsi melalui Fusi Keterampilan: Untuk mengatasi keterbatasan metode kontrol robot humanoid yang ada dalam generalisasi multi-tugas dan skalabilitas, para peneliti mengusulkan SkillBlender, sebuah kerangka kerja reinforcement learning hierarkis. Kerangka kerja ini pertama-tama melatih keterampilan primitif yang tidak bergantung pada tugas dan berorientasi pada tujuan, kemudian secara dinamis menggabungkan keterampilan ini saat melakukan tugas manipulasi gerak yang kompleks, hanya memerlukan rekayasa hadiah spesifik tugas yang minimal. Sementara itu, diluncurkan benchmark simulasi SkillBench untuk evaluasi. Eksperimen menunjukkan bahwa metode ini dapat secara signifikan meningkatkan akurasi dan kelayakan berbagai tugas manipulasi gerak (Sumber: HuggingFace Daily Papers)
Makalah Terbaru: Kerangka Kerja U-CoT+ – Memisahkan Pemahaman dan Penalaran CoT Terpandu untuk Mendeteksi Meme Berbahaya: Untuk mengatasi tantangan efisiensi sumber daya, fleksibilitas, dan interpretabilitas dalam deteksi meme berbahaya, para peneliti mengusulkan kerangka kerja U-CoT+. Kerangka kerja ini pertama-tama mengubah meme visual menjadi deskripsi teks yang mempertahankan detail melalui alur kerja konversi meme-ke-teks fidelitas tinggi, sehingga memisahkan interpretasi meme dari klasifikasi, memungkinkan Large Language Models (LLM) umum untuk melakukan deteksi yang efisien sumber daya. Selanjutnya, dikombinasikan dengan pedoman interpretatif yang dibuat manusia, model dipandu dalam penalaran di bawah prompt CoT zero-shot, meningkatkan adaptabilitas dan interpretabilitas terhadap berbagai platform dan perubahan waktu (Sumber: HuggingFace Daily Papers)
Makalah Terbaru: CRAFT – Pengujian Red Team Agen yang Efektif dan Patuh terhadap Kebijakan: Menanggapi masalah kepatuhan agen LLM berorientasi tugas terhadap kebijakan yang ketat (seperti kelayakan pengembalian dana), para peneliti mengusulkan model ancaman baru, yang berfokus pada pengguna antagonis yang mencoba memanfaatkan agen berbasis kebijakan untuk keuntungan pribadi. Untuk itu, mereka mengembangkan CRAFT, sistem pengujian red team multi-agen, yang memanfaatkan strategi persuasi sadar kebijakan untuk menyerang agen yang patuh terhadap kebijakan dalam skenario layanan pelanggan, yang hasilnya lebih unggul daripada metode jailbreak tradisional. Sementara itu, diluncurkan benchmark tau-break, untuk mengevaluasi ketahanan agen terhadap perilaku manipulatif semacam itu (Sumber: HuggingFace Daily Papers)
Makalah Terbaru: Kegagalan Retriever Padat pada Kueri Sederhana dan Dilema Granularitas Embedding: Penelitian mengungkap batasan encoder teks: embedding mungkin tidak mengenali entitas atau peristiwa berbutir halus dalam semantik, yang menyebabkan retriever padat mungkin gagal bahkan dalam kasus sederhana. Untuk menyelidiki fenomena ini, makalah ini memperkenalkan dataset evaluasi Tionghoa CapRetrieval (paragraf adalah keterangan gambar, kueri adalah frasa entitas/peristiwa). Evaluasi zero-shot menunjukkan bahwa encoder mungkin berkinerja buruk pada pencocokan berbutir halus. Fine-tuning encoder dengan strategi pembuatan data yang diusulkan dapat meningkatkan kinerja, tetapi juga mengungkap “dilema granularitas”, yaitu embedding kesulitan menyelaraskan dengan semantik keseluruhan sambil mengekspresikan signifikansi berbutir halus (Sumber: HuggingFace Daily Papers)
Makalah Terbaru: pLSTM – Jaringan Penanda Transformasi Sumber Linear yang Dapat Diparalelkan: Menanggapi keterbatasan arsitektur rekuren yang ada (seperti xLSTM, Mamba) yang terutama cocok untuk data sekuensial atau memerlukan pemrosesan data multidimensi secara berurutan, para peneliti mengusulkan pLSTM (jaringan penanda transformasi sumber linear yang dapat diparalelkan). pLSTM memperluas multidimensionalitas ke RNN linear, menggunakan gerbang sumber, transformasi, dan penanda yang bekerja pada graf garis dari graf asiklik terarah (DAG) umum, mencapai paralelisasi yang mirip dengan pemindaian asosiatif paralel dan bentuk rekuren terbagi. Metode ini menunjukkan kemampuan ekstrapolasi dan kinerja yang baik pada tugas visi komputer sintetis dan graf molekuler, serta benchmark visi komputer (Sumber: HuggingFace Daily Papers)
Makalah Terbaru: DeepVideo-R1 – Fine-tuning Video Diperkuat melalui Regresi Sadar Kesulitan GRPO: Menanggapi kekurangan reinforcement learning dalam aplikasi Video Large Language Models (Video LLM), para peneliti mengusulkan DeepVideo-R1, sebuah Video LLM yang dilatih melalui Reg-GRPO (GRPO regresif) yang mereka usulkan dan strategi augmentasi data sadar kesulitan. Reg-GRPO merekonstruksi target GRPO sebagai tugas regresi, secara langsung memprediksi fungsi keuntungan dalam GRPO, menghilangkan ketergantungan pada tindakan pengamanan seperti pemangkasan, sehingga lebih langsung memandu kebijakan. Augmentasi data sadar kesulitan secara dinamis meningkatkan sampel pelatihan pada tingkat kesulitan yang dapat dipecahkan. Eksperimen menunjukkan bahwa DeepVideo-R1 secara signifikan meningkatkan kinerja penalaran video (Sumber: HuggingFace Daily Papers)
Makalah Terbaru: Kerangka Kerja Penyempurnaan Diri untuk Meningkatkan ASR dengan Data Sintetis TTS: Para peneliti mengusulkan kerangka kerja penyempurnaan diri yang hanya menggunakan dataset tidak berlabel untuk meningkatkan kinerja Automatic Speech Recognition (ASR). Kerangka kerja ini pertama-tama menggunakan model ASR yang ada untuk menghasilkan label semu pada ucapan tidak berlabel, kemudian menggunakan label semu ini untuk melatih sistem Text-to-Speech (TTS) fidelitas tinggi. Selanjutnya, pasangan ucapan-teks yang disintesis TTS digunakan untuk memandu pelatihan sistem ASR asli, membentuk perbaikan diri loop tertutup. Eksperimen pada Bahasa Mandarin Taiwan menunjukkan bahwa metode ini dapat secara signifikan mengurangi tingkat kesalahan, menyediakan jalur praktis untuk peningkatan kinerja ASR sumber daya rendah atau domain spesifik (Sumber: HuggingFace Daily Papers)
Makalah Terbaru: Peta Atensi Setia yang Melekat pada Vision Transformer: Para peneliti mengusulkan metode berbasis atensi yang menggunakan masker atensi biner yang dipelajari, memastikan bahwa hanya wilayah gambar yang diperhatikan yang memengaruhi prediksi. Metode ini bertujuan untuk mengatasi bias yang mungkin timbul dari konteks terhadap persepsi objek, terutama ketika objek muncul dalam latar belakang non-distribusi. Melalui kerangka kerja dua tahap (tahap pertama menemukan bagian objek dan mengidentifikasi wilayah yang relevan dengan tugas, tahap kedua memanfaatkan masker atensi input untuk membatasi bidang reseptif untuk analisis terfokus), pelatihan bersama mencapai peningkatan ketahanan model terhadap korelasi palsu dan latar belakang non-distribusi (Sumber: HuggingFace Daily Papers)
Makalah Terbaru: ViCrit – Tugas Agen Reinforcement Learning yang Dapat Diverifikasi untuk Persepsi Visual VLM: Untuk mengatasi kurangnya tugas persepsi visual dalam VLM yang sekaligus menantang dan dapat diverifikasi secara jelas, para peneliti memperkenalkan ViCrit (Visual Caption Hallucination Critic). Ini adalah tugas agen RL yang melatih VLM untuk menemukan halusinasi visual halus dan sintetis yang disuntikkan ke dalam paragraf keterangan gambar yang ditulis manusia. Dengan menyuntikkan satu kesalahan deskripsi visual halus ke dalam keterangan sekitar 200 kata, dan meminta model untuk menemukan rentang kesalahan berdasarkan gambar dan keterangan yang dimodifikasi, tugas ini menyediakan hadiah biner yang mudah dihitung dan jelas. Model yang dilatih dengan ViCrit menunjukkan peningkatan signifikan pada berbagai benchmark VL (Sumber: HuggingFace Daily Papers)
Makalah Terbaru: Melampaui Atensi Homogen – LLM Hemat Memori Berbasis Cache KV Aproksimasi Fourier: Untuk mengatasi masalah kebutuhan memori cache KV yang meningkat seiring dengan bertambahnya panjang konteks dalam LLM, para peneliti mengusulkan FourierAttention, sebuah kerangka kerja tanpa pelatihan. Kerangka kerja ini memanfaatkan peran heterogen dimensi kepala Transformer: dimensi rendah memprioritaskan konteks lokal, dimensi tinggi menangkap dependensi jarak jauh. Dengan memproyeksikan dimensi yang tidak sensitif terhadap konteks panjang ke basis Fourier ortogonal, FourierAttention mengaproksimasi evolusi temporalnya dengan koefisien spektral panjang tetap. Evaluasi pada model LLaMA menunjukkan bahwa metode ini mencapai akurasi konteks panjang terbaik pada LongBench dan NIAH, dan mengoptimalkan memori melalui kernel Triton kustom FlashFourierAttention (Sumber: HuggingFace Daily Papers)
Makalah Terbaru: JAFAR – Upsampler Universal untuk Meningkatkan Fitur Apapun pada Resolusi Apapun: Menanggapi masalah fitur spasial resolusi rendah dari output encoder visual dasar yang tidak dapat memenuhi kebutuhan tugas hilir, para peneliti memperkenalkan JAFAR, sebuah upsampler fitur yang ringan dan fleksibel. JAFAR dapat meningkatkan resolusi spasial fitur visual dari encoder visual dasar apapun ke resolusi target apapun. JAFAR menggunakan modul berbasis atensi, yang dimodulasi melalui transformasi fitur spasial (SFT), untuk memfasilitasi penyelarasan semantik antara kueri resolusi tinggi yang berasal dari fitur gambar tingkat rendah dan kunci resolusi rendah yang kaya semantik. Eksperimen menunjukkan bahwa JAFAR dapat secara efektif memulihkan detail spasial berbutir halus dan mengungguli metode yang ada dalam berbagai tugas hilir (Sumber: HuggingFace Daily Papers)
Makalah Terbaru: SwS – Sintesis Masalah yang Didorong oleh Kelemahan yang Dirasakan Sendiri dalam Reinforcement Learning: Menanggapi kelangkaan set masalah berkualitas tinggi dan dapat diverifikasi jawabannya dalam RLVR (Reinforcement Learning with Verifiable Rewards) saat melatih LLM untuk menyelesaikan tugas penalaran kompleks (seperti masalah matematika), para peneliti mengusulkan kerangka kerja SwS (Self-aware Weakness-driven Problem Synthesis). SwS secara sistematis mengidentifikasi kekurangan model (masalah di mana model terus gagal belajar dalam pelatihan RL), mengekstrak konsep inti dari kasus kegagalan ini, dan mensintesis masalah baru untuk memperkuat area lemah model dalam pelatihan penguatan berikutnya. Kerangka kerja ini memungkinkan model untuk mengidentifikasi dan mengatasi kelemahannya sendiri dalam RL, mencapai peningkatan kinerja yang signifikan pada beberapa benchmark penalaran utama (Sumber: HuggingFace Daily Papers)
Makalah Terbaru: Belajar Token “Lanjutkan Berpikir” untuk Meningkatkan Kemampuan Ekspansi Saat Pengujian: Untuk meningkatkan kinerja model bahasa dalam memperluas langkah penalaran melalui komputasi tambahan saat pengujian, para peneliti mengeksplorasi kelayakan mempelajari token khusus “lanjutkan berpikir” (<|continue-thinking|>). Mereka melatih embedding token ini hanya melalui reinforcement learning, sambil menjaga bobot model versi distilasi DeepSeek-R1 tetap beku. Eksperimen menunjukkan bahwa, dibandingkan dengan model dasar dan metode ekspansi saat pengujian yang menggunakan token tetap (seperti “Wait”) untuk pemaksaan anggaran, token yang dipelajari mencapai akurasi yang lebih tinggi pada benchmark matematika standar, terutama dalam kasus di mana token tetap dapat meningkatkan akurasi model dasar, token yang dipelajari dapat membawa perbaikan yang lebih besar (Sumber: HuggingFace Daily Papers)
Makalah Terbaru: LoRA-Edit – Pengeditan Video Terpandu Frame Pertama yang Terkendali melalui Fine-tuning LoRA Sadar Masker: Untuk mengatasi masalah metode pengeditan video yang ada yang bergantung pada pra-pelatihan skala besar dan kurangnya fleksibilitas, para peneliti mengusulkan LoRA-Edit, metode fine-tuning LoRA berbasis masker untuk mengadaptasi model Image-to-Video (I2V) yang telah dilatih sebelumnya untuk pengeditan video yang fleksibel. Metode ini, sambil mempertahankan area latar belakang, mampu menyebarkan efek pengeditan yang terkendali dan menggabungkan informasi referensi lainnya (seperti sudut pandang alternatif atau status adegan) sebagai jangkar visual. Melalui strategi penyesuaian LoRA yang digerakkan oleh masker, model belajar dari video input (struktur spasial dan petunjuk gerak) dan gambar referensi (panduan penampilan), mencapai pembelajaran spesifik wilayah (Sumber: HuggingFace Daily Papers)
Makalah Terbaru: Infinity Instruct – Memperluas Pemilihan dan Sintesis Instruksi untuk Meningkatkan Model Bahasa: Untuk mengatasi kekurangan dataset instruksi open-source yang ada yang sebagian besar terkonsentrasi pada domain sempit (seperti matematika, pengkodean), yang menyebabkan kemampuan generalisasi terbatas, para peneliti meluncurkan Infinity-Instruct, sebuah dataset instruksi berkualitas tinggi yang bertujuan untuk meningkatkan kemampuan dasar dan percakapan LLM melalui proses dua tahap. Tahap pertama, menggunakan teknik pemilihan data campuran untuk menyaring 7,4 juta instruksi dasar berkualitas tinggi dari lebih dari 100 juta sampel. Tahap kedua, melalui proses dua tahap pemilihan instruksi, evolusi, dan penyaringan diagnostik, mensintesis 1,5 juta instruksi percakapan berkualitas tinggi. Eksperimen fine-tuning pada berbagai model open-source menunjukkan bahwa dataset ini dapat secara signifikan meningkatkan kinerja model pada benchmark dasar dan kepatuhan instruksi (Sumber: HuggingFace Daily Papers)
Makalah Terbaru: Kandidat Dahulu, Distilasi Kemudian – Kerangka Kerja Guru-Murid untuk Anotasi Data yang Didorong LLM: Menanggapi masalah dalam metode anotasi data LLM yang ada di mana LLM secara langsung menentukan satu label emas yang mungkin salah karena ketidakpastian, para peneliti mengusulkan paradigma anotasi kandidat baru: mendorong LLM untuk menghasilkan semua label yang mungkin ketika tidak pasti. Untuk memastikan tugas hilir mendapatkan label tunggal, dikembangkan kerangka kerja guru-murid CanDist, yang menggunakan Small Language Model (SLM) untuk mendistilasi anotasi kandidat. Secara teoritis dibuktikan bahwa mendistilasi anotasi kandidat dari LLM guru lebih unggul daripada menggunakan anotasi tunggal secara langsung. Eksperimen memvalidasi efektivitas metode ini (Sumber: HuggingFace Daily Papers)
Makalah Terbaru: Med-PRM – Model Penalaran Medis dengan Hadiah Proses Verifikasi Bertahap dan Terpandu: Untuk mengatasi keterbatasan Large Language Models dalam menemukan dan mengoreksi kesalahan langkah penalaran spesifik dalam pengambilan keputusan klinis, para peneliti memperkenalkan Med-PRM, sebuah kerangka kerja pemodelan hadiah proses. Kerangka kerja ini memanfaatkan teknik generasi yang diperkuat oleh pencarian untuk memvalidasi setiap langkah penalaran terhadap basis pengetahuan medis yang sudah mapan (pedoman klinis dan literatur). Dengan cara berbutir halus ini untuk mengevaluasi kualitas penalaran secara akurat, Med-PRM mencapai kinerja SOTA pada beberapa benchmark QA medis dan tugas diagnosis terbuka, dan dapat diintegrasikan dengan model kebijakan yang kuat (seperti Meerkat) secara plug-and-play, secara signifikan meningkatkan akurasi model kecil (parameter 8B) (Sumber: HuggingFace Daily Papers)
Makalah Terbaru: Gesekan Umpan Balik – LLM Kesulitan Menyerap Umpan Balik Eksternal Secara Penuh: Penelitian secara sistematis mengkaji kemampuan LLM untuk menyerap umpan balik eksternal. Dalam eksperimen, model pemecah masalah mencoba menyelesaikan masalah, kemudian generator umpan balik dengan jawaban benar yang hampir lengkap memberikan umpan balik yang ditargetkan, dan pemecah masalah mencoba lagi. Hasilnya menunjukkan bahwa bahkan dalam kondisi yang hampir ideal, model SOTA termasuk Claude 3.7 masih menunjukkan penolakan terhadap umpan balik, yang disebut “gesekan umpan balik”. Meskipun penggunaan peningkatan suhu bertahap dan penolakan eksplisit terhadap jawaban salah sebelumnya menunjukkan perbaikan, model masih belum mencapai kinerja target. Penelitian mengecualikan faktor-faktor seperti kepercayaan diri model yang berlebihan dan keakraban data, bertujuan untuk mengungkap hambatan inti ini dalam perbaikan diri LLM (Sumber: HuggingFace Daily Papers)
💼 Bisnis
Meta mengakuisisi 49% saham Scale AI senilai $14,3 miliar, pendiri Alexandr Wang bergabung dengan tim super intelijen Meta: Meta mengumumkan akuisisi 49% saham tanpa hak suara di perusahaan anotasi data AI, Scale AI, senilai $14,3 miliar. Pendiri Scale AI, Alexandr Wang, seorang jenius Tionghoa-Amerika berusia 28 tahun, akan tetap menjadi anggota dewan direksi dan memimpin tim intinya untuk bergabung dengan tim super intelijen Meta yang dibentuk secara pribadi oleh Zuckerberg. Akuisisi ini dianggap sebagai upaya Meta untuk meningkatkan kemampuan AI-nya setelah kinerja Llama 4 yang kurang memuaskan, melalui akuisisi talenta dengan harga selangit, bertujuan untuk mengintegrasikan AI secara mendalam ke semua produknya. Scale AI memulai dengan menyediakan layanan data anotasi manual berkualitas tinggi berskala besar, dengan klien termasuk Waymo, OpenAI, dll. Langkah ini menimbulkan kekhawatiran tentang netralitas platform dan keamanan datanya, dan klien seperti Google mungkin akan menghentikan kerja sama (Sumber: 36氪)

Strategi All in AI Kunlun Wanwei menyebabkan kerugian pertama dalam sepuluh tahun sejak IPO, prospek komersialisasi AI belum jelas: Sejak Kunlun Wanwei mengumumkan strategi “All in AGI & AIGC”, perusahaan ini secara aktif berinvestasi dalam model besar (model besar Tiangong) dan aplikasi seperti musik AI (Mureka), sosial AI (Linky), video AI (SkyReels), kantor AI (Skywork Super Agents), serta chip komputasi AI. Namun, investasi R&D yang tinggi dan biaya promosi pasar menyebabkan perusahaan mengalami kerugian pertama dalam sepuluh tahun sejak IPO pada tahun 2024 (1,59 miliar yuan), dan kerugian berlanjut pada kuartal pertama 2025. Meskipun beberapa aplikasi AI seperti Mureka dan Linky telah mulai menghasilkan pendapatan, profitabilitas keseluruhan bisnis AI dan daya saing pasar masih menghadapi tantangan, dan apakah perusahaan dapat mewujudkan “mimpi perusahaan besar” melalui AI masih harus diuji oleh pasar (Sumber: 36氪)

OpenAI mungkin menguji iklan di ChatGPT, tekanan profitabilitas mendorong eksplorasi model bisnis: Beberapa pengguna berbayar ChatGPT Plus melaporkan bahwa mereka menemui iklan sisipan saat menggunakan mode suara premium, yang memicu diskusi tentang apakah OpenAI mulai menguji iklan di antara pengguna berbayar. Sebelumnya dilaporkan bahwa OpenAI sedang mempertimbangkan untuk memperkenalkan iklan untuk memperluas pendapatan. Mengingat biaya operasional model besar AI yang tinggi dan tekanan profitabilitas (diperkirakan merugi $44 miliar sebelum 2029), serta ketidakpastian waktu realisasi AGI, OpenAI mencari model monetisasi baru seperti iklan dianggap sebagai pilihan yang tak terhindarkan untuk keberlanjutan bisnisnya, terutama dalam situasi penetrasi berbayar yang relatif rendah (Sumber: 36氪)

🌟 Komunitas
AI memiliki potensi besar di bidang ilmu data, Databricks aktif merekrut: Matei Zaharia dari Databricks percaya bahwa peningkatan produktivitas AI di bidang ilmu data akan lebih signifikan daripada pengkodean yang dibantu AI. Databricks memimpin tren ini melalui produk seperti Lakeflow Designer dan Genie Deep Research, dan secara aktif merekrut peneliti dan insinyur di bidang ini, menunjukkan tingginya perhatian industri terhadap inovasi ilmu data yang didorong AI (Sumber: matei_zaharia)
Perbedaan “kepribadian” LLM memengaruhi perilaku sirkuit agen: Peneliti Fabian Stelzer mengamati bahwa Large Language Models (LLM) yang berbeda memiliki perbedaan “kepribadian”, yang menyebabkan mereka berperilaku berbeda saat menjalankan tugas siklus agentik. Misalnya, Claude cenderung menjalankan alat secara serial, sedangkan GPT-4.1 sangat lebih suka eksekusi paralel, bahkan mengabaikan permintaan serial; model Haiku lebih “agresif” dalam memicu alat. Pengamatan ini menekankan pentingnya mempertimbangkan karakteristik LLM yang mendasari dan konsekuensi fungsional dari “keadaan emosional” saat merancang dan mengevaluasi sistem multi-agen (Sumber: fabianstelzer, menhguin)
LLM “berpikir” bergantung pada output Token, tanpa output tidak ada analisis yang efektif: Pengguna dotey menyampaikan temuan xincmm saat men-debug prompt ReAct: jika diharapkan LLM menganalisis terlebih dahulu sebelum melakukan operasi (seperti menggambar), tetapi tidak membiarkannya mengeluarkan Token dari proses analisis, LLM mungkin langsung melewati langkah analisis. Ini membuktikan bahwa proses “berpikir” LLM diwujudkan dengan menghasilkan Token, dan “analisis” yang didefinisikan dalam prompt, jika tidak ada output konten aktual, maka AI tidak benar-benar melakukan analisis tersebut. Ini memiliki signifikansi panduan untuk merancang prompt LLM yang efektif (Sumber: dotey)

Keterbatasan AI dalam tugas tertentu: Terence Tao mengatakan AI kurang “intuisi matematis”: Matematikawan Terence Tao menunjukkan bahwa meskipun bukti yang dihasilkan AI saat ini tampak sempurna di permukaan (lulus “tes mata”), mereka sering kekurangan “intuisi matematis” yang halus dan khas manusia, dan cenderung membuat beberapa kesalahan non-manusia. Dia percaya bahwa kecerdasan sejati bukan hanya tampak benar, tetapi lebih pada kemampuan untuk “mencium” apa yang nyata. Ini mengungkap keterbatasan AI saat ini dalam pemahaman mendalam dan penilaian intuitif (Sumber: ecsquendor)
Tantangan konten yang dihasilkan AI dengan hukum fisika nyata: Pengguna karminski3 saat menguji generasi kode dengan Doubao Seed 1.6 dan DeepSeek-R1 (mensimulasikan animasi 3D pembongkaran cerobong asap dengan peledakan) menemukan bahwa meskipun model dapat menghasilkan kode dan mensimulasikan animasi, masih ada perbedaan dan ruang untuk perbaikan dalam mereplikasi proses fisik nyata (seperti efek gelombang kejut, cara struktur runtuh). Doubao Seed 1.6 lebih mendekati kenyataan dalam efek partikel dan simulasi keruntuhan struktur, sedangkan DeepSeek berkinerja lebih baik dalam efek pencahayaan dan asap. Ini mencerminkan tantangan AI dalam memahami dan mensimulasikan fenomena fisik yang kompleks (Sumber: karminski3)
Programmer senior dipecat karena terlalu bergantung pada AI untuk menulis kode, tidak mau melakukan modifikasi manual, dan menakut-nakuti karyawan baru bahwa AI akan menggantikan mereka: Sebuah postingan Reddit yang direpost oleh 36Kr menceritakan kasus seorang programmer dengan pengalaman 30 tahun yang dipecat oleh perusahaannya karena terlalu kecanduan AI (seperti sepenuhnya bergantung pada Copilot Agent untuk mengirimkan PR, menolak memodifikasi kode secara manual, menghabiskan 5 hari untuk menyelesaikan tugas 1 hari, dan menyebarkan teori penggantian AI kepada karyawan magang). Insiden ini memicu diskusi tentang batas penggunaan AI yang wajar dalam pengembangan perangkat lunak, dan dampak AI terhadap nilai karir pengembang (Sumber: 36氪)
“Aliran” dan “kepribadian” AI memengaruhi pengalaman pengguna: Umpan balik pengguna menunjukkan AI terlalu “setuju secara positif”: Pengguna komunitas Reddit membahas bahwa saat berinteraksi dengan AI (terutama Claude), AI cenderung terlalu optimis dan secara positif menyetujui pandangan pengguna, kurang tantangan yang efektif dan umpan balik kritis yang mendalam, membuat pengguna merasa seperti berada di “ruang gema”. “Kelelahan nada AI” ini mendorong pengguna untuk mencari cara agar AI berperilaku lebih netral dan lebih kritis, misalnya melalui prompt tertentu. Ini mencerminkan tantangan AI saat ini dalam mensimulasikan dialog manusia yang nyata dan beragam serta memberikan wawasan yang benar-benar mendalam (Sumber: Reddit r/ClaudeAI)
Di era AI, nilai umpan balik manusia menonjol, tetapi platform interaksi manusia nyata menghadapi infiltrasi konten AI: Pengguna Reddit menunjukkan bahwa dalam konteks konten yang dihasilkan AI yang semakin meningkat, umpan balik dan opini manusia yang nyata menjadi lebih berharga, dan platform seperti Reddit dihargai karena karakteristik interaksi manusianya. Namun, platform ini juga menghadapi tantangan infiltrasi konten yang dihasilkan AI (seperti komentar bot, postingan yang ditulis dengan bantuan AI), membuat identifikasi pandangan manusia yang nyata menjadi lebih sulit, dan menimbulkan kekhawatiran tentang keaslian komunikasi online di masa depan (Sumber: Reddit r/ArtificialInteligence)
“Teman” AI mungkin menjadi hal biasa? Tren dan diskusi tentang pengguna yang membangun hubungan emosional dengan AI: Diskusi tentang pendamping AI dan teman AI muncul di media sosial dan komunitas Reddit. Beberapa pengguna percaya bahwa karena karakteristik AI yang tidak berprasangka dan selalu mendukung, teman AI mungkin menjadi hal biasa dalam 5 tahun ke depan, dan sudah terlihat dalam aplikasi seperti Endearing AI, Replika, Character.ai. Pengguna lain berbagi pengalaman mereka membangun hubungan percakapan yang mendalam dengan AI seperti ChatGPT, bahkan menganggapnya sebagai “sahabat terbaik”. Hal ini memicu pemikiran luas tentang interaksi emosional manusia-AI, peran AI dalam dukungan emosional, dan potensi dampak sosialnya (Sumber: Ronald_vanLoon, Reddit r/artificial, Reddit r/ArtificialInteligence)

Masa depan startup “pembungkus” AI memicu diskusi: Komunitas Reddit membahas prospek sejumlah besar startup AI yang melakukan pembungkusan (menambahkan UI, rantai prompt, atau fine-tuning untuk domain tertentu) pada model dasar seperti GPT atau Claude. Para diskutant mempertanyakan apakah aplikasi “pembungkus” semacam ini dapat mempertahankan daya saing setelah iterasi fungsi platform model dasar itu sendiri, dan apakah mereka dapat membangun parit pertahanan yang nyata. Pandangan berpendapat bahwa fokus pada domain vertikal tertentu, mengakumulasi data sendiri, dan melampaui pembungkusan sederhana mungkin menjadi jalur pengembangan berkelanjutan mereka (Sumber: Reddit r/LocalLLaMA)
Diskusi perbandingan potensi penggantian AI dalam diagnosis medis dan rekayasa perangkat lunak: Komunitas Reddit membahas bahwa AI mungkin menggantikan dokter lebih cepat daripada insinyur perangkat lunak senior. Alasannya adalah banyak diagnosis medis mengikuti protokol yang sudah ada, dan AI mahir dalam menafsirkan hasil tes dan mengidentifikasi gejala; sedangkan rekayasa perangkat lunak sering melibatkan banyak pengetahuan implisit dan komunikasi kebutuhan yang kompleks, yang sulit dikuasai sepenuhnya oleh AI. Pandangan ini memicu pemikiran lebih lanjut tentang kedalaman aplikasi AI dan kemungkinan penggantian di berbagai bidang profesional, tetapi juga dibantah oleh para profesional seperti dokter, yang menekankan kompleksitas operasi aktual dan pentingnya penilaian manusia (Sumber: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
💡 Lainnya
Manusia digital AI Luo Yonghao melakukan siaran perdana di e-commerce Baidu, GMV melampaui 55 juta yuan: Manusia digital AI Luo Yonghao melakukan siaran langsung penjualan perdana di platform e-commerce Baidu, menarik lebih dari 13 juta penonton, dengan total nilai transaksi barang (GMV) melampaui 55 juta yuan. Manusia digital ini dibuat oleh platform “Huiboxing” e-commerce Baidu berdasarkan model besar Wenxin 4.5, mampu meniru nada bicara, aksen, dan ekspresi mikro Luo Yonghao, serta melakukan respons cerdas. Siaran langsung ini menunjukkan potensi model “AI + pembawa acara ternama”, serta tata letak Baidu dalam teknologi “manusia digital berdaya persuasi tinggi” dan bidang e-commerce AI (Sumber: 36氪)

Baidu, Tencent, dan perusahaan lain meningkatkan perekrutan talenta AI, meluncurkan rencana perekrutan skala besar: Baidu meluncurkan proyek perekrutan talenta AI terkemuka terbesarnya, “Program AIDU”, dengan lowongan pekerjaan meningkat 60% YoY, berfokus pada bidang mutakhir seperti algoritma model besar dan arsitektur dasar, serta menawarkan gaji tanpa batas atas. Demikian pula, Tencent juga menarik talenta AI global dengan mengadakan kompetisi algoritma “Rekomendasi Generatif Semua Moda”, menawarkan hadiah jutaan dan tawaran rekrutmen kampus. Langkah-langkah ini mencerminkan kebutuhan mendesak dan tata letak strategis raksasa teknologi Tiongkok akan talenta terkemuka di tengah persaingan sengit di bidang AI (Sumber: 量子位, 量子位)

Baidu meluncurkan layanan bantuan pengisian formulir pendaftaran ujian masuk perguruan tinggi AI yang komprehensif, mengintegrasikan berbagai model dan big data: Menanggapi kompleksitas pengisian formulir pendaftaran yang disebabkan oleh reformasi ujian masuk perguruan tinggi baru, Baidu meluncurkan alat bantu pengisian formulir pendaftaran AI gratis. Layanan ini terintegrasi di halaman khusus “Ujian Masuk Perguruan Tinggi” di Aplikasi Baidu, menyediakan “Asisten Pendaftaran AI” untuk rekomendasi institusi dan jurusan serta analisis probabilitas penerimaan, mendukung agen cerdas “Konsultasi Pendaftaran AI” multi-model seperti Wenxin dan DeepSeek R1 untuk konsultasi yang dipersonalisasi. Selain itu, layanan ini juga menggabungkan big data pencarian eksklusif Baidu untuk menyediakan analisis prospek kerja jurusan, tes MBTI, serta siaran langsung dari kantor penerimaan mahasiswa baru dan sesi tanya jawab dengan senior, bertujuan untuk membantu calon mahasiswa mengatasi kesenjangan informasi dan membuat pilihan pendaftaran yang lebih sesuai (Sumber: 36氪)